
Flood Susceptibility Assessment Using Multi-Tier Feature Selection and Ensemble Boosting Machine Learning Models

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
2. Materials and Methods
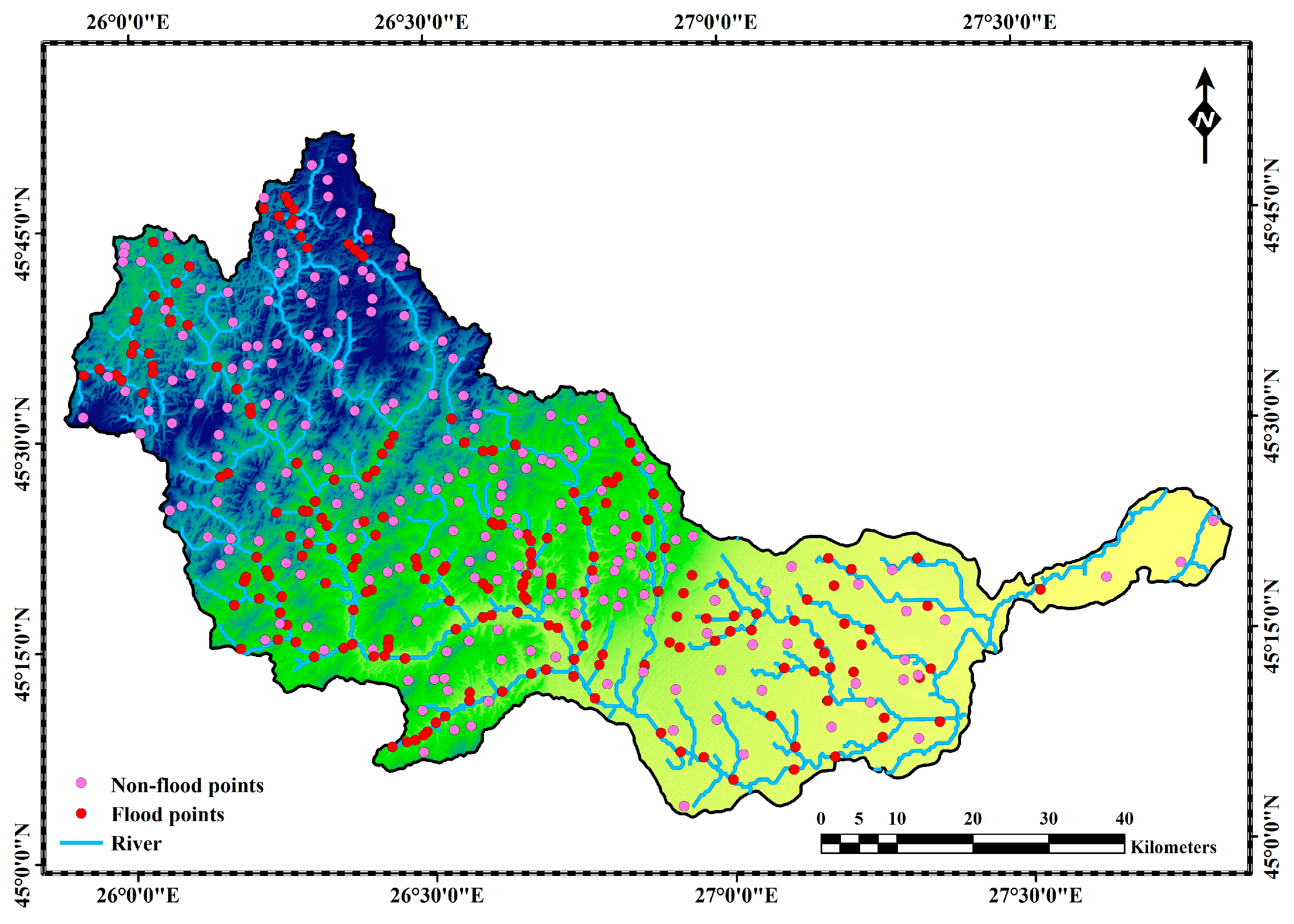
2.1. Study Area: Overview of the Buzău River Catchment
2.2. Methodological Framework for Susceptibility Modeling
2.3. Flood Inventory Dataset and Data Splitting Strategy
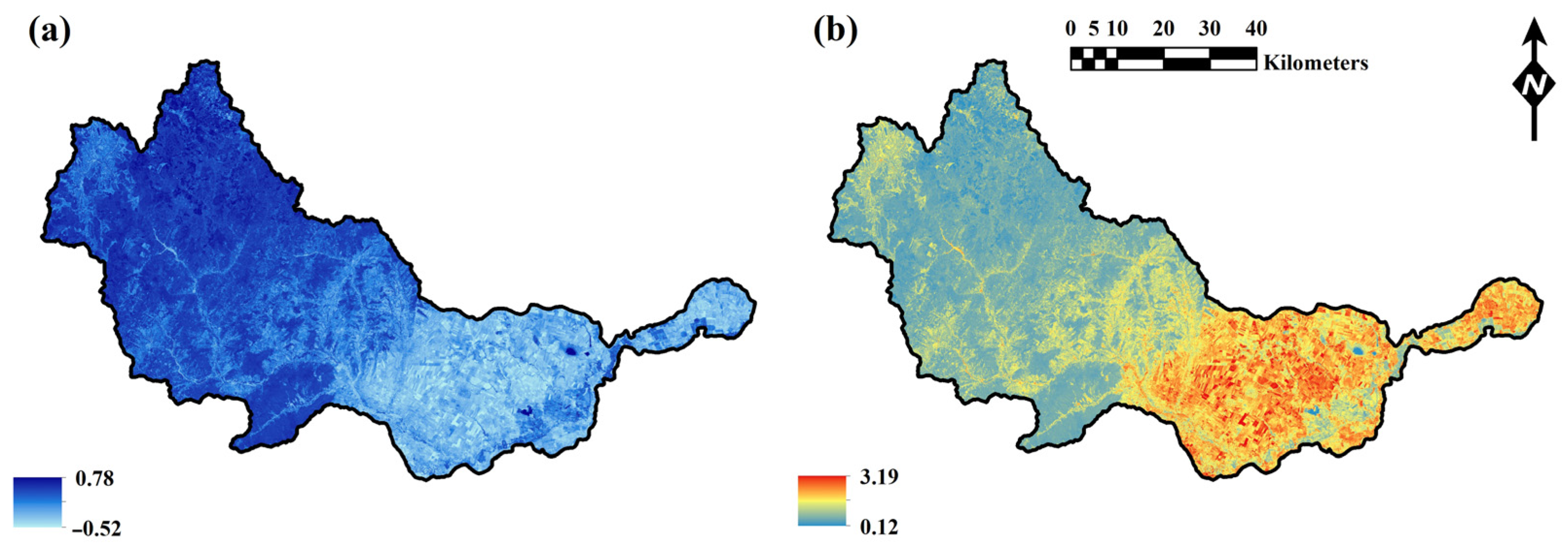
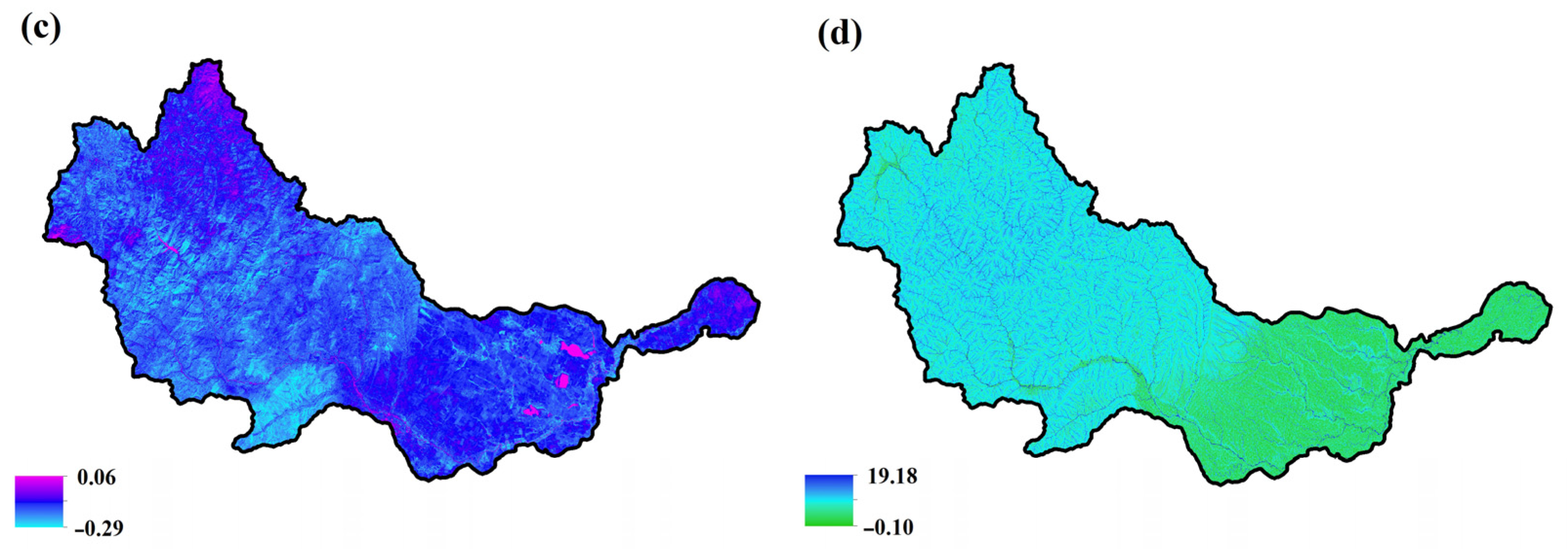
2.4. Derivation of Conditioning Factors
2.5. Feature Selection Techniques
2.5.1. Variance Inflation Factor (VIF)
2.5.2. Condition Index (CI)
2.5.3. Mutual Information (MI)
2.5.4. Information Gain (IG)
2.6. Machine Learning (ML) Algorithms
2.6.1. Adaptive Boosting (AdaBoost)
2.6.2. Gradient Boosting Algorithms
2.7. Performance Evaluation Techniques
2.7.1. Mean Absolute Error (MAE) and Root Mean Square Error (RMSE)
2.7.2. R-Squared (R2)
2.7.3. Accuracy, Precision, Recall, and F1-Score
2.7.4. Kappa Index (κ-Index)
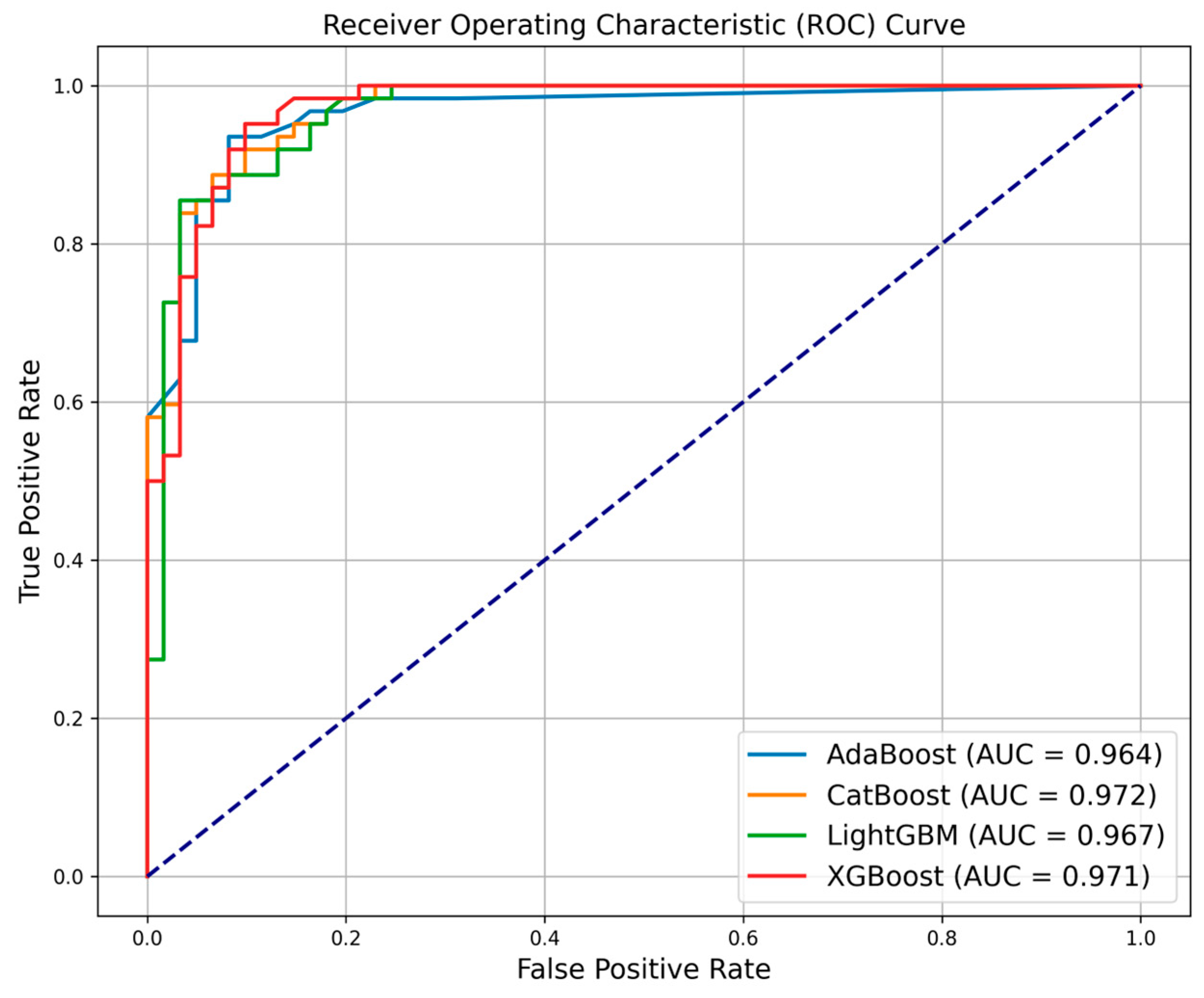
2.7.5. Receiver Operating Characteristic (ROC) Curve
2.7.6. Precision Recall Curve (PRC)
2.8. Factor Importance Evaluation: SHapley Additive exPlanations (SHAP)
3. Results
3.1. Conditioning Factors Selected Through Various Feature Selection Methods
3.2. Flood Susceptibility Models and Their Performance
3.3. Results of Susceptibility Model Evaluation Using Various Performance Metrics
4. Discussion
4.1. Role and Importance of Conditioning Factors
4.2. Interpretation of Model Performance Outcomes
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sl. No. | Conditioning Factor | VIF Score |
|---|---|---|
| 1 | LSWI | 138.576 |
| 2 | UI | 68.691 |
| 3 | NDISI | 33.641 |
| 4 | Soil Clay Content | 8.081 |
| 5 | NDGI | 7.756 |
| 6 | Soil Bulk Density | 6.694 |
| 7 | TWI | 4.996 |
| 8 | Elevation | 3.594 |
| 9 | Slope | 3.592 |
| 10 | SPI | 3.234 |
| 11 | NDWI | 2.570 |
| 12 | Distance from Rivers | 1.487 |
| 13 | LULC | 1.378 |
| Sl. No. | Conditioning Factor | VIF Score |
|---|---|---|
| 1 | UI | 23.294 |
| 2 | NDISI | 20.292 |
| 3 | Soil Clay Content | 7.857 |
| 4 | NDGI | 6.603 |
| 5 | Soil Bulk Density | 6.569 |
| 6 | TWI | 4.949 |
| 7 | Slope | 3.583 |
| 8 | SPI | 3.170 |
| 9 | Elevation | 3.048 |
| 10 | NDWI | 2.309 |
| 11 | Distance from Rivers | 1.487 |
| 12 | LULC | 1.373 |
References
- Petrucci, O.; Aceto, L.; Bianchi, C.; Bigot, V.; Brázdil, R.; Pereira, S.; Kahraman, A.; Kılıç, Ö.; Kotroni, V.; Llasat, M.C.; et al. Flood Fatalities in Europe, 1980–2018: Variability, Features, and Lessons to Learn. Water 2019, 11, 1682. [Google Scholar] [CrossRef]
- Chen, J.; Shi, X.; Gu, L.; Wu, G.; Su, T.; Wang, H.M.; Kim, J.S.; Zhang, L.; Xiong, L. Impacts of Climate Warming on Global Floods and Their Implication to Current Flood Defense Standards. J. Hydrol. 2023, 618, 129236. [Google Scholar] [CrossRef]
- Furtak, K.; Wolińska, A. The Impact of Extreme Weather Events as a Consequence of Climate Change on the Soil Moisture and on the Quality of the Soil Environment and Agriculture—A Review. CATENA 2023, 231, 107378. [Google Scholar] [CrossRef]
- Gatto, A.; Martellozzo, F.; Clo’, S.; Ciulla, L.; Segoni, S. The Downward Spiral Entangling Soil Sealing and Hydrogeological Disasters. Environ. Res. Lett. 2024, 19, 084023. [Google Scholar] [CrossRef]
- Liu, Q.; Du, M.; Wang, Y.; Deng, J.; Yan, W.; Qin, C.; Liu, M.; Liu, J. Global, Regional and National Trends and Impacts of Natural Floods, 1990–2022. Bull. World Health Organ. 2024, 102, 410–420. [Google Scholar] [CrossRef]
- Paprotny, D.; Terefenko, P.; Śledziowski, J. HANZE v2.1: An Improved Database of Flood Impacts in Europe from 1870 to 2020. Earth Syst. Sci. Data 2024, 16, 5145–5170. [Google Scholar] [CrossRef]
- Economic Losses from Weather- and Climate-Related Extremes in Europe. Available online: https://www.eea.europa.eu/en/analysis/indicators/economic-losses-from-climate-related (accessed on 13 May 2025).
- Morlot, M.; Brilly, M.; Šraj, M. Characterisation of the Floods in the Danube River Basin through Flood Frequency and Seasonality Analysis. Acta Hydrotech. 2019, 32, 73–89. [Google Scholar] [CrossRef]
- Bezak, N.; Petan, S.; Kobold, M.; Brilly, M.; Bálint, Z.; Balabanova, S.; Cazac, V.; Csík, A.; Godina, R.; Janál, P.; et al. A Catalogue of the Flood Forecasting Practices in the Danube River Basin. River Res. Appl. 2021, 37, 909–918. [Google Scholar] [CrossRef]
- Leščešen, I.; Basarin, B.; Pavić, D.; Mudelsee, M.; Pekarova, P.; Mesaroš, M. Are Extreme Floods on the Danube River Becoming More Frequent? A Case Study of Bratislava Station. J. Water Clim. Chang. 2024, 15, 1300–1312. [Google Scholar] [CrossRef]
