
Salinity Forecasting on Raw Water for Water Supply in the Chao Phraya River



Abstract
1. Introduction
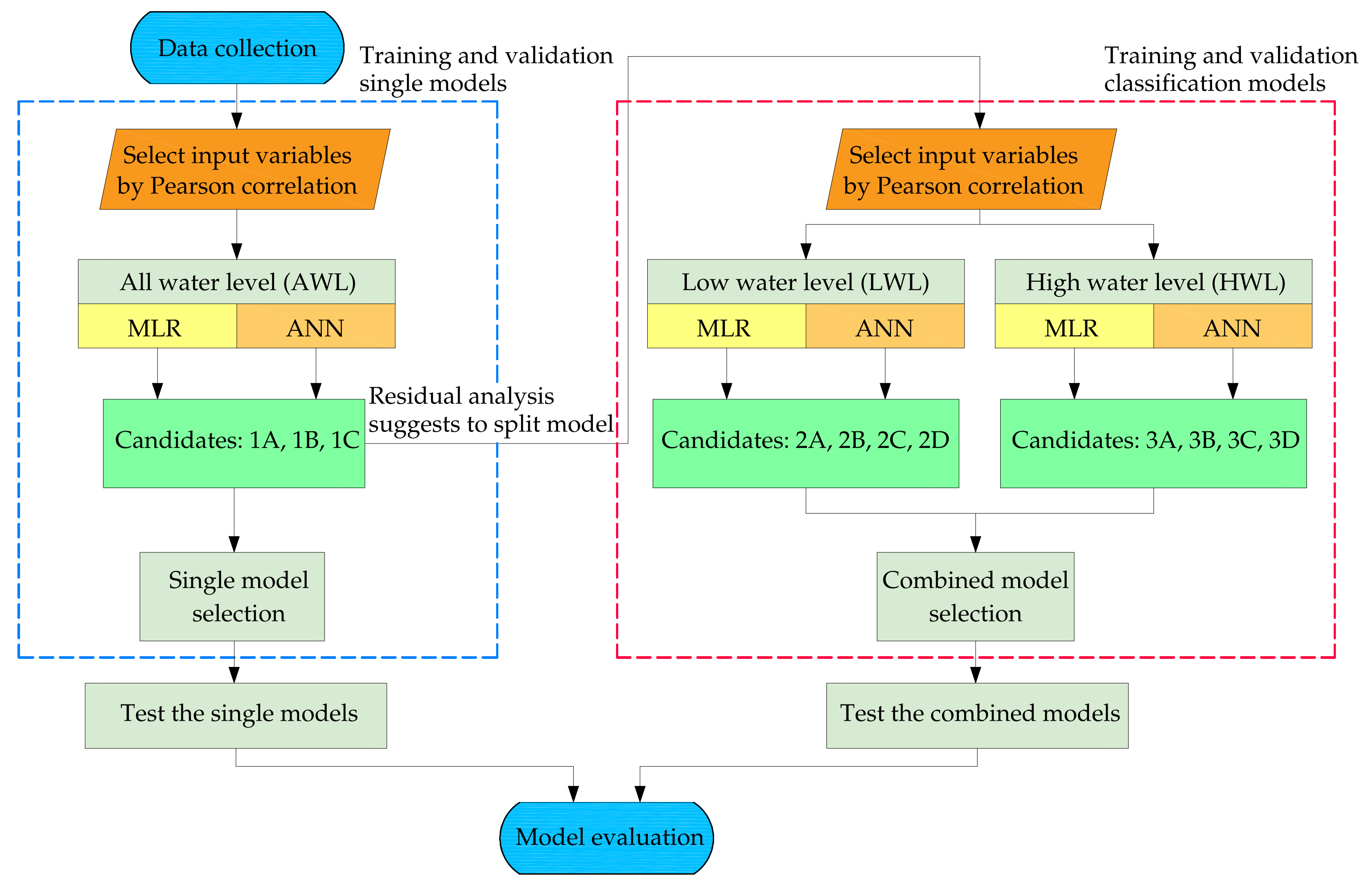
2. Materials and Methods
2.1. Study Site and Data Collection
2.2. Selection of the Predictor Variables
2.3. Model Development and Parameter Selection
3. Results and Discussion
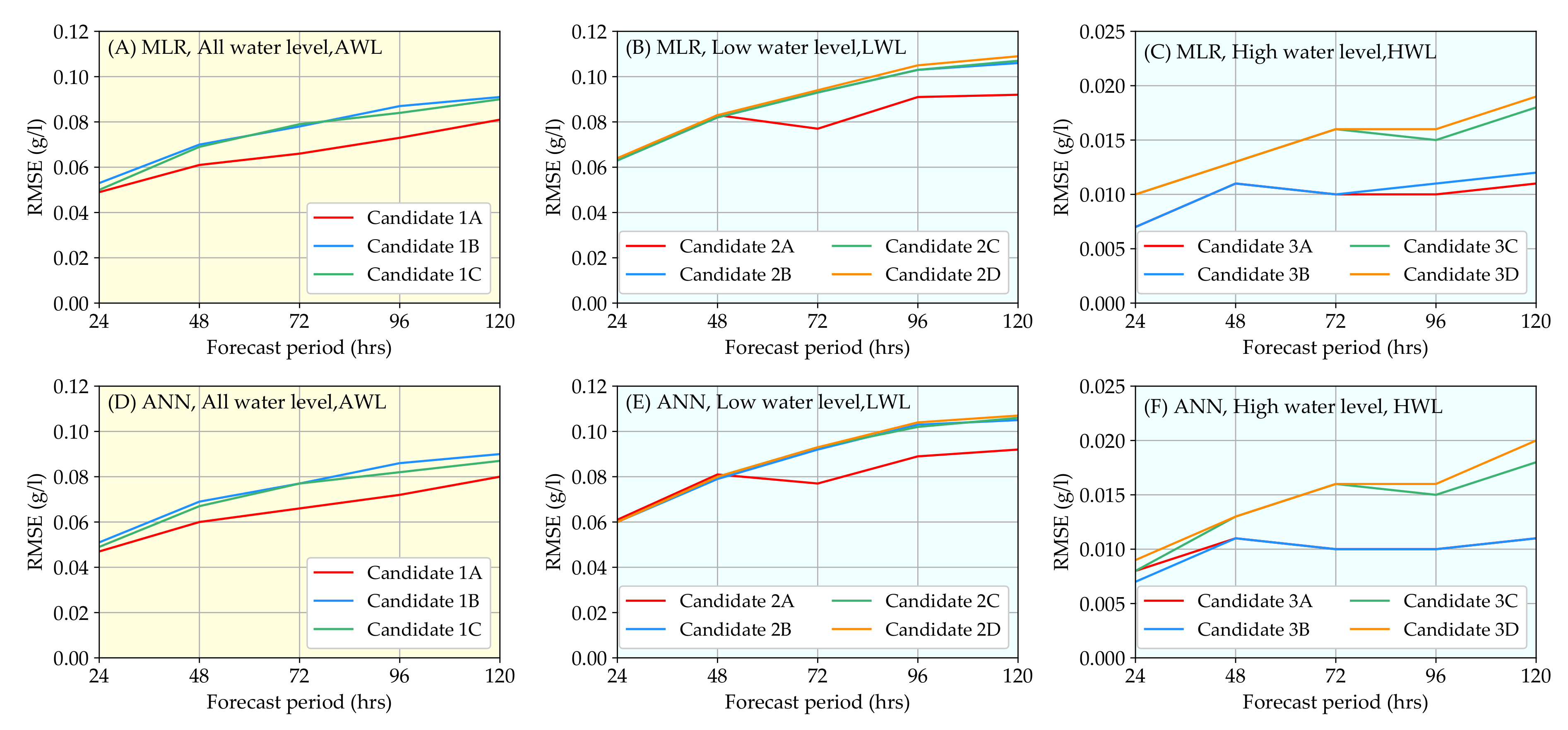
3.1. Model Performance Comparison and Validation
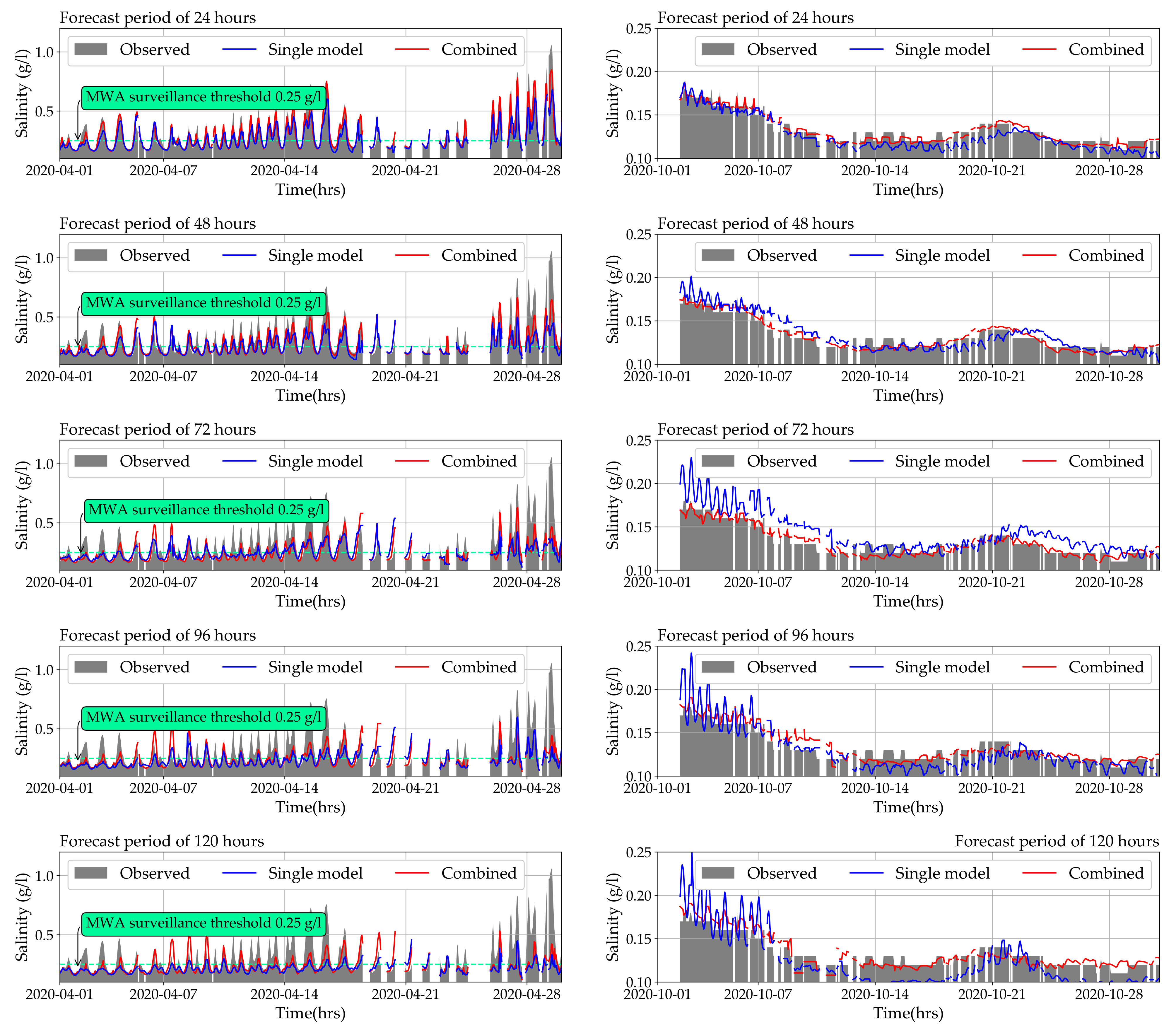
3.2. Model Test: Comparing Continuous Forecasting with Real Data
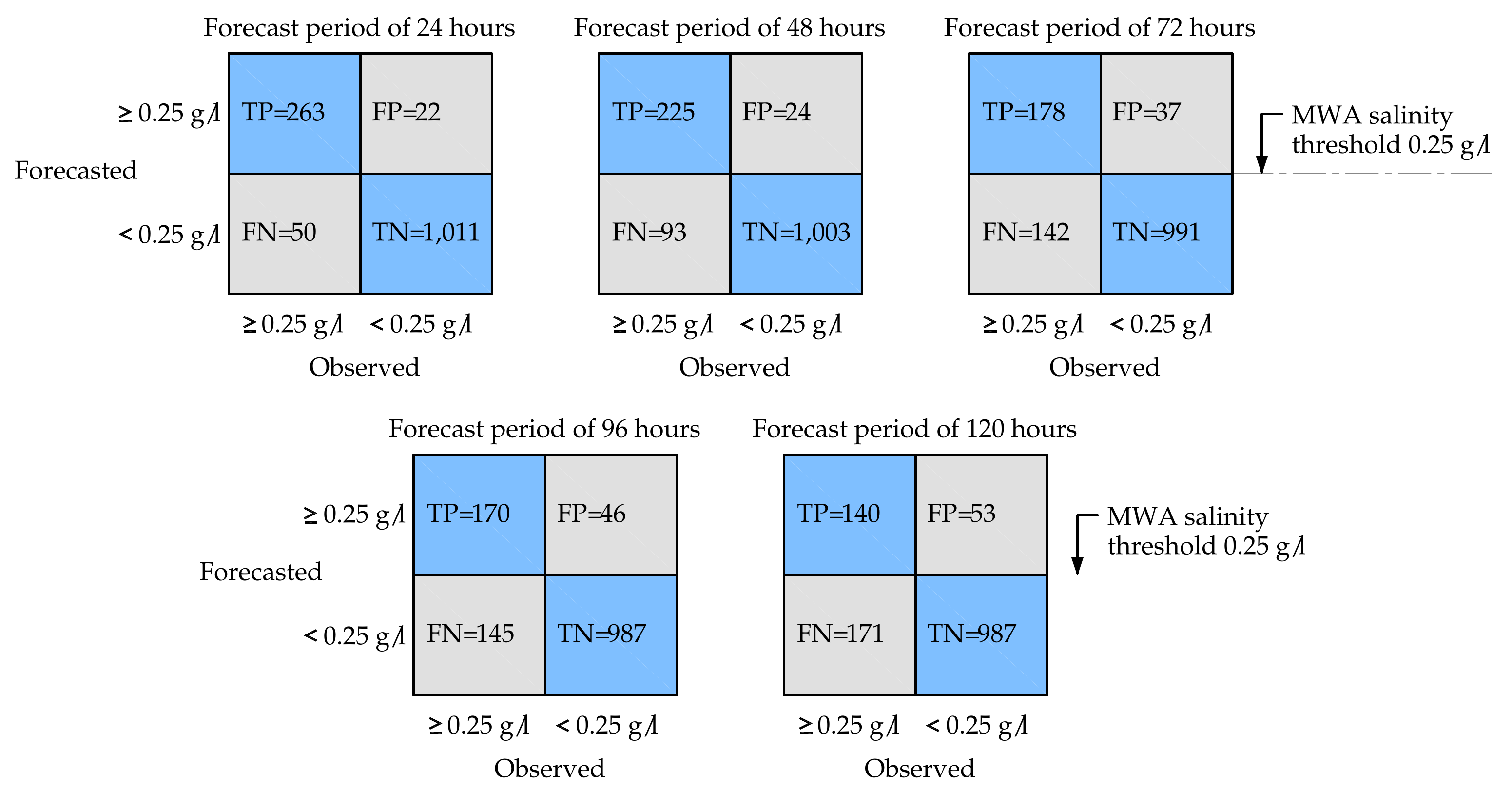
3.3. An Application of the Model as an Alarm System
- Case 1:
- Observed salinity ≥ 0.25 , and forecasted salinity ≥ 0.25 is true positive (TP);
- Case 2:
- Observed salinity ≥ 0.25 , and forecasted salinity < 0.25 is false negative (FN);
- Case 3:
- Observed salinity < 0.25 , and forecasted salinity < 0.25 is true negative (TN);
- Case 4:
- Observed salinity < 0.25 , and forecasted salinity ≥ 0.25 is false positive (FP).
4. Conclusions
- The residual analysis of the the multiple linear regression (MLR) indicated that the model behaviours were different at high and low water levels, therefore, a two-stage model (the combined model) was proposed, analysed and compared to the single model;
- Two model fitting methods, which were the MLR and the artificial neuron network (ANN), were investigated;
- The combined model using MLR and ANN performed better than single models in forecasting hourly salinity at 24 to 120 h;
- When the forecast period increased from 24 to 120 h, the forecasting performances of all the models decreased rapidly. Still, the combined model performed better than the single model in all cases;
- The forecasting model can be effectively utilized as an alarm system. The confusion matrix shows the performance of the alarm system for early warning of a saltwater intrusion event at various forecast periods. The accuracy decreases as the forecast periods increases. In practice, a suitable forecast period can be selected based on the user’s needs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MWA | The Metropolitan Waterworks Authority |
