1. Introduction
Rain pattern and intensity are the most commonly used parameters for describing rainfall characteristics and are important factors that affect hydrological processes [
1,
2], playing a crucial role in the analysis of hydrological, hydraulic, and water quality models. With the increasing sample size of hydro-meteorological data and the continuous development of artificial intelligence technology, the use of machine learning methods to extract important characteristics of rainfall-runoff from large amounts of hydrological data can better identify hydrological regularities [
3,
4], improve the scientificity and reliability of rainfall classification, and provide powerful technical support for efficient flood forecasting.
Rain pattern is numerically represented by the distribution process of rainfall intensity over a time scale. Early research was based on a statistical analysis of large amounts of measured rainfall data. In 1956, Soviet researchers such as Pakhomova and M.B. Morokov [
5] statistically analyzed a large amount of measured rainfall data and summarized seven classic rainfall types, known as model rain patterns. In 1957, Keifer and Chu [
6] proposed the Chicago rainfall type. In 1967, Huff [
7] divided rainfall into four types based on the different locations of rainfall types in the analysis of storm rainfall types in Illinois, known as the Huff rainfall type. In 1975, Pilgrim and Cordery [
8] proposed a generalized rainfall type, using the mean proportional value of hourly rainfall for many years of measured rainfall data as the unit rainfall distribution value, known as the P&C rainfall type. In 1980, Yen and Chow [
9] proposed a triangular rainfall type. In 1964, Zhao Guangrong [
10] statistically analyzed the heavy rainfall in Guangdong Province and roughly divided it into three types and eight categories. In 1994, Wang Min [
11] and others proposed a design storm rainfall type for Beijing based on rainfall data. There are substantial differences between various rainfall types, and currently, there is no unified rainfall type as a design basis.
Rain pattern is one of the most important front-end input data for rainfall-runoff simulation, and it has a significant impact on the simulation results of both rainfall-runoff experimental models, physical mechanism hydrological models, and data-driven hydrological models. Wu Zhangchun et al. [
12] found that under the same average rainfall intensity within the runoff duration, the peak of the triangular rain pattern in the middle or at the back was more than 30% higher than that of the uniform rain pattern through indoor simulation of rainfall-runoff experiments. Based on the seven rain patterns proposed by Pakhomova, M.B. Morokov, and others, Cen Guoping [
13] used a fuzzy identification method to statistically analyze and classify rain patterns at four precipitation stations and conducted rainfall-runoff experimental studies. The results showed that rain pattern has significant effects on peak flow and flow process lines. Zhao Kangqian [
14] classified six rainfall events using model rain patterns, selected 12 parameters that varied within the interval, compared SWMM simulation total runoff and peak variable changes, and analyzed the sensitivity of parameters. The results showed that rain pattern has a significant impact on parameter sensitivity. Zhang Xiaoyuan [
15] designed three rain patterns: single peak, double peak, and triple peak for SWMM hydrological parameter sensitivity analysis, and the results showed that rain patterns significantly impacted parameter sensitivity and recognition performance. Tu Xinyu [
16] used the constructed HEC-HMS model to simulate peak flow rates corresponding to different rain patterns and fixed total rainfall amounts. The results showed that the peak flow rates simulated for different rain patterns had significant deviations, and rain patterns had a significant impact on rainfall-runoff calculation. Yang Senxiong [
17] used seven model rain patterns to perform fuzzy identification and classification on 43 rainfall events and used the SWMM model to predict rainfall-runoff. The results showed that the rainfall-runoff simulation results of different rain patterns had significant differences, indicating that the rain pattern has a significant impact on the generalization performance and accuracy of the model prediction. Based on the characteristics of rain patterns, the DTW hierarchical clustering algorithm was used for rainfall event classification, and the data set was reconstructed based on the classification results. A deep learning model was used to construct an integrated data-driven model for rainfall-runoff prediction, and the prediction results were higher than those without clustering rain patterns, indicating that rain pattern has a significant impact on the prediction performance of rainfall events.
In the process of establishing the relationship between rainfall and runoff, if only one rain pattern is used to represent the comprehensive rainfall distribution process in the area, the diversity of rainfall itself will be ignored. Due to the important role of rainfall patterns in simulating rainfall-runoff, diverse rainfall patterns can avoid homogenization of model parameters, ensuring accurate, precise, and scientific simulation of rainfall runoff in hydrological models. Therefore, it is necessary to conduct a diversity classification study of rainfall patterns in the basin.
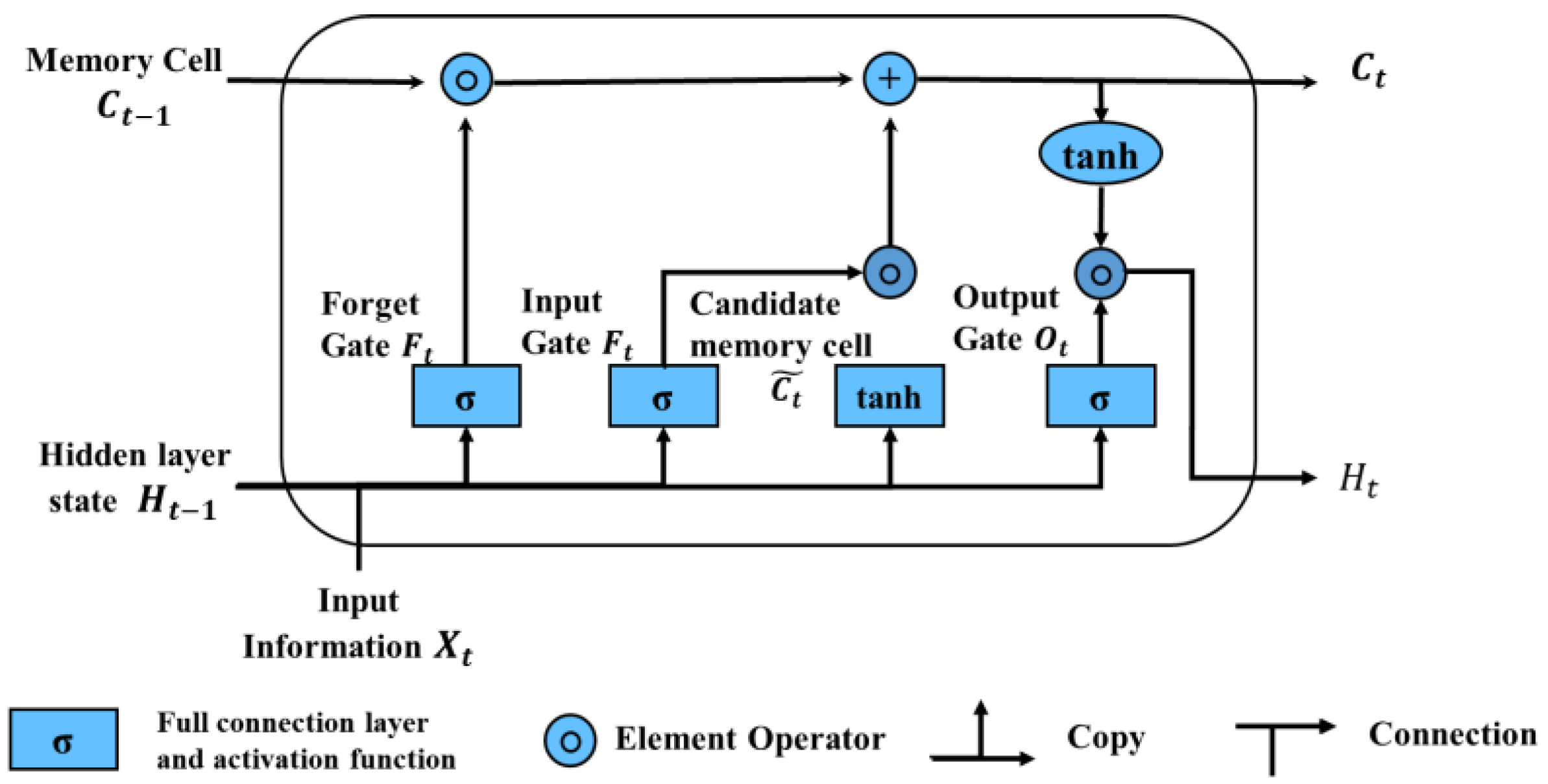
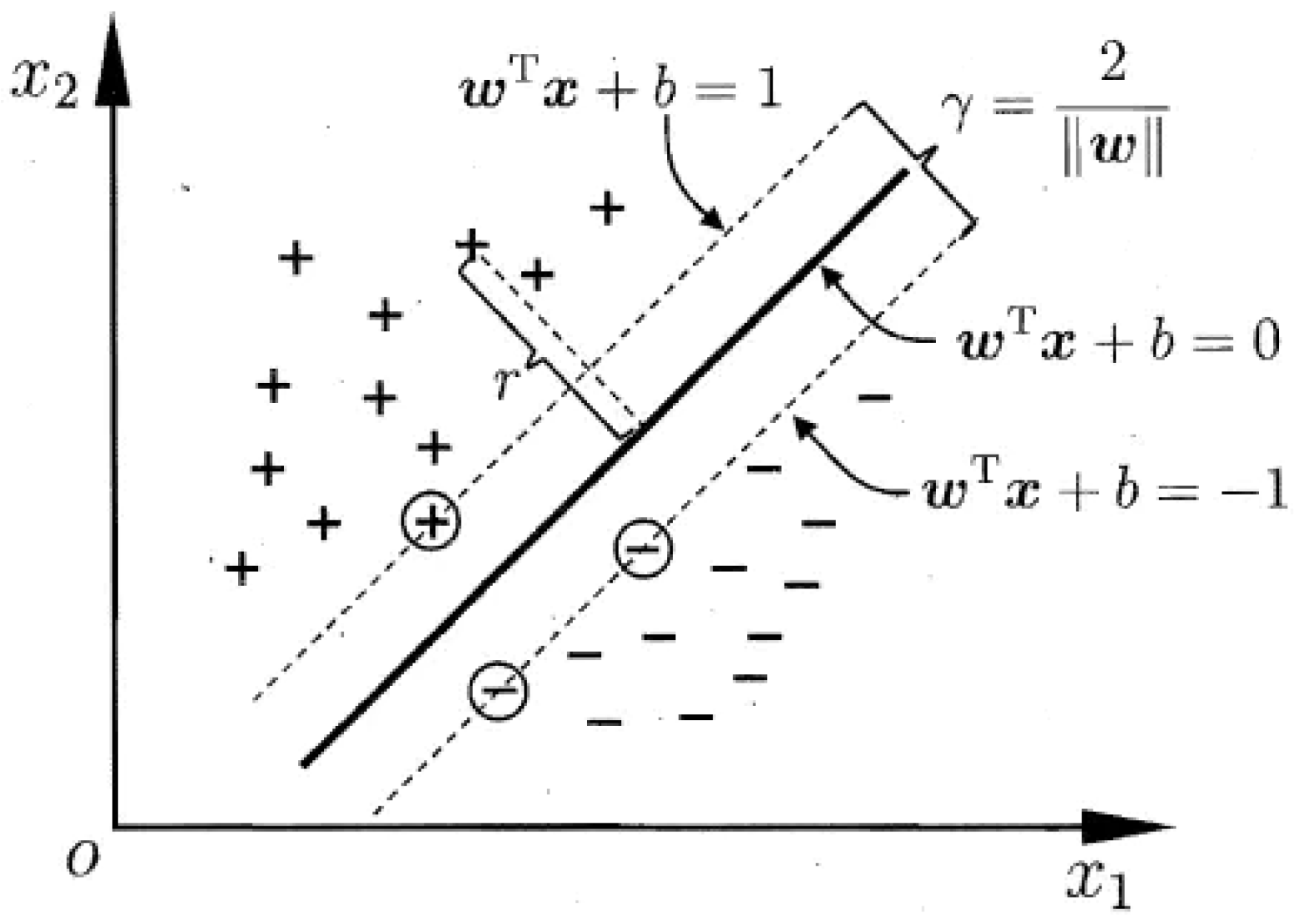
Traditional rain pattern classification methods are cumbersome and lack strong visualization, which hinders their application. With the development of machine learning algorithms, cluster analysis is more objective and fully reflects the rainfall process. Gupta et al. [
18] used K-means clustering to classify different types of heavy rain patterns in Texas based on the spatial characteristics of hourly rainfall. Gao et al. [
19] used K-means clustering analysis to classify and optimize the rain patterns at Dongyang station, dividing them into uniform, late peak, central peak, and early peak types. Yin Shuiqing [
20] used the dynamic K-means clustering method to classify rainfall data from 14 meteorological stations in China, dividing the rainfall process into four patterns: early-stage, mid-stage, late-stage, and uniform, based on the rain peak position as the measurement standard. Liu Yuanyuan [
21] analyzed the rain patterns in Beijing during the flood season using the DTW method and fuzzy pattern recognition. Hu Rui et al. [
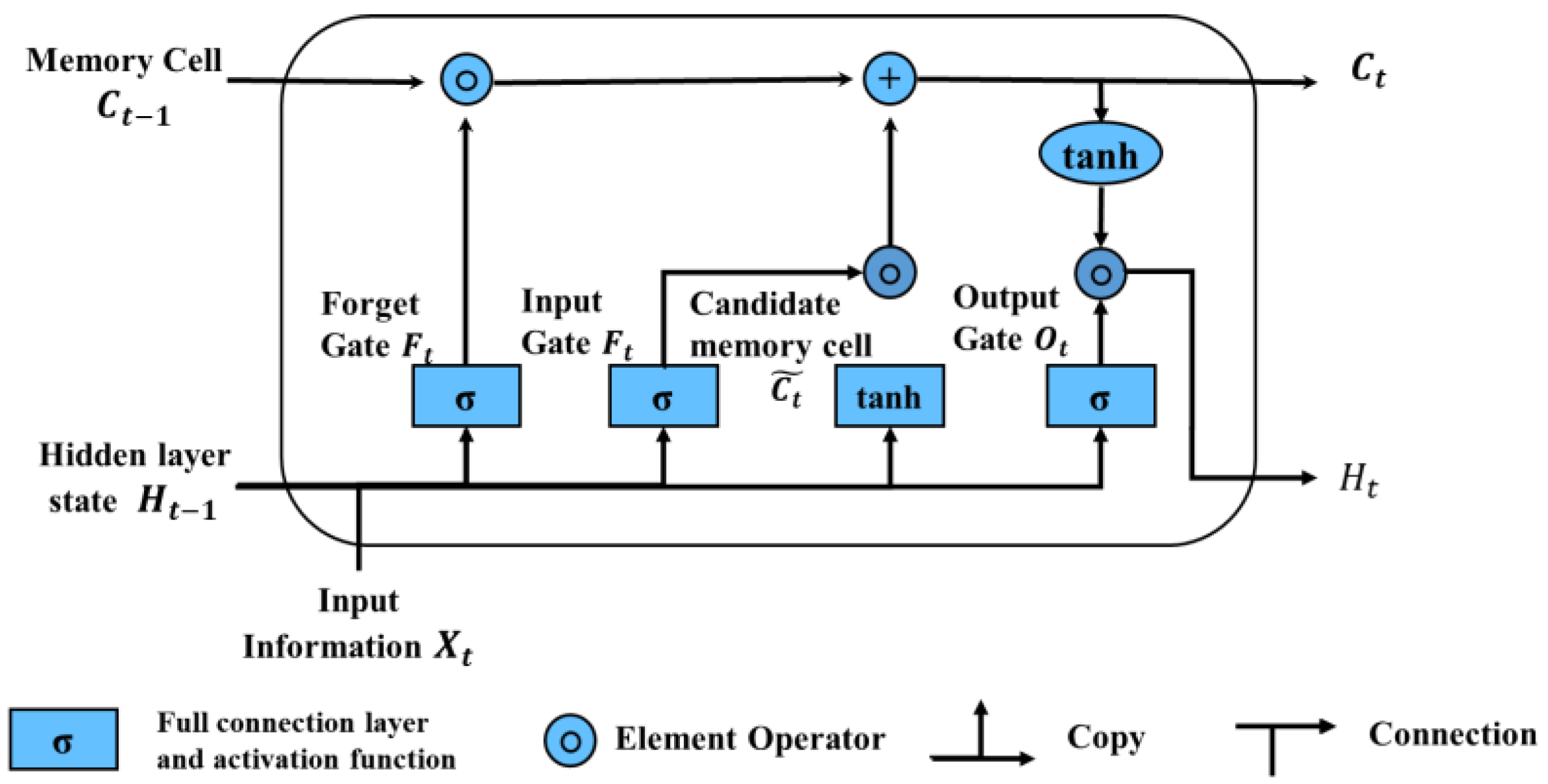
22] summarized the rain pattern laws at the Baoji meteorological station in Shaanxi Province using the Ward clustering method in hierarchical clustering. Previous research mostly used DTW-based fuzzy recognition methods and K-means clustering for rainfall pattern clustering, with other AI methods less commonly used in rainfall pattern classification applications. The Long- and Short-Term Memory (LSTM) neural network model can handle long-term memory information and has high model prediction accuracy. Support Vector Machines (SVM) perform well on a small sample and nonlinear problems, with good generalization ability. A Decision Tree (DT) is a tree-like structure that represents a mapping relationship between object attributes and object values. It has a simple structure, can handle massive data, and has a fast computational speed and high classification accuracy. The lightweight gradient boosting machine (LightGBM) in the ensemble learning model has low memory consumption and fast training speed and still has good performance when processing large-scale data.
