1. Introduction
A Water Distribution System (WDS) plays a crucial role in delivering potable drinking water from a treatment plant to households and other types of water utility customers, e.g., industrial and commercial users. The capital investments and maintenance costs of such underground infrastructure are large; hence a detailed cost-effectiveness analysis at the design stage is necessary to facilitate the decision-making. In the past, this task was usually given to experienced engineers who have a sound understanding of the entire system. As a WDS tends to grow larger and more complex over time due to urbanization and system expansion, it is challenging for engineers to design a large-scale network considering a number of performance measures by merely relying on domain-specific knowledge and experience.
Advances in WDS simulation and optimization techniques, which emerged in the mid-1970s [
1], provide promising tools to support decision making for WDS design tasks. Initially, the optimal design of WDSs was often formulated as a single-objective optimization problem. This means minimizing the total costs while meeting all the design criteria including minimum nodal pressure heads at junctions and/or economical flow velocities within pipes [
2,
3,
4]. However, this approach was often criticized for compromising on other essential aspects of WDS performance, such as reliability, water quality, and vulnerability [
5,
6,
7]. An optimal least-cost solution is likely to result in less resilient infrastructure that cannot cope with unexpected conditions (e.g., pipe burst or power outage). Later, the multi-objective formulation (i.e., two or three objectives considered simultaneously) was introduced by the research community. This has the advantage of being able to identify the trade-off between costs and hydraulic performance (e.g., system reliability) explicitly [
8]. As more advanced optimization tools have become available in recent years, the many-objective formulation (i.e., with more than three objectives concerned) became increasingly popular [
9,
10]. In this approach, the highly complex interrelationships among different goal attainments, also known as the hypersurface [
11], can be visualized and analyzed, thus facilitating a better-informed decision-making process [
12].
During the period when the focus changed from the single-objective to many-objective formulations, advances in optimization algorithms were the main driving force behind a series of breakthroughs in both the algorithmic framework and computational efficiency. In particular, multi-objective evolutionary algorithms (MOEAs) have attracted more attention as they can identify the Pareto front more efficiently than traditional operations research methods (e.g., linear and non-linear programming). MOEAs do not require the gradient or derivative information of the objective functions, and they start the optimization from multiple locations using the population-based search mechanism. Therefore, the pursuit of more powerful MOEAs has become an active and cutting-edge direction in the research community. From the mid-1980s to nowadays, many MOEAs have been created. Among those, the Non-dominated Sorting Genetic Algorithm II (NSGA-II) [
13] has been extensively applied to a wide range of disciplines including water engineering. As the continuous development of more powerful MOEAs, some hybrid algorithms have gained growing attention in the last decade. The two most-cited such algorithms are a multialgorithm, genetically adaptive multiobjective (AMALGAM) method [
14] and the Borg MOEA [
15], which embed diversified search operators (four and six, respectively) to improve the robustness and accuracy of MOEAs. Inspired by AMALGAM and Borg, a tailored MOEA for the optimal design of WDSs called GALAXY was developed and validated on a range of benchmark design problems with increasing complexities [
16]. These hybrid MOEAs have great potential in shaping the future of this research area.
Despite considerable success in the creation of more advanced MOEAs, there is a rare discussion of some fundamental questions regarding their applications to WDS optimization. That is, by developing new MOEAs and verifying them on selected benchmark design problems, do we really understand these tools well or have sufficient confidence in applying them on larger, real-world design problems? Currently, MOEAs are, to a large extent, black-box tools, which limits their utility to researchers and practitioners. This is particularly true when the parameterization issues are considered. Quite often they have a number of parameters that need to be tuned for best performance. The main challenges of applying MOEAs involve their reliability, robustness, and accuracy, which are profoundly influenced by the choices of the most appropriate algorithm and the corresponding parameter values [
17]. The fine-tuning of these parameters before an application is a common rule-of-thumb, although further guidelines on how to do that are generally lacking.
