
Development of Monthly Scale Precipitation-Forecasting Model for Indian Subcontinent using Wavelet-Based Deep Learning Approach

 ,
, 
Abstract
:1. Introduction
- The development of a singular ELM and WT-ELM for precipitation forecasting at a monthly and seasonal level using climate indices and local climatic predictor variables.
- The comparison of the proposed approach with other methods, such as multiple linear regression models, artificial neural networks, and the wavelet neural network approaches at the country and basin scale.
2. Study Area and Data Used
2.1. Rainfall Data
2.2. Global Predictors Data
- (i)
- Indian Ocean Dipole (IOD), also called Indian Nino, is an irregular oscillation of sea surface temperature in the western Indian Ocean and affects rainfall variability in East Africa, India, Indonesia, and Southern Australia [22]. IOD is one of the major climate drivers for rainfall in India and is also referred to as the difference in sea surface temperature (SST) anomalies in the region in IOD West at 50 E to 70 E and also IOD East at 10 S to 10 N. Data are downloaded from https://www.esrl.noaa.gov/psd/gcos_wgsp/Timeseries/Data/dmi.long.data (accessed on 22 June 2023) and are available at monthly scale from the period of 1870 to 2018.
- (ii)
- North Atlantic Oscillation (NAO) is a weather phenomenon that occurs in the North Atlantic Ocean, and its fluctuations are calculated based on the difference between subpolar low and subtropical high. Monthly data for these climatic indices can be obtained from the NOAA Climate Prediction Centre (CPC). The data are available for each month from 1948 to 2018.
