
Machine Learning Approach for Rapid Estimation of Five-Day Biochemical Oxygen Demand in Wastewater

 ,
,  ,
,  ,
,
Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Required Time (Median) | Measurement Range (mg L−1) | References |
|---|---|---|---|
| Chemical or Electrochemical measurement | |||
| Standard reference method | 5 days | 0–6 | ISO 5815-1:2003 [18]; Jouanneau et al. [1] |
| Modified reference method | 5 days | 0–6 | McDonagh et al. [19]; McEvoy et al. [20]; Xiong et al. [21]; Xu et al. [22] |
| Photometric method | 5 days | 0–6 | Jouanneau et al. [1] |
| Manometric method | 5 days | 0–700 | Jouanneau et al. [1] |
| BOD prediction | |||
| Biosensor based on bioluminescent bacteria | 72 min | 0–200 | Sakaguchi et al. [23,24] |
| Microbial fuel cells | 315 min | 0–200 | Jouanneau et al. [1]; Kim et al. [25] |
| Biosensor with entrapped bacteria | 10 min | 0–500 | Karube [26]; Liu et al. [27] |
| Approach | Number of Input Variables | Input Variables | Output Variables | R2 | Type of Water | References |
|---|---|---|---|---|---|---|
| ANN | 4 | TSS, TS, pH, T | BOD, COD | 0.63–0.81 | wastewater | Zare Abyaneh [28] |
| ANN | 11 | pH, TS, T-Alk, T-Hard, Cl, PO43−, K, Na, NH4-N, NO3-N, COD | DO, BOD | 0.77–0.85 | river water | Singh et al. [29] |
| ANFIS | 9 | pH, alkalinity, T-Hard, TS, TDS, K, PO43−, NO3−, DO | BOD | 0.69–0.85 | river water | Ahmed and Ali Shah [30] |
