
FM-GRU: A Time Series Prediction Method for Water Quality Based on seq2seq Framework

 ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Statistics and Machine Learning Methods
2.2. Deep Learning Methods
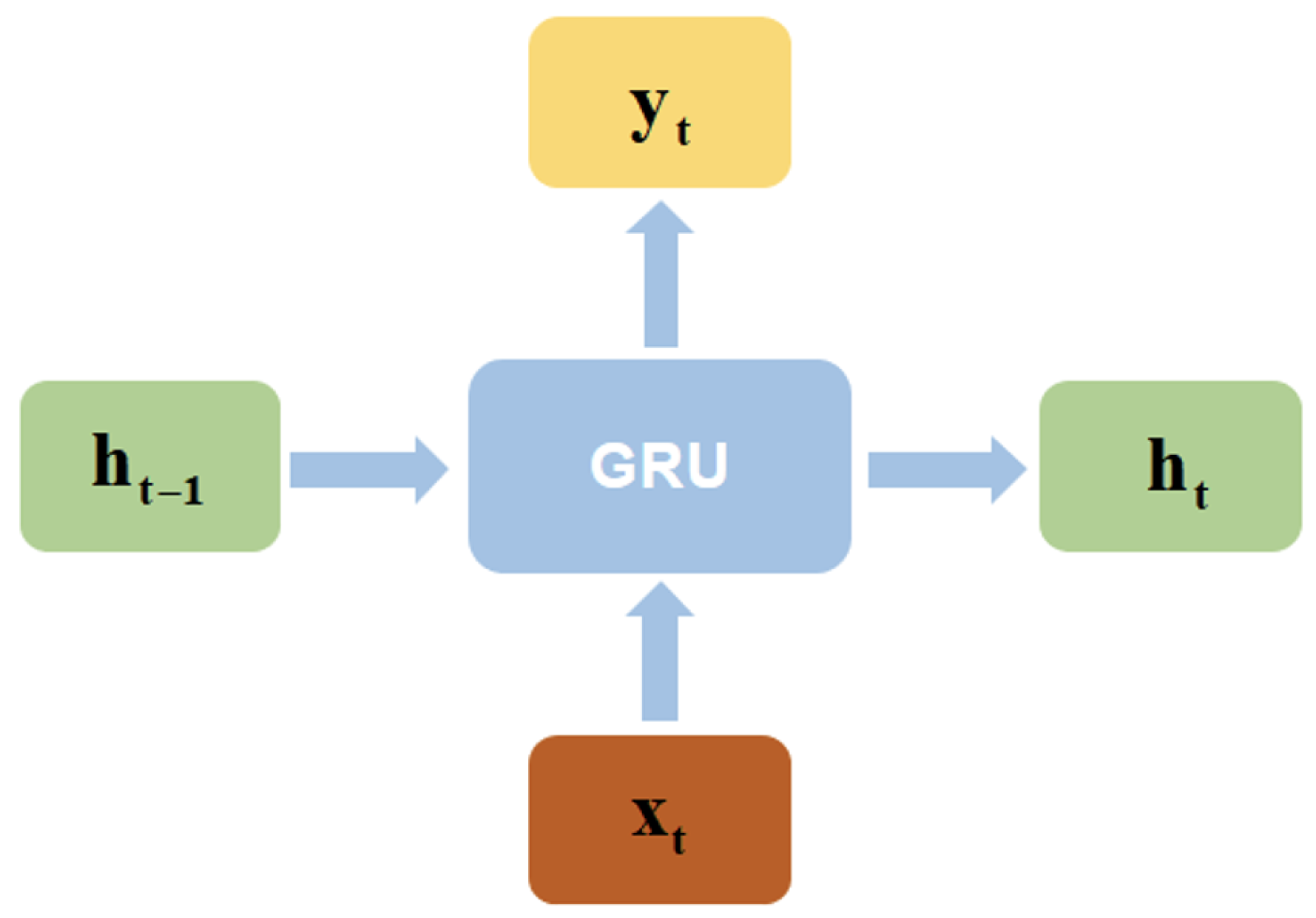
2.3. Preliminaries
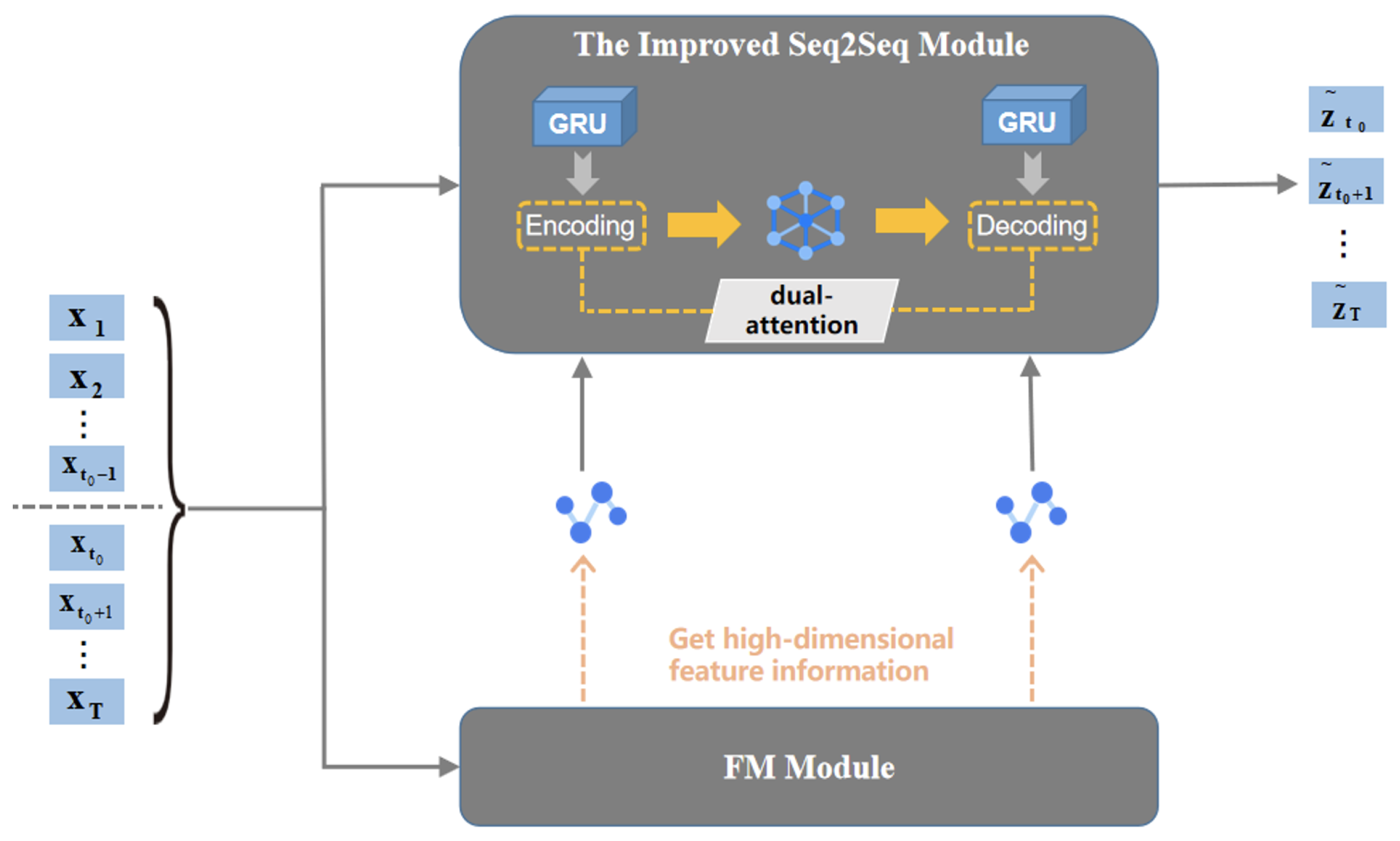
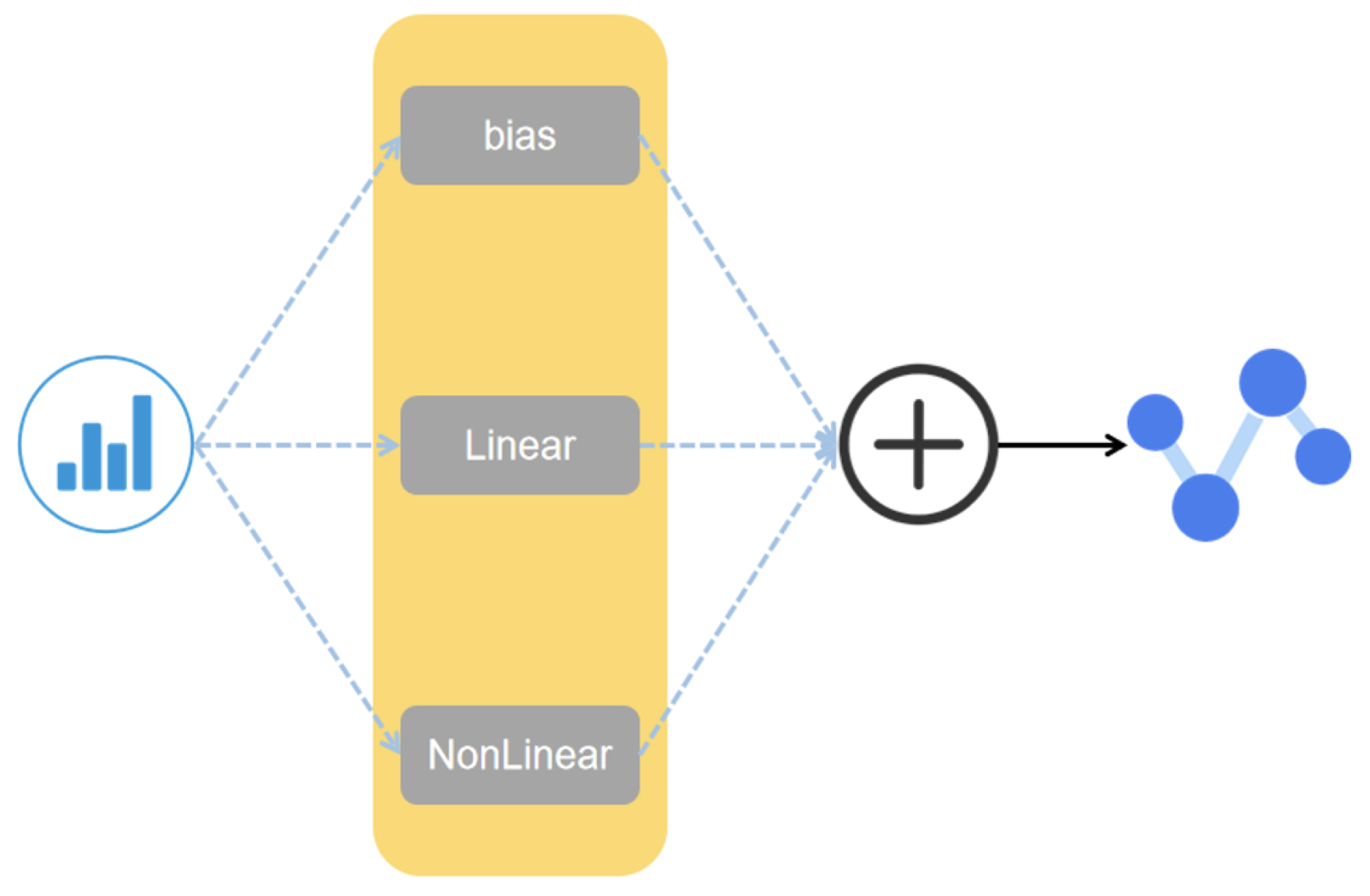
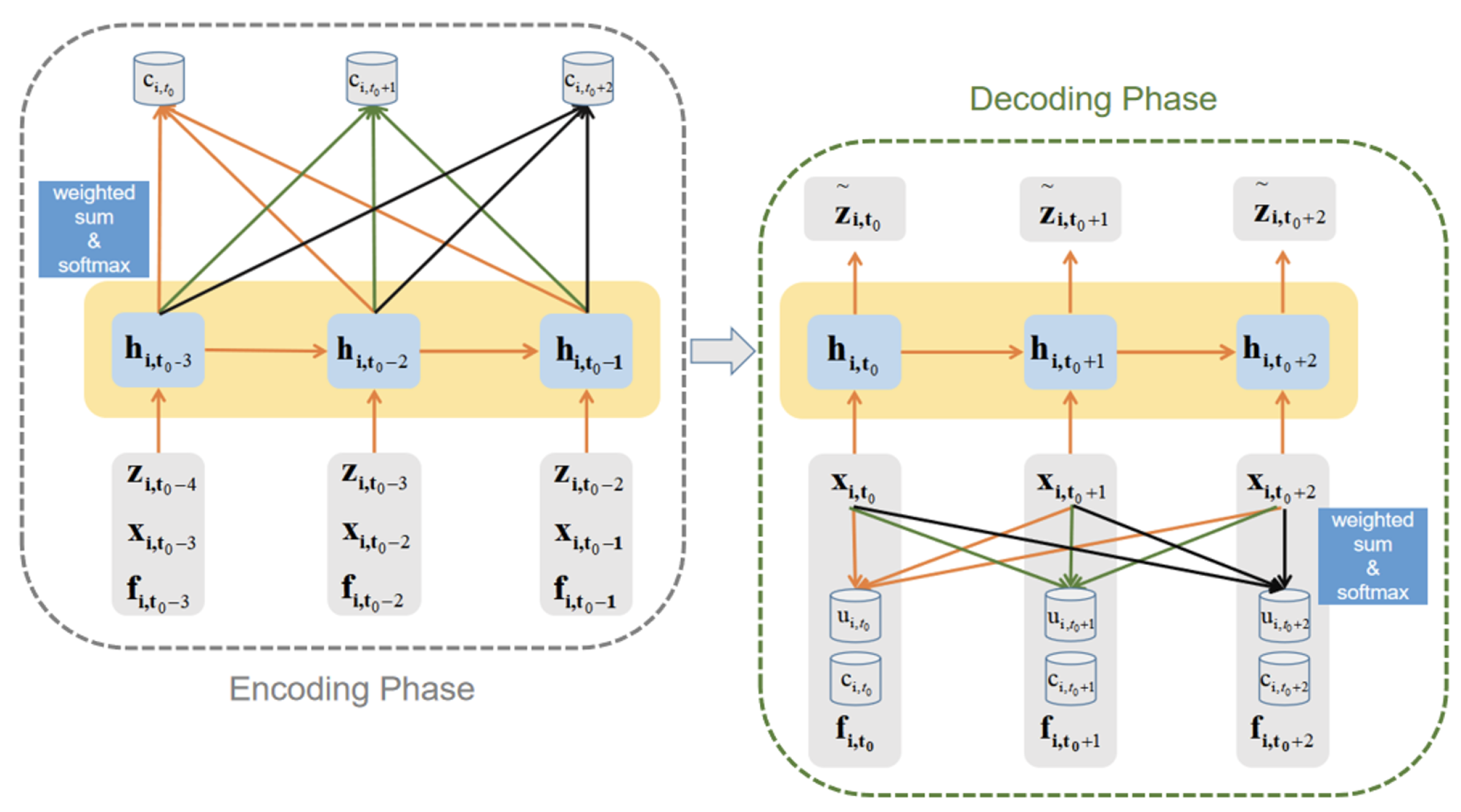
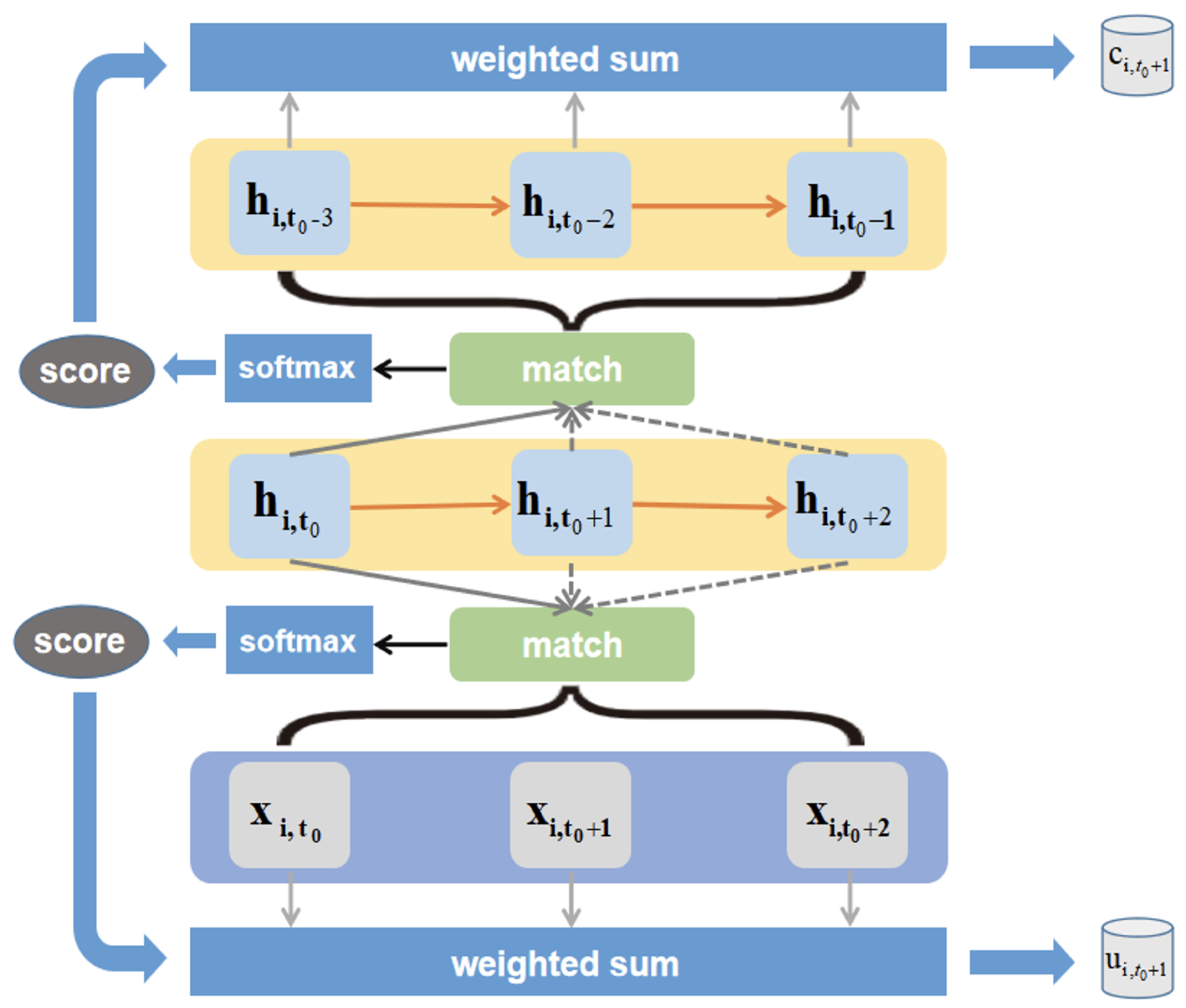
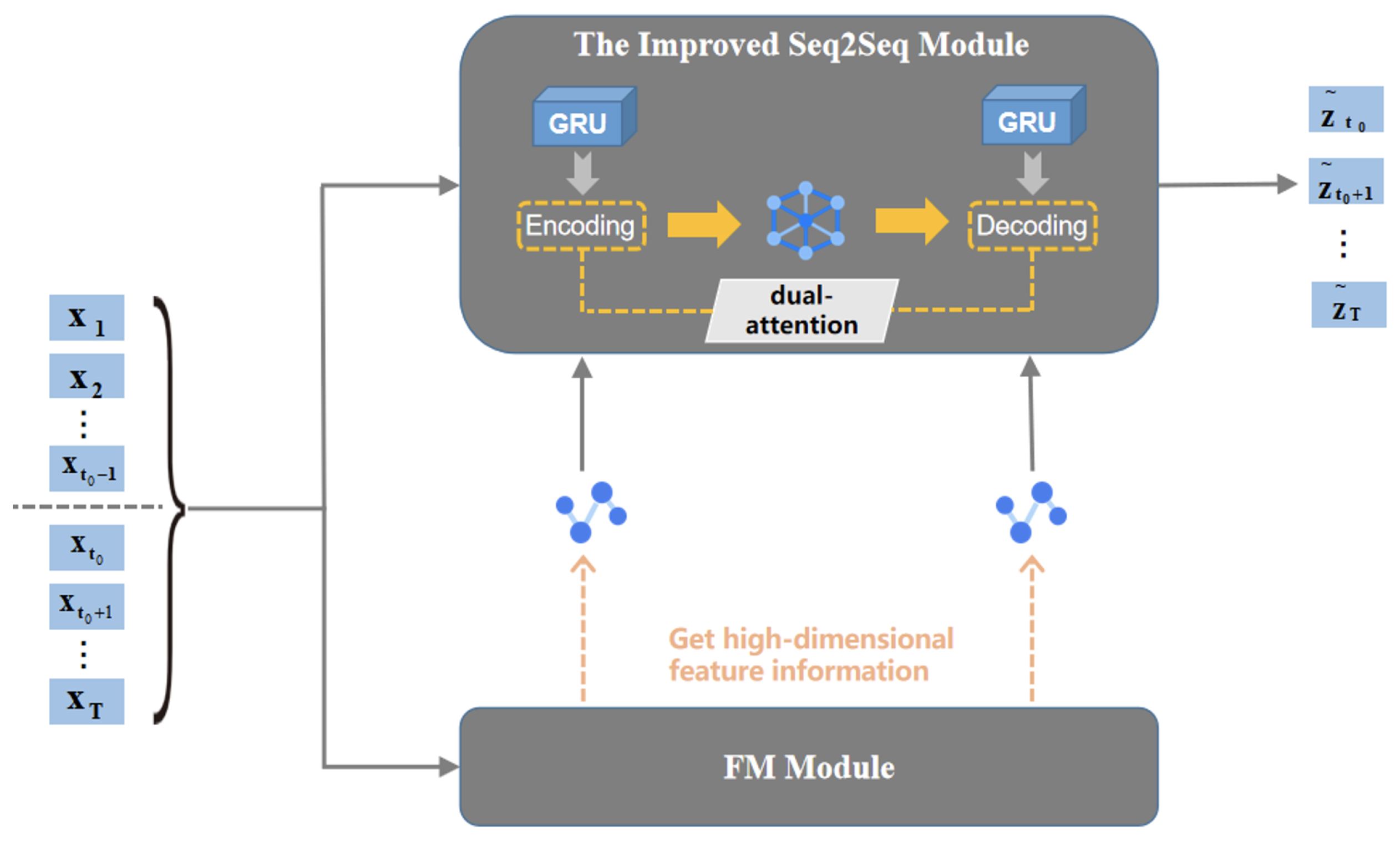
3. Model Framework
3.1. Overall Framework
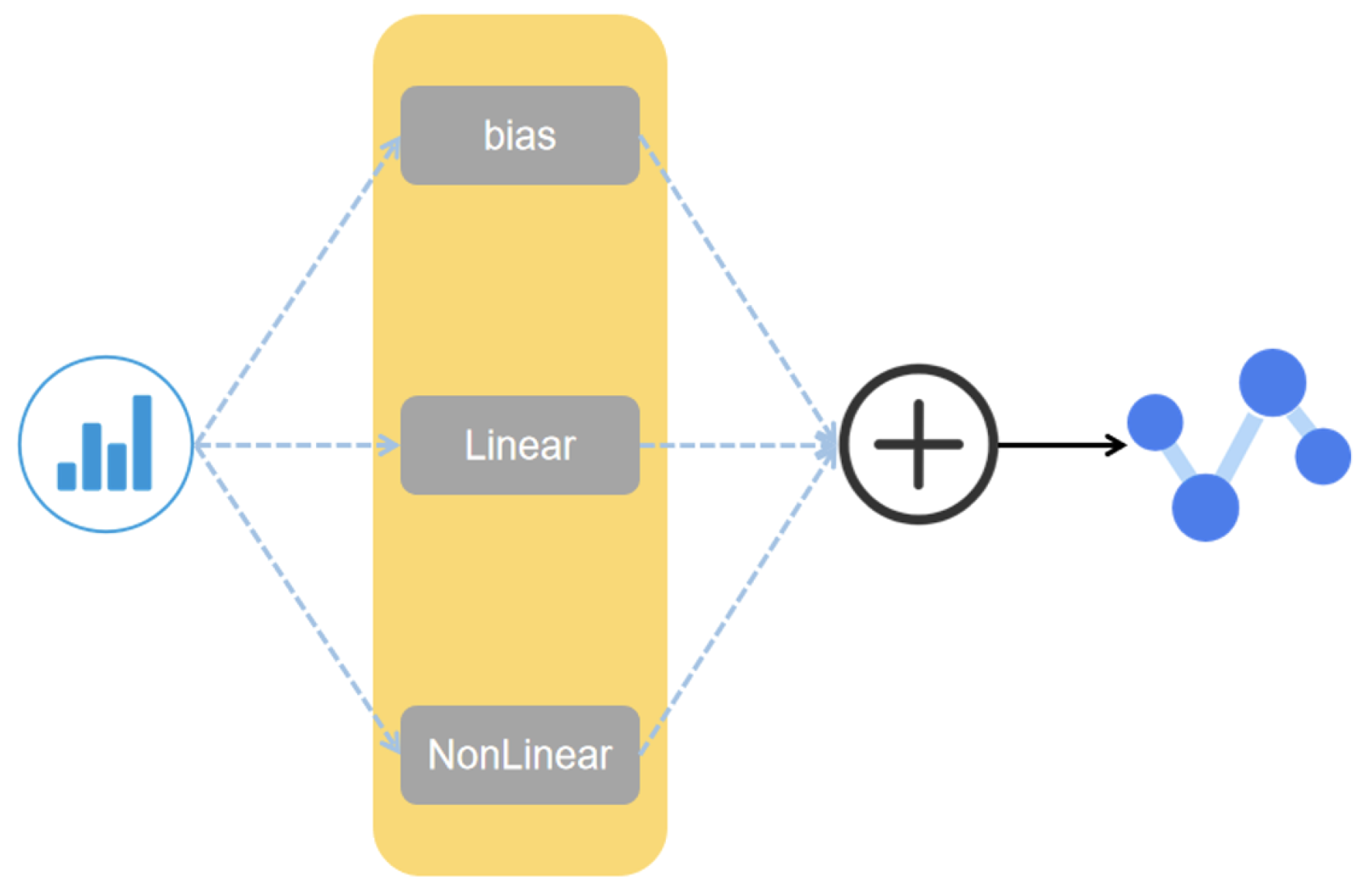
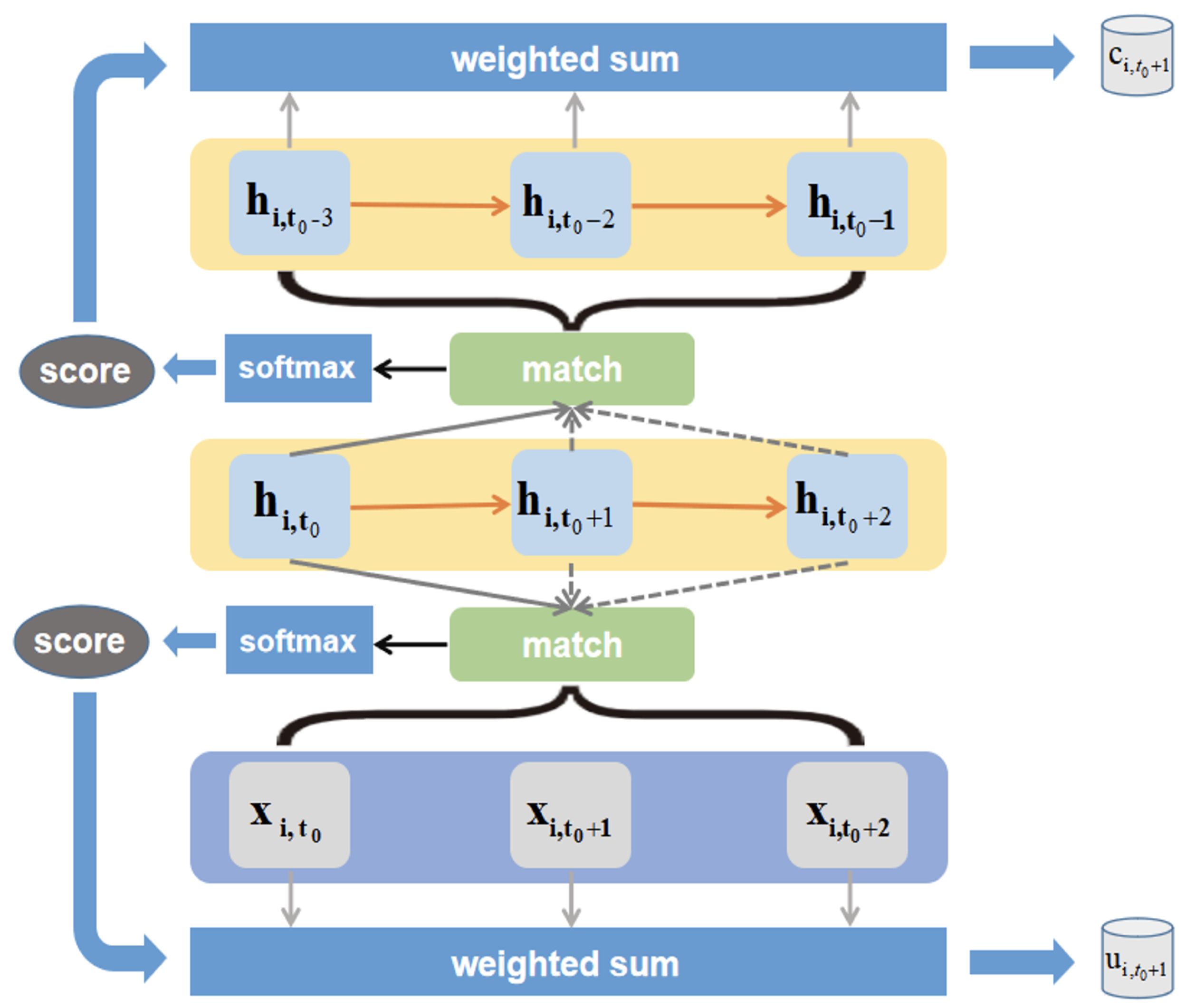
3.2. FM Module
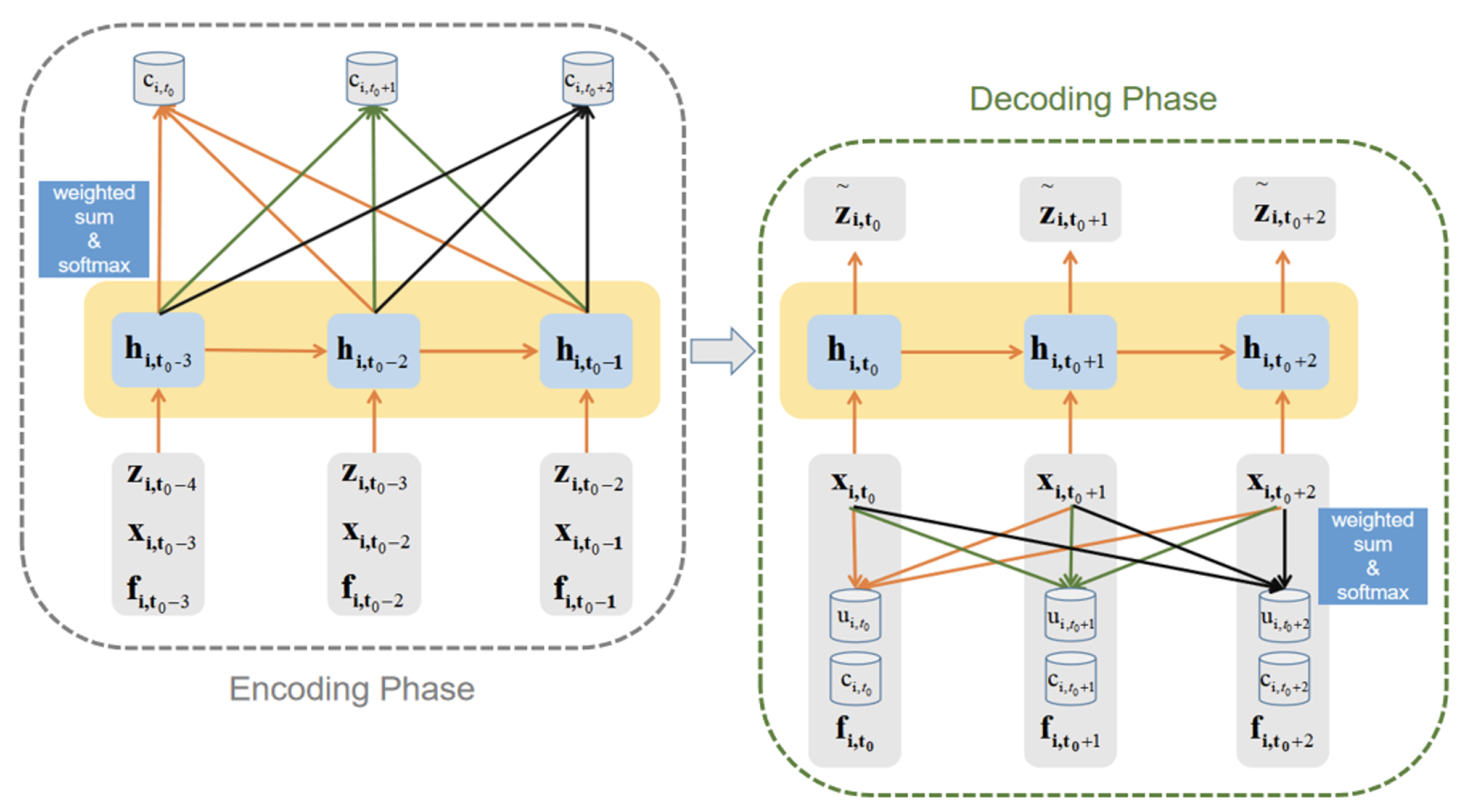
3.3. The Improved seq2seq Framework
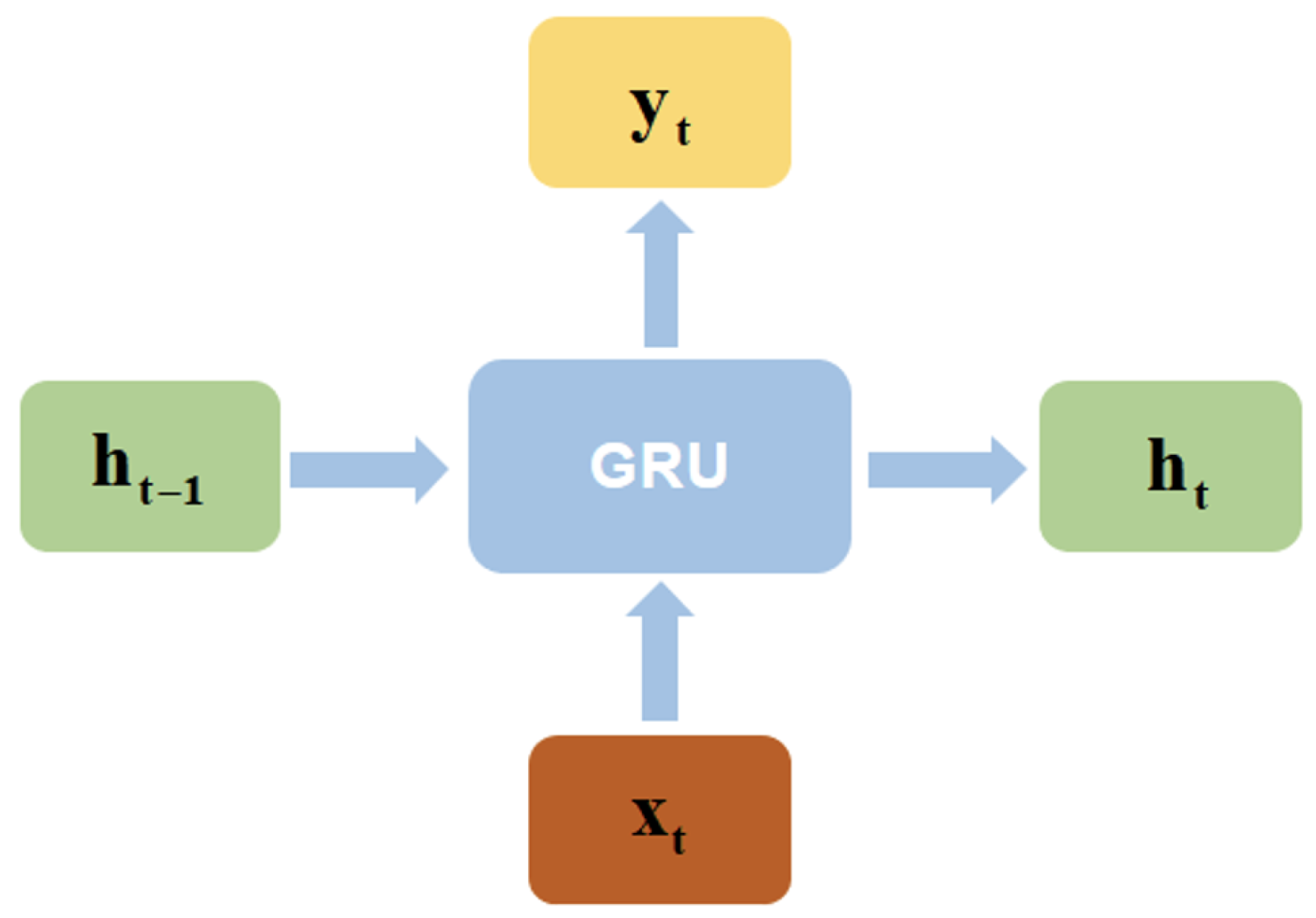
3.4. FM-GRU
| Algorithm 1 TSF using FM-GRU |
| Input: A multivariate time series R(N*T), encode_step, decode_step, K and all the other model parameters. Output:
|
4. Experiment
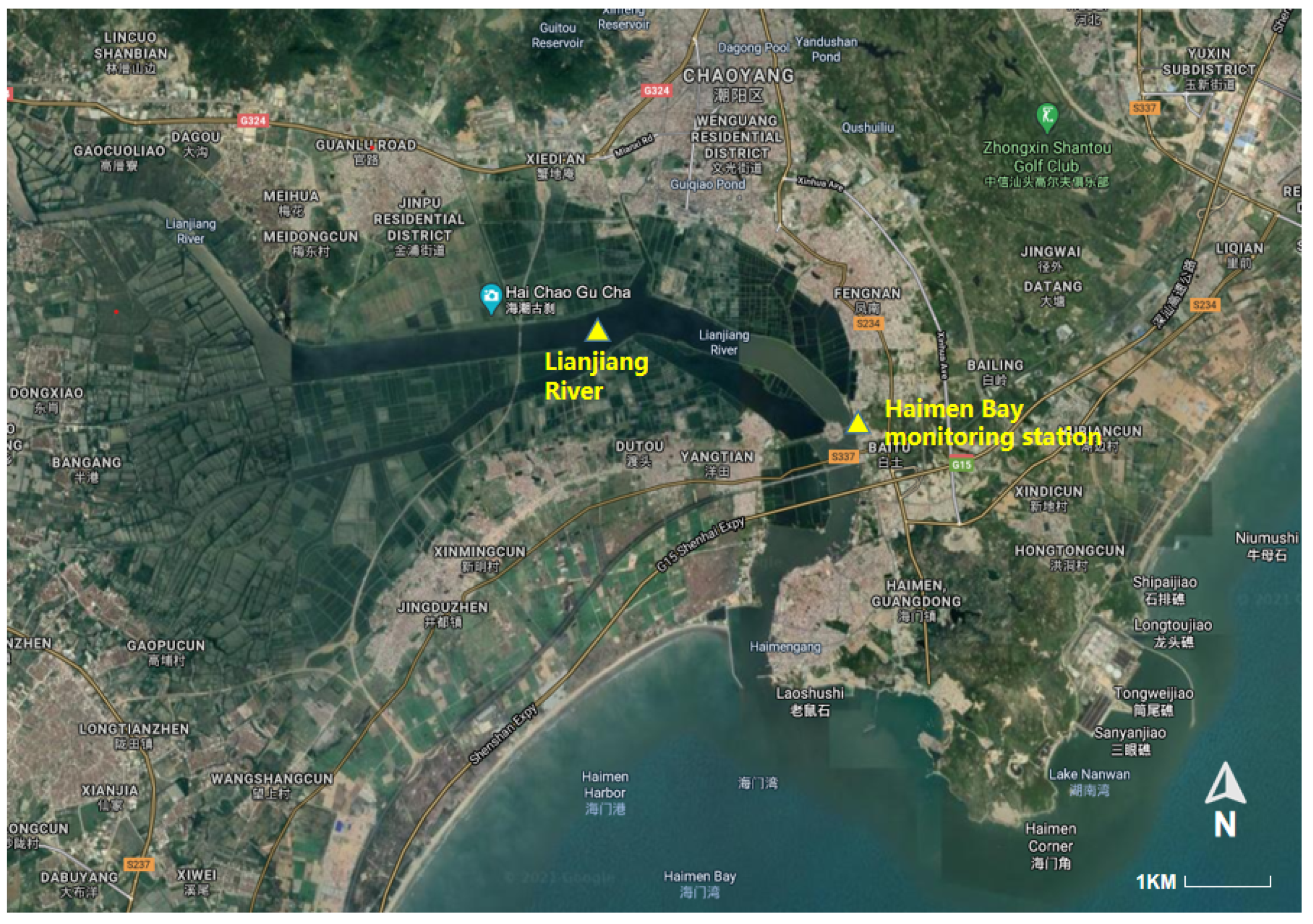
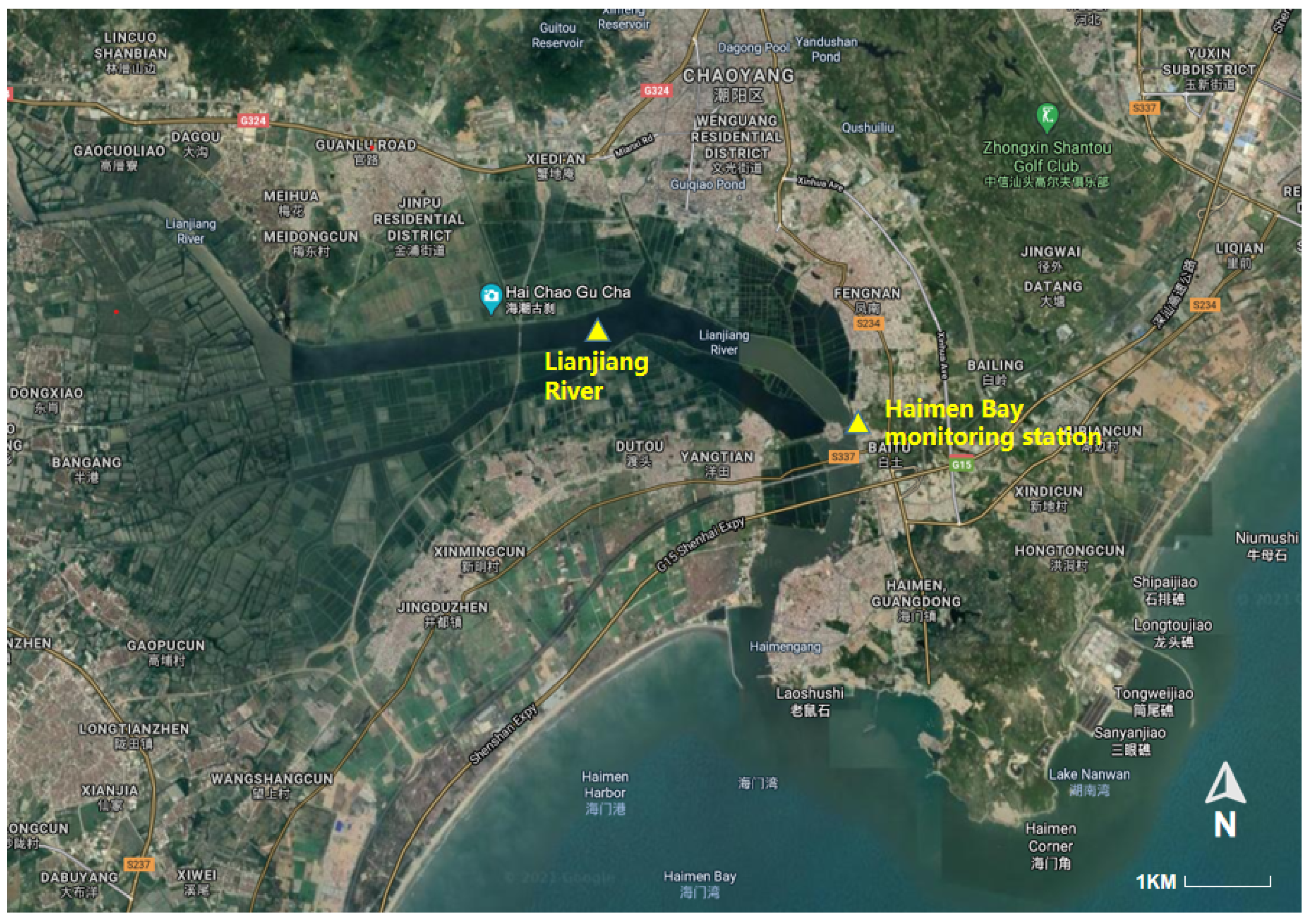
4.1. Dataset Description
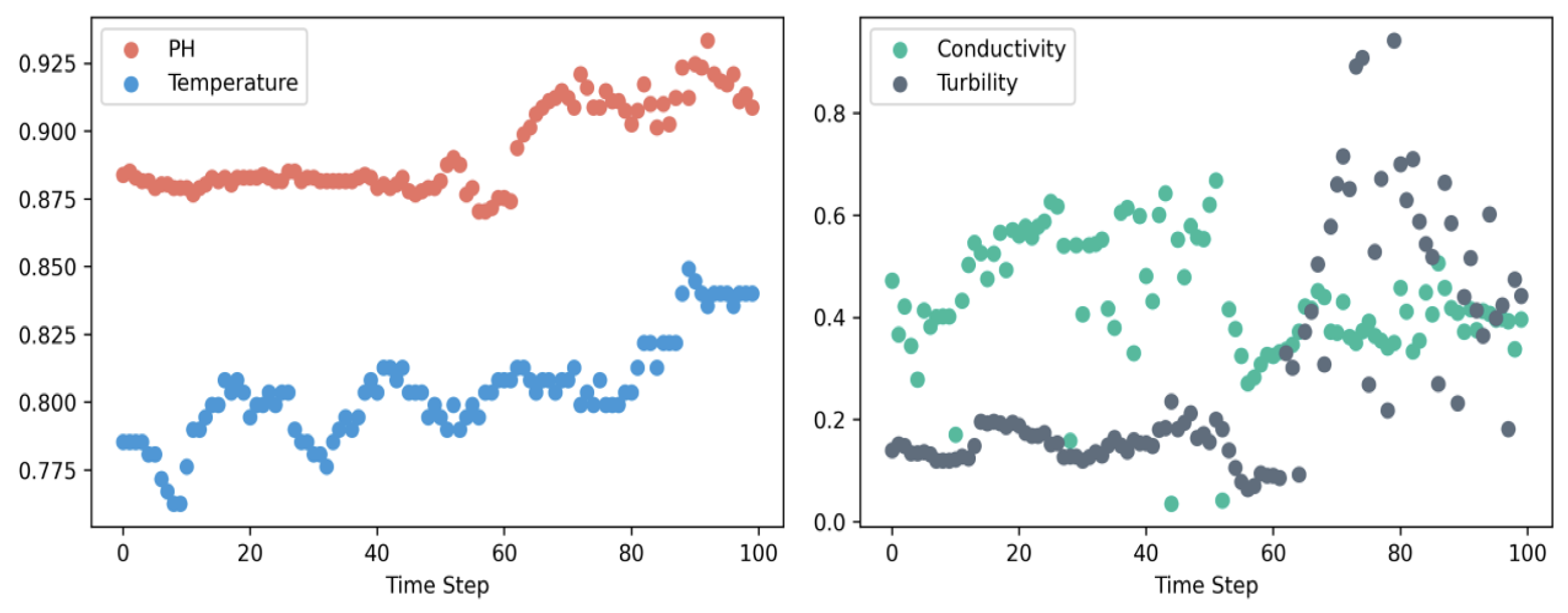