- (iii)
- Nino 3.4 index: El Nino and La Nina events are most commonly defined by the Nino 3.4 index. The anomalies of Nino 3.4 are thought to represent east-central Tropical Pacific SSTs. The data are available from 1870 to 2019 on a monthly scale.
- (iv)
- Pacific Decadal Oscillation (PDO) is often referred to as El Nino but acts at a larger scale, with a pattern mostly observed in North Pacific [23]. Extreme phases of the PDO index have been classified as warm or cool based on the ocean temperature anomalies in the tropical and northeast Pacific Ocean, and the length of the data available is from 1948 to 2018. The NAO, NINO 3.4, and PDO data are downloaded from https://www.esrl.noaa.gov/psd/data/climateindices/list/ (accessed on 22 June 2023).
3. Methods
3.1. Wavelet Transform (WT)
3.2. Extreme Learning Machines (ELM)
3.3. Wavelet Hybrid Models
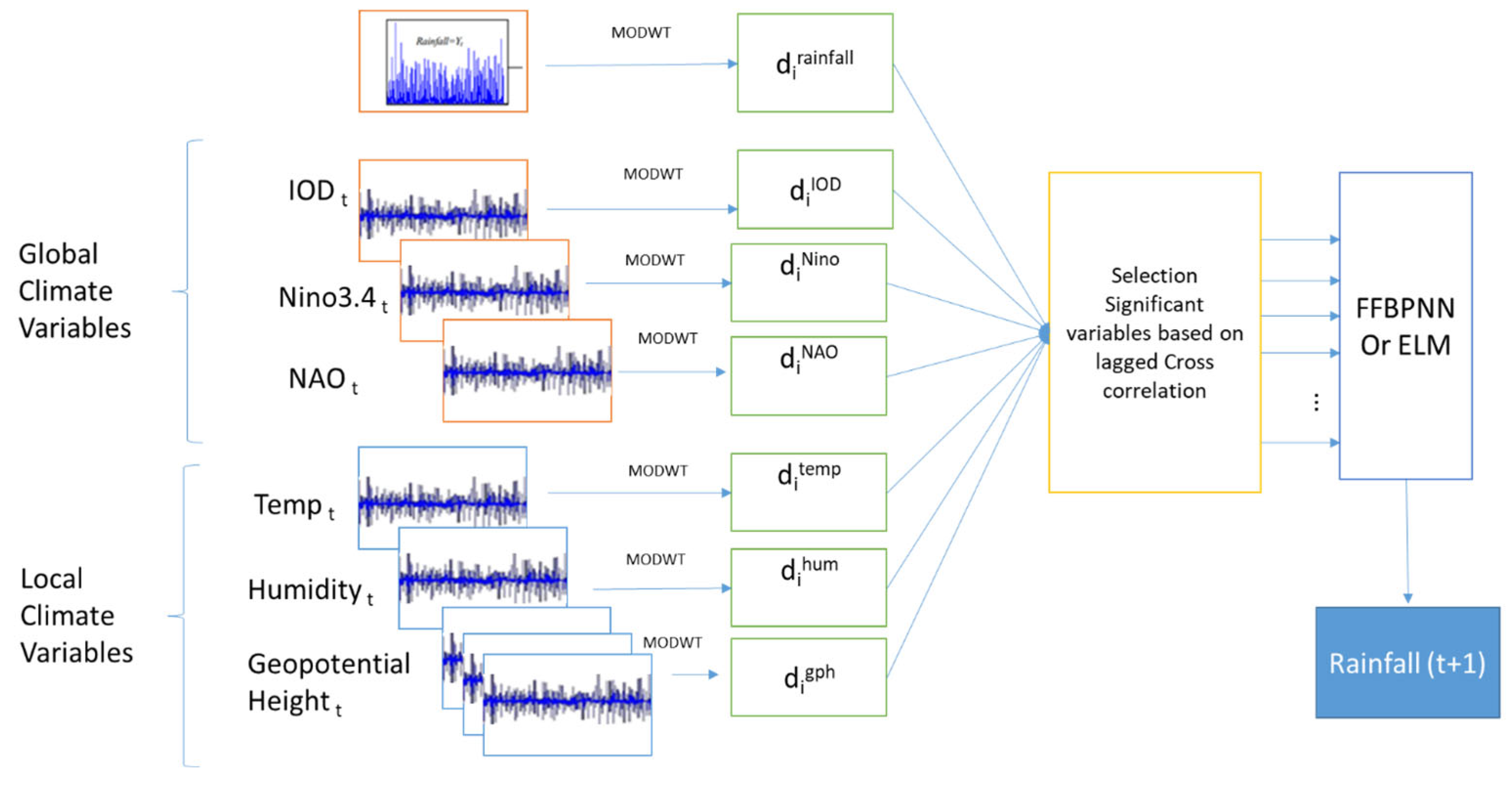
4. Methodology
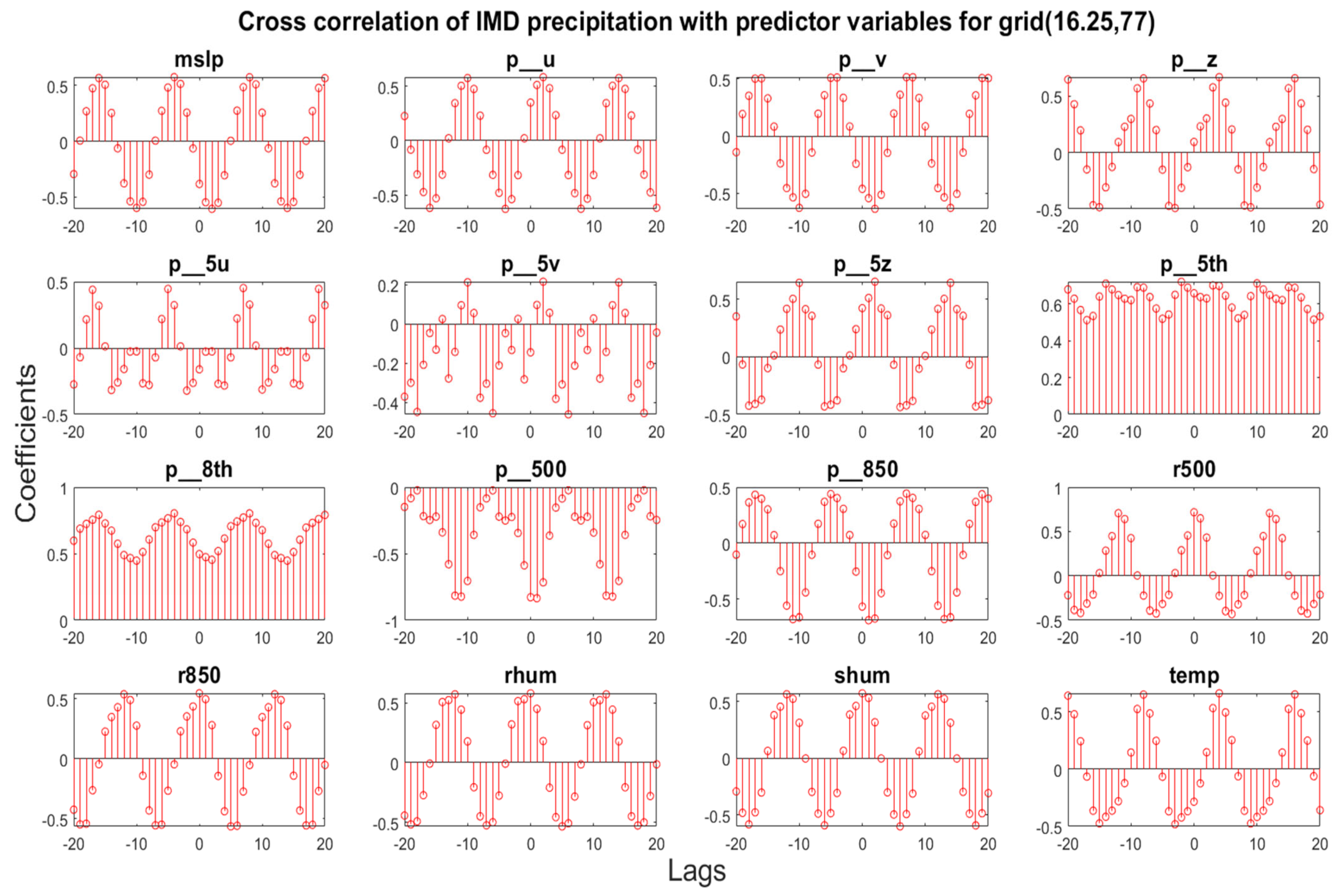
4.1. STEP: Identification of Significant Variables
4.2. STEP:1 Selection of Predictor Variables
4.3. STEP 2 Standardization
4.4. Step 3: Model Development
4.4.1. Single-Scale Models (MLR, FFBP-NN, ELM)
4.4.2. Wavelet Hybrid Models (WT-FFBP-NN and WT-ELM)
4.4.3. Performance Measures
- Root Mean Square Error (RMSE)
- Correlation (R2)
- Nash Sutcliffe Efficiency (NSE)
- Most Absolute Error (MAE)where represents the ith observed data, represents the simulated data from the models, is the mean of the data set, and n is the number of observations.
