Immune Evolution Particle Filter for Soil Moisture Data Assimilation


Abstract
1. Introduction
2. Materials and Methods
2.1. Bayesian Filtering
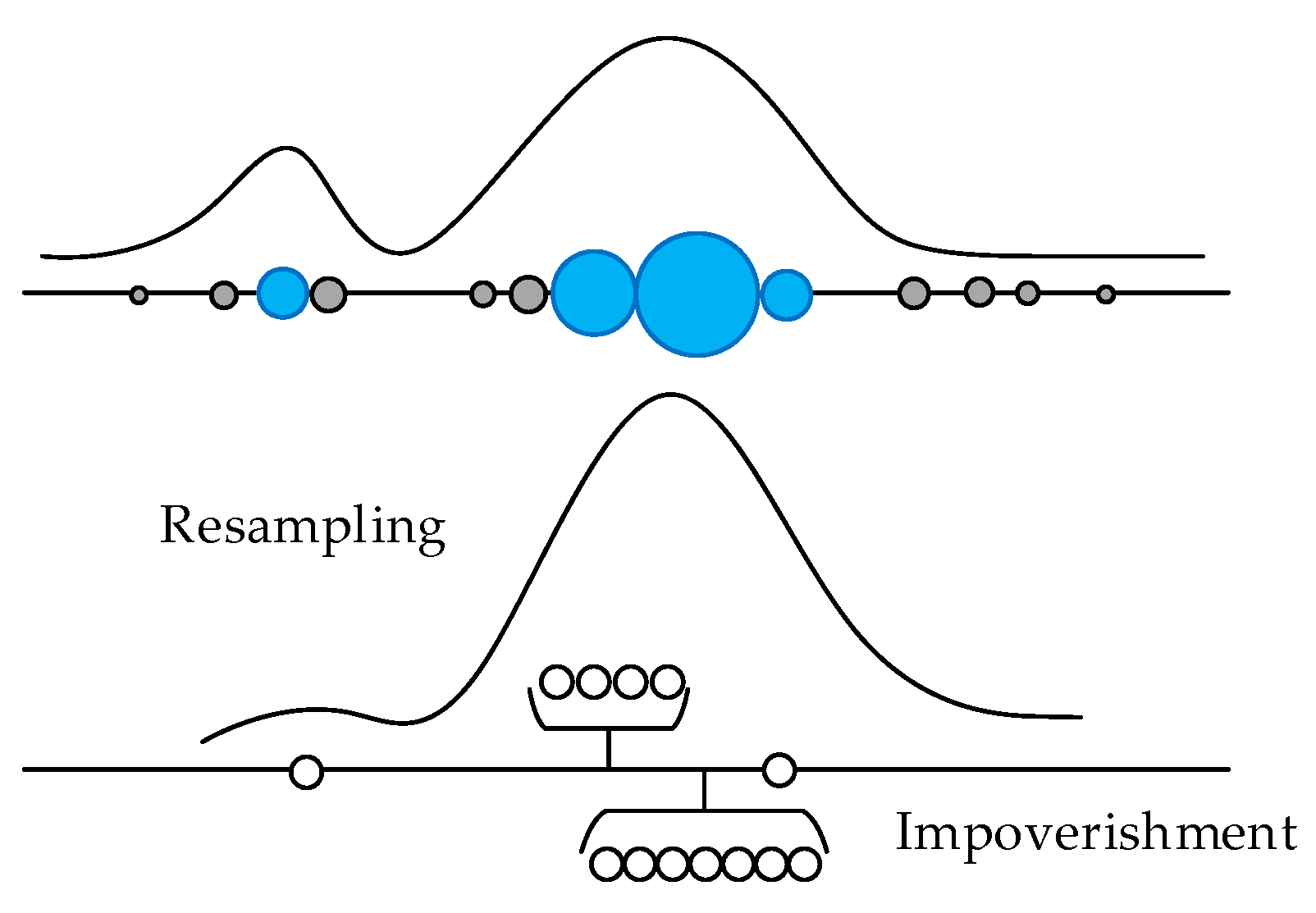
2.2. Particle Filter Method
2.3. Problem Formulation
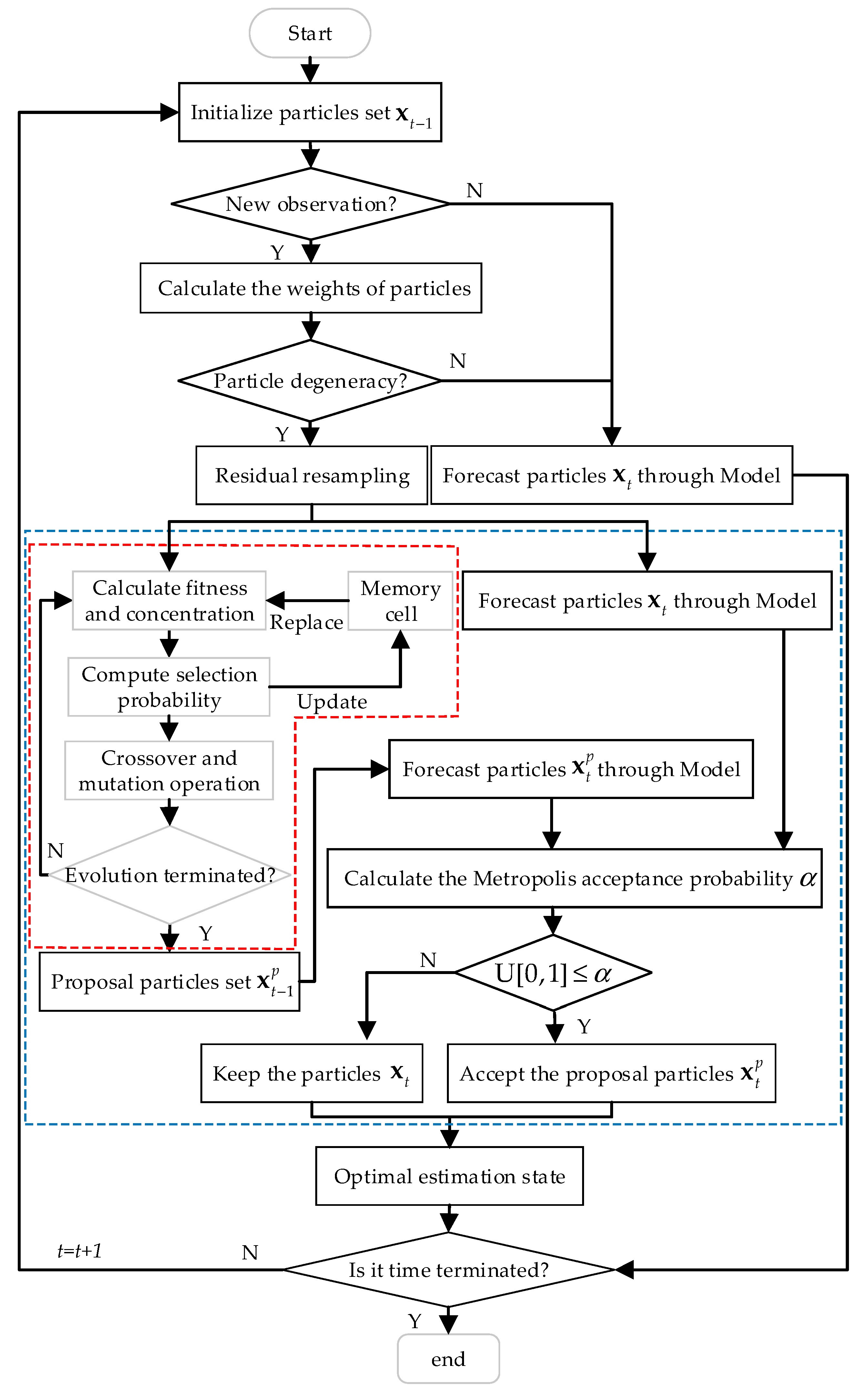
2.4. Immune Evolution Particle Filter with MCMC
2.4.1. Immune Evolution Algorithm (IEA)
2.4.2. Immune Evolution Particle Filter Proposed
2.4.3. Markov chain Monte Carlo (MCMC) Simulation
3. Results and Discussion
3.1. Lorenz96 Model Experiment
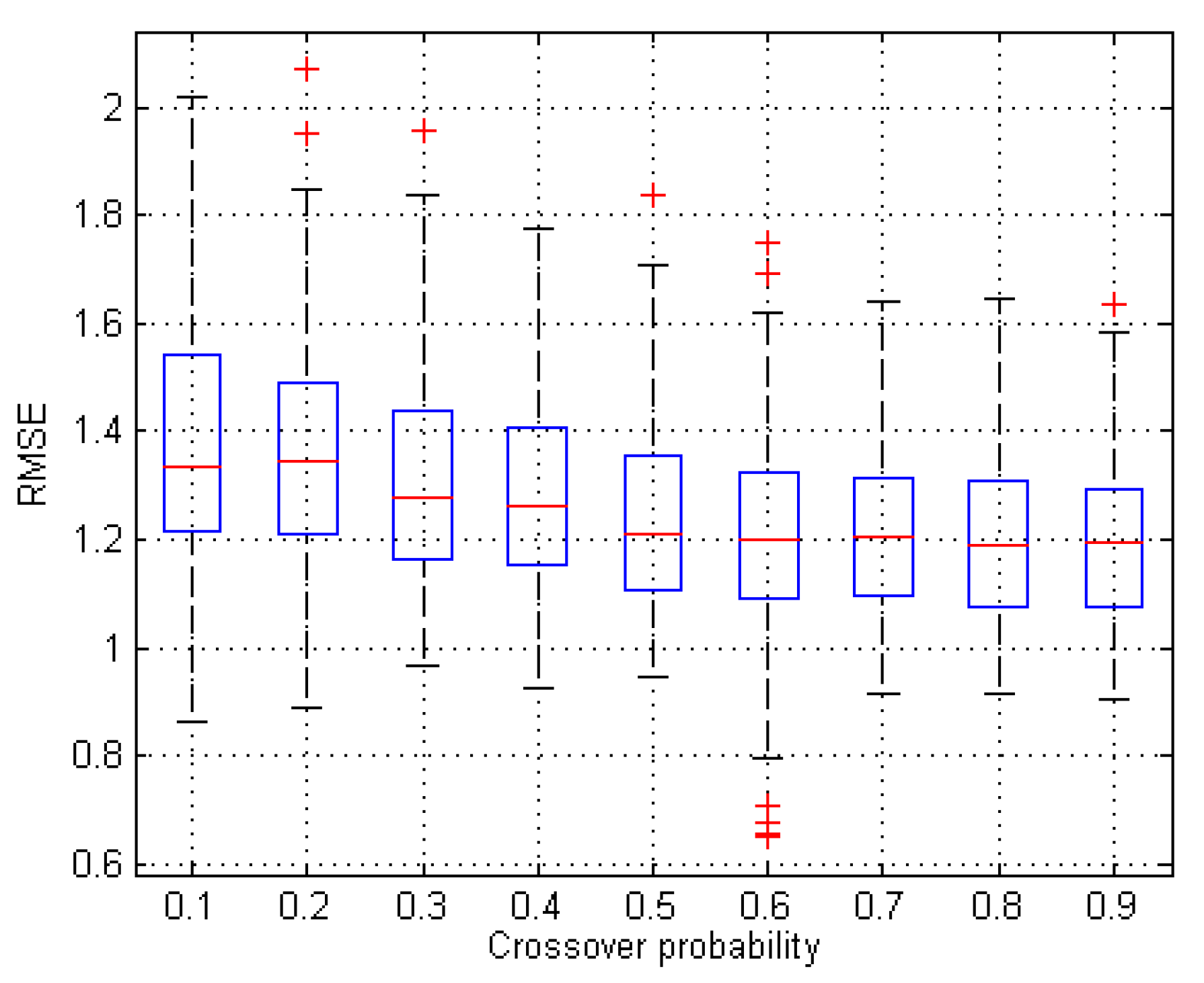
3.1.1. Sensitivity Analysis
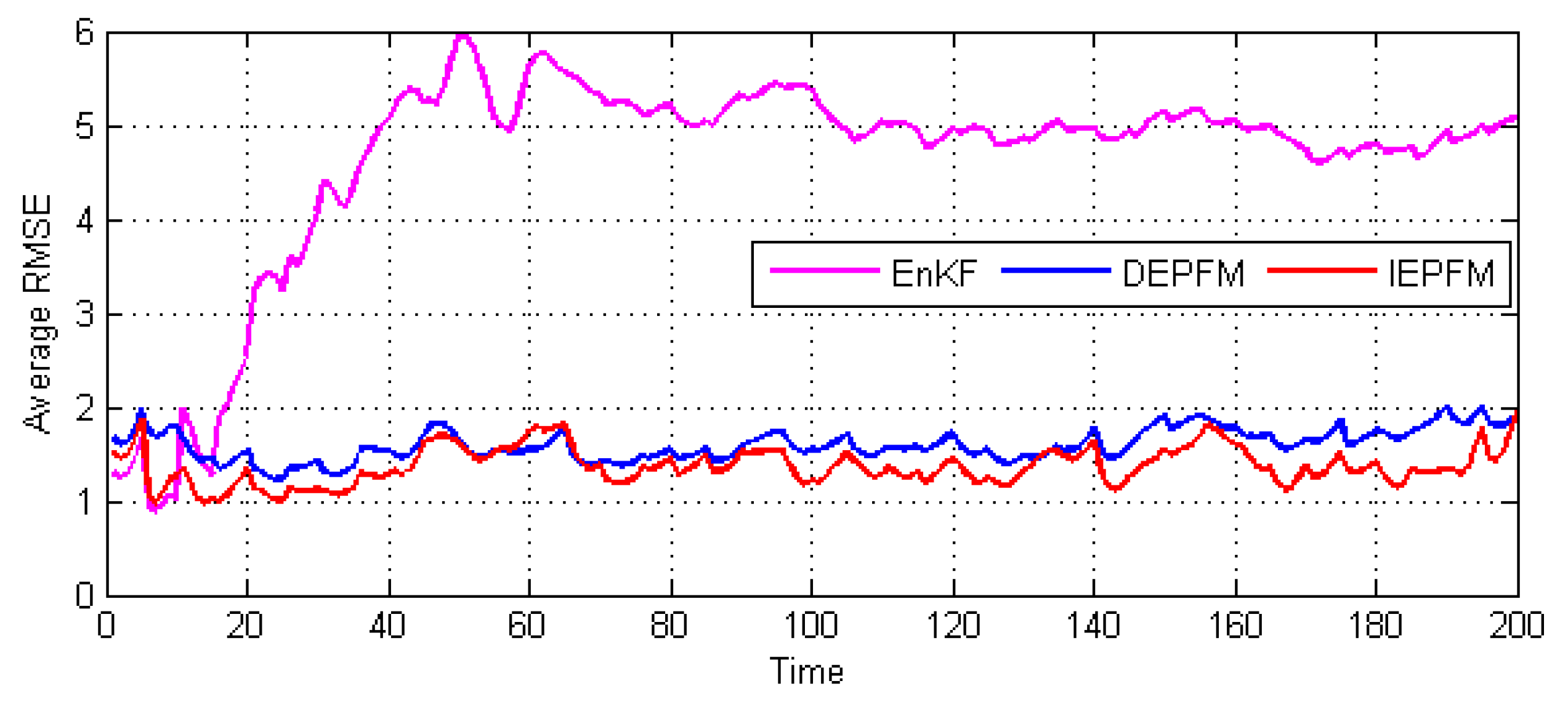
3.1.2. Performance Comparisons
3.1.3. Comparison of Computation Time
3.2. Soil Moisture Data Assimilation Experiment
3.2.1. Study Area
3.2.2. The Land Surface Model and Data Preparation
3.2.3. Observations Preparation
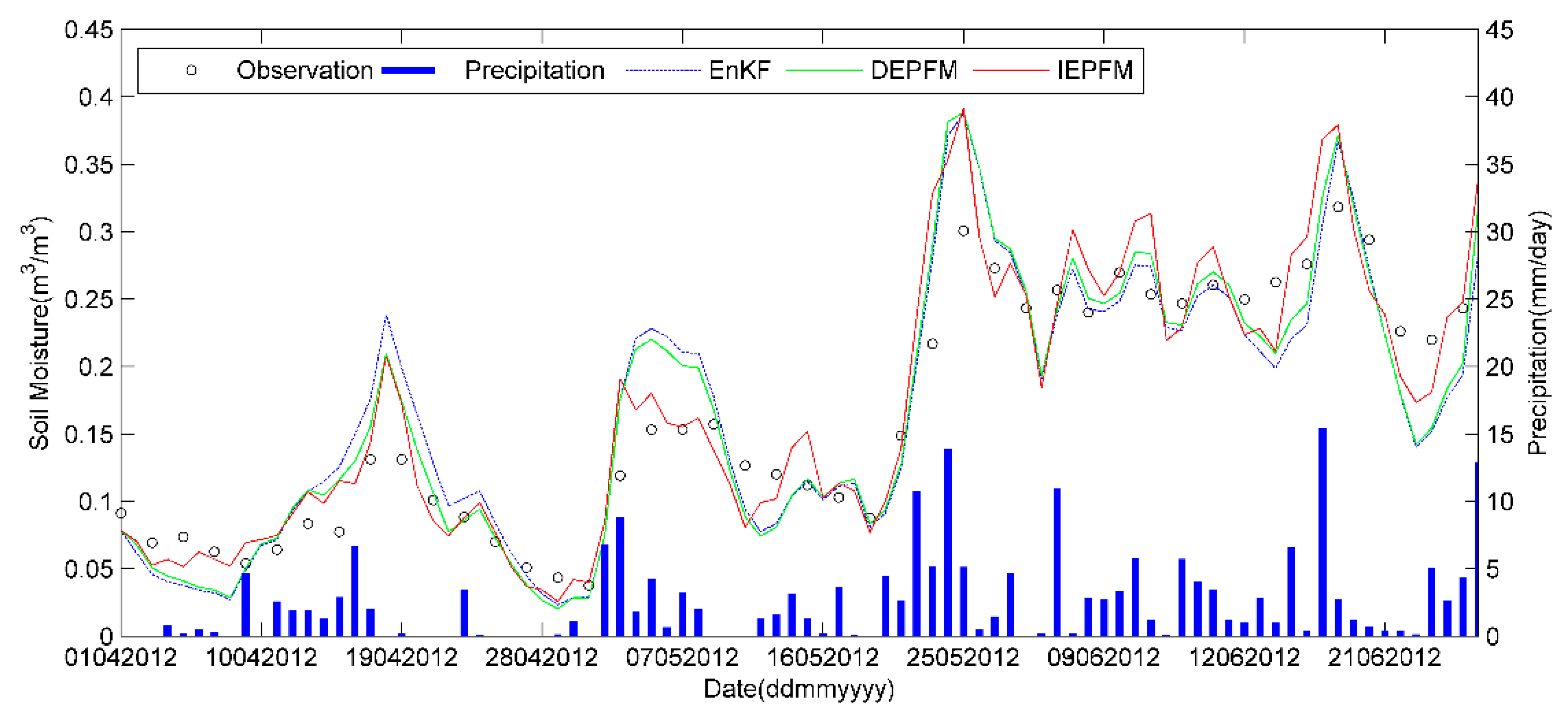
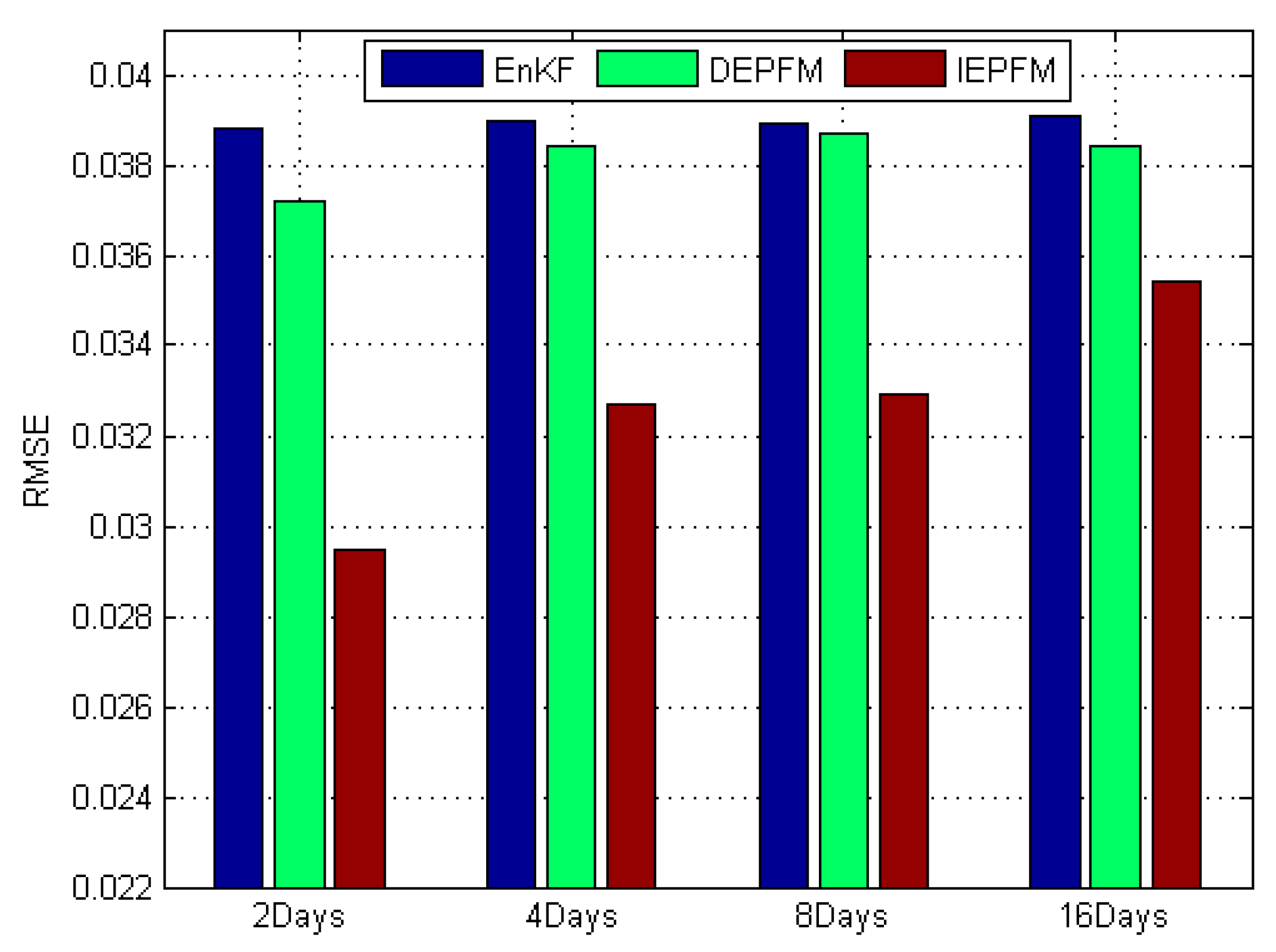
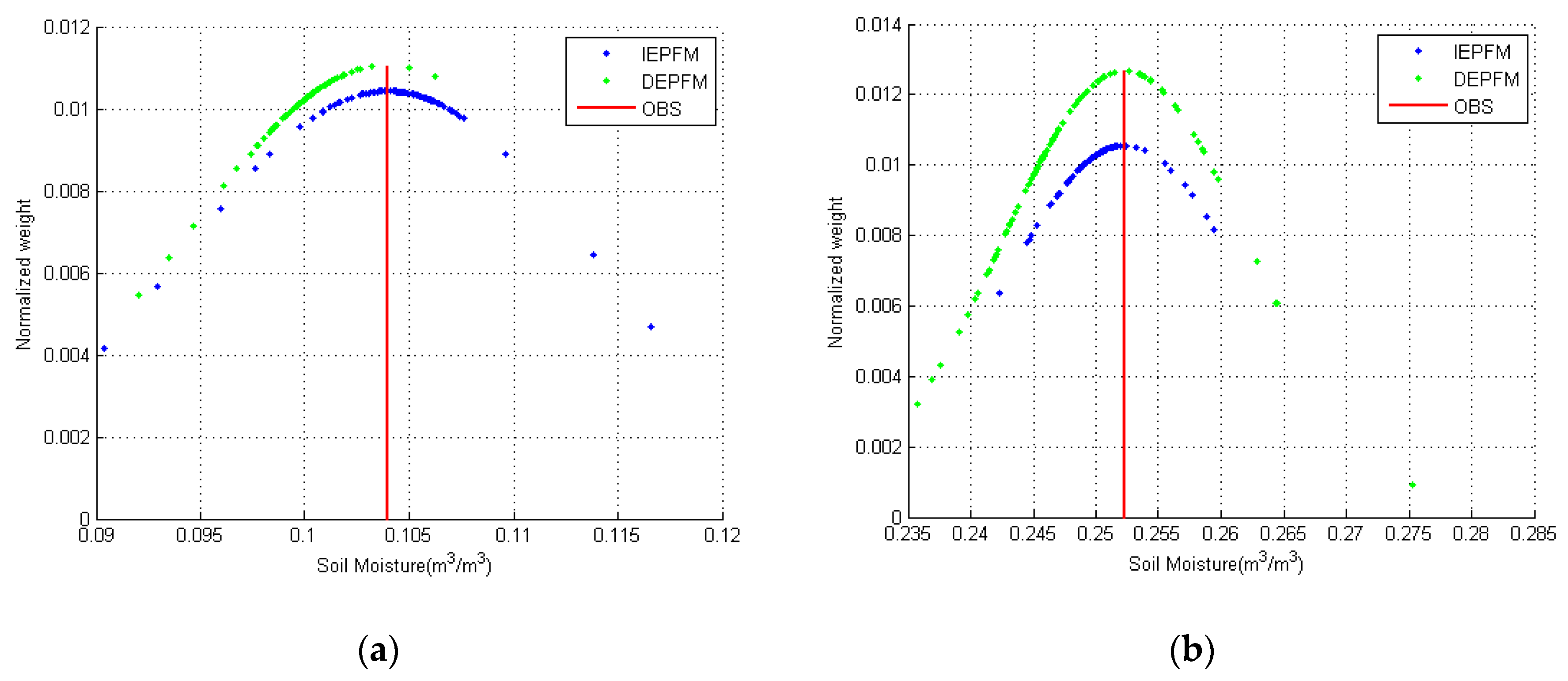
3.2.4. Results and Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Parrens, M.; Wigneron, J.P.; Richaume, P.; Mialon, A.; Al Bitar, A.; Fernandez-Moran, R.; Kerr, Y.H. Global-scale surface roughness effects at L-band as estimated from SMOS observations. Remote Sens. Environ. 2016, 181, 122–136. [Google Scholar] [CrossRef]
