
Predicting Discharges in Sewer Pipes Using an Integrated Long Short-Term Memory and Entropy A-TOPSIS Modeling Framework




Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Area and Data Used
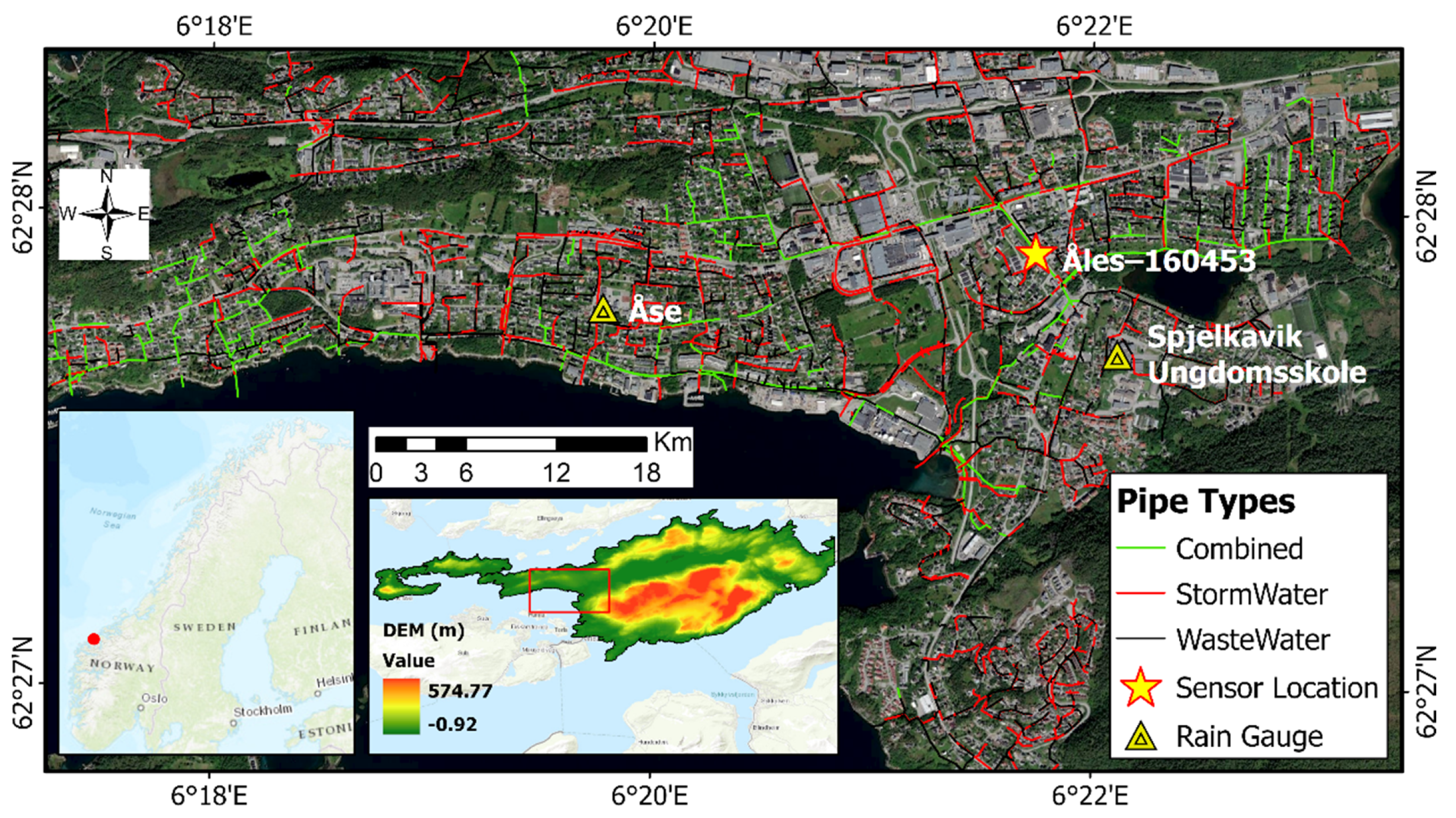
2.1.1. Description of the Study Area and Sensors Installation
2.1.2. Data Collection and Transmission
2.2. Proposed LSTM Architecture for Predicting Discharges in Sewer Pipes
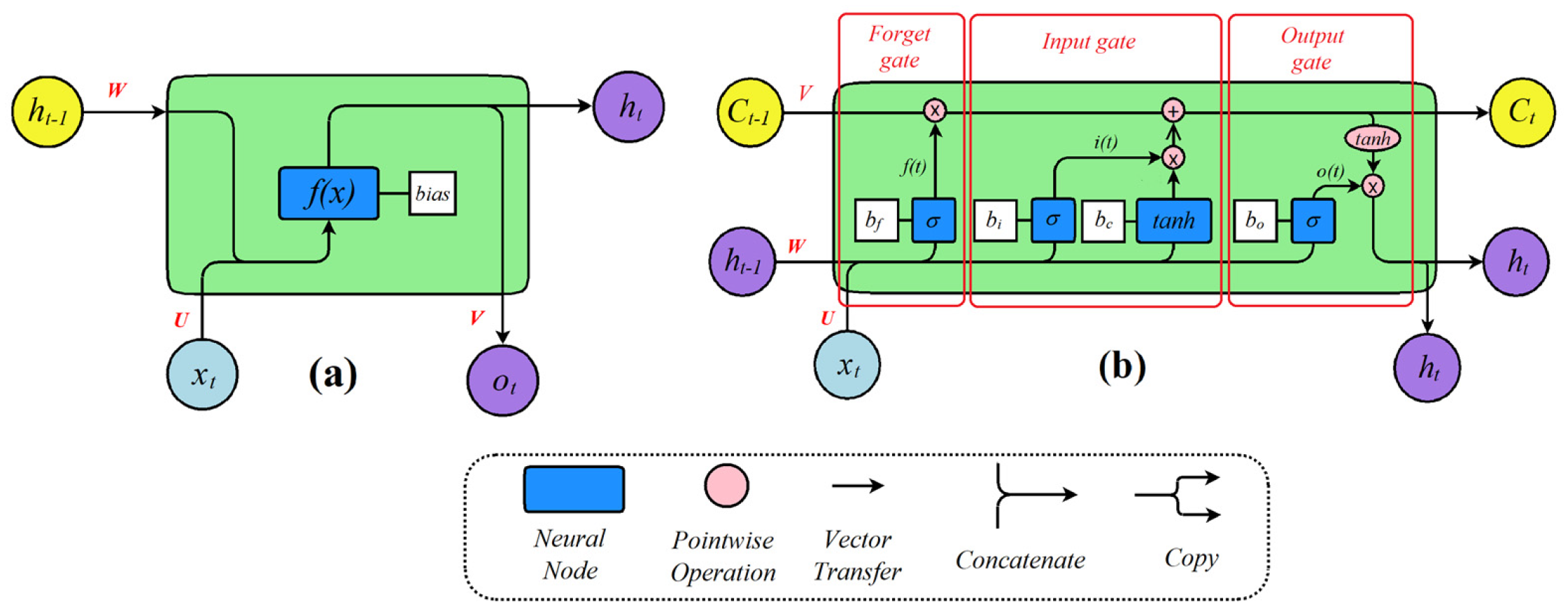
2.2.1. Long Short-Term Memory
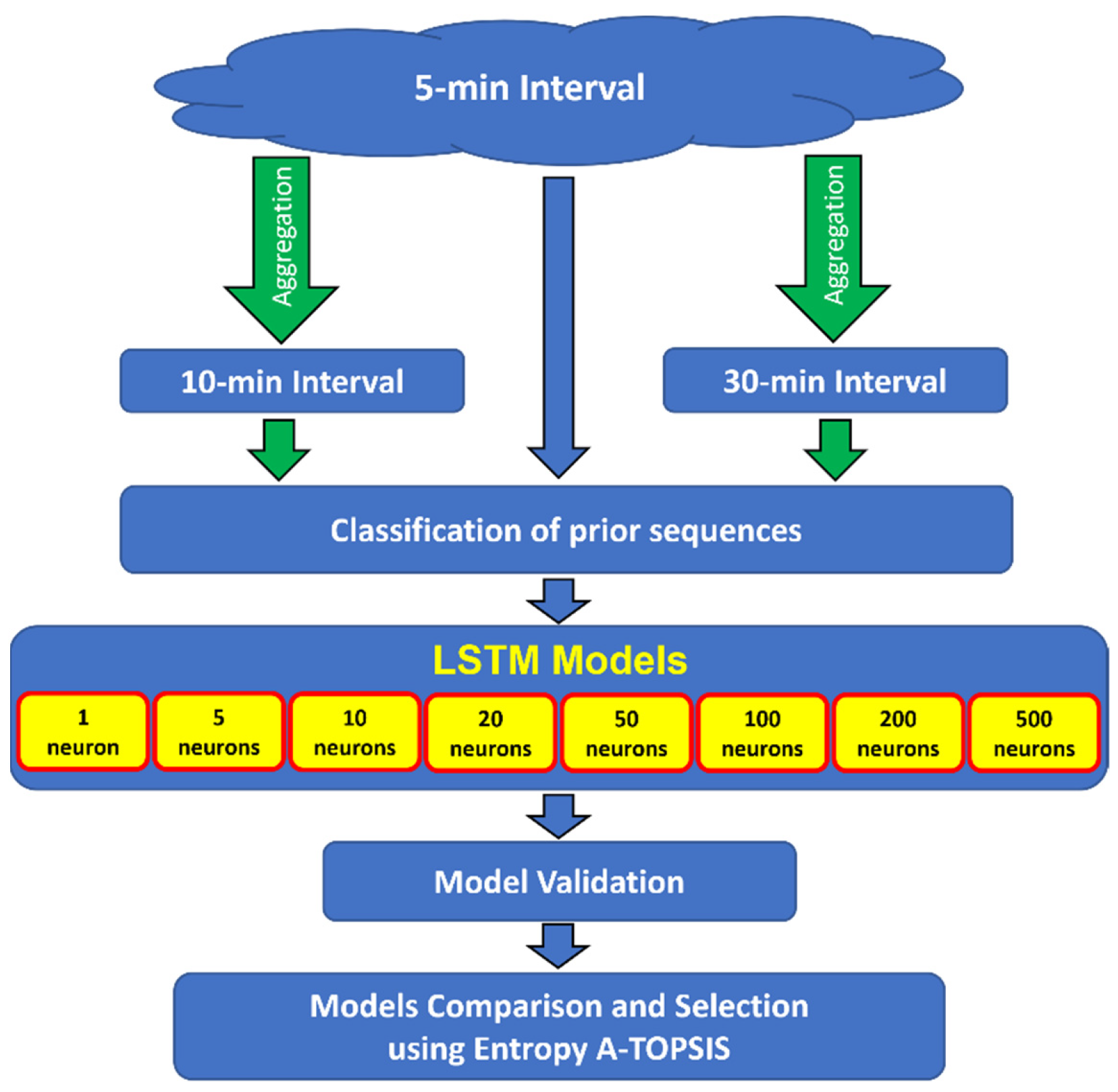
2.2.2. Entropy A-TOPSIS for Optimal LSTM Architecture Selection
- Step 1: Determine the mean (M) and standard deviations (µ) metrics:
- Step 2: Normalize the mean and standard deviations metrics:
- Step 3: Identify positive ideal solution () and negative ideal solution of the mean and standard deviation normalized metrics:
- Step 4: Determine the entropy values of the mean and standard deviation normalized data matrices as follows:
- Step 5: Compute the weighted Euclidean distances for the mean and standard deviation values:
- Step 6: Compute the relative closeness coefficient of the mean () and standard deviation ():
- Step 7: The final relative closeness coefficient is calculated by repeating steps 1 to 6. However, in this case, the input matrix is The overview of the entire procedure is shown in Figure 3.
2.2.3. Model Design and Implementation
3. Results