| HII | Hydro Informatics Institute |
| RTN | Royal Thai Navy |
| MLR | Multiple Linear Regression |
| ANN | Artificial Neural Network |
| FP | Forecast Period |
| LWL | Low Water Level |
| HWL | High Water Level |
| AWL | All Water Level |
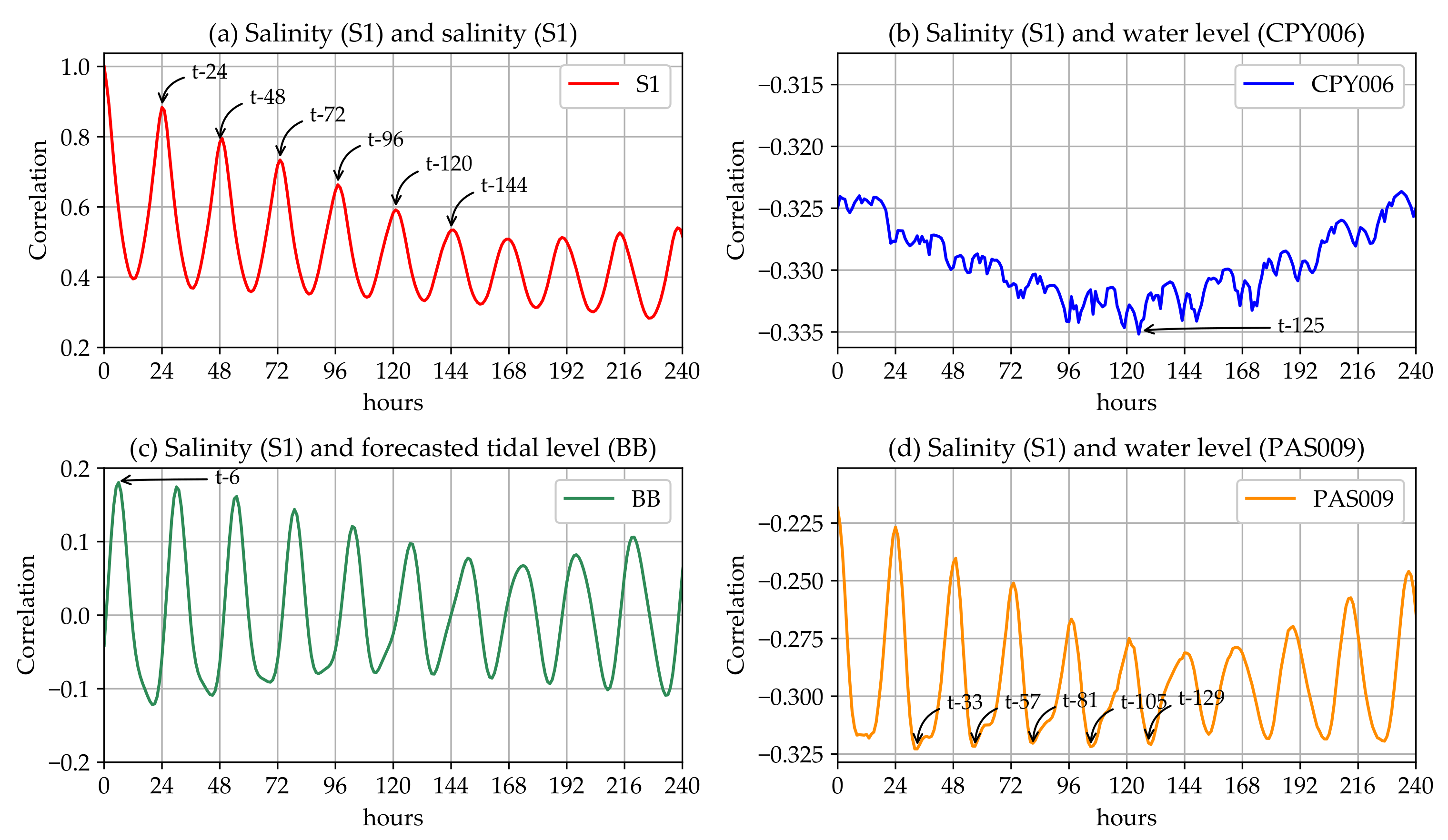
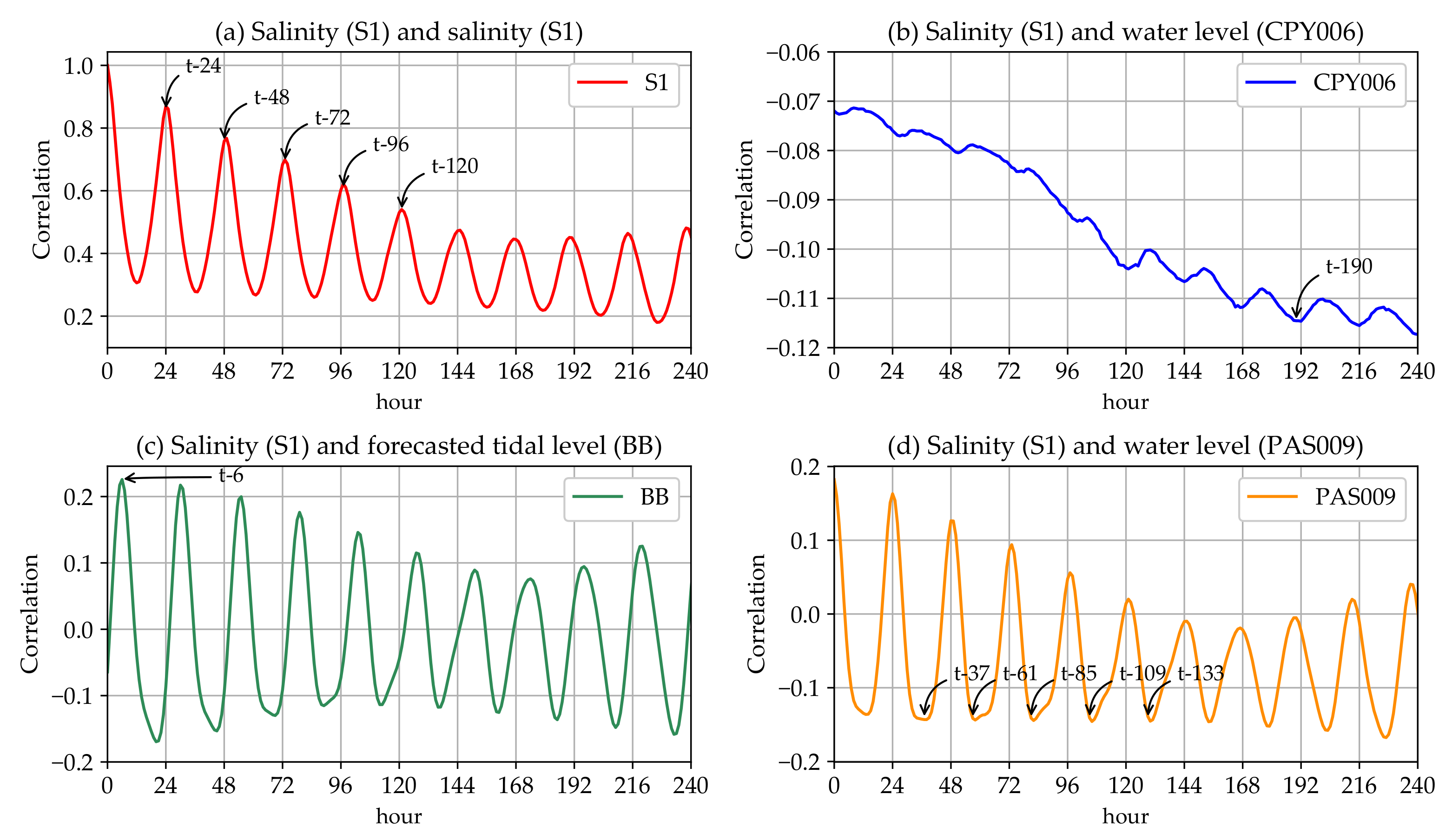
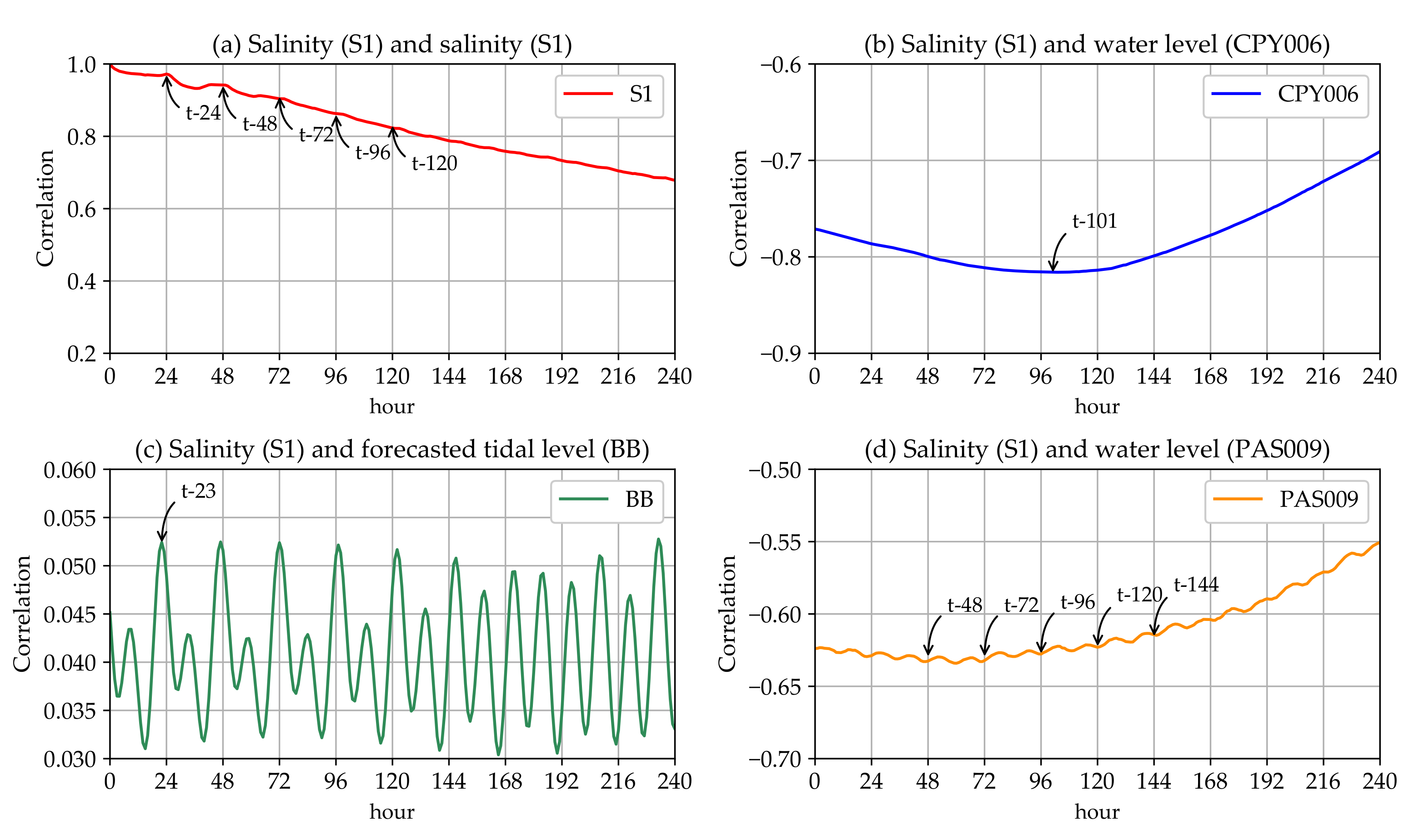
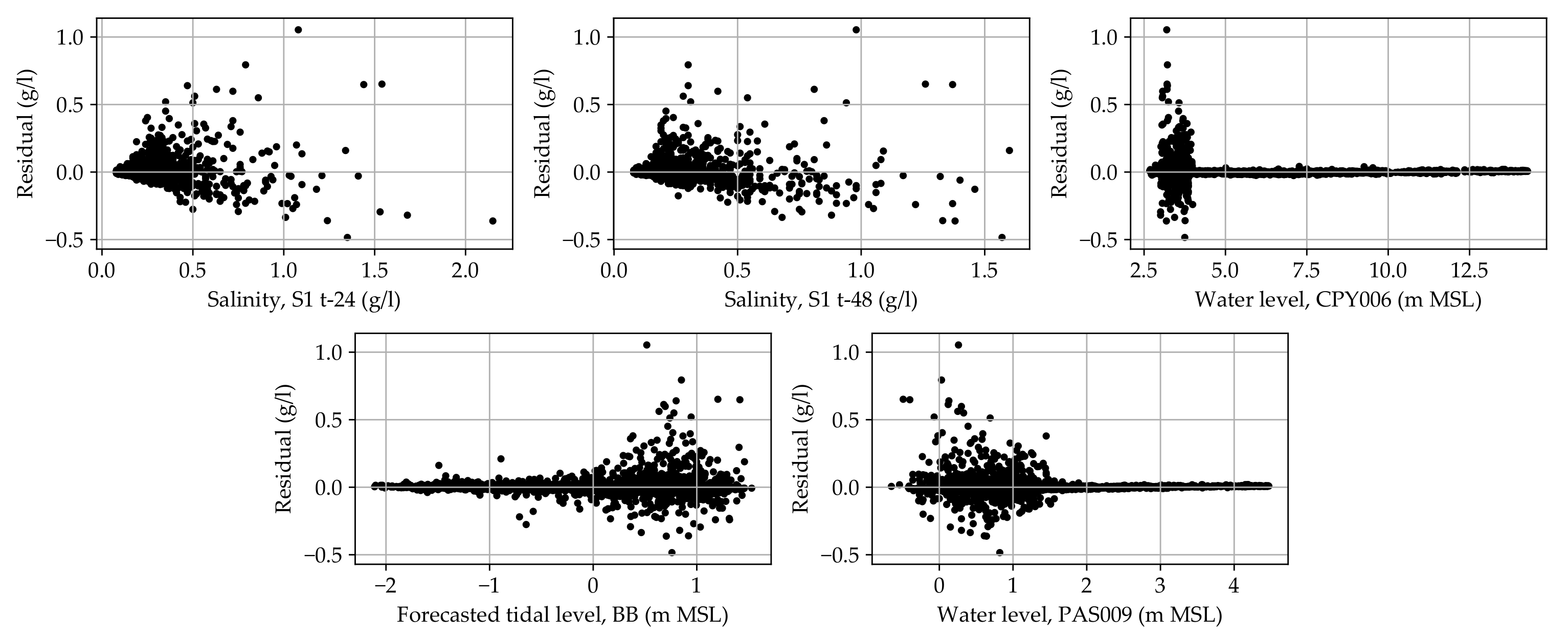
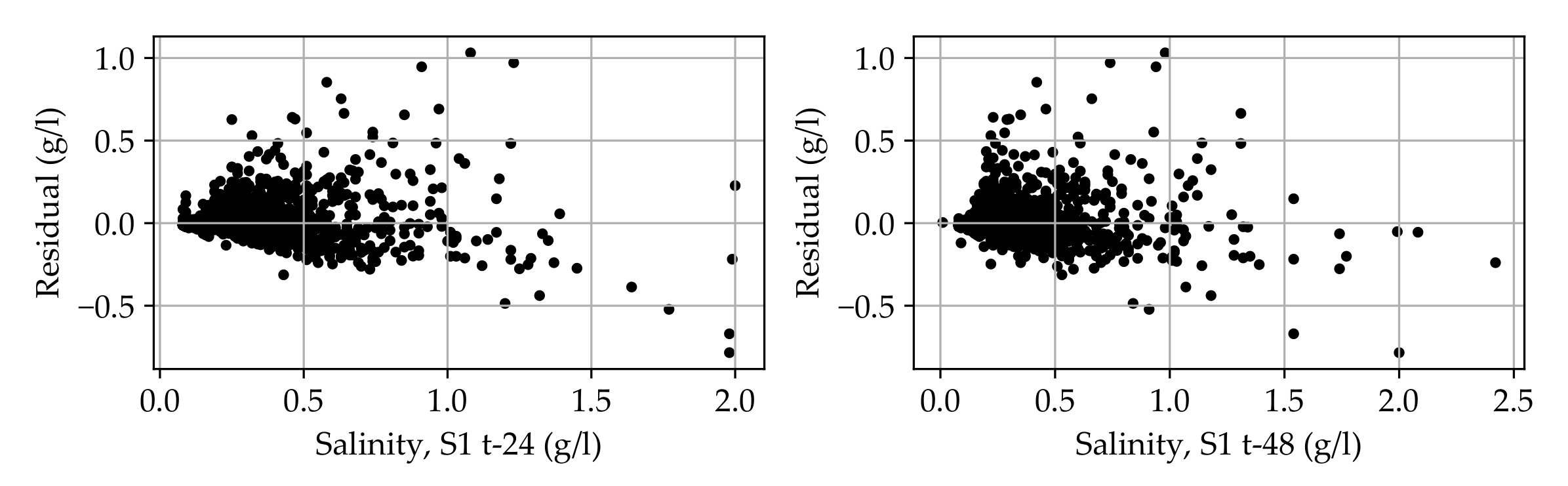
Appendix A. The Residual Analysis and the Model Validation
Appendix A.1. The Residual Analysis and the Single Model Validation




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Forecast Period (h) | Candidate 1A | Candidate 1B | Candidate 1C | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | RMSE | MAPE | ||||
| 24 | 0.783 | 0.049 | 6.260 | 0.800 | 0.053 | 6.981 | 0.806 | 0.050 | 6.699 |
| 48 | 0.673 | 0.061 | 9.638 | 0.642 | 0.070 | 10.777 | 0.609 | 0.069 | 10.305 |
| 72 | 0.583 | 0.066 | 11.993 | 0.529 | 0.078 | 13.492 | 0.518 | 0.079 | 12.753 |
| 96 | 0.471 | 0.073 | 14.076 | 0.443 | 0.087 | 15.880 | 0.429 | 0.084 | 15.101 |
| 120 | 0.371 | 0.081 | 15.204 | 0.389 | 0.091 | 17.597 | 0.363 | 0.090 | 16.810 |
| Forecast Period (h) | Candidate 1A | Candidate 1B | Candidate 1C | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | Structure | RMSE | MAPE | Structure | RMSE | MAPE | Structure | ||||
| 24 | 0.800 | 0.047 | 5.939 | 5-6-1 | 0.812 | 0.051 | 6.353 | 4-2-1 | 0.814 | 0.049 | 6.087 | 2-9-1 |
| 48 | 0.686 | 0.060 | 8.894 | 5-9-1 | 0.655 | 0.069 | 9.531 | 4-5-1 | 0.636 | 0.067 | 8.482 | 2-3-1 |
| 72 | 0.595 | 0.066 | 10.729 | 5-17-1 | 0.544 | 0.077 | 11.980 | 4-5-1 | 0.545 | 0.077 | 10.221 | 2-4-1 |
| 96 | 0.488 | 0.072 | 12.493 | 5-8-1 | 0.456 | 0.086 | 14.608 | 4-18-1 | 0.457 | 0.082 | 11.942 | 2-10-1 |
| 120 | 0.391 | 0.080 | 13.912 | 5-5-1 | 0.405 | 0.090 | 15.845 | 4-17-1 | 0.409 | 0.087 | 12.889 | 2-4-1 |
Appendix A.2. The Residual Analysis and the Combined Model Validation
| Forecast Period (h) | Candidate 2A | Candidate 2B | ||||