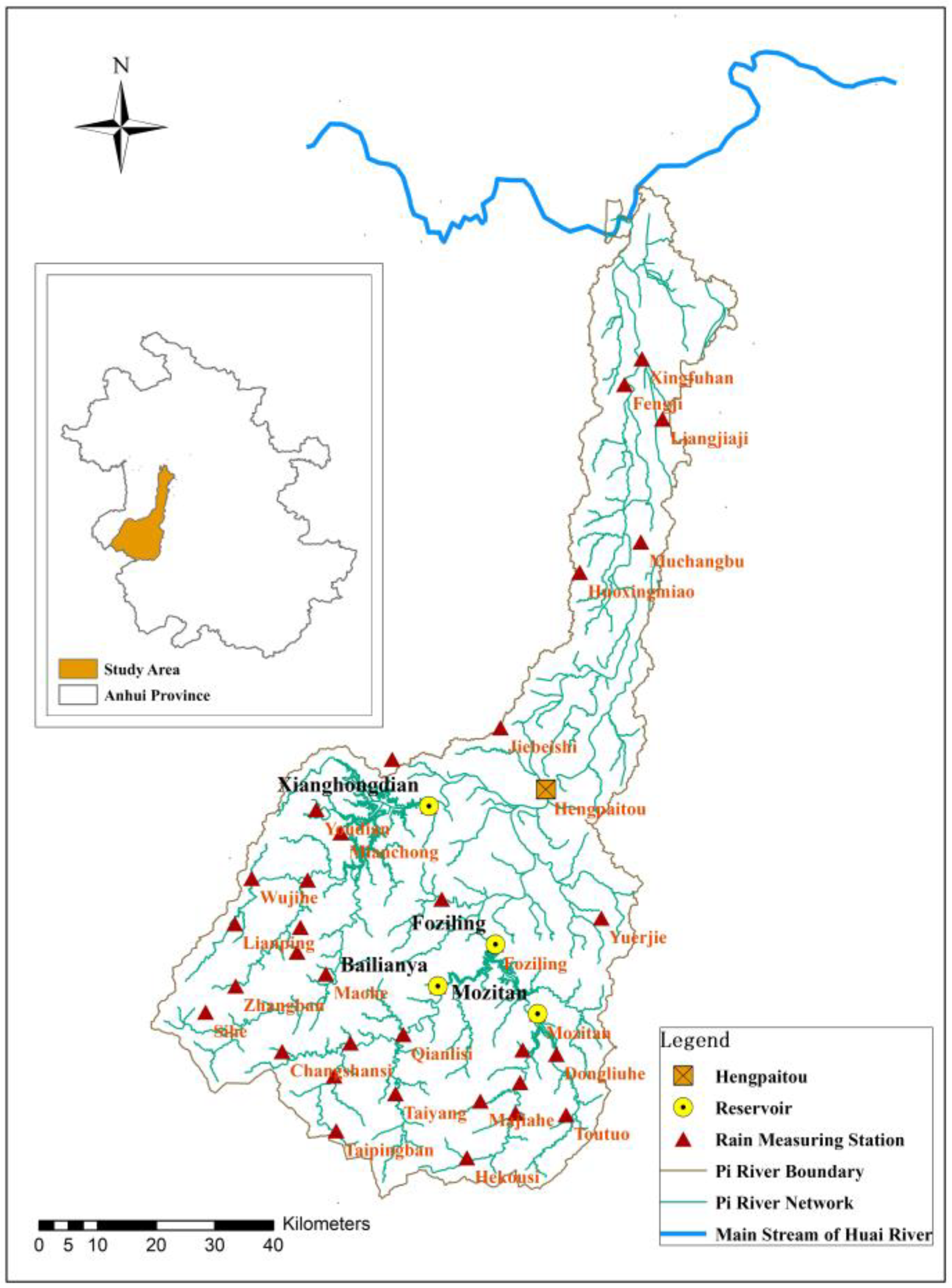
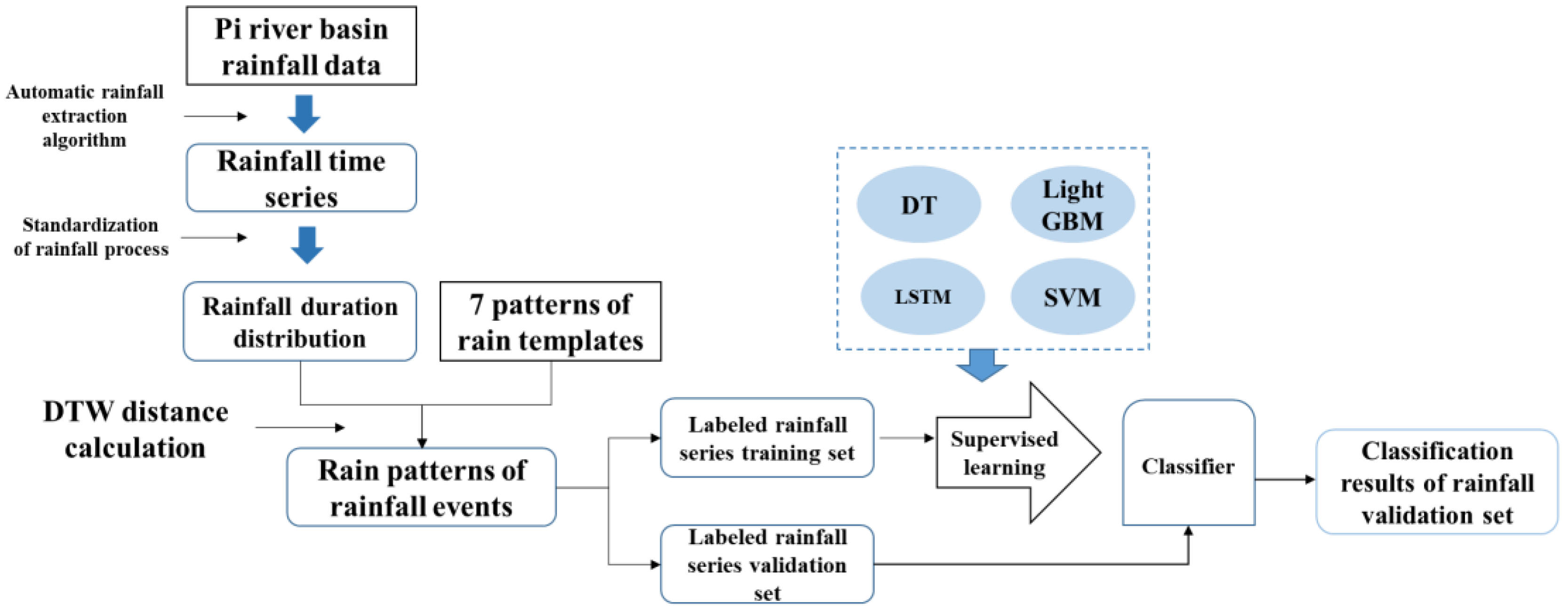
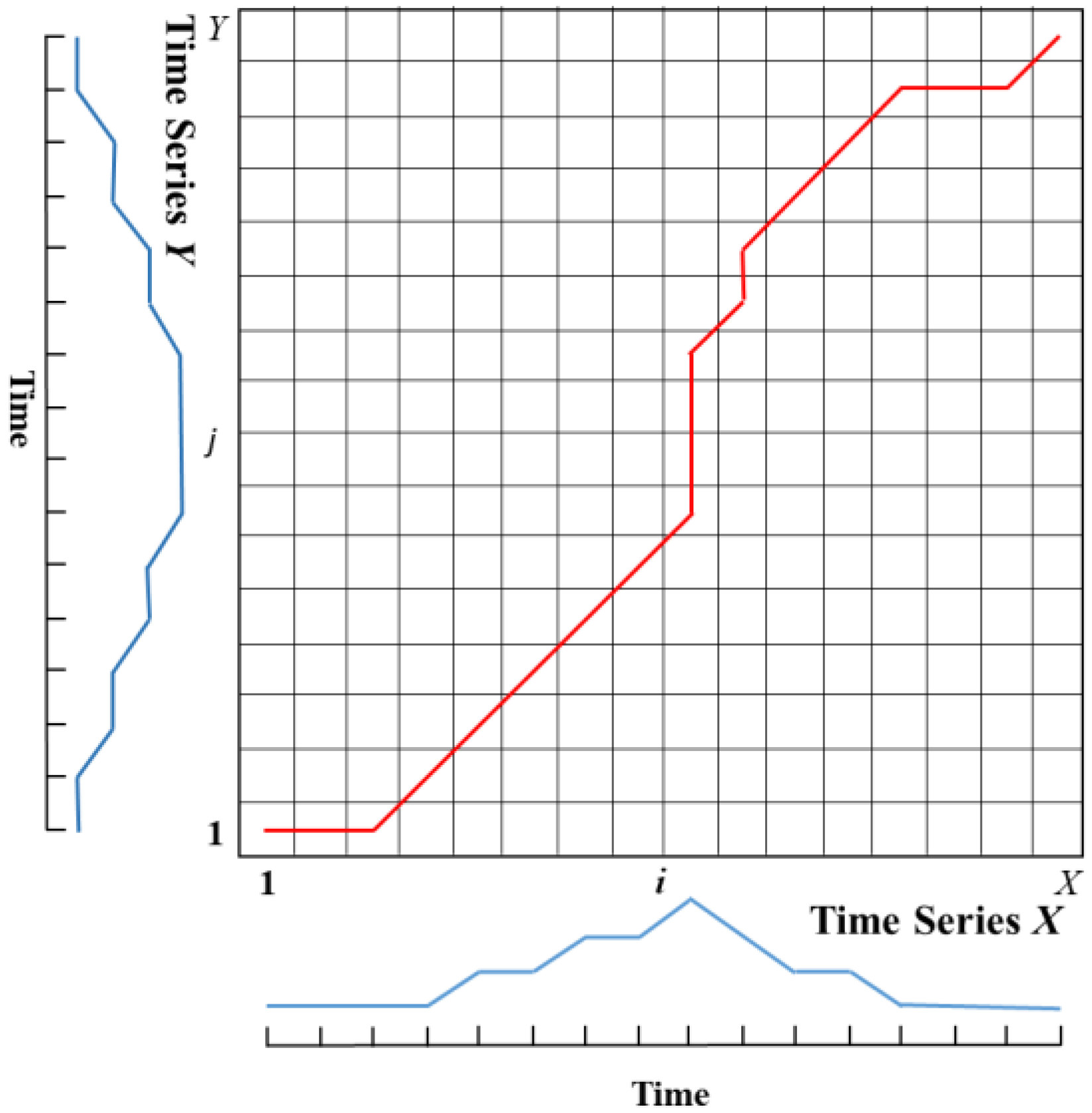
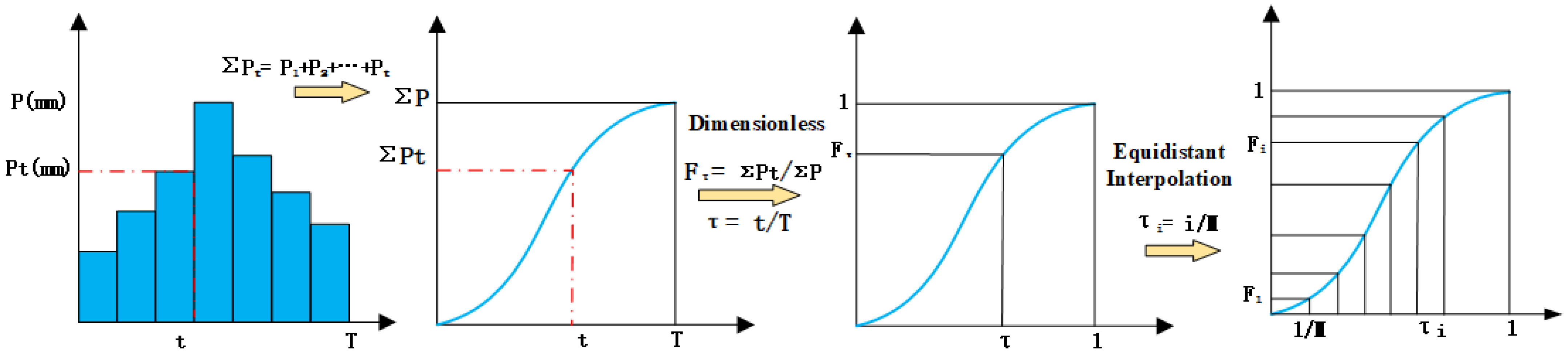
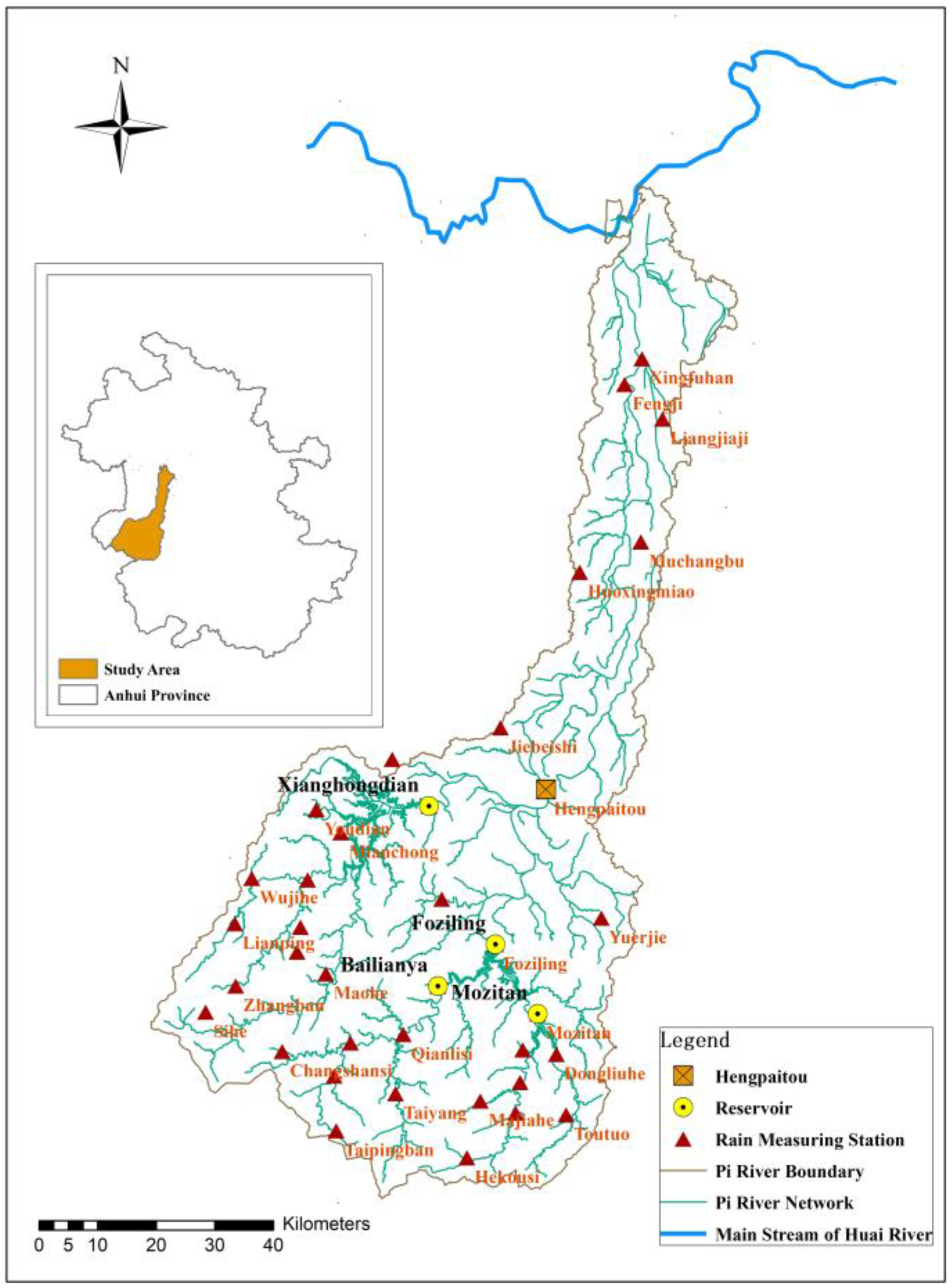
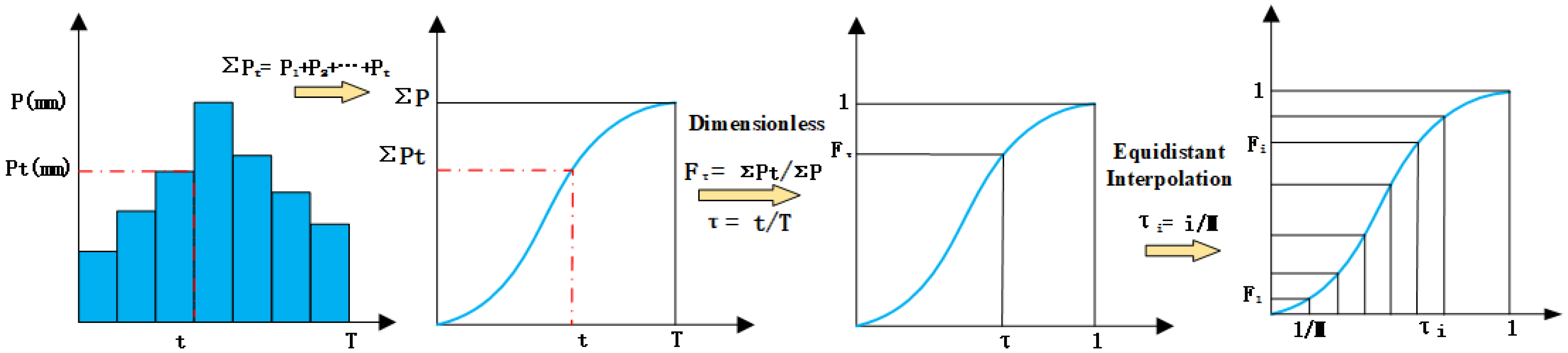
Although the spatial distribution of rainfall is of great significance, the current study is focused on temporal patterns. This study is based on nearly 20 years of extracted long-term and hourly precipitation data from the Pi River Basin in Anhui Province. Rainfall events were identified. With seven rain patterns as the standard, the Dynamic Time Warping (DTW) distance calculation method was used to classify the rainfall patterns for each rainfall event, and rainfall pattern classification obtained by using DTW was used as the benchmark results. On this basis, four machine learning classification models (DT, LSTM, LightGBM, and SVM) were constructed. Standardized rainfall time series were treated as independent variables, and DTW classification results were used as dependent variables to study the supervised classification of rainfall patterns. The recognition effects of the four classification models and the influence of sampling size on classification accuracy were compared and analyzed to explore the applicability of classification model algorithms in the field of rainfall pattern classification. The research results can provide technical support for identifying -rainfall-runoff similarity, hydrological simulation, and forecasting.
