A Novel Lazy Serpent Algorithm for the Prioritization of Leak Repairs in Water Networks




Abstract
1. Introduction
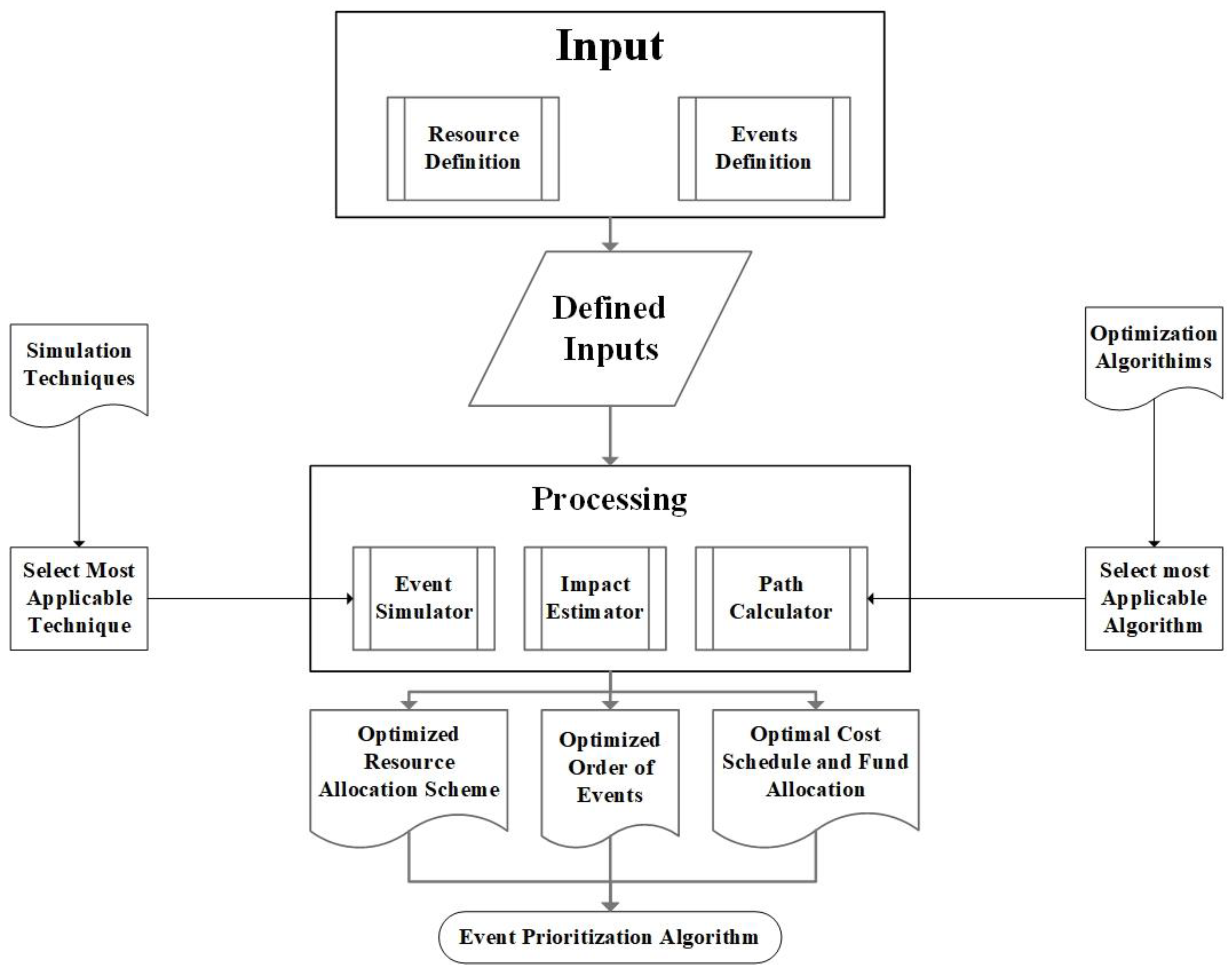
2. Methodology and Implementation
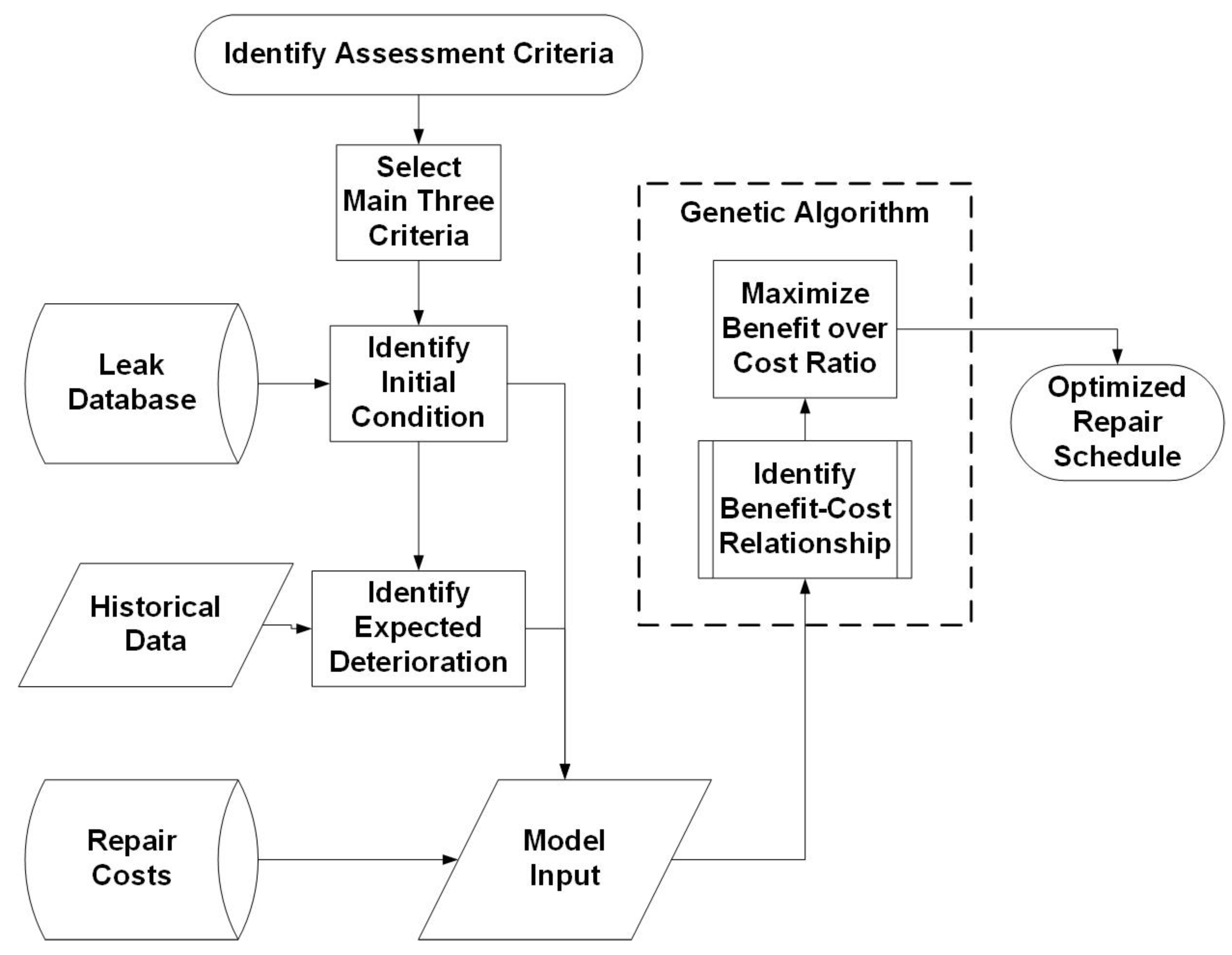
2.1. Definition
2.2. Inputs
2.2.1. Event Input
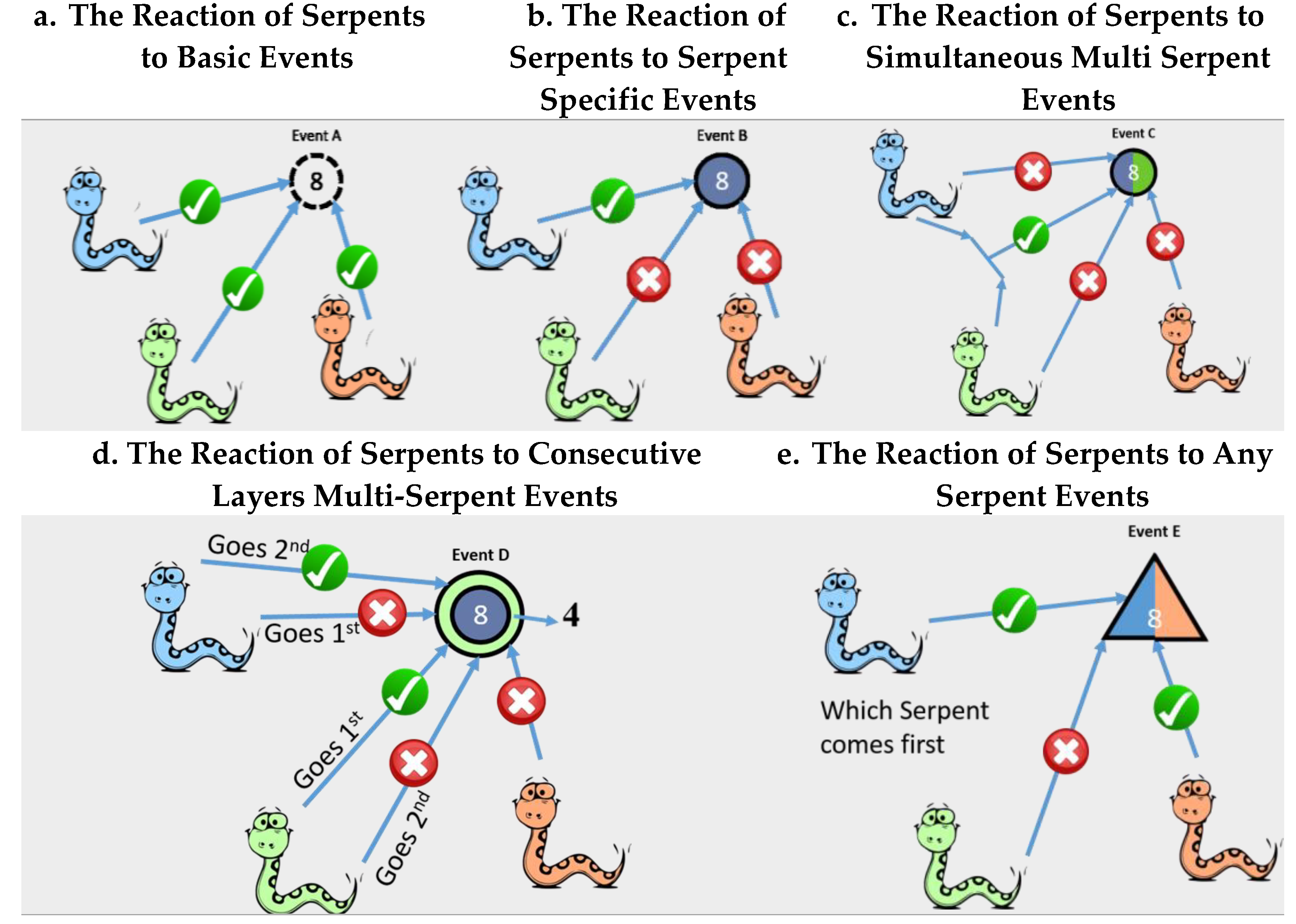
Basic Events (B)
Serpent Specific Events (SS)
Multi-Serpent Events (MS)
- (a)
- Simultaneous: a simultaneous event is an event that requires the existence of two specific resources or more at the same time to be completed. Once commenced, all resources will suffer the same delay (tn) required for the event, but the cost of the event (cn) will be one regardless of the number of resources used. Further costs as the operational costs of each serpent are referred to as energy consumption; this concept will be explored later. Figure 3c displays how serpents react in the presence of a simultaneous event. Event C is not tackled when only one of the blue or green serpent is available; only when when both are available at the same time, event C is tackled and completed. A simultaneous event is drawn as a circle that is equally divided by the colors representing the required serpents along with the amount of the required time t0.
- (b)
- Consecutive-Layers: Although prioritization algorithms do not normally deal with events with interdependencies, a certain type of event was noted with certain interdependencies that require being tweaked into the Lazy Serpent Algorithm. Consecutive-layers events are those that require more than one resource to be completed. The required resources must be available in a certain order. Therefore, consecutive-layers events are considered layered events that change their color after a serpent completes a layer to become another task that requires another resource. Figure 3d illustrates this concept by displaying event D that has a green outer layer and a blue sublayer. Event D will be treated as a green event until a green serpent (resource) is available to complete it. When completed, event D becomes a blue event and waits for an available blue serpent to be finalized. The blue serpent cannot tackle event D before the green serpent. Only after the green serpent is done can the blue serpent tackle event D. In terms of cost, a consecutive-layers event will not be charged until completion, i.e., until all layers are resolved. In this figure, the first layer requires four days to be performed, after which the event will become a blue event and require eight days to be finalized. On the level of coding and mathematical representation, consecutive-layers events are considered serpent-specific events based on their initial layer, as in Equation (3). However, after the primary interaction is completed, the devour command will trigger another command as in Equation (5), which is the transform command. The command transforms the event into another event after the serpent-event interaction. The equation displays the transformation of an event Ai from its first layer (Ai1) to its second layer (Ai2).
