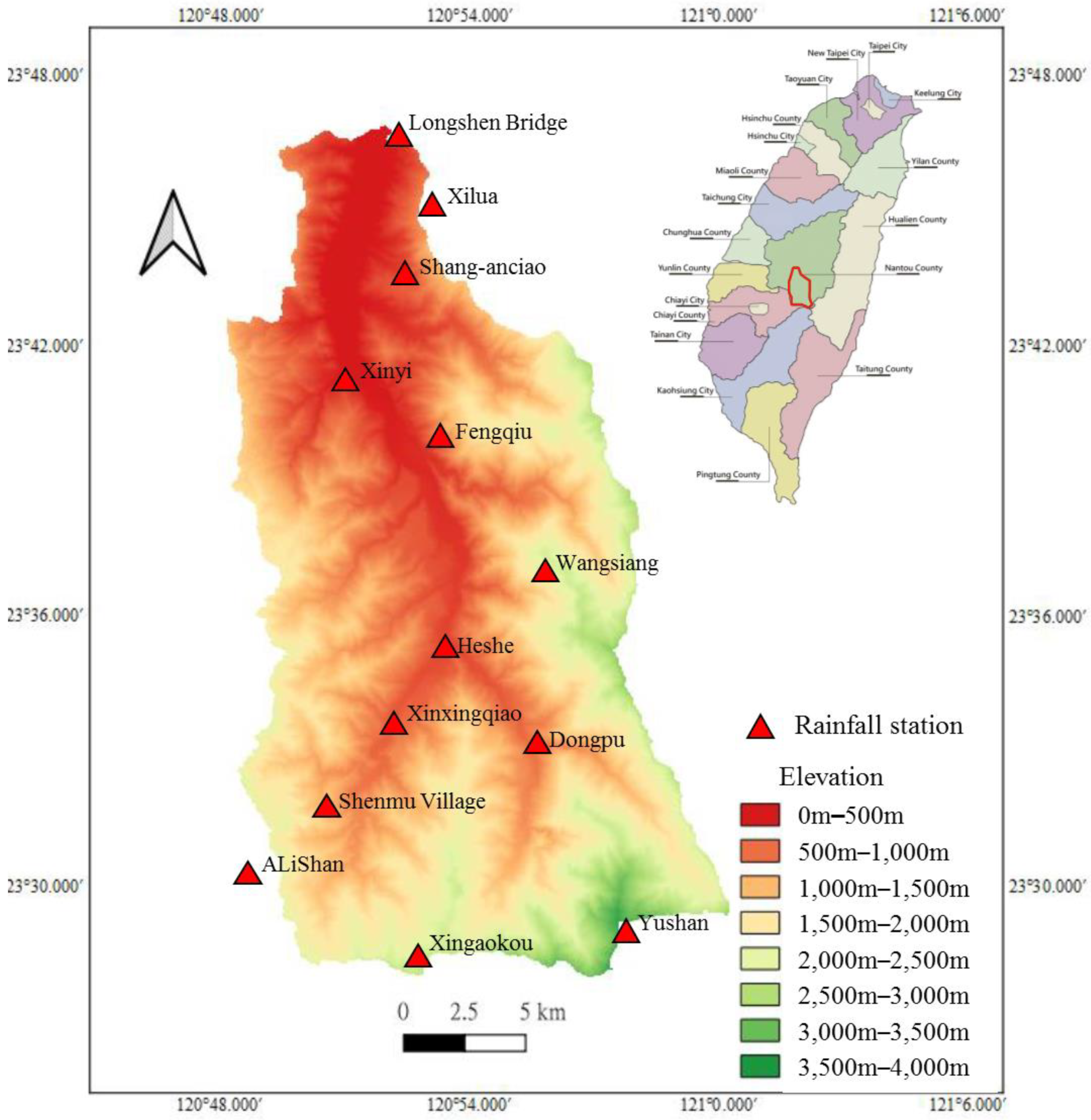
Figure 1.
Location map of the Chenyoulan watershed.
Figure 1.
Location map of the Chenyoulan watershed.
