Deriving Design Flood Hydrographs Based on Copula Function: A Case Study in Pakistan




Abstract
1. Introduction
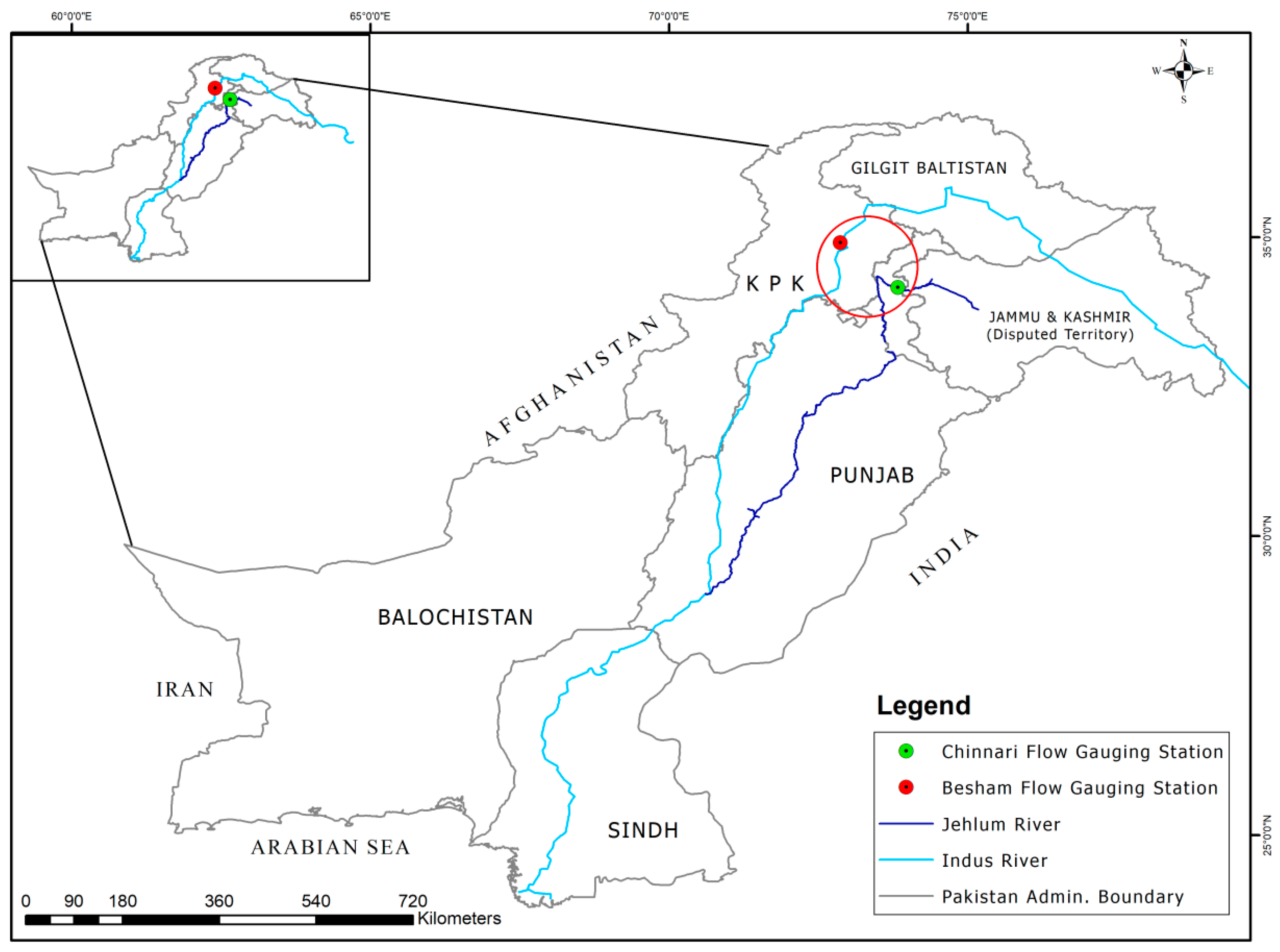
2. Study Basin and Hydrological Data
3. Methods
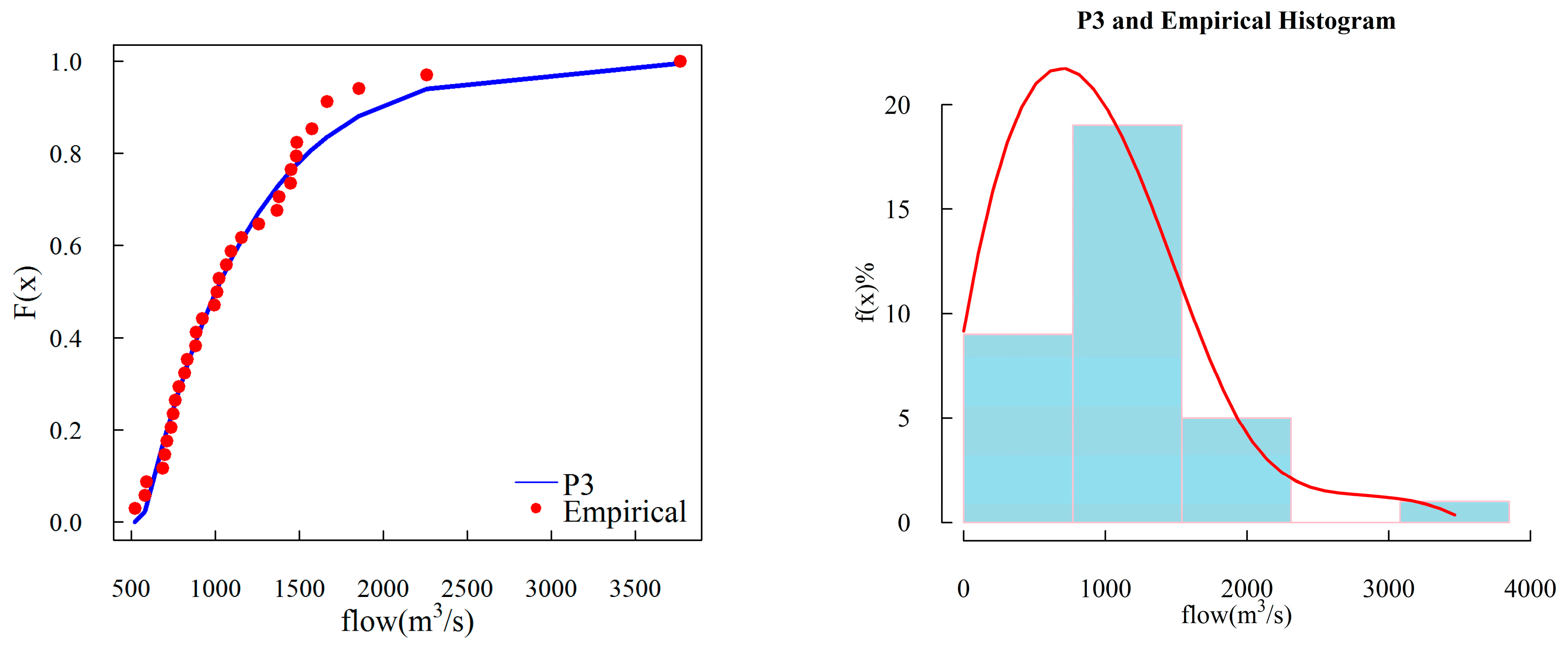
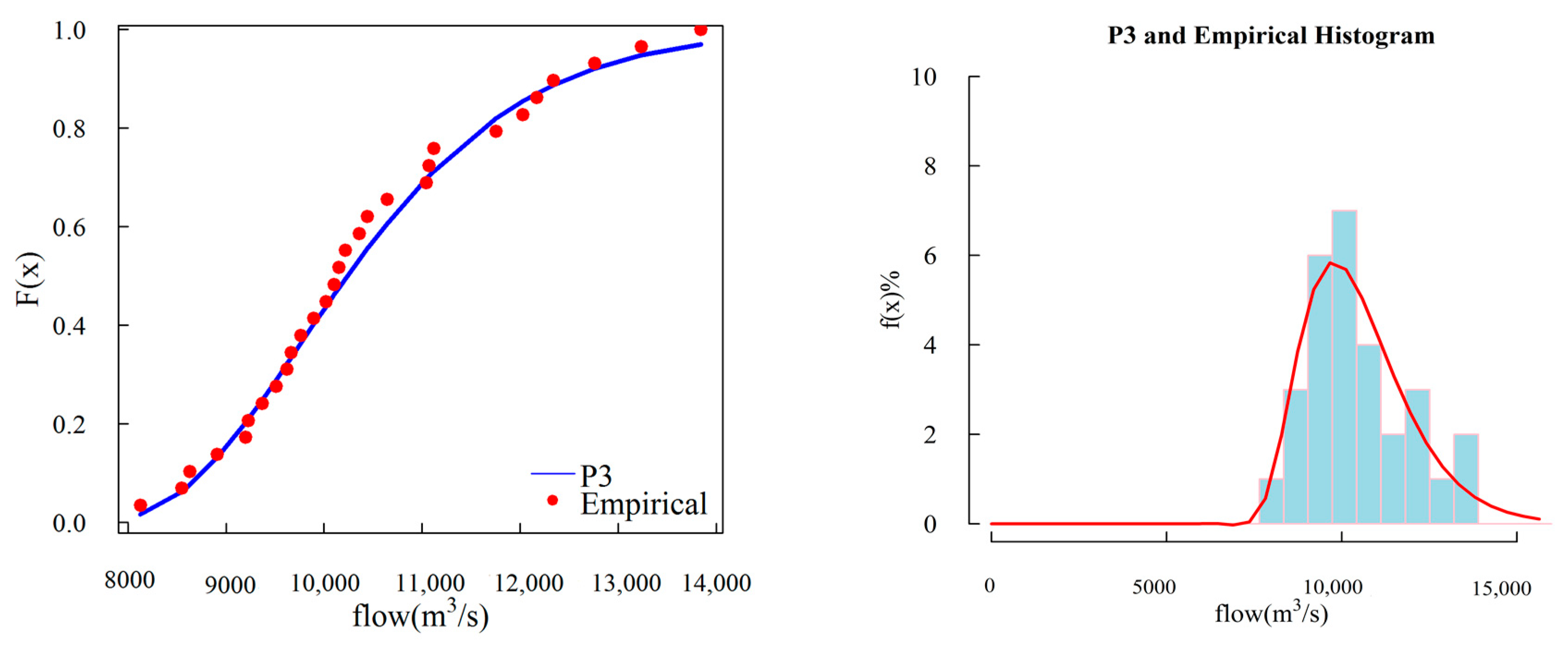
3.1. Selection of Marginal Distribution
3.2. Traditional Methods of Deriving DFH
3.3. Peak and Volume Amplitude Method
3.4. Deriving Joint Design Floods Based on Copulas
3.4.1. EFC Method
3.4.2. MLC Method
3.5. Joint Return Period
- (1)
- “OR” case, either Q > q or W > w, i.e.,
- (2)
- “AND” case, both Q > q or W > w, i.e.,
3.6. Procedure for DFH Generation
- (1)
- The ratio between the hydrological pairs of flood peak and volume is determined.
- (2)
- The normalized ratio RT varying within (0, 1) is estimated by:whereas maximum and minimum values are represented by and respectively.
- (3)
- The normalized ratio between M hydrological pairs of the observed hydrograph is also determined using steps 1 and 2 and is represented as , k = 1, …, M.
- (4)
- The square sum of deviations between and for M pairs are calculated as follows for each simulated hydrological pair (, ) covered by single JRP .
- (5)
- The observed TFH offering narrowest ratio (min) is chosen.
- (6)
- The hydrological pair (, ) is transformed into corresponding DFH by amplifying the selected observed TFH values.where DFH is the desired design flood hydrograph resulting from amplification of the observed hydrograph and TFH is observed discharge, against time t respectively. is flood volume of observed values against a 15-day flood duration ; is the peak flow of observed hydrograph.
4. Application and Discussion
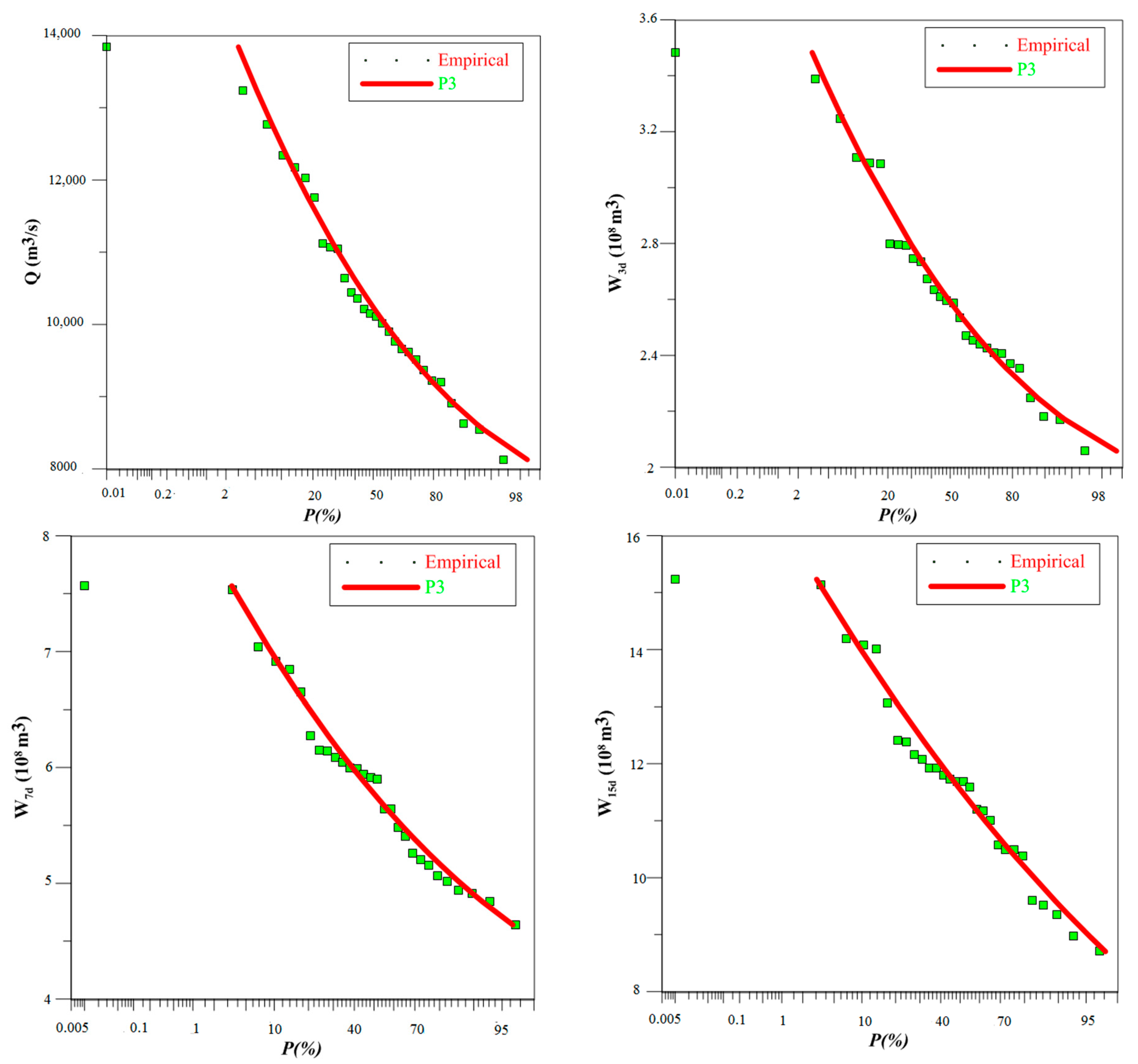
4.1. Selection of Marginal Distribution
4.2. Comparison of Copulas
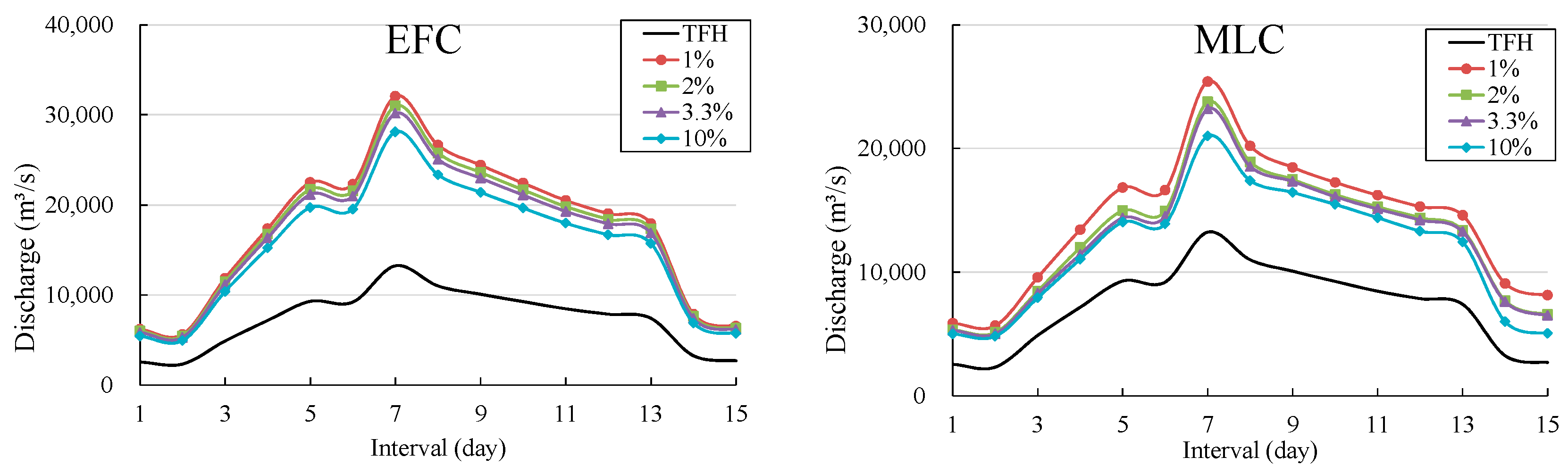
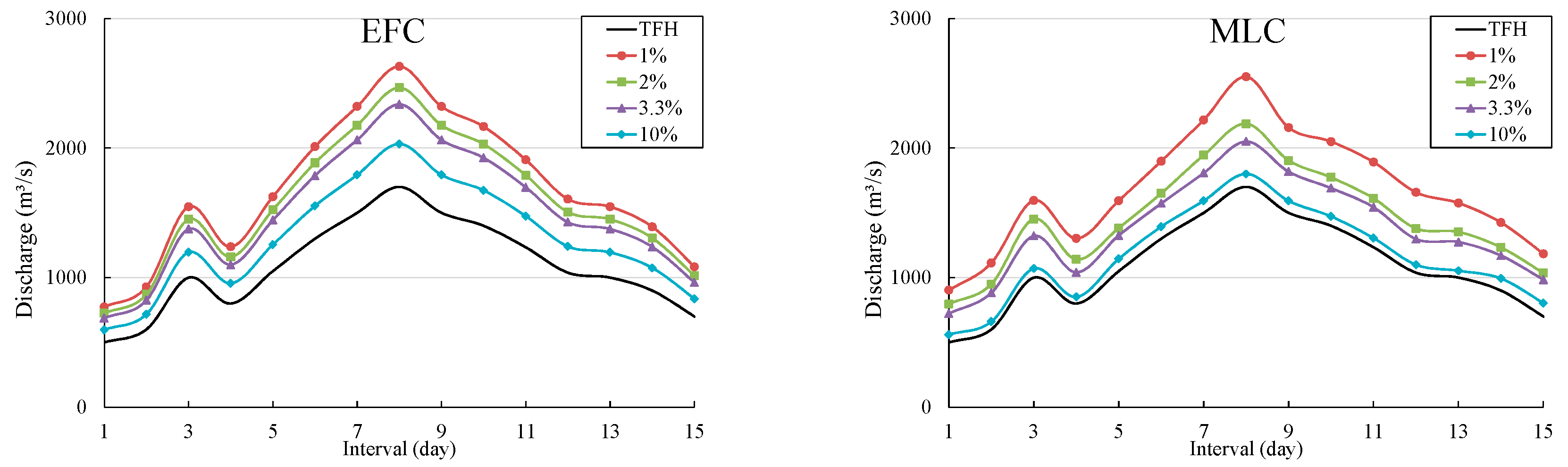
4.3. Derivation of DFH
