
Efficient Digital-Elevation-Model-Based Flow Direction Estimation Using Priority Queue with Flow Distance and Zigzag Route Considerations



Abstract
1. Introduction
2. Improved Priority-Flood Algorithm
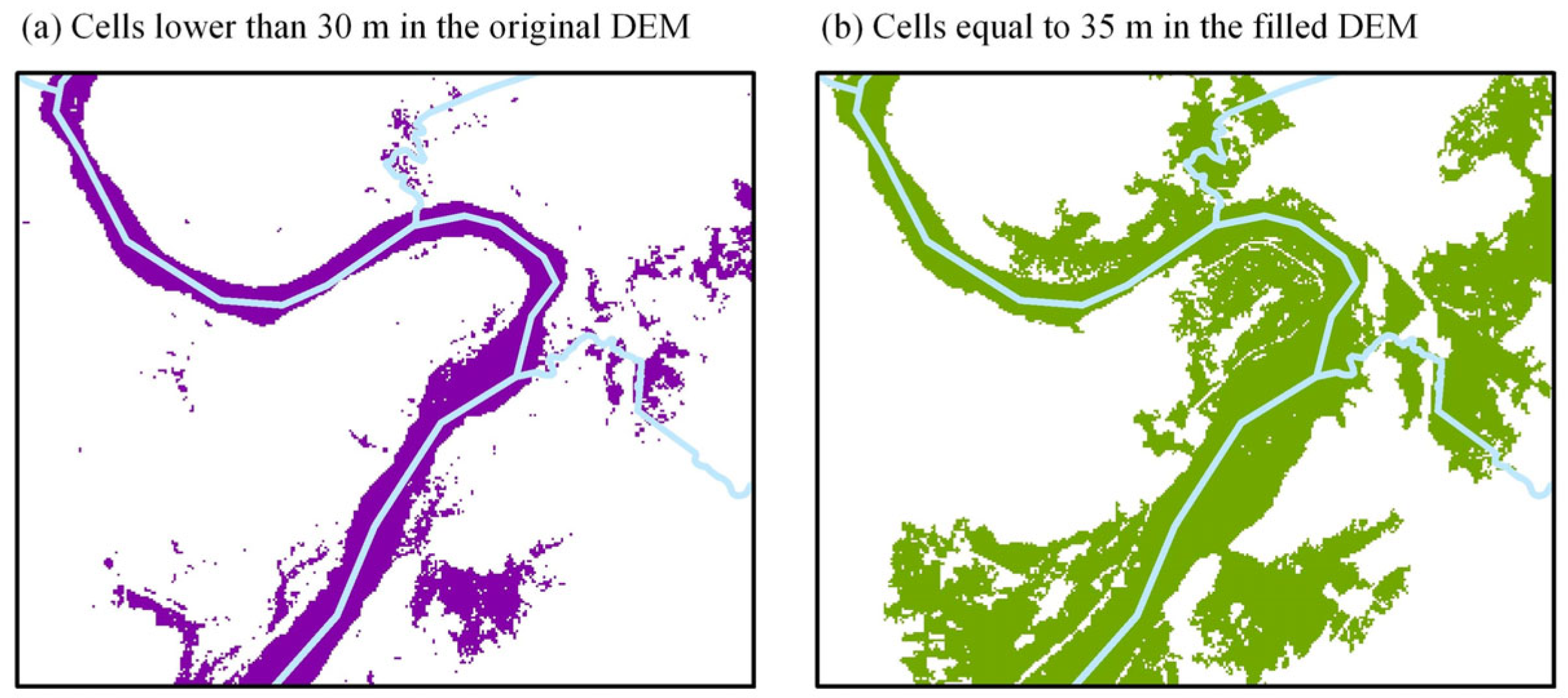
2.1. Issues in the Existing Algorithms
| Algorithm 1 Pseudo-code of a framework for Priority-Flood algorithms. Upon input, DEM is an array storing the elevation for each cell. Upon output, FlowDirs is an array containing the flow direction assigned to each cell. Notably, if a cell in the array falls within the regions lacking valid elevation values, both DEM and FlowDirs assign it the value NoDATA. On line 8, a cell on terrain edges must be located at the outermost ring of the array or neighboring to a cell with the elevation value NoDATA |
| Require: DEM 1: Let PQ be a stable priority queue sorting cells by ascending elevations; cells at the same elevation are arranged according to the insertion order. 2: Let Closed and FlowDirs be matrices having the same dimensions with DEM. 3: Initialize Closed to FALSE 4: for all cell c 5: if DEM[c] is NoDATA 6: FlowDirs[c] ← NoDATA 7: Closed[c] ← TRUE 8: else if c is on the terrain edges 9: PQ.push(c) 10: Closed[c] ← TRUE 11: Dir[c] ← Zero 12: while PQ is not empty 13: c ← PQ.pop() 14: if c is not depression or flat 15: call D8 algorithm for c ◄ Only used by Wang and Liu (2006) [20] 16: for all neighbors n of c ◄ Cardinal neighbors first [27] 17: if Closed[n] is FALSE 18: FlowDirs [n] ← c 19: Closed[n] ← TRUE 20: if DEM[n] < DEM[c] 21: DEM[n] ← DEM[c] ◄ Excluded by Metz et al. (2011) [26] 22: PQ.push(n) 23: return FlowDirs |
2.2. Framework of the Improved Algorithm
3. Materials and Algorithms for Assessments
4. Results and Discussion
4.1. Accuracy of the Extracted Drainage Networks
4.2. Computation Efficiency
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1 Pseudo-code of the DZFlood algorithm. Upon input, DEM is an array storing the elevation for each cell. Upon output, FlowDirs is an array containing the flow direction of each cell. In this algorithm, the function Length[a, b] computes the distance between the cells a and b. If a and b are cardinal neighbors, the distance is equal to the size of a cell. If a and b are diagonal neighbors, the distance is 1.414 times the size of a cell. The matrix Closed is adopted to record whether a cell has been scanned |
