1. Introduction
Since 2003, Environment and Climate Change Canada (ECCC) has been producing hourly surface analyses of pollutants covering North America [
1,
2] which became operational products in February 2013 [
3]. The analyses are produced using an optimum interpolation scheme that combines the operational air quality forecast model GEM-MACH output [
4] (CHRONOS model output was used prior to 2010 [
5]) with real-time hourly observations of O
3, PM
2.5, PM
10, NO
2, and SO
2 from the AirNow gateway with additional observations from Canada. As those surface analyses are not used to initialize an air quality model, it raises the issue on how to evaluate them. We conduct routine evaluations using the same set of observations as those used to produce the analysis. Once in a while, when there is a change in the system, a more thorough evaluation is conducted where we leave out a certain fraction of the observations and use them as independent observations, a process known as cross-validation. Observations used in producing the analysis are called
active observations while those not used for evaluation are
passive observations. Cross-validation is used to validate any model that depends on data. In air quality applications it has been used, for example, for mapping and exposure models [
6,
7,
8]. The purpose of this two-part paper is to examine the relative merit of using active or passive observations (or independent observations in general) viewed from different evaluation metrics, but also to develop, in the second part, a mathematical framework to estimate the analysis error, and in doing so, to improve the analysis.
The evaluation of an analysis is important, even in the case where it is used to initialize an air quality forecast model, since the evaluation of the resulting air quality forecast may not be a good measure of the quality of the analysis. In air quality forecasting, the forecast error growth is small, depicts little sensitivity to initial conditions and is in fact more sensitive to numerous modeling errors such as: photochemistry, clouds, meteorology, boundary conditions and emissions just to name a few [
9,
10,
11,
12,
13]. Furthermore, chemical species that are observed are incomplete compared to species needed to initialize an air quality model, incomplete in terms of the number of species observed as well as in their kind [
9,
11,
13,
14]. Only a fraction of the observed species (either of secondary or primary pollutants) are usable for data assimilation; important chemical mechanisms are left completely unobserved and for aerosols, information on size distribution is quite limited and almost nonexistent when it comes to speciation [
9,
13]. In addition, the observational coverage is limited to the surface or to total column measurements which, up until now, were available at one or two local times per day. There are thus many assumptions to be made from an analysis to a proper 3D initial chemical condition and surface emission correction and its subsequent impact on the air quality forecast. These considerations warrant an independent evaluation of the quality of the analysis on its own [
15].
Evaluating an analysis with observations is quite different from evaluating a model with observations, since analyses are created from observations. From a statistical point of view, the observation and analysis cannot be considered independent. However, let us assume that observation errors are spatially uncorrelated. Then, since the passive and active observation sites are never collocated, then the errors from passive observations are uncorrelated with errors of active observations (i.e., observations that are used for the analysis). Furthermore, since the modelling errors are usually assumed to be uncorrelated with observation errors, then it is also uncorrelated with the analysis errors. Cross-validation thus offers a means to evaluate analyses with statistically independent (passive) observations [
16].
In part one of this paper, we evaluate the relative merit of passive and active observations in the evaluation of analyses using standard metrics used for model evaluation. We show how and when the use of active observations can be misleading and that passive observations can provide a means to identify optimal analyses. Our examples show that optimal analyses, at the independent observation sites, have much smaller biases than the model biases and increase the correlation coefficient by nearly a factor of 2.
The paper is thus organized as follows. First we present the analysis scheme we will be using, as well as the cross-validation design, the evaluation metrics and the configuration of the experiments. Then in
Section 3, we assess the quality of the analyses in both active and passive observation spaces using standard air quality evaluation metrics, identify some pitfalls of some metrics and advocate using active observations. Conclusions are presented in
Section 4.
3. Verification against Passive and Active Observations
In this series of experiments, analyses of O
3 and PM
2.5 were produced using a fixed homogeneous isotropic correlation function, where the correlation length was obtained by maximum likelihood using a second-order auto-regressive model and error variances computed using a local Hollingsworth-Lönnberg fit [
17]. A correlation length of 124 km was obtained for O
3 and of 196 km for PM
2.5. Our correlation length is defined from the curvature at the origin as in Daley [
27] and is different from the length-scale parameter of the correlation model (see Ménard et al. [
17] for a discussion of these issues). We did a series of 60-days analyses for different values of
and
but such that their sum respects the innovation variance consistency,
, an important condition for an optimal analysis [
25], as explained in
Section 2.4. This is the experimental procedure that has been used to generate the
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7. The results are shown for a wide range of variance ratios
from
to
in
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 7 in particular. Note that
corresponds to a very large observation weight while
correspond to very small observation weight.
