
Floodborne Objects Type Recognition Using Computer Vision to Mitigate Blockage Originated Floods

 , , ,
, , ,
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Floodborne Objects Recognition Dataset (FORD)
3.2. Background to Computer Vision Object Detection Models
3.2.1. Faster R-CNN
3.2.2. You Only Look Once version 4 (YOLOv4)
3.3. Research Approach
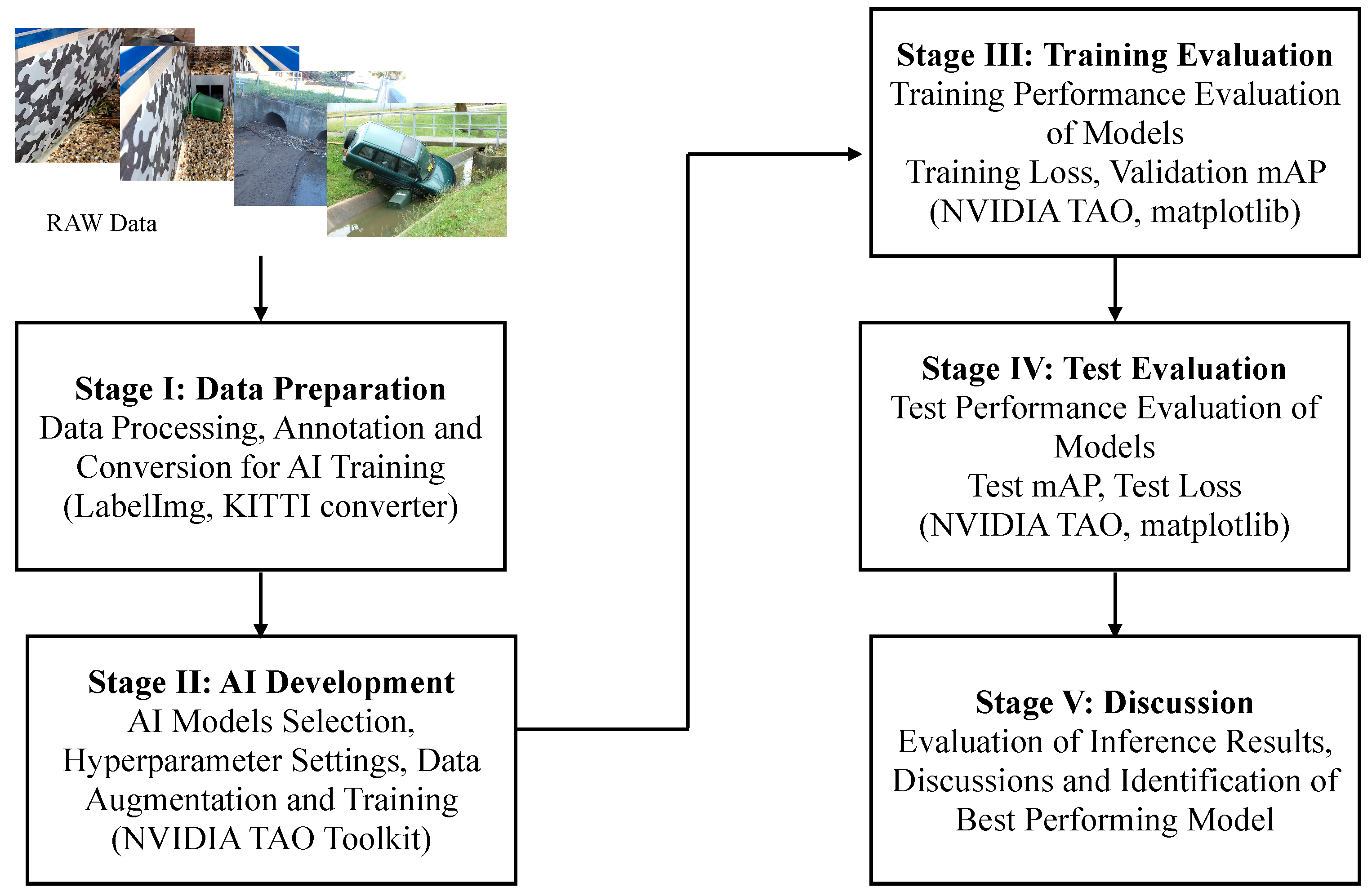
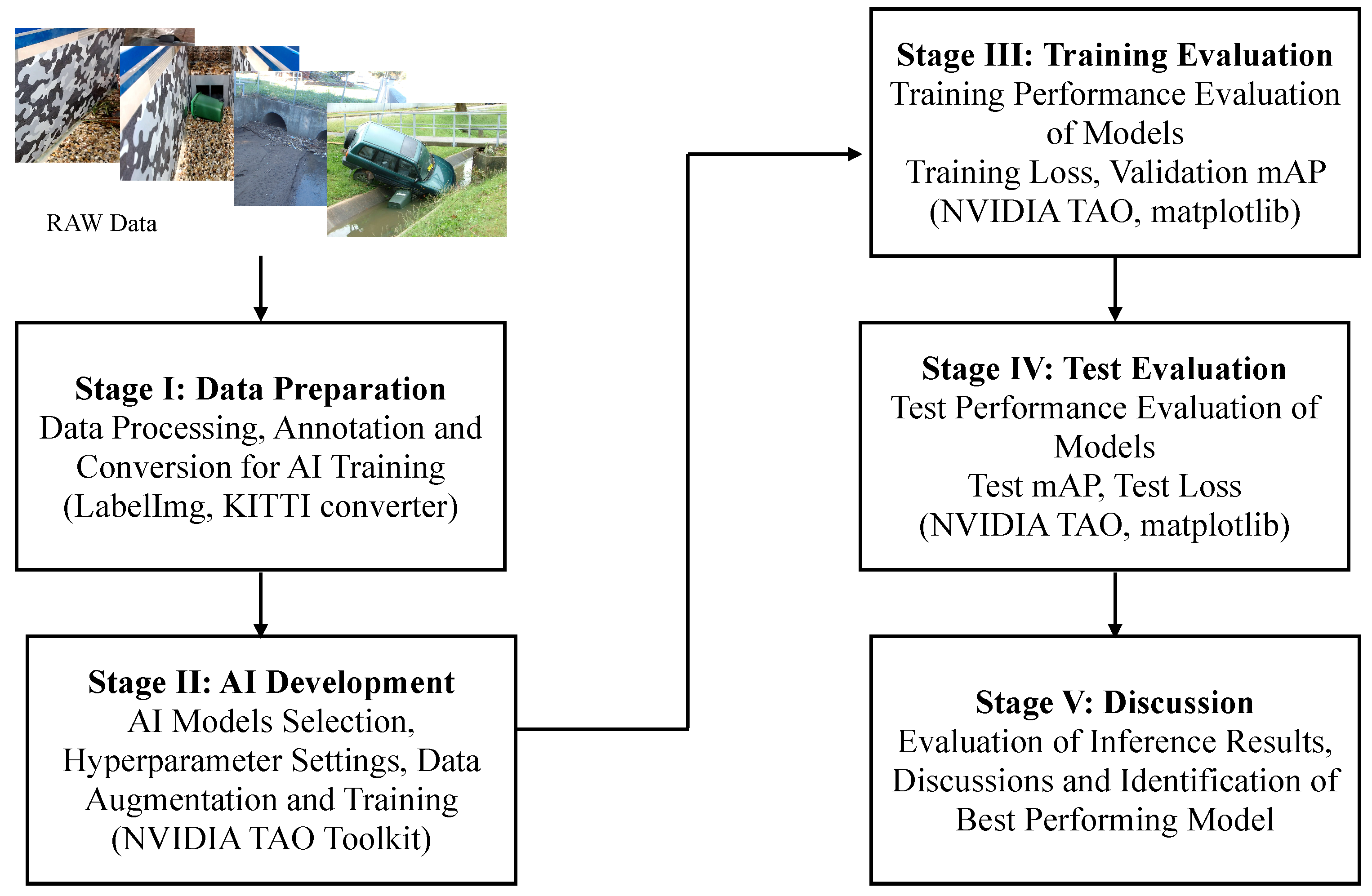
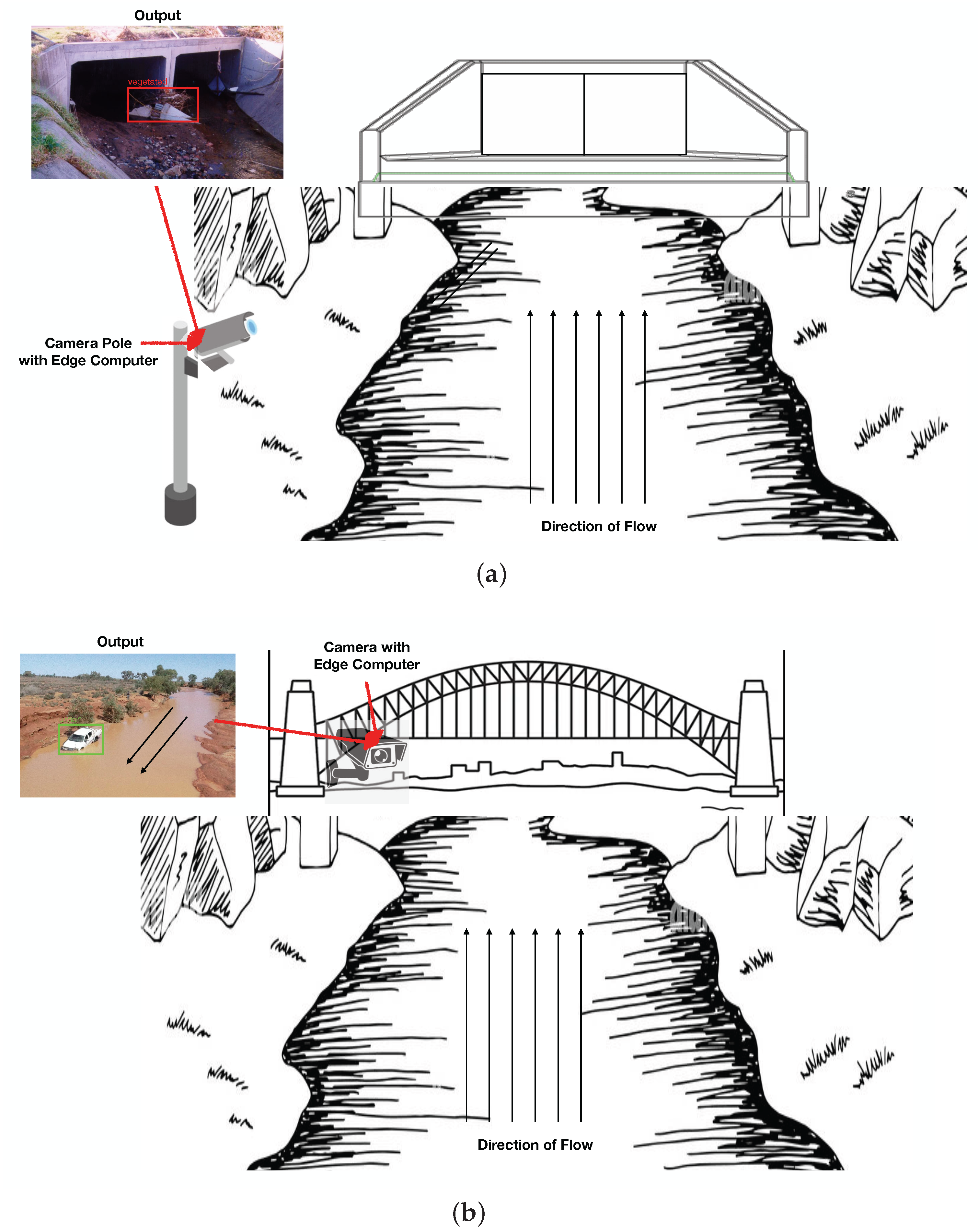
- Stage I: Data Preparation—At the first stage, the raw images from the WCC records were processed and annotated for training the computer vision object detection models. In context to data processing stage, firstly, the images from the records were manually sorted to select the suitable candidates for training. Presence of floodborne objects accumulated at culverts or within the catchment was used as the criterion to sort the images. Secondly, the selected images were cropped where required to remove the background noise and were converted to unified format for consistency. Once the final set of images was decided, they were annotated/labelled with ground truth bounding boxes of vegetation and urban objects in the images. For the labelling of images, an open source image annotation tool called LabelImg [65] was used, which, by default, saved the labels in XML format (i.e., one of the formats to which bounding box labels can be saved). Within the computer vision domain, there are different platforms developed to facilitate the training of the state-of-the-art models, including Detectron2, TensorFlow Object Detection API, NVIDIA Train Adapt Optimize (TAO) and DarkNet. Each of these platforms requires the ground truth labels to be stored in a specific data format, for example, Detectron2 accepts .json format labels, TensorFlow API accepts XML format labels, NVIDIA TAO accepts KITTI labels and DarkNet accepts .txt format labels. For this research, NVIDIA TAO toolkit was used for training, which is a framework designed to simplify and accelerate the development of AI-oriented industrial solutions.
- Stage II: AI Development—At the second stage, the AI models were developed and trained using the labelled data from Stage I. In the process of AI development, firstly, the object detection models were selected from the available model zoo based on the performance reported in the literature. As a result, keeping the robustness and hardware deployment as key factors, Faster R-CNN (i.e., robust detection performance) and YOLOv4 (i.e., suitable for hardware deployment) model variants were selected to be trained for the floodborne object type recognition problem. Secondly, for each selected model, hyperparameters, including training epochs, learning rate, optimization function and regularization technique, were set using default off-the-shelf values. Furthermore, different data augmentation techniques (i.e., one of the conventional approaches used in computer vision model training where input image is subjected to different transformations towards creating multiple variants of same image) were also used during the training process to enhance the performance. All the models reported in this study were trained using the NVIDIA TAO platform.
