A Robust and Transferable Model for the Prediction of Flood Losses on Household Contents

 , ,
, ,
Abstract
1. Introduction
2. Material and Methods
2.1. Data
2.1.1. Quality Check
2.1.2. Data Distribution
2.2. Regression Model
2.2.1. Data Transformation and Fitting
2.2.2. Cross-Validation
2.2.3. Assessment of Transferability
3. Results
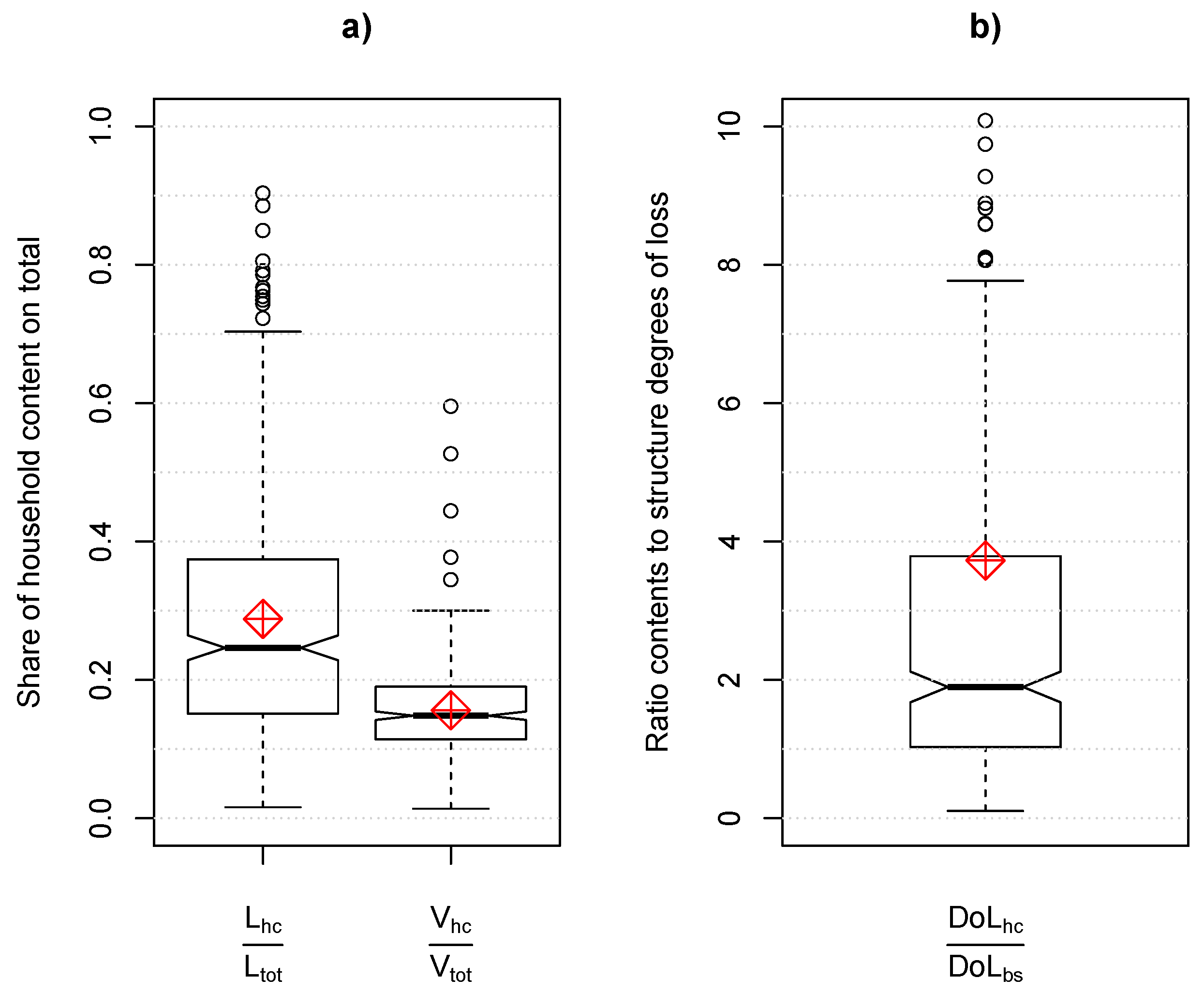
3.1. On the Role of Household Contents
3.2. Model Fitting
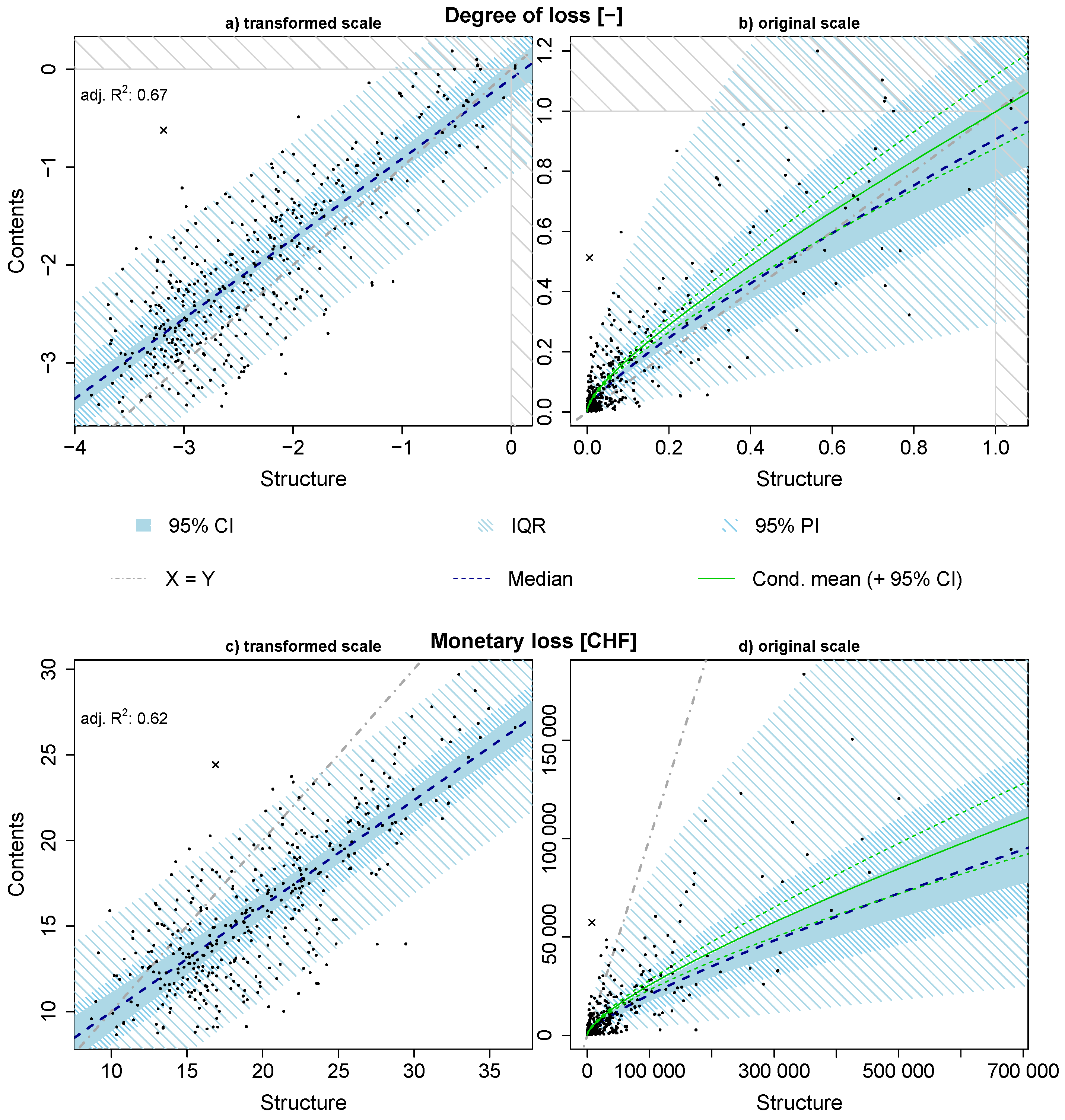
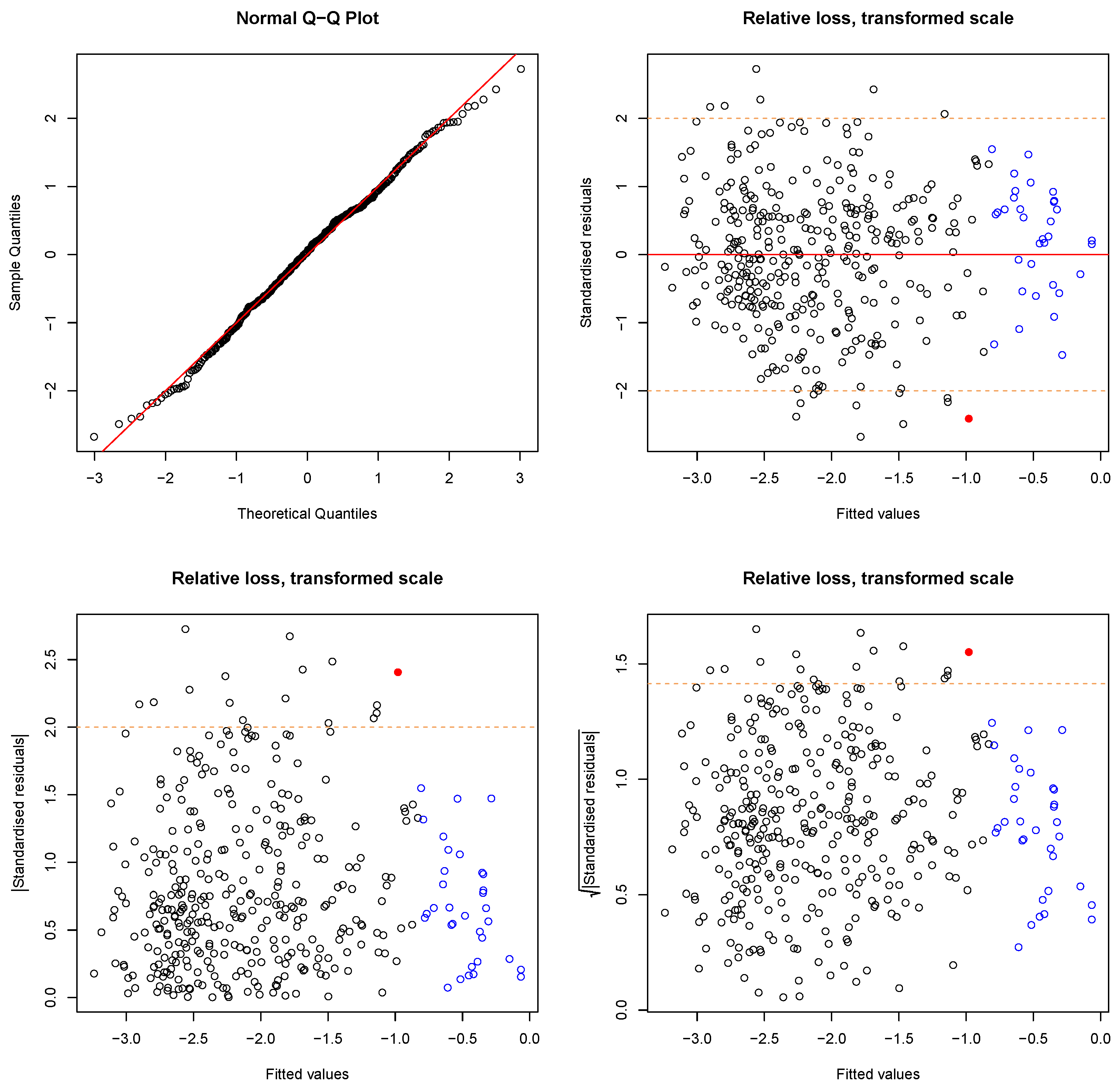
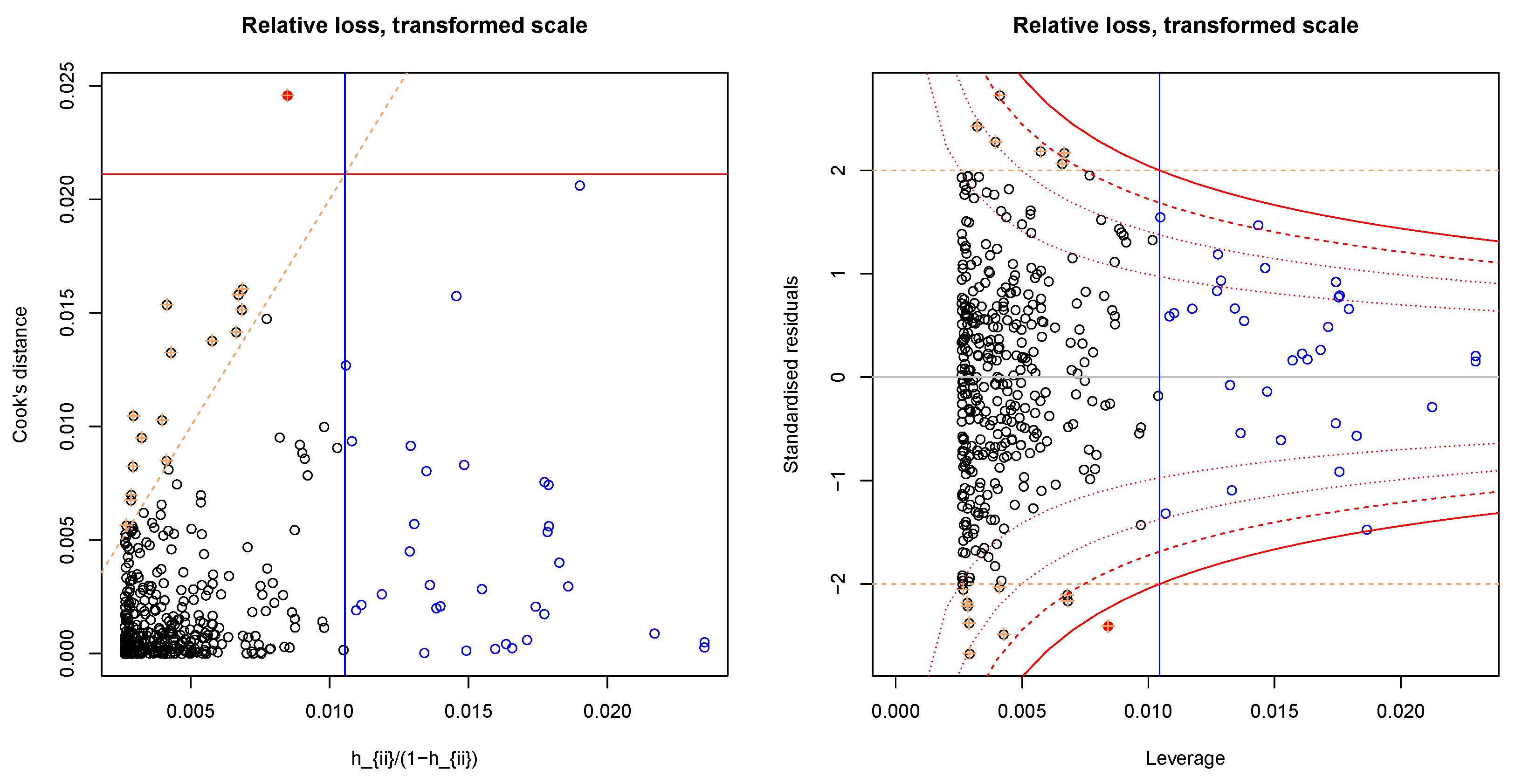
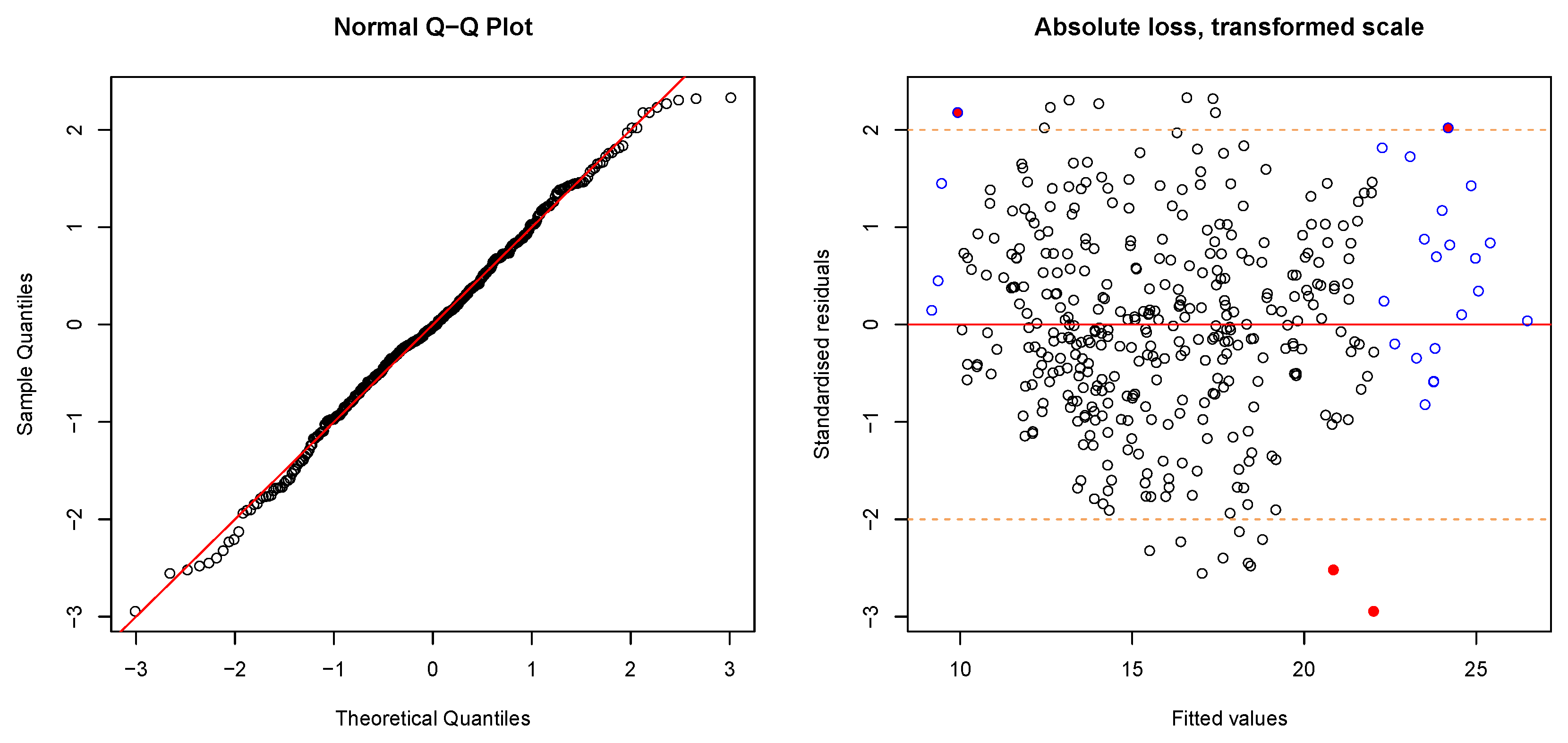
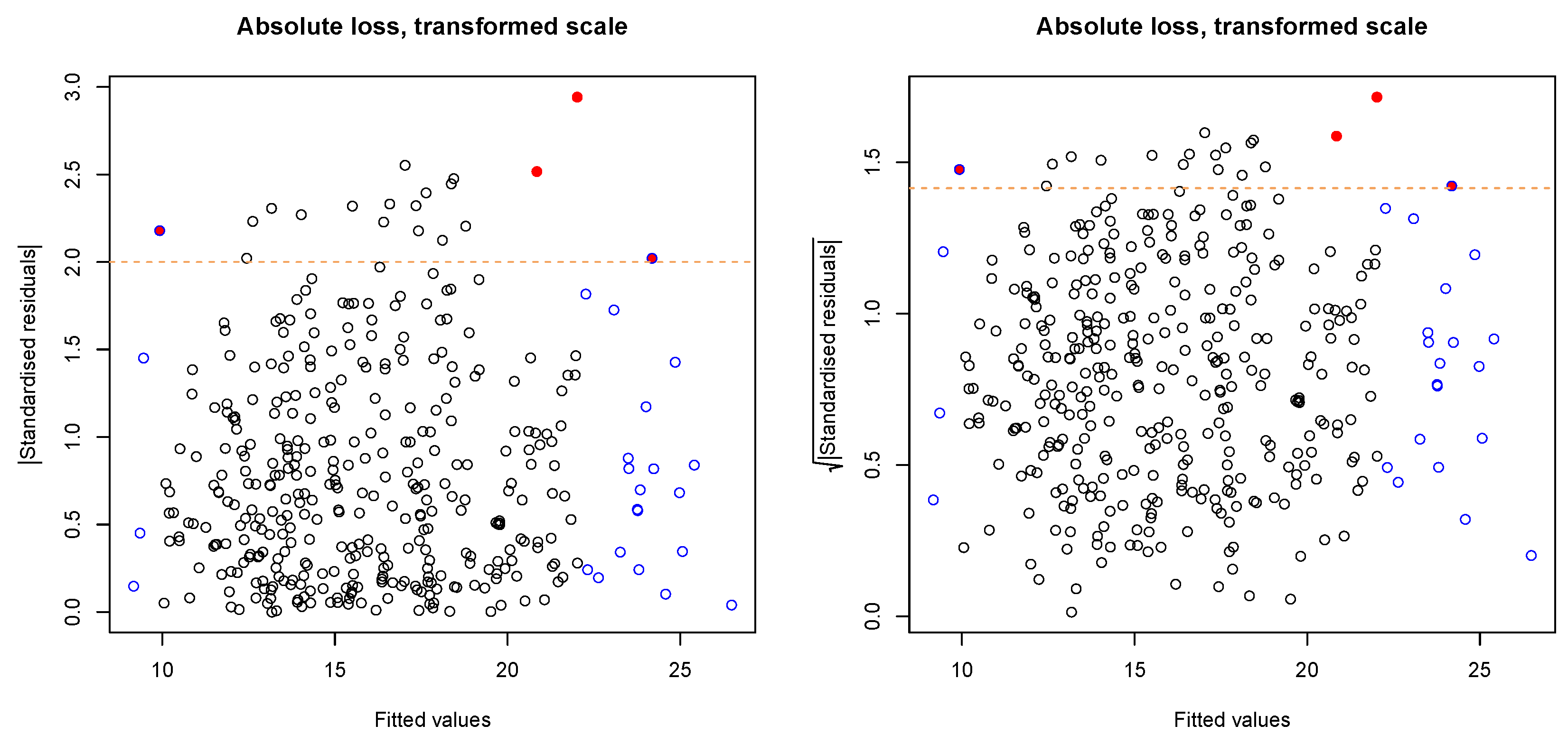
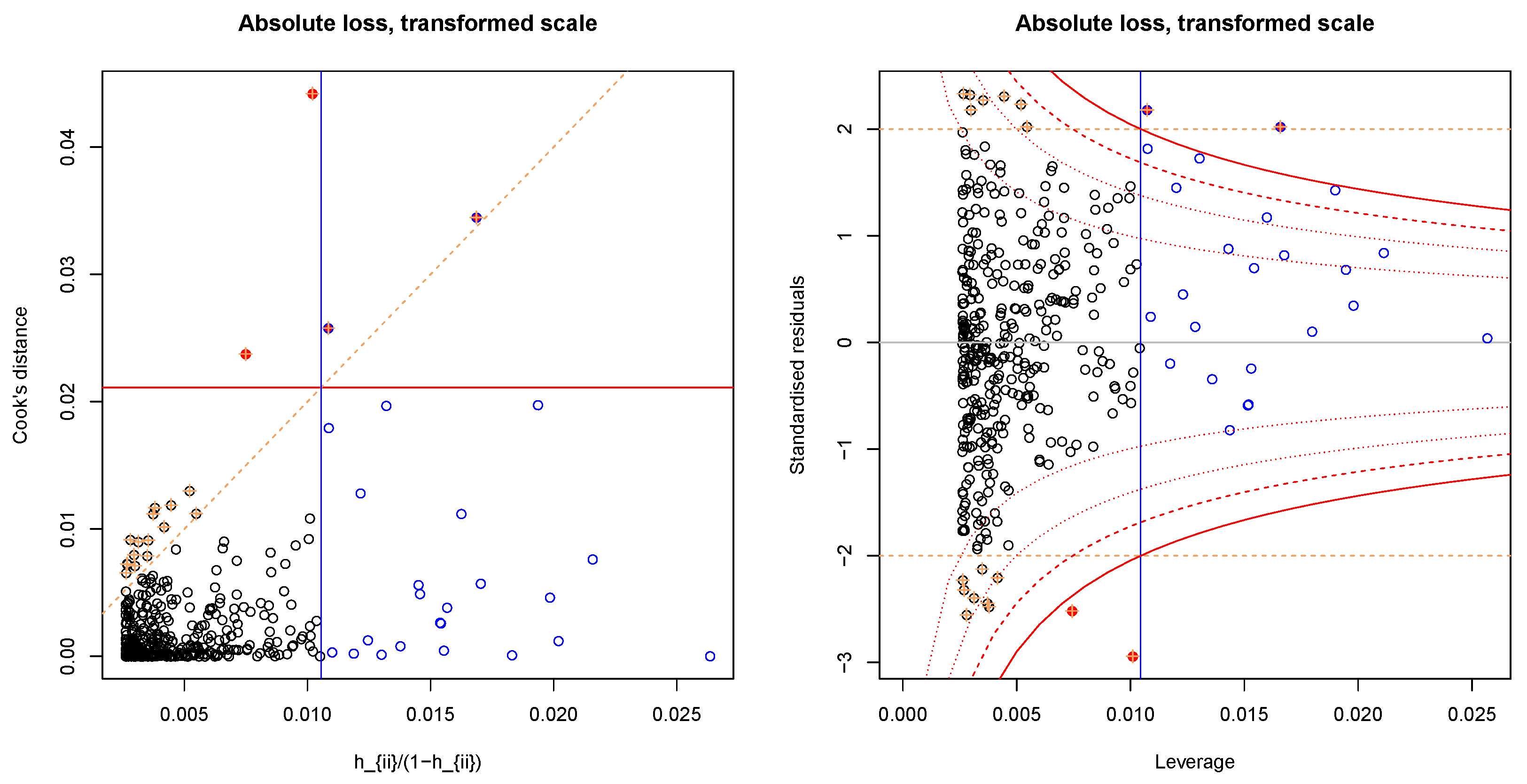
3.2.1. Data Transformation
3.2.2. Regression Model
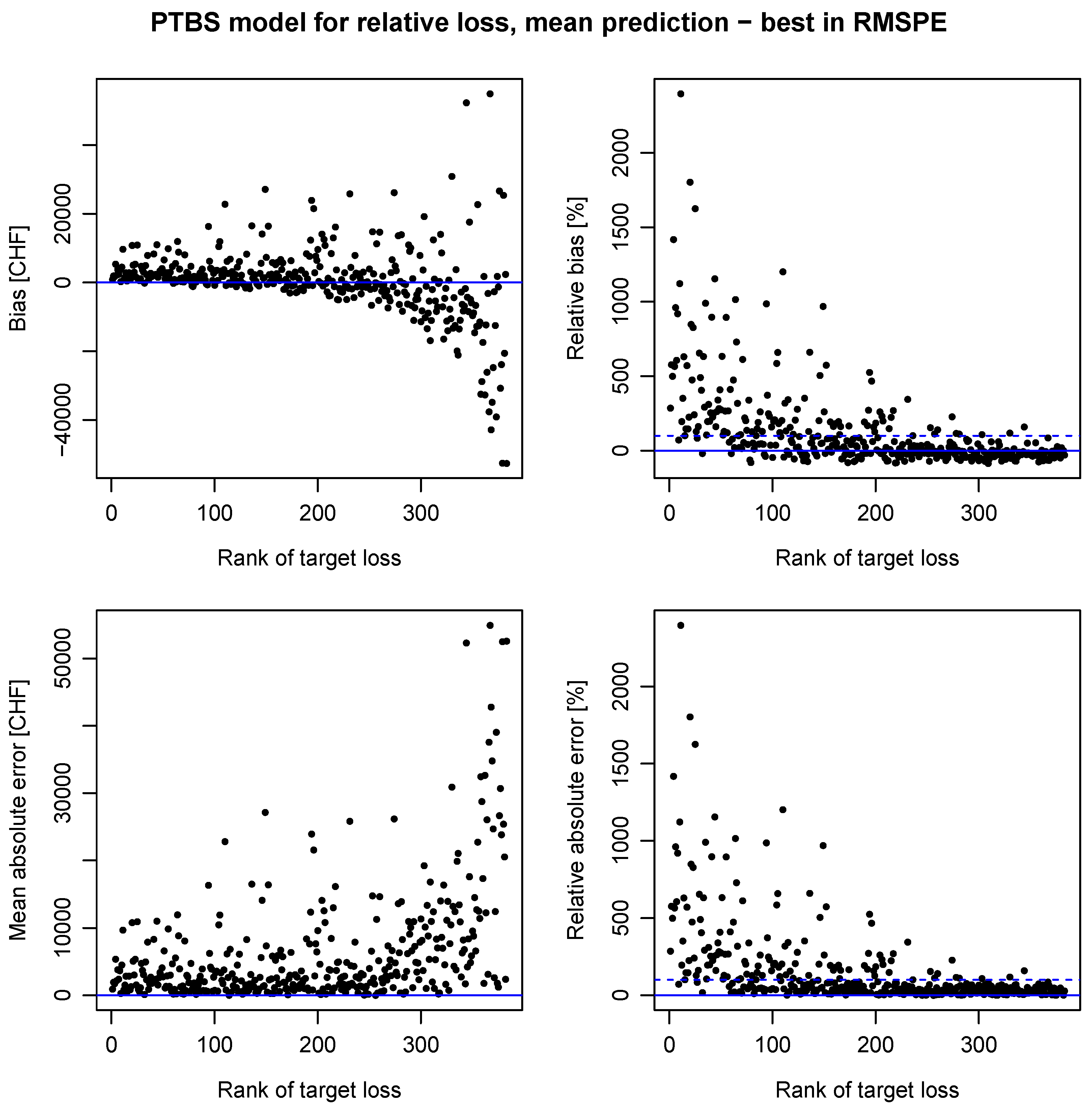
3.3. Cross-Validation
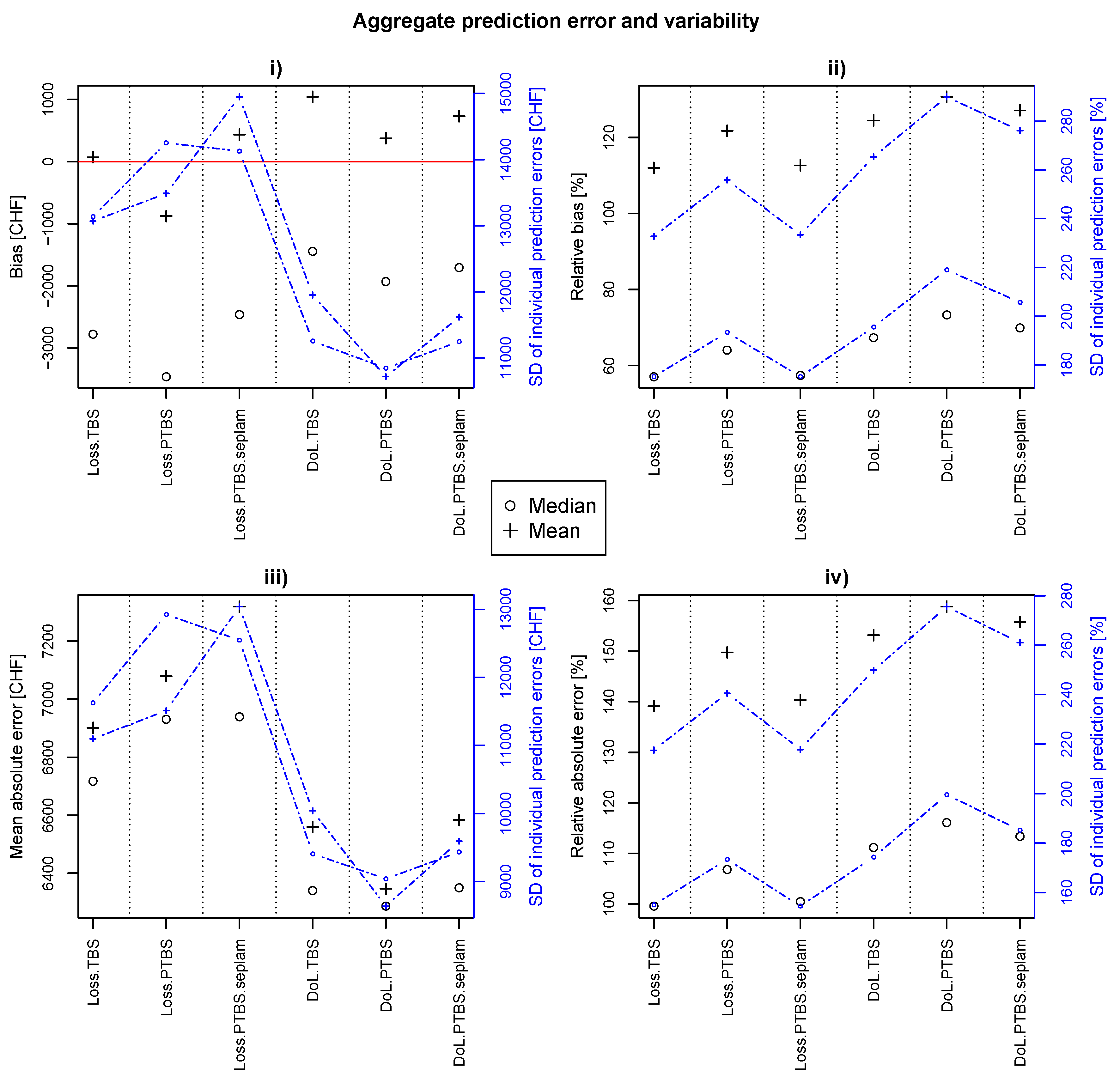
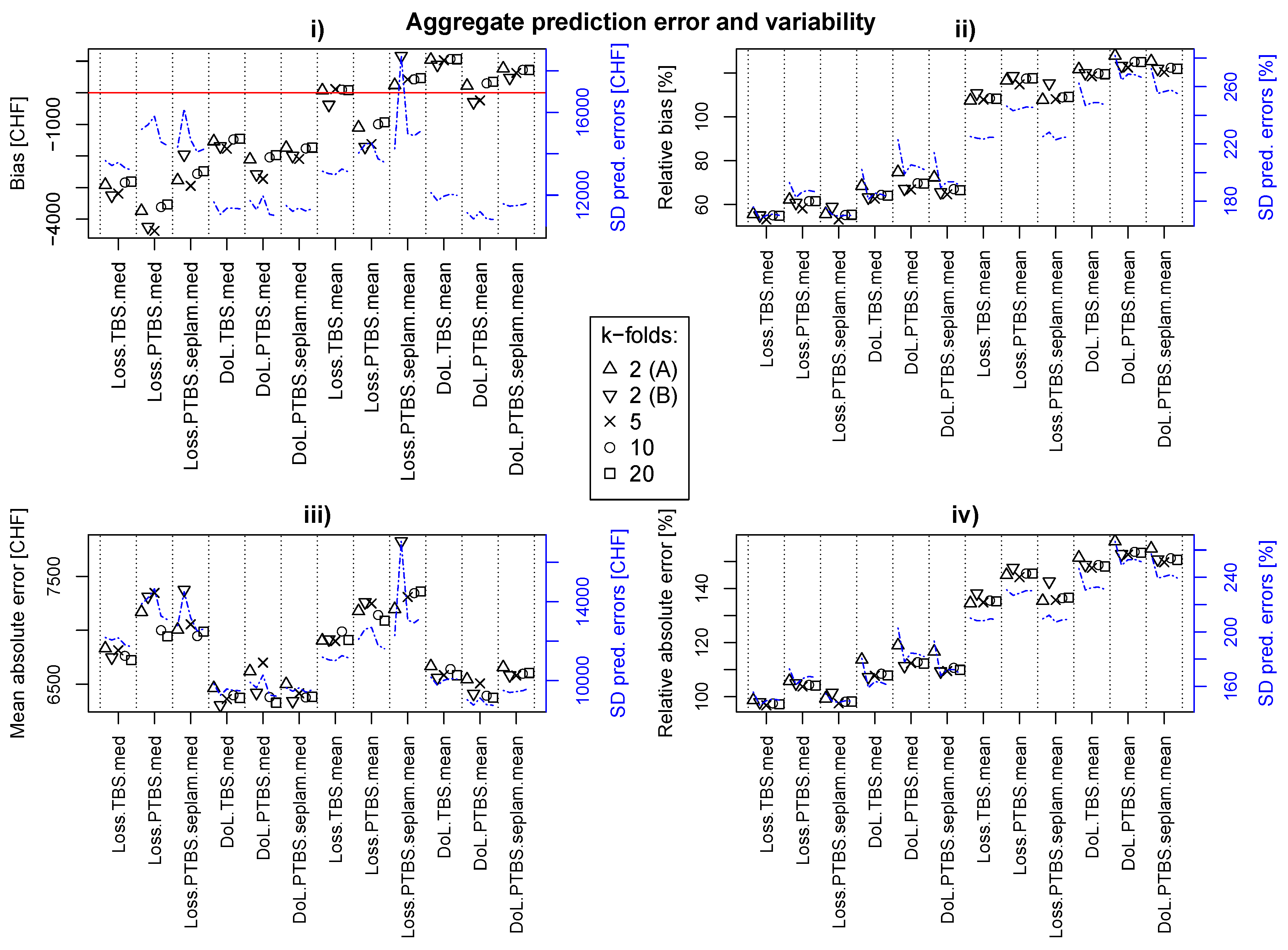
3.4. Transferability
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| BP | Breusch-Pagan (test) |
| CI | Confidence Interval |
| DoL | Degree of Loss |
| FOEN | Federal Office of Environment |
| FOWG | Federal Office of Water and Geology |
| PSL | Pound Sterling Live |
| PTBS | Pseudo-Transform-Both-Sides |
| PTBS.seplam | Pseudo-Transform-Both-Sides with separate transformation parameters for x and y |
| SW | Shapiro-Wilks (test) |
| TBS | Transform-Both-Sides |
Appendix A
Appendix A.1

Appendix A.2

Appendix B
Appendix B.1


Appendix B.2

Appendix C

Appendix D

Appendix D.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Relative Loss Model | Monetary Loss Model | |
|---|---|---|
| Spearman’s | 0.746 | 0.720 |
| Kendall’s | 0.556 | 0.527 |
| Maximum Likelihood Estimate | 0.205 | 0.131 |
| CI * | (0.144, 0.265) | (0.068, 0.193) |
| 0.495 | 2.745 | |
| −0.098 | 3.798 | |
| CI * | (−0.255, 0.060) | (2.179, 5.416) |
| 0.817 | 0.618 | |
| CI * | (0.750, 0.884) | (0.560, 0.676) |
| adjusted R | 0.668 | 0.618 |
| Shapiro-Wilks p-value | 0.385 | 0.245 |
| Breusch-Pagan p-value | 0.742 | 0.221 |