3.1. Forecasting the Next 1-h Sequence
3.2. Forecasting the Next 2-h Sequence
3.3. Forecasting Discharges Using Aggregated Time Intervals
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Meaning |
| LSTM | Long Short-Term Memory |
| CSSs | Combined Sewer Systems |
| CSOs | Combined Sewer Overflows |
| WWTPs | Wastewater Treatment Plants |
| IoT | Internet of Things |
| ARMA | Auto-Regressive Moving Average |
| ARIMA | Auto-Regressive Integrated Moving Average |
| AR | Auto-Regressive |
| MA | Moving Average |
| GP | Genetic Programming |
| ANNs | Artificial Neural Networks |
| SVM | Support Vector Machine |
| ERNN | Elman’s Recurrent Neural Networks |
| RNN | Recurrent Neural Networks |
| SCADA | Supervisory Control And Data Acquisition |
| TOPSIS | The Technique for Order Preference by Similarity to Ideal Solution |
| WSN | Wireless Sensor Network |
| The sigmoid activation function | |
| The weights | |
| The bias | |
| MAPE | Mean Absolute Percentage Error |
| RMSE | Root Mean Square Error |
| R2 | Coefficient of determination |
| observed value | |
| predicted value | |
| The mean value of the observed value | |
| The relative closeness coefficient | |
| of the mean metric | |
| of the standard deviation metric | |
| The weighted Euclidean distance | |
| The entropy value | |
| of the normalized metric |
References