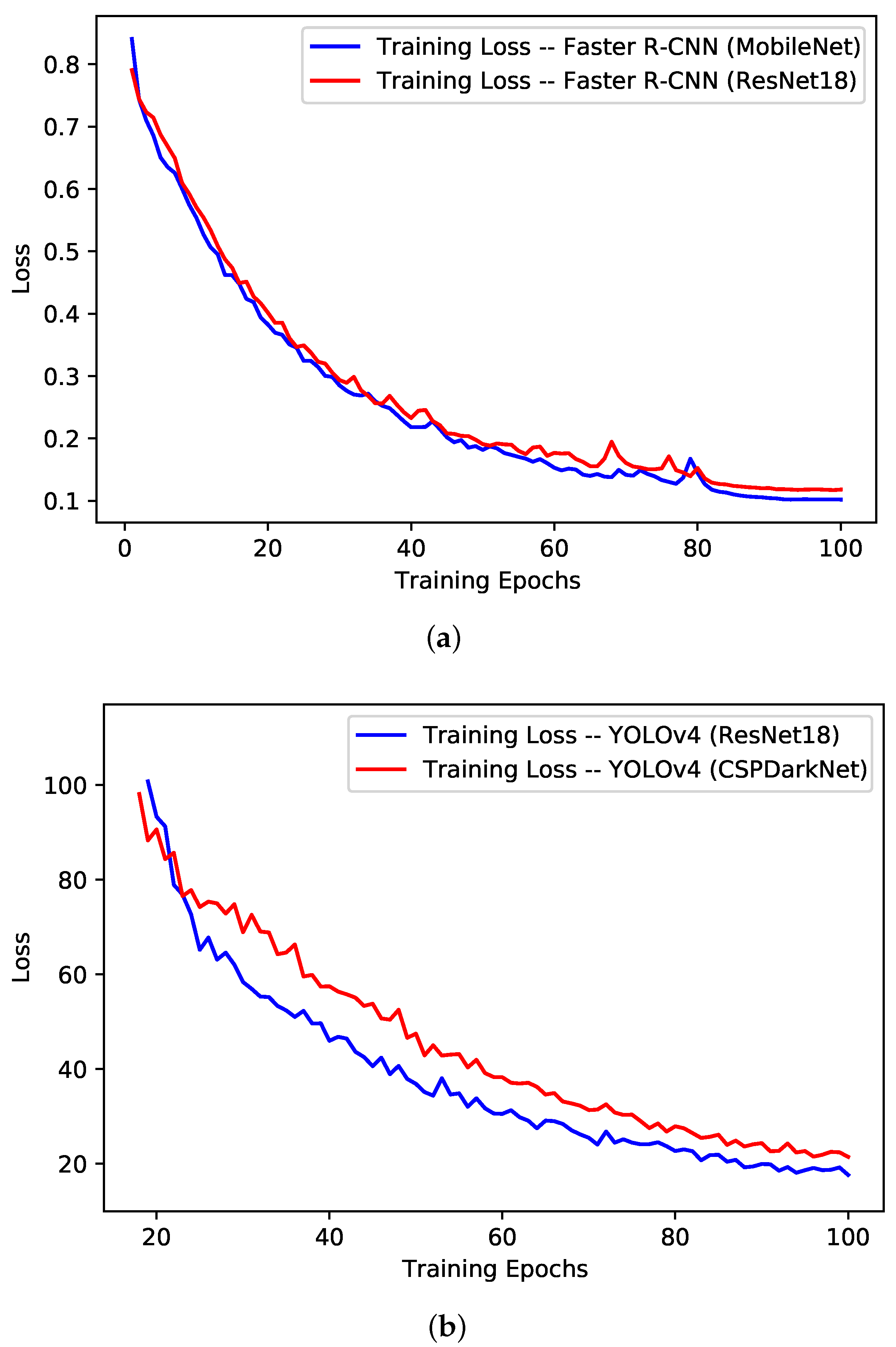
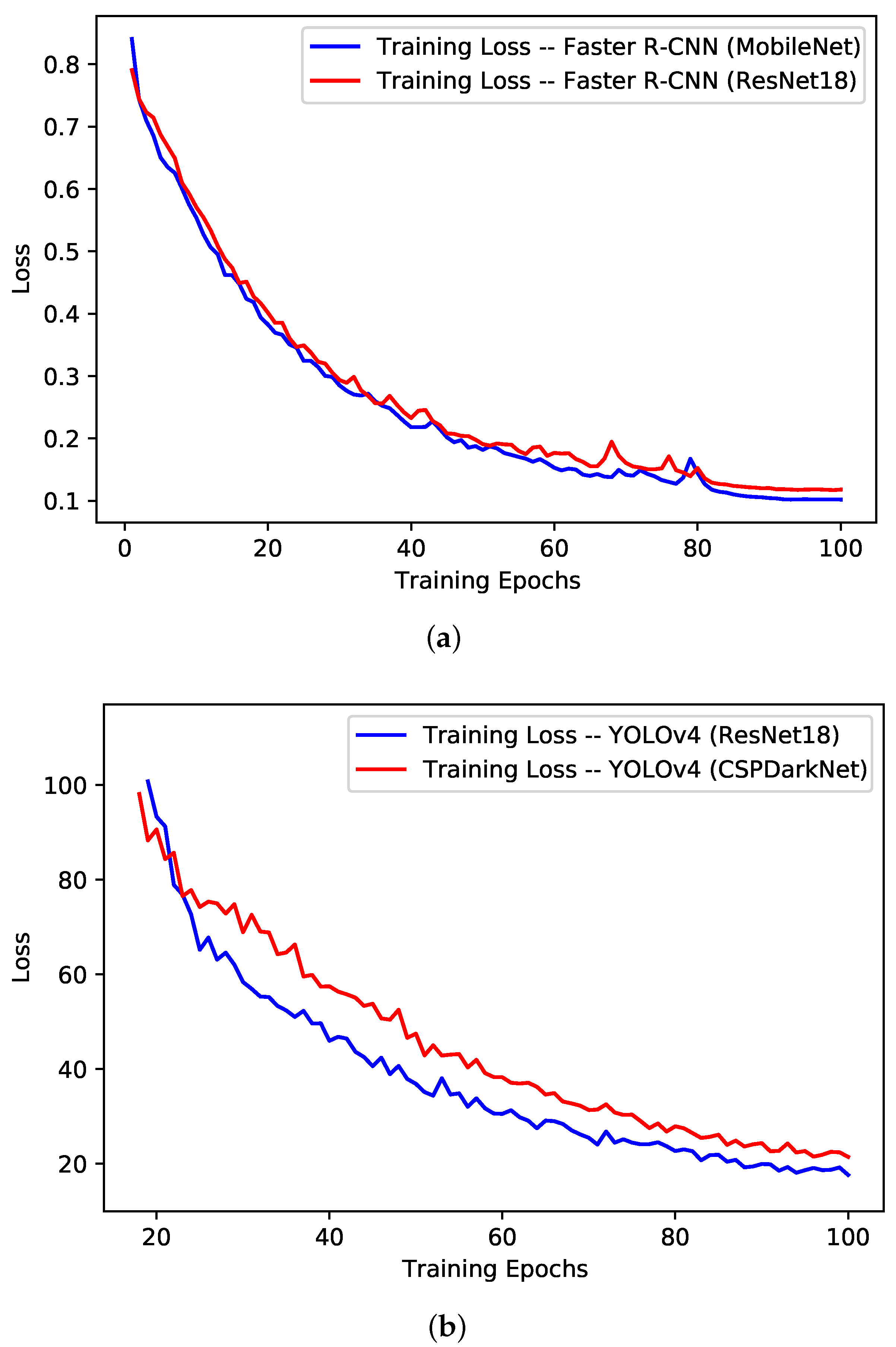
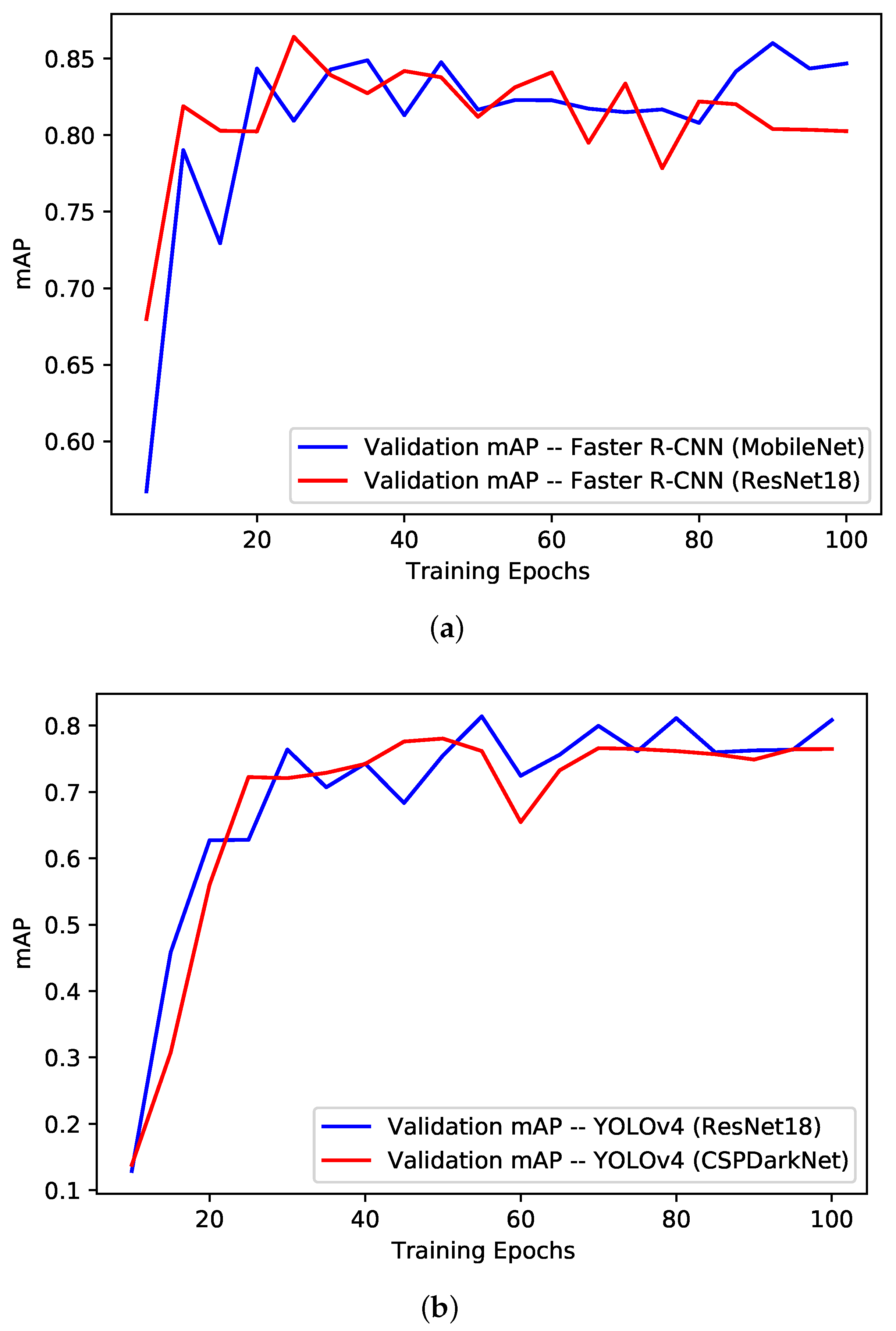
- Stage III: Training Evaluation—At the third stage, the models were evaluated for their performance during the training phase using different standard evaluation measures including training loss per epoch, training time per epoch and validation mAP. In context of the deep learning computer vision models, the loss of a model refers to the prediction error (i.e., predicted-actual) and is a measure to assess how well a model has performed. In the training process, deep learning models use optimization functions (e.g., Stochastic Gradient Descent (SGD), Adaptive Momentum (adam)) with the objective to minimize the loss function using the backpropagation approach. The aim of assessing the training performance is to ensure that the training process did not involve any abnormal behaviour, specifically overfitting. Training loss and mAP curves are standard indicators to observe any abnormalities. Usually, for a normal training process, the loss curve should follow the negative exponential trend, while the mAP should follow the positive exponential trend.
- Stage IV: Test Evaluation—At the fourth stage, the trained object detection models were evaluated against the unseen validation data and were compared to identify the best performing model(s). Evaluation was performed using test mAP and AP for each of the two floodborne object classes.
- Stage V: Discussion—At the fifth and final stage, the inference results from the models, specifically with best test performance, were analysed and discussed in detail to report the important insights from the experiments. Furthermore, performance of the proposed approach was linked with existing literature, and different implications of the research were presented. In addition, potential limitations of the research were highlighted, and future directions were discussed.