References
- United Nations International Strategy for Disaster Reduction (UNISDR). Global Assessment Report on Disaster Risk Reduction (GAR) 2015: Making Development Sustainable: The Future of Disaster Risk Management; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Intergovernmental Panel on Climate Change (IPCC). Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation: Special Report of Working Groups I and II of The Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Ward, P.J.; Jongman, B.; Weiland, F.S.; Bouwman, A.; van Beek, R.; Bierkens, M.F.P.; Ligtvoet, W.; Winsemius, H.C. Assessing flood risk at the global scale: Model setup, results, and sensitivity. Environ. Res. Lett. 2013, 8, 044019. [Google Scholar] [CrossRef]
- Sampson, C.C.; Smith, A.M.; Bates, P.D.; Neal, J.C.; Alfieri, L.; Freer, J.E. A high-resolution global flood hazard model. Water Resour. Res. 2015, 51, 7358–7381. [Google Scholar] [CrossRef] [PubMed]
- Alfieri, L.; Cohen, S.; Galantowicz, J.; Schumann, G.J.P.; Trigg, M.A.; Zsoter, E.; Prudhomme, C.; Kruczkiewicz, A.; Coughlan de Perez, E.; Flamig, Z.; et al. A global network for operational flood risk reduction. Environ. Sci. Policy 2018, 84, 149–158. [Google Scholar] [CrossRef]
- Hirabayashi, Y.; Mahendran, R.; Koirala, S.; Konoshima, L.; Yamazaki, D.; Watanabe, S.; Kim, H.; Kanae, S. Global flood risk under climate change. Nat. Clim. Chang. 2013, 3, 816–821. [Google Scholar] [CrossRef]
- Ward, P.J.; Jongman, B.; Aerts Jeroen, C.J.H.; Bates, P.D.; Botzen, W.J.W.; Diaz Loaiza, A.; Hallegatte, S.; Kind, J.M.; Kwadijk, J.; Scussolini, P.; et al. A global framework for future costs and benefits of river-flood protection in urban areas. Nat. Clim. Chang. 2017, 7, 642. [Google Scholar] [CrossRef]
- Badoux, A.; Andres, N.; Techel, F.; Hegg, C. Natural hazard fatalities in Switzerland from 1946 to 2015. Nat. Hazards Earth Syst. Sci. 2016, 16, 2747–2768. [Google Scholar] [CrossRef]
