
Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Naïve Method
2.2. Long Short-Term Memory Model
2.3. Objective Functions for LSTM Training
2.4. Evaluation Metrics
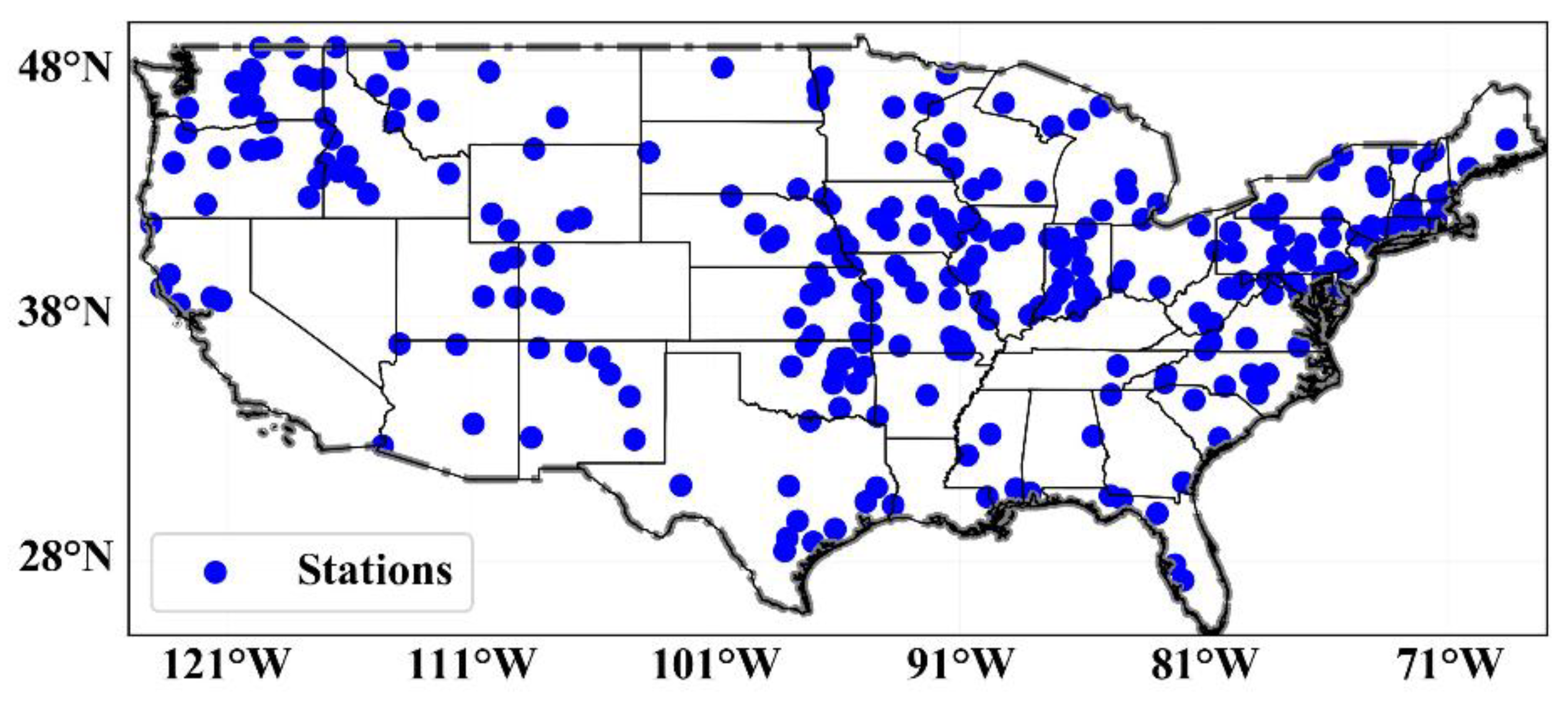
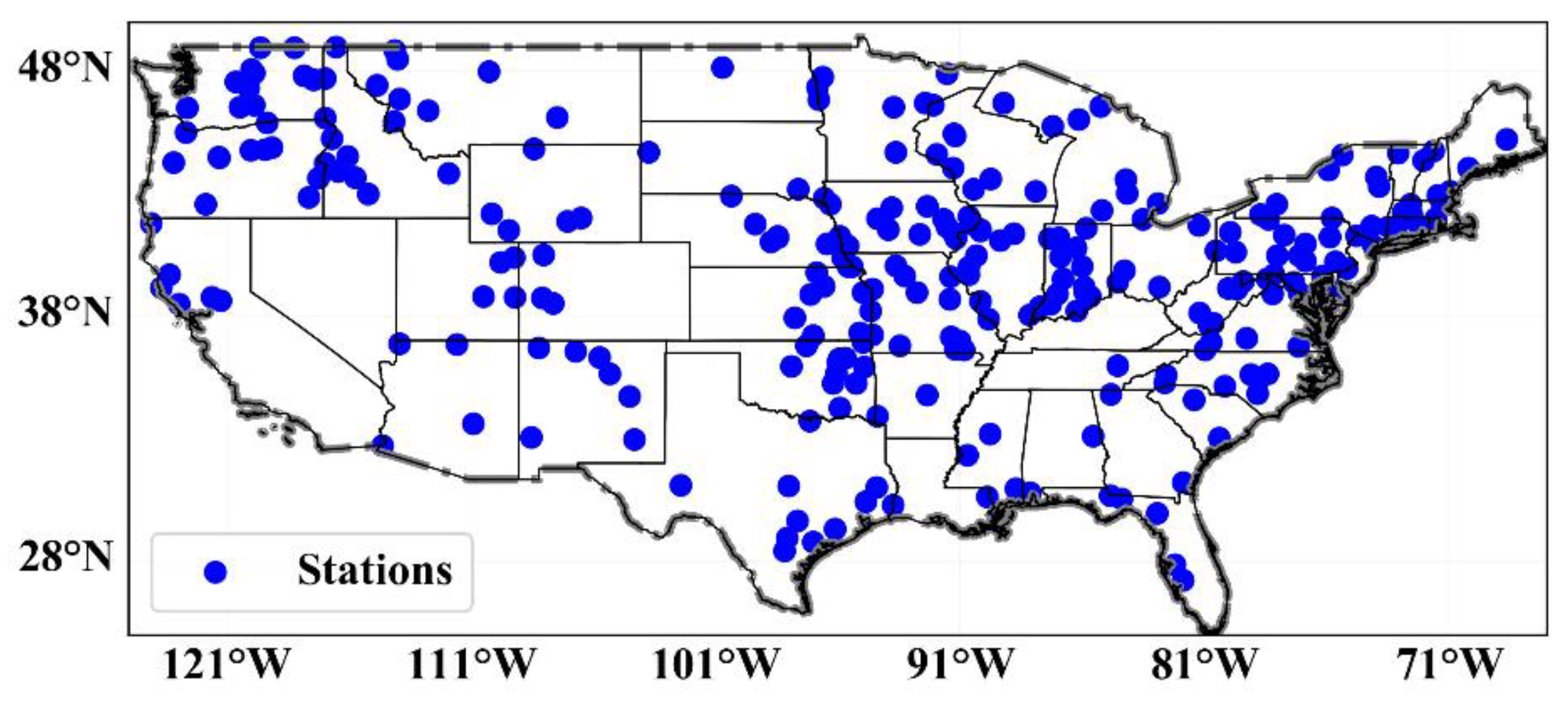
2.5. Data
3. Results
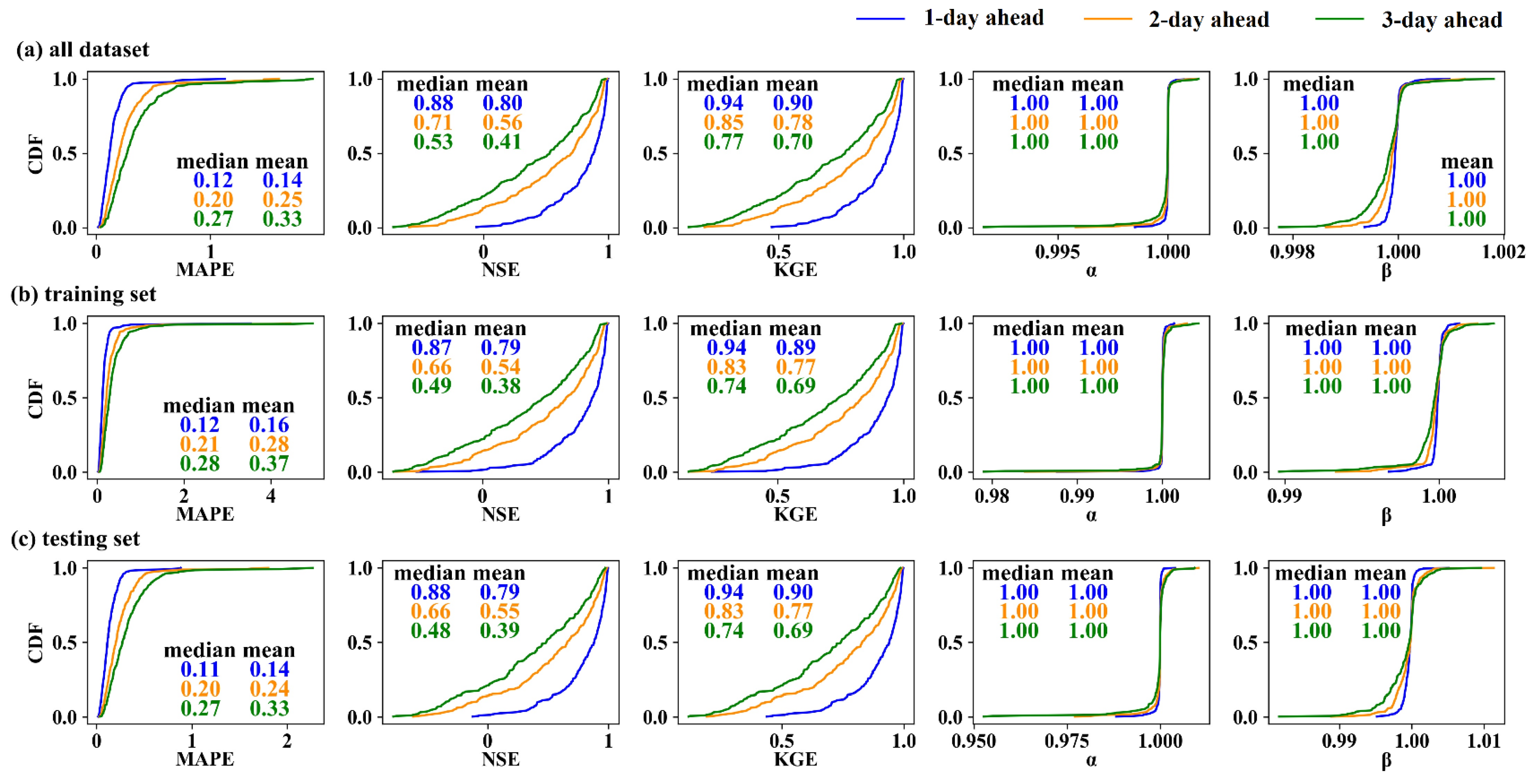
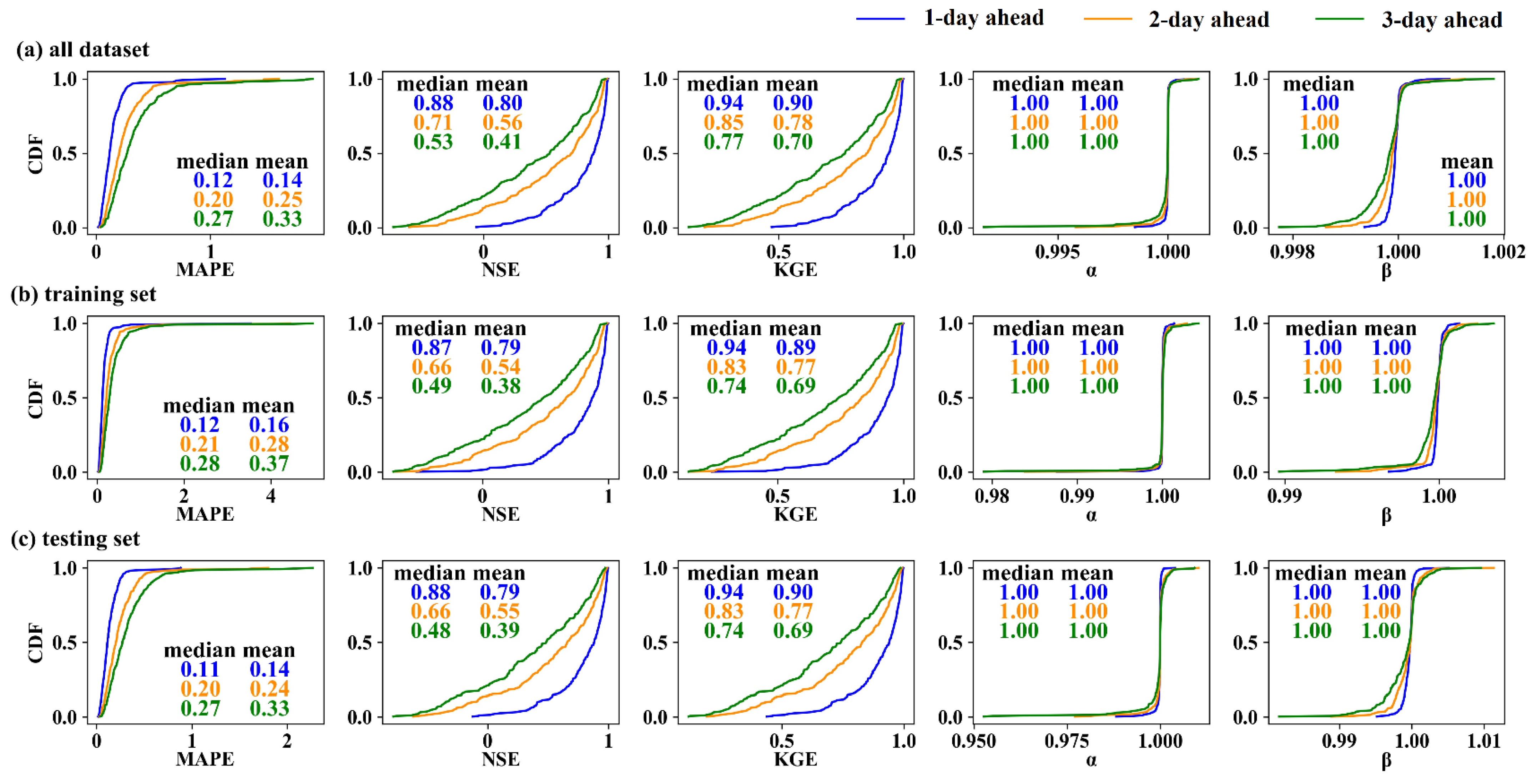
3.1. Forecasting Performance of the Naïve Method
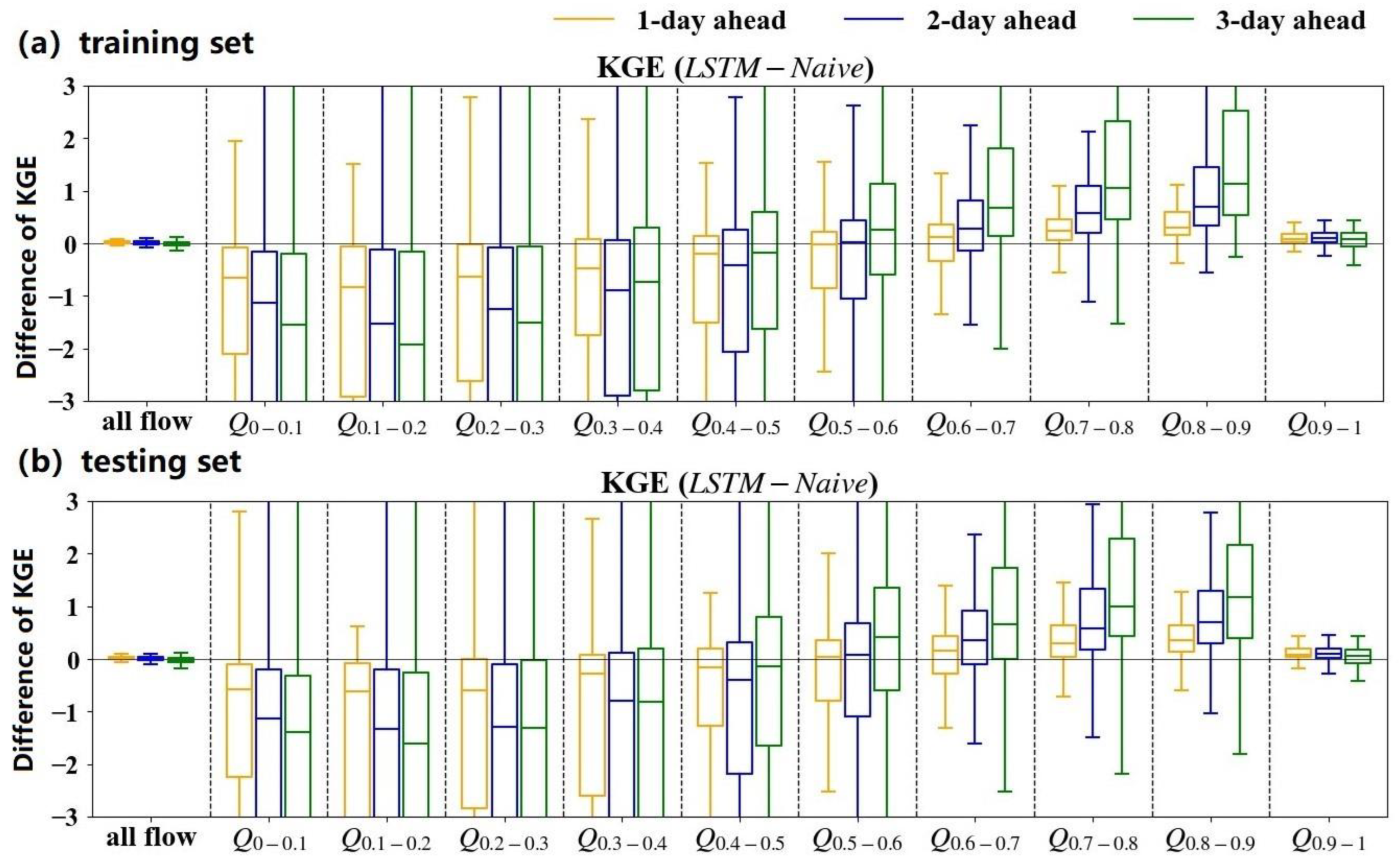
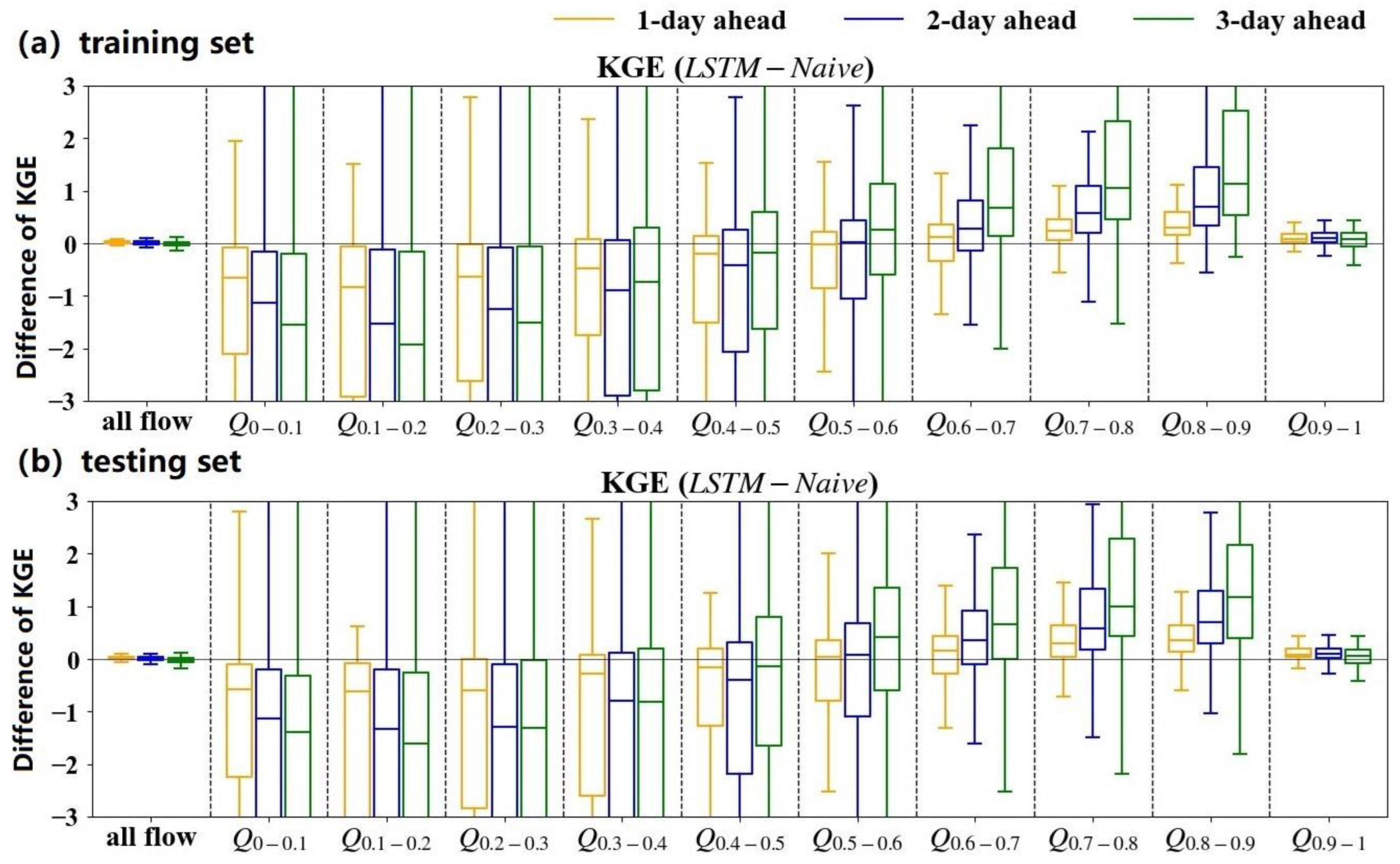
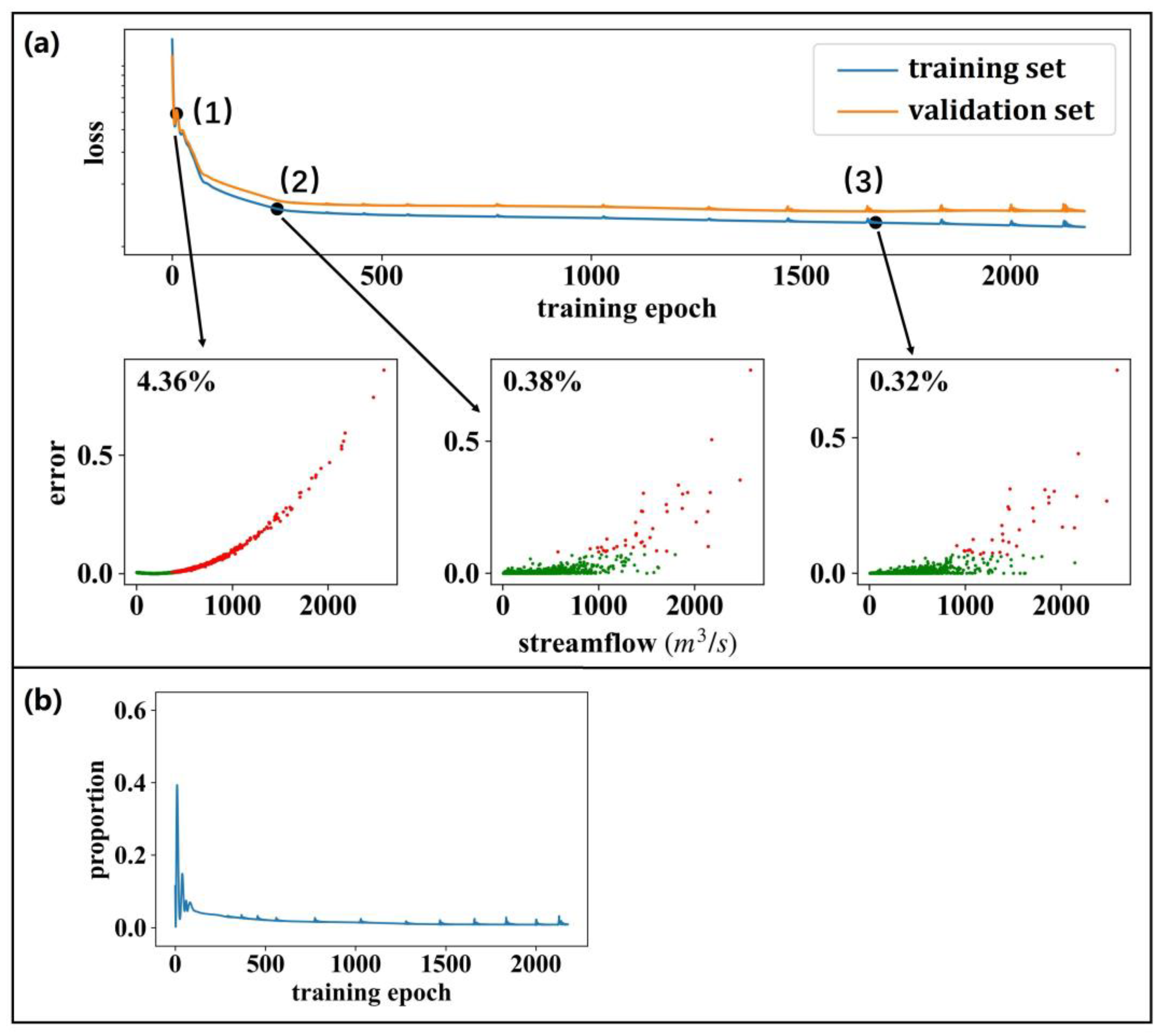
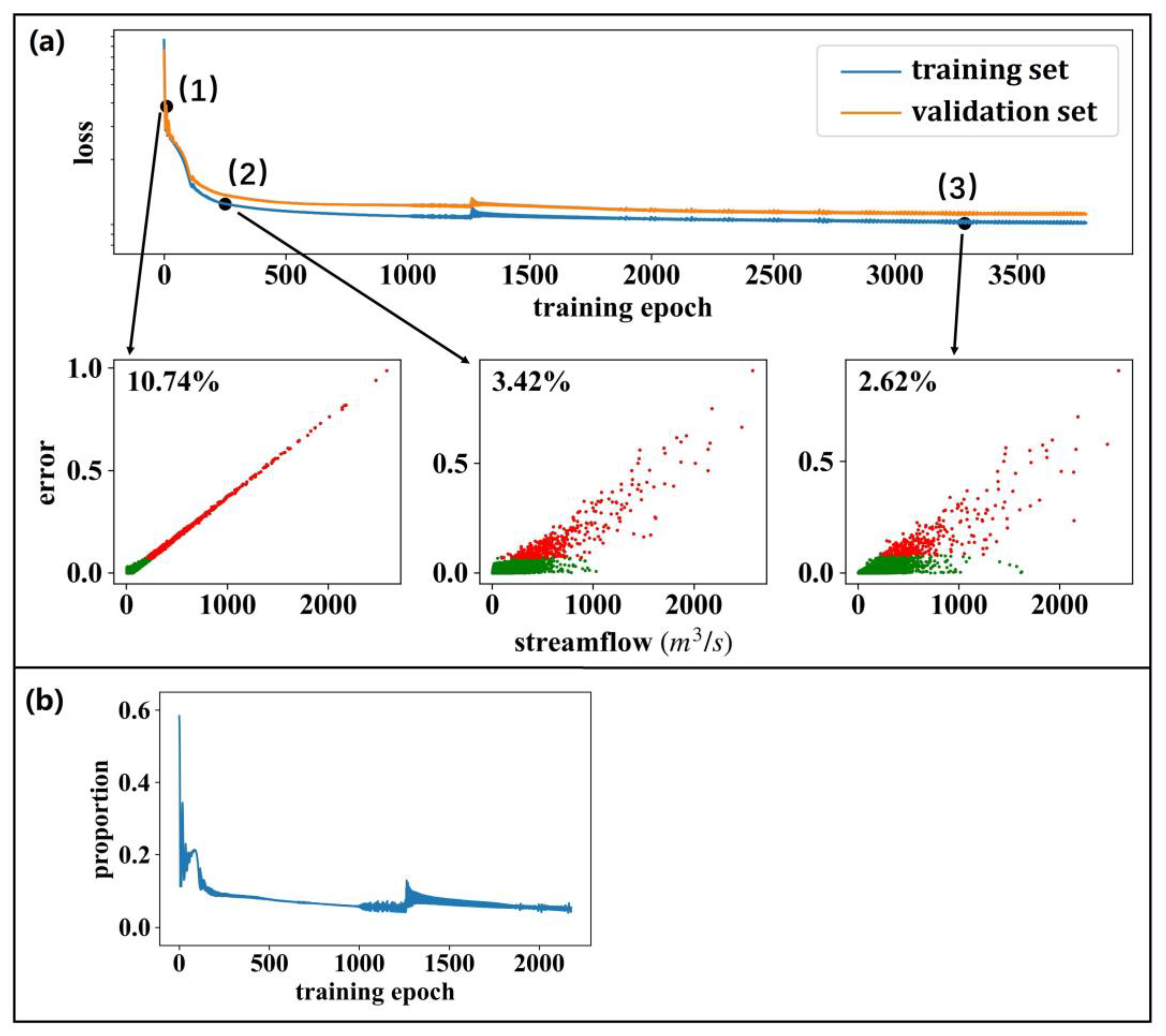
3.2. Benchmarking the LSTM Models by the Naïve Method
4. Discussion
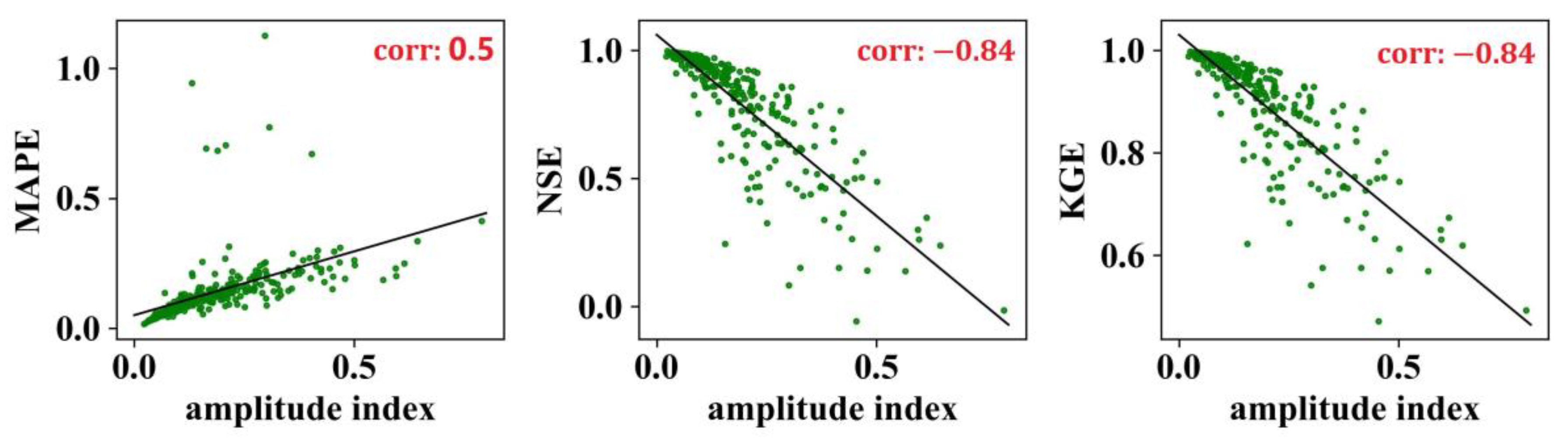
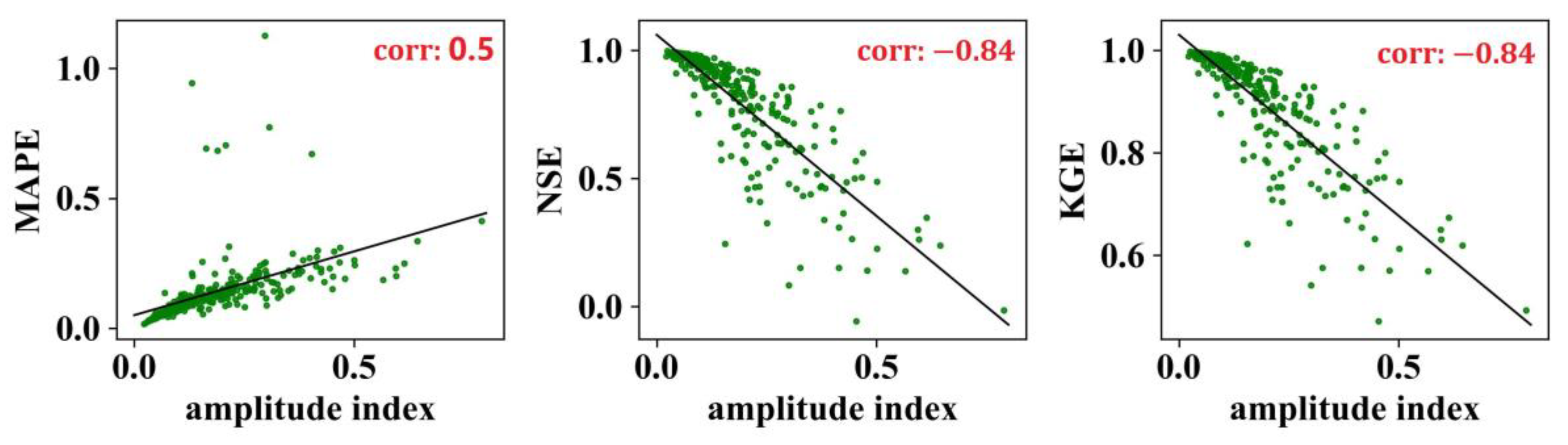
4.1. Characteristics of the Naïve Method
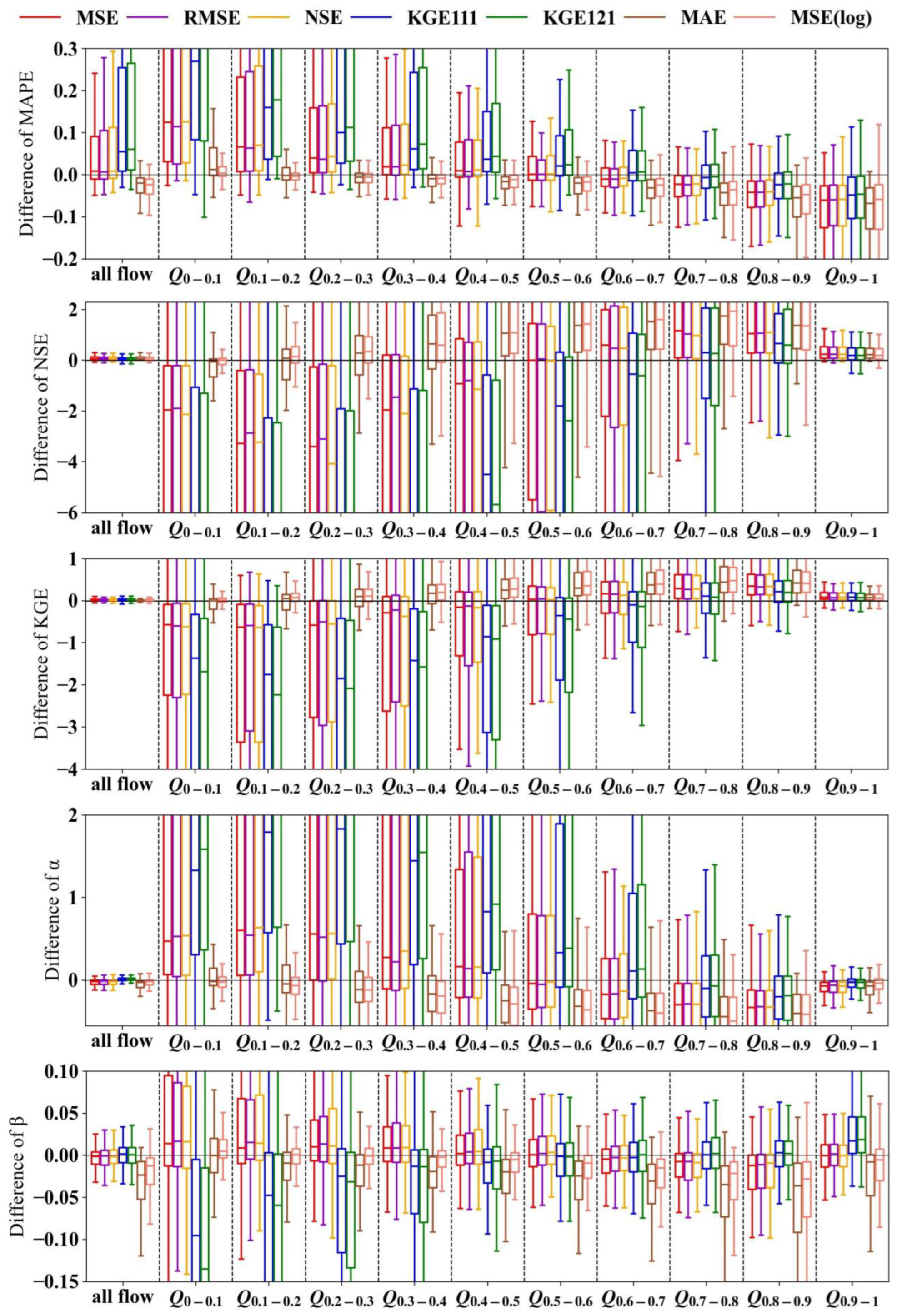
4.2. Selection of Objective Function
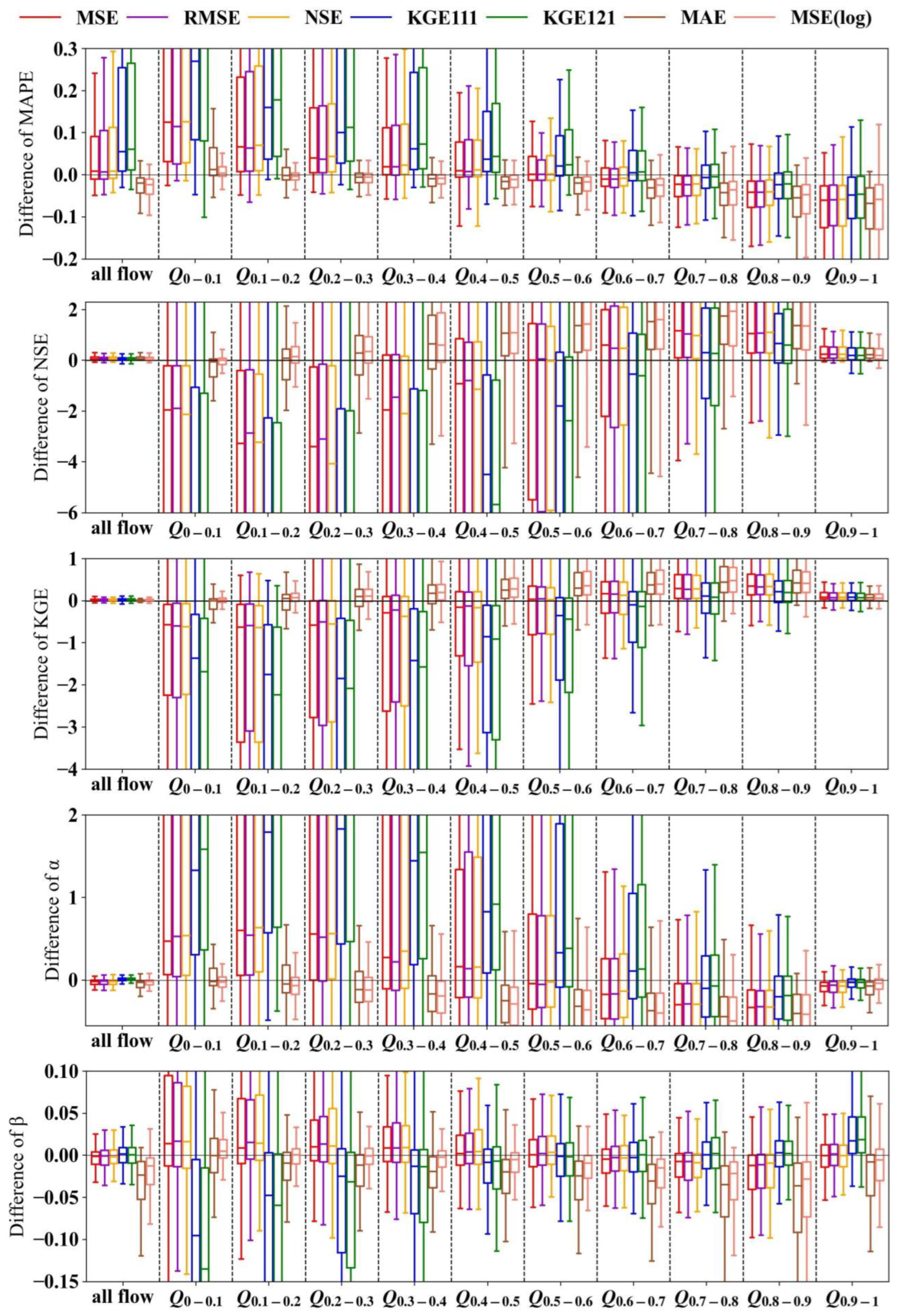
4.2.1. Importance of Objective Function
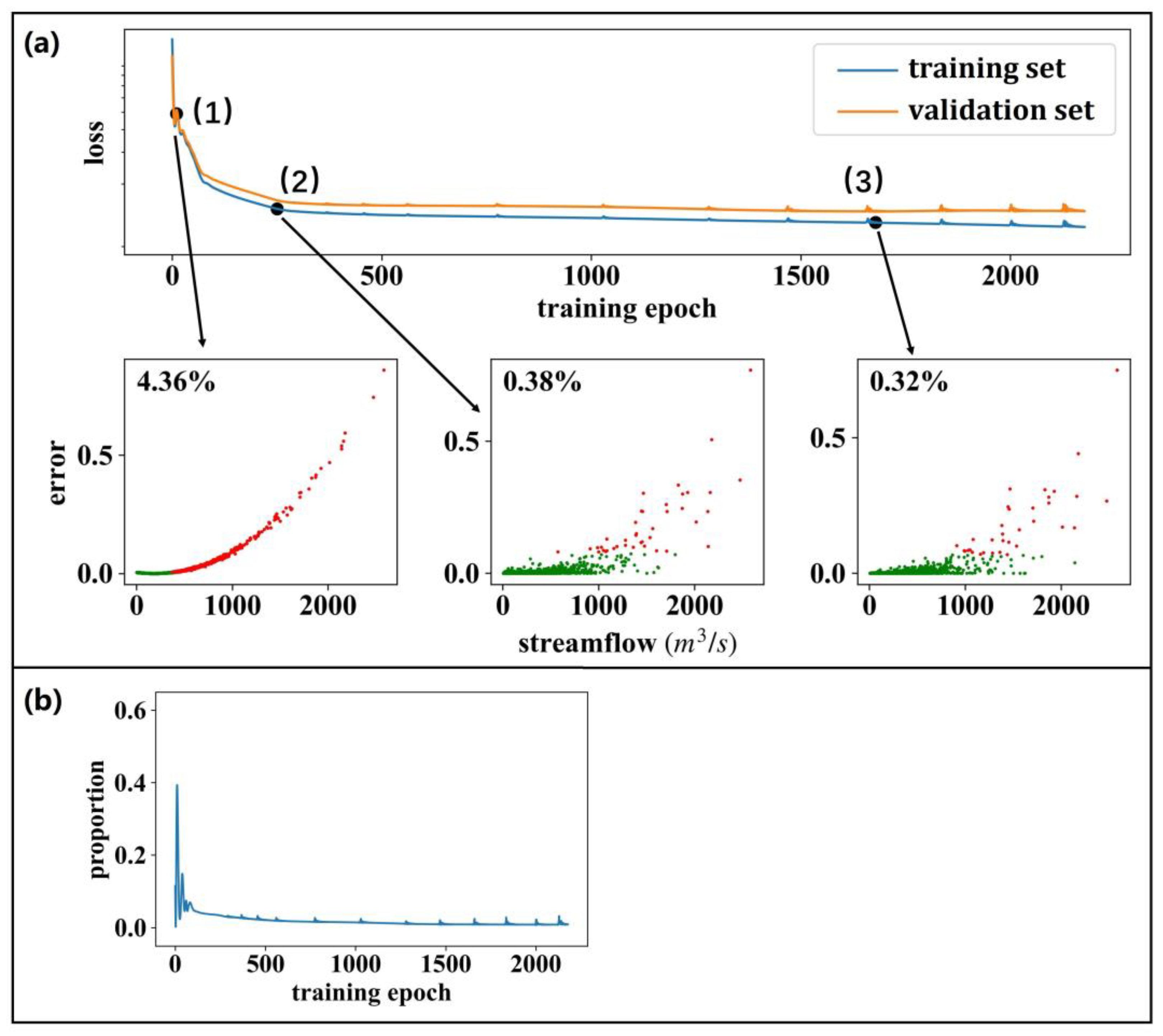
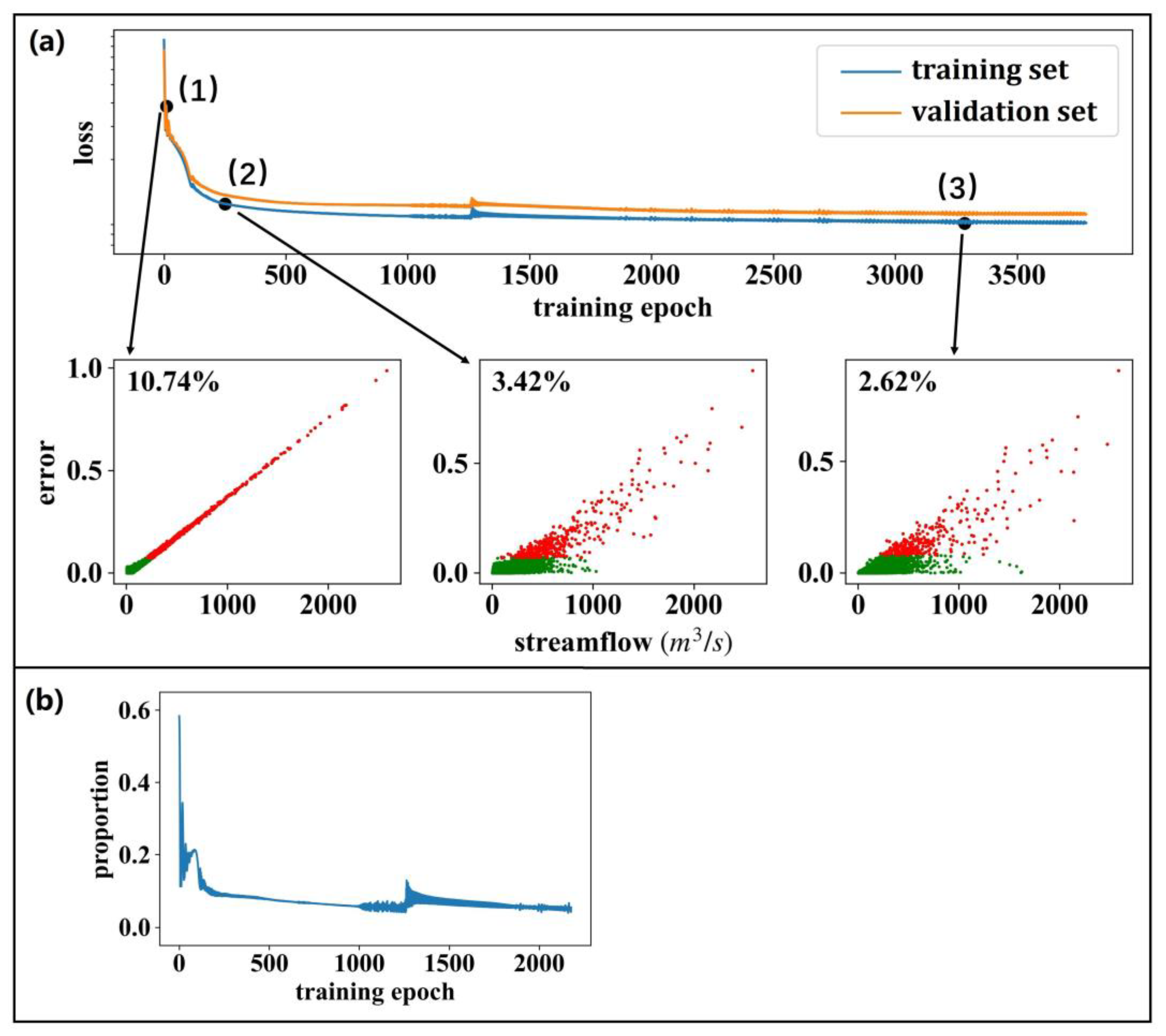
4.2.2. Flaw of the Squared Error-Based Objective Function
4.3. Assessment of Streamflow Modeling
4.3.1. Comparisons with a General Benchmark Method
4.3.2. Evaluating Model Performance in Multiple Dimensions with Various Metrics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karimizadeh, K.; Yi, J. Modeling Hydrological Responses of Watershed Under Climate Change Scenarios Using Machine Learning Techniques. Water Resour. Manag. 2023, preprint. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, D.; Band, S.S.; Jun, C.; Bateni, S.M.; Moslehpour, M.; Pai, H.