
A Django-Based Modeling Platform for Predicting Soil Moisture in Agricultural Fields



Abstract
1. Introduction
2. Prediction Platform and Prediction Model
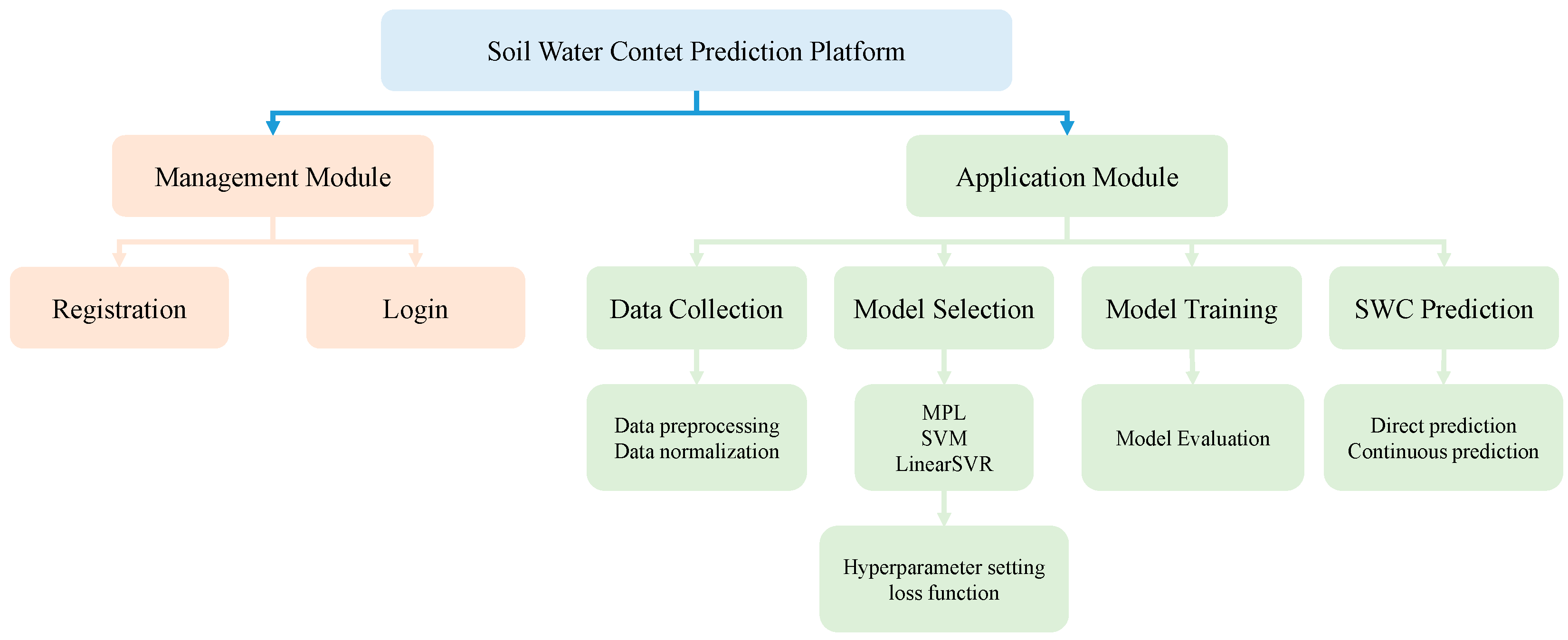
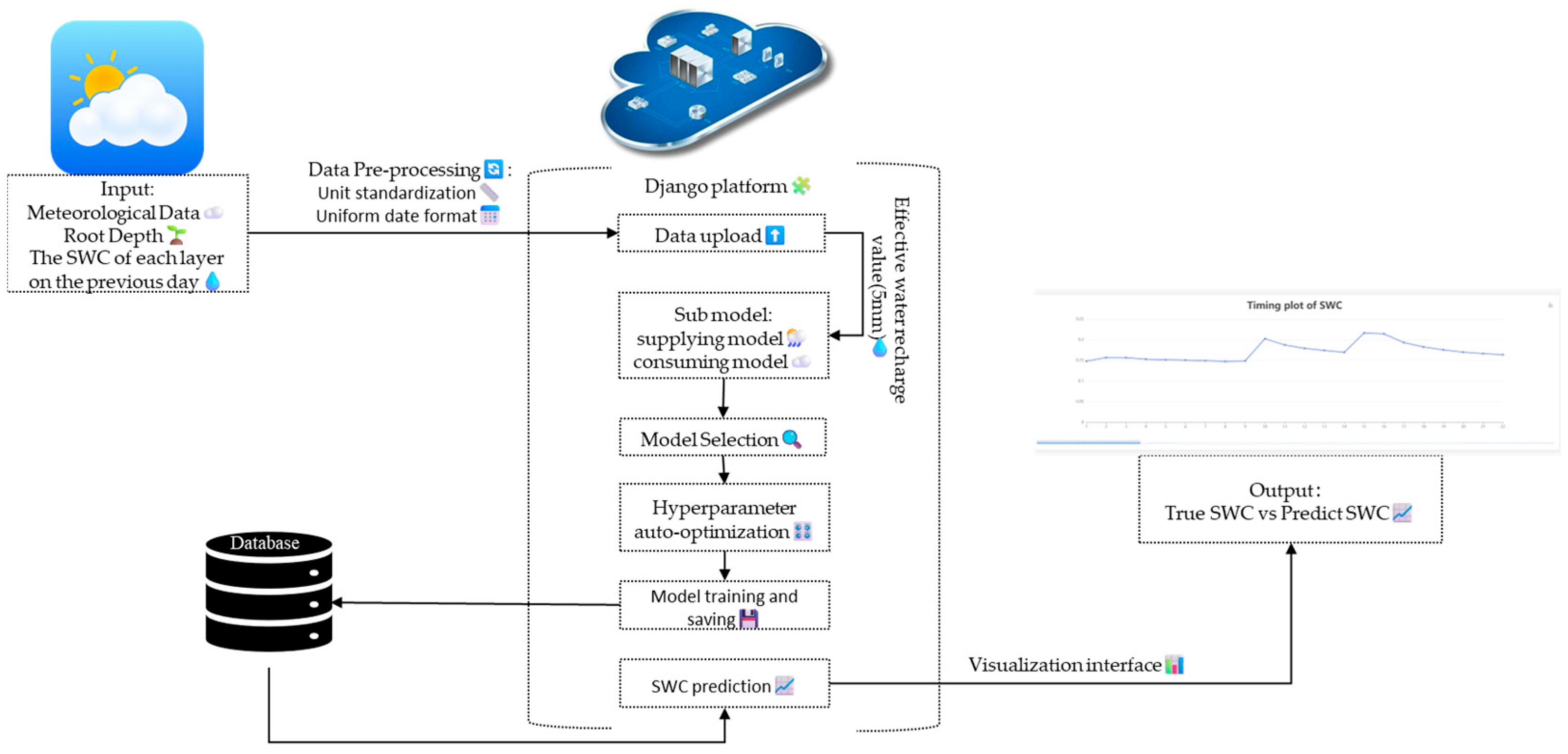
2.1. Prediction Platform Framework Based on Django
2.2. SWC Prediction Models
2.2.1. Prediction Model Framework
2.2.2. Prediction Sub-Models Based on Machine Learning
2.3. Platform Operation Process
3. Prediction Model Performance Evaluation and Discussion
3.1. Testing Data and Evaluation Index
3.1.1. Testing Data
3.1.2. Model Evaluation Indicators
3.2. Performance Evaluation of the Different Models
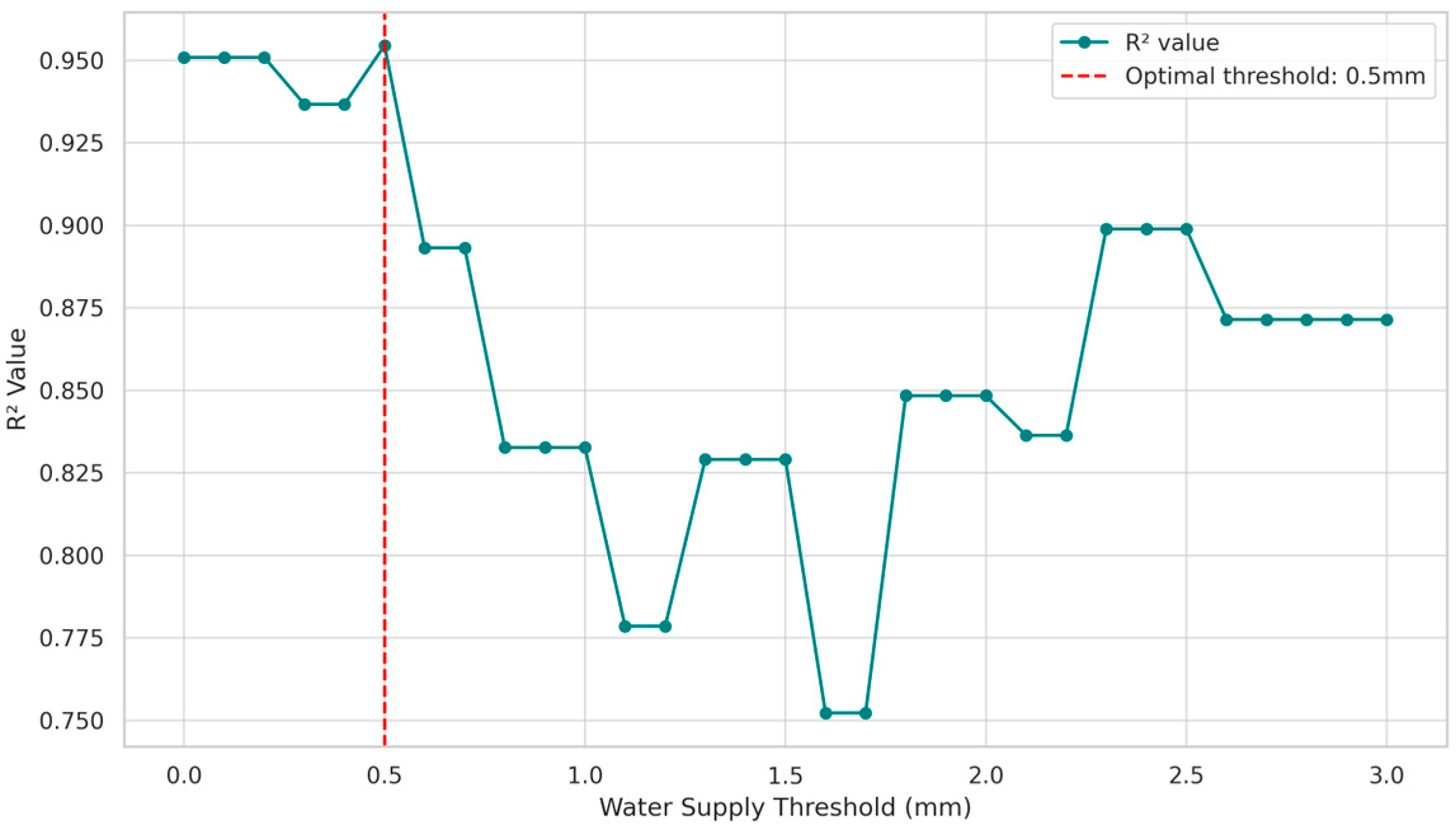
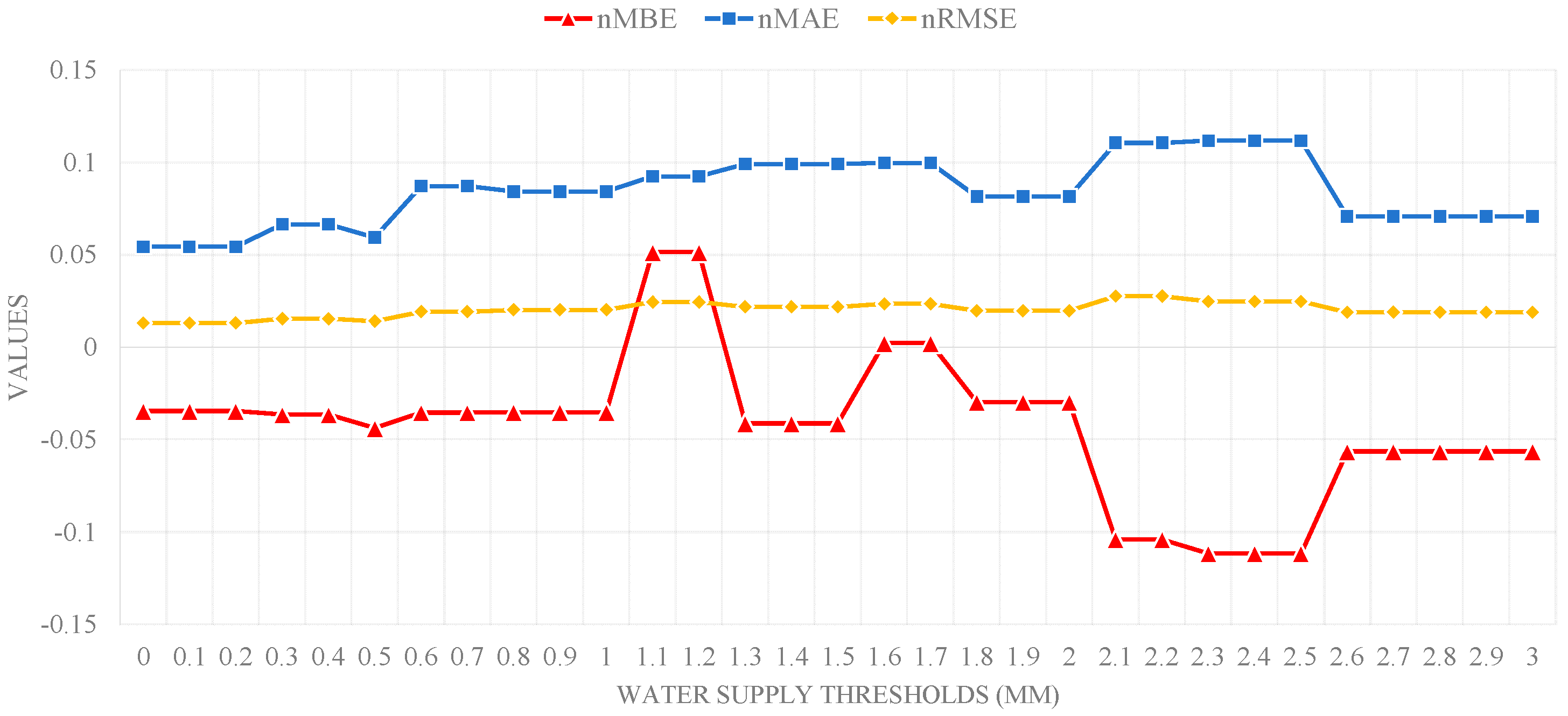
3.3. Influence of Threshold for on Prediction Performance
3.4. Influence of Hyperparameter Selection on Prediction Performance
3.5. Influence of Activation Functions on MLP Performance
4. Prediction Platform Application
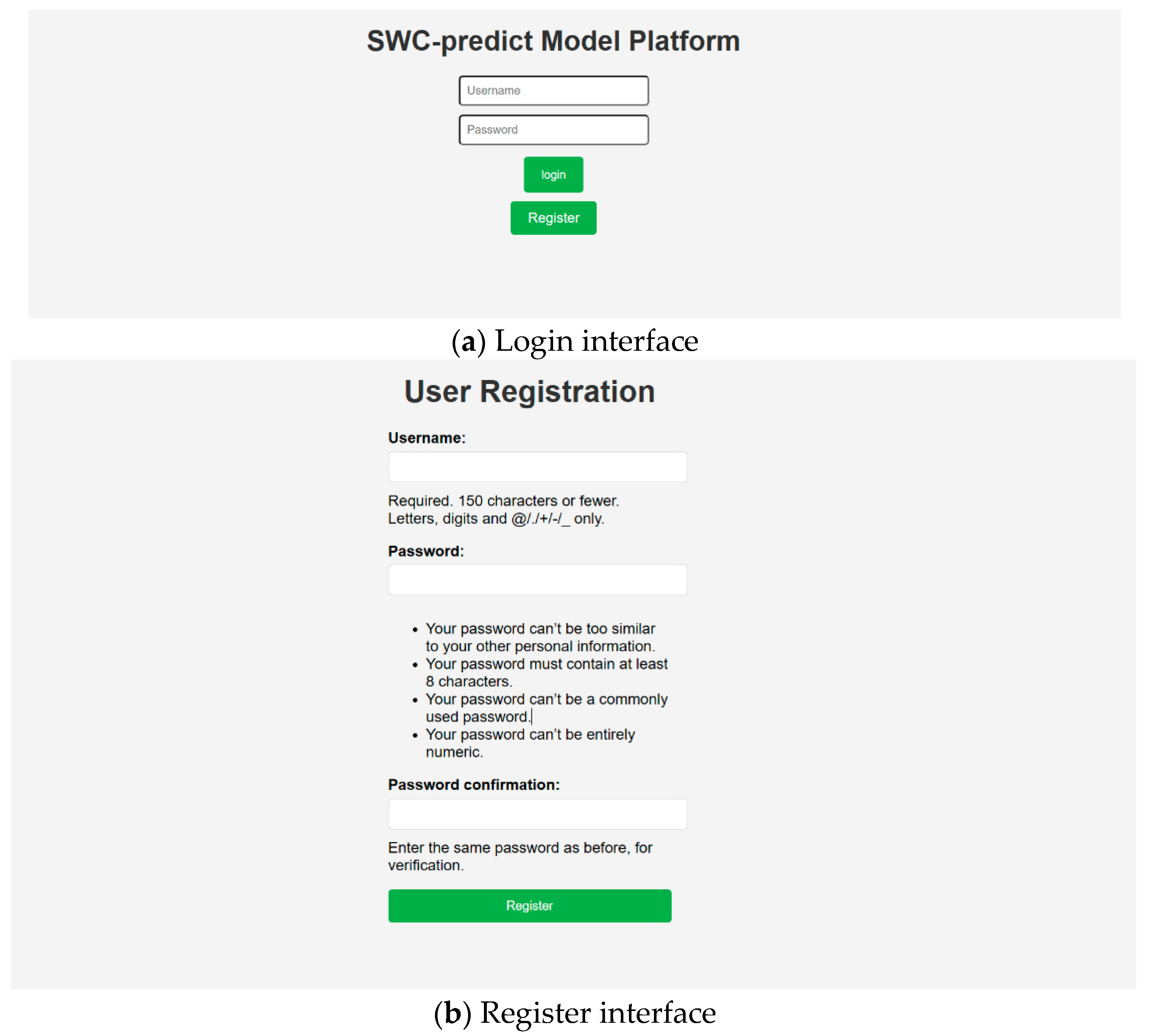
4.1. Registration and Login
4.2. Data Collection
4.3. Model Selection and Training
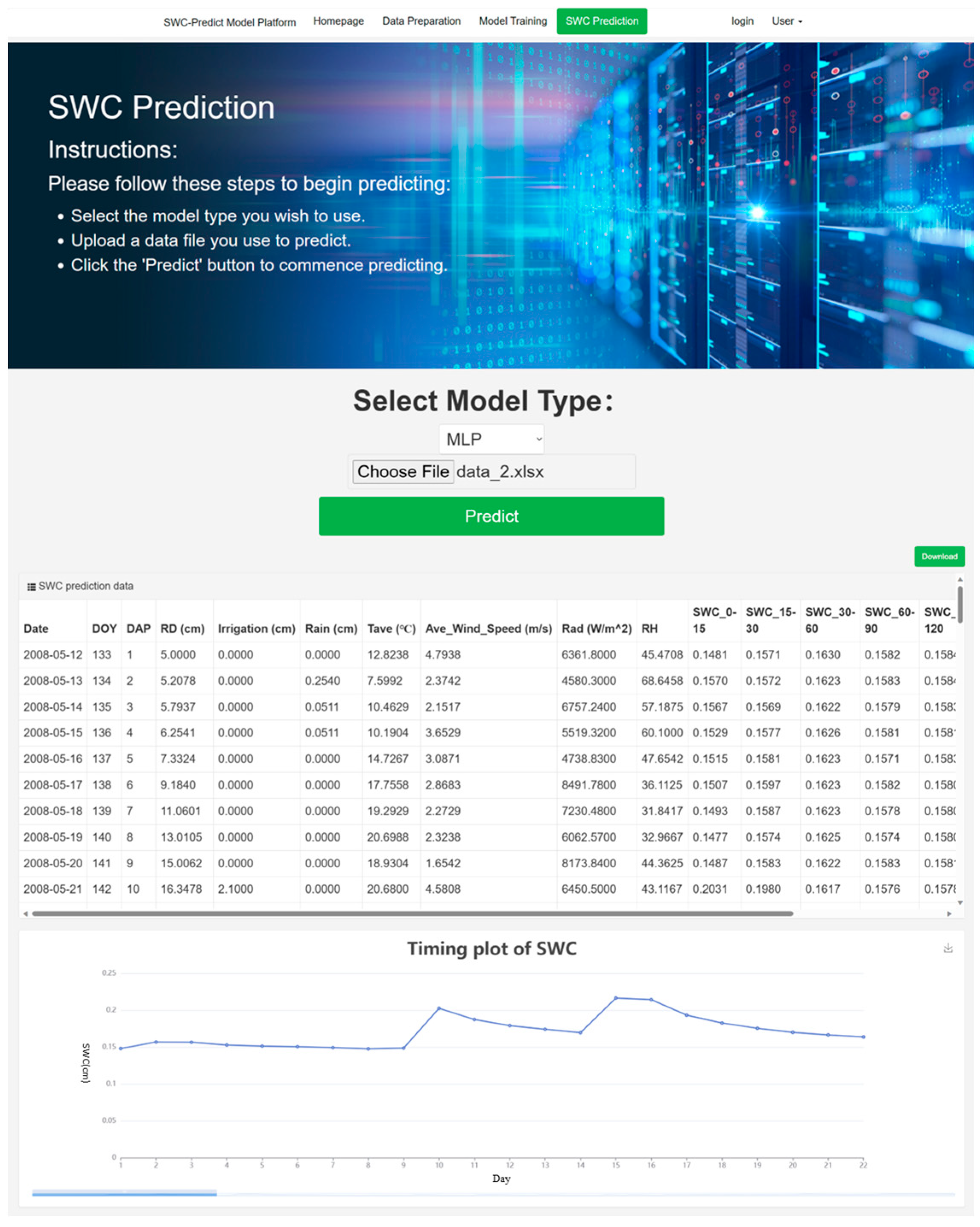
4.4. SWC Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huffman, R.L. Soil and Water Conservation Engineering; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2013. [Google Scholar]
