
A Novel EPANET Integration for the Diffusive–Dispersive Transport of Contaminants




Abstract
:1. Introduction
2. Materials and Methods
2.1. Case Study
2.2. EPANET-DD Model
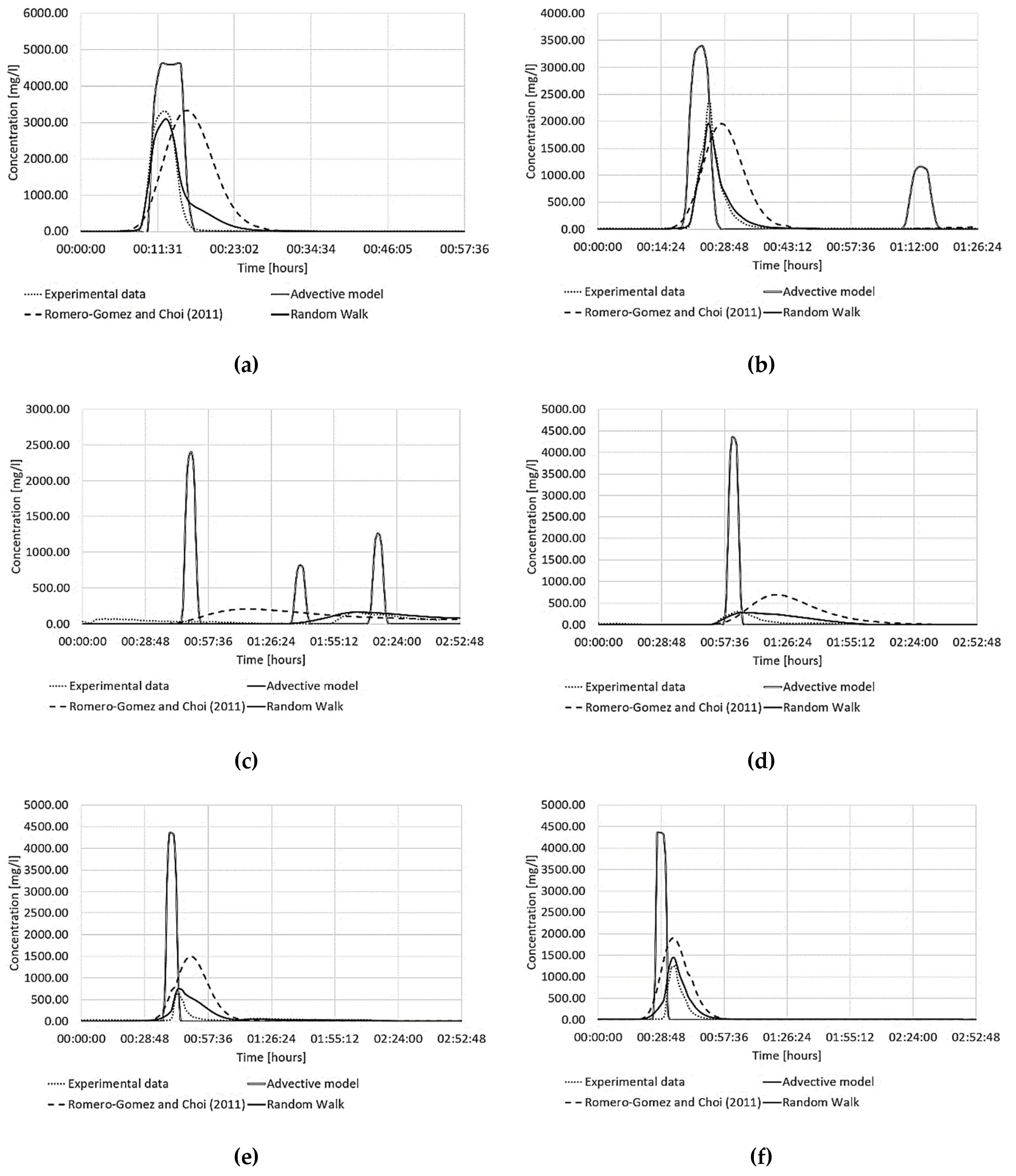
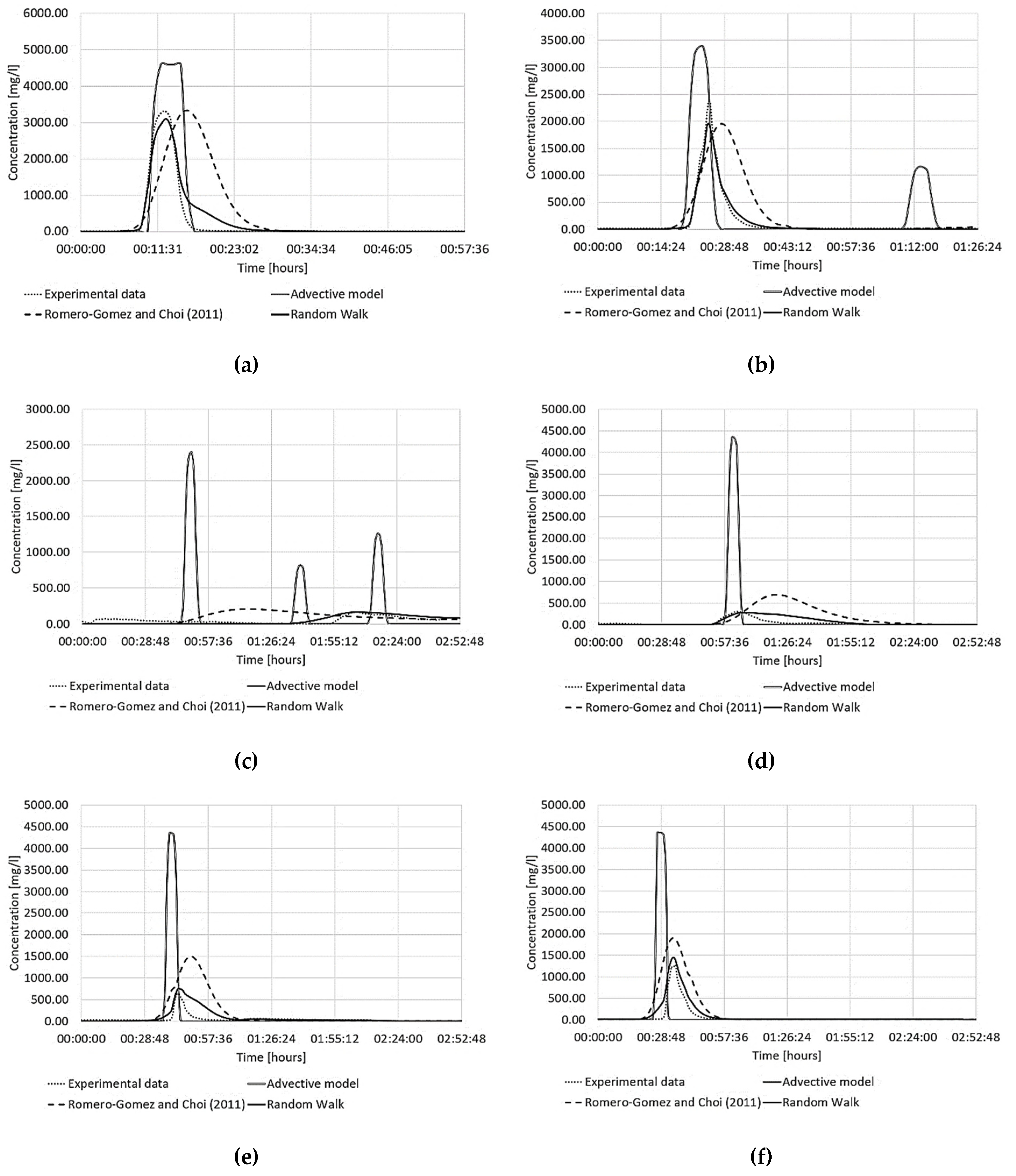
3. Results and Discussion
4. Conclusions
- The advective model works well only in locations close to the contamination node, where it can intercept the contamination’s peak even for lower values. In fact, relatively high values of the KGE, NSE and R2 coefficients were observed at node 6 near the contamination node (0.44, 0.52, 0.29 respectively).