| ANN | 11 | pH, T-Alk, T-Hard, TS, COD, NH4-N, NO3-N, Cl, PO43−, K, Na | DO, BOD | 0.74–0.90 | river water | Basant et al. [31] |
| ANN | 8 | T, turbidity, pH, CND, TDS, TSS, DO, COD | BOD | 0.69 | wastewater | Asami et al. [32] |
2. Research Significance
3. Materials and Methods
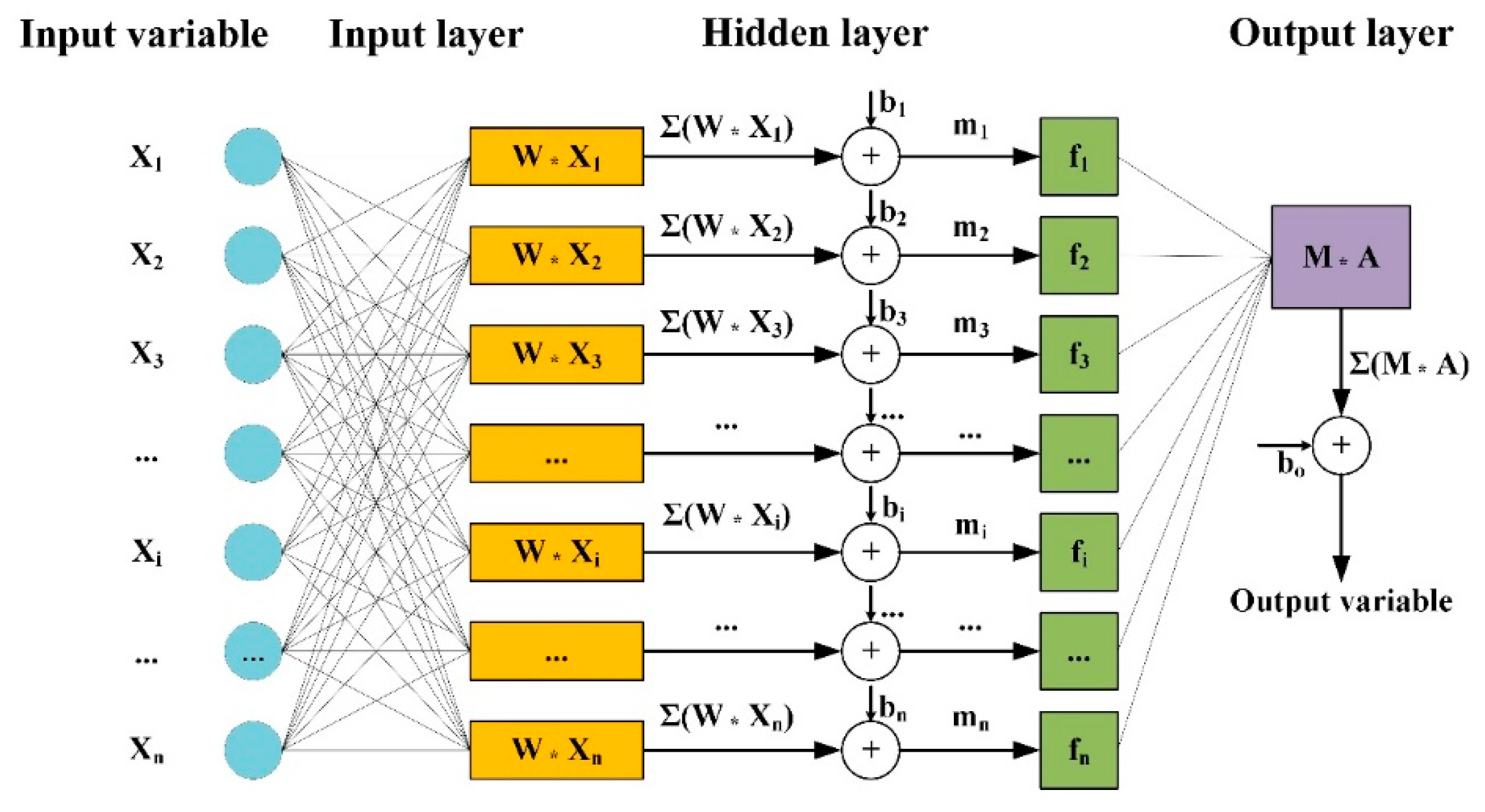
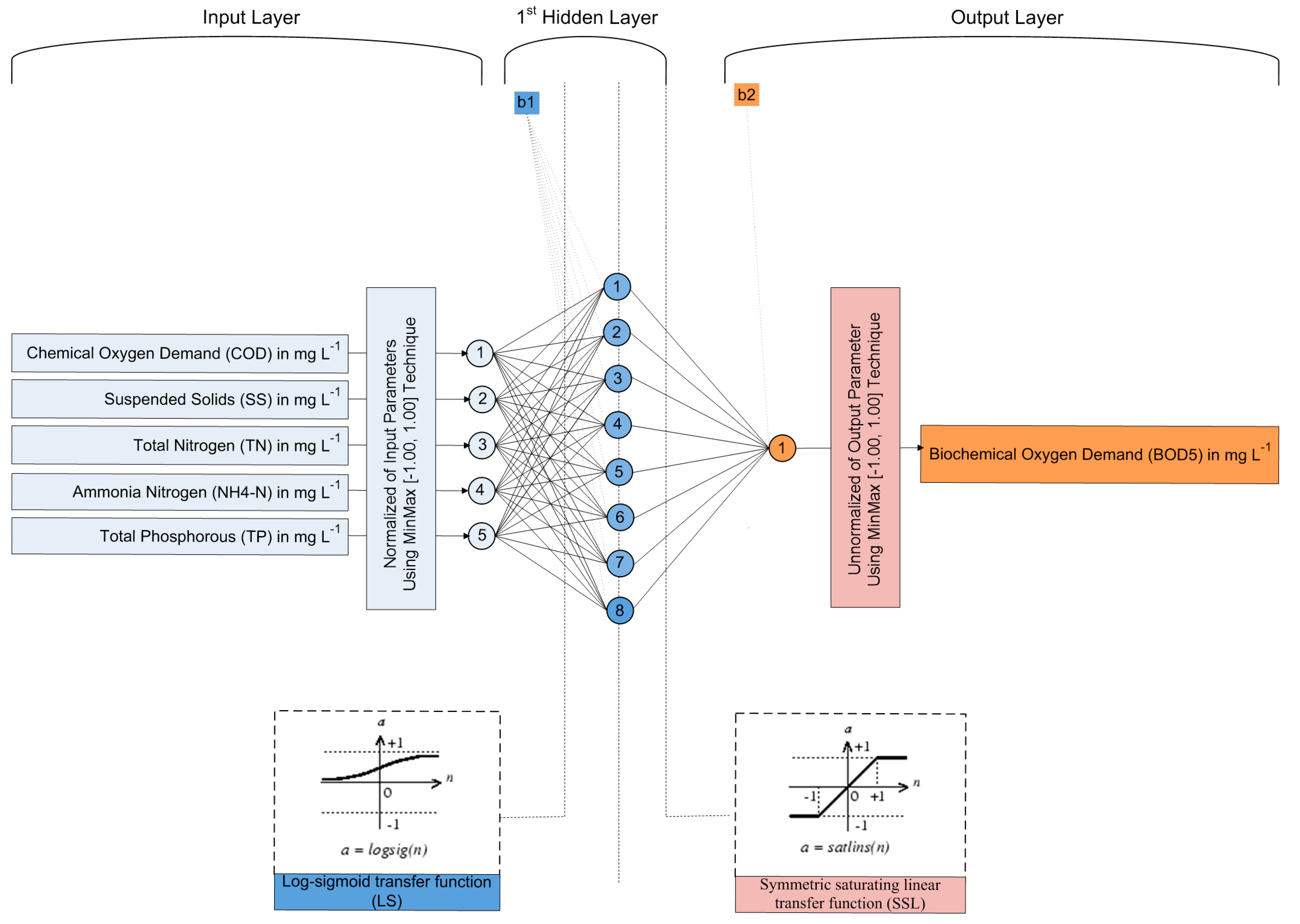
3.1. Artificial Neural Networks
3.2. Experimental Database
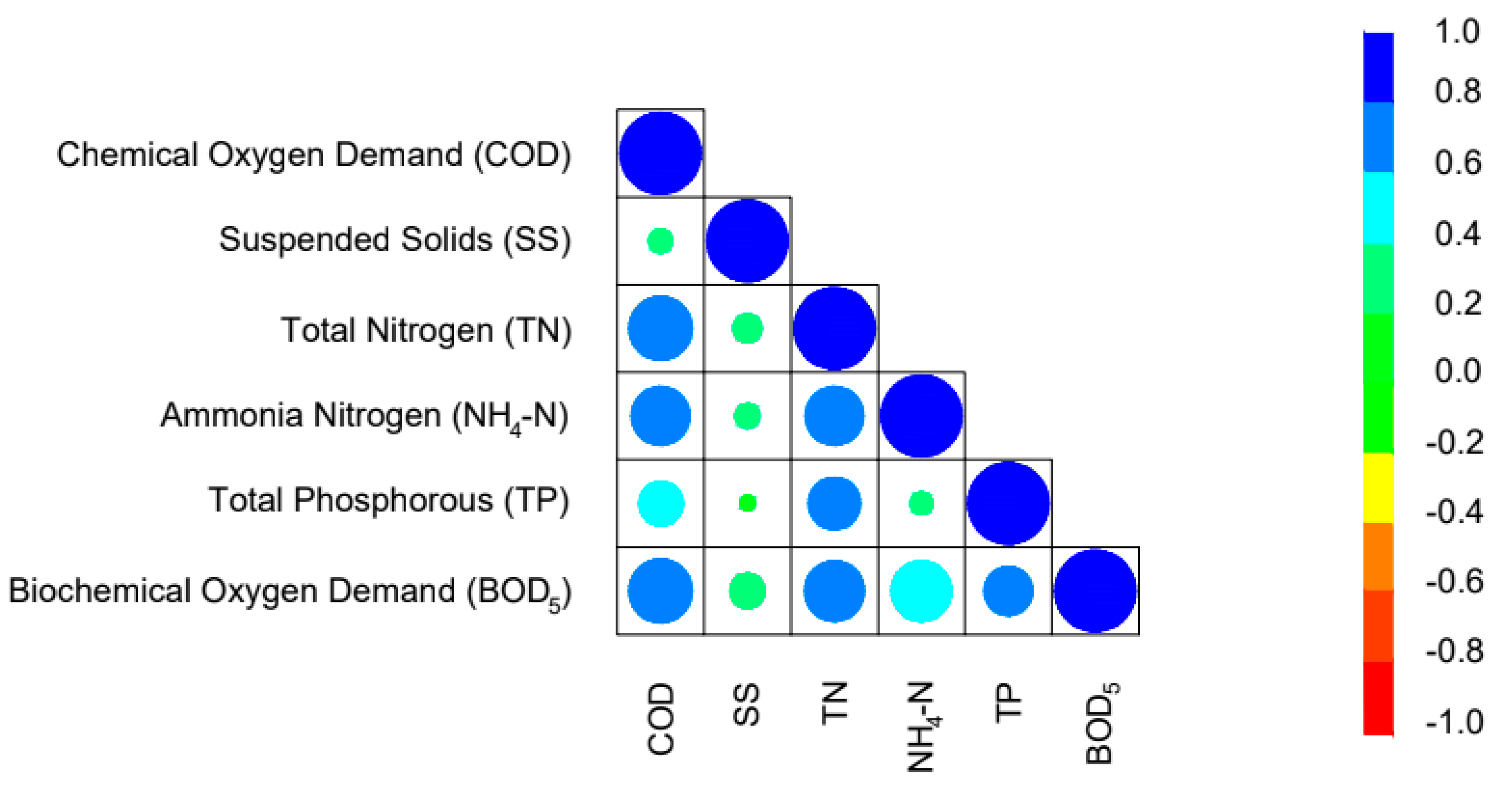
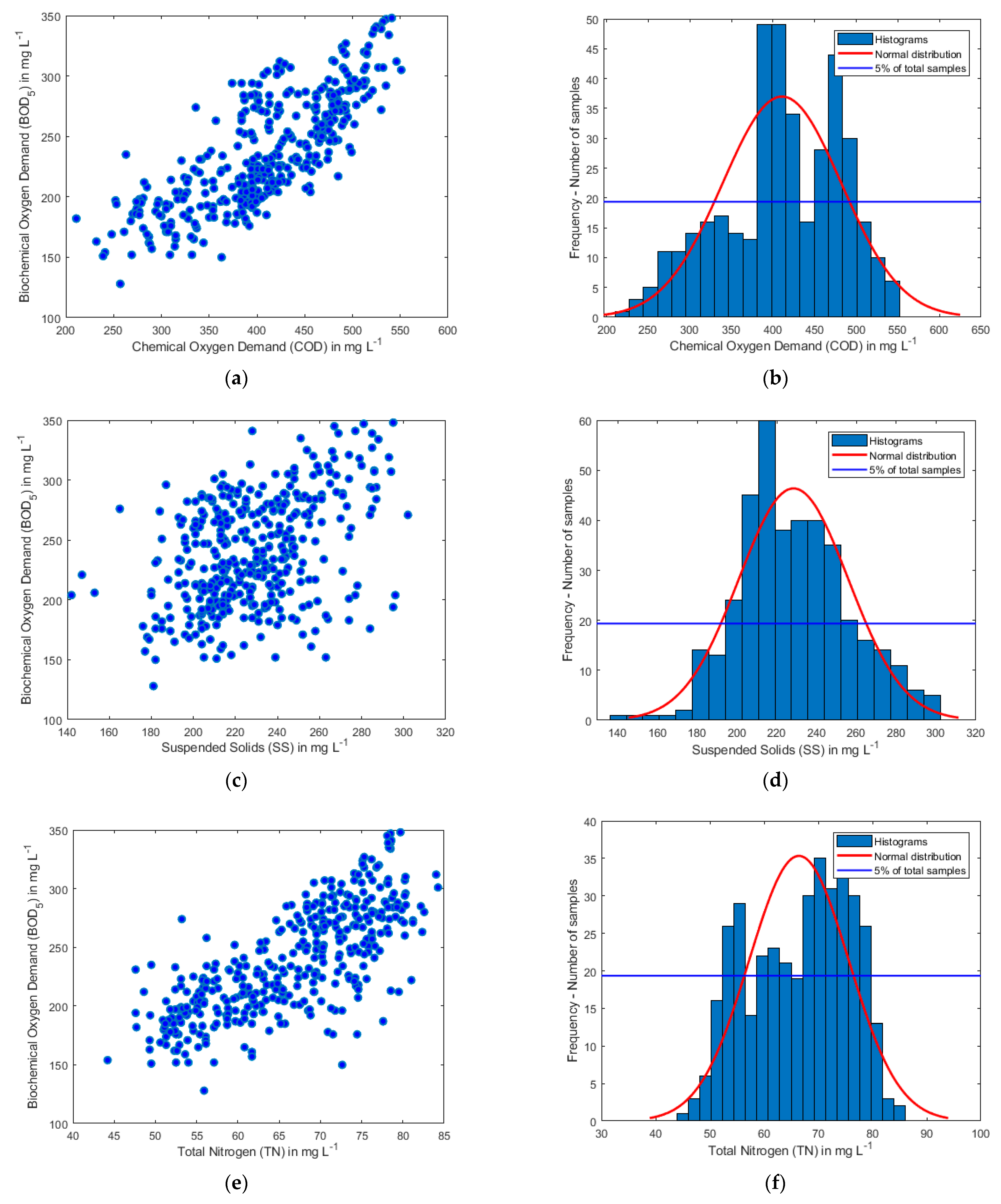
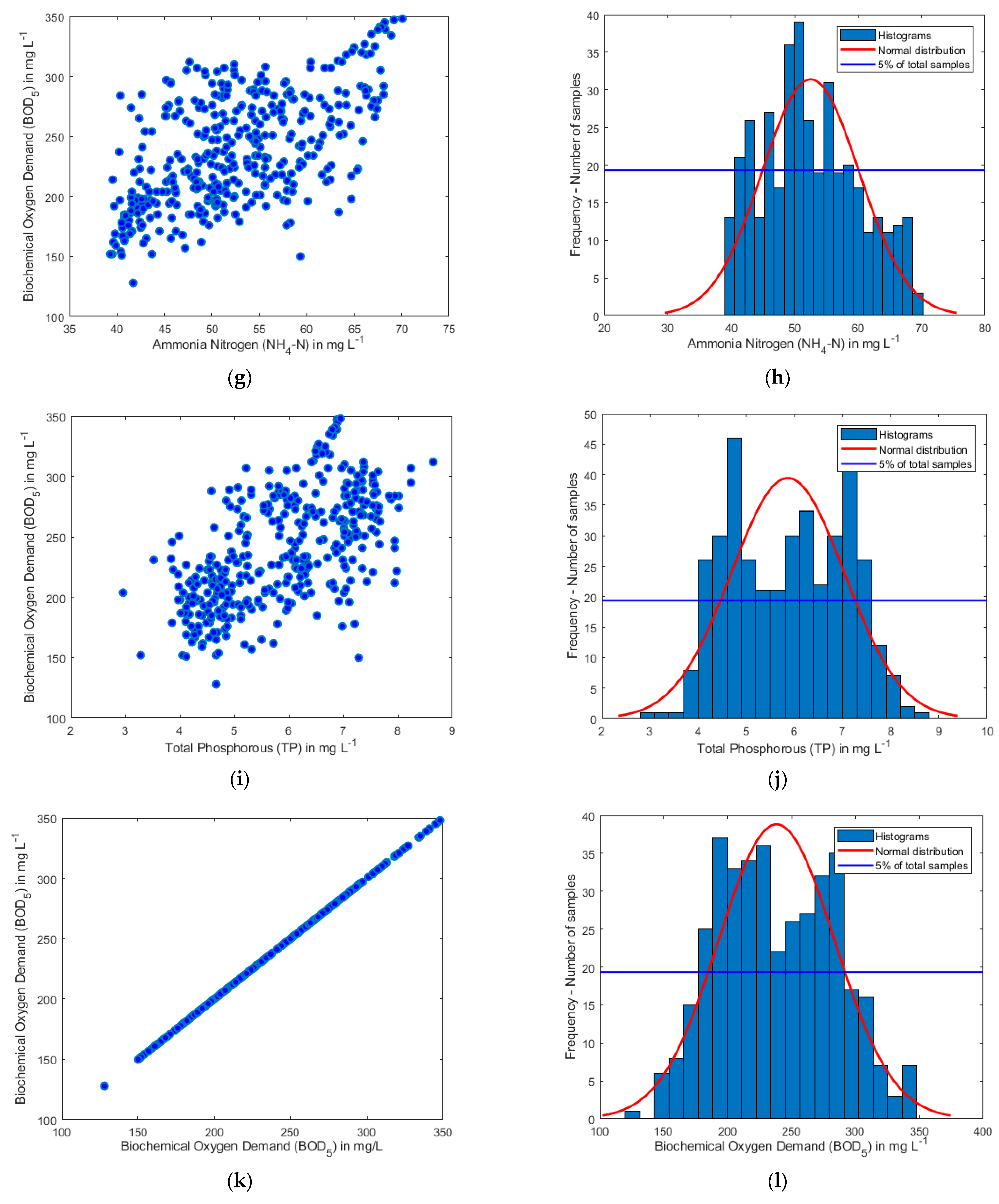
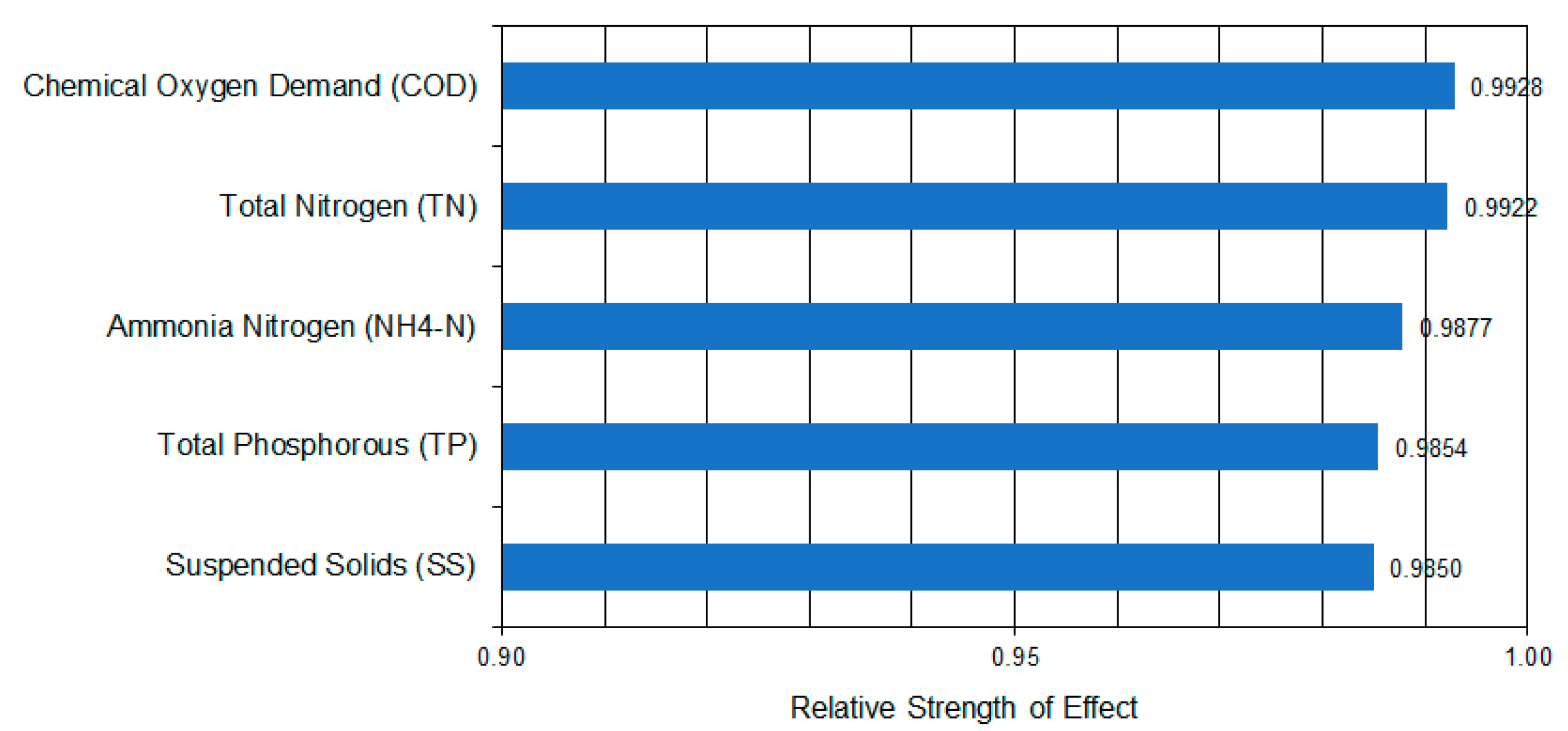
3.3. Sensitivity Analysis of the BOD5 on the Input Parameters Based on the Experimental Database
3.4. Performance Indexes
4. Results and Discussion
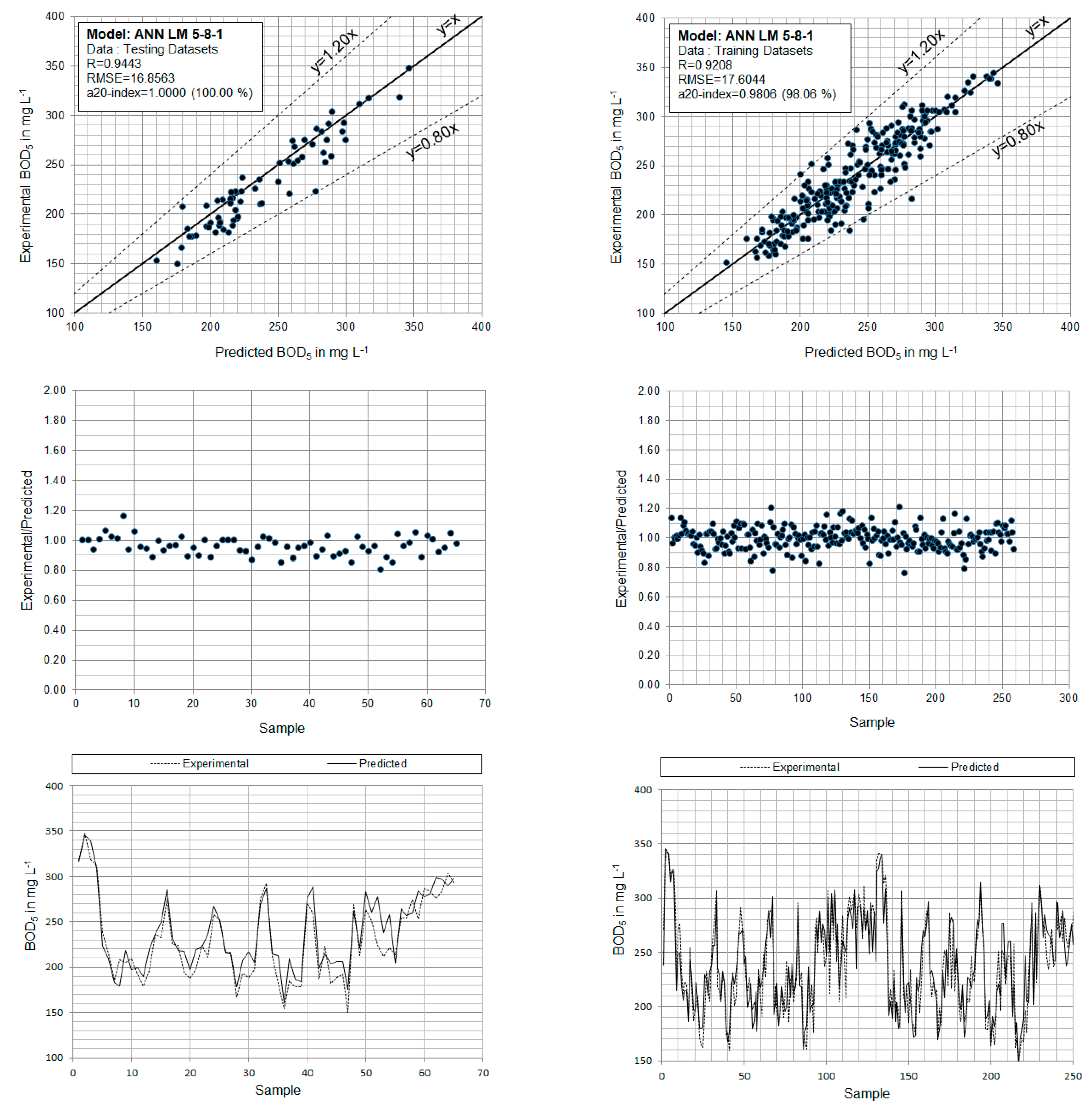
4.1. Development of ANN Models
4.2. Closed-Form Equation for the Estimation of BOD5 in Wastewater
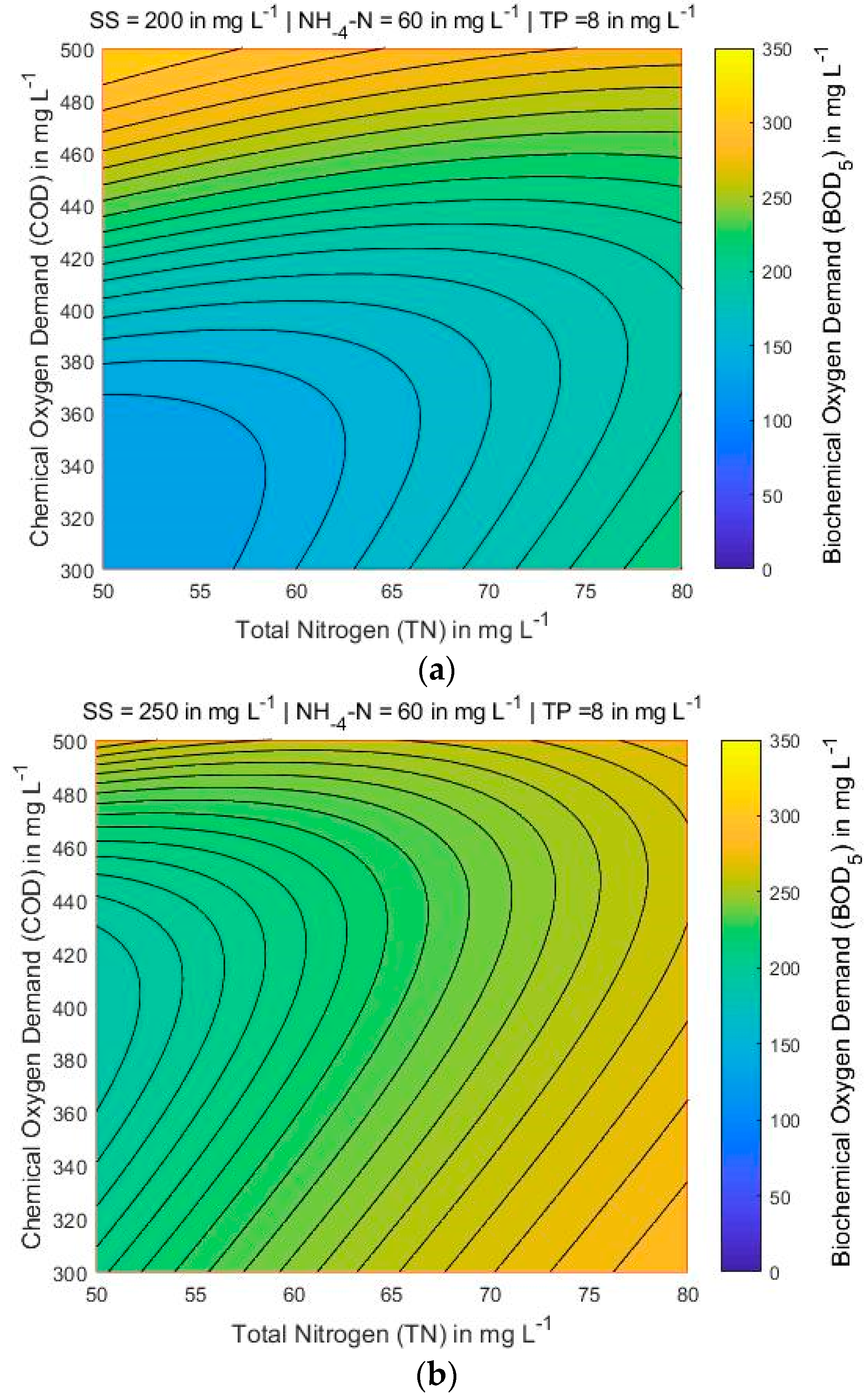
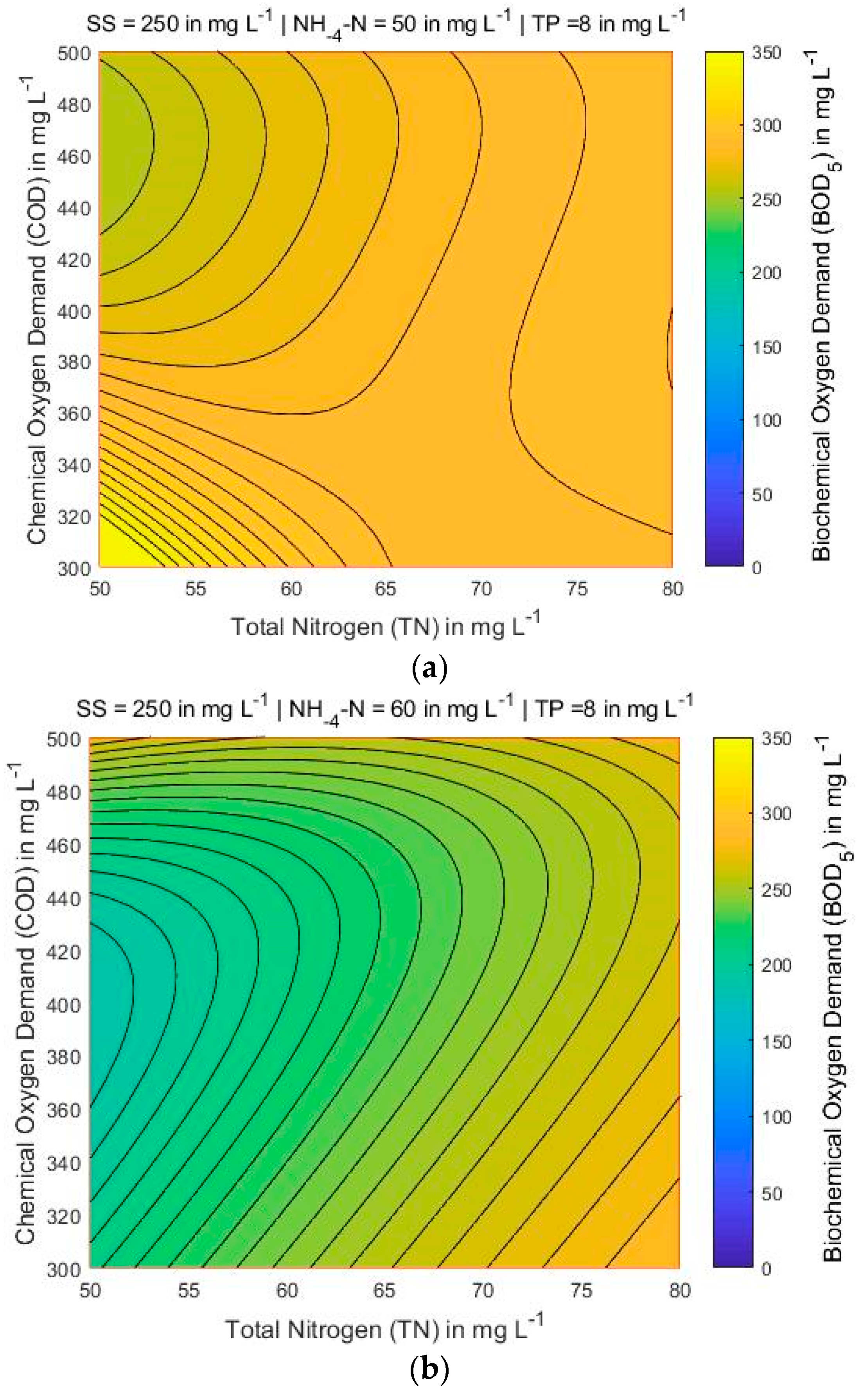
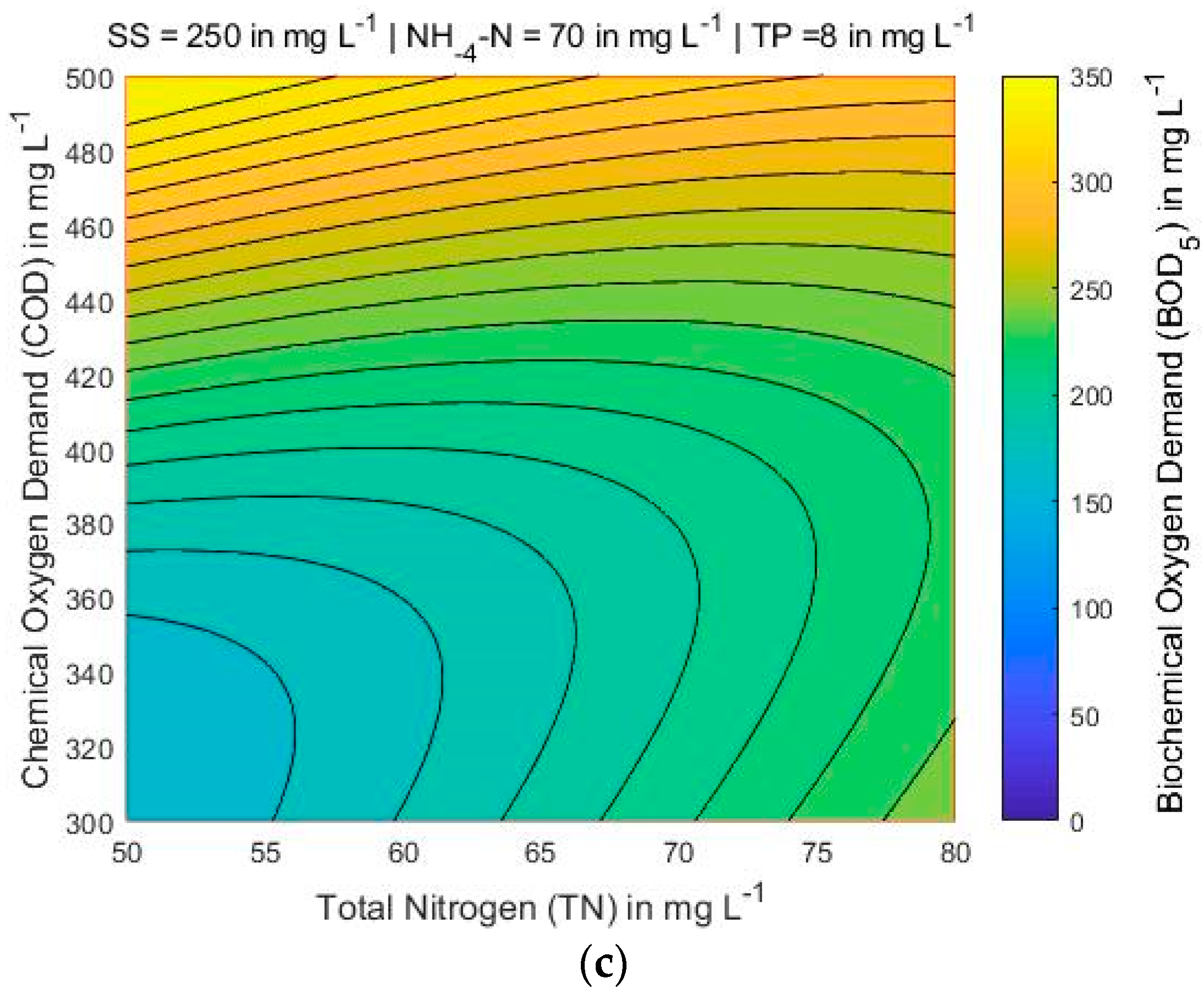
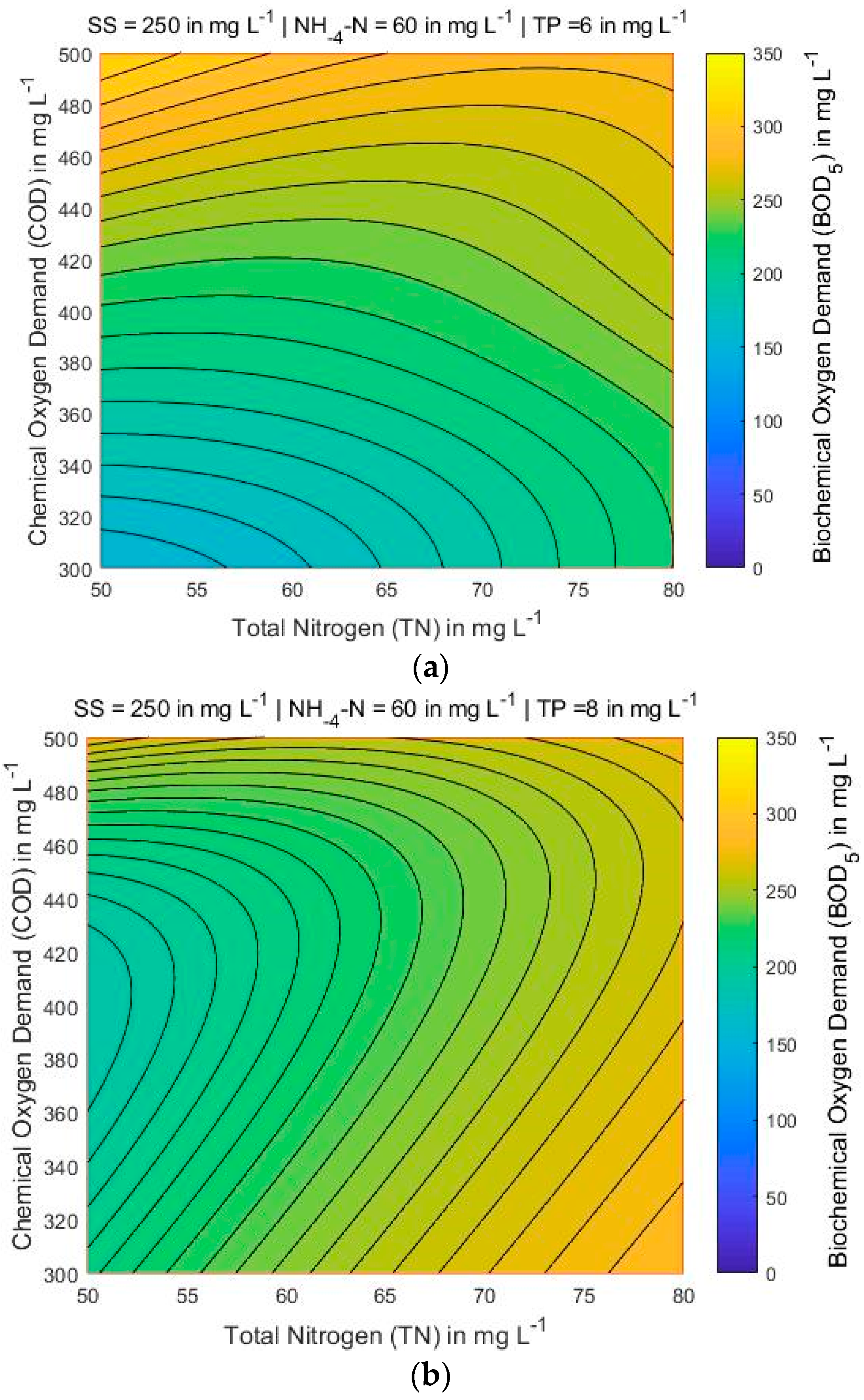
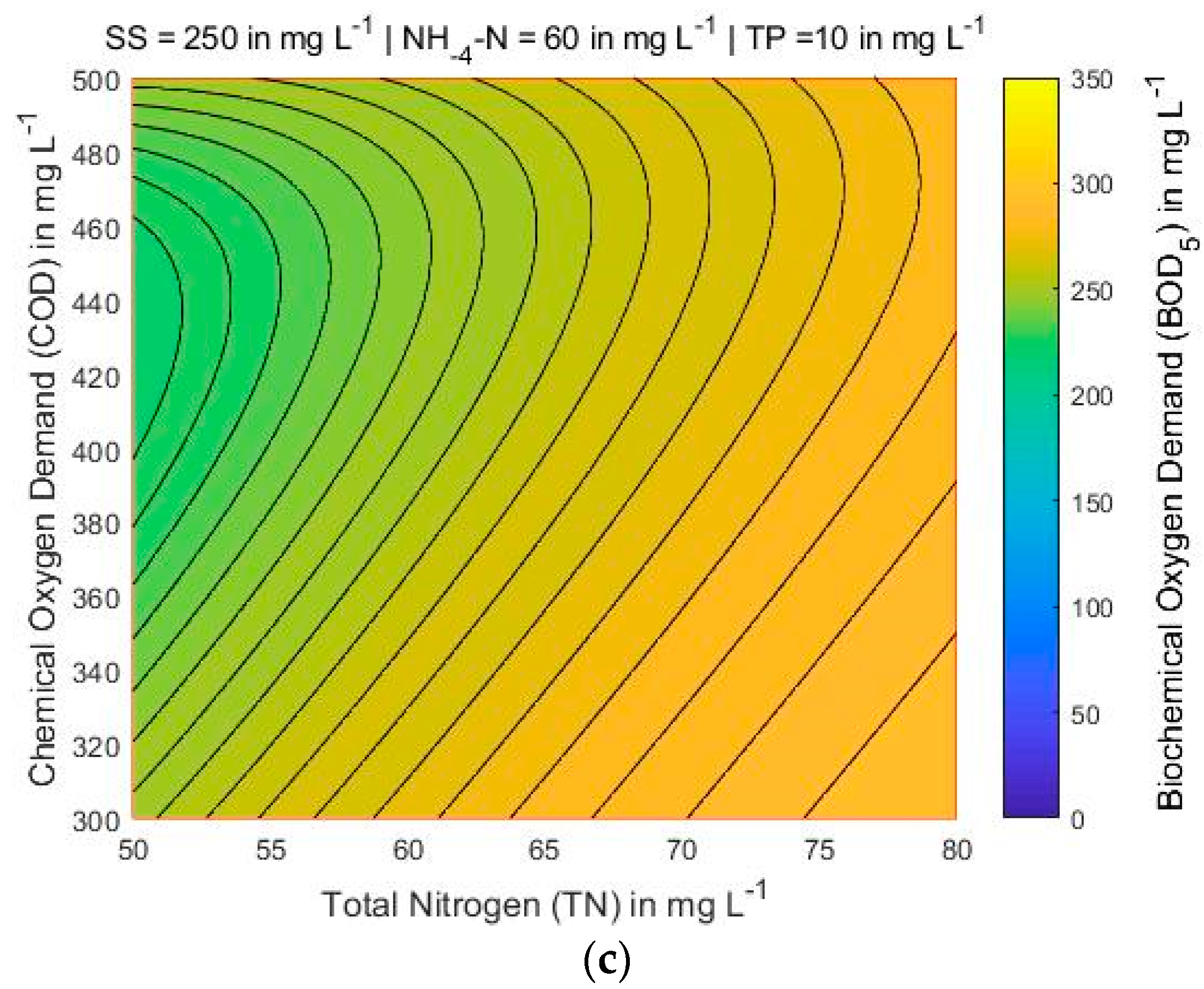
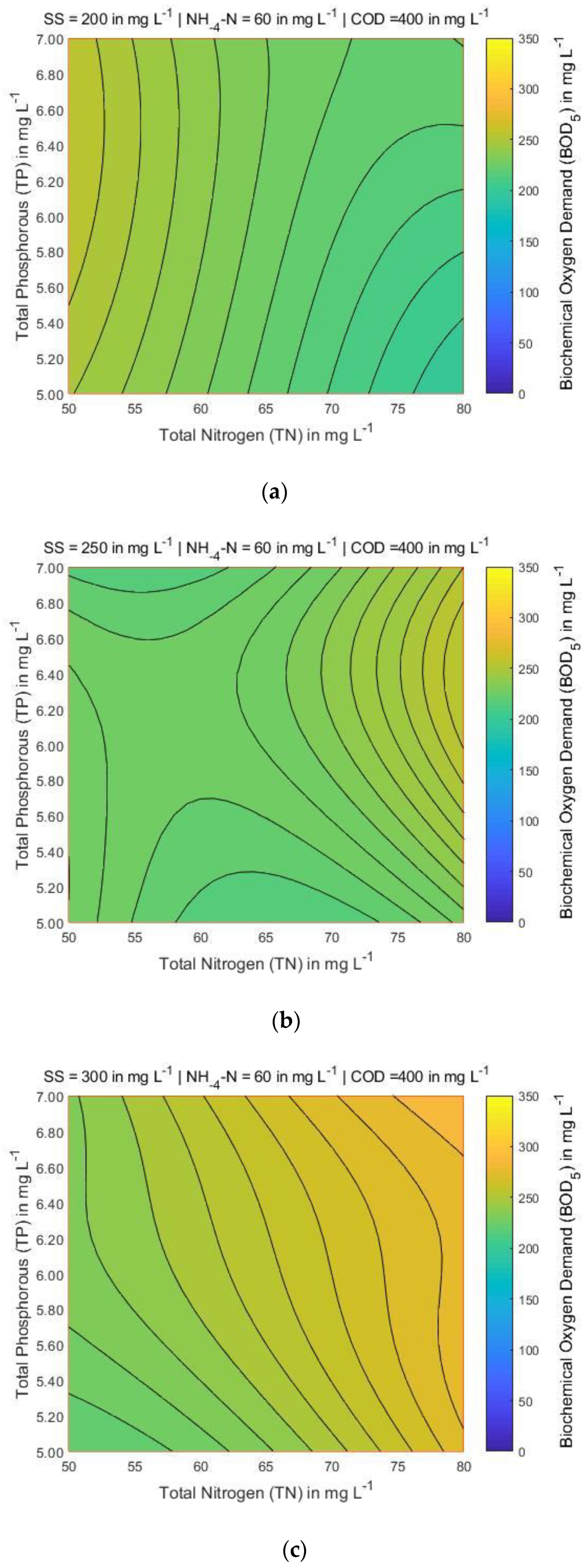
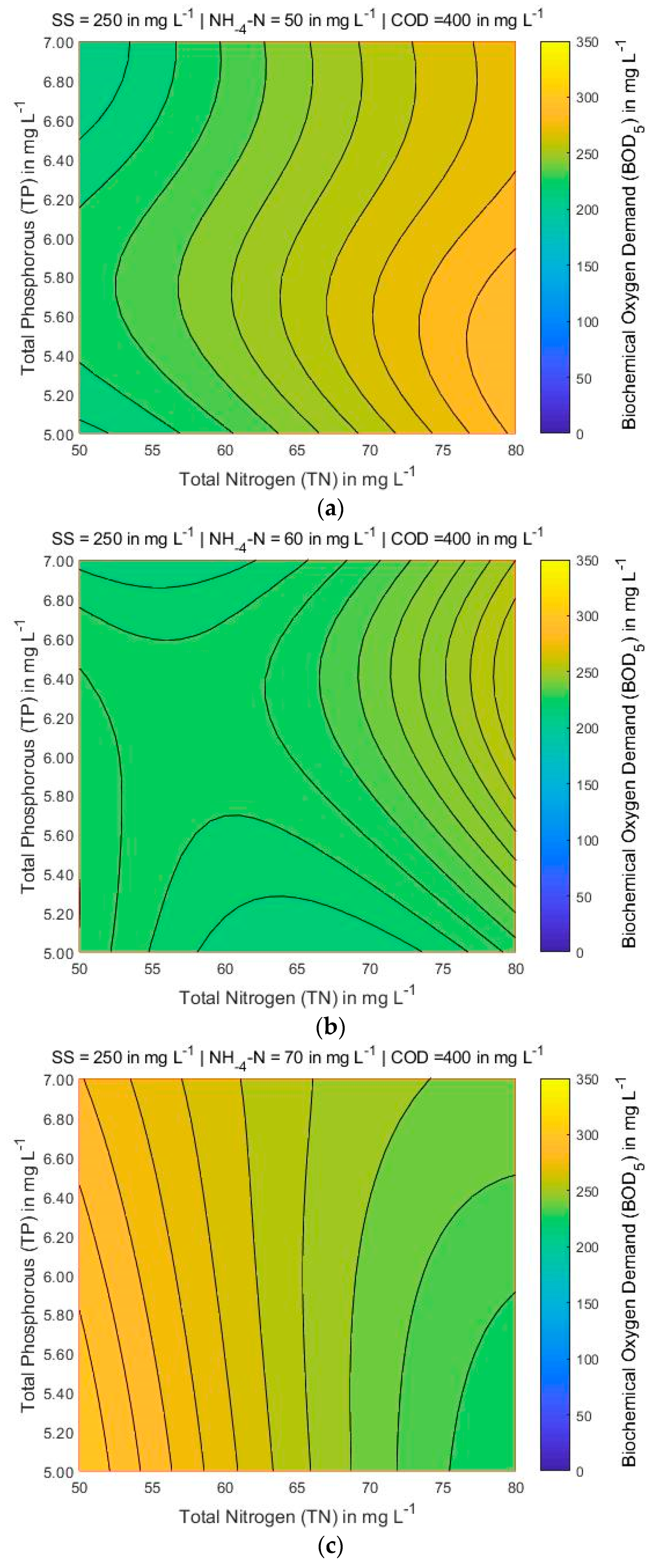
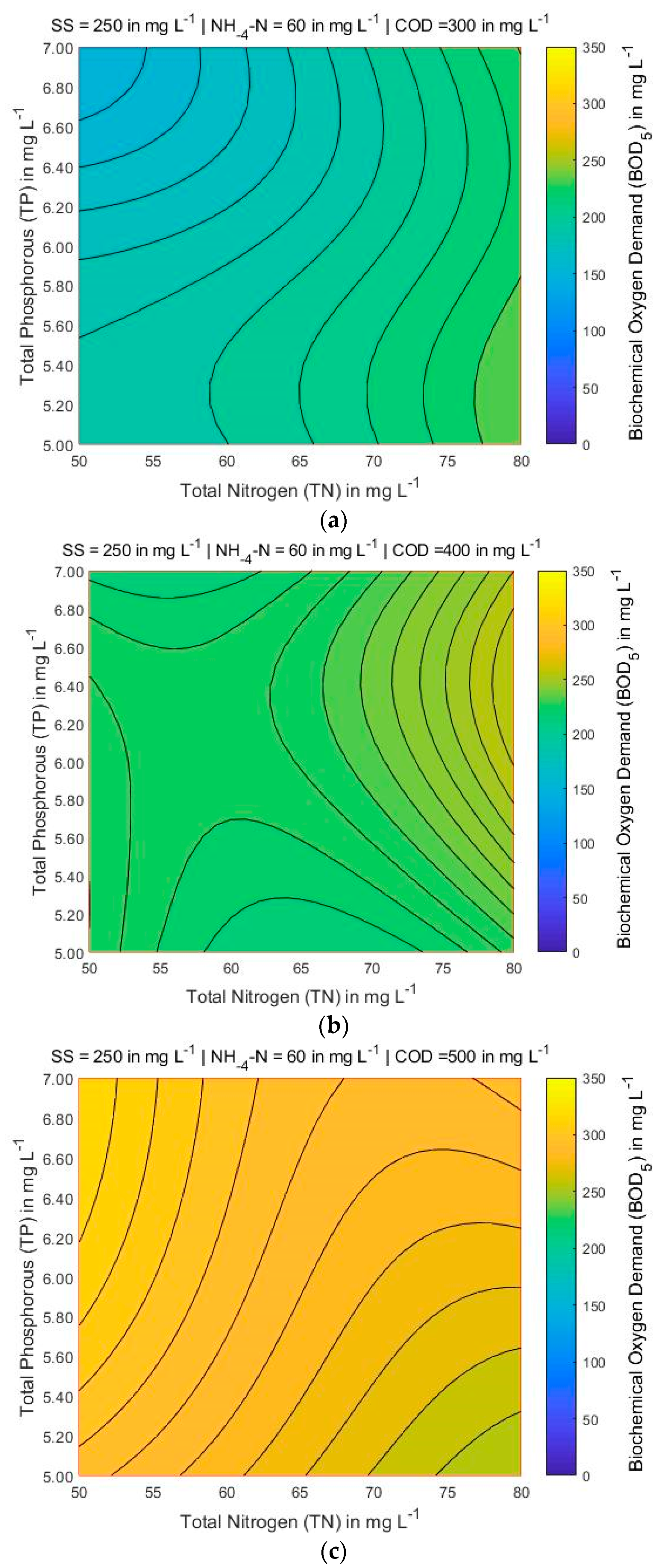
4.3. Mapping of BOD5
5. Limitations and Future Works
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Notation
| ANN(s) | Artificial Neural Network(s) |
| BOD | Biochemical Oxygen Demand |
| BPNN | Back Propagation Neural Network |
| COD | Chemical Oxygen Demand |
| CS | Compressive Strength |
