
Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
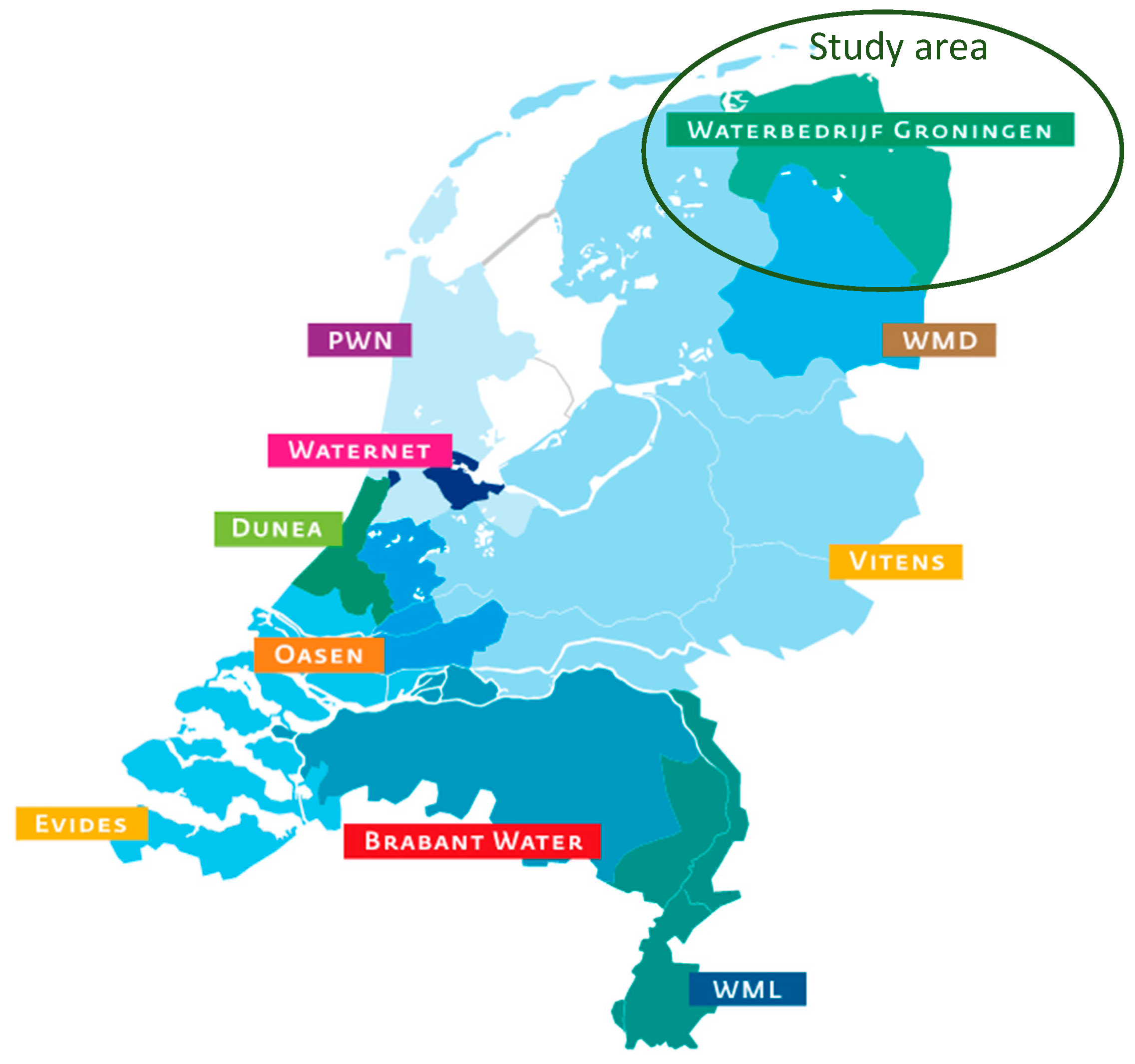
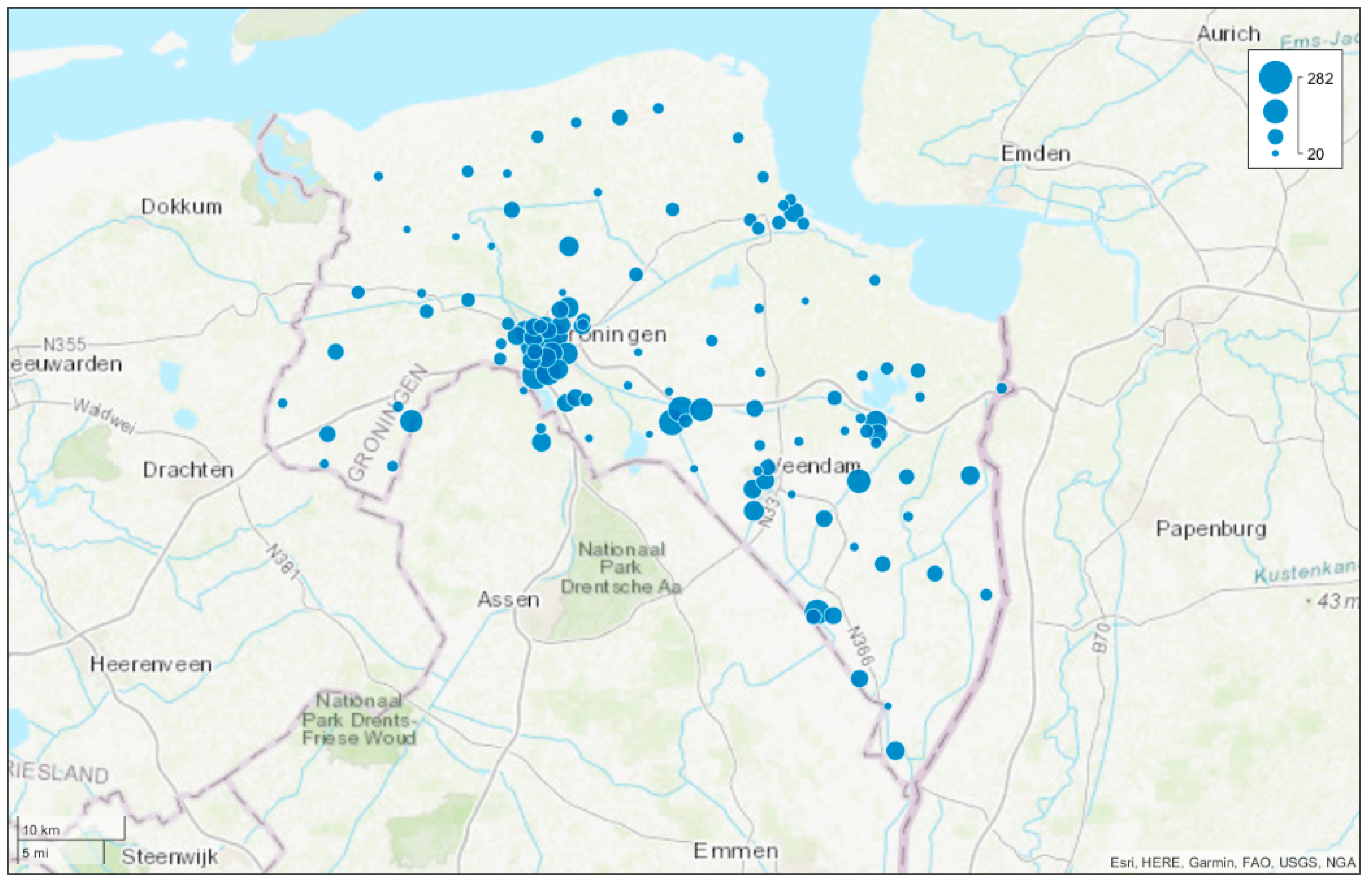
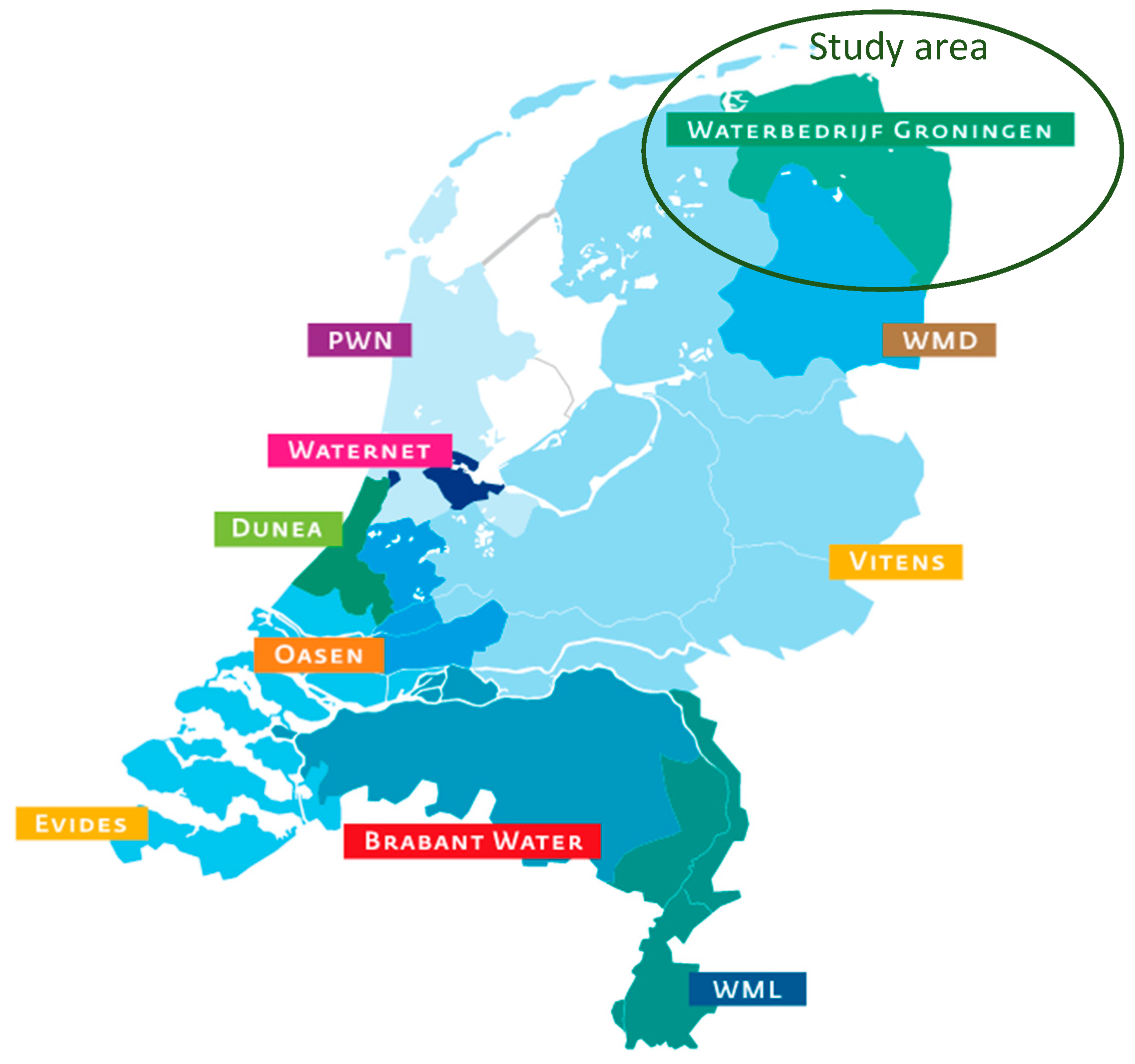
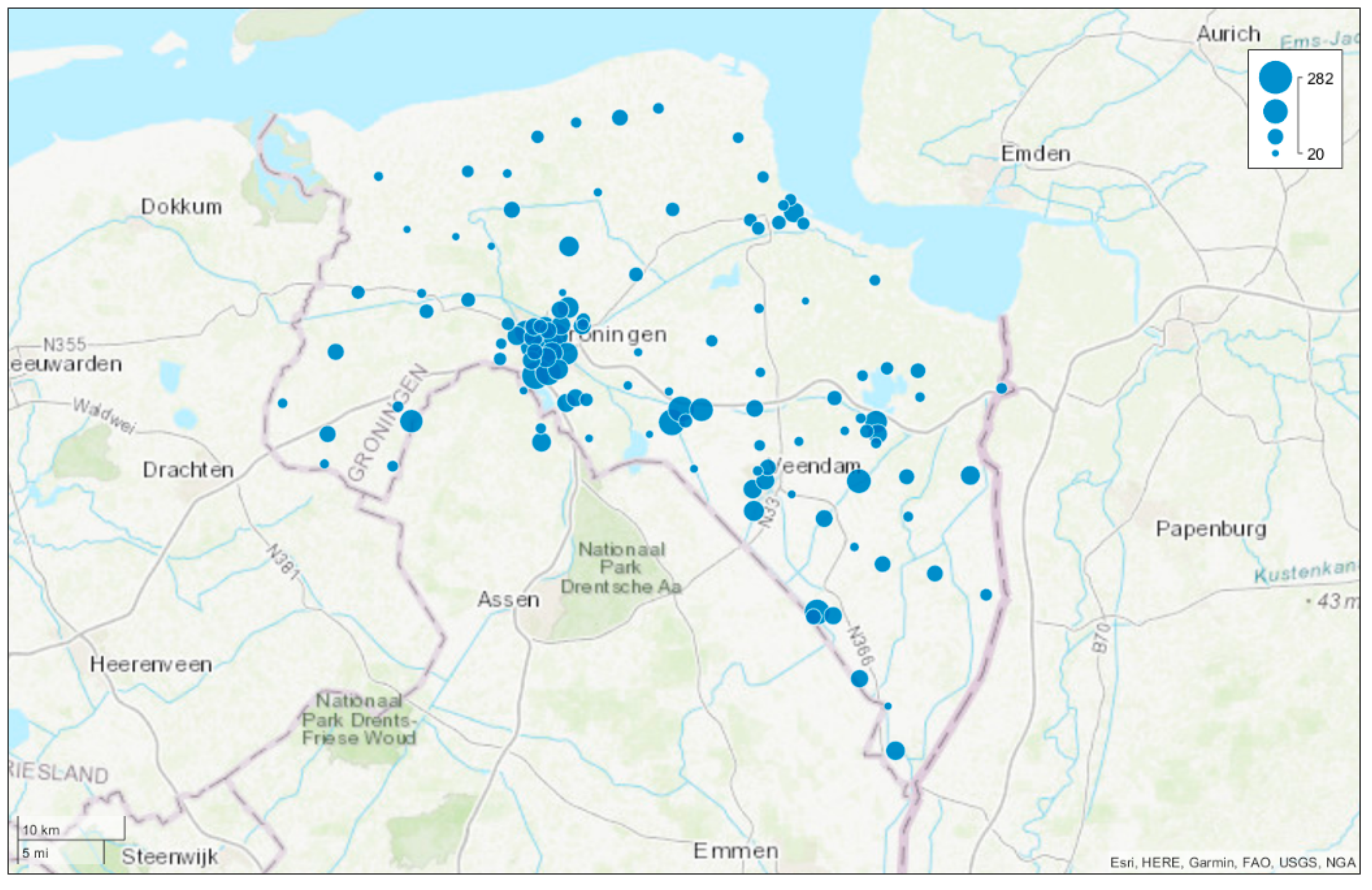
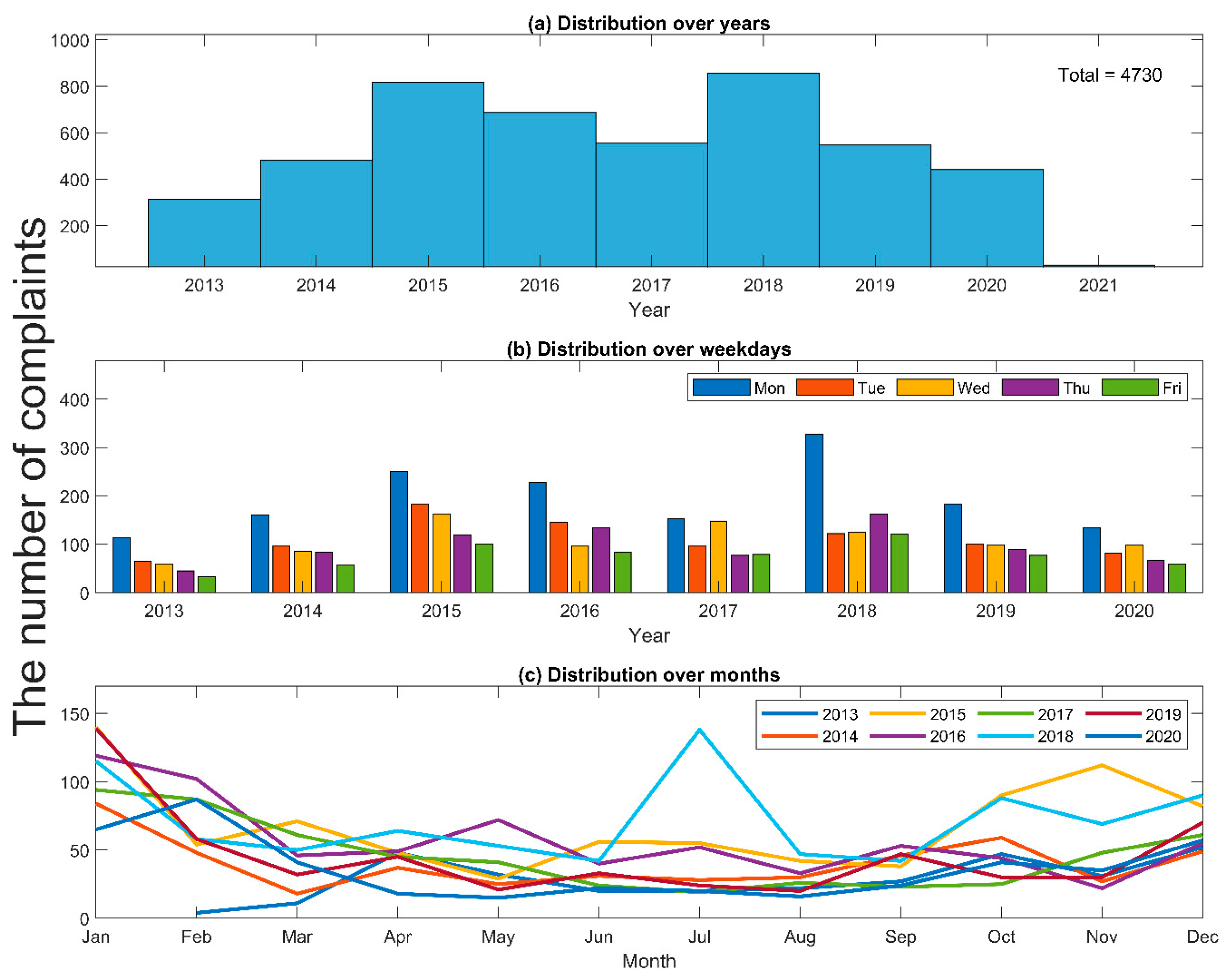
2.1. Customer Complaints about Drinking Water Issues
2.2. Natural Language Processing
2.2.1. Lexical Analysis
2.2.2. Syntactic Analysis
2.2.3. Vectorization of Words
2.2.4. Discourse Analysis
2.3. Tools and Software
3. Results
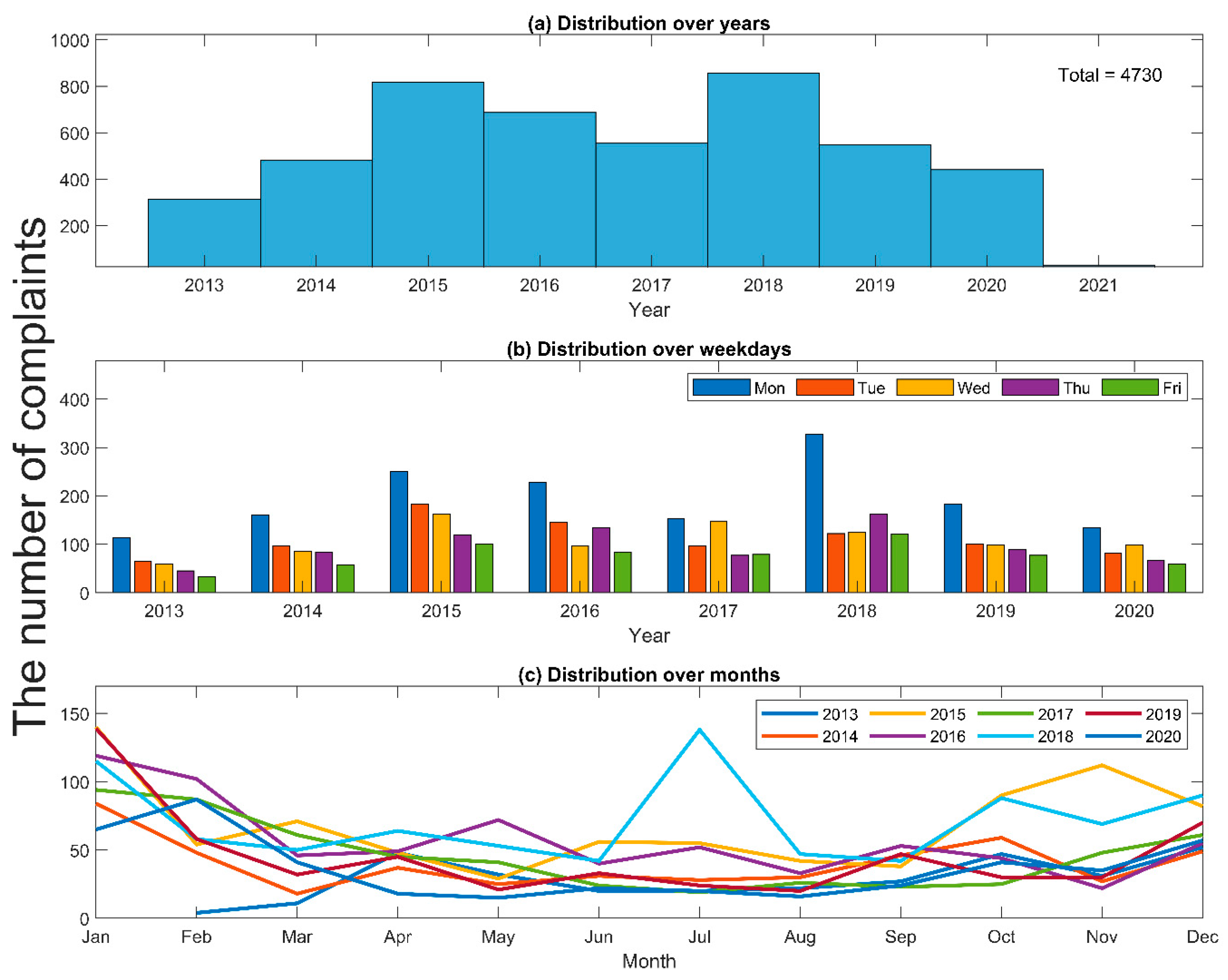
3.1. Lexical and Syntactic Analysis of Customer Complaints