-T.; Hsu, C.-C.; Ameri, R. Monthly River Discharge Forecasting Using Hybrid Models Based on Extreme Gradient Boosting Coupled with Wavelet Theory and Lévy–Jaya Optimization Algorithm. Water Resour. Manag. 2023, 37, 3953–3972. [Google Scholar] [CrossRef]
- Bakhshi Ostadkalayeh, F.; Moradi, S.; Asadi, A.; Moghaddam Nia, A.; Taheri, S. Performance Improvement of LSTM-based Deep Learning Model for Streamflow Forecasting Using Kalman Filtering. Water Resour. Manag. 2023, 37, 3111–3127. [Google Scholar] [CrossRef]
- Sherman, L.K. Streamflow from rainfall by the unit-graph method. Eng. News Record 1932, 108, 501–505. [Google Scholar]
- Horton, R.E. Surface Runoff Phenomena. Part 1. Analysis of the Hydrograph. Horton Hydrologic Laboratory Publication 101. Edward Bros., Ann Arbor, Michigan. Horton Hydrol. Lab. 1935, 101. [Google Scholar]
- Penman, H.L.; Keen, B.A. Natural evaporation from open water, bare soil and grass. Proc. R. Soc. Lond. Ser. A Math. Phys. Sci. 1948, 193, 120–145. [Google Scholar]
- Sivapalan, M.; Takeuchi, K.; Franks, S.W.; Gupta, V.K.; Karambiri, H.; Lakshmi, V.; Liang, X.; Mcdonnell, J.J.; Mendiondo, E.M.; O’Connell, P.E.; et al. IAHS decade on predictions in ungauged basins (PUB), 2003–2012: Shaping an exciting future for the hydrological sciences. Hydrol. Sci. J. 2003, 48, 857–880. [Google Scholar] [CrossRef]
- Ren-Jun, Z. The Xinanjiang model applied in China. J. Hydrol. 1992, 135, 371–381. [Google Scholar] [CrossRef]
