
Research on Water-Level Recognition Method Based on Image Processing and Convolutional Neural Networks



Abstract
:1. Introduction
2. Materials and Methods
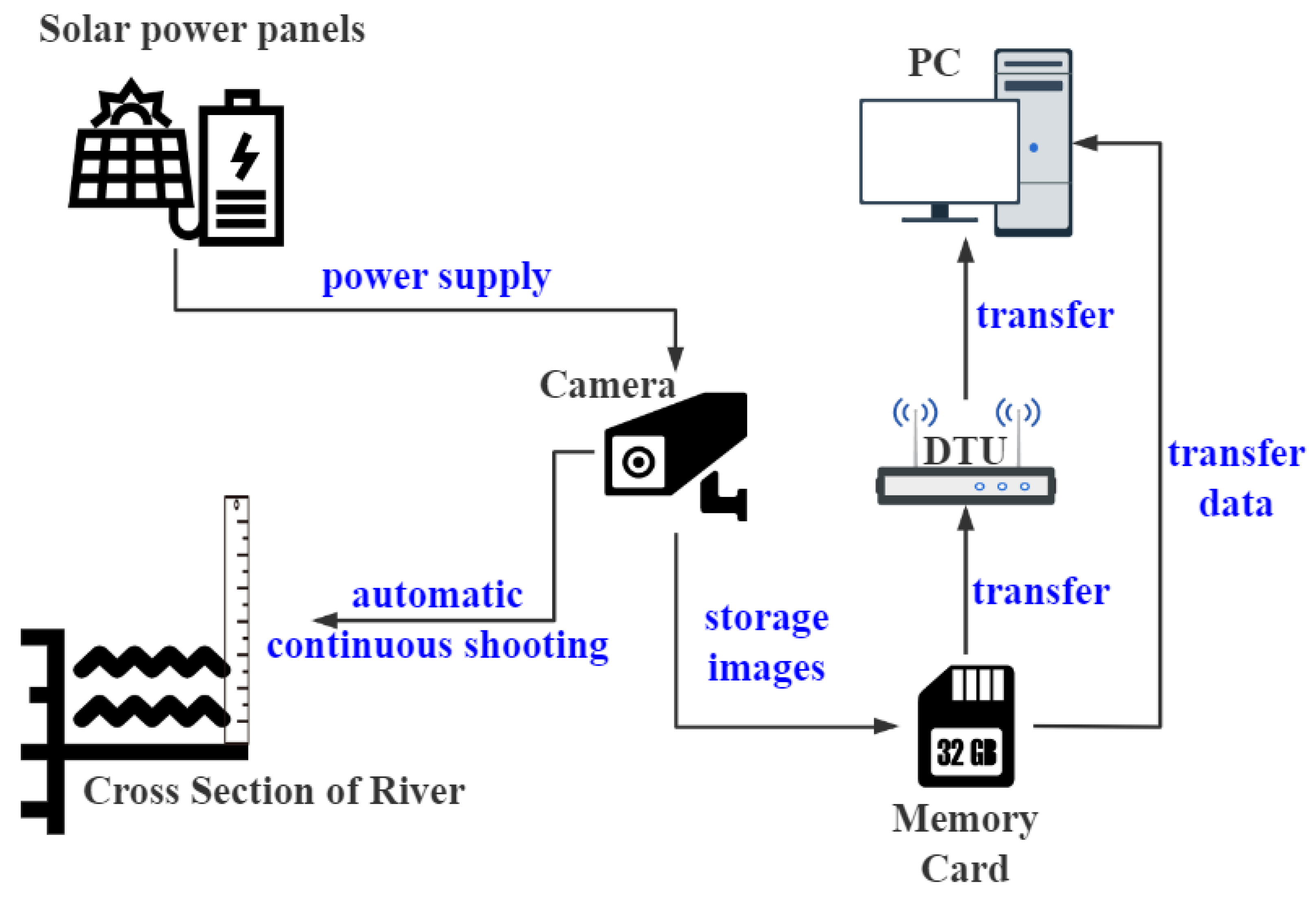
2.1. Study Region and Data Acquisition
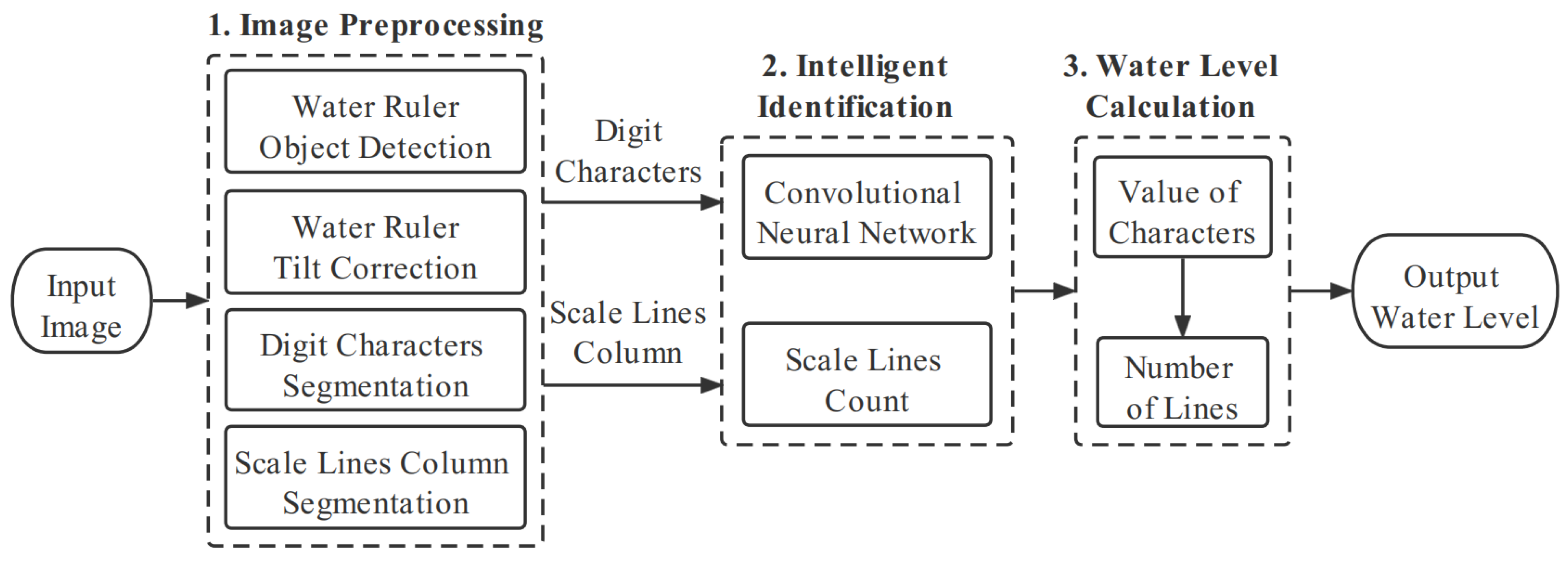
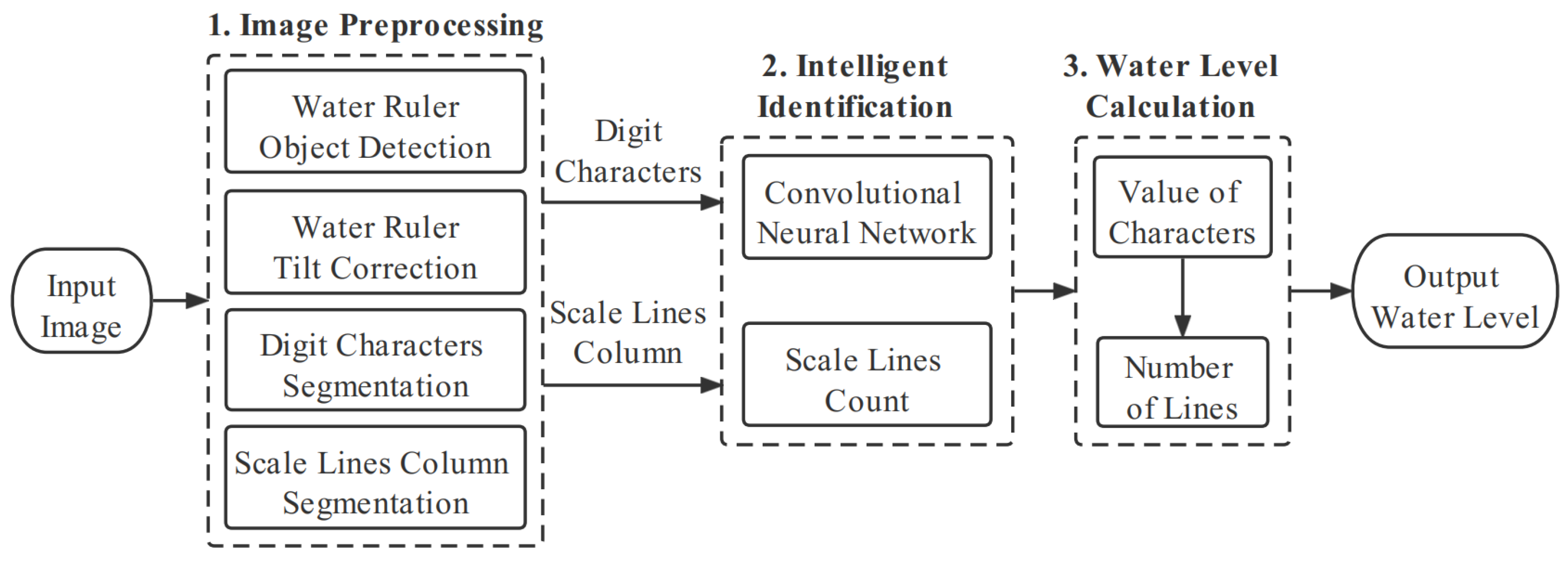
2.2. Processing Flow of the Water Level Image Recognition System
2.3. Gray Level Transformation
2.3.1. Graying
2.3.2. Binarization
- Traverse all the pixels of the image and count the histogram of the gray distribution.
- Normalize the histogram and set the ratio of the number of pixels with gray value to the total number of pixels as .
- Assuming that the current threshold is , the normalized histogram can calculate the target pixel ratio . the normalized histogram can calculate the target pixel ratio , under the current division, as well as the average gray level of the target area . under the current division, as well as the average gray level of the target area .
- 4.
- To make the intra-class variance the smallest and the inter-class variance the largest, it is equivalent to making the largest. OTSU, introduced in the paper, uses the largest between-class variance:
- 5.
- Traverse all the values of T from 0 to 255 to find the value of t that maximizes , that is, the global threshold of the image.