Most recently, Cisty et al. [
18] employed the NSGA-II to solve the optimal design of a large real-world irrigation network. They tested varying standard settings of associated parameters (i.e., crossover and mutation probabilities, as well as the population sizes), rather than adopting the recommended settings (fixed values) from literature. By using this approach, a new best-known least-cost solution was found for the problem they studied. Their work highlights the potential for obtaining equally good, if not better, solutions with existing optimization methods but with their parameters suitably selected to take full advantage of methods’ capabilities. More importantly, knowing the efficient value ranges for the parameters is necessary to avoid the time-consuming process of fine-tuning.
Motivated by the work mentioned above, this paper reverts to the classical NSGA-II rather than hybrid MOEAs in an attempt to explore the interrelationships among algorithm parameters and discover their impact on the performance. In particular, we aim to address the following two questions: (1) How do various parameters within NSGA-II influence its performance, and (2) can we develop practical guidelines for settings those parameters? By addressing the above questions, this paper contributes to the gaining of in-depth knowledge of NSGA-II applied to the optimal design of WDSs and an effective way for the research community to take full advantage of this optimization tool with improved performance. Furthermore, we also hope to influence the development of new MOEAs by opening the black-box and providing some insights into the behavior of the search operators.
The remainder of this paper is structured as follows.
Section 2 provides a moderate introduction to NSGA-II and a representative summary of its applications to the WDS design problems. Then, the proposed methodology of investigating the parameterization of NSGA-II is detailed in
Section 3.
Section 4 includes a short description of each case study and the experimental setup. The results obtained from three case studies and related discussion are demonstrated in
Section 5. Finally,
Section 6 draws key conclusions and identifies research limitations.
2. Current Understanding of NSGA-II
NSGA-II is arguably the most popular MOEA in the water research community. It is acknowledged as an “industry standard” algorithm that has been successfully applied to a variety of water resources optimization problems [
12,
17,
19]. It features a fast non-dominated sorting approach to ranking solutions primarily based on the Pareto dominance relationship. Solutions with higher rankings survive and are selected to reproduce. For those solutions that are non-dominated to each other (i.e., with the same ranking), a secondary sorting criterion known as the crowding distance is used to further discriminate among solutions. Solutions with larger crowding distances are preferred in this approach. The standard NSGA-II implements a binary tournament selection to establish the mating pool (i.e., parents) and applies the Simulated Binary Crossover (SBX) and the Polynomial Mutation (PM) with designated probabilities to create children from parents [
13]. The implicit elitism strategy ensures the best solutions ever found in the search history are always retained in the population. This allows a new population to be derived from the combination of parents and their offspring via the fast non-dominated sorting approach. NSGA-II also provides a constraint-handling technique to efficiently deal with constrained problems and supports both binary and real coding representations.
NSGA-II has various parameters which may have different impacts on its computational effectiveness. The most often studied are the population size (PS), the number of function evaluations (NFEs), the probability of SBX (Pc), and the probability of PM (Pm). PS and NFEs together determine the total computational budget applied to a given problem. That is, the ratio of NFEs to PS is equal to the number of generations over which NSGA-II will evolve. Note that a larger number of generations normally ensures better convergence of NSGA-II. However, the convergence rate declines significantly as the optimization proceeds, and only minor improvements may be achieved with an additional computational budget. However, it is also essential to pay particular attention to PS, as an inadequately small value may result in a crowded population, i.e., with a number of similar solutions, rather than a diversified set. This normally leads to premature convergence due to the insufficient exchange of new information in the gene pool of the population. Pc and Pm control the chance of each chromosome undergoing the crossover and mutation processes, respectively. A widely adopted strategy is to keep a high value of Pc (e.g., 0.9) and a low value of Pm (e.g., the inverse of the number of decision variables (NDVs), 1/NDVs). The crossover rate, as the predominant search driver, plays a critical role during optimization. The mutation rate contributes mainly to prevent the population from being trapped in local optima.