- Phien, H.N.; Pradhan, P. The tank model in rainfall-runoff modelling. Water SA 1983, 9, 93–102. [Google Scholar]
- Ragan, R.M.; Jackson, T.J. Runoff Synthesis Using Landsat and SCS Model. J. Hydraul. Div. 1980, 106, 667–678. [Google Scholar] [CrossRef]
- Sittner, W.T.; Schauss, C.E.; Monro, J.C. Continuous hydrograph synthesis with an API-type hydrologic model. Water Resour. Res. 1969, 5, 1007–1022. [Google Scholar] [CrossRef]
- Fang, L.; Huang, J.; Cai, J.; Nitivattananon, V. Hybrid approach for flood susceptibility assessment in a flood-prone mountainous catchment in China. J. Hydrol. 2022, 612, 128091. [Google Scholar] [CrossRef]
- Yang, J.; Wang, J.; Hu, Y.; Li, B.; Zhao, J.; Liang, Z. Flood risk mapping for the area with mixed floods and human impact: A case study of Yarkant River Basin in Xinjiang, China. Environ. Res. Commun. 2023, 5, 095005. [Google Scholar] [CrossRef]
- Chen, S.; Fu, Y.H.; Wu, Z.; Hao, F.; Hao, Z.; Guo, Y.; Geng, X.; Li, X.; Zhang, X.; Tang, J.; et al. Informing the SWAT model with remote sensing detected vegetation phenology for improved modeling of ecohydrological processes. J. Hydrol. 2023, 616, 128817. [Google Scholar] [CrossRef]
- Cerbelaud, A.; Lefèvre, J.; Genthon, P.; Menkes, C. Assessment of the WRF-Hydro uncoupled hydro-meteorological model on flashy watersheds of the Grande Terre tropical island of New Caledonia (South-West Pacific). J. Hydrol. Reg. Stud. 2022, 40, 101003. [Google Scholar] [CrossRef]
