Global River Monitoring Using Semantic Fusion Networks




Abstract
1. Introduction
2. Materials and Methods
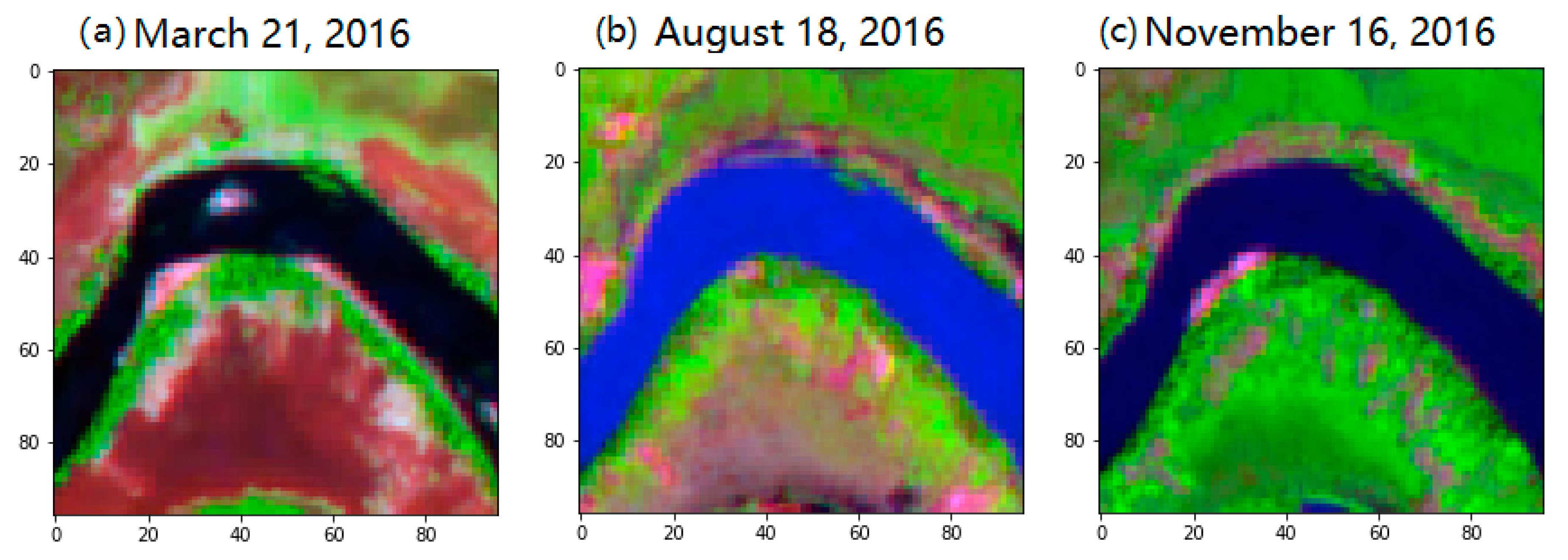
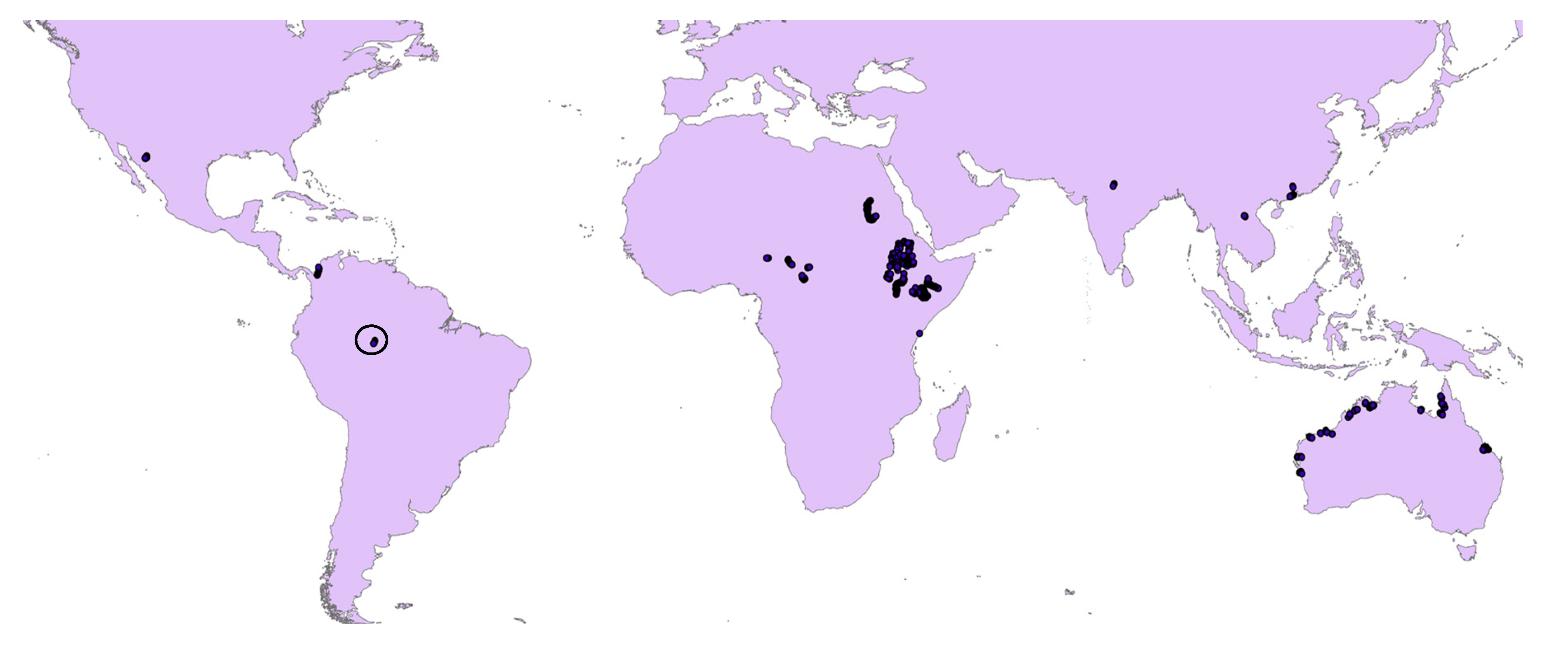
2.1. Study Area and Data
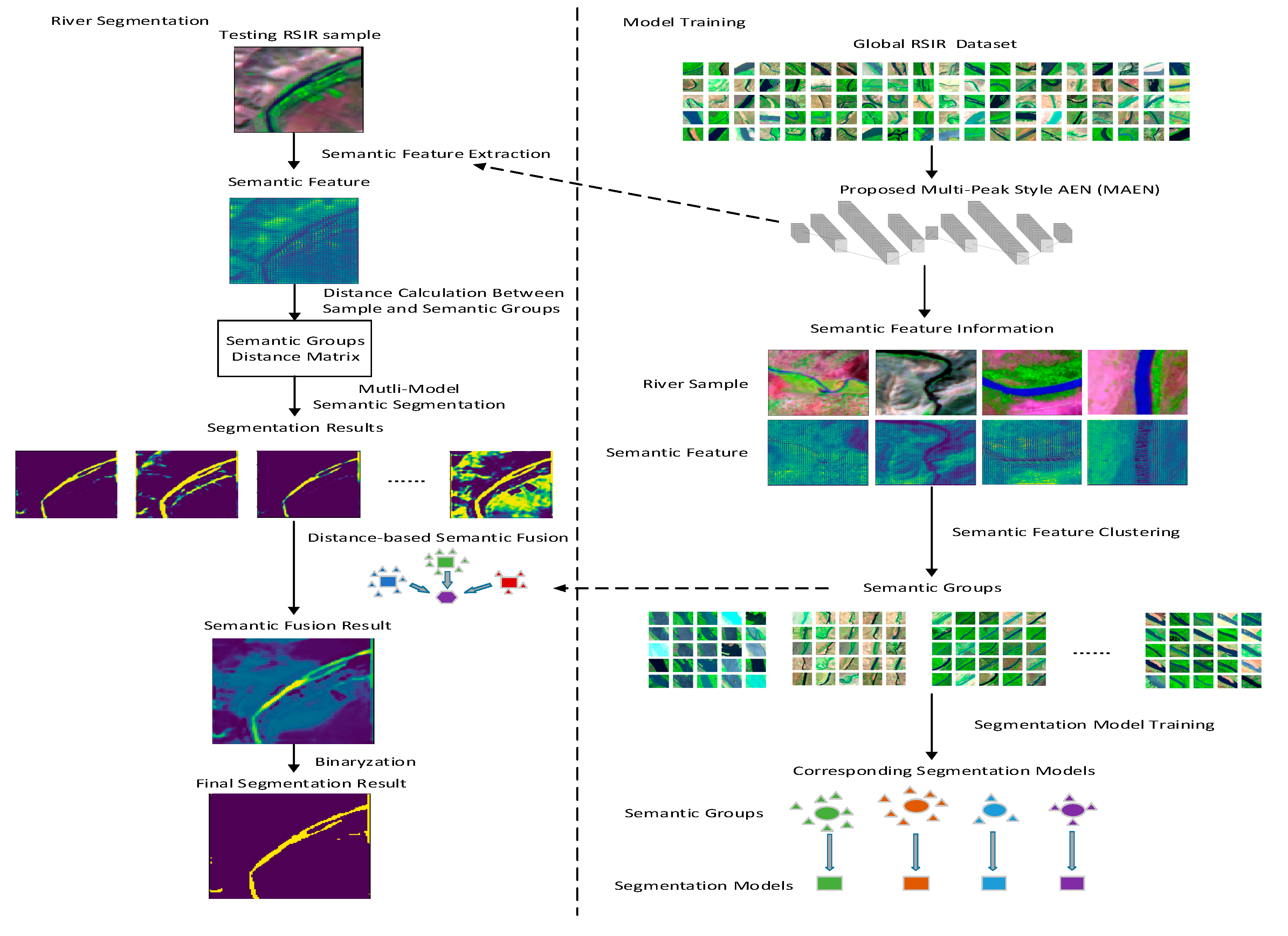
2.2. Proposed Method
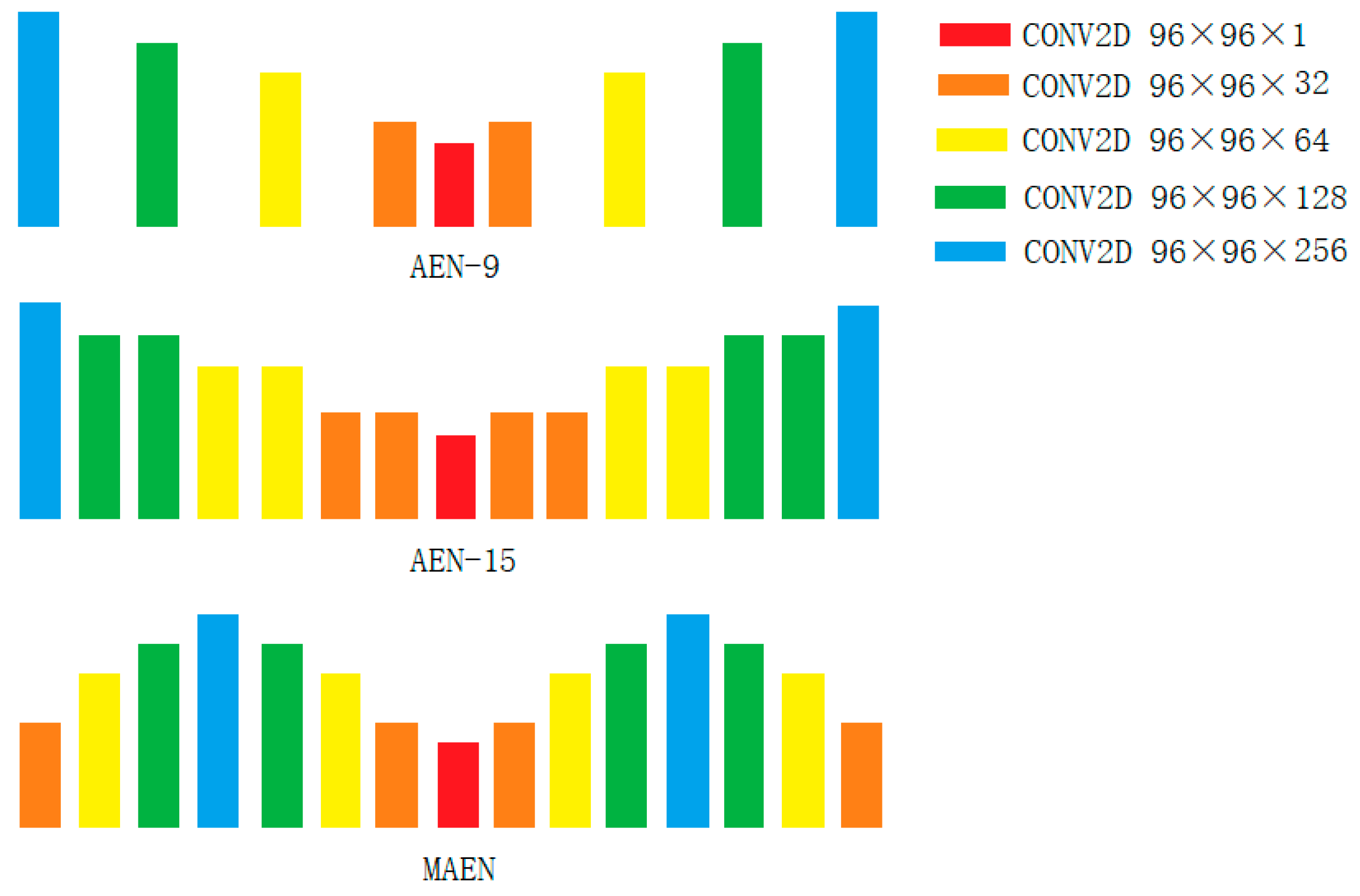
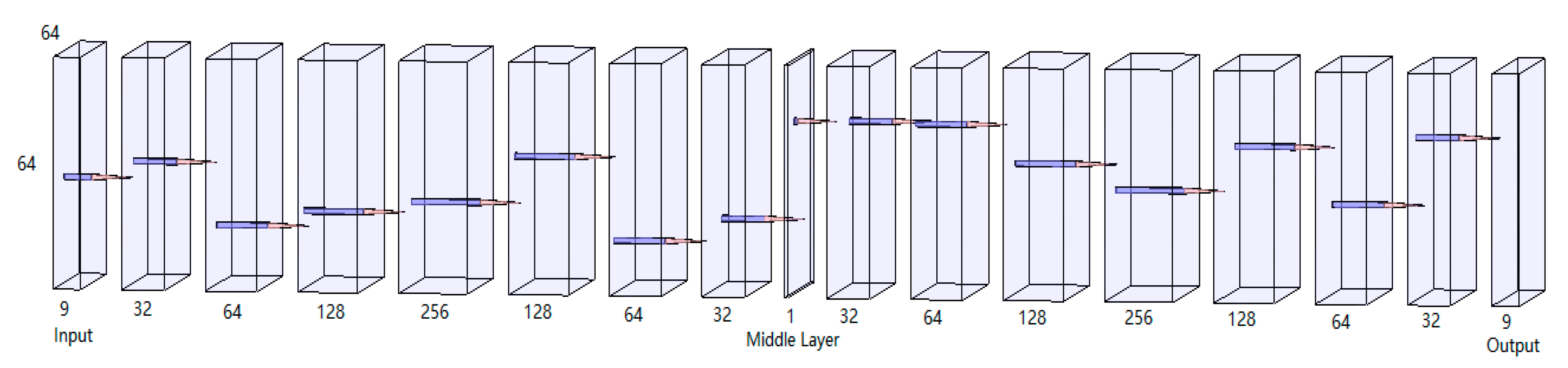
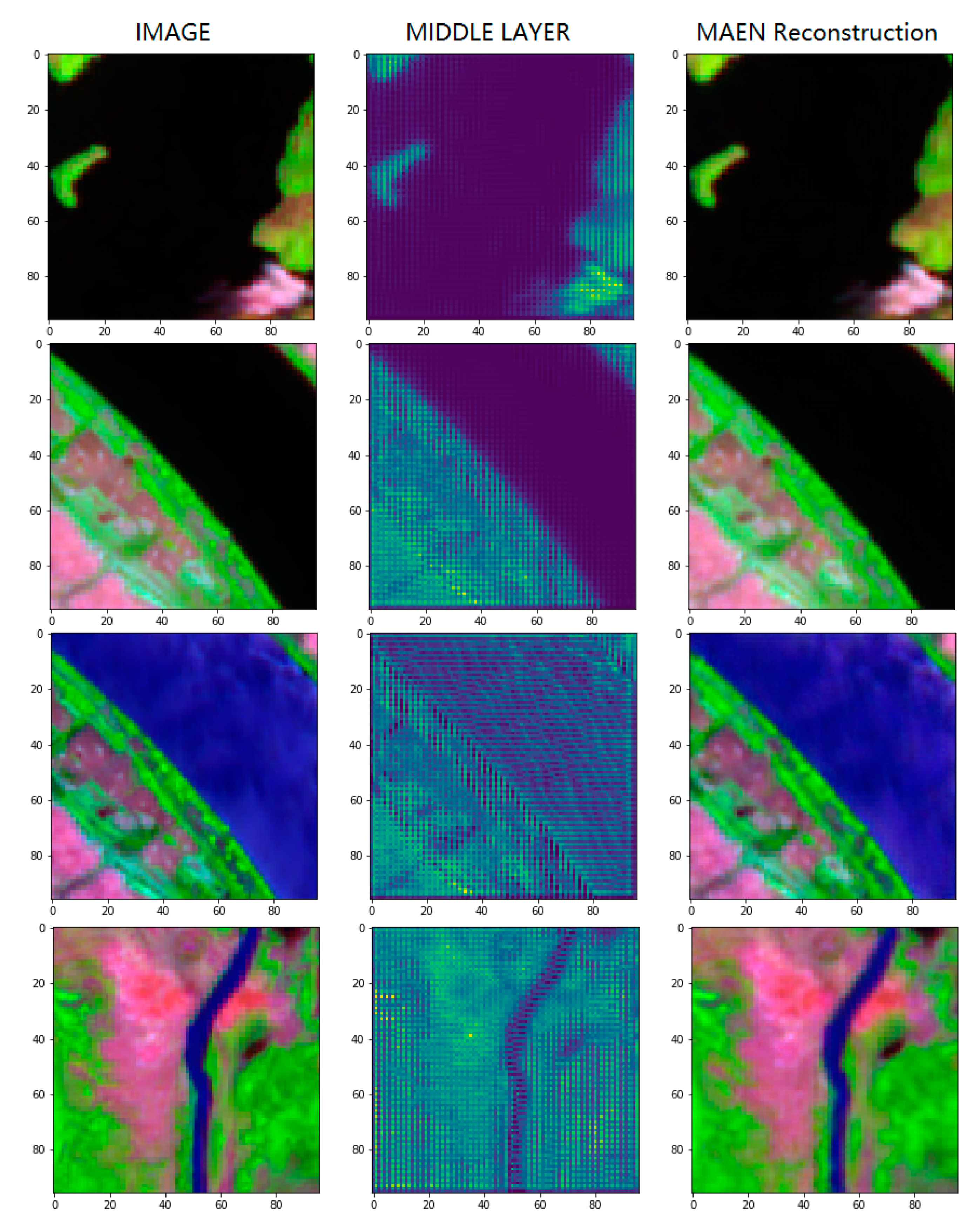
2.2.1. Semantic Feature Extraction Based on MAEN
2.2.2. Manifold Learning-Based Clustering
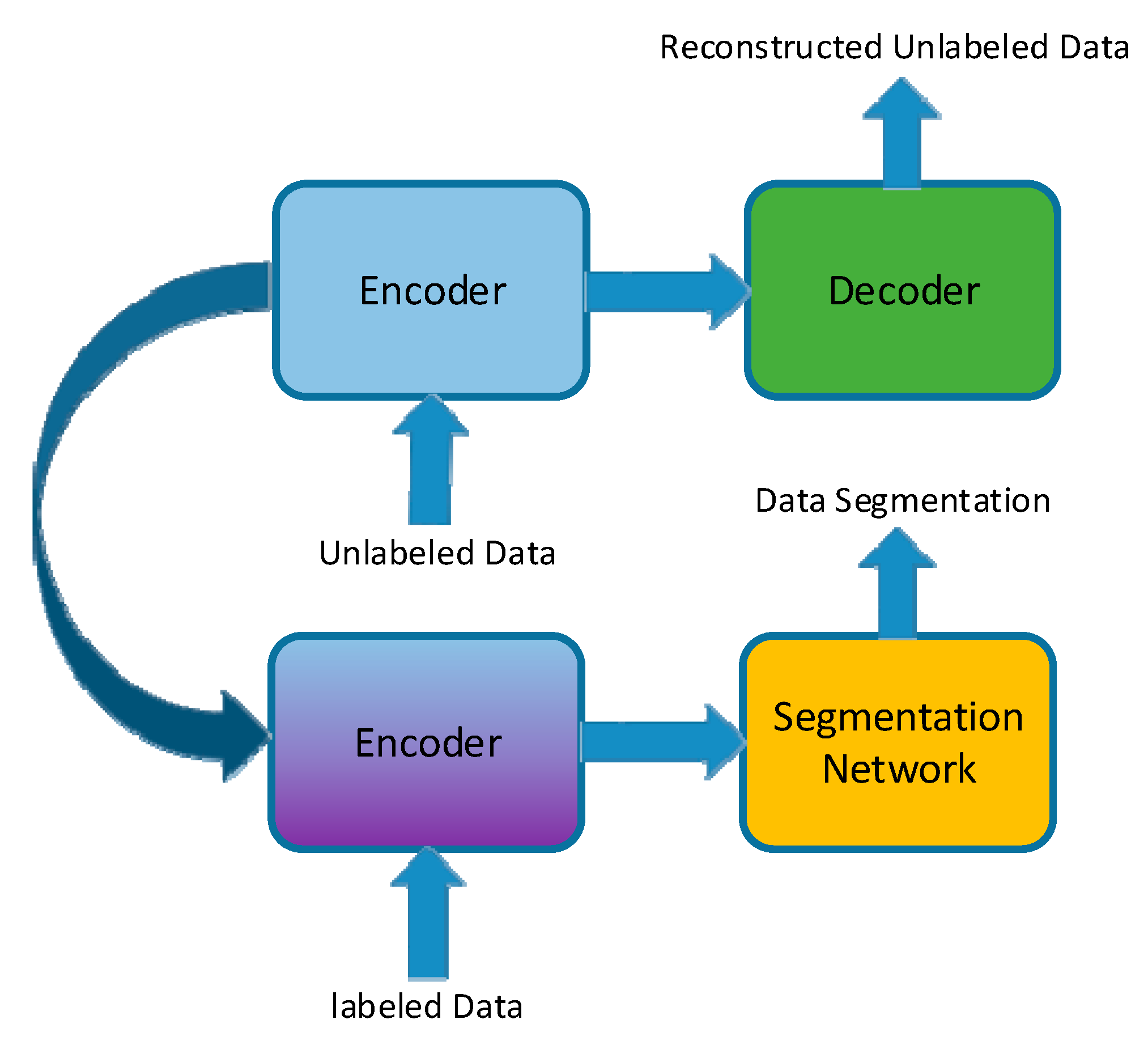
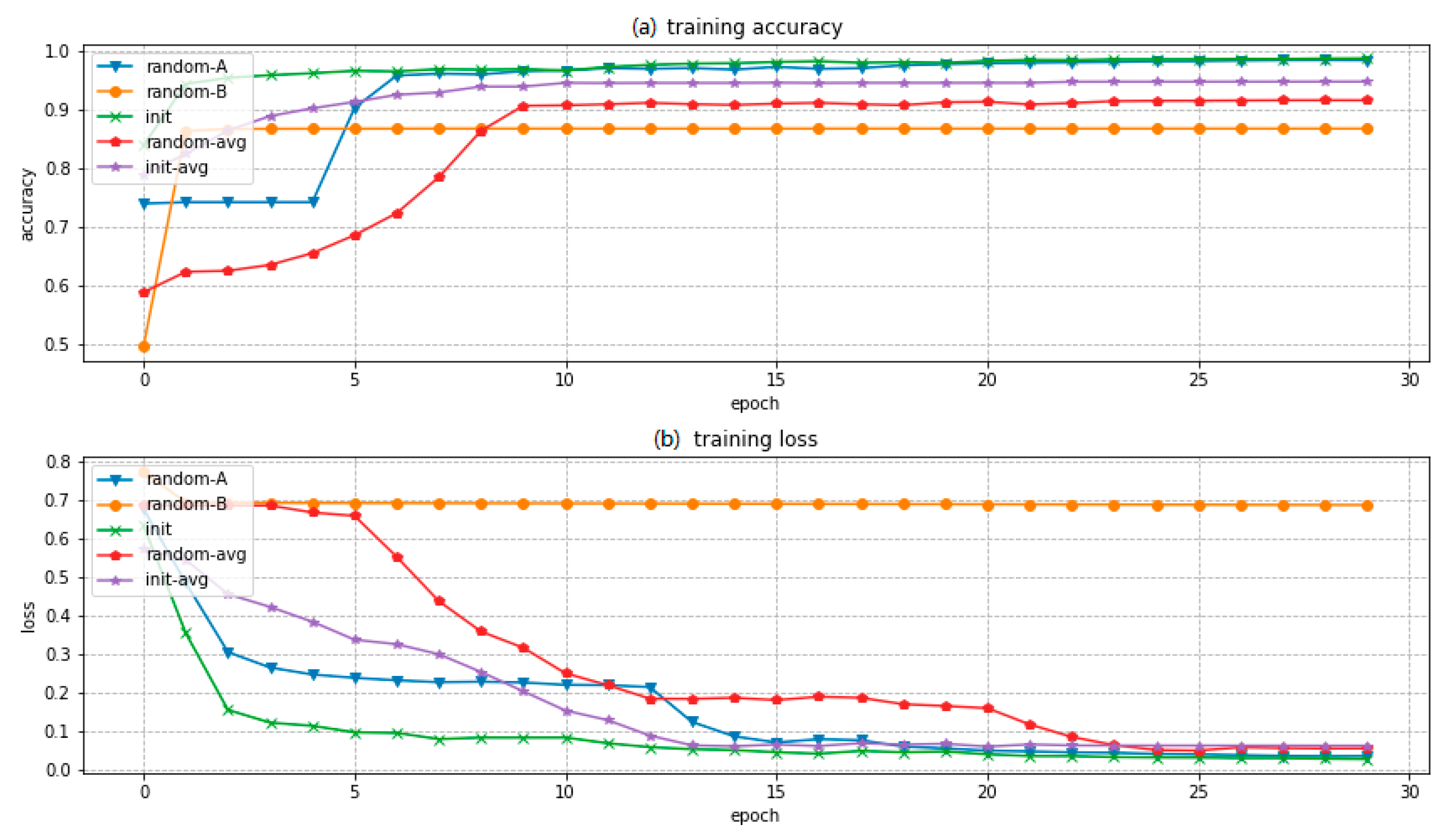
2.2.3. Semi-Supervised Learning Based on Information Transform
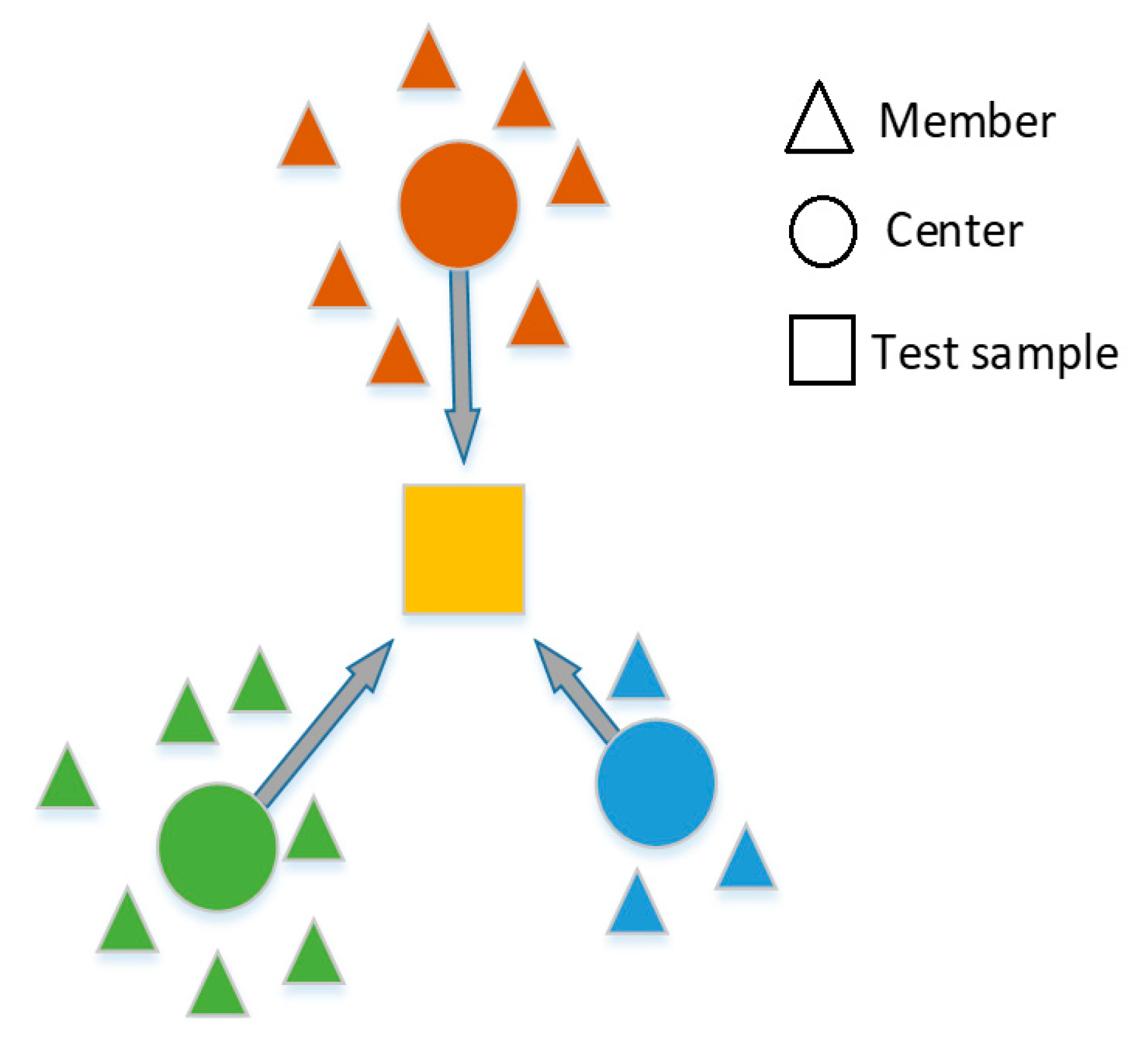
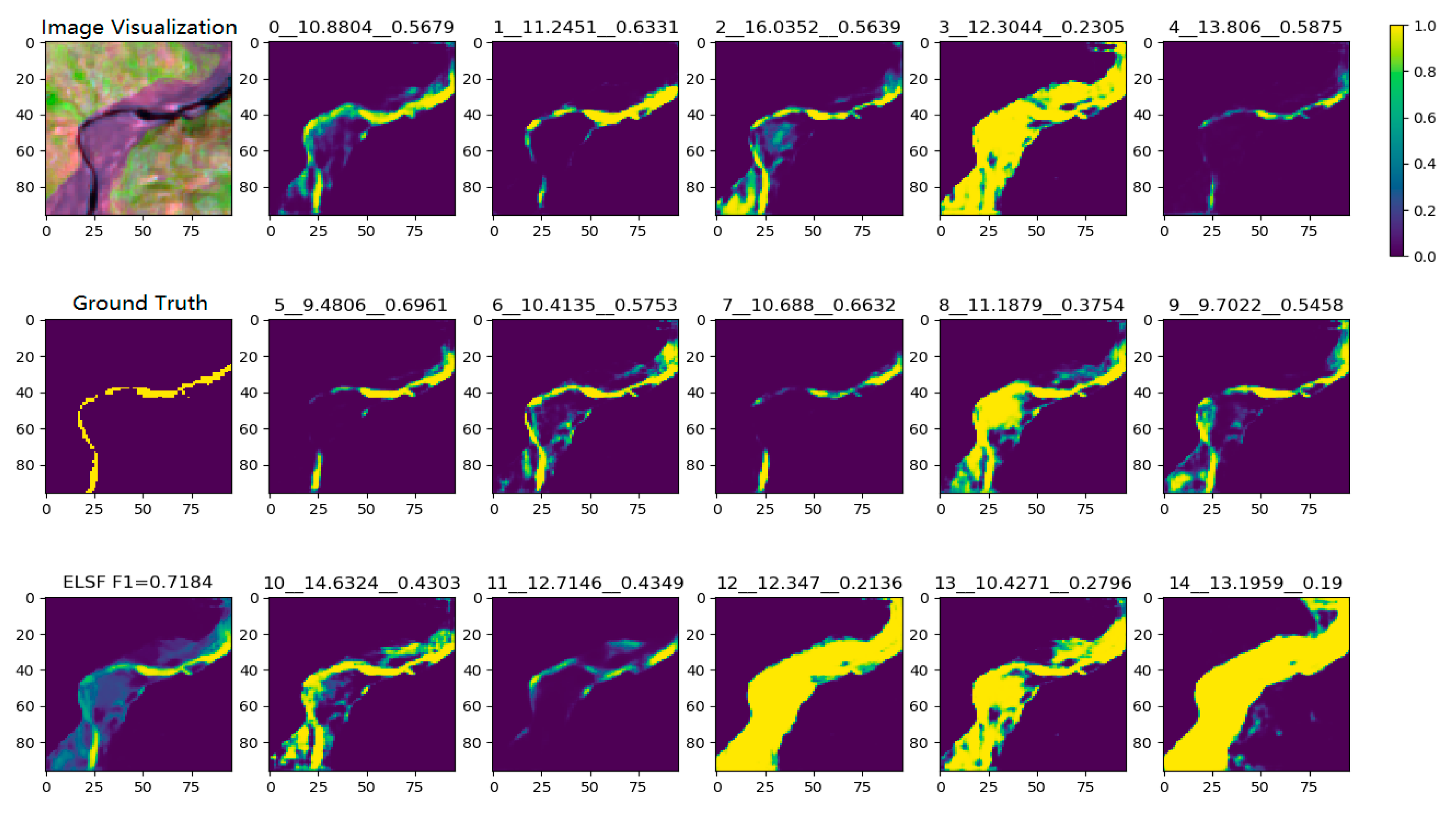
2.2.4. Ensemble Learning-Based Similarity Fusion
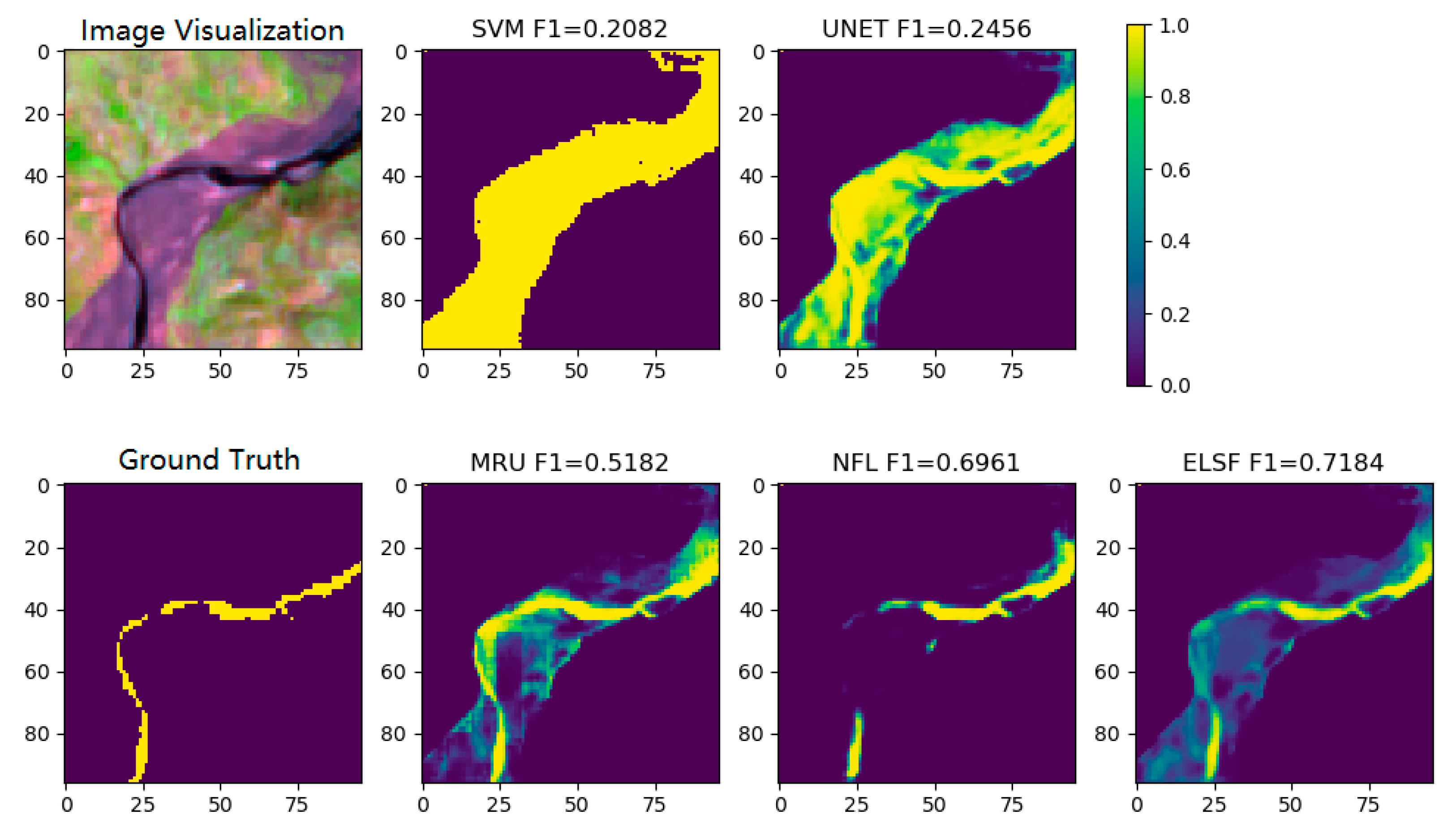
2.3. Four Algorithms (SVM, UNet, MultiResUNet, NFL) Used for Comparison with ELSF
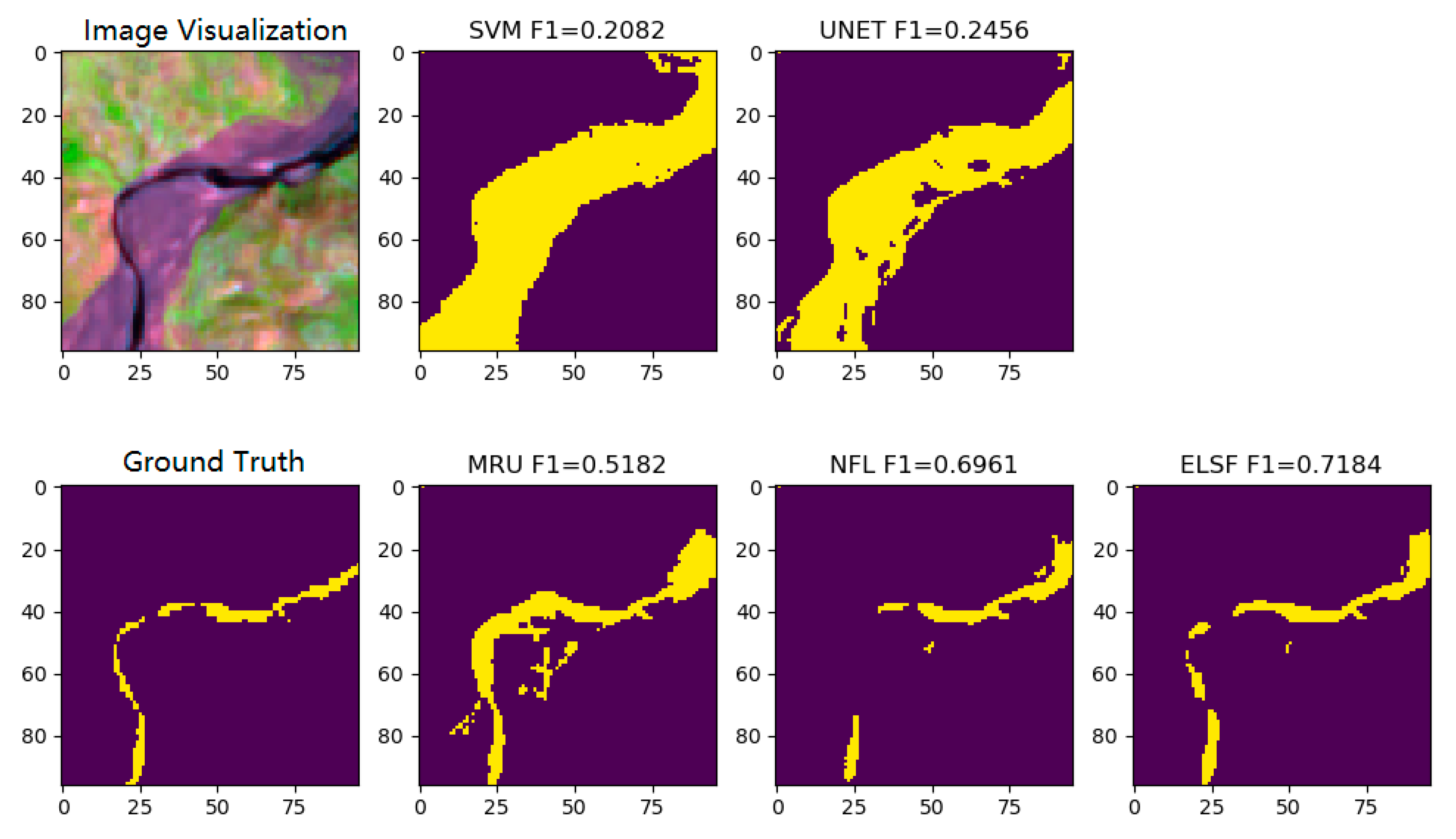
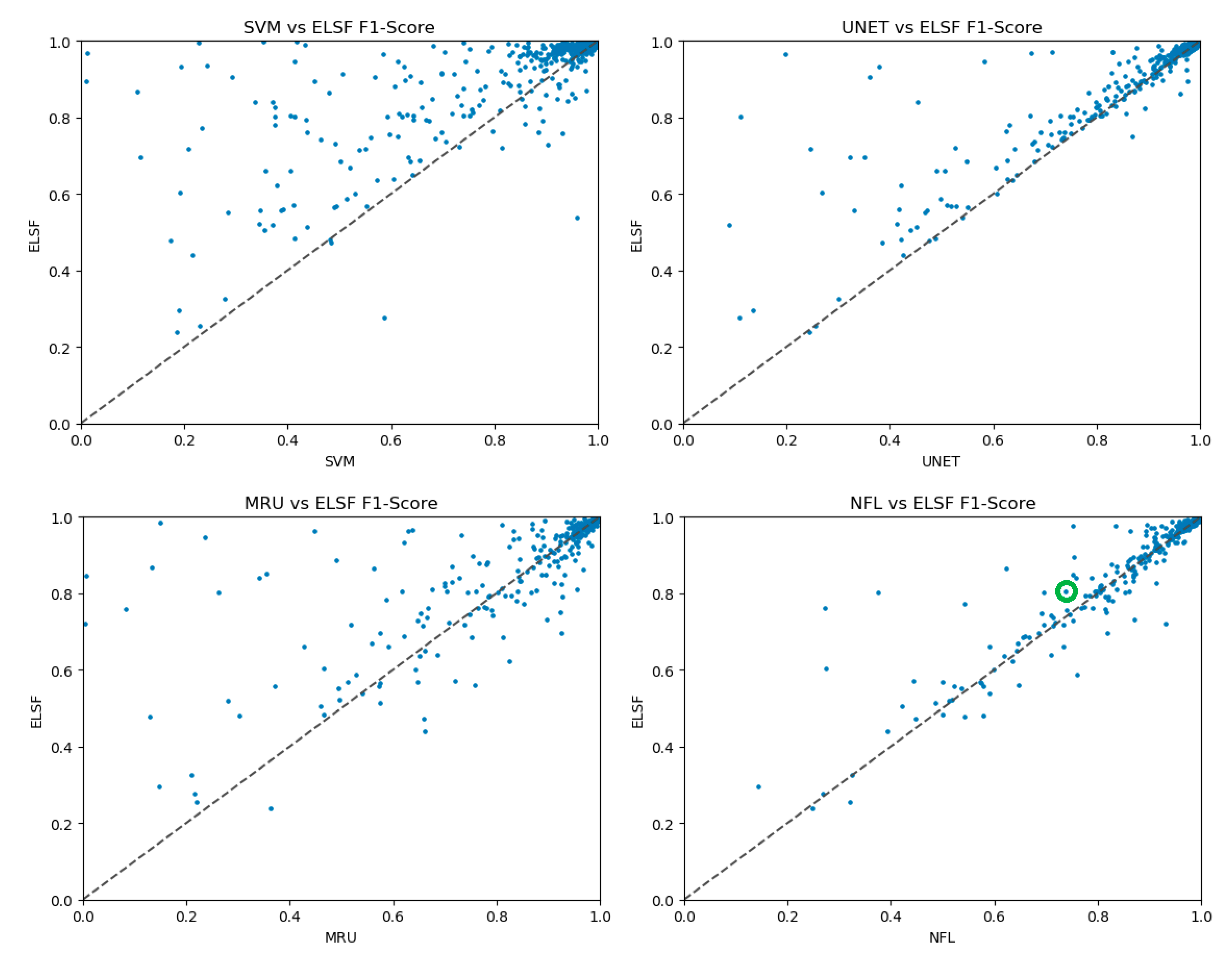
3. Results and Discussion
3.1. Experiment Setup
3.2. Semantic Feature Extraction Based on MAEN
3.3. Semi-Supervised Learning Based on Information Transform
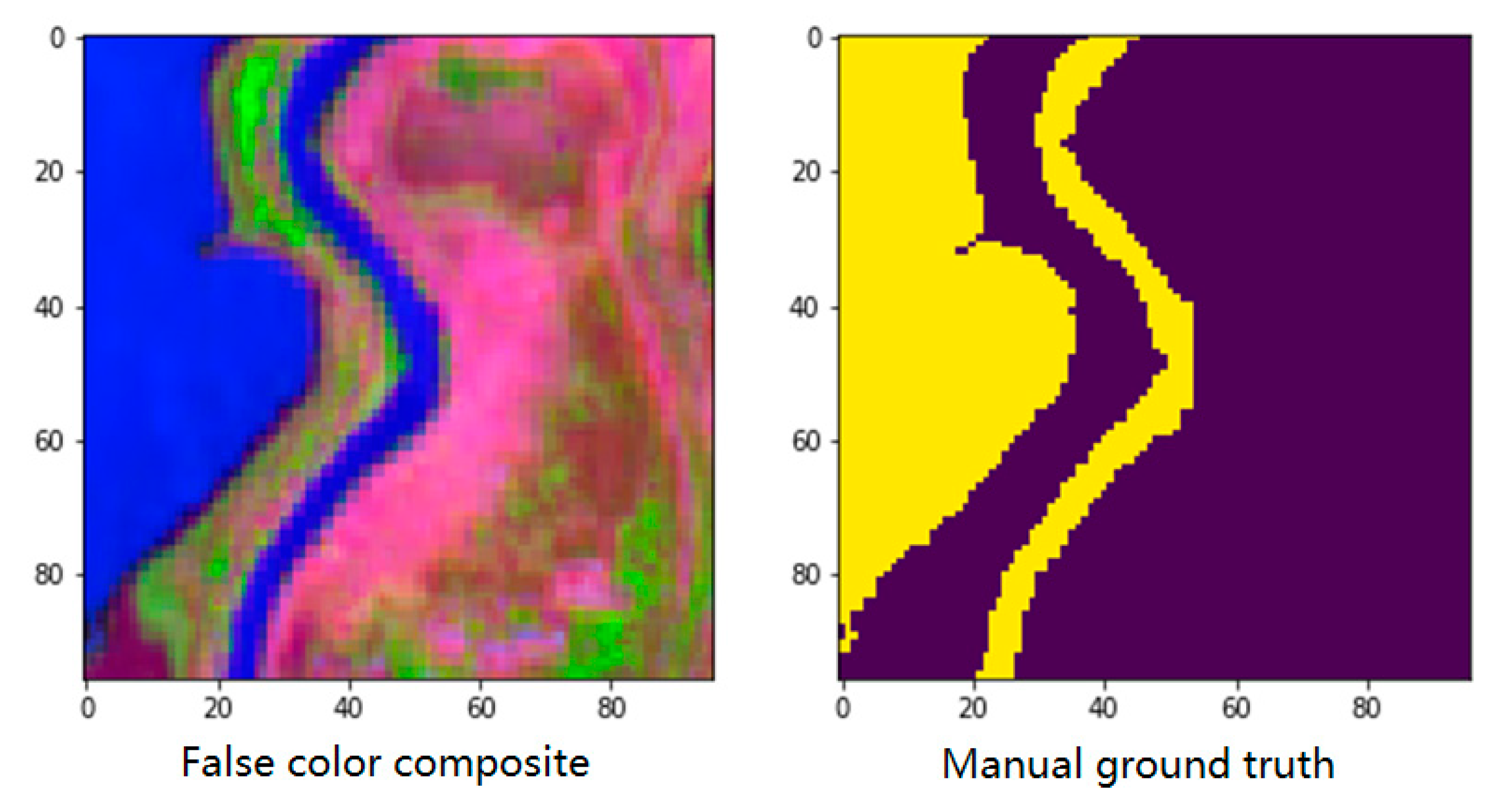
3.4. Global River Segmentation
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pekel, J.-F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.L.; Chau, K.W. Prediction of rainfall time series using modular soft computingmethods. Eng. Appl. Artif. Intel. 2013, 26, 997–1007. [Google Scholar] [CrossRef]