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yin, J.; Gentine, P.; Zhou, S.; Sullivan, C.S.; Wang, R.; Zhang, Y.; Guo, S. Large increase in global storm runoff extremes driven by climate and anthropogenic changes. Nat. Commun. 2018, 9, 4389. [Google Scholar] [CrossRef] [PubMed]
- ICOLD (International Congress on Large Dams). Selection of Design Flood; Bulletin Report 82; ICOLD: Paris, France, 1992. [Google Scholar]
- ASCE. Hydrology Hand-Book, 2nd ed.; Manuals and Reports on Engineering Practices No. 28; ASCE: Reston, VA, USA, 1996. [Google Scholar]
- Yin, J.; Guo, S.; He, S.; Guo, J.; Hong, X.; Liu, Z. A copula-based analysis of projected climate changes to bivariate flood quantiles. J. Hydrol. 2018, 566, 23–42. [Google Scholar] [CrossRef]
- U.S. Water Resources Council (USWRC). Guidelines for Determining Flow Frequency, Bulletin 17B; U.S. Water Resources Council (USWRC): Washington, DC, USA, 1981.
- MWR (Ministry of Water Resources). Regulation for Calculating Design Flood of Water Resources and Hydropower Projects; Water Resources & Hydropower Press: Beijing, China, 2006. (In Chinese) [Google Scholar]
- Vittal, H.; Singh, J.; Kumar, P.; Karmakar, S. A framework for multivariate data-based at-site flood frequency analysis: Essentiality of the conjugal application of parametric and nonparametric approaches. J. Hydrol. 2015, 525, 658–675. [Google Scholar] [CrossRef]
- Smith, K. Environmental Hazards: Assessing Risk and Reducing Disaster; Routledge: Abingdon, UK, 2003. [Google Scholar]
- Chen, L.; Singh, V.P.; Shenglian, G.; Hao, Z.; Li, T. Flood coincidence risk analysis using multivariate copula functions. J. Hydrol. Eng. 2011, 17, 742–755. [Google Scholar] [CrossRef]
- Li, T.; Guo, S.; Chen, L.; Guo, J. Bivariate flood frequency analysis with historical information based on copula. J. Hydrol. Eng. 2012, 18, 1018–1030. [Google Scholar] [CrossRef]
- Liu, P.; Li, L.; Guo, S.; Xiong, L.; Zhang, W.; Zhang, J.; Xu, C.-Y. Optimal design of seasonal flood limited water levels and its application for the Three Gorges Reservoir. J. Hydrol. 2015, 527, 1045–1053. [Google Scholar] [CrossRef]