Any-Serpent Events (AS)
2.2.2. Resource Input (Serpent Definition)
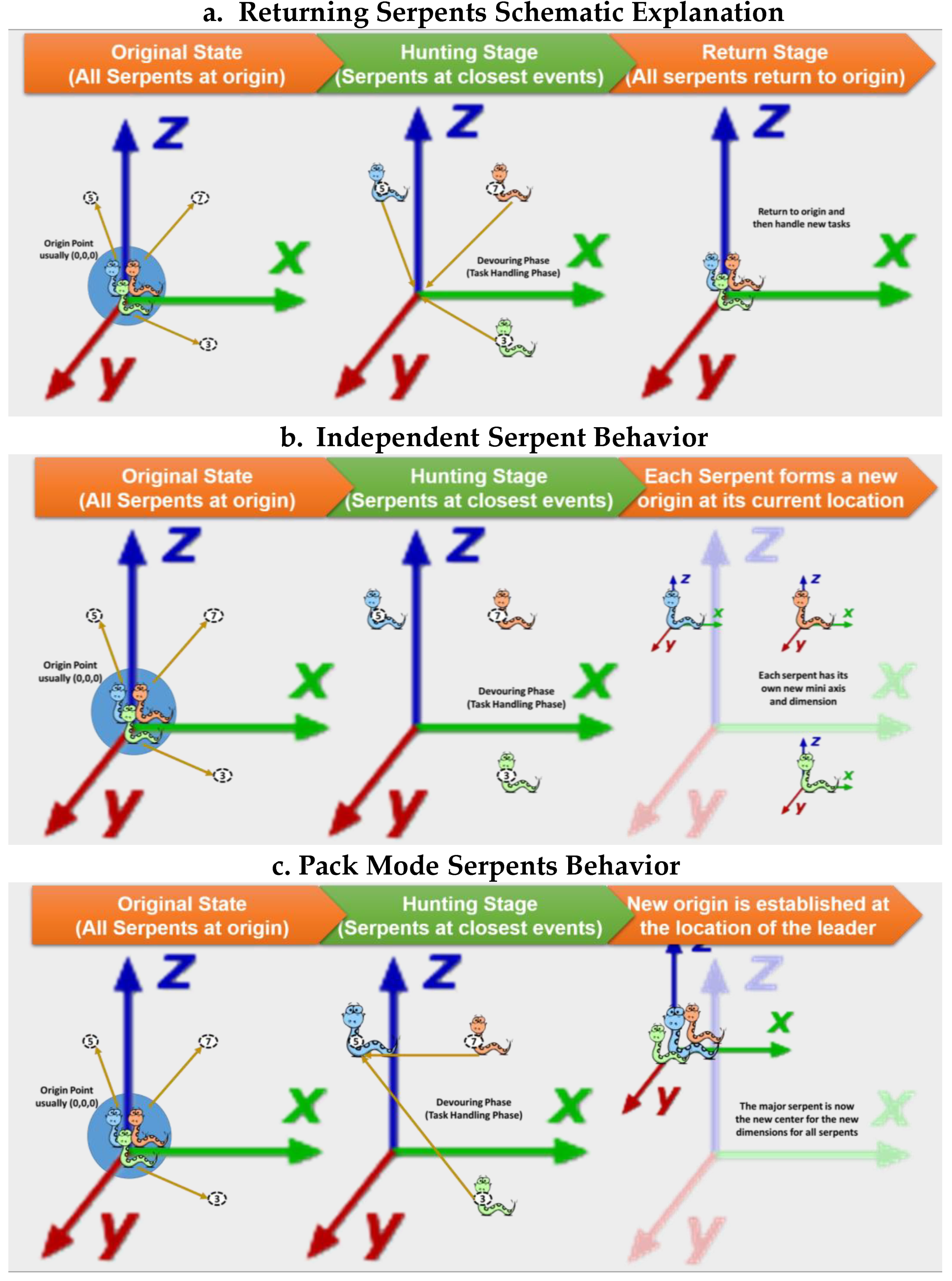
- Returning behavior assumes that all serpents will return to their headquarters, i.e., the point of origin specified by the user, which is default set at (0, 0, 0). Therefore, whenever a serpent (resource) finishes a task, the serpent will return to the origin point to select the next best event to tackle. Figure 4a displays this behavior as all serpents first set out to their targets and, after completing each task, the serpents shall return to the point of origin. Since the green serpent had the event with the lowest time consumption, it returns to the origin first and it immediately sets on to go to a new target if it exists, whereas the orange serpent would be the last to return to the origin point due to having its event requiring the most time.
- Establishing behavior—In practice, not all resources return to their starting point once they finish the task they are assigned. Rather, the resource would search for the problem nearest to its location to tackle it. Thus, the concept of establishing serpents or establishing behavior was developed to simulate the reality on the field. Establishing serpents can establish new origins as they are on their paths to determine the next best solution. Establishing serpents are divided into two main categories, independent and pack mode, which are defined as follows:
- (a)
- Independent—In this category, it is assumed that each resource selects the location of the finished task and establishes its respective location as a new point of origin. Immediately after setting the new point of origin, the serpent moves to select the event location closest to the newly established origin and solves it. After solving the second event, the serpent establishes the new location as a new origin point and this process goes on. Figure 4b illustrates the approach with more clarity. As highlighted, all serpents start at the origin point (0, 0, 0) and then move towards their targets. Later, after completing their tasks, each serpent has its origin point and it selects its next target accordingly.
- (b)
- Pack Mode—In some situations, a moving resource will be referenced as a strategic point or a moving command center that other units have to return to when they are done. Thus, a pack mode behavior requires the central resource to be selected and identified. The chief resource becomes the origin point as it moves and all other serpents have to return to the current location of the chief serpent (central resource) before going onto their next target. Figure 4c displays this behavior by showing the chief blue serpent at the origin point before each serpent embarks on its task. After completion, all serpents return to the blue serpent’s current location before heading off to their new tasks.
2.2.3. Boundaries
- Free/Unbound—The primary assumption in the unbound setup is that energy (money) and time are abundant and can be spent openly. The field of the algorithm has no constraints and thus the algorithm runs until all events are completed and solved. Furthermore, the algorithm tries to figure out the best path with the lowest time and energy consumption. Equation (11) illustrates the optimization goal of this mode, which is to find the maximum benefit-to-cost ratio for all possible schedules.
- Time-Bound—In this approach, it is mainly assumed that energy (fund) is abundant but time is scarce. Thus, a time limit (T) exists, forcing the algorithm to stop after the running time (trun) reaches the time limit (T). Thus, the main aim of the algorithm is to maximize the benefit-to-cost ratio within the time limit regardless of cost. In Equation (12), the previously mentioned conditions and goals can be summarized by an optimization equation.
- Energy Bound—The exact reverse of a time boundary is an energy boundary (E). The main assumption is that time is abundant and holds no constraints whereas funds are scarce and must be efficiently allocated. Therefore, the algorithm tends to maximize the number of tasks performed for a specific amount of energy (funds). Equation (13) displays the approach of maximizing the benefit-to-cost ratio for a maximum allotted energy or fund (E) that the solution expenditure or cost (erun) must never exceed.