5. Results and Discussions
5.1. Forecasting Using Single Scale Models
5.2. For the Krishna River Basin
5.2.1. Results of the Models Using Only Global Climate Indices as Predictors
5.2.2. Results of the Models Using Only Local Climate Variables as Predictors
5.2.3. Results of Models with Both Global Climate Variables and Local Predictor Variables
5.3. Model Application for the Different Regions in India
5.4. Central India
5.5. North India
5.6. Peninsular India
5.7. Northwest
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Multiple Learning Regression (MLR)
Appendix A.2. Artificial Neural Networks (ANN)
References
- Trenberth, K.E.; Smith, L.; Qian, T.; Dai, A.; Fasullo, J. Estimates of the Global Water Budget and Its Annual Cycle Using Observational and Model Data. J. Hydrometeorol. 2007, 8, 758–769. [Google Scholar] [CrossRef]
- Elahi, E.; Khalid, Z.; Tauni, M.Z.; Zhang, H.; Lirong, X. Extreme weather events risk to crop-production and the adaptation of innovative management strategies to mitigate the risk: A retrospective survey of rural Punjab, Pakistan. Technovation 2022, 117, 102255. [Google Scholar] [CrossRef]
- Wijeratne, V.P.I.S.; Li, G.; Mehmood, M.S.; Abbas, A. Assessing the Impact of Long-Term ENSO, SST, and IOD Dynamics on Extreme Hydrological Events (EHEs) in the Kelani River Basin (KRB), Sri Lanka. Atmosphere 2023, 14, 79. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. A Wavelet-Based Second Order Nonlinear Model for Forecasting Monthly Rainfall. Water Resour. Manag. 2014, 28, 5411–5431. [Google Scholar] [CrossRef]
- Yilmaz, A.G.; Muttil, N. Runoff Estimation by Machine Learning Methods and Application to the Euphrates Basin in Turkey. J. Hydrol. Eng. 2014, 19, 1015–1025. [Google Scholar] [CrossRef]
- Feng, G.-L.; Yang, J.; Zhi, R.; Zhao, J.-H.; Gong, Z.-Q.; Zheng, Z.-H.; Xiong, K.-G.; Qiao, S.-B.; Yan, Z.; Wu, Y.-P.; et al. Improved prediction model for flood-season rainfall based on a nonlinear dynamics-statistic combined method. Chaos Solitons Fractals 2020, 140, 110160. [Google Scholar] [CrossRef]
- Cuo, L.; Pagano, T.C.; Wang, Q.J. A Review of Quantitative Precipitation Forecasts and Their Use in Short- to Medium-Range Streamflow Forecasting. J. Hydrometeorol. 2011, 12, 713–728. [Google Scholar] [CrossRef]
- Hao, Z.; Singh, V.P.; Xia, Y. Seasonal Drought Prediction: Advances, Challenges, and Future Prospects. Rev. Geophys. 2018, 56, 108–141. [Google Scholar] [CrossRef]
- Bauer, H.-S.; Schwitalla, T.; Wulfmeyer, V.; Bakhshaii, A.; Ehret, U.; Neuper, M.; Caumont, O. Quantitative precipitation estimation based on high-resolution numerical weather prediction and data assimilation with WRF—A performance test. Tellus Ser. A Dyn. Meteorol. Oceanogr. 2015, 67, 25047. [Google Scholar] [CrossRef]
- Stensrud, D.J.; Xue, M.; Wicker, L.J.; Kelleher, K.E.; Foster, M.P.; Schaefer, J.T.; Schneider, R.S.; Benjamin, S.G.; Weygandt, S.S.; Ferree, J.T.; et al. Convective-scale warn-on-forecast system: A vision for 2020. Bull. Am. Meteorol. Soc. 2009, 90, 1487–1500. [Google Scholar] [CrossRef]
- Saha, S.K.; Pokhrel, S.; Chaudhari, H.S.; Dhakate, A.; Shewale, S.; Sabeerali, C.T.; Salunke, K.; Hazra, A.; Mahapatra, S.; Rao, A.S. Improved simulation of Indian summer monsoon in latest NCEP climate forecast system free run. Int. J. Climatol. 2013, 34, 1628–1641. [Google Scholar] [CrossRef]
