1. Introduction
The predominant role of several nonstationary and nonlinear variables in transformation of rainfall into runoff makes it difficult to comprehend [
1]. Moreover, the spatiotemporal variability in rainfall intensity and uniformity adds to the complexity of modelling basin response to catchment precipitation [
2]. However, the direct involvement of rainfall in runoff generation and runoff in streams, rivers, and even floods, makes it one of the most focused hydrological phenomena. The natural disasters such as fluvial and pluvial floods and hydrological droughts are also determined by the rainfall–runoff relationship of any basin [
3]. Therefore, precise and accurate rainfall–runoff modelling is important for effective management of water resources and prediction and prevention of natural calamities. The relationship between rainfall and runoff is also empirically expressed in the mass balance equation [
4]. From the equation it can be observed that both rainfall/precipitation (
P) and runoff (
R) play a decisive role in storage change (
dS), while infiltration (
I) and evaporation losses (
E) are also to be considered for an accurate estimation of change in water storage.
Owing to the direct participation of rainfall in the generation of runoff, hydrologists and researchers worldwide have been trying to understand the exact relationship between the two hydrological variables. Rainfall–runoff modelling has been the prime focus of hydrology research for a long time. It has brought the research area to an advanced phase of maturity and diversity in context of mathematical and methodological background [
5]. However, the remaining discrepancy in rainfall–runoff relation and the emergence of machine learning is promising. These computational techniques either reduce the parametric requirement or enhance modelling accuracy, or even serve both purposes [
6]. The rational method of runoff estimation by Mulvaney [
7] is often rated as the first attempt of rainfall–runoff modelling [
6]. However, significant advances in different conceptual and physical models were introduced in the field of hydrology. The mean annual method [
8], unit hydrographs [
9] and instantaneous unit hydrographs [
10], Stanford Watershed Model (SWM) [
11], and Huggins–Monke model [
12] are some of the significant names.
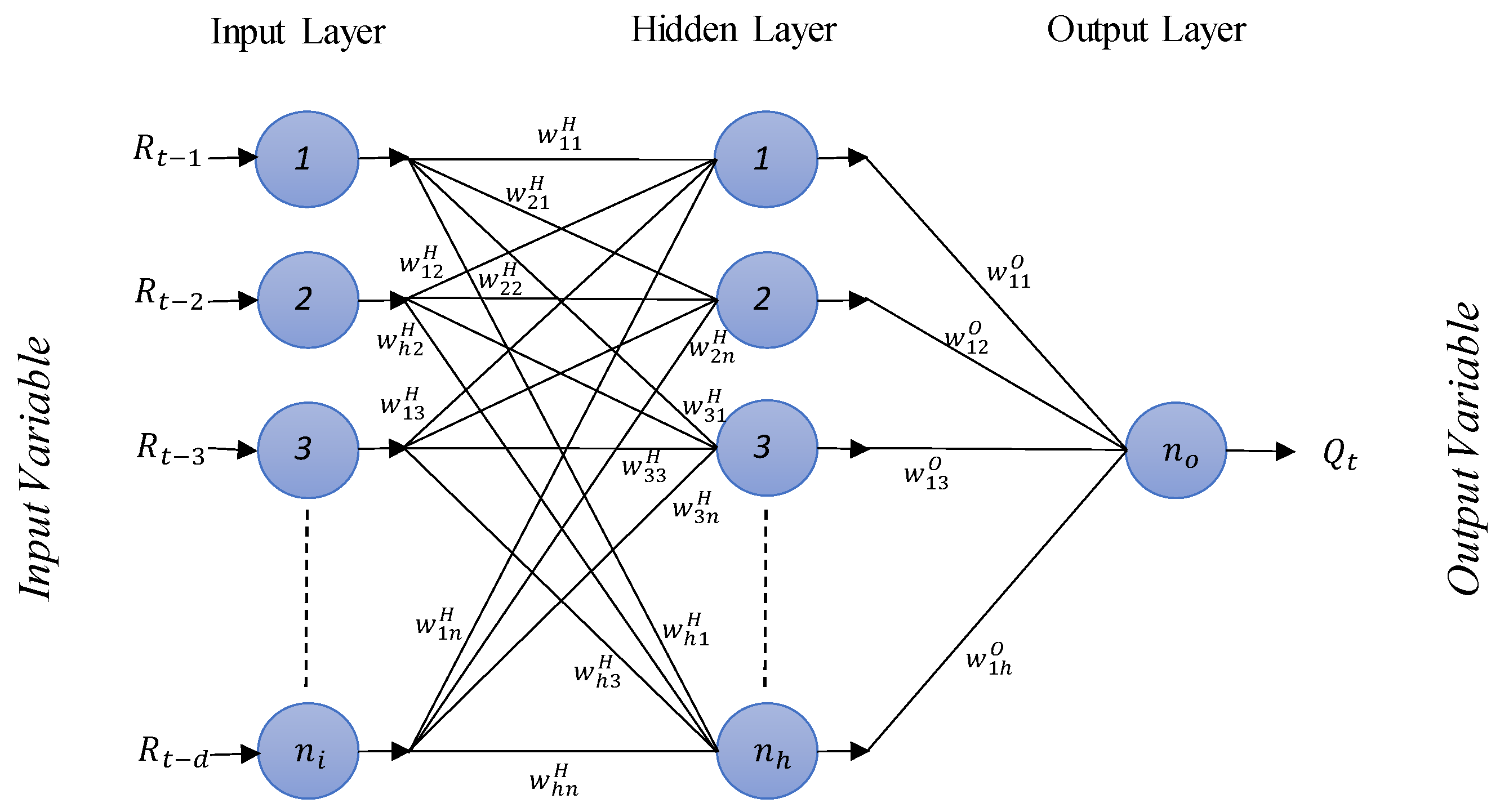
The initial application of machine learning in rainfall–runoff modelling [
13] and rainfall forecasting [
14] set modelling in hydrology to a whole new direction. Artificial neural networks (ANN) gained massive popularity in rainfall–runoff modelling [
2,
15,
16,
17,
18,
19,
20,
21,
22] and rainfall forecasting [
23,
24,
25,
26,
27,
28,
29]. Other techniques of machine learning, such as gene expression programming (GEP), single decision tree (SDT), decision tree forest (DTF) and tree boost (TB), were also extensively used by researchers [
30,
31,
32].
Earlier studies compared machine learning techniques with conventional conceptual or physical-based models while the recent studies probed deeper into machine learning models for better results. For example, Shoaib et. al [
21] compared the performance of wavelet-based multilayer perceptron neural networks (MLPNN) and radial basis function neural networks (RBFNN) in rainfall–runoff modelling of the Brosna River basin. The authors suggested that data pre-processing with wavelet transformation significantly enhanced modelling efficiency of both techniques. Similarly, Asadi et. al [
15] pre-processed ANN inputs using a standardization process and enhanced the performance of simple ANN models in the Haughton and Calliope river basins. Kumar et. al [
17] contrasted the performance of emotional neural networks (ENN) and typical ANN models in rainfall–runoff modelling. The authors concluded that ENN outperformed ANN rainfall–runoff modelling of Sone command, Bihar. Sharghi et. al [
20] also implemented an emotional artificial neural network (EANN) and compared its performance with wavelet-based ANN (WANN) models. This study also marked EANN to be better than ANN and WANN in rainfall–runoff modelling application. In another study, Sharghi et al. [
33] coupled EANN models with wavelet transformation (WEANN). The authors observed that WEANN outperformed WANN and EANN when applied to the rainfall–runoff modelling problem of the Trinity River basin. Similarly, Poonia and Tiwari [
18] implemented newer variants of ANN, RBFNN, and feed-forward back propagation model (FFBP) for modelling the Hoshangabad Basin, Narmada River. The authors observed that RBF yielded higher modelling as compared to FFBP models.
