Clustering of Time Series Water Quality Data Using Dynamic Time Warping: A Case Study from the Bukhan River Water Quality Monitoring Network


Abstract
1. Introduction
2. Material and Methods
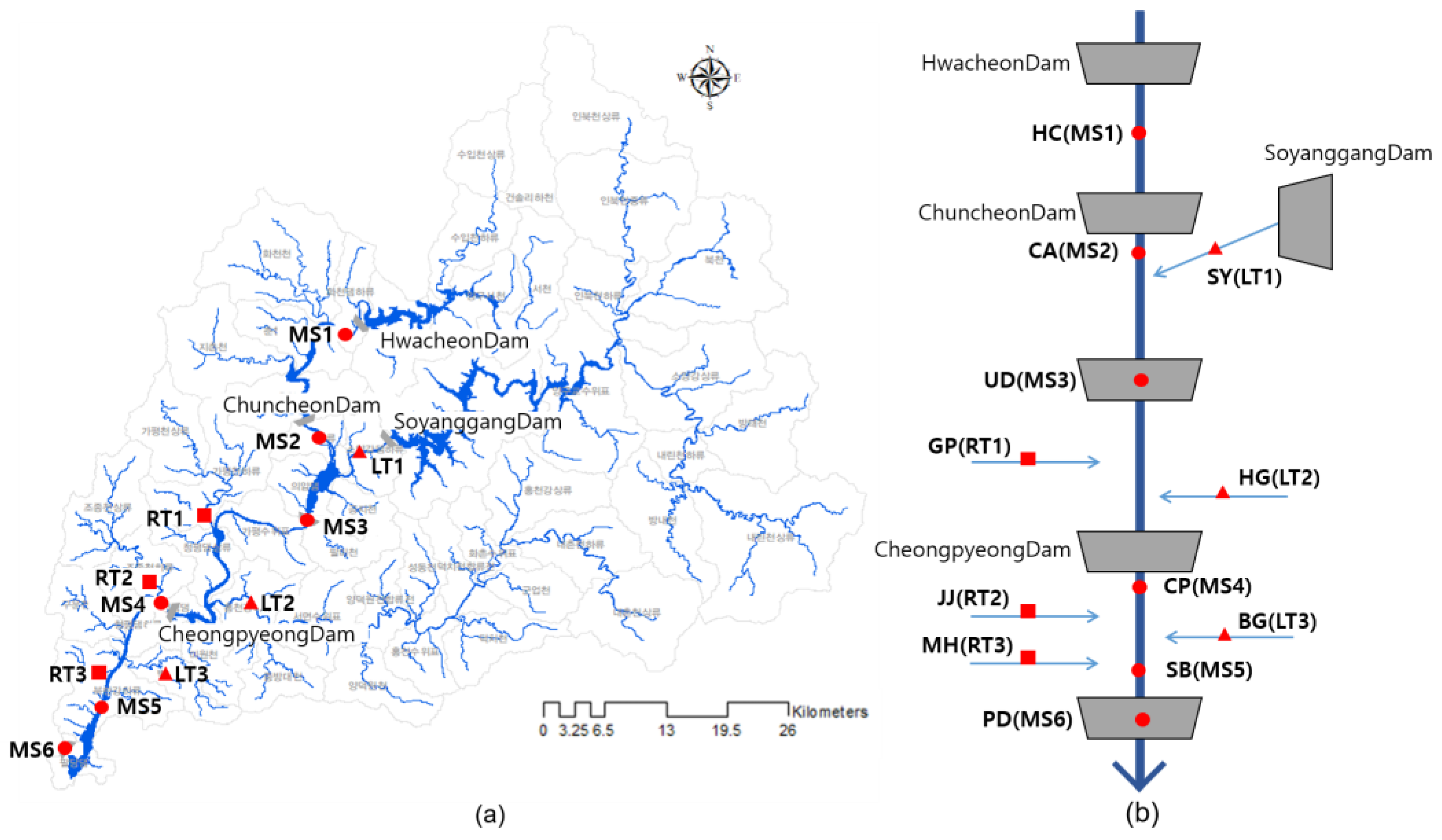
2.1. Study Site
2.2. Data
Missing Data
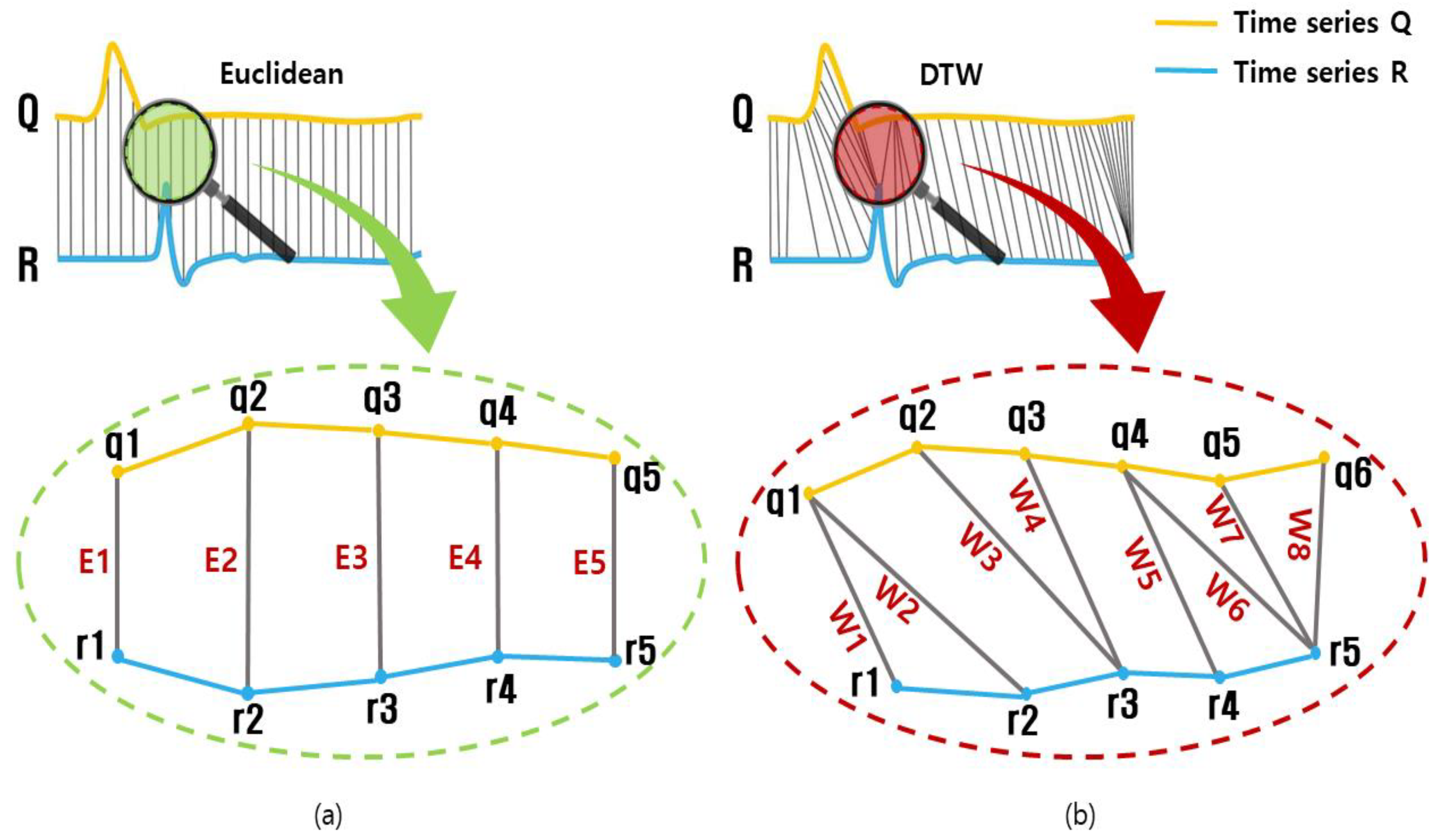
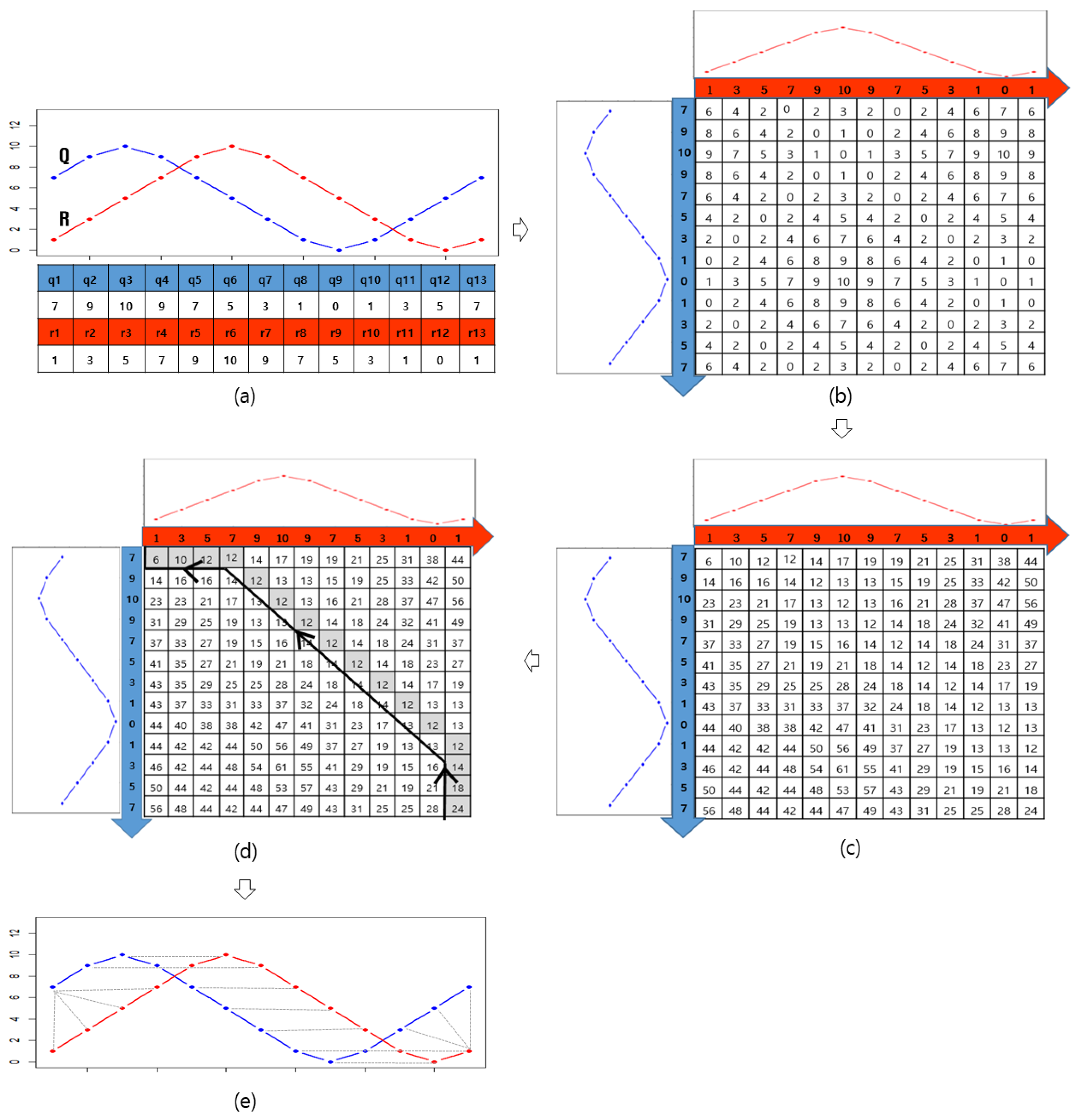
2.3. Dynamic Time Warping
2.4. Clustering Method
2.5. Clustering Validation Index
3. Results
3.1. Optimization CVI
3.2. Comparison of the Euclidean and Dynamic Time Warping Algorithms
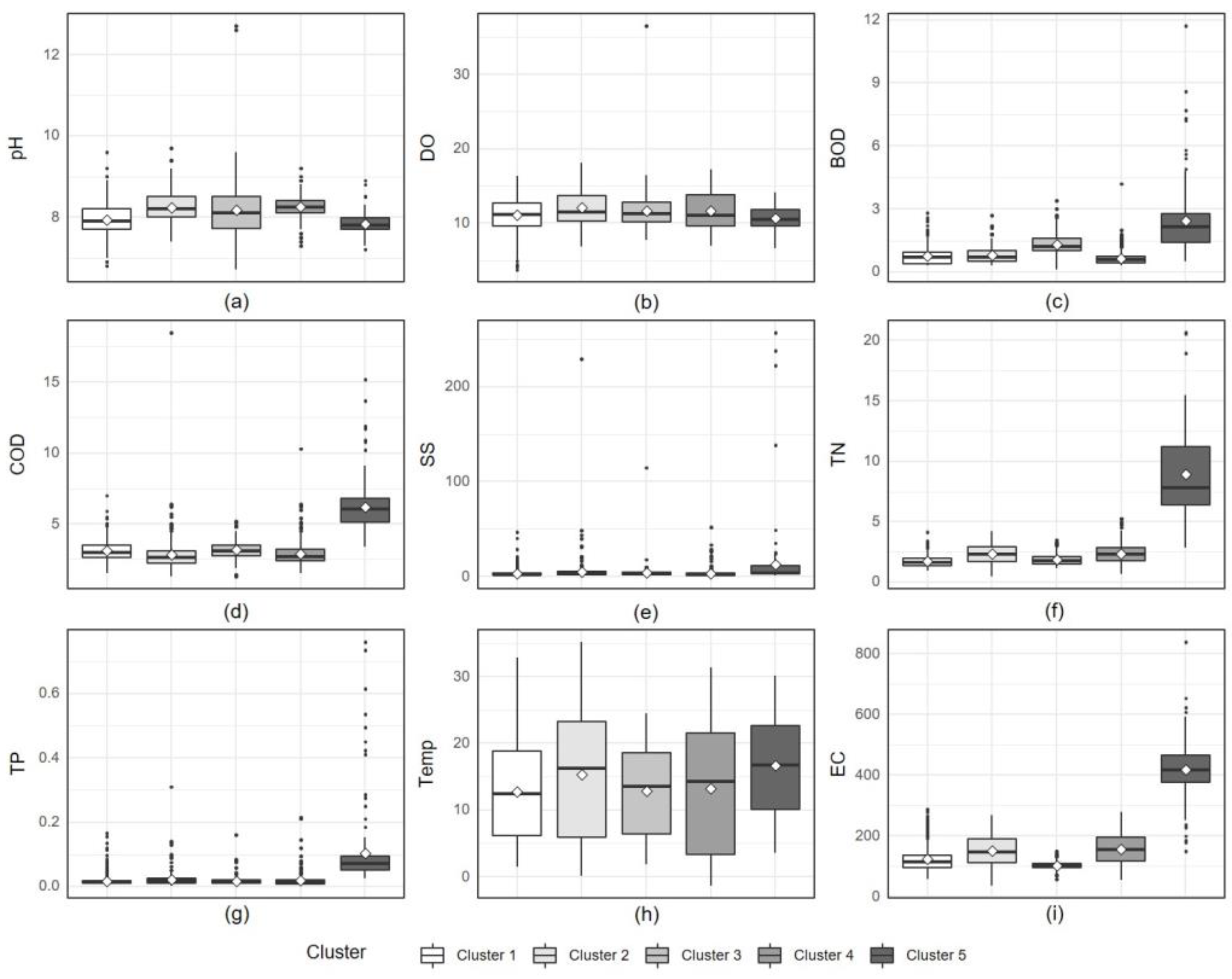
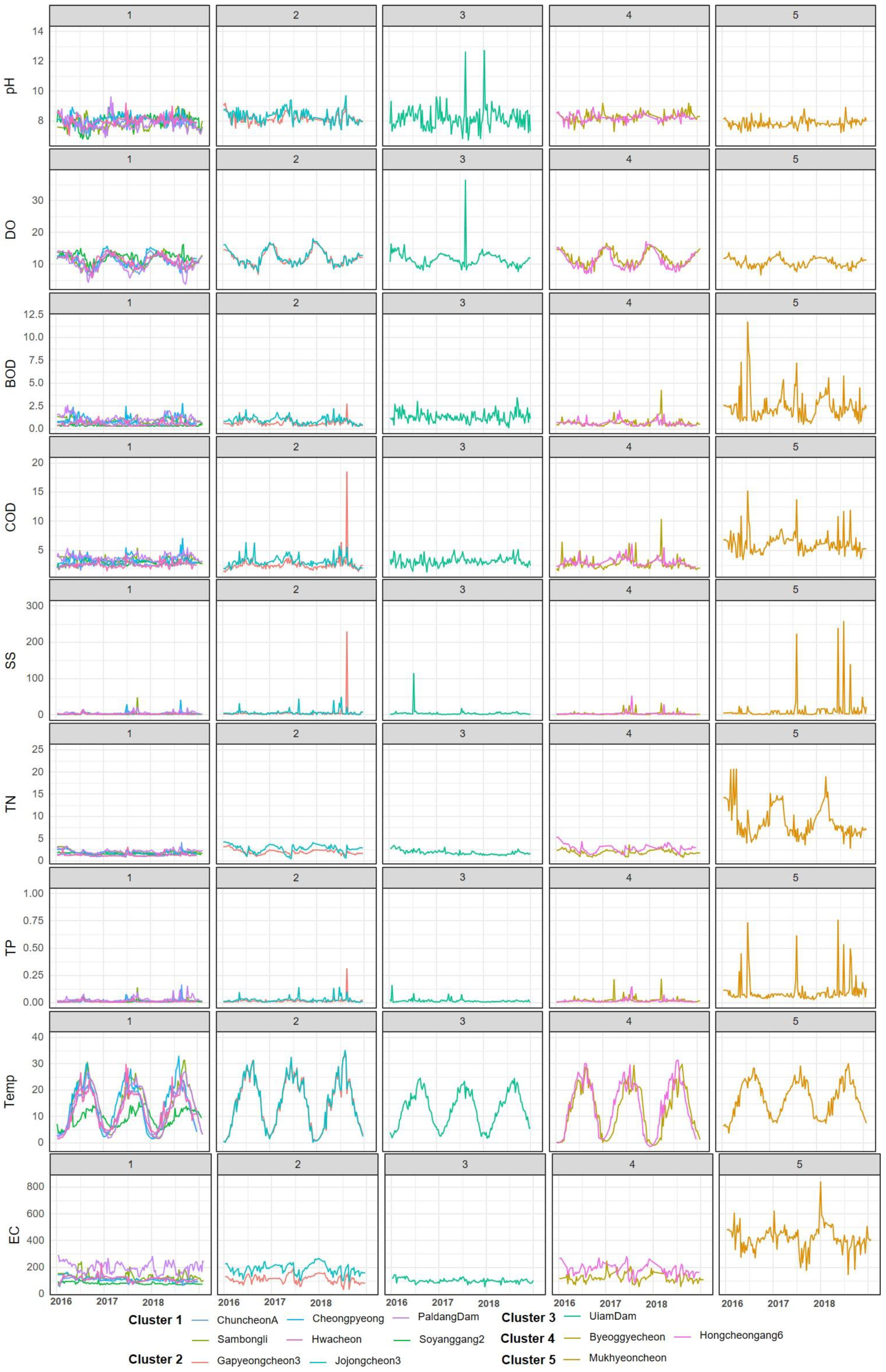
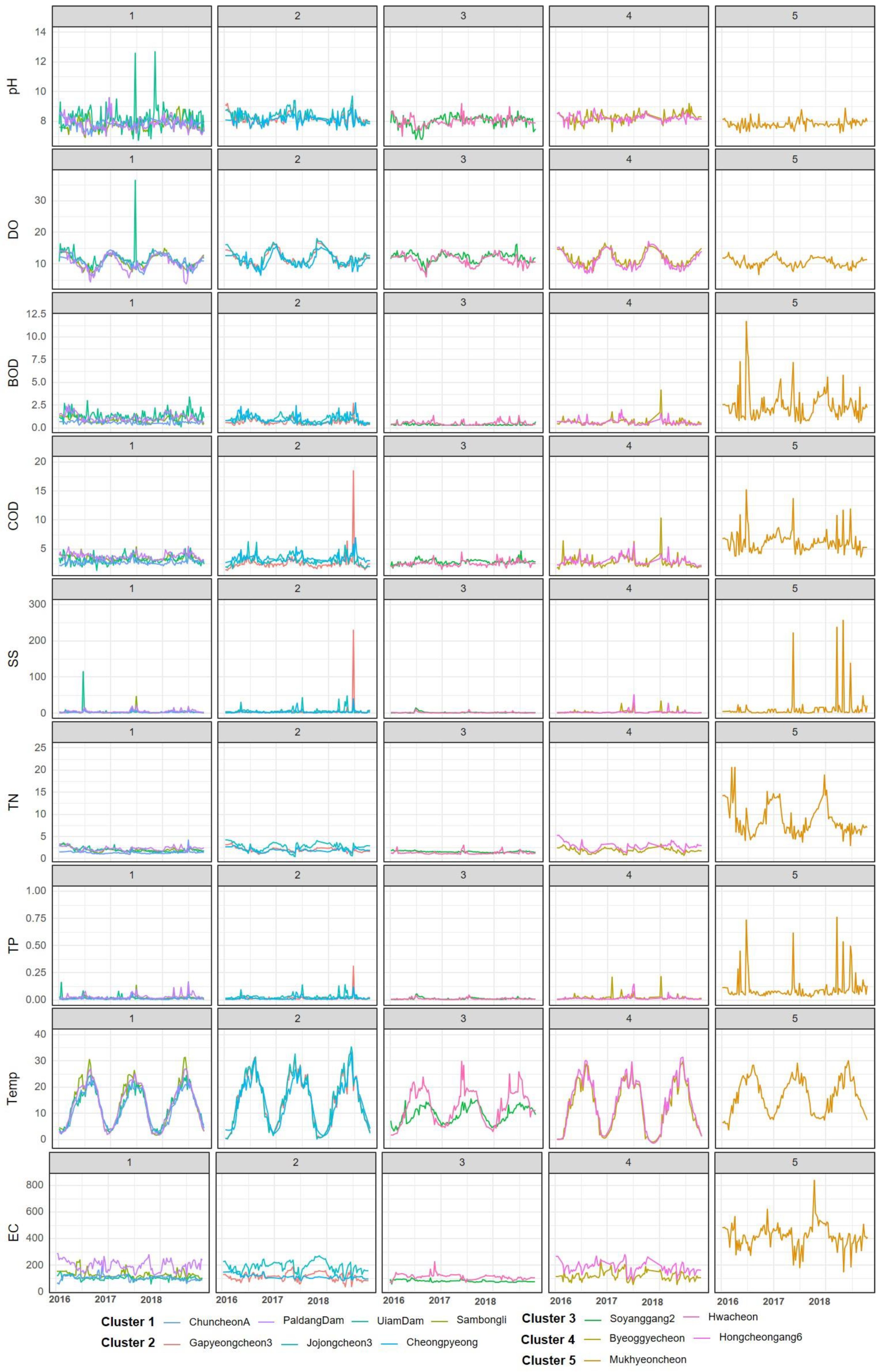
3.3. Comparison of Water Quality Characteristics for Each Cluster
4. Discussion
4.1. Comparison of Clustering and Water Quality Patterns
4.2. Limits and Future Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Driver, H.E.; Kroeber, A.L. Quantitative Expression of Cultural Relationships. In American Archeology and Ethnology; University of California Press: Berkeley, CA, USA, 1932; Volume 31, pp. 211–256. [Google Scholar]
- Aubert, A.H.; Tavenard, R.; Emonet, R.; de Lavenne, A.; Malinowski, S.; Guyet, T.; Quiniou, R.; Odobez, J.-M.; Merot, P.; Gascuel-Odoux, C. Clustering flood events from water quality time series using Latent Dirichlet Allocation model. Water Resour. Res. 2013, 49, 8187–8199. [Google Scholar] [CrossRef]
- Lyra, G.B.; Oliveira-Júnior, J.F.; Zeri, M. Cluster analysis applied to the spatial and temporal variability of monthly rainfall in Alagoas state, Northeast of Brazil. Int. J. Climatol. 2014, 34, 3546–3558. [Google Scholar] [CrossRef]
