1. Introduction
Taiwan, located at the intersection of East Asia and the western Pacific, is subject to the long-term influence of the winter northeasterly monsoon and the summer southwesterly monsoon. This makes northern Taiwan especially susceptible to the transport of acidic pollutants, including acidic wet deposition from East Asia and mainland China. The precursor pollutants of acid rain undergo extensive chemical reactions in the atmosphere and within clouds, forming sulfuric acid and suspended particles, which then settle to the ground through dry and wet deposition processes [
1,
2,
3]. Therefore, the study of acid rain pollution in Taiwan must account for the impacts of long-range transport of these pollutants.
The pH concentration of acidic wet deposition in the environment has a significant impact on human health and economic assets. Therefore, this study utilizes monitoring data on air quality and meteorological factors as attribute data, combined with air mass trajectory information, to fully account for factors such as seasonal atmospheric transport and pollutant source regions. The aim is to develop a model capable of accurately predicting the pH concentration of rainwater in the target area, allowing the public to be alerted to the threats posed by acid rain pollution in advance.
Atmospheric acidification, acid rain (the acidity of wet deposition), global chemical changes caused by ozone, ecological imbalance, and climate change induced by greenhouse gases are recognized as the four major environmental challenges facing humanity [
4,
5]. Research indicates that the formation of acid rain is influenced not only by local acidic substances but also by high-altitude pollutants, which can affect acid rain formation over distances of hundreds to thousands of kilometers through atmospheric transport [
6,
7]. Regional transport is thus considered a key factor in the intensification of acid rain within affected areas [
8,
9].
Regarding research on rainwater pH, most studies have focused on two major areas: regional sampling analysis and simulated estimation of the impact of pollutants on rainwater acidity. Sample analysis can reveal certain characteristics of acid rain in a specific region. However, since acid rain is the result of multifactorial interactions, any analysis must encompass a range of factors [
10,
11]. Geographic location, topography, precursor pollutants, and meteorological conditions are commonly used to predict the distribution of acid rain [
12,
13,
14]. A comprehensive long-term study on acid deposition initiated in 1990 revealed that acid rain has become widespread across Taiwan, with the probability of occurrence exceeding 50% [
2]. Urban areas, particularly Taipei in northern Taiwan, experienced higher rates, with occurrences reaching up to 85%, while suburban areas recorded fewer events. Similar studies in Northeast China also examined the spatiotemporal variations of acid rain, providing further insights into regional pollution dynamics.
Understanding airflow trajectory patterns and exploring the characteristics of acid rain under different seasonal climate patterns are crucial for investigating the pH of rainwater [
15,
16]. This emphasizes the significance of comprehending pollutant transport and dispersion processes to gain insights into the factors affecting acid rain characteristics. Many studies have applied the use of air mass back trajectory (AMBT), which serves the purpose of tracking the air mass origins at specific locations [
17,
18,
19]. Using the AMBT model, the acidic aerosol sources can be classified.
As a subtropical island nation with a near-equatorial climate, Taiwan’s weather patterns are strongly influenced by warm, moist air currents and oceanic conditions. Additionally, its proximity to the mainland exposes it to continental climate influences. In their aerosol study of Keelung City, Taiwan, Chen and Chen [
3] noted that most nitrogen species are associated with inorganic particles originating from mainland China, influenced by factors such as continental weathering, biomass burning, and anthropogenic combustion.
Acid rain, driven by the interaction of multiple variables and the cross-border transport of pollutants, poses challenges for accurately predicting acidic wet deposition. Early studies relied on statistical regression models; for example, Stein et al. [
20] used a simple regression model to estimate annual sulfate wet deposition at monitoring sites during the 1980s, effectively assessing the impact of changes in pollutant emissions on sulfate concentrations in precipitation.
In recent years, machine learning, as part of artificial intelligence (AI) technologies, has also been applied to predict rainwater pH. For instance, Ma [
21] used an artificial neural network (ANN) for acid deposition predictions, collecting data from monitoring sites across the U.S. As ANN technology has advanced, more research has been dedicated to estimating acid rain [
14,
15]. Zhu et al. [
22] proposed an intelligent optimization algorithm to predict the pollutants responsible for acid rain, namely nitrogen dioxide and sulfur dioxide. They employed a support vector regression model combined with the Cuckoo Search and Grey Wolf Optimizer. Tao et al. [
23] proposed a flexible method using multilayer perceptron (MLP) neural network analysis to estimate the in situ aerosol acidity of ambient fine particles, based on inputs of water-soluble ions and meteorological parameters.
Although AI algorithms have rapidly advanced in recent years, introducing various sophisticated methods such as the long short-term memory (LSTM) networks [
24] and Transformer networks [
25], significantly improving predictive accuracy, current research gaps remain in the estimation of acid rain using these advanced AI algorithms. As highlighted in the aforementioned literature review, studies in this area are still relatively scarce. Recent studies utilizing various machine learning approaches (excluding neural network-based models), such as gated recurrent units (GRUs) [
26] and Transformers [
27,
28,
29], have proven highly effective in handling time-series data. Despite their potential, however, no research to date has specifically applied these RNN-based models to acid rain forecasting.