4.2. Data Preprocessing
4.3. Compared Methods and Evaluation Metrics
4.4. Experimental Settings
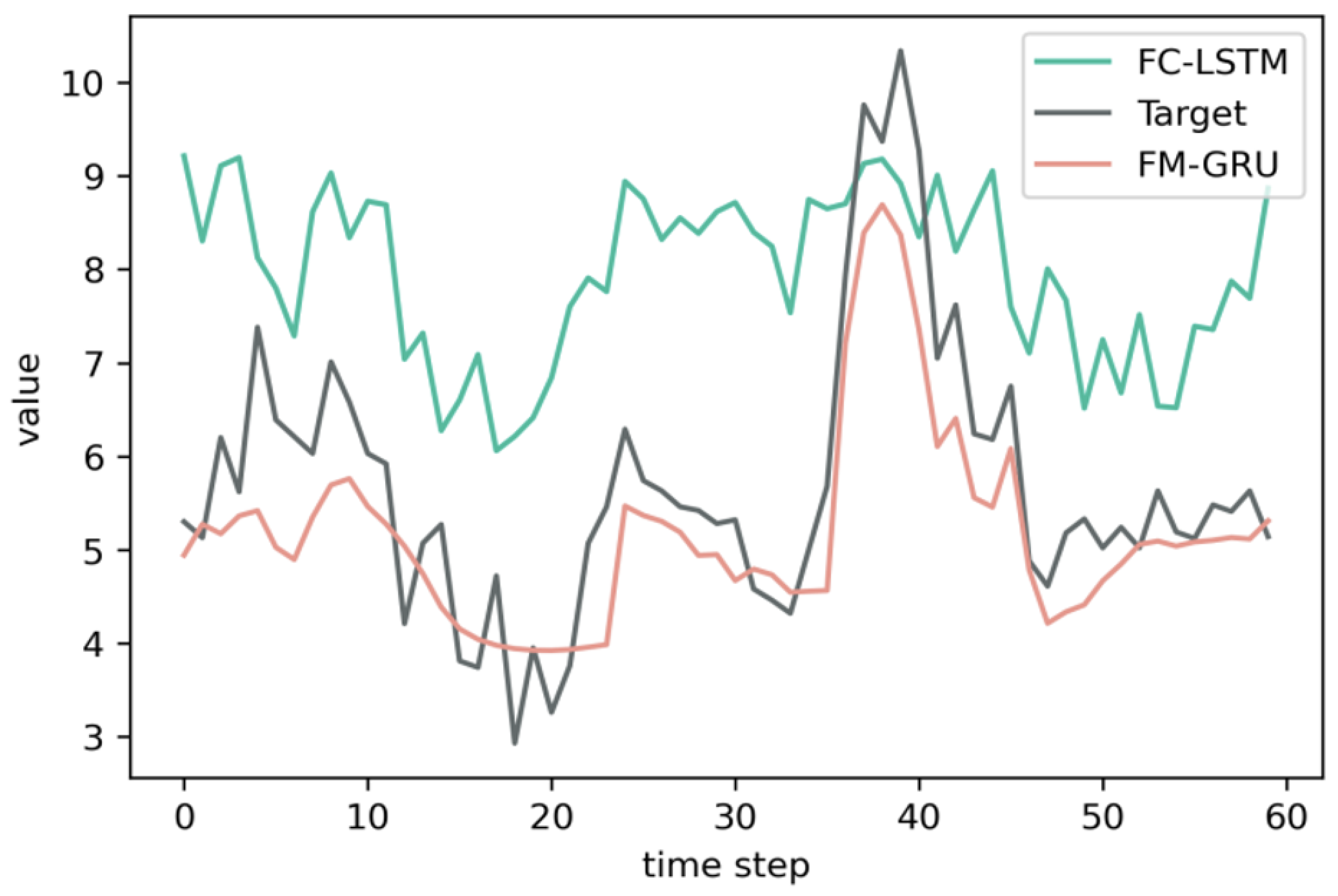
4.5. Experiment Results
4.6. Ablation Experiment
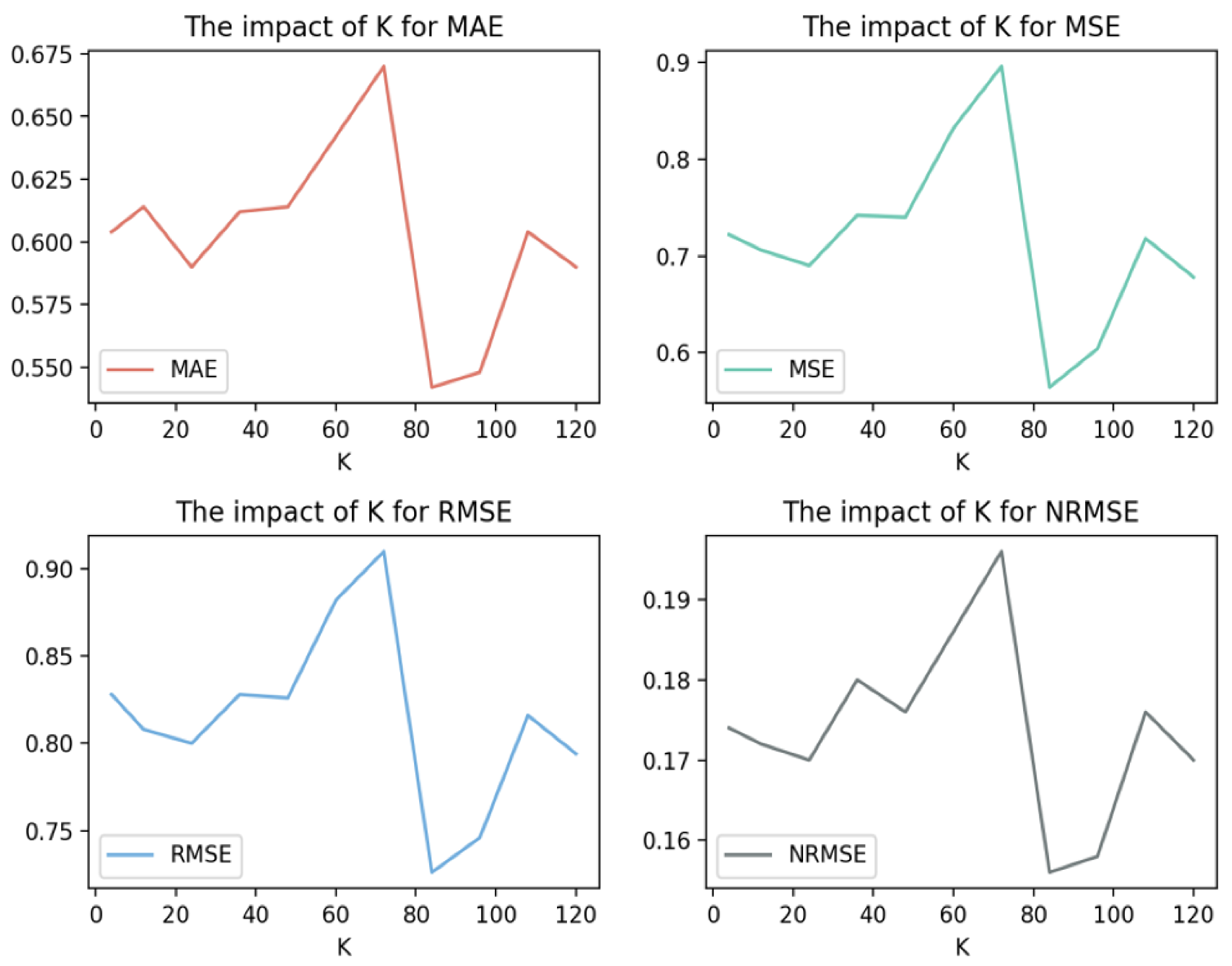
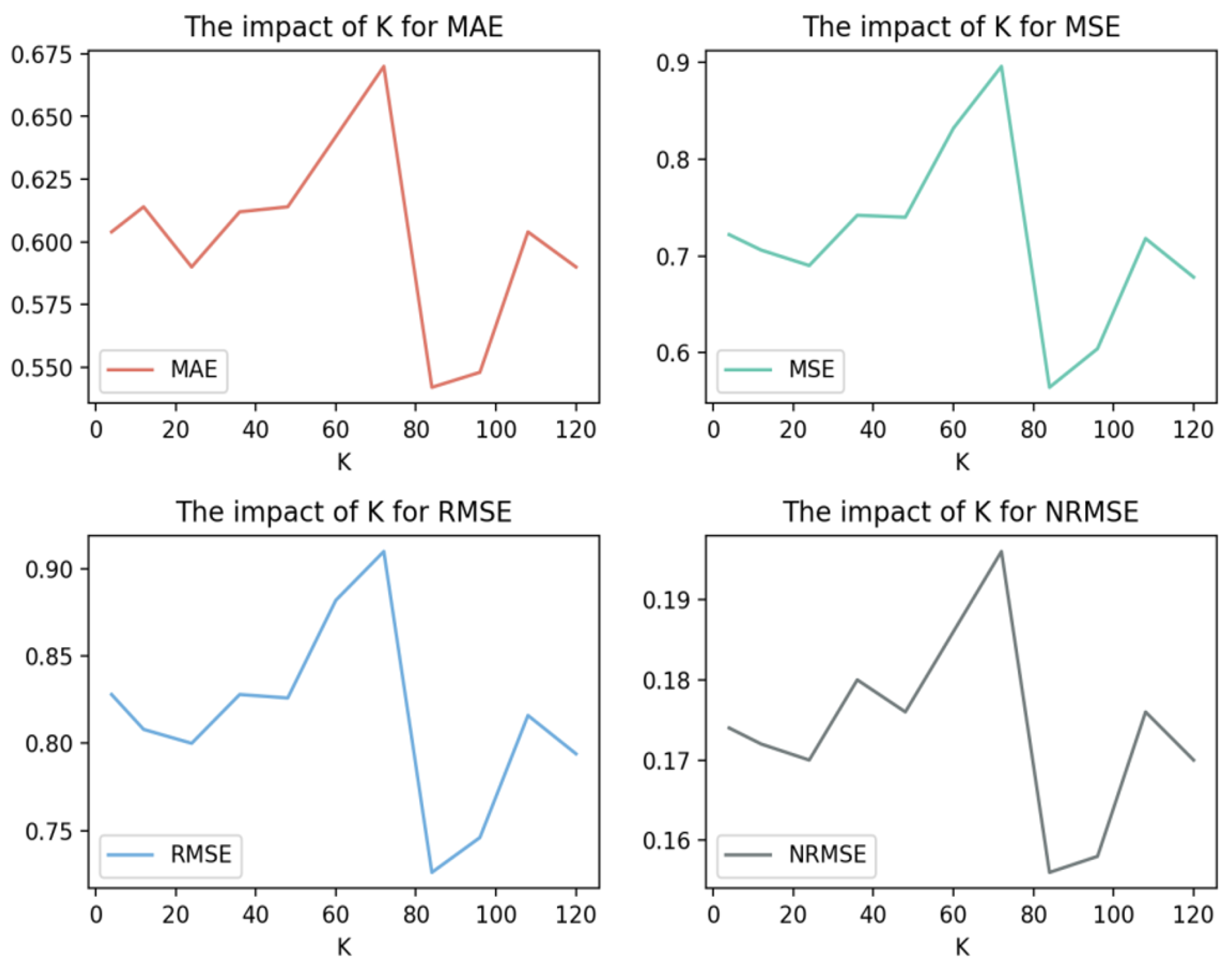
4.7. Impact of the Parameter K
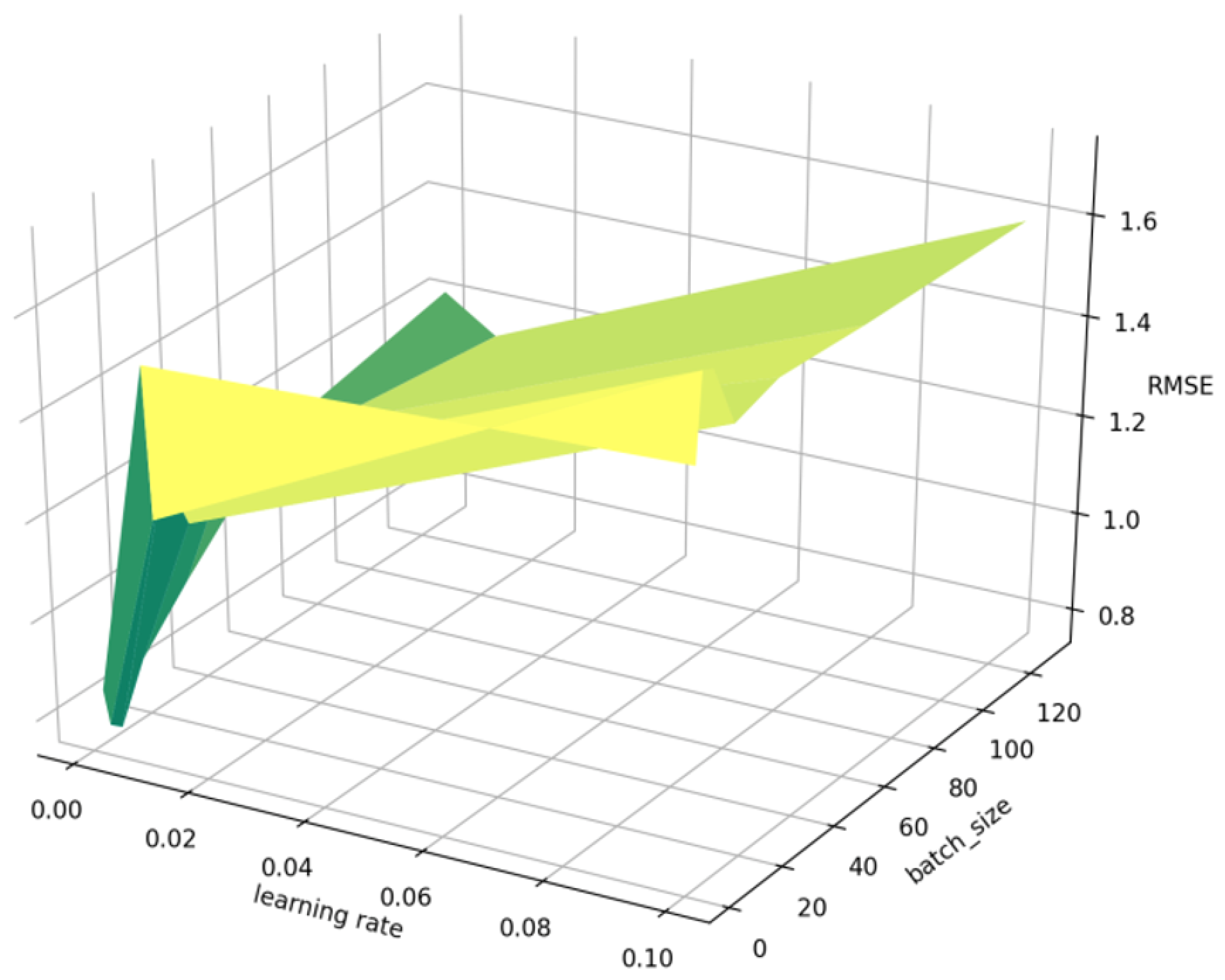
4.8. Impact of the Parameter Learning_Rate and Batch_Size
4.9. Experiments on the Generalization Ability of the Model
5. Discussion of Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Son, G.; Kim, D.; Kim, Y.D.; Lyu, S.; Kim, S. A Forecasting Method for Harmful Algal Bloom (HAB)-Prone Regions Allowing Preemptive Countermeasures Based Only on Acoustic Doppler Current Profiler Measurements in a Large River. Water 2020, 12, 3488. [Google Scholar] [CrossRef]
- Terêncio, D.P.S.; Cortes, R.M.V.; Pacheco, F.A.L.; Moura, J.P.; Fernandes, L.F.S. A Method for Estimating the Risk of Dam Reservoir Silting in Fire-Prone Watersheds: A Study in Douro River, Portugal. Water 2020, 12, 2959. [Google Scholar] [CrossRef]
