Simulation, state selection, and cost estimation are applied to analyze the influence of different states on both the control effect and construction cost of DRL. Different state scenarios based on the location of pipeline network nodes and information type (water level, flow, or both) are designed according to the characteristics of UDSs and are used to train different DRL agents. The cost of each input scenario is calculated using the collected price information from different service providers in China. The following section provides details on the applied methods.
2.1. Case Study and Rainfall Data
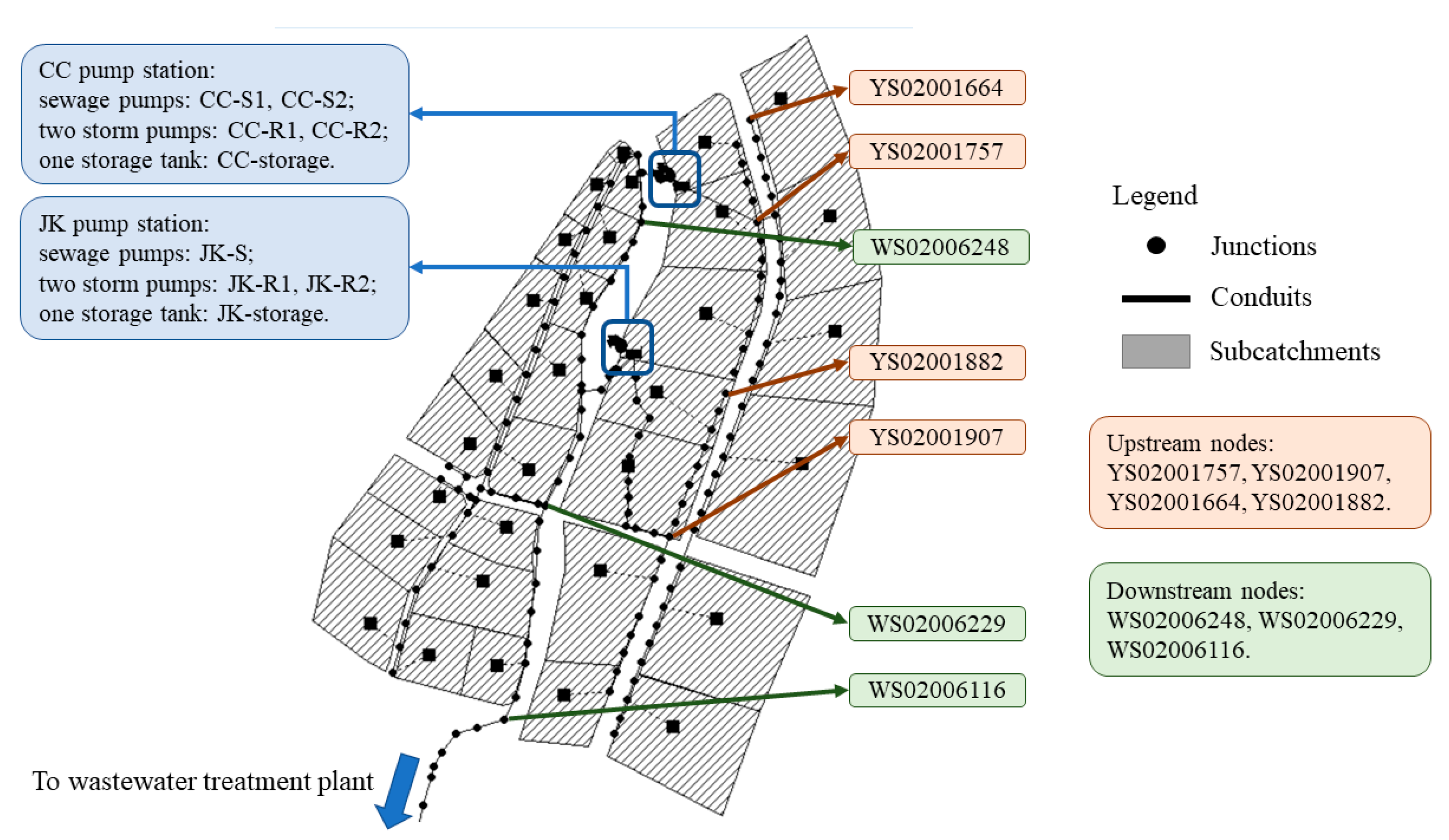
The case study is a real-world combined UDS located in eastern China, which has 139 nodes, 140 pipelines, and three pump stations. In this study, we focus on the area with a high level of flooding and CSO, thus only two pump stations are considered. Its storm water management model (SWMM) is shown in
Figure 1. The version of SWMM is 5.1 [
27]. In dry periods, the sewage pumps transfer water from the storage tanks downstream, while on rainy days, the storm pumps discharge excess water into a nearby river as the CSO. During heavy rainfalls, the maximum capacity of the pumping stations might exceed the maximum capacity of the pipeline network, causing both flooding and CSO in this area. Therefore, its control system needs to smartly balance the water volume both upstream and downstream to minimize the total CSO and flooding. These pump stations have a rule-based heuristic control (HC) system that operates the pumps to start/stop working based on a sequence of water level threshold values [
21]. The threshold values are shown in
Table 1. The system is named HC in this study. More details of this case can be found in our previous studies [
6,
19,
20,
21,
28].