- Chen, Z.; Song, N.; Liu, X.; Wang, J. Water-saving irrigation management and decision support system. Trans. Chin. Soc. Agric. Eng. 2009, 25, 1–6. [Google Scholar]
- Gu, Z.; Qi, Z.; Ma, L.; Gui, D.; Xu, J.; Fang, Q.; Yuan, S.; Feng, G. Development of an irrigation scheduling software based on model predicted crop water stress. Comput. Electron. Agric. 2017, 143, 221–298. [Google Scholar] [CrossRef]
- Tan, J.; Cui, Y.; Zhang, P. The development and application of real-time irrigation forecasting and irrigation water decision support system. China Rural. Water Hydropower 2015, 07, 1–4+9. [Google Scholar]
- Yang, S.; Wang, J.; Zhou, J. Decision support system based on variable irrigation mathematical model. Trans. Chin. Soc. Agric. Eng. 2005, 11, 37–40. [Google Scholar]
- Kamath, R.; Balachandra, M.; Prabhu, S. Raspberry Pi as visual sensor nodes in precision agriculture: A study. IEEE Access 2019, 7, 45110–45122. [Google Scholar] [CrossRef]
- Hu, Y.; Li, H.; Wang, W.; Li, Q. Application of Remote Sensing in Monitoring the Soil Moisture of the Irrigation Area in the Lower Yellow River Coastal Area. J. Coast. Res. 2019, 94, 96–100. [Google Scholar] [CrossRef]
- Shi, W.Q.; Xu, X.Y.; Zhang, W.; Zhang, P.; Sun, H.; Hu, J. Prediction Model of Soil Moisture Content in Northern Cold Region Based on Near-Infrared Spectroscopy. Spectrosc. Spectr. Anal. 2022, 42, 1704–1710. [Google Scholar]
