1. Introduction
Hunan Province is located in the southeast inland of China, with abundant rainfall but extremely uneven temporal and spatial distribution. Due to frequent and high-intensity rainfall and short confluence time in hilly areas, the flood rises and falls steeply, which can very easily cause mountain torrents. The climate, underlying surface and geomorphic types in hilly areas are diverse, and most of them are areas without data. This is an important challenge for flood forecasting and early warning in hilly areas.
The hydrological model is an important tool for understanding the laws of hydrological science, analyzing hydrological processes and studying hydrological cycle mechanisms [
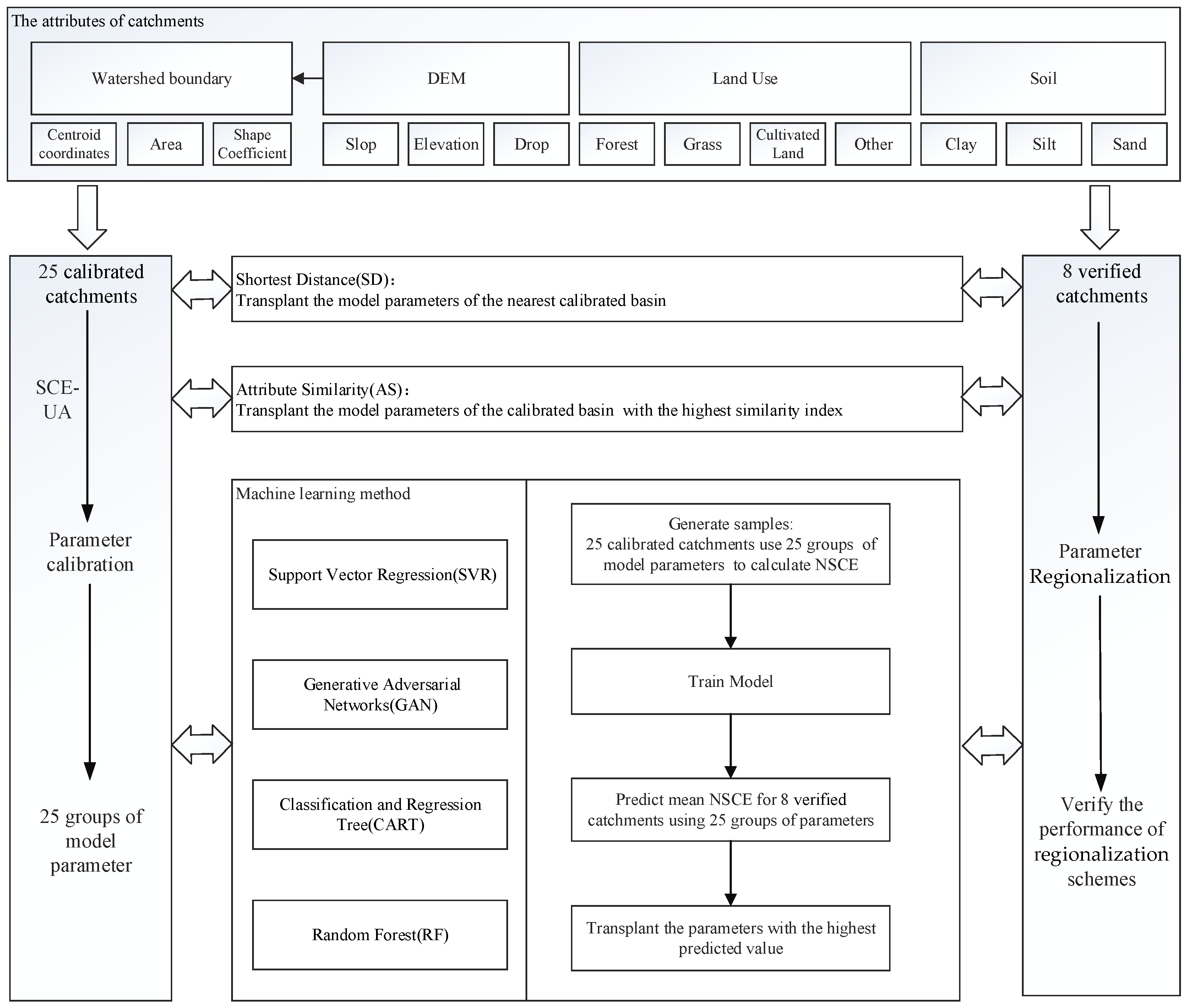
1]. How to identify hydrological parameters in ungauged areas accurately is an important area of research for PUB (Prediction in Ungauged Basins). The regionalization method is usually used to determine the parameters of hydrological models for ungauged basins at present, and the commonly used methods include shortest distance, attribute similarity, regression, average, machine learning, etc. The main idea of the regionalization method is to analyze the relationship between model parameters and characteristic attributes of basins, and the parameters of the hydrological model for ungauged basins are deduced from the calibration results of gauged basins [
2].
The parameter transplant method includes the shortest distance method and the attribute similarity method. Among them, the distance approach refers to finding one or more basins adjacent to the research object in the geographical location. The attribute similarity method is used to find a basin that is similar to the research basin in attributes. Young achieved the ideal result of parameter transplant by computing the spatial distance between 260 catchments in the UK [
3]. Parajka et al. selected indicators such as watershed area, average slope, watershed latitude, river network density, vegetation coverage, drought index, etc., to analyze the similarity of watershed attributes and complete parameter transplantation. The results show that attribute selection plays a decisive role in the performance of transplantation [
4]. Li et al. compared the shortest distance method with the attribute similarity method and pointed out that the performance of transplantation results is affected by the density of hydrological stations, and it is easier to achieve better results in areas with dense hydrological stations [
5].
The parameter regression method is mainly used to establish the functional relationship between watershed characteristics and model parameters. Yokoo et al. established a multiple linear regression equation between the Tank model parameters and soil, geology and land use data [
6]. Cheng et al. established a regression equation between the SCS model parameter CN, concentration time and soil, land use, average slope and river length [
7]. Based on the parameter regionalization method combining spatial proximity and stepwise regression analysis, Yao et al. found that stepwise regression analysis can effectively deduce the sensitive parameters [
8]. Sun et al. pointed out that the parametric regression method is prone to the phenomenon of “the same effect of different parameters”, and the basin properties screening is highly subjective, which is not suitable for small samples [
9].
