
Estimation of Threshold Rainfall in Ungauged Areas Using Machine Learning


Abstract
:1. Introduction
2. Theoretical Background
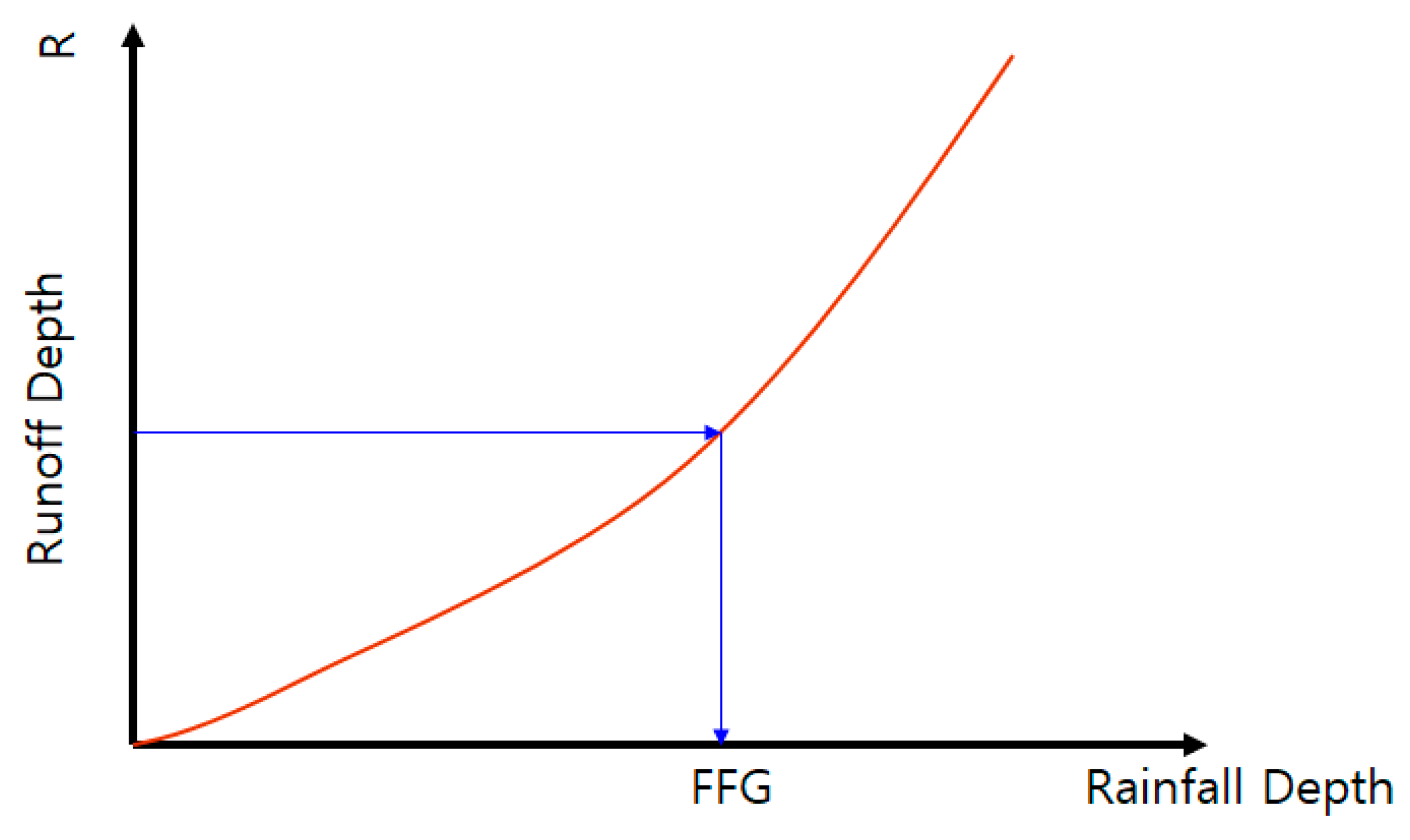
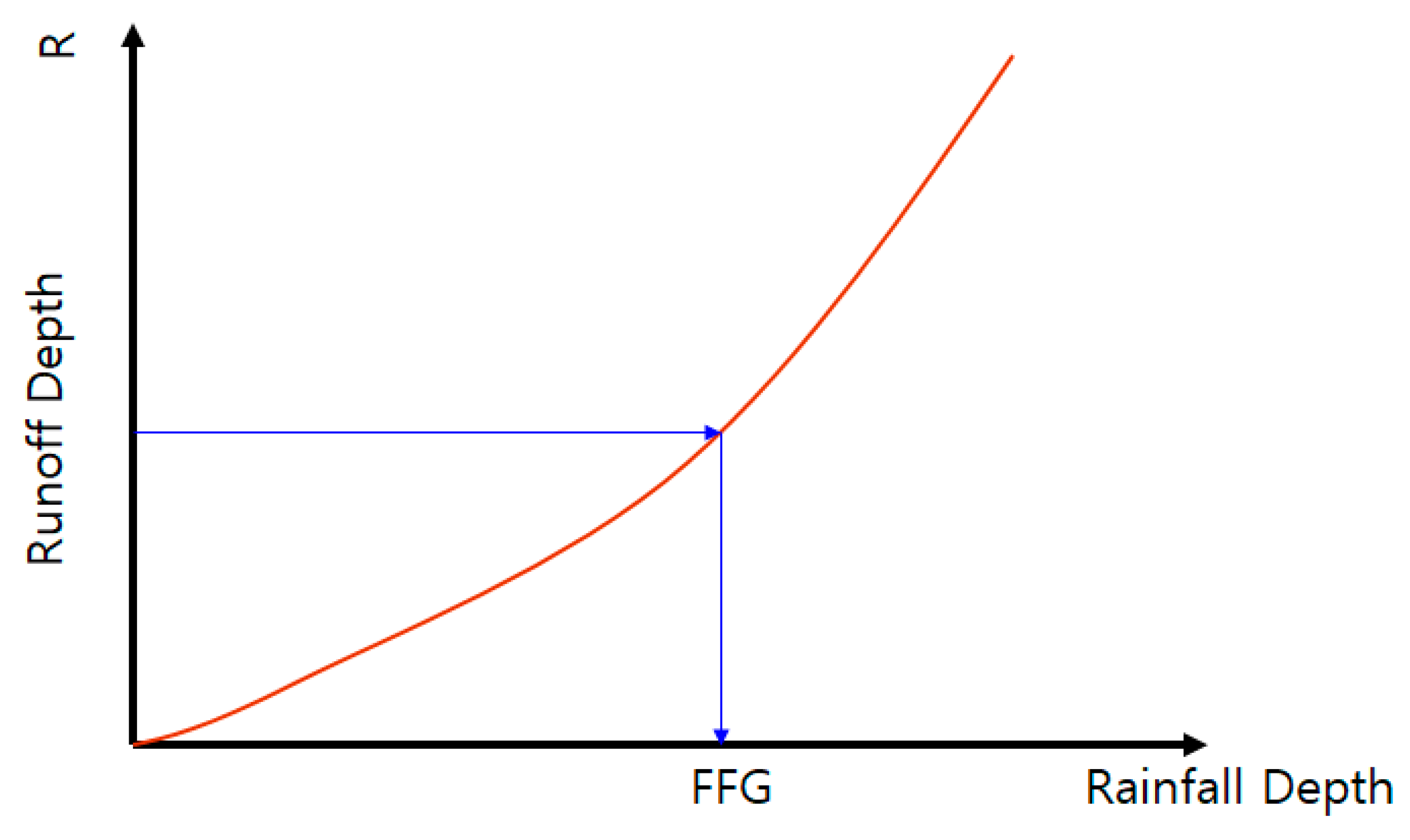
2.1. Definition of Threshold Rainfall
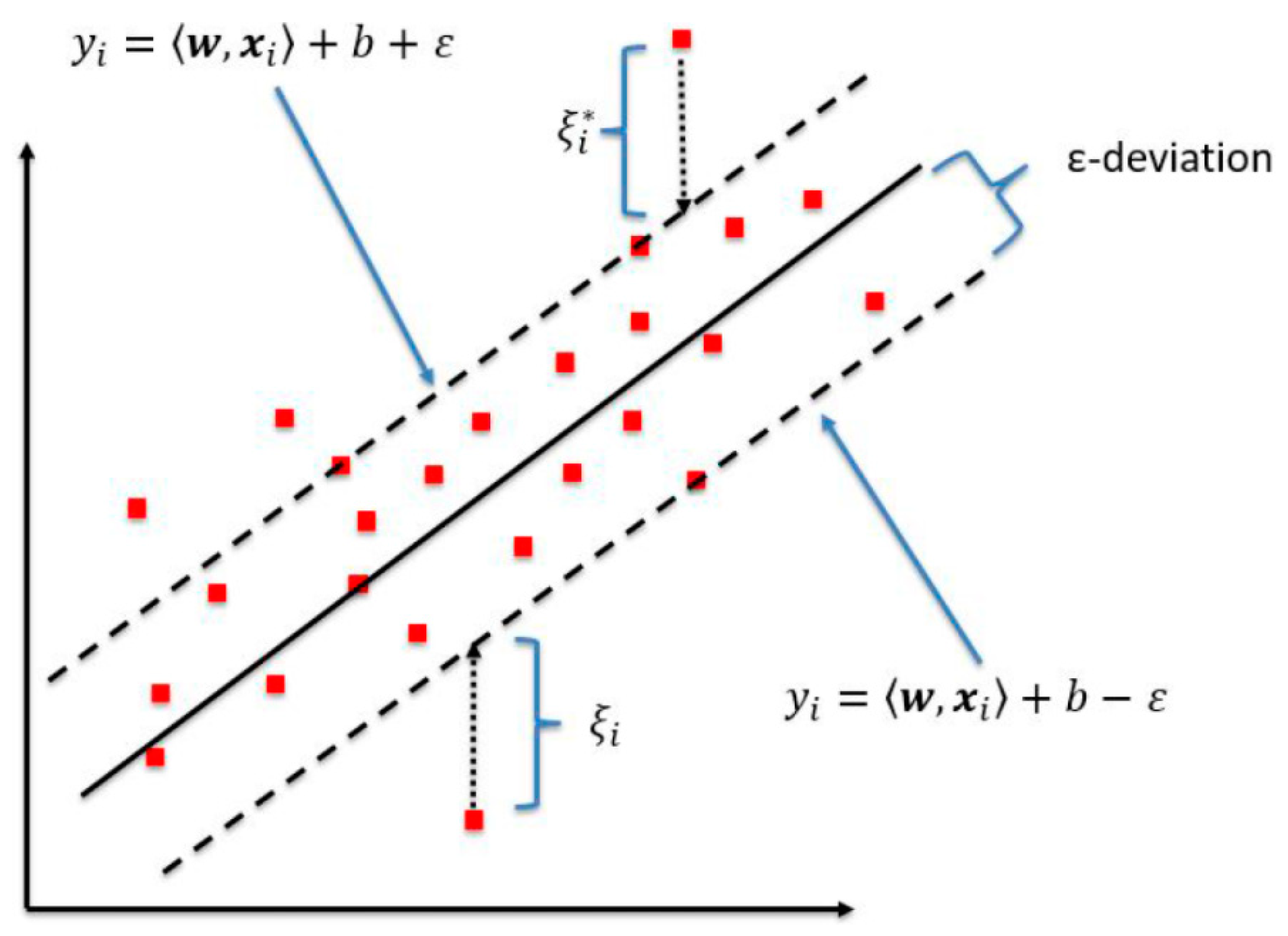