5. Results and Discussion
5.1. Classification Results of DTW Rainfall Patterns
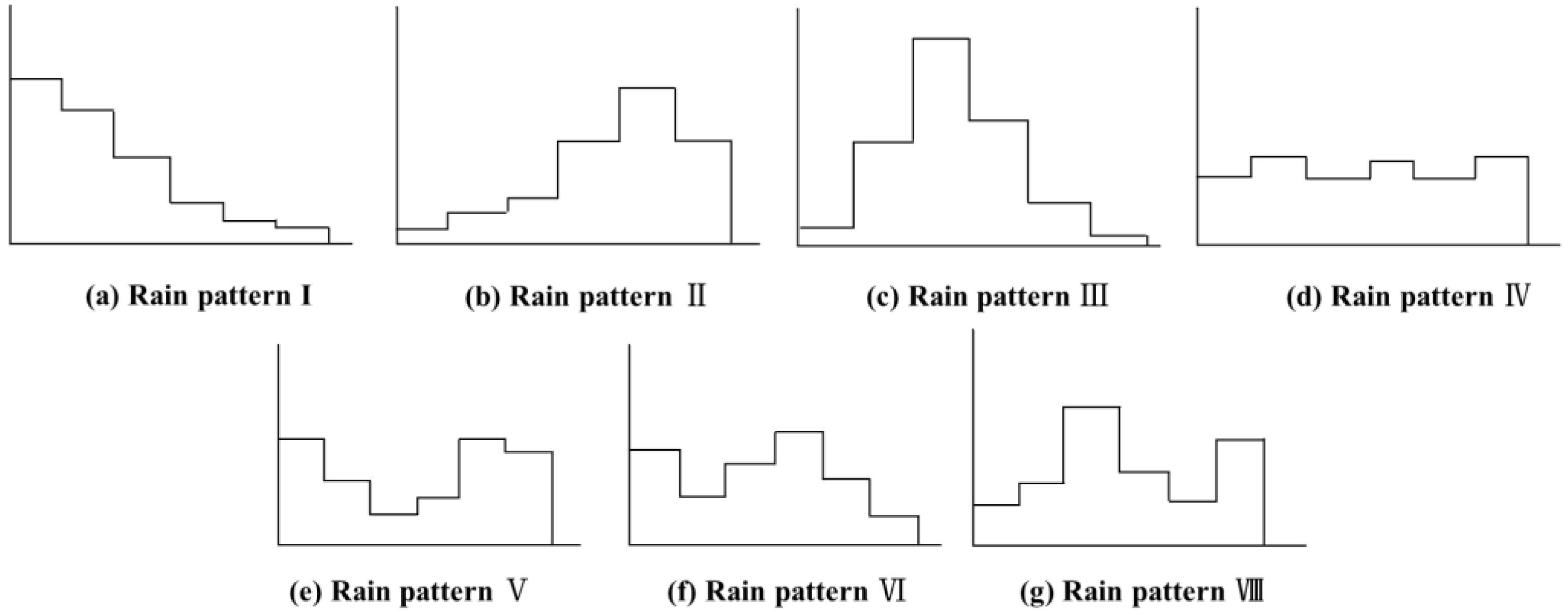
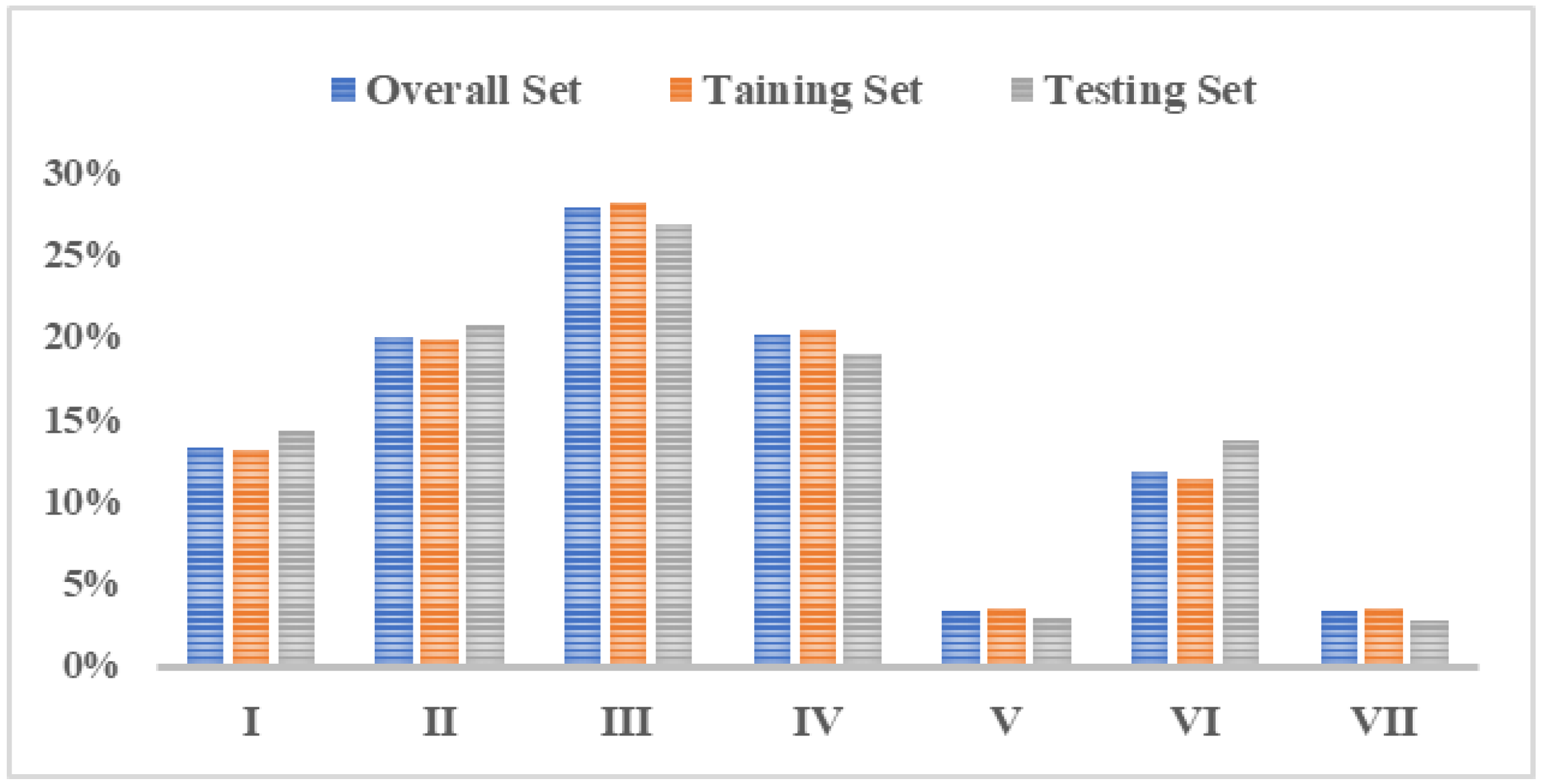
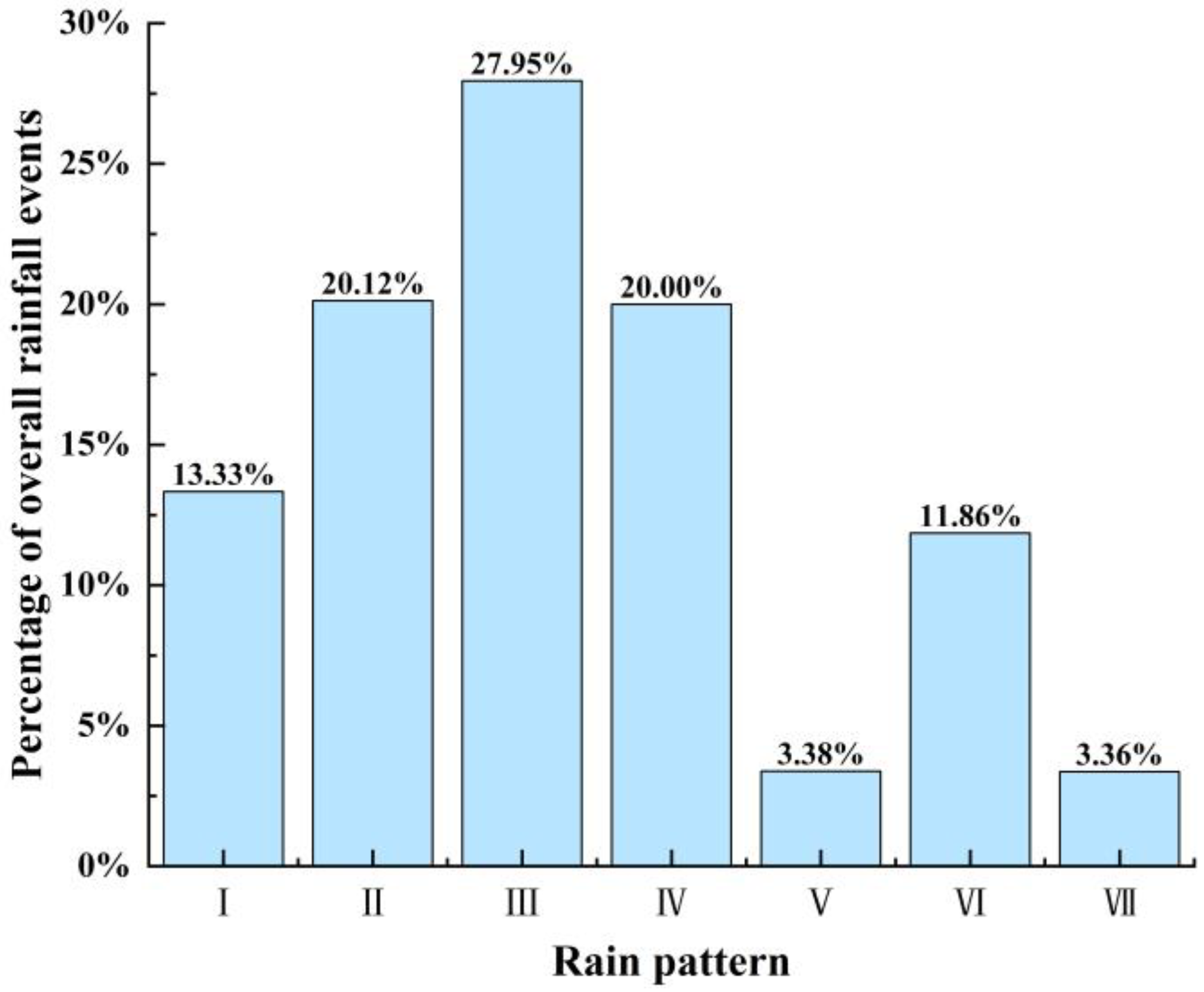
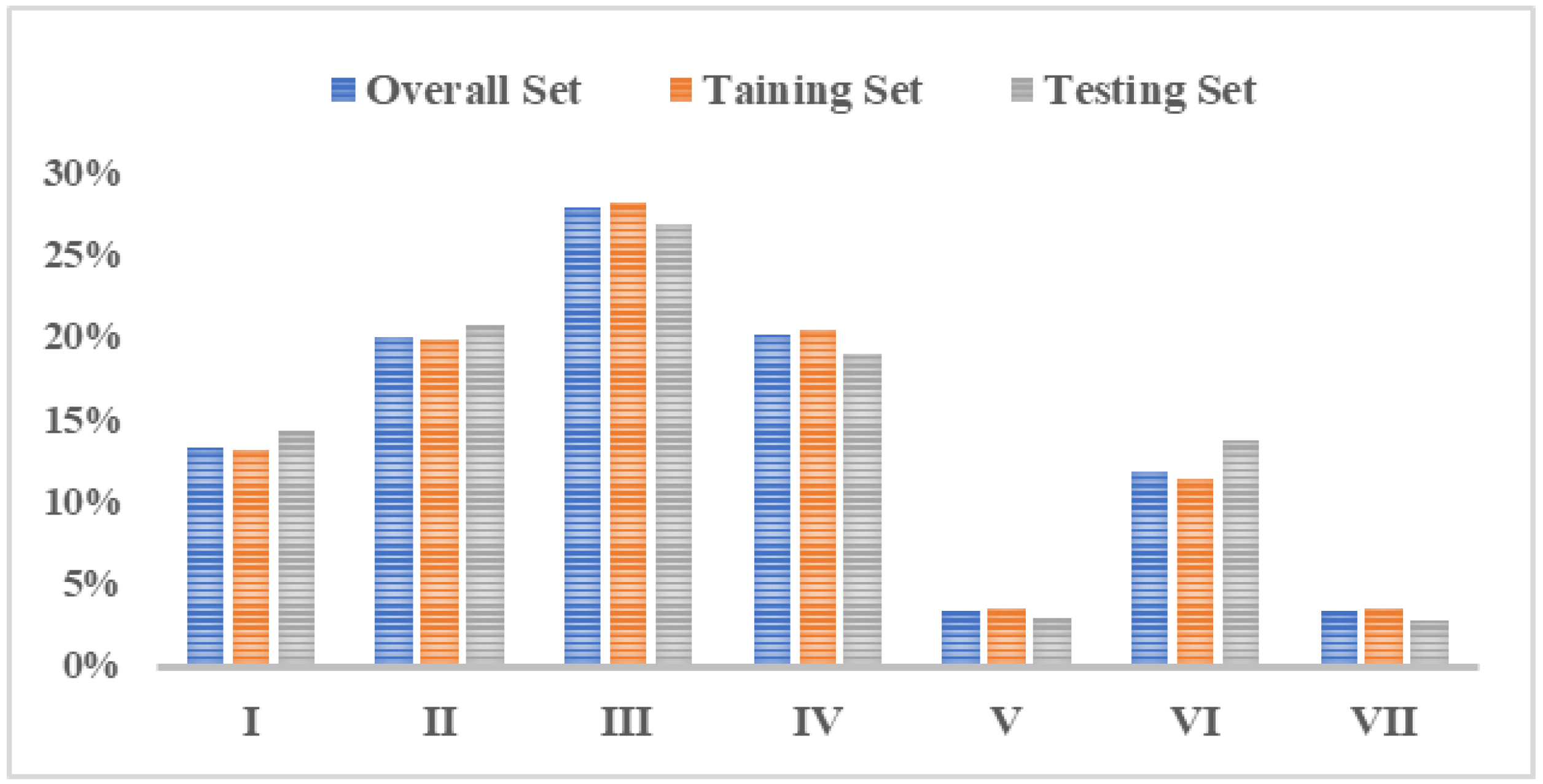
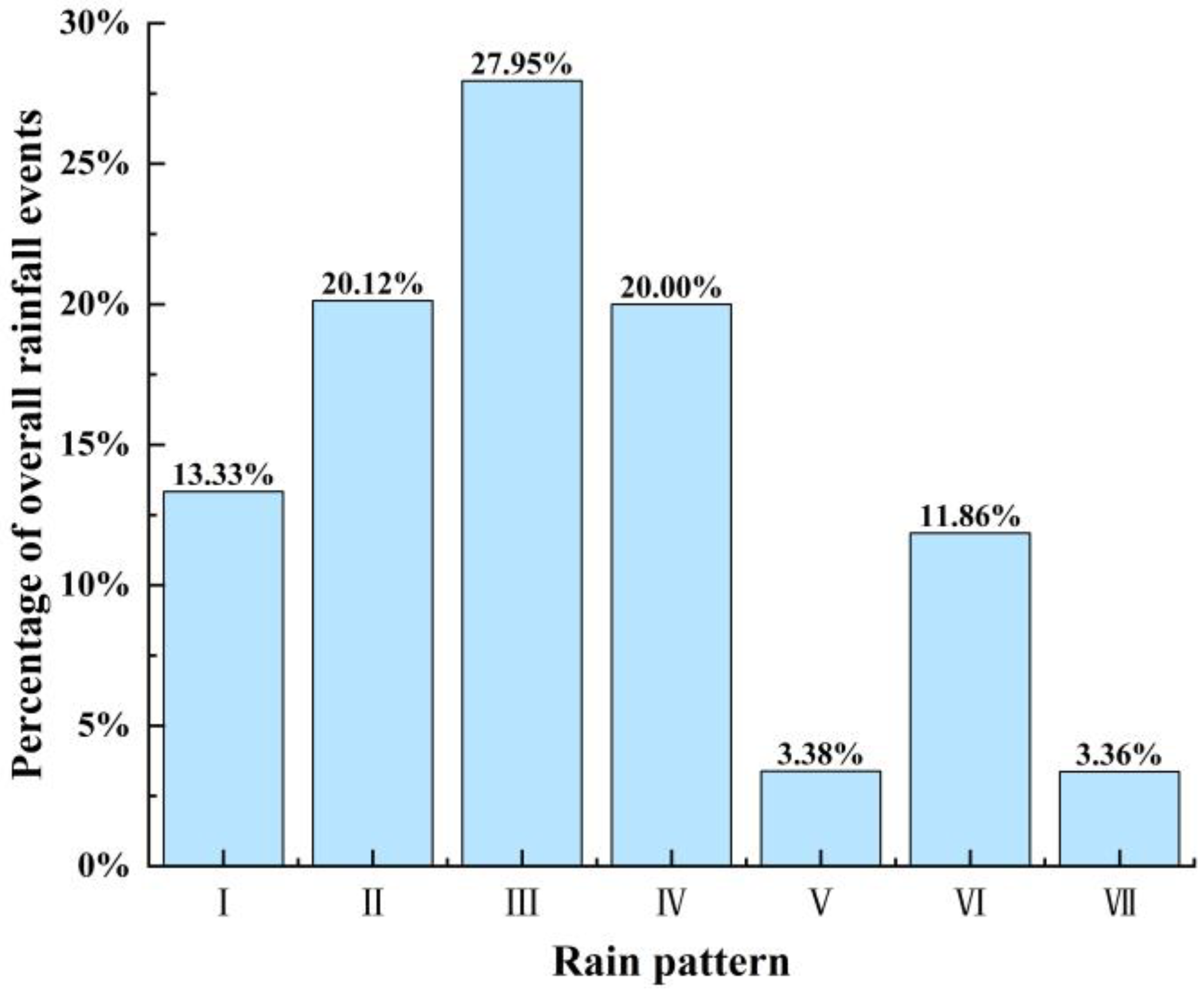
Percentages of different rain patterns in the Pi River Basin are shown in
Figure 10. According to
Table 1 and
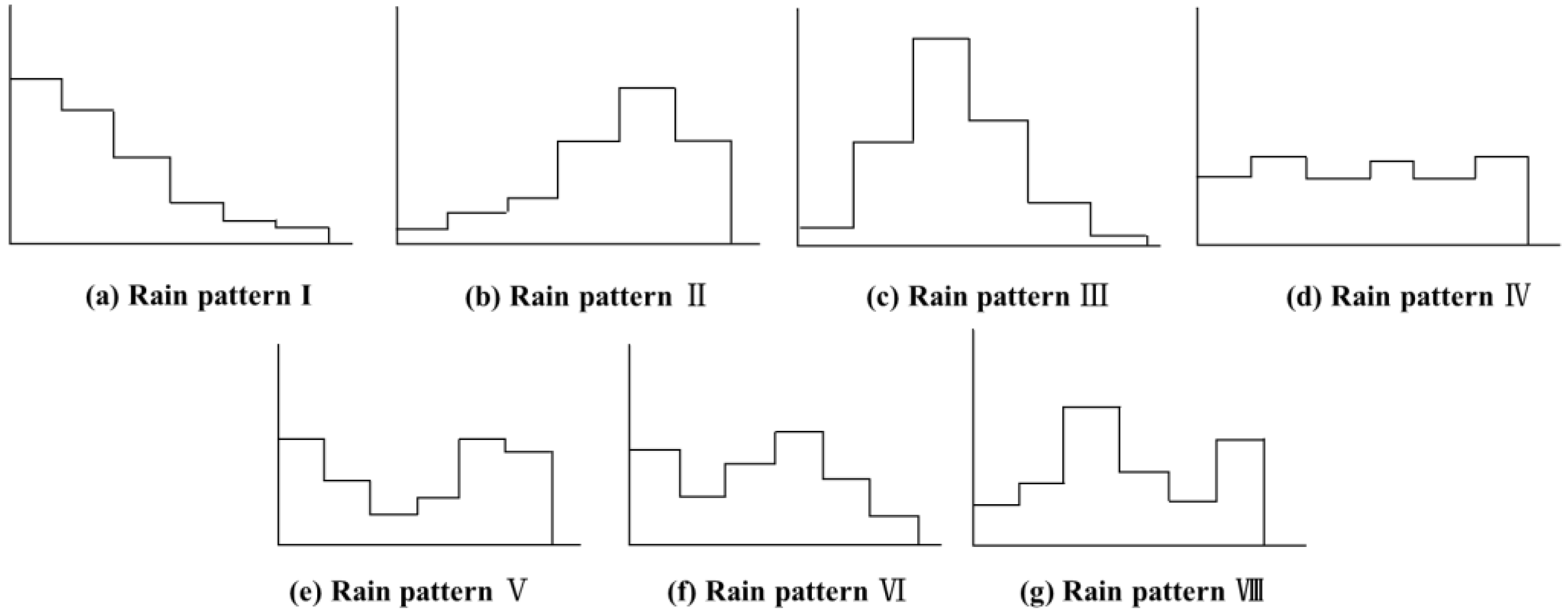
Figure 10, the rainfall patterns in the Pi River Basin are dominated by single-peak rainfall, mainly the pattern Ⅲ of mid-single-peak and the pattern Ⅱ of late-single-peak, which account for 27.95% and 20.12% of the total number of rainfall events, respectively. This is consistent with the research results in reference [
34]. The rainfall duration is relatively long, which lasts for 22.2 h and 21.17 h, and the rainfall intensity is also high, at 0.99 mm/h and 0.96 mm/h, which indicates long-duration heavy rainfall. The second most common pattern is the pattern Ⅳ of uniform rainfall, which accounts for 20% of the total number of rainfall events, with a shorter average rainfall duration of 9.44 h and an average rainfall intensity of 0.95 mm/h. Double-peak rainfall is relatively rare in the basin, with the pattern Ⅵ of rainfall accounting for 11.86% of the total number of rainfall events and the patterns Ⅴ and Ⅶ of double-peak rainfall accounting for only 3.38% and 3.36% of the total number of rainfall events, respectively. However, the rainfall duration is long, and the rainfall intensity is high, and they all belong to long-duration heavy rainfall.