- Emad, A.M.S.A.-H.; Ahmed, M.T.; Eethar, M.A.-O. Assessment of water quality of Euphrates River using cluster analysis. J. Environ. Prot. 2012, 3, 1629–1633. [Google Scholar] [CrossRef]
- Azhar, S.C.; Aris, A.Z.; Yusoff, M.K.; Ramli, M.F.; Juahir, H. Classification of river water quality using multivariate analysis. Procedia Environ. Sci. 2015, 30, 79–84. [Google Scholar] [CrossRef]
- Bellman, R.; Kalaba, R. On adaptive control processes. IRE Trans. Autom. Control 1959, 4, 1–9. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Dürrenmatt, D.J.; Del Giudice, D.; Rieckermann, J. Dynamic time warping improves sewer flow monitoring. Water Res. 2013, 47, 3803–3816. [Google Scholar] [CrossRef] [PubMed]
- Woo, H.; Boccelli, D.L.; Uber, J.G.; Janke, R.; Su, Y. Dynamic time warping for quantitative analysis of tracer study time-series water quality data. J. Water Res. Plan. Manag. 2019, 145, 04019052. [Google Scholar] [CrossRef]
- Dupas, R.; Tavenard, R.; Fovet, O.; Gilliet, N.; Grimaldi, C.; Gascuel-Odoux, C. Identifying seasonal patterns of phosphorus storm dynamics with dynamic time warping. Water Resour. Res. 2015, 51, 8868–8882. [Google Scholar] [CrossRef]
- Ouyang, R.; Ren, L.; Cheng, W.; Zhou, C. Similarity search and pattern discovery in hydrological time series data mining. Hydrol. Process. Int. J. 2010, 24, 1198–1210. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. References. In Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons, Inc.: Hoboken, NY, USA, 1990; ISBN 978-0-47031680-1. [Google Scholar]