- Butler, D.; Digman, C.; Makropoulos, C.; Davies, J.W. Urban Drainage, 4th ed.; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2018. [Google Scholar]
- Water, N. The Water Services in Norway; Vangsvegen 143: Hamar, Norway, 2014. [Google Scholar]
- Petrie, B. A review of combined sewer overflows as a source of wastewater-derived emerging contaminants in the environment and their management. Environ. Sci. Pollut. Res. 2021, 28, 32095–32110. [Google Scholar] [CrossRef]
- Hernes, R.R.; Gragne, A.S.; Abdalla, E.M.H.; Braskerud, B.C.; Alfredsen, K.; Muthanna, T.M. Assessing the effects of four SUDS scenarios on combined sewer overflows in Oslo, Norway: Evaluating the low-impact development module of the Mike Urban model. Hydrol. Res. 2020, 51, 1437–1454. [Google Scholar] [CrossRef]
- Nilsen, V.; Lier, J.A.; Bjerkholt, J.T.; Lindholm, O.G. Analysing urban floods and combined sewer overflows in a changing climate. J. Water Clim. Chang. 2011, 2, 260–271. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, F.; Chen, J.; Li, J. Risk Analysis for Reservoir Real-Time Optimal Operation Using the Scenario Tree-Based Stochastic Optimization Method. Water 2018, 10, 606. [Google Scholar] [CrossRef] [Green Version]
- Report of the 17th Meeting (16–17 May 2019) to the International Committee for Weights and Measures; Consultative Committee for Mass and Related Quantities (CCM), Bureau International des Poids et Mesures: Sèvres, France, 2019; p. 29.