5.2. Comparison and Analysis of Four Machine Learning Classification Methods
The accuracy evaluation of the four classification methods is shown in
Table 3, and the loss convergence is shown in
Figure 11,
Figure 12 and
Figure 13.
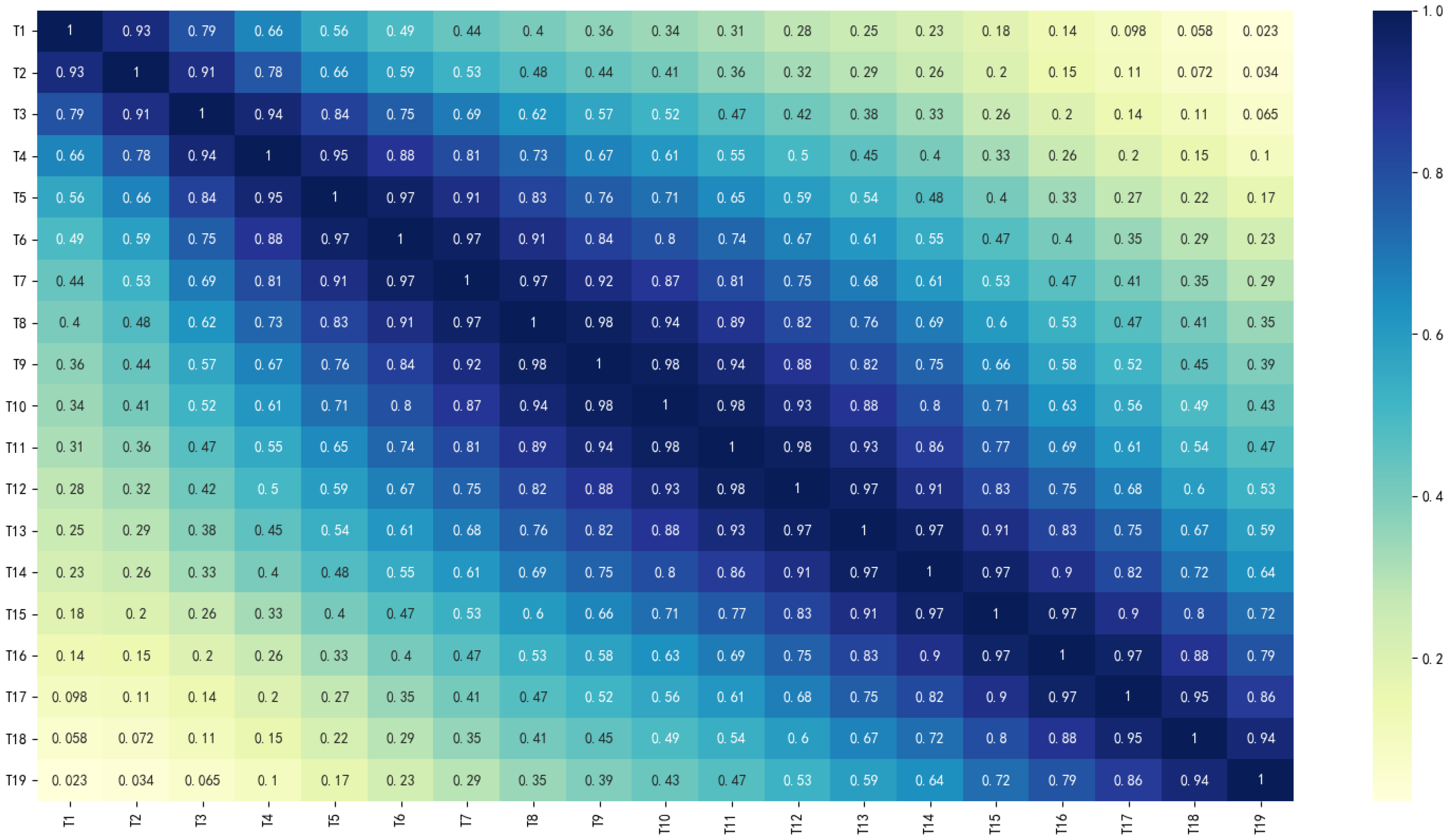
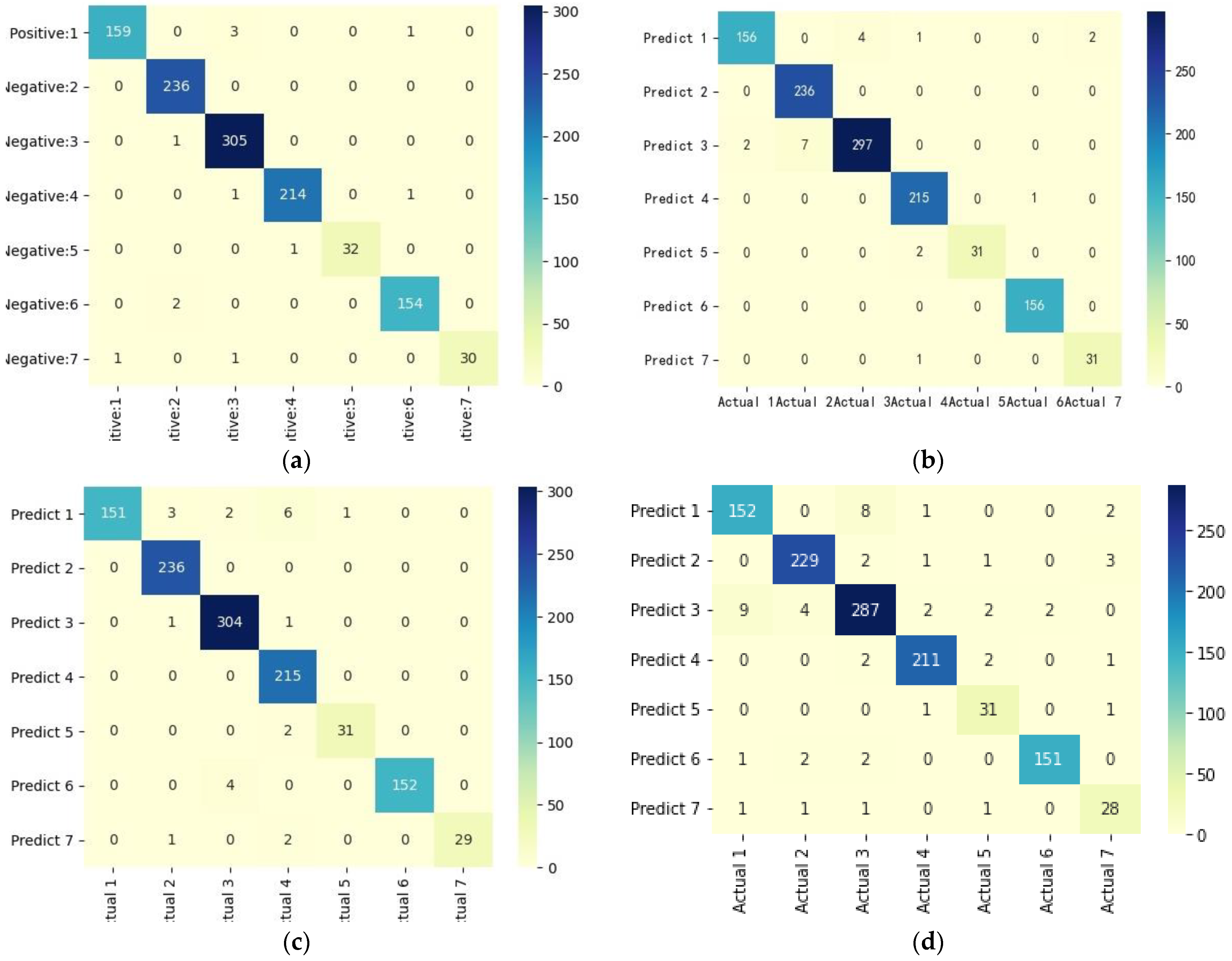
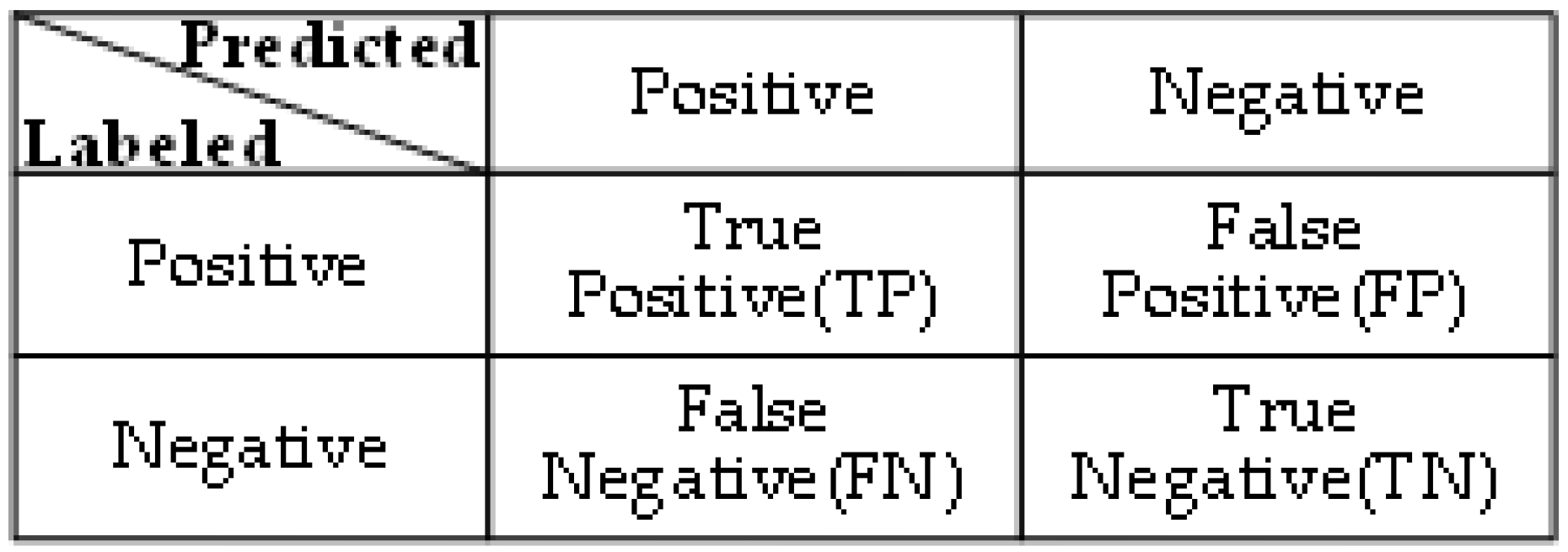
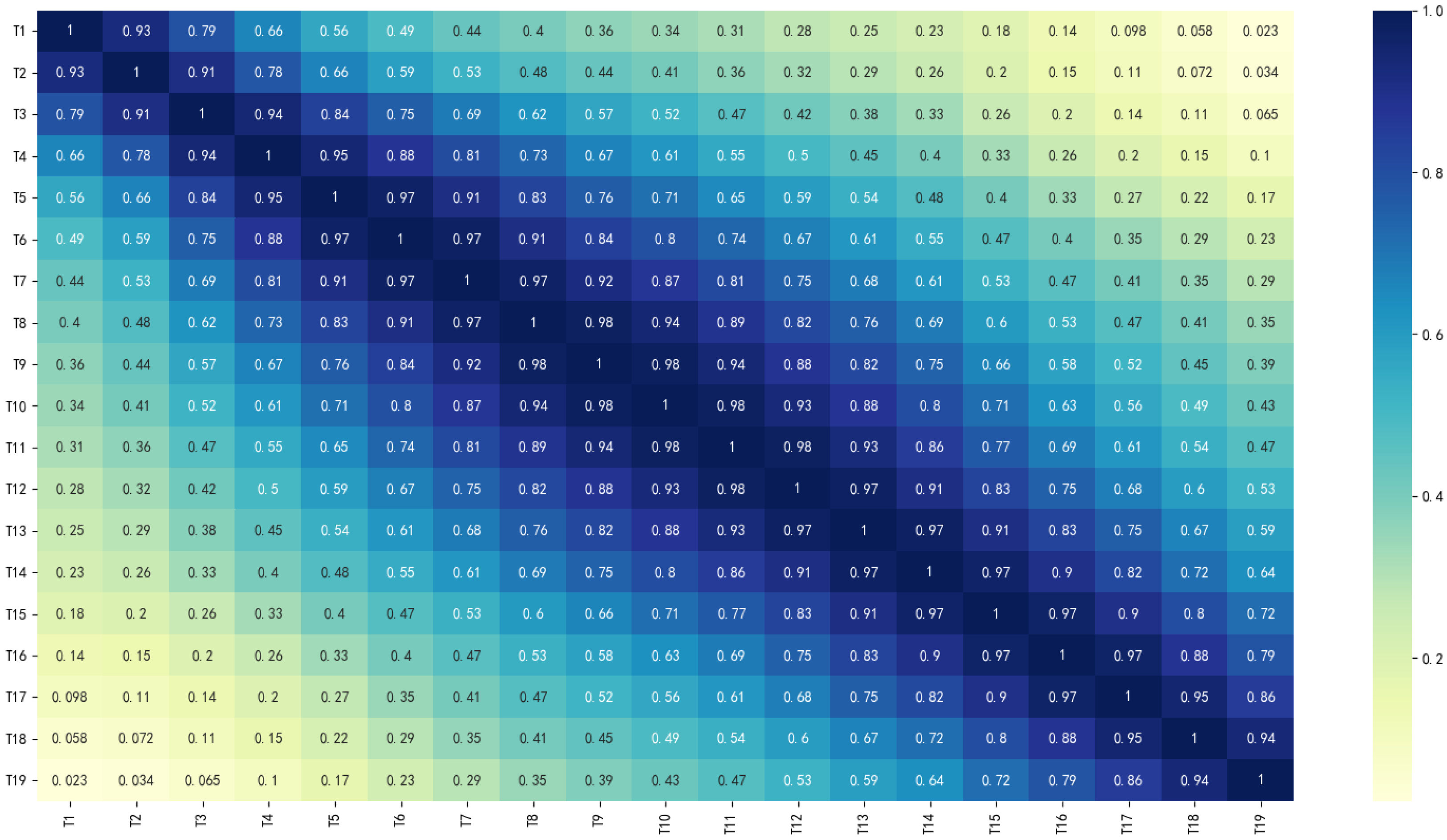
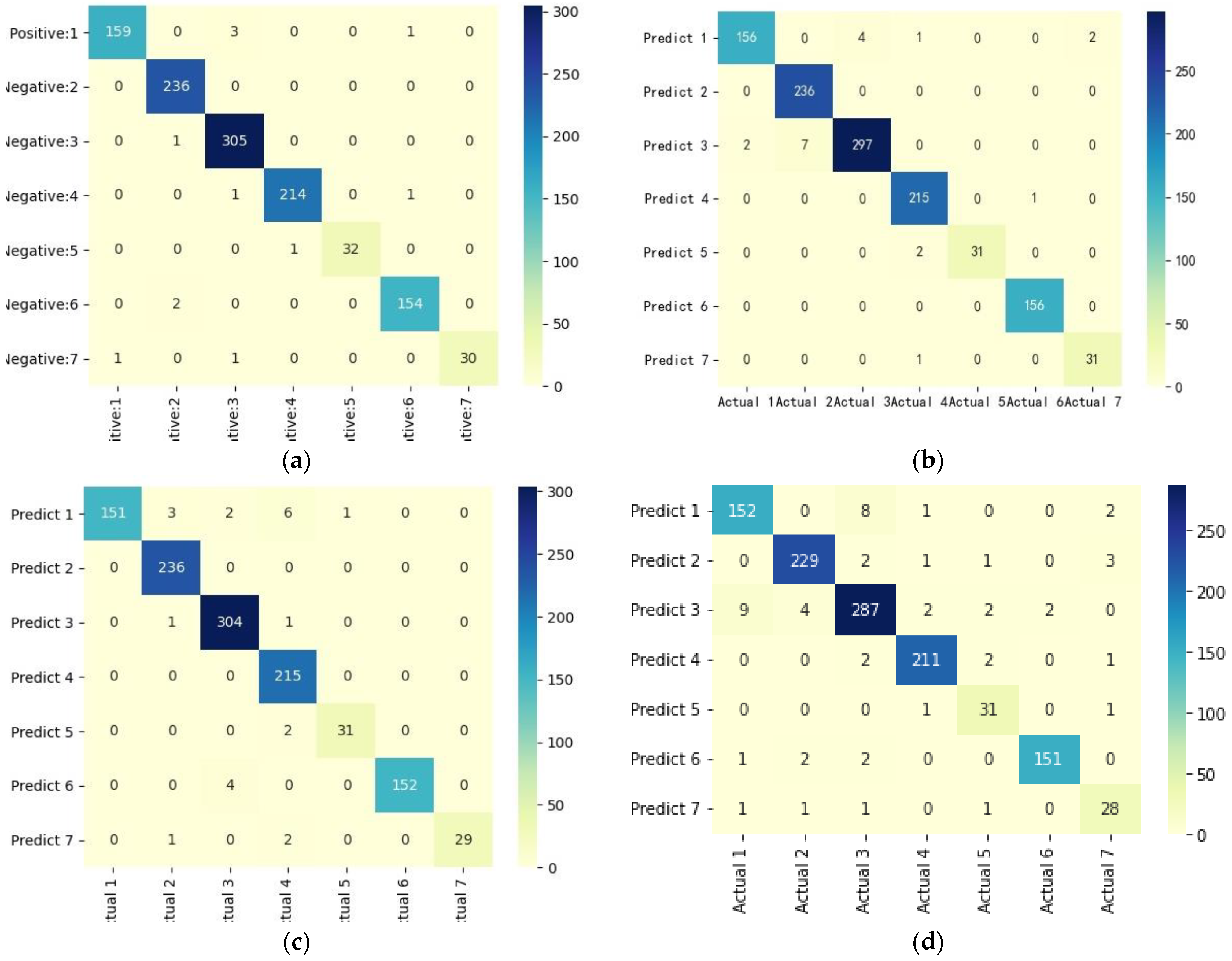
Figure 14 shows the correlation coefficient of each factor index, which explains the unsatisfactory training effect of DT model; The confusion matrices of the classification results were visualized, and the results are shown in
Figure 15.
