1. Introduction
Hydrological phenomena have multidimensional characteristics; therefore, more than one variable is required to be considered in simultaneous analyses of the hydrological phenomena [
1]. The multivariate probability model accounts for the multidimensional characteristics. However, traditional multivariate probability models that are widely used in the analysis of hydrological data were derived on the basis of univariate probability distribution [
2,
3,
4,
5,
6]. They assume that random variables follow the distribution model that is utilized in the derivation of multivariate probability distribution model [
7]. Hence, they provide limited performances for analysis of the random variables when each random variable follows a different distribution model.
The copula model has been widely adopted as an alternative to mitigate the limitation of the traditional multivariate probability model in the frequency analysis of multidimensional data. In field of the hydrology, the copula model has been used in the analyses of various hydrometeorological phenomena, such as rainfall, flood, drought, and groundwater. For modeling rainfall events, a rainfall event can be characterized by rainfall volume, duration, and intensity. Reference [
8] performed a bivariate frequency analysis of extreme rainfall events to determine design criteria of hydro-infrastructure. Two of the total volume, duration, and peak intensity were selected as random variables of the bivariate probability distribution. Reference [
9] investigated bivariate frequency analysis of rainfall data specifically for urban infrastructure design. They employed the copula model to derive more realistic design storms.
For drought, many studies have modeled and analyzed drought characteristics and indices, such as SPI, SPEI, and PDSI [
10,
11,
12,
13,
14]. Since droughts are characterized by more than one variable, the copula model has gained popularity in risk assessment of drought [
15]. Reference [
16] analyzed droughts by utilizing three variables (duration, severity, and minimum flow) with bivariate and trivariate Plakett copulas. Reference [
17] showed multi-site real-time assessment of droughts with variables of drought duration and average intensity. Reference [
18] developed a regional drought frequency analysis based on trivariate copulas by considering the spatio-temporal variations of drought events.
Flood characteristics can be characterized by peak discharge, flood volume, and duration. Reference [
19] derived bivariate distributions of flood peak and volume, as well as flood volume and duration, by using the copula model for flood data of Louisiana and Canada. Reference [
20] performed flood frequency analysis and compared return periods of univariate and multivariate probability distributions.
Since use of the copula model has been widely used for hydrometeorological data, accurate estimation of copula parameter has become an important issue to be investigated. Reference [
21] suggested the semiparametric estimator based on dependence measurement, such as Kendall’s tau (τ) statistic for Archimedean copula, which is called method of moments (by using the function relationship between copula parameter and dependence measure) or Non-Parametric (NP) method. But the NP method cannot be applicable for all of the copulas when a direct relation between the copula parameter and Kendall’s tau does not exist [
10].
Reference [
22] proposed the copula parameter estimator by using a pseudo-likelihood which is called the Maximum Pseudo-Likelihood (MPL) method or canonical maximum likelihood method. In this method, before estimating the copula parameter, the marginal empirical distribution function is converted by
, where
is rank of the data and
is the sample size. This Weibull plotting position formula could underestimate the return period due to its own formula as referred by Reference [
23]. As a parametric inference, Reference [
24] suggested the estimation method of Inference Functions for Margins (IFM) for multivariate models. This method makes inference computationally feasible for many multivariate models. Other notable methods have also been recently developed. Reference [
25,
26] performed bivariate frequency analysis under the Bayesian paradigm for flood and drought, respectively. Furthermore, Reference [
27] developed the Multivariate Copula Analysis Toolbox (MvCAT) which includes 26 copula families and a Bayesian parameter estimation framework. Reference [
28] introduced a new estimation method for bivariate copula parameters with bivariate L-moments and performed extensive simulation experiment.
Among these parameter estimation methods, the MPL method is one of the most popular methods due to its simplicity and flexibility. However, skewness of the random variable may degrade the capacity of the MPL method because of the Weibull plotting position formula. Since most hydrometeorological data in extreme frequency analysis have a positive coefficient of skewness, the MPL method should be modified to improve the accuracy of parameter estimation.
This study proposes the modified maximum pseudo-likelihood (MMPL) method by replacing the plotting position formula, which considers skewness of the data in the bivariate case. Various plotting position formulas were tested for the MMPL method. To evaluate the performance of the MMPL method for copula, a simulation experiment was carried out with various conditions, such as dependence between variables, marginal distribution type, sample size, and coefficient of skewness. Its performance was compared to the performance of the MPL and IFM methods for conventional semi-parametric and parametric methods. A bivariate frequency analysis of extreme rainfall events in South Korea was then performed for a case study of a real data set. Performances of the three tested methods were evaluated in the case study. Results of this study may provide an alternative to fit the copula model in multivariate frequency analysis of the hydrometeorological variables.
This study is organized as follows:
Section 2 describes theoretical backgrounds about copula and conventional parameter estimation methods.
Section 3 describes the MMPL method.
Section 4 presents the simulation procedure and its results.
Section 5 includes application contents for weather stations in South Korea.
Section 6 includes a discussion on the results of this paper, and
Section 7 presents the conclusions.
3. Modified Maximum Pseudo-Likelihood Method (MMPL)
In the original MPL method, the probability obtained by the Weibull plotting position formula is used for random variables of the copula model. As mentioned above, the Weibull plotting position formula cannot reproduce the proper characteristics of some type of distributions. Many hydrometeorological variables follow skewed distribution types, such as Gamma, Weibull, Gumbel, and generalized extreme value (GEV). In the current study, the MMPL method is proposed in which the Weibull plotting position formula is replaced by several plotting position formulas which consider skewness of data set. The MMPL method proposed in this study is designated for modeling extreme events.
Many studies have examined plotting position formulas for extreme value analysis [
44,
45,
46]. In this study, six plotting position formulas were derived based on the extreme value distribution which were utilized for the MMPL method on behalf of the existing (Weibull) plotting position formula of the original MPL method: (1) three formulas which employ additional parameters to consider the embedded skewness [
47,
48,
49]; and (2) three formulas which employ sample coefficient of skewness in the plotting position formula [
50,
51,
52]. The six plotting position formulas utilized in this study are shown in
Table 1.
Reference [
48] suggested the general plotting position formula for various probability distributions and defined as Equation (7):
where
is order,
is sample size, and
is the parameter of the plotting position formula. The Weibull formula takes
and reproduces for the uniform distribution. The GEV takes
[
48]. The unbiased plotting position formula based on reduced variates was developed by Reference [
47], which takes
. Reference [
46] proposed the plotting position formula for extreme value (EV) nested distributions, which takes
.
Reference [
50] introduced an unbiased plotting position formula for the GEV distribution by using the probability weighted moment method to estimate the exact plotting positions. Similarly, Reference [
51] suggested that the plotting position formula including a coefficient of skewness for the GEV distribution, and Reference [
52] derived a plotting position formula using the adaptation of the theoretical reduced variates of the GEV distribution and suggested the plotting position formula by using a genetic algorithm.