| Require: DEM 1: Let PQ be a priority queue sorting cells with ascending elevations. Cells at the same elevation are arranged with ascending flow distance values. 2: Let Closed, NSD, FD, and FlowDirs be matrixes with the same dimensions as DEM. 3: Initialize Closed to FALSE 4: Initialize NSD and FD to zero 5: for all cell c 6: if DEM[c] is NoDATA 7: FlowDirs[c] ← NoDATA 8: Closed[c] ← TRUE 9: else if c is on the terrain edges 10: PQ.push(c) 11: Closed[c] ← TRUE 12: FlowDirs [c] ← zero 13: while PQ is not empty 14: c ← PQ.pop() 15: m ← the downstream cell of c following FlowDirs[c] 16: Smax = (DEM[c] − DEM[m])/Length[c, m] 17: if Smax is equal to zero 18: FlatDirAdjust(c, m, FlowDirs, FD, NSD) ◄ Algorithm A2 19: for all neighbors n of c 20: if Closed[n] is FALSE 21: FlowDirs[n] ← c 22: if DEM[n] < DEM[c] 23: DEM[n] ← DEM[c] ◄ only adopted for depression filling 24: if DEM[n] is equal to DEM[c] 25: FD[n] ← FD[c] + Length[c, n] 26: PQ.push(n) 27: Closed[n] ← TRUE 28: Else if Smax > 0 29: S = (DEM[c] − DEM[n])/Length[c, n] 30: if S > Smax 31: FlowDirs[c] ← n ◄ adopted for the steepest downslope direction 32: Smax = S 33: Return FlowDirs |
| Algorithm A2 Pseudo-code of FlatDirAdjust. This function is used to adjust the flow direction assigned to any cell c in flat regions. Upon input, (1) m is the downstream cell pointed by the initial flow direction of c, (2) FlowDirs is an array recording the drainage directions of all cells, (3) FD is an array recording the flow distance from any flat cell to the outlet of the flat region, and (4) NSD is the number of continuous cells with the same flow direction downstream from the cell along the flow path over the flat region. The function Length[a, b] computes the distance between cells a and b. If a and b are cardinal neighbors, the distance is equal to the size of a cell. If a and b are diagonal neighbors, the distance is 1.414 times the size of a cell |
| Require: c, m, FlowDirs, FD, NSD for all cells k adjacent to both c and m if (FD[k] + Length[c, k]) is equal to FD[c] if FlowDirs[k] is equal to Direction(c to k) if FlowDirs[m] is equal to Direction(c to m) if NSD[m] > NSD[k] FlowDirs[c] ← k NSD[c] ← NSD[k] + 1 else NSD[c] ← NSD[m] + 1 else if FlowDirs[m] is equal to Direction(c to m) FlowDirs[c] ← k else if NSD[m] > NSD[k] FlowDirs[c] ← k |
References
- Hickey, R. Slope Length Calculations from a DEM within ARC/INFO Grid. Comput. Environ. Urban Syst. 1994, 18, 365–380. [Google Scholar] [CrossRef]
- Riihimäki, H.; Kemppinen, J.; Kopecký, M.; Luoto, M. Topographic Wetness Index as a Proxy for Soil Moisture: The Importance of Flow Routing Algorithm and Grid Resolution. Water Resour. Res. 2021, 57, e2021WR029871. [Google Scholar] [CrossRef]
- Zhou, G.; Wei, H.; Fu, S. A Fast and Simple Algorithm for Calculating Flow Accumulation Matrices from Raster Digital Elevation. Front. Earth Sci. 2019, 13, 317–326. [Google Scholar] [CrossRef]
- Tabunshchik, V.; Dzhambetova, P.; Gorbunov, R.; Gorbunova, T.; Nikiforova, A.; Drygval, P.; Kerimov, I.; Kiseleva, M. Delineation and Morphometric Characterization of Small- and Medium-Sized Caspian Sea Basin River Catchments Using Remote Sensing and GISs. Water 2025, 17, 679. [Google Scholar] [CrossRef]