- Molteni, F.; Buizza, R.; Palmer, T.N.; Petroliagis, T. The ECMWF Ensemble Prediction System: Methodology and validation. Q. J. R. Meteorol. Soc. 1996, 122, 73–119. [Google Scholar] [CrossRef]
- Choubin, B.; Khalighi-Sigaroodi, S.; Malekian, A.; Kişi, Ö. Multiple linear regression, multi-layer perceptron network and adaptive neuro-fuzzy inference system for forecasting precipitation based on large-scale climate signals. Hydrol. Sci. J. 2016, 61, 1001–1009. [Google Scholar] [CrossRef]
- Xu, L.; Chen, N.; Zhang, X.; Chen, Z. An evaluation of statistical, NMME and hybrid models for drought prediction in China. J. Hydrol. 2018, 566, 235–249. [Google Scholar] [CrossRef]
- Ghamariadyan, M.; Imteaz, M.A. A wavelet artificial neural network method for medium-term rainfall prediction in Queensland (Australia) and the comparisons with conventional methods. Int. J. Climatol. 2021, 41, E1396–E1416. [Google Scholar] [CrossRef]
- Chowdhury, R.K.; Beecham, S. Australian rainfall trends and their relation to the southern oscillation index. Hydrol. Process 2010, 24, 504–514. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Application of artificial neural networks to rainfall forecasting in Queensland, Australia. Adv. Atmos. Sci. 2012, 29, 717–730. [Google Scholar] [CrossRef]
- Rivera, D.; Lillo, M.; Uvo, C.B.; Billib, M.; Arumí, J.L. Forecasting monthly precipitation in Central Chile: A self-organizing map approach using filtered sea surface temperature. Theor. Appl. Climatol. 2012, 107, 1–13. [Google Scholar] [CrossRef]
- Barzegar, R.; Moghaddam, A.A.; Adamowski, J.; Ozga-Zielinski, B. Multi-step water quality forecasting using a boosting ensemble multi-wavelet extreme learning machine model. Stoch. Environ. Res. Risk Assess. 2018, 32, 799–813. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Zounemat-Kermani, M. Modelling long-term groundwater fluctuations by extreme learning machine using hydro-climatic data. Hydrol. Sci. J. 2017, 63, 63–73. [Google Scholar] [CrossRef]
- Li, B.; Cheng, C. Monthly discharge forecasting using wavelet neural networks with extreme learning machine. Sci. China Technol. Sci. 2014, 57, 2441–2452. [Google Scholar] [CrossRef]
- Ummenhofer, C.C.; Gupta, A.S.; England, M.H.; Reason, C.J.C. Contributions of Indian Ocean Sea Surface Temperatures to Enhanced East African Rainfall. J. Clim. 2009, 22, 993–1013. [Google Scholar] [CrossRef]
- Rathinasamy, M.; Agarwal, A.; Sivakumar, B.; Marwan, N.; Kurths, J. Wavelet analysis of precipitation extremes over India and teleconnections to climate indices. Stoch. Stoch. Environ. Res. Risk Assess. 2019, 33, 2053–2069. [Google Scholar] [CrossRef]
- Daubechies, I. The wavelet transform, time-frequency localization and signal analysis. IEEE Trans. Inf. Theory 1990, 36, 961–1005. [Google Scholar] [CrossRef]
- Küçük, M.; Tigli, E.; Ağiralioğlu, N. Wavelet Transform Analysis for Nonstationary Rainfall-Runoff-Temperature Processes. 2004. Available online: http://www.r-project.org (accessed on 22 June 2023).
- Park, J.; Mann, M.E. Paper No. 1 • Page 1 Copyright. 2000. Available online: http://earthinteractions.org (accessed on 22 June 2023).
- Grossmann; Morlet, J. Decomposition of Hardy Functions into Square Integrable Wavelets of Constant Shape*. 1984. Available online: https://epubs.siam.org/terms-privacy (accessed on 22 June 2023).