6. Discussion
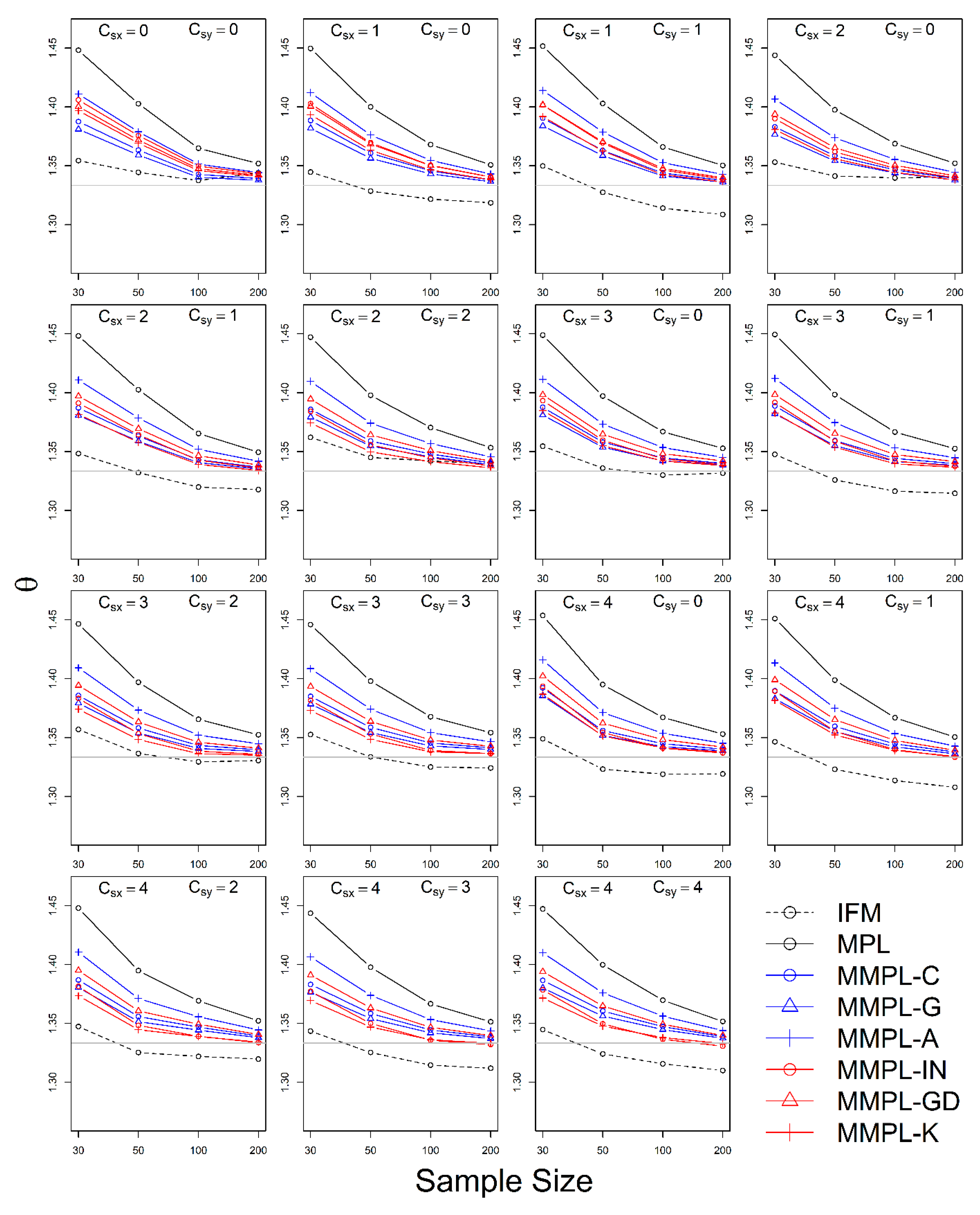
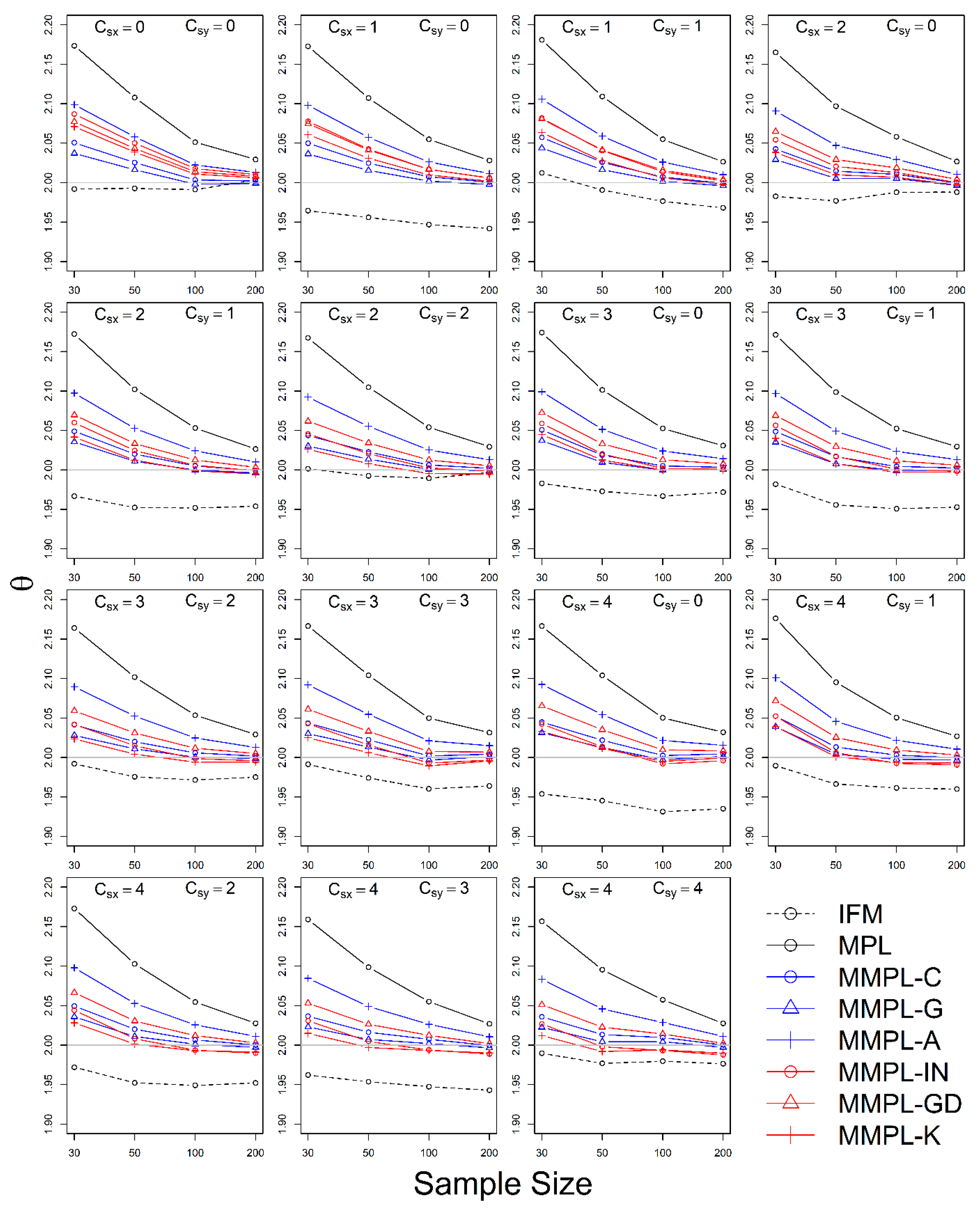
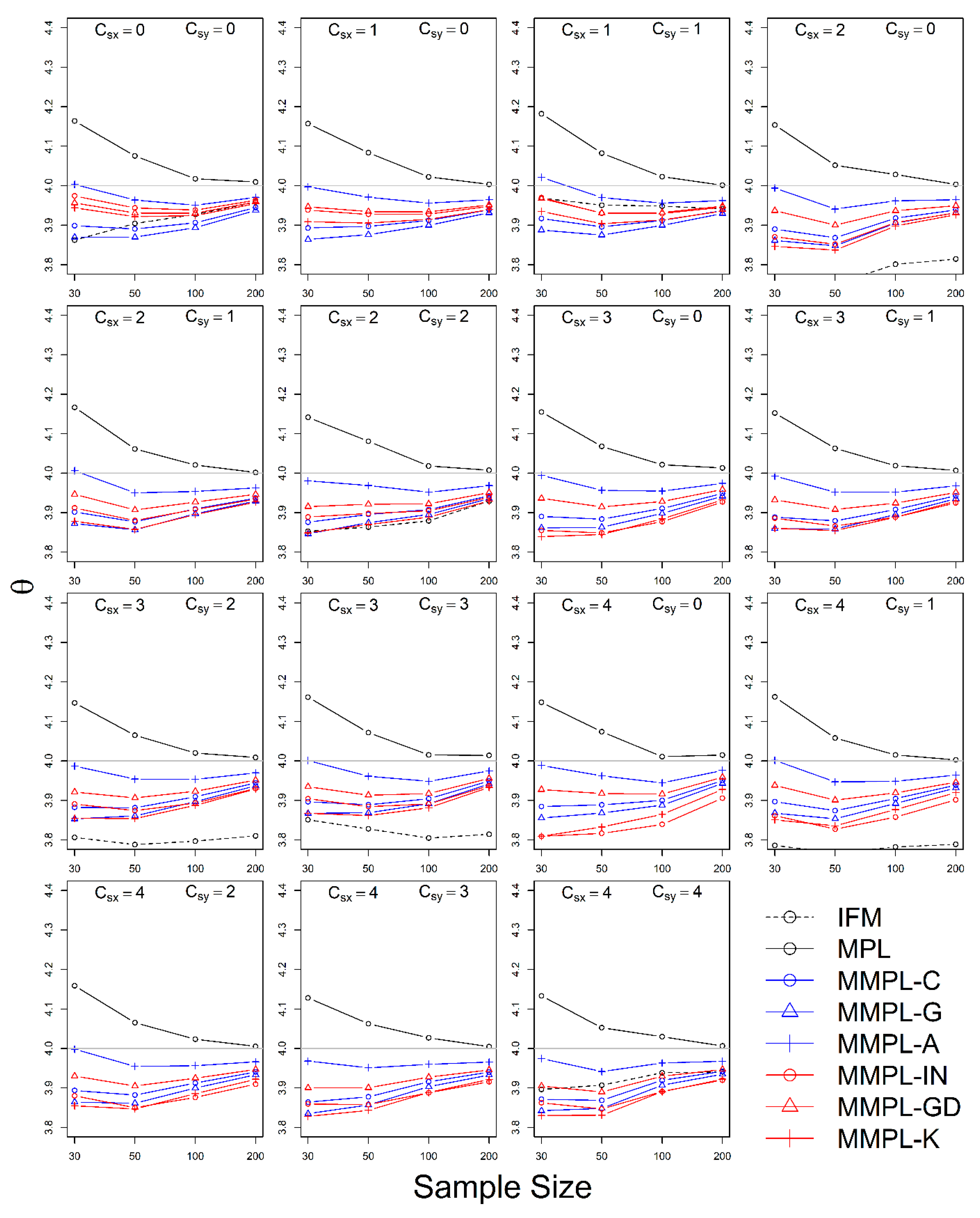
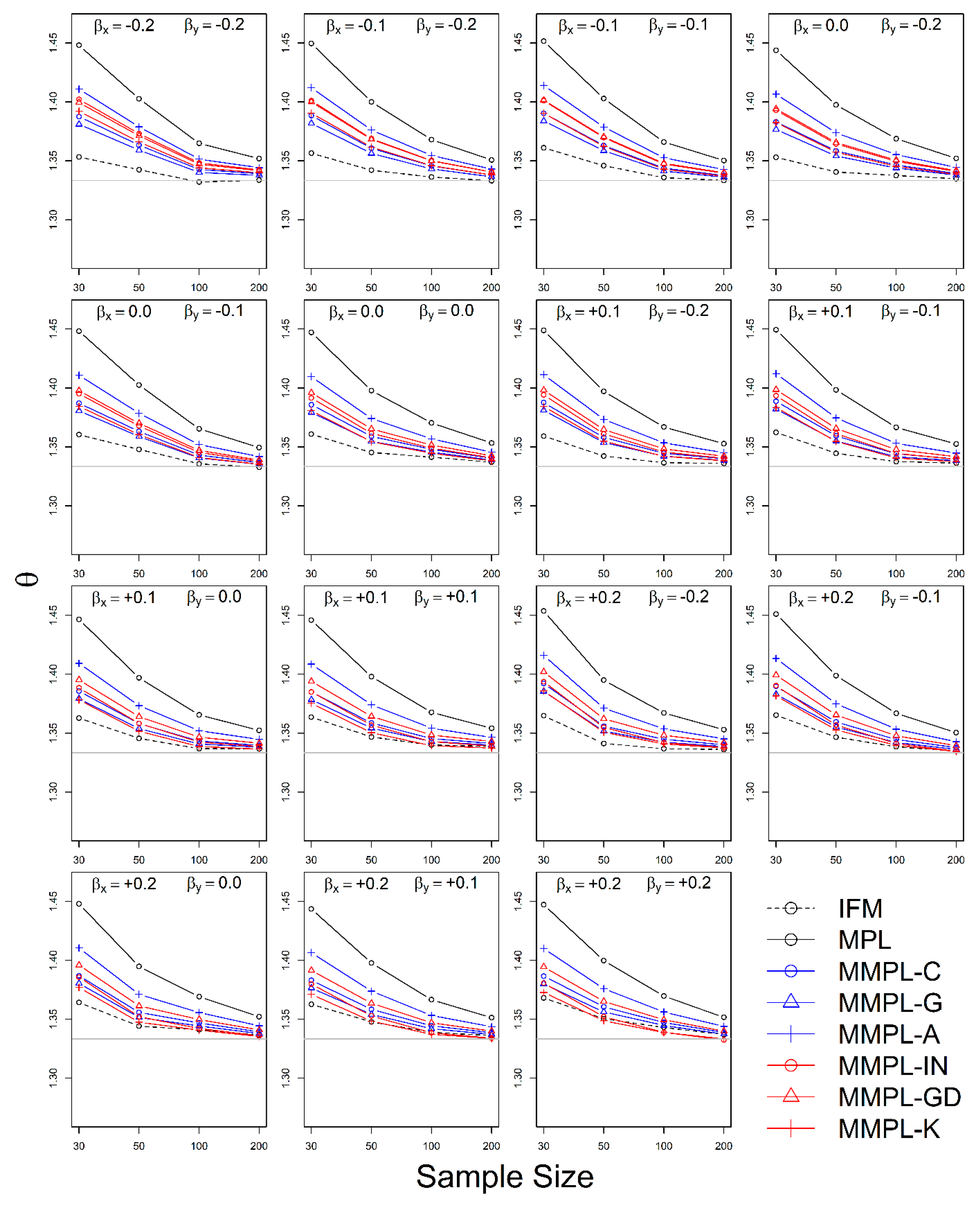
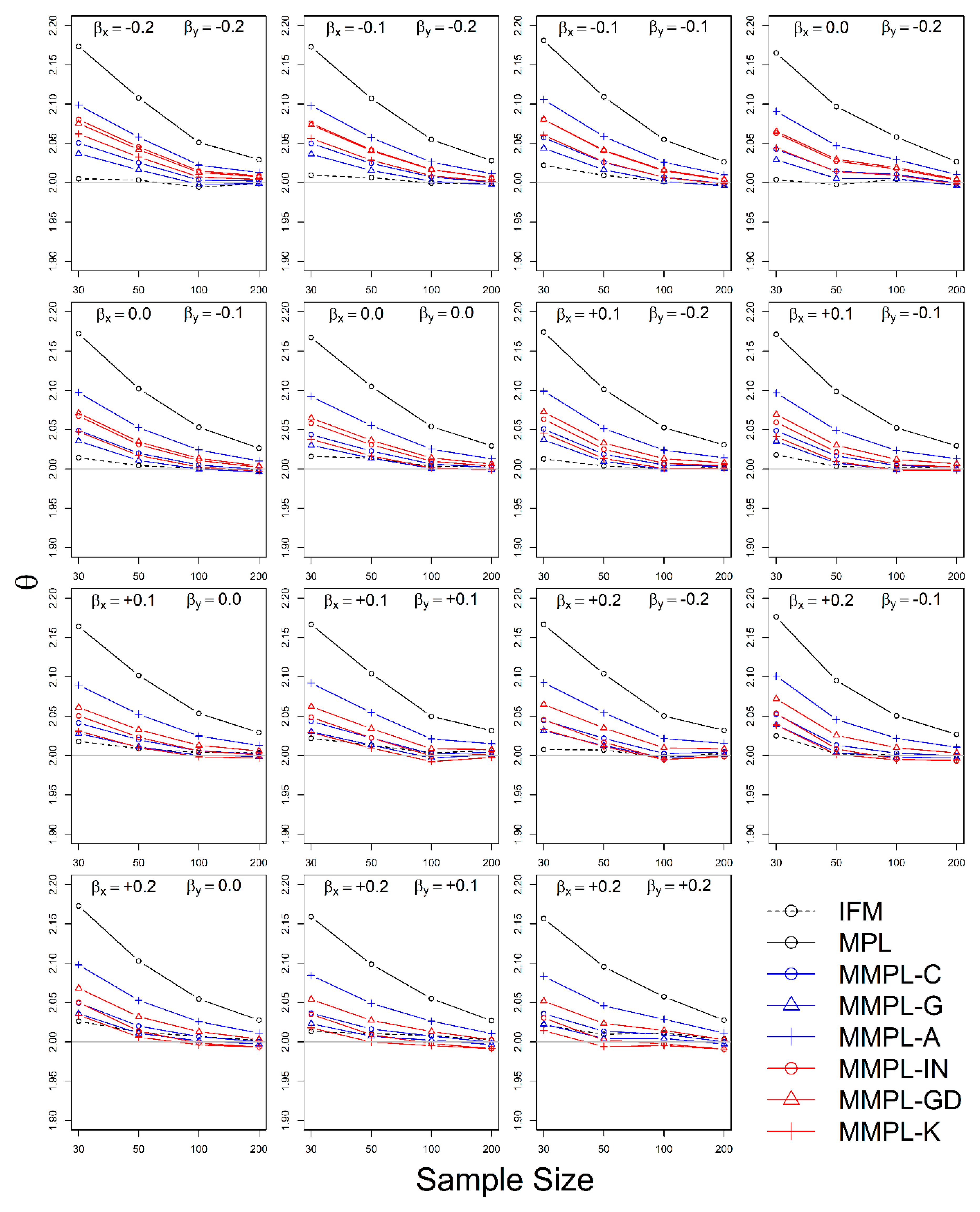
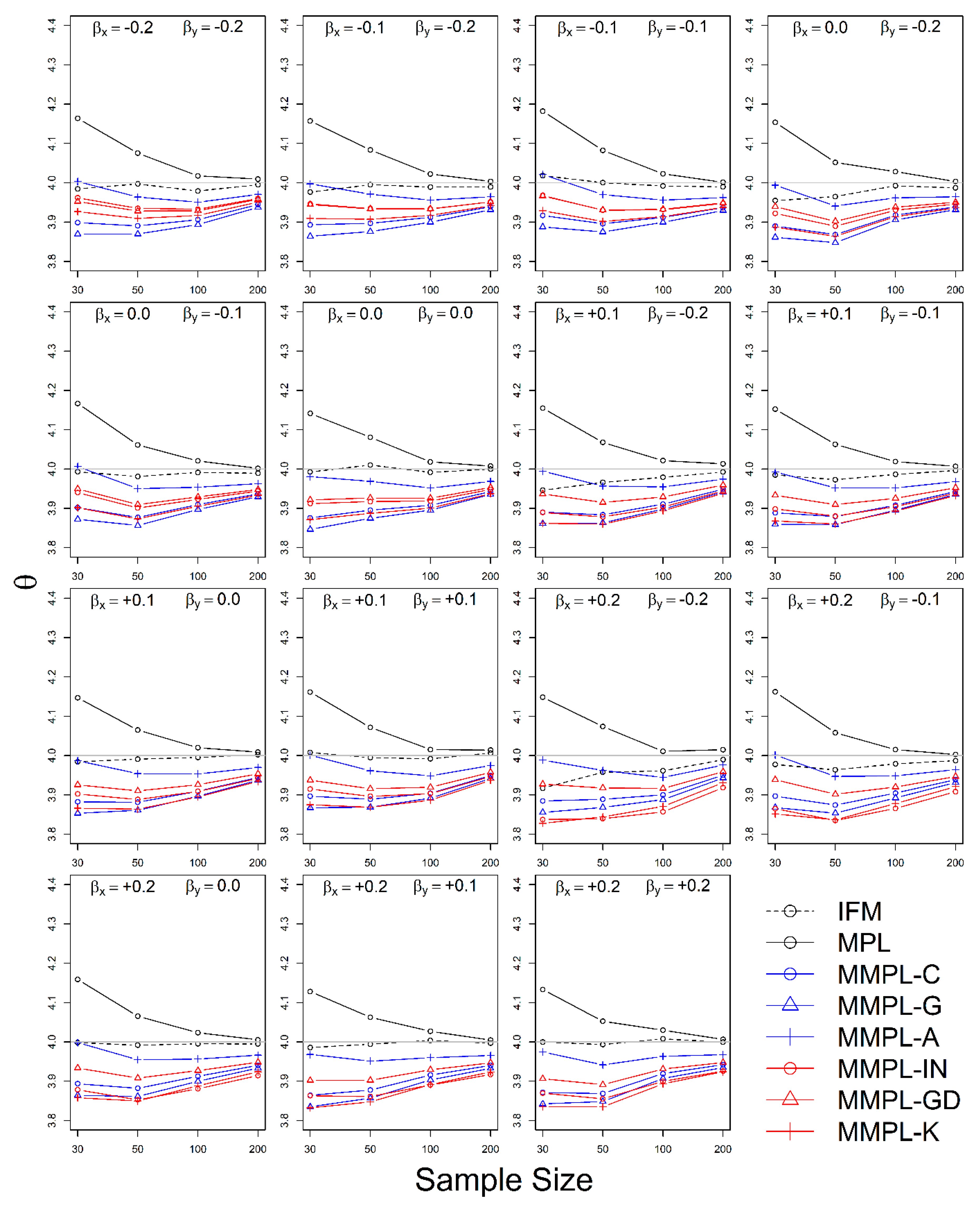
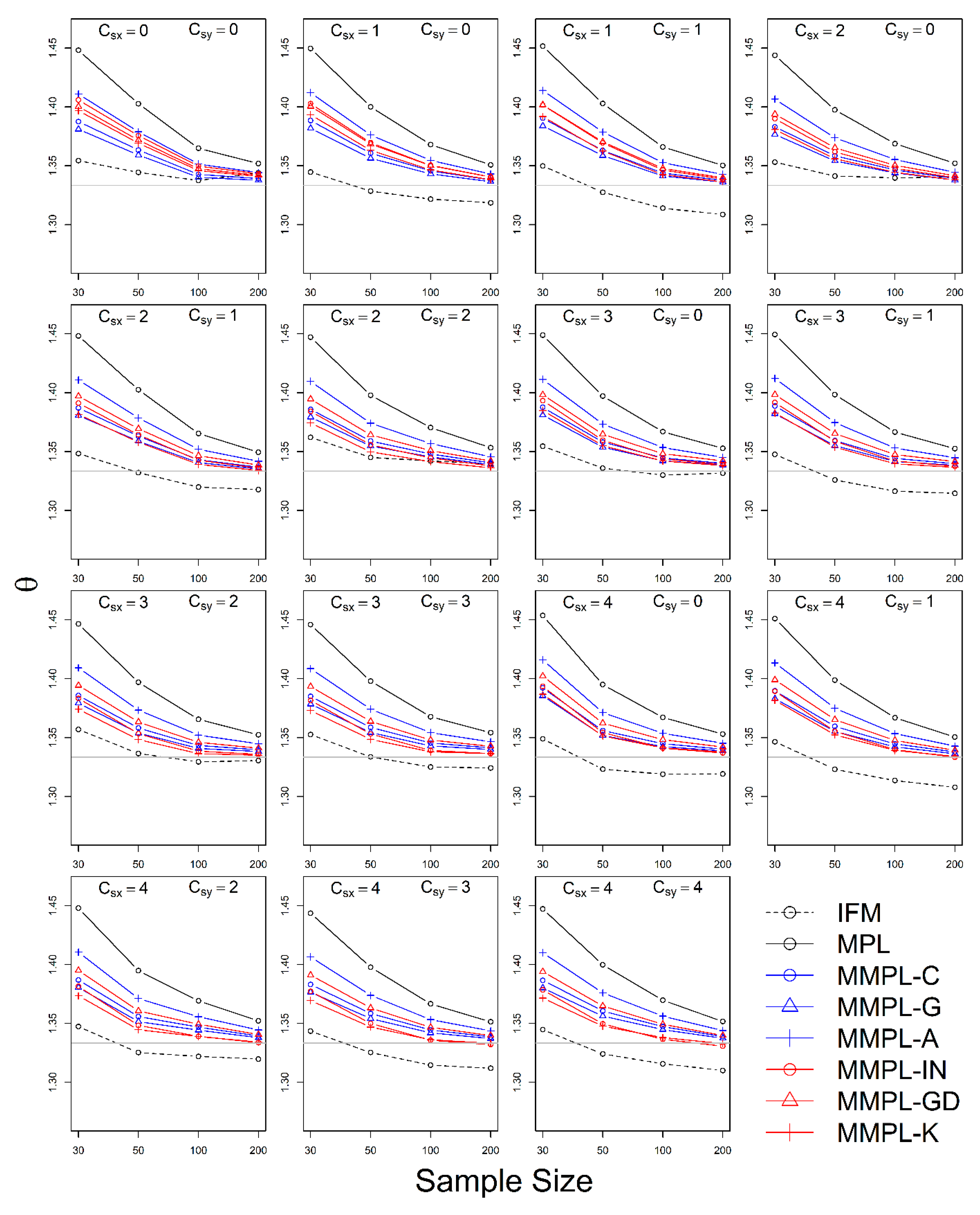
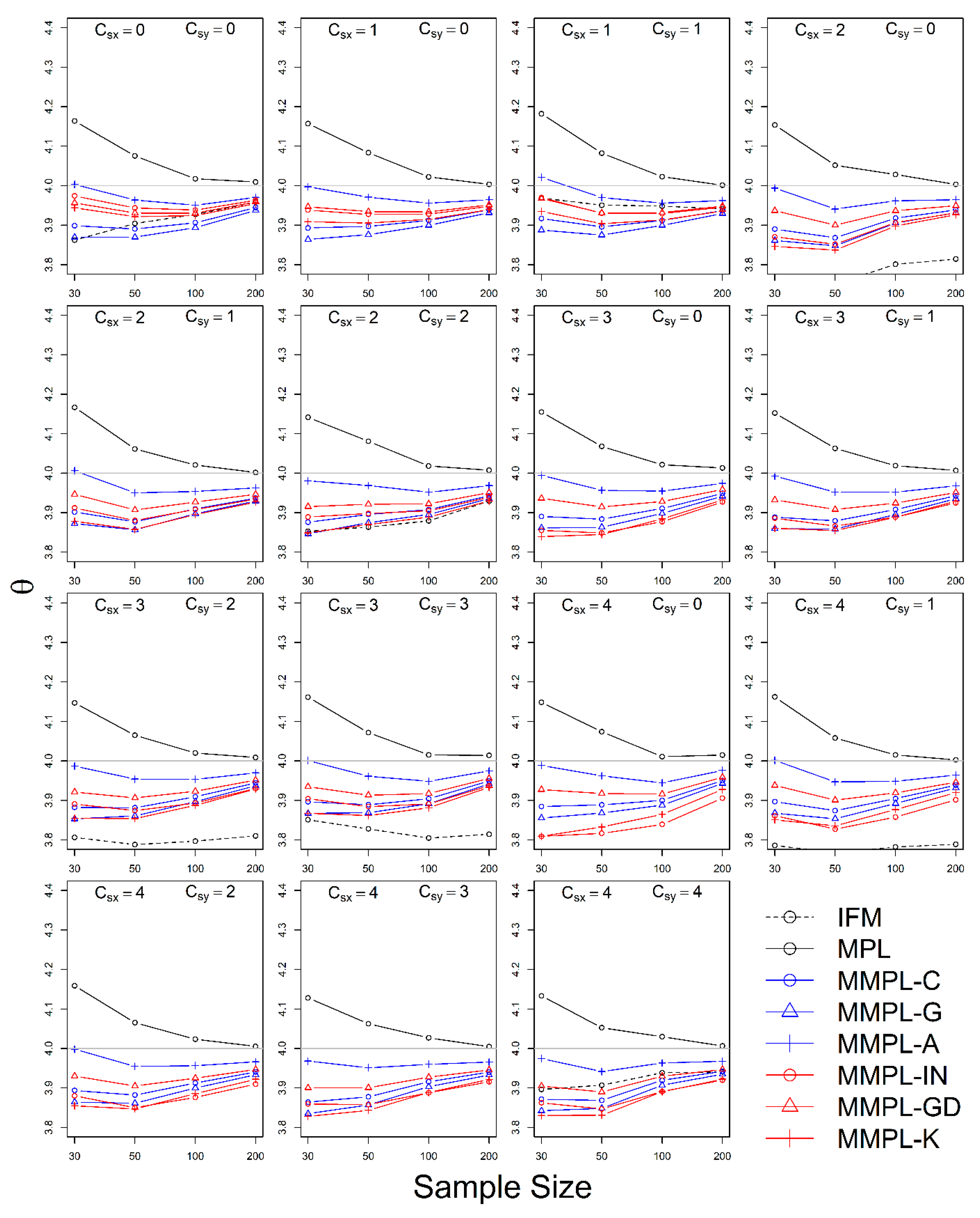
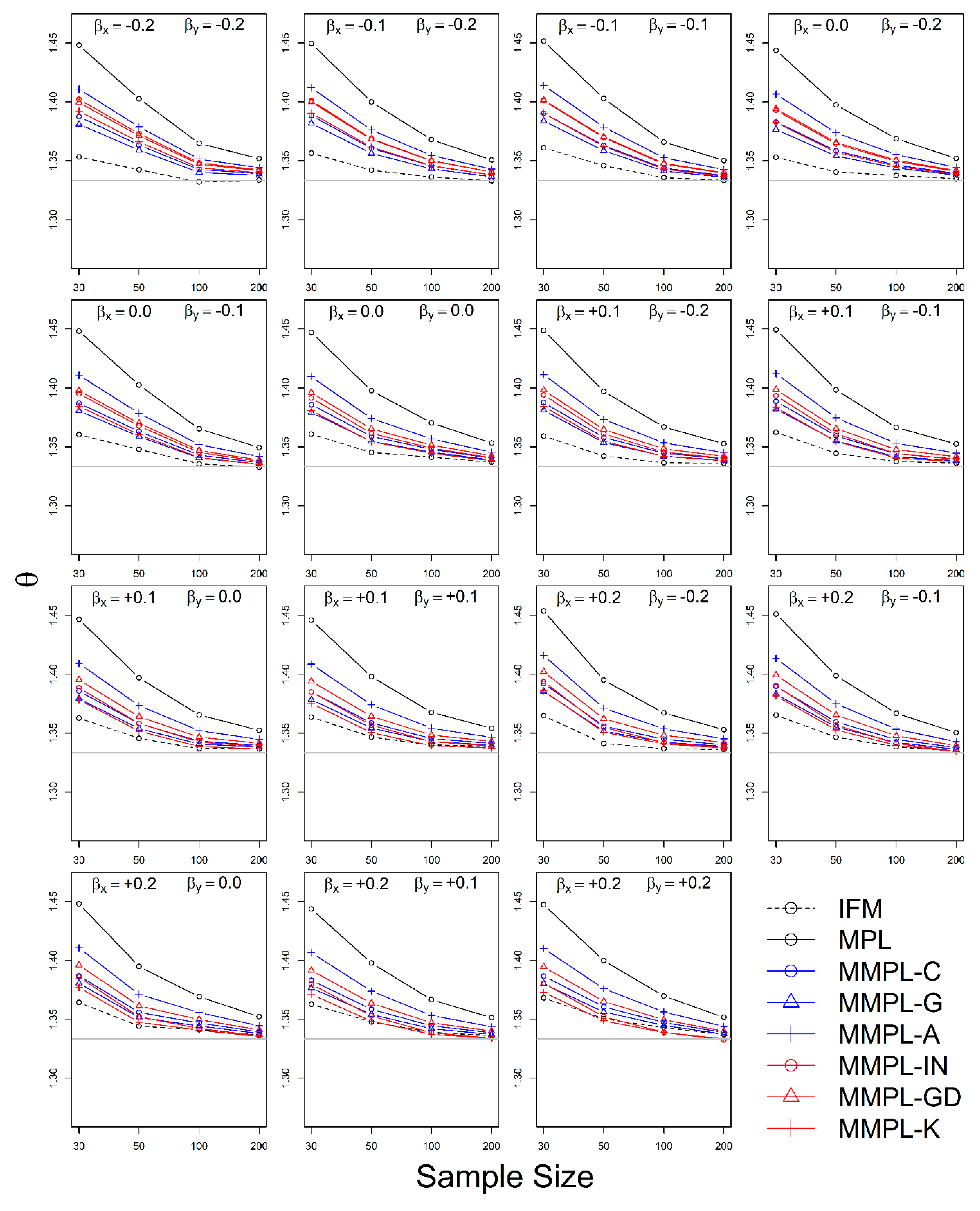
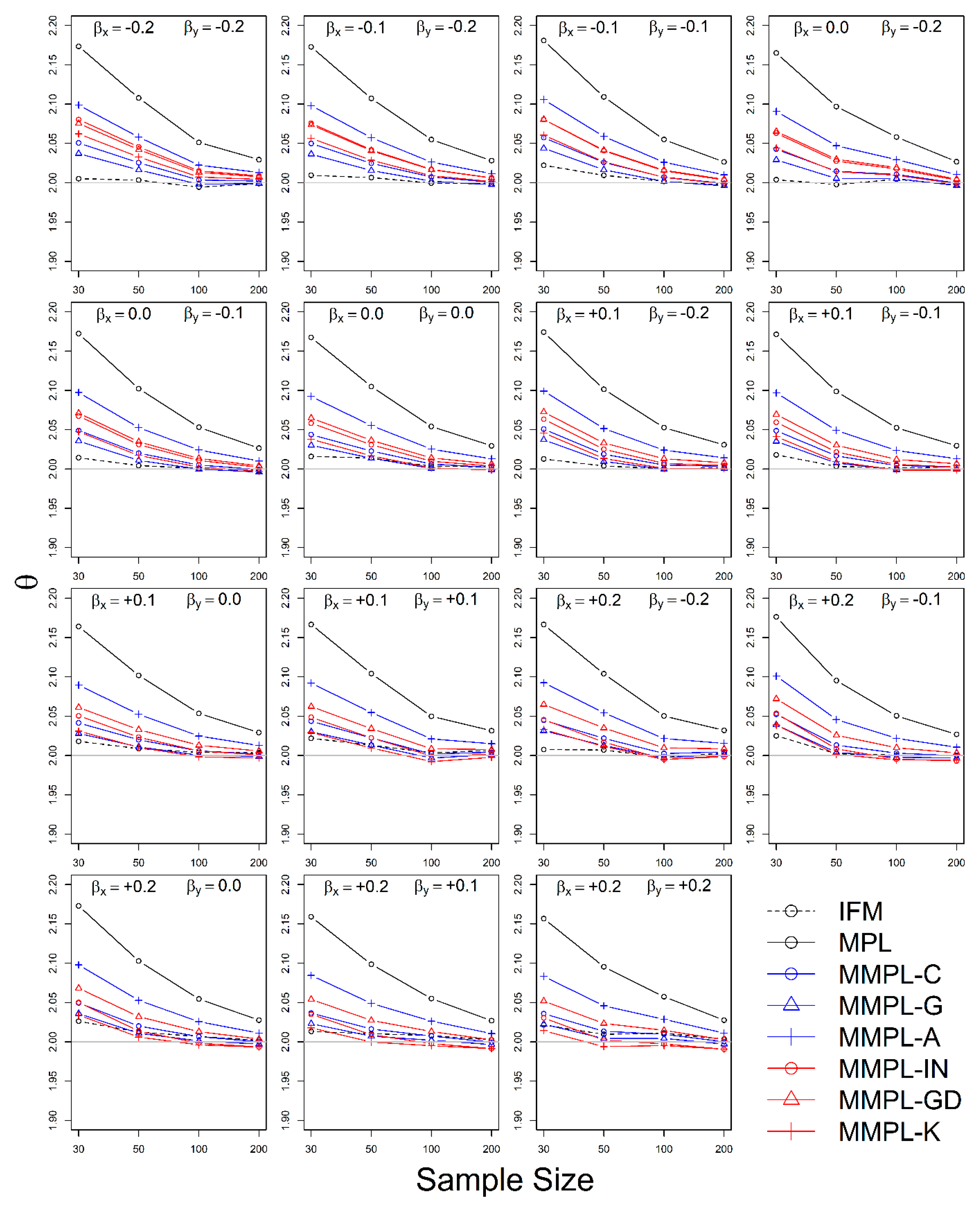
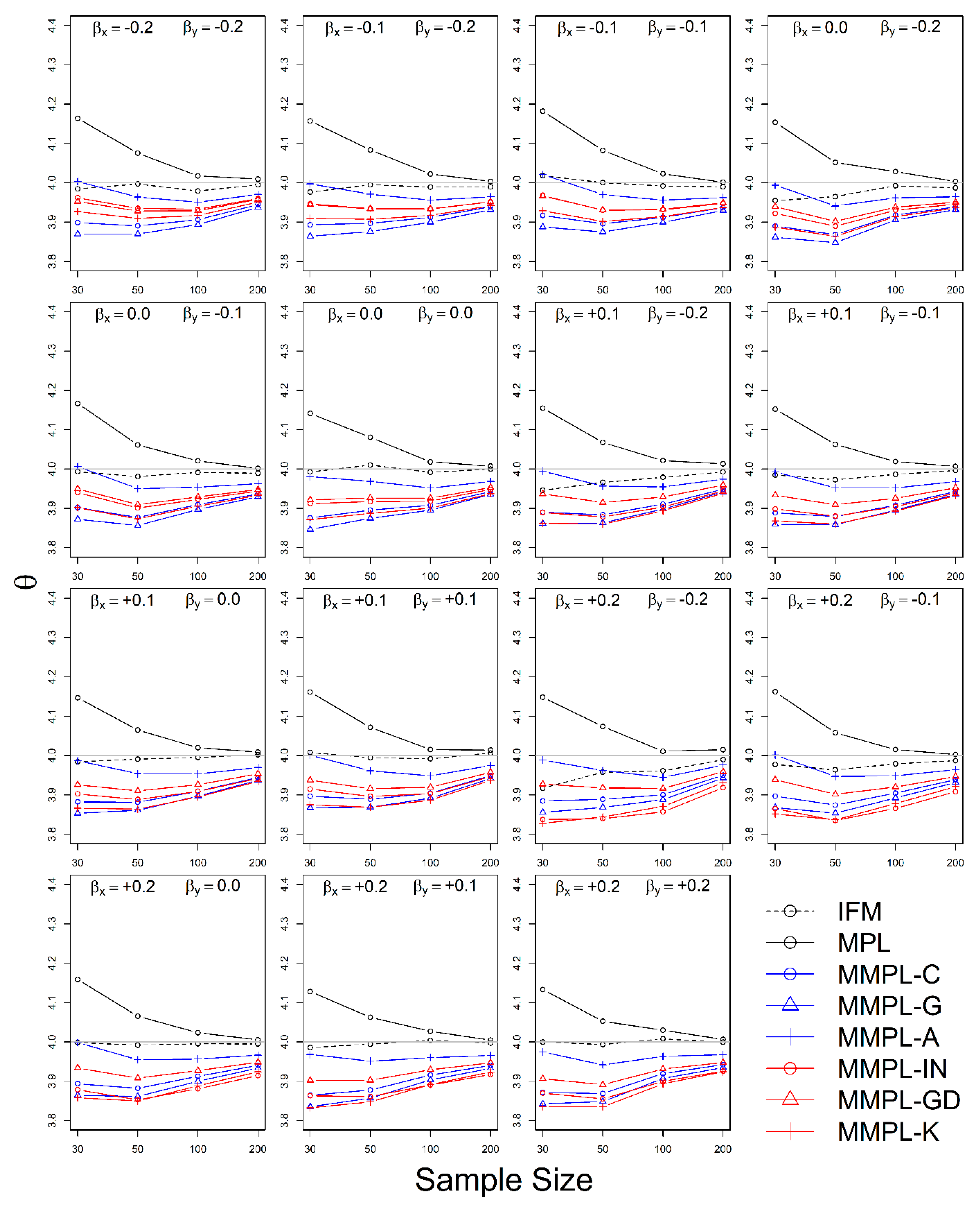
The simulation experiment is designed by a variety of conditions, such as correlation, sample size, the unknown and known marginal distributions, and coefficients of