As highlighted above, RNN-based models have not yet been utilized for acid rain prediction. While models like LSTM and GRU have been applied in other areas of environmental science, their specific application to acid rain forecasting remains unexplored. This study, therefore, pioneers the use of RNN-based models for predicting acid rain.
The primary goal of this study is to develop a model capable of accurately predicting the acidity or alkalinity of rainwater in the target area. This approach aims to provide the public with timely information about the risks associated with acid rain pollution, aligning with the need for effective early prevention strategies. Utilizing monitoring data on air quality, water quality, and meteorological factors, this study employs an ANN model to estimate rainwater pH. Considering Taiwan’s complex climate and the influence of continental monsoons, incorporating the AMBT model to classify external acidic aerosol sources offers a promising approach. A review of the current literature reveals that no ANN model has yet been integrated with the AMBT model to predict rainwater pH. By including information on air mass trajectories, this study can comprehensively account for factors such as seasonal atmospheric transport and the geographic origins of pollution sources.
To summarize, the highlights of this study are as follows:
Use of HY-SPLIT Model: This study utilizes the Hybrid Single-Particle Lagrangian Integrated Trajectory (HY-SPLIT) model, developed by the National Oceanic and Atmospheric Administration (NOAA) [
30,
31], to classify acidic aerosol sources through air mass back trajectory (AMBT) analysis. HY-SPLIT calculates the movement paths of air masses, providing a critical framework for identifying the origins and transport pathways of pollutants. For related studies, see [
17,
18,
19].
Application of AI Technologies: This research employs AI technologies, specifically machine learning, to estimate rainwater acidity. Two ANNs are utilized: deep neural networks (DNNs) with an MLP architecture and LSTM networks. The study establishes correlations between key pollutants and other relevant factors. The performance of these models in predicting rainwater acidity is then evaluated and compared. For related studies on DNN applications in acid rain forecasting, see [
21,
22,
23]. As previously noted, no research has yet applied LSTM networks specifically to acid rain forecasting.