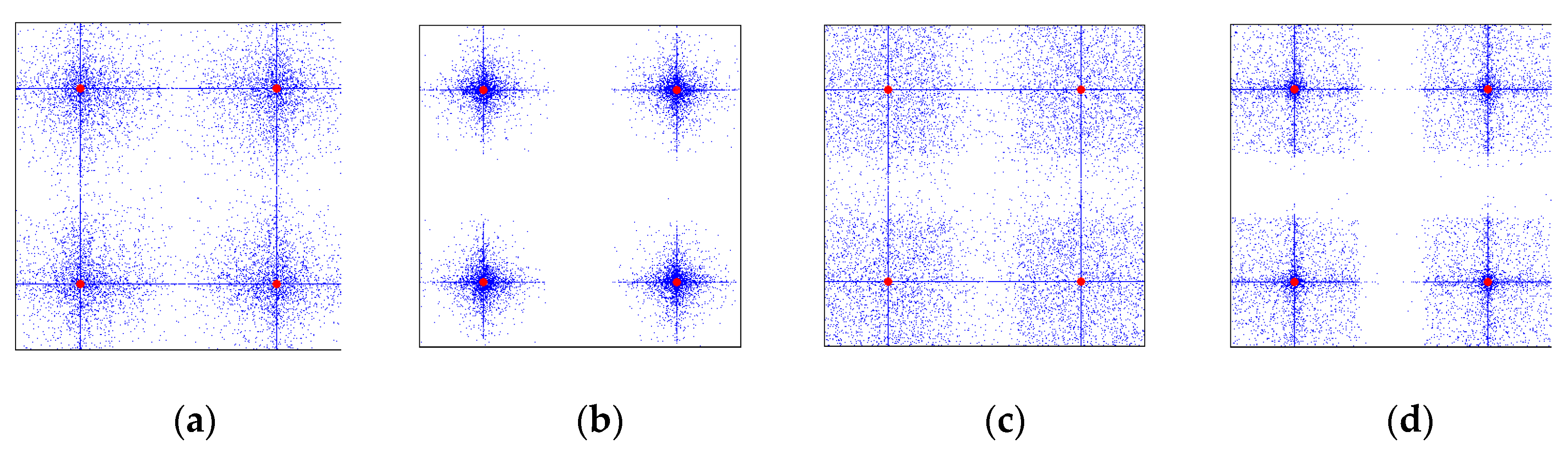
There are another two important parameters which may significantly affect the performance of NSGA-II, which are the distribution indices of SBX and PM (denoted as
DIc and
DIm, respectively). As previously mentioned, SBX and PM are the main search operators within NSGA-II, producing improved children from parents with designated probabilities (i.e.,
Pc and
Pm). SBX mimics the search behavior of the single-point crossover used in binary-coded genetic algorithms and is suitable for optimization problems with real or discrete decision variables. The positions of children points are distributed around their parents following the exponential laws of
DIc (for more details, see [
20]). Similar to SBX, the search behavior of PM also depends on the exponential laws of
DIm. As such, each distribution index directly influences the Euclidean distance of the offspring from their parents in the decision variable space (eventually reflected in the objective space). Explicitly, a larger value of
DIc or
DIm keeps the offspring similar (i.e., close) to their parents. In contrast, a smaller value increases the probability of generating offspring substantially different (i.e., far) from their parents (
Figure 1). In short,
DIc and
DIm control the search step sizes, while
Pc and
Pm determine the likelihood of implementing such search steps in the decision variable space. Consequently, a proper combination of these five parameters (i.e.,
PS,
Pc,
Pm,
DIc, and
DIm), in addition to a sufficient computational budget, can lead to a better and more robust search behavior of NSGA-II, thus eventually improving the quality of Pareto fronts obtained.