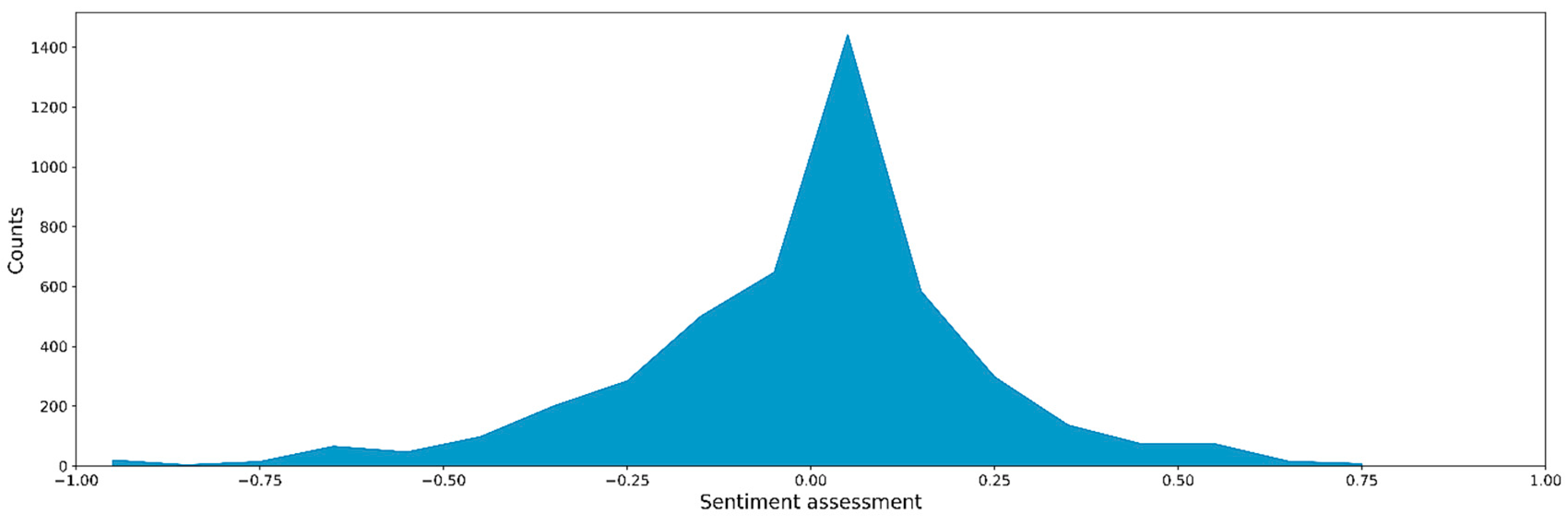
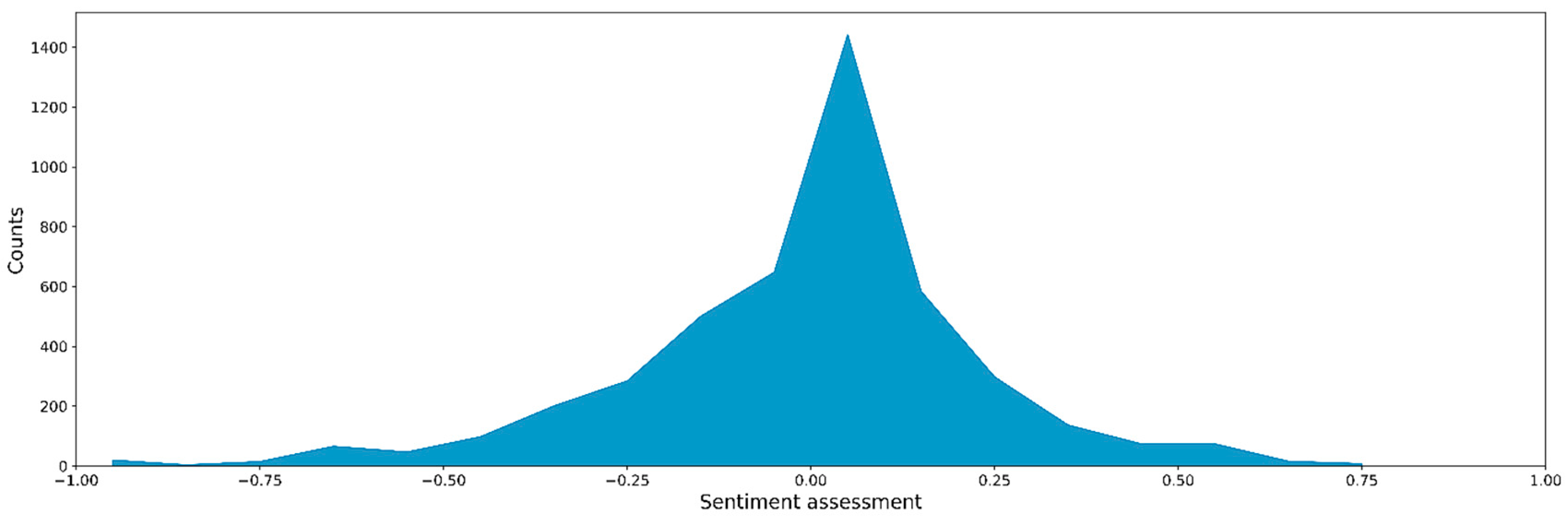
3.2. Similarity and Sentiment Analyses of Customer Complaints
4. Discussion
4.1. How Can Water Utilities Currently Benefit from the Latest NLP Techniques
4.2. How Will Water Utilities Benefit More from NLP in the near Future
5. Conclusions
- Via a lexical analysis, it was determined that NLP can remove unnecessary words and symbols and determine the lemmas of essential words in customer complaints. This implies that current NLP techniques are capable of analyzing words in sentences and extracting key information in terms of words.