- Wilson, J.P.; Lam, C.S.; Deng, Y. Comparison of the Performance of Flow-routing Algorithms used in GIS-based Hydrologic Analysis. Hydrol. Process. 2007, 21, 1026–1044. [Google Scholar] [CrossRef]
- Wu, P.; Liu, J.; Han, X.; Feng, M.; Fei, J.; Shen, X. An Improved Triangular Form-Based Multiple Flow Direction Algorithm for Determining the Nonuniform Flow Domain over Grid Networks. Water Resour. Res. 2022, 58, e2021WR031706. [Google Scholar] [CrossRef]
- O’Callaghan, J.F.; Mark, D.M. The Extraction of Drainage Networks from Digital Elevation Data. Comput. Vis. Graph. 1984, 28, 328–344. [Google Scholar]
- Khan, A.; Richards, K.S.; Parker, G.T.; McRobie, A.; Mukhopadhyay, B. How Large is the Upper Indus Basin? The Pitfalls of Auto-delineation using DEMs. J. Hydrol. 2014, 509, 442–453. [Google Scholar] [CrossRef]
- Lindsay, J.B.; Creed, I.F. Removal of Artifact Depressions from Digital Elevation Models: Towards a Minimum Impact Approach. Hydrol. Process. 2005, 19, 3113–3126. [Google Scholar] [CrossRef]
- Chen, B.; Ma, C.; Xiao, Y.; Gao, H.; Shi, P.; Zheng, J. Retaining Relative Height Information: An Enhanced Technique for Depression Treatment in Digital Elevation Models. Water 2021, 13, 3347. [Google Scholar] [CrossRef]
- Jenson, S.K.; Domingue, J.O. Extracting Topographic Structure from Digital Elevation Data for Geographic Information System Analysis. Photogramm. Eng. Remote Sens. 1988, 54, 1593–1600. [Google Scholar]
- Liu, Y.; Zhang, W.; Xu, J. Another Fast and Simple DEM Depression-Filling Algorithm Based on Priority Queue Structure. Atmos. Ocean Sci. Lett. 2009, 2, 214–219. [Google Scholar]
- Barnes, R. Parallel Priority-Flood Depression Filling for Trillion Cell Digital Elevation Models on Desktops or Clusters. Comput. Geosci. 2016, 96, 56–68. [Google Scholar] [CrossRef]
- Soille, P.; Gratin, C. An Efficient Algorithm for Drainage Network Extraction on DEMs. J. Vis. Commun. Image R. 1994, 5, 181–189. [Google Scholar] [CrossRef]
- Nardi, F.; Grimaldi, S.; Santini, M.; Petroselli, A.; Ubertini, L. Hydrogeomorphic Properties of Simulated Drainage Patterns using Digital Elevation Models: The Flat Area Issue. Hydrolog. Sci. J. 2008, 53, 1176–1193. [Google Scholar] [CrossRef]
- Martz, L.; Garbrecht, J. The Treatment of Flat Areas and Depressions in Automated Drainage Analysis of Raster Digital Elevation Models. Hydrol. Process. 1998, 12, 843–855. [Google Scholar] [CrossRef]
- Su, C.; Wang, X.; Feng, C.; Huang, Z.; Zhang, X. An Integrated Algorithm for Depression Filling and Assignment of Drainage Directions over Flat Surfaces in Digital Elevation Models. Earth Sci. Inform. 2015, 8, 895–905. [Google Scholar] [CrossRef]