- Mostafa, R.R.; Kisi, O.; Adnan, R.M.; Sadeghifar, T.; Kuriqi, A. Modeling Potential Evapotranspiration by Improved Machine Learning Methods Using Limited Climatic Data. Water 2023, 15, 486. [Google Scholar] [CrossRef]
- Adnan, R.M.; Mostafa, R.R.; Dai, H.-L.; Heddam, S.; Kuriqi, A.; Kisi, O. Pan evaporation estimation by relevance vector machine tuned with new metaheuristic algorithms using limited climatic data. Eng. Appl. Comput. Fluid Mech. 2023, 17, 2192258. [Google Scholar] [CrossRef]
- Dorado-Guerra, D.Y.; Corzo-Pérez, G.; Paredes-Arquiola, J.; Pérez-Martín, M. Machine learning models to predict nitrate concentration in a river basin. Environ. Res. Commun. 2022, 4, 125012. [Google Scholar] [CrossRef]
- Madhushani, C.; Dananjaya, K.; Ekanayake, I.U.; Meddage, D.P.P.; Kantamaneni, K.; Rathnayake, U. Modeling streamflow in non-gauged watersheds with sparse data considering physiographic, dynamic climate, and anthropogenic factors using explainable soft computing techniques. J. Hydrol. 2024, 631, 130846. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.K.; Hochreiter, S.; Nearing, G.S. Toward Improved Predictions in Ungauged Basins: Exploiting the Power of Machine Learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar] [CrossRef]
- Feng, D.; Fang, K.; Shen, C. Enhancing Streamflow Forecast and Extracting Insights Using Long-Short Term Memory Networks With Data Integration at Continental Scales. Water Resour. Res. 2020, 56, e2019WR026793. [Google Scholar] [CrossRef]