- Alihosseini, M.; Thamsen, P.U. Analysis of sediment transport in sewer pipes using a coupled CFD-DEM model and experimental work. Urban Water J. 2019, 16, 259–268. [Google Scholar] [CrossRef]
- Butler, D.; May, R.; Ackers, J. Self-Cleansing Sewer Design Based on Sediment Transport Principles. J. Hydraul. Eng. 2003, 129, 276–282. [Google Scholar] [CrossRef]
- Fu, X.; Goddard, H.; Wang, X.; Hopton, M.E. Development of a scenario-based stormwater management planning support system for reducing combined sewer overflows (CSOs). J. Environ. Manag. 2019, 236, 571–580. [Google Scholar] [CrossRef]
- Hanssen-Bauer, I.; Førland, E.J.; Haddeland, I.; Hisdal, H.; Lawrence, D.; Mayer, S.; Nesje, A.; Nilsen, J.E.Ø.; Sandven, S.; Sandø, A.B.; et al. Climate in Norway 2100—A knowledge base for climate adaptation. NCCS Rep. 2017, 1, 2017. [Google Scholar]
- Wang, W.-C.; Chau, K.-W.; Cheng, C.-T.; Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Erlend; Lindholm, G.; Ratnaweera, H. Enhancing Operation of a Sewage Pumping Station for Inter Catchment Wastewater Transfer by Using Deep Learning and Hydraulic Model. arXiv Prepr. 2018, 1811, 06367. [Google Scholar]
- Zhang, D.; Martinez, N.; Lindholm, G.; Ratnaweera, H. Manage Sewer In-Line Storage Control Using Hydraulic Model and Recurrent Neural Network. Water Resour. Manag. 2018, 32, 2079–2098. [Google Scholar] [CrossRef]
- Saleh, F.; Ducharne, A.; Flipo, N.; Oudin, L.; Ledoux, E. Impact of river bed morphology on discharge and water levels simulated by a 1D Saint–Venant hydraulic model at regional scale. J. Hydrol. 2013, 476, 169–177. [Google Scholar] [CrossRef]
- Habert, J.; Ricci, S.; Le Pape, E.; Thual, O.; Piacentini, A.; Goutal, N.; Jonville, G.; Rochoux, M. Reduction of the uncertainties in the water level-discharge relation of a 1D hydraulic model in the context of operational flood forecasting. J. Hydrol. 2016, 532, 52–64. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.-L.; Xiang, X.-H.; Wang, C.-H.; Chen, X.; Xu, C.-Y.; Yu, Z. Coupled Hydraulic and Kalman Filter Model for Real-Time Correction of Flood Forecast in the Three Gorges Interzone of Yangtze River, China. J. Hydrol. Eng. 2013, 18, 1416–1425. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Valipour, M. Number of required observation data for rainfall forecasting according to the climate conditions. Am. J. Sci. Res. 2012, 74, 79–86. [Google Scholar]
- Uvo, C.B.; Graham, N.E. Seasonal runoff forecast for northern South America: A statistical model. Water Resour. Res. 1998, 34, 3515–3524. [Google Scholar] [CrossRef]
- Rosenberg, E.A.; Wood, A.W.; Steinemann, A.C. Statistical applications of physically based hydrologic models to seasonal streamflow forecasts. Water Resour. Res. 2011, 47, W00h14. [Google Scholar] [CrossRef]
- Apel, H.; Abdykerimova, Z.; Agalhanova, M.; Baimaganbetov, A.; Gavrilenko, N.; Gerlitz, L.; Kalashnikova, O.; Unger-Shayesteh, K.; Vorogushyn, S.; Gafurov, A. Statistical forecast of seasonal discharge in Central Asia using observational records: Development of a generic linear modelling tool for operational water resource management. Hydrol. Earth Syst. Sci. 2018, 22, 2225–2254. [Google Scholar] [CrossRef] [Green Version]
- Lee, Y.-S.; Tong, L.-I. Forecasting time series using a methodology based on autoregressive integrated moving average and genetic programming. Knowl.-Based Syst. 2011, 24, 66–72. [Google Scholar] [CrossRef]
- Li, J.; Zong, Q. The Forecasting of the Elevator Traffic Flow Time Series Based on ARIMA and GP. Adv. Mater. Res. 2012, 588–589, 1466–1471. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Pai, P.-F.; Lin, C.-S. A hybrid ARIMA and support vector machines model in stock price forecasting. Omega 2005, 33, 497–505. [Google Scholar] [CrossRef]
- Aladag, C.H.; Egrioglu, E.; Kadilar, C. Forecasting nonlinear time series with a hybrid methodology. Appl. Math. Lett. 2009, 22, 1467–1470. [Google Scholar] [CrossRef] [Green Version]
- Vanrolleghem, P.A.; Kamradt, B.; Solvi, A.-M.; Muschalla, D. Making the best of two hydrological flow routing models: Nonlinear outflow-volume relationships and backwater effects model. In Proceedings of the 8th International Conference on Urban Drainage Modelling, Tokyo, Japan, 7–12 September 2009. [Google Scholar]
- Qin, M.; Li, Z.; Du, Z. Red tide time series forecasting by combining ARIMA and deep belief network. Knowl.-Based Syst. 2017, 125, 39–52. [Google Scholar] [CrossRef]
- Altwaijry, N.; Al-Turaiki, I. Arabic handwriting recognition system using convolutional neural network. Neural Comput. Appl. 2021, 33, 2249–2261. [Google Scholar] [CrossRef]