- Sardá-Espinosa, A. Comparing time-series clustering algorithms in r using the dtwclust package. R package vignette. Pattern Recognit. 2017, 12, 41. [Google Scholar] [CrossRef]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; PéRez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Dunn, J.C. Well-separated clusters and optimal fuzzy partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, 1, 224–227. [Google Scholar] [CrossRef] [PubMed]
- Gurrutxaga, I.; Albisua, I.; Arbelaitz, O.; Martín, J.I.; Muguerza, J.; Pérez, J.M.; Perona, I. SEP/COP: An efficient method to find the best partition in hierarchical clustering based on a new cluster validity index. Pattern Recognit. 2010, 43, 3364–3373. [Google Scholar] [CrossRef]
- Kim, M.; Ramakrishna, R.S. New indices for cluster validity assessment. Pattern Recognit. Lett. 2005, 26, 2353–2363. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Abbreviation | Station | Abbreviation | ||
|---|---|---|---|---|---|
| Main stream (MS) | Hwacheon | HC (MS1) | Right tributary (RT) | Gapyeongcheon3 (stream) | GP (RT1) |
| Chuncheon A | CA (MS2) | Jojongcheon3 (stream) | JJ (RT2) | ||
| UiamDam | UD (MS3) | Mukhyeoncheon (stream) | MH (RT3) | ||
| Cheongpyeong | CP (MS4) | Left tributary (LT) | Soyanggang2 (river) | SY (LT1) | |
| Sambongli | SB (MS5) | Hongcheongang6 (river) | HG (LT2) | ||
| PaldangDam | PD (MS6) | Byeoggyecheon (stream) | BG (LT3) |
| Variable | Description | Mean | SD | |
|---|---|---|---|---|
| pH | Hydrogen Ion Concentration | 8.05 | 0.45 | |
| DO | Dissolved Oxygen | mg/L | 11.04 | 2.06 |
| BOD | Biochemical Oxygen Demand | mg/L | 0.98 | 0.92 |
| COD | Chemical Oxygen Demand | mg/L | 3.30 | 1.32 |
| SS | Suspended Solid | mg/L | 4.64 | 14.42 |