2.4. Morphological Processing
2.4.1. Dilation and Erosion
2.4.2. Dilation and Erosion
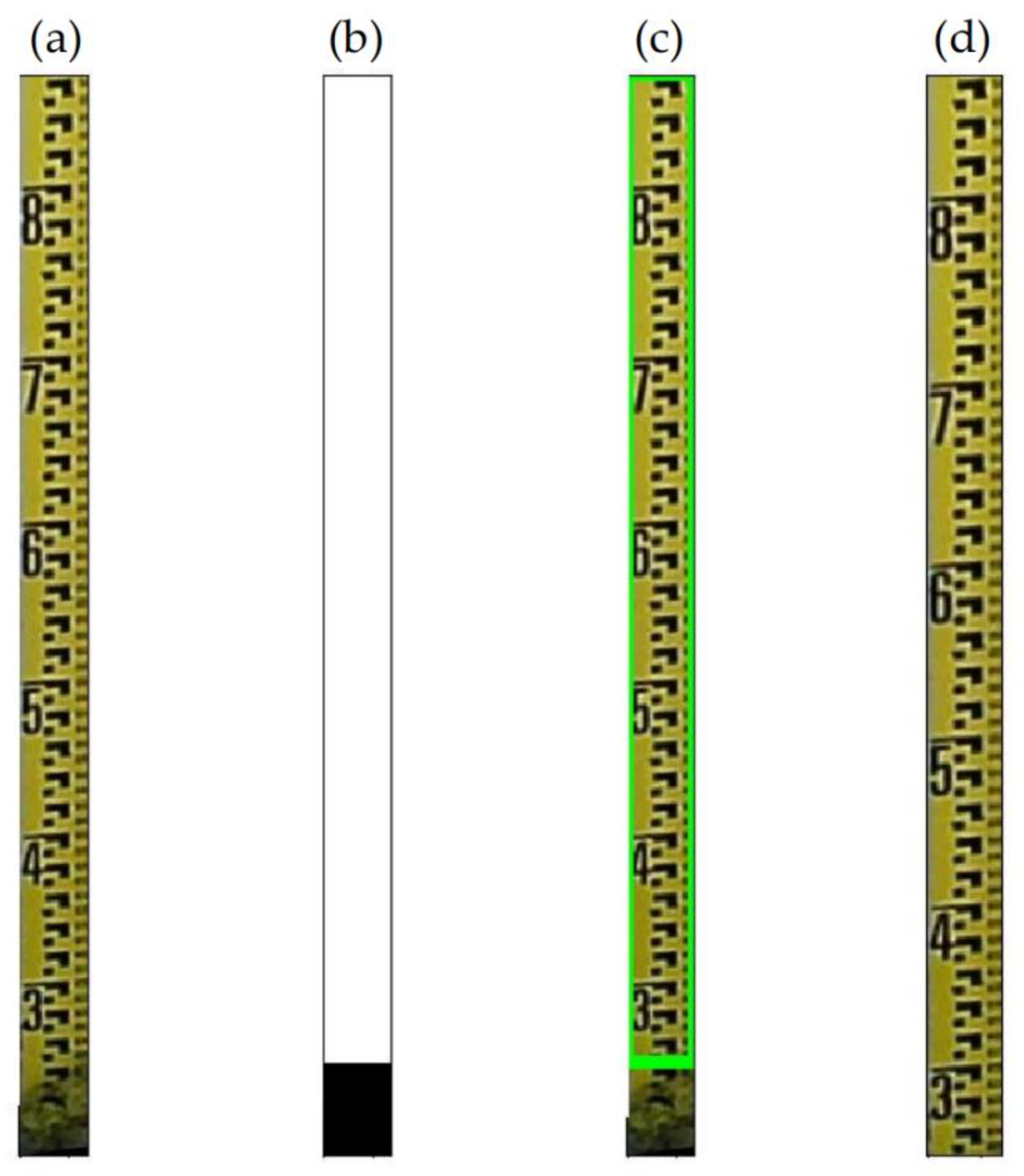
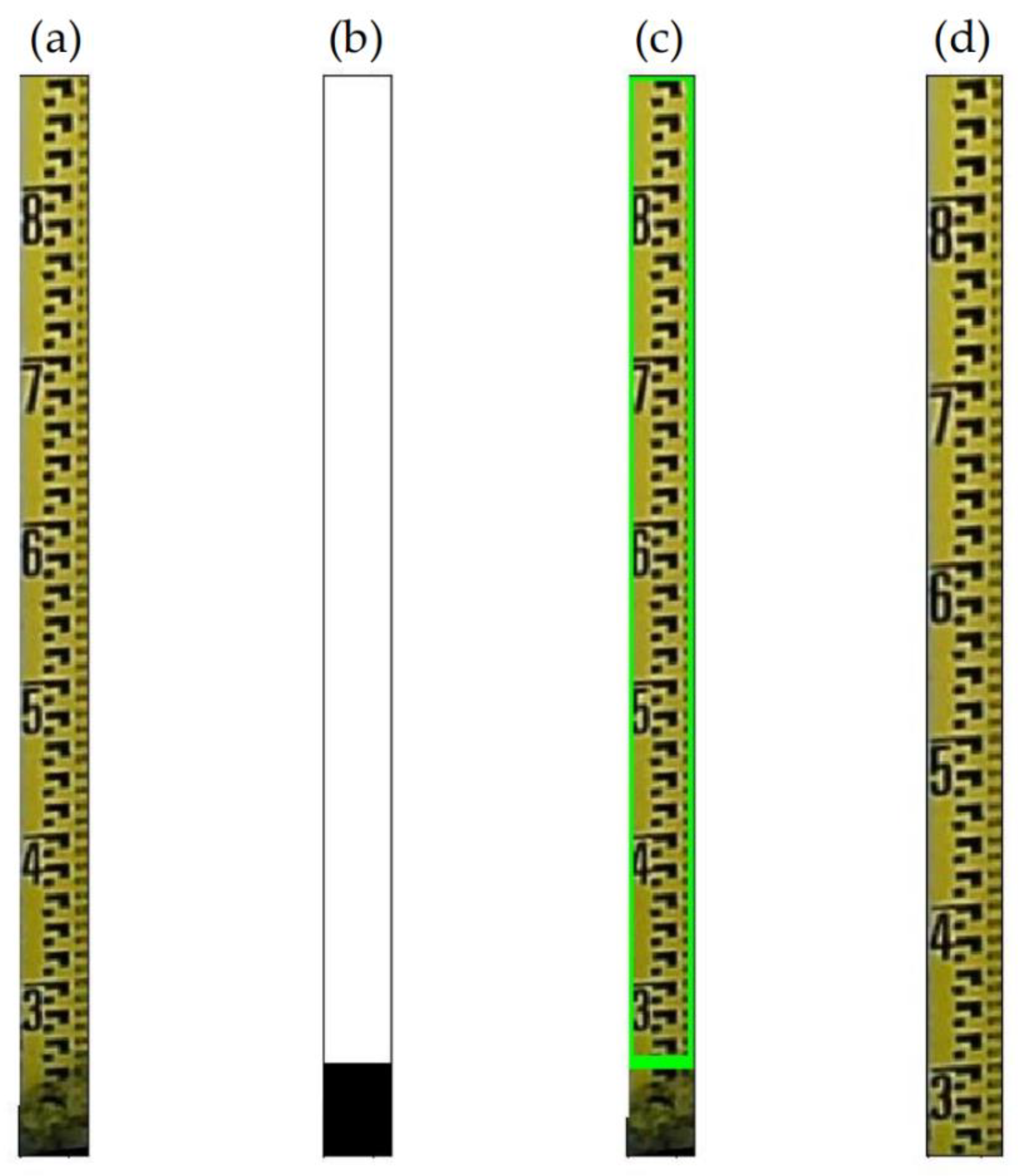
2.5. Extraction of Regions of Interest
2.5.1. Edge Detection
- 1.
- We use a Gaussian filter to convolve the image in order to filter out noise and smooth the image to prevent the false detection caused by noise. The convolution kernel scale of 3 × 3 or 5 × 5 is commonly used.The following formula is the generating equation of the Gaussian filter kernel with a size of (2k + 1) × (2k + 1):If a 3 × 3 window in the image is A and the pixel to be filtered is , after Gaussian filtering, the brightness value of pixel is:where is the convolution symbol, and means the sum of all elements in the matrix.
- 2.
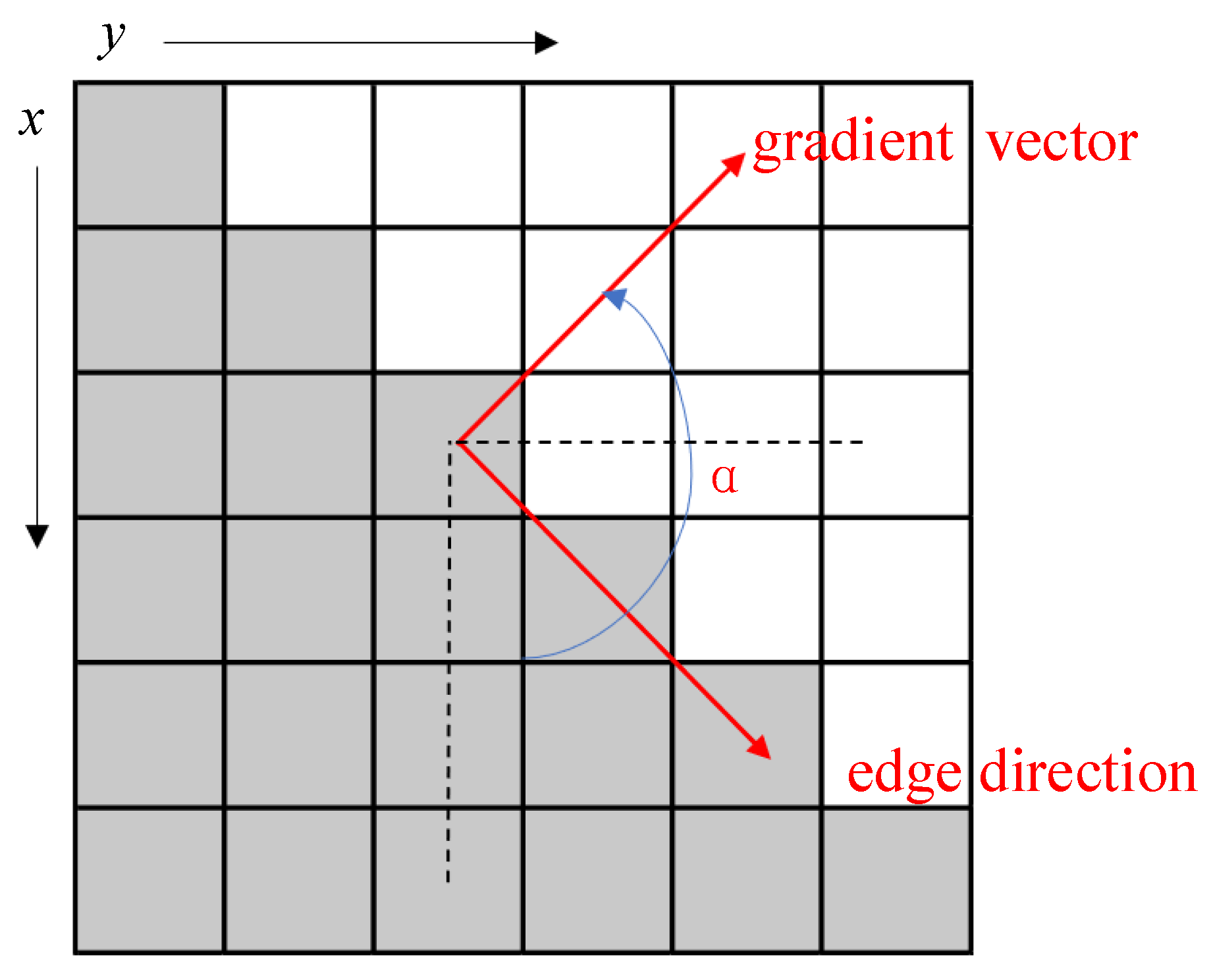
- The magnitude and direction of the ladder are calculated to estimate the edge strength and direction at each point.where is the gradient strength, the is the gradient direction, is the first derivative value in the horizontal direction, is the first derivative value in the vertical direction.