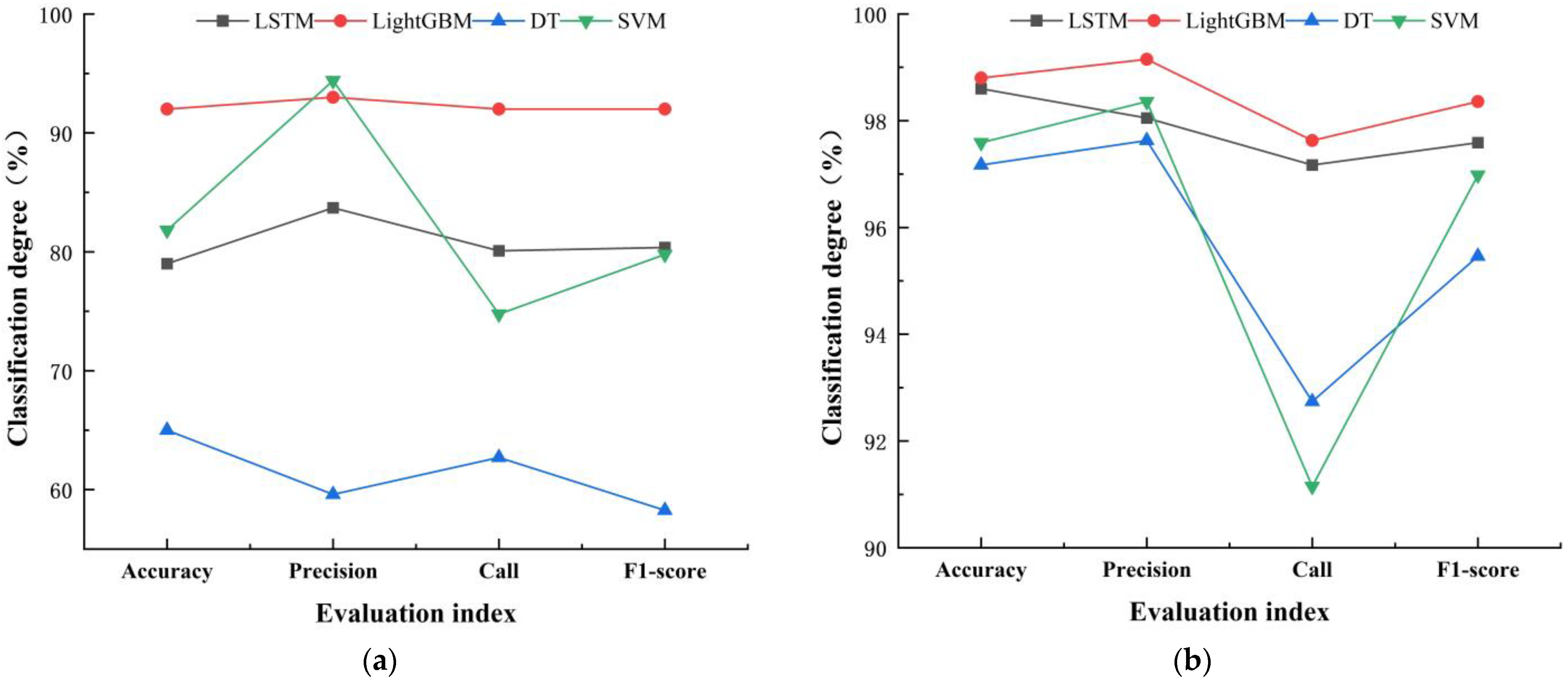
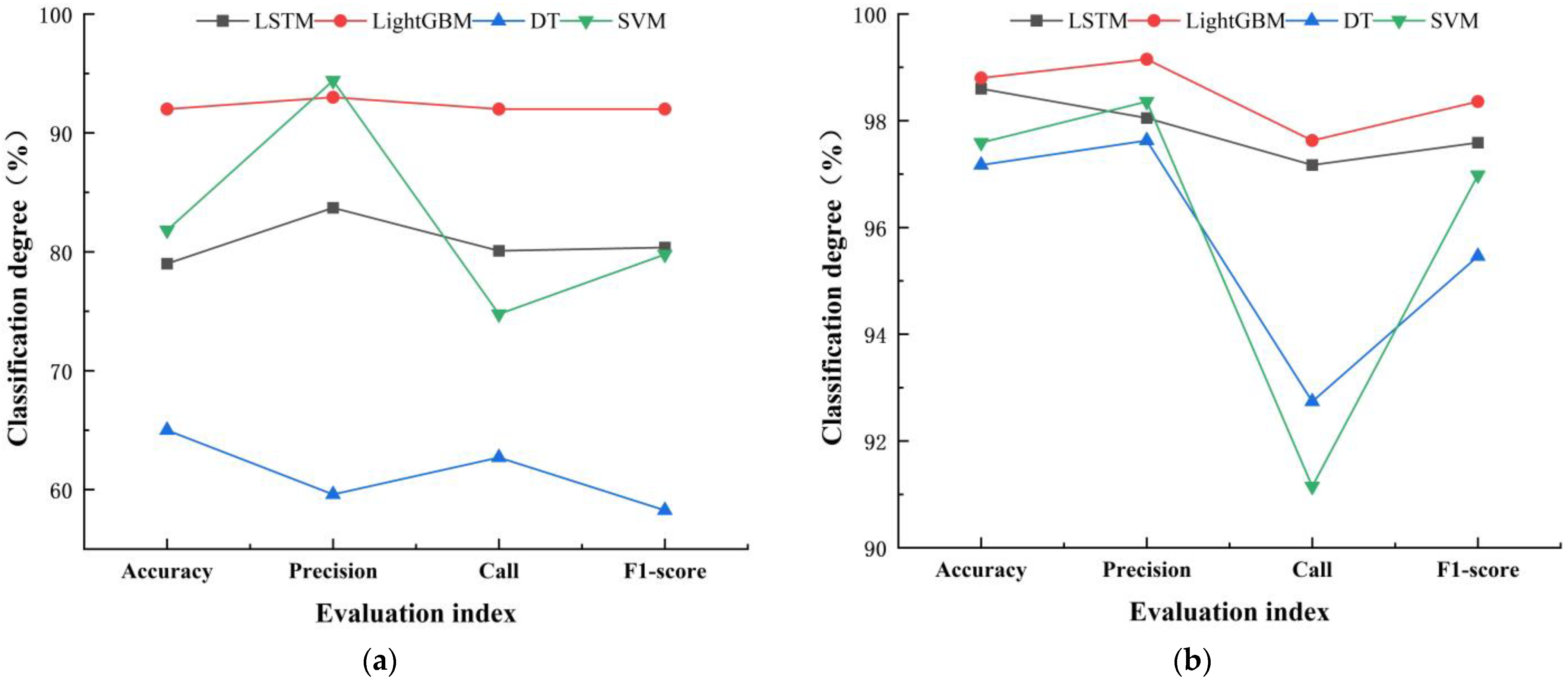
As shown in
Table 3, with DTW rainfall classification results as the reference benchmark, all four classification models achieved satisfactory classification accuracy. Among them, the LightGBM classification method had the highest accuracy, precision, recall, and F
1 score values for the rainfall classification dataset, which were 98.95%, 99.25%, 97.96%, and 98.58%, respectively. The accuracy and F
1 score were respectively improved by 0.18% and 0.27% compared to the LSTM classification method, by 1.32% and 1.26% compared to the SVM method, and by 3.6% and 5.4% compared to the DT method. Therefore, it can be seen that the LightGBM algorithm has improved all indicators of rainfall classification accuracy and is superior to the other three models.
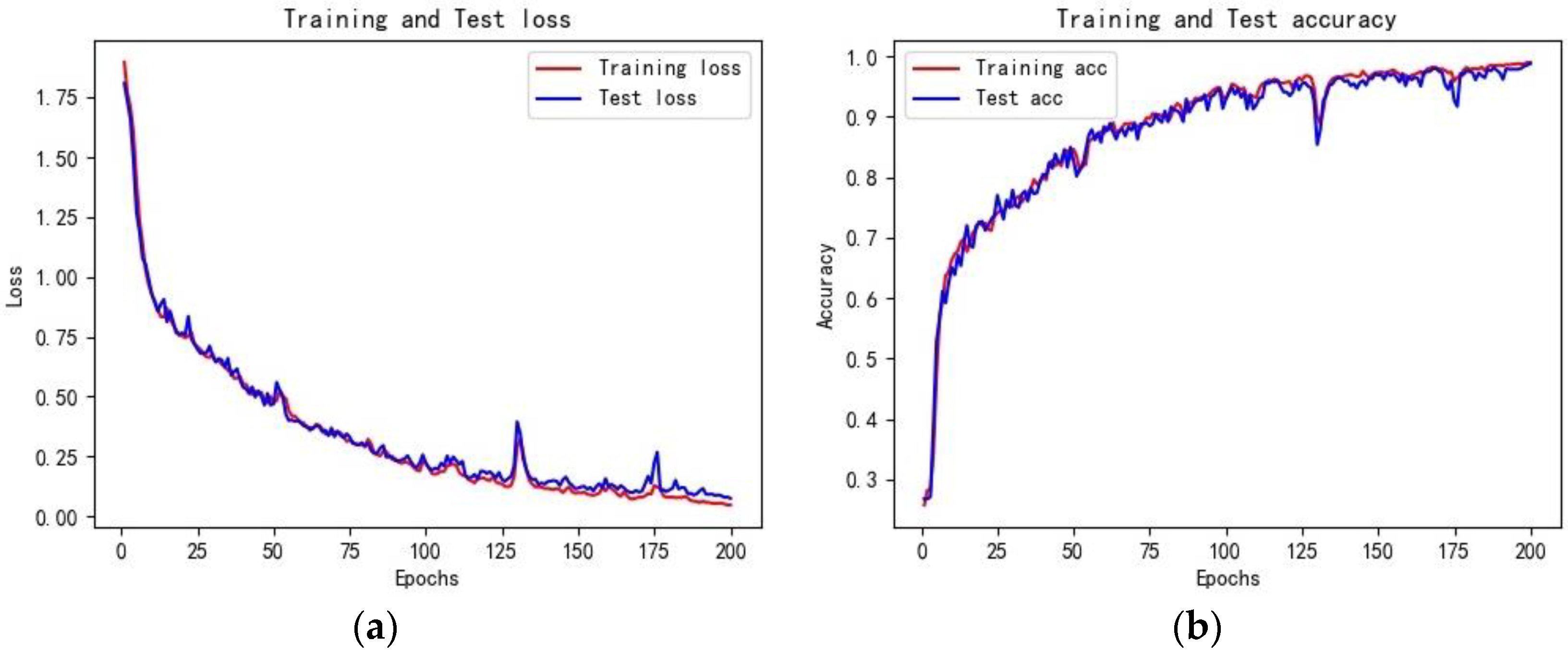
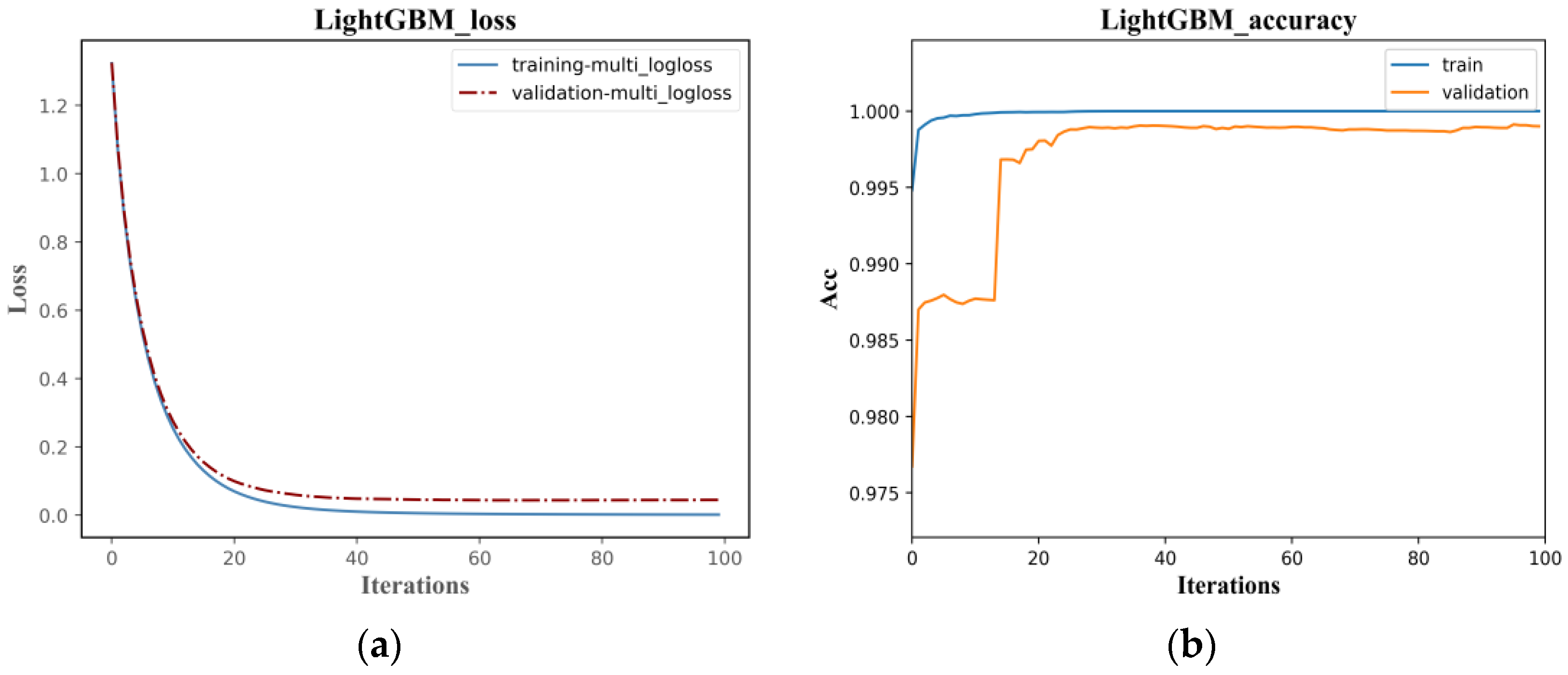
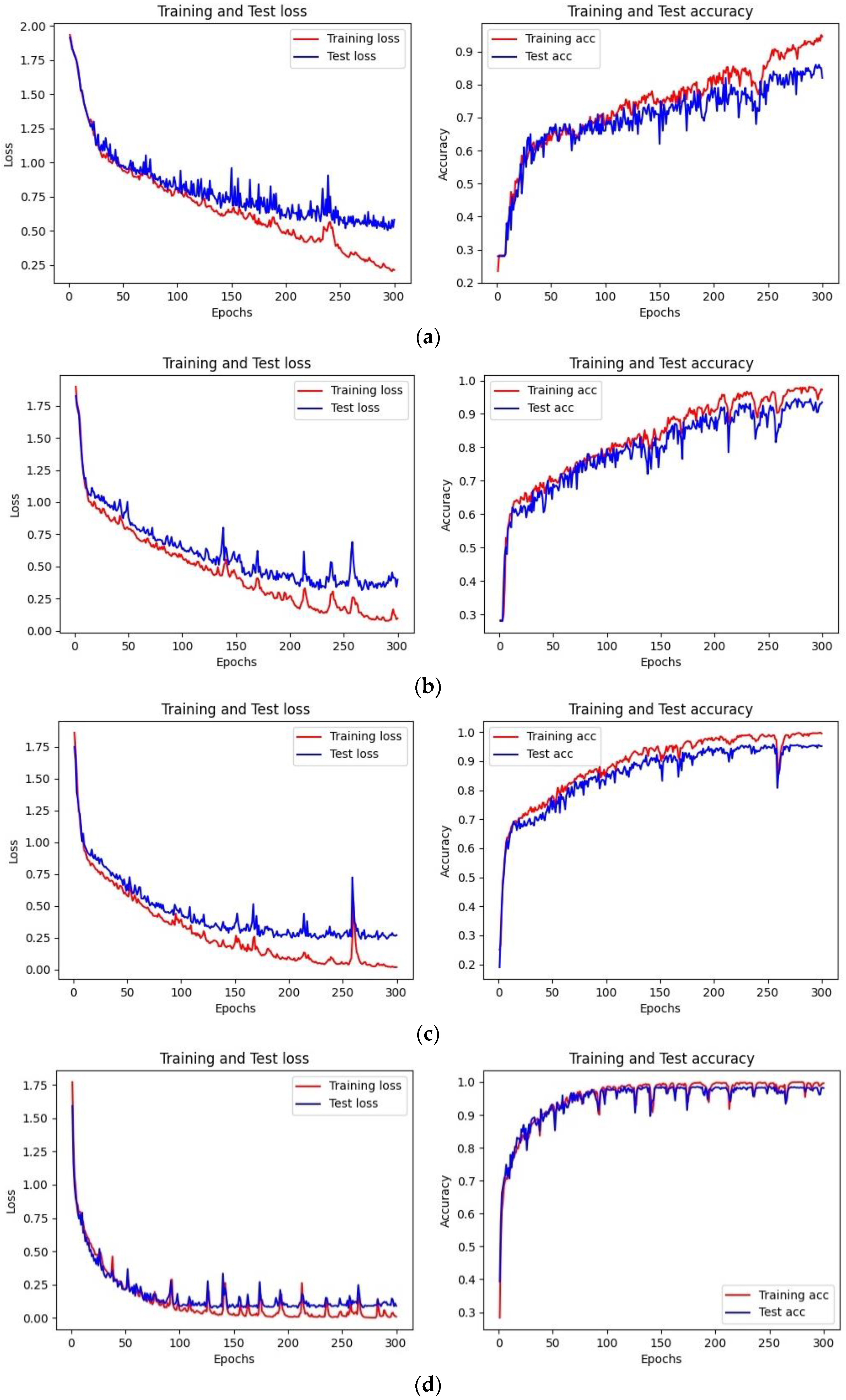
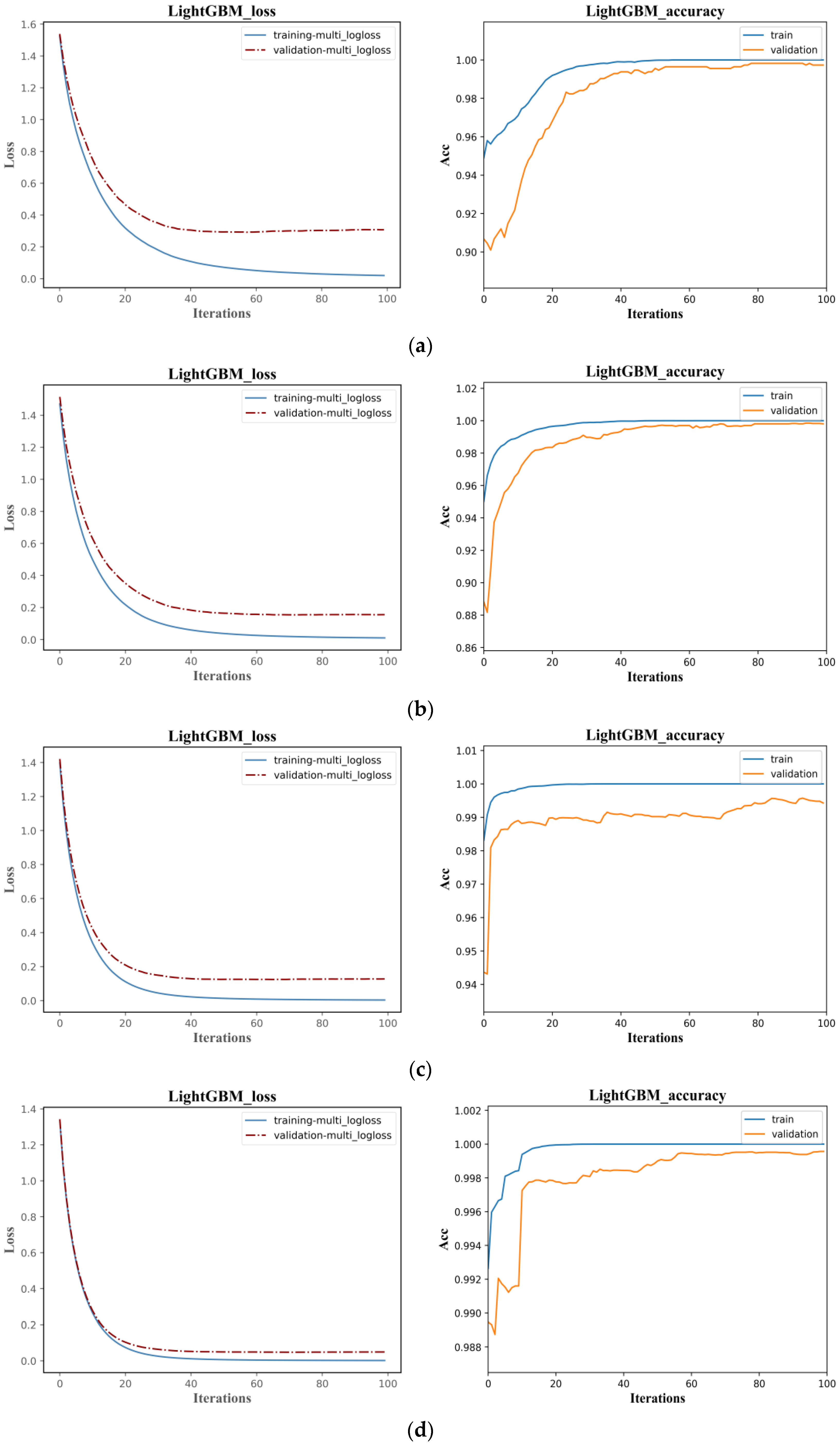
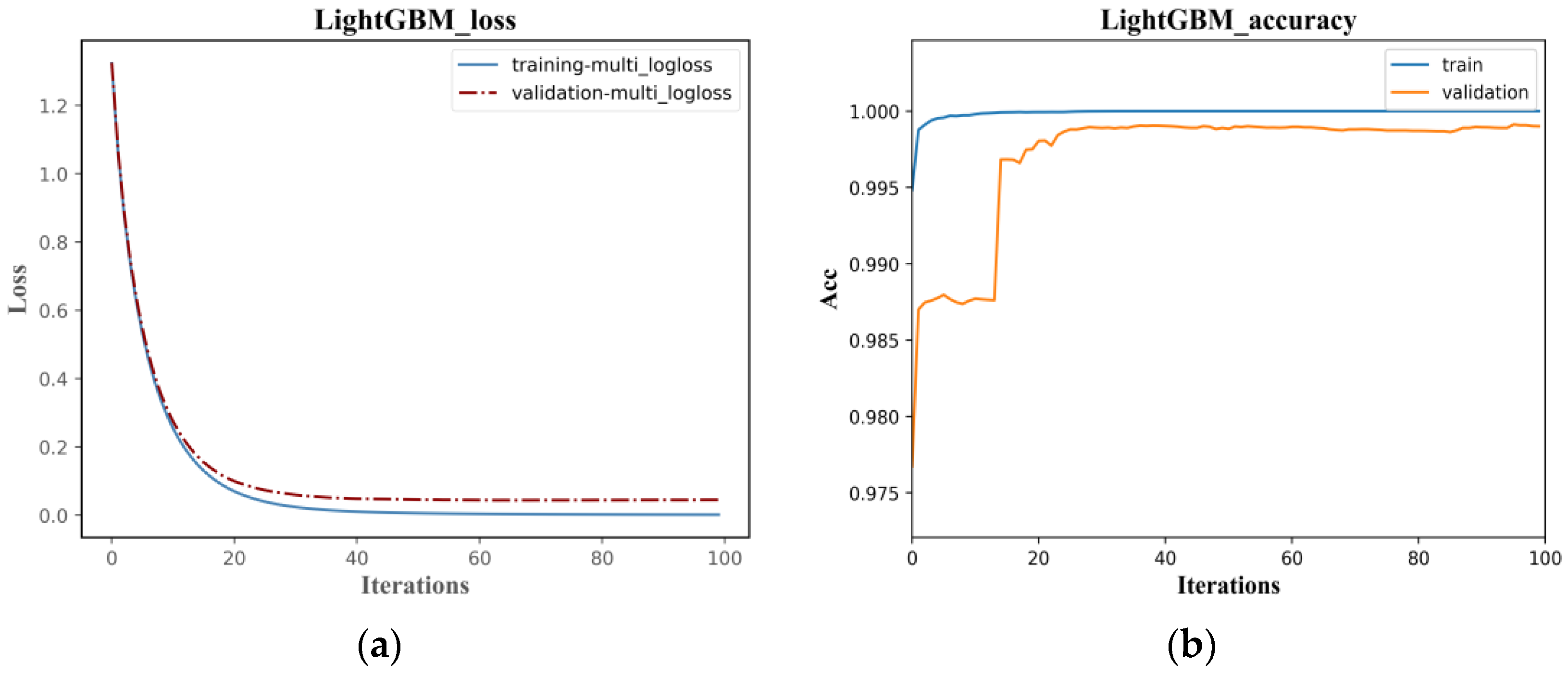
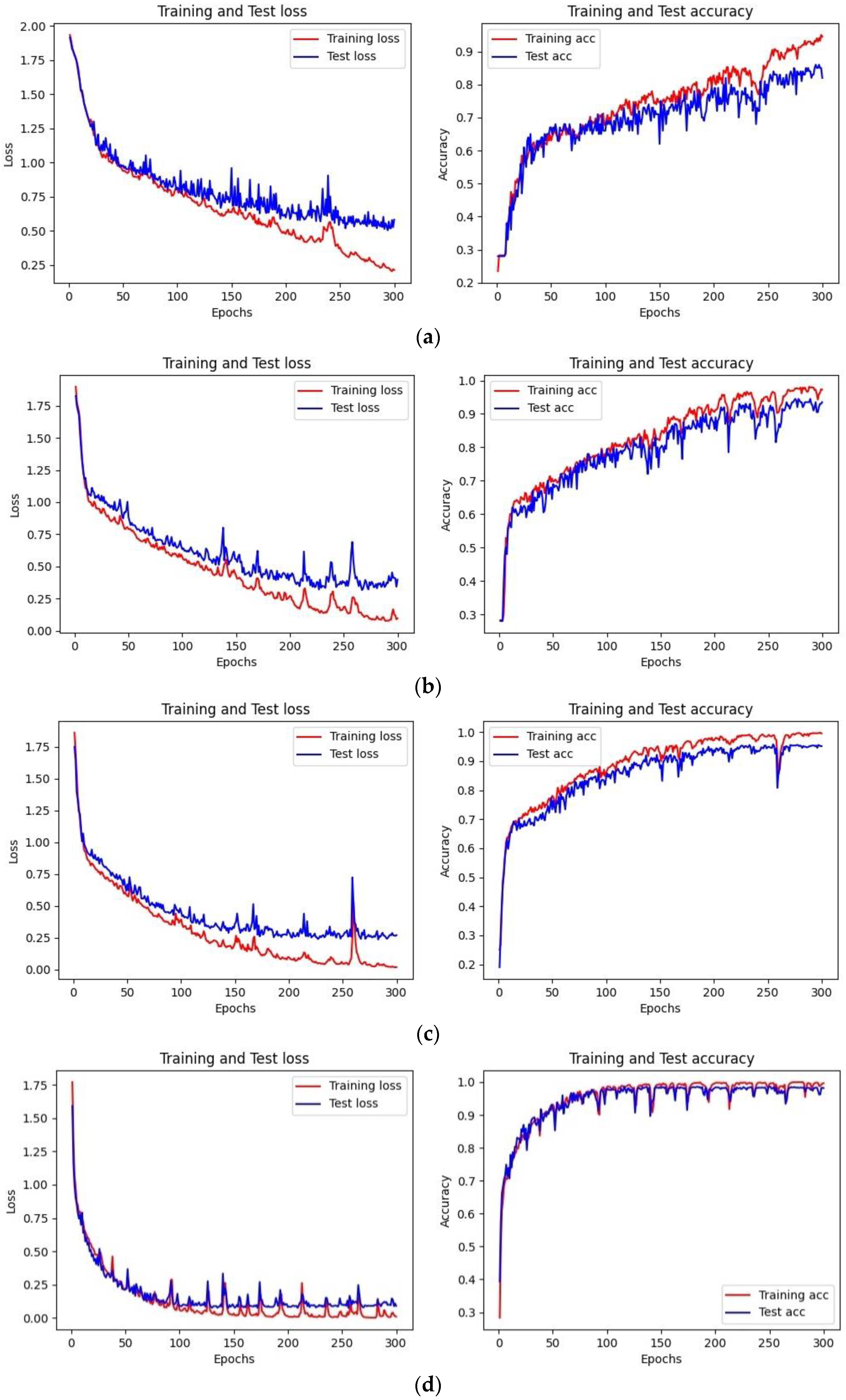
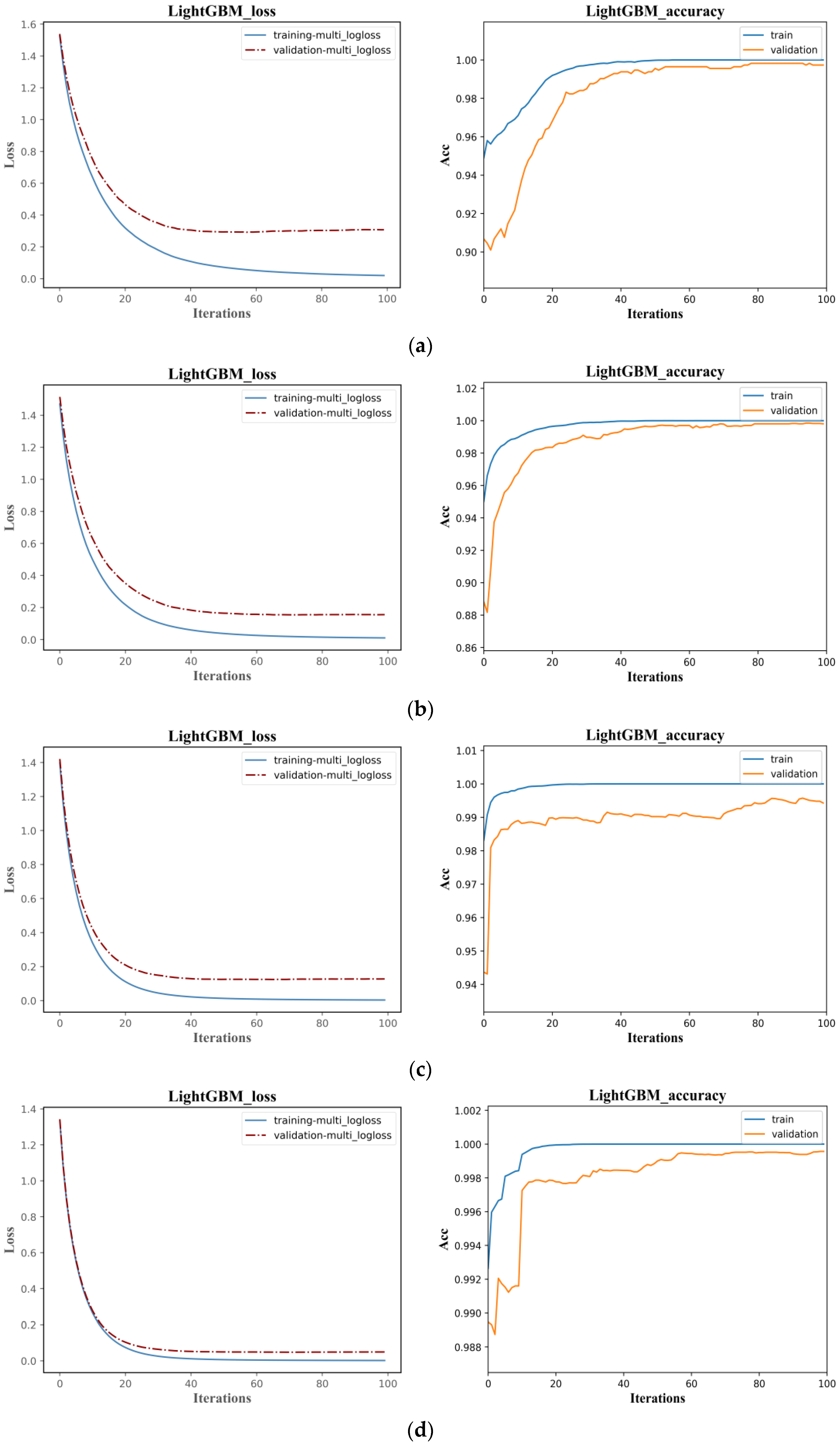
The classification accuracy of the LightGBM and LSTM models are similar, but the training efficiency of LightGBM is much higher than LSTM. As shown in
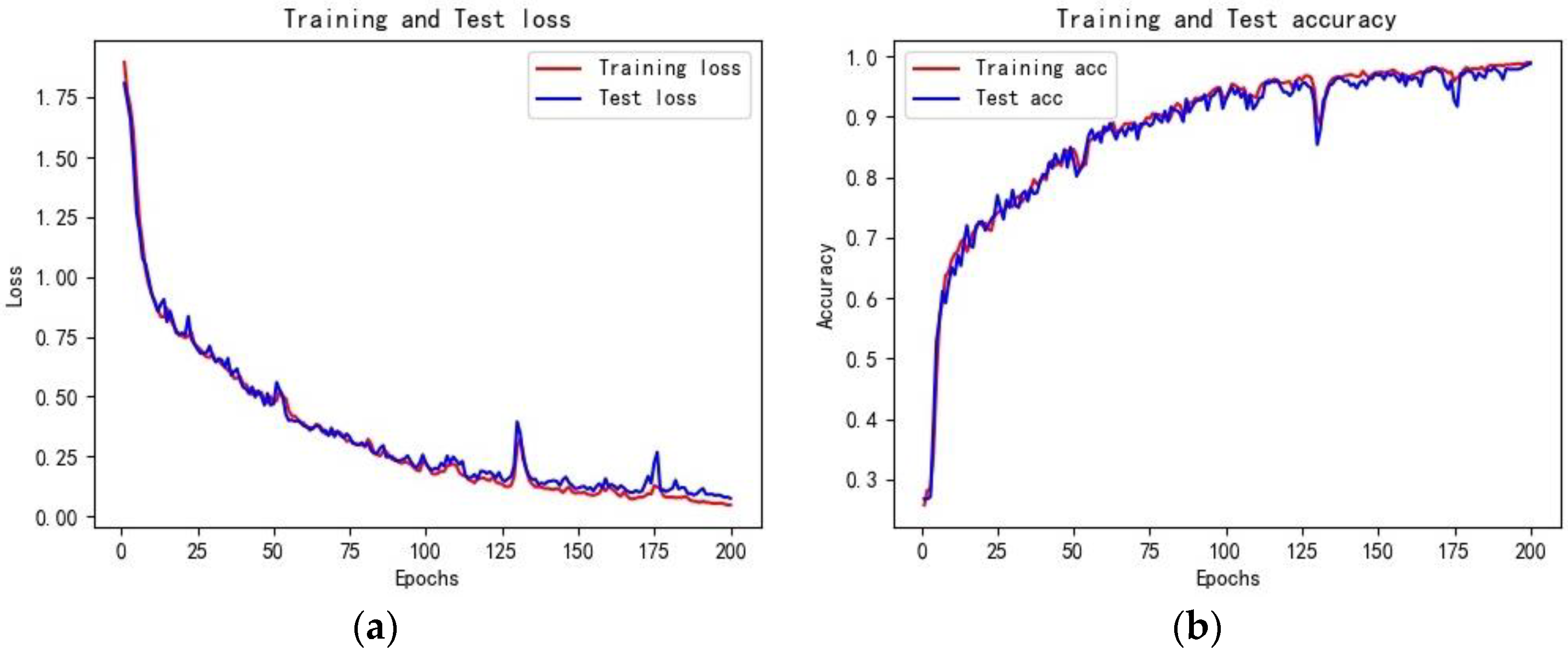
Figure 12, the Loss function in the LightGBM classification model converges after 20 iterations, with the optimal cross-entropy losses of the training and validation sets being 0.0013 and 0.0444, respectively. The training set accuracy quickly converges in the early iterations, and the validation set accuracy tends to be stable after 20 iterations, with an overall shorter training time. Compared to the LightGBM model, the initial accuracy of the training and validation sets in the LSTM classification model is relatively low, with values of 0.2180 and 0.2680, respectively, and the Loss function values are high at 1.9296 and 1.8437, as shown in
Figure 11. With the increase of the iteration times, the Loss function values gradually decrease, and the growth rate of accuracy increases. The accuracy reaches 0.9901 and 0.9871 after 200 iterations, with the Loss values decreasing to 0.0673 and 0.0809, respectively. The model tends to be stable and converges, but the training time is longer than that of LightGBM. Compared to the LightGBM model, the LSTM model has a relatively complex structure, and the characteristics of the recurrent network determine that the model cannot process data well in parallel. Additionally, the LSTM model has more parameters, resulting in lower training efficiency.