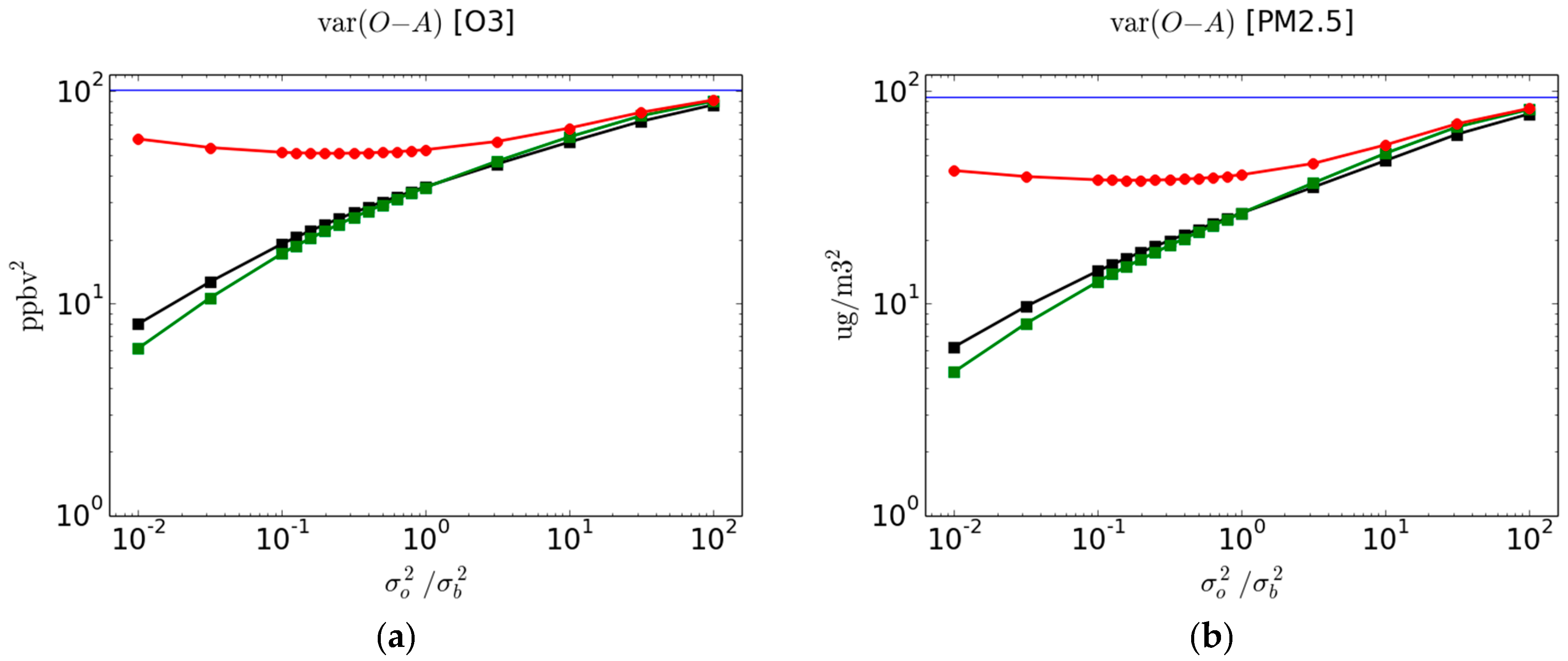
The
using passive observations (red curve with circles) and active observations (black curve with squares) is presented in
Figure 2 for O
3 (left panel) and PM
2.5 (right panel). The solid blue line represents
, the variance of observation-minus-model, i.e., prior to an analysis. As mentioned in
Section 2.4, in the cross-validation experiments we averaged the verification metric over the 3-fold subsets so that, in effect, the total number of observations that end up being used for verification is
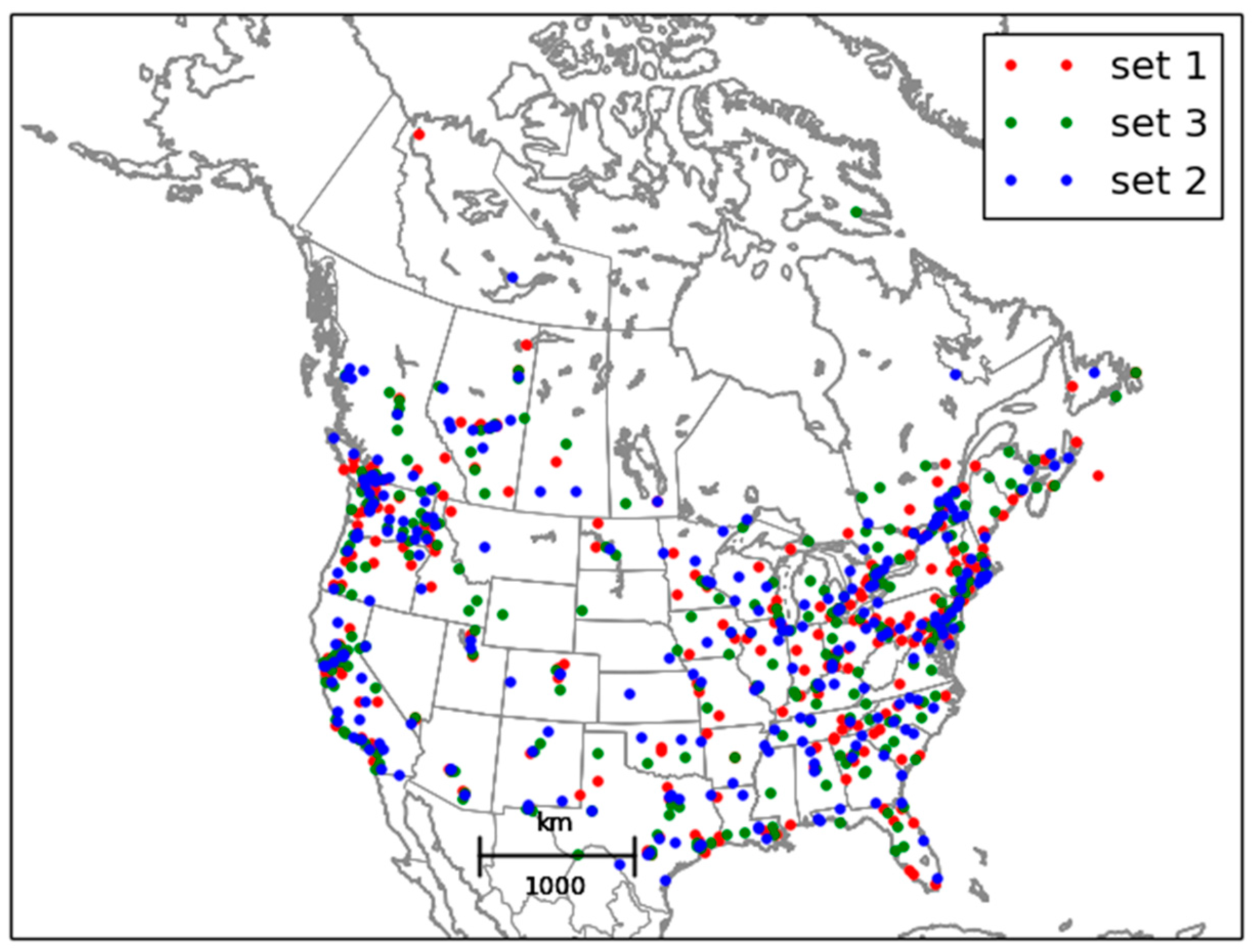
, the total number of stations. We thus argue that the verification sampling error for the cross-validation experiments (red curve) is the same as for the active observations using the full analysis (i.e., analysis using the total number of stations; black curve). In addition, note that from
Figure 1 the station sampling strategy gives rise to spatially random selection of stations, so that the individual metric on each set should be comparable. Furthermore, there is roughly 1300 quality controlled O
3 observations over the domain and 750 PM
2.5 quality controlled observations, each with 60 time samples or less. To give some qualitative idea of the sampling error, the different metric values for the individual 3-fold sets are presented in the
Supplementary Material Figures S1 and S2, where we can see that for
and
the metric values for the individual sets are nearly indistinguishable from the means of the 3-subset.