- Swiss Re. Floods in Switzerland—An Underestimated Risk; Swiss Re: Zürich, Switzerland, 2012. [Google Scholar]
- Andres, N.; Badoux, A. Unwetterschäden in der Schweiz im Jahr 2016: Rutschungen, Murgänge, Hochwasser und Sturzereignisse. Wasser Energ. Luft 2017, 109, 97–104. [Google Scholar]
- Staffler, H.; Pollinger, R.; Zischg, A.; Mani, P. Spatial variability and potential impacts of climate change on flood and debris flow hazard zone mapping and implications for risk management. Nat. Hazards Earth Syst. Sci. 2008, 8, 539–558. [Google Scholar] [CrossRef]
- Ernst, J.; Dewals, B.J.; Detrembleur, S.; Archambeau, P.; Erpicum, S.; Pirotton, M. Micro-scale flood risk analysis based on detailed 2D hydraulic modelling and high resolution geographic data. Nat. Hazards 2010, 55, 181–209. [Google Scholar] [CrossRef]
- Zischg, A.; Schober, S.; Sereinig, N.; Rauter, M.; Seymann, C.; Goldschmidt, F.; Bäk, R.; Schleicher, E. Monitoring the temporal development of natural hazard risks as a basis indicator for climate change adaptation. Nat. Hazards 2013, 67, 1045–1058. [Google Scholar] [CrossRef]
- Fuchs, S.; Keiler, M.; Zischg, A. A spatiotemporal multi-hazard exposure assessment based on property data. Nat. Hazards Earth Syst. Sci. 2015, 15, 2127–2142. [Google Scholar] [CrossRef]
- Fuchs, S.; Röthlisberger, V.; Thaler, T.; Zischg, A.; Keiler, M. Natural Hazard Management from a Coevolutionary Perspective: Exposure and Policy Response in the European Alps. Ann. Am. Assoc. Geogr. 2016, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zischg, A.P.; Mosimann, M.; Bernet, D.B.; Röthlisberger, V. Validation of 2D flood models with insurance claims. J. Hydrol. 2018, 557, 350–361. [Google Scholar] [CrossRef]
- Papathoma-Köhle, M.; Kappes, M.; Keiler, M.; Glade, T. Physical vulnerability assessment for alpine hazards: State of the art and future needs. Nat. Hazards 2011, 58, 645–680. [Google Scholar] [CrossRef]