Integration of AMBT Analysis and AI Technologies: To enhance prediction accuracy, this study integrates air mass trajectory data with AI models to account for the influence of atmospheric circulation on the transport of foreign chemical substances. Specifically, this approach combines machine learning techniques with meteorological data to deliver more accurate predictions of rainwater acidity. The proposed integrated model is novel and has not been documented in the existing literature. Details of this model are provided in
Section 3: Methodology.
Given that the northern region of Taiwan is highly industrialized and urbanized, it is likely to exhibit a high degree of pollution dependence. Additionally, this region is influenced by its unique climatic conditions. Therefore, the northern region of Taiwan is chosen as the research area for this study.
2. Research Area and Data
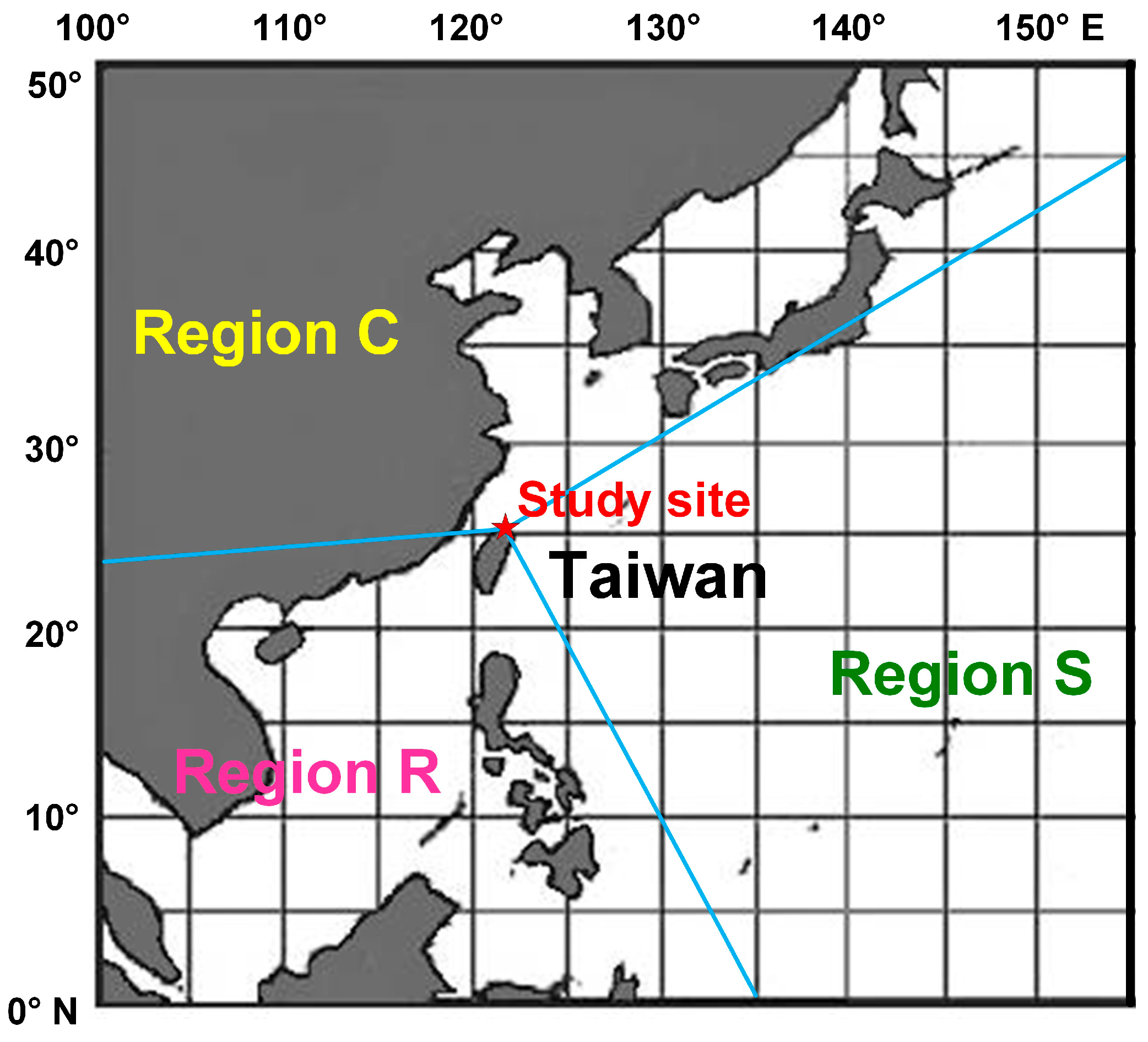
The study area is the Yangming monitoring station, located in the Greater Taipei metropolitan area in northern Taiwan (
Figure 1). The Yangming monitoring station is situated within Yangmingshan National Park in Taipei City. According to Taiwan’s Ministry of Environment (MOE), the station is classified as a “park station”, distinct from general stations, traffic stations, or background stations.
The data utilized in this research were obtained from Taiwan’s MOE, comprising daily air quality monitoring values and acid rain monitoring data collected from 2008 to 2020. The dataset includes approximately 4700 daily records. A total of 13 monitoring parameters were analyzed, encompassing pollutants, acid rain, and meteorological data (as summarized in
Table 1). These parameters include particulate matter (PM2.5), suspended particulates (PM10), ozone (O
3), sulfur dioxide (SO
2), carbon monoxide (CO), carbon dioxide (CO
2), nitrogen monoxide (NO), nitrogen dioxide (NO
2), nitrogen oxides (NO
x), rainwater conductivity (RAIN_COND), acid rain pH (PH_RAIN), atmospheric temperature (AMB_TEMP), rainfall intensity (RAIN_INT), and relative humidity (RH). The respective units for these parameters are also provided in
Table 1.
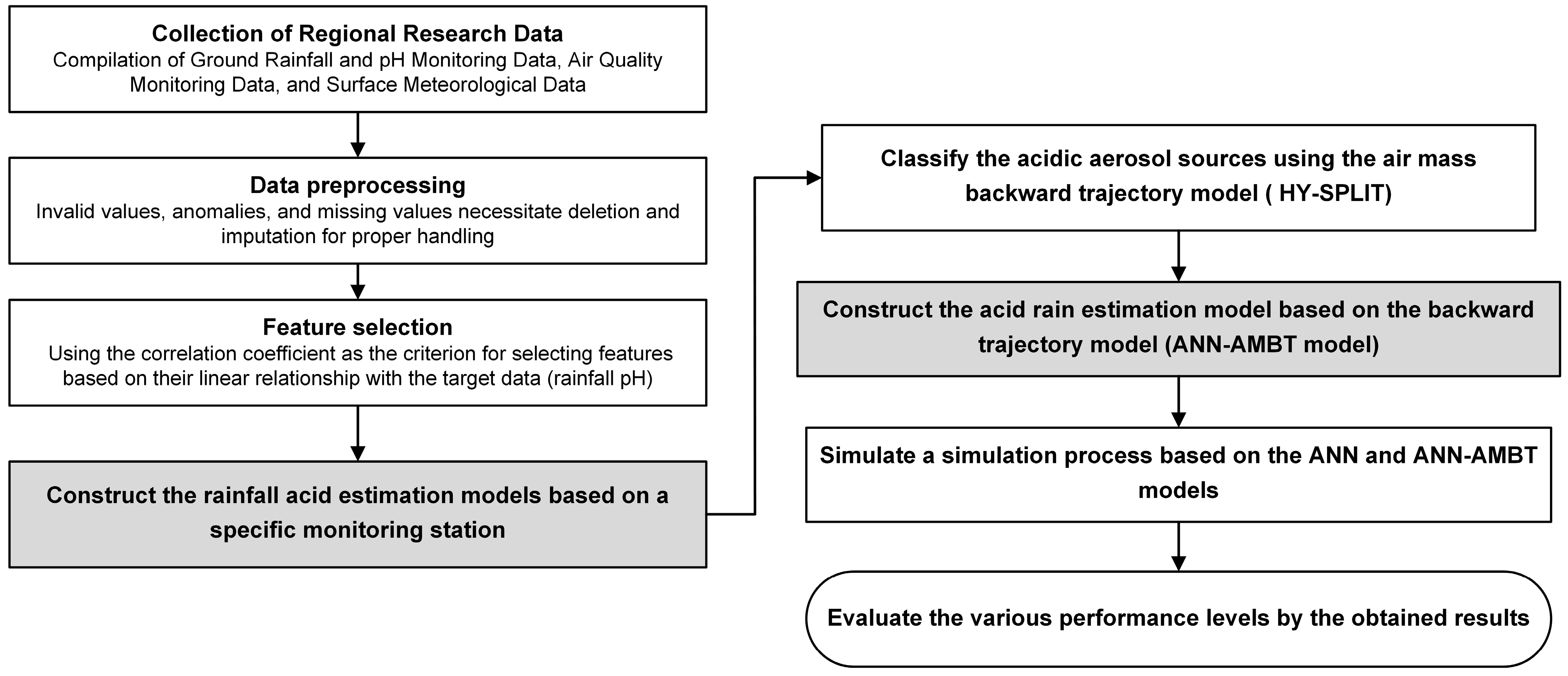
Regarding data quality, some raw data included invalid values due to instrument errors, program checks, manual inspections, or equipment malfunctions. These issues also resulted in missing values, unreasonable negative values, or null entries. Among these, unreasonable negative values refer to cases where air quality monitoring parameters (e.g., PM10 and PM2.5) theoretically have a background value greater than zero. Hence, monitoring values recorded as negative or zero were deemed invalid.