- 3.
- Non-maximum SuppressionNon-Maximum Suppression is an edge thinning technique which can help suppress all gradient values other than the local maximum to 0. According to the gradient direction, the gradient amplitude is suppressed by Non-Maximum Suppression to eliminate the stray response caused by edge detection. In essence, this operation is a further refinement of the results of the Sobel and Prewitt operators for meeting the third standard. The algorithm of non-maximum suppression for each pixel in the gradient image is:(1) Compare the gradient intensity of the current pixel with two pixels along the positive and negative gradient direction (not the edge direction).(2) If the gradient intensity of the current pixel is the largest compared with the other two pixels, the pixel remains as an edge point, otherwise, the pixel will be suppressed.Generally, for more accurate calculation, linear interpolation is used between two adjacent pixels across the gradient direction to obtain the pixel gradient to be compared.
- 4.
- Apply Double-Threshold Detection to determine true and potential edges.
- 5.
- Finally, edge detection is completed by suppressing isolated weak edges (low threshold points).
2.5.2. Contour Detection
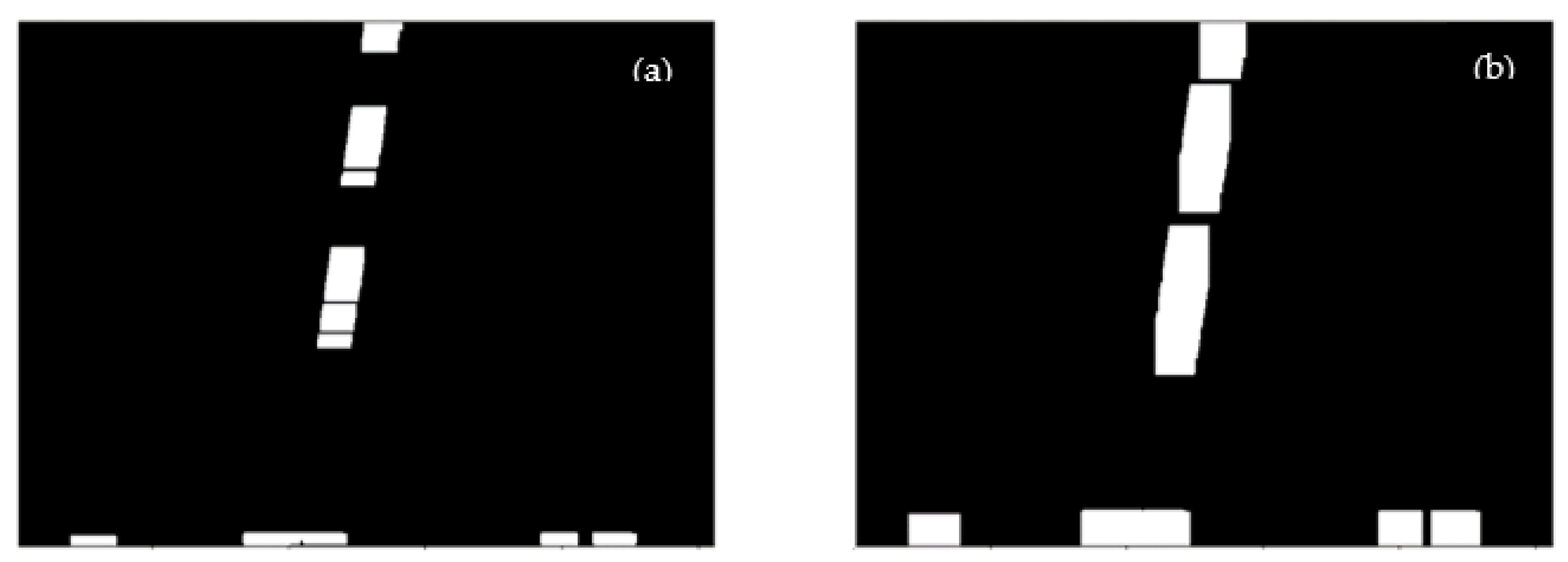
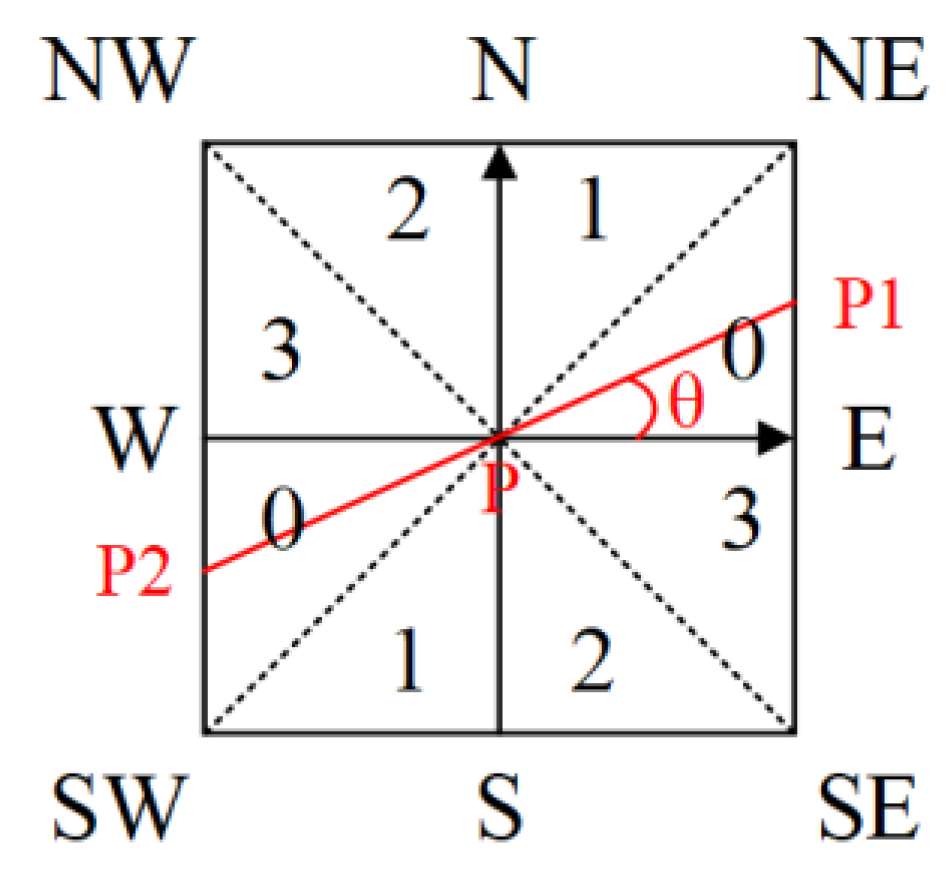
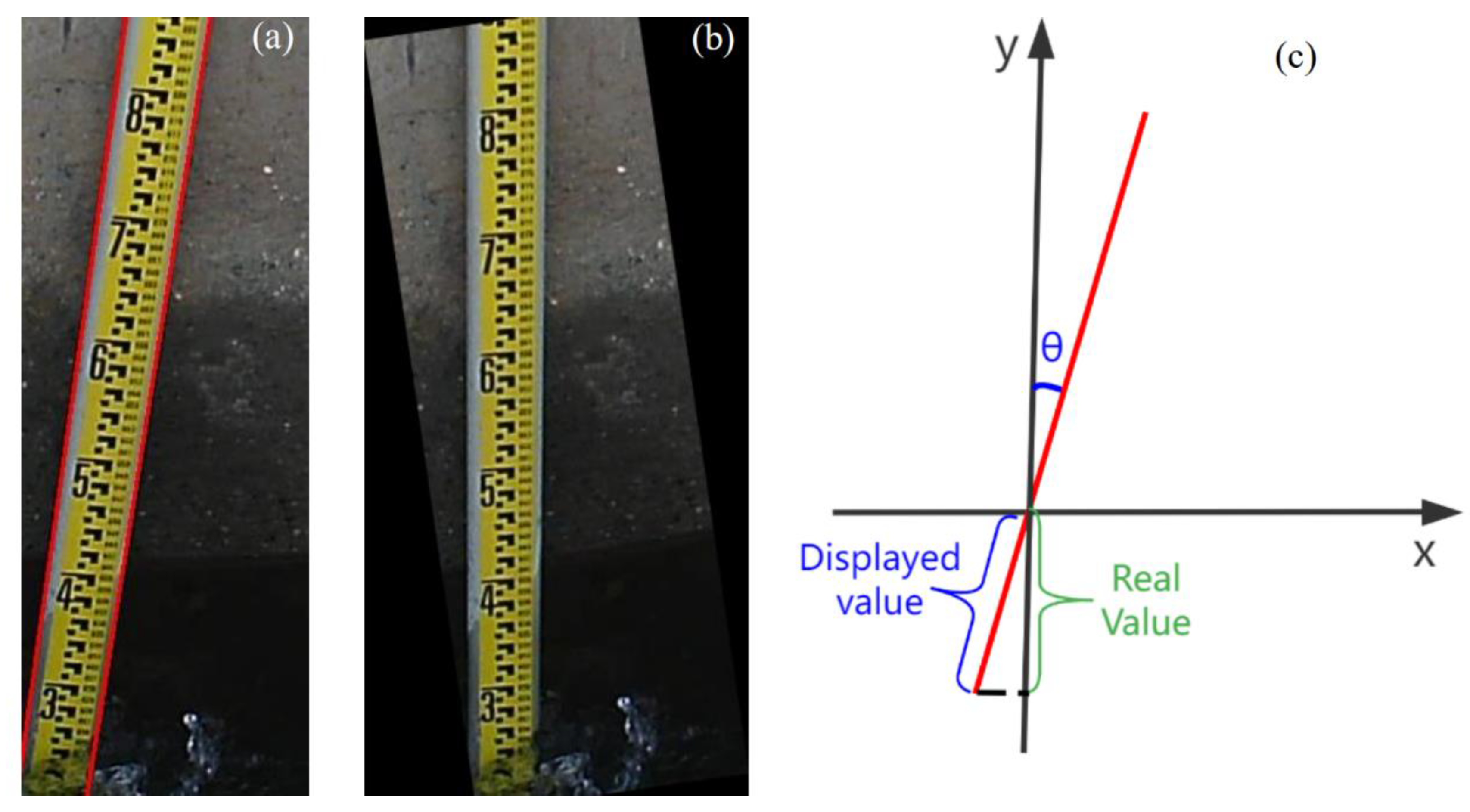
2.5.3. Tilt Correction
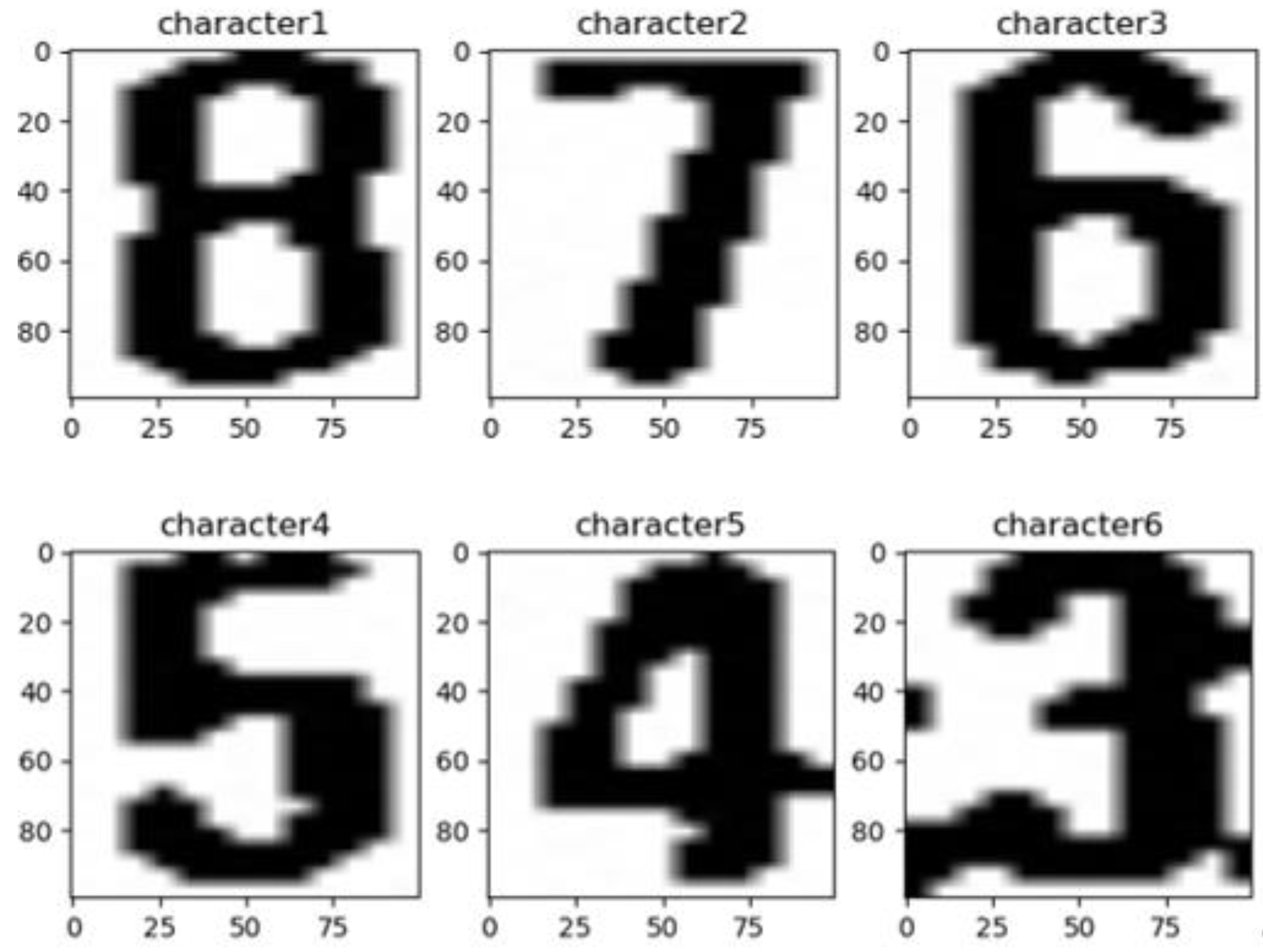
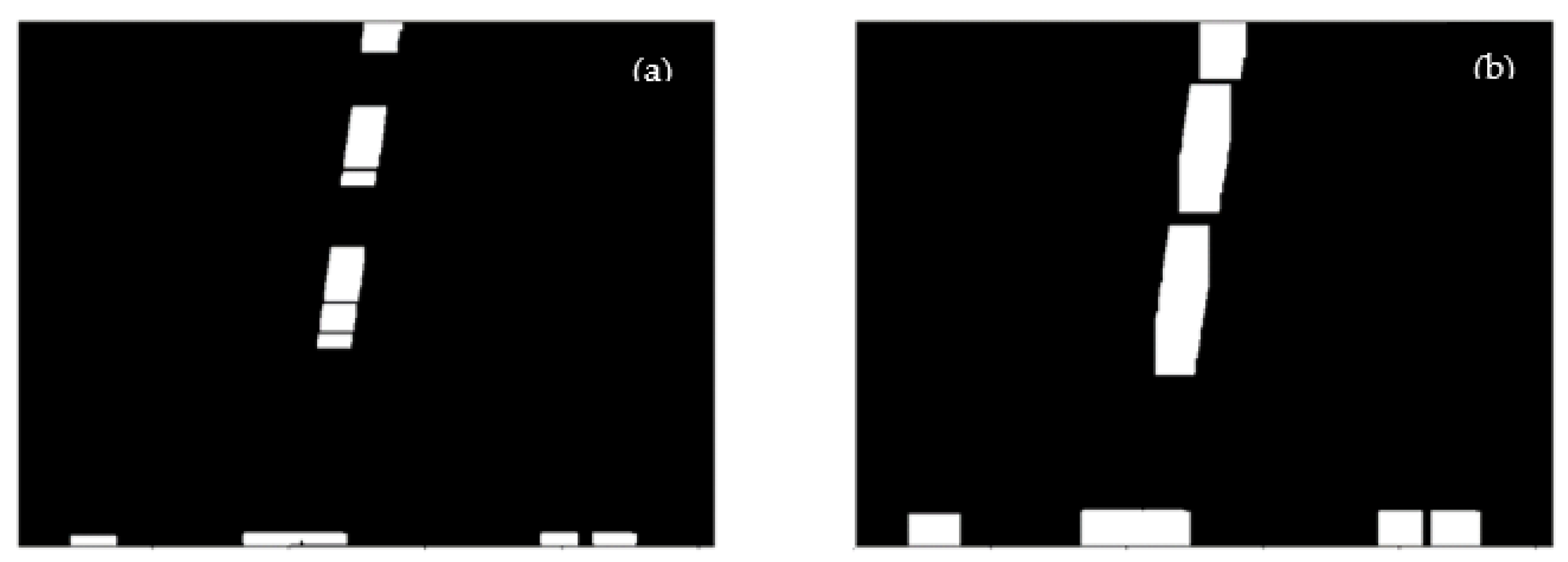
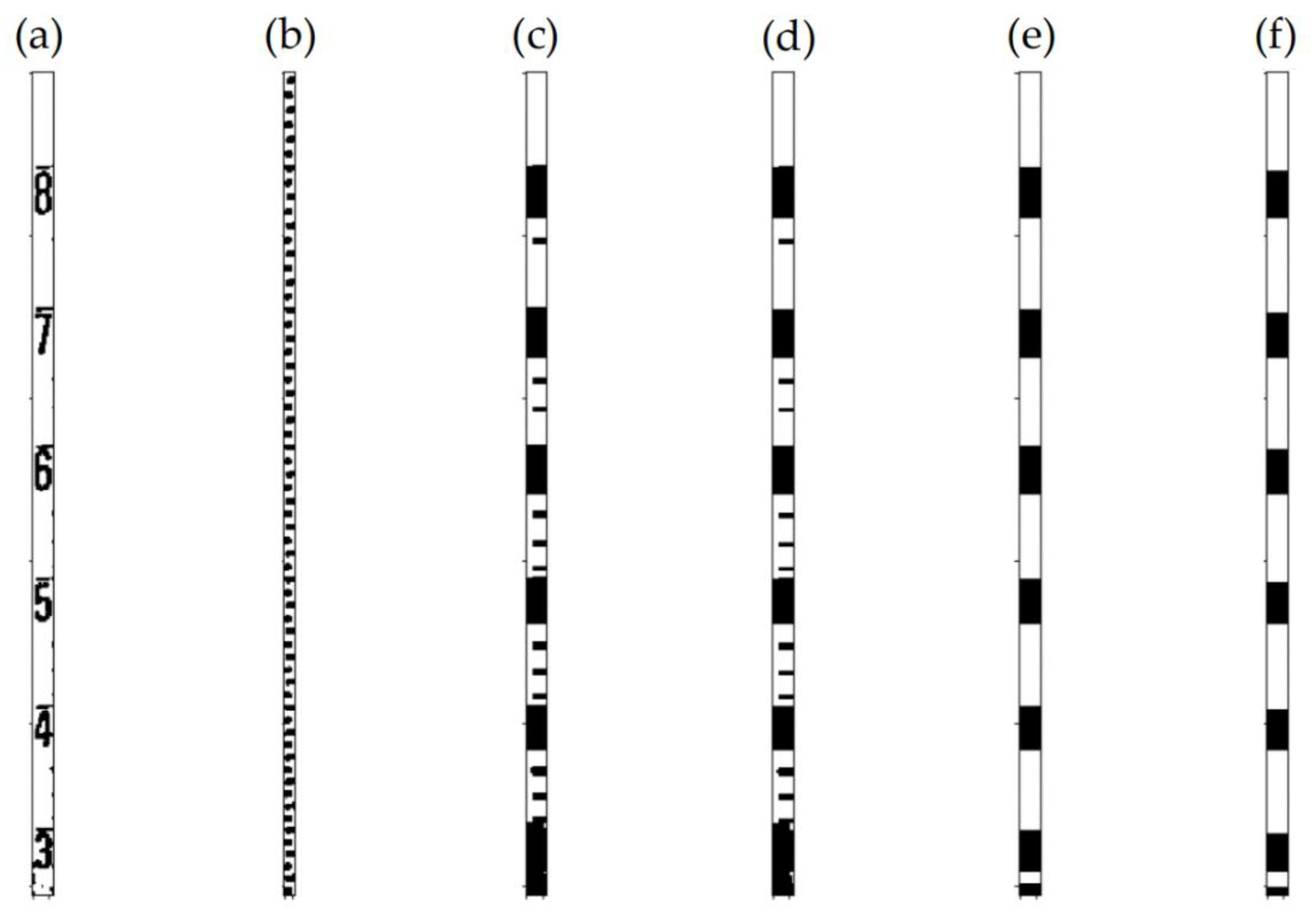
2.6. Character Positioning and Segmentation
2.7. Identification and Calculation the Value of Water Level
- Recognize characters and return coordinates: The CNN is designed to classify and recognize the segmented digital characters, take the largest character among all recognized characters, and return the position coordinates of the character.