| HL | Hard-limit transfer function |
| HTS | Hyperbolic Tangent Sigmoid transfer function |
| Li | Linear transfer function |
| LS | Log-Sigmoid transfer function |
| MAPE | Mean Absolute Percentage Error |
| MSE | Mean Square Error |
| Effective Porosity | |
| Number of input parameters | |
| Number of hidden layers | |
| Number of output parameters | |
| Number of datasets | |
| NRB | Normalized Radial Basis transfer function |
| NH4-N | Ammonia Nitrogen |
| PLi | Positive Linear transfer function |
| R | Pearson correlation coefficient |
| RB | Radial Basis transfer function |
| Schmidt hammer rebound number | |
| SHL | Symmetric hard-limit transfer function |
| SM | Soft Max transfer function |
| SS | Suspended Solids |
| SSE | Sum Square Error |
| SSL | Symmetric Saturating Linear transfer function |
| TB | Triangular Basis transfer function |
| TN | Total Nitrogen |
| TP | Total Phosphorous |
| UCS | Unconfined Compressive Strength |
| Ultrasonic Pulse Velocity | |
| WWTP(s) | Wastewater Treatment Plant(s) |
Appendix A
| SN | Transfer Function/Equation/Matlab Function | Graph |
|---|---|---|
| 1 | The symmetric saturating linear transfer function (SSL) |  |
| 2 | The log-sigmoid transfer function (LS) |  |
References
- Jouanneau, S.; Recoules, L.; Durand, M.J.; Boukabache, A.; Picot, V.; Primault, Y.; Lakel, A.; Sengelin, M.; Barillon, B.; Thouand, G. Methods for Assessing Biochemical Oxygen Demand (BOD): A Review. Water Res. 2014, 49, 62–82. [Google Scholar] [CrossRef] [PubMed]