- Chang, D.L.; Yang, S.H.; Hsieh, S.L.; Wang, H.J.; Yeh, K.C. Artificial Intelligence Methodologies Applied to Prompt Pluvial Flood Estimation and Prediction. Water 2020, 12, 3552. [Google Scholar] [CrossRef]
- Hosmer, D.W., Jr.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression; John Wiley Sons: Hoboken, NJ, USA, 2013; Volume 398. [Google Scholar]
- Jaynes, E.T. On the rationale of maximum-entropy methods. Proc. IEEE 1982, 70, 939–952. [Google Scholar] [CrossRef]
- Cardoso, C.A.V.; Cruz, G.L. Forecasting natural gas consumption using ARIMA models and artificial neural networks. IEEE Lat. Am. Trans. 2016, 14, 2233–2238. [Google Scholar] [CrossRef]
- Tianliang, L.; Liming, H.; Haipeng, L. Prediction and analysis of chaotic time series on the basis of support vector. J. Syst. Eng. Electron. 2008, 19, 806–811. [Google Scholar] [CrossRef]
- Behzad, M.; Asghari, K.; Eazi, M.; Palhang, M. Generalization performance of support vector machines and neural networks in runoff modeling. Expert Syst. Appl. 2009, 36, 7624–7629. [Google Scholar] [CrossRef]