- Brocca, L.; Ciabatta, L.; Massari, C.; Camici, S.; Tarpanelli, A. Soil Moisture for Hydrological Applications: Open Questions and New Opportunities. Water 2017, 9, 140. [Google Scholar] [CrossRef]
- Kirby, J.M.; Mainuddin, M.; Ahmad, M.D.; Gao, L. Simplified Monthly Hydrology and Irrigation Water Use Model to Explore Sustainable Water Management Options in the Murray-Darling Basin. Water Resour. Manag. 2013, 27, 4083–4097. [Google Scholar] [CrossRef]
- Lievens, H. SMOS soil moisture assimilation for improved hydrologic simulation in the Murray Darling Basin, Australia. Remote Sens. Environ. 2015, 168, 146–162. [Google Scholar] [CrossRef]
- Huang, C.; Xin, L.; Ling, L. Retrieving soil temperature profile by assimilating MODIS LST products with ensemble Kalman filter. Remote Sens. Environ. 2008, 112, 1320–1336. [Google Scholar] [CrossRef]
- Moradkhani, H. Hydrologic remote sensing and land surface data assimilation. Sensors 2008, 8, 2986–3004. [Google Scholar] [CrossRef] [PubMed]
- Dumedah, G.; Coulibaly, P. Evolutionary assimilation of streamflow in distributed hydrologic modeling using in-situ soil moisture data. Adv. Water Resour. 2013, 53, 231–241. [Google Scholar] [CrossRef]