Machine learning research mainly includes SOM classification and the CART decision tree method. Yi et al. used hierarchical clustering analysis HCA and unsupervised neural network SOM methods to divide the sub basins of Dianchi Lake basin into 7 groups based on 16 physical characteristics, and they believed that the basin parameters of the same group can be transplanted to each other [
10]. Ragettli et al. took 35 basins in different regions of China as the research object, comprehensively considering the physical properties of watersheds and the spatial distance of watersheds; the CART tree model was used to optimize the parameter transplantation rules, and the results show that the CART tree has better parameter adaptability [
11]. Liu et al. conducted a parametric zoning study on 19 small catchments in Henan Province; the success rate of parameter transplantation based on the CART tree is about 20% higher than that of random transplantation [
12].
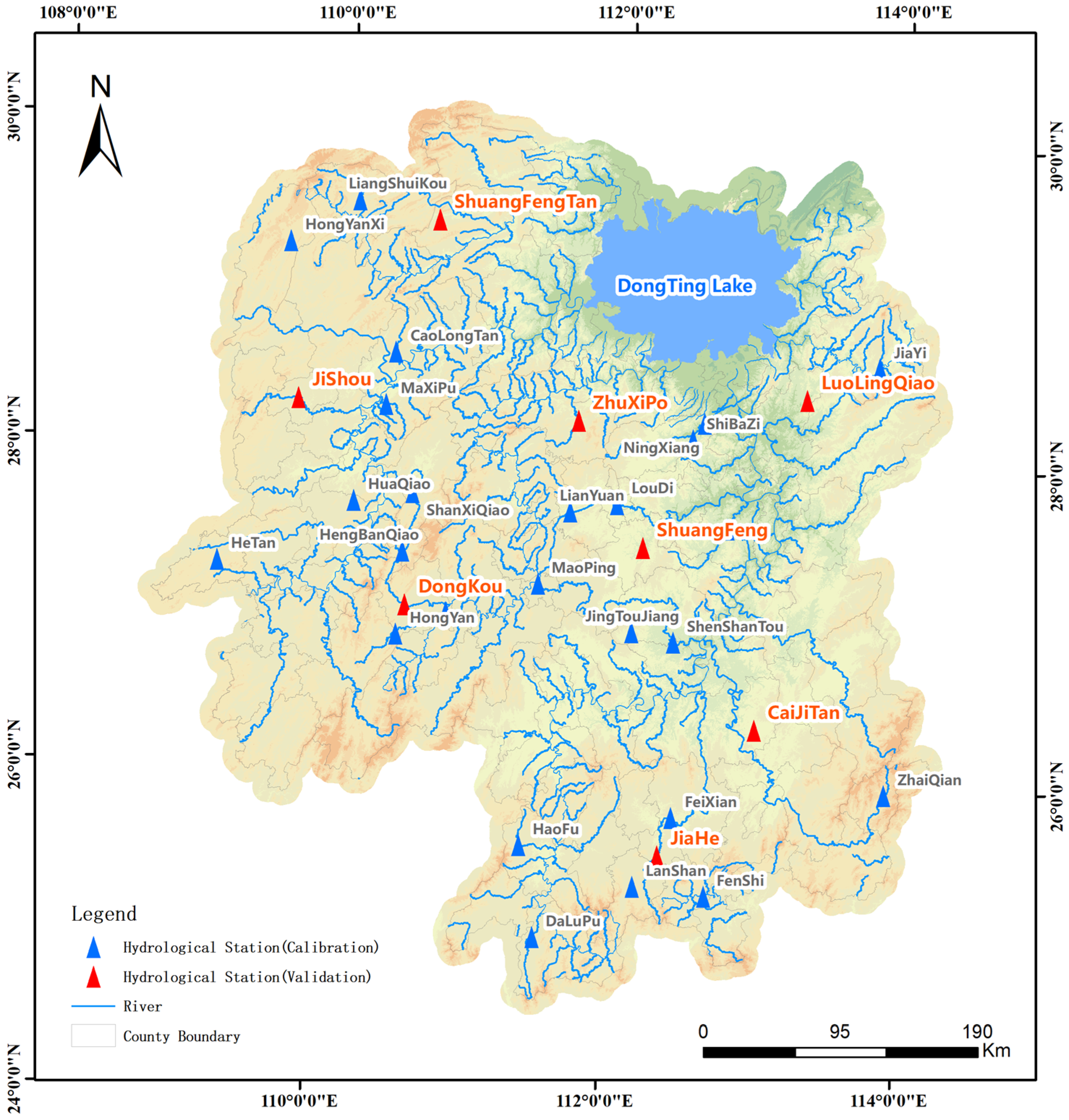
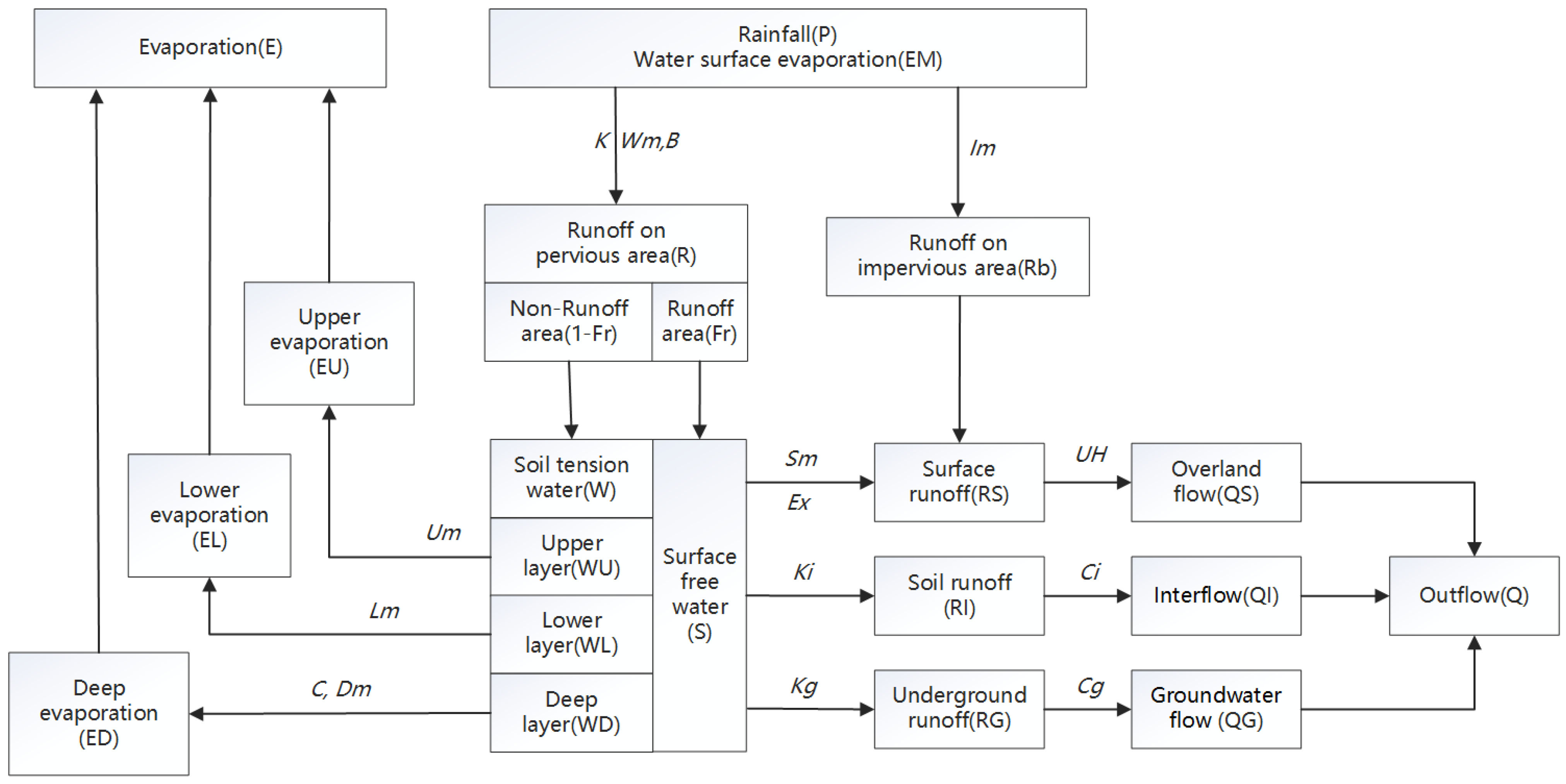
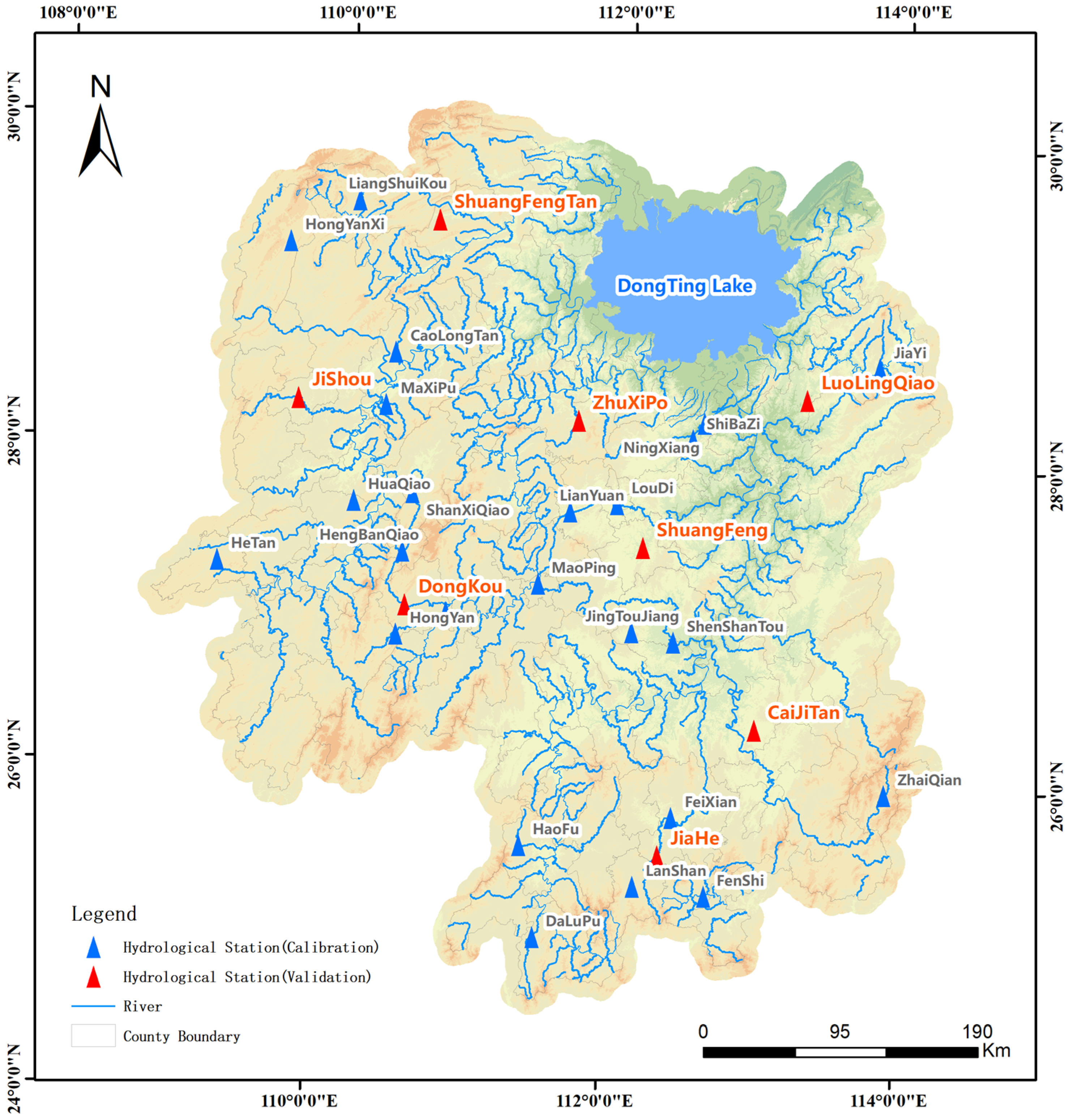
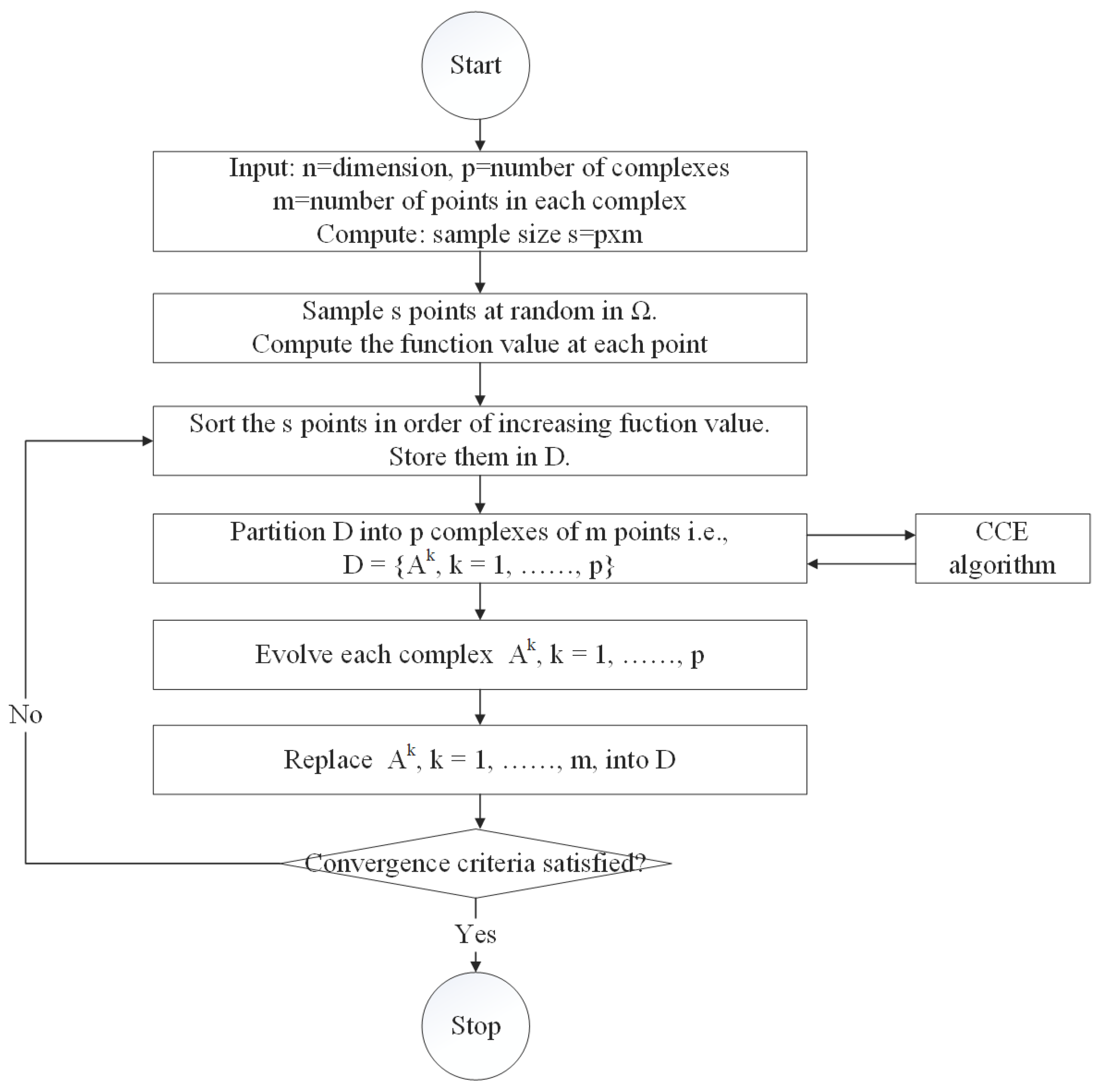
The advantage of the CART tree is that it is easy to interpret and the mapping between basin characteristics and transplantation rules is intuitive. In recent years, with the advent of machine learning algorithms, more and more models have been used to create parameter transplantation schemes. However, many machine learning algorithms usually require a large number of samples, and data showing that hydrological model modeling can be used for parameter calibration is often very limited, so it is necessary to reasonably build a large number of learning samples, or to study intelligent algorithms suitable for small sample research. In this study, 33 small and medium-sized catchments in Hunan Province were taken as examples. We constructed distributed hydrological models of these catchments and selected four machine