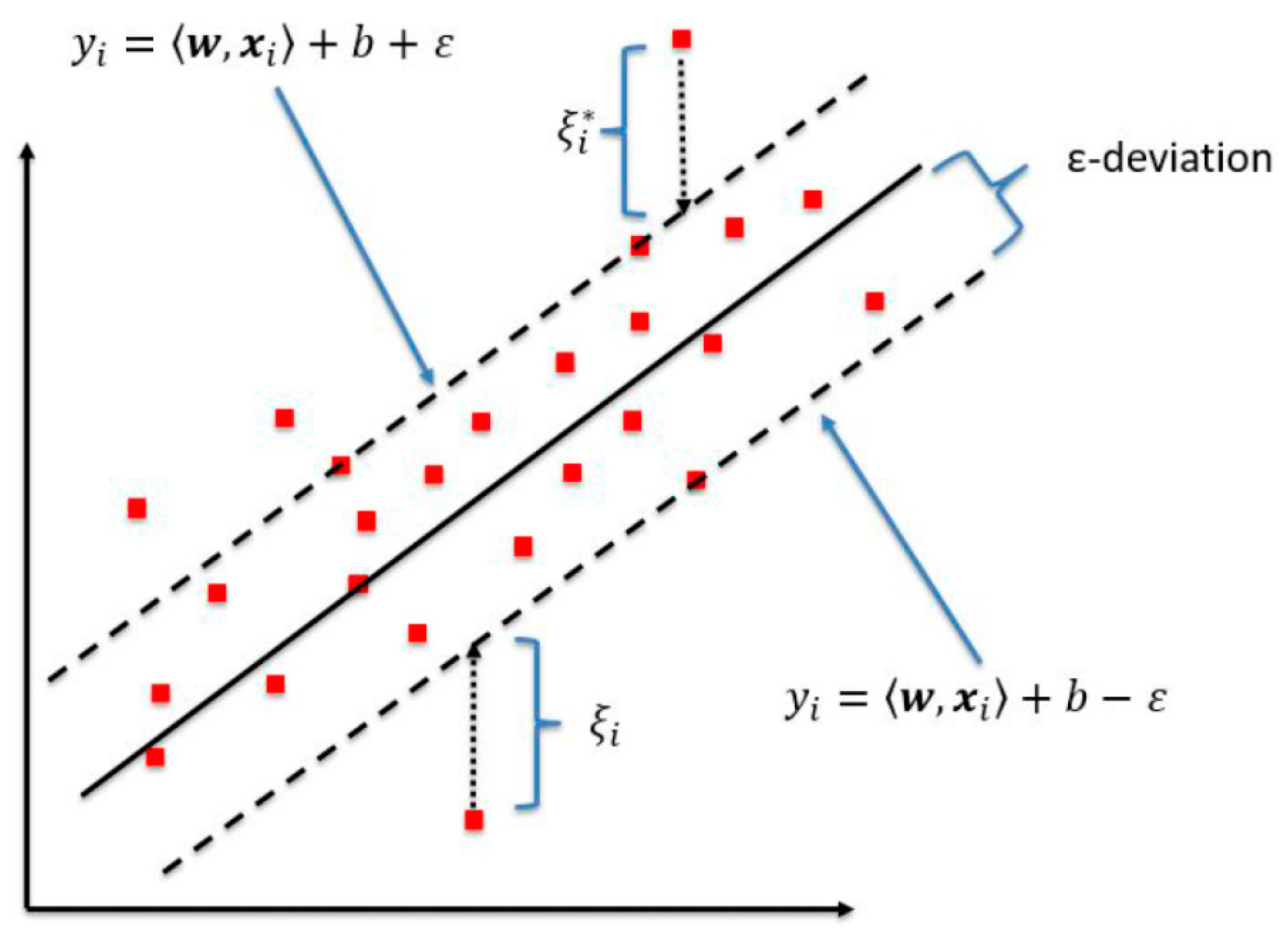
2.2. Machine Learning Method
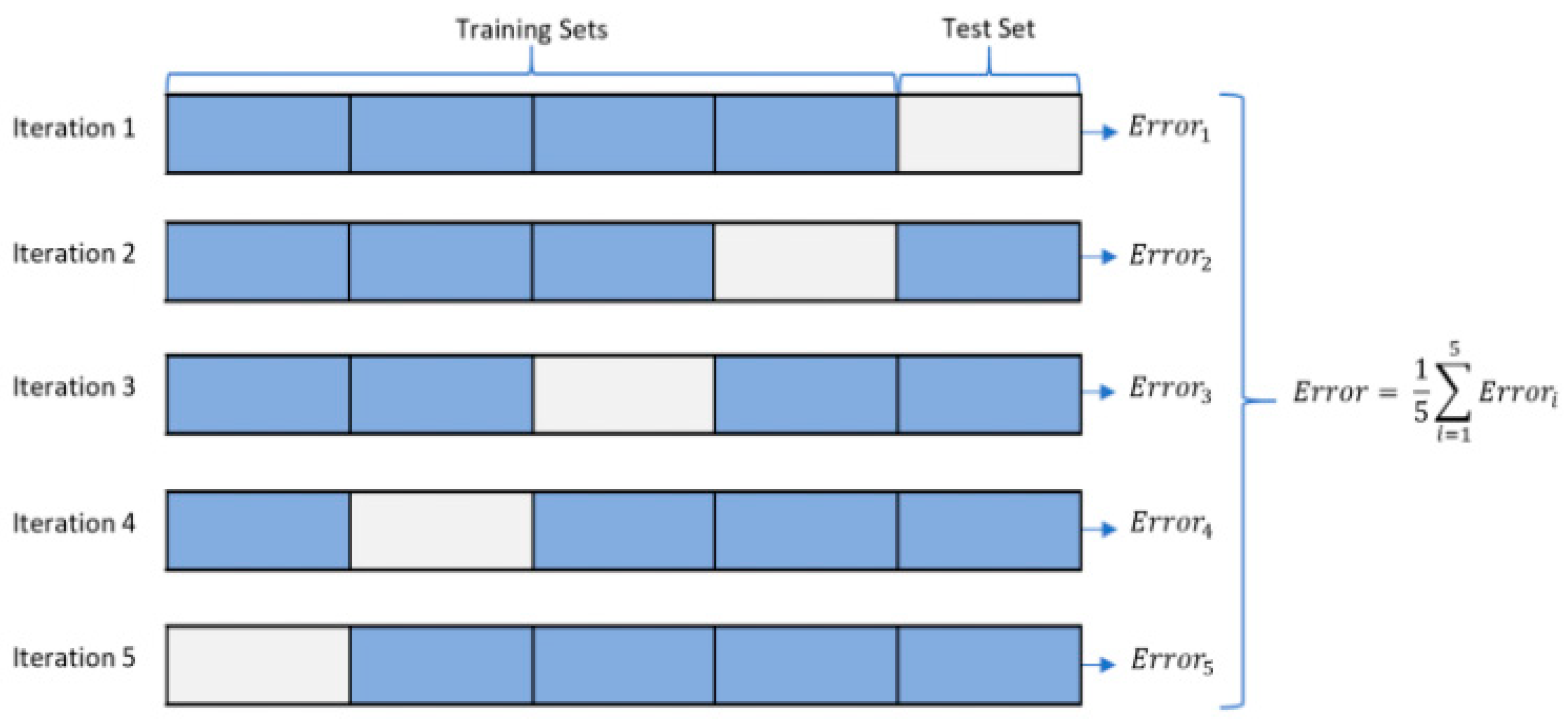
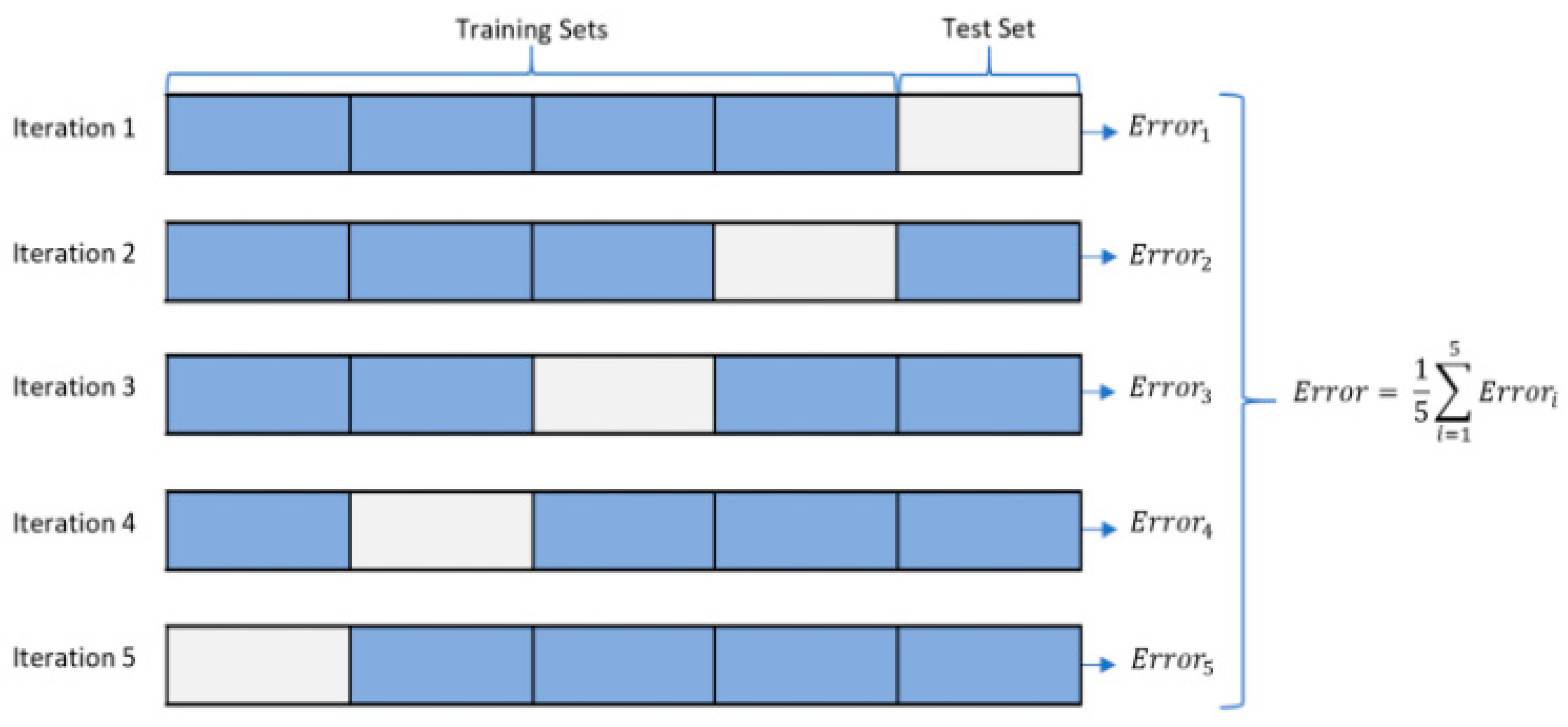
2.3. Performance Assessment Using K-Fold Cross Validation
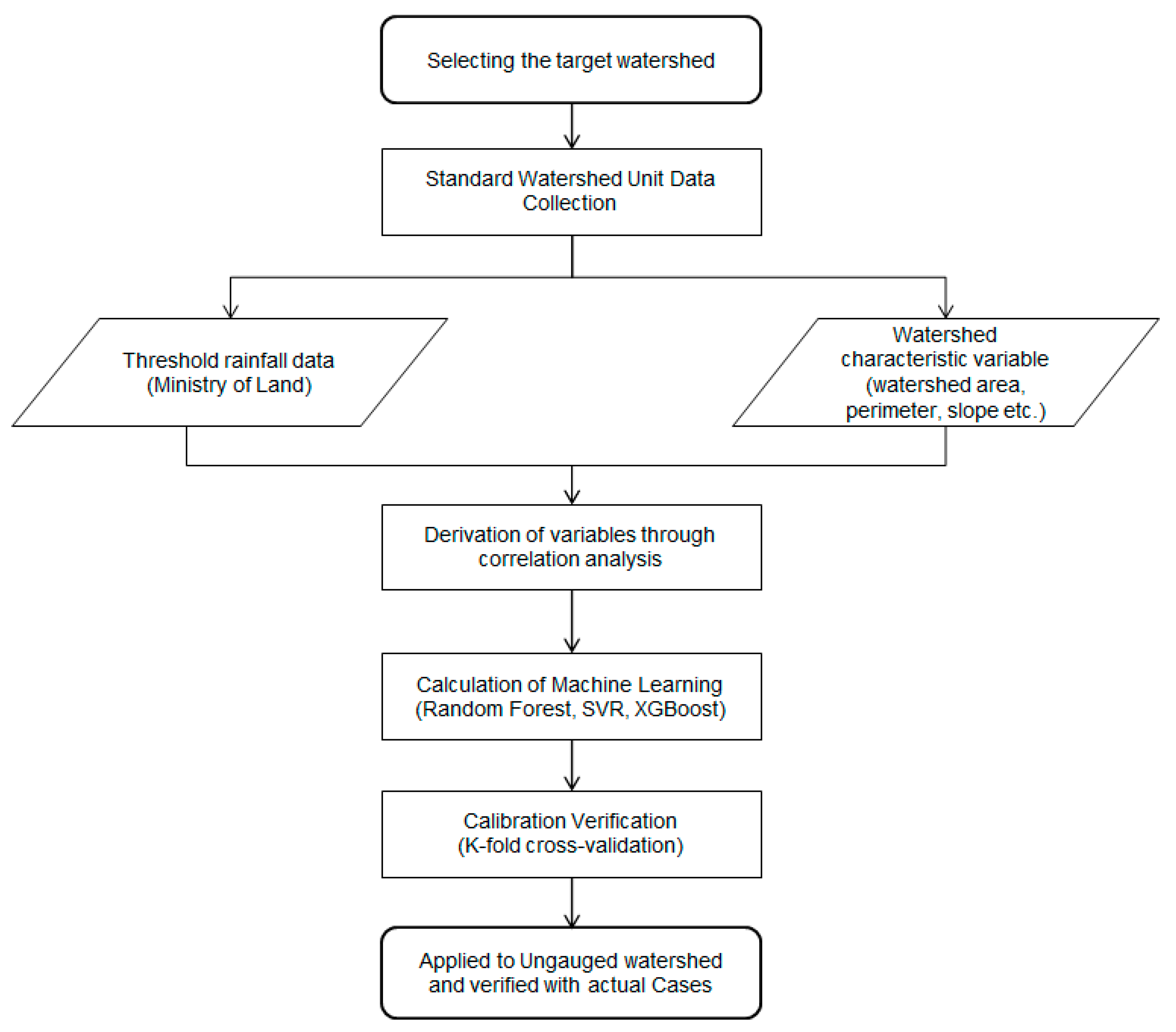
3. Selection of Target Watersheds and Variables
