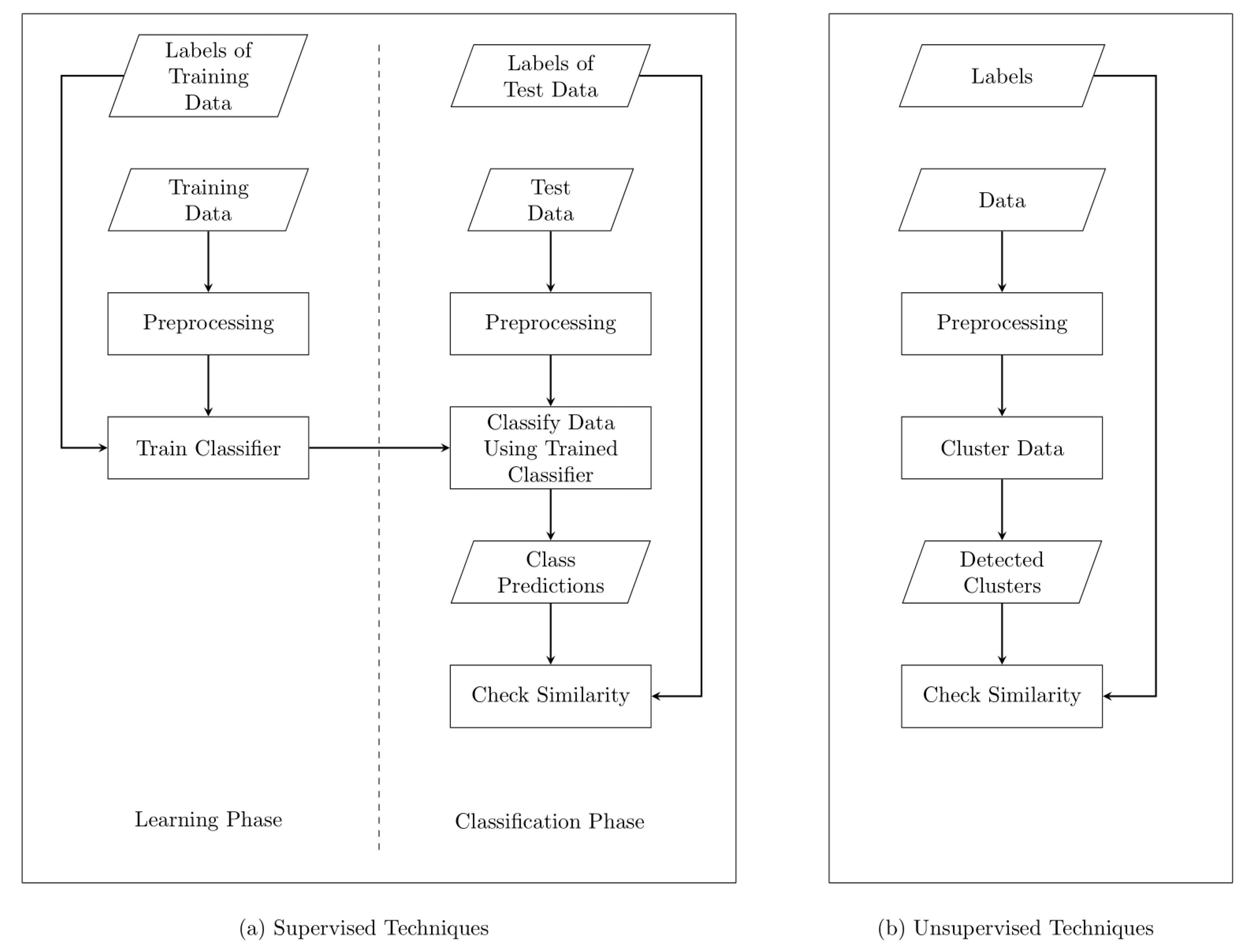
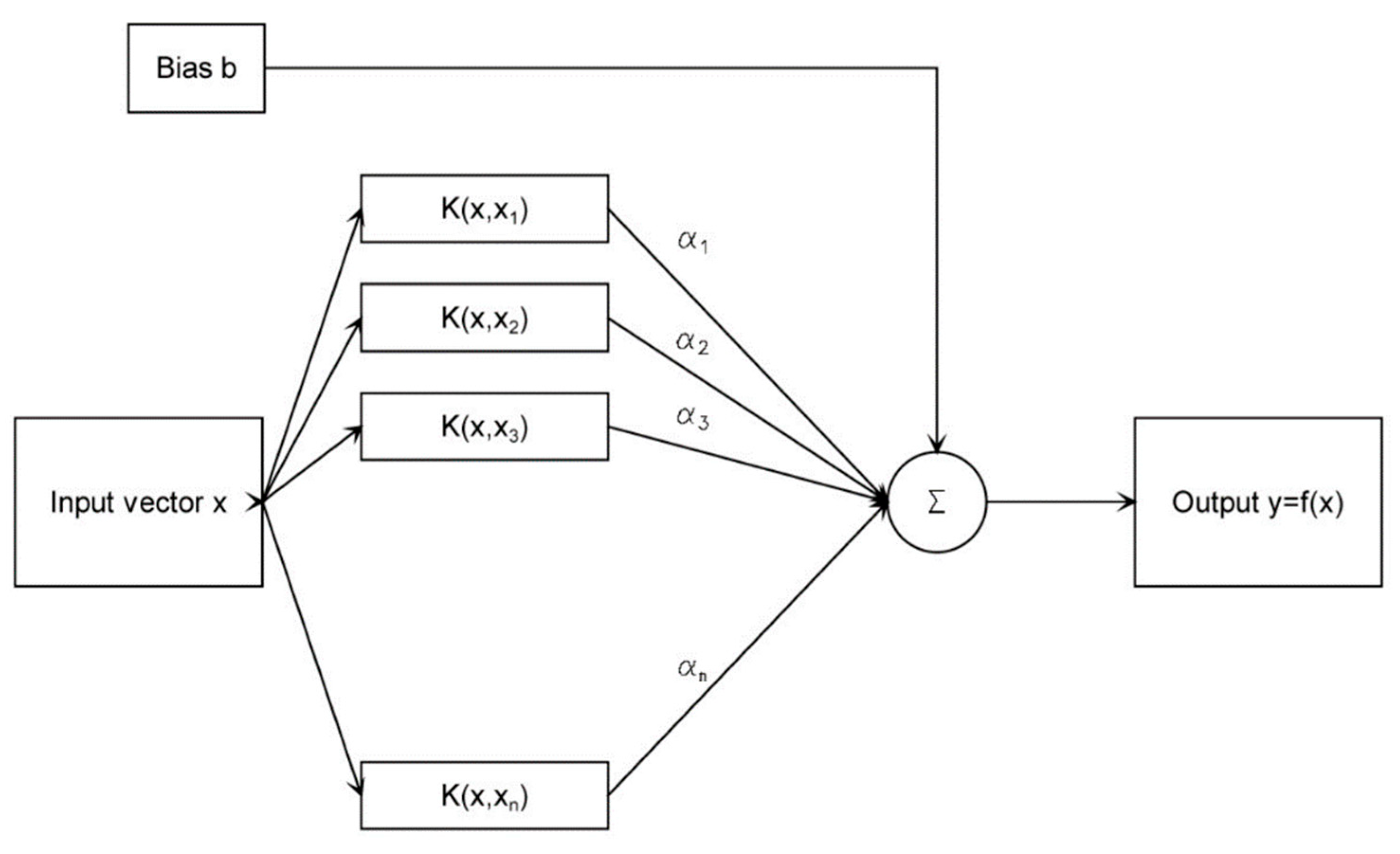
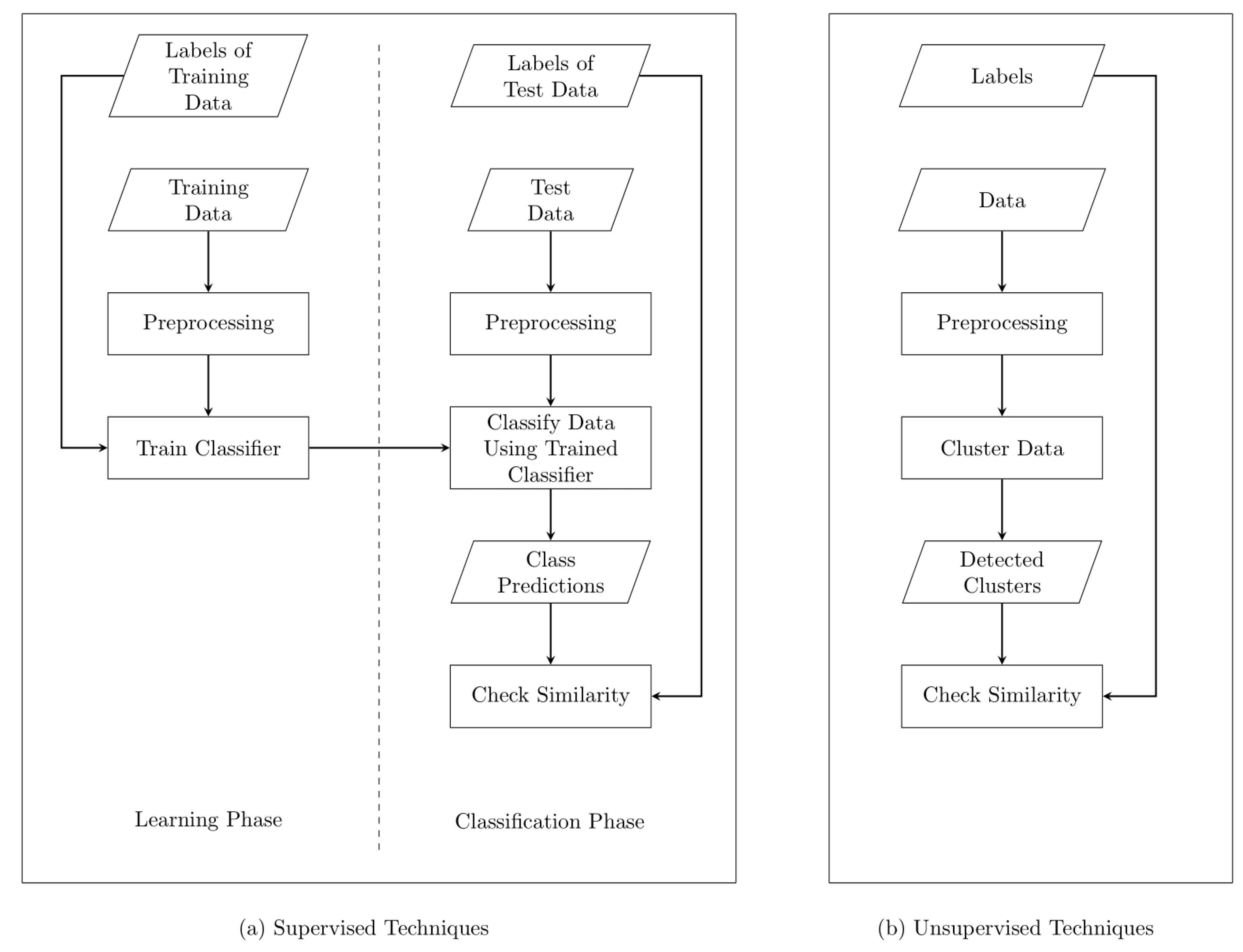
1. Introduction
In recent years, climate change and population growth have exacerbated water scarcity and accelerated the vulnerability of water supply systems. A comprehensive and detailed understanding of water demand as well as water end-uses will improve the resilience of these systems. With the water consumption data generated and transmitted by smart water meters, advanced analysis of water demand using data-driven approaches is facilitated. In particular, the categorization of water use events into residential end-uses like washing machine, faucet or toilet permits a detailed investigation of the impact of different end-uses as well as the inhabitants on the overall demand. With the recent advances in artificial intelligence, categorization of residential water end-use can be resolved as classification problem using Machine Learning (ML) techniques, thus having inherent real-time capability, scalability and generalizability. On a basic level, ML techniques can be subdivided into supervised and unsupervised approaches. The former directly perform a categorization/classification of data with given categories. Consequently, training data with labels annotating the samples’ categories are necessary. The latter search for groups of similar data points in the dataset in the absence of labels.
Both unsupervised and supervised approaches are widely applied in studies on end-use classifications of water use events. For example, Pastor-Jabaloyes et al. [
1] proposed an unsupervised approach formulating a Partition Around Medoids clustering method using Gower distance as a similarity measure in the feature space, which is spanned by the volume and the average flow rate of the water use events. A clustering algorithm based on Dynamic Time Warping (DTW) as the similarity measure between events is described by Nguyen et al. [
2]. This algorithm was refined to a hybrid method comprising k-medoids clustering, DTW and a swarm-intelligence-based global optimization, i.e., Artificial Bee Colony algorithm. Later, this approach was extended with a hybrid method consisting of Self-Organizing Maps and a k-means algorithm in the subsequent publications [
3,
4]. Most supervised approaches are based on Hidden Markov Models and a subsequent optimization [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16], but Artificial Neural Networks [
9,
10,
11,
12,
13], Decision Trees [
14] and Multi-category Robust Linear Programming [
17] are used as well. Support Vector Machines (SVMs) were employed by Vitter et al. [
18] to categorize water events using water consumption data and coincident electricity data. Furthermore, Carranza et al. [
19] identified residential water end-uses in data measured by precision water meters equipped with pulse emitters using SVMs.