learning models—Support Vector Regression, Generative Adversarial Networks, Classification and Regression Tree, and Random Forest—to create different parametric regionalization schemes and compared them with two traditional methods—Shortest Distance and Attribute Similarity. By analyzing the transplantation results of different schemes, it can provide a reference for determining the parameters of the distributed hydrological model in ungauged areas, which is very valuable for flash flood forecasting and early warning.
4. Discussion
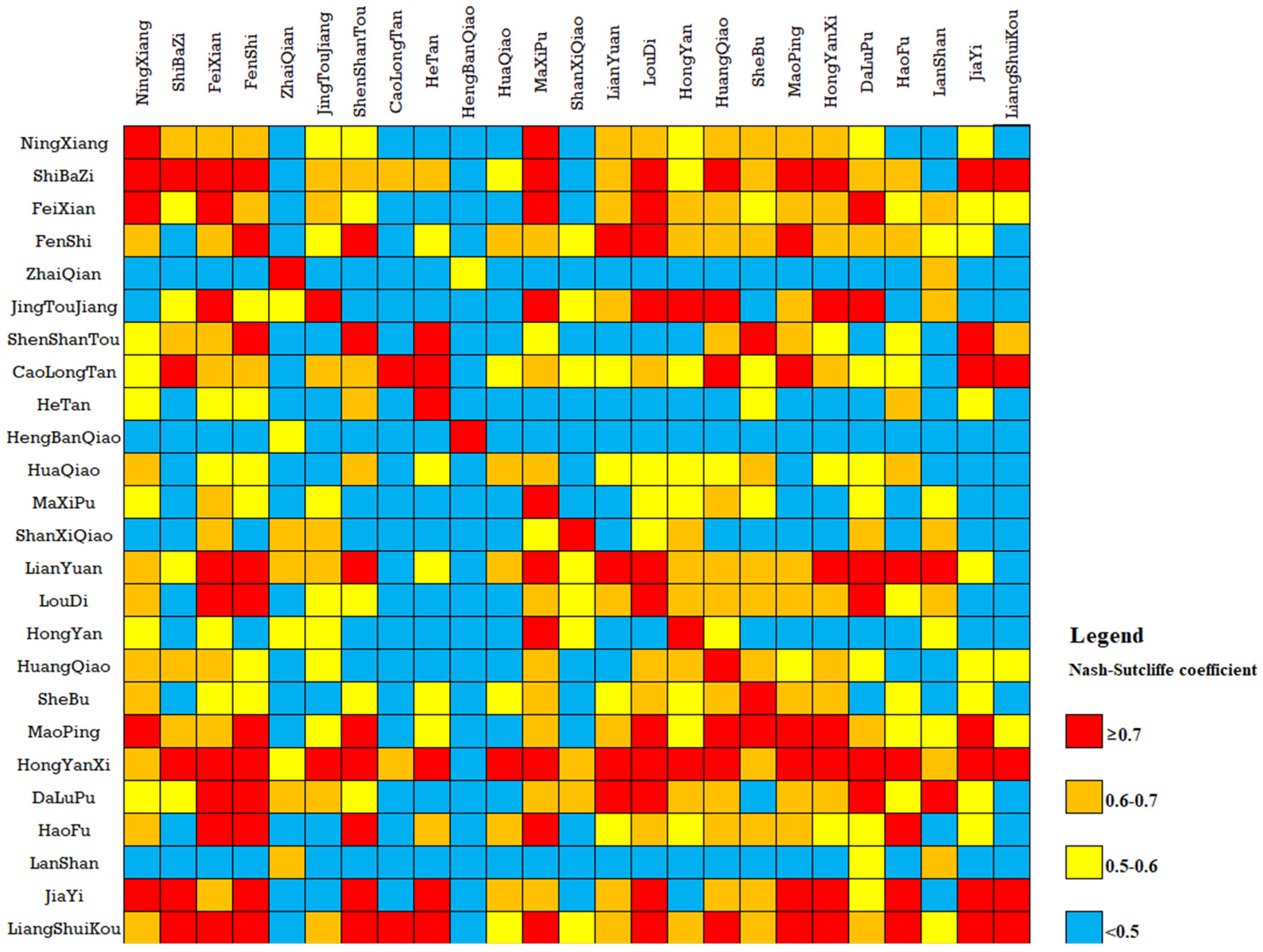
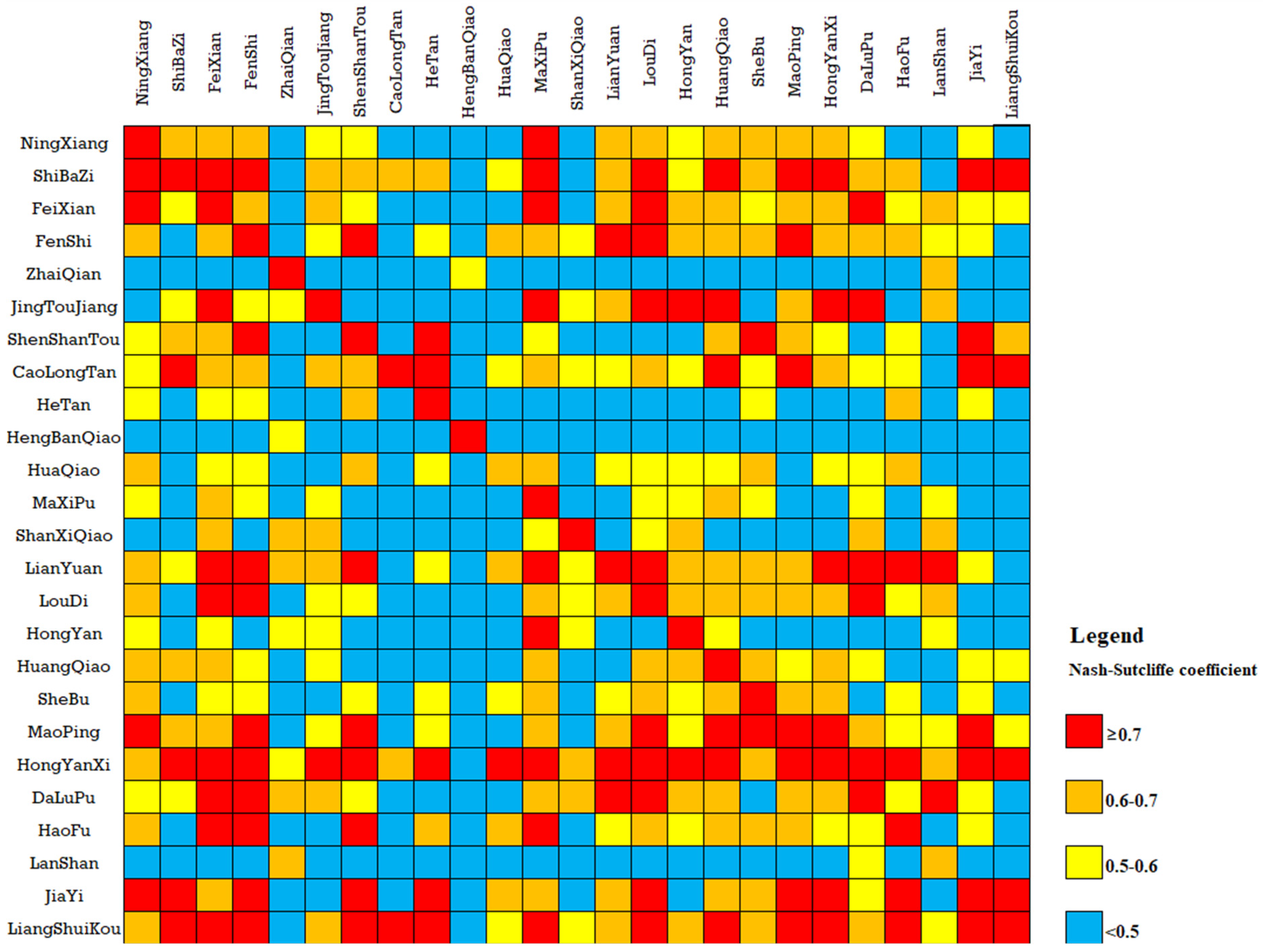
It can be seen from
Table 6 that two groups, CaojiTan-ZhaiQian and DongKou-HengBanQiao, performed poorly when using the transplantation parameters of the SD method, with average NSCE of 0.27 and 0.29, respectively. When the AS method was used for transplant parameters, two groups had poor results, namely JiaHe-JiaYi and JiShou-ShanXiQiao, with average NSCEs of 0.31 and 0.46, respectively.
Table 8 shows the attributes of these groups of catchments.
It can be seen from
Table 8 that DongKou and HengBanQiao are not only close, but also most of the attributes are similar except for the area and average drop. The area of DongKou is 931 km
2, and the area of HengBanQiao is 31 km
2. Their average drops are 458.6 m and 274.67 m, respectively. It is obvious that the different areas will lead to large differences in concentration time, and the average drop may significantly affect the concentration speed, which is the most critical factor affecting the geomorphic unit hydrograph [
18]. Similarly, compared with JiaHe and JiaYi, their attributes are very similar, except for average elevation and drop. Therefore, we can infer that if the attributes of two catchments are very close, but their average drop difference is significant, this is likely to cause a failed transplantation. The opposite conclusion cannot be established.