- Kubanek, M.; Bobulski, J.; Kulawik, J. A Method of Speech Coding for Speech Recognition Using a Convolutional Neural Network. Symmetry 2019, 11, 1185. [Google Scholar] [CrossRef] [Green Version]
- Araújo, R.d.A.; Nedjah, N.; Oliveira, A.L.I.; Meira, S.R.d.L. A deep increasing–decreasing-linear neural network for financial time series prediction. Neurocomputing 2019, 347, 59–81. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Pavlyshenko, B.M. Machine-Learning Models for Sales Time Series Forecasting. Data 2019, 4, 15. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Li, W.; Cook, C.; Zhu, C.; Gao, Y. Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5457–5466. [Google Scholar]
- Yue, B.; Fu, J.; Liang, J. Residual Recurrent Neural Networks for Learning Sequential Representations. Information 2018, 9, 56. [Google Scholar] [CrossRef] [Green Version]
- Manaswi, N.K. RNN and LSTM, in Deep Learning with Applications Using Python: Chatbots and Face, Object, and Speech Recognition with TensorFlow and Keras; Apress: Berkeley, CA, USA, 2018; pp. 115–126. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Jenckel, M.; Bukhari, S.S.; Dengel, A. Training LSTM-RNN with Imperfect Transcription: Limitations and Outcomes. In Proceedings of the 4th International Workshop on Historical Document Imaging and Processing, Kyoto, Japan, 10–11 November 2017; Association for Computing Machinery: Kyoto, Japan, 2017; pp. 48–53. [Google Scholar]
- Xu, D.; Cheng, W.; Zong, B.; Song, D.; Ni, J.; Yu, W.; Liu, Y.; Chen, H.; Zhang, X. Tensorized LSTM with Adaptive Shared Memory for Learning Trends in Multivariate Time Series. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1395–1402. [Google Scholar]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Its Appl. 2019, 519, 127–139. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-series well performance prediction based on Long Short-Term Memory (LSTM) neural network model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. An Introduction to Feature Selection, in Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 487–519. [Google Scholar]
- Norway, S. Statistics Norway. 2020. Available online: https://www.ssb.no/kommunefakta/ (accessed on 20 April 2020).
- CLIMATE-DATA.ORG. Ålesund Climate: Average Temperature, Weather by Month, Ålesund Water Temperature—Climate-Data.org. 2021. Available online: https://en.climate-data.org/europe/norway/m%C3%B8re-og-romsdal/alesund-9937/ (accessed on 20 April 2020).
- Zhang, D.; Lindholm, G.; Ratnaweera, H. Use long short-term memory to enhance Internet of Things for combined sewer overflow monitoring. J. Hydrol. 2018, 556, 409–418. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Salman, A.G.; Heryadi, Y.; Abdurahman, E.; Suparta, W. Single Layer & Multi-layer Long Short-Term Memory (LSTM) Model with Intermediate Variables for Weather Forecasting. Procedia Comput. Sci. 2018, 135, 89–98. [Google Scholar]
- Li, Y.; Cao, H. Prediction for Tourism Flow based on LSTM Neural Network. Procedia Comput. Sci. 2018, 129, 277–283. [Google Scholar] [CrossRef]
- Tien Bui, D.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the Hoa Binh province of Vietnam: A comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 2012, 171–172, 12–29. [Google Scholar] [CrossRef]
- Krohling, R.A.; Pacheco, A.G.C. A-TOPSIS—An Approach Based on TOPSIS for Ranking Evolutionary Algorithms. Procedia Comput. Sci. 2015, 55, 308–317. [Google Scholar] [CrossRef] [Green Version]
- Pacheco, A.G.C.; Krohling, R.A. Ranking of Classification Algorithms in Terms of Mean–Standard Deviation Using A-TOPSIS. Ann. Data Sci. 2018, 5, 93–110. [Google Scholar] [CrossRef] [Green Version]
- Vazquezl, M.Y.L.; Peñafiel, L.A.B.; Muñoz, S.X.S.; Martinez, M.A.Q. A Framework for Selecting Machine Learning Models Using TOPSIS. In International Conference on Applied Human Factors and Ergonomics; Springer: Cham, Switzerland, 2021; pp. 119–126. [Google Scholar]
- Jingwen, H. Combining entropy weight and TOPSIS method For information system selection. In Proceedings of the 2008 IEEE International Conference on Automation and Logistics, Qingdao, China, 1–3 September 2008. [Google Scholar]
- Deng, H.; Yeh, C.-H.; Willis, R.J. Inter-company comparison using modified TOPSIS with objective weights. Comput. Oper. Res. 2000, 27, 963–973. [Google Scholar] [CrossRef]
- Scikit Learn. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html#mean-absolute-percentage-error (accessed on 15 May 2021).