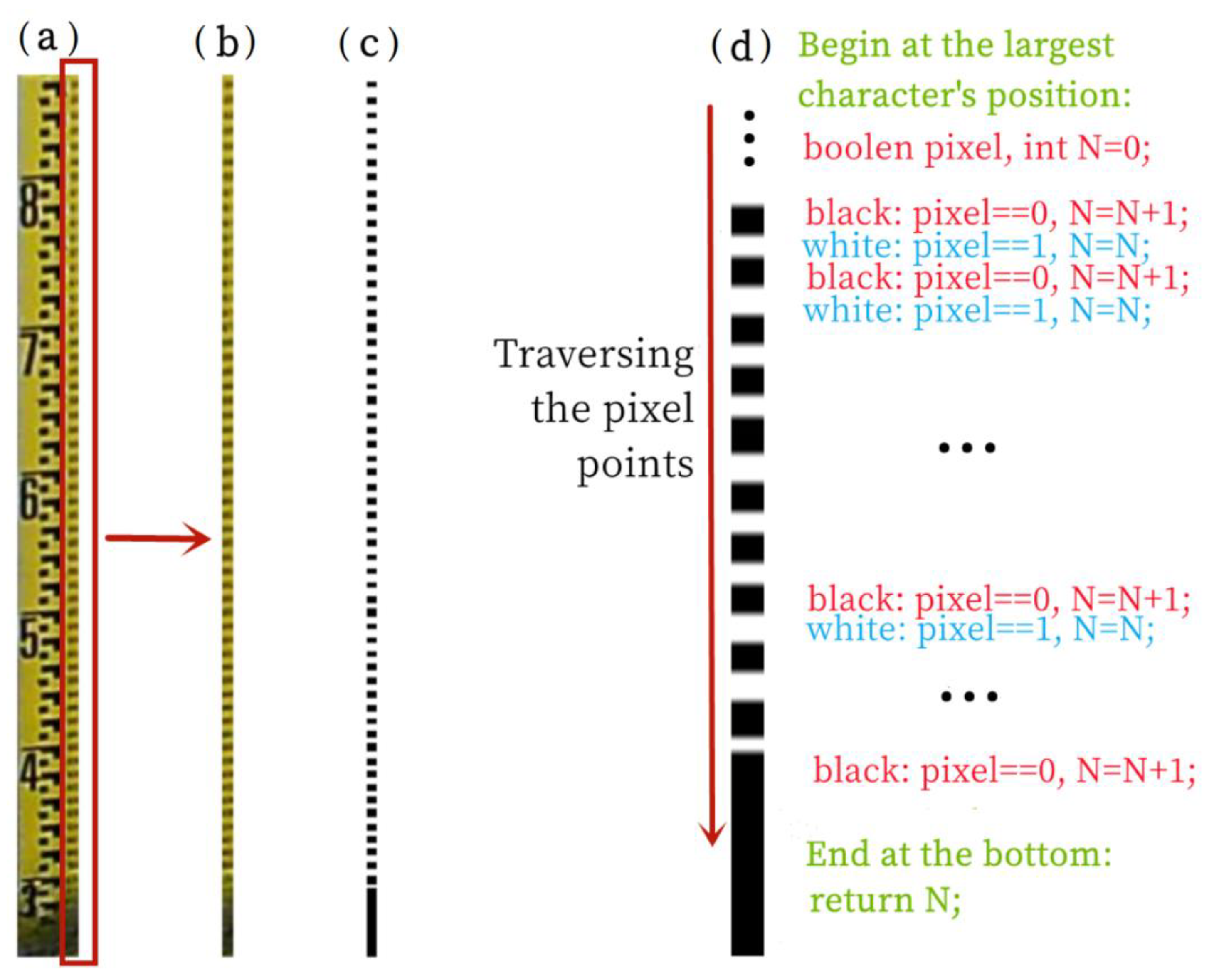
- Count the number of scale lines: A counter that counts down the scale line based on the coordinate position of the largest recognized numeric character (after a series of preprocessing operations is set up, and the pixels are traversed and counted using the pixel variation of the binary image).
- Calculate the value of water level: The value of the largest numeric character identified in step (1) is used, and the value of the counter in step 2 (the value of the number of tick marks traversed) is used, which is the final water level value.
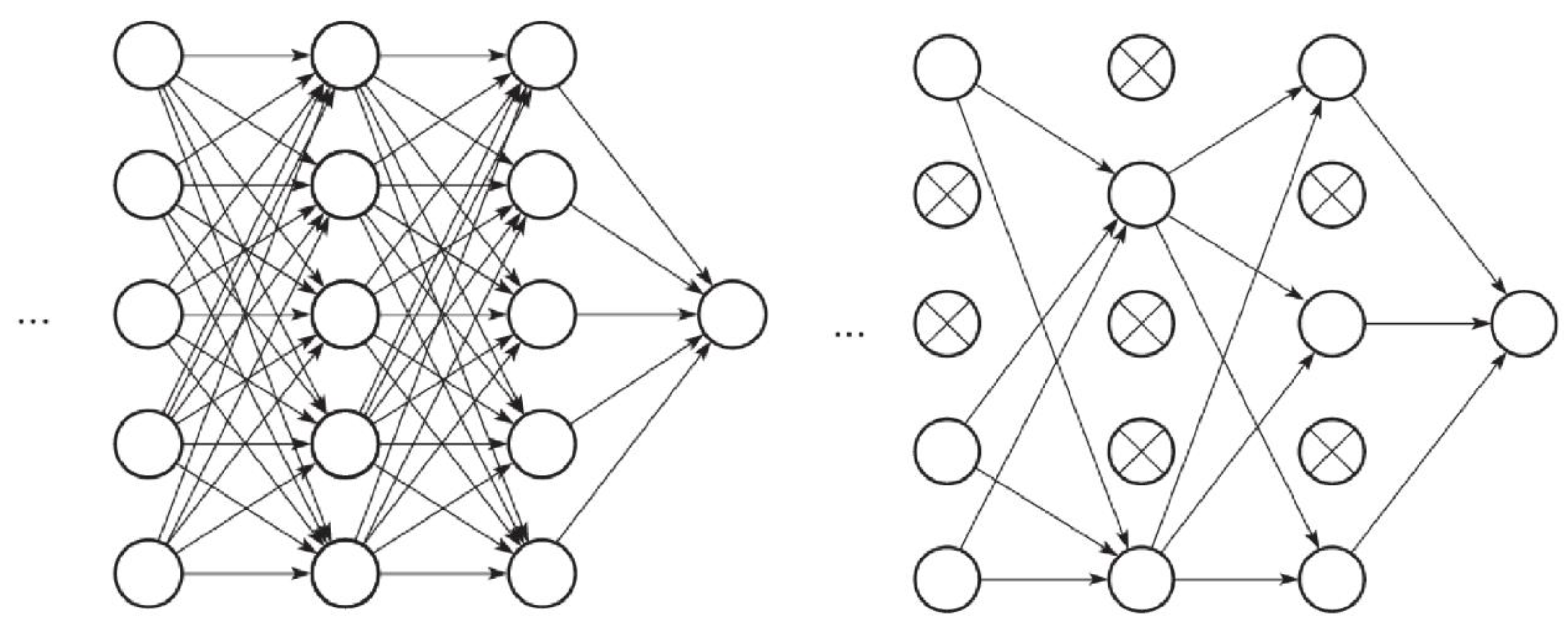
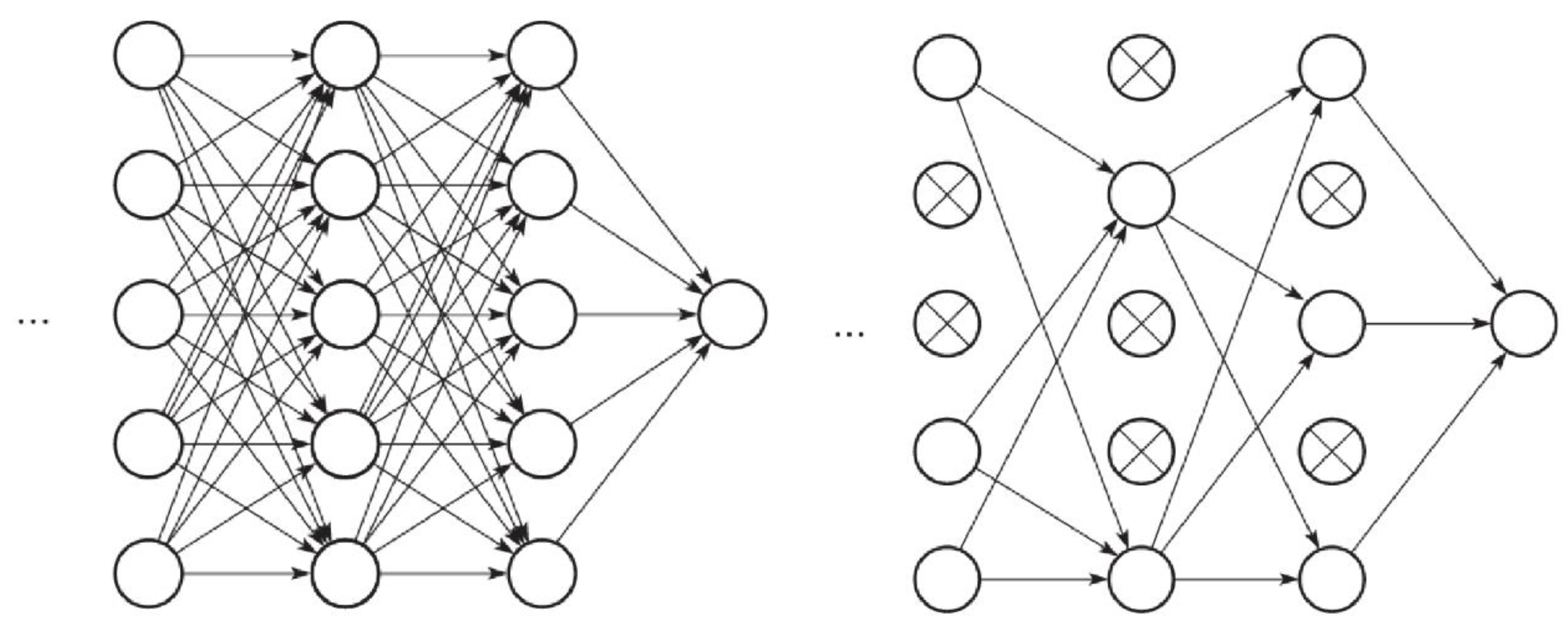
2.7.1. Design of CNN
2.7.2. Train the CNN
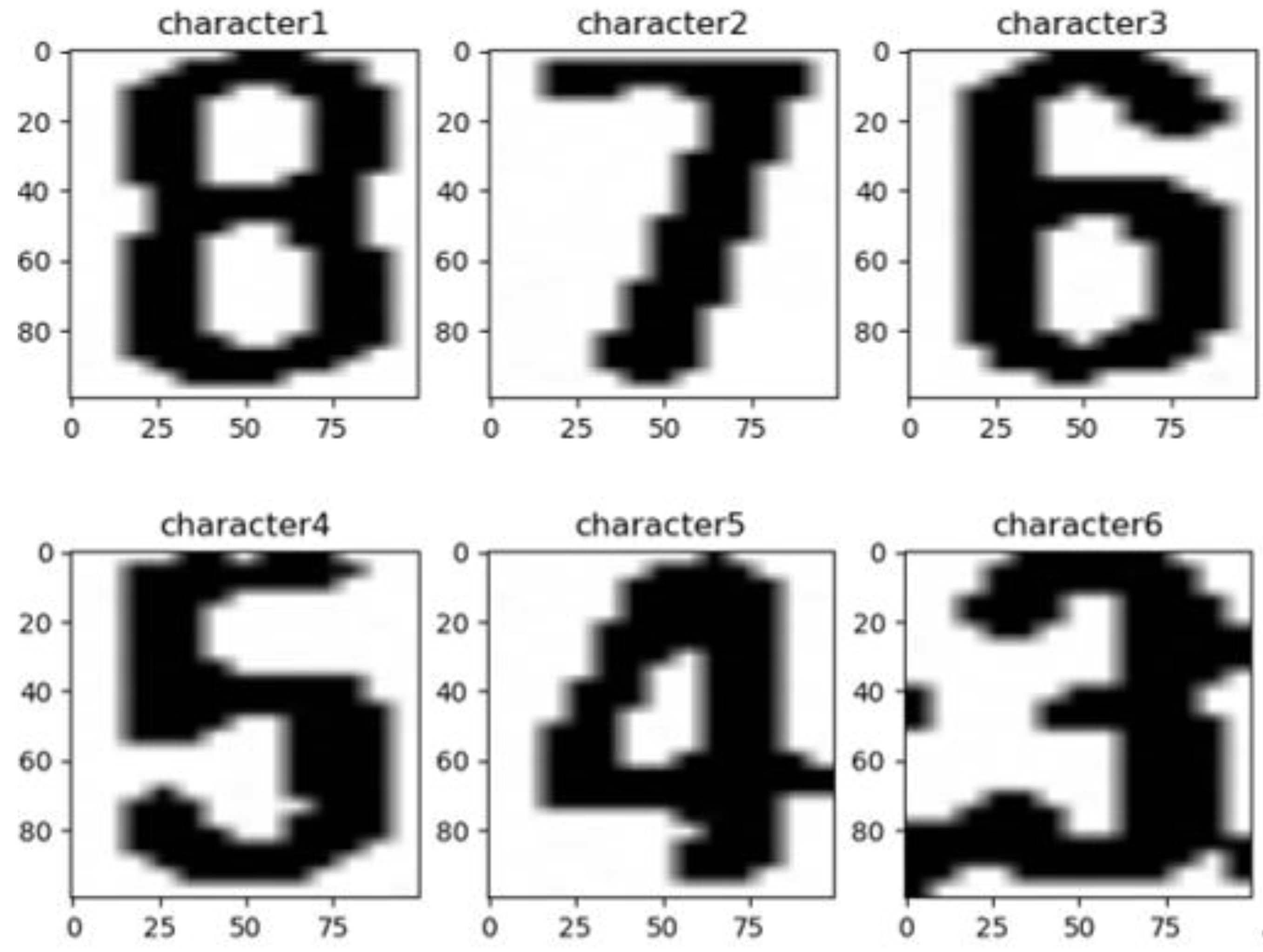
- Ten image samples are selected containing printed numeric characters 0–9, each containing 1016 binary images with a size of , for a total of 10,160 numeric character images. We randomly assign 80% of the training set and 20% of the validation set to be the data set to train the CNN.
- After 50 epochs of iterative training, the training results show that when the loss function converges, the recognition accuracy of the neural network on the verification set reaches 97-98%, which is shown in Figure 20.
- Save the best training results as h5 model, evaluate the model and call it in the test phase.
2.8. Extraction of Scale Line and Calculation of Water Level
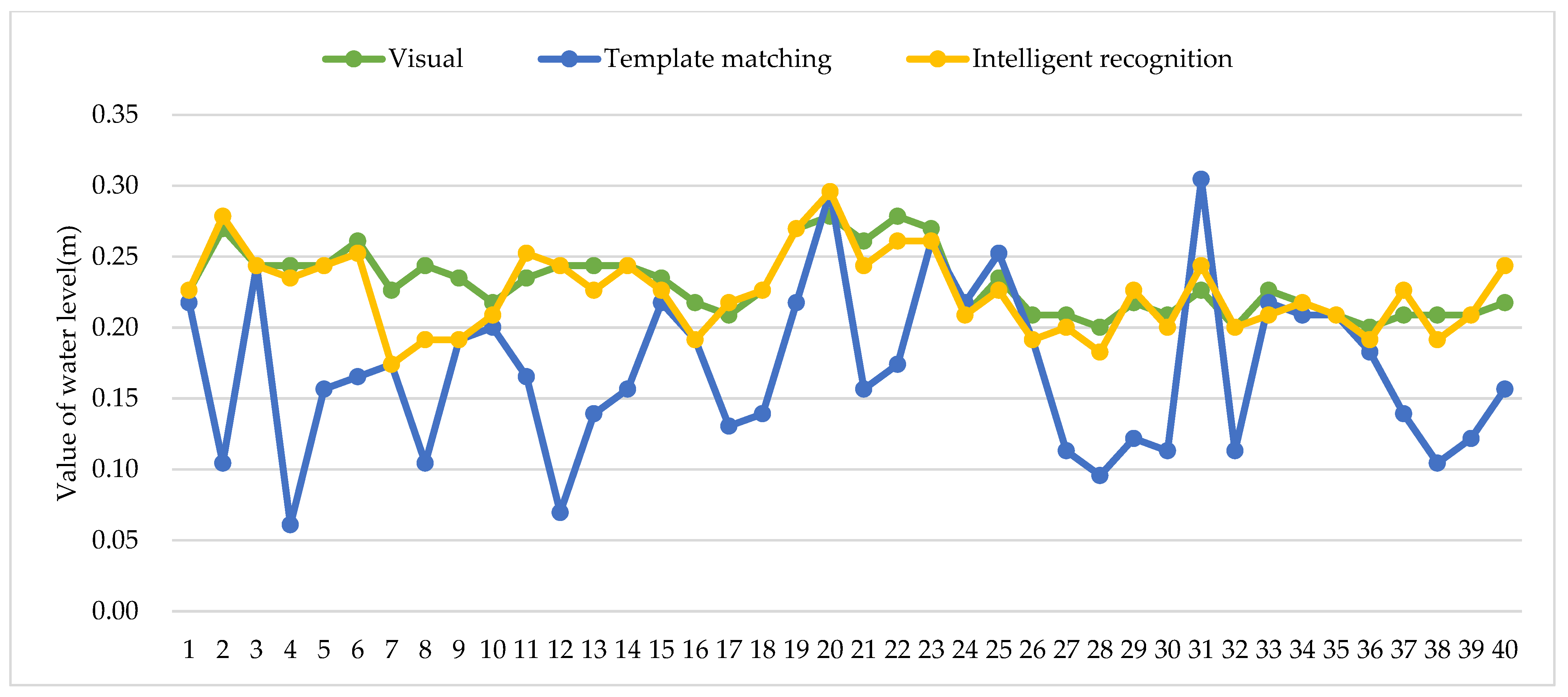
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| ANN | Artificial Neural Networks |
| CV | Computer Vision |
| SVM | Support Vector Machine |
| ILSVRC | ImageNet Large Scale Visual Recognition Challenge |
| CNY | China Yuan |
| DTU | Data Transfer Unit |
References
- Mosavi, A.; Ozturk, P.; Chau, K. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Danso-Amoako, E.; Scholz, M.; Kalimeris, N.; Yang, Q.; Shao, J. Predicting Dam Failure Risk for Sustainable Flood Retention Basins: A Generic Case Study for the Wider Greater Manchester Area. Comput. Environ. Urban Syst. 2012, 36, 423–433. [Google Scholar] [CrossRef]
- Li, X.; Cheng, X.; Gong, P.; Yan, K. Design and Implementation of a Wireless Sensor Network-Based Remote Water-Level Monitoring System. Sensors 2011, 11, 1706–1720. [Google Scholar] [CrossRef] [PubMed]
- Takagi, Y.; Yoneoka, T.; Mori, H.; Yoda, M.; Tsujikawa, A. Development of a Water Level Measuring System Using Image Processing. In Proceedings of the Iwa Conference on Instrumentation, Malmö, Sweden, 3–7 June 2001. [Google Scholar]
- Buyong, L.; Byoungyoon, P. Development of High Precision Underground Water Level Meter Using a Buoyant Rod Load Cell Technique. Korean J. Agric. For. Meteorol. 1999, 1, 36–40. [Google Scholar]
- Kim, J.; Han, Y.; Hahn, H. Image-based Water Level Measurement Method under Stained Ruler. J. Meas. Sci. Instrum. 2010, 1, 28–31. [Google Scholar] [CrossRef]
- Arshad, B.; Ogie, R.; Barthelemy, J.; Pradhan, B.; Verstaevel, N.; Perez, P. Computer Vision and IoT-Based Sensors in Flood Monitoring and Mapping: A Systematic Review. Sensors 2019, 19, 5012. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing; Prentice Hall Press: Upper Saddle River, NJ, USA, 2008; Volume 28, pp. 484–486. [Google Scholar]