- Ahuja, L.R.; Ma, L.; Lascano, R.J.; Saseendran, S.A.; Fang, Q.X.; Nielsen, D.C.; Wang, E.; Colaizzi, P.D. Syntheses of the current model applications for managing water and needs for experimental data and model improvements to enhance these applications. Adv. Agric. Syst. Model. 2014, 5, 399–438. [Google Scholar]
- Saseendran, S.A.; Ahuja, L.R.; Ma, L.; Trout, T.J. Modeling for best management of the effects of irrigation frequencies, initial water, and nitrogen on corn. Adv. Agric. Syst. Model. 2014, 5, 25–52. [Google Scholar]
- Huang, L.; Jiang, X.; Jia, Z.; Zhou, H.; Zhou, L.; Rong, Z. Hyperspectral monitoring of nutrient content in pear trees based on deep learning. Spectrosc. Spectr. Anal. 2024, 44, 3543–3552. [Google Scholar]
- Chen, K.; Lei, X.; Li, F.; Wen, J. Drip moisture prediction of processing tomatoes based on BP networks. China Rural. Water Hydropower 2012, 9, 1–4. [Google Scholar]
- Huang, F.; Zhang, Y.; Zhang, Y.; Shangguan, W.; Li, Q.; Li, L.; Jiang, S. Interpreting Conv-LSTM for spatio-temporal soil moisture prediction in China. Agriculture 2023, 13, 971. [Google Scholar] [CrossRef]
- Xu, L.; Yu, H.; Chen, Z.; Du, W.; Chen, N.; Huang, M. Hybrid Deep Learning and S2S Model for Improved Sub-Seasonal Surface and Root-Zone Soil Moisture Forecasting. Remote Sens. 2023, 15, 3410. [Google Scholar] [CrossRef]