- Mueller, N.; Lewis, A.; Roberts, D.; Ring, S.; Melrose, R.; Sixsmith, J.; Lymburner, L.; Mclntyre, A.; Tan, P.; Curnow, S.; et al. Water observations from space: Mapping surface water from 25 years of Landsat imagery across Australia. Remote Sens. Environ. 2016, 174, 341–352. [Google Scholar] [CrossRef]
- Tweed, S.; Marc, L.; Ian, C. Groundwater–surface water interaction and the impact of a multi-year drought on lakes conditions in South-East Australia. J. Hydrol. 2009, 379, 41–53. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.N.; Xia, D.Z.; Liu, Y.Y. An Analysis of Land Use Change Dynamics and Its Impacts on Hydrological Processes in the Jialing River Basin. Water 2014, 6, 3758–3782. [Google Scholar] [CrossRef]
- Akbari, M.; Torabi Haghighi, A.; Aghayi, M.M.; Javadian, M.; Tajrishy, M.; Kløve, B. Assimilation of satellite-based data for hydrological mapping of precipitation and direct runoff coefficient for the Lake Urmia Basin in Iran. Water 2019, 11, 1624. [Google Scholar] [CrossRef]
- Homsi, R.; Shiru, M.S.; Shahid, S.; Ismail, T.; Harun, S.B.; Al-Ansari, N.; Yaseen, Z.M. Precipitation projection using a cmip5 gcm ensemble model: A regional investigation of syria. J. Eng. Appl. Comp. Fluid. 2020, 14, 90–106. [Google Scholar] [CrossRef]