- Dual Boundaries—The main condition under this boundary is that both energy and time are scarce. Thus, the algorithm tends to maximize the number of tasks performed within the limits of time and energy, as displayed in Equation (14).
2.2.4. Proposed Solution: Inverse Pyramid
2.3. Genetic Algorithm Comparative Model
- -
- B/C = benefit-to-cost ratio;
- -
- x, y, and z = main assessment factors;
- -
- L, M, and N = factor adjustment weights;
- -
- I = represents the number of the event under study;
- -
- ci = cost of repairing the event i.
3. Results and Discussion
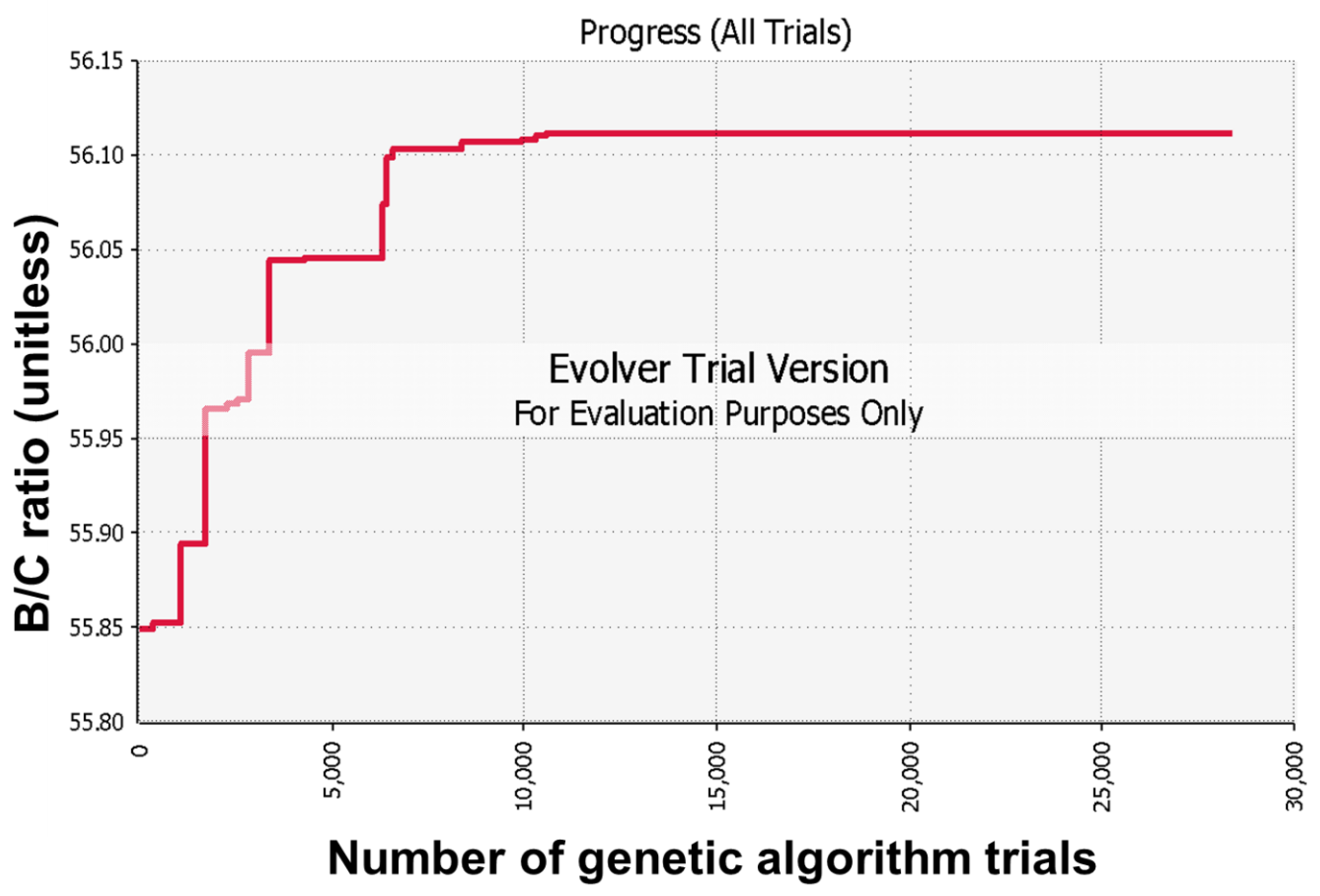
3.1. Genetic Algorithm Model Implementation and Results
3.2. Lazy Serpent Model Comparative Results
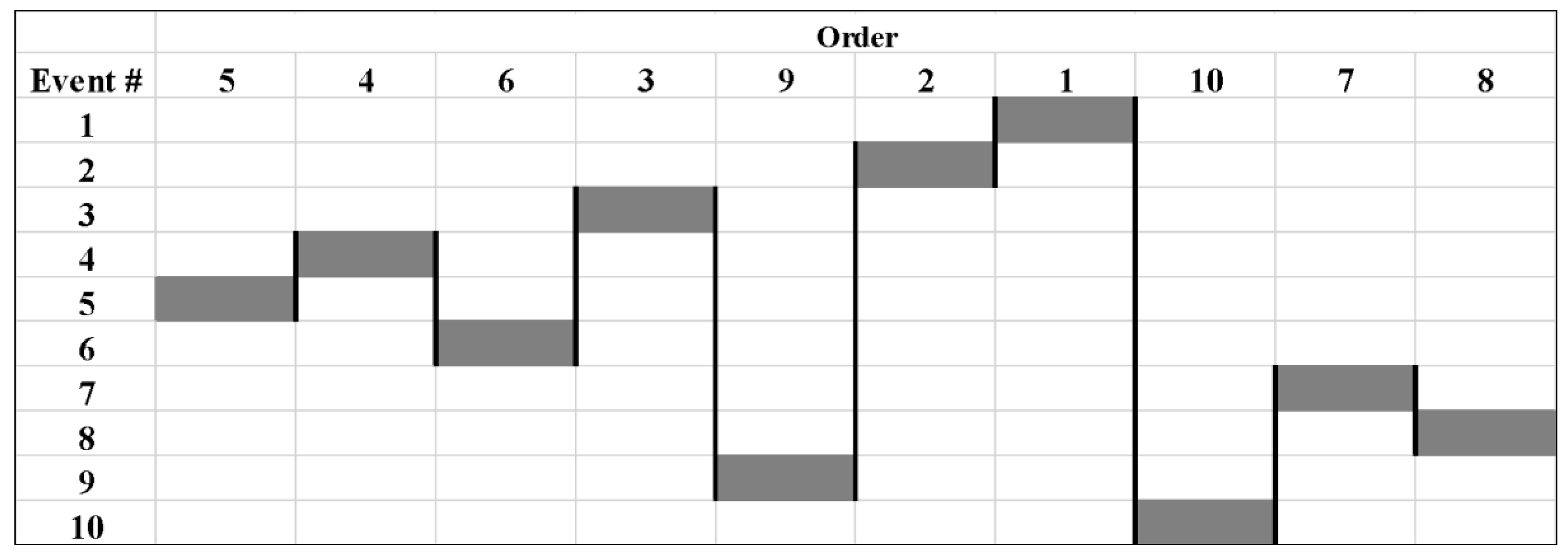
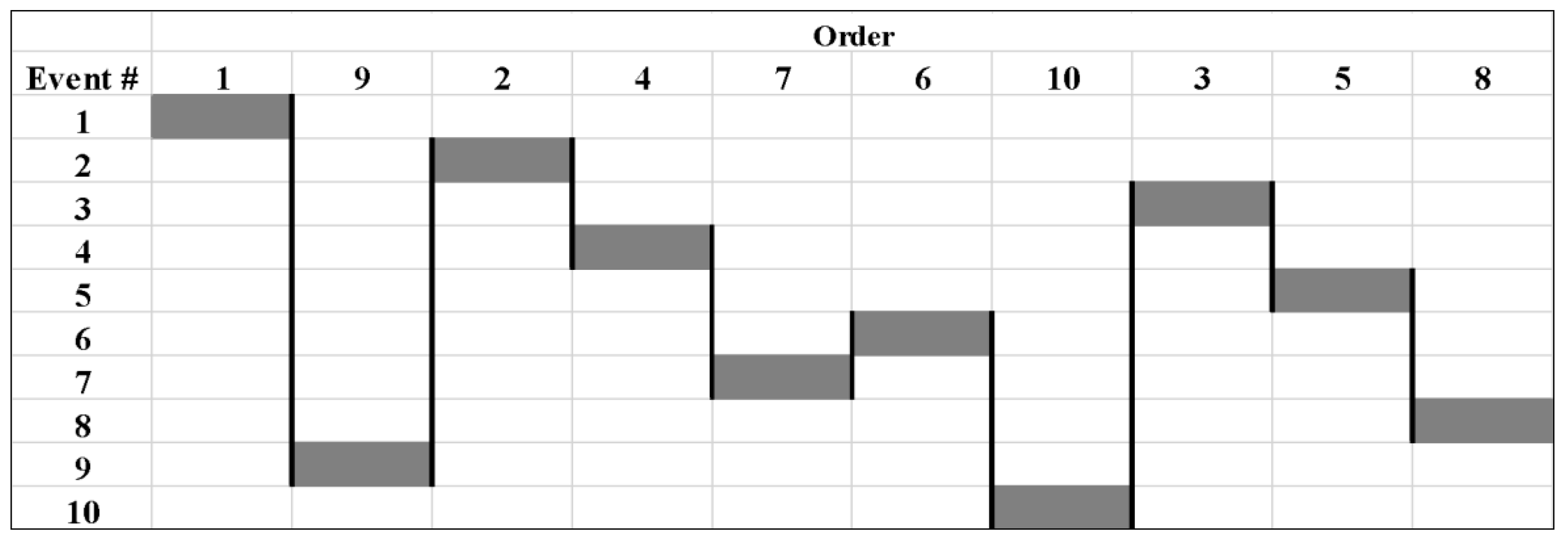
3.2.1. The Basic Lazy Serpent Results
3.2.2. The Inverse Lazy Serpent Results
3.2.3. The Selective Lazy Serpent Results
3.3. Comparative Analysis of Scheduling Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Data Availability Statement
Appendix A
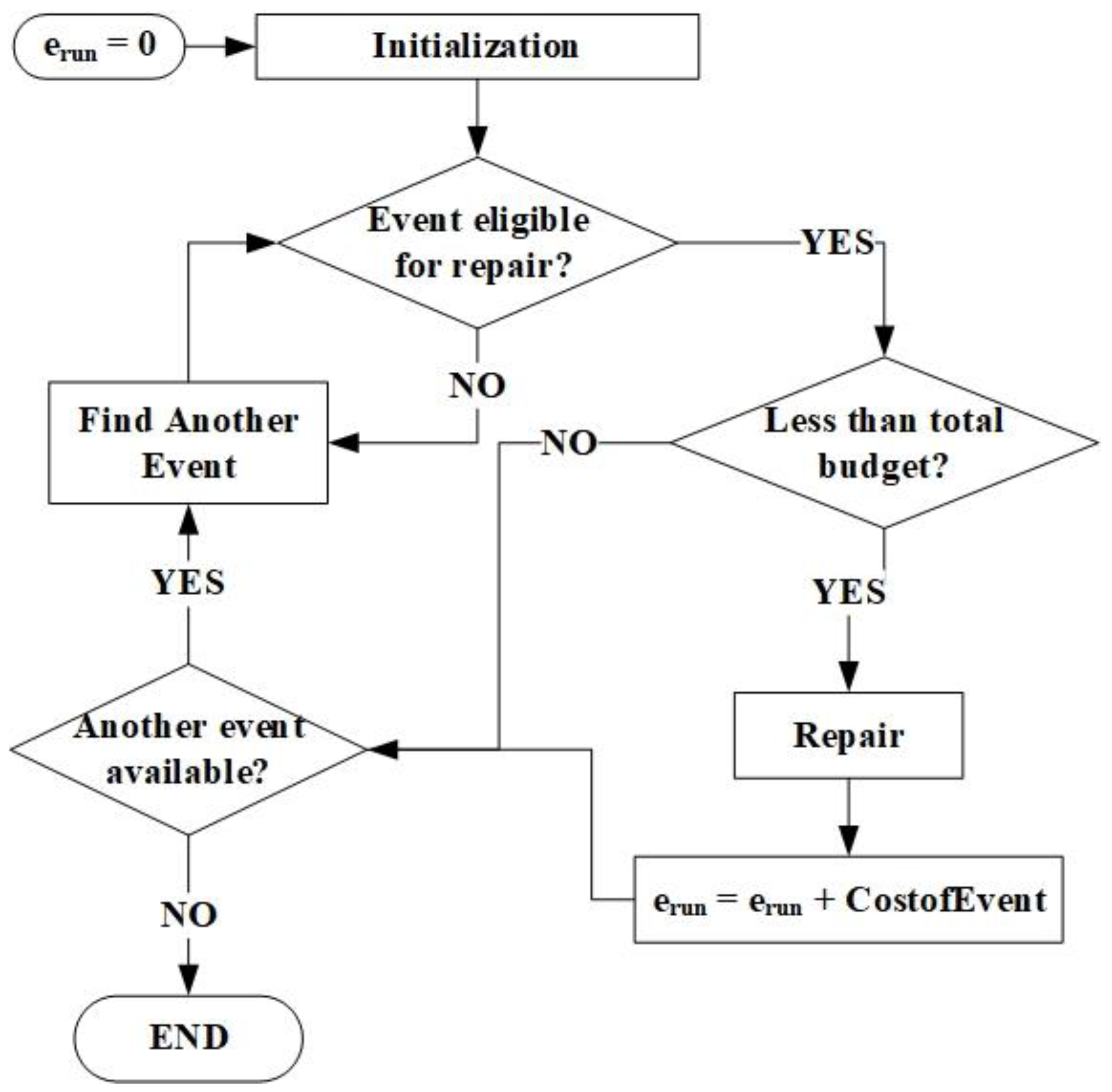
Pseudocode
- Allocate data space
- Input event function in the x direction
- Input event function in the y direction
- Input event function in the z direction
- Input event repair time
- Input event repair cost
- Store event
- Develop event distance from origin point based on coordinates
- Check for an idle serpent
- If serpent(s) is(are) not idle at time T more to time (T + 1)
- If serpent is idle resolve event with the least distance
- Add repair time of event to time elapsed
- Add repair cost of event to total costs
- Develop event distance from origin point based on coordinates
- Check for an idle serpent
- If serpent(s) is(are) not idle at time T more to time (T + 1)
- If serpent is idle check if the color of the event matches the color of the serpent
- If the color does not match check other serpents
- If no serpents are available move time (T) to time (T + 1)
- If serpent color matches resolve the event
- Add repair time of event to time elapsed
- Add repair cost of event to total costs
- Identify simultaneous event
- Check if distance to serpent 1 is minimum
- If true proceed to check serpent 2
- If false, skip event, handle closest event instead
- Check if distance to serpent 2 is minimum
- Check if color of serpent 1 and color of serpent 2 are equal to the colors 1 and 2 of the event
- If true resolve the event
- Add repair time of event to time elapsed