Both supervised and unsupervised approaches proposed in the literature demonstrate high performance in terms of accuracy with the particular dataset utilized in corresponding experiments. However, these datasets are often acquired in different countries or regions. Consequently, the underlying consumer behavior represented by the consumption data varies. Moreover, each dataset has a specific time resolution. Thus, the characteristic of the datasets utilized in the state-of-the-art literature differs largely. As the methods proposed in the aforementioned studies are mainly customized to the particular dataset, the generalizability of each method is not proven. Moreover, the particular datasets applied in the state-of-the-arts are commonly not publicly available. Hence, the corresponding implementation (e.g., setting of model hyperparameters) of the proposed ML models is not traceable. This results in a decreased reproducibility of the methods. Finally, to the best of our knowledge a comprehensive comparison of both supervised and unsupervised approaches on a common database has not been performed yet.
In this paper, we focus on a comparative evaluation of supervised and unsupervised ML techniques on a common dataset for the application of residential water end-use classification and aim at deriving a decision support for the selection of the appropriate approach, revealing possible pitfalls of water end-use classification. For this purpose, we implemented a large variety of ML-based approaches proposed in the state-of-the-art literature, i.e., the clustering algorithm based on DTW established by Nguyen et al. [
2], k-means, Density-Based Spatial Clustering of Applications with Noise (DBSCAN), Ordering Points To Identify the Clustering Structure (OPTICS), Clustering in Arbitrary Subspaces based on the Hough transform (CASH), as well as two classifiers based on Support Vector Machines (SVM). Subsequently, the methods are evaluated on a common database generated using a stochastic water consumption simulation framework. The validation of different algorithms with a common dataset guarantees the comparability of the evaluation results. Finally, evaluation results are analyzed and discussed in detail, with the intention to draw implications and recommendations of experiment set-ups for data-driven water end-use classification in general.
3. Results and Discussion
The datasets described in
Section 2.1 are addressed as
1P,
2P,
3P,
4P,
5P and