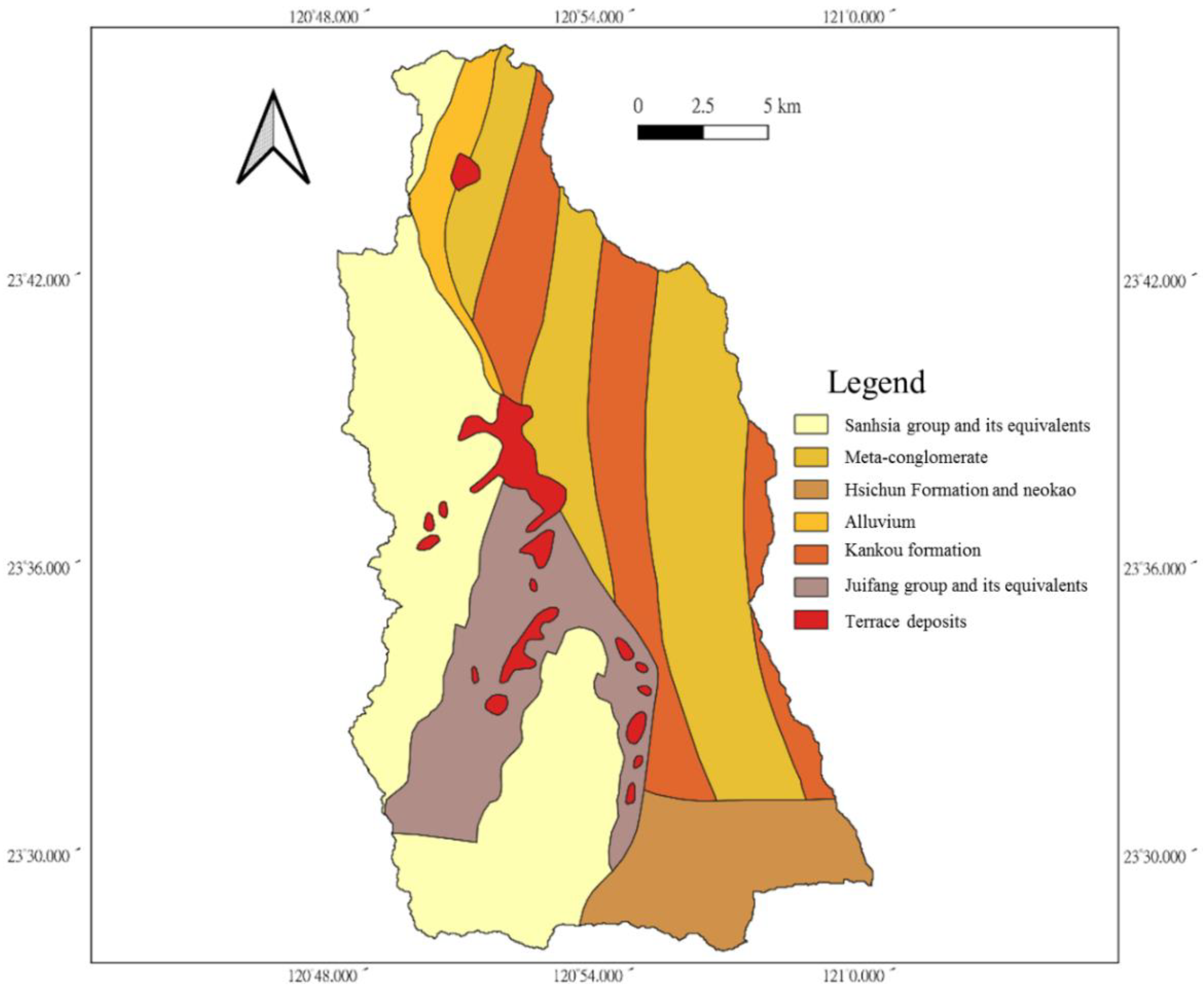
Figure 2.
Stratigraphic distribution map of the Chenyoulan watershed.
Figure 2.
Stratigraphic distribution map of the Chenyoulan watershed.
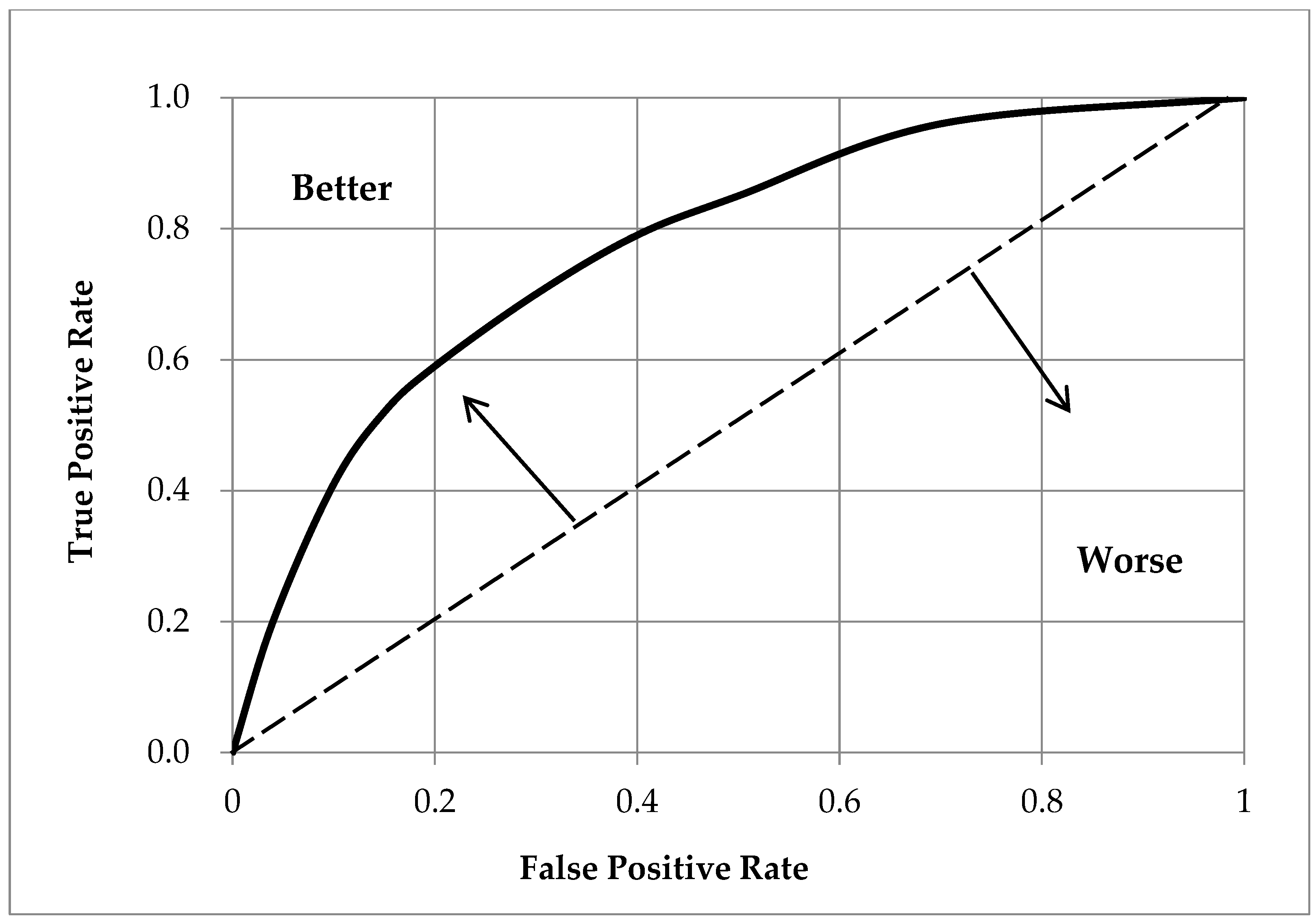
Figure 3.
Schematic of a receiver operating characteristic