|---|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | |||
| 24 | 0.720 | 0.063 | 7.459 | 0.731 | 0.063 | 8.053 |
| 48 | 0.557 | 0.083 | 11.249 | 0.565 | 0.082 | 12.815 |
| 72 | 0.518 | 0.077 | 13.899 | 0.476 | 0.093 | 15.705 |
| 96 | 0.364 | 0.091 | 16.039 | 0.364 | 0.103 | 18.263 |
| 120 | 0.310 | 0.092 | 17.981 | 0.300 | 0.106 | 19.803 |
| Forecast Period (h) | Candidate 2C | Candidate 2D | ||||
| RMSE | MAPE | RMSE | MAPE | |||
| 24 | 0.731 | 0.063 | 8.082 | 0.729 | 0.064 | 7.813 |
| 48 | 0.564 | 0.082 | 12.895 | 0.557 | 0.083 | 12.244 |
| 72 | 0.474 | 0.093 | 15.816 | 0.461 | 0.094 | 14.788 |
| 96 | 0.360 | 0.103 | 18.408 | 0.339 | 0.105 | 17.137 |
| 120 | 0.295 | 0.107 | 19.974 | 0.263 | 0.109 | 18.777 |
| Forecast Period (h) | Candidate 2A | Candidate 2B | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | Structure | RMSE | MAPE | Structure | |||
| 24 | 0.731 | 0.061 | 6.895 | 4-16-1 | 0.753 | 0.060 | 7.162 | 3-4-1 |
| 48 | 0.575 | 0.081 | 10.553 | 4-18-1 | 0.593 | 0.079 | 11.659 | 3-3-1 |
| 72 | 0.526 | 0.077 | 12.622 | 4-3-1 | 0.486 | 0.092 | 14.241 | 3-6-1 |
| 96 | 0.380 | 0.089 | 14.834 | 4-8-1 | 0.376 | 0.103 | 16.532 | 3-18-1 |
| 120 | 0.325 | 0.092 | 16.762 | 4-10-1 | 0.316 | 0.105 | 18.710 | 3-9-1 |
| Forecast Period (h) | Candidate 2C | Candidate 2D | ||||||
| RMSE | MAPE | Structure | RMSE | MAPE | Structure | |||
| 24 | 0.754 | 0.060 | 7.364 | 2-3-1 | 0.752 | 0.060 | 6.486 | 1-3-1 |
| 48 | 0.593 | 0.080 | 11.421 | 2-3-1 | 0.588 | 0.080 | 9.887 | 1-4-1 |
| 72 | 0.483 | 0.093 | 14.256 | 2-8-1 | 0.475 | 0.093 | 12.878 | 1-3-1 |
| 96 | 0.381 | 0.102 | 16.815 | 2-5-1 | 0.353 | 0.104 | 13.900 | 1-14-1 |
| 120 | 0.307 | 0.106 | 17.989 | 2-14-1 | 0.288 | 0.107 | 15.692 | 1-6-1 |
| Forecast Period (h) | Candidate 3A | Candidate 3B | ||||
|---|---|---|---|---|---|---|
| RMSE | MAPE | RMSE | MAPE | |||
| 24 | 0.950 | 0.007 | 2.656 | 0.950 | 0.007 | 2.647 |
| 48 | 0.884 | 0.011 | 4.413 | 0.884 | 0.011 | 4.398 |
| 72 | 0.878 | 0.010 | 5.280 | 0.877 | 0.010 | 5.286 |
| 96 | 0.869 | 0.010 | 5.932 | 0.869 | 0.011 | 5.957 |