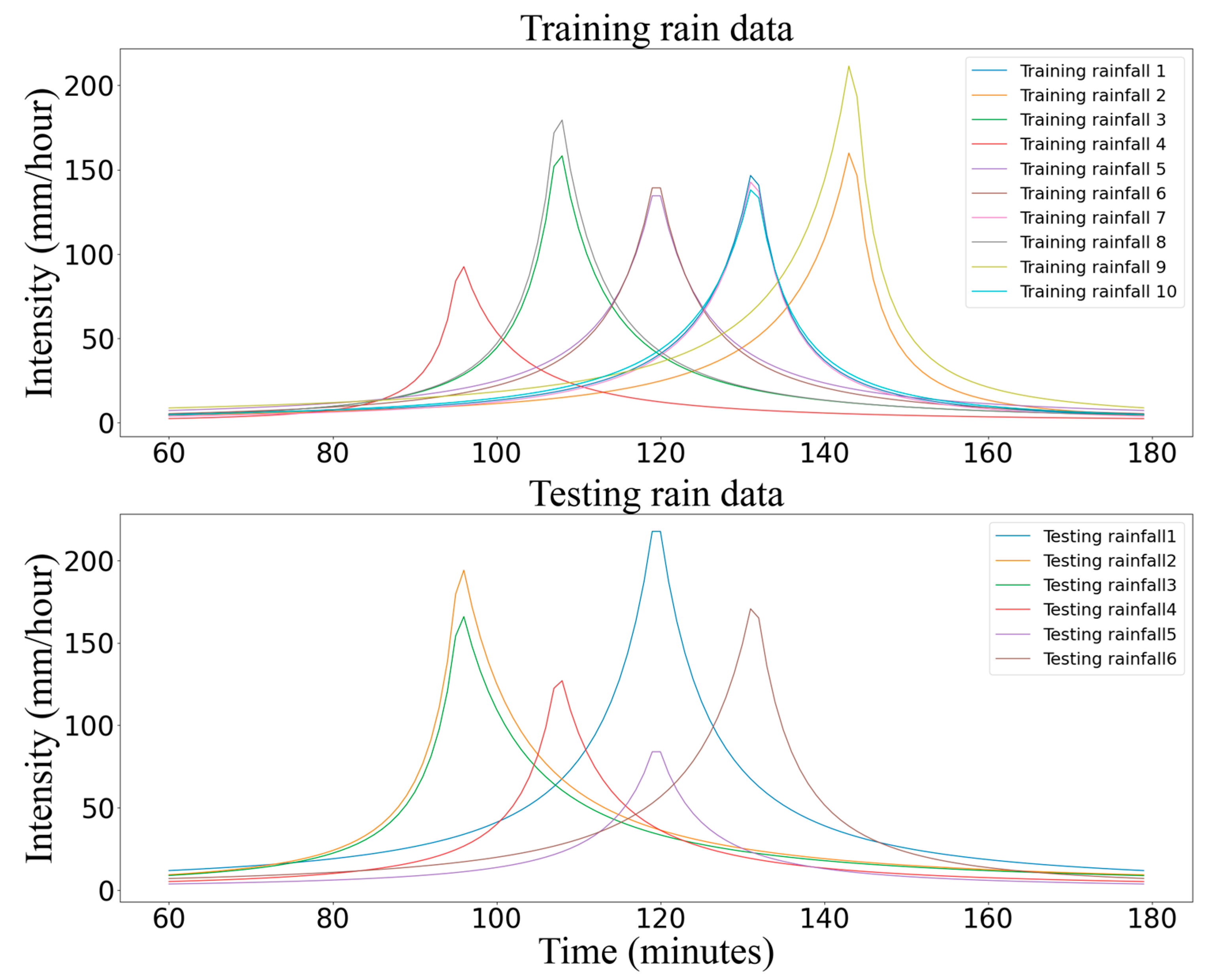
The rainfall data used in this study for DRL training and testing are designed rainfalls based on Chicago histograms (Equation (1)), where
is the storm intensity before the rainfall peak;
is the storm intensity after the rainfall peak;
and
are corresponding rainfall duration time;
is the rainfall intensity with a recurrence period of one year;
is an empirical constant;
is the rainstorm return period;
is the peak intensity position coefficient (or time-to-peak ratio); and
and
are the parameters related to the region. These parameters are randomly selected within the range provided by historical research on the rainstorm intensity in the study area. The detailed values are provided by previous studies [
19,
20] and are shown in
Table 2. These rainfalls are shown in
Figure 2.
2.2. Deep Reinforcement Learning for Flooding and Overflow Mitigation
When establishing DRL for a UDS, its model, e.g., SWMM, is applied as an environment controlled by a DRL agent, while its agent is established by a deep neural network to input real-time state and output action. The state is real-time information on UDS, which includes the water level and flow of pipeline network nodes, rainfall intensity, and so on. In this study, the influence of different states on the control effect of DRL is mainly studied. Different state selection scenarios based on the node’s location and information type (water level or flow) are designed and used to train different DRLs for comparison. Details of scenarios are provided in
Section 2.3. The action refers to the control command in the next time period, which generally includes the startup/shutoff of a valve or a pump, etc. There are two pump stations in this case study and each of them has corresponding stormwater pumps and sewage pumps, thus the action is the control command of all these pumps (startup/shutoff). The system needs a reward to score the control effectiveness of action in real-time according to a control objective, e.g., flooding and CSO mitigation. The reward in this study is calculated using Equation (2), where
is the total CSO of time
t;
is the total flooding of time
t; and
is the total inflow of time
t.