- Via a syntactic analysis, it was determined that NLP can address the relationship between words as well as the functionality of words. Therefore, syntactic analysis is more useful when attempting to extract structured information—for example, for identifying the detailed information (e.g., location, time) of a water problem or a request.
- Both lexical and syntactic analyses can be undertaken manually by humans. However, recent advances in deep learning enable machines to (partially) perform these activities in place of humans. The key component is word vectorization, which represents words as numerical vectors in a high-dimensional space. Using machine-readable vectors, similar information can be detected; sentiments can be analyzed; and, more importantly, intents can be recognized.
- This study presents a fundamental investigation of applying NLP to automate text processing for the water sector. With the anticipated research outcomes of NLP in the future, NLP will be able to automate text processing further and more deeply, including text generation, interaction with humans, and connection to digital databases.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations Transformer |
| DIET | Dual Intent and Entity Transformer |
| DL | Deep Learning |
| FAQ | Frequently Asked Questions |
| NLG | Natural Language Generation |
| NLP | Natural Language Processing |
| NLU | Natural Language Understanding |
| POS | Part of Speech |
| WBG | Waterbedrijf Groningen (Water Utility Groningen) |
Appendix A
Appendix B
- (1)
- Please replace the meter.
- (2)
- With this letter, I want to make an appointment for the installation of a new water meter.
- (3)
- would like to have a new meter installed
- (1)
- I would like to see this refunded to my account
- (2)
- This is a repair of the water company itself, so these costs are not on me.
- (3)
- For the above reasons, I hereby object to the imposed administration costs and do not agree to payment.
- (1)
- Our water meter beeps very annoyingly.
- (2)
- I have a lot of water at the meter behind the front door.
- (3)
- There is also a leakage from the main water tap.
- (1)
- a fairly low water pressure
- (2)
- reduced water pressure
- (3)
- We currently have no water.
- (1)
- The water from the tap was brown and sandy.
- (2)
- As of today, tap water smells and tastes strange.
- (3)
- The water has a strange metallic (copper) smell.