- Weerts, A.H.; El Serafy, G.Y.H. Particle Filtering and Ensemble Kalman Filtering for state updating with hydrological conceptual rainfall runoff models. Water Resour. Res. 2006, 42, 123–154. [Google Scholar] [CrossRef]
- Evensen, G. Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics. J. Geophys. Res. Ocean. 1994, 99, 10143–10162. [Google Scholar] [CrossRef]
- Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEE Proc. F Radar Signal Process. 1993, 140, 107–113. [Google Scholar] [CrossRef]
- Montzka, C.; Moradkhani, H.; Weihermüller, L.; Franssen, H.J.H.; Canty, M.; Vereecken, H. Hydraulic parameter estimation by remotely-sensed top soil moisture observations with the particle filter. J. Hydrol. 2011, 399, 410–421. [Google Scholar] [CrossRef]
- Mattern, J.P.; Dowd, M.; Fennel, K. Particle filter-based data assimilation for a three-dimensional biological ocean model and satellite observations. J. Geophys Res. Ocean. 2013, 118, 2746–2760. [Google Scholar] [CrossRef]
- Fan, Y.R.; Huang, G.H.; Baetz, B.W.; Li, Y.P.; Huang, K.; Li, Z.; Xiong, L.H. Parameter uncertainty and temporal dynamics of sensitivity for hydrologic models: A hybrid sequential data assimilation and probabilistic collocation method. Environ. Model. Softw. 2016, 86, 30–49. [Google Scholar] [CrossRef]