- Add repair cost of event to total costs
- Identify if event is consecutive
- If true
- Check if event is resolved (If true: create successor event at the same coordinates)
- Identify any serpent event
- Check if any idle serpent is at minimum distance
- If true
- Check if serpent color belongs to the allowed color range (If true: (1) Resolve event, (2) Add repair time of event to time elapsed, (3) Add repair cost of event to total costs)
References
- Davis, S. Priority Algorithms. Available online: http://cseweb.ucsd.edu/~sdavis/res_exam.pdf (accessed on 24 January 2017).
- Colorni, A.; Dorigo, M.; Maniezzo, V. A Genetic Algorithm to Solve the Timetable Problem; Politecnico di Milano: Milan, Italy, 1992; pp. 60–90. [Google Scholar]
- Moselhi, O.; Hassanein, A. Optimized Scheduling of Linear Projects. J. Constr. Eng. Manag. 2003, 129, 664–673. [Google Scholar] [CrossRef]
- Elshaboury, N.; Mohammed Abdelkader, E.; Marzouk, M. Application of Modified Invasive Weed Algorithm for Condition-based Budget Allocation of Water Distribution Networks. In Proceedings of the 1st Joint International Conference on Design and Construction of Smart City Components (JIC Smart Cities), Cairo, Egypt, 17–19 December 2019. [Google Scholar]
- Costa, D.G.; de Oliveira, F.P. A prioritization approach for optimization of multiple concurrent sensing applications in smart cities. Future Gener. Comput. Syst. 2020, 108, 228–243. [Google Scholar] [CrossRef]
- Costa, D.G.; Vasques, F.; Portugal, P.; Aguiar, A. A distributed multi-tier emergency alerting system exploiting sensors-based event detection to support smart city applications. Sensors 2020, 20, 170. [Google Scholar] [CrossRef] [PubMed]
- Costa, D.G.; Guedes, L.A. Exploiting the sensing relevancies of source nodes for optimizations in visual sensor networks. Multimed. Tools Appl. 2013, 64, 549–579. [Google Scholar] [CrossRef]
- El-Zahab, S.; Abdelkader, E.M.; Zayed, T. An accelerometer-based leak detection system. Mech. Syst. Signal Process. 2018, 108, 276–291. [Google Scholar] [CrossRef]
- Borgonovo, E. Epistemic uncertainty in the ranking and categorization of probabilistic safety assessment model elements: Issues and findings. Risk Anal. Int. J. 2008, 28, 983–1001. [Google Scholar] [CrossRef] [PubMed]