- Renaud, O.; Starck, J.-L.; Murtagh, F. Wavelet-Based Combined Signal Filtering and Prediction. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2005, 35, 1241–1251. [Google Scholar] [CrossRef] [PubMed]
- Adamowski, J.; Sun, K. Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J. Hydrol. 2010, 390, 85–91. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. Comparative study of different wavelets for hydrologic forecasting. Comput. Geosci. 2012, 46, 284–295. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Huang, G.-B. What are Extreme Learning Machines? Filling the Gap Between Frank Rosenblatt’s Dream and John von Neumann’s Puzzle. Cognit. Comput. 2015, 7, 263–278. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Jaafar, O.; Deo, R.C.; Kisi, O.; Adamowski, J.; Quilty, J.; El-Shafie, A. Stream-flow forecasting using extreme learning machines: A case study in a semi-arid region in Iraq. J. Hydrol. 2016, 542, 603–614. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. An extreme learning machine model for the simulation of monthly mean streamflow water level in eastern Queensland. Environ. Monit. Assess. 2016, 188, 1–24. [Google Scholar] [CrossRef]
- Deo, R.C.; Şahin, M. Application of the Artificial Neural Network model for prediction of monthly Standardized Precipitation and Evapotranspiration Index using hydrometeorological parameters and climate indices in eastern Australia. Atmos. Res. 2015, 161–162, 65–81. [Google Scholar] [CrossRef]
- Swapna, P.; Roxy, M.K.; Aparna, K.; Kulkarni, K.; Prajeesh, A.G.; Ashok, K.; Krishnan, R.; Moorthi, S.; Kumar, A.; Goswami, B.N. The IITM Earth System Model: Transformation of a Seasonal Prediction Model to a Long-Term Climate Model. Bull. Am. Meteorol. Soc. 2015, 96, 1351–1367. [Google Scholar] [CrossRef]
- Ren, H.-L.; Lu, B.; Wan, J.; Tian, B.; Zhang, P. Identification Standard for ENSO Events and Its Application to Climate Monitoring and Prediction in China. J. Meteorol. Res. 2018, 32, 923–936. [Google Scholar] [CrossRef]
- Sehgal, V.; Lakhanpal, A.; Maheswaran, R.; Khosa, R.; Sridhar, V. Application of multi-scale wavelet entropy and multi-resolution Volterra models for climatic downscaling. J. Hydrol. 2018, 556, 1078–1095. [Google Scholar] [CrossRef]
- Kannan, S.; Ghosh, S. Prediction of daily rainfall state in a river basin using statistical downscaling from GCM output. Stoch. Environ. Res. Risk Assess. 2011, 25, 457–474. [Google Scholar] [CrossRef]
- Lakhanpal, A.; Sehgal, V.; Maheswaran, R.; Khosa, R.; Sridhar, V. A non-linear and non-stationary perspective for downscaling mean monthly temperature: A wavelet coupled second order Volterra model. Stoch. Environ. Res. Risk Assess. 2017, 31, 2159–2181. [Google Scholar] [CrossRef]
- Kumar, Y.P.; Maheswaran, R.; Agarwal, A.; Sivakumar, B. Intercomparison of downscaling methods for daily precipitation with emphasis on wavelet-based hybrid models. J. Hydrol. 2021, 599, 126373. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. Wavelet Volterra Coupled Models for forecasting of nonlinear and non-stationary time series. Neurocomputing 2015, 149, 1074–1084. [Google Scholar] [CrossRef]
- Olive, D.J. Prediction intervals for regression models. Comput. Stat. Data Anal. 2006, 51, 3115–3122. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour, M.R.; Kisi, O.; Nourani, V. A new approach for simulating and forecasting the rainfall-runoff process within the next two months. J. Hydrol. 2017, 548, 588–597. [Google Scholar] [CrossRef]
- Kişi, Ö. Neural Networks and Wavelet Conjunction Model for Intermittent Streamflow Forecasting. J. Hydrol. Eng. 2009, 14, 773–782. [Google Scholar] [CrossRef]
- Nourani, V.; Komasi, M.; Mano, A. A Multivariate ANN-Wavelet Approach for Rainfall–Runoff Modeling. Water Resour. Manag. 2009, 23, 2877–2894. [Google Scholar] [CrossRef]
- Okkan, U.; Fistikoglu, O. Evaluating climate change effects on runoff by statistical downscaling and hydrological model GR2M. Theor. Appl. Climatol. 2013, 117, 343–361. [Google Scholar] [CrossRef]
- Ahmed, B.; Al Noman, A. Land cover classification for satellite images based on normalization technique and Artificial Neural Network. In Proceedings of the 2015 International Conference on Computer and Information Engineering (ICCIE), Rajshahi, Bangladesh, 26–27 November 2015; pp. 138–141. [Google Scholar] [CrossRef]
- Vu, M.T.; Aribarg, T.; Supratid, S.; Raghavan, S.V.; Liong, S.-Y. Statistical downscaling rainfall using artificial neural network: Significantly wetter Bangkok? Theor. Appl. Climatol. 2015, 126, 453–467. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Widrow, B.; Lehr, M.A. The basic ideas in neural networks. Commun. ACM 1994, 37, 87–92. [Google Scholar] [CrossRef]
- Kuligowski, R.J.; Barros, A.P. Localized Precipitation Forecasts from a Numerical Weather Prediction Model Using Artificial Neural Networks. Weather Forecast. 1998, 13, 1194–1204. [Google Scholar] [CrossRef]
- Tokar, A.S.; Markus, M. Precipitation-Runoff Modeling Using Artificial Neural Networks and Conceptual Models. J. Hydrol. Eng. 2000, 5, 156–161. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks and Learning Machines; Pearson: London, UK, 2008; Volume 3, ISBN 978-0131471399. [Google Scholar]
- Shanmuganathan, S. Studies in Computational Intelligence 628 Artificial Neural Network Modelling; Springer: Berlin/Heidelberg, Germany, 2016; Volume 628, Available online: http://www.springer.com/series/7092 (accessed on 22 June 2023).