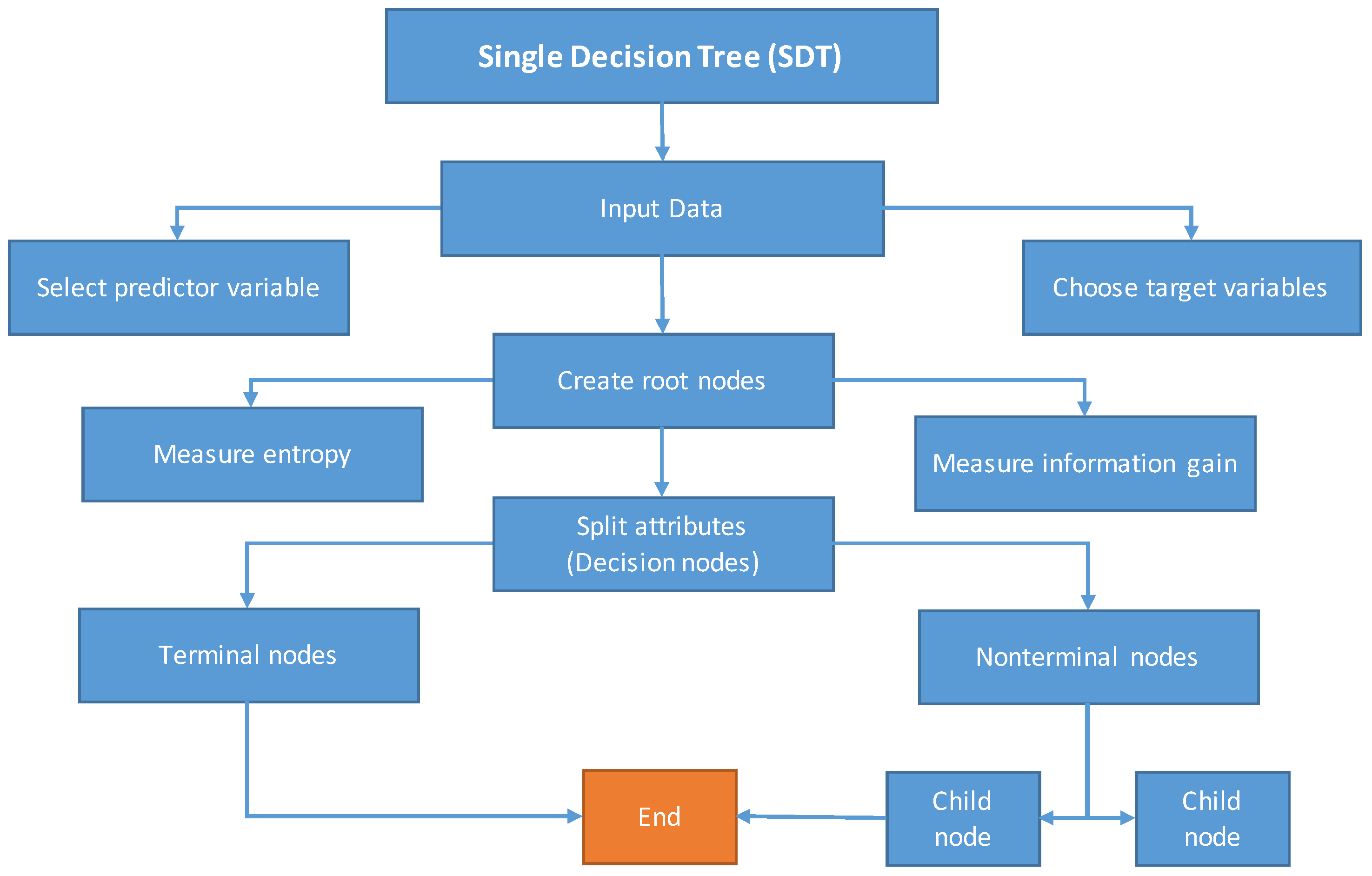
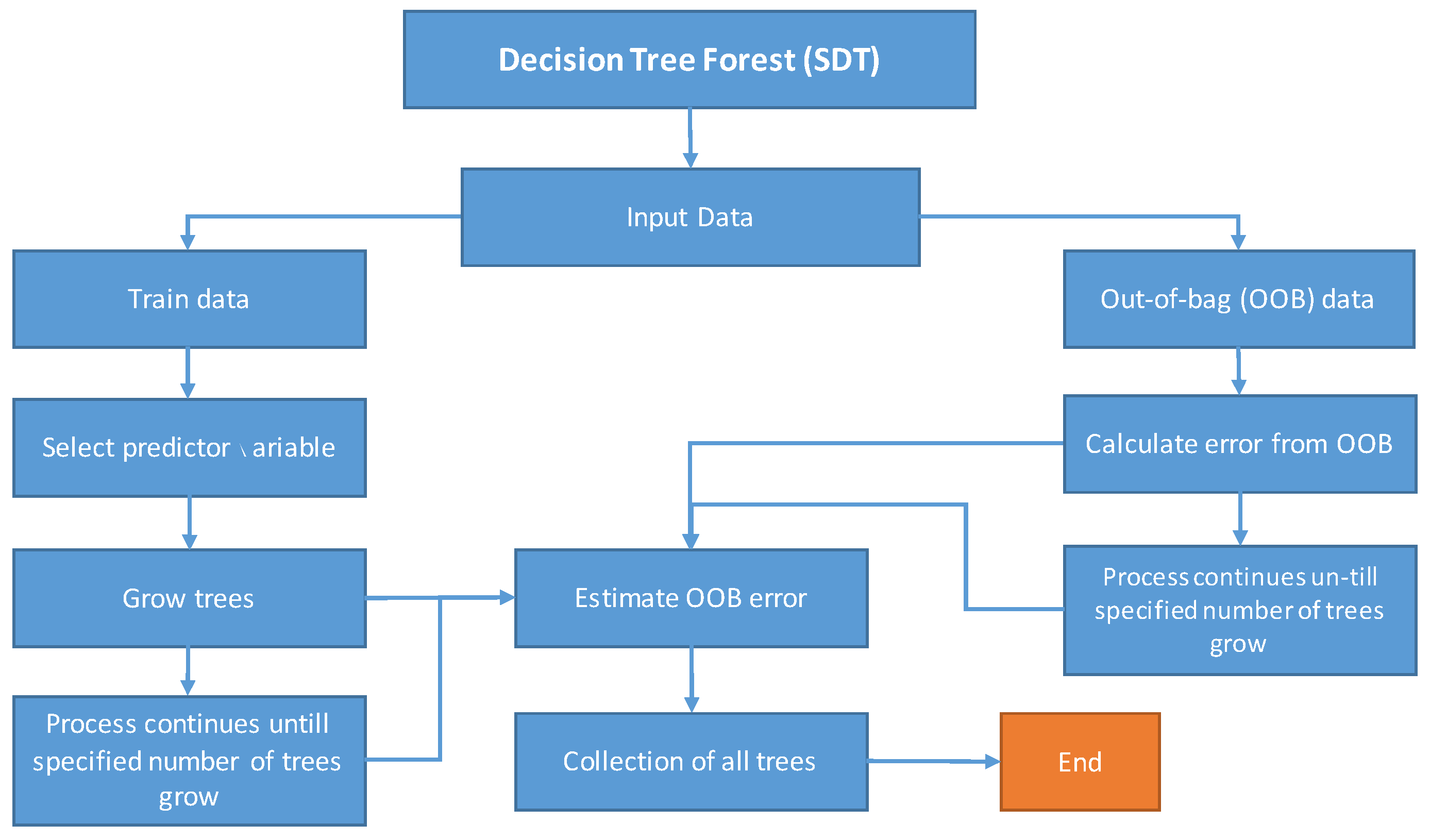
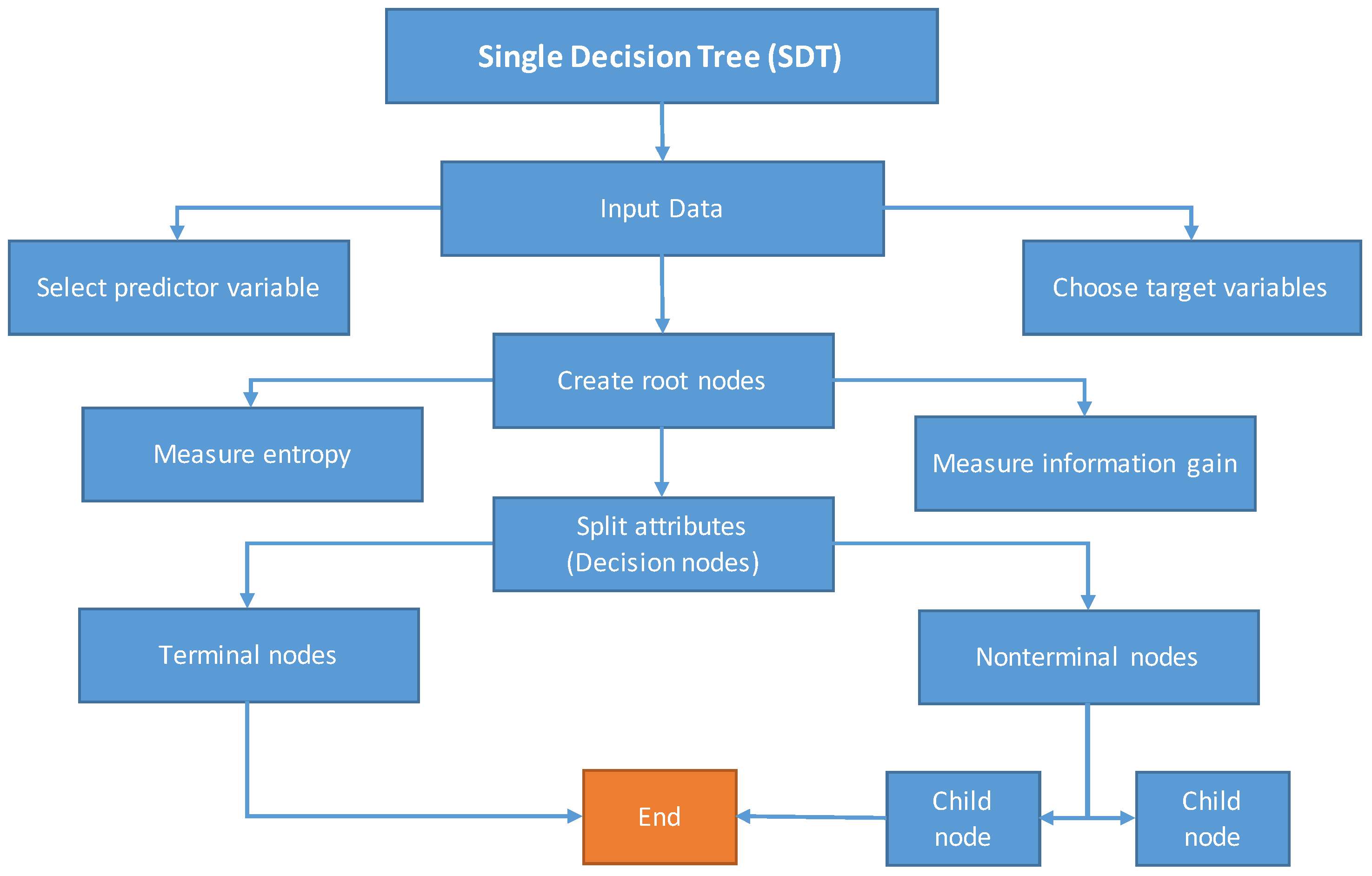
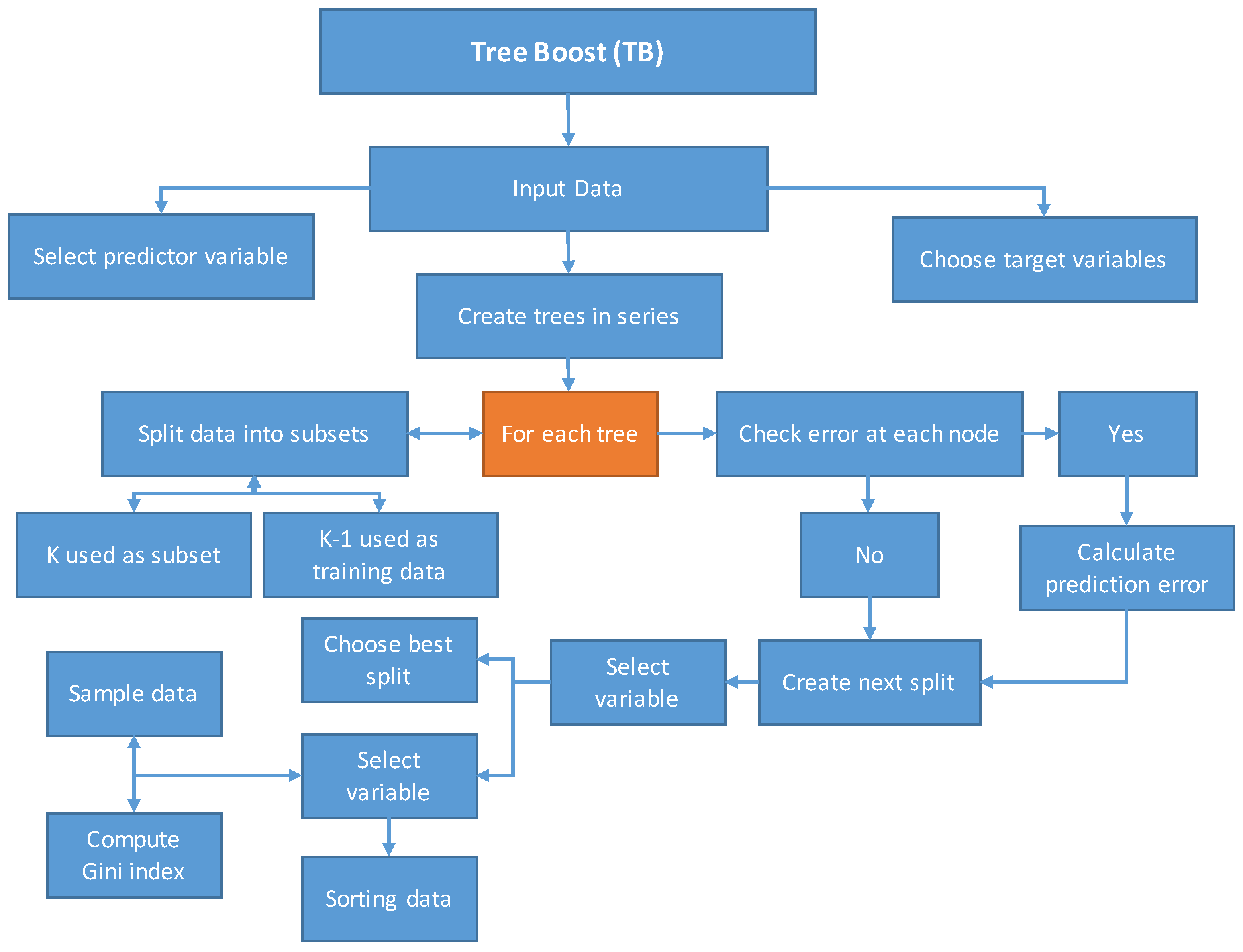
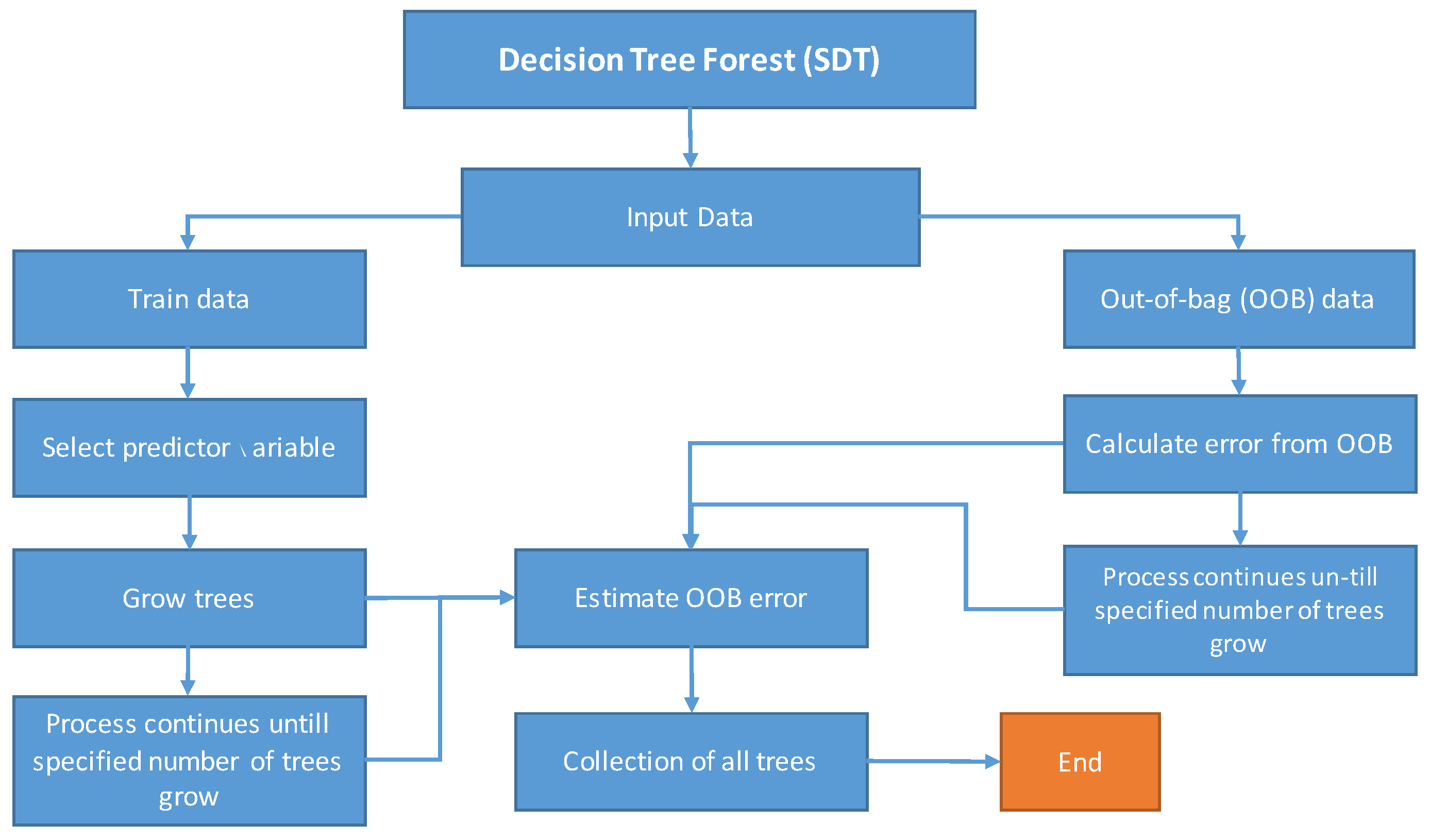
Contrastingly, other data-driven soft computing techniques, including DTF, TB, SDT, and GEP, have confined application in rainfall–runoff relation extraction problems. However, these techniques have been used for different hydrological problems. Aytek et al. [
34] employed GEP models for rainfall–runoff simulation of Juniata River basin in the USA. The authors contrasted model performance with that of ANN variants, FFBP, and generalized regression neural networks (GRNN). It was concluded that GEP performed well in comparison with ANN models, and thus could be used as an ANN alternative subject to fulfilment of parametric requirement. Nourani et. al [
35] coupled M5 decision tree with wavelet transformation for rainfall–runoff modelling and compared its performance with simple ANN and M5 tree models. In conclusion, the wavelet coupled M5 decision tree model performed better than both the ANN and M5 tree models. Lee et al. [