- Modarres, M. Risk Analysis in Engineering: Techniques, Tools, and Trends; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Pham, H. Safety and Risk Modeling and Its Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Toppila, A.; Salo, A. A computational framework for prioritization of events in fault tree analysis under interval-valued probabilities. IEEE Trans. Reliab. 2013, 62, 583–595. [Google Scholar] [CrossRef]
- Zio, E. Risk importance measures. In Safety and Risk Modeling and Its Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 151–196. [Google Scholar]
- Buckley, J.J. Fuzzy Probabilities: New Approach and Applications; Studies in Fuzziness and Soft Computing 115; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005; p. 168. [Google Scholar]
- Utkin, L.V.; Coolen, F.P.A. Imprecise reliability: An introductory overview. In Computational Intelligence in Reliability Engineering; Springer: Berlin/Heidelberg, Germany, 2007; pp. 261–306. [Google Scholar]
- Weichselberger, K. The theory of interval-probability as a unifying concept for uncertainty. Int. J. Approx. Reason. 2000, 24, 149–170. [Google Scholar] [CrossRef]
- Morcous, G.; Lounis, Z. Maintenance optimization of infrastructure networks using genetic algorithms. Autom. Constr. 2005, 14, 129–142. [Google Scholar] [CrossRef]
- Elbehairy, H.; Elbeltagi, E.; Hegazy, T.; Soudki, K. Comparison of two evolutionary algorithms for optimization of bridge deck repairs. Comput. Civ. Infrastruct. Eng. 2006, 21, 561–572. [Google Scholar] [CrossRef]
- Giustolisi, O.; Berardi, L. Prioritizing Pipe Replacement: From Multiobjective Genetic Algorithms to Operational Decision Support. J. Water Resour. Plan. Manag. 2009, 135, 484–492. [Google Scholar] [CrossRef]
- Cai, X.; Li, K.N. Genetic algorithm for scheduling staff of mixed skills under multi-criteria. Eur. J. Oper. Res. 2000, 125, 359–369. [Google Scholar] [CrossRef]
- Colombo, A.F.; Karney, B.W. Energy and Costs of Leaky Pipes: Toward Comprehensive Picture. J. Water Resour. Plan. Manag. 2002, 128, 441–450. [Google Scholar] [CrossRef]
- Marzouk, M.; Abdelakder, E. A hybrid fuzzy-optimization method for modeling construction emissions. Decis. Sci. Lett. 2020, 9, 1–20. [Google Scholar] [CrossRef]
- Razali, N.M.; Geraghty, J. Genetic algorithm performance with different selection strategies in solving TSP. In Proceedings of the World Congress on Engineering, London, UK, 6–8 July 2011; Volume 2, pp. 1–6. [Google Scholar]
- Elbeltagi, E.; Hegazy, T.; Grierson, D. Comparison among five evolutionary-based optimization algorithms. Adv. Eng. Inform. 2005, 19, 43–53. [Google Scholar] [CrossRef]