6P, referring to the number of inhabitants in the simulated household. The following sections provide the evaluation of the supervised and unsupervised techniques using these six datasets. The employed code is executed with python 3.7, making use of the ELKI version 0.7.5 and the scikit-learn version 0.23.1. ELKI is run with OpenJDK 13.0.33. Upon calling CASH with OpenJDK, 12 GB are allocated for its execution. All experiments were conducted with the same hardware, equipped with an Intel(R) Core(TM) i9-8950HK CPU @ 2.90GHz (6 cores), 16 GB RAM and a 64 bit Windows 10 operating system.
3.1. Evaluation of the Supervised Techniques
For a fair comparison, we calculated accuracy and precision both for multi-class and binary SVMs. In detail, precision, recall and f1-score for all classified end-uses are first estimated for the multi-class SVMs. The accuracy is computed in the subsequent step. For binary SVMs, confusion matrices are used to compute accuracies and precisions of the classifiers, as the number of positive and negative samples is highly unbalanced. The split of training and test data is 0.8 to 0.2 for all experiments conducted.
3.1.1. Evaluation Results
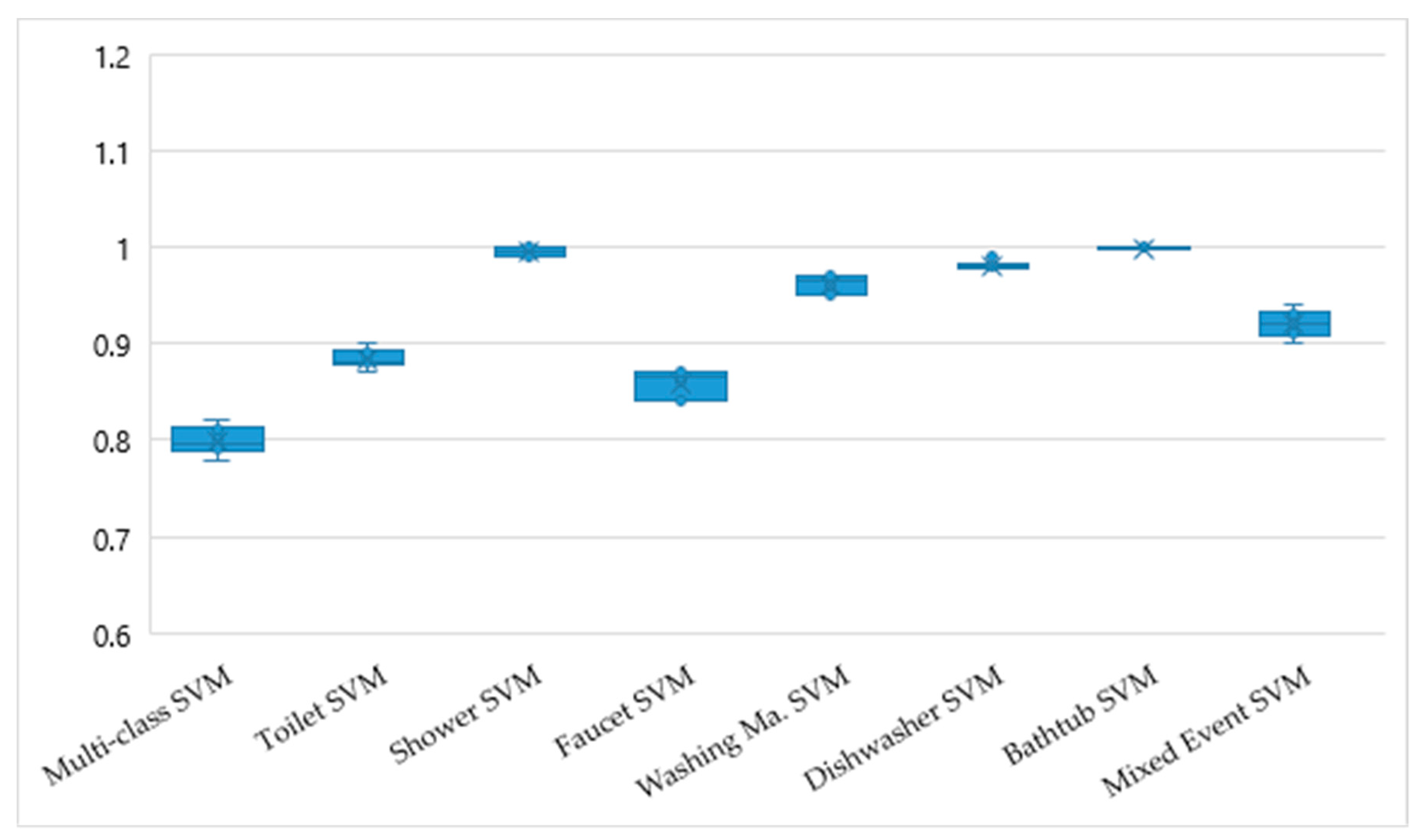
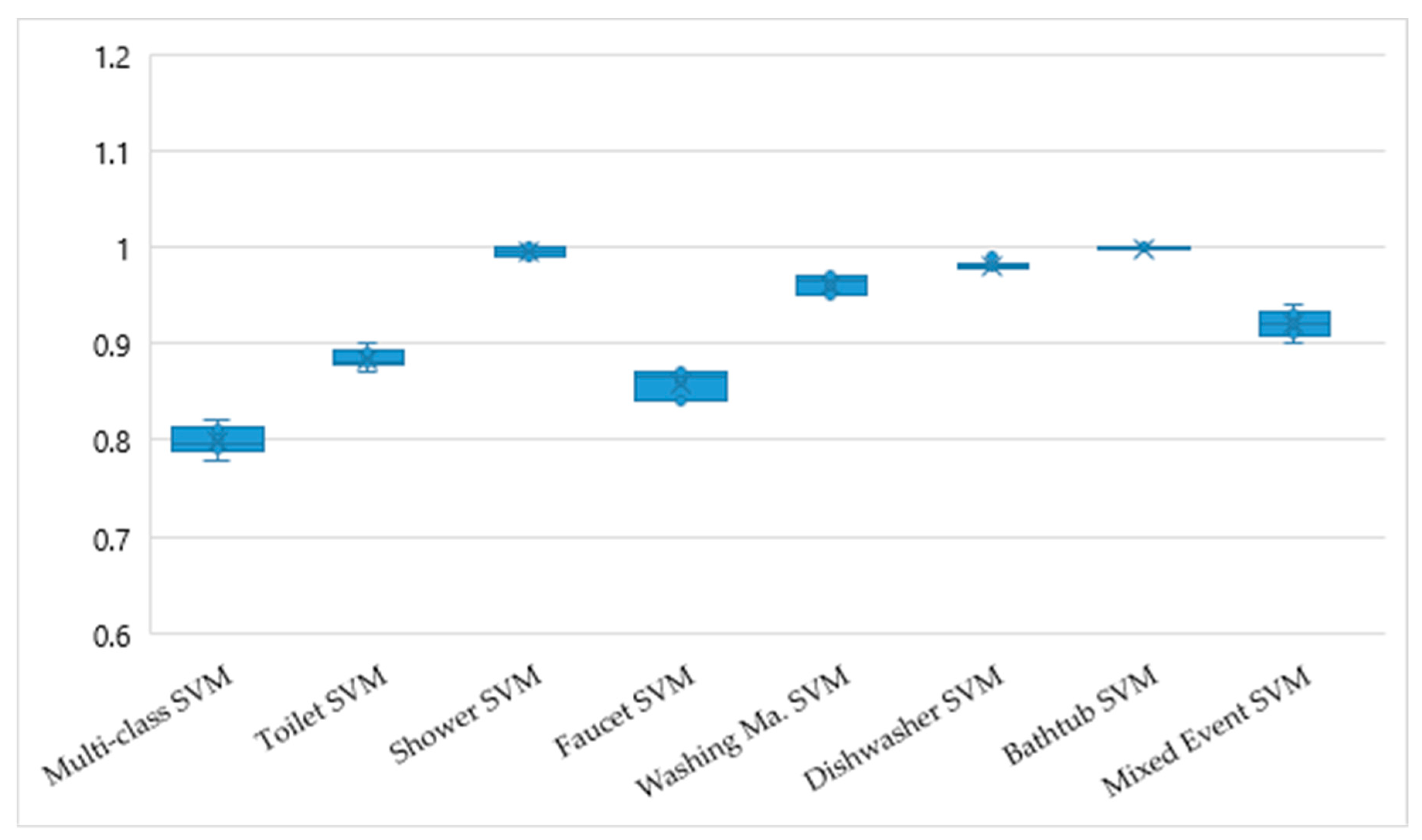
Figure 4 presents the quantitative comparison of the accuracies for multi-class and binary SVMs. The evaluation results for the multi-class SVMs are detailed in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6. The precisions, recalls and f1-scores for the
dishwasher class have values close to zero. For the classes
washing machine,
bathtub, as well as
overlapping events, the corresponding values are slightly higher than 0.5. Lastly, the precisions, recalls and f1-scores for the
toilet,
shower and
faucet classes have a range between 0.73 and 0.96. The accuracies/micro averages of the classifiers vary between 0.78 and 0.82 as depicted in
Figure 4.
Confusion matrices depicted in
Table A7 demonstrate the performance of the binary SVMs. For the end-uses
shower, washing machine,
dishwasher and
bathtub, the binary SVMs have a high accuracy. The accuracy of binary SVMs for end-use events
toilet and
faucet are relatively low but still outperform the multi-class SVM. Compared to
bathtub and
shower, the precisions for
toilet, faucet and
washing machine are significantly lower (refer to the confusion matrix in A7). In case of
dishwasher, the precision is not computable, since there is no true positive event recognized.
3.1.2. Discussion
At first sight, binary SVMs seem to outperform the multi-class SVM (refer to
Figure 4). In case of
shower and