36] applied DTF and TB techniques in spatial mapping of flood susceptibility in Seoul, South Korea. It was observed that the machine learning techniques performed better than other conventional methods used in the study. Similarly, Raza et al. [
37] used SDT, TB, and DTF, to estimate reference evapotranspiration in different climate zones of Pakistan. TB models yielded better results than SDT and DTF in most locations, while in general, machine learning techniques outperformed conventional methods of evapotranspiration estimation, such as the Penman–Monteith (FAO-56 method) [
38].
A comprehensive literature review of above-cited streamline studies exhibits a clear gap in terms of an encompassing research work that compares the performance of major machine learning techniques in rainfall–runoff modelling. Moreover, the effect of data pre-processing with wavelet transformation on the performance of GEP, TB, SDT, and DTF is still unclear. To address this research gap, the main objectives of this study are: (1) to apply the major machine learning techniques ANN, GEP, SDT, TB, and DTF in a single research work, (2) to couple every technique with wavelet transformation in order to assess the effect of pre-processing on model performance. This study provides comprehensive research on machine learning application in rainfall–runoff modelling along with implementation of wavelet pre-processing. Other machine learning approaches include regression models (linear and logistic), support vector machine (SVM), k-nearest neighbour (KNN), naive Bayes, and gradient boosting models, but the selection of abovementioned techniques (ANN, GEP, SDT, TB, and DTF) for analysis is due to their up-to-date modelling variants, and overwhelming and continuous application in hydrological and environmental problems. The selected techniques have been separately studied in hydrological context in earlier studies of various authors [
21,
22,
25,
39,
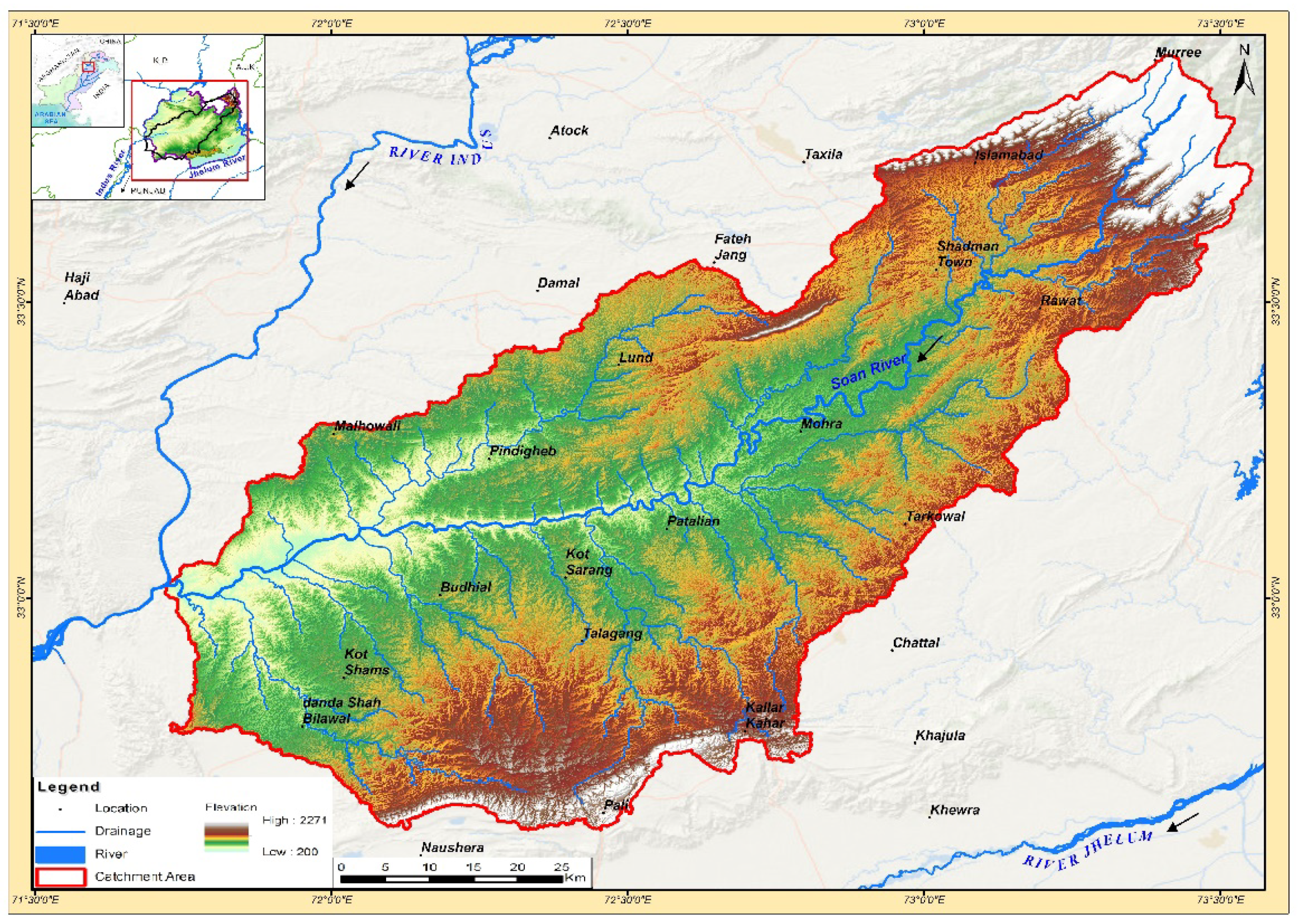
40]. However, basin-wide study encompassing ML techniques and wavelet transformation in the Pothohar region is a novel attempt provided in this research report.