- Shiri, J.; Shamshirband, S.; Kisi, O.; Karimi, S.; Bateni, S.M.; Nezhad, S.H.H.; Hashemi, A. Prediction of water-level in the Urmia Lake using the extreme learning machine approach. Water Resour. Manag. 2016, 30, 5217–5229. [Google Scholar] [CrossRef]
- Yang, J.H.; Cheng, C.H.; Chan, C.P. A Time-Series Water Level Forecasting Model Based on Imputation and Variable Selection Method. Comput. Intell. Neurosci. 2017, 8734214. [Google Scholar] [CrossRef] [Green Version]
- Guo, T.; He, W.; Jiang, Z.; Chu, X.; Malekian, R.; Li, Z. An improved LSSVM model for intelligent prediction of the daily water level. Energies 2019, 12, 112. [Google Scholar] [CrossRef] [Green Version]
- Xiao, Q.; Si, Y. Time series prediction using graph model. In Proceedings of the 3rd IEEE International Conference on Computer and Communications (ICCC), Chengdu, China, 10–13 December 2017; pp. 1358–1361. [Google Scholar]
- Winata, G.I.; Kampman, O.P.; Fung, P. Attention-based lstm for psychological stress detection from spoken language using distant supervision. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6204–6208. [Google Scholar]