| TN | Total Nitrogen | mg/L | 2.46 | 1.99 |
| TP | Total Phosphorus | mg/L | 0.03 | 0.06 |
| Temp | Temperature | °C | 14.96 | 7.54 |
| EC | Electrical Conductivity | μmhos/cm | 152.76 | 86.24 |
| Mainstream | |||||||||
| Hwacheon | Chuncheon A | UiamDam | |||||||
| Variable | Mean | SD | N | Mean | SD | N | Mean | SD | N |
| pH | 8.01 | 0.32 | 149 | 7.83 | 0.25 | 149 | 8.17 | 0.78 | 150 |
| DO | 11.10 | 1.78 | 149 | 10.43 | 2.10 | 149 | 11.60 | 2.68 | 150 |
| BOD | 0.53 | 0.25 | 149 | 0.59 | 0.17 | 149 | 1.31 | 0.55 | 150 |
| COD | 2.55 | 0.48 | 149 | 2.74 | 0.41 | 149 | 3.16 | 0.70 | 150 |
| SS | 1.92 | 1.59 | 149 | 2.56 | 1.99 | 149 | 4.05 | 9.37 | 150 |
| TN | 1.29 | 0.36 | 149 | 1.31 | 0.33 | 149 | 1.89 | 0.49 | 150 |
| TP | 0.01 | 0.01 | 149 | 0.01 | 0.02 | 149 | 0.02 | 0.02 | 150 |
| Temp | 13.91 | 6.20 | 149 | 13.71 | 5.89 | 149 | 12.89 | 6.64 | 150 |
| EC | 113.31 | 19.73 | 149 | 106.13 | 18.66 | 149 | 101.83 | 14.69 | 150 |
| Cheongpyeong | Sambongli | PaldangDam | |||||||
| Variable | Mean | SD | N | Mean | SD | N | Mean | SD | N |
| pH | 8.11 | 0.32 | 149 | 7.79 | 0.44 | 155 | 7.82 | 0.42 | 155 |
| DO | 10.86 | 1.84 | 149 | 10.40 | 1.74 | 155 | 10.10 | 2.40 | 155 |
| BOD | 1.00 | 0.49 | 149 | 0.90 | 0.29 | 155 | 1.16 | 0.38 | 155 |
| COD | 3.50 | 0.66 | 149 | 3.46 | 0.49 | 155 | 3.79 | 0.52 | 155 |
| SS | 3.91 | 4.66 | 149 | 3.37 | 4.39 | 155 | 5.16 | 3.52 | 155 |
| TN | 1.87 | 0.38 | 149 | 1.88 | 0.33 | 155 | 2.20 | 0.41 | 155 |
| TP | 0.02 | 0.02 | 149 | 0.02 | 0.01 | 155 | 0.03 | 0.02 | 155 |
| Temp | 16.58 | 7.42 | 149 | 15.64 | 7.69 | 155 | 13.78 | 7.72 | 155 |