- Frame, J.M.; Kratzert, F.; Klotz, D.; Gauch, M.; Shalev, G.; Gilon, O.; Qualls, L.M.; Gupta, H.V.; Nearing, G.S. Deep learning rainfall–runoff predictions of extreme events. Hydrol. Earth Syst. Sci. 2022, 26, 3377–3392. [Google Scholar] [CrossRef]
- Frame, J.M.; Kratzert, F.; Raney, A.; Rahman, M.; Salas, F.R.; Nearing, G.S. Post-Processing the National Water Model with Long Short-Term Memory Networks for Streamflow Predictions and Model Diagnostics. JAWRA J. Am. Water Resour. Assoc. 2021, 57, 885–905. [Google Scholar] [CrossRef]
- Nearing, G.S.; Kratzert, F.; Sampson, A.K.; Pelissier, C.S.; Klotz, D.; Frame, J.M.; Prieto, C.; Gupta, H.V. What Role Does Hydrological Science Play in the Age of Machine Learning? Water Resour. Res. 2021, 57, e2020WR028091. [Google Scholar] [CrossRef]
- Mizukami, N.; Rakovec, O.; Newman, A.J.; Clark, M.P.; Wood, A.W.; Gupta, H.V.; Kumar, R. On the choice of calibration metrics for “high-flow” estimation using hydrologic models. Hydrol. Earth Syst. Sci. 2019, 23, 2601–2614. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, D.; Zhu, J.; Sun, W.; Shen, C.; Shangguan, W. Development of objective function-based ensemble model for streamflow forecasts. J. Hydrol. 2024, 632, 130861. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F.; De Marinis, G. Stacked machine learning algorithms and bidirectional long short-term memory networks for multi-step ahead streamflow forecasting: A comparative study. J. Hydrol. 2022, 613, 128431. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Hochreiter, S.; Nearing, G.S. A note on leveraging synergy in multiple meteorological data sets with deep learning for rainfall–runoff modeling. Hydrol. Earth Syst. Sci. 2021, 25, 2685–2703. [Google Scholar] [CrossRef]