- Hein, T.; Schwarz, U.; Habersack, H.; Nichersu, I.; Preiner, S.; Willby, N.; Weigelhofer, G. Current Status and Restoration Options for Floodplains along the Danube River. Sci. Total Environ. 2016, 543, 778–790. [Google Scholar] [CrossRef]
- Eder, M.; Perosa, F.; Hohensinner, S.; Tritthart, M.; Scheuer, S.; Gelhaus, M.; Cyffka, B.; Kiss, T.; Van Leeuwen, B.; Tobak, Z.; et al. How Can We Identify Active, Former, and Potential Floodplains? Methods and Lessons Learned from the Danube River. Water 2022, 14, 2295. [Google Scholar] [CrossRef]
- Romanescu, G.; Stoleriu, C. Causes and Effects of the Catastrophic Flooding on the Siret River (Romania) in July–August 2008. Nat. Hazards 2013, 69, 1351–1367. [Google Scholar] [CrossRef]
- Romanescu, G.; Cimpianu, C.I.; Mihu-Pintilie, A.; Stoleriu, C.C. Historic Flood Events in NE Romania (Post-1990). J. Maps 2017, 13, 787–798. [Google Scholar] [CrossRef]
- Sekulova, F.; van den Bergh, J.C.J.M. Floods and Happiness: Empirical Evidence from Bulgaria. Ecol. Econ. 2016, 126, 51–57. [Google Scholar] [CrossRef]
- Momčilović Petronijević, A.; Petronijević, P. Floods and Their Impact on Cultural Heritage—A Case Study of Southern and Eastern Serbia. Sustainability 2022, 14, 14680. [Google Scholar] [CrossRef]
- Petrović, A.M.; Leščešen, I.; Radevski, I. Unveiling Torrential Flood Dynamics: A Comprehensive Study of Spatio-Temporal Patterns in the Šumadija Region, Serbia. Water 2024, 16, 991. [Google Scholar] [CrossRef]
- Ana, J. Assessment of Pluvial Floods Potential on the Rivers of the Republic of Moldova. Present Environ. Sustain. Dev. 2018, 12, 121–133. [Google Scholar] [CrossRef]
- Agayar, E.; Armon, M.; Wernli, H. The Catastrophic Floods in 2008, 2010 and 2020 in Western Ukraine: Hydrometeorological Processes and the Role of Upper-Level Dynamics. In Proceedings of the EGU General Assembly 2025, Vienna, Austria, 27 April–2 May 2025. [Google Scholar] [CrossRef]
- Albano, R.; Samela, C.; Crăciun, I.; Manfreda, S.; Adamowski, J.; Sole, A.; Sivertun, Å.; Ozunu, A. Large Scale Flood Risk Mapping in Data Scarce Environments: An Application for Romania. Water 2020, 12, 1834. [Google Scholar] [CrossRef]
- Albulescu, A.C. Exploring the Links between Flood Events and the COVID-19 Infection Cases in Romania in the New Multi-Hazard-Prone Era. Nat. Hazards 2023, 117, 1611–1631. [Google Scholar] [CrossRef]
- Armaş, I.; Dobre, D.; Fekete, A.; Rufat, S.; Albulescu, A.C. Hinging on the Preparedness of First Responders. A Case Study on the 2021 Flood Operations in Romania. Int. J. Disaster Risk Red. 2025, 116, 105008. [Google Scholar] [CrossRef]
- Costache, R.; Crăciun, A.; Ciobotaru, N.; Bărbulescu, A. Intelligent Methods for Estimating the Flood Susceptibility in the Danube Delta, Romania. Water 2024, 16, 3511. [Google Scholar] [CrossRef]
- Popescu, N.C.; Bărbulescu, A. A Practical Approach on Reducing the Flood Impact: A Case Study from Romania. Appl. Sci. 2024, 14, 10378. [Google Scholar] [CrossRef]
- Popa, M.C.; Simion, A.G.; Peptenatu, D.; Dima, C.; Draghici, C.C.; Florescu, M.; Dobrea, C.R.; Diaconu, D.C. Spatial Assessment of Flash-flood Vulnerability in the Moldova River Catchment (N Romania) Using the FFPI. J. Flood Risk Manag. 2020, 13, e12624. [Google Scholar] [CrossRef]
- Costache, R.; Arabameri, A.; Costache, I.; Crăciun, A.; Md Towfiqul Islam, A.R.; Abba, S.I.; Sahana, M.; Pham, B.T. Flood Susceptibility Evaluation through Deep Learning Optimizer Ensembles and GIS Techniques. J. Environ. Manag. 2022, 316, 115316. [Google Scholar] [CrossRef]
- Ionescu, C.S.; Gogoașe-Nistoran, D.E.; Baciu, C.A.; Cozma, A.; Motovilnic, I.; Brașovanu, L. The Impact of a Clay-Core Embankment Dam Break on the Flood Wave Characteristics. Hydrology 2025, 12, 56. [Google Scholar] [CrossRef]
- Constantin-Horia, B.; Simona, S.; Gabriela, P.; Adrian, S. Human Factors in the Floods of Romania. In Proceedings of the Threats to Global Water Security; Jones, J.A.A., Vardanian, T.G., Hakopian, C., Eds.; Springer: Dordrecht, The Netherlands, 2009; pp. 187–192. [Google Scholar] [CrossRef]
- Peptenatu, D.; Grecu, A.; Simion, A.G.; Gruia, K.A.; Andronache, I.; Draghici, C.C.; Diaconu, D.C. Deforestation and Frequency of Floods in Romania. In Water Resources Management in Romania; Negm, A.M., Romanescu, G., Zeleňáková, M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 279–306. [Google Scholar] [CrossRef]
- World Bank. Romania Water Diagnostic Report: Moving Toward EU Compliance, Inclusion, and Water Security; World Bank: Washington, DC, USA, 2018. [Google Scholar]
- Cojoc, G.M.; Romanescu, G.; Tirnovan, A. Exceptional Floods on a Developed River: Case Study for the Bistrita River from the Eastern Carpathians (Romania). Nat. Hazards 2015, 77, 1421–1451. [Google Scholar] [CrossRef]