| EC | 112.41 | 16.06 | 149 | 127.52 | 27.20 | 155 | 198.62 | 37.69 | 155 |
| Right tributary | |||||||||
| Gapyeongcheon3 (stream) | Jojongcheon3 (stream) | Mukhyeoncheon (stream) | |||||||
| Variable | Mean | SD | N | Mean | SD | N | Mean | SD | N |
| pH | 8.15 | 0.34 | 149 | 8.31 | 0.44 | 149 | 7.82 | 0.30 | 153 |
| DO | 11.37 | 1.90 | 149 | 11.56 | 2.03 | 149 | 10.34 | 1.34 | 153 |
| BOD | 0.66 | 0.35 | 149 | 0.94 | 0.40 | 149 | 2.38 | 1.75 | 153 |
| COD | 2.62 | 1.63 | 149 | 3.15 | 0.88 | 149 | 6.17 | 1.94 | 153 |
| SS | 4.32 | 21.12 | 149 | 5.74 | 8.00 | 149 | 12.08 | 38.83 | 153 |
| TN | 1.90 | 0.47 | 149 | 2.60 | 0.81 | 149 | 3.34 | 3.50 | 153 |
| TP | 0.01 | 0.03 | 149 | 0.03 | 0.02 | 149 | 0.10 | 0.13 | 153 |
| Temp | 17.36 | 8.37 | 149 | 17.61 | 8.62 | 149 | 18.29 | 6.11 | 153 |
| EC | 108.94 | 28.74 | 149 | 182.71 | 36.91 | 149 | 406.71 | 91.45 | 153 |
| Left tributary | |||||||||
| Soyanggang2 (river) | Hongcheongang6 (river) | Byeoggyecheon (stream) | |||||||
| Variable | Mean | SD | N | Mean | SD | N | Mean | SD | N |
| pH | 8.00 | 0.40 | 154 | 8.21 | 0.24 | 149 | 8.28 | 0.33 | 153 |
| DO | 12.14 | 1.42 | 154 | 10.34 | 2.00 | 149 | 11.37 | 1.94 | 153 |
| BOD | 0.36 | 0.12 | 154 | 0.62 | 0.31 | 149 | 0.61 | 0.41 | 153 |
| COD | 2.78 | 0.41 | 154 | 3.00 | 0.74 | 149 | 2.78 | 1.12 | 153 |
| SS | 1.70 | 1.86 | 154 | 2.94 | 5.91 | 149 | 3.22 | 5.34 | 153 |
| TN | 1.59 | 0.15 | 154 | 2.65 | 0.74 | 149 | 1.79 | 0.55 | 153 |
| TP | 0.01 | 0.01 | 154 | 0.02 | 0.02 | 149 | 0.02 | 0.03 | 153 |
| Temp | 9.50 | 3.14 | 154 | 16.92 | 8.12 | 149 | 15.10 | 8.27 | 153 |