| 120 | 0.845 | 0.011 | 6.386 | 0.844 | 0.012 | 6.432 |
| Forecast Period (h) | Candidate 3C | Candidate 3D | ||||
| RMSE | MAPE | RMSE | MAPE | |||
| 24 | 0.935 | 0.010 | 2.897 | 0.935 | 0.010 | 2.937 |
| 48 | 0.858 | 0.013 | 5.318 | 0.859 | 0.013 | 5.304 |
| 72 | 0.809 | 0.016 | 6.211 | 0.807 | 0.016 | 6.108 |
| 96 | 0.816 | 0.015 | 7.147 | 0.802 | 0.016 | 7.695 |
| 120 | 0.753 | 0.018 | 7.980 | 0.729 | 0.019 | 9.016 |
| Forecast Period (h) | Candidate 3A | Candidate 3B | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | Structure | RMSE | MAPE | Structure | |||
| 24 | 0.946 | 0.008 | 2.650 | 4-5-1 | 0.948 | 0.007 | 2.713 | 3-12-1 |
| 48 | 0.879 | 0.011 | 4.489 | 4-3-1 | 0.884 | 0.011 | 4.277 | 3-3-1 |
| 72 | 0.881 | 0.010 | 5.156 | 4-3-1 | 0.880 | 0.010 | 5.181 | 3-3-1 |
| 96 | 0.872 | 0.010 | 5.809 | 4-2-1 | 0.871 | 0.010 | 5.796 | 3-7-1 |
| 120 | 0.849 | 0.011 | 6.274 | 4-6-1 | 0.848 | 0.011 | 6.254 | 3-4-1 |
| Forecast Period (h) | Candidate 3C | Candidate 3D | ||||||
| RMSE | MAPE | Structure | RMSE | MAPE | Structure | |||
| 24 | 0.946 | 0.008 | 3.156 | 2-4-1 | 0.944 | 0.009 | 3.139 | 1-17-1 |
| 48 | 0.863 | 0.013 | 5.262 | 2-2-1 | 0.852 | 0.013 | 5.231 | 1-4-1 |
| 72 | 0.805 | 0.016 | 6.162 | 2-5-1 | 0.797 | 0.016 | 6.309 | 1-4-1 |
| 96 | 0.812 | 0.015 | 6.857 | 2-2-1 | 0.794 | 0.016 | 7.618 | 1-11-1 |
| 120 | 0.772 | 0.018 | 7.292 | 2-2-1 | 0.726 | 0.020 | 8.927 | 1-17-1 |
References
- World Health Organization. Acceptable aspects: Taste, Odour and Appearance. Guidelines for Drinking-Water Quality, 4th ed.; Incorporating the 1st Addendum; World Health Organization: Geneva, Switzerland, 2008; pp. 219–230. [Google Scholar]
- Chong, Y.J.; Khan, A.; Scheelbeek, P.; Butler, A.; Bowers, D.; Vineis, P. Climate change and salinity in drinking water as a global problem: Using remote-sensing methods to monitor surface water salinity. Int. J. Remote Sens. 2014, 35, 1585–1599. [Google Scholar] [CrossRef]
- Kaushal, S.S. Increased salinization decreases safe drinking water. Environ. Sci. Technol. 2016, 50, 2765–2766. [Google Scholar] [CrossRef] [PubMed]