Table 6 shows an example with the best results (LuoLingQiao-LianYuan). The average NSCE of transplantation can reach 0.86, which is excellent according to the evaluation criteria. However, the attributes of the two catchments, including the average drop, differed significantly (as shown in
Table 5).
From the above cases, it can be seen that the applicable conditions and scope of parameter transplantation are relatively complex, and a single factor cannot be considered in isolation. When multiple attributes are considered for parameter transplantation, the results may not be satisfactory for catchments with similar attributes sometimes, so precisely defining the similarity index is a challenge.
In contrast, machine learning methods can discover more hidden rules in data. However, the methods of machine learning cannot all achieve satisfactory results. Comparing only the average NSCE, the results of SVR and CART were even worse than the AS method. In order to better compare the performance of different methods,
Table 9 shows the optimal value, worst value and average value obtained using different methods.
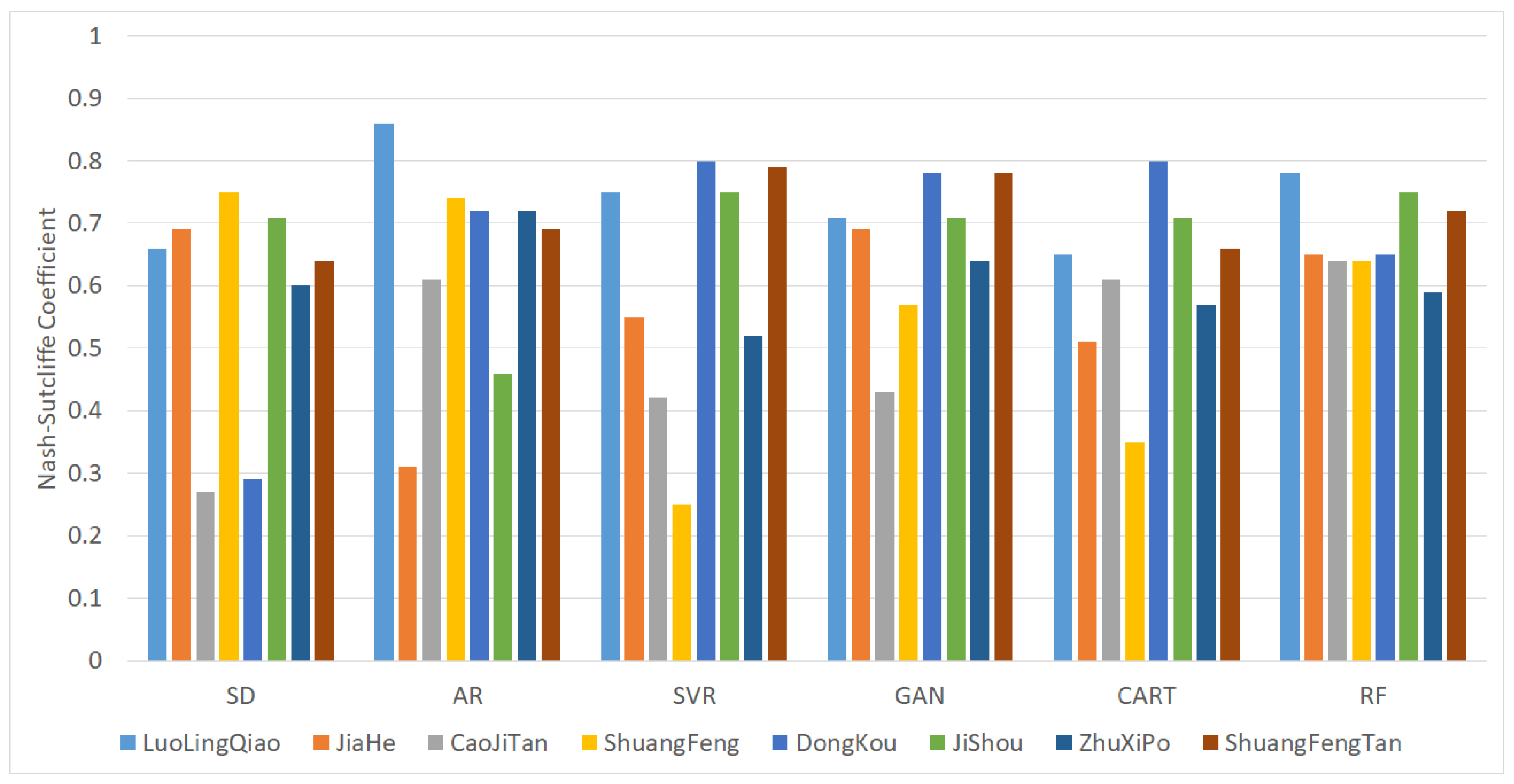
Figure 8 shows the average NSCEs for the different methods.
It can be seen from
Table 9 that the average and worst Nash–Sutcliffe coefficients of the simulation results using the random forest model are the highest. Among the best NSCE results in
Table 9, AR > SVR ≥ CART > RF ≥ GAN > SD, with AR performing best and SD performing worst. The worst result of NSCE is RF > GAN > CART > AR > SD > SVR; RF is the best and SVR is the worst. According to the NSCE average results, RF > GAN > AR > CART> SVR > SD; RF performed the best and SD performed the worst.
Table 10 summarizes the validation results of the different methods and shows the percentage of catchments with an average NSCE greater than 0.9, greater than 0.7 and less than 0.9, greater than 0.5 and less than 0.7, and less than 0.5.
It can be seen from
Table 10 that all of the NSCE results of RF are greater than 0.5, which is not achieved by all of the other methods. According to national criteria for flood forecasting in China, if the average NSCE is less than 0.5, the simulation result is unsatisfactory for online flood forecasting. Therefore, the RF model has better performance than the other methods.