| EC | 79.88 | 8.13 | 154 | 180.59 | 39.28 | 149 | 118.48 | 31.62 | 153 |
| # of Cluster | Clustering Validation Index | ||||||
|---|---|---|---|---|---|---|---|
| Sil | CH | DB | MDB | D | COP | ||
| Euclidean algorithm | 2 | 0.160 | 12.436 | 1.257 | 1.257 | 0.701 | 0.668 |
| 3 | 0.140 | 6.578 | 1.245 | 1.245 | 0.776 | 0.532 | |
| 4 | 0.131 | 4.430 | 1.054 | 1.091 | 0.776 | 0.464 | |
| 5 | 0.050 | 3.384 | 0.939 | 1.066 | 0.659 | 0.423 | |
| DTW algorithm | 2 | 0.106 | 7.649 | 1.493 | 1.493 | 0.763 | 0.681 |
| 3 | 0.128 | 3.981 | 1.338 | 1.353 | 0.824 | 0.594 | |
| 4 | 0.130 | 2.737 | 1.116 | 1.144 | 0.824 | 0.514 | |
| 5 | 0.044 | 3.064 | 1.028 | 1.135 | 0.624 | 0.476 | |
| Euclidean Algorithm | DTW Algorithm | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| pH | Cluster | 4 | 2 | 3 | 1 | 5 | 4 | 2 | 3 | 1 | 5 |
| Mean | 8.251 | 8.192 | 8.017 | 7.915 | 7.826 | 8.255 | 8.242 | 8.174 | 7.932 | 7.829 | |
| Group | a | a | b | c | c | a | a | a | b | c | |
| DO | Cluster | 2 | 3 | 4 | 1 | 5 | 2 | 4 | 3 | 1 | 5 |
| Mean | 11.798 | 11.718 | 11.603 | 10.863 | 10.599 | 12.047 | 11.613 | 11.598 | 11.076 | 10.596 | |
| Group | a | a | a | b | b | a | a | ab | bc | c | |
| BOD | Cluster | 5 | 1 | 2 | 4 | 3 | 5 | 3 | 2 | 1 | 4 |
| Mean | 2.466 | 0.995 | 0.838 | 0.652 | 0.437 | 2.420 | 1.313 | 0.723 | 0.752 | 0.647 | |
| Group | a | b | c | d | e | a | b | c | cd | d | |
| COD | Cluster | 5 | 1 | 2 | 4 | 3 | 5 | 3 | 1 | 4 | 2 |
| Mean | 6.229 | 3.274 | 3.016 | 2.883 | 2.645 | 6.200 | 3.157 | 3.116 | 2.874 | 2.810 | |
| Group | a | b | c | c | d | a | b | b | c | c | |
| SS | Cluster | 5 | 2 | 1 | 4 | 3 | 5 | 2 | 3 | 1 | 4 |