curve as indicative of classification accuracy.
Figure 3.
Schematic of a receiver operating characteristic curve as indicative of classification accuracy.
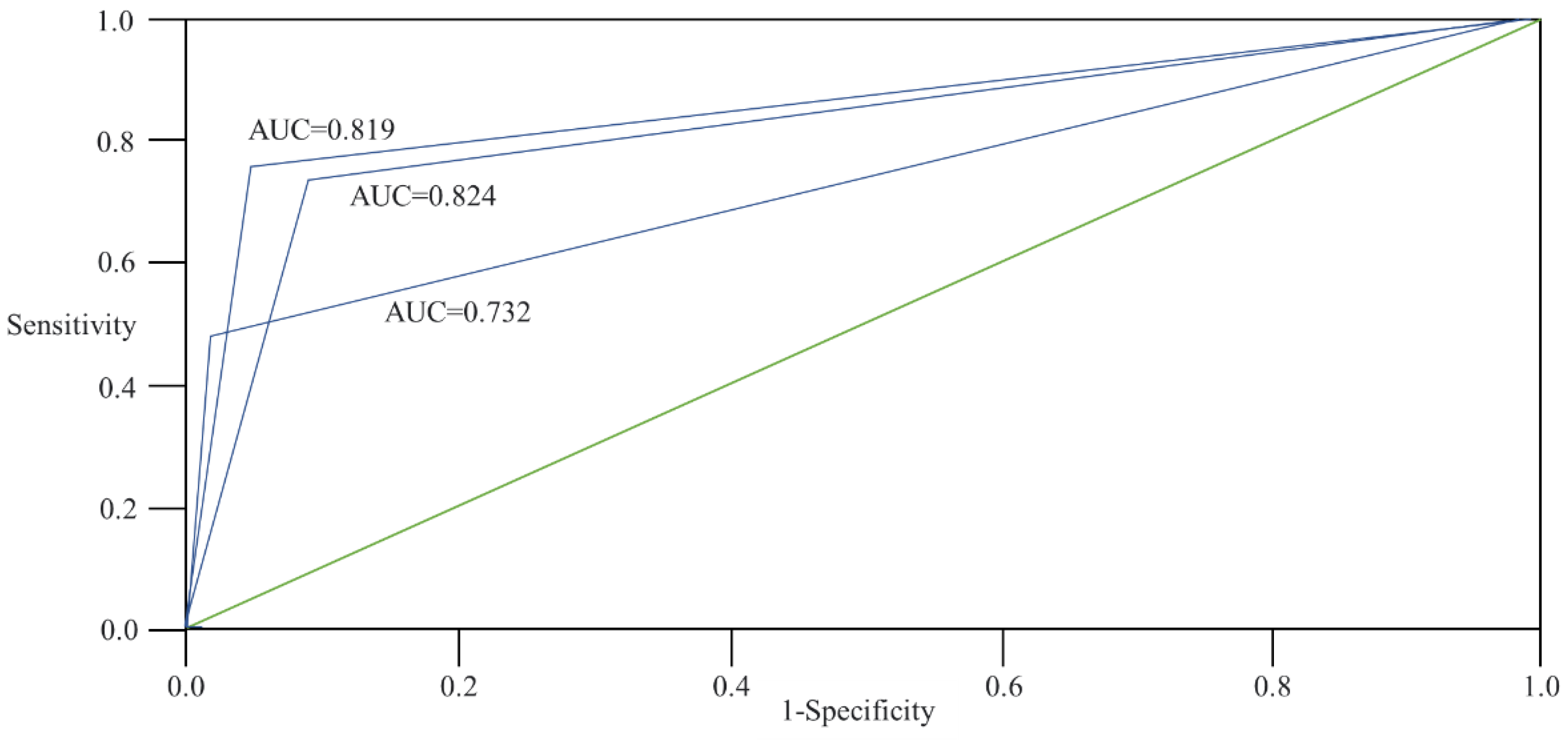
Figure 4.
Receiver operating characteristic curve, discriminant analysis, logistic