- Duro, D.C.; Coops, N.C.; Wulder, M.A.; Han, T. Development of a large area biodiversity monitoring system driven by remote sensing. Prog. Phys. Geog. 2007, 31, 235–260. [Google Scholar] [CrossRef]
- Alsdorf, D.E.; Rodriguez, E.; Lettenmaier, D.P. Measuring surface water from space. Rev. Geophys. 2007, 45, 1–24. [Google Scholar] [CrossRef]
- Nourani, V.; Ghasemzade, M.; Mehr, A.D.; Sharghi, E. Investigating the effect of hydroclimatological variables on urmia lake water level using wavelet coherence measure. J. Water Clim. Chang. 2019, 10, 13–29. [Google Scholar] [CrossRef]
- Gleason, C.J.; Smith, L.C. Toward global mapping of river discharge using satellite images and at-many-stations hydraulic geometry. Proc. Natl. Acad. Sci. USA 2014, 111, 4788–4791. [Google Scholar] [CrossRef] [PubMed]
- Isikdogan, F.A.; Bovik, C.; Passalacqua, P. Surface water mapping by deep learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Haas, E.M.; Bartholomé, E.; Combal, B. Time series analysis of optical remote sensing data for the mapping of temporary surface water bodies in sub-Saharan western Africa. J. Hydrol. 2009, 370, 52–63. [Google Scholar] [CrossRef]
- Gao, B.C. NDWI–A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of normalized difference water index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Xu, H.Q. A study on information extraction of water body with the modified normalized difference water index (MNDWI). J. Remote Sens. 2005, 9, 589–595. [Google Scholar]