- Konapala, G.; Kao, S.-C.; Painter, S.L.; Lu, D. Machine learning assisted hybrid models can improve streamflow simulation in diverse catchments across the conterminous US. Environ. Res. Lett. 2020, 15, 104022. [Google Scholar] [CrossRef]
- Ghobadi, F.; Kang, D. Multi-Step Ahead Probabilistic Forecasting of Daily Streamflow Using Bayesian Deep Learning: A Multiple Case Study. Water 2022, 14, 3672. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, D.; Wang, G.; Qiu, J.; Long, K.; Du, Y.; Xie, H.; Wei, Z.; Shangguan, W.; Dai, Y. A hybrid deep learning algorithm and its application to streamflow prediction. J. Hydrol. 2021, 601, 126636. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards learning universal, regional, and local hydrological behaviors via machine learning applied to large-sample datasets. Hydrol. Earth Syst. Sci. 2019, 23, 5089–5110. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2013. [Google Scholar]
- Luo, R.; Wang, J.; Gates, I. Machine learning for accurate methane concentration predictions: Short-term training, long-term results. Environ. Res. Commun. 2023, 5, 081003. [Google Scholar] [CrossRef]
- Zhong, M.; Zhang, H.; Jiang, T.; Guo, J.; Zhu, J.; Wang, D.; Chen, X. A Hybrid Model Combining the Cama-Flood Model and Deep Learning Methods for Streamflow Prediction. Water Resour. Manag. 2023, 37, 4841–4859. [Google Scholar] [CrossRef]