- Humblot-Renaux, G.; Marchegiani, L.; Moeslund, T.B.; Gade, R. Navigation-Oriented Scene Understanding for Robotic Autonomy: Learning to Segment Driveability in Egocentric Images. IEEE Robot. Autom. Lett. 2021, 7, 2913–2920. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hadji, I.; Wildes, R.P. What Do We Understand About Convolutional Networks? arXiv 2018, arXiv:1803.08834. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. arXiv 2013, arXiv:1311.2901. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Wei, L.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Boston, MA, USA, 2015; pp. 1–9. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Convolutional Neural Networks for Water Body Extraction from Landsat Imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. Available online: https://www.worldscientific.com/doi/10.1142/S1469026817500018 (accessed on 7 April 2022). [CrossRef]
- Bai, Y.; Chen, Z.; Jingjing, X.; Li, C. Daily Reservoir Inflow Forecasting Using Multiscale Deep Feature Learning with Hybrid Models. J. Hydrol. 2015, 532, 193–206. [Google Scholar] [CrossRef]
- Sabbatini, L.; Palma, L.; Belli, A.; Sini, F.; Pierleoni, P. A Computer Vision System for Staff Gauge in River Flood Monitoring. Inventions 2021, 6, 79. [Google Scholar] [CrossRef]
- Jafari, N.H.; Li, X.; Chen, Q.; Le, C.-Y.; Betzer, L.P.; Liang, Y. Real-Time Water Level Monitoring Using Live Cameras and Computer Vision Techniques. Comput. Geosci. 2021, 147, 104642. [Google Scholar] [CrossRef]
- Narayanan, R.; Lekshmy, V.M.; Rao, S.; Sasidhar, K. A Novel Approach to Urban Flood Monitoring Using Computer Vision. In Proceedings of the Fifth International Conference on Computing, Communications and Networking Technologies (ICCCNT), Hefei, China, 11–13 July 2014; IEEE: Hefei, China, 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Cheng, R.; Yang, Y.; Han, C.; Liu, J.; Kang, E.; Song, Y.; Liu, Z. Field Experimental Research on Hydrological Function over Several Typical Underlying Surfaces in the Cold Regions of Western China. Adv. Earth Sci. 2014, 29, 507–514. [Google Scholar] [CrossRef]
- Han, C.; Chen, R.; Liu, Z.; Yang, Y.; Liu, J.; Song, Y.; Wang, L.; Liu, G.; Guo, S.; Wang, X. Cryospheric Hydrometeorology Observation in the Hulu Catchment (CHOICE), Qilian Mountains, China. Vadose Zone J. 2018, 17, 180058. [Google Scholar] [CrossRef]
- Wang, K.; Cheng, G.; Xiao, H.; Jiang, H. The Westerly Fluctuation and Water Vapor Transport over the Qilian-Heihe Valley. Sci. China Ser. D Earth Sci. 2004, 47, 32–38. [Google Scholar] [CrossRef]
- Beniston, M.; Farinotti, D.; Stoffel, M.; Andreassen, L.M.; Coppola, E.; Eckert, N.; Fantini, A.; Giacona, F.; Hauck, C.; Huss, M.; et al. The European Mountain Cryosphere: A Review of Its Current State, Trends, and Future Challenges. Cryosphere 2018, 12, 759–794. [Google Scholar] [CrossRef]
- Tarun, K.; Karun, V.; Tarun, K.; Karun, V. A Theory Based on Conversion of RGB Image to Gray Image. Int. J. Comput. Appl. 2010, 7, 7–10. [Google Scholar] [CrossRef]
- Gu, M.; Su, B.; Wang, M.; Wang, Z. Survey on decolorization methods. Appl. Res. Comput. 2019, 36, 1286–1292. [Google Scholar] [CrossRef]
- Cao, L.; Jiao, L.; Li, Z.; Liu, T.; Zhong, Y. Grayscale Image Colorization Using an Adaptive Weighted Average Method. J. Imaging Sci. Technol. 2017, 61, 60502-1–60502-60510. [Google Scholar] [CrossRef]
- Sauvola, J.; Pietikäinen, M. Adaptive Document Image Binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Otsu, N. A Tlreshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Jain, A.; Dubes, R. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988; Volume 32, ISBN 0-13-022278-X. [Google Scholar]
- Serra, J. Introduction to Mathematical Morphology. Comput. Vis. Graph. Image Process. 1986, 35, 283–305. [Google Scholar] [CrossRef]
- Heijmans, H.J.A.M.; Ronse, C. The Algebraic Basis of Mathematical Morphology, I. Dilations and Erosions. Comput. Vis. Graph. Image Process. 1990, 50, 245–295. [Google Scholar] [CrossRef]