- Lee, T.; Shin, J.-Y.; Kim, J.-S.; Singh, V.P. Stochastic simulation on reproducing long-term memory of hydroclimatological variables using deep learning model. J. Hydrol. 2020, 582, 124540. [Google Scholar] [CrossRef]
- Gauch, M.; Kratzert, F.; Klotz, D.; Nearing, G.; Lin, J.; Hochreiter, S. Rainfall–runoff prediction at multiple timescales with a single Long Short-Term Memory network. Hydrol. Earth Syst. Sci. 2021, 25, 2045–2062. [Google Scholar] [CrossRef]
- Wikipedia. Keras. 2021. Available online: https://en.wikipedia.org/wiki/Keras (accessed on 12 May 2021).
- Li, X.-M.; Ma, Y.; Leng, Z.-H.; Zhang, J.; Lu, X.-X. High-Accuracy Remote Sensing Water Depth Retrieval for Coral Islands and Reefs Based on LSTM Neural Network. J. Coast. Res. 2020, 102, 21–32. [Google Scholar] [CrossRef]
- Chen, X.; Feng, F.; Wu, J.; Liu, W. Anomaly detection for drinking water quality via deep biLSTM ensemble. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Kyoto, Japan, 15–19 July 2018; Association for Computing Machinery: Kyoto, Japan, 2018; pp. 3–4. [Google Scholar]
- Muharemi, F.; Logofătu, D.; Leon, F. Machine learning approaches for anomaly detection of water quality on a real-world data set. J. Inform. Telecommun. 2019, 3, 294–307. [Google Scholar] [CrossRef] [Green Version]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Liu, Z. A method of SVM with Normalization in Intrusion Detection. Procedia Environ. Sci. 2011, 11, 256–262. [Google Scholar] [CrossRef] [Green Version]
- Troiano, L.; Villa, E.M.; Loia, V. Replicating a Trading Strategy by Means of LSTM for Financial Industry Applications. IEEE Trans. Ind. Inform. 2018, 14, 3226–3234. [Google Scholar] [CrossRef]
- Salas, F.R.; Somos-Valenzuela, M.A.; Dugger, A.; Maidment, D.R.; Gochis, D.J.; David, C.H.; Yu, W.; Ding, D.; Clark, E.P.; Noman, N. Towards Real-Time Continental Scale Streamflow Simulation in Continuous and Discrete Space. JAWRA J. Am. Water Resour. Assoc. 2018, 54, 7–27. [Google Scholar] [CrossRef]
- Brian Cosgrove, C.K. The National Water Model. Available online: https://water.noaa.gov/about/nwm (accessed on 8 June 2021).
- Tran, T.T.; Lee, T.; Kim, J.-S. Increasing Neurons or Deepening Layers in Forecasting Maximum Temperature Time Series? Atmosphere 2020, 11, 1072. [Google Scholar] [CrossRef]
- Thi Kieu Tran, T.; Lee, T.; Shin, J.-Y.; Kim, J.-S.; Kamruzzaman, M. Deep Learning-Based Maximum Temperature Forecasting Assisted with Meta-Learning for Hyperparameter Optimization. Atmosphere 2020, 11, 487. [Google Scholar] [CrossRef]
- Lee, J.; Kim, C.-G.; Lee, J.E.; Kim, N.W.; Kim, H. Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water 2018, 10, 1448. [Google Scholar] [CrossRef] [Green Version]
- Ke, J.; Liu, X. Empirical Analysis of Optimal Hidden Neurons in Neural Network Modeling for Stock Prediction. In Proceedings of the 2008 IEEE Pacific-Asia Workshop on Computational Intelligence and Industrial Application, Wuhan, China, 19–20 December 2008. [Google Scholar]
- Alam, S.; Kaushik, S.C.; Garg, S.N. Assessment of diffuse solar energy under general sky condition using artificial neural network. Appl. Energy 2009, 86, 554–564. [Google Scholar] [CrossRef]