- Stancalie, G.; Craciunescu, V.; Irimescu, A. Development of a Downstream Emergency Response Service for Flood and Related Risks in Romania Based on Satellite Data. E3S Web Conf. 2016, 7, 17007. [Google Scholar] [CrossRef]
- Tudose, N.C.; Ungurean, C.; Davidescu, Ș.; Clinciu, I.; Marin, M.; Nita, M.D.; Adorjani, A.; Davidescu, A. Torrential Flood Risk Assessment and Environmentally Friendly Solutions for Small Catchments Located in the Romania Natura 2000 Sites Ciucas, Postavaru and Piatra Mare. Sci. Total Environ. 2020, 698, 134271. [Google Scholar] [CrossRef]
- Romanescu, G.; Stoleriu, C.C. Exceptional Floods in the Prut Basin, Romania, in the Context of Heavy Rains in the Summer of 2010. Nat. Hazard. Earth Syst. Sci. 2017, 17, 381–396. [Google Scholar] [CrossRef]
- Ionita, M.; Nagavciuc, V. Shedding Light on the Devastating Floods in June 1897 in Romania: Early Instrumental Observations and Synoptic Analysis. J. Hydrometeorol. 2024, 25, 1729–1745. [Google Scholar] [CrossRef]
- Romania: Floods-DREF Operation N° MDRRO006—Romania|ReliefWeb. Available online: https://reliefweb.int/report/romania/romania-floods-dref-operation-ndeg-mdrro006 (accessed on 26 May 2025).
- Floods in Central-Eastern Europe—September 2024. Available online: http://emergency.copernicus.eu/news/floods-in-central-eastern-europe-september-2024/ (accessed on 26 May 2025).
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood Susceptibility Mapping Using Frequency Ratio and Weights-of-Evidence Models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Sharma, A.; Poonia, M.; Rai, A.; Biniwale, R.B.; Tügel, F.; Holzbecher, E.; Hinkelmann, R. Flood Susceptibility Mapping Using GIS-Based Frequency Ratio and Shannon’s Entropy Index Bivariate Statistical Models: A Case Study of Chandrapur District, India. ISPRS Int. J. Geo-Inf. 2024, 13, 297. [Google Scholar] [CrossRef]
- Edamo, M.L.; Ayele, E.G.; Ukumo, T.Y.; Kassaye, A.A.; Haile, A.P. Capability of Logistic Regression in Identifying Flood-Susceptible Areas in a Small Watershed. H2Open J. 2024, 7, 351–374. [Google Scholar] [CrossRef]
- Senan, C.P.C.; Ajin, R.S.; Danumah, J.H.; Costache, R.; Arabameri, A.; Rajaneesh, A.; Sajinkumar, K.S.; Kuriakose, S.L. Flood Vulnerability of a Few Areas in the Foothills of the Western Ghats: A Comparison of AHP and F-AHP Models. Stoch. Environ. Res. Risk Assess. 2023, 37, 527–556. [Google Scholar] [CrossRef]
- Yariyan, P.; Avand, M.; Abbaspour, R.A.; Torabi Haghighi, A.; Costache, R.; Ghorbanzadeh, O.; Janizadeh, S.; Blaschke, T. Flood Susceptibility Mapping Using an Improved Analytic Network Process with Statistical Models. Geomat. Nat. Hazard. Risk 2020, 11, 2282–2314. [Google Scholar] [CrossRef]
- Lyu, H.M.; Yin, Z.Y. Flood Susceptibility Prediction Using Tree-Based Machine Learning Models in the GBA. Sustain. Cities Soc. 2023, 97, 104744. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Mansor, S.; Ahmad, N. Flood Susceptibility Assessment Using GIS-Based Support Vector Machine Model with Different Kernel Types. CATENA 2015, 125, 91–101. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling Flood Susceptibility Using Data-Driven Approaches of Naïve Bayes Tree, Alternating Decision Tree, and Random Forest Methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Aydin, H.E.; Iban, M.C. Predicting and Analyzing Flood Susceptibility Using Boosting-Based Ensemble Machine Learning Algorithms with SHapley Additive ExPlanations. Nat. Hazards 2023, 116, 2957–2991. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Z.; Wang, L.; Ding, X.; Wang, S. Improving the Accuracy of Flood Susceptibility Prediction by Combining Machine Learning Models and the Expanded Flood Inventory Data. Remote Sens. 2023, 15, 3601. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Peng, L. Flood Susceptibility Mapping Using Convolutional Neural Network Frameworks. J. Hydrol. 2020, 582, 124482. [Google Scholar] [CrossRef]
- Chen, C.; Wang, J.; Li, D.; Sun, X.; Zhang, J.; Yang, C.; Zhang, B. Unraveling Nonlinear Effects of Environment Features on Green View Index Using Multiple Data Sources and Explainable Machine Learning. Sci. Rep. 2024, 14, 30189. [Google Scholar] [CrossRef] [PubMed]
- Mienye, I.D.; Sun, Y. A Survey of Ensemble Learning: Concepts, Algorithms, Applications, and Prospects. IEEE Access 2022, 10, 99129–99149. [Google Scholar] [CrossRef]
- Ajin, R.S.; Segoni, S.; Fanti, R. Optimization of SVR and CatBoost Models Using Metaheuristic Algorithms to Assess Landslide Susceptibility. Sci. Rep. 2024, 14, 24851. [Google Scholar] [CrossRef]