| Mean | 12.753 | 4.619 | 3.744 | 2.973 | 1.180 | 12.393 | 5.017 | 4.055 | 3.016 | 3.004 | |
| Group | a | b | bc | bc | c | a | b | b | b | b | |
| TN | Cluster | 5 | 4 | 2 | 1 | 3 | 5 | 2 | 4 | 3 | 1 |
| Mean | 8.896 | 2.348 | 2.204 | 1.838 | 1.432 | 8.955 | 2.363 | 2.348 | 1.890 | 1.708 | |
| Group | a | b | b | c | d | a | b | b | c | c | |
| TP | Cluster | 5 | 1 | 2 | 4 | 3 | 5 | 2 | 4 | 3 | 1 |
| Mean | 0.104 | 0.019 | 0.019 | 0.018 | 0.011 | 0.102 | 0.021 | 0.018 | 0.017 | 0.016 | |
| Group | a | b | b | bc | c | a | b | b | b | b | |
| Temp | Cluster | 5 | 2 | 4 | 1 | 3 | 5 | 2 | 4 | 3 | 1 |
| Mean | 16.725 | 14.945 | 13.241 | 13.097 | 11.006 | 16.691 | 15.263 | 13.205 | 12.887 | 12.735 | |
| Group | a | a | b | b | c | a | a | b | b | b | |
| EC | Cluster | 5 | 4 | 2 | 1 | 3 | 5 | 4 | 2 | 1 | 3 |
| Mean | 418.594 | 156.011 | 137.684 | 132.976 | 96.678 | 418.398 | 155.536 | 150.155 | 123.336 | 101.827 | |
| Group | a | b | c | c | d | a | b | b | c | d | |
| Cluster | Station | Variable | Location | |
|---|---|---|---|---|
| Characteristics | Characteristics | |||
| Euclidean algorithm | 1 | CA(MS2), UD(MS3), SB(MS5), PD(MS6) | low: pH, DO | Mainstream |
| 2 | GP(RT1), JJ(RT2), CP(MS4), | high: pH, DO, Temp | Right tributary Mainstream Midstream | |
| 3 | SY(LT1), HC(MS1) | high: DO | Left tributary Mainstream Upstream | |
| low: BOD, COD, SS, TN, TP, Temp, EC | ||||
| 4 | BG(LT3), HG(LT2) | high: pH, DO | Left downstream tributary | |
| 5 | MH(RT3) | high: BOD, COD, SS, TN, TP, Temp, EC | Right downstream tributary | |
| low: pH, DO | ||||
| DTW algorithm | 1 | HC(MS1), CA(MS2), CP(MS4), SB(MS5), PD(MS6), SY(LT1) | low: TN, Temp | Left tributary Mainstream |