- Santos, C.A.G.; Kisi, O.; da Silva, R.M.; Zounemat-Kermani, M. Wavelet-based variability on streamflow at 40-year timescale in the Black Sea region of Turkey. Arab. J. Geosci. 2018, 11, 169. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Predictands |
|---|---|
| Global | Indian Oceanic Dipole (IOD) North Atlantic Oscillation (NAO) NINO Pacific Decadal Oscillation (PDO) |
| Local | Mean Sea level pressure (mslp) Zonal velocity component (p_u) Meridional velocity component (p_v) Vorticity (p_z) Specific humidity (shum) Relative humidity (rhum) Surface air temperature (temp) Zonal velocity component (p5_u) Meridional velocity component (p5_v) Vorticity (p5_z) Wind direction (p5th) Geopotential height (p500) Relative humidity (r500) Wind direction (p8th) Geopotential height (p850) Relative humidity (r850) |
| Models | Input | Wavelet Transform | Output |
|---|---|---|---|
| Single-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Global Teleconnection | No | Precipitation at t + 1 |
| Single-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Local Climate Variables | No | Precipitation at t + 1 |
| Single-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Global Teleconnection+ Local Climate Variables | No | Precipitation at t + 1 |
| Multi-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Global Teleconnection | Yes | Precipitation at t + 1 |
| Multi-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Local Climate Variables | Yes | Precipitation at t + 1 |
| Multi-Scale Models (FFBP-NN, ELM, MLR) | Lagged Precipitation and Global Teleconnection + Local Climate Variables | Yes | Precipitation at t + 1 |
| Station | MLR | |||
|---|---|---|---|---|
| RMSE (mm) | Correlation | NSE | MAE (mm) | |
| 1 | 0.096 | 0.355 | 0.164 | 0.099 |
| 2 | 0.160 | 0.332 | 0.124 | 0.100 |
| 3 | 0.162 | 0.376 | 0.137 | 0.105 |
| 4 | 0.144 | 0.309 | 0.157 | 0.092 |
| 5 | 0.048 | 0.309 | 0.119 | 0.055 |
| FFBP-NN | ||||
| 1 | 0.090 | 0.694 | 0.481 | 0.058 |
| 2 | 0.091 | 0.680 | 0.458 | 0.063 |
| 3 | 0.092 | 0.669 | 0.446 | 0.065 |
| 4 | 0.063 | 0.730 | 0.529 | 0.032 |
| 5 | 0.052 | 0.713 | 0.504 | 0.036 |
| ELM | ||||
| 1 | 0.070 | 0.407 | 0.407 | 0.053 |
| 2 | 0.101 | 0.489 | 0.403 | 0.067 |
| 3 | 0.157 | 0.343 | 0.343 | 0.117 |
| 4 | 0.122 | 0.419 | 0.419 | 0.096 |
| 5 | 0.052 | 0.561 | 0.515 | 0.037 |
| WT FFBP-NN | ||||
| 1 | 0.111 | 0.598 | 0.385 | 0.077 |
| 2 | 0.106 | 0.644 | 0.403 | 0.075 |
| 3 | 0.113 | 0.572 | 0.385 | 0.078 |
| 4 | 0.113 | 0.567 | 0.391 | 0.078 |
| 5 | 0.108 | 0.636 | 0.383 | 0.080 |
| WT ELM | ||||
| 1 | 0.093 | 0.785 | 0.494 | 0.064 |
| 2 | 0.088 | 0.803 | 0.452 | 0.063 |
| 3 | 0.125 | 0.812 | 0.418 | 0.088 |
| 4 | 0.096 | 0.798 | 0.465 | 0.063 |
| 5 | 0.113 | 0.848 | 0.434 | 0.076 |
| Station | MLR | |||
|---|---|---|---|---|
| RMSE (mm) | Correlation | NSE | MAE (mm) | |