- Riedel, K.; Kunze, G.; König, A. Microbial Sensors on a Respiratory Basis for Wastewater Monitoring. In History and Trends in Bioprocessing and Biotransformation; Dutta, N.N., Hammar, F., Haralampidis, K., Karanth, N.G., König, A., Krishna, S.H., Kunze, G., Nagy, E., Orlich, B., Osbourn, A.E., et al., Eds.; Advances in Biochemical Engineering/Biotechnology; Springer: Berlin/Heidelberg, Germany, 2002; Volume 75, pp. 81–118. ISBN 978-3-540-42371-3. [Google Scholar]
- Ngoc, L.T.B.; Tu, T.A.; Hien, L.T.T.; Linh, D.N.; Tri, N.; Duy, N.P.H.; Cuong, H.T.; Phuong, P.T.T. Simple Approach for the Rapid Estimation of BOD5 in Food Processing Wastewater. Environ. Sci. Pollut. Res. 2020, 27, 20554–20564. [Google Scholar] [CrossRef]
- Alexakis, D.; Kagalou, I.; Tsakiris, G. Assessment of Pressures and Impacts on Surface Water Bodies of the Mediterranean. Case Study: Pamvotis Lake, Greece. Environ. Earth Sci. 2013, 70, 687–698. [Google Scholar] [CrossRef]
- Alexakis, D.; Tsihrintzis, V.A.; Tsakiris, G.; Gikas, G.D. Suitability of Water Quality Indices for Application in Lakes in the Mediterranean. Water Resour. Manag. 2016, 30, 1621–1633. [Google Scholar] [CrossRef]
- Gamvroula, D.E.; Alexakis, D.E. Evaluating the Performance of Water Quality Indices: Application in Surface Water of Lake Union, Washington State-USA. Hydrology 2022, 9, 116. [Google Scholar] [CrossRef]