- Bishnoi, A. Noise Removal with Morphological Operations Opening and Closing Using Erosion and Dilation. Int. J. Multidiscip. Educ. Res. 2014, 4, 01–04. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- Wang, N.; Li, X. An Improved Edge Detection Algorithm Based on the Canny Operator. J. Shenzhen Univ. 2015, 2, 149–153. (In Chinese) [Google Scholar]
- Suzuki, S. Topological Structural Analysis of Digitized Binary Images by Border Following. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Kaehler, A.; Bradski, G. Learning OpenCV 3: Computer Vision in C++ with the OpenCV Library, 1st ed.; O’Reilly Media: Sebastopol, CA, USA, 2016; ISBN 978-1-4919-3799-0. [Google Scholar]
- Xiaohang, L.; Jia, G.; Fulun, P.; Jianjun, M.; Cheng, W.; Bo, S. Improved algorithm of road detection based on Hough transform. J. Appl. Opt. 2016, 37, 229–234. [Google Scholar] [CrossRef]
- Yang, X.; Song, K. Algorithm of Document Image Segmentation Based on Projection Method. J. Chengdu Univ. Sci. Ed. 2009, 28, 139–141. (In Chinese) [Google Scholar]
- Pothuganti, S. Analysis on Solutions for Over-Fitting and Under-Fitting in Machine Learning Algorithms. Int. J. Innov. Res. Sci. Eng. Technol. 2018, 7, 12401–12404. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar] [CrossRef]
- Miller, G.N.; Anderson, R.L.; Rogers, S.C.; Lynnworth, L.C.; Studley, W.B.; Wade, W.R. High Temperature, High Pressure Water Level Sensor. In Proceedings of the Ultrasonics Symposium, Boston, MA, USA, 5–7 November 1980; pp. 877–881. [Google Scholar] [CrossRef]
- Reddy, S.; Rameshshabadkar; Reddy, Y.; Kumar, A.R. Sensor Based Spontaneous Water Level Recognition in Smart Cities Environment. Int. J. Civ. Eng. Technol. 2017, 8, 297–301. Available online: IJCIET_08_12_034.pdf(iaeme.com) (accessed on 12 April 2022).
- Kim, J. 16 Ch × 200 GHz DWDM-Passive Optical Fiber Sensor Network Based on a Power Measurement Method for Water-Level Monitoring of the Spent Fuel Pool in a Nuclear Power Plant. Sensors 2021, 21, 4055. [Google Scholar] [CrossRef]
- Shon, J.C. Water Level Sensor. Suwon-City, KR. January 2003. Available online: https://www.freepatentsonline.com/y2003/0010117.html (accessed on 12 April 2022).
- Chetpattananondh, K.; Tapoanoi, T.; Phukpattaranont, P.; Jindapetch, N. A Self-Calibration Water Level Measurement Using an Interdigital Capacitive Sensor. Sens. Actuators A Phys. 2014, 209, 175–182. [Google Scholar] [CrossRef]
- Boon, J.D.; Brubaker, J.M. Acoustic-microwave water level sensor comparisons in an estuarine environment. In Proceedings of the OCEANS 2008, Quebec City, QC, Canada, 15–18 September 2008; pp. 1–5. [Google Scholar] [CrossRef]
- Takagi, Y.; Tsujikawa, A.; Takato, M.; Saito, T.; Kaida, M. Development of a Noncontact Liquid Level Measuring System Using Image Processing. Water Sci. Technol. 1998, 37, 381–387. [Google Scholar] [CrossRef]
- Sun, T.; Zhang, C.; Li, L.; Tian, H.; Qian, B.; Wang, J. Research on Image Segmentation and Extraction Algorithm for Bicolor Water Level Gauge. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; IEEE: Guiyang, China, 2013; pp. 2779–2783. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | Param |
|---|---|---|
| sequential (Sequential) | (None, 28, 28, 3) | 0 |
| rescaling_1 (Rescaling) | (None, 28, 28, 3) | 0 |
| conv2d (Conv2D) | (None, 28, 28, 16) | 448 |
| max_pooling2d (MaxPooling2D) | (None, 14, 14, 16) | 0 |
| conv2d_1 (Conv2D) | (None, 14, 14, 32) | 4640 |
| max_pooling2d_1 (MaxPooling2D) | (None, 7, 7, 32) | 0 |
| conv2d_2 (Conv2D) | (None, 7, 7, 64) | 18,496 |
| max_pooling2d_2 (MaxPooling2D) | (None, 3, 3, 64) | 0 |
| dropout (Dropout) | (None, 3, 3, 64) | 0 |
| flatten (Flatten) | (None, 576) | 0 |
| dense (Dense) | (None, 10) | 73,856 |