- Hartanto, I.M.; Van Der Kwast, J.; Alexandridis, T.K.; Almeida, W.; Song, Y.; van Andel, S.J.; Solomatine, D.P. Data assimilation of satellite-based actual evapotranspiration in a distributed hydrological model of a controlled water system. Int. J. Appl. Earth Obs. Geoinf. 2017, 57, 123–135. [Google Scholar] [CrossRef]
- Vrugt, J.A.; ter Braak, C.J.; Diks, C.G.; Schoups, G. Hydrologic data assimilation using particle Markov chain Monte Carlo simulation: Theory, concepts and applications. Adv. Water Resour. 2013, 51, 457–478. [Google Scholar] [CrossRef]
- Elsheikh, A.H.; Hoteit, I.; Wheeler, M.F. A nested sampling particle filter for nonlinear data assimilation. Q. J. R. Meteorol. Soc. 2014, 140, 1640–1653. [Google Scholar] [CrossRef]
- Plaza Guingla, D.A.; Pauwels, V.R.; De Lannoy, G.J.; Matgen, P.; Giustarini, L.; De Keyser, R. Improving particle filters in rainfall-runoff models: Application of the resample-move step and the ensemble Gaussian particle filter. Water Resour. Res. 2013, 49, 4005–4021. [Google Scholar] [CrossRef]