- Lassiter, A. Rising seas, changing salt lines, and drinking water salinization. Curr. Opin. Environ. Sustain. 2021, 50, 208–214. [Google Scholar] [CrossRef]
- Intaboot, N.; Taesombat, W. A Study of the Calibration of Salinity Dispersion in the Thachin Estuarine. In Proceedings of the 5th International Symposium on Fusion of Science and Technology (ISFT), New Delhi, India, 18–22 January 2016; pp. 101–105. [Google Scholar]
- Lam, N.T. Real-Time Prediction of Salinity in the Mekong River Delta. In Proceedings of the 10th International Conference on Asian and Pacific Coasts (APAC 2019), Hanoi, Vietnam, 25–28 September 2019; pp. 1461–1468. [Google Scholar]
- Alizadeh, M.J.; Kavianpour, M.R. Development of wavelet-ANN models to predict water quality parameters in Hilo Bay, Pacific Ocean. Mar. Pollut. Bull. 2015, 98, 171–178. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour, M.R.; Danesh, M.; Adolf, J.; Shamshirband, S.; Chau, K.W. Effect of river flow on the quality of estuarine and coastal waters using machine learning models. Eng. Appl. Comput. Fluid Mech. 2018, 12, 810–823. [Google Scholar] [CrossRef]
- Melesse, A.M.; Khosravi, K.; Tiefenbacher, J.P.; Heddam, S.; Kim, S.; Mosavi, A.; Pham, B.T. River water salinity prediction using hybrid machine learning models. Water 2020, 12, 2951. [Google Scholar] [CrossRef]
- Jin, T.; Cai, S.; Jiang, D.; Liu, J. A data-driven model for real-time water quality prediction and early warning by an integration method. Environ. Sci. Pollut. Res. 2019, 26, 30374–30385. [Google Scholar] [CrossRef]
- Huang, W.; Foo, S. Neural network modeling of salinity variation in Apalachicola River. Water Res. 2002, 36, 356–362. [Google Scholar] [CrossRef]
- Hu, J.; Liu, B.; Peng, S. Forecasting salinity time series using RF and ELM approaches coupled with decomposition techniques. Stoch. Environ. Res. Risk Assess. 2019, 33, 1117–1135. [Google Scholar] [CrossRef]
- Zhou, F.; Liu, B.; Duan, K. Coupling wavelet transform and artificial neural network for forecasting estuarine salinity. J. Hydrol. 2020, 588, 125127. [Google Scholar] [CrossRef]