- Lu, J.; Tan, L.; Jiang, H. Review on convolutional neural network (CNN) applied to plant leaf disease classification. Agriculture 2021, 11, 707. [Google Scholar] [CrossRef]
- Gu, Z.; Zhu, T.; Jiao, X.; Xu, J.; Qi, Z. Evaluating the Neural Network Ensemble Method in Predicting Soil Moisture in Agricultural Fields. Agronomy 2021, 11, 1521. [Google Scholar] [CrossRef]
- Shi, J.; Yang, H.; Wang, F.; Sun, P. Collaborative inversion of soil moisture over summer maize covered surfaces based on multi-source remote sensing data. China Rural. Water Hydropower 2024, 8, 136–143. [Google Scholar]
- Kamienski, C.; Soininen, J.P.; Taumberger, M.; Fernandes, S.; Toscano, A.; Cinotti, T.S.; Maia, R.F.; Neto, A.T. SWAMP: An IoT-based Smart Water Management Platform for Precision Irrigation in Agriculture. In Proceedings of the IEEE Global IoT Summit 2018, Bilbao, Spain, 4–7 June 2018. [Google Scholar]
- Li, S. Research on Key Technologies of Cloud Service Platform for Farmland Soil Moisture Monitoring and Intelligent Irrigation. Ph.D. Thesis, Chinese Academy of Agricultural Sciences, Beijing, China, 2017. [Google Scholar]
- Gu, W.; Yang, L.; Li, T. The development and application of irrigation water decision support system based on real-time weather information. Water Sav. Irrig. 2017, 02, 103–105. [Google Scholar]