- Fuchs, S.; Frazier, T.; Siebeneck, L. Physical Vulnerability. In Vulnerability and Resilience to Natural Hazards; Fuchs, S., Thaler, T., Eds.; Cambridge University Press: Cambridge, UK, 2018; pp. 32–52. [Google Scholar]
- Fuchs, S.; Birkmann, J.; Glade, T. Vulnerability assessment in natural hazard and risk analysis: Current approaches and future challenges. Nat. Hazards 2012, 64, 1969–1975. [Google Scholar] [CrossRef]
- Papathoma-Köhle, M. Vulnerability curves vs. vulnerability indicators: Application of an indicator-based methodology for debris-flow hazards. Nat. Hazards Earth Syst. Sci. 2016, 16, 1771–1790. [Google Scholar] [CrossRef]
- Akbas, S.; Blahut, J.; Sterlacchini, S. Critical Assessment of Existing Physical Vulnerability Estimation Approaches for Debris Flows. In Proceedings of the Landslide Processes: From Geomorphologic Mapping to Dynamic Modeling, Strasbourg, France, 6–7 February 2009; Volume 67. [Google Scholar]
- United Nations Disaster Relief Organization (UNDRO). Natural Disasters and Vulnerability Analysis; Office of The United Nations Disaster Relief Co-Ordinator: Geneva, Switzerland, 1980. [Google Scholar]
- Totschnig, R.; Sedlacek, W.; Fuchs, S. A quantitative vulnerability function for fluvial sediment transport. Nat. Hazards 2011, 58, 681–703. [Google Scholar] [CrossRef]
- Papathoma-Köhle, M.; Zischg, A.; Fuchs, S.; Glade, T.; Keiler, M. Loss estimation for landslides in mountain areas—An integrated toolbox for vulnerability assessment and damage documentation. Environ. Modell. Softw. 2015, 63, 156–169. [Google Scholar] [CrossRef]
- Hydrotec. Hochwasser-Aktionsplan Angerbach. In Teil I: Berichte Und Anlagen; Studie im Auftrag desStUA Düsseldorf; Hydrotec Ingenieurgesellschaft für Wasser und Umwelt mbH: Aachen, Germany, 2001. [Google Scholar]
- Dutta, D.; Herath, S.; Musiake, K. A mathematical model for flood loss estimation. J. Hydrol. 2003, 277, 24–49. [Google Scholar] [CrossRef]
- Jonkman, S.N.; Bočkarjova, M.; Kok, M.; Bernardini, P. Integrated hydrodynamic and economic modelling of flood damage in the Netherlands. Ecol. Econ. 2008, 66, 77–90. [Google Scholar] [CrossRef]