The difference between the verification against passive observations in cross-validation analyses (red curve) and the verification against active observations using full analyses (black curve) can be attributed to two effects: (1) the analysis used in the cross-validation uses 2/3rd of the total number of observations and thus the analysis error has larger variance than analyses using all observations, (2) since the analysis error variance has typically a local minimum at the individual active observation sites and increases away from it (see for example
Figure 4a in [
28] i.e., Part II of this paper), an evaluation of the analysis error at passive sites (i.e., away from the active sites) has larger error variance than those evaluated at the active sites [
16]. We may call this the distance effect of passive observation sites. In order to separate these two effects, we also display the 3-fold average of the metric verifying against active observation for the cross-validation analyses as a green curve with squares. Thus in summary we display a;
red curve: using analysis with observations with an evaluation at passive sites
green curve: using analysis with observations with an evaluation at active sites
black curve: using analysis with observations with an evaluation at active sites.
The difference between the red and green curves show the influence of distance between passive and active observation sites, whereas the difference between the green and black curves show the influence of having different number of observations in creating the analysis for verification.
Let us first examine the results of verifying against active observations. As the observation weights get smaller (i.e., ), the analysis draws closer to the background, so that increases toward . On the other end, when the continuously decreases as diminishes to ultimately reach zero. This is in effect an expected result from the inner working of an analysis scheme that the analysis error variance goes when the observation error variance goes to zero. This effect does not depend on the observed values or the model values. For this reason, the using active observations cannot provide a true measure of the quality of an analysis.
Now let us examine the results of verifying against passive observations with cross-validation analyses. As the observation weights get smaller (i.e., ), as for active observations the analysis draws closer to the background, so that increases toward . On the other end when the using passive observation increases as diminishes, whereas the evaluated at the active observation sites (green and black curves) decreases, indicating that the analysis tries to overfit active observations which results in a spatially noisy analysis between the active observation sites. Somewhere in between these two extreme values of lies a minimum of where there is neither an overfitting nor an underfitting to the active observations. This “optimal” ratio, that is found by inspection, actually corresponds the optimal analysis. It is also where the analysis error variance with respect to the truth is minimum, but to show this last statement requires an extensive analysis of the problem that we will discuss in part two of this study.
We also computed the verification of the subset of active observations used in the cross-validation experiments with green curves. The difference between the black and green curves indicate the effect of having more observations in the analysis. One would expect that having a larger number of observations in the full analysis active compared to the active for the cross-validation analyses would result in slightly smaller . This is indeed observed between the black and green curves when the observation weight is small (i.e., ). However, surprisingly, when the observation weight is large, , we observe the opposite. This intriguing behavior may indicate an inconsistency between the assumption of uniform error variances for and (assumed in the input error statistics) and the real spatial distribution of error variances. This discrepancy being simply amplified when the observation weight is large and when there are less observations to produce the analysis.
The difference between at passive sites and active sites (with the same number of observations to construct the analyses) is substantial. For O3 and for an optimal ratio, the at passive sites is 51.02 ppbv2 (red curve) while at active sites is 22.77 ppbv2 (green curve). For PM2.5 and for an optimal ratio, the at passive sites is 38.09 (red curve) while at active sites is 15.41 (green curve). For both species, the error variance at active sites gives a significant overestimation of the error variance by more than a factor of 2.
In
Figure 3, we present the correlation metric between the observations and the analysis using, as in
Figure 2, the verification against passive observations in cross-validation analyses (red curve), the verification against active observations using full analyses (black curve) and the verification against active observations in the cross-validation analyses (green curve). The blue curve depicts the correlation between the model and the observations, that is the prior correlation.
The evaluation against passive observations with cross-validation analyses (red curve) shows a maximum at the same values of than for the . We argue that the same arguments of underfitting and overfitting are responsible for this maximum. The correlation between the active observations and the analysis (black and green curves) increases as the observation weight increases ( decreases), theoretically reaching a value 1 for , which is again unrealistic and simply shows the impact of ill-prescribed error statistics in an analysis scheme. The gain in correlation between independent observations and analysis is significant. For O3, it increases from a value of 0.55 with respect to the model to a value of 0.74 with respect to an optimal analysis (when is optimal). For PM2.5, the correlation against the model has a value of 0.3 which basically has no skill, to a value of 0.54 for optimal analysis, which represent a modest but useable skill. The correlation evaluated at the active sites for an optimal ratio, is 0.85 for O3 (green curve) and 0.74 for PM2.5 (green curve), being a substantial overestimation with respect to values obtained at passive sites.