- Bi, H.; Ma, J.; Wang, F. An Improved Particle Filter Algorithm Based on Ensemble Kalman Filter and Markov Chain Monte Carlo Method. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6134–6147. [Google Scholar] [CrossRef]
- Dumedah, G.; Coulibaly, P. Integration of an evolutionary algorithm into the ensemble Kalman filter and the particle filter for hydrologic data assimilation. J. Hydroinf. 2014, 16, 74–94. [Google Scholar] [CrossRef]
- Mechri, R.; Ottlé, C.; Pannekoucke, O.; Kallel, A. Genetic particle filter application to land surface temperature downscaling. J. Geophys. Res. Atmos. 2014, 119, 2131–2146. [Google Scholar] [CrossRef]
- Yin, S.; Zhu, X. Intelligent Particle Filter and Its Application to Fault Detection of Nonlinear System. IEEE Trans. Ind. Electron. 2015, 62, 3852–3861. [Google Scholar] [CrossRef]
- Qu, Y.; Qian, X.; Song, H.; Xing, Y.; Li, Z.; Tan, J. Soil Moisture Investigation Utilizing Machine Learning Approach Based Experimental Data and Landsat5-TM Images: A Case Study in the Mega City Beijing. Water 2018, 10, 423. [Google Scholar] [CrossRef]
- Abbaszadeh, P.; Moradkhani, H.; Yan, H.X. Enhancing hydrologic data assimilation by evolutionary Particle Filter and Markov Chain Monte Carlo. Adv. Water Resour. 2018, 111, 192–204. [Google Scholar] [CrossRef]