- Roy, D.K.; Sarkar, T.K.; Munmun, T.H.; Paul, C.R.; Datta, B. A Review on the Applications of Machine Learning and Deep Learning to Groundwater Salinity Modeling: Present Status, Challenges, and Future Directions. Discov. Water 2025, 5, 16. [Google Scholar] [CrossRef]
- Ding, Y.; Zhu, H.; Chen, R.; Li, R. An Efficient AdaBoost Algorithm with the Multiple Thresholds Classification. Appl. Sci. 2022, 12, 5872. [Google Scholar] [CrossRef]
- Hussain, S.S.; Zaidi, S.S.H. AdaBoost Ensemble Approach with Weak Classifiers for Gear Fault Diagnosis and Prognosis in DC Motors. Appl. Sci. 2024, 14, 3105. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Ganie, S.M.; Pramanik, P.K.D.; Zhao, Z. Ensemble Learning with Explainable AI for Improved Heart Disease Prediction Based on Multiple Datasets. Sci. Rep. 2025, 15, 13912. [Google Scholar] [CrossRef]
- Rizkallah, L.W. Enhancing the Performance of Gradient Boosting Trees on Regression Problems. J. Big Data 2025, 12, 35. [Google Scholar] [CrossRef]
- Abujayyab, S.K.M.; Kassem, M.M.; Khan, A.A.; Wazirali, R.; Coşkun, M.; Taşoğlu, E.; Öztürk, A.; Toprak, F. Wildfire Susceptibility Mapping Using Five Boosting Machine Learning Algorithms: The Case Study of the Mediterranean Region of Turkey. Adv. Civ. Eng. 2022, 2022, 3959150. [Google Scholar] [CrossRef]
- Deng, J.; Ji, W.; Liu, H.; Li, L.; Wang, Z.; Hu, Y.; Wang, Y.; Zhou, Y. Development and Validation of a Machine Learning-Based Framework for Assessing Metabolic-Associated Fatty Liver Disease Risk. BMC Public Health 2024, 24, 2545. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, N.; Ngo, D. Comparative Analysis of Boosting Algorithms for Predicting Personal Default. Cogent Econ. Fin. 2025, 13, 2465971. [Google Scholar] [CrossRef]
- Hajji, S.; Krimissa, S.; Abdelrahman, K.; Boudhar, A.; Elaloui, A.; Ismaili, M.; El Bouzekraoui, M.; Chikh Essbiti, M.; Kahal, A.Y.; Mondal, B.K.; et al. Enhancing Flood Prediction through Remote Sensing, Machine Learning, and Google Earth Engine. Front. Water 2025, 7, 1514047. [Google Scholar] [CrossRef]
- Tian, J.; Chen, Y.; Yang, L.; Li, D.; Liu, L.; Li, J.; Tang, X. Enhancing Urban Flood Susceptibility Assessment by Capturing the Features of the Urban Environment. Remote Sens. 2025, 17, 1347. [Google Scholar] [CrossRef]
- Shi, S.; Zhao, F.; Ren, X.; Meng, Z.; Dang, X.; Wu, X. Soil Infiltration Properties Are Affected by Typical Plant Communities in a Semi-Arid Desert Grassland in China. Water 2022, 14, 3301. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, Q.; Liu, S.; Li, J.; Geng, J.; Wang, L. Key Soil Properties Influencing Infiltration Capacity after Long-Term Straw Incorporation in a Wheat (Triticum Aestivum L.)—Maize (Zea Mays L.) Rotation System. Agric. Ecosyst. Environ. 2023, 344, 108301. [Google Scholar] [CrossRef]
- Wang, D.; Chen, J.; Tang, Z.; Zhang, Y. Effects of Soil Physical Properties on Soil Infiltration in Forest Ecosystems of Southeast China. Forests 2024, 15, 1470. [Google Scholar] [CrossRef]
- Popa, M.C.; Peptenatu, D.; Drăghici, C.C.; Diaconu, D.C. Flood Hazard Mapping Using the Flood and Flash-Flood Potential Index in the Buzău River Catchment, Romania. Water 2019, 11, 2116. [Google Scholar] [CrossRef]
- Costache, R.; Arabameri, A.; Elkhrachy, I.; Ghorbanzadeh, O.; Pham, Q.B. Detection of Areas Prone to Flood Risk Using State-of-the-Art Machine Learning Models. Geomat. Nat. Hazards Risk 2021, 12, 1488–1507. [Google Scholar] [CrossRef]
- Costache, R.; Popa, M.C.; Tien Bui, D.; Diaconu, D.C.; Ciubotaru, N.; Minea, G.; Pham, Q.B. Spatial Predicting of Flood Potential Areas Using Novel Hybridizations of Fuzzy Decision-Making, Bivariate Statistics, and Machine Learning. J. Hydrol. 2020, 585, 124808. [Google Scholar] [CrossRef]
- Nguyen, Q.H.; Ly, H.-B.; Ho, L.S.; Al-Ansari, N.; Le, H.V.; Tran, V.Q.; Prakash, I.; Pham, B.T. Influence of Data Splitting on Performance of Machine Learning Models in Prediction of Shear Strength of Soil. Math. Probl. Eng. 2021, 2021, 4832864. [Google Scholar] [CrossRef]
- Segoni, S.; Ajin, R.S.; Nocentini, N.; Fanti, R. Insights Gained from the Review of Landslide Susceptibility Assessment Studies in Italy. Remote Sens. 2024, 16, 4491. [Google Scholar] [CrossRef]
- Kaya, C.M.; Derin, L. Parameters and Methods Used in Flood Susceptibility Mapping: A Review. J. Water Clim. Chang. 2023, 14, 1935–1960. [Google Scholar] [CrossRef]
- Mabdeh, A.N.; Ajin, R.S.; Razavi-Termeh, S.V.; Ahmadlou, M.; Al-Fugara, A. Enhancing the Performance of Machine Learning and Deep Learning-Based Flood Susceptibility Models by Integrating Grey Wolf Optimizer (GWO) Algorithm. Remote Sens. 2024, 16, 2595. [Google Scholar] [CrossRef]