- Mbabazi, D.; Migliaccio, K.W.; Crane, J.H.; Fraisse, C.; Zotarelli, L.; Morgan, K.T.; Kiggundu, N. An irrigation schedule testing model for optimization of the Smartirrigation avocado app. Agric. Water Manag. 2017, 179, 390–400. [Google Scholar] [CrossRef]
- Wu, M.C.; Sheu, Y.H.; Liu, S.H.; Shieh, J.Y.; Su, H.K. Design of a Composite IoT Sensor Stack System for Smart Agriculture. Lect. Notes Data Eng. Commun. Technol. 2023, 177, 250–260. [Google Scholar]
- Zhang, T.; Liao, M.; Zhang, R.; Huang, W.; Shao, M. Design and implementation of traffic accident data visual analysis system based on Django. Softw. Guide 2023, 22, 112–117. [Google Scholar]
- Wang, D. Design of the online education platform for Python courses based on the Django framework. Inf. Comput. 2023, 35, 242–244. [Google Scholar]
- Gu, Z.; Zhu, T.; Jiao, X.; Xu, J.; Qi, Z. Neural network soil moisture model for irrigation scheduling. Comput. Electron. Agric. 2021, 180, 105801. [Google Scholar] [CrossRef]
- Achieng, K.O. Modelling of soil moisture retention curve using machine learning techniques: Artificial and deep neural networks vs support vector regression models. Comput. Geosci. 2019, 133, 104320. [Google Scholar] [CrossRef]
- Lacasse, M.A. Application of Support Vector Regression to the Prediction of the Long-Term Impacts of Climate Change on the Moisture Performance of Wood Frame and Massive Timber Walls. Buildings 2021, 11, 188. [Google Scholar] [CrossRef]