- Requena, A.I.; Mediero, L.; Garrote, L. A bivariate return period based on copulas for hydrologic dam design: Accounting for reservoir routing in risk estimation. Hydrol. Earth Syst. Sci. 2013, 17, 3023–3038. [Google Scholar] [CrossRef]
- Volpi, E.; Fiori, A. Design event selection in bivariate hydrological frequency analysis. Hydrol. Sci. J. 2012, 57, 1506–1515. [Google Scholar] [CrossRef]
- Goel, N.K.; Seth, S.M.; Chandra, S. Multivariate modeling of flood flows. J. Hydraul. Eng. 1998, 124, 146–155. [Google Scholar] [CrossRef]
- Yue, S.; Ouarda, T.; Bobée, B.; Legendre, P.; Bruneau, P. The gumbel mixed model for flood frequency analysis. J. Hydrol. 1999, 226, 88–100. [Google Scholar] [CrossRef]
- Shiau, J.-T. Return period of bivariate distributed extreme hydrological events. Stoch. Environ. Res. Risk Assess. 2003, 17, 42–57. [Google Scholar] [CrossRef]
- Xiao, Y.; Guo, S.; Liu, P.; Yan, B.; Chen, L. Design flood hydrograph based on multicharacteristic synthesis index method. J. Hydrol. Eng. 2009, 14, 1359–1364. [Google Scholar] [CrossRef]
- Pramanik, N.; Panda, R.K.; Sen, D. Development of design flood hydrographs using probability density functions. Hydrol. Process. 2010, 24, 415–428. [Google Scholar] [CrossRef]
- Mediero, L.; Jiménez-Álvarez, A.; Garrote, L. Design flood hydrographs from the relationship between flood peak and volume. Hydrol. Earth Syst. Sci. Discuss. 2010, 7, 4817–4849. [Google Scholar] [CrossRef]
- Serinaldi, F.; Grimaldi, S. Synthetic design hydrographs based on distribution functions with finite support. J. Hydrol. Eng. 2010, 16, 434–446. [Google Scholar] [CrossRef]
- Fuentes-Mariles, O.A.; Domínguez-Mora, R.; Arganis-Juarez, M.L.; Herrera-Alanís, J.L.; Carrizosa-Elizondo, E.; Sánchez-Cruz, J.A. Estimate of design hydrographs for the angostura dam, sonora, using statistical and spectral methods. Water Resour. Manag. 2015, 29, 4021–4043. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Asymmetric copula in multivariate flood frequency analysis. Adv. Water Resour. 