- FOEN. EconoMe 4.0. Wirksamkeit und Wirtschaftlichkeit von Schutzmassnahmen gegen Naturgefahren. Handbuch/Dokumentation; Federal Office of Environment FOEN: Bern, Switzerland, 2015. [Google Scholar]
- Dottori, F.; Figueiredo, R.; Martina, M.L.V.; Molinari, D.; Scorzini, A.R. INSYDE: A synthetic, probabilistic flood damage model based on explicit cost analysis. Nat. Hazards Earth Syst. Sci. 2016, 16, 2577–2591. [Google Scholar] [CrossRef]
- Kreibich, H.; Seifert, I.; Merz, B.; Thieken, A.H. Development of FLEMOcs—A new model for the estimation of flood losses in the commercial sector. Hydrol. Sci. J. 2010, 55, 1302–1314. [Google Scholar] [CrossRef]
- Thieken, A.H.; Müller, M.; Kreibich, H.; Merz, B. Flood damage and influencing factors: New insights from the August 2002 flood in Germany. Water Resour. Res. 2005, 41, 314. [Google Scholar] [CrossRef]
- Federal Office for Water and Geology (FOWG). Bericht über die Hochwasserereignisse 2005; Federal Office for Water and Geology: Bern, Switzerland, 2005. [Google Scholar]
- PSL. Euro to Swiss Franc Spot Exchange Rates for 2005 from the Bank of England; The Economy News Ltd.: Workingham, UK, 2018. [Google Scholar]
- Thieken, A.H.; Olschewski, A.; Kreibich, H.; Kobsch, S.; Merz, B. Development and evaluation of FLEMOps—A new F lood L oss E stimation MO del for the p rivate s ector. In Flood Recovery, Innovation and Response I; Proverbs, D., Brebbia, C.A., Penning-Rowsell, E., Eds.; WIT Press: Southampton, UK, 2008; pp. 315–324. [Google Scholar] [CrossRef]
- Chinh, D.; Dung, N.; Gain, A.; Kreibich, H. Flood Loss Models and Risk Analysis for Private Households in Can Tho City, Vietnam. Water 2017, 9, 313. [Google Scholar] [CrossRef]
- Carisi, F.; Schröter, K.; Domeneghetti, A.; Kreibich, H.; Castellarin, A. Development and assessment of uni- and multivariable flood loss models for Emilia-Romagna (Italy). Nat. Hazards Earth Syst. Sci. 2018, 18, 2057–2079. [Google Scholar] [CrossRef]