| 1 | 0.053 | 0.573 | 0.573 | 0.037 |
| 2 | 0.091 | 0.536 | 0.536 | 0.057 |
| 3 | 0.123 | 0.597 | 0.597 | 0.084 |
| 4 | 0.096 | 0.646 | 0.646 | 0.063 |
| 5 | 0.058 | 0.442 | 0.442 | 0.033 |
| FFBP-NN | ||||
| 1 | 0.055 | 0.545 | 0.545 | 0.038 |
| 2 | 0.086 | 0.576 | 0.576 | 0.054 |
| 3 | 0.012 | 0.600 | 0.600 | 0.078 |
| 4 | 0.092 | 0.678 | 0.678 | 0.058 |
| 5 | 0.062 | 0.713 | 0.362 | 0.031 |
| ELM | ||||
| 1 | 0.066 | 0.473 | 0.473 | 0.039 |
| 2 | 0.094 | 0.496 | 0.496 | 0.060 |
| 3 | 0.127 | 0.565 | 0.565 | 0.089 |
| 4 | 0.094 | 0.653 | 0.653 | 0.062 |
| 5 | 0.057 | 0.423 | 0.423 | 0.032 |
| WT FFBP-NN | ||||
| 1 | 0.109 | 0.771 | 0.556 | 0.069 |
| 2 | 0.082 | 0.779 | 0.549 | 0.057 |
| 3 | 0.084 | 0.753 | 0.505 | 0.063 |
| 4 | 0.061 | 0.787 | 0.563 | 0.041 |
| 5 | 0.070 | 0.765 | 0.520 | 0.052 |
| WT ELM | ||||
| 1 | 0.118 | 0.779 | 0.575 | 0.087 |
| 2 | 0.086 | 0.765 | 0.557 | 0.065 |
| 3 | 0.078 | 0.817 | 0.579 | 0.054 |
| 4 | 0.075 | 0.738 | 0.518 | 0.056 |
| 5 | 0.084 | 0.742 | 0.518 | 0.063 |
| Station | MLR | |||
|---|---|---|---|---|
| RMSE (mm) | Correlation | NSE | MAE (mm) | |
| 1 | 0.053 | 0.578 | 0.334084 | 0.037 |
| 2 | 0.09 | 0.533 | 0.284089 | 0.057 |
| 3 | 0.122 | 0.602 | 0.362404 | 0.084 |
| 4 | 0.096 | 0.653 | 0.426409 | 0.063 |
| 5 | 0.059 | 0.439 | 0.192721 | 0.034 |
| FFBP-NN | ||||
| 1 | 0.05 | 0.616 | 0.379456 | 0.035 |
| 2 | 0.083 | 0.604 | 0.364816 | 0.049 |
| 3 | 0.108 | 0.691 | 0.477481 | 0.069 |
| 4 | 0.087 | 0.714 | 0.509796 | 0.053 |
| 5 | 0.052 | 0.56 | 0.3136 | 0.032 |
| ELM | ||||
| 1 | 0.051 | 0.68 | 0.4624 | 0.034 |
| 2 | 0.065 | 0.757 | 0.573049 | 0.042 |
| 3 | 0.09 | 0.784 | 0.614656 | 0.064 |
| 4 | 0.075 | 0.782 | 0.611524 | 0.047 |
| 5 | 0.037 | 0.754 | 0.568516 | 0.026 |
| WT FFBP-NN | ||||
| 1 | 0.033 | 0.892 | 0.795664 | 0.055 |
| 2 | 0.072 | 0.849 | 0.720801 | 0.052 |
| 3 | 0.077 | 0.784 | 0.614656 | 0.056 |
| 4 | 0.061 | 0.802 | 0.643204 | 0.036 |
| 5 | 0.044 | 0.82 | 0.6724 | 0.022 |
| WT ELM | ||||
| 1 | 0.03 | 0.925 | 0.855625 | 0.052 |
| 2 | 0.069 | 0.843 | 0.710649 | 0.053 |
| 3 | 0.075 | 0.813 | 0.660969 | 0.058 |
| 4 | 0.053 | 0.847 | 0.717409 | 0.035 |
| 5 | 0.033 | 0.779 | 0.606841 | 0.013 |
| Station | Central India | |||
|---|---|---|---|---|
| RMSE (mm) | Correlation | NSE | MAE (mm) | |
| 1 | 0.0718 | 0.9084 | 0.8152 | 0.0059 |
| 2 | 0.0680 | 0.8751 | 0.7200 | 0.0491 |
| 3 | 0.0757 | 0.9260 | 0.8538 | 0.0584 |
| 4 | 0.0755 | 0.8775 | 0.7574 | 0.0567 |
| North India | ||||
| 1 | 0.0733 | 0.8437 | 0.7012 | 0.0537 |
| 2 | 0.0610 | 0.8864 | 0.7733 | 0.0447 |
| 3 | 0.0800 | 0.8286 | 0.6816 | 0.0581 |
| 4 | 0.0728 | 0.7804 | 0.5477 | 0.0554 |
| Peninsular | ||||
| 1 | 0.0927 | 0.8406 | 0.6619 | 0.0686 |
| 2 | 0.1009 | 0.7936 | 0.6112 | 0.0780 |
| 3 | 0.0419 | 0.9324 | 0.8580 | 0.0325 |