- Uttsha, M.M.; Haque, A.N.; Banna, T.T.; Deowan, S.A.; Islam, A.; Babu, H.M.H. Enhancing agricultural automation through weather invariant soil parameter prediction using machine learning. Heliyon 2024, 10, 10. [Google Scholar] [CrossRef]
- Ma, L.; Trout, T.J.; Ahuja, L.R.; Bausch, W.C.; Saseendran, S.A.; Malone, R.W.; Nielsen, D.C. Calibrating RZWQM2 model for maize responses to deficit irrigation. Agric. Water Manag. 2012, 103, 140–149. [Google Scholar] [CrossRef]
- Ma, L.; Niu, W.; Li, G.; Du, Y.; Sun, J.; Siddique, K.H.M. Crop Yield Prediction Based on Bacterial Biomarkers and Machine Learning. J. Soil. Sci. Plant Nutr. 2024, 24, 2798–2814. [Google Scholar] [CrossRef]
- Han, Q.; Zeng, Y.; Zhang, L.; Cira, C.-I.; Prikaziuk, E.; Duan, T.; Wang, C.; Szabó, B.; Manfreda, S.; Zhuang, R.; et al. Ensemble of optimised machine learning algorithms for predicting surface soil moisture content at global scale. Geosci. Model. Dev. Discuss. 2023, 16, 5825–5845. [Google Scholar] [CrossRef]
- Singh, T.; Kundroo, M.; Kim, T. WSN-Driven Advances in Soil Moisture Estimation: A Machine Learning Approach. Electronics 2024, 13, 1590. [Google Scholar] [CrossRef]
- Li, S.; Zhu, P.; Song, N.; Li, C.; Wang, J. Regional Soil Moisture Estimation Leveraging Multi-Source Data Fusion and Automated Machine Learning. Remote Sens. 2025, 17, 837. [Google Scholar] [CrossRef]