- Kahraman, C.; Tolga, E.; Ulukan, Z. Justification of manufacturing technologies using fuzzy benefit/cost ratio analysis. Int. J. Prod. Econ. 2000, 66, 45–52. [Google Scholar] [CrossRef]
- Tung, Y.-K. Probability distribution for benefit/cost ratio and net benefit. J. Water Resour. Plan. Manag. 1992, 118, 133–150. [Google Scholar] [CrossRef][Green Version]
- Abdelkader, E.; Al-Sakkaf, A.; Ahmed, R. A comprehensive comparative analysis of machine learning models for predicting heating and cooling loads. Decis. Sci. Lett. 2020, 9, 409–420. [Google Scholar] [CrossRef]
- Abdelkader, E.M.; Marzouk, M.; Zayed, T. A self-adaptive exhaustive search optimization-based method for restoration of bridge defects images. Int. J. Mach. Learn. Cybern. 2020, 11, 1–58. [Google Scholar]
- Rodriguez-Fdez, I.; Canosa, A.; Mucientes, M.; Bugarin, A. STAC: A web platform for the comparison of algorithms using statistical tests. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015; pp. 1–8. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
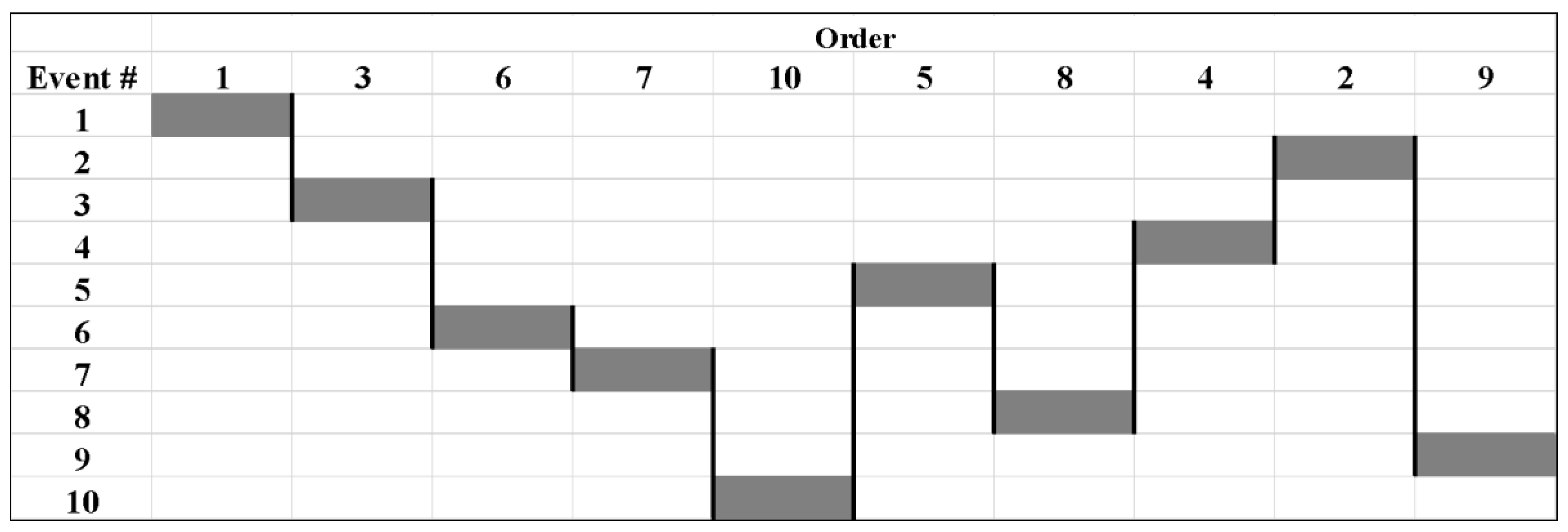
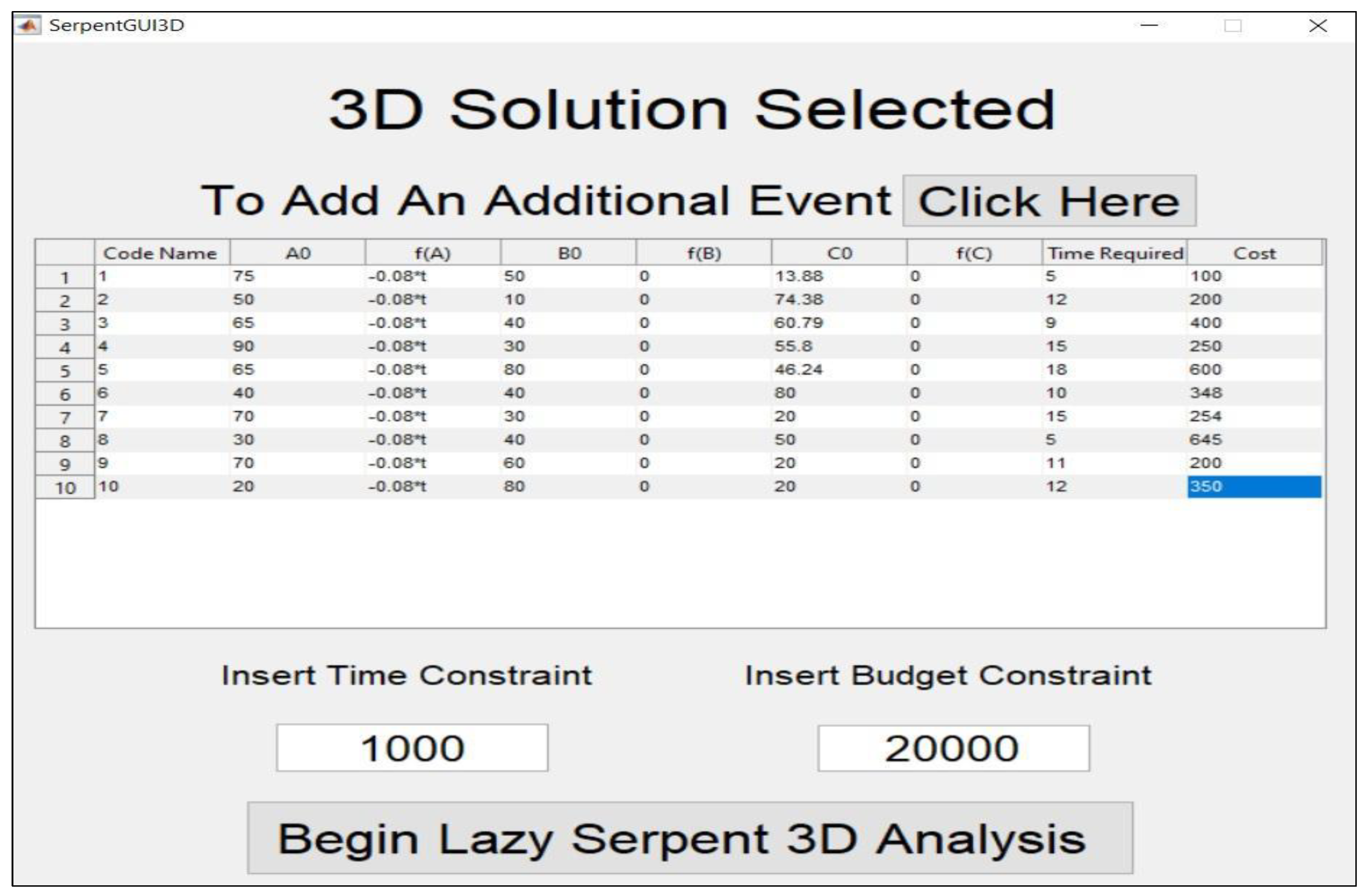
| ID | Order | Condition | Criticality | COF | Repair Period (Days) | Repair Cost ($) | Condition at Repair | Criticality | COF | B/C |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 75 | 50 | 13.88 | 5 | 100 | 75 | 50 | 13.88 | 13.89 |
| 2 | 3 | 50 | 10 | 74.38 | 12 | 200 | 48.72 | 10 | 74.38 | 6.65 |
| 3 | 6 | 65 | 40 | 60.79 | 9 | 400 | 61.56 | 40 | 60.79 | 4.06 |
| 4 | 7 | 90 | 30 | 55.8 | 15 | 250 | 85.84 | 30 | 55.8 | 6.87 |
| 5 | 10 | 65 | 80 | 46.24 | 18 | 600 | 57.48 | 80 | 46.24 | 3.06 |
| 6 | 5 | 40 | 40 | 80 | 10 | 348 | 37.36 | 40 | 80 | 4.52 |
| 7 | 8 | 70 | 30 | 20 | 15 | 254 | 64.64 | 30 | 20 | 4.51 |
| 8 | 4 | 30 | 40 | 50 | 5 | 645 | 27.76 | 40 | 50 | 1.83 |
| 9 | 2 | 70 | 60 | 20 | 11 | 200 | 69.6 | 60 | 20 | 7.48 |
| 10 | 9 | 20 | 80 | 20 | 12 | 350 | 13.44 | 80 | 20 | 3.24 |
| B/CSum = 56.11 | ||||||||||
| Algorithm/Approach | Inverse Lazy Serpent | Basic Lazy Serpent | FIFO | Genetic Algorithm | Selective Lazy Serpent |
|---|---|---|---|---|---|
| Results (B/C ratio) | 5.531 | 5.581 | 5.585 | 5.611 | 5.619 |
| Time Consumed | 8 s | 8 s | 0 | 67 min | 20 s |
| Pair of Algorithms | Inverse Lazy Serpent | Basic Lazy Serpent | FIFO | Genetic Algorithm | Selective Lazy Serpent |
|---|---|---|---|---|---|
| Inverse Lazy Serpent | ( = 1) | ( = 2.7 × 10−3) | ( = 2.7 × 10−3) | ( = 7.69 × 10−3) | ( = 2.7 × 10−3) |