The DRL agent needs to be trained before practical application. Its training process consists of two steps: sampling and updating. The sampling process uses a DRL agent to control a UDS model through simulation and collects state, action, and reward data during control. The updating process selects a DRL update algorithm with respect to the type of DRL agent and uses it to train the DRL agent with the collected data to maximize the weighted total reward, i.e., the q-value function of Equation (3);
,
, and
are the state, action, and reward of the DRL method;
γ is the discount factor between 0 and 1, used to guarantee the convergence of
q value and govern the temporal context of the reward;
k is the number of forward time-steps;
T is the total number of time-steps;
π is the policy function used by the agent to provide action with respect to state, and is a deep neural network in this study. After multiple epochs of sampling and updating, the trained DRL agent is able to find the action that obtains the highest
q value in play, and thus it becomes an expert in controlling UDS.
DRLs can be classified as value-based or policy-based. The value-based DRL uses a deep neural network to predict the
q value of all the available actions and selects the action with the highest corresponding
q value for control (Mnih et al., 2015). This study is more concerned with the influence of different state selections on DRL control output than on the
q value prediction; therefore, proximal policy optimization (PPO) is used. It belongs to the policy-based models [
29,
30] which use a deep neural network to approximate policy function (input state and output action). Then, this deep neural network is trained by one of the gradient-based algorithms. In this study, Adam [
31] is used as the training algorithm. One special feature of the policy-based method is that its gradient cannot be directly obtained by the derivatives of
q value function. Instead, an estimator called policy gradient (Equation (4)) [
30] is used as the gradient of the deep neural network in the Adam algorithm, where
is the
q value,
is the policy function based on a deep neural network with parameter
. The training process of PPO and its implementation of PPO in a simulated environment is described in
Figure 3.