To address this, data preprocessing was performed. First, raw data with poor quality control were removed, including the aforementioned invalid values. Missing data were then handled using interpolation or extrapolation methods. After preprocessing, all 13 attributes underwent further analysis to confirm their statistical validity (as shown in
Table 1). The statistical summary, including minimum and maximum values, mean, and standard deviation for each attribute, indicated that the data fell within reasonable ranges.
4. Modeling and Evaluation
This study begins by selecting input attributes based on their correlation with the pH of rainwater at the target monitoring station. According to Zhang et al. [
37], the correlation coefficient ranges from −1 to 1. A coefficient of |r| < 0.2 indicates a very weak or no correlation, 0.2 ≤ |r| < 0.4 suggests a weak correlation, 0.4 ≤ |r| < 0.6 indicates a moderate correlation, and |r| ≥ 0.6 signifies a strong correlation. When setting the thresholds, a higher threshold results in fewer parameters being selected (e.g., if |r| is greater than 0.3, only three parameters are included), which could potentially affect the model’s quality. Ultimately, we selected parameters with |r| greater than 0.2 as input features.
Table 2 presents the results of the correlation analysis for various parameters, including PM2.5, PM10, O
3, SO
2, CO, RAIN_COND, PH_RAIN, and AMB_TEMP, evaluated against a threshold of r = 0.2. The analysis reveals that, apart from rainwater conductivity (RAIN_COND), the pH of rainwater is highly correlated with particulate matter concentrations (PM2.5 and PM10). This finding suggests that acidic aerosols significantly influence rainwater acidity in the region.
Features demonstrating a strong or meaningful correlation with the target variable (i.e., rainwater pH) were selected as inputs to enhance the predictive performance of the models. This approach ensures the input data captures relevant patterns for LSTM to model temporal dependencies and for DNN to identify complex nonlinear relationships effectively.
4.1. Modeling of ANN Models
The data are divided into training and validation sets using data from 2008 to 2016 (9 years) and a testing set from 2017 to 2020 (4 years) to achieve parameter verification and model evaluation objectives. Python was used as the programming language, and the Keras library, running on top of TensorFlow, was employed to develop and train the neural network models. These tools were selected for their flexibility, ease of use, and robust support for machine learning and deep learning applications. The study employs a trial-and-error approach to iteratively adjust and optimize the nonlinear mapping relationships between inputs and outputs, enhancing the model’s ability to fit the target values more accurately.
For the DNN model, several parameters require optimization, including the learning rate, the number of hidden layers, and the number of neurons per hidden layer. To optimize these networks, the study employs the Adam optimizer [
38], known for its adaptive learning rates that adjust dynamically based on estimates of the first and second moments of the gradient.
Learning Rate: This parameter is crucial during the training process as it affects the convergence speed of the model. A larger learning rate can speed up convergence but may cause oscillations (damping) and prevent reaching the function’s minimum. Conversely, a smaller learning rate results in slower convergence and may lead to getting stuck in local minima, requiring many iterations to approach the target value. The study starts with an initial learning rate of 0.1 and incrementally adjusts it by 0.1 to find the optimal learning rate.
Number of Hidden Layers: A basic neural network model consists of three layers: input, hidden, and output. The number of hidden layers can vary, with two layers generally providing better performance compared to one layer. However, too many layers may hinder convergence and increase errors [
39]. The study begins with one hidden layer and increases the number of layers until the parameter values diverge to find the optimal configuration. The number of neurons per hidden layer is initially set to 10.
Number of Neurons per Hidden Layer: The number of neurons in the hidden layers significantly impacts the network’s computational capability. If the number of neurons is too low, the network may fail to model the relationship between inputs and outputs effectively. Conversely, too many neurons can lead to overfitting, where the model performs well on training data but poorly on new data. The study explores neuron counts in increments of 10 to find the appropriate range.
The results of the DNN parameter optimization are summarized in
Table 3. The optimal configuration identified is a learning rate of 0.1, two hidden layers, each with 60 neurons.