- Horiuchi, Y.; Matsuura, T.; Tebakari, T.; Wongsa, S. Meta-analysis of Water Quality Characteristics in the Lower Chaophraya River, Thailand. In Proceedings of the 22nd IAHR-APD Congress 2020, Sapporo, Japan, 14–17 September 2020. [Google Scholar]
- Wongsa, S. Impact of climate change on water resources management in the lower Chao Phraya Basin, Thailand. J. Geosci. Environ. Prot. 2015, 3, 53. [Google Scholar] [CrossRef]
- Sriratana, L.; Bisalyaputra, K. Reconnaissance Study on Saltwater Intrusion Control at Main Raw Water Pumping Station of Metropolitan Waterworks Authority (Thailand). Int. J. Eng. Technol. 2019, 11, 33–38. [Google Scholar] [CrossRef]
- Wang, Q.; Wang, S. Machine learning-based water level prediction in Lake Erie. Water 2020, 12, 2654. [Google Scholar] [CrossRef]
- Quilty, J.; Adamowski, J. Addressing the incorrect usage of wavelet-based hydrological and water resources forecasting models for real-world applications with best practices and a new forecasting framework. J. Hydrol. 2018, 563, 336–353. [Google Scholar] [CrossRef]
- Keskin, T.E.; Düğenci, M.; Kaçaroğlu, F. Prediction of water pollution sources using artificial neural networks in the study areas of Sivas, Karabük and Bartın (Turkey). Environ. Earth Sci. 2015, 73, 5333–5347. [Google Scholar] [CrossRef]
- Rajaee, T.; Khani, S.; Ravansalar, M. Artificial intelligence-based single and hybrid models for prediction of water quality in rivers: A review. Chemom. Intell. Lab. Syst. 2020, 200, 103978. [Google Scholar] [CrossRef]
- ASCE. Artificial neural networks in hydrology. I: Preliminary concepts. Chemom. Intell. Lab. Syst. 2000, 5, 115–123. [Google Scholar]
- Haddad, K.; Zaman, M.; Rahman, A.; Shrestha, S. Regional flood modelling: Use of Monte Carlo cross-validation for the best model selection. In World Environmental and Water Resources Congress 2010: Challenges of Change; ASCE: Reston, VA, USA, 2010; pp. 2831–2840. [Google Scholar]
- Nwanganga, F.; Chapple, M. Practical Machine Learning in R; John Wiley & Sons: Hoboken, NJ, USA, 2020. [Google Scholar]