- Islam, T.; Zeleke, E.B.; Afroz, M.; Melesse, A.M. A Systematic Review of Urban Flood Susceptibility Mapping: Remote Sensing, Machine Learning, and Other Modeling Approaches. Remote Sens. 2025, 17, 524. [Google Scholar] [CrossRef]
- Suharyadi, R.; Umarhadi, D.A.; Awanda, D.; Widyatmanti, W. Exploring Built-Up Indices and Machine Learning Regressions for Multi-Temporal Building Density Monitoring Based on Landsat Series. Sensors 2022, 22, 4716. [Google Scholar] [CrossRef]
- Oñate-Valdivieso, F.; Oñate-Paladines, A.; Collaguazo, M. Spatiotemporal Dynamics of Soil Impermeability and Its Impact on the Hydrology of an Urban Basin. Land 2022, 11, 250. [Google Scholar] [CrossRef]
- Cao, R.; Feng, Y.; Liu, X.; Shen, M.; Zhou, J. Uncertainty of Vegetation Green-Up Date Estimated from Vegetation Indices Due to Snowmelt at Northern Middle and High Latitudes. Remote Sens. 2020, 12, 190. [Google Scholar] [CrossRef]
- Laonamsai, J.; Julphunthong, P.; Saprathet, T.; Kimmany, B.; Ganchanasuragit, T.; Chomcheawchan, P.; Tomun, N. Utilizing NDWI, MNDWI, SAVI, WRI, and AWEI for Estimating Erosion and Deposition in Ping River in Thailand. Hydrology 2023, 10, 70. [Google Scholar] [CrossRef]
- Xiang, K.; Yuan, W.; Wang, L.; Deng, Y. An LSWI-Based Method for Mapping Irrigated Areas in China Using Moderate-Resolution Satellite Data. Remote Sens. 2020, 12, 4181. [Google Scholar] [CrossRef]
- Chan, J.Y.L.; Leow, S.M.H.; Bea, K.T.; Cheng, W.K.; Phoong, S.W.; Hong, Z.W.; Chen, Y.L. Mitigating the Multicollinearity Problem and Its Machine Learning Approach: A Review. Mathematics 2022, 10, 1283. [Google Scholar] [CrossRef]
- Odhiambo Omuya, E.; Onyango Okeyo, G.; Waema Kimwele, M. Feature Selection for Classification Using Principal Component Analysis and Information Gain. Expert Syst. Appl. 2021, 174, 114765. [Google Scholar] [CrossRef]
- Qu, K.; Xu, J.; Hou, Q.; Qu, K.; Sun, Y. Feature Selection Using Information Gain and Decision Information in Neighborhood Decision System. Appl. Soft Comp. 2023, 136, 110100. [Google Scholar] [CrossRef]
- Sinha, A.; Nikhil, S.; Ajin, R.S.; Danumah, J.H.; Saha, S.; Costache, R.; Rajaneesh, A.; Sajinkumar, K.S.; Amrutha, K.; Johny, A.; et al. Wildfire Risk Zone Mapping in Contrasting Climatic Conditions: An Approach Employing AHP and F-AHP Models. Fire 2023, 6, 44. [Google Scholar] [CrossRef]
- Kim, J.H. Multicollinearity and Misleading Statistical Results. Korean J. Anesthesiol. 2019, 72, 558–569. [Google Scholar] [CrossRef]
- Dar, I.S.; Chand, S.; Shabbir, M.; Kibria, B.M.G. Condition-Index Based New Ridge Regression Estimator for Linear Regression Model with Multicollinearity. Kuwait J. Sci. 2023, 50, 91–96. [Google Scholar] [CrossRef]
- Huang, L.; Zhou, X.; Shi, L.; Gong, L. Time Series Feature Selection Method Based on Mutual Information. Appl. Sci. 2024, 14, 1960. [Google Scholar] [CrossRef]
- Sulaiman, M.A.; Labadin, J. Feature Selection with Mutual Information for Regression Problems. In Proceedings of the 2015 9th International Conference on IT in Asia (CITA), Sarawak, Malaysia, 4–5 August 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Vergara, J.R.; Estévez, P.A. A Review of Feature Selection Methods Based on Mutual Information. Neural Comput. Appl. 2014, 24, 175–186. [Google Scholar] [CrossRef]
- Prasetiyowati, M.I.; Maulidevi, N.U.; Surendro, K. Determining Threshold Value on Information Gain Feature Selection to Increase Speed and Prediction Accuracy of Random Forest. J. Big Data 2021, 8, 84. [Google Scholar] [CrossRef]
- Omer, Z.M.; Shareef, H. Comparison of Decision Tree Based Ensemble Methods for Prediction of Photovoltaic Maximum Current. Energy Convers. Manag. X 2022, 16, 100333. [Google Scholar] [CrossRef]
- Khan, A.A.; Chaudhari, O.; Chandra, R. A Review of Ensemble Learning and Data Augmentation Models for Class Imbalanced Problems: Combination, Implementation and Evaluation. Expert Syst. Appl. 2024, 244, 122778. [Google Scholar] [CrossRef]
- Levent, İ.; Şahin, G.; Işık, G.; van Sark, W.G.J.H.M. Comparative Analysis of Advanced Machine Learning Regression Models with Advanced Artificial Intelligence Techniques to Predict Rooftop PV Solar Power Plant Efficiency Using Indoor Solar Panel Parameters. Appl. Sci. 2025, 15, 3320. [Google Scholar] [CrossRef]
- Shen, F.; Jha, I.; Isleem, H.F.; Almoghayer, W.J.K.; Khishe, M.; Elshaarawy, M.K. Advanced Predictive Machine and Deep Learning Models for Round-Ended CFST Column. Sci. Rep. 2025, 15, 6194. [Google Scholar] [CrossRef]
- Boldini, D.; Grisoni, F.; Kuhn, D.; Friedrich, L.; Sieber, S.A. Practical Guidelines for the Use of Gradient Boosting for Molecular Property Prediction. J. Cheminform. 2023, 15, 73. [Google Scholar] [CrossRef]