4. Conclusions
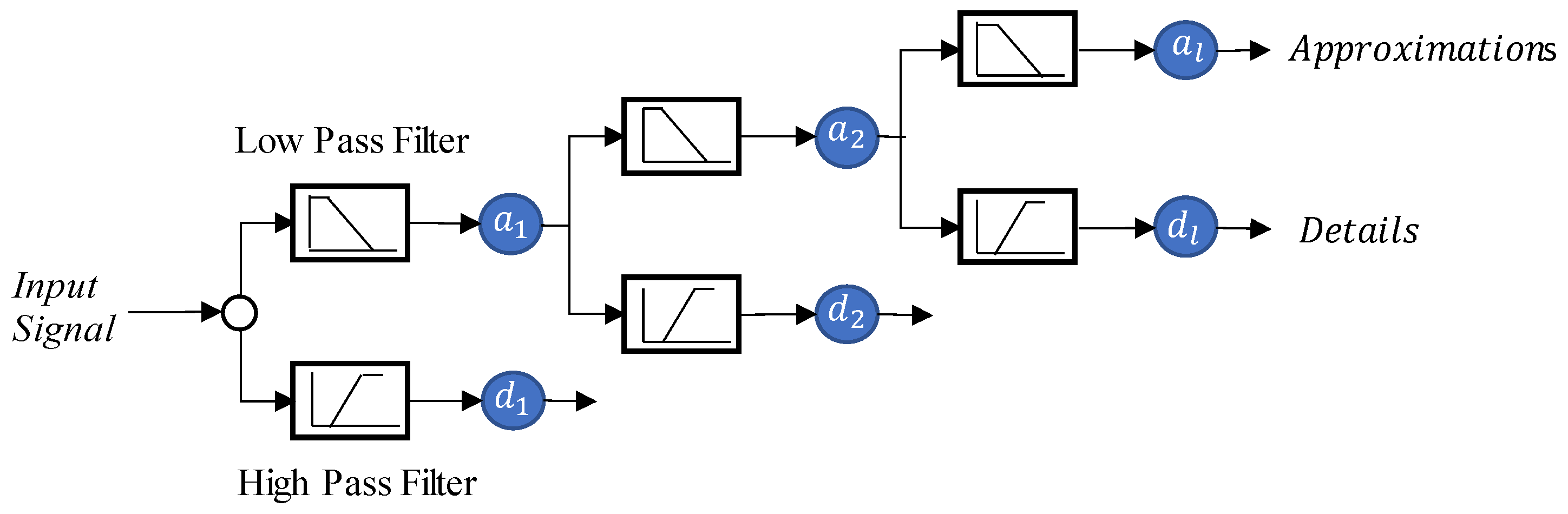
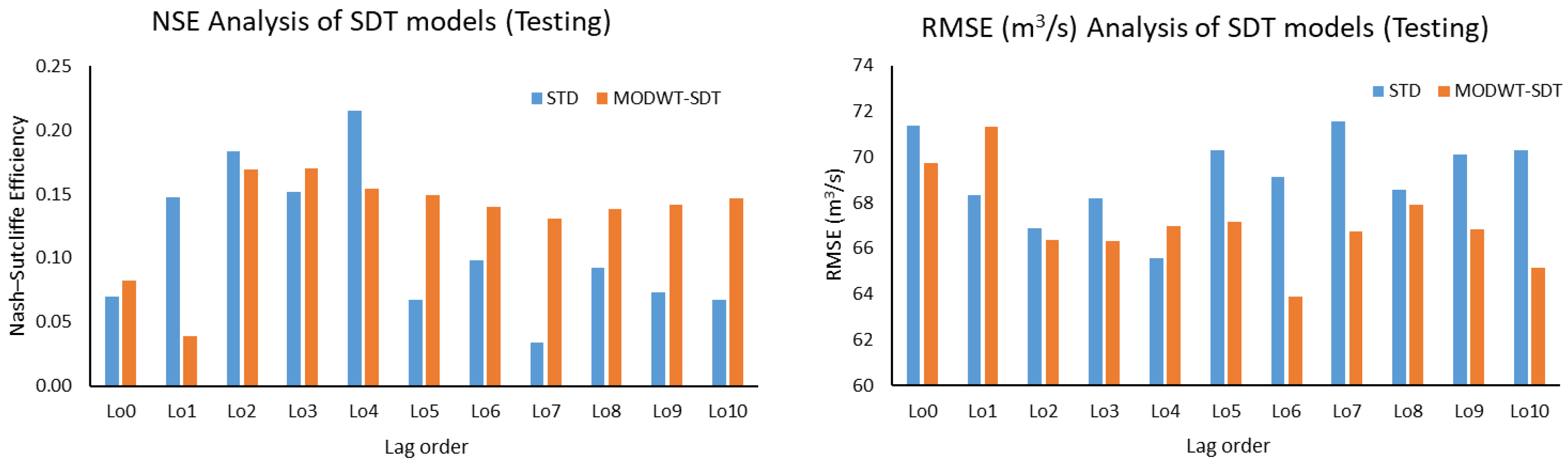
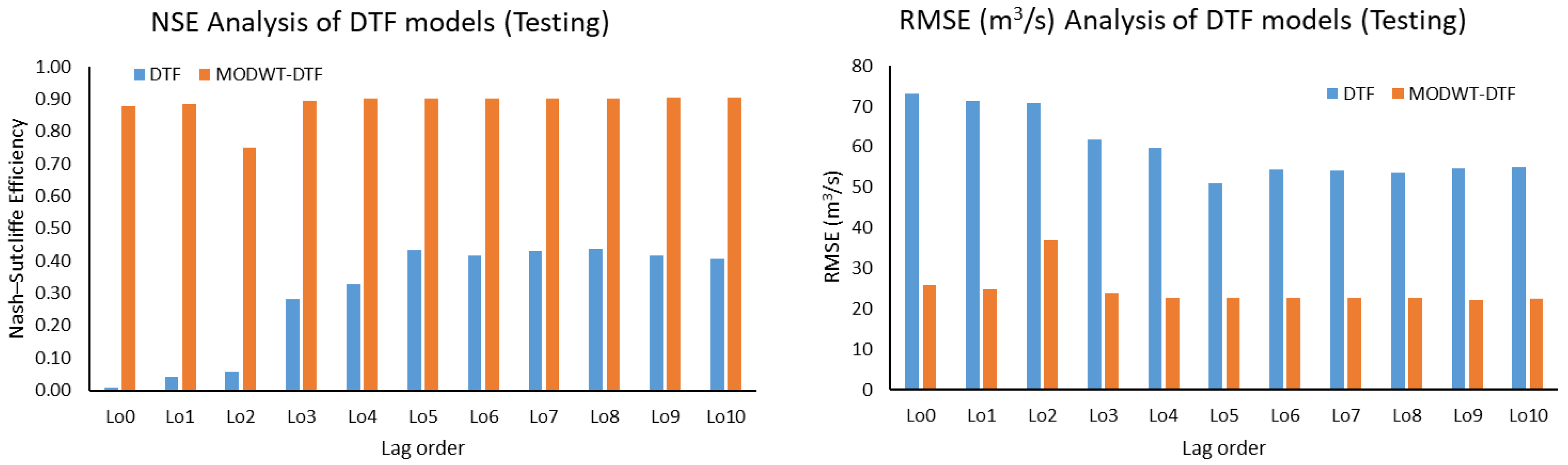
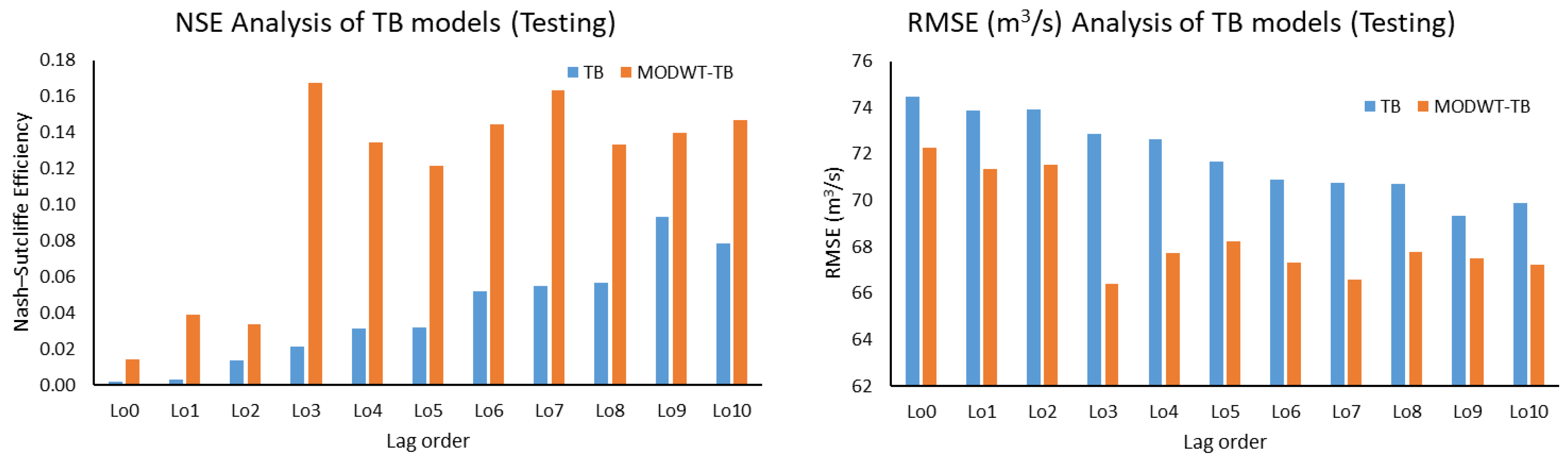
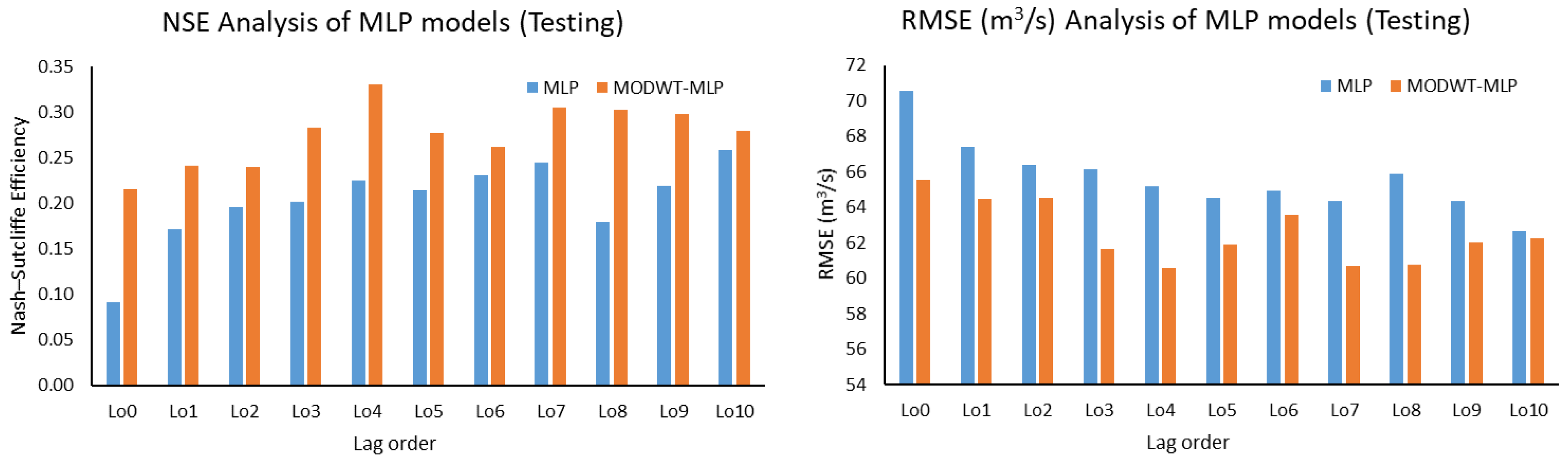
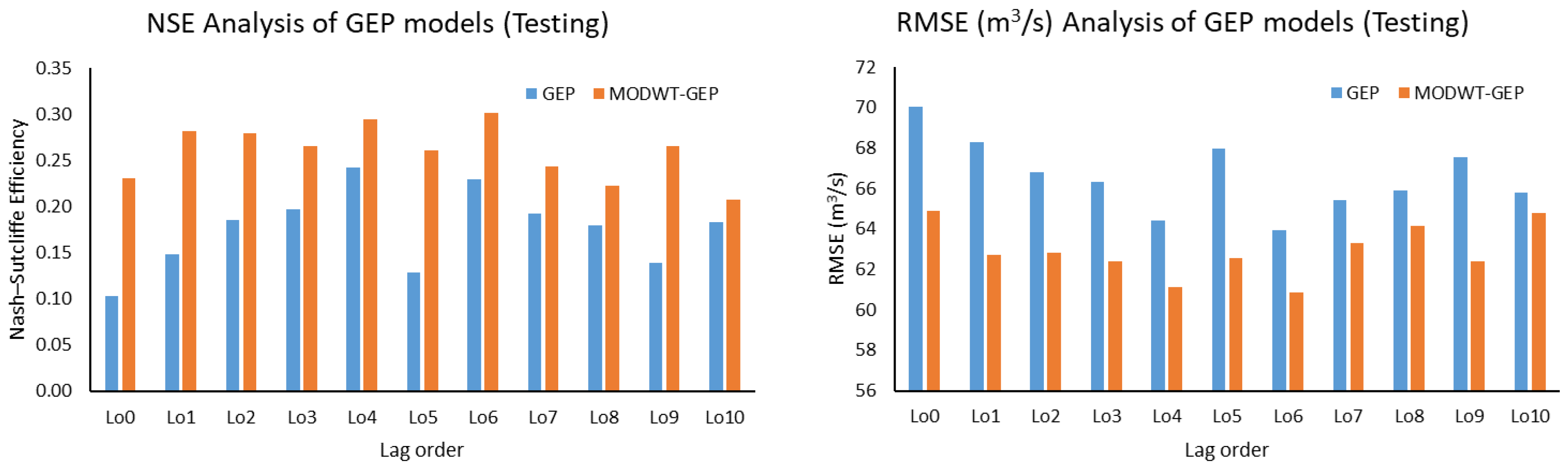
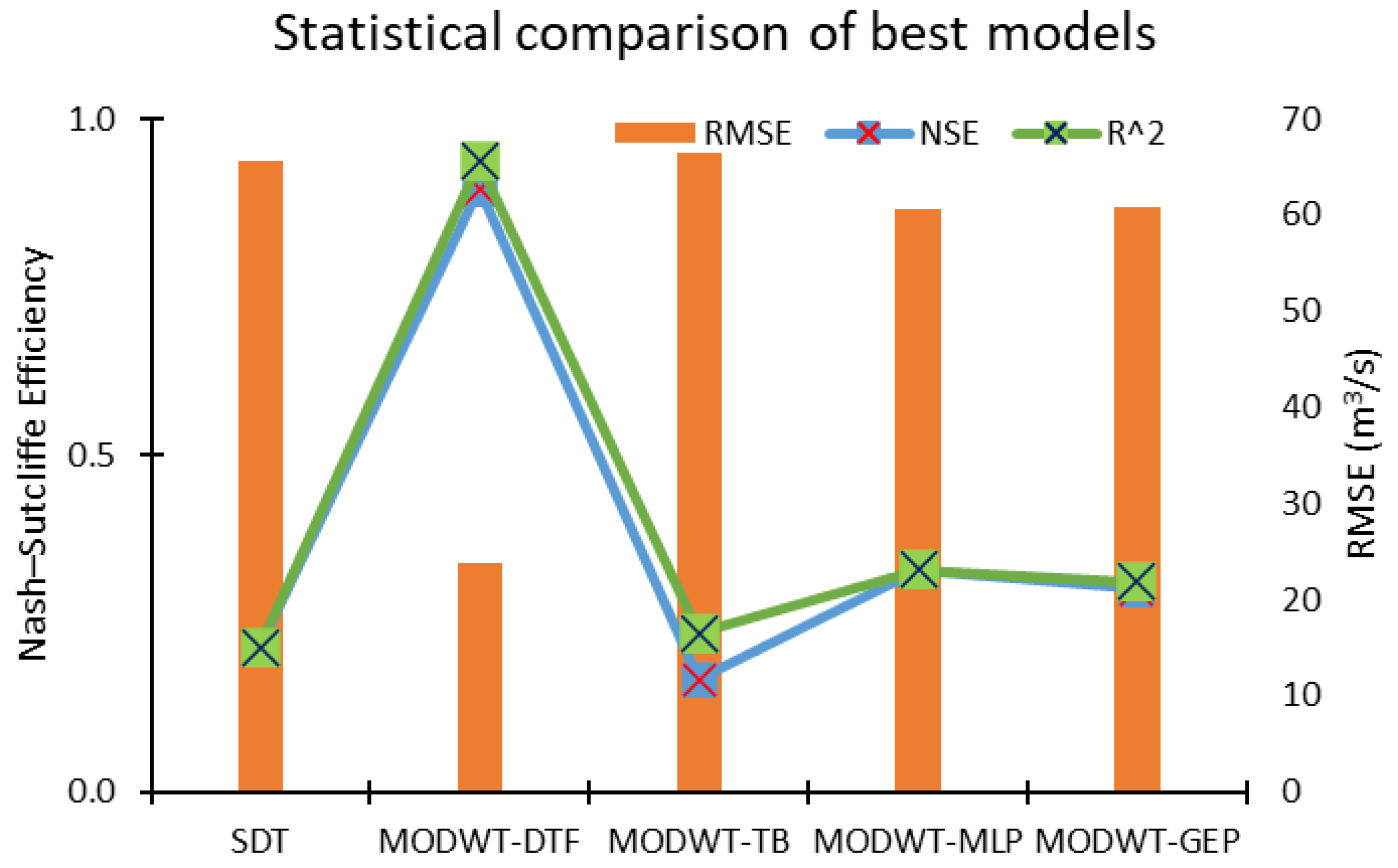
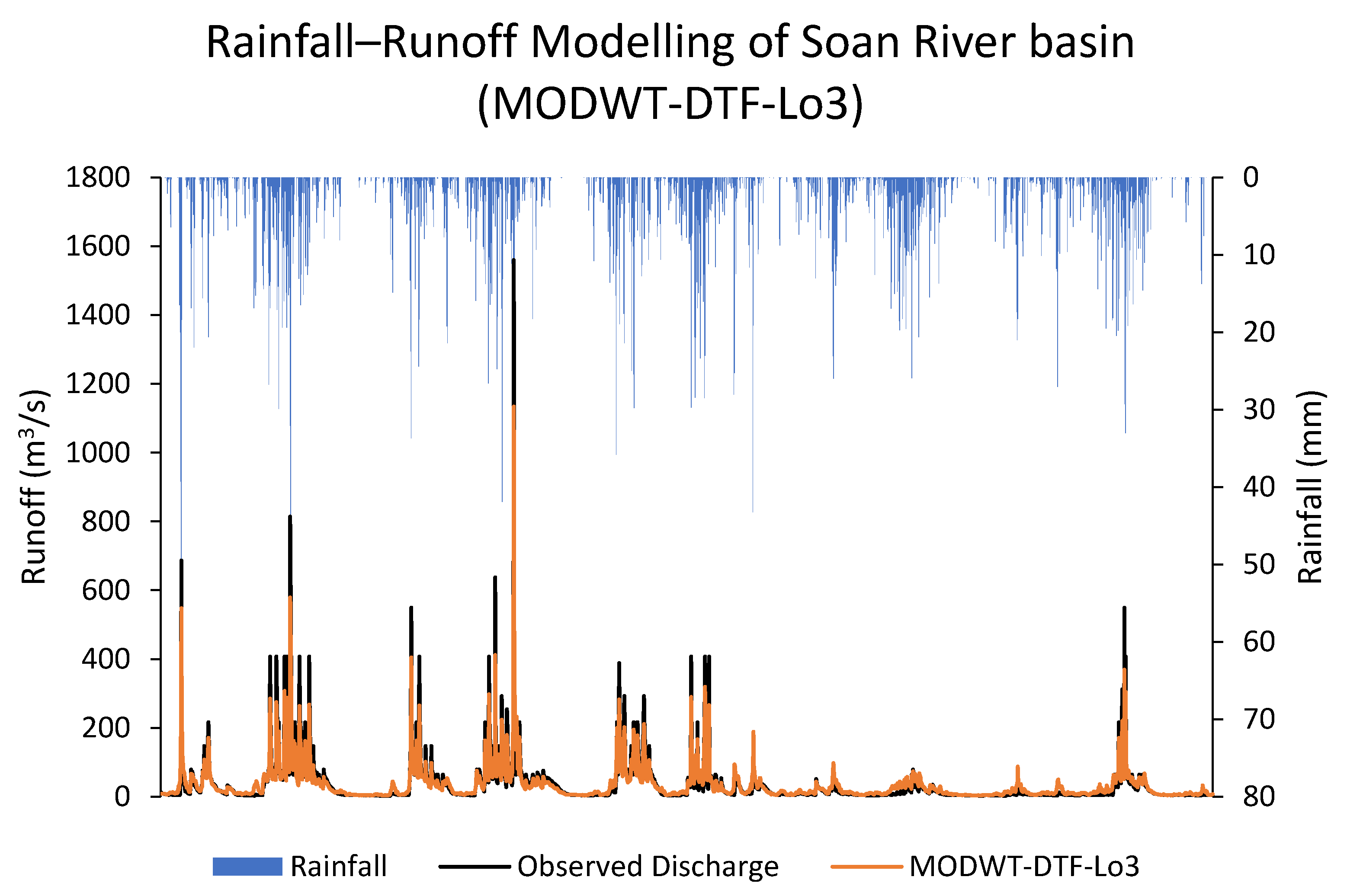
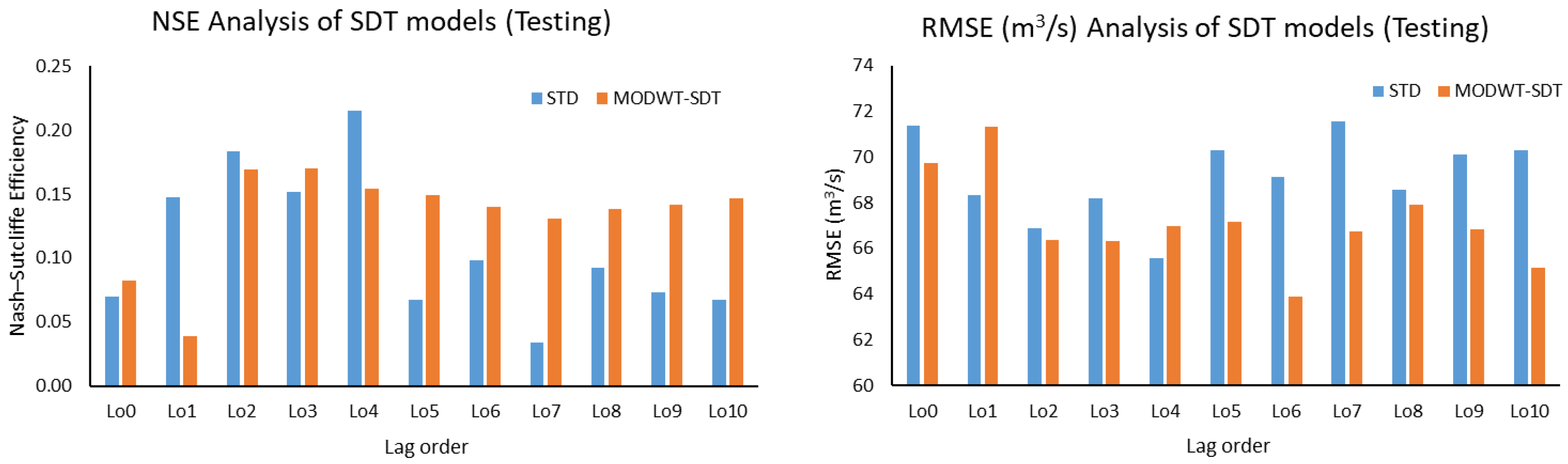
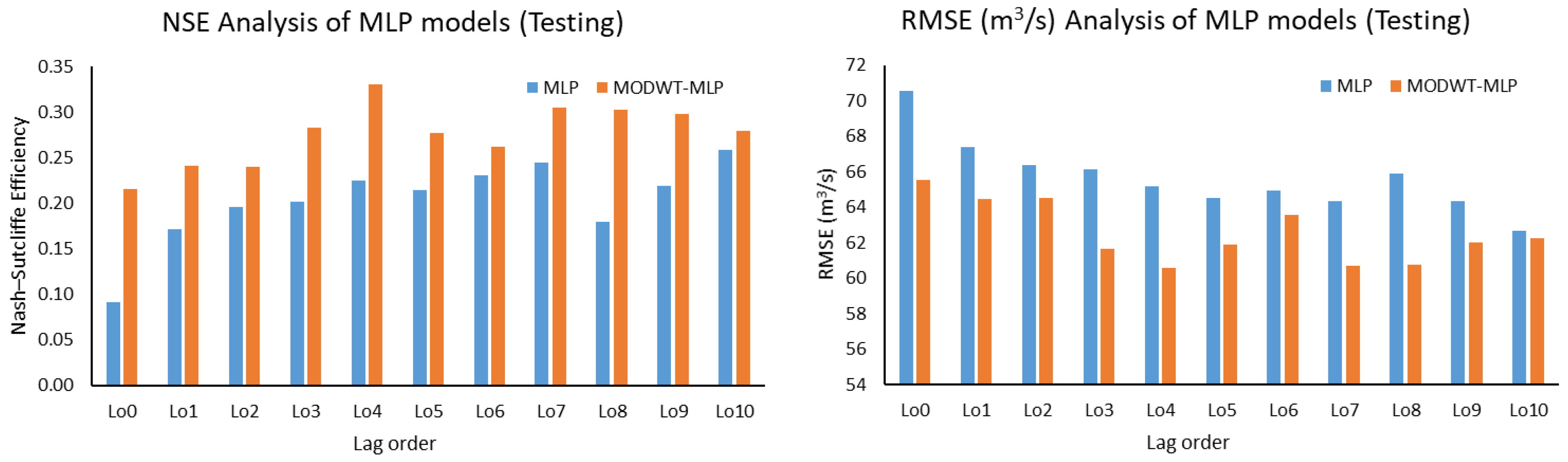
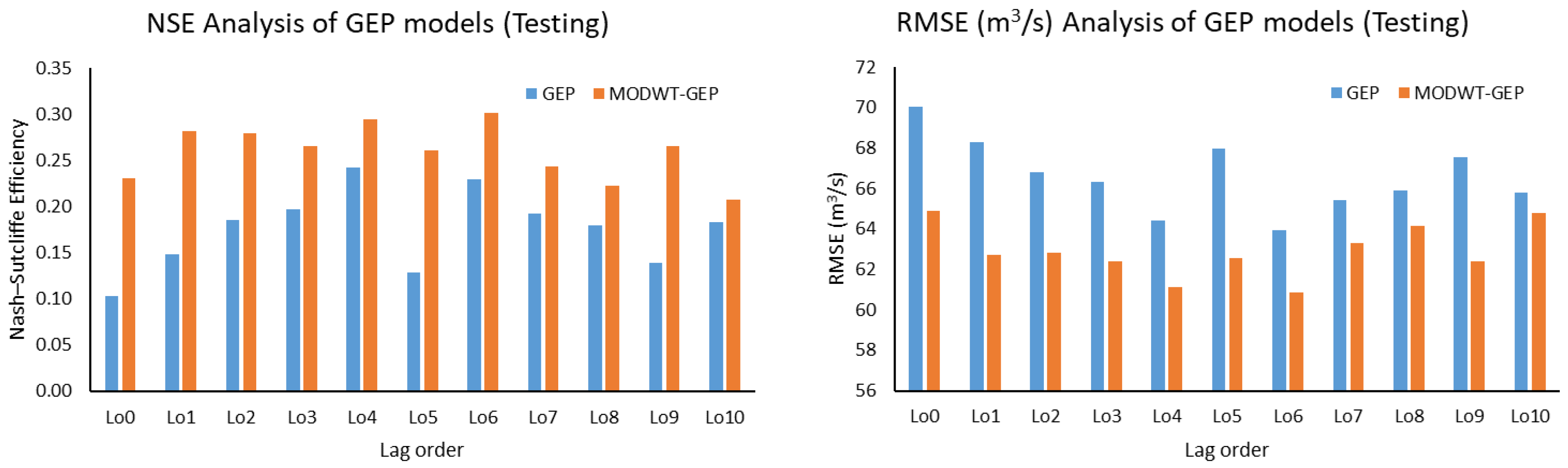
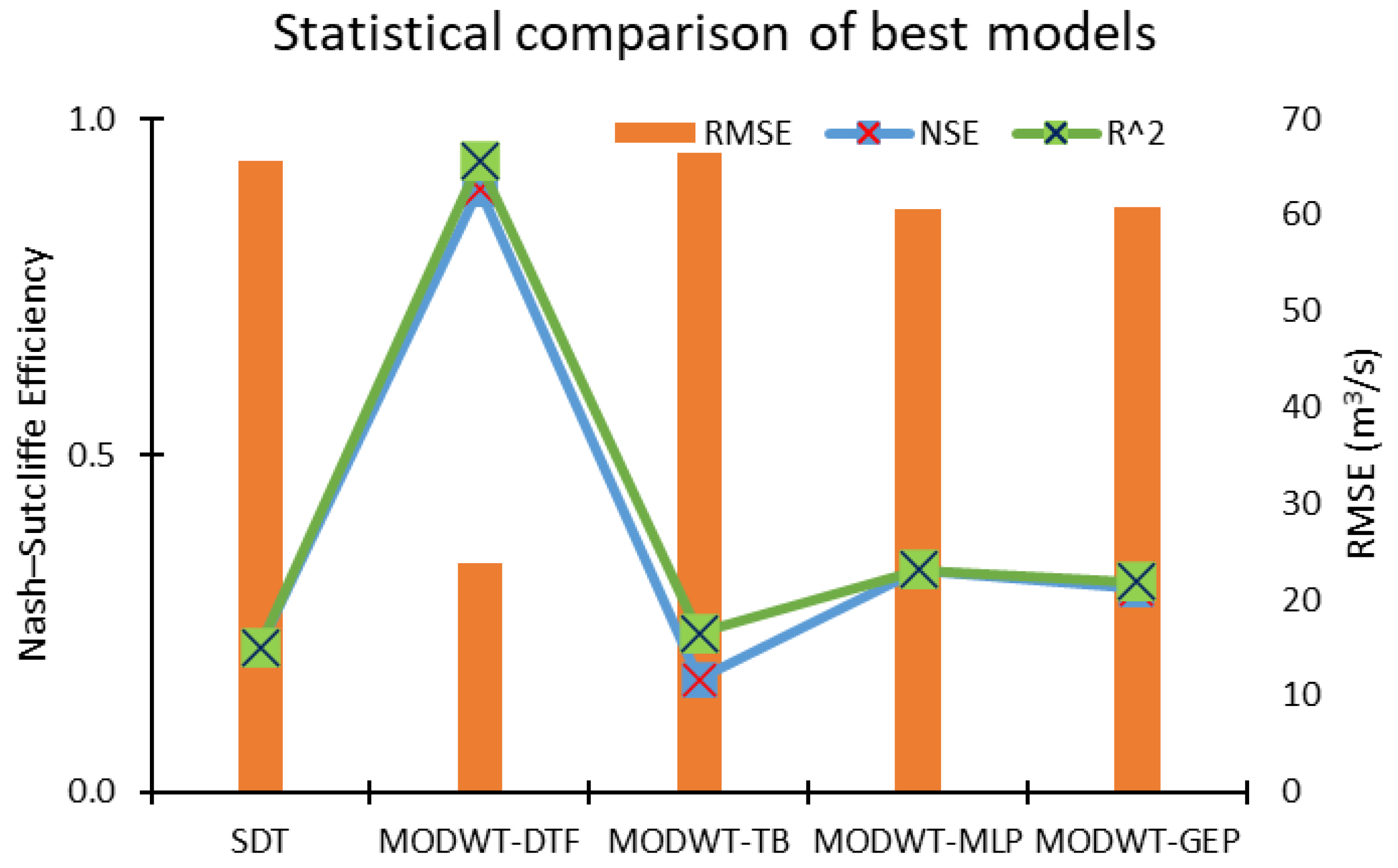