2006, 29, 1155–1167. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Bivariate flood frequency analysis using the copula method. J. Hydrol. Eng. 2006, 11, 150–164. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Frequency analysis via copulas: Theoretical aspects and applications to hydrological events. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef]
- He, S.; Guo, S.; Liu, Z.; Yin, J.; Chen, K.; Wu, X. Uncertainty analysis of hydrological multi-model ensembles based on CBP-BMA method. Hydrol. Res. 2018, 49, 1636–1651. [Google Scholar] [CrossRef]
- Shiau, J.-T.; Feng, S.; Nadarajah, S. Assessment of hydrological droughts for the Yellow River, China, using copulas. Hydrol. Process. 2007, 21, 2157–2163. [Google Scholar] [CrossRef]
- Chowdhary, H.; Escobar, L.A.; Singh, V.P. Identification of suitable copulas for bivariate frequency analysis of flood peak and flood volume data. Hydrol. Res. 2011, 42, 193–216. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. On the use of copulas in hydrology: Theory and practice. J. Hydrol. Eng. 2007, 12, 369–380. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Trivariate flood frequency analysis using the gumbel–hougaard copula. J. Hydrol. Eng. 2007, 12, 431–439. [Google Scholar] [CrossRef]
- Chen, L.; Singh, V.P.; Guo, S.; Mishra, A.K.; Guo, J. Drought analysis using copulas. J. Hydrol. Eng. 2012, 18, 797–808. [Google Scholar] [CrossRef]
- Yin, J.; Guo, S.; Liu, Z.; Yang, G.; Zhong, Y.; Liu, D. Uncertainty analysis of bivariate design flood estimation and its impacts on reservoir routing. Water Resour. Manag. 2018, 32, 1795–1809. [Google Scholar] [CrossRef]
- Tahir, A.A.; Hakeem, S.A.; Hu, T.; Hayat, H.; Yasir, M. Simulation of snowmelt-runoff under climate change scenarios in a data-scarce mountain environment. Int. J. Digit. Earth. 2017, 12, 910–930. [Google Scholar] [CrossRef]
- Hosking, J.R.M. L-Moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Yin, J.; Guo, S.; Liu, Z.; Chen, K.; Chang, F.-J.; Xiong, F. Bivariate seasonal design flood estimation based on copulas. J. Hydrol. Eng. 2017, 22, 05017028. [Google Scholar] [CrossRef]