- Cheng, S.; Lin, Z.; Sun, Y.; Li, H.; Ren, X. Fast and Simultaneous Detection of Dissolved BOD and Nitrite in Wastewater by Using Bioelectrode with Bidirectional Extracellular Electron Transport. Water Res. 2022, 213, 118186. [Google Scholar] [CrossRef] [PubMed]
- Zeinolabedini, M.; Najafzadeh, M. Comparative Study of Different Wavelet-Based Neural Network Models to Predict Sewage Sludge Quantity in Wastewater Treatment Plant. Environ. Monit. Assess. 2019, 191, 163. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Zeinolabedini, M. Derivation of Optimal Equations for Prediction of Sewage Sludge Quantity Using Wavelet Conjunction Models: An Environmental Assessment. Environ. Sci. Pollut. Res. 2018, 25, 22931–22943. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Zeinolabedini, M. Prognostication of Waste Water Treatment Plant Performance Using Efficient Soft Computing Models: An Environmental Evaluation. Measurement 2019, 138, 690–701. [Google Scholar] [CrossRef]
- Gunjal, S.; Khobragade, M.; Chaware, C. Prediction of BOD from Wastewater Characteristics and Their Interactions Using Regression Neural Network: A Case Study of Naidu Wastewater Treatment Plant, Pune, India. In Recent Trends in Construction Technology and Management; Ranadive, M.S., Das, B.B., Mehta, Y.A., Gupta, R., Eds.; Lecture Notes in Civil Engineering; Springer Nature: Singapore, 2023; Volume 260, pp. 571–577. ISBN 978-981-19214-4-5. [Google Scholar]