| Basic Lazy Serpent | ( = 2.7 × 10−3) | ( = 1) | ( = 2.7 × 10−3) | ( = 7.69 × 10−3) | ( = 2.7 × 10−3) |
| FIFO | ( = 2.7 × 10−3) | ( = 2.7 × 10−3) | ( = 1) | ( = 7.69 × 10−3) | ( = 2.7 × 10−3) |
| Genetic Algorithm | ( = 7.69 × 10−3) | ( = 7.69 × 10−3) | ( = 7.69 × 10−3) | ( = 1) | ( = 7.69 × 10−3) |
| Selective Lazy Serpent | ( = 2.7 × 10−3) | ( = 2.7 × 10−3) | ( = 2.7 × 10−3) | ( = 7.69 × 10−3) | ( = 1) |
| Pair of Algorithms | Inverse Lazy Serpent | Basic Lazy Serpent | FIFO | Genetic Algorithm | Selective Lazy Serpent |
|---|---|---|---|---|---|
| Inverse Lazy Serpent | ( = 1) | ( = 0) | ( = 0) | ( = 0) | ( = 0) |
| Basic Lazy Serpent | ( = 0) | ( = 1) | ( = 0) | ( = 0) | ( = 0) |
| FIFO | ( = 0) | ( = 0) | ( = 1) | ( = 0) | ( = 0) |
| Genetic Algorithm | ( = 0) | ( = 0) | ( = 0) | ( = 1) | ( = 0) |
| Selective Lazy Serpent | ( = 0) | ( = 0) | ( = 0) | ( = 0) | ( = 1) |
| Pair of Algorithms | Inverse Lazy Serpent | Basic Lazy Serpent | FIFO | Genetic Algorithm | Selective Lazy Serpent |
|---|---|---|---|---|---|
| Inverse Lazy Serpent | ( = 1) | ( = 4.66×10−5) | ( = 4.66 × 10−5) | ( = 1.61 × 10−4) | ( = 4.66 × 10−5) |
| Basic Lazy Serpent | ( = 4.66 × 10−5) | ( = 1) | ( = 4.66 × 10−5) | ( = 1.61 × 10−4) | ( = 4.66 × 10−5) |
| FIFO | ( = 4.66 × 10−5) | ( = 4.66 × 10−5) | ( = 1) | ( = 1.61 × 10−4) | ( = 4.66 × 10−5) |
| Genetic Algorithm | ( = 1.61 × 10−4) | ( = 1.61 × 10−4) | ( = 1.61 × 10−4) | ( = 1) | ( = 1.61 × 10−4) |
| Selective Lazy Serpent | ( = 4.66 × 10−5) | ( = 4.66 × 10−5) | ( = 4.66 × 10−5) | ( = 1.61 × 10−4) | ( = 1) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Zahab, S.; Al-Sakkaf, A.; Mohammed Abdelkader, E.; Zayed, T. A Novel Lazy Serpent Algorithm for the Prioritization of Leak Repairs in Water Networks. Water 2020, 12, 2235. https://doi.org/10.3390/w12082235
El-Zahab S, Al-Sakkaf A, Mohammed Abdelkader E, Zayed T. A Novel Lazy Serpent Algorithm for the Prioritization of Leak Repairs in Water Networks. Water. 2020; 12(8):2235. https://doi.org/10.3390/w12082235
Chicago/Turabian StyleEl-Zahab, Samer, Abobakr Al-Sakkaf, Eslam Mohammed Abdelkader, and Tarek Zayed. 2020. "A Novel Lazy Serpent Algorithm for the Prioritization of Leak Repairs in Water Networks" Water 12, no. 8: 2235. https://doi.org/10.3390/w12082235
APA StyleEl-Zahab, S., Al-Sakkaf, A., Mohammed Abdelkader, E., & Zayed, T. (2020). A Novel Lazy Serpent Algorithm for the Prioritization of Leak Repairs in Water Networks. Water, 12(8), 2235. https://doi.org/10.3390/w12082235