- Barnes, R.; Lehman, C.; Mulla, D. An Efficient Assignment of Drainage Direction over Flat Surfaces in Raster Digital Elevation Models. Comput. Geosci. 2014, 62, 128–135. [Google Scholar] [CrossRef]
- Liu, X.; Wang, N.; Shao, J.; Chu, X. An Automated Processing Algorithm for Flat Areas Resulting from DEM Filling and Interpolation. ISPRS Int. J. Geo-Inf. 2017, 6, 376. [Google Scholar] [CrossRef]
- Wang, L.; Liu, H. An Efficient Method for Identifying and Filling Surface Depressions in Digital Elevation Models for Hydrologic Analysis and Modelling. Int. J. Geogr. Inf. Sci. 2006, 20, 193–213. [Google Scholar] [CrossRef]
- Magalhães, S.V.G.; Andrade, M.V.A.; Franklin, W.R.; Pena, G.C. A Linear Time Algorithm to Compute the Drainage Network on Grid Terrains. J. Hydroinform. 2014, 16, 1227–1234. [Google Scholar] [CrossRef]
- Gomes, T.L.; Magalhães, S.V.G.; Andrade, M.V.A.; Franklin, W.R.; Pena, G.C. Efficiently Computing the Drainage Network on Massive Terrains using External Memory Flooding Process. Geoinformatica 2015, 19, 671–692. [Google Scholar] [CrossRef]
- Tahmasebi Nasab, M.; Zhang, J.; Chu, X. A New Depression-dominated Delineation (D-cubed) Method. for Improved Watershed Modelling. Hydrol. Process. 2017, 31, 3364–3378. [Google Scholar] [CrossRef]
- Liu, K.; Song, C.; Ke, L.; Jiang, L.; Ma, R. Automatic Watershed Delineation in the Tibetan Endorheic Basin: A Lake-oriented Approach Based on Digital Elevation Models. Geomorphology 2020, 358, 107127. [Google Scholar] [CrossRef]
- Yamazaki, D.; Baugh, C.A.; Bates, P.D.; Kanae, S.; Alsdorf, D.E.; Oki, T. Adjustment of a Spaceborne DEM for Use in Floodplain Hydrodynamic Modeling. J. Hydrol. 2012, 436–437, 81–91. [Google Scholar] [CrossRef]
- Metz, M.; Mitasova, H.; Harmon, R. Efficient Extraction of Drainage Networks from Massive, Radar-based Elevation Models with Least Cost Path Search. Hydrol. Earth Syst. Sci. 2011, 15, 667–678. [Google Scholar] [CrossRef]
- Barnes, R.; Lehman, C.; Mulla, D. Priority-flood: An Optimal Depression-filling and Watershed-labeling Algorithm for Digital Elevation Models. Comput. Geosci. 2014, 62, 117–127. [Google Scholar] [CrossRef]
- Schiavo, P.; Riva, M.; Guadagnini, L.; Zehe, E.; Guadagnini, A. Probabilistic Identification of Preferential Groundwater Networks. J. Hydrol. 2022, 610, 127906. [Google Scholar] [CrossRef]
- Zhang, H.; Yao, Z.; Yang, Q.; Li, S.; Baartman, J.E.M.; Gai, L.; Yao, M.; Yang, X.; Ritsema, C.J.; Geissen, V. An Integrated Algorithm to Evaluate Flow Direction and Flow Accumulation in Flat Regions of Hydrologically Corrected DEMs. Catena 2017, 151, 174–181. [Google Scholar] [CrossRef]
- Liu, J.; Chen, X.; Zhang, X.; Hoagland, K.D. Grid Digital Elevation Model Based Algorithms for Determination of Hillslope Width Functions through Flow Distance Transforms. Water Resour. Res. 2012, 48, W04532. [Google Scholar] [CrossRef]