This study used five machine learning techniques (SDT, TB, DTF, MLP, and GEP) with and without combination of maximal overlap discrete wavelet transformation (MODWT). From the comparative analysis of the simple and MODWT-based models, it can be concluded that MODWT-based models outperformed simple models, except SDT, where the simple SDT model yielded higher accuracy than MODWT-SDT models. Moreover, it was observed that MODWT-SDT performed better than SDT models at higher lag orders. Additionally, it was observed that MODWT pre-processing improved the performance of simple models, but it did not necessarily push the accuracy within acceptable or satisfactory range, whereas the comparative analysis of the best performing models from technique established that DTF outperformed the other four techniques, when coupled with MODWT. Highest modelling accuracy, equal to 90%, was produced at MODWT-DTF at Lo3. Meanwhile, the same model produced a minimum RMSE of 23.79 m3/s. This performance enhancement reflects the tendency of data pre-processing with MODWT (or any other wavelet model) to extract hidden information within the univariate time series. Hence, wavelet pre-processing can be reliably applied to problems involving multiple variables to attain better outcomes with reduced parametric requirement and parsimonious modelling. However, the results of wavelet technique can also change depending on the type, topography, and features of the basin; therefore, selection of wavelet family, wavelet type, and level of decomposition must be done correctly to achieve better outcomes.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}