In addition, the parameter tuning for LSTM neural networks includes the number of hidden layers and the number of neurons per hidden layer. The parameter adjustment process follows the same method as for the DNN, where the number of hidden layers is initially set to 1 and gradually increased until the parameters diverge to find the optimal number of layers. Similarly, the number of neurons per hidden layer starts at the default value of 10 and is adjusted accordingly.
The results of the LSTM model parameter tuning are shown in
Table 4. The tuning initially involved adjusting the number of neurons per hidden layer, starting from 20. The model converged at this number but gradually showed signs of overfitting as more neurons were added. For the number of hidden layers, the optimal convergence was achieved with six layers, each containing 20 neurons. Therefore, the best parameter combination for the LSTM model is one hidden layer with 20 neurons per layer.
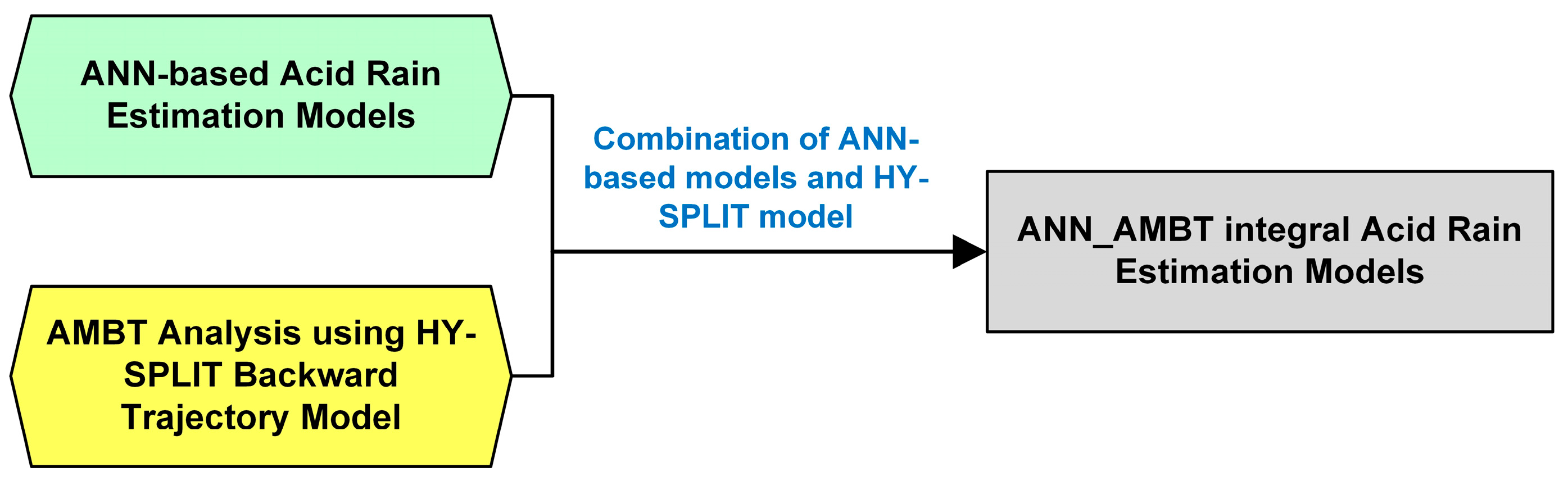
4.2. ANN_AMBT Modeling
As highlighted earlier, the ANN_AMBT modeling serves as an integral framework that merges the predictive power of ANN-based estimation models with the spatial and temporal analytical capabilities of the AMBT model. Specifically, the HY-SPLIT trajectories are employed to track the movement and origins of air masses arriving at a designated location. For this study, the AMBT model is configured to trace four-day backward trajectories of air masses, focusing on the Keelung area (near Yangming station). This setup aligns with the methodology outlined in [
3], providing a robust approach to estimate the sources of air masses influencing acid rain formation.