- In all other cases, the contamination event was anticipated and had a shorter duration than that detected by the experimental campaign. As a result, much lower or even negative values of the three coefficients were obtained.
- The Romero-Gomez and Choi model can represent the dispersive behaviour of the contaminant. Still, it poorly represents the experimental data regarding delay or anticipation of the contamination peak and overestimating the contaminant mass. This was confirmed by the coefficients KGE, NSE, R2 which resulted in some nodes (6, 7, 9, 10) being worse than those obtained using the advective model.
- The new EPANET-DD model produced the best results in terms of adaptability with the experimental data. It simultaneously represented the peak time and provided better accuracy than the Romero-Gomez and Choi model. In fact, the coefficients considered were very high and, in some cases, close to unity.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rossman, L.A. Epanet Users Manual; United States Environmental Protection Agency: Washington, DC, USA, 1994; pp. 1–122.
- Rossman, L.A.; Clark, R.M.; Grayman, W.M. Modeling Chlorine Residuals in Drinking—Water Distribution Systems. J. Environ. Eng. 1994, 120, 803–820. [Google Scholar] [CrossRef]
- Todini, E.; Pilati, S. A gradient method for the analysis of pipe networks. In Proceedings of the International Conference on Computer Applications for Water Supply and Distribution, Leicester, UK, 8–10 September 1987. [Google Scholar]
- Rossman, L.A.; Boulos, P.F.; Altman, T. Discrete Volume—Element Method for Network Water—Quality Models. J. Water Resour. Plan. Manag. 1993, 119, 505–517. [Google Scholar] [CrossRef]
- Rossman, L. Epanet 2 Users Manual; Environmental Protection Agency: Washington, DC, USA, 2000.
- Rossman, L.A.; Woo, H.; Tryby, M.; Shang, F.; Janke, R.; Haxton, T. EPANET 2.2 User Manual; United States Environmental Protection Agency: Washington, DC, USA, 2000.
- Shang, F.; Uber, J.G.; Rossman, L. EPANET Multi Species Extension Software and User’s Manual; United States Environmental Protection Agency: Washington, DC, USA, 2011.
- Piazza, S.; Blokker, E.J.M.; Freni, G.; Puleo, V.; Sambito, M. Impact of diffusion and dispersion of contaminants in water distribution networks modelling and monitoring. Water Supply 2019, 20, 46–58. [Google Scholar] [CrossRef]
- Choi, C.Y.; Shen, J.Y.; Austin, R.G. Development of a Comprehensive Solute Mixing Model (AZRED) for Double-Tee, Cross, and Wye Junctions. Water Distrib. Syst. Anal. 2009, 1–10. [Google Scholar] [CrossRef]
- Romero-Gomez, P.; Ho, C.K.; Choi, C.Y. Mixing at Cross Junctions in Water Distribution Systems. I: Numerical Study. J. Water Resour. Plan. Manag. 2008, 134, 285–294. [Google Scholar] [CrossRef]
- Romero-Gomez, P.; Choi, C.Y. Axial Dispersion Coefficients in Laminar Flows of Water-Distribution Systems. J. Hydraul. Eng. 2011, 137, 1500–1508. [Google Scholar] [CrossRef]
- Hart, J.R.; Guymer, I.; Sonnenwald, F.; Stovin, V.R. Residence Time Distributions for Turbulent, Critical, and Laminar Pipe Flow. J. Hydraul. Eng. 2016, 142. [Google Scholar] [CrossRef]
- Delay, F.; Ackerer, P.; Danquigny, C. Simulating Solute Transport in Porous or Fractured Formations Using Random Walk Particle Tracking: A Review. Vadose Zone J. 2005, 4, 360–379. [Google Scholar] [CrossRef]