regression analysis, and artificial neural network; AUC = area under curve.
Figure 4.
Receiver operating characteristic curve, discriminant analysis, logistic regression analysis, and artificial neural network; AUC = area under curve.
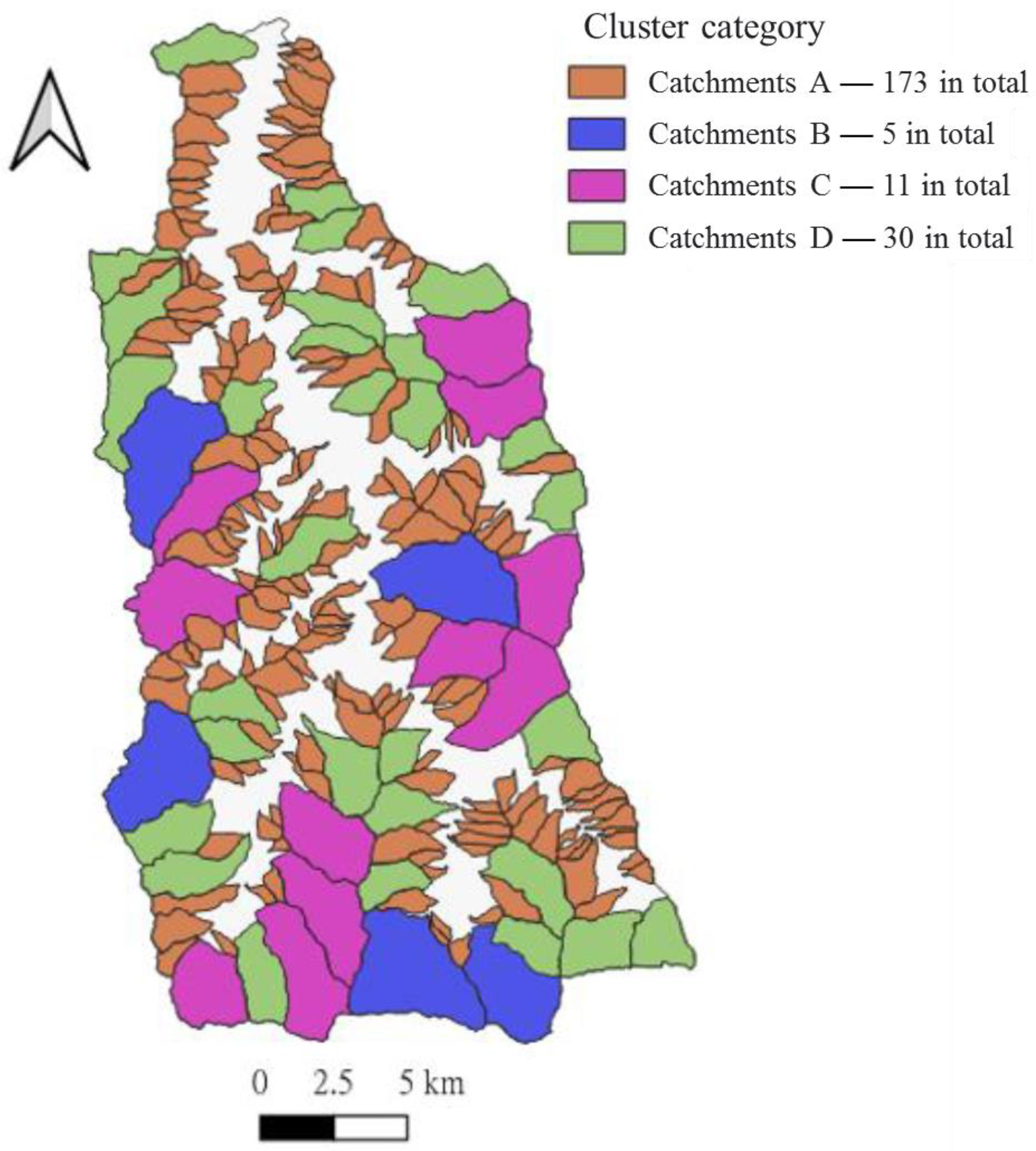
Figure 5.