- Peterson, L.E. Covariance matrix self-adaptation evolution strategies and other metaheuristic techniques for neural adaptive learning. Soft Comput. 2011, 15, 1483–1495. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | R2 | nMBE | nMAE | nRMSE |
|---|---|---|---|---|
| MLP | 0.9545 | −0.0438 | 0.0594 | 0.0141 |
| SVR | 0.9197 | −0.0756 | 0.0823 | 0.0202 |
| LinearSVR | 0.9227 | −0.0930 | 0.1618 | 0.0331 |
| Random Forest | 0.9246 | −0.0981 | 0.1025 | 0.0235 |
| XGBoost | 0.9103 | −0.0542 | 0.0913 | 0.0200 |
| MLP (h1, h2) | R2 | nMBE | nMAE | nRMSE |
|---|---|---|---|---|
| (13, 12) | 0.9988 | −0.0001 | 0.0046 | 0.0013 |
| (16, 15) | 0.9989 | −0.0001 | 0.0044 | 0.0012 |
| (29, 15) | 0.9991 | −0.0002 | 0.0041 | 0.0010 |
| MLP (h1,h2) | R2 | nMBE | nMAE | nRMSE |
|---|---|---|---|---|
| (13, 12) | 0.9121 | −0.1625 | 0.1634 | 0.0334 |
| (16, 15) | 0.9249 | −0.0525 | 0.0818 | 0.0012 |
| (29, 15) | 0.9544 | −0.0438 | 0.0594 | 0.0141 |
| Activation Function | R2 | nMBE | nMAE | nRMSE |
|---|---|---|---|---|
| Identity | 0.8586 | 0.1211 | 0.1359 | 0.0278 |
| Logistic | 0.8852 | 0.0823 | 0.1321 | 0.0202 |
| Tanh | 0.9327 | –0.0520 | 0.0725 | 0.0150 |
| Relu | 0.9545 | –0.0438 | 0.0594 | 0.0142 |
| Models | Hyperparameters (Default Value) |
|---|---|
| MLP | Hidden layers (m = 1), learning rate (lr = 0.001), hidden nodes (h ∈ [10,50]) |
| SVM | Regularization parameter (C ∈ [1,10]), tolerance error parameter (ε = 0.01) |