- Gerl, T.; Kreibich, H.; Franco, G.; Marechal, D.; Schroter, K. A Review of Flood Loss Models as Basis for Harmonization and Benchmarking. PLoS ONE 2016, 11, e0159791. [Google Scholar] [CrossRef] [PubMed]
- Cammerer, H.; Thieken, A.H.; Lammel, J. Adaptability and transferability of flood loss functions in residential areas. Nat. Hazards Earth Syst. Sci. 2013, 13, 3063–3081. [Google Scholar] [CrossRef]
- Amadio, M.; Mysiak, J.; Carrera, L.; Koks, E. Improving flood damage assessment models in Italy. Nat. Hazards 2016, 82, 2075–2088. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2016. [Google Scholar]
- Weisberg, S. Simple Linear Regression. In Applied Linear Regression; John Wiley & Sons, Inc.: Oxford, UK, 2005; pp. 19–46. [Google Scholar] [CrossRef]
- Good, P.I.; Hardin, J.W. Univariate Regression. In Common Errors in Statistics (and How to Avoid Them); John Wiley & Sons, Inc.: Oxford, UK, 2003; pp. 127–143. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 7th ed.; Pearson Addison Wesley: Harlow, UK; New York, NY, USA, 2012. [Google Scholar]
- Breusch, T.S.; Pagan, A.R. A Simple Test for Heteroscedasticity and Random Coefficient Variation. Econometrica 1979, 47, 1287–1294. [Google Scholar] [CrossRef]
- Weisberg, S. Outliers and Influence. In Applied Linear Regression; John Wiley & Sons, Inc.: Oxford, UK, 2005; pp. 194–210. [Google Scholar] [CrossRef]
- Royston, J.P. An Extension of Shapiro and Wilk’s W Test for Normality to Large Samples. Appl. Stat. 1982, 31, 115–124. [Google Scholar] [CrossRef]
- Box, G.E.P.; Tidwell, P.W. Transformation of the Independent Variables. Technometrics 1962, 4, 531–550. [Google Scholar] [CrossRef]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. Ser. B 1964, 26, 211–252. [Google Scholar]
- Carroll, R.J.; Ruppert, D. Power Transformations when Fitting Theoretical Models to Data. J. Am. Stat. Assoc. 1984, 79, 321–328. [Google Scholar] [CrossRef]