- Gaurang, P.; Ganatra, A.; Kosta, Y.; Panchal, D. Behaviour Analysis of Multilayer Perceptronswith Multiple Hidden Neurons and Hidden Layers. Int. J. Comput. Theory Eng. 2011, 3, 332–337. [Google Scholar]
- Cominola, A.; Giuliani, M.; Castelletti, A.; Rosenberg, D.E.; Abdallah, A.M. Implications of data sampling resolution on water use simulation, end-use disaggregation, and demand management. Environ. Model. Softw. 2018, 102, 199–212. [Google Scholar] [CrossRef] [Green Version]
- Kirstein, J.K.; Høgh, K.; Rygaard, M.; Borup, M. A case study on the effect of smart meter sampling intervals and gap-filling approaches on water distribution network simulations. J. Hydroinform. 2020, 23, 66–75. [Google Scholar] [CrossRef]
- Croce, S.; Marcelloni, F.; Vecchio, M. Reducing Power Consumption in Wireless Sensor Networks Using a Novel Approach to Data Aggregation. Comput. J. 2007, 51, 227–239. [Google Scholar] [CrossRef]
- Al-Karaki, J.N.; Ul-Mustafa, R.; Kamal, A.E. Data aggregation in wireless sensor networks—Exact and approximate algorithms. In Proceedings of the 2004 Workshop on High Performance Switching and Routing 2004, HPSR, Phoenix, AZ, USA, 19–21 April 2004. [Google Scholar]
- Lazzerini, B.; Marcelloni, F.; Vecchio, M.; Croce, S.; Monaldi, E. A Fuzzy Approach to Data Aggregation to Reduce Power Consumption in Wireless Sensor Networks. In Proceedings of the NAFIPS 2006—2006 Annual Meeting of the North American Fuzzy Information Processing Society, Montreal, QC, Canada, 3–6 June 2006. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step Back–Step Ahead | Neurons | MAPE | RMSE (×10−3) | R2 | ξ | Rank |
|---|---|---|---|---|---|---|
| 12–12 | 1 | 0.216 ± 0.126 | 1.820 ± 1.005 | −0.401 ± 1.184 | - | - |
| 5 | 0.104 ± 0.083 | 0.903 ± 0.660 | 0.597 ± 0.763 | 0 | 7 | |
| 10 | 0.090 ± 0.060 | 0.796 ± 0.480 | 0.721 ± 0.554 | 0.374 | 6 | |
| 20 | 0.076 ± 0.001 | 0.680 ± 0.004 | 0.848 ± 0.002 | 0.994 | 3 | |
| 50 | 0.076 ± 0.001 | 0.677 ± 0.004 | 0.850 ± 0.002 | 0.999 | 2 | |
| 100 | 0.076 ± 0.001 | 0.677 ± 0.004 | 0.850 ± 0.002 | 0.999 | 1 | |
| 200 | 0.076 ± 0.001 | 0.678 ± 0.007 | 0.849 ± 0.003 | 0.987 | 4 | |
| 500 | 0.078 ± 0.003 | 0.691 ± 0.024 | 0.843 ± 0.011 | 0.949 | 5 | |
| 24–12 | 1 | 0.243 ± 0.130 | 2.014 ± 1.036 | −0.666 ± 1.222 | - | - |
| 5 | 0.090 ± 0.060 | 0.795 ± 0.481 | 0.720 ± 0.556 | 0.153 | 6 | |
| 10 | 0.077 ± 0.001 | 0.691 ± 0.010 | 0.843 ± 0.005 | 0.972 | 3 | |
| 20 | 0.076 ± 0.001 | 0.686 ± 0.010 | 0.846 ± 0.004 | 0.993 | 2 | |
| 50 | 0.076 ± 0.001 | 0.684 ± 0.010 | 0.846 ± 0.003 | 1.000 | 1 | |
| 100 | 0.087 ± 0.045 | 0.774 ± 0.380 | 0.758 ± 0.383 | 0.340 | 5 | |
| 200 | 0.096 ± 0.055 | 0.841 ± 0.453 | 0.704 ± 0.458 | 0.094 | 7 | |
| 500 | 0.079 ± 0.003 | 0.700 ± 0.020 | 0.839 ± 0.009 | 0.916 | 4 | |
| 36–12 | 1 | 0.260 ± 0.123 | 2.149 ± 0.975 | −0.815 ± 1.173 | - | - |
| 5 | 0.118 ± 0.098 | 1.016 ± 0.786 | 0.468 ± 0.913 | 0.372 | 6 | |
| 10 | 0.078 ± 0.001 | 0.695 ± 0.010 | 0.841 ± 0.005 | 0.996 | 2 | |
| 20 | 0.085 ± 0.036 | 0.755 ± 0.286 | 0.787 ± 0.250 | 0.834 | 4 | |
| 50 | 0.077 ± 0.001 | 0.693 ± 0.010 | 0.842 ± 0.003 | 1.000 | 1 | |