We have conducted an extensive literature survey regarding the applications of NSGA-II to WDS design problems (see
Table 1) and found that fine-tuning of the NSGA-II parameters had often not been performed. Instead, authors followed the recommended settings from literature, mainly originated from Deb et al. [
13]. The ranges of the three primary parameters—namely
PS,
Pc, and
Pm—were found to be within the following bounds:
PS ∈ [40,1000],
Pc ∈ [0.80,0.98], and
Pm ∈ o(1/
NDVs).
NFEs was often determined according to the size of the design problems, with larger cases using higher
NFEs values. Surprisingly, only a few previous studies focused on the fine-tuning of
DIc and
DIm, which implies that the potential of NSGA-II might not be fully utilized in those applications.
Though using different parameter combinations proved to be an effective way of eliminating the need for fine-tuning, Cisty et al. [
18] did not elaborate on how various parameters were altered in their experiment. In other words, the two key questions related to the parameters setting and practical guidance for their selection were not adequately addressed. The current understanding and applications of NSGA-II reveal the gaps between the potential of this classic MOEA and the knowledge of its parameterization. Therefore, by improving our understanding of the complicated nexus among different parameters, we aim to provide guidance for future utilization of NSGA-II, i.e., by alleviating the criticism of the black-box characteristics of MOEAs to a great extent.
4. Case Studies
We selected three benchmark networks from the literature to illustrate how the parameterization of NSGA-II affects its performance and which parameter(s) has a dominant impact on the quality of solutions obtained. In particular, two widely used small cases were chosen, namely the New York tunnel [
35] and the Hanoi [
36], as well as a larger irrigation network design problem [
37].
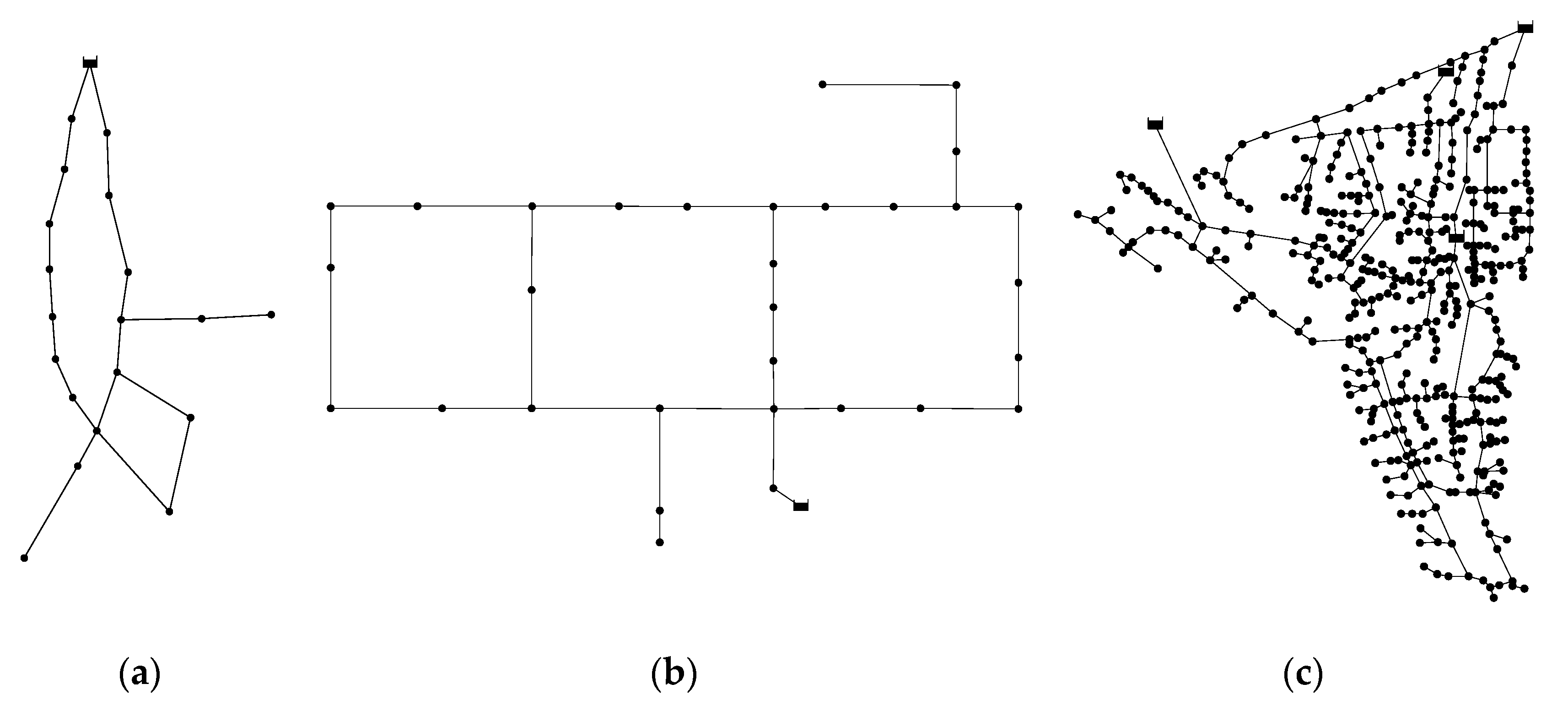
Figure 2 shows the layout of each network. For detailed information including the available pipe sizes and the associated unit costs of these cases, readers are referred to the following website
http://tinyurl.com/cwsbenchmarks/.
4.1. New York Tunnel Network (NYT)