Distribution of clusters.
Figure 5.
Distribution of clusters.
Table 1.
Rainfall classification by the Central Meteorological Bureau of the Ministry of Communications.
Table 1.
Rainfall classification by the Central Meteorological Bureau of the Ministry of Communications.
| Type of Alert | Rainfall Classification | Definition |
|---|
| Heavy rain special | Heavy rain | Above 80 mm/24 h or 40 mm/1 h |
| Torrential rain | Extremely heavy rain | Above 200 mm/24 h or 100 mm/3 h |
| Torrential rain | Above 350 mm/24 h or 200 mm/3 h |
| Extremely torrential rain | Above 500 mm/24 h |
Table 2.
Terrestrial factors.
Table 2.
Terrestrial factors.
| Parameter | Description of Calculation | Meaning (Where Not Self-Explanatory) |
|---|
| Total area of catchment | A = a × n
A: grid area [];n: number of grids | |
| Average elevation of catchment area | {h: elevation of the grid} | |
| Average slope of catchment area | {slope: slope value of the grid} | |
| Total curvature | {Z: total curvature of the grid} | The rate of change representing the slope or direction of slope |
| Roughness | | The difference between the maximum and minimum of the surrounding elevation |
| Terrain Ruggedness Index, TPI | | The center-point elevation minus the average of the surrounding elevations |
| Topographic Position Index, TRI | | The average of the difference between the elevation of the center point and the surrounding elevation |
Table 3.
Strata scoring criteria.
Table 3.
Strata scoring criteria.
| Formation Name | Score | Landslide Ratio | Formation Name | Score | Landslide Ratio |
|---|
| Sanhsia group and its equivalents | 10 | 2.8% | Tatungshan formation | 1.91 | 0.28% |
| Meta-conglomerate | 9.76 | 2.73% | Terrace deposits | 1.87 | 0.27% |
| Lushan formation | 7.42 | 2% | Toukoshan formation and its equivalents | 1.8 | 0.25% |
| Chinshui shale and its equivalents | 6.73 | 1.78% | Cholan formation and its equivalents | 1.79 | 0.25% |
| Kankou formation | 5.81 | 1.5% | Hsichun formation and Neokao formation | 1.28 | 0.09% |
| Juifang group and its equivalents | 3.81 | 0.87% | Alluvium | 1.03 | 0.01% |
| Yehliu group and its equivalents | 3.69 | 0.84% | Lateritic terrace deposits | 1.03 | 0.01% |
| Tananao schists | 2.21 | 0.38% | Basic rock | 1 | 0% |
Table 4.
Scoring criteria for fault assessment.
Table 4.
Scoring criteria for fault assessment.
| Distance between Assessment Point and Fault Zone | Score | Distance between Assessment Point and Fault Zone | Score |
|---|
| <100 m | 10 | 600–700 m | 4 |
| 100–200 m | 9 | 700–800 m | 3 |
| 200–300 m | 8 | 800–900 m | 2 |
| 300–400 m | 7 | 900–1000 m | 1 |
| 400–500 m | 6 | >1000 m | 0 |
| 500–600 m | 5 | | |
Table 5.
Six rainfield-cutting methods.
Table 5.
Six rainfield-cutting methods.
| Method | Correction Method | Start of Rain | End of Rain | Method |
|---|
| 1 | | No rain for previous 24 h | No rain for 24 consecutive hours | 1 |
| 2 | 1 | No rain for previous 12 h | No rain for 12 consecutive hours | 2 |
| 3 | | Hourly rainfall is greater than 4 mm | Rainfall is less than 4 mm for three consecutive hours | 3 |
| 4 | | Cumulative rainfall is at least 10 mm in the first 24 h | Cumulative rainfall is less than 10 mm for 24 h | 4 |
| 5 | 3 | Hourly rainfall is greater than 4 mm | Rainfall is less than 4 mm for six consecutive hours | 5 |
| 6 | 4 | Cumulative rainfall is at least 10 mm in the first 12 h | Cumulative rainfall is less than 10 mm for 12 h | 6 |
Table 6.