4. Experimental Protocols and Evaluation Measures
5. Results
5.1. Training Performance
5.2. Testing Performance
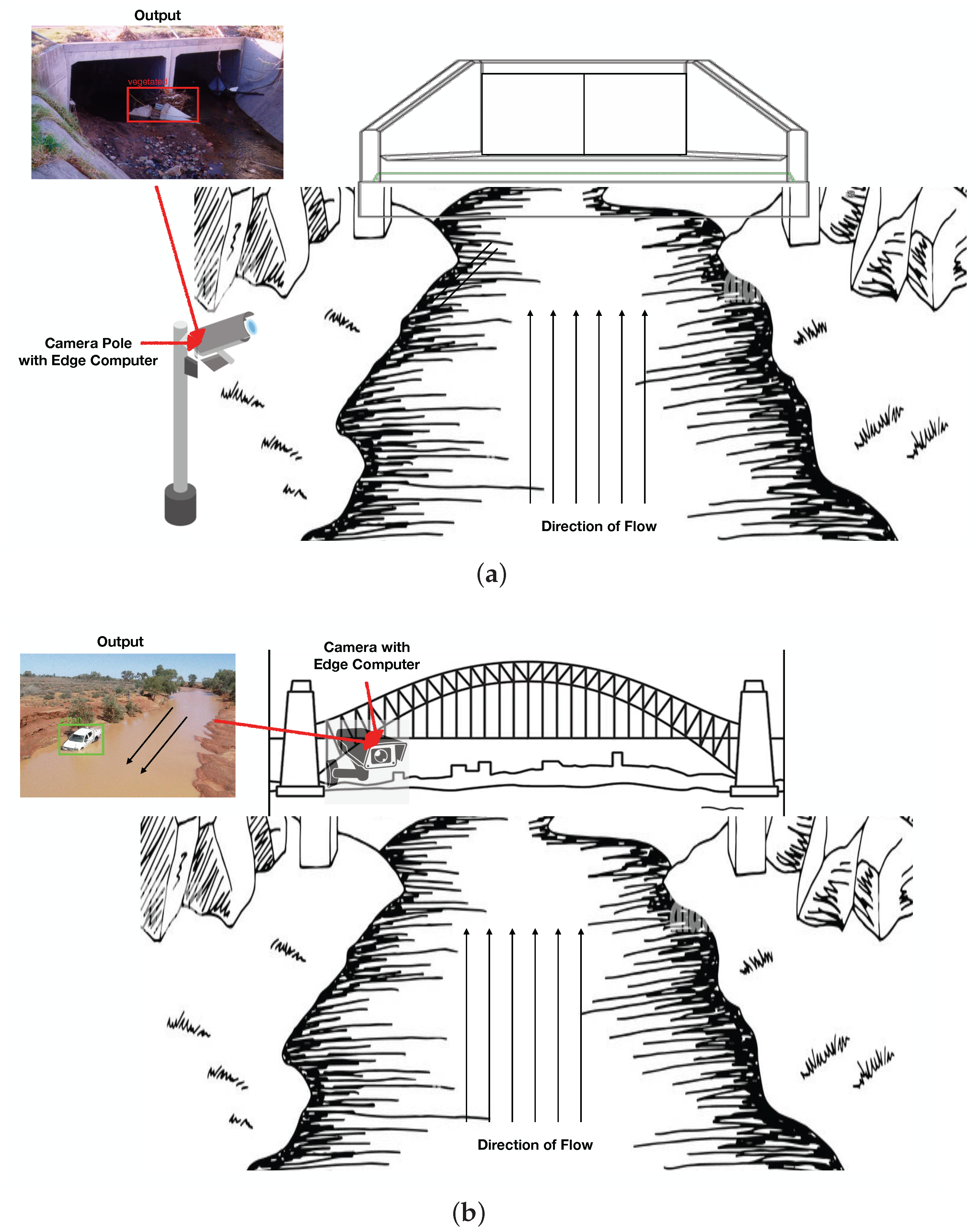
6. Discussion
6.1. Research Implications
6.2. Limitations and Future Directions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| CNN | Convolutional Neural Network |
| RPN | Region Proposal Network |
| FORD | Floodborne Objects Recognition Dataset |
| AP | Average Precision |
| mAP | Mean Average Precision |
| IoU | Intersection of Union |
| SVM | Support Vector Machine |
| MAP | Feature Map Attention |
| FLS | Forward Looking Sonar Images |
| WCC | Wollongong City Council |
| ICOB | Images of Culvert Opening and Blockage |
| VHD | Visual Hydraulics-Lab Dataset |
| CSP | Cross Stage Partial Connections |
| SAT | Self Adversarial Training |
| WRC | Weighted Residual Connections |
| CmBN | Cross Mini-Batch Normalizations |
| TAO | Train Adapt Optimize |
| SGD | Stochastic Gradient Descent |
| Adam | Adaptive Momentum |
| GPU | Graphical Processing Unit |
| GANs | Generative Adversarial Networks |
References
- Feng, Q.; Liu, J.; Gong, J. Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier—A case of Yuyao, China. Water 2015, 7, 1437–1455. [Google Scholar] [CrossRef]
- Nogueira, K.; Fadel, S.G.; Dourado, Í.C.; Werneck, R.D.O.; Muñoz, J.A.; Penatti, O.A.; Calumby, R.T.; Li, L.T.; dos Santos, J.A.; Torres, R.D.S. Exploiting ConvNet diversity for flooding identification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1446–1450. [Google Scholar] [CrossRef]
- Nofal, O.M.; van de Lindt, J.W. High-resolution flood risk approach to quantify the impact of policy change on flood losses at community-level. Int. J. Disaster Risk Reduct. 2021, 62, 102429. [Google Scholar] [CrossRef]
- Abdel-Mooty, M.N.; Yosri, A.; El-Dakhakhni, W.; Coulibaly, P. Community flood resilience categorization framework. Int. J. Disaster Risk Reduct. 2021, 61, 102349. [Google Scholar] [CrossRef]
- Istrati, D.; Hasanpour, A. Numerical Investigation of Dam Break-Induced Extreme Flooding of Bridge Superstructures. In Proceedings of the 3rd International Conference on Natural Hazards & Infrastructure, Athens, Greece, 5–7 July 2022; pp. 1–15. [Google Scholar]
- Riaz, M.Z.B.; Yang, S.Q.; Sivakumar, M.; Enever, K.; Miguntanna, N.S.; Khalil, U. Direct measurements of hydrodynamic forces induced by tidal bores. Water Resour. Res. 2021, 57, e2020WR028970. [Google Scholar] [CrossRef]
- Chiew, Y.M.; Melville, B.W. Local scour around bridge piers. J. Hydraul. Res. 1987, 25, 15–26. [Google Scholar] [CrossRef]
- Riaz, M.Z.B.; Yang, S.Q.; Sivakumar, M.; Enever, K.; Khalil, U.; Miguntanna, N.S. Evaluation of force transducer for the observation of sediment entrainment in rapidly-varied flows. J. Atmos. Ocean. Technol. 2022, 57, e2020WR028970. [Google Scholar]
- Yang, S.Q.; Riaz, M.Z.B.; Sivakumar, M.; Enever, K.; Miguntanna, N.S. Three-dimensional velocity distribution in straight smooth channels modeled by modified log-law. J. Fluids Eng. 2020, 142, 011401. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Perez, P.; Cooper, J.; Li, W. A scaled physical model study of culvert blockage exploring complex relationships between influential factors. Australas. J. Water Resour. 2021, 1–14. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Li, W.; Perez, P. Automating visual blockage classification of culverts with deep learning. Appl. Sci. 2021, 11, 7561. [Google Scholar] [CrossRef]
- Iqbal, U.; Bin Riaz, M.Z.; Barthelemy, J.; Perez, P. Prediction of Hydraulic Blockage at Culverts using Lab Scale Simulated Hydraulic Data. Urban Water J. 2022, 1–14. [Google Scholar] [CrossRef]
- French, R.; Jones, M. Culvert blockages in two Australian flood events and implications for design. Australas. J. Water Resour. 2015, 19, 134–142. [Google Scholar] [CrossRef]
- Rigby, E.; Silveri, P. Causes and effects of culvert blockage during large storms. In Proceedings of the Ninth International Conference on Urban Drainage (9ICUD), Engineers Australia: Lloyd Center Doubletree Hotel, Portland, OR, USA, 8–13 September 2002; pp. 1–16. [Google Scholar]
- WBM; BMT. Newcastle Flash Flood 8 June 2007 (the Pasha Bulker Storm) Flood Data Compendium. In Prepared for Newcastle City Council, BMT WBM, Broadmeadow; NSW Flood Data Portal: Wollongong, Australia, 2008. [Google Scholar]