The New York Tunnel Network (NYT) was first proposed as a rehabilitation activity undertaken in an existing tunnel system which was the primary water distribution system of the city of New York, USA. The NYT is comprised of twenty-one pipes organized in two loops, nineteen demand nodes, and one reservoir with a fixed head of 91.44 m (300 ft.). All the existing pipes are considered for duplication to meet the projected future demand. The Hazen-Williams roughness coefficient for both new and existing pipes is 100. The minimum pressure of all the demand nodes is fixed at 77.72 m (255 ft.) except for nodes 16 and 17 that are 79.25 m (260 ft.) and 83.15 m (272.8 ft.), respectively. A selection of fifteen diameter sizes is available as well as a ‘do nothing’ option. Therefore, the search space is equal to 1621 ≈ 1.93 × 1025 discrete combinations.
4.2. Hanoi Network (HAN)
The Hanoi Network (HAN) resembles a water distribution system in Hanoi, the capital of Vietnam. The HAN consists of thirty-four pipes organized in three loops, thirty-one demand nodes, and one reservoir with a fixed head of 100.0 m. The Hazen-Williams roughness coefficient for all pipes is 130. The minimum head above the ground elevation of each node is 30.0 m. There are six commercially available pipe sizes, ranging from 304.8 mm (12.0 in.) to 1016.0 mm (40.0 in.). Therefore, the search space is equal to 634 ≈ 2.87 × 1026 discrete combinations. Due to a very limited range of pipe sizes, the HAN has a vast region of infeasible solutions in the landscape of decision variables, thus increasing the level of difficulty to identify near-optimal solutions.
4.3. Balerma Irrigation Network (BIN)
The Balerma Irrigation Network (BIN) represents an adaptation of the existing irrigation system in the Sol-Poniente irrigation district, which is located in Balerma province of Almería, Spain. The distinguishing feature of this network is that all nodes have the same demand of 5.55 L/s across the network. The BIN has 454 relatively short pipes, 443 demand nodes (hydrants), and four reservoirs with fixed heads between 112.0 m and 127.0 m. The material of pipes is polyvinyl chloride (PVC). The Darcy-Weisbach roughness coefficient of 0.0025 mm is applied to all the pipes. The minimum pressure head above the ground elevation is 20.0 m for all the demand nodes. There are a total of ten commercially available sizes, ranging from 113.0 mm to 581.8 mm. Therefore, the search space is equal to 10454 discrete combinations.