- Di Baldassarre, G.; Laio, F.; Montanari, A. Design flood estimation using model selection criteria. Phys. Chem. Earth Parts A/B/C 2009, 34, 606–611. [Google Scholar] [CrossRef]
- Haddad, K.; Rahman, A.; Stedinger, J.R. Regional flood frequency analysis using Bayesian generalized least squares: A comparison between quantile and parameter regression techniques. Hydrol. Process 2012, 26, 1008–1021. [Google Scholar] [CrossRef]
- Chen, L.; Zhang, Y.; Zhou, J.; Singh, V.P.; Guo, S.; Zhang, J. Real-time error correction method combined with combination flood forecasting technique for improving the accuracy of flood forecasting. J. Hydrol. 2015, 521, 157–169. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Bivariate rainfall frequency distributions using Archimedean copulas. J. Hydrol. 2007, 332, 93–109. [Google Scholar] [CrossRef]
- Guo, S. A discussion on unbiased plotting positions for the general extreme value distribution. J. Hydrol. 1990, 121, 33–44. [Google Scholar] [CrossRef]
- Yue, S.; Ouarda, T.B.M.J.; Bobée, B.; Legendre, P.; Bruneau, P. Approach for describing statistical properties of flood hydrograph. J. Hydrol. Eng. 2002, 7, 147–153. [Google Scholar] [CrossRef]
- Chow, V.T. Applied Hydrology; Tata McGraw-Hill Education: New York, NY, USA, 1988. [Google Scholar]
- De Michele, C.; Salvadori, G.; Canossi, M.; Petaccia, A.; Rosso, R. Bivariate statistical approach to check adequacy of dam spillway. J. Hydrol. Eng. 2005, 10, 50–57. [Google Scholar] [CrossRef]
- U.S. Soil Conservation Service (U.S. SCS). Hydrology. In National Engineering Handbook; U.S. Department of Agriculture: Washington, DC, USA, 1985. [Google Scholar]