- Luengo Hendriks, C. Revisiting priority queues for image analysis. Pattern Recogn. 2010, 43, 3003–3012. [Google Scholar] [CrossRef]
- Wu, P.; Liu, J.; Han, X.; Liang, Z.; Liu, Y.; Fei, J. Nondispersive Drainage Direction Simulation based on Flexible Triangular Facets. Water Resour. Res. 2020, 55, e2019WR026507. [Google Scholar] [CrossRef]
- Orlandini, S.; Moretti, G.; Corticelli, M.A.; Santangelo, P.E.; Capra, A.; Rivola, R.; Albertson, J.D. Evaluation of Flow Direction Methods against Field Observations of Overland Flow Dispersion. Water Resour. Res. 2012, 48, W10523. [Google Scholar] [CrossRef]
- Lindsay, J.B. The Practice of DEM Stream Burning Revisited. Earth Surf. Process. Landf. 2016, 41, 658–668. [Google Scholar] [CrossRef]
- Moretti, G.; Orlandini, S. Thalweg and Ridge Network Extraction from Unaltered Topographic Data as a Basis for Terrain Partitioning. J. Geophys. Res. 2023, 128, e2022JF006943. [Google Scholar] [CrossRef]
- Yan, D.; Wang, K.; Qin, T.; Weng, B.; Wang, H.; Bi, W.; Li, X.; Li, M.; Lu, Z.; Liu, F.; et al. A Data Set of Global River Networks and Corresponding Water Resources Zones Divisions. Sci. Data 2019, 6, 219. [Google Scholar] [CrossRef]
- O’Brien, G.R.; Wheaton, J.M.; Fryirs, K.; Macfarlane, W.W.; Brierley, G.; Whitehead, K.; Gilbert, J.; Volk, C. Mapping Valley Bottom Confinement at the Network Scale. Earth Surf. Process. Landf. 2019, 44, 1828–1845. [Google Scholar] [CrossRef]
- Schiavo, M. Quantile-Based Approach for Improving the Identification of Preferential Groundwater Networks. Water 2025, 17, 282. [Google Scholar] [CrossRef]
- Berkowitz, B.; Zehe, E. Surface Water and Groundwater: Unifying Conceptualization and Quantification of the Two “Water Worlds”. Hydrol. Earth Syst. Sci. 2020, 24, 1831–1858. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, P.; Liu, J.; Xv, K.; Han, X. Efficient Digital-Elevation-Model-Based Flow Direction Estimation Using Priority Queue with Flow Distance and Zigzag Route Considerations. Water 2025, 17, 1273. https://doi.org/10.3390/w17091273
Wu P, Liu J, Xv K, Han X. Efficient Digital-Elevation-Model-Based Flow Direction Estimation Using Priority Queue with Flow Distance and Zigzag Route Considerations. Water. 2025; 17(9):1273. https://doi.org/10.3390/w17091273
Chicago/Turabian StyleWu, Pengfei, Jintao Liu, Kaili Xv, and Xiaole Han. 2025. "Efficient Digital-Elevation-Model-Based Flow Direction Estimation Using Priority Queue with Flow Distance and Zigzag Route Considerations" Water 17, no. 9: 1273. https://doi.org/10.3390/w17091273
APA StyleWu, P., Liu, J., Xv, K., & Han, X. (2025). Efficient Digital-Elevation-Model-Based Flow Direction Estimation Using Priority Queue with Flow Distance and Zigzag Route Considerations. Water, 17(9), 1273. https://doi.org/10.3390/w17091273