4.4. Experimental Setup
The NYT and HAN have been widely used in most previous works as small and real-world WDS design problem. The currently best-known solutions to the least-cost design of NYT and HAN are
$38.64 million and
$6.081 million, respectively [
38]. The BIN has also attracted the attention of optimization technique developers, and the recently updated least-cost solution is €1,921,400 [
18]. With these best-known solutions, it is convenient to evaluate the performance of NSGA-II by the indicators of
Freq and
Avg under different parameter value combinations. The
NFEs set for solving the NYT and HAN design problems are 0.5 and 0.6 million, respectively. Both design problems are solved 100 times independently using different random seeds with the designated
NFEs. For the BIN problem, due to a significantly increased search space size, the
NFEs are extended to five million which is ten times of that for the NYT problem. However, due to the excessive runtime for this problem, the number of independent optimization runs is reduced to 50 times.
6. Conclusions
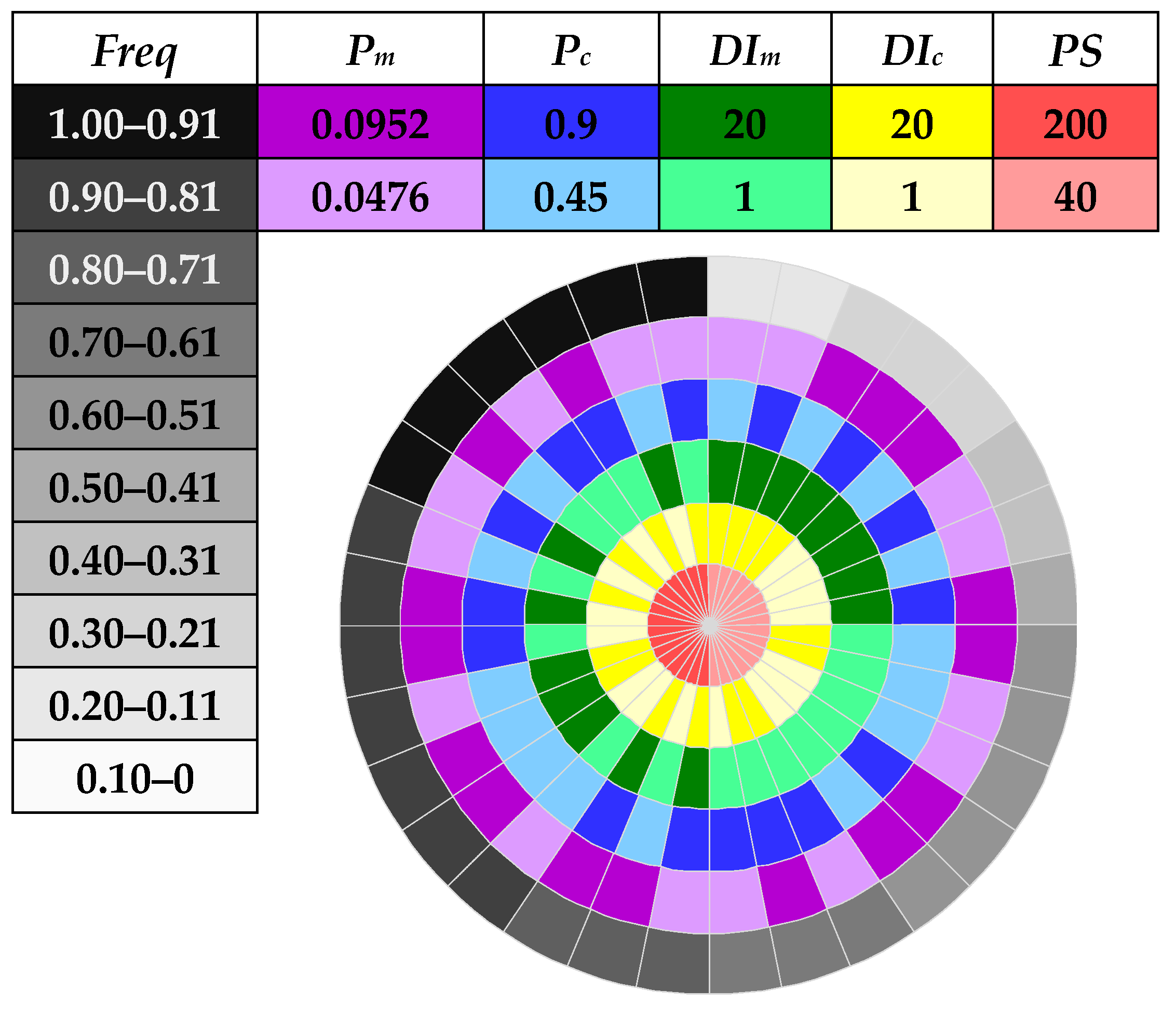
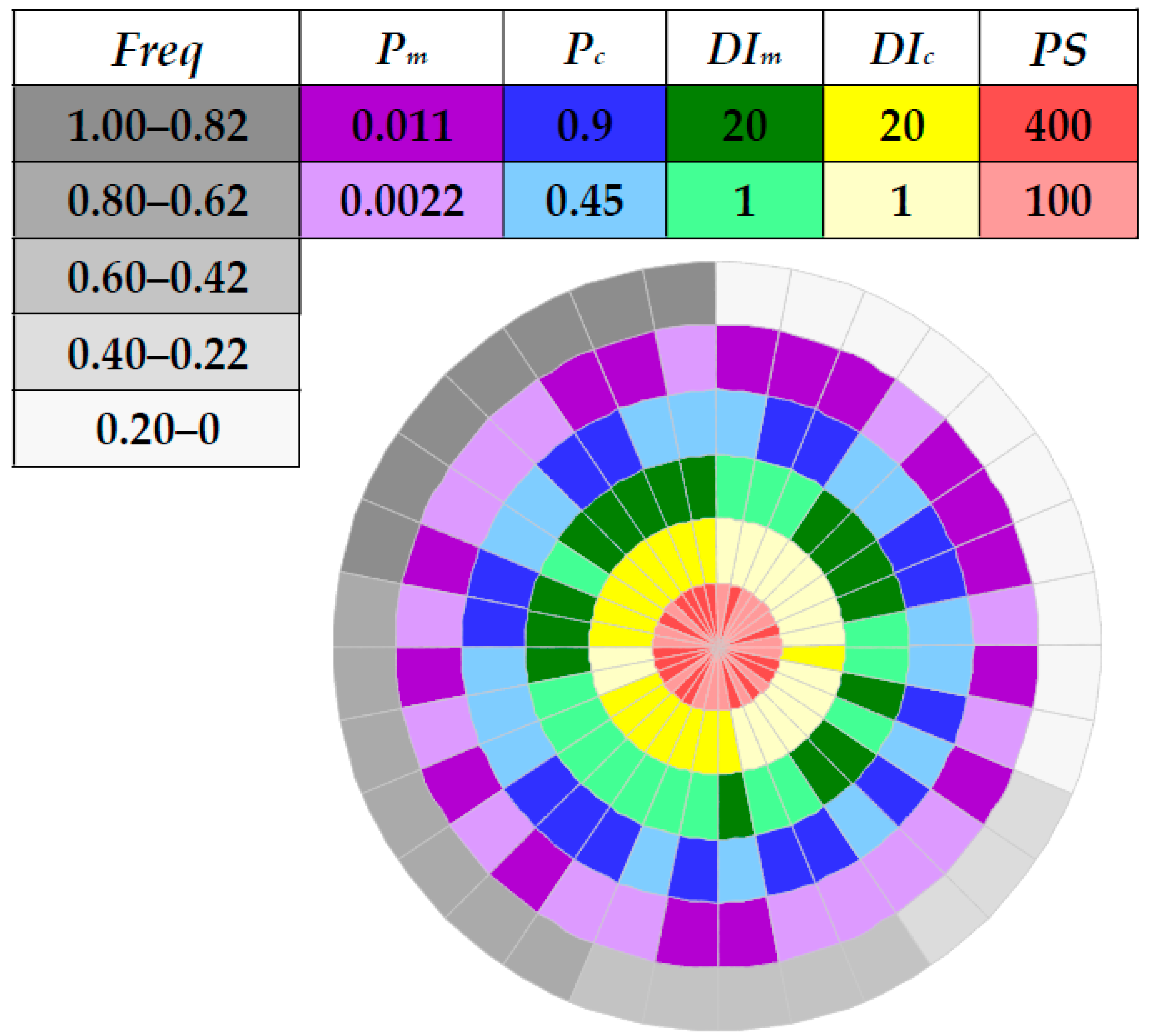
This paper has proposed a simple yet effective methodology to capture the impact of various parameters on the performance of NSGA-II. In particular, by selecting two representative values from within the range of each key parameter and using the proposed compass plot, one can intuitively identify the interrelationship among different parameters and their influence on the behavior of NSGA-II, which in turn facilitates the identification of general guidelines for setting those parameters. As a spin-off, a more effective strategy of reducing the search space size has been realized when comparing the performance of NSGA-II with application to the design of a real-world irrigation network, following the derived guidelines of parameter settings.