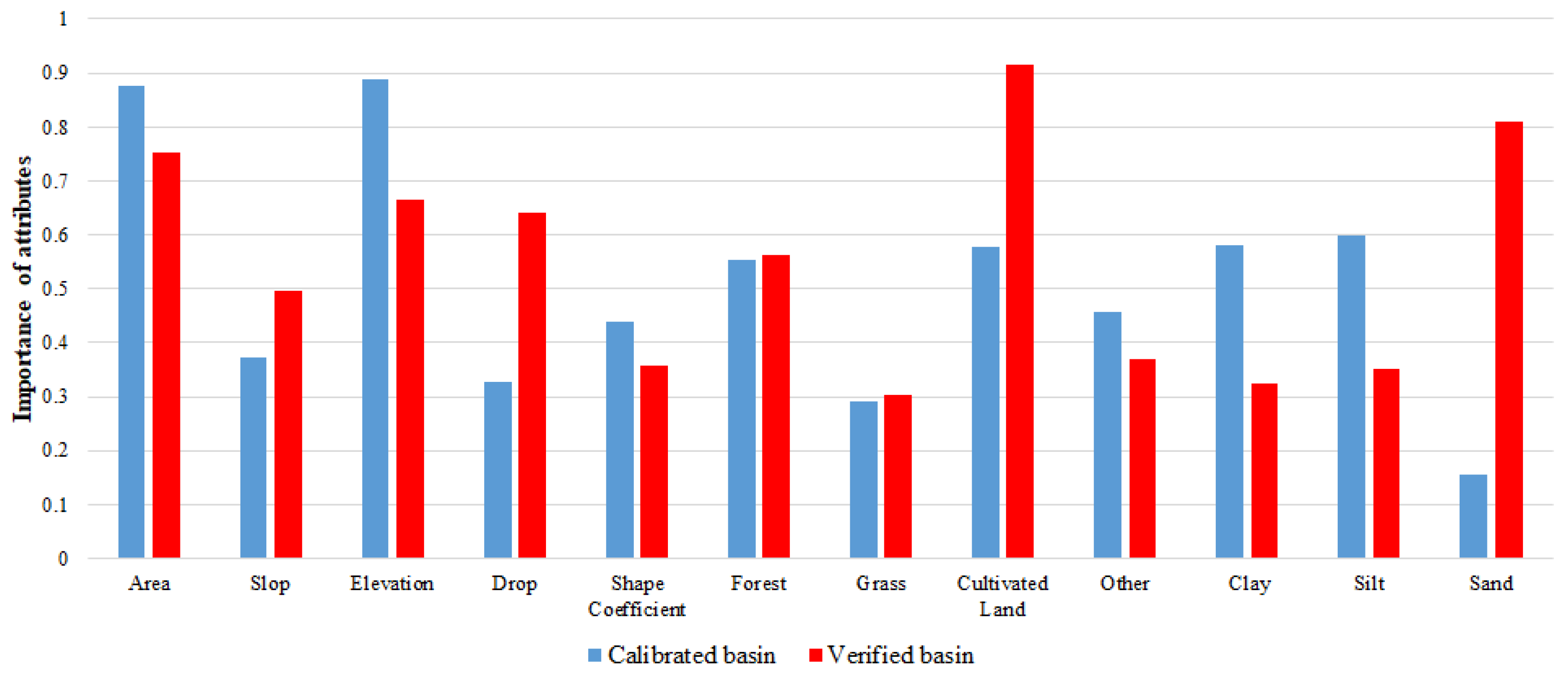
Figure 9 lists the importance of each attribute in the RF model. The most important attribute for prediction using the RF model is the percentage of cultivated land area within the transplanted catchment, followed by the area and average elevation of the calibration catchment. It is well known that slope is a significant impact on hydrological models. However, from the parameter importance of the RF model, the influence of slope is smaller than that of cultivated land, which may be another issue that needs further research.
5. Conclusions
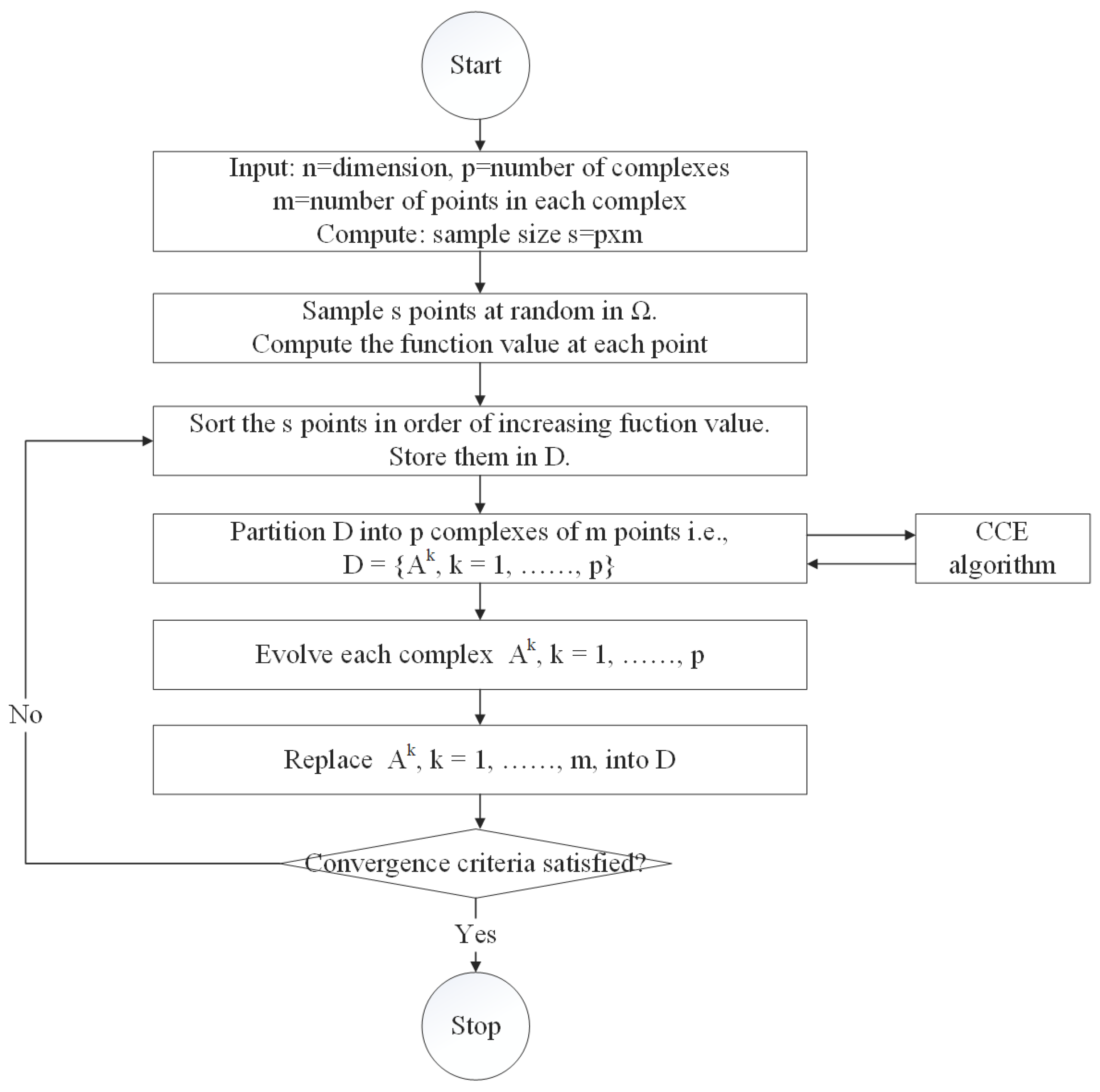
In this study, the distribution hydrological models of 33 small and medium-sized catchments in Hunan Province were constructed. The model parameters of 25 catchments were calibrated by using the SCE-UA algorithm. The parameter regionalization scheme including Shortest Distance (SD), Attribute Similarity (AS), Support Vector Regression (SVR), Generative Adversarial Networks (GAN), Classification and Regression Tree (CART) and Random Forest (RF) were validated using data from eight catchments. The main conclusions are as follows:
- (1)
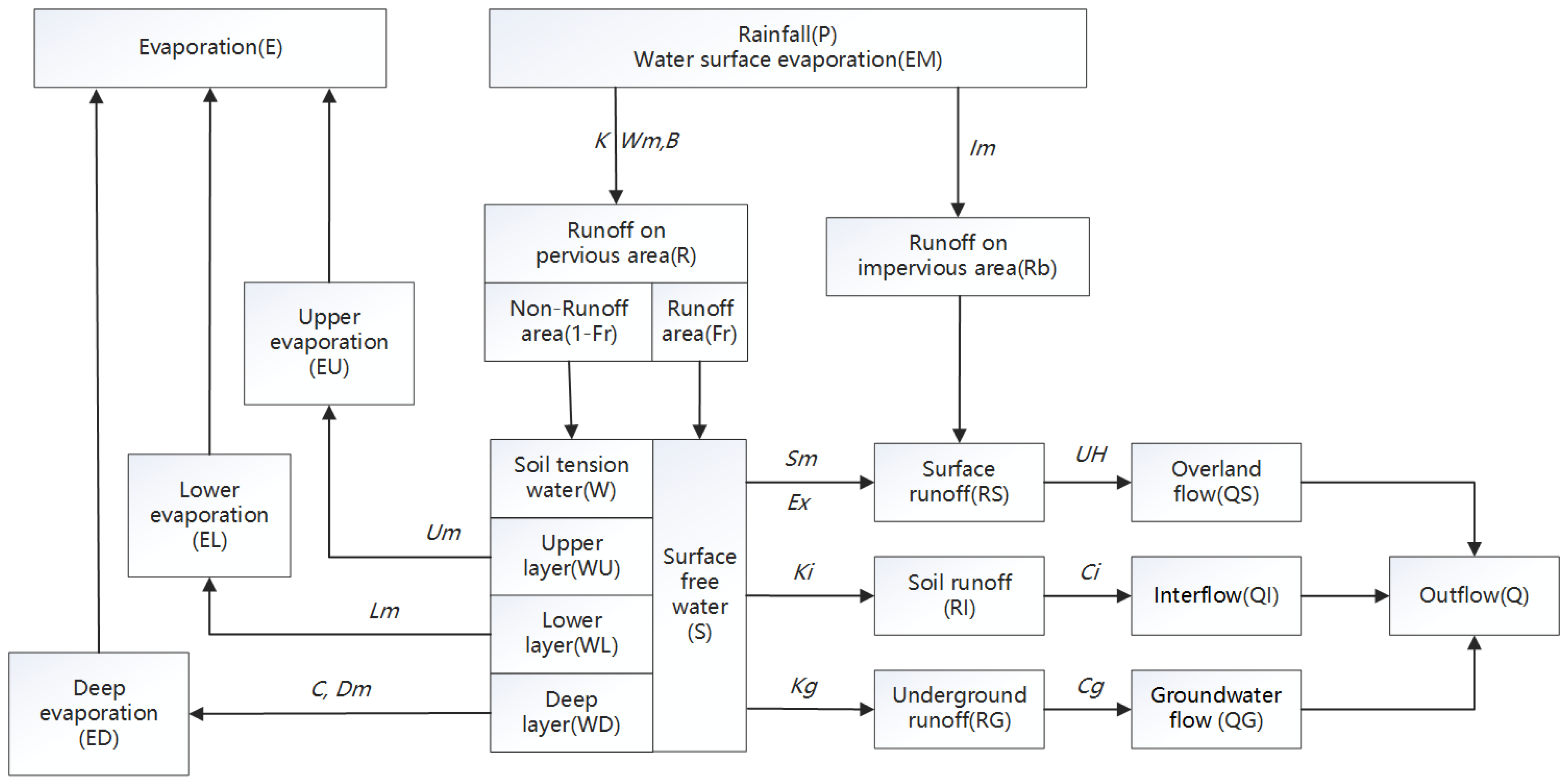
A total of 426 floods of 25 catchments were selected to calibrate the model parameters. Among the simulation results of these 25 catchments, there are 23 catchments with an average NSCE greater than 0.7, and 2 between 0.5 and 0.7. According to national criteria for flood forecasting in China, most calibration parameters meet the requirements of online flood forecasting. The distributed model based on the Xinanjiang model and geomorphic unit hydrograph is suitable for most areas of Hunan Province.
- (2)