bathtub, binary SVMs demonstrate high performance in terms of accuracy and precision. This is the consequence of the characteristics of both events, i.e., both of them are characterized by a sharp ascent of flow rate, where the high flow rate is continuous for several minutes, mainly without any interruption.
However, the conclusion that binary SVMs outperform the multi-class SVM has to be made with care, as the imbalance in the sample distribution shifts the evaluation metrics for binary SVMs to higher values. For instance, the binary SVM is not able to recognize any
dishwasher events. Although the corresponding accuracy is 100%, this classifier still fails to identify the
dishwasher events correctly. Similar results can be observed for
washing machine, where the binary SVM has a high accuracy but a relatively low precision. These results indicate that the classification framework described in this study comprising data preprocessing, feature extraction and binary SVMs are not ideal for water end-uses, where a single water consumption pattern is not representative for the end-use event. More concretely, an end-use event of
dishwasher or
washing machine usually continues for more than an hour. However, the water consumptions assembling these end-uses are usually several separated consumptions patterns with large temporal intervals of interruption. Since the time series sequences are considered as coherent when the temporal interval of interruption is less than 150 s (refer to
Section 2.1), the end-uses
dishwasher or
washing machine are not described by the selected features precisely.
For the end-uses toilet and faucet, binary SVMs tend to have high false positive and false negative rates. It indicates, that these two events are often confused with other end-uses. Both of them are abrupt and short events corresponds to a sharp curve of consumption volume and flow rate. Thus, additional features with more discriminative power should be utilized to increase the performance of the classification.
Hence, we can conclude that the classifier is not the single critical factor for the accuracy and the precision, as data preprocessing and feature extraction also affect the overall result. Moreover, datasets solely including the water consumption data might not be sufficient for the identification of complex end-uses (e.g., washing machine or dishwasher), since significant prior knowledge, i.e., program settings of the machine or accurate start and end time of the program, are not comprised in the datasets.