The main conclusions are as follows. First, there is a hierarchy of impact imposed by the five NSGA-II parameters, which implies that their influences are not equally significant. Based on the results obtained in the selected benchmark design problems of WDSs,
PS tends to be the paramount parameter that has a more profound impact on the performance of NSGA-II than the other ones, followed by
DIc and
DIm. In contrast, the values of
Pc and
Pm are of minor impact on the effectiveness of NSGA-II in this paper. These findings highlight some aspects that were often neglected in previous studies, with many papers cited in
Table 1 having used a fixed
PS of 100, a recommended
Pc and
Pm in combination with default or unknown
DIc and
DIm, no matter how large the search space size was.
Second, the interrelationships among the five key parameters are complex and are case by case dependent. Thus, it is highly recommended to fine-tune these five parameters, preferably following the method proposed in this paper, to confirm which combinations have great potential to identify the near-optimal solutions. This suggestion can save the computational budget and time substantially when dealing with larger, real-world design problems.
Last but not least, the key recommendation for applying NSGA-II to the optimal design of WDSs is to use a reasonably large PS, which usually depends on the scale of the design problem. This will significantly improve the diversity of the initial population, thus lowering the risk of getting trapped in local optima and increasing the probability of finding near-optimal solutions. The second recommendation is to pay particular attention to the choices of DIc and DIm, rather than Pc and Pm, since the former two parameters are more important to affect the positions of the offspring generated from their parents. Considering the discrete nature of WDS design problems and the monotonicity of DIc and DIm, their ranges should be kept between 1 and 20. By contrast, default values of Pc and Pm (i.e., 0.9 and 1/NDVs) are expected to be sufficient (no need of fine-tuning).
There are some limitations of the current work, which are elaborated as follows. First, since the impact of parameter settings on the performance of NSGA-II are usually non-linear, it is therefore unknown to what extent selecting two representative values within the range of each parameter can adequately reflect the underlying correlation among various parameters. Second, the characteristics of the design problems being solved and their effect on the parameterization of NSGA-II is not considered in this work. Several relevant studies have pointed out that the behavior of MOEAs has a close interrelationship with the landscape of the search space [
12,
15,
39]. Therefore, possible changes to the problem formulations may be able to reveal more of the nature of the complicated nexus between optimization problems and MOEAs. Whether this underlying relationship can significantly affect the understanding and application of MOEAs is a worthy future direction for research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}