- Du, Y.; Zhang, Y.; Ling, F.; Wang, Q.; Li, W.; Li, X. Water bodies’ mapping from sentinel-2 imagery with modified normalized difference water index at 10-m spatial resolution produced by sharpening the SWIR band. Remote Sens. 2016, 8, 354. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud cloud shadow and snow detection for Landsats 4–7 8 and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Shamshirband, S.; Hashemi, S.; Salimi, H.; Samadianfard, S.; Asadi, E.; Shadkani, S.; Mosavi, A.; Naipour, N. Predicting Standardized Streamflow index for hydrological drought using machine learning models. J. Eng. Appl. Comp. Fluid. 2019, 14, 339–350. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- ShieYui, L.; Sivapragasam, C. Flood Stage Forecasting With Support Vector Machines. J. Am. Water. Resour. As. 2002, 38, 173–186. [Google Scholar]
- Asefa, T.; Kemblowski, M.; Lall, U.; Urroz, G. Support vector machines for nonlinear state space reconstruction: Application to the great salt lake time series. Water Resour. Res. 2005, 41, 1–10. [Google Scholar] [CrossRef]
- Pal, M. Ensemble learning with decision tree for remote sensing classification. World Acad. Sci. Eng. Technol. 2007, 36, 258–260. [Google Scholar]