Overlapping results, Typhoon Haitang and the 2005 Landslide Catalogue.
Table 6.
Overlapping results, Typhoon Haitang and the 2005 Landslide Catalogue.
Accuracy
NDVI Difference | Landslide Accuracy | Non-Landslide Accuracy | Overall Accuracy |
|---|
| 0.15 | 83.6% | 86.9% | 86.6% |
| 0.2 | 70.6% | 94.2% | 93.7% |
| 0.25 | 57.4% | 97.2% | 96.3% |
Table 7.
Overlapping results, Typhoon Morakot and the 2009 Landslide Catalogue.
Table 7.
Overlapping results, Typhoon Morakot and the 2009 Landslide Catalogue.
Accuracy
NDVI Difference | Landslide Accuracy | Non-Landslide Accuracy | Overall Accuracy |
|---|
| 0.15 | 72.7% | 86.6% | 86.3% |
| 0.2 | 61.5% | 95.3% | 95.2% |
| 0.25 | 32.6% | 95.5% | 95.5% |
Table 8.
Pearson’s correlation coefficients.
Table 8.
Pearson’s correlation coefficients.
| | Total Area of Catchment | Average Elevation of Catchment Area | Average Slope of Catchment Area | Total Curvature | Roughness | TPI | TRI |
|---|
| Total area of catchment | 1.000 | 0.438 | 0.251 | 0.103 | 0.258 | −0.002 | 0.252 |
| Average elevation of catchment area | 0.438 | 1.000 | 0.774 | 0.079 | 0.678 | −0.109 | 0.680 |
| Average slope of catchment area | 0.251 | 0.774 | 1.000 | 0.109 | 0.985 | −0.105 | 0.988 |
| Total curvature | 0.103 | 0.079 | 0.109 | 1.000 | 0.122 | 0.706 | 0.107 |
| Roughness | 0.258 | 0.678 | 0.985 | 0.122 | 1.000 | −0.120 | 0.998 |
| Topo-graphic Position Index, TPI | −0.002 | −0.109 | −0.105 | 0.706 | −0.120 | 1.000 | −0.140 |
| Terrain Rugged-ness Index, TRI | 0.252 | 0.680 | 0.988 | 0.107 | 0.998 | −0.140 | 1.000 |
Table 9.
Total variation interpretation, principal component analysis.
Table 9.
Total variation interpretation, principal component analysis.
| Ingredient | Initial Eigenvalues | Sum of Squares Loading Extraction |
|---|
| Sum | Variation (%) | Accumulation (%) | Sum | Variation (%) | Accumulation (%) |
|---|
| 1 | 3.686 | 52.661 | 52.661 | 3.686 | 52.661 | 52.661 |
| 2 | 1.614 | 23.055 | 75.716 | 1.614 | 23.055 | 75.716 |
| 3 | 0.951 | 13.587 | 89.303 | | | |
| 4 | 0.372 | 5.312 | 94.614 | | | |
| 5 | 0.359 | 5.126 | 99.740 | | | |
| 6 | 0.016 | 0.233 | 99.973 | | | |
| 7 | 0.002 | 0.027 | 100.000 | | | |
Table 10.
Characteristic vector table of local factors, principal component analysis.
Table 10.
Characteristic vector table of local factors, principal component analysis.
| Terrestrial Factor | Ingredients |
|---|
| One | Two |
|---|
| Total area of catchment | 0.412 | 0.725 |
| Average elevation of catchment area | 0.810 | −0.004 |
| Average slope of catchment area | 0.967 | −0.008 |
| Total curvature | 0.131 | 0.894 |
| Roughness | 0.972 | −0.009 |
| Topographic Position Index, TPI | −0.135 | 0.893 |
| Terrain Ruggedness Index, TRI | 0.972 | −0.029 |
Table 11.
Pearson’s correlation coefficient table.
Table 11.
Pearson’s correlation coefficient table.
| Factor | Maximum Daily Rain | Maximum Hourly Rainfall | Mean Hourly Rainfall | Maximum 24-h Rainfall | Cumulative Rainfall |
|---|
| Maximum daily rain | 1.000 | 0.287 | 0.425 | 0.905 | 0.726 |
| Maximum hourly rainfall | 0.287 | 1.000 | 0.589 | 0.301 | 0.239 |
| Mean hourly rainfall | 0.425 | 0.589 | 1.000 | 0.367 | 0.017 |
| Maximum 24-h rainfall | 0.905 | 0.301 | 0.367 | 1.000 | 0.830 |
| Cumulative rainfall | 0.726 | 0.239 | 0.017 | 0.830 | 1.000 |
Table 12.