- Yin, J.; Guo, S.; Wu, X.; Yang, G.; Xiong, F.; Zhou, Y. A meta-heuristic approach for multivariate design flood quantile estimation incorporating historical information. Hydrol. Res. 2019, 50, 526–544. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Multivariate real-time assessment of droughts via copula-based multi-site Hazard Trajectories and Fans. J. Hydrol. 2015, 526, 101–115. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas; Springer Science & Business Media: New York, NY, USA, 2006. [Google Scholar]
- Zhang, Q.; Qi, T.; Singh, V.P.; Chen, Y.D.; Xiao, M. Regional frequency analysis of droughts in china: A multivariate perspective. Water Resour. Manag. 2015, 29, 1767–1787. [Google Scholar] [CrossRef]
- Chebana, F.; Ouarda, T. Multivariate quantiles in hydrological frequency analysis. Environmetrics 2011, 22, 63–78. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C. Estimating strategies for multiparameter multivariate extreme value copulas. Hydrol. Earth Syst. Sci. 2011, 15, 141–150. [Google Scholar] [CrossRef]
- Li, T.; Guo, S.; Liu, Z.; Xiong, L.; Yin, J. Bivariate design flood quantile selection using copulas. Hydrol. Res. 2017, 48, 997–1013. [Google Scholar] [CrossRef]
- Gräler, B.; Berg, M.J.V.D.; Vandenberghe, S.; Petroselli, A.; Grimaldi, S.; De Baets, B.; Verhoest, N.E.C.; Verhoest, N. Multivariate return periods in hydrology: A critical and practical review focusing on synthetic design hydrograph estimation. Hydrol. Earth Syst. Sci. 2013, 17, 1281–1296. [Google Scholar] [CrossRef]
- Özban, A. Some new variants of Newton’s method. Appl. Math. Lett. 2004, 17, 677–682. [Google Scholar] [CrossRef]
- Sraj, M.; Bezak, N.; Brilly, M. Bivariate flood frequency analysis using the copula function: A case study of the Litija station on the Sava River. Hydrol. Process 2015, 29, 225–238. [Google Scholar] [CrossRef]
- Chen, L.; Guo, S.; Yan, B.; Liu, P.; Fang, B. A new seasonal design flood method based on bivariate joint distribution of flood magnitude and date of occurrence. Hydrol. Sci. J. 2010, 55, 1264–1280. [Google Scholar] [CrossRef]
- Xiong, F.; Guo, S.; Chen, L.; Chang, F.-J.; Zhong, Y.; Liu, P. Identification of flood seasonality using an entropy-based method. Stoch. Environ. Res. Risk Assess. 2018, 32, 3021–3035. [Google Scholar] [CrossRef]