- Zhang, H.J. State and parameter estimation of two land surface models using the ensemble Kalman filter and the particle filter. Hydrol. Earth Syst. Sci. 2017, 21, 4927–4958. [Google Scholar] [CrossRef]
- Vrugt, J.A. Markov chain Monte Carlo simulation using the DREAM software package: Theory, concepts, and MATLAB implementation. Environ. Model. Softw. 2016, 75, 273–316. [Google Scholar] [CrossRef]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Dudek, G. An Artificial Immune System for Classification with Local Feature Selection. IEEE Trans. Evolut. Comput. 2012, 16, 847–860. [Google Scholar] [CrossRef]
- De Castro, L.N.; Timmis, J.I. Artificial immune systems as a novel soft computing paradigm. Soft Comput. 2003, 7, 526–544. [Google Scholar] [CrossRef]
- Dasgupta, D.; Yu, S.H.; Nino, F. Recent Advances in Artificial Immune Systems: Models and Applications. Appl. Soft Comput. 2011, 11, 1574–1587. [Google Scholar] [CrossRef]
- Han, H.; Ding, Y.S.; Hao, K.R.; Liang, X. An evolutionary particle filter with the immune genetic algorithm for intelligent video target tracking. Comput. Math. Appl. 2011, 62, 2685–2695. [Google Scholar] [CrossRef]