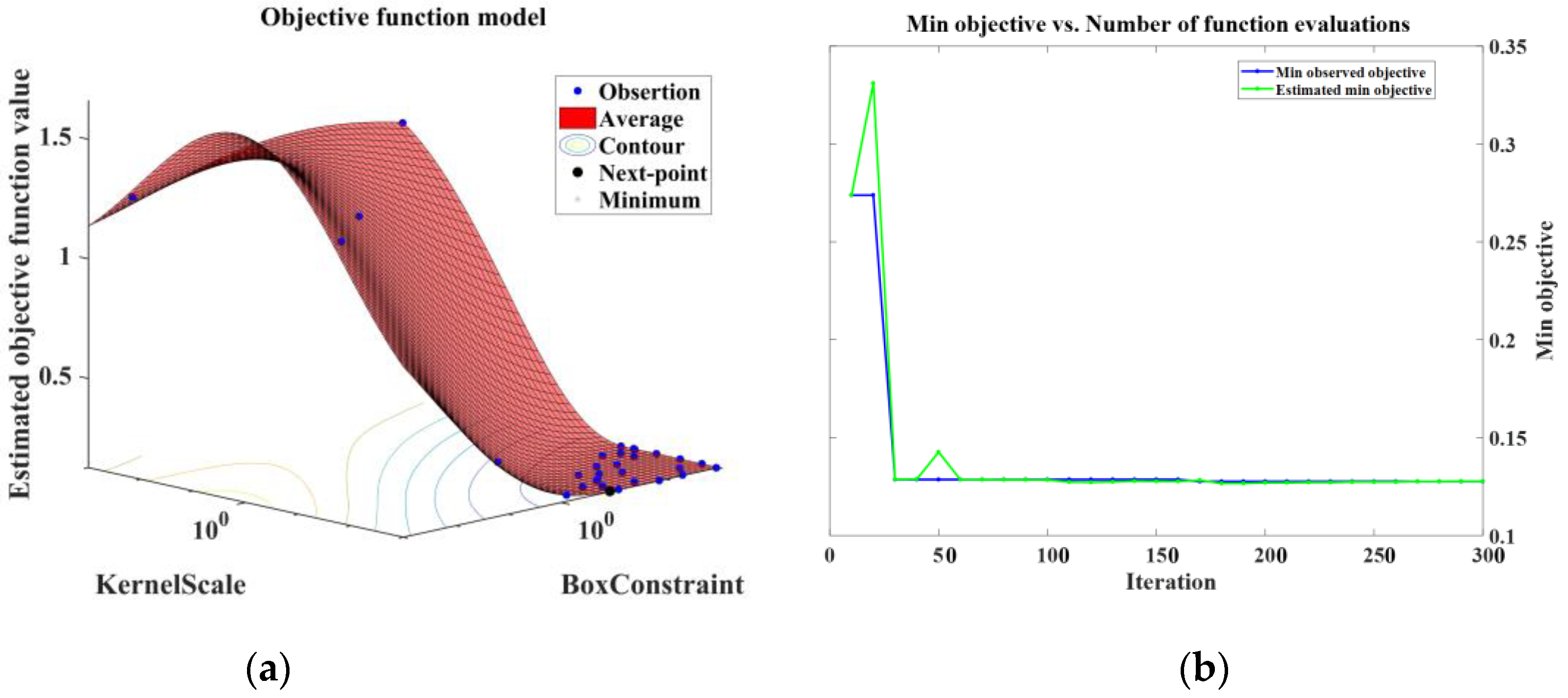
The classification accuracy of the SVM model is slightly lower than that of LightGBM and LSTM. The model uses quadratic programming to solve support vectors, involving the calculation of m-order matrices. Meanwhile, it utilizes a Bayesian-based hyperparameter optimization function to perform ten-fold cross-validation to minimize the best fit of the ‘Box Constraint’ and ‘Kernel Scale’ parameters. Due to a large amount of data, it requires a significant amount of machine memory and computation time, and it is not easy to find the optimal Kernel Function and classification parameters. It can be seen from
Figure 13 that in the initial iterations, the cross-validation loss is relatively high, at 1.2774, but it quickly decreases and stabilizes at around 0.1284 after 30 iterations, eventually reaching convergence. Therefore, the classification efficiency of SVM is between that of LightGBM and LSTM.
Compared with the above three classification models, the classification performance of the DT model is the worst, but its training speed is fast, which is related to its simple model structure and fewer parameters. Previous studies have shown that DT performs well in small-scale, weakly autocorrelated datasets. The rainfall dataset used in this study is a time series with strong autocorrelation and cross-correlation, as shown in
Figure 14, and the DT classification performance is normal, which verifies the relevant research conclusions.
Figure 15 shows the confusion matrix of the four rainfall pattern classification models. Visually, all four models have achieved good classification performance, among which the LightGBM confusion matrix had the darkest diagonal color and the best classification effect, followed by the LSTM model and DT with the worst classification performance. All four models had a certain degree of misclassification, and the misclassified objects were not completely consistent.
Table 4 shows the recall rate of each rain pattern based on different classification models.
In the rainfall dataset, the distribution of each rainfall pattern is uneven, with pattern III and pattern II rainfall samples accounting for 27.95% and 20.12% of the total, while pattern V and pattern VII account for only 3.38% and 3.36%, respectively. The average recall of pattern III and pattern II rainfall are 97.47% and 99.26%, respectively, while the recall of pattern V and pattern VII are lower, at only 94.70% and 92.19%. This indicates that when the sample distribution of each class is imbalanced, i.e., the number of samples of a certain class is much smaller than that of other classes, it will affect the classification accuracy of the model. In the classification of pattern V and pattern VII rainfall, the LightGBM model has a recall of 96.97% and 93.75%, with low classification errors, indicating that good classification results can be achieved even on imbalanced data.
Overall, in terms of model classification accuracy, training efficiency, classification performance, and stability, the LightGBM algorithm has the highest accuracy, fastest training efficiency, good classification performance, and stability on imbalanced data compared to the other three models. Therefore, it has strong applicability in the rainfall pattern classification of the Pi River Basin.
5.3. Analysis of Classification Results with Samples of Different Magnitudes
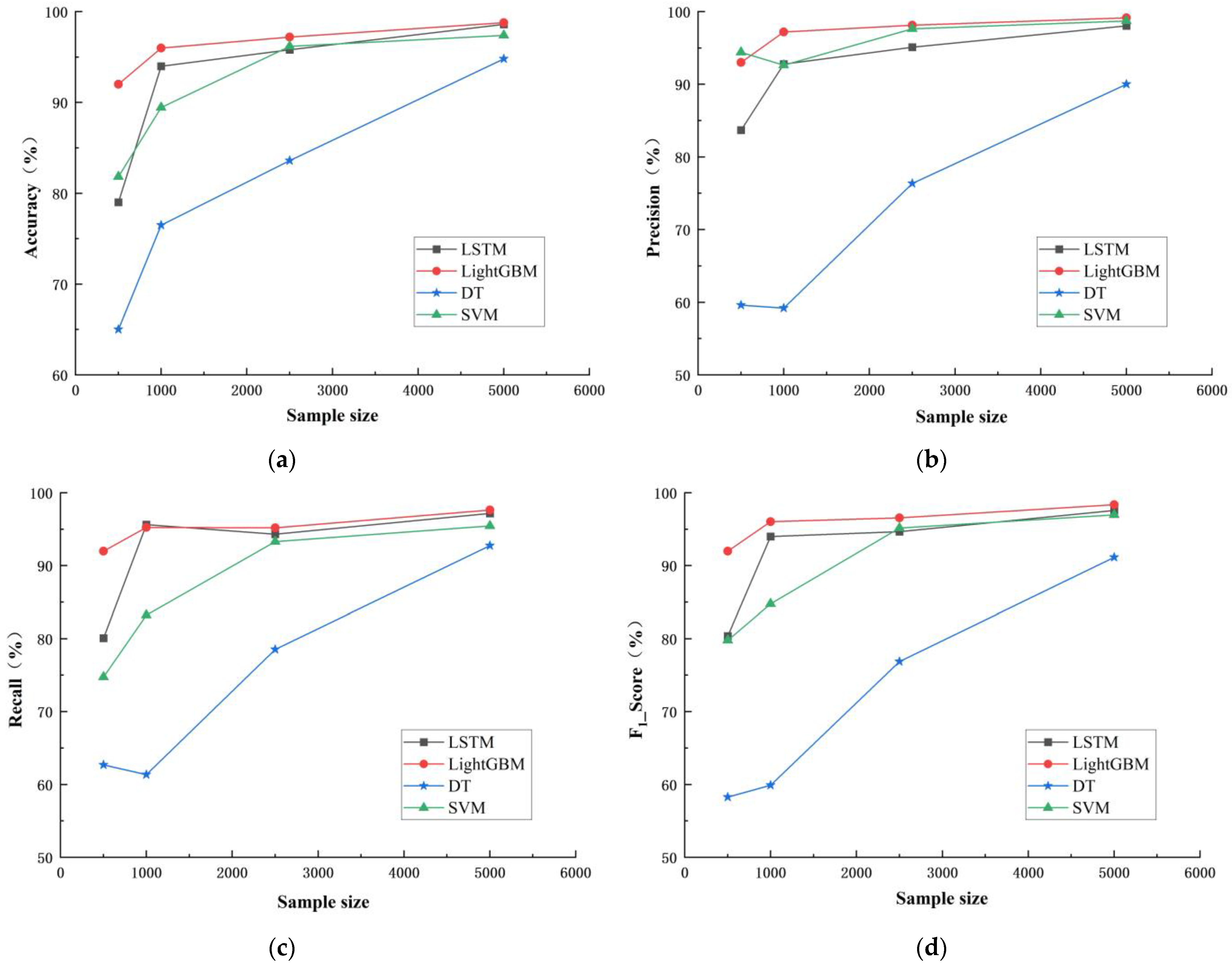
Under the conditions of 500, 1000, 2500, and 5000 rain pattern samples, four models were used to conduct classification simulation of rain pattern respectively, and the classification accuracy of four models were compiled and calculated for each rain pattern quantity, as illustrated in
Table 5, according to the classification results, the distribution of four indexes including accuracy, precision, recall, and F
1 score under different rain pattern samples are shown in
Figure 16.
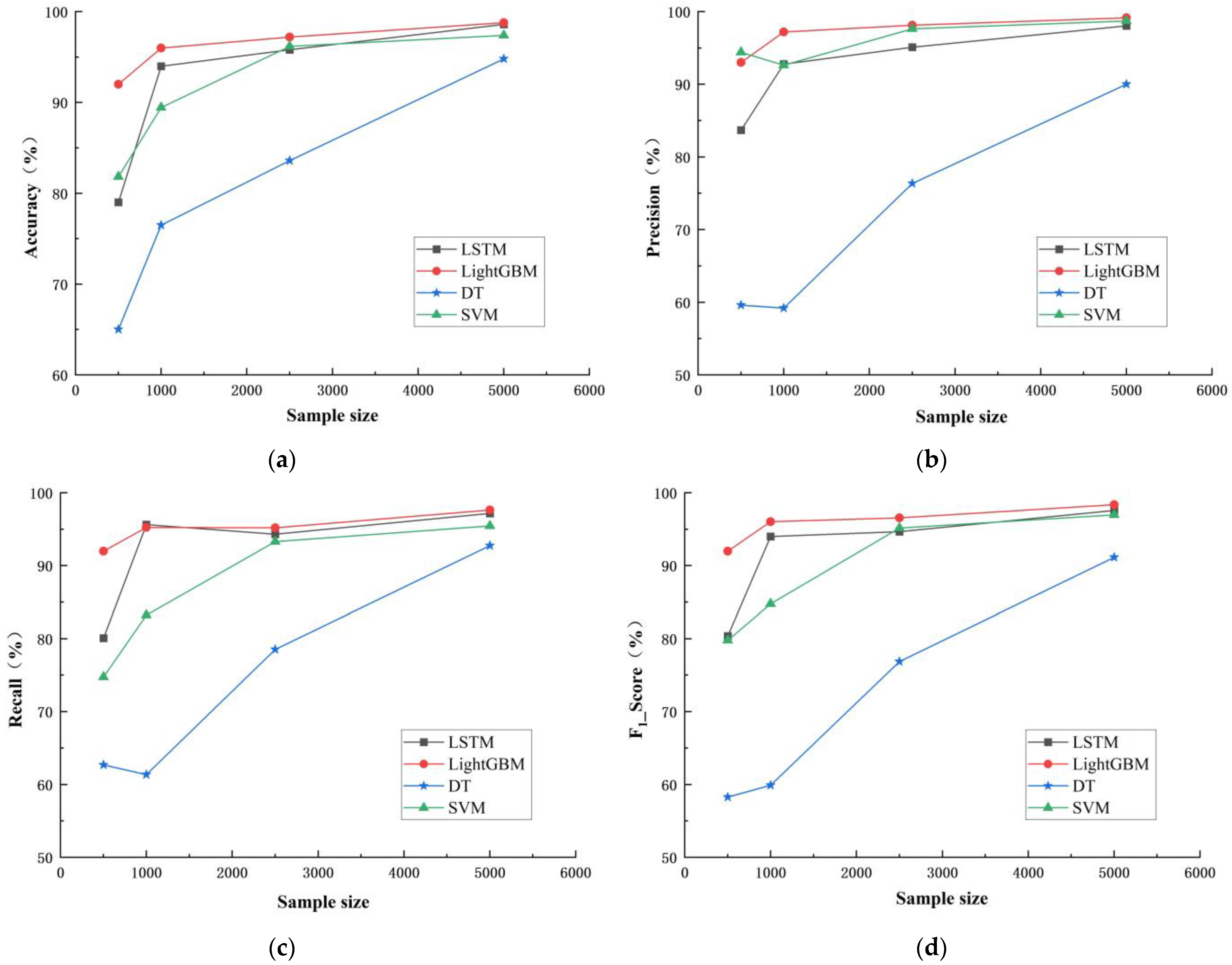
As can be seen from
Table 5 and
Figure 16, the accuracy, precision, recall, and F
1 score of the four classification models generally increased as the sample size increased from 500 to 5000. Among them, the evaluation indicators of LightGBM and LSTM models did not increase significantly after the sample size increased to 1000, while those of DT and SVM models steadily increased with the increase in sample size. This indicates that the sample size has a significant impact on the accuracy of classification models.
In order to further analyze the influence of different rain pattern samples on the model classification process, this study has compiled the changes in the loss function and accuracy of four models under different rain pattern samples. Taking LSTM and LightGBM models as examples, this study shows the changes in the loss function and accuracy of the models under the sizes of 500, 1000, 2500, and 5000 rain pattern samples, as shown in
Figure 17 and
Figure 18.
Overall speaking, as the number of samples increased, the Loss function values of the LSTM and LightGBM models on the training and validation sets steadily decreased, while the accuracy values steadily increased and eventually reached a stable convergence state. The initial and convergence Loss function values of the LSTM and LightGBM models were higher on small samples and lower on large samples. Taking the LSTM model as an example, when the sample size was 500, the initial value of the validation set Loss function was 1.9153, and the convergence speed was slow. After 300 iterations, it converged to 0.5182; when the sample sizes were 1000 and 2500, the initial values of the Loss function were 1.8786 and 1.7898, respectively, and the iteration speed accelerated. It reached stability at around 250 iterations and converged to 0.3681 and 0.2503, respectively. When the sample size was 5000, the initial value of the Loss function was 1.6438, and it converged quickly, stabilizing at around 100 iterations and converging to 0.1045. This shows that increasing the number of samples in machine learning classification helps to improve classification accuracy and training efficiency.
Previous studies have suggested that SVM models have certain advantages in dealing with small sample data [
35,
36,
37]. In order to explore the performance of SVM models in handling classification problems with different numbers of rain pattern samples, this study compared a statistical analysis of the evaluation indicators of four models at rain pattern sample sizes of 500 and 5000, respectively, and presented the results in
Figure 19.