- Zhong, Y.; Guo, S.; Liu, Z.; Wang, Y.; Yin, J. Quantifying differences between reservoir inflows and dam site floods using frequency and risk analysis methods. Stoch. Environ. Res. Risk Assess. 2018, 32, 419–433. [Google Scholar] [CrossRef]
- Naz, S.; Iqbal, M.J.; Akhter, S.M.; Hussain, I. The gumbel mixed model for flood frequency analysis of tarbela. Nucleus 2016, 53, 171–179. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| River | Variable | Data Length (Years) | Sample Statistics Values | ||
|---|---|---|---|---|---|
| Mean | L-Cv | L-Cs | |||
| Indus | Q (m3/s) | 29 | 10,474.62 | 0.1384 | 0.6383 |
| W3d (108 m3) | 29 | 2.651 | 0.1371 | 0.6817 | |
| W7d (108 m3) | 29 | 5.867 | 0.135 | 0.536 | |
| W15d (108 m3) | 29 | 11.67 | 0.147 | 0.369 | |
| Jhelum | Q (m3/s) | 34 | 970.69 | 0.378 | 0.670 |
| W3d (108 m3) | 34 | 0.229 | 0.349 | 0.345 | |
| W7d (108 m3) | 34 | 0.493 | 0.335 | 0.320 | |
| W15d (108 m3) | 34 | 0.976 | 0.334 | 0.382 | |
| Copula Function | |||
|---|---|---|---|
| Gumbel-Hougaard | |||
| Clayton | |||
| Frank |
| Location | Criteria | Probability Distributions | |||||
|---|---|---|---|---|---|---|---|
| GPA | GNO | GLO | WEI | P3 | GEV | ||
| Indus River | AIC | −184.90 | −199.85 | −191.44 | −197.11 | −199.90 | −200.18 |
| RMSE | 0.0372 | 0.02874 | 0.0332 | 0.03013 | 0.0287 | 0.02858 | |
| Jhelum River | AIC | −223.05 | −229.96 | −216.66 | −224.79 | −225.68 | −224.70 |
| RMSE | 0.0344 | 0.0311 | 0.0378 | 0.0335 | 0.0331 | 0.0336 | |
| River | Variable | G–H | Clayton | Frank | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| θ | Dn | Pv | θ | Dn | Pv | θ | Dn | Pv | ||
| Indus | Qmax-W3d | 22.56 | 0.031 | 0.012 | 43.11 | 0.037 | 0.024 | 88.55 | 0.039 | 0.022 |
| Qmax-W7d | 5.21 | 0.032 | 0.023 | 8.41 | 0.039 | 0.029 | 19.02 | 0.035 | 0.031 | |
| Qmax-W15d | 2.57 | 0.028 | 0.031 | 3.14 | 0.030 | 0.035 | 8.23 | 0.037 | 0.029 | |
| Jhelum | Qmax-W3d | 14.38 | 0.033 | 0.024 | 26.77 | 0.039 | 0.029 | 55.84 | 0.037 | 0.033 |