skewness of data. The results of the simulation experiments showed, the proposed parameter estimation method led to improvements in the performances of parameter estimation for the copula model when margins follow skewed distribution models as compared to the conventional MPL method.
In the case of the unknown marginal distribution, the parameter estimate of the MMPL method led to the best performance, and the MPL and IFM methods follow. When marginal distribution information is unavailable, the MMPL and MPL methods have the advantage compared to the IFM method, because they fit the copula model regardless of the marginal distribution. Even though the IFM method shows better performance than the MPL and the MMPL methods at small sample size, the IFM method generally shows the worst performance for most combinations of coefficient of skewness. Moreover, it often shows severe underestimation of the parameter estimate for large sample sizes. In the case of known marginal distribution, the performance of the IFM method is expected to be better than the MPL and MMPL methods. The MMPL method provides the best performance in fitting the copula model in some cases with the large values of shape parameters and sample size based on the simulation experiments. The large value of the shape parameter can lead to large uncertainty in the parameter estimation of GEV distribution [
57]. The performance of the MMPL method may be better than the IFM method for large shape parameters (large coefficient of skewness) because some employed plotting positions take coefficient of skewness into consideration.
The MMPL methods employed in this study are classified into two groups: adopting plotting position formula without coefficient of skewness and with coefficient of skewness. According to the results of simulation experiments, the MMPL-G method, which belongs to the former group, is considered the best parameter estimation method for data sets with small coefficients of skewness. The MMPL-K method, which belongs to the latter group, is considered the best MMPL method for data sets with large coefficients of skewness. The MMPL methods with plotting position formulas that consider coefficient of skewness might be a good choice when the sum of coefficients of skewness is larger than or equal to three based on the results of simulation experiments. Thus, the MMPL-K method would be the best alternative among the tested MMPL and MPL methods for fitting the copula model to the skewed data of hydrometeorological variables.