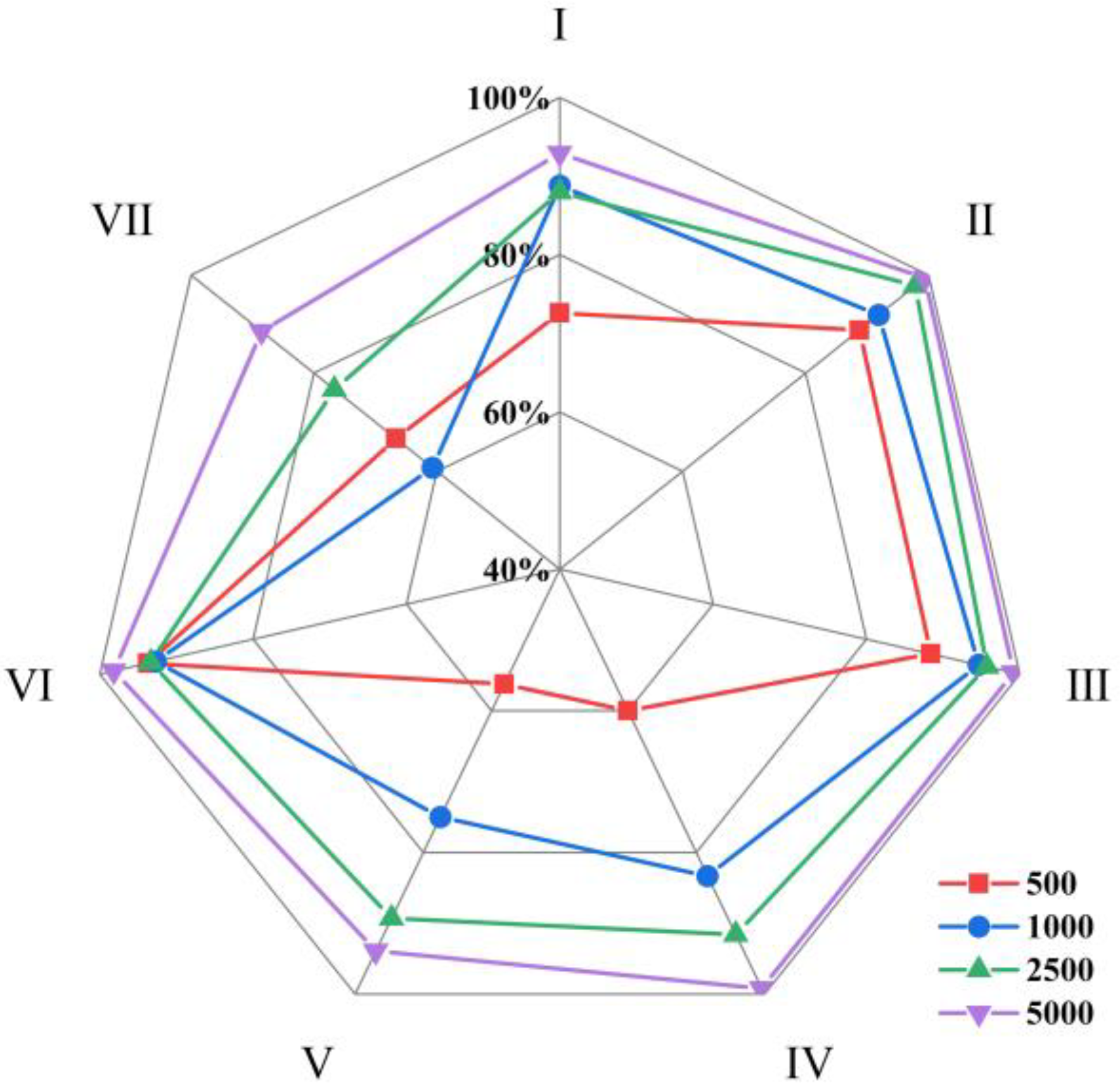
When the sample size was 500, SVM had an accuracy rate of 81.82%, which was higher than LSTM and DT, and a precision rate of 94.40%, which was the highest among the four classification models. When the sample size increased to 5000, compared with the other three models, the accuracy and precision of SVM both decreased, and the recall tended to be the lowest among the four models. This result indicates that relative to large samples, SVM has certain advantages in handling small sample classification problems.
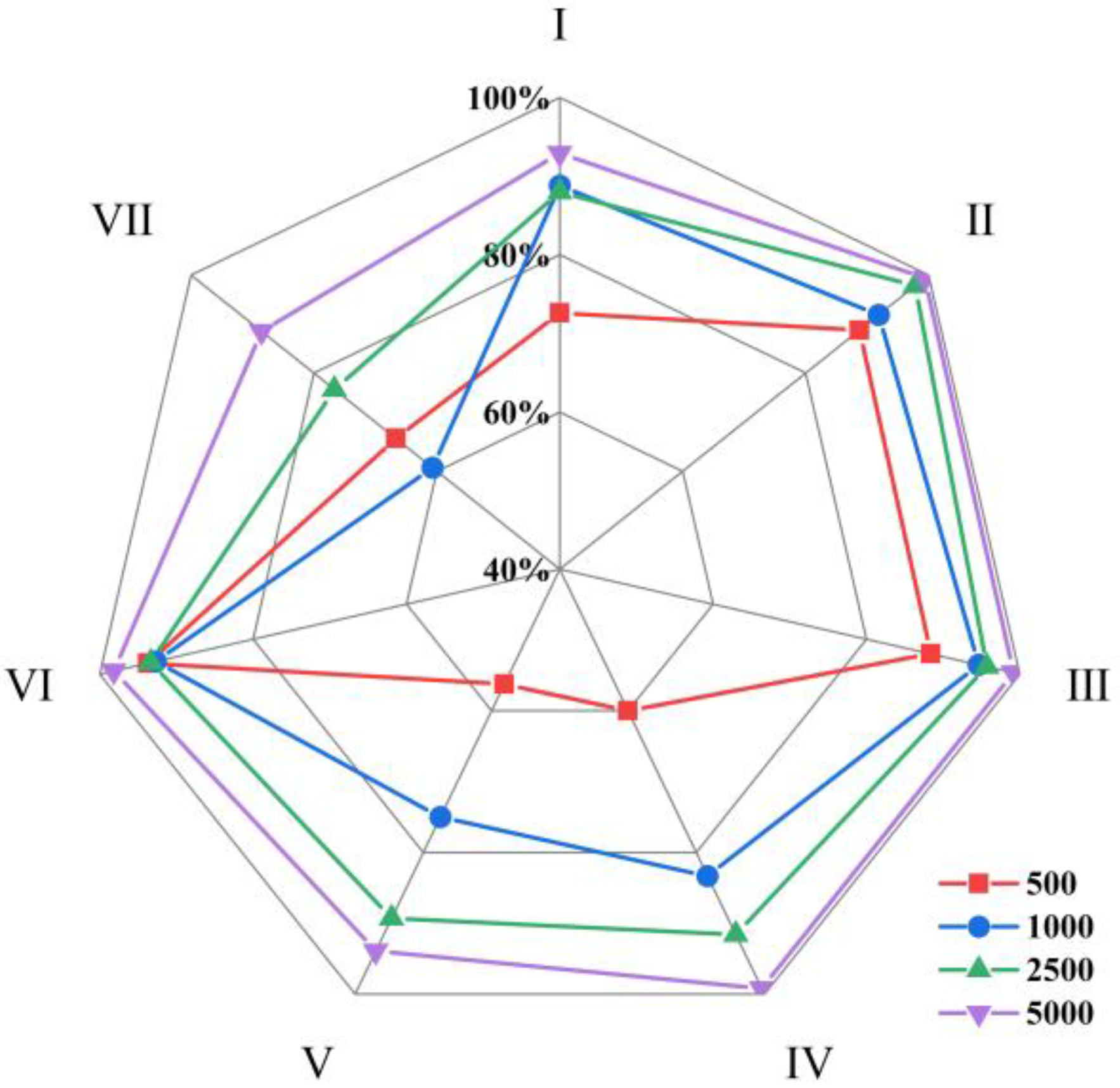
In order to investigate the impact of sample size on the accuracy of imbalanced sample classification, this study calculated the average recall of seven rain patterns of four models at sample sizes of 500, 1000, 2500, and 5000, as shown in
Figure 20.
The average recall of each rain pattern for the four machine learning classification models at different sample sizes was calculated. The average recall for the pattern Ⅴ and pattern Ⅶ were lower than those of other rain patterns at different sample sizes, indicating that uneven distribution of rain patterns can affect classification performance. When the sample size was 500, the average recall of the pattern Ⅳ, which accounted for 20% of the total rainfall events, was only 60.00%, lower than that of the pattern Ⅵ, which accounted for 3.35% of the total rainfall events. This is because when the sample size is small, the rain-type distribution model is unstable, leading to unstable classification results.
5.4. Analysis of Characteristics Significance
LightGBM is a classification and regression technique that is not only suitable for nonlinear data modeling but also for analyzing the significance of variables to assist in characteristics selection and remove characteristics that are irrelevant or redundant to the target variable during the machine learning process, ultimately improving model accuracy and reducing runtime.
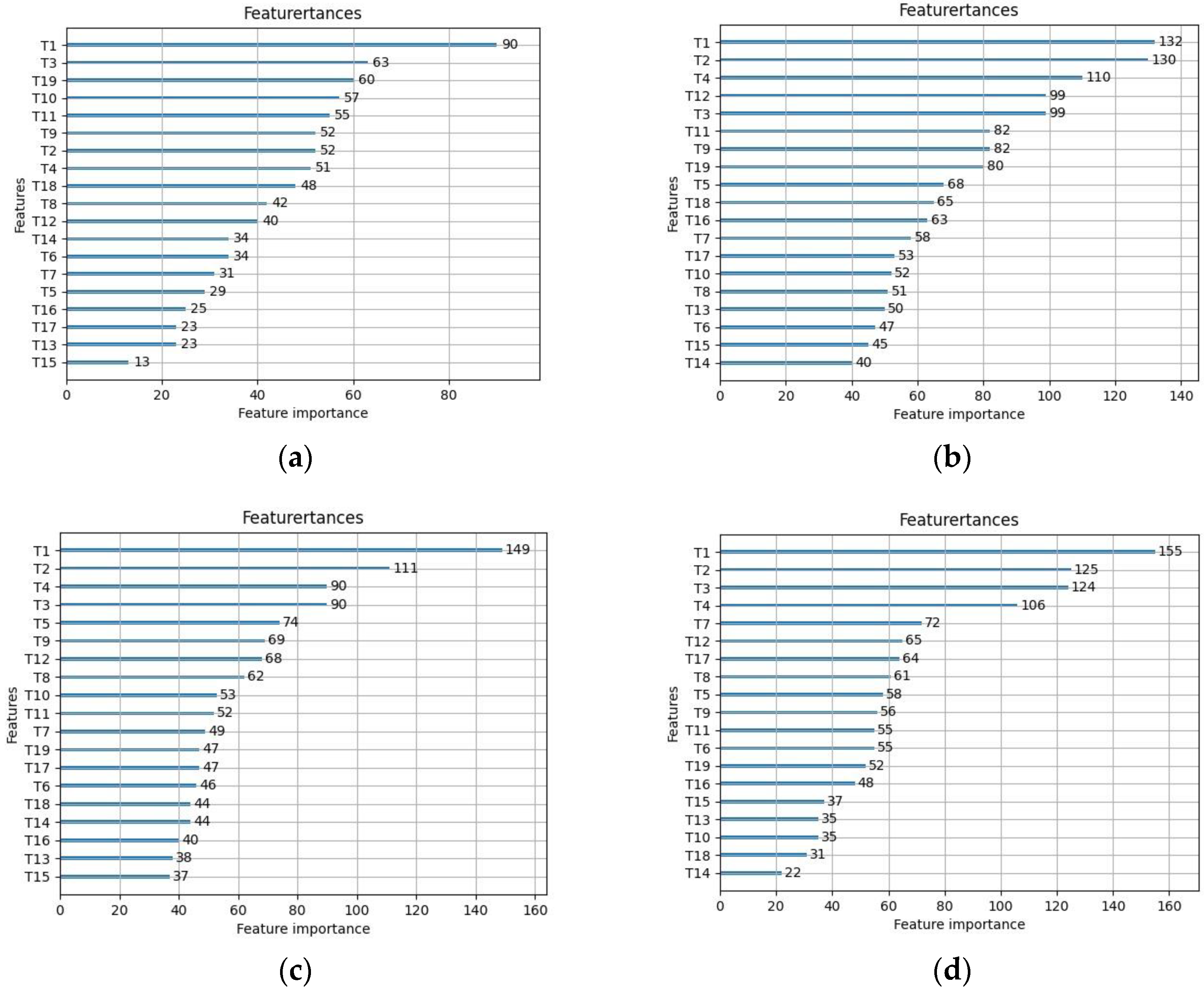
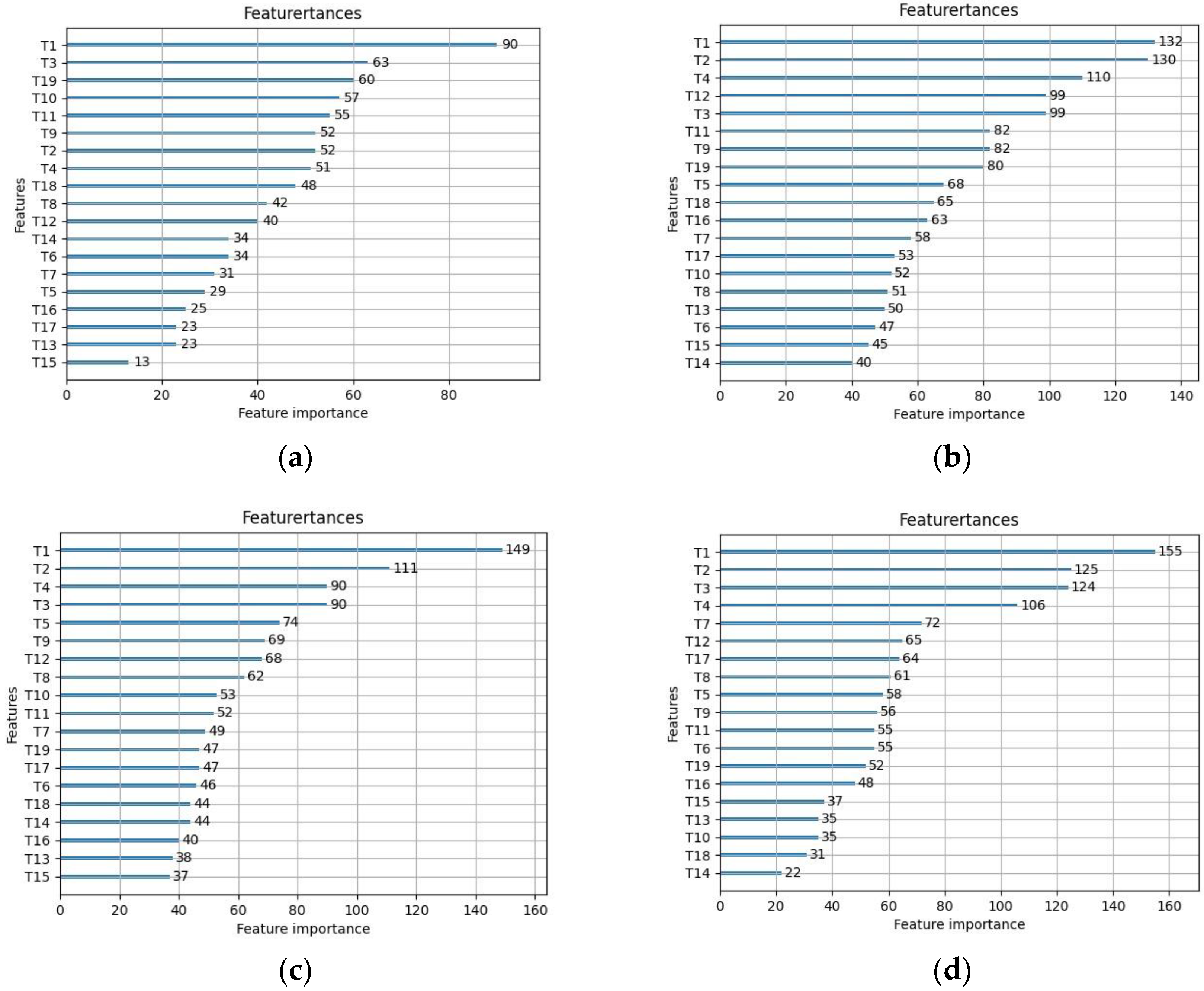
By using LightGBM to sort the significance of characteristics for different sample sizes, it can be observed from
Figure 21 that the significance of each characteristic variable varies greatly with different sample sizes, mainly because the overall features are unstable in small samples, resulting in large classification result bias. The characteristic variable “T1” has the highest importance in all sample sizes and has a significant impact on the accuracy of classification results. As the sample size increases, the significance of characteristic variables “T2” and “T4” gradually increases and tends to stabilize. Characteristic variables “T14” and “T15” have poor importance and can be considered for removal to improve model classification accuracy.
6. Conclusions
Based on the analysis of precipitation events in the Pi River Basin using the DTW method, this article builds classification models based on DT, LSTM, SVM, and LightGBM algorithms. Through comparative analysis, it is found that the four machine learning models have strong generalization performance in precipitation event classification and achieve relatively good classification results. The specific conclusions are as follows:
(1) The overall classification effect of the LightGBM model is better than the other three models. Compared with LSTM and SVM models, LightGBM has simpler modeling, supports input of categorical features, is faster in speed, occupies less memory, and has higher learning accuracy and efficiency, about which the accuracy and F1 score were 98.95% and 98.58%, respectively, and the loss function and accuracy converged quickly after only 20 iterations. The imbalance in the number distribution of sample categories in the dataset will affect the classification accuracy of the model. LightGBM has significant advantages in solving classification problems with imbalanced category distribution. In practical applications, appropriate classification algorithms and data preprocessing methods can be selected based on the actual situation to achieve the classification goals more effectively.
(2) The sample size has a significant impact on the accuracy of the classification model. The reason is that the overall distribution is severely imbalanced in small samples, and increasing the sample size can improve the classification accuracy and training efficiency in machine learning classification. Compared with the other three models, the SVM model performs well in the small sample problem and has higher classification accuracy.
In summary, this article verifies the applicability of machine learning models in the field of rainfall pattern classification and expands the application scope of machine learning technology. Based on the current work, further research can be carried out, such as expanding one-dimensional rainfall time series to precipitation image sequence high-dimensional data to explore the classification of high-dimensional spatiotemporal sequences using machine learning methods; conducting random simulation on measured rainfall data, upgrading the sample size, adding noise data, and exploring the application effect of machine learning methods under conditions of large dataset randomness, mixed noise, and imbalanced categories.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}