- Hu, Y.; Du, W.; Yang, C.; Wang, Y.; Huang, T.; Xu, X.; Li, W. Source Identification and Prediction of Nitrogen and Phosphorus Pollution of Lake Taihu by an Ensemble Machine Learning Technique. Front. Environ. Sci. Eng. 2023, 17, 55. [Google Scholar] [CrossRef]
- Ismail, S.; Ahmed, M.F. Hydrogeochemical Characterization of the Groundwater of Lahore Region Using Supervised Machine Learning Technique. Environ. Monit. Assess. 2023, 195, 5. [Google Scholar] [CrossRef] [PubMed]
- Zhou, P.; Li, Z.; El-Dakhakhni, W.; Smyth, S.A. Prediction of Bisphenol A Contamination in Canadian Municipal Wastewater. J. Water Process Eng. 2022, 50, 103304. [Google Scholar] [CrossRef]
- Zhong, H.; Yuan, Y.; Luo, L.; Ye, J.; Chen, M.; Zhong, C. Water Quality Prediction of MBR Based on Machine Learning: A Novel Dataset Contribution Analysis Method. J. Water Process Eng. 2022, 50, 103296. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine Learning: Trends, Perspectives, and Prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef] [PubMed]
- Huang, R.; Ma, C.; Ma, J.; Huangfu, X.; He, Q. Machine Learning in Natural and Engineered Water Systems. Water Res. 2021, 205, 117666. [Google Scholar] [CrossRef]
- ISO 5815-1:2003; Water Quality-Determination of Biochemical Oxygen Demand after N Days (BODn)-Part 1: Dilution and Seeding Method with Allylthiourea Addition. International Organization for Standardization: Geneva, Switzerland, 2003.