- So, B. Enhanced Gradient Boosting for Zero-Inflated Insurance Claims and Comparative Analysis of CatBoost, XGBoost, and LightGBM. Scandinav. Actuar. J. 2024, 10, 1013–1035. [Google Scholar] [CrossRef]
- Karunasingha, D.S.K. Root Mean Square Error or Mean Absolute Error? Use Their Ratio as Well. Inform. Sci. 2022, 585, 609–629. [Google Scholar] [CrossRef]
- Romeo, G. Chapter 13—Data Analysis for Business and Economics. In Elements of Numerical Mathematical Economics with Excel; Romeo, G., Ed.; Academic Press: Boston, MA, USA, 2020; pp. 695–761. [Google Scholar] [CrossRef]
- Ross, S.M. Chapter 12—Linear Regression. In Introductory Statistics, 3rd ed.; Ross, S.M., Ed.; Academic Press: Boston, MA, USA, 2010; pp. 537–604. [Google Scholar] [CrossRef]
- AlZoman, R.M.; Alenazi, M.J.F. A Comparative Study of Traffic Classification Techniques for Smart City Networks. Sensors 2021, 21, 4677. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Darabi, S.; Blaschke, T.; Lakes, T. QADI as a New Method and Alternative to Kappa for Accuracy Assessment of Remote Sensing-Based Image Classification. Sensors 2022, 22, 4506. [Google Scholar] [CrossRef]
- Nayak, R.; Pati, U.C.; Das, S.K. A Comprehensive Review on Deep Learning-Based Methods for Video Anomaly Detection. Image Vis. Comput. 2021, 106, 104078. [Google Scholar] [CrossRef]
- Nahm, F.S. Receiver Operating Characteristic Curve: Overview and Practical Use for Clinicians. Korean J. Anesthesiol. 2022, 75, 25–36. [Google Scholar] [CrossRef] [PubMed]
- Melo, F. Area under the ROC Curve. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; pp. 38–39. [Google Scholar] [CrossRef]
- Fu, G.-H.; Xu, F.; Zhang, B.-Y.; Yi, L.-Z. Stable Variable Selection of Class-Imbalanced Data with Precision-Recall Criterion. Chemom. Intell. Lab. Syst. 2017, 171, 241–250. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef]
- Rasheed, K.; Qayyum, A.; Ghaly, M.; Al-Fuqaha, A.; Razi, A.; Qadir, J. Explainable, Trustworthy, and Ethical Machine Learning for Healthcare: A Survey. Comput. Biol. Med. 2022, 149, 106043. [Google Scholar] [CrossRef]
- Keleko, A.T.; Kamsu-Foguem, B.; Ngouna, R.H.; Tongne, A. Health Condition Monitoring of a Complex Hydraulic System Using Deep Neural Network and DeepSHAP Explainable XAI. Adv. Eng. Softw. 2023, 175, 103339. [Google Scholar] [CrossRef]
- Huang, X.; Kroening, D.; Ruan, W.; Sharp, J.; Sun, Y.; Thamo, E.; Wu, M.; Yi, X. A Survey of Safety and Trustworthiness of Deep Neural Networks: Verification, Testing, Adversarial Attack and Defence, and Interpretability. Comput. Sci. Rev. 2020, 37, 100270. [Google Scholar] [CrossRef]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure Mode and Effects Analysis of RC Members Based on Machine-Learning-Based SHapley Additive ExPlanations (SHAP) Approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Khodaei, H.; Nasiri Saleh, F.; Nobakht Dalir, A.; Zarei, E. Future Flood Susceptibility Mapping under Climate and Land Use Change. Sci. Rep. 2025, 15, 12394. [Google Scholar] [CrossRef]
- Tariq, A.; Yan, J.; Ghaffar, B.; Qin, S.; Mousa, B.G.; Sharifi, A.; Huq, M.E.; Aslam, M. Flash Flood Susceptibility Assessment and Zonation by Integrating Analytic Hierarchy Process and Frequency Ratio Model with Diverse Spatial Data. Water 2022, 14, 3069. [Google Scholar] [CrossRef]
- Al-Kindi, K.M.; Alabri, Z. Investigating the Role of the Key Conditioning Factors in Flood Susceptibility Mapping Through Machine Learning Approaches. Earth Syst. Environ. 2024, 8, 63–81. [Google Scholar] [CrossRef]
- Suwanno, P.; Yaibok, C.; Pornbunyanon, T.; Kanjanakul, C.; Buathongkhue, C.; Tsumita, N.; Fukuda, A. GIS-Based Identification and Analysis of Suitable Evacuation Areas and Routes in Flood-Prone Zones of Nakhon Si Thammarat Municipality. IATSS Resear. 2023, 47, 416–431. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, X.; Qi, Z.; Cui, C. Flood Sensitivity Assessment of Super Cities. Sci. Rep. 2023, 13, 5582. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, D.S.; Bharat, A. Nature-Based Solutions for Flood–Drought Mitigation Using a Composite Framework: A Case-Based Approach. J. Water Clim. Chang. 2023, 14, 778–795. [Google Scholar] [CrossRef]
- Ma, S.; Wang, L.-J.; Jiang, J.; Zhao, Y.-G. Land Use/Land Cover Change and Soil Property Variation Increased Flood Risk in the Black Soil Region, China, in the Last 40 Years. Environ. Impact Assess. Rev. 2024, 104, 107314. [Google Scholar] [CrossRef]
- Saco, P.M.; McDonough, K.R.; Rodriguez, J.F.; Rivera-Zayas, J.; Sandi, S.G. The Role of Soils in the Regulation of Hazards and Extreme Events. Philos. Trans. R. Soc. B 2021, 376, 20200178. [Google Scholar] [CrossRef]