References
- Borg, A.; Boldt, M.; Rosander, O.; Ahlstrand, J. E-mail classification with machine learning and word embeddings for improved customer support. Neural Comput. Appl. 2021, 33, 1881–1902. [Google Scholar] [CrossRef]
- Dong, L.; Spencer, M.C.; Biagi, A. A Semi-supervised Multi-task Learning Approach to Classify Customer Contact Intents. In Proceedings of the 4th Workshop on e-Commerce and NLP, Bangkok, Thailand, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 49–57. [Google Scholar]
- Liu, X.; He, P.; Chen, W.; Gao, J. Multi-Task Deep Neural Networks for Natural Language Understanding. arXiv 2019, arXiv:1901.11504. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Elina, M.; Elina, M.; Santaholma, M.; Issco, E.T.I.T.I.M. Grammar sharing techniques for rule-based multilingual NLP systems Grammar sharing techniques for rule-based multilingual NLP systems. In Proceedings of the 16th Nordic Conference of Computational Linguistics (NODALIDA), Tartu, Estonia, 25–26 May 2007. [Google Scholar]
- Tootooni, M.S.; Pasupathy, K.S.; Heaton, H.A.; Clements, C.M.; Sir, M.Y. CCMapper: An adaptive NLP-based free-text chief complaint mapping algorithm. Comput. Biol. Med. 2019, 113, 103398. [Google Scholar] [CrossRef]
- Afzal, N.; Sohn, S.; Abram, S.; Scott, C.G.; Chaudhry, R.; Liu, H.; Kullo, I.J.; Arruda-Olson, A.M. Mining peripheral arterial disease cases from narrative clinical notes using natural language processing. J. Vasc. Surg. 2017, 65, 1753–1761. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qiu, X.P.; Sun, T.X.; Xu, Y.G.; Shao, Y.F.; Dai, N.; Huang, X.J. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013-Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013; pp. 1–12. [Google Scholar]
- Hake, P.; Rehse, J.R.; Fettke, P. Toward Automated Support of Complaint Handling Processes: An Application in the Medical Technology Industry. J. Data Semant. 2021, 10, 41–56. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kalyan, K.S.; Rajasekharan, A.; Sangeetha, S. AMMUS: A Survey of Transformer-based Pretrained Models in Natural Language Processing. arXiv 2021, arXiv:2108.05542. [Google Scholar]
- Tang, X.; Mou, H.; Liu, J.; Du, X. Research on automatic labeling of imbalanced texts of customer complaints based on text enhancement and layer-by-layer semantic matching. Sci. Rep. 2021, 11, 11849. [Google Scholar] [CrossRef]
- Prabhu, S.; Mohamed, M.; Misra, H. Multi-class Text Classification using BERT-based Active Learning. arXiv 2021, arXiv:2104.14289. [Google Scholar]
- Kumar, A.; Dabas, V. A social media complaint workflow automation tool using sentiment intelligence. In Lecture Notes in Engineering and Computer Science, Proceedings of The World Congress on Engineering, London, UK, 29 June–1 July 2016; Newswood Limited: Hong Kong, China; pp. 176–181.
- Hanks, P. Lexical Analysis: Norms and Exploitations; MIT Press: Cambridge, MA, USA, 2013; ISBN 0262018578. [Google Scholar]
- SpaCy Guides: Linguistic Features. Available online: https://spacy.io/usage/linguistic-features#language-data (accessed on 11 February 2022).
- Koopman, H.; Sportiche, D.; Stabler, E. An Introduction to Syntactic Analysis and Theory; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 1118470478. [Google Scholar]
- Petrov, S.; Das, D.; McDonald, R. A universal part-of-speech tagset. arXiv 2012, arXiv:1104.2086. [Google Scholar]
- Yamada, H.; Matsumoto, Y. Statistical Dependency Analysis with Support Vector machines. In Proceedings of the 8th International Conference on Parsing Technologies, Nancy, France, 23–25 April 2003. [Google Scholar]
- Johansson, R. Dependency-Based Semantic Analysis of Natural-Language Text. Ph.D. Thesis, Lund University, Lund, Sweden, 2008. [Google Scholar]
- SpaCy Guides: Visualizers. Available online: https://spacy.io/usage/visualizers (accessed on 11 February 2022).
- SpaCy Trained Pipelines: Dutch. Available online: https://spacy.io/models/nl (accessed on 11 February 2022).
- Github Resources Textblob-nl Sentiment Model. Available online: https://github.com/gvisniuc/textblob-nl (accessed on 11 February 2022).
- SpaCy. Available online: https://spacy.io/ (accessed on 11 February 2022).
- Thinc: A Refreshing Functional Take on Deep Learning, Compatible with Your Favorite Libraries. Available online: https://github.com/explosion/thinc (accessed on 11 February 2022).
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural architectures for named entity recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 9 June 2016; pp. 260–270. [Google Scholar] [CrossRef]
- Rasa. Available online: https://rasa.com/ (accessed on 11 February 2022).
- Introducing DIET: State-of-the-Art Architecture That Outperforms Fine-Tuning BERT and Is 6X Faster to Train. Available online: https://rasa.com/blog/introducing-dual-intent-and-entity-transformer-diet-state-of-the-art-performance-on-a-lightweight-architecture/ (accessed on 11 February 2022).