- Krehbiel, T.C. Correlation coefficient rule of thumb. Decis. Sci. J. Innov. Educ. 2004, 2, 97–100. [Google Scholar] [CrossRef]
- Le, D.; Huang, W.; Johnson, E. Neural network modeling of monthly salinity variations in oyster reef in Apalachicola Bay in response to freshwater inflow and winds. Neural. Comput. Appl. 2019, 31, 6249–6259. [Google Scholar] [CrossRef]
- Qi, S.; Bai, Z.; Ding, Z.; Jayasundara, N.; He, M.; Sandhu, P.; Seneviratne, S.; Kadir, T. Enhanced Artificial Neural Networks for Salinity Estimation and Forecasting in the Sacramento-San Joaquin Delta of California. J. Water Resour. Plan. Manag. 2021, 147, 04021069. [Google Scholar] [CrossRef]
- Palani, S.; Liong, S.Y.; Tkalich, P. An ANN application for water quality forecasting. Mar. Pollut. Bull. 2008, 56, 1586–1597. [Google Scholar] [CrossRef] [PubMed]
- Sha, J.; Li, X.; Zhang, M.; Wang, Z.L. Comparison of Forecasting Models for Real-Time Monitoring of Water Quality Parameters Based on Hybrid deep-learning Neural Networks. Water 2021, 13, 1547. [Google Scholar] [CrossRef]
- EL Hamidi, M.J.; Larabi, A.; Faouzi, M. Numerical Modeling of Saltwater Intrusion in the Rmel-Oulad Ogbane Coastal Aquifer (Larache, Morocco) in the Climate Change and Sea-Level Rise Context (2040). Water 2021, 13, 2167. [Google Scholar] [CrossRef]
- Rong, G.; Li, K.; Han, L.; Alu, S.; Zhang, J.; Zhang, Y. Hazard Mapping of the Rainfall–Landslides Disaster Chain Based on GeoDetector and Bayesian Network Models in Shuicheng County, China. Water 2020, 12, 2572. [Google Scholar] [CrossRef]








| Model | Case | Candidate | |
|---|---|---|---|
| MLR | ANN | ||
| Single model | AWL | 1A: Equation (1) | 1A: Equation (1) |
| Combined model | LWL | 2A: Equation (4) | 2A: Equation (4) |
| HWL | 3A: Equation (8) | 3B: Equation (9) | |
| Forecast Period (h) | MLR | ANN | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | NSE | RMSE | MAPE | NSE | |||
| 24 | 0.860 | 0.073 | 10.487 | 0.776 | 0.865 | 0.069 | 10.327 | 0.796 |