- Mileusnić, Z.I.; Saljnikov, E.; Radojević, R.L.; Petrović, D.V. Soil Compaction Due to Agricultural Machinery Impact. J. Terramech. 2022, 100, 51–60. [Google Scholar] [CrossRef]
- Singh, O.; Shahi, U.P.; Dutta, D.; Shivangi; Rajput, V.D.; Singh, A. Strategic Tillage for Improved Soil Health and Nutrient Dynamics. In Strategic Tillage and Soil Management—New Perspectives; de Sousa, R.N., Ed.; IntechOpen: London, UK, 2024. [Google Scholar] [CrossRef]
- Szejba, D. Importance of the Influence of Drained Clay Soil Retention Properties on Flood Risk Reduction. Water 2020, 12, 1315. [Google Scholar] [CrossRef]
- Zhang, F.; Gao, Y. Composite Extraction Index to Enhance Impervious Surface Information in Remotely Sensed Imagery. Egypt. J. Remote Sens. Sp. Sci. 2023, 26, 141–150. [Google Scholar] [CrossRef]
- Öztürk, Ş.; Yılmaz, K.; Dinçer, A.E.; Kalpakcı, V. Effect of Urbanization on Surface Runoff and Performance of Green Roofs and Permeable Pavement for Mitigating Urban Floods. Nat. Hazard 2024, 120, 12375–12399. [Google Scholar] [CrossRef]
- Shrestha, S.; Dahal, D.; Poudel, B.; Banjara, M.; Kalra, A. Flood Susceptibility Analysis with Integrated Geographic Information System and Analytical Hierarchy Process: A Multi-Criteria Framework for Risk Assessment and Mitigation. Water 2025, 17, 937. [Google Scholar] [CrossRef]
- Pistocchi, A.; Calzolari, C.; Malucelli, F.; Ungaro, F. Soil Sealing and Flood Risks in the Plains of Emilia-Romagna, Italy. J. Hydrol. Reg. Stud. 2015, 4, 398–409. [Google Scholar] [CrossRef]
- Frene, J.P.; Pandey, B.K.; Castrillo, G. Under Pressure: Elucidating Soil Compaction and Its Effect on Soil Functions. Plant Soil 2024, 502, 267–278. [Google Scholar] [CrossRef]
- Ashfaq, S.; Tufail, M.; Niaz, A.; Muhammad, S.; Alzahrani, H.; Tariq, A. Flood Susceptibility Assessment and Mapping Using GIS-Based Analytical Hierarchy Process and Frequency Ratio Models. Glob. Planet. Chang. 2025, 251, 104831. [Google Scholar] [CrossRef]
- Nedkov, R. Normalized Differential Greenness Index for Vegetation Dynamics Assessment. Comptes Rendus De L’academie Bulg. Des Sci. 2017, 70, 1143–1146. [Google Scholar]
- Xu, J.; Tang, Y.; Xu, J.; Chen, J.; Bai, K.; Shu, S.; Yu, B.; Wu, J.; Huang, Y. Evaluation of Vegetation Indexes and Green-Up Date Extraction Methods on the Tibetan Plateau. Remote Sens. 2022, 14, 3160. [Google Scholar] [CrossRef]
- Hidayat, M.; Djufri, D.; Basri, H.; Ismail, N.; Idroes, R.; Ikhwali, M.F. Influence of Vegetation Type on Infiltration Rate and Capacity at Ie Jue Geothermal Manifestation, Mount Seulawah Agam, Indonesia. Heliyon 2024, 10, e25783. [Google Scholar] [CrossRef]
- Firoozi, A.A.; Firoozi, A.A. Water Erosion Processes: Mechanisms, Impact, and Management Strategies. Result. Eng. 2024, 24, 103237. [Google Scholar] [CrossRef]
- Sahin, E.K. Comparative Analysis of Gradient Boosting Algorithms for Landslide Susceptibility Mapping. Geocarto Int. 2022, 37, 2441–2465. [Google Scholar] [CrossRef]
- Szczepanek, R. Daily Streamflow Forecasting in Mountainous Catchment Using XGBoost, LightGBM and CatBoost. Hydrology 2022, 9, 226. [Google Scholar] [CrossRef]
- Yavuz Ozalp, A.; Akinci, H.; Zeybek, M. Comparative Analysis of Tree-Based Ensemble Learning Algorithms for Landslide Susceptibility Mapping: A Case Study in Rize, Turkey. Water 2023, 15, 2661. [Google Scholar] [CrossRef]
- Heddam, S. Explainability of Machine Learning Using Shapley Additive ExPlanations (SHAP): CatBoost, XGBoost and LightGBM for Total Dissolved Gas Prediction. In Machine Learning and Granular Computing: A Synergistic Design Environment; Pedrycz, W., Chen, S.-M., Eds.; Springer: Cham, Switzerland, 2024; pp. 1–25. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for Big Data: An Interdisciplinary Review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef] [PubMed]
- Kharazi Esfahani, P.; Peiro Ahmady Langeroudy, K.; Khorsand Movaghar, M.R. Enhanced Machine Learning—Ensemble Method for Estimation of Oil Formation Volume Factor at Reservoir Conditions. Sci. Rep. 2023, 13, 15199. [Google Scholar] [CrossRef] [PubMed]
- Onyelowe, K.C.; Kamchoom, V.; Hanandeh, S.; Ebid, A.M.; Llamuca Llamuca, J.L.; Cayán Martínez, J.C.; Rose, E.; Awoyera, P.; Avudaiappan, S. Predicting the Strengths of Basalt Fiber Reinforced Concrete Mixed with Fly Ash Using AML and Hoffman and Gardener Techniques. Sci. Rep. 2025, 15, 12074. [Google Scholar] [CrossRef] [PubMed]
- Ileri, K. Comparative Analysis of CatBoost, LightGBM, XGBoost, RF, and DT Methods Optimised with PSO to Estimate the Number of k-Barriers for Intrusion Detection in Wireless Sensor Networks. Int. J. Mach. Learn. Cyber. 2025. [Google Scholar] [CrossRef]