- Huang, H.; Liang, Z.; Li, B.; Wang, D.; Li, Y. Combination of multiple data-driven models for long-term monthly runoff predictions based on bayesian model averaging. Water Resour. Manag. 2019, 33, 3321–3338. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Tantanee, S. How to explain and predict the shape parameter of the generalized extreme value distribution of streamflow extremes using a big dataset. J. Hydrol. 2019, 574, 628–645. [Google Scholar] [CrossRef]
- Bhuiyan, M.A.E.; Nikolopoulos, E.I.; Anagnostou, E.N.; Quintana-Seguí, P.; Barella-Ortiz, A. Anonparametric statistical technique for combining global precipitation datasets: Development and hydrological evaluationover the iberian peninsula. Hydrol. Earth Syst. Sci. 2018, 22, 1371–1389. [Google Scholar] [CrossRef]
- Ehsan, B.M.A.; Begum, F.; Ilham, S.J.; Khan, R.S. Advanced wind speed prediction using convective weather variables through machine learning application. Comput. Geosci-UK 2019, 1, 1–9. [Google Scholar]
- Jia, X.W.; Khandelwal, A.; Mulla, D.J.; Pardey, P.G.; Kumar, V. Bringing automated, remote-sensed, machine learning methods to monitoring crop landscapes at scale. Agric. Econ. Czech. 2019, 50, 41–50. [Google Scholar] [CrossRef]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J. R-CNN-Based Ship Detection from High Resolution Remote Sensing Imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef]