| Qmax-W7d | 6.45 | 0.029 | 0.039 | 10.90 | 0.040 | 0.033 | 24.03 | 0.035 | 0.041 | |
| Qmax-W15d | 4.49 | 0.031 | 0.033 | 6.98 | 0.033 | 0.035 | 16.12 | 0.038 | 0.037 | |
| River | Indus | Jhelum | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Return Period | 100 | 50 | 30 | 10 | 100 | 50 | 30 | 10 | |
| Q (m3/s) | P3/LM | 14,975 | 14,267 | 13,729 | 12,491 | 2117 | 1935 | 1798 | 1481 |
| MLC | 15,229 | 14,842 | 14,084 | 12,606 | 2080 | 1918 | 1796 | 1512 | |
| EFC | 15,942 | 15,143 | 14,711 | 12,993 | 2157 | 1977 | 1839 | 1527 | |
| W3D (108 m3) | P3/LM | 3.68 | 3.52 | 3.34 | 3.14 | 0.46 | 0.42 | 0.40 | 0.34 |
| MLC | 3.75 | 3.62 | 3.46 | 3.18 | 0.47 | 0.43 | 0.41 | 0.34 | |
| EFC | 3.71 | 3.57 | 3.42 | 3.16 | 0.47 | 0.43 | 0.40 | 0.34 | |
| W7D (108 m3) | P3/LM | 8.02 | 7.78 | 7.55 | 6.75 | 0.96 | 0.89 | 0.84 | 0.72 |
| MLC | 8.25 | 7.98 | 7.68 | 7.02 | 0.99 | 0.92 | 0.86 | 0.74 | |
| EFC | 8.21 | 7.90 | 7.59 | 6.95 | 0.97 | 0.90 | 0.85 | 0.73 | |
| W15D (108 m3) | P3/LM | 16.3 | 15.6 | 15.1 | 14.0 | 1.87 | 1.75 | 1.65 | 1.42 |
| MLC | 16.6 | 15.9 | 15.4 | 14.3 | 1.95 | 1.82 | 1.71 | 1.46 | |
| EFC | 16.3 | 15.7 | 15.3 | 14.2 | 1.90 | 1.78 | 1.68 | 1.45 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizwan, M.; Guo, S.; Yin, J.; Xiong, F. Deriving Design Flood Hydrographs Based on Copula Function: A Case Study in Pakistan. Water 2019, 11, 1531. https://doi.org/10.3390/w11081531
Rizwan M, Guo S, Yin J, Xiong F. Deriving Design Flood Hydrographs Based on Copula Function: A Case Study in Pakistan. Water. 2019; 11(8):1531. https://doi.org/10.3390/w11081531
Chicago/Turabian StyleRizwan, Muhammad, Shenglian Guo, Jiabo Yin, and Feng Xiong. 2019. "Deriving Design Flood Hydrographs Based on Copula Function: A Case Study in Pakistan" Water 11, no. 8: 1531. https://doi.org/10.3390/w11081531
APA StyleRizwan, M., Guo, S., Yin, J., & Xiong, F. (2019). Deriving Design Flood Hydrographs Based on Copula Function: A Case Study in Pakistan. Water, 11(8), 1531. https://doi.org/10.3390/w11081531