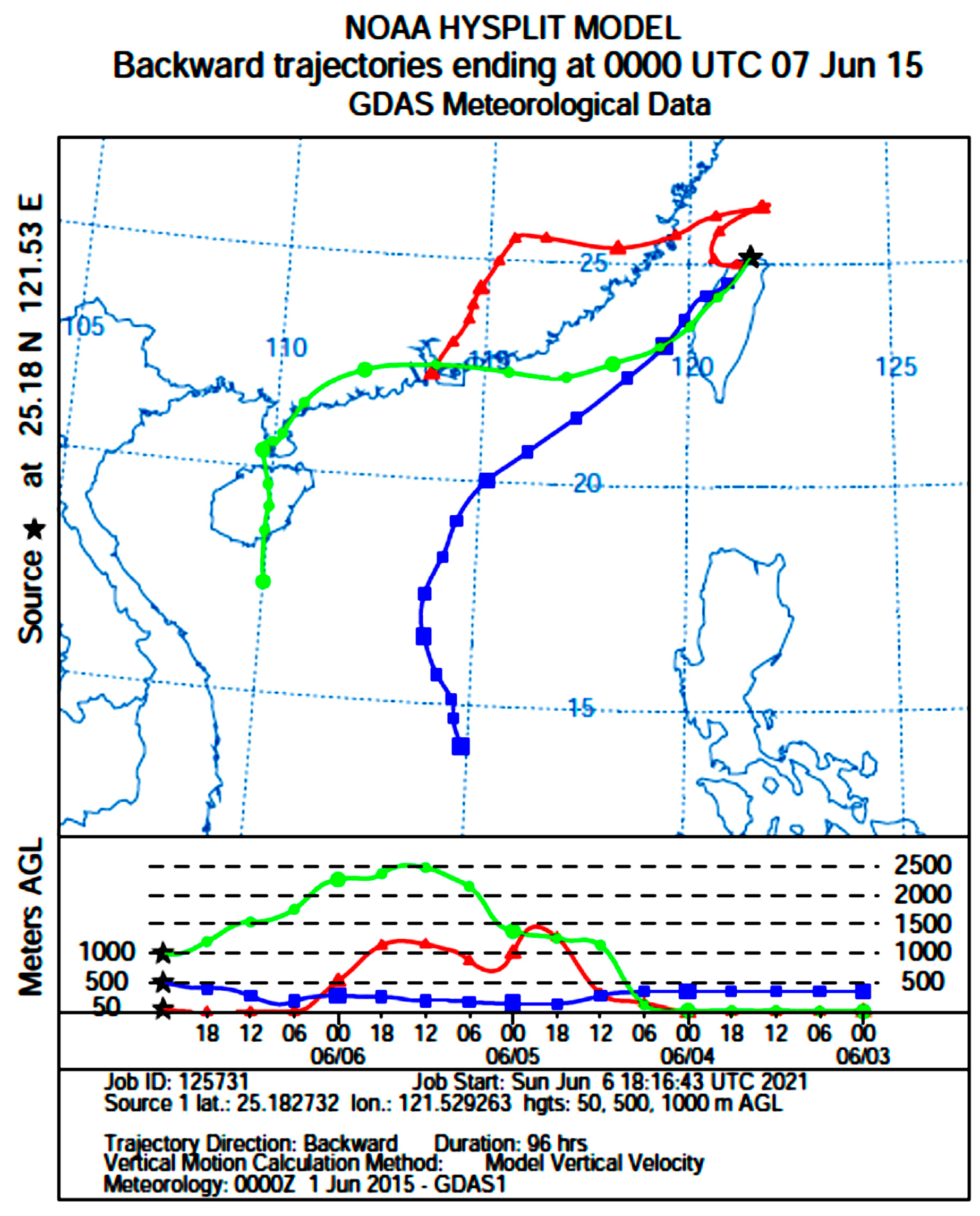
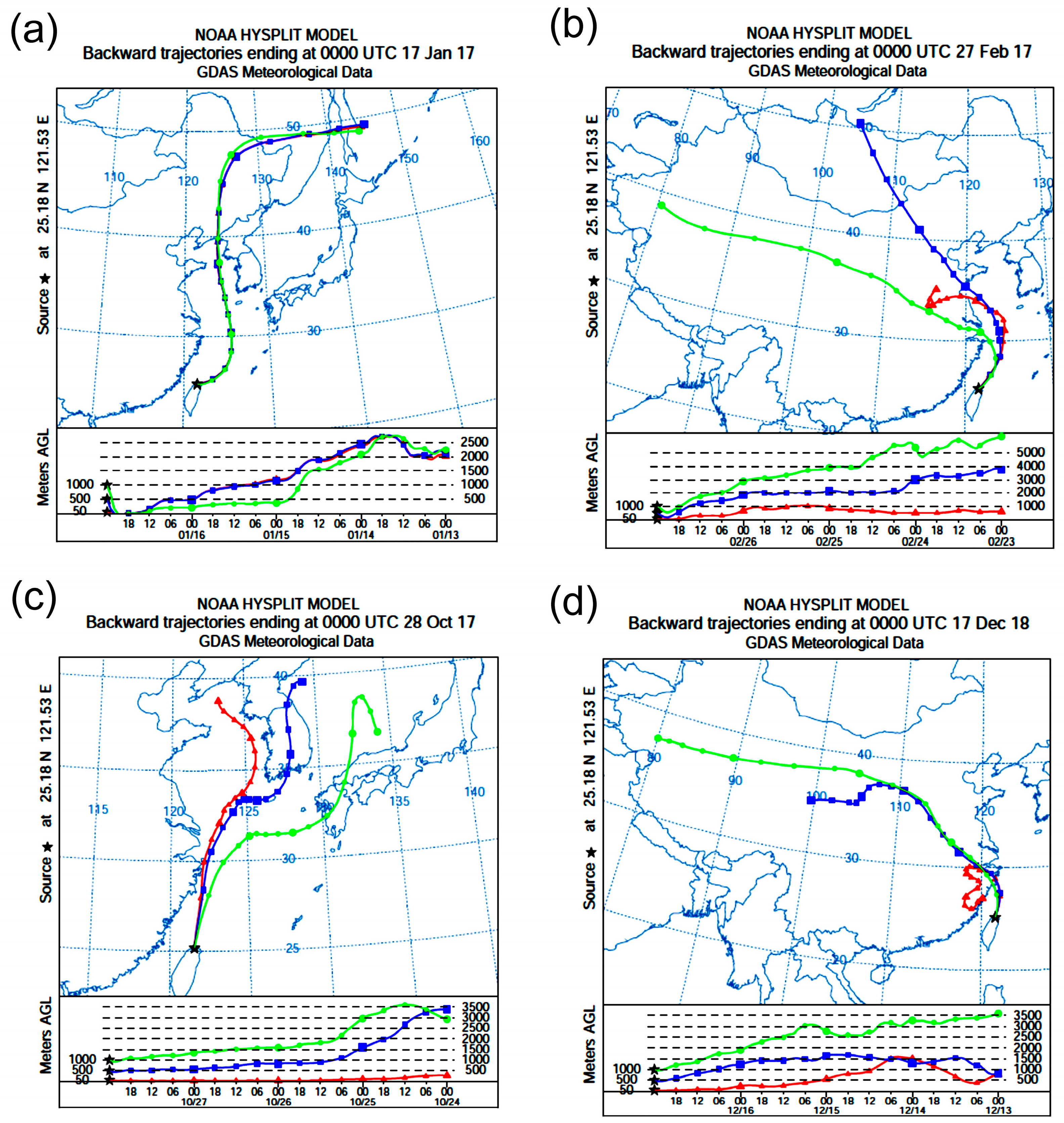
According to Chen and Chen [
3], AMBTs were conducted at 100 m, 500 m, and 1000 m above ground level to represent airflow trajectories at surface, middle, and high altitudes, respectively. In this study, the AMBT model was simulated at three different altitudes above ground level: 50 m (red line), 500 m (blue line), and 1000 m (green line), representing low-, mid-, and high-elevation airflows, respectively (see
Figure 4). In the figure, the star symbol indicates the research location, with each node covering a six-hour interval. The regional long-range pollution information obtained at each altitude was then classified into the three regions outlined in
Figure 1: Region C, Region R, and Region S.
Since rainwater pH values are only available on rainy days, this study estimates air mass back trajectories for 2035 rainy days. The air quality and meteorological data associated with these days are categorized according to the height levels (50, 500, and 1000 m). The classification of these trajectories is based on the regional zones (C, R, and S Regions). Subsequently, machine learning models are established for each classified region, resulting in the creation of the ANN_AMBT integral model. This model integrates ANN with AMBT data to enhance the accuracy of acid rain pH predictions.
Table 5 presents the best parameter combinations for DNN and LSTM models after parameter adjustment, using air mass trajectory data obtained from different heights. The results show that using air mass trajectory classification data results in lower errors compared to using only ground monitoring parameters. Additionally, at height levels of 50, 500, and 1000 m, the LSTM model consistently achieves smaller RMSE errors compared to the DNN model.
6. Conclusions
The study employs advanced artificial intelligence technologies to develop models for estimating acid rain, utilizing machine learning algorithms such as DNN and LSTM neural networks. Given the high levels of industrialization and urbanization in northern Taiwan, combined with the impact of seasonal monsoons bringing foreign pollutants, this region was selected as the focus of the study.