- Mou, L.; Bruzzone, L.; Zhu, X.X. Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 924–993. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, Q.; Lin, J.; Wang, D.; Liu, X.; Zhuang, J. Simulating Reservoir Operation Using a Recurrent Neural Network Algorithm. Water 2019, 11, 865. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.W. ANN-based interval forecasting of streamflow discharges using the LUBE method and MOFIPS. Eng. Appl. Artif. Intel. 2014, 45, 429–440. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Miao, Z.; Fu, K.; Sun, H.; Sun, X.; Yan, M. Automatic water-body segmentation from high-resolution satellite images via deep networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 602–606. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for High Resolution Remote Sensing Imagery Using a Fully Convolutional Network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Yu, L.; Wang, Z.; Tian, S.; Ye, F.; Ding, J.; Kong, J. Convolutional neural networks for water body extraction from Landsat imagery. Int. J. Comput. Intell. Appl. 2017, 16, 1750001. [Google Scholar] [CrossRef]
- Sunaga, Y.; Natsuaki, R.; Hirose, A. Land form classification and similar land-shape discovery by using complex-valued convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7907–7917. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.; Yu, A.; Zhang, P.; Wan, G.; Wang, R. Deep few-shot learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2290–2304. [Google Scholar] [CrossRef]
- Song, W.; Wang, L.; Liu, P.; Choo, K.K.R. Improved t-SNE based manifold dimensional reduction for remote sensing data processing. Multimed Tools Appl. 2019, 78, 4311–4326. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia. Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Guo, X.; Huang, X.; Zhang, L.; Zhang, L.; Plaza, A.; Benediktsson, J.A. Support tensor machines for classification of hyperspectral remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3248–3264. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Spring: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Maulik, U.; Chakraborty, D. Remote sensing image classification: A survey of support-vector-machine-based advanced techniques. IEEE Geosci. Remote Sens. Mag. 2017, 5, 33–52. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Type | Detail | |
|---|---|---|
| Sources | Sentinel-2 | |
| resolution | temporal | 10 days |
| spatial | 10 m, 20 m, 60 m | |
| spectral range | 0.04–0.24 μm | |
| orbital altitude | 786 km | |
| Algorithm | Parameter Type | Parameter Set |
|---|---|---|
| SVM | Kernel Type | RBF |
| UNet | Learning Rate | 0.0001 |
| Loss function | Binary Cross Entropy | |
| MultiResUNet | Learning Rate | 0.0001 |