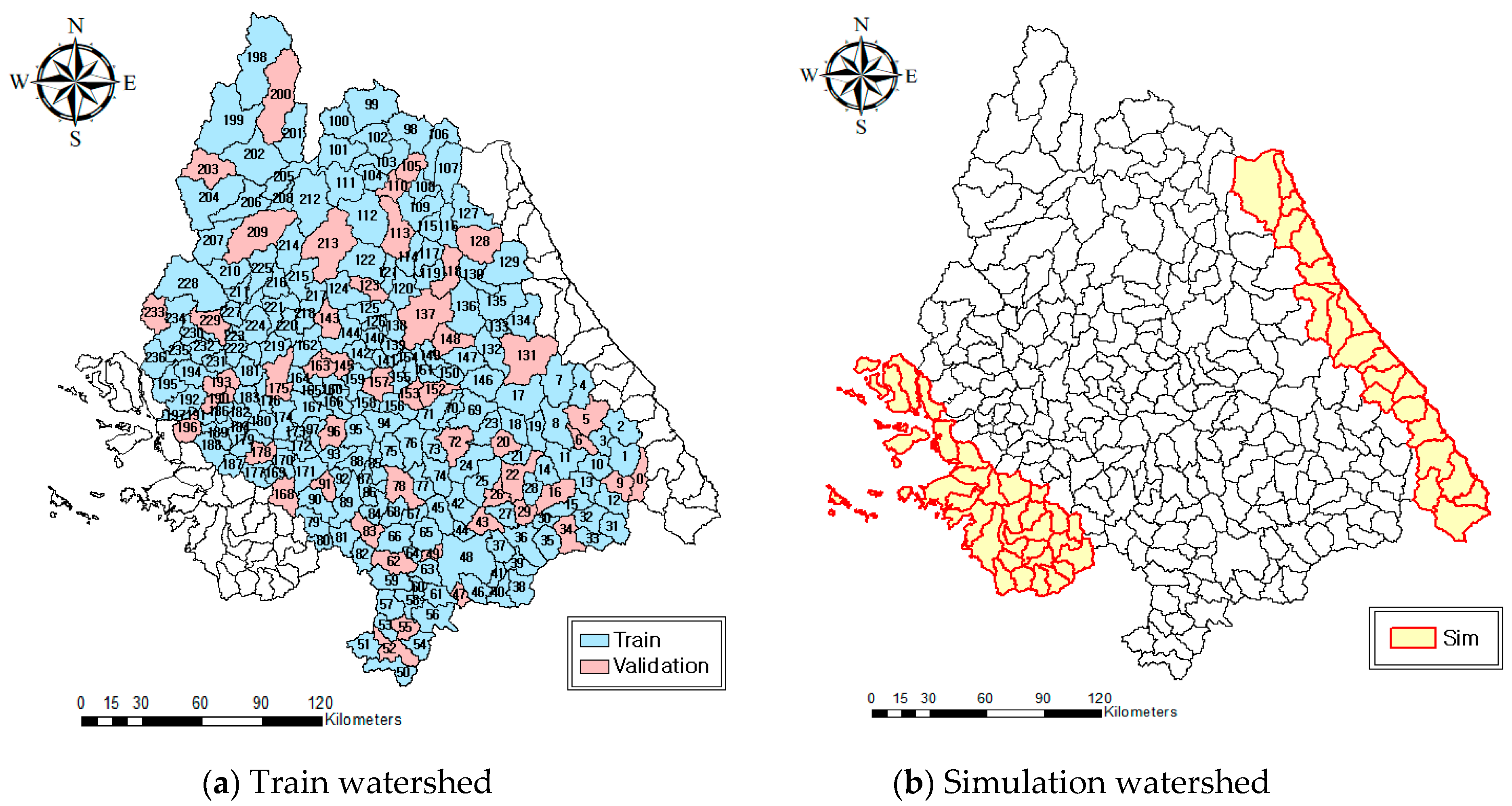
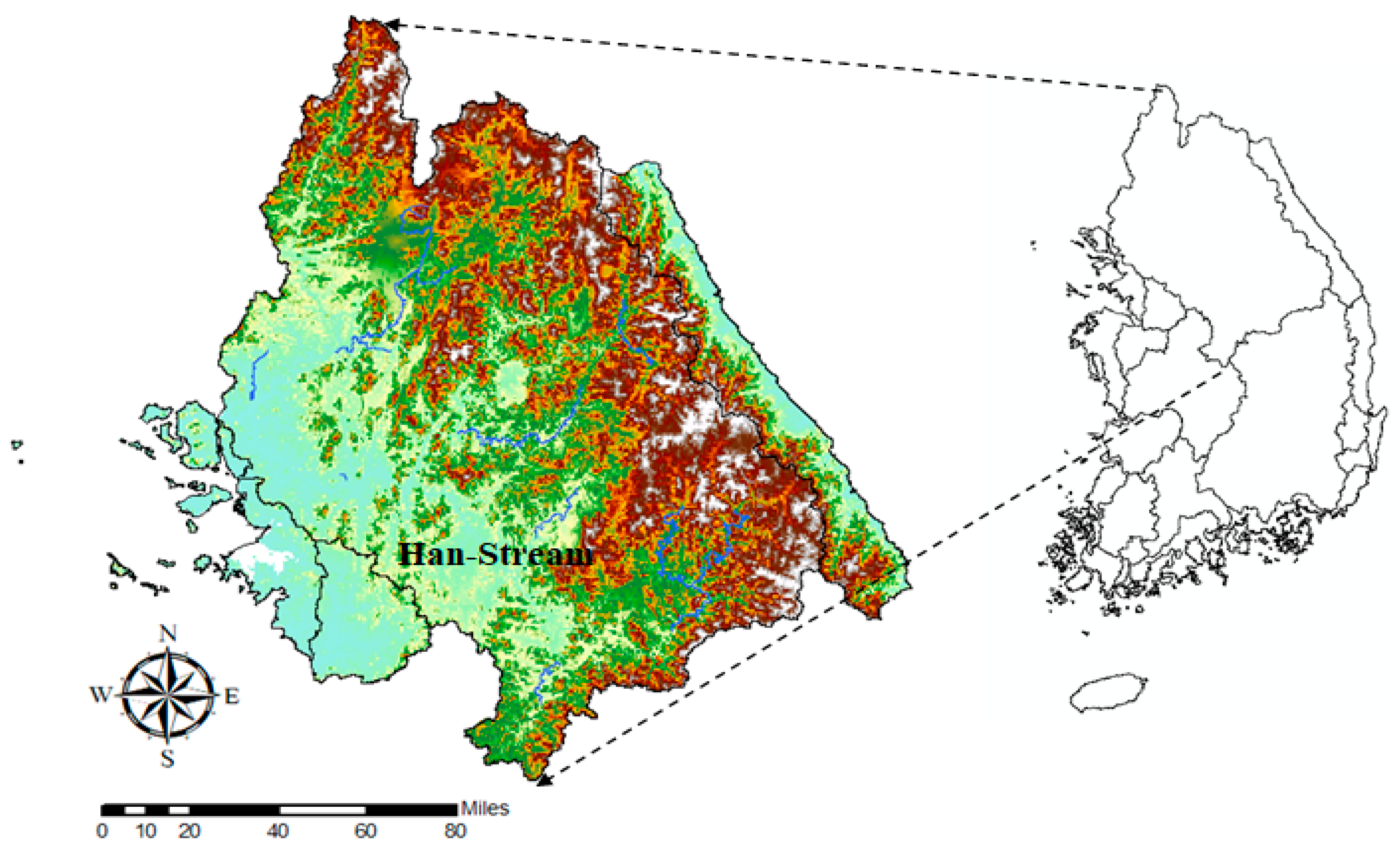
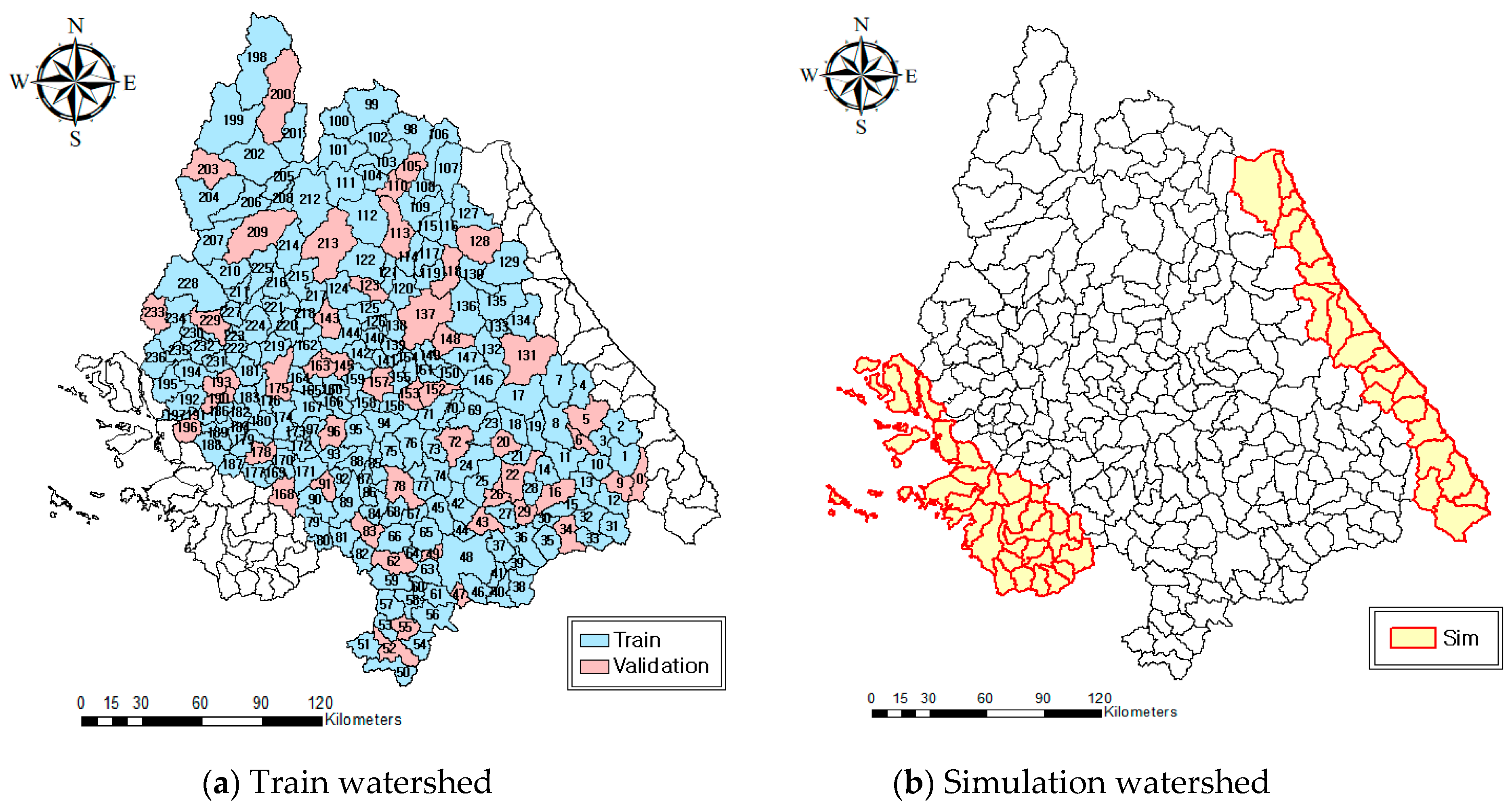
3.1. Selection of Target Watersheds
3.2. Dependent and Independent Variables
4. Machine Learning Application and Results
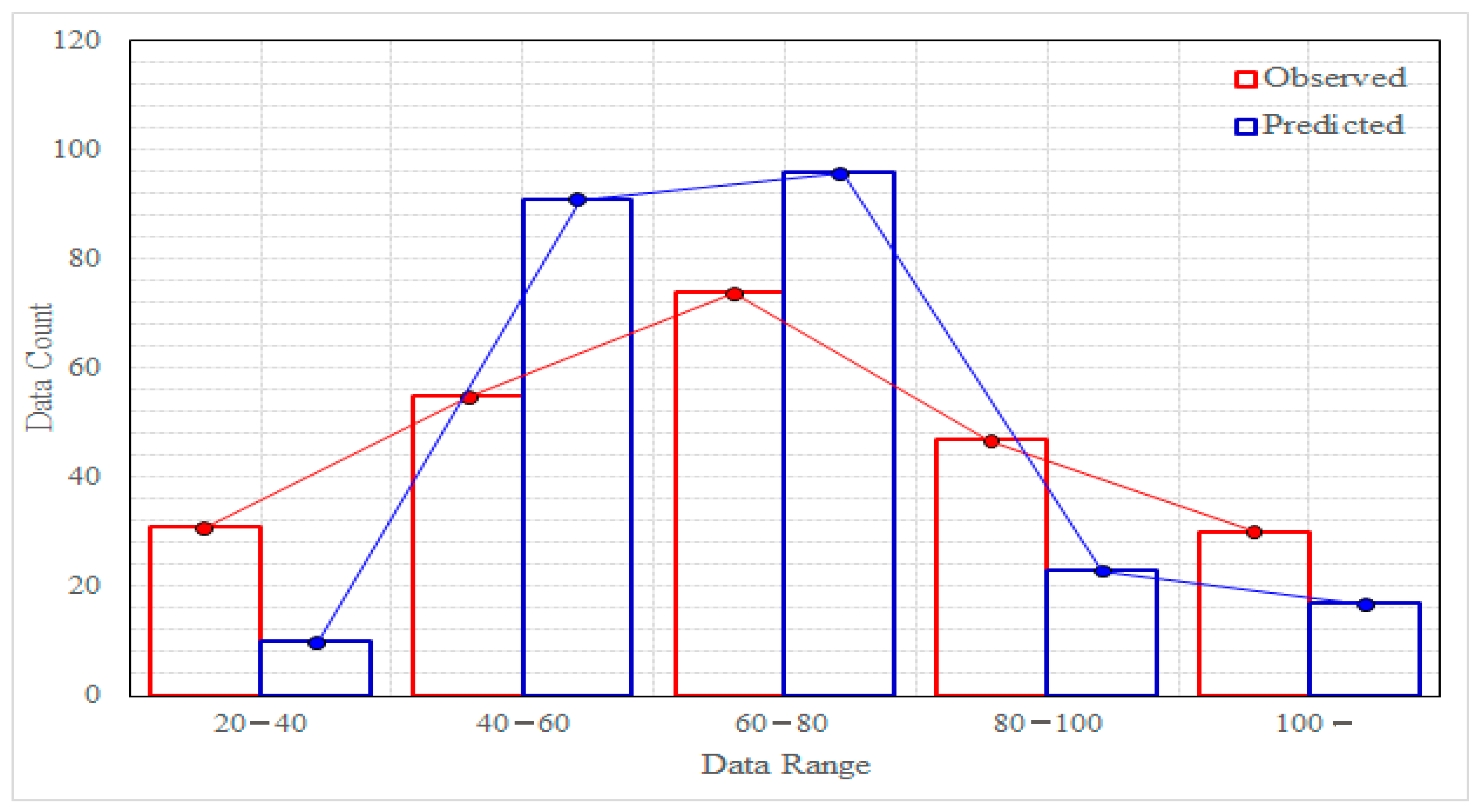