- McDonagh, C.; Kolle, C.; McEvoy, A.K.; Dowling, D.L.; Cafolla, A.A.; Cullen, S.J.; MacCraith, B.D. Phase Fluorometric Dissolved Oxygen Sensor. Sens. Actuators B Chem. 2001, 74, 124–130. [Google Scholar] [CrossRef]
- McEvoy, A.K.; McDonagh, C.M.; MacCraith, B.D. Dissolved Oxygen Sensor Based on Fluorescence Quenching of Oxygen-Sensitive Ruthenium Complexes Immobilized in Sol–Gel-Derived Porous Silica Coatings. Analyst 1996, 121, 785–788. [Google Scholar] [CrossRef]
- Xiong, X.; Xiao, D.; Choi, M.F. Dissolved Oxygen Sensor Based on Fluorescence Quenching of Oxygen-Sensitive Ruthenium Complex Immobilized on Silica–Ni–P Composite Coating. Sens. Actuators B Chem. 2006, 117, 172–176. [Google Scholar] [CrossRef]
- Xu, W.; McDonough, R.C.; Langsdorf, B.; Demas, J.N.; DeGraff, B.A. Oxygen Sensors Based on Luminescence Quenching: Interactions of Metal Complexes with the Polymer Supports. Anal. Chem. 1994, 66, 4133–4141. [Google Scholar] [CrossRef]
- Sakaguchi, T.; Kitagawa, K.; Ando, T.; Murakami, Y.; Morita, Y.; Yamamura, A.; Yokoyama, K.; Tamiya, E. A Rapid BOD Sensing System Using Luminescent Recombinants of Escherichia Coli. Biosens. Bioelectron. 2003, 19, 115–121. [Google Scholar] [CrossRef]
- Sakaguchi, T.; Morioka, Y.; Yamasaki, M.; Iwanaga, J.; Beppu, K.; Maeda, H.; Morita, Y.; Tamiya, E. Rapid and Onsite BOD Sensing System Using Luminous Bacterial Cells-Immobilized Chip. Biosens. Bioelectron. 2007, 22, 1345–1350. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.H.; Chang, I.S.; Cheol Gil, G.; Park, H.S.; Kim, H.J. Novel BOD (Biological Oxygen Demand) Sensor Using Mediator-Less Microbial Fuel Cell. Biotechnol. Lett. 2003, 25, 541–545. [Google Scholar] [CrossRef] [PubMed]
- Karube, I.; Matsunaga, T.; Mitsuda, S.; Suzuki, S. Microbial Electrode BOD Sensors. Biotechnol. Bioeng. 1977, 19, 1535–1547. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Zhao, H.; Zhong, L.; Liu, C.; Jia, J.; Xu, X.; Liu, L.; Dong, S. A Biofilm Reactor-Based Approach for Rapid on-Line Determination of Biodegradable Organic Pollutants. Biosens. Bioelectron. 2012, 34, 77–82. [Google Scholar] [CrossRef]
- Zare Abyaneh, H. Evaluation of Multivariate Linear Regression and Artificial Neural Networks in Prediction of Water Quality Parameters. J. Environ. Health Sci. Eng. 2014, 12, 40. [Google Scholar] [CrossRef] [Green Version]
- Singh, K.P.; Basant, A.; Malik, A.; Jain, G. Artificial Neural Network Modeling of the River Water Quality—A Case Study. Ecol. Model. 2009, 220, 888–895. [Google Scholar] [CrossRef]
- Ahmed, A.A.M.; Shah, S.M.A. Application of Adaptive Neuro-Fuzzy Inference System (ANFIS) to Estimate the Biochemical Oxygen Demand (BOD) of Surma River. J. King Saud Univ. Eng. Sci. 2017, 29, 237–243. [Google Scholar] [CrossRef] [Green Version]
- Basant, N.; Gupta, S.; Malik, A.; Singh, K.P. Linear and Nonlinear Modeling for Simultaneous Prediction of Dissolved Oxygen and Biochemical Oxygen Demand of the Surface Water—A Case Study. Chemom. Intell. Lab. Syst. 2010, 104, 172–180. [Google Scholar] [CrossRef]
- Asami, H.; Golabi, M.; Albaji, M. Simulation of the Biochemical and Chemical Oxygen Demand and Total Suspended Solids in Wastewater Treatment Plants: Data-Mining Approach. J. Clean. Prod. 2021, 296, 126533. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Gavriilaki, E.; Asteris, P.G.; Touloumenidou, T.; Koravou, E.-E.; Koutra, M.; Papayanni, P.G.; Karali, V.; Papalexandri, A.; Varelas, C.; Chatzopoulou, F.; et al. Genetic Justification of Severe COVID-19 Using a Rigorous Algorithm. Clin. Immunol. 2021, 226, 108726. [Google Scholar] [CrossRef] [PubMed]
- Asteris, P.G.; Gavriilaki, E.; Touloumenidou, T.; Koravou, E.; Koutra, M.; Papayanni, P.G.; Pouleres, A.; Karali, V.; Lemonis, M.E.; Mamou, A.; et al. Genetic Prediction of ICU Hospitalization and Mortality in COVID-19 Patients Using Artificial Neural Networks. J. Cell. Mol. Med. 2022, 26, 1445–1455. [Google Scholar] [CrossRef] [PubMed]
- Upadhyay, A.K.; Shukla, S. Correlation Study to Identify the Factors Affecting COVID-19 Case Fatality Rates in India. Diabetes Metab. Syndr. Clin. Res. Rev. 2021, 15, 993–999. [Google Scholar] [CrossRef] [PubMed]
- Niazkar, H.R.; Niazkar, M. Application of Artificial Neural Networks to Predict the COVID-19 Outbreak. Glob. Health Res. Policy 2020, 5, 50. [Google Scholar] [CrossRef] [PubMed]
- Mahanty, C.; Kumar, R.; Asteris, P.G.; Gandomi, A.H. COVID-19 Patient Detection Based on Fusion of Transfer Learning and Fuzzy Ensemble Models Using CXR Images. Appl. Sci. 2021, 11, 11423. [Google Scholar] [CrossRef]
- Rahimi, I.; Gandomi, A.H.; Asteris, P.G.; Chen, F. Analysis and Prediction of COVID-19 Using SIR, SEIQR, and Machine Learning Models: Australia, Italy, and UK Cases. Information 2021, 12, 109. [Google Scholar] [CrossRef]
- Asteris, P.G.; Douvika, M.G.; Karamani, C.A.; Skentou, A.D.; Chlichlia, K.; Cavaleri, L.; Daras, T.; Armaghani, D.J.; Zaoutis, T.E. A Novel Heuristic Algorithm for the Modeling and RiskAssessment of the COVID-19 Pandemic Phenomenon. Comput. Model. Eng. Sci. 2020, 125, 815–828. [Google Scholar] [CrossRef]
- APHA; AWWA; WPCF. Standard Methods for the Examination of Water and Wastewater, 20th ed.; American Public Health Association: Washington, DC, USA, 1999. [Google Scholar]
- Jong, Y.-H.; Lee, C.-I. Influence of Geological Conditions on the Powder Factor for Tunnel Blasting. Int. J. Rock Mech. Min. Sci. 2004, 41, 533–538. [Google Scholar] [CrossRef]
- Bardhan, A.; Biswas, R.; Kardani, N.; Iqbal, M.; Samui, P.; Singh, M.P.; Asteris, P.G. A Novel Integrated Approach of Augmented Grey Wolf Optimizer and ANN for Estimating Axial Load Carrying-Capacity of Concrete-Filled Steel Tube Columns. Constr. Build. Mater. 2022, 337, 127454. [Google Scholar] [CrossRef]
- Mahmood, W.; Mohammed, A.S.; Asteris, P.G.; Kurda, R.; Armaghani, D.J. Modeling Flexural and Compressive Strengths Behaviour of Cement-Grouted Sands Modified with Water Reducer Polymer. Appl. Sci. 2022, 12, 1016. [Google Scholar] [CrossRef]
- Mahmood, W.; Mohammed, A.S.; Sihag, P.; Asteris, P.G.; Ahmed, H. Interpreting the Experimental Results of Compressive Strength of Hand-Mixed Cement-Grouted Sands Using Various Mathematical Approaches. Arch. Civ. Mech. Eng. 2022, 22, 19. [Google Scholar] [CrossRef]
- Emad, W.; Salih, A.; Kurda, R.; Asteris, P.G.; Hassan, A. Nonlinear Models to Predict Stress versus Strain of Early Age Strength of Flowable Ordinary Portland Cement. Eur. J. Environ. Civ. Eng. 2022, 26, 8433–8457. [Google Scholar] [CrossRef]
- Asteris, P.G.; Apostolopoulou, M.; Armaghani, D.J.; Cavaleri, L.; Chountalas, A.T.; Guney, D.; Hajihassani, M.; Hasanipanah, M.; Khandelwal, M.; Karamani, C.; et al. On the Metaheuristic Models for the Prediction of Cement-Metakaolin Mortars Compressive Strength. Metaheu Comp. Appl. 2020, 1, 63–69. [Google Scholar] [CrossRef]
- Asteris, P.G.; Argyropoulos, I.; Cavaleri, L.; Rodrigues, H.; Varum, H.; Thomas, J.; Lourenço, P.B. Masonry Compressive Strength Prediction Using Artificial Neural Networks. In Transdisciplinary Multispectral Modeling and Cooperation for the Preservation of Cultural Heritage; Moropoulou, A., Korres, M., Georgopoulos, A., Spyrakos, C., Mouzakis, C., Eds.; Communications in Computer and Information Science; Springer International Publishing: Cham, Switzerland, 2019; Volume 962, pp. 200–224. ISBN 978-3-030-12959-0. [Google Scholar]
- Armaghani, D.J.; Asteris, P.G.; Fatemi, S.A.; Hasanipanah, M.; Tarinejad, R.; Rashid, A.S.A.; Huynh, V.V. On the Use of Neuro-Swarm System to Forecast the Pile Settlement. Appl. Sci. 2020, 10, 1904. [Google Scholar] [CrossRef] [Green Version]
- Lu, S.; Koopialipoor, M.; Asteris, P.G.; Bahri, M.; Armaghani, D.J. A Novel Feature Selection Approach Based on Tree Models for Evaluating the Punching Shear Capacity of Steel Fiber-Reinforced Concrete Flat Slabs. Materials 2020, 13, 3902. [Google Scholar] [CrossRef]
- Le, T.-T. Practical Machine Learning-Based Prediction Model for Axial Capacity of Square CFST Columns. Mech. Adv. Mater. Struct. 2022, 29, 1782–1797. [Google Scholar] [CrossRef]
- Le, T.-T.; Asteris, P.G.; Lemonis, M.E. Prediction of Axial Load Capacity of Rectangular Concrete-Filled Steel Tube Columns Using Machine Learning Techniques. Eng. Comput. 2022, 38, 3283–3316. [Google Scholar] [CrossRef]
- Le, T.-T.; Le, M.V. Development of User-Friendly Kernel-Based Gaussian Process Regression Model for Prediction of Load-Bearing Capacity of Square Concrete-Filled Steel Tubular Members. Mater. Struct. 2021, 54, 59. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A Comparative Study of ANN and ANFIS Models for the Prediction of Cement-Based Mortar Materials Compressive Strength. Neural Comput. Appl. 2021, 33, 4501–4532. [Google Scholar] [CrossRef]
- Asteris, P.G.; Mokos, V.G. Concrete Compressive Strength Using Artificial Neural Networks. Neural Comput. Appl. 2020, 32, 11807–11826. [Google Scholar] [CrossRef]