- Chakraborty, D.; Ghosh, A.; Saha, S. Chapter 2—A Survey on Internet-of-Thing Applications Using Electroencephalogram. In Emergence of Pharmaceutical Industry Growth with Industrial IoT Approach; Balas, V.E., Solanki, V.K., Kumar, R., Eds.; Academic Press: Boston, MA, USA, 2020; pp. 21–47. [Google Scholar] [CrossRef]







| Dataset | Source | Conditioning Factor | Scale/Spatial Resolution |
|---|---|---|---|
| SRTM DEM | https://earthexplorer.usgs.gov/ (accessed on 20 April 2025) | Slope | 30 m |
| Elevation | |||
| Stream Power Index (SPI) | |||
| Topographic Wetness Index (TWI) | |||
| CORINE Land Cover | https://land.copernicus.eu/en/products/corine-land-cover (accessed on 20 April 2025) | Land Use/Land Cover (LULC) | 100 m |
| SoilGrids | https://soilgrids.org/ (accessed on 20 April 2025) | Soil Clay Content | 250 m |
| Soil Bulk Density | |||
| HydroSHEDS | https://www.hydrosheds.org/products/hydrorivers (accessed on 20 April 2025) | Distance from Rivers | - |
| Landsat 8 and 9 imagery | https://earthexplorer.usgs.gov/ (accessed on 20 April 2025) | Normalized Difference Impervious Surface Index (NDISI) | 100 m |
| Sentinel-2 imagery | https://browser.dataspace.copernicus.eu/ (accessed on 20 April 2025) | Urban Index (UI) | 20 m |
| Normalized Difference Greenness Index (NDGI) | 10 m | ||
| Normalized Difference Water Index (NDWI) | 10 m | ||
| Land Surface Water Index (LSWI) | 20 m |
| Sl. No. | Conditioning Factor | VIF Score |
|---|---|---|
| 1 | Soil Clay Content | 7.844 |
| 2 | Soil Bulk Density | 6.548 |
| 3 | NDGI | 6.330 |
| 4 | NDISI | 5.566 |
| 5 | TWI | 4.888 |
| 6 | Slope | 3.539 |
| 7 | SPI | 3.072 |
| 8 | Elevation | 2.872 |
| 9 | NDWI | 1.763 |
| 10 | Distance from Rivers | 1.486 |
| 11 | LULC | 1.360 |
| Sl. No. | Conditioning Factor | CI |
|---|---|---|
| 1 | TWI | 7.550 |
| 2 | Distance from Rivers | 6.490 |
| 3 | SPI | 5.810 |
| 4 | Slope | 3.400 |
| 5 | NDWI | 2.960 |
| 6 | NDISI | 2.460 |
| 7 | NDGI | 2.360 |
| 8 | LULC | 1.940 |
| 9 | Elevation | 1.570 |
| 10 | Soil Bulk Density | 1.310 |
| 11 | Soil Clay Content | 1.000 |
| Sl. No. | Conditioning Factor | MI Score |
|---|---|---|
| 1 | Slope | 0.452 |
| 2 | TWI | 0.403 |
| 3 | Distance from Rivers | 0.348 |
| 4 | SPI | 0.211 |
| 5 | LULC | 0.187 |
| 6 | Elevation | 0.146 |
| 7 | Soil Bulk Density | 0.141 |
| 8 | NDGI | 0.107 |
| 9 | NDISI | 0.100 |
| 10 | Soil Clay Content | 0.042 |
| 11 | NDWI | 0.012 |
| Sl. No. | Conditioning Factor | IG Score |
|---|---|---|
| 1 | Slope | 0.451 |
| 2 | Distance from Rivers | 0.400 |
| 3 | TWI | 0.375 |
| 4 | LULC | 0.326 |
| 5 | NDGI | 0.116 |
| 6 | NDISI | 0.110 |
| 7 | Elevation | 0.099 |
| 8 | Soil Bulk Density | 0.088 |
| 9 | Soil Clay Content | 0.007 |
| 10 | NDWI | 0.001 |
| 11 | SPI | 0.000 |
| Model | MAE | RMSE | R2 | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| AdaBoost | 0.088 | 0.117 | 0.173 | 0.229 | 0.880 | 0.787 |
| CatBoost | 0.074 | 0.097 | 0.146 | 0.182 | 0.919 | 0.838 |
| LightGBM | 0.082 | 0.111 | 0.164 | 0.211 | 0.892 | 0.804 |
| XGBoost | 0.079 | 0.102 | 0.151 | 0.192 | 0.914 | 0.817 |
| AdaBoost | CatBoost | LightGBM | XGBoost | |
|---|---|---|---|---|
| Precision | 0.904 | 0.928 | 0.906 | 0.916 |
| Recall | 0.887 | 0.917 | 0.885 | 0.909 |
| F1-Score | 0.885 | 0.913 | 0.894 | 0.908 |
| Accuracy | 0.886 | 0.912 | 0.894 | 0.908 |
| κ-index | 0.782 | 0.841 | 0.801 | 0.825 |
| Sl. No. | Conditioning Factor | Mean_Abs_SHAP |
|---|---|---|
| 1 | Slope | 0.232 |
| 2 | Distance from Rivers | 0.155 |
| 3 | TWI | 0.061 |
| 4 | LULC | 0.034 |
| 5 | NDISI | 0.026 |
| 6 | Soil Bulk Density | 0.022 |
| 7 | Elevation | 0.019 |
| 8 | NDGI | 0.017 |
| 9 | Soil Clay Content | 0.015 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ajin, R.S.; Costache, R.; Bărbulescu, A.; Fanti, R.; Segoni, S. Flood Susceptibility Assessment Using Multi-Tier Feature Selection and Ensemble Boosting Machine Learning Models. Water 2025, 17, 2041. https://doi.org/10.3390/w17142041
Ajin RS, Costache R, Bărbulescu A, Fanti R, Segoni S. Flood Susceptibility Assessment Using Multi-Tier Feature Selection and Ensemble Boosting Machine Learning Models. Water. 2025; 17(14):2041. https://doi.org/10.3390/w17142041
Chicago/Turabian StyleAjin, Rajendran Shobha, Romulus Costache, Alina Bărbulescu, Riccardo Fanti, and Samuele Segoni. 2025. "Flood Susceptibility Assessment Using Multi-Tier Feature Selection and Ensemble Boosting Machine Learning Models" Water 17, no. 14: 2041. https://doi.org/10.3390/w17142041
APA StyleAjin, R. S., Costache, R., Bărbulescu, A., Fanti, R., & Segoni, S. (2025). Flood Susceptibility Assessment Using Multi-Tier Feature Selection and Ensemble Boosting Machine Learning Models. Water, 17(14), 2041. https://doi.org/10.3390/w17142041