4.1. Validation of Prediction Models
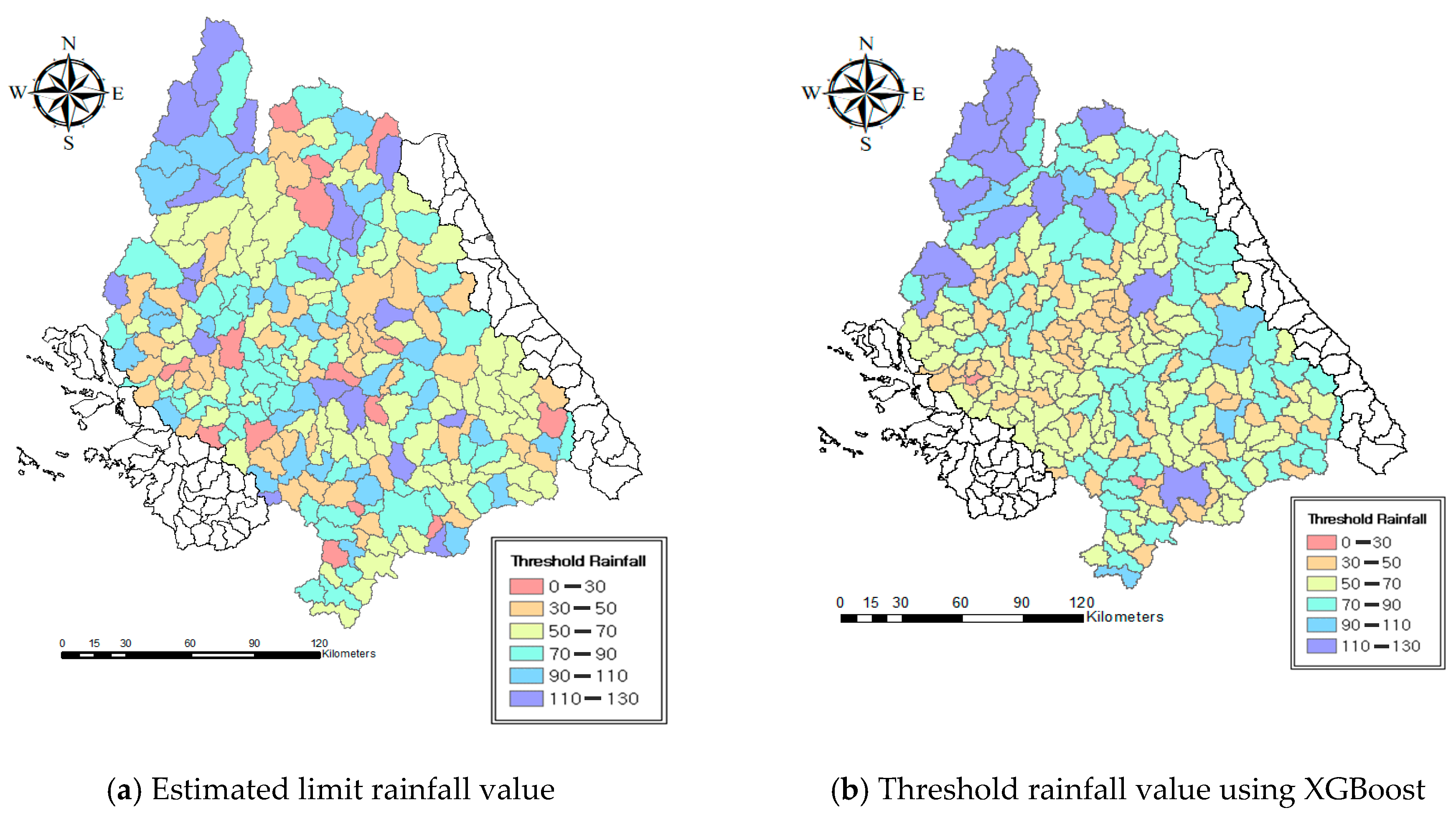
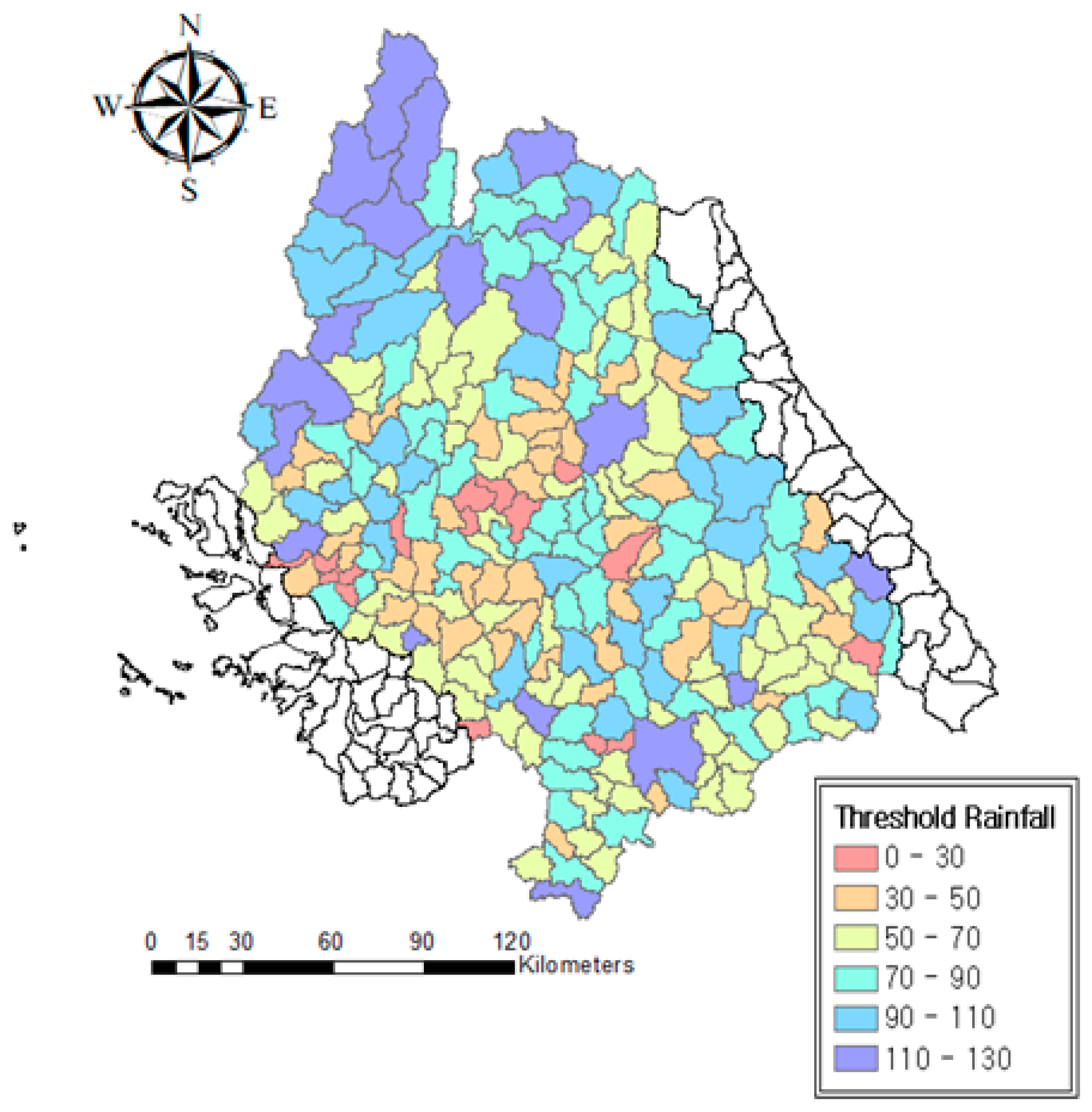
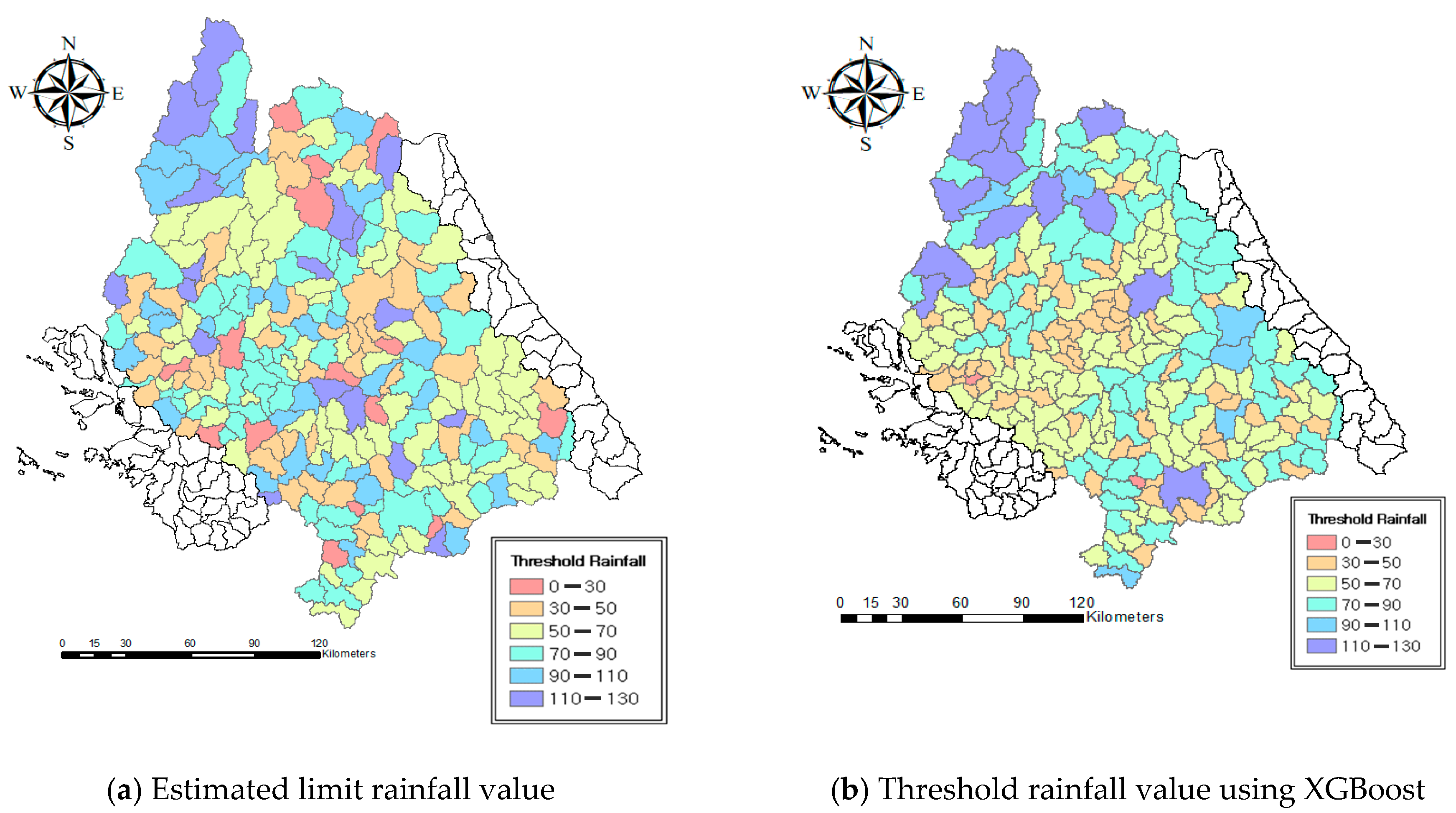
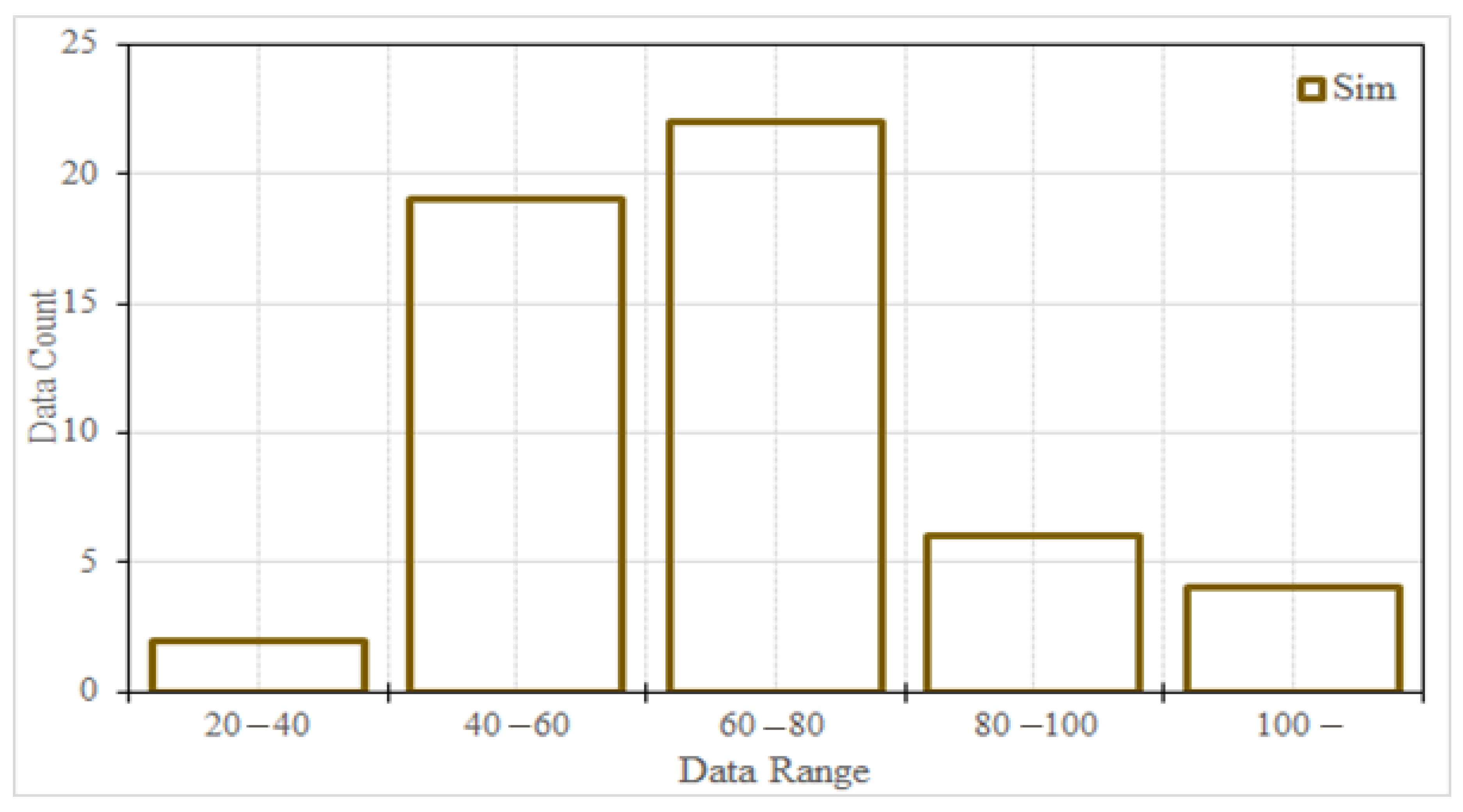
4.2. Calculation of Threshold Rainfalls in Ungauged Watersheds