- Eliades, D.G.; Kyriakou, M.; Vrachimis, S.; Polycarpou, M.M. EPANET-MATLAB Toolkit: An Open-Source Software for Interfacing EPANET with MATLAB, The Netherlands. In Proceedings of the 14th International Conference on Computing and Control for the Water Industry (CCWI), Amsterdam, NL, Canada, 7–9 November 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Kinzelbach, W.; Uffink, G. The Random Walk Method and Extensions in Groundwater Modelling. Transp. Processes Porous Media 1991, 761–787. [Google Scholar] [CrossRef]
- LaBolle, E.M.; Tompson, A.F.B.; Fogg, G.E. Random-Walk Simulation of Transport in Heterogeneous Porous Media: Local Mass-Conservation Problem and Implementation Methods. Water Resour. Res. 1996, 32, 583–593. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Gupta, H.V.; Kling, H.; Yilmaz, K.K.; Martinez, G.F. Decomposition of the mean squared error and NSE performance criteria: Implications for improving hydrological modelling. J. Hydrol. 2009, 377, 80–91. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Functions | Descriptions |
|---|---|
| getLinkVelocity | Current computed flow velocity (read only) |
| getLinkFlows | Current computed flow rate (read only) |
| getLinkHeadloss | Current computed head loss (read only) |
| getNodeHydaulicHead | Retrieves the computed values of all hydraulic heads |
| getNodeActualDemand | Retrieves the computed value of all actual demands |
| getNodePressure | Retrieves the computed values of all node pressures |
| Node 6 | Node 7 | Node 9 | Node 10 | |
|---|---|---|---|---|
| σ [mH2O] | 0.01 | 0.15 | 0.05 | 0.09 |
| Link 5 | Link 6 | Link 7 | Link 9 | Link 10 | Link 11 | Link 13 | |
|---|---|---|---|---|---|---|---|
| Roughness [mm] | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| σ [m3/h] | 0.12 | 0.12 | 0.08 | 0.11 | 0.11 | 0.11 | 0.15 |
| Node 5 | Node 8 | Node 11 | |
|---|---|---|---|
| σ [L/min] | 0.45 | 0.07 | 0.07 |
| Link 4 | Link 6 | Link 7 | Link 9 | Link 10 | Link 11 | Link 12 | Link 13 | |
|---|---|---|---|---|---|---|---|---|
| Reynolds (Re) | 4112 | 200 | 3598 | 1542 | 514 | 2056 | 1542 | 3598 |
| Flow regime | Turbulent | Laminar | Transition | Laminar | Laminar | Transition | Laminar | Transition |
| Node | Advective Model | Romero-Gomez and Choi (2011) Model | EPANET-DD Model | ||||||
|---|---|---|---|---|---|---|---|---|---|
| KGE | NSE | R2 | KGE | NSE | R2 | KGE | NSE | R2 | |
| 6 | 0.44 | 0.52 | 0.29 | −0.60 | −0.72 | 0.21 | 0.63 | 0.69 | 0.49 |
| 7 | 0.25 | 0.59 | 0.68 | −0.08 | −0.15 | 0.12 | 0.81 | 0.84 | 0.76 |
| 8 | −0.55 | −1.50 | 0.08 | 0.01 | 0.35 | 0.04 | 0.45 | 0.43 | 0.92 |
| 9 | 0.22 | 0.18 | 0.43 | −1.58 | −5.57 | 0.13 | 0.29 | 0.35 | 0.17 |
| 10 | 0.34 | −0.01 | 0.19 | −4.35 | −14.81 | 0.09 | −0.15 | −0.54 | 0.55 |
| 11 | −0.30 | −0.62 | 0.05 | −0.94 | −1.18 | 0.79 | 0.42 | 0.76 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piazza, S.; Sambito, M.; Freni, G. A Novel EPANET Integration for the Diffusive–Dispersive Transport of Contaminants. Water 2022, 14, 2707. https://doi.org/10.3390/w14172707
Piazza S, Sambito M, Freni G. A Novel EPANET Integration for the Diffusive–Dispersive Transport of Contaminants. Water. 2022; 14(17):2707. https://doi.org/10.3390/w14172707
Chicago/Turabian StylePiazza, Stefania, Mariacrocetta Sambito, and Gabriele Freni. 2022. "A Novel EPANET Integration for the Diffusive–Dispersive Transport of Contaminants" Water 14, no. 17: 2707. https://doi.org/10.3390/w14172707
APA StylePiazza, S., Sambito, M., & Freni, G. (2022). A Novel EPANET Integration for the Diffusive–Dispersive Transport of Contaminants. Water, 14(17), 2707. https://doi.org/10.3390/w14172707