| Linear SVM | Regularization parameter (C ∈ [1,10]), tolerance error parameter (ε = 0.2) |
| Grid Search | Random Search | |
|---|---|---|
| R2 of Soil Layer1 | 0.999926 | 0.999926 |
| R2 of Soil Layer2 | 0.999633 | 0.999633 |
| R2 of Soil Layer3 | 0.999937 | 0.999937 |
| R2 of Soil Layer4 | 0.999870 | 0.999870 |
| R2 of Soil Layer5 | 0.999920 | 0.999920 |
| R2 of Soil Layer6 | 0.999953 | 0.999938 |
| R2 of Soil Layer7 | 0.999874 | 0.999874 |
| Iteration time | 2.4468 s | 1.2525 s |
| Iteration number | 21 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, P.; Gu, Z.; Zou, H.; Zhu, T.; Li, Z. A Django-Based Modeling Platform for Predicting Soil Moisture in Agricultural Fields. Water 2025, 17, 1753. https://doi.org/10.3390/w17121753
Gan P, Gu Z, Zou H, Zhu T, Li Z. A Django-Based Modeling Platform for Predicting Soil Moisture in Agricultural Fields. Water. 2025; 17(12):1753. https://doi.org/10.3390/w17121753
Chicago/Turabian StyleGan, Pengyu, Zhe Gu, Hongyan Zou, Tingting Zhu, and Zhenye Li. 2025. "A Django-Based Modeling Platform for Predicting Soil Moisture in Agricultural Fields" Water 17, no. 12: 1753. https://doi.org/10.3390/w17121753
APA StyleGan, P., Gu, Z., Zou, H., Zhu, T., & Li, Z. (2025). A Django-Based Modeling Platform for Predicting Soil Moisture in Agricultural Fields. Water, 17(12), 1753. https://doi.org/10.3390/w17121753