- Ye, Q.; Yang, X.; Chen, C.; Wang, J. River Water Quality Parameters Prediction Method Based on LSTM-RNN Model. In Proceedings of the 2019 Chinese Control In addition, Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 3024–3028. [Google Scholar]
- Dong, Q.; Lin, Y.; Bi, J.; Yuan, H. An Integrated Deep Neural Network Approach for Large-Scale Water Quality Time Series Prediction. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3537–3542. [Google Scholar]
- Tang, G.; Wu, Y.; Li, C.; Wong, P.K.; Xiao, Z.; An, X. A Novel Wind Speed Interval Prediction based on Error Prediction Method. IEEE Trans. Ind. Inform. 2020, 16, 6806–6815. [Google Scholar] [CrossRef]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-term water quality variable prediction using a hybrid CNN–LSTM deep learning model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Pan, M.; Zhou, H.; Cao, J.; Liu, Y.; Hao, J.; Li, S.; Chen, C.H. Water Level Prediction Model Based on GRU and CNN. IEEE Access 2020, 8, 60090–60100. [Google Scholar] [CrossRef]
- Baek, S.S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- Wang, R.; Peng, C.; Gao, J.; Gao, Z.; Jiang, H. A dilated convolution network-based LSTM model for multi-step prediction of chaotic time series. Comput. Appl. Math. 2020, 39, 30. [Google Scholar] [CrossRef]
- Kutner, M.H.; Nachtsheim, C.J.; Neter, J. Applied linear regression model. Technometrics 2004, 26, 415–416. [Google Scholar]
- Turner, C.R.; Fuggetta, A.; Lavazza, L.; Wolf, A.L. A conceptual basis for feature engineering. J. Syst. Softw. 1999, 49, 3–35. [Google Scholar] [CrossRef]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; Volume 49, pp. 995–1000. [Google Scholar]
- Lyu, Z.; Dong, Y.; Huo, C.; Ren, W. Deep Match to Rank Model for Personalized Click-Through Rate Prediction. AAAI Conf. Artif. Intell. 2020, 34, 156–163. [Google Scholar] [CrossRef]
- Qin, J.; Zhang, W.; Wu, X.; Jin, J.; Fang, Y.; Yu, Y. User Behavior Retrieval for Click-Through Rate Prediction. arXiv 2020, arXiv:2005.14171. [Google Scholar]