| 100 | 0.089 ± 0.049 | 0.790 ± 0.392 | 0.747 ± 0.404 | 0.755 | 5 | |
| 200 | 0.137 ± 0.138 | 1.154 ± 1.032 | 0.230 ± 1.697 | 0 | 7 | |
| 500 | 0.083 ± 0.018 | 0.733 ± 0.122 | 0.819 ± 0.078 | 0.926 | 3 |
| Step Back–Step Ahead | Neurons | MAPE | RMSE (×10−3) | R2 | ξ | Rank |
|---|---|---|---|---|---|---|
| 12–24 | 1 | 0.233 ± 0.119 | 1.953 ± 0.96 | −0.536 ± 1.189 | - | - |
| 5 | 0.148 ± 0.104 | 1.255 ± 0.84 | 0.265 ± 1.025 | 0 | 7 | |
| 10 | 0.109 ± 0.057 | 0.946 ± 0.46 | 0.642 ± 0.559 | 0.575 | 6 | |
| 20 | 0.096 ± 0.004 | 0.842 ± 0.03 | 0.767 ± 0.019 | 0.980 | 4 | |
| 50 | 0.095 ± 0.001 | 0.837 ± 0.01 | 0.770 ± 0.003 | 0.996 | 1 | |
| 100 | 0.094 ± 0.002 | 0.832 ± 0.02 | 0.773 ± 0.008 | 0.994 | 2 | |
| 200 | 0.096 ± 0.002 | 0.844 ± 0.02 | 0.766 ± 0.013 | 0.984 | 3 | |
| 500 | 0.100 ± 0.009 | 0.874 ± 0.08 | 0.748 ± 0.047 | 0.933 | 5 | |
| 24–24 | 1 | 0.240 ± 0.127 | 1.993 ± 1.02 | −0.628 ± 1.265 | - | - |
| 5 | 0.120 ± 0.080 | 1.034 ± 0.64 | 0.523 ± 0.775 | 0.323 | 6 | |
| 10 | 0.091 ± 0.002 | 0.812 ± 0.02 | 0.784 ± 0.008 | 0.989 | 3 | |
| 20 | 0.091 ± 0.002 | 0.811 ± 0.01 | 0.784 ± 0.007 | 0.994 | 2 | |
| 50 | 0.091 ± 0.001 | 0.808 ± 0.01 | 0.786 ± 0.003 | 1.000 | 1 | |
| 100 | 0.096 ± 0.019 | 0.855 ± 0.19 | 0.749 ± 0.153 | 0.868 | 5 | |
| 200 | 0.093 ± 0.004 | 0.826 ± 0.03 | 0.776 ± 0.016 | 0.967 | 4 | |
| 500 | 0.123 ± 0.118 | 1.034 ± 0.86 | 0.421 ± 1.539 | 0 | 7 | |
| 36–24 | 1 | 0.258 ± 0.120 | 2.142 ± 0.96 | −0.796 ± 1.207 | - | - |
| 5 | 0.098 ± 0.006 | 0.857 ± 0.04 | 0.758 ± 0.021 | 0.991 | 2 | |
| 10 | 0.104 ± 0.045 | 0.918 ± 0.36 | 0.683 ± 0.383 | 0.823 | 4 | |
| 20 | 0.097 ± 0.003 | 0.860 ± 0.03 | 0.757 ± 0.014 | 1.000 | 1 | |
| 50 | 0.100 ± 0.010 | 0.899 ± 0.11 | 0.731 ± 0.074 | 0.958 | 3 | |
| 100 | 0.131 ± 0.082 | 1.137 ± 0.65 | 0.443 ± 0.757 | 0.554 | 6 | |
| 200 | 0.149 ± 0.161 | 1.237 ± 1.17 | 0.071 ± 2.157 | 0 | 7 | |
| 500 | 0.111 ± 0.061 | 0.975 ± 0.49 | 0.614 ± 0.622 | 0.722 | 5 |
| Aggregation | MAPE | RMSE (×10−3) | R2 |
|---|---|---|---|
| 5-min Interval | 0.118 | 0.996 | 0.674 |
| 10-min Interval | 0.069 | 1.265 | 0.866 |
| 30-min Interval | 0.072 | 3.835 | 0.859 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, L.V.; Tornyeviadzi, H.M.; Bui, D.T.; Seidu, R. Predicting Discharges in Sewer Pipes Using an Integrated Long Short-Term Memory and Entropy A-TOPSIS Modeling Framework. Water 2022, 14, 300. https://doi.org/10.3390/w14030300
Nguyen LV, Tornyeviadzi HM, Bui DT, Seidu R. Predicting Discharges in Sewer Pipes Using an Integrated Long Short-Term Memory and Entropy A-TOPSIS Modeling Framework. Water. 2022; 14(3):300. https://doi.org/10.3390/w14030300
Chicago/Turabian StyleNguyen, Lam Van, Hoese Michel Tornyeviadzi, Dieu Tien Bui, and Razak Seidu. 2022. "Predicting Discharges in Sewer Pipes Using an Integrated Long Short-Term Memory and Entropy A-TOPSIS Modeling Framework" Water 14, no. 3: 300. https://doi.org/10.3390/w14030300
APA StyleNguyen, L. V., Tornyeviadzi, H. M., Bui, D. T., & Seidu, R. (2022). Predicting Discharges in Sewer Pipes Using an Integrated Long Short-Term Memory and Entropy A-TOPSIS Modeling Framework. Water, 14(3), 300. https://doi.org/10.3390/w14030300