| Loss function | Binary Cross Entropy | |
| NFL | Learning Rate | 0.0001 |
| Loss function | Binary Cross Entropy | |
| ELSF | Learning Rate | 0.0001 |
| Loss function | Binary Cross Entropy |
| AEN Model | Distribution Value | |
|---|---|---|
| Average | Median | |
| AEN-9 | 6215.76 | 4120.43 |
| AEN-15 | 4109.92 | 2052.95 |
| MAEN | 3778.49 | 1540.60 |
| Algorithm | Precision | Recall | F1 |
|---|---|---|---|
| SVM | 85.61 | 95.61 | 87.63 |
| UNet | 90.42 | 95.71 | 91.27 |
| MultiResUNet | 92.56 | 94.03 | 91.59 |
| NFL | 92.01 | 95.73 | 92.76 |
| ELSF | 92.84 | 95.82 | 93.32 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Z.; Jia, K.; Jia, X.; Khandelwal, A.; Kumar, V. Global River Monitoring Using Semantic Fusion Networks. Water 2020, 12, 2258. https://doi.org/10.3390/w12082258
Wei Z, Jia K, Jia X, Khandelwal A, Kumar V. Global River Monitoring Using Semantic Fusion Networks. Water. 2020; 12(8):2258. https://doi.org/10.3390/w12082258
Chicago/Turabian StyleWei, Zhihao, Kebin Jia, Xiaowei Jia, Ankush Khandelwal, and Vipin Kumar. 2020. "Global River Monitoring Using Semantic Fusion Networks" Water 12, no. 8: 2258. https://doi.org/10.3390/w12082258
APA StyleWei, Z., Jia, K., Jia, X., Khandelwal, A., & Kumar, V. (2020). Global River Monitoring Using Semantic Fusion Networks. Water, 12(8), 2258. https://doi.org/10.3390/w12082258