- Xu, J.; Zheng, Z.; Lyu, M.R. Web service personalized quality of service prediction via reputation-based matrix factorization. IEEE Trans. Reliab. 2015, 65, 28–37. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley Sons: Hoboken, NJ, USA, 2012; Volume 821. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Temperature | PH | Conductivity | Turbidity | Dissolved Oxygen |
|---|---|---|---|---|---|
| Magnitude | C | ∖ | S/cm | NTU | mg/L |
| MAX | 21.90 | 8.10 | 5360 | 500 | 10.68 |
| MIN | 16.70 | 7.05 | 141 | 1 | 1.25 |
| Mean | 18.8 | 7.43 | 2918 | 76 | 4.72 |
| Median | 18.90 | 7.44 | 2930 | 55 | 4.69 |
| Mode | 19.60 | 7.33 | 2152 | 36 | 5.48 |
| SD | 0.88 | 0.20 | 875 | 76 | 1.59 |
| Model/Metrics | MAE | MSE | RMSE | NRMSE |
|---|---|---|---|---|
| HA | 4.36 | 21.4 | 4.62 | 0.97 |
| Arima | 1.88 | 6.29 | 2.51 | 2.62 |
| LR | 1.85 | 4.58 | 2.14 | 0.66 |
| XGBoost | 1.2 | 2.26 | 1.50 | 0.39 |
| FFNN | 2.28 | 6.52 | 2.55 | 0.79 |
| FC-LSTM | 1.73 | 3.85 | 1.96 | 0.48 |
| FC-GRU | 1.75 | 3.91 | 1.98 | 0.50 |