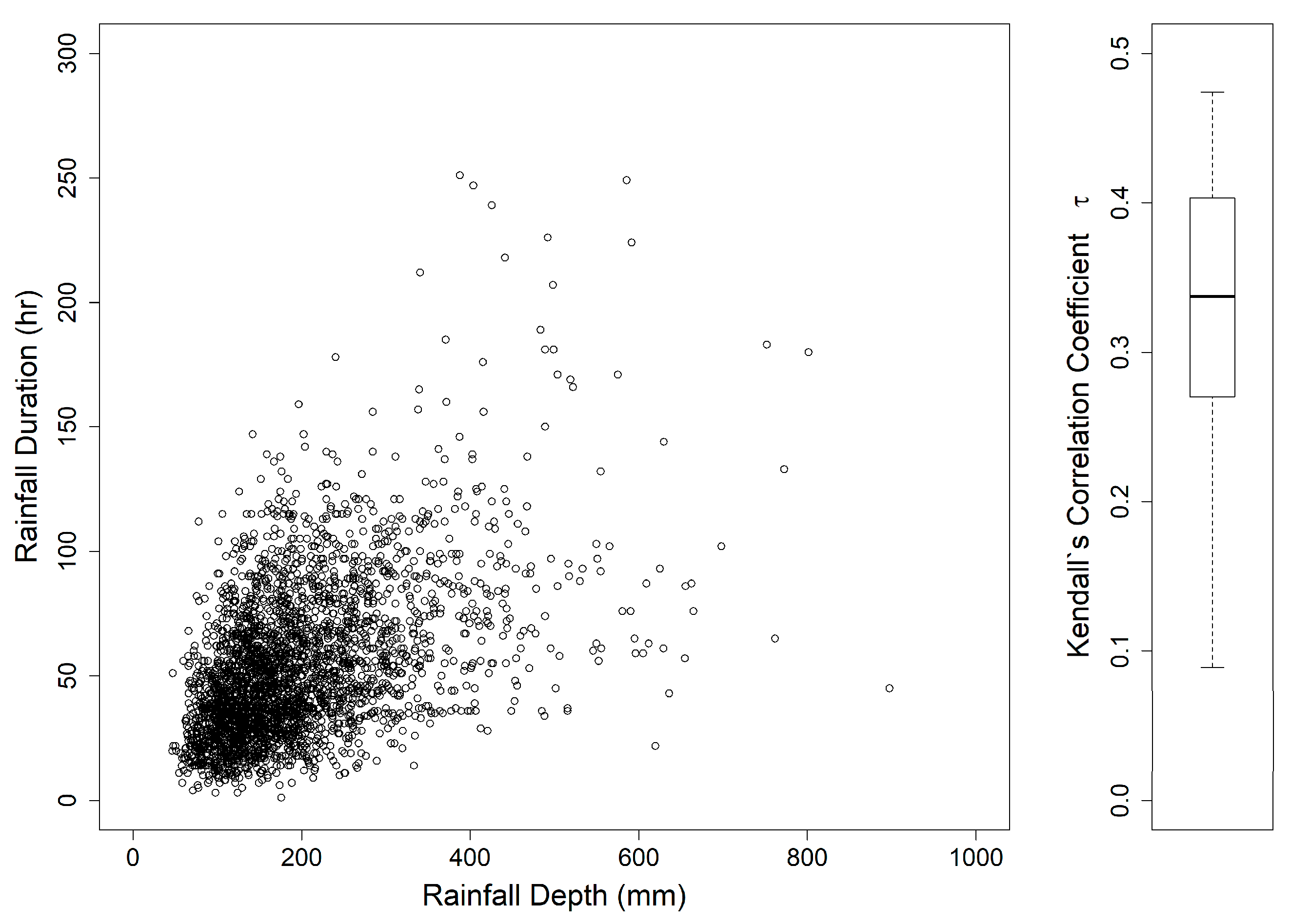
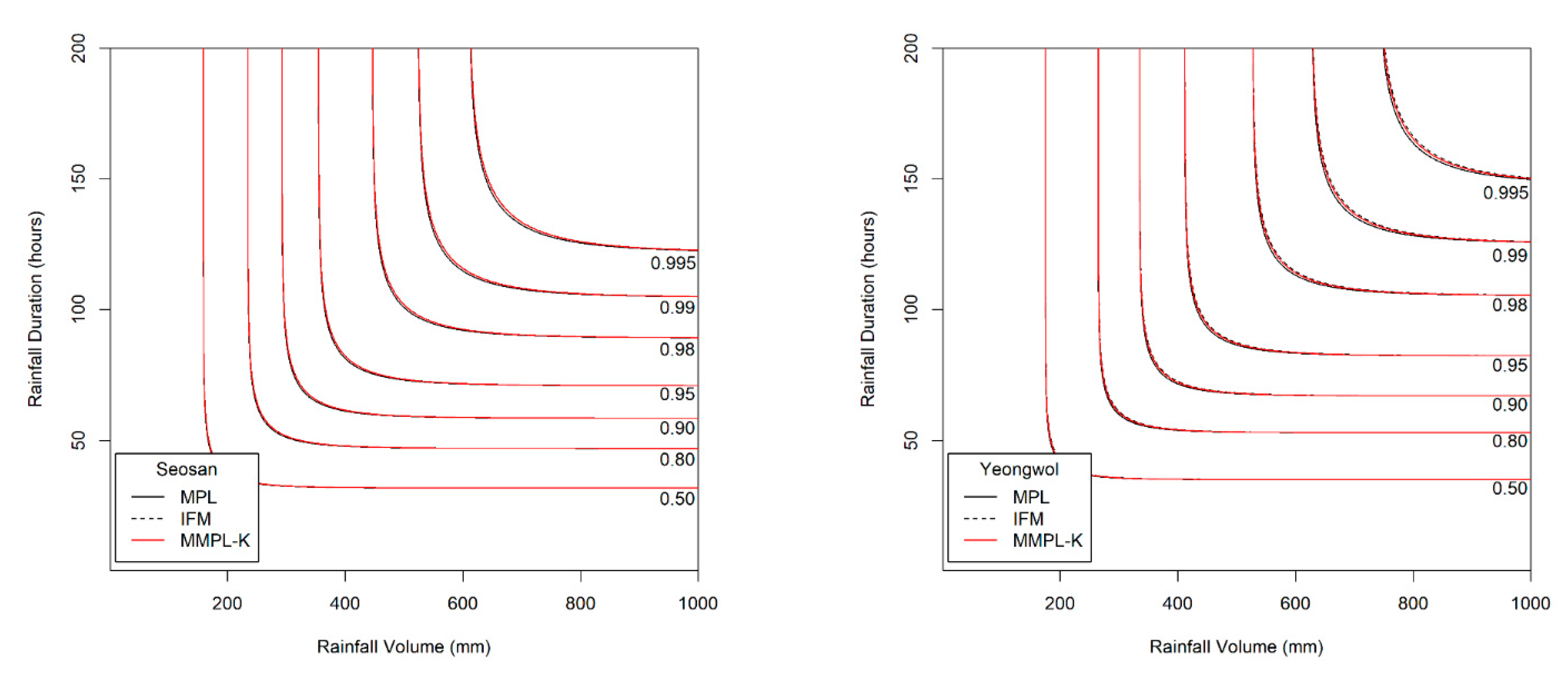
The MMPL method underestimates the copula parameter when the dependence of two variables is too strong. For example, when Kendall’s
is 0.75 (see
Figure 4 and
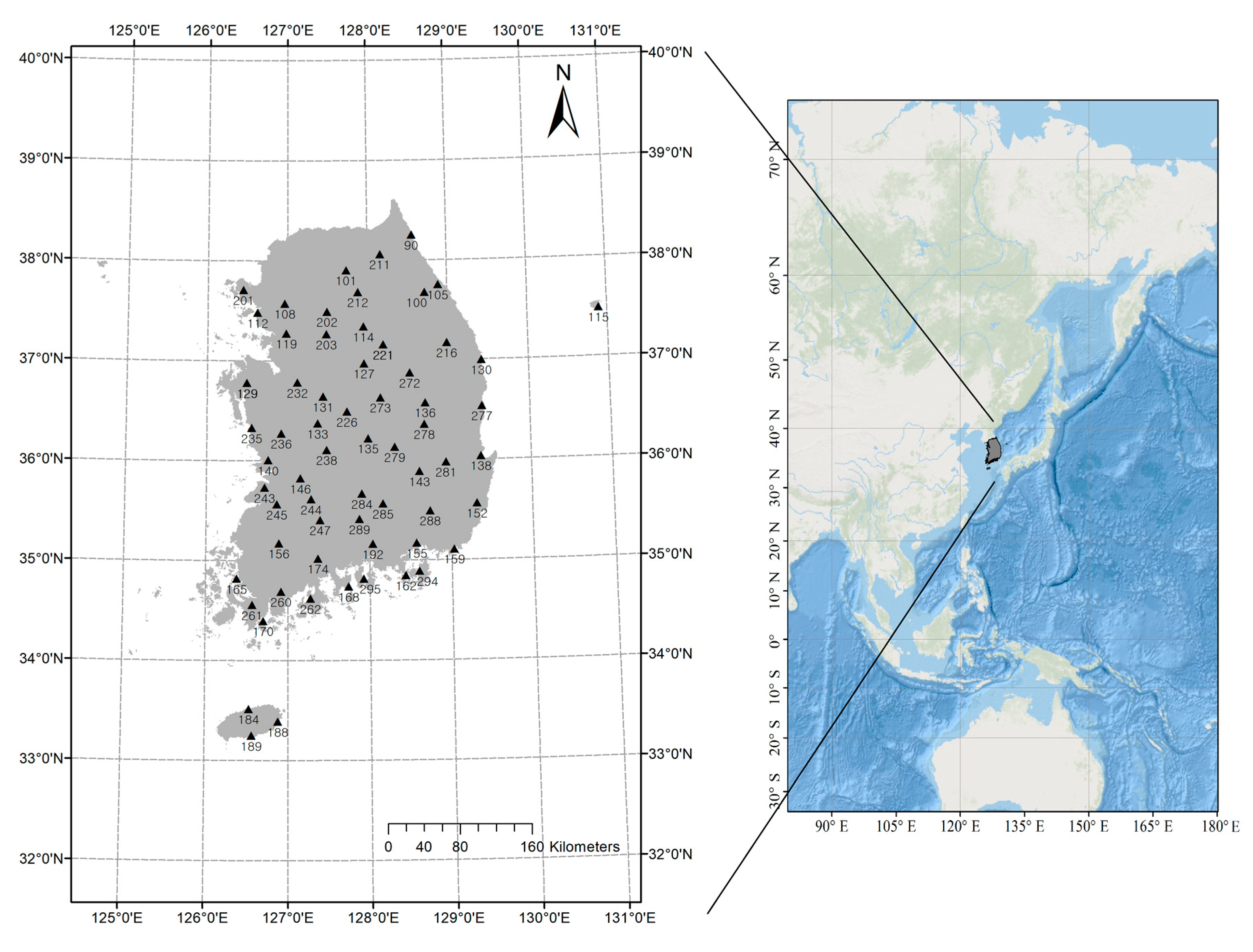
Figure 7), the MPL and IFM methods provide good performances, except for the MMPL-A method, which, in this case, is considered the best method among the employed MMPL methods. Seventy-five hundredths is an unrealistically large coefficient at the applied 64 stations as shown in
Figure 9. All Kendall’s
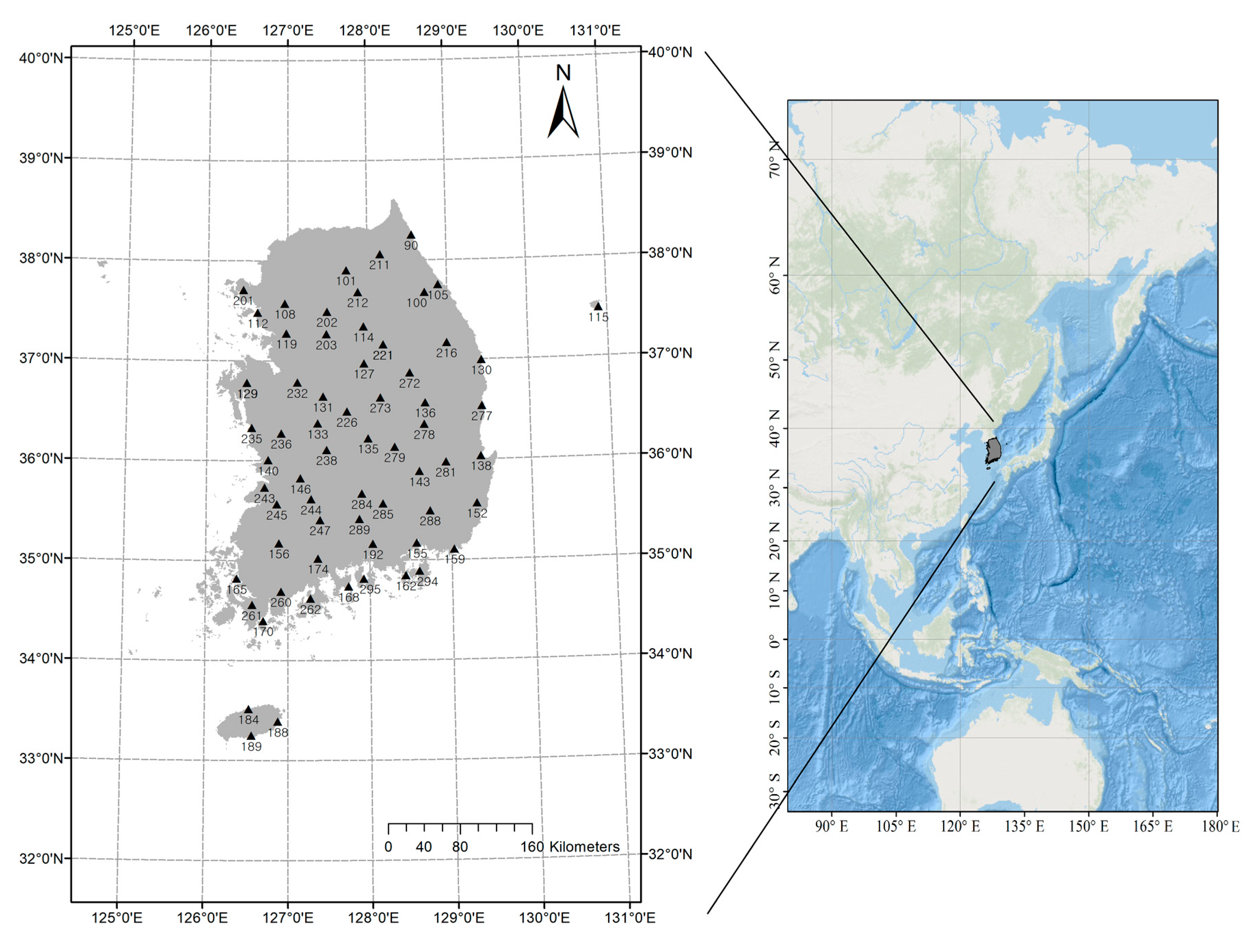
are smaller than 0.5 at the applied 64 stations. For the skewed data, such as extreme precipitation and flood, the data sets with a very strong correlation may be infrequent. Thus, the MMPL method would be an alternative to the copula fitting methods for skewed data of hydrometeorological variables.
In this study, the bias is employed as a measure of accuracy compared to given true values of the copula parameter in the simulation experiment. For application of the real data sets, the parameter of population copula is unknown. Thus the bias may not be a good evaluation measure for real data sets. To overcome this drawback, goodness-of-fit tests are often used, and many of them examine goodness-of-fit by comparing empirical and estimated models. Because the empirical copula of goodness-of-fit tests, such as Kolmogorov- or Cramer-von Mises-type statistics, are based on the Weibull plotting position, the conventional goodness-of-fit tests are inappropriate for the MMPL methods. The goodness-of-fit tests should be modified or proposed for measuring goodness-of-fit of the copula model fitted by the MMPL method in the future.
7. Conclusions
In this study, a new parameter estimation method for the copula model was proposed. The proposed method is a modified version of the MPL method (MMPL). Six MMPL methods were proposed, and their performances and applicability were evaluated for the bivariate Gumbel copula model via the simulation experiments and case study to the extreme precipitation events. According to the results of the current study, the conclusions are as follows:
The MMPL methods suggested in this paper prefers to estimate the parameters in a multivariate frequency analysis using the copula model for hydrometeorological data. The MMPL methods provide better performance than the original MPL method when the values of Kendall’s tau () are moderate ( and ) in the simulation experiments regardless of unknown and known marginal distribution. However, for the case of , which is very rare as shown in the applications, the original MPL method performs better than the MPL method, especially for large sample sizes showing convergence to the true value as the sample size increases. Among the MMPL methods, the MMPL-K and MMPL-G methods can be the best methods depending on the statistical characteristics of applied data.
The original MPL method generally overestimates the parameters and shows the worst performance among the applied methods, but the parameter estimates converge to the true values as the sample size increases regardless of unknown and known marginal distributions and combinations of coefficient of skewness. However, this method shows comparably competitive to the best method, particularly when the sample size is large () and .
The IFM method, as expected, shows the worst performances except for small sample size of 30 and underestimates the parameters severely as the Kendall’s tau increases in the case of unknown marginal distribution. However, in the case of known marginal distribution (GEV), the IFM method shows the best performance, while the MMPL-K method provides better performance than the IFM method when the sum of the shape parameters is larger than or equal to 0.2 in large sample sizes () for the cases of moderate Kendall’s tau values. In addition, the IFM method generally performs the best even though Kendall’s tau is unrealistically large ().
Finally, the suggested MMPL methods generally perform better than the original MPL method, except with very strong and unrealistic Kendall’s tau value (), regardless of unknown and known marginal distributions. In addition, the MMPL methods perform marginally better than the IFM method when the sum of the shape parameters is larger than or equal to 0.2 in large sample sizes (), except , even in the case of known marginal distribution. In conclusion, the MMPL-K and MMPL-G methods are appropriate methods of fitting the Gumbel copula model for the case of moderate Kendall’s tau values. Particularly, the MMPL-K method generally provides more accurate parameter estimates in the case of unknown marginal distribution when the sum of the coefficients of skewness is larger than or equal to three with , and in the case of known marginal distribution when the sum of the shape parameters is larger than 0.2 with .




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}