- Vatanchi, S.M.; Etemadfard, H.; Maghrebi, M.F.; Shad, R. A Comparative Study on Forecasting of Long-term Daily Streamflow using ANN, ANFIS, BiLSTM and CNN-GRU-LSTM. Water Resour. Manag. 2023, 37, 4769–4785. [Google Scholar] [CrossRef]
- Sushanth, K.; Mishra, A.; Mukhopadhyay, P.; Singh, R. Real-time streamflow forecasting in a reservoir-regulated river basin using explainable machine learning and conceptual reservoir module. Sci. Total Environ. 2023, 861, 160680. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, D.; Meng, Y.; Sun, W.; Qiu, J.; Shangguan, W.; Cai, J.; Kim, Y.; Dai, Y. Bias learning improves data driven models for streamflow prediction. J. Hydrol. Reg. Stud. 2023, 50, 101557. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Wang, Y.; Jian, Z.; Chen, K.; Wang, Y.; Liu, L. Water quality prediction method based on LSTM neural network. In Proceedings of the International Conference on Intelligent Systems & Knowledge Engineering 2017, Nanjing, China, 24–26 November 2017. [Google Scholar]
- Bowes, B.D.; Sadler, J.M.; Morsy, M.M.; Behl, M.; Goodall, J.L. Forecasting Groundwater Table in a Flood Prone Coastal City with Long Short-term Memory and Recurrent Neural Networks. Water 2019, 11, 1098. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lee, J.S.; Choi, H.I. A rebalanced performance criterion for hydrological model calibration. J. Hydrol. 2022, 606, 127372. [Google Scholar] [CrossRef]