- Weisberg, S. Nonlinear Regression. In Applied Linear Regression; John Wiley & Sons, Inc.: Oxford, UK, 2005; pp. 233–250. [Google Scholar] [CrossRef]
- Maciejewski, R.; Pattath, A.; Ko, S.; Hafen, R.; Cleveland, W.S.; Ebert, D.S. Automated Box-Cox Transformations for Improved Visual Encoding. IEEE Trans. Vis. Comput. Graph 2013, 19, 130–140. [Google Scholar] [CrossRef] [PubMed]
- Ruppert, D.; Matteson, D.S. Statistics and Data Analysis for Financial Engineering; Springer: New York, NY, USA, 2015. [Google Scholar] [CrossRef]
- Perry, M.B.; Walker, M.L. A Prediction Interval Estimator for the Original Response When Using Box-Cox Transformations. J. Qual. Technol. 2015, 47, 278–297. [Google Scholar] [CrossRef]
- Duan, N. Smearing Estimate: A Nonparametric Retransformation Method. J. Am. Stat. Assoc. 1983, 78, 605–610. [Google Scholar] [CrossRef]
- Taylor, J.M.G. The Retransformed Mean after a Fitted Power Transformation. J. Am. Stat. Assoc. 1986, 81, 114–118. [Google Scholar] [CrossRef]
- Sakia, R.M. Retransformation bias: A look at the box-cox transformation to linear balanced mixed ANOVA models. Metrika 1990, 37, 345–351. [Google Scholar] [CrossRef]
- Rothery, P. A cautionary note on data transformation: Bias in back-transformed means. Bird Study 1988, 35, 219–221. [Google Scholar] [CrossRef]
- Weisberg, S. Polynomials and Factors. In Applied Linear Regression; John Wiley & Sons, Inc.: Oxford, UK, 2005; pp. 115–146. [Google Scholar]
- Davison, A.C.; Hinkley, D.V. Linear Regression. In Bootstrap Methods and Their Application; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 1997; pp. 256–325. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. Model Assessment and Selection. In The Elements of Statistical Learning; Hastie, T., Tibshirani, R., Friedman, J., Eds.; Springer Series in Statistics; Springer: New York, NY, USA, 2009; pp. 219–259. [Google Scholar] [CrossRef]