| 4 | 0.1030 | 0.8728 | 0.7602 | 0.0781 |
| Northwest | ||||
| 1 | 0.0784 | 0.9178 | 0.8401 | 0.0603 |
| 2 | 0.0628 | 0.8873 | 0.7437 | 0.0448 |
| 3 | 0.0802 | 0.7611 | 0.5025 | 0.0578 |
| 4 | 0.0696 | 0.8356 | 0.6765 | 0.0532 |
| Climatic Variable | Original Scale | D1 | D2 | D3 | D4 | D5 | D6 | D7 | D8 | D9 | D10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| p5zas | 0.011 | 0.011 | 0.051 | 0.061 | 0.061 | 0.081 | 0.161 | 0.361 | 0.421 | 0.271 | 0.121 |
| p5th | 0.131 | 0.001 | −0.009 | −0.019 | −0.059 | −0.069 | −0.079 | 0.001 | 0.361 | 0.141 | 0.081 |
| p8th | −0.019 | 0.001 | 0.001 | 0.011 | 0.001 | −0.029 | −0.159 | −0.369 | −0.409 | −0.329 | −0.109 |
| rhum | 0.111 | 0.021 | 0.031 | 0.061 | 0.121 | 0.201 | 0.331 | 0.401 | 0.361 | 0.331 | 0.171 |
| shum | 0.141 | 0.011 | 0.031 | 0.051 | 0.101 | 0.171 | 0.321 | 0.421 | 0.411 | 0.371 | 0.161 |
| temp | 0.071 | −0.009 | −0.019 | −0.049 | −0.099 | −0.159 | −0.199 | −0.129 | 0.051 | 0.011 | 0.021 |
| mslp | −0.079 | −0.039 | −0.079 | −0.139 | −0.169 | −0.149 | −0.239 | −0.349 | −0.389 | −0.349 | −0.099 |
| uas | 0.021 | 0.021 | 0.041 | 0.081 | 0.151 | 0.191 | 0.291 | 0.431 | 0.401 | 0.371 | 0.091 |
| vas | −0.029 | 0.021 | 0.041 | 0.061 | 0.071 | 0.081 | 0.031 | −0.269 | −0.399 | −0.319 | −0.139 |
| zas | 0.171 | 0.011 | 0.221 | 0.021 | 0.021 | 0.021 | 0.001 | 0.021 | 0.071 | 0.041 | 0.031 |
| p5 uas | −0.159 | 0.011 | 0.021 | 0.031 | 0.061 | 0.081 | 0.061 | −0.029 | −0.379 | −0.179 | −0.089 |
| p5 vas | 0.021 | 0.021 | 0.031 | 0.021 | 0.001 | −0.019 | −0.019 | −0.109 | −0.269 | −0.089 | −0.009 |
| p500 | 0.091 | −0.029 | −0.069 | −0.119 | −0.149 | −0.159 | −0.209 | −0.289 | −0.369 | −0.119 | −0.009 |
| p850 | −0.059 | −0.039 | −0.089 | −0.159 | −0.199 | −0.209 | −0.359 | −0.469 | −0.439 | −0.379 | −0.089 |
| r500 | 0.101 | 0.011 | 0.041 | 0.071 | 0.111 | 0.181 | 0.311 | 0.431 | 0.421 | 0.371 | 0.121 |
| r850 | 0.051 | 0.021 | 0.041 | 0.071 | 0.141 | 0.211 | 0.321 | 0.411 | 0.351 | 0.301 | 0.141 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeditha, P.K.; Anusha, G.S.; Nandikanti, S.S.S.; Rathinasamy, M. Development of Monthly Scale Precipitation-Forecasting Model for Indian Subcontinent using Wavelet-Based Deep Learning Approach. Water 2023, 15, 3244. https://doi.org/10.3390/w15183244
Yeditha PK, Anusha GS, Nandikanti SSS, Rathinasamy M. Development of Monthly Scale Precipitation-Forecasting Model for Indian Subcontinent using Wavelet-Based Deep Learning Approach. Water. 2023; 15(18):3244. https://doi.org/10.3390/w15183244
Chicago/Turabian StyleYeditha, Pavan Kumar, G. Sree Anusha, Siva Sai Syam Nandikanti, and Maheswaran Rathinasamy. 2023. "Development of Monthly Scale Precipitation-Forecasting Model for Indian Subcontinent using Wavelet-Based Deep Learning Approach" Water 15, no. 18: 3244. https://doi.org/10.3390/w15183244