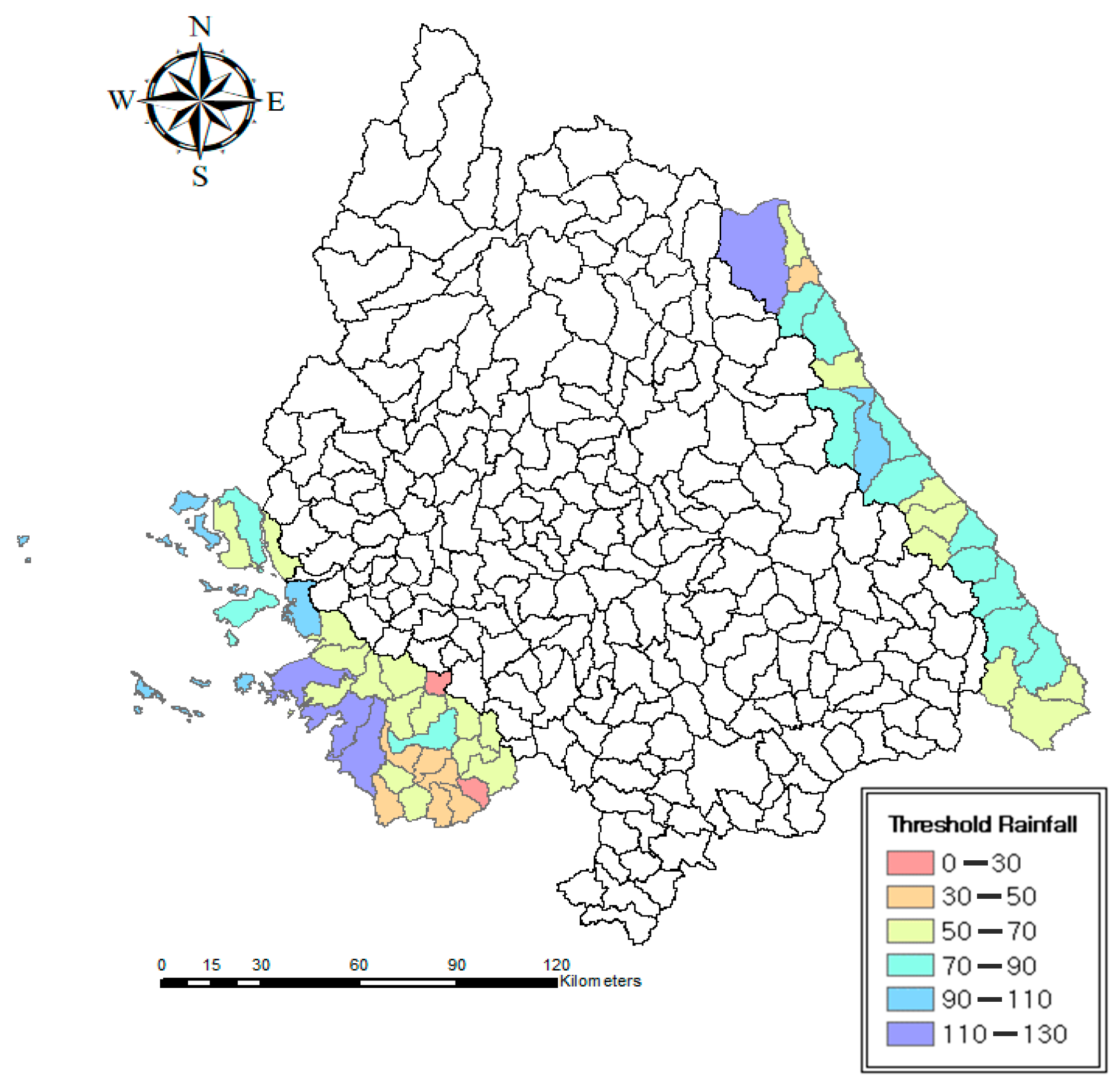
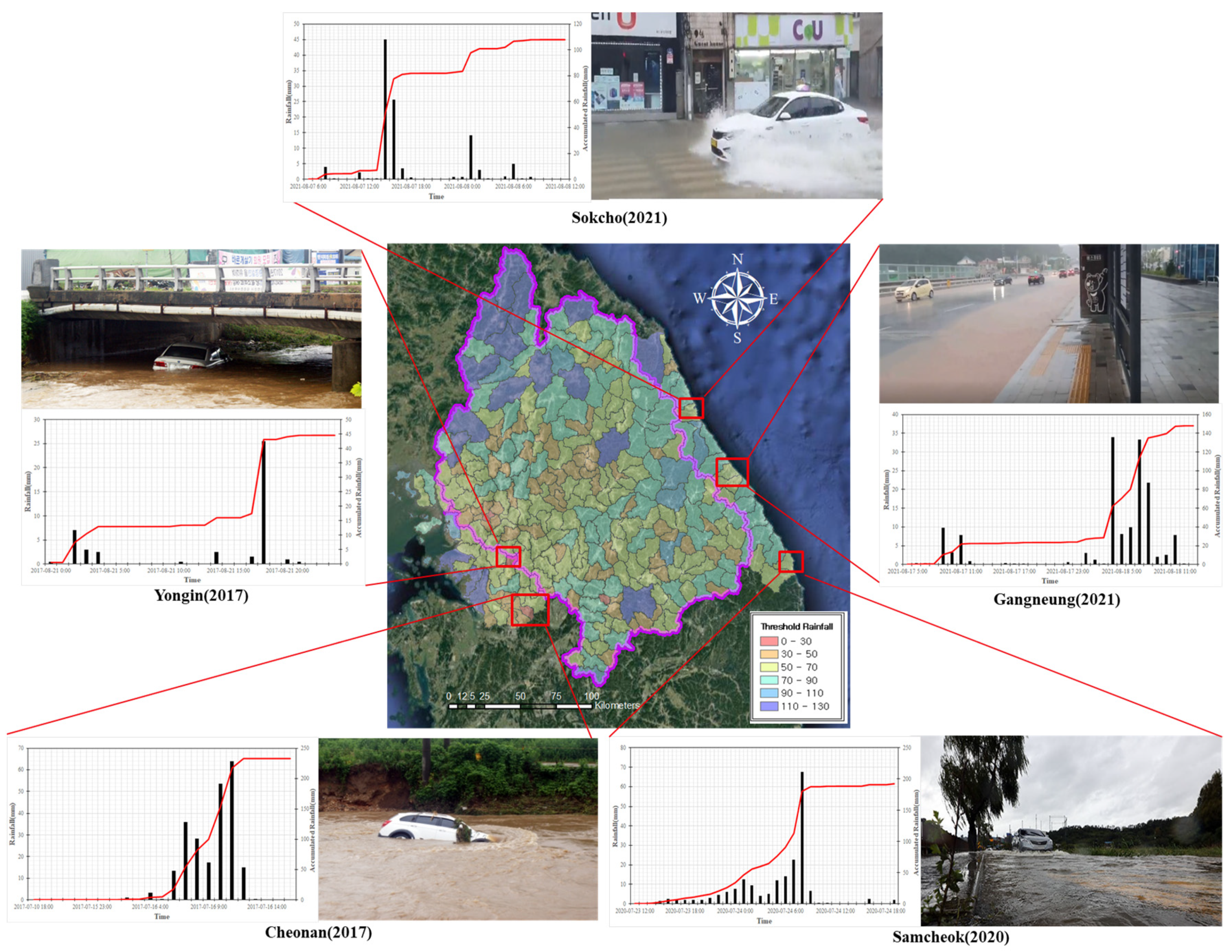
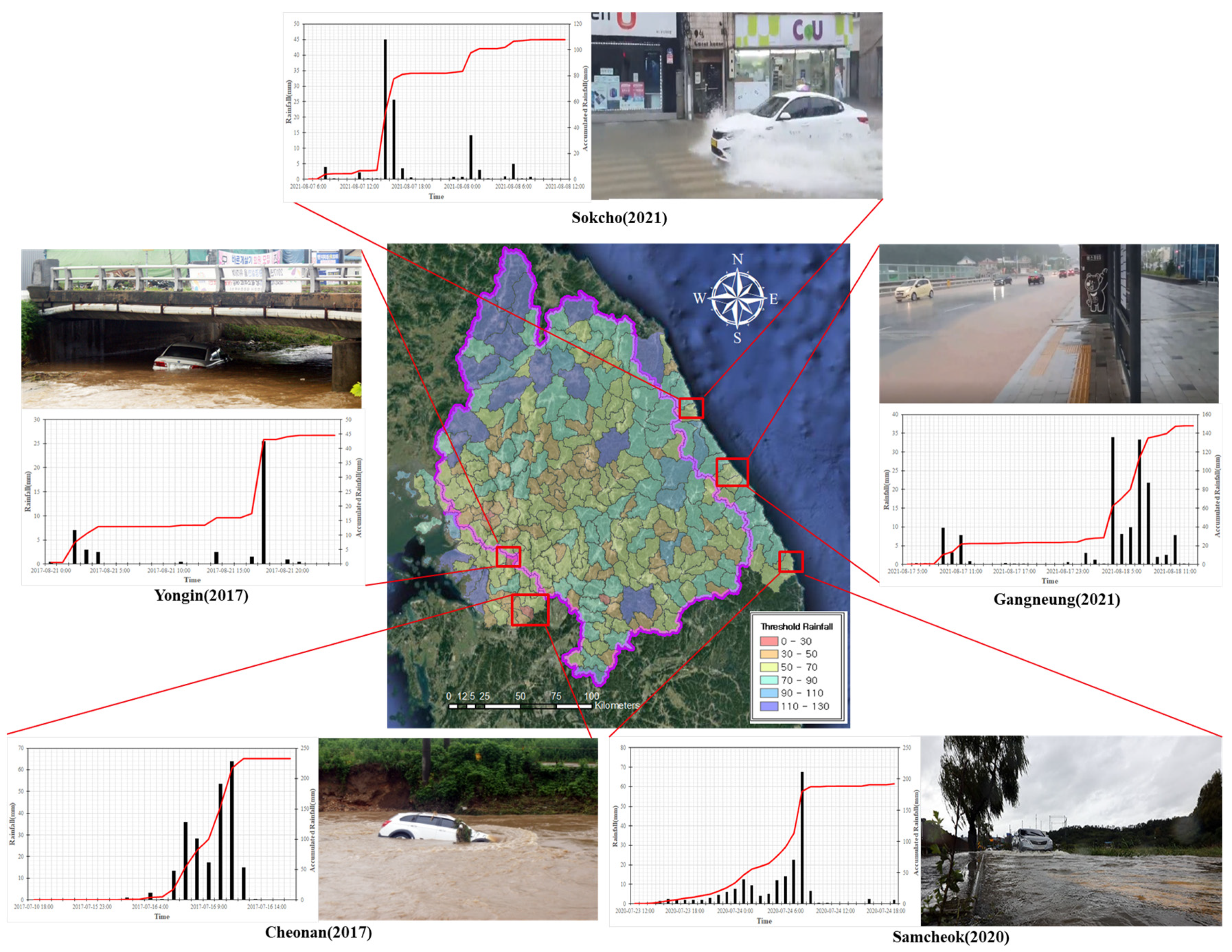
4.3. Validation Using Real World Cases and Assessment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, J.Y.; Choi, C.H.; Kang, D.S.; Kim, B.S.; Kim, T.W. Estimating Design Floods at Ungauged Watersheds in South Korea Using Machine Learning Models. Water 2020, 12, 3022. [Google Scholar] [CrossRef]
- WMO. Guideline on Multi-Hazard Impact-Based Forecast and Warning System; WMO-No. 1150; World Meteorological Organization: Geneva, Switzerland, 2015; p. 22. [Google Scholar]
- Jeong, K.Y. Impact Forecast Vision and Direction. Meteorol. Technol. Policy 2016, 9, 6–22. [Google Scholar]
- Go, Y.H. Development and Activation of Impact Forecasting Service. Available online: https://www.kma.go.kr/down/t_policy/t_policy_201706.pdf (accessed on 2 June 2021).