- Wang, M.; Feng, S.; He, C.; Li, Z.; Xue, Y. An Artificial Immune System Algorithm with Social Learning and Its Application in Industrial PID Controller Design. Math. Probl. Eng. 2017. [Google Scholar] [CrossRef]
- Yang, Z.; Ding, Y.; Jin, Y.; Hao, K. Immune-Endocrine System Inspired Hierarchical Coevolutionary Multiobjective Optimization Algorithm for IoT Service. IEEE Trans. Cybern. 2018. [Google Scholar] [CrossRef] [PubMed]
- Andrieu, C.; Doucet, A.; Holenstein, R. Particle Markov chain Monte Carlo methods. J. R. Stat. Soc. 2010, 72, 269–342. [Google Scholar] [CrossRef]
- Lorenz, E.N. Predictability: A problem partly solved. Proc. Semin. Predict. 1995, 1, 1–18. [Google Scholar]
- Bryan, B.A.; Gao, L.; Ye, Y.; Sun, X.; Connor, J.D.; Crossman, N.D.; Liu, Z. China’s response to a national land-system sustainability emergency. Nature 2018, 559, 193–204. [Google Scholar] [CrossRef] [PubMed]
- Su, Z.; Wen, J.; Dente, L.; Velde, R.; Wang, L.; Ma, Y.; Hu, Z. The Tibetan Plateau observatory of plateau scale soil moisture and soil temperature (Tibet-Obs) for quantifying uncertainties in coarse resolution satellite and model products. Hydrol. Earth Syst. Sci. 2011, 15, 2303–2316. [Google Scholar] [CrossRef]