Coefficients of Fisher’s discriminant classification function.
Table 12.
Coefficients of Fisher’s discriminant classification function.
| Factor | 0 | 1 | Coefficient Vector (1–0) |
|---|
| Total area of catchment area | −0.001 | 0.010 | 0.01 |
| Type of stratum | 0.895 | 0.865 | −0.03 |
| Distance from fault | 0.857 | 0.855 | −0.002 |
| Average slope of catchment area | 0.770 | 0.775 | 0.005 |
| Total curvature | −14.663 | −15.045 | −0.382 |
| Maximum daily rainfall | 0.024 | 0.031 | 0.008 |
| Average NDVI before the event | 31.857 | 36.255 | 4.397 |
| Hourly rainfall | 0.219 | 0.160 | −0.059 |
| Constant | −33.138 | −38.222 | −5.084 |
Table 13.
Discriminant-analysis judgments.
Table 13.
Discriminant-analysis judgments.
| | Classification Result | Total |
|---|
| | Category | 0 | 1 |
|---|
Training sample
(1095 rows) | 0 | 891 (91.5%) | 83 (8.5%) | 974 (100%) |
| 1 | 29 (24%) | 92 (76%) | 121 (100%) |
| Correct discrimination rate = [(891 + 92)/(974 + 121)] × 100% = 89.8% |
| | Classification result | Total |
| | Category | 0 | 1 |
Validation sample
(219 rows) | 0 | 160 (88.9%) | 20 (11.1%) | 180 (100%) |
| 1 | 13 (33.3%) | 26 (66.7%) | 39 (100%) |
| Correct discrimination rate = [(160 + 26)/(180 + 39)] × 100% = 84.9% |
| | Classification result | Total |
| | Category | 0 | 1 |
Overall sample
(1314 rows) | 0 | 1051 (91.1%) | 103 (8.9%) | 1154 (100%) |
| 1 | 42 (26.3%) | 118 (73.7%) | 160 (100%) |
| Correct discrimination rate = [(1051 + 118)/(1154 + 160)] × 100% = 89% |
Table 14.
Table of coefficients for logistic regression.
Table 14.
Table of coefficients for logistic regression.
| Code | Factor | Coefficient | Coefficient Value |
|---|
| Total area of the catchment area | | 0.007 |
| Type of stratum | | −0.045 |
| Distance from the fault | | 0.018 |
| Average slope of the catchment area | | 0.043 |
| Maximum daily rainfall | | 0.008 |
| Average NDVI before the event | | 3.160 |
| Total curvature | | −2.639 |
| Hourly rainfall | | −0.116 |
| | Constant | | −4.473 |
Table 15.
Logistic-regression judgments.
Table 15.
Logistic-regression judgments.
| | Classification Result | Total |
|---|
| | Category | 0 | 1 |
|---|
Training sample
(1095 rows) | 0 | 962 (98.8%) | 12 (1.2%) | 974 (100%) |
| 1 | 57 (47.1%) | 64 (52.9%) | 121 (100%) |
| Accurate discrimination rate = [(962 + 64)/(974 + 121)] × 100% = 93.7% |
Validation sample
(219 rows) | 0 | 173 (96.1%) | 7 (3.9%) | 180 (100%) |
| 1 | 26 (66.7%) | 13 (33.3%) | 39 (100%) |
| Accurate discrimination rate = [(173 + 13)/(180 + 39)] × 100% = 84.9% |
Overall sample
(1314 rows) | 0 | 1135 (98.4%) | 19 (1.6%) | 1154 (100%) |
| 1 | 83 (51.9%) | 77 (48.1%) | 160 (100%) |
| Accurate discrimination rate = [(1135 + 77)/(1154 + 160)] × 100% = 92.2% |
Table 16.
Back-propagation neural network judgments.
Table 16.
Back-propagation neural network judgments.
| Training Sample (920 Rows) | Classification Result | Total |
|---|
| | Category | 0 | 1 |
|---|
| Original category | Number
(920 rows) | 0 | 793 (97.5%) | 20 (2.5%) | 813 (100%) |
| 1 | 35 (32.7%) | 72 (67.3%) | 107 (100%) |
| Accurate discrimination rate = [(962 + 64)/(974 + 121)] × 100% = 93.7% |
| Original category | Number
(394 rows) | 0 | 327 (95.9%) | 14 (4.1%) | 341 (100%) |
| 1 | 14 (26.4%) | 39 (73.6%) | 53 (100%) |
| Accurate discrimination rate = [(173 + 13)/(180 + 39)] × 100% = 84.9% |
| Original category | Number
(1314 rows) | 0 | 1120 (97.1%) | 34 (2.9%) | 1154 (100%) |
| 1 | 49 (30.6%) | 111 (69.4%) | 160 (100%) |
| Accurate discrimination rate = [(1120 + 111)/(1154 + 160)] × 100% = 93.7% |
Table 17.