A limitation to our results is that the experiments were only conducted on datasets with a high temporal resolution. The accuracy and precision of the classifiers likely depend on this resolution. Thus, with datasets of lower resolution, the accuracy and precision of the classifiers might significantly deteriorate.
3.2. Evaluation of the Unsupervised Techniques
In contrast to the evaluation of supervised techniques, accuracy and precision cannot be computed for the evaluation of unsupervised techniques directly, as the clusters recognized by clustering methods are not necessarily equivalent to the end-use classes. For instance, we identified 10 clusters by using the k-means method; however, there are only seven end-uses in the simulated database. Furthermore, the identified clusters are not assigned to any end-use classes inherently; hence, the list of clusters will be a permutation of the list of end-uses. For these reasons, the Adjusted Rand Index (ARI) and the Adjusted Mutual Information (AMI), which are commonly used to assess whether detected clusters correspond to ground truth classes, are utilized as evaluation metrics.
Moreover, for CASH, DBSCAN, OPTICS and the clustering algorithm based on DTW, the number of detected clusters is presented. For k-means, the number of clusters is a hyperparameter fixed to ten (refer to
Section 2.4.2) in this study.
3.2.1. Evaluation Results
The evaluation results for the unsupervised techniques described from
Section 2.4.1,
Section 2.4.2,
Section 2.4.3,
Section 2.4.4 and
Section 2.4.5 are summarized in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 respectively. Obviously, the number of the estimated clusters differs from the actual number of end-uses greatly. With regard to the similarity between the estimated clusters and the real end-use classes (refer to ARI and AMI values), the performance of the clustering methods can be ordered as k-means, DTW-based method, DBSCAN, CASH and OPTICS, in descending order. All clustering methods demonstrate low ARI and AMI values for all experiments conducted.
3.2.2. Discussion
The evaluation results for all clustering algorithms show that the identified clusters do not correspond to the ground truth end-use classes. One reason why the unsupervised techniques are not able to estimate the end-uses in the given datasets is that clustering methods generally take the most significant differences in a dataset into account. This might not be the end-uses but the variation of consumer behaviors in the household or other effects which are not related to the end-use classification. Moreover, single end-uses might possess a variety of different consumption patterns. For example, a washing machine shows different patterns depending on its program settings, the wash load or even the different sections of a wash cycle. These differences within individual end-uses make the task of separating end-use categories through clustering more challenging, especially since the most significant differences in a dataset determine the outcome of clustering.
In summary, unsupervised methods alone are not sufficient to detect the correct end-uses fully automatically. Similar to the experiments with supervised methods (refer to
Section 3.1.2), the dataset has a single specific temporal resolution. As a consequence, the quantitative results cannot be applied to datasets with lower temporal resolution directly. Furthermore, the synthetic dataset utilized in this study is generated stochastically, based on the real-world consumption data from cities within the U.S. Hence, it encodes the country specific water consumption behaviors and other factors (e.g., economy, weather etc.) For instance, end-uses like washing machine might have a lower variety of different consumption patterns in countries or region with lower per capita income, as entry-level washing machines with less program settings are more affordable. A lower variety of consumption patterns within an end-use would reduce the complexity of identifying clusters corresponding to the end-use classes. Additionally, the choice of features used for clustering affects the evaluation results as well. Another set of features might have a higher descriptive power to represent the underlying data and thus has the discriminative capacity to distinguish the end-use classes.
4. Conclusions
In this work, we perform a comprehensive quantitative comparison of several supervised and unsupervised ML techniques for residential water end-use classification. A common database is created with a stochastic simulation tool based on real consumption data. One of the most important findings of the quantitative results is that the unsupervised methods alone, i.e., clustering techniques, are not sufficient to detect the correct end-uses of domestic water consumption fully automatically. This is somewhat consistent with the implications of the state-of-the-art literatures: In the context of end-use classifications, clustering techniques are commonly employed in combination with manual processing [
1] or supervised techniques [
2,
3,
4]. Another conclusion we can draw from this study is that supervised ML techniques pose an efficient way to perform water end-use classification. A possible explanation for this is that prior knowledge regarding the end-use classes (e.g., class labels) are commonly provided when using supervised ML methods.
To sum up,
our first recommendation for the experiment set-up of residential water end-use classification is to
incorporate prior knowledge as much as possible. More concretely, this can be realized by understanding the structure of the water network, by acquiring meta-information about each consumer (e.g., size of the household, location, devices etc.) or by generating labels manually or automatically. The benefits of these activities are various. First, the utilization of prior knowledge increases the overall performance of the classification methods. Moreover, it leads to a deep understanding of water consumption behavior and consequently facilitates the feature engineering step as well as the preprocessing. Finally, known operations encoded in prior knowledge increase the interpretability of algorithms based on neural networks and reduce the number of trainable parameters at the same time [
28].