| FM-GRU | 0.57 | 0.64 | 0.77 | 0.16 |
| Model/Metrics | MAE | MSE | RMSE | NRMSE |
|---|---|---|---|---|
| Baseline Model | 0.65 | 0.83 | 0.88 | 0.19 |
| FM-GRU | 0.57 | 0.64 | 0.77 | 0.16 |
| Model | NRMSE () |
|---|---|
| HA | 5.7 |
| Arima | 4.9 |
| LR | 2.0 |
| XGBoost | 0.7 |
| FFNN | 3.2 |
| FC-LSTM | 3.1 |
| FC-GRU | 3.0 |
| FM-GRU | 0.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Wang, K.; Lin, C.; Xiao, L.; Huang, X.; Zhang, Y. FM-GRU: A Time Series Prediction Method for Water Quality Based on seq2seq Framework. Water 2021, 13, 1031. https://doi.org/10.3390/w13081031
Xu J, Wang K, Lin C, Xiao L, Huang X, Zhang Y. FM-GRU: A Time Series Prediction Method for Water Quality Based on seq2seq Framework. Water. 2021; 13(8):1031. https://doi.org/10.3390/w13081031
Chicago/Turabian StyleXu, Jianlong, Kun Wang, Che Lin, Lianghong Xiao, Xingshan Huang, and Yufeng Zhang. 2021. "FM-GRU: A Time Series Prediction Method for Water Quality Based on seq2seq Framework" Water 13, no. 8: 1031. https://doi.org/10.3390/w13081031