| 48 | 0.741 | 0.099 | 14.975 | 0.585 | 0.735 | 0.096 | 12.150 | 0.605 |
| 72 | 0.530 | 0.115 | 18.886 | 0.416 | 0.576 | 0.110 | 16.255 | 0.469 |
| 96 | 0.412 | 0.120 | 19.731 | 0.299 | 0.460 | 0.119 | 16.100 | 0.319 |
| 120 | 0.365 | 0.113 | 21.556 | 0.272 | 0.448 | 0.111 | 18.280 | 0.290 |
| Forecast Period (h) | MLR | ANN | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAPE | NSE | RMSE | MAPE | NSE | |||
| 24 | 0.888 | 0.058 | 8.131 | 0.853 | 0.892 | 0.054 | 7.671 | 0.875 |
| 48 | 0.734 | 0.091 | 13.177 | 0.643 | 0.748 | 0.085 | 11.168 | 0.687 |
| 72 | 0.583 | 0.108 | 14.922 | 0.480 | 0.599 | 0.104 | 13.624 | 0.514 |
| 96 | 0.449 | 0.120 | 16.249 | 0.338 | 0.493 | 0.111 | 15.531 | 0.434 |
| 120 | 0.392 | 0.117 | 16.797 | 0.283 | 0.448 | 0.107 | 16.172 | 0.395 |
| Forcast Period (h) | MLR | ANN |
|---|---|---|
| 24 | 9.03% | 9.03% |
| 48 | 9.02% | 11.94% |
| 72 | 13.33% | 8.75% |
| 96 | 11.54% | 26.50% |
| 120 | 3.89% | 26.58% |
| Forecast Period (h) | Accuracy | Sensitivity (True Positive Rate) | Specificity (False Positive Rate) | MCC |
|---|---|---|---|---|
| 24 | 0.947 | 0.840 | 0.979 | 0.847 |
| 48 | 0.913 | 0.708 | 0.977 | 0.748 |
| 72 | 0.867 | 0.556 | 0.964 | 0.605 |
| 96 | 0.858 | 0.540 | 0.955 | 0.571 |
| 120 | 0.834 | 0.450 | 0.949 | 0.480 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Changklom, J.; Lamchuan, P.; Pornprommin, A. Salinity Forecasting on Raw Water for Water Supply in the Chao Phraya River. Water 2022, 14, 741. https://doi.org/10.3390/w14050741
Changklom J, Lamchuan P, Pornprommin A. Salinity Forecasting on Raw Water for Water Supply in the Chao Phraya River. Water. 2022; 14(5):741. https://doi.org/10.3390/w14050741
Chicago/Turabian StyleChangklom, Jiramate, Phakawat Lamchuan, and Adichai Pornprommin. 2022. "Salinity Forecasting on Raw Water for Water Supply in the Chao Phraya River" Water 14, no. 5: 741. https://doi.org/10.3390/w14050741
APA StyleChangklom, J., Lamchuan, P., & Pornprommin, A. (2022). Salinity Forecasting on Raw Water for Water Supply in the Chao Phraya River. Water, 14(5), 741. https://doi.org/10.3390/w14050741