Nevertheless, challenges and difficulties of acquiring prior knowledge should be considered. For instance, manual labeling tends to produce inaccurate labels, since human-beings are not predestined for repetitive tasks. Thus, quality checks of the manual labels are necessary. Furthermore, technical remedies could be utilized to generate accurate end-use labels. Additional sensor data, such as machine internal time logger or external electricity logger, can be used as labels for washing machines or dishwashers. Finally, a fully automatic labeling of some other daily end-use events (e.g., toilet and faucet) can be achieved with an additional smart water meter installed directly on the water faucet.
A further implication derived from our study is that the
database for water end-use classification needs to be representative. As stated in the introduction, one of the major limitations of the state-of-the-art literature is that the databases are commonly acquired in a specific country/region. Although our study provides a first comprehensive comparison between supervised and unsupervised ML methods, the utilized database still suffers from the same limitation (refer to
Section 3.1.2 and
Section 3.2.2). Hence, the quantitative results in the state-of-the-art as well as in our study can be hardly applied to other datasets. In order to increase the generalizability and reproducibility of ML techniques for end-use classification, we suggest to
establish a large representative dataset comprising raw data and annotations from various countries or regions for future research. For this purpose, end consumers in different circumstances (e.g., housing and household situation, age, gender etc.) need to be encouraged to participate. Considering the above-mentioned aspects, crowdsourcing approaches which have been applied for medical applications [
29] could be a possible solution. A suitable framework to implement such approaches successfully is the so-called citizen science project, where the citizens are contributing to a scientific project actively with their resources and knowledge. Scientific results and other output of the project are accessible to the participants as an exemplary reward.
Previously, we concluded that one shortcoming of our study with regard to its generalizability is the temporal resolution of the utilized synthetic database, since it is fixed to 10 s. However, Cominola et al. [
16] found that accurate end-use disaggregation is only possible with a temporal resolution of less than a minute. As end-use disaggregation and end-use classification are linked closely (disaggregation, unlike classification, separates overlapping events into the individual end-uses), we infer that a lower temporal resolution would also give less accurate results for end-use classification. For example, an end-use event with a duration shorter than one minute (e.g., faucet or toilet) cannot be described by water consumption data with a lower frequency, i.e., less temporal resolution. Therefore, the choice of the temporal resolution in our dataset is based on the requirement of the use-case, since we are aiming at recognizing all common residential water end-uses. This leads us to our
next implication: The
characteristics of the underlying database should
meet the requirement of the water end-use classification task. An orientation for the estimation of an optimal temporal resolution (i.e., frequency) is given by the Nyquist sampling theorem. It states that a system with uniform sampling can reconstruct a continuous function (i.e., analog signal) adequately, only if the sampling rate is at least two times the maximum frequency of the original signal.
A final recommendation derived from our study is that we should be aware of the “class imbalance” problem for water end-use classification. In common residential households, events like faucet and toilet occur more frequently than bathtub, washing machine or dishwasher. Furthermore, bathtub, washing machine or dishwasher are not always available in each household. Consequently, the water end-use classification problem generally suffers from an imbalanced class distribution, which could result in a lower classification accuracy of ML models. Effective ways to handle it are upsampling of the minority class or downsampling of the majority class. The former can be realized with data augmentation techniques, whilst the latter can be achieved by removing redundant data.
In future work, it would be desirable to test the implemented methods on datasets from other regions of the world. Another promising future direction to improve the accuracy and generalizability of residential water end-use classification would be the systematic exploration and evaluation of hybrid techniques combining supervised and unsupervised methods. Encouraging results of hybrid techniques have already been presented in previous studies [
2,
3,
4], on which comparative experiments could be conducted. Last but not least, we would like to point out the potential of deep neural networks to resolve end-use classification. Recently, deep neural networks have achieved tremendous success in various disciplines, such as medical image processing, computer vision, space or geoscience. Although artificial neural networks have been applied for end-use classification with promising results (refer to [
11,
12,
13,
14]), the networks employed as classifiers still have a shallow structure. Sophisticated neural networks in combination with deep learning techniques may benefit the entire end-use classification process comprising data preprocessing, feature extraction and classification. A potential candidate is the Recurrent Neural Network (RNN), which is well-suited to time series data, since it has the capability to maintain the internal state from time-step to time-step. The training of such a network requires large amounts of annotated water consumption data. The widespread use of smart water meters with high temporal resolution counteracts this challenge.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}