Table of coefficients for logistic regression.
Table 17.
Table of coefficients for logistic regression.
| Factor | Significance | Importance of Normalization |
|---|
| Total area of the catchment area | 0.247 | 100.0% |
| Maximum daily rainfall | 0.206 | 83.2% |
| Maximum hourly rainfall | 0.164 | 66.5% |
| Maximum hourly rainfall | 0.134 | 54.3% |
| Total curvature | 0.077 | 31.3% |
| Type of stratum | 0.065 | 26.3% |
| Average slope of the catchment area | 0.061 | 24.8% |
| Distance from the fault | 0.045 | 18.2% |
Table 18.
Area under curve discrimination-ability thresholds (Hanley and McNeil, 1982) [
25].
Table 18.
Area under curve discrimination-ability thresholds (Hanley and McNeil, 1982) [
25].
| Value of Area under the Receiver Operating Characteristic Curve (AUC) | Discrimination Ability |
|---|
| AUC ≧ 0.9 | Excellent discrimination ability |
| 0.7 ≦ AUC < 0.9 | Good discrimination ability |
| 0.5 ≦ AUC < 0.7 | Fair discrimination ability |
| AUC = 0.5 | No ability to discriminate |
Table 19.
Receiver operating characteristic curve evaluation table.
Table 19.
Receiver operating characteristic curve evaluation table.
Observed Value
Predictive Value | Unstable | Stable |
|---|
| Unstable | TP | FP |
| true positive | false positive |
| Stable | FN | TN |
| false negative | true negative |
Table 20.
K-means test for group differences.
Table 20.
K-means test for group differences.
| Impact Factor | Cluster A | Cluster B | Cluster C | Cluster D | Sort by Size |
|---|
| Total catchment area (hectares) | 70.152 | 1067.59 | 680.815 | 329.178 | B > C > D > A |
| Type of stratum | 7.444 | 6.220 | 8.902 | 7.395 | C > A > D > B |
| Distance from fault | 2.249 | 0.800 | 0.091 | 1.433 | A > D > B > C |
| Average slope of catchment area (degrees) | 33.086 | 38.294 | 36.486 | 35.002 | B > C > D > A |
| Total curvature (degrees) | −0.0001 | 0.006 | 0.002 | −0.003 | B > C > A > D |
Table 21.
Statistics relevant to the destruction ratio of each cluster.
Table 21.
Statistics relevant to the destruction ratio of each cluster.
| Items | Total Number | Number of Destructive Events | Destruction as a Percentage of the Cluster | Percentage of Total Damage |
|---|
| Cluster |
|---|
| Cluster A | 1038 | 42 | 4.1% | 26.3% |
| Cluster B | 30 | 20 | 66.7% | 12.5% |
| Cluster C | 66 | 34 | 51.5% | 21.3% |
| Cluster D | 180 | 64 | 35.6% | 40% |
Table 22.
Number and percentage of damaged areas per cluster, by typhoon event.
Table 22.
Number and percentage of damaged areas per cluster, by typhoon event.
| Cluster | A | B | C | D |
|---|
| Typhoon | (173 Areas) | (5 Areas) | (11 Areas) | (30 Areas) |
|---|
| Typhoon Mindulle | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Typhoon Haitang | 18 (10.4%) | 5 (100%) | 11 (100%) | 26 (86.7%) |
| Typhoon Kalmaegi | 0 (0%) | 0 (0%) | 0 (0%) | 0 (0%) |
| Typhoon Sinlaku | 4 (2.3%) | 5 (100%) | 7 (63.6%) | 11 (36.7%) |
| Typhoon Morakot | 8 (4.6%) | 5 (100%) | 8 (72.7%) | 13 (43.3%) |
| Typhoon Saola | 12 (6.9%) | 5 (100%) | 8 (72.7%) | 14 (46.7%) |
Table 23.
Number of damaged areas and maximum hourly and daily rainfall, by typhoon event.
Table 23.
Number of damaged areas and maximum hourly and daily rainfall, by typhoon event.
| Statistic | Number of Damaged Areas | Maximum Hourly Rainfall (mm/h) | Maximum Daily Rainfall (mm/day) |
|---|
| Typhoon |
|---|
| Typhoon Mindulle | 0 | 48.4 | 281.6 |
| Typhoon Haitang | 60 | 18.0 | 171.5 |
| Typhoon Kalmaegi | 0 | 67.5 | 295.5 |
| Typhoon Sinlaku | 27 | 27.6 | 299.5 |
| Typhoon Morakot | 34 | 41.4 | 329.1 |
| Typhoon Saola | 39 | 16.9 | 170.1 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}