| 2 | GP(RT1), JJ(RT2) | high: pH, DO, Temp | Right midstream tributary | |
| low: COD | ||||
| 3 | UD(MS3) | high: pH | Mainstream | |
| low: TN, Temp, EC | ||||
| 4 | HG(LT2), BG(LT3) | high: pH, DO | Left downstream tributary | |
| low: BOD, COD, Temp | ||||
| 5 | MH(RT3) | high: BOD, COD, SS, TN, TP, Temp, EC | Right downstream tributary | |
| low: pH, DO |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Kim, J.; Hwang, J.; Lee, E.; Lee, K.-J.; Oh, J.; Park, J.; Heo, T.-Y. Clustering of Time Series Water Quality Data Using Dynamic Time Warping: A Case Study from the Bukhan River Water Quality Monitoring Network. Water 2020, 12, 2411. https://doi.org/10.3390/w12092411
Lee S, Kim J, Hwang J, Lee E, Lee K-J, Oh J, Park J, Heo T-Y. Clustering of Time Series Water Quality Data Using Dynamic Time Warping: A Case Study from the Bukhan River Water Quality Monitoring Network. Water. 2020; 12(9):2411. https://doi.org/10.3390/w12092411
Chicago/Turabian StyleLee, Seulbi, Jaehoon Kim, Jongyeon Hwang, EunJi Lee, Kyoung-Jin Lee, Jeongkyu Oh, Jungsu Park, and Tae-Young Heo. 2020. "Clustering of Time Series Water Quality Data Using Dynamic Time Warping: A Case Study from the Bukhan River Water Quality Monitoring Network" Water 12, no. 9: 2411. https://doi.org/10.3390/w12092411
APA StyleLee, S., Kim, J., Hwang, J., Lee, E., Lee, K.-J., Oh, J., Park, J., & Heo, T.-Y. (2020). Clustering of Time Series Water Quality Data Using Dynamic Time Warping: A Case Study from the Bukhan River Water Quality Monitoring Network. Water, 12(9), 2411. https://doi.org/10.3390/w12092411