- SpaCy. Dependency Tree. Available online: https://github.com/clir/clearnlp-guidelines/blob/master/md/specifications/dependency_labels_old.md (accessed on 11 February 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
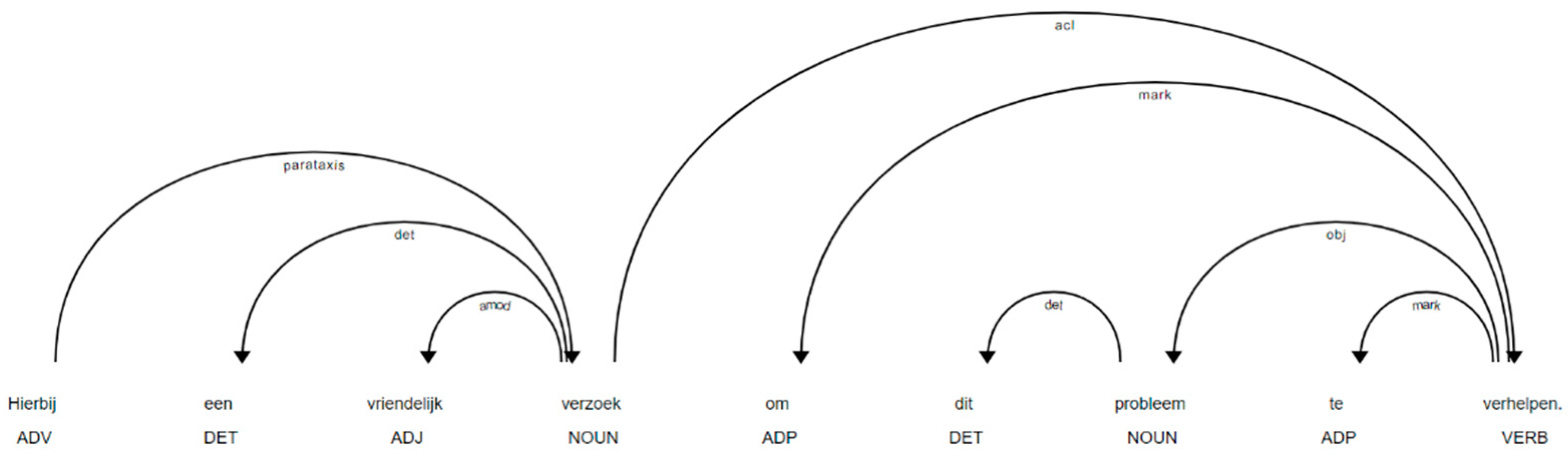
| Number | Orginal Text | Translation | Lemma | Is_Stop | Is_Punct | POS | DEP |
|---|---|---|---|---|---|---|---|
| 1 | Geachte | Dear | geacht | FALSE | FALSE | ADJ | adjectival modifier |
| 2 | heer/mevrouw | sir/madam | heer/mevrouw | FALSE | FALSE | NOUN | nominal subject |
| 3 | , | , | , | FALSE | TRUE | SYM | punctuation |
| 4 | Sinds | Since | sinds | TRUE | FALSE | ADP | case marking |
| 5 | het | the | het | TRUE | FALSE | DET | determiner |
| 6 | wisselen | change | wisselen | FALSE | FALSE | VERB | modifier of nominal |
| 7 | van | of | van | TRUE | FALSE | ADP | case marking |
| 8 | de | the | de | TRUE | FALSE | DET | determiner |
| 9 | watermeter | water meter | watermeter | FALSE | FALSE | NOUN | modifier of nominal |
| 10 | is | is | zijn | TRUE | FALSE | VERB | copula |
| 11 | de | the | de | TRUE | FALSE | DET | determiner |
| 12 | druk | pressure | druk | FALSE | FALSE | NOUN | nominal subject |
| 13 | vrij | rather | vrij | TRUE | FALSE | ADJ | adverbial modifier |
| 14 | laag | low | laag | FALSE | FALSE | ADJ | ROOT |
| 15 | . | . | . | FALSE | TRUE | SYM | punctuation |
| 16 | Vooral | Mostly | vooral | TRUE | FALSE | ADV | adjectival modifier |
| 17 | met | with | met | TRUE | FALSE | ADP | case marking |
| 18 | douchen | showering | douchen | FALSE | FALSE | AUX | oblique nominal |
| 19 | is | is | zijn | TRUE | FALSE | VERB | copula |
| 20 | dit | this | dit | TRUE | FALSE | PRON | nominal subject |
| 21 | hinderlijk | annoying | hinderlijk | FALSE | FALSE | ADJ | ROOT |
| 22 | . | . | . | FALSE | TRUE | SYM | punctuation |
| 23 | Hierbij | Hereby | hierbij | FALSE | FALSE | ADV | ROOT |
| 24 | een | a | een | TRUE | FALSE | DET | determiner |
| 25 | vriendelijk | friendly | vriendelijk | FALSE | FALSE | ADJ | adjectival modifier |
| 26 | verzoek | request | verzoek | FALSE | FALSE | NOUN | parataxis |
| 27 | om | for | om | TRUE | FALSE | ADP | marker |
| 28 | dit | this | dit | TRUE | FALSE | DET | determiner |
| 29 | probleem | problem | probleem | FALSE | FALSE | NOUN | object |
| 30 | te | to | te | TRUE | FALSE | ADP | marker |
| 31 | verhelpen | resolve | verhelpen | FALSE | FALSE | VERB | clausal modifier of noun (adjectival clause) |
| 32 | . | . | . | FALSE | TRUE | SYM | punctuation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, X.; Vertommen, I.; Tsiami, L.; van Thienen, P.; Paraskevopoulos, S. Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility. Water 2022, 14, 674. https://doi.org/10.3390/w14040674
Tian X, Vertommen I, Tsiami L, van Thienen P, Paraskevopoulos S. Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility. Water. 2022; 14(4):674. https://doi.org/10.3390/w14040674
Chicago/Turabian StyleTian, Xin, Ina Vertommen, Lydia Tsiami, Peter van Thienen, and Sotirios Paraskevopoulos. 2022. "Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility" Water 14, no. 4: 674. https://doi.org/10.3390/w14040674
APA StyleTian, X., Vertommen, I., Tsiami, L., van Thienen, P., & Paraskevopoulos, S. (2022). Automated Customer Complaint Processing for Water Utilities Based on Natural Language Processing—Case Study of a Dutch Water Utility. Water, 14(4), 674. https://doi.org/10.3390/w14040674