- Liang, X.; Lettenmaier, D.P.; Wood, E.F.; Burges, S.J. A simple hydrologically based model of land surface water and energy fluxes for general circulation models. J. Geophys. Res. Atmos. 1994, 99, 14415–14428. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ensemble Size | EnKF | DEPFM | IEPFM |
|---|---|---|---|
| 4.6244 | 3.2236 | 2.4721 | |
| 4.6222 | 1.8439 | 1.8256 | |
| 4.6128 | 1.5260 | 1.3661 | |
| 4.6710 | 1.2242 | 1.1160 | |
| 4.6685 | 1.1864 | 1.1038 |
| DA Algorithms | RMSE | MAB | R |
|---|---|---|---|
| EnKF | 0.0388 | 0.0303 | 0.9103 |
| DEPFM | 0.0372 | 0.0291 | 0.9181 |
| IEPFM | 0.0295 | 0.0225 | 0.9502 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, F.; An, R.; Sun, Y. Immune Evolution Particle Filter for Soil Moisture Data Assimilation. Water 2019, 11, 211. https://doi.org/10.3390/w11020211
Ju F, An R, Sun Y. Immune Evolution Particle Filter for Soil Moisture Data Assimilation. Water. 2019; 11(2):211. https://doi.org/10.3390/w11020211
Chicago/Turabian StyleJu, Feng, Ru An, and Yaxing Sun. 2019. "Immune Evolution Particle Filter for Soil Moisture Data Assimilation" Water 11, no. 2: 211. https://doi.org/10.3390/w11020211
APA StyleJu, F., An, R., & Sun, Y. (2019). Immune Evolution Particle Filter for Soil Moisture Data Assimilation. Water, 11(2), 211. https://doi.org/10.3390/w11020211