- Sun, W.; Peng, T.; Luo, Y.; Zhang, C.; Hua, L.; Ji, C.; Ma, H. Hybrid short-term runoff prediction model based on optimal variational mode decomposition, improved Harris hawks algorithm and long short-term memory network. Environ. Res. Commun. 2022, 4, 045001. [Google Scholar] [CrossRef]
- Li, D.; Marshall, L.; Liang, Z.; Sharma, A.; Zhou, Y. Characterizing distributed hydrological model residual errors using a probabilistic long short-term memory network. J. Hydrol. 2021, 603, 126888. [Google Scholar] [CrossRef]
- Yilmaz, K.K.; Gupta, H.V.; Wagener, T. A process-based diagnostic approach to model evaluation: Application to the NWS distributed hydrologic model. Water Resour. Res. 2008, 44, W09417. [Google Scholar] [CrossRef]
- Mcmillan, H.K. A review of hydrologic signatures and their applications. WIREs Water 2020, 8, e1499. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Wang, D.; Jiang, T.; Kang, A. Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method. Water 2024, 16, 777. https://doi.org/10.3390/w16050777
Lin Y, Wang D, Jiang T, Kang A. Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method. Water. 2024; 16(5):777. https://doi.org/10.3390/w16050777
Chicago/Turabian StyleLin, Yongen, Dagang Wang, Tao Jiang, and Aiqing Kang. 2024. "Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method" Water 16, no. 5: 777. https://doi.org/10.3390/w16050777
APA StyleLin, Y., Wang, D., Jiang, T., & Kang, A. (2024). Assessing Objective Functions in Streamflow Prediction Model Training Based on the Naïve Method. Water, 16(5), 777. https://doi.org/10.3390/w16050777