The study area was selected as the Yangming station in the Taipei metropolitan area. Based on the trajectory patterns of pollutant sources, three potential pollution source regions were defined: the mainland China and Japanese archipelago under the northeast monsoon system (Region C), the Philippines and Indochina Peninsula under the southwest monsoon system (Region R), and the Pacific Ocean under the western Pacific high-pressure system (Region S). Data were categorized according to these regions to develop neural network models. The study developed models for air mass sources at three different heights (50 m, 500 m, and 1000 m). Additionally, a benchmark model was established based solely on the attributes of surface monitoring stations, without incorporating AMBT information. In this study, the benchmark model refers to an ANN model that relies exclusively on ground station attributes (LSTM_No_AMBT) and serves as a baseline for comparison.
The research results are as follows:
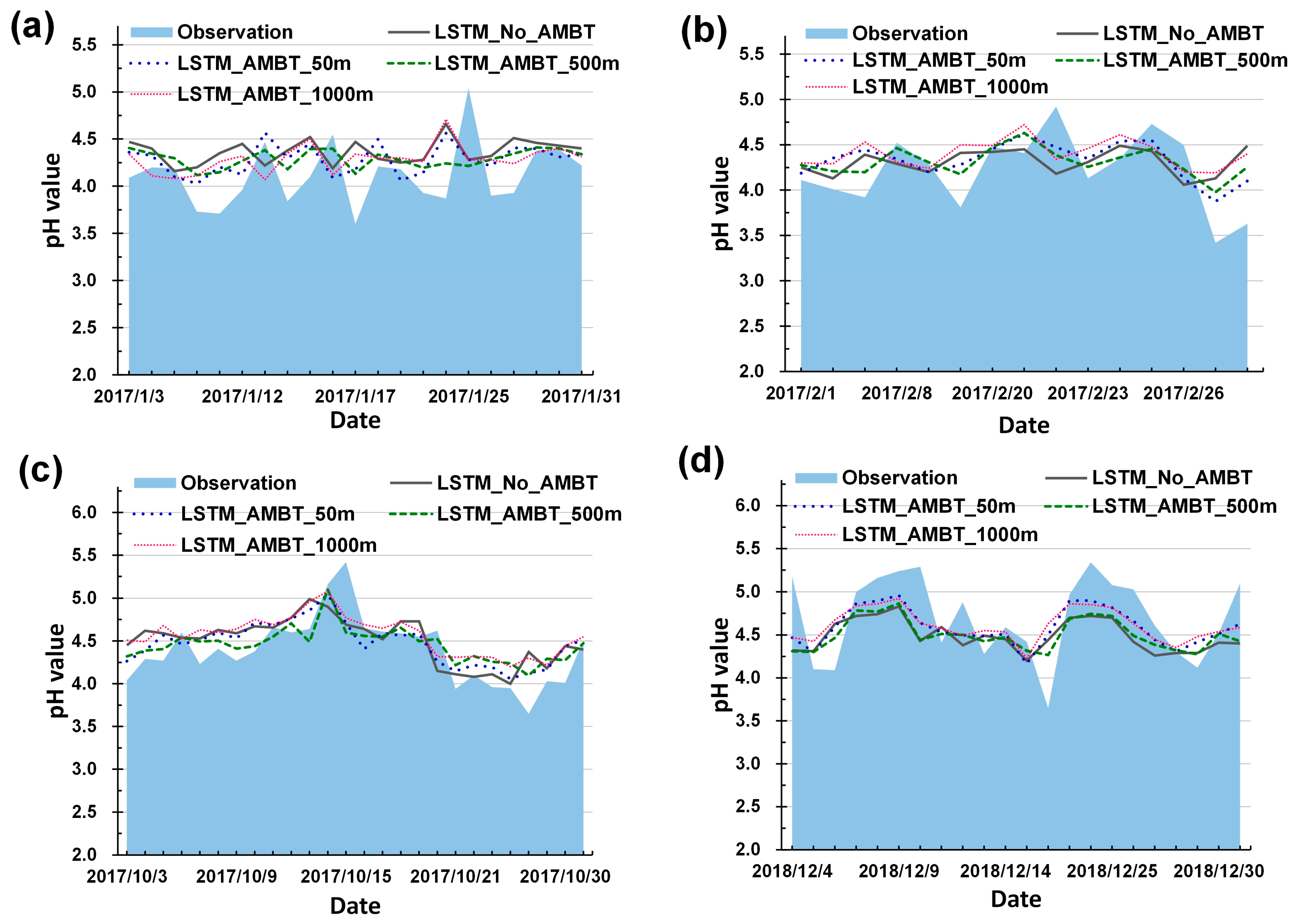
ANN Model Results: The use of LSTM networks significantly outperforms DNNs. Since acid rain pH data are discontinuous (monitoring values are only available during rainfall), and considering environmental physical effects (such as rain washout and removal), the occurrence of events before and after does have an impact. Thus, LSTM networks have an advantage in handling data with delay attributes.
LSTM_AMBT Models Comparison: The LSTM_AMBT models utilizing three different heights of air mass trajectories (surface 50 m, mid-altitude 500 m, and high-altitude 1000 m)—namely LSTM_No_AMBT, LSTM_AMBT_50m, LSTM_AMBT_500m, and LSTM_AMBT_1000m—demonstrated better performance in describing the variation profile of rainwater pH compared to the model without air mass trajectory information (LSTM_No_AMBT).
Seasonal Considerations: The Yangming station experiences severe acid rain almost exclusively in winter (December to February). During this season, the trajectory model in the optimal model can consider the pathways of external pollutants due to seasonal variations, thus adapting well to the higher frequency of acid rain occurrences in winter. This highlights the accuracy and feasibility of the ANN_AMBT model in predicting severe acid rain pollution events.
Future recommendations include the following:
The study used altitudes of 50 m, 500 m, and 1000 m above ground level to represent airflow trajectories at surface, middle, and high altitudes, respectively, and to test suitable heights. While these heights are commonly used, we acknowledge that variations in the selected heights could influence the results. Therefore, we suggest future research to explore the effects of using different heights, such as extending the range to 50 to 1500 m at 100 m intervals, to further validate and refine our findings.
The study suggests that the model tends to underestimate pH values when the rainwater pH is above 5.15. This is likely due to the lower frequency of such extreme events (severe acid rain) in the collected data (approximately 15% at Yangmingshan station). This discrepancy affects the pH value predictions. Future work should focus on increasing the sample size of severe acid rain events to improve model training and potentially resolve this issue.
Regarding the proposed methodology, the study utilized year-round data to predict acid rain occurrences. However, the methodology did not specifically develop the ANN_AMBT combination models based on seasonal variations. In the study area, acid rain frequently occurs during the winter season (approximately from November to February in Taiwan). Therefore, it is suggested that future research focuses on developing season-based ANN_AMBT models tailored to periods with a higher likelihood of acid rain occurrence. Such an approach could potentially improve the accuracy of acid rain prediction models.
In this study, we selected LSTM due to its robustness and widespread validation in time-series tasks, particularly in environmental modeling. This choice aligns well with the size of our dataset and the available computational resources. For future work, we suggest exploring the potential advantages of advanced methods, such as Transformers and hybrid models like convolutional LSTMs, to further improve the accuracy and generalizability of our model.
As mentioned in
Section 5.2, the limitations of AMBT may affect the accuracy and reliability of the study results. To mitigate these impacts, future researchers intending to adopt the methodology presented in this study are advised to carefully select appropriate ANN models and data sources. Additionally, incorporating supplementary methods to validate the AMBT results is recommended to enhance the credibility of the study’s conclusions.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}