- Lee, D.H.; Kim, G.Y. Weather Disaster Impact Forecast. KISTEP Technol. Trend Brief 2019, 10, p1–p4. [Google Scholar]
- FFC (Flood Forecasting Centre). Flood Guidance Statement User Guide (Version 4); Flood Forecasting Centre: Exeter, UK, 2017; p. 6. [Google Scholar]
- Lee, B.J. Analysis on Inundation Characteristics for Flood Impact Forecasting in Gangnam Drainage Basin. Korean Meteorol. Soc. 2017, 27, 189–197. [Google Scholar]
- Kim, B.S.; Hong, J.B.; Kim, H.S.; Yoon, S.Y. Development of Flash Flood model Using Digital Terrain Analysis Model and Rainfall RADAR: I. Methodology and Model Development. J. Korean Soc. Civ. Eng. B 2007, 27, 151–159. [Google Scholar]
- Kim, B.S.; Kim, H.S. Estimation of the Flash Flood Severity using Runoff hydrograph and Flash flood index. J. Korea Water Resour. Assoc. 2008, 41, 185–196. [Google Scholar] [CrossRef] [Green Version]
- Cho, B.G.; Ji, H.S.; Bae, D.H. Development and Evaluation of Computational Method for Korean Threshold Runoff. J. Korea Water Resour. Assoc. 2011, 44, 875–887. [Google Scholar] [CrossRef] [Green Version]
- Chung, I.M.; Lee, C.W.; Kim, J.T.; Na, H.N.; Kim, N.W. Development of Threshold Runoff Simulation Method for Runoff Analysis of Jeju Island. J. Environ. Sci. Int. 2011, 20, 1347–1355. [Google Scholar] [CrossRef]
- Park, J.B.; Kang, D.G.; Park, M.J. Rainfall Thresholds Estimation to Develop Flood Forecasting and Warning System for Nakdong Small River Basins. J. Korean Soc. Hazard Mitig. 2013, 13, 311–317. [Google Scholar] [CrossRef] [Green Version]
- Kang, H.S.; Choi, C.W.; Lee, H.S.; Hwang, J.G.; Moon, H.J. Development of an ANN-Based Urban Flood Alert Criteria Prediction Model and the Impact of Training Data Augmentation. J. Korean Soc. Hazard Mitig. 2021, 21, 257–264. [Google Scholar] [CrossRef]
- Huff, F.A. Time Distribution of Rainfall in Heavy Storms. Water Resour. Res. 1967, 3, 1007–1019. [Google Scholar] [CrossRef]
- Lee, S.H.; Kang, D.H.; Kim, B.S. A Study on the Method of Calculating the Threshold Rainfall for Rainfall Impact Forecasting. J. Korean Soc. Hazard Mitig. 2018, 18, 93–102. [Google Scholar] [CrossRef] [Green Version]
- Zagorecki, A.T.; Johnson, D.E.; Ristvej, J. Data mining and machine learning in the context of disaster and crisis management. Int. J. Emerg. Manag. 2013, 9, 351–365. [Google Scholar] [CrossRef]
- Chang, F.-J.; Guo, S. Advances in hydrologic forecasts and water resources management. Water 2020, 12, 1819. [Google Scholar] [CrossRef]
- Park, J.; Park, J.-H.; Choi, J.-S.; Joo, J.C.; Park, K.; Yoon, H.C.; Park, C.Y.; Lee, W.H.; Heo, T.-Y. Ensemble Model Development for the Prediction of a Disaster Index in Water Treatment Systems. Water 2020, 12, 3195. [Google Scholar] [CrossRef]
- Jung, S.H.; Lee, D.E.; Lee, K.S. Prediction of River Water Level Using Deep-Learning Open Library. J. Korean Soc. Hazard Mitig. 2018, 18, 1–11. [Google Scholar] [CrossRef]
- Kao, I.F.; Zhou, Y.; Chang, L.C.; Chang, F.J. Exploring a Long Short-Term Memory based Encoder-Decoder framework for multi-step-ahead flood forecasting. J. Hydrol. 2020, 583, 124631. [Google Scholar] [CrossRef]
- Chang, L.C.; Chang, F.J.; Yang, S.N.; Tsai, F.H.; Chang, T.H.; Herricks, E.E. Self-organizing maps of typhoon tracks allow for flood forecasts up to two days in advance. Nat. Commun. 2020, 11, 1983. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chang, F.J.; Tsai, M.J. A nonlinear spatio-temporal lumping of radar rainfall for modeling multi-step-ahead inflow forecasts by data-driven techniques. J. Hydrol. 2016, 535, 256–269. [Google Scholar] [CrossRef]
- Zhou, Y.; Guo, S.; Chang, F.J. Explore an evolutionary recurrent ANFIS for modelling multi-step-ahead flood forecasts. J. Hydrol. 2019, 570, 343–355. [Google Scholar] [CrossRef]
- Choi, C.H.; Kim, J.S.; Kim, D.H.; Lee, J.H.; Kim, D.H.; Kim, H.S. Development of Heavy Rain Damage Prediction Functions in the Seoul Capital Area Using Machine Learning Techniques. J. Korean Soc. Hazard Mitig. 2018, 18, 435–447. [Google Scholar] [CrossRef] [Green Version]
- Choi, C.H. Development of Combined Heavy Rain Damage Prediction Models Using Machine Learning and Effectiveness of Disaster Prevention Projects. Ph.D. Thesis, Inha University, Incheon, Korea, 2019. [Google Scholar]
- Yen, M.H.; Liu, D.W.; Hsin, Y.C.; Lin, C.E.; Chen, C.C. Application of the deep learning for the prediction of rainfall in Southern Taiwan. Sci. Rep. 2019, 9, 12774. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, Y.M.; Ko, C.M.; Shin, S.C.; Kim, B.S. The Development of a Rainfall Correction Technique based on Machine Learning for Hydrological Applications. J. Environ. Sci. Int. 2019, 28, 125–135. [Google Scholar] [CrossRef]
- Yu, B.I. Study on Flash Floods and Debris Flow Guidance of Gangwon-do. Master’s Thesis, Kangwon University, Chuncheon-si, Korea, 2016. [Google Scholar]
- Kim, D.W.; Hong, S.J.; Kim, J.W.; Han, D.G.; Hong, I.P.; Kim, H.S. Water Quality Analysis of Hongcheon River Basin under Climate Change. J. Wetl. Res. 2015, 17, 348–358. [Google Scholar] [CrossRef]
- Suh, J.D. Foreign Exchange Rate Forecasting Using the GARCH extended Random Forest Model. J. Ind. Econ. Bus. 2016, 29, 1607–1628. [Google Scholar]
- Choi, C.H.; Park, K.H.; Park, H.K.; Lee, M.J.; Kim, J.S.; Kim, H.S. Development of Heavy Rain Damage Prediction Function for Public Facility Using Machine Learning. J. Korean Soc. Hazard Mitig. 2017, 17, 443–450. [Google Scholar] [CrossRef]
- Jang, D.R. A Study on the Art Price Prediction Model Using Machine Learning. Master’s Thesis, Hongik University, Seoul, Korea, 2020. [Google Scholar]
- Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Kleynhans, T.; Montanaro, M.; Gerace, A.; Kanan, C. Predicting Top-of-Atmosphere Thermal Radiance Using MERRA-2 Atmospheric Data with Deep Learning. Remote Sens. 2017, 9, 1133. [Google Scholar] [CrossRef] [Green Version]
- Kim, I.H.; Lee, K.S. Tree based ensemble model for developing and evaluating automated valuation models: The case of Seoul residential apartment. J. Korean Data Inf. Sci. Soc. 2020, 31, 375–389. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Tie, Y.L. LightGBM: A Highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3149–3157. [Google Scholar]
- Ioannou, K.; Karampatzakis, D.; Amanatidis, P.; Aggelopoulos, V.; Karmiris, I. Low-Cost Automatic Weather Stations in the Internet of Things. Information 2021, 12, 146. [Google Scholar] [CrossRef]
- Stefanidis, S.; Dafis, S.; Stathis, D. Evaluation of Regional Climate Models (RCMs) Performance in Simulating Seasonal Precipitation over Mountainous Central Pindus (Greece). Water 2020, 12, 2750. [Google Scholar] [CrossRef]
- Ioannou, K.; Myronidis, D.; Lefakis, P.; Stathis, D. The use of artificial neural networks (anns) for the forecast of precipitation levels of lake doirani(N. greece). Fresenius Environ. Bull. 2010, 19, 1921–1927. [Google Scholar]
- Choo, K.S.; Kang, D.H.; Kim, B.S. A Study on the Estimation of the Threshold Rainfall in Standard Watershed Units. J. Korean Soc. Disaster Secur. 2021, 14, 1–11. [Google Scholar]
- Myronidis, D.; Ivanova, E. Generating Regional Models for Estimating the Peak Flows and Environmental Flows Magnitude for the Bulgarian-Greek Rhodope Mountain Range Torrential Watersheds. Water 2020, 12, 784. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 | 290 |
| mean | 144.6 | 324.0 | 35.4 | 253.3 | 1.7 | 58.7 | 12.9 | 67.3 | 1.0 | 0.4 | 2.4 | 0.7 | 13.3 | 1376 | 1.8 |
| Max | 571.6 | 930.3 | 65.1 | 302.7 | 4.0 | 87.9 | 63.3 | 262.3 | 3.6 | 0.7 | 12.6 | 9.5 | 36.8 | 3921.4 | 4.4 |
| min | 39.0 | 4.9 | 4.0 | 103.7 | 0.1 | 33.7 | 0.0 | 32.7 | 0.0 | 0.0 | 0.1 | 0.3 | 0.9 | 32.8 | 0.7 |
| Model | MAE | RMSE | RMSLE | |
|---|---|---|---|---|
| Support Vector | Fold 1 | 15 | 19 | 0.26 |
| Fold 2 | 23 | 38 | 0.4 | |
| Fold 3 | 19 | 26 | 0.29 | |
| Fold 4 | 21 | 26 | 0.47 | |
| Fold 5 | 28 | 38 | 0.34 | |
| Random Forest | Fold 1 | 12 | 19 | 0.28 |
| Fold 2 | 20 | 32 | 0.46 | |
| Fold 3 | 16 | 20 | 0.34 | |
| Fold 4 | 22 | 27 | 0.47 | |
| Fold 5 | 21 | 26 | 0.45 | |
| XGBoost | Fold 1 | 14 | 20 | 0.28 |
| Fold 2 | 20 | 33 | 0.38 | |
| Fold 3 | 16 | 20 | 0.29 | |
| Fold 4 | 21 | 27 | 0.46 | |
| Fold 5 | 25 | 37 | 0.35 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, K.-S.; Oh, C.-H.; Choi, J.-R.; Kim, B.-S. Estimation of Threshold Rainfall in Ungauged Areas Using Machine Learning. Water 2022, 14, 859. https://doi.org/10.3390/w14060859
Chu K-S, Oh C-H, Choi J-R, Kim B-S. Estimation of Threshold Rainfall in Ungauged Areas Using Machine Learning. Water. 2022; 14(6):859. https://doi.org/10.3390/w14060859
Chicago/Turabian StyleChu, Kyung-Su, Cheong-Hyeon Oh, Jung-Ryel Choi, and Byung-Sik Kim. 2022. "Estimation of Threshold Rainfall in Ungauged Areas Using Machine Learning" Water 14, no. 6: 859. https://doi.org/10.3390/w14060859