In this study, the architecture of the deep neural network is M-30-30-30-1. M is the size of the input layer and is related to the selection of pipeline nodes and input type. There are 3 hidden layers and each of them has 30 nodes. The output layer has 1 node, which represents the action. Since there are a total of 7 pumps, each of them has two kinds of settings (startup/shutoff), thus there are 27 combinations of all possible actions of pumps, that is, the output of the deep neural network is between 1 and 128 in this study. The trained system is named PPO in this study.
2.3. The Design of State Selection Scenarios
As mentioned above, existing DRL studies lack optimal design for system inputs, so the influence of state selection on the DRL control effect is still unknown. This study investigates the influence of state selection on DRL through state design. Specifically, different state selection scenarios based on different node locations and the type of information (water level or flow) are provided to train different DRL agents for comparison.
The DRL agent needs to provide the action of pumps that can obtain the highest
q value in the next time period based on real-time states. Therefore, the data that reflects the real-time situation of the UDS and provides effective information for pump controlling can all be used as a state, and the most related one is the information on the forebay storage tanks of all the pump stations. Meanwhile, pump stations need to balance the water volume both upstream and downstream to avoid the situation in which a large amount of stormwater and sewage water run into a node simultaneously. Therefore, with the pump station as the center, the information on its upstream and downstream nodes can also support the control of the DRL agent. The distance between the node and the pump station can be used as a reference for node selection. Studies on control systems have provided analysis methods of controllability of networks [
32,
33] and important nodes on a network [
34]. However, none of them is for black-box control systems of urban drainage pipeline networks, and thus they need to be adjusted to fulfill the hydrodynamic properties of pipeline systems. Therefore, they are not considered in this study.
Based on the above two points, the state selection scenarios designed in this study are divided into four categories: storage tank nodes only (state-1), storage tank nodes and upstream nodes (state-2), storage tank nodes and downstream nodes (state-3), and storage tank nodes and both upstream and downstream nodes (state-4).
In addition to node location, the flow or water level information provided by each node also affects DRL control performance. Therefore, the use of flow or water level is also considered in the state selection. In the previous study, the flooding value was used as a state of DRLs [
19]. This is available in a simulated environment but is not considered in this study due to the difficulty of flooding real-time monitoring in practical applications.
The state selection scenarios based on the integration of node location and information types are shown in
Table 3, and the location of each node is shown in
Figure 2. Each scenario is used to construct a PPO-based DRL (named PPO) to analyze the effect of state selection on the control effectiveness. Since many studies have confirmed the necessity of rainfall information for real-time control [
14,
19], real-time rain intensity is used as one of the input states in all the scenarios.
2.4. The Unit Cost of DRL Data Monitoring
The construction of a DRL real-time control system requires an online data monitoring system, control actuators, a data and computing center, and a data transmission network. The control actuators in this study are the pumps in the two pump stations. A data and computing center is used to collect all the online monitoring data and run the DRL agent to provide real-time control actions. Since dispatching facilities and a control center are already available in this case area, the costs of these parts are the same for all the scenarios and are ignored in this study.
The data transmission in the case study mainly relies on wireless base stations for real-time communication. Since the case UDS is located in an urban area with well-developed network facilities, there is no need to establish a dedicated network and the cost of this part depends on the network communication service. The online data monitoring system is used to obtain real-time water flow and water level data. The selection of flow or water level leads to different costs of system construction as the price of their monitoring facilities is significantly different.
Accordingly, the construction cost difference of all the state selection scenarios mainly comes from the cost of the online data monitoring system. Thus, this cost is mainly analyzed in this study to reveal the cost-effectiveness of each state selection. Referring to the existing quotations of online monitoring service providers in five different regions of China (Shanghai, Wuhan, Shenzhen, Chongqing, and Fujian), the unit prices of different water level and flow monitoring, software support, and network communication services are obtained and shown in
Table 4, and the final cost can be calculated by multiplying the unit price by the quantity.
It is worth mentioning that the prices here are heavily influenced by the cost of installation labor and network services in different regions of China, as well as the principles of monitoring equipment; therefore, there is a difference among them and they can only be used as a reference.







{kind=link}
{kind=link}
{kind=link}
{kind=link}