- Walther, B.A.; Moore, J.L. The concepts of bias, precision and accuracy, and their use in testing the performance of species richness estimators, with a literature review of estimator performance. Ecography 2005, 28, 815–829. [Google Scholar] [CrossRef]
- Wenger, S.J.; Olden, J.D. Assessing transferability of ecological models: An underappreciated aspect of statistical validation. Methods Ecol. Evol. 2012, 3, 260–267. [Google Scholar] [CrossRef]
- Sokal, R.; Rohlf, F. The Principles and Practice of Statistics In Biological Research. In Series of Books in Biology; Freeman, W.H., Ed.; WH Freeman and Company: San Francisco, CA, USA, 1969. [Google Scholar]
- Davino, C.; Furno, M.; Vistocco, D. Quantile Regression; John Wiley & Sons, Ltd.: Oxford, UK, 2014. [Google Scholar] [CrossRef]




| OW | SZ | TI | UR | VS | |
|---|---|---|---|---|---|
| Share of content loss on total building loss * | 0.22 | 0.23 | 0.32 | 0.21 | 0.26 |
| Mean/median loss fraction ** | 0.27/0.22 | 0.31/0.28 | 0.33/0.28 | 0.25/0.24 | 0.28/0.24 |
| Mean/median DoL rati o *** | 2.8/1.67 | 3.81/1.94 | 6.22/2.62 | 2.69/1.81 | 2.32/1.49 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mosimann, M.; Frossard, L.; Keiler, M.; Weingartner, R.; Zischg, A.P. A Robust and Transferable Model for the Prediction of Flood Losses on Household Contents. Water 2018, 10, 1596. https://doi.org/10.3390/w10111596
Mosimann M, Frossard L, Keiler M, Weingartner R, Zischg AP. A Robust and Transferable Model for the Prediction of Flood Losses on Household Contents. Water. 2018; 10(11):1596. https://doi.org/10.3390/w10111596
Chicago/Turabian StyleMosimann, Markus, Linda Frossard, Margreth Keiler, Rolf Weingartner, and Andreas Paul Zischg. 2018. "A Robust and Transferable Model for the Prediction of Flood Losses on Household Contents" Water 10, no. 11: 1596. https://doi.org/10.3390/w10111596
APA StyleMosimann, M., Frossard, L., Keiler, M., Weingartner, R., & Zischg, A. P. (2018). A Robust and Transferable Model for the Prediction of Flood Losses on Household Contents. Water, 10(11), 1596. https://doi.org/10.3390/w10111596