| dense_1 (Dense) | (None, 10) | 1290 |
| Ruler No | Visual (m) | Template Matching | Intelligent Recognition | ||||
|---|---|---|---|---|---|---|---|
| Value (m) | Error | Time (s) | Value (m) | Error | Time (s) | ||
| 1 | 0.23 | 0.22 | 4.35% | 8.32 | 0.23 | 0.00% | 6.94 |
| 2 | 0.27 | 0.10 | 62.96% | 8.44 | 0.28 | 3.70% | 6.82 |
| 3 | 0.24 | 0.24 | 0.00% | 8.73 | 0.24 | 0.00% | 4.59 |
| 4 | 0.24 | 0.06 | 75.00% | 8.96 | 0.23 | 4.17% | 4.58 |
| 5 | 0.24 | 0.16 | 33.33% | 9.29 | 0.24 | 0.00% | 4.58 |
| 6 | 0.26 | 0.17 | 34.62% | 9.74 | 0.25 | 3.85% | 4.58 |
| 7 | 0.23 | 0.17 | 26.09% | 9.35 | 0.17 | 26.09% | 4.56 |
| 8 | 0.24 | 0.10 | 58.33% | 8.93 | 0.19 | 20.83% | 4.6 |
| 9 | 0.23 | 0.19 | 17.34% | 8.78 | 0.19 | 17.39% | 4.61 |
| 10 | 0.22 | 0.20 | 9.01% | 9.48 | 0.21 | 4.55% | 4.61 |
| 11 | 0.23 | 0.17 | 26.09% | 8.89 | 0.25 | 8.70% | 4.6 |
| 12 | 0.24 | 0.07 | 70.83% | 8.26 | 0.24 | 0.00% | 6.86 |
| 13 | 0.24 | 0.14 | 41.67% | 9.27 | 0.23 | 4.17% | 4.53 |
| 14 | 0.24 | 0.16 | 33.33% | 8.92 | 0.24 | 0.00% | 4.63 |
| 15 | 0.23 | 0.22 | 4.35% | 9.32 | 0.23 | 0.00% | 4.66 |
| 16 | 0.22 | 0.19 | 13.64% | 9.63 | 0.19 | 13.64% | 4.59 |
| 17 | 0.21 | 0.13 | 38.10% | 8.64 | 0.22 | 4.76% | 4.44 |
| 18 | 0.23 | 0.14 | 39.13% | 9.33 | 0.23 | 0.00% | 4.58 |
| 19 | 0.27 | 0.22 | 18.52% | 8.28 | 0.27 | 0.00% | 4.37 |
| 20 | 0.28 | 0.30 | 7.14% | 8.72 | 0.30 | 7.14% | 4.61 |
| 21 | 0.26 | 0.16 | 38.46% | 8.37 | 0.24 | 7.69% | 4.56 |
| 22 | 0.28 | 0.17 | 39.29% | 8.88 | 0.26 | 7.14% | 4.58 |
| 23 | 0.27 | 0.26 | 3.70% | 8.96 | 0.26 | 3.70% | 4.6 |
| 24 | 0.21 | 0.22 | 4.76% | 8.92 | 0.21 | 0.00% | 4.61 |
| 25 | 0.23 | 0.25 | 8.70% | 8.94 | 0.23 | 0.00% | 4.63 |
| 26 | 0.21 | 0.19 | 9.52% | 8.95 | 0.19 | 9.52% | 4.6 |
| 27 | 0.21 | 0.11 | 47.62% | 9.04 | 0.20 | 4.76% | 4.6 |
| 28 | 0.20 | 0.10 | 50.00% | 9.1 | 0.18 | 10.00% | 4.58 |
| 29 | 0.22 | 0.12 | 45.45% | 9.12 | 0.23 | 4.55% | 4.58 |
| 30 | 0.21 | 0.11 | 47.62% | 8.09 | 0.20 | 4.76% | 4.68 |
| 31 | 0.23 | 0.30 | 30.43% | 8.8 | 0.24 | 4.35% | 4.64 |
| 32 | 0.20 | 0.11 | 45.00% | 8.21 | 0.20 | 0.00% | 4.36 |
| 33 | 0.23 | 0.22 | 4.35% | 9.01 | 0.21 | 8.70% | 4.63 |
| 34 | 0.22 | 0.21 | 4.55% | 8.17 | 0.22 | 0.00% | 4.47 |
| 35 | 0.21 | 0.21 | 0.00% | 8.38 | 0.21 | 0.00% | 4.19 |
| 36 | 0.20 | 0.18 | 10.00% | 9.09 | 0.19 | 5.00% | 4.63 |
| 37 | 0.21 | 0.14 | 33.33% | 9.21 | 0.23 | 9.52% | 4.62 |
| 38 | 0.21 | 0.10 | 52.38% | 9 | 0.19 | 9.52% | 4.57 |
| 39 | 0.21 | 0.12 | 42.86% | 9.81 | 0.21 | 0.00% | 4.59 |
| 40 | 0.22 | 0.16 | 27.27% | 8.94 | 0.24 | 9.09% | 4.59 |
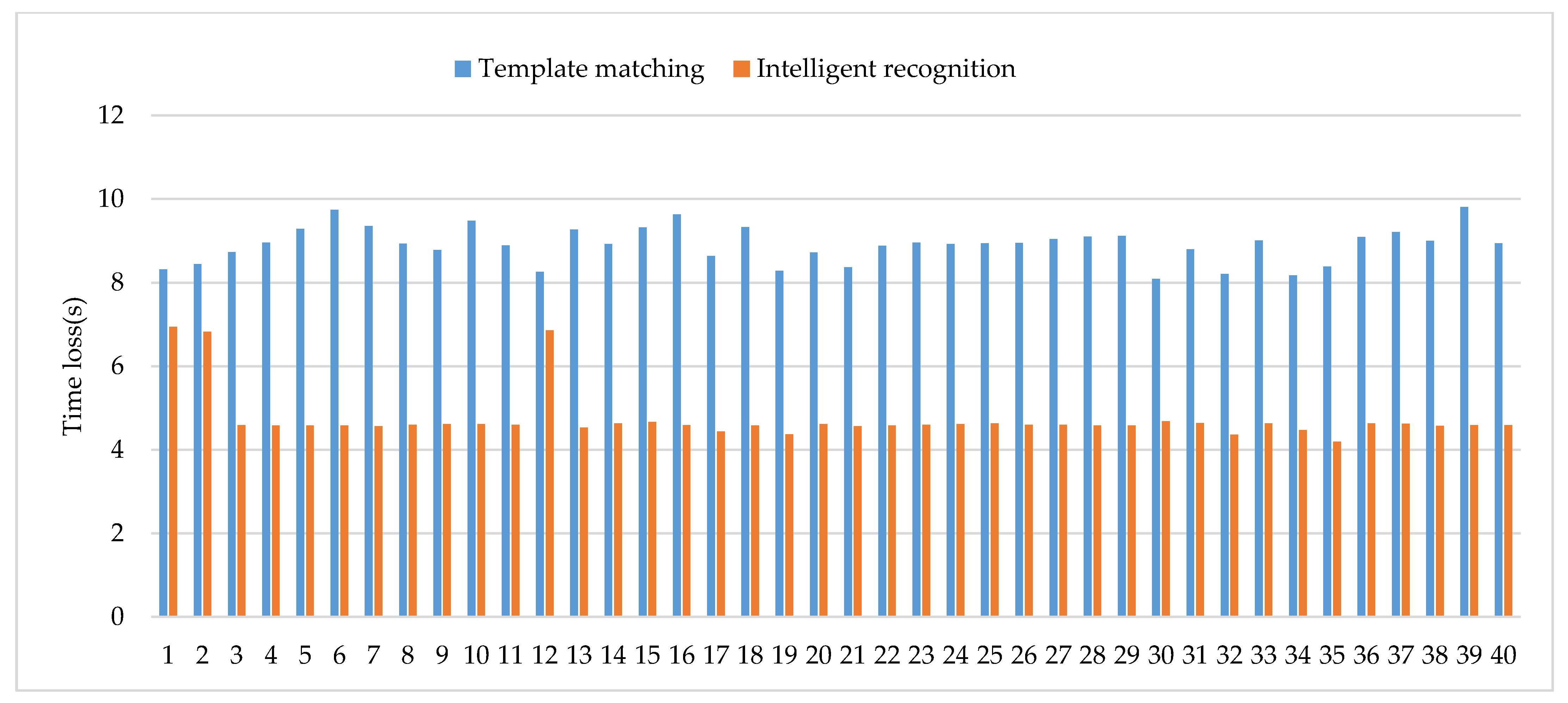
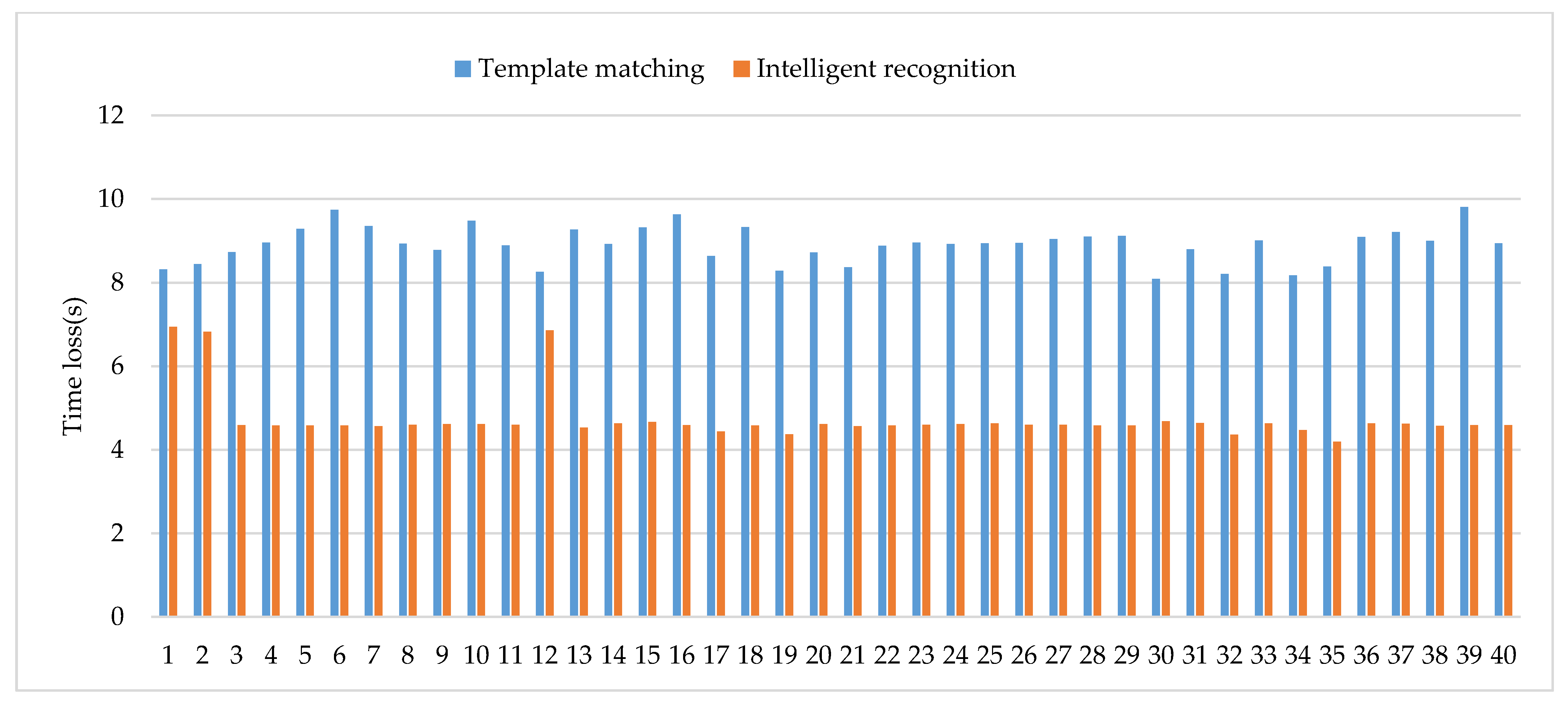
| Average | — | — | 28.98% | 8.91 | — | 5.43% | 4.74 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dou, G.; Chen, R.; Han, C.; Liu, Z.; Liu, J. Research on Water-Level Recognition Method Based on Image Processing and Convolutional Neural Networks. Water 2022, 14, 1890. https://doi.org/10.3390/w14121890
Dou G, Chen R, Han C, Liu Z, Liu J. Research on Water-Level Recognition Method Based on Image Processing and Convolutional Neural Networks. Water. 2022; 14(12):1890. https://doi.org/10.3390/w14121890
Chicago/Turabian StyleDou, Gang, Rensheng Chen, Chuntan Han, Zhangwen Liu, and Junfeng Liu. 2022. "Research on Water-Level Recognition Method Based on Image Processing and Convolutional Neural Networks" Water 14, no. 12: 1890. https://doi.org/10.3390/w14121890
APA StyleDou, G., Chen, R., Han, C., Liu, Z., & Liu, J. (2022). Research on Water-Level Recognition Method Based on Image Processing and Convolutional Neural Networks. Water, 14(12), 1890. https://doi.org/10.3390/w14121890