Based on the watershed attributes and cross validation results of model parameters, six parameter regionalization schemes including SD, AR, SVR, GAN, CART and RF were generated, and 136 floods of 8 catchments were used for verification. The average values of the Nash–Sutcliffe coefficients of each scheme were 0.58, 0.64, 0.60, 0.66, 0.61 and 0.68, and the worst values were 0.27, 0.31, 0.25, 0.43, 0.35 and 0.59. The Nash–Sutcliffe coefficients of the RF model are all greater than 0.5, which cannot be achieved by other methods. The RF model is the most stable solution and significantly outperforms other methods. Using the random forest model to regionalize parameters can improve the accuracy of flood simulation in ungauged areas, which is of great significance for flash flood forecasting and early warning.
- (3)
The applicable conditions and scope of parameter transplantation are relatively complex, and a single factor cannot be considered in isolation, and the attributes of adjacent catchments may also vary greatly. The result of the attribute similarity method is not very stable, and transplantation can fail when most of the attributes of two catchments are similar, but if the attributes are very different, sometimes good results will be achieved. According to the parameter importance analyzed by the RF model, the slope is not so important, while the cultivated land area is the key to decision making. This result goes against common sense and deserves further research.
There are many factors that affect the accuracy of parameter transplantation. In practice, continuous data collection is required to improve the quality of the underlying dataset. With the accumulation of data and the continuous improvement of the regionalization model, the accuracy of parameter transplantation can be improved.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}