- BBC. Pentre Flood: ‘Woody Debris’ Blocking Culvert was Main Cause, Report Finds; BBC: London, UK, 2021. [Google Scholar]
- Hasanpour, A.; Istrati, D.; Buckle, I.G. Multi-Physics Modeling of Tsunami Debris Impact on Bridge Decks. In Proceedings of the 3rd International Conference on Natural Hazards & Infrastructure, Athens, Greece, 5–7 July 2022; pp. 1–16. [Google Scholar]
- Haehnel, R.B.; Daly, S.F. Maximum Impact Force of Woody Debris on Floodplain Structures. J. Hydraul. Eng. 2004, 130, 112–120. [Google Scholar] [CrossRef]
- Istrati, D.; Hasanpour, A.; Buckle, I. Numerical investigation of tsunami-borne debris damming loads on a coastal bridge. In Proceedings of the 17 World Conference on Earthquake Engineering, Sendai, Japan, 13–18 September 2020; Volume 27. [Google Scholar]
- Nkwunonwo, U.; Whitworth, M.; Baily, B. A review of the current status of flood modelling for urban flood risk management in the developing countries. Sci. Afr. 2020, 7, e00269. [Google Scholar] [CrossRef]
- Mignot, E.; Li, X.; Dewals, B. Experimental modelling of urban flooding: A review. J. Hydrol. 2019, 568, 334–342. [Google Scholar] [CrossRef]
- Jain, S.K.; Mani, P.; Jain, S.K.; Prakash, P.; Singh, V.P.; Tullos, D.; Kumar, S.; Agarwal, S.; Dimri, A. A Brief review of flood forecasting techniques and their applications. Int. J. River Basin Manag. 2018, 16, 329–344. [Google Scholar] [CrossRef]
- Ranit, A.B.; Durge, P. Different techniques of flood forecasting and their applications. In Proceedings of the International Conference on Research in Intelligent and Computing in Engineering (RICE), San Salvador, El Salvador, 22–24 August 2018; pp. 1–3. [Google Scholar]
- Oudenbroek, K.; Naderi, N.; Bricker, J.D.; Yang, Y.; Van der Veen, C.; Uijttewaal, W.; Moriguchi, S.; Jonkman, S.N. Hydrodynamic and debris-damming failure of bridge decks and piers in steady flow. Geosciences 2018, 8, 409. [Google Scholar] [CrossRef]
- Iverson, R.M. The physics of debris flows. Rev. Geophys. 1997, 35, 245–296. [Google Scholar] [CrossRef]
- Borga, M.; Stoffel, M.; Marchi, L.; Marra, F.; Jakob, M. Hydrogeomorphic response to extreme rainfall in headwater systems: Flash floods and debris flows. J. Hydrol. 2014, 518, 194–205. [Google Scholar] [CrossRef]
- Thomas, H.; Nisbet, T. Modelling the hydraulic impact of reintroducing large woody debris into watercourses. J. Flood Risk Manag. 2012, 5, 164–174. [Google Scholar] [CrossRef]
- Banihabib, M.E.; Jurik, L.; Kazemi, M.S.; Soltani, J.; Tanhapour, M. A hybrid intelligence model for the prediction of the peak flow of debris floods. Water 2020, 12, 2246. [Google Scholar] [CrossRef]
- Iverson, R.M.; Denlinger, R.P. Mechanics of debris flows and debris-laden flash floods. In Proceedings of the Seventh Federal Interagency Sedimentation Conference, Reno, NV, USA, 25–29 March 2001; pp. IV-1–IV-8. [Google Scholar]
- Hasanpour, A.; Istrati, D.; Buckle, I. Coupled SPH–FEM modeling of tsunami-borne large debris flow and impact on coastal structures. J. Mar. Sci. Eng. 2021, 9, 1068. [Google Scholar] [CrossRef]
- Trujillo-Vela, M.G.; Galindo-Torres, S.A.; Zhang, X.; Ramos-Cañón, A.M.; Escobar-Vargas, J.A. Smooth particle hydrodynamics and discrete element method coupling scheme for the simulation of debris flows. Comput. Geotech. 2020, 125, 103669. [Google Scholar] [CrossRef]
- Ruffini, G.; Briganti, R.; De Girolamo, P.; Stolle, J.; Ghiassi, B.; Castellino, M. Numerical modelling of flow-debris interaction during extreme hydrodynamic events with DualSPHysics-CHRONO. Appl. Sci. 2021, 11, 3618. [Google Scholar] [CrossRef]
- Keyes, D.E.; McInnes, L.C.; Woodward, C.; Gropp, W.; Myra, E.; Pernice, M.; Bell, J.; Brown, J.; Clo, A.; Connors, J.; et al. Multiphysics simulations: Challenges and opportunities. Int. J. High Perform. Comput. Appl. 2013, 27, 4–83. [Google Scholar] [CrossRef]
- Amini, M.; Memari, A.M. Performance of Residential Buildings in Hurricane Prone Coastal Regions and Lessons Learned for Damage Mitigation. In Proceedings of the 5th Residential Building Design & Construction Conference, Conference Center Hotel in State College, State College, PA, USA, 6 March 2020; pp. 4–6. [Google Scholar]
- Ravazzolo, D.; Spreitzer, G.; Tunnicliffe, J.; Friedrich, H. The effect of large wood accumulations with rootwads on local geomorphic changes. Water Resour. Res. 2022, 58, e2021WR031403. [Google Scholar] [CrossRef]
- Bilby, R.E.; Ward, J.W. Changes in characteristics and function of woody debris with increasing size of streams in western Washington. Trans. Am. Fish. Soc. 1989, 118, 368–378. [Google Scholar] [CrossRef]
- Braudrick, C.A.; Grant, G.E. When do logs move in rivers? Water Resour. Res. 2000, 36, 571–583. [Google Scholar] [CrossRef]
- Braudrick, C.A.; Grant, G.E.; Ishikawa, Y.; Ikeda, H. Dynamics of wood transport in streams: A flume experiment. Earth Surf. Process. Landforms J. Br. Geomorphol. Group 1997, 22, 669–683. [Google Scholar] [CrossRef]
- Ruiz-Villanueva, V.; Mazzorana, B.; Bladé, E.; Bürkli, L.; Iribarren-Anacona, P.; Mao, L.; Nakamura, F.; Ravazzolo, D.; Rickenmann, D.; Sanz-Ramos, M.; et al. Characterization of wood-laden flows in rivers. Earth Surf. Process. Landforms 2019, 44, 1694–1709. [Google Scholar] [CrossRef]
- Schalko, I.; Schmocker, L.; Weitbrecht, V.; Boes, R.M. Laboratory study on wood accumulation probability at bridge piers. J. Hydraul. Res. 2020, 58, 566–581. [Google Scholar] [CrossRef]
- Ameen, O.F.; Younus, M.H.; Aziz, M.; Azmi, A.I.; Ibrahim, R.R.; Ghoshal, S. Graphene diaphragm integrated FBG sensors for simultaneous measurement of water level and temperature. Sens. Actuators A Phys. 2016, 252, 225–232. [Google Scholar] [CrossRef]
- Yang, L.; Driscol, J.; Sarigai, S.; Wu, Q.; Lippitt, C.D.; Morgan, M. Towards Synoptic Water Monitoring Systems: A Review of AI Methods for Automating Water Body Detection and Water Quality Monitoring Using Remote Sensing. Sensors 2022, 22, 2416. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.Y.; Cheng, C.Y.; Cheng, S.C.; Cheng, Y.H.; Lo, W.C.; Jiang, W.L.; Nan, F.H.; Chang, S.H.; Ubina, N.A. A Low-Cost AI Buoy System for Monitoring Water Quality at Offshore Aquaculture Cages. Sensors 2022, 22, 4078. [Google Scholar] [CrossRef] [PubMed]
- Nazarian, E.; Taylor, T.; Weifeng, T.; Ansari, F. Machine-learning-based approach for post event assessment of damage in a turn-of-the-century building structure. J. Civ. Struct. Health Monit. 2018, 8, 237–251. [Google Scholar] [CrossRef]
- Fallahian, M.; Khoshnoudian, F.; Meruane, V. Ensemble classification method for structural damage assessment under varying temperature. Struct. Health Monit. 2018, 17, 747–762. [Google Scholar] [CrossRef]
- Cheng, Y.; Zhu, J.; Jiang, M.; Fu, J.; Pang, C.; Wang, P.; Sankaran, K.; Onabola, O.; Liu, Y.; Liu, D.; et al. FloW: A Dataset and Benchmark for Floating Waste Detection in Inland Waters. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11 October 2021; pp. 10953–10962. [Google Scholar]
- Aleem, A.; Tehsin, S.; Kausar, S.; Jameel, A. Target Classification of Marine Debris Using Deep Learning. Intell. Autom. Soft Comput. 2022, 32, 73–85. [Google Scholar] [CrossRef]
- van Lieshout, C.; van Oeveren, K.; van Emmerik, T.; Postma, E. Automated river plastic monitoring using deep learning and cameras. Earth Space Sci. 2020, 7, e2019EA000960. [Google Scholar] [CrossRef]
- Zhang, Y.; Xiao, D.; Liu, Y.; Wu, H. An algorithm for automatic identification of multiple developmental stages of rice spikes based on improved Faster R-CNN. Crop. J. 2022. [Google Scholar] [CrossRef]
- Gai, R.; Chen, N.; Yuan, H. A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Comput. Appl. 2021, 1–12. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- MacVicar, B.; Piégay, H. Implementation and validation of video monitoring for wood budgeting in a wandering piedmont river, the Ain River (France). Earth Surf. Process. Landforms 2012, 37, 1272–1289. [Google Scholar] [CrossRef]
- Benacchio, V.; Piégay, H.; Buffin-Bélanger, T.; Vaudor, L. A new methodology for monitoring wood fluxes in rivers using a ground camera: Potential and limits. Geomorphology 2017, 279, 44–58. [Google Scholar] [CrossRef]
- Ghaffarian, H.; Lemaire, P.; Zhi, Z.; Tougne, L.; MacVicar, B.; Piégay, H. Automated quantification of floating wood pieces in rivers from video monitoring: A new software tool and validation. Earth Surf. Dyn. 2021, 9, 519–537. [Google Scholar] [CrossRef]
- Lin, F.; Hou, T.; Jin, Q.; You, A. Improved YOLO Based Detection Algorithm for Floating Debris in Waterway. Entropy 2021, 23, 1111. [Google Scholar] [CrossRef]
- Majchrowska, S.; Mikołajczyk, A.; Ferlin, M.; Klawikowska, Z.; Plantykow, M.A.; Kwasigroch, A.; Majek, K. Deep learning-based waste detection in natural and urban environments. Waste Manag. 2022, 138, 274–284. [Google Scholar] [CrossRef]
- Proença, P.F.; Simões, P. Taco: Trash annotations in context for litter detection. arXiv 2020, arXiv:2003.06975. [Google Scholar]
- Aral, R.A.; Keskin, Ş.R.; Kaya, M.; Hacıömeroğlu, M. Classification of trashnet dataset based on deep learning models. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2058–2062. [Google Scholar]
- Fulton, M.; Hong, J.; Islam, M.J.; Sattar, J. Robotic detection of marine litter using deep visual detection models. In Proceedings of the 2019 international conference on robotics and automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5752–5758. [Google Scholar]
- Kraft, M.; Piechocki, M.; Ptak, B.; Walas, K. Autonomous, onboard vision-based trash and litter detection in low altitude aerial images collected by an unmanned aerial vehicle. Remote Sens. 2021, 13, 965. [Google Scholar] [CrossRef]
- Huang, K.; Lei, H.; Jiao, Z.; Zhong, Z. Recycling waste classification using vision transformer on portable device. Sustainability 2021, 13, 11572. [Google Scholar] [CrossRef]
- Lynch, S. OpenLitterMap. com–open data on plastic pollution with blockchain rewards (littercoin). Open Geospat. Data, Softw. Stand. 2018, 3, 6. [Google Scholar] [CrossRef] [Green Version]
- Tzutalin, D. LabelImg (2015). GitHub Repos. Available online: https://github.Com/tzutalin/labelImg (accessed on 12 July 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
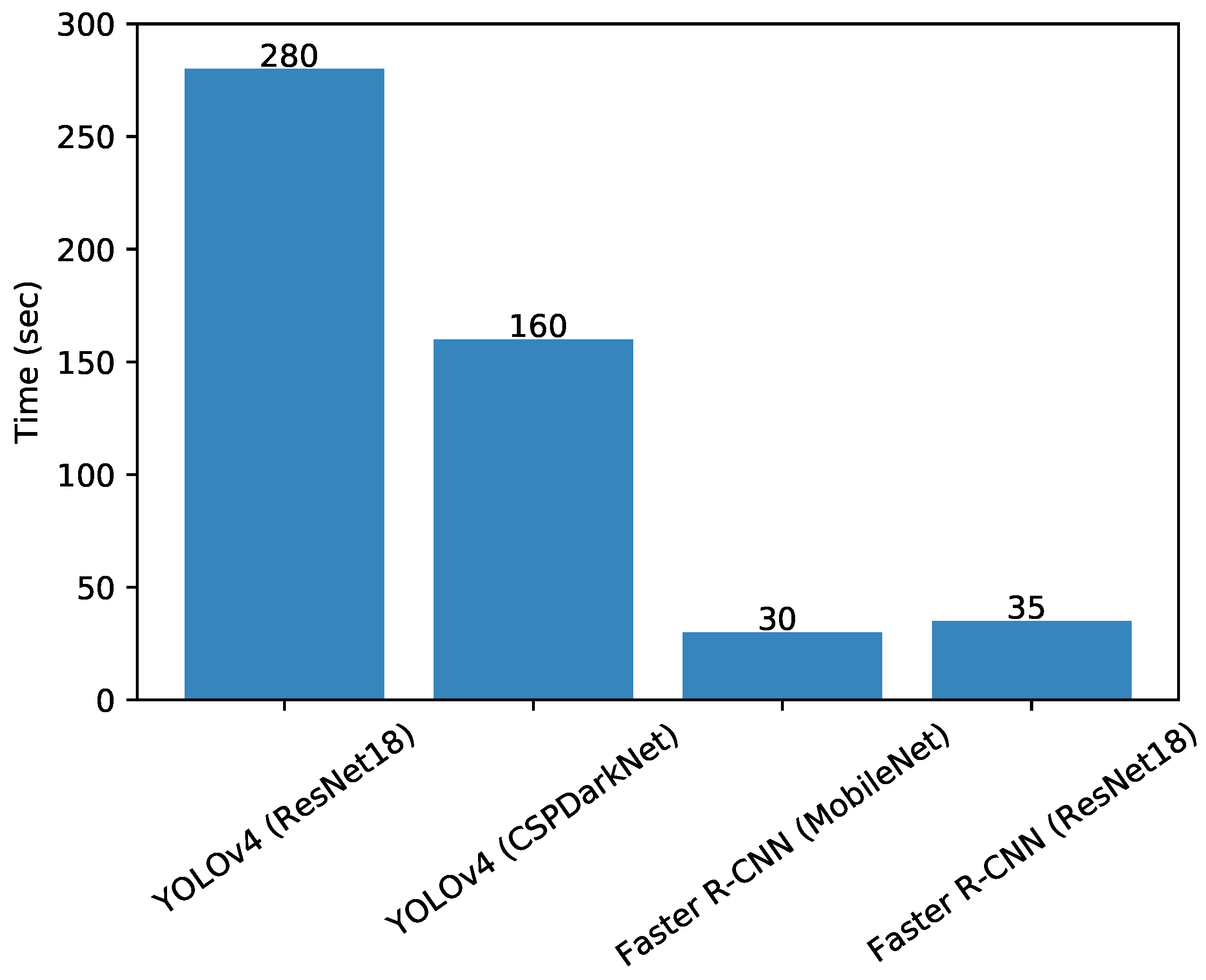{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Addressed Problem | Dataset | Proposed Approach | Performance |
|---|---|---|---|---|---|
| MacVicar and Piegay [54] | 2012 | wood detection | custom dataset | conventional methods | NA |
| Benacchio et al. [55] | 2017 | wood detection | custom dataset | conventional methods | of |
| Lieshout et al. [48] | 2020 | floating plastic | custom dataset | Faster R-CNN | mAp of |
| debris detection | (1300 images) | 68.7% | |||
| Cheng et al. [46] | 2021 | marine debris | custom dataset | DSSD, RetinaNet, | mAP of |
| detection | (2000 images) | YOLOv3, Faster R-CNN | 43% for Cascade | ||
| Cascade R-CNN | |||||
| Ghaffarian et al. [56] | 2021 | river wood | NA | Conventional static | 21% improved |
| detection | and dynamic masking | error rate | |||
| Lin et al. [57] | 2021 | floating debris | custom dataset | Improved YOLOv5 | mAP of |
| detection | (2400 images) | 77% | |||
| Majchrowska et al. [58] | 2022 | waste material | TACO, TrashCan, | EfficientDet-D2 | mAP of |
| detection | Trash-ICRA, UAVVaste, | EfficientNet-B2 | 70% | ||
| drinking-waste | |||||
| Aleem et al. [47] | 2022 | marine debris | FLS dataset | Faster R-CNN | IoU of |
| detection | (1865 images) | 3.78 |
| Model | Training Loss | mAP | Mean Precision | Mean Recall |
|---|---|---|---|---|
| Faster R-CNN Models | ||||
| MobileNet Backbone | 0.1044 | 0.8601 | 0.2515 | 0.8827 |
| ResNet18 Backbone | 0.3492 | 0.8642 | 0.0713 | 0.8990 |
| YOLOv4 Models | ||||
| ResNet18 Backbone | 34.87 | 0.8138 | NA | NA |
| CSPDarkNet Backbone | 47.48 | 0.7804 | NA | NA |
| Model | mAP | ||
|---|---|---|---|
| Faster R-CNN (Resnet18 Backbone) | 0.8007 | 0.7236 | 0.8778 |
| Faster R-CNN (MobileNet Backbone) | 0.8445 | 0.7544 | 0.9345 |
| YOLOv4 (ResNet18 Backbone) | 0.7826 | 0.7393 | 0.8331 |
| YOLOv4 (CSPDarkNet Backbone) | 0.7616 | 0.7115 | 0.8114 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iqbal, U.; Riaz, M.Z.B.; Barthelemy, J.; Hutchison, N.; Perez, P. Floodborne Objects Type Recognition Using Computer Vision to Mitigate Blockage Originated Floods. Water 2022, 14, 2605. https://doi.org/10.3390/w14172605
Iqbal U, Riaz MZB, Barthelemy J, Hutchison N, Perez P. Floodborne Objects Type Recognition Using Computer Vision to Mitigate Blockage Originated Floods. Water. 2022; 14(17):2605. https://doi.org/10.3390/w14172605
Chicago/Turabian StyleIqbal, Umair, Muhammad Zain Bin Riaz, Johan Barthelemy, Nathanael Hutchison, and Pascal Perez. 2022. "Floodborne Objects Type Recognition Using Computer Vision to Mitigate Blockage Originated Floods" Water 14, no. 17: 2605. https://doi.org/10.3390/w14172605