- Asteris, P.G.; Nguyen, T.-A. Prediction of Shear Strength of Corrosion Reinforced Concrete Beams Using Artificial Neural Network. J. Sci. Transp. Tech. 2022, 2, 1–12. [Google Scholar]
- Li, N.; Asteris, P.G.; Tran, T.-T.; Pradhan, B.; Nguyen, H. Modelling the Deflection of Reinforced Concrete Beams Using the Improved Artificial Neural Network by Imperialist Competitive Optimization. Steel Compos. Struct. 2022, 42, 733–745. [Google Scholar] [CrossRef]
- Lemonis, M.E.; Daramara, A.G.; Georgiadou, A.G.; Siorikis, V.G.; Tsavdaridis, K.D.; Asteris, P.G. Ultimate Axial Load of Rectangular Concrete-Filled Steel Tubes Using Multiple ANN Activation Functions. Steel Compos. Struct. 2022, 42, 459–475. [Google Scholar] [CrossRef]
- Asteris, P.G.; Rizal, F.I.M.; Koopialipoor, M.; Roussis, P.C.; Ferentinou, M.; Armaghani, D.J.; Gordan, B. Slope Stability Classification under Seismic Conditions Using Several Tree-Based Intelligent Techniques. Appl. Sci. 2022, 12, 1753. [Google Scholar] [CrossRef]
- Asteris, P.G.; Lourenço, P.B.; Hajihassani, M.; Adami, C.-E.N.; Lemonis, M.E.; Skentou, A.D.; Marques, R.; Nguyen, H.; Rodrigues, H.; Varum, H. Soft Computing-Based Models for the Prediction of Masonry Compressive Strength. Eng. Struct. 2021, 248, 113276. [Google Scholar] [CrossRef]
- Asteris, P.G.; Skentou, A.D.; Bardhan, A.; Samui, P.; Lourenço, P.B. Soft Computing Techniques for the Prediction of Concrete Compressive Strength Using Non-Destructive Tests. Constr. Build. Mater. 2021, 303, 124450. [Google Scholar] [CrossRef]
- Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Kotsonis, E.A.; Lourenço, P.B. Prediction of Cement-Based Mortars Compressive Strength Using Machine Learning Techniques. Neural Comput. Appl. 2021, 33, 13089–13121. [Google Scholar] [CrossRef]
















| Variable | Symbol | Units | Category | Data Used in NN Models | ||||
|---|---|---|---|---|---|---|---|---|
| Min | Average | Max | STD | CV | ||||
| Chemical Oxygen Demand | COD | mg L−1 | Input | 211.00 | 410.73 | 551.00 | 71.37 | 0.17 |
| Suspended Solids | SS | mg L−1 | Input | 142.00 | 228.34 | 302.00 | 27.64 | 0.12 |
| Total Nitrogen | TN | mg L−1 | Input | 44.20 | 66.44 | 84.25 | 9.17 | 0.14 |
| Ammonia Nitrogen | NH4-N | mg L−1 | Input | 39.30 | 52.52 | 70.10 | 7.67 | 0.15 |
| Total Phosphorous | TP | mg L−1 | Input | 2.96 | 5.86 | 8.65 | 1.17 | 0.20 |
| Biochemical Oxygen Demand | BOD5 | mg L−1 | Output | 128.00 | 238.27 | 348.00 | 45.35 | 0.19 |
| Variable | Symbol | COD | SS | TN | NH4-N | TP | BOD5 |
|---|---|---|---|---|---|---|---|
| Chemical Oxygen Demand | COD | 1.00 | 0.29 | 0.78 | 0.72 | 0.54 | 0.78 |
| Suspended Solids | SS | 0.29 | 1.00 | 0.35 | 0.30 | 0.18 | 0.43 |
| Total Nitrogen | TN | 0.78 | 0.35 | 1.00 | 0.72 | 0.64 | 0.74 |
| Ammonia Nitrogen | NH4-N | 0.72 | 0.30 | 0.72 | 1.00 | 0.27 | 0.58 |
| Total Phosphorous | TP | 0.54 | 0.18 | 0.64 | 0.27 | 1.00 | 0.60 |
| Biochemical Oxygen Demand | BOD5 | 0.78 | 0.43 | 0.74 | 0.58 | 0.60 | 1.00 |
| Parameter | Value | Matlab Function(s) |
|---|---|---|
| Training Algorithm | Levenberg-Marquardt Algorithm | trainlm |
| Normalization | Without any normalization Minmax in the range [0.10–0.90], [0.00–1.00] and [−1.00–1.00] Zscore | Mapminmax zscore |
| Number of Hidden Layers | 1 | |
| Number of Neurons per Hidden Layer | 1 to 50 by step 1 | |
| Control random number generation | 10 different random generation | rand(seed, generator), where the generator range from 1 to 10 by step 1 |
| Training Goal | 0 | |
| Epochs | 200 | |
| Cost Function | Mean Square Error (MSE) Sum Square Error (SSE) | mse sse |
| Transfer Functions | Hyperbolic Tangent Sigmoid transfer function (HTS) Log-sigmoid transfer function (LS) Linear transfer function (Li) Positive linear transfer function (PLi) Symmetric saturating linear transfer function (SSL) Soft max transfer function (SM) Competitive transfer function (Co) Triangular basis transfer function (TB) Radial basis transfer function (RB) Normalized radial basis transfer function (NRB) Hard-limit transfer function (HL) Symmetric hard-limit transfer function (SHL) | tansig logsig purelin poslin satlins softmax compet tribas radbas radbasn hardlim hardlims |
| Ranking | Normalization Technique | Cost Function | Transfer Function | Architecture | Datasets Performance Indices | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Input Layer | Output Layer | Testing | Training | All | |||||||
| R | RMSE | R | RMSE | R | RMSE | ||||||
| 1 | Minmax [−1.00, 1.00] | MSE | logsig | satlins | 5-8-1 | 0.9443 | 16.8563 | 0.9208 | 17.6044 | 0.9217 | 17.6065 |
| 2 | Minmax [0.10, 0.90] | MSE | poslin | satlins | 5-29-1 | 0.9421 | 17.8418 | 0.9057 | 19.1355 | 0.9110 | 18.7234 |
| 3 | Minmax [−1.00, 1.00] | SSE | tribas | tansig | 5-14-1 | 0.9407 | 17.7982 | 0.9319 | 16.3818 | 0.9287 | 16.8636 |
| 4 | Minmax [0.10, 0.90] | MSE | tansig | purelin | 5-13-1 | 0.9406 | 17.5336 | 0.9238 | 17.2764 | 0.9214 | 17.6425 |
| 5 | Minmax [0.10, 0.90] | MSE | softmax | radbas | 5-17-1 | 0.9400 | 17.7336 | 0.9156 | 18.1454 | 0.9164 | 18.2035 |
| 6 | Minmax [−1.00, 1.00] | MSE | tansig | purelin | 5-11-1 | 0.9400 | 17.5935 | 0.9298 | 16.6148 | 0.9224 | 17.5536 |
| 7 | Minmax [0.10, 0.90] | MSE | logsig | satlins | 5-8-1 | 0.9399 | 17.5855 | 0.9161 | 18.1001 | 0.9179 | 18.0053 |
| 8 | Minmax [0.10, 0.90] | SSE | softmax | logsig | 5-29-1 | 0.9396 | 17.7540 | 0.9311 | 16.4914 | 0.9275 | 17.0689 |
| 9 | Minmax [0.10, 0.90] | SSE | satlins | purelin | 5-15-1 | 0.9394 | 18.6357 | 0.9012 | 19.6172 | 0.9066 | 19.3523 |
| 10 | Minmax [0.00, 1.00] | MSE | logsig | satlins | 5-5-1 | 0.9393 | 18.7060 | 0.9136 | 18.4874 | 0.9150 | 18.5984 |
| 11 | Minmax [0.10, 0.90] | SSE | softmax | satlins | 5-26-1 | 0.9393 | 18.1376 | 0.9077 | 18.9646 | 0.9116 | 18.7815 |
| 12 | Minmax [0.00, 1.00] | MSE | softmax | purelin | 5-41-1 | 0.9388 | 17.8211 | 0.9217 | 17.5291 | 0.9215 | 17.7143 |
| 13 | Minmax [0.10, 0.90] | MSE | tansig | purelin | 5-8-1 | 0.9388 | 17.6942 | 0.9160 | 18.1425 | 0.9179 | 17.9936 |
| 14 | Minmax [0.10, 0.90] | MSE | softmax | radbas | 5-23-1 | 0.9388 | 19.0606 | 0.9135 | 18.4091 | 0.9155 | 18.4651 |
| 15 | Minmax [0.10, 0.90] | MSE | logsig | logsig | 5-12-1 | 0.9387 | 16.7798 | 0.9320 | 16.3995 | 0.9282 | 16.8627 |
| 16 | Minmax [0.00, 1.00] | MSE | softmax | purelin | 5-22-1 | 0.9387 | 18.2816 | 0.9105 | 18.6790 | 0.9125 | 18.6410 |
| 17 | Minmax [0.00, 1.00] | MSE | softmax | poslin | 5-22-1 | 0.9387 | 18.2816 | 0.9105 | 18.6790 | 0.9125 | 18.6410 |
| 18 | Minmax [0.00, 1.00] | MSE | tansig | satlins | 5-6-1 | 0.9386 | 17.5546 | 0.9164 | 18.0637 | 0.9166 | 18.1632 |
| 19 | Zscore | MSE | poslin | purelin | 5-9-1 | 0.9385 | 18.1809 | 0.9076 | 18.9472 | 0.9105 | 18.7648 |
| 20 | Minmax [0.00, 1.00] | SSE | tansig | purelin | 5-7-1 | 0.9384 | 17.1610 | 0.9100 | 18.7052 | 0.9110 | 18.7294 |
| Model | Datasets | Performance Indices | ||||
|---|---|---|---|---|---|---|
| a20-Index | R | RMSE | MAPE | VAF | ||
| ANN LM 5-8-1 | Training | 0.9806 | 0.9208 | 17.6044 | 0.0582 | 84.7803 |
| Test | 1 | 0.9443 | 16.8563 | 0.0571 | 89.1499 | |
| IW{1,1} | |||||||
|---|---|---|---|---|---|---|---|
| (8 × 3) | (1 × 8) | (8 × 1) | (1 × 1) | ||||
| 3.8747 | −3.3026 | 0.8841 | 9.8281 | −1.9581 | 2.9497 | 9.6809 | −0.4917 |
| −3.8650 | 3.1701 | 0.9485 | −1.1494 | 1.9099 | −2.6746 | 2.1566 | |
| 1.2295 | −2.3973 | −1.2553 | 2.7258 | −2.3405 | −2.3231 | 1.0974 | |
| −4.6036 | 3.7836 | 0.8690 | −4.0565 | 7.1579 | −1.1579 | −1.3150 | |
| −3.0096 | 3.4372 | 0.3911 | −0.1472 | 2.3667 | 2.2639 | 2.2077 | |
| −1.0593 | −4.5452 | 1.0995 | −4.5926 | −1.9055 | −0.6063 | 6.0657 | |
| −4.7120 | 3.0951 | −2.9974 | −9.7771 | 2.9426 | 2.6242 | −10.6922 | |
| 1.6124 | −9.0346 | 0.1278 | 3.6006 | 8.0047 | 0.3364 | 7.7832 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asteris, P.G.; Alexakis, D.E.; Tsoukalas, M.Z.; Gamvroula, D.E.; Guney, D. Machine Learning Approach for Rapid Estimation of Five-Day Biochemical Oxygen Demand in Wastewater. Water 2023, 15, 103. https://doi.org/10.3390/w15010103
Asteris PG, Alexakis DE, Tsoukalas MZ, Gamvroula DE, Guney D. Machine Learning Approach for Rapid Estimation of Five-Day Biochemical Oxygen Demand in Wastewater. Water. 2023; 15(1):103. https://doi.org/10.3390/w15010103
Chicago/Turabian StyleAsteris, Panagiotis G., Dimitrios E. Alexakis, Markos Z. Tsoukalas, Dimitra E. Gamvroula, and Deniz Guney. 2023. "Machine Learning Approach for Rapid Estimation of Five-Day Biochemical Oxygen Demand in Wastewater" Water 15, no. 1: 103. https://doi.org/10.3390/w15010103
APA StyleAsteris, P. G., Alexakis, D. E., Tsoukalas, M. Z., Gamvroula, D. E., & Guney, D. (2023). Machine Learning Approach for Rapid Estimation of Five-Day Biochemical Oxygen Demand in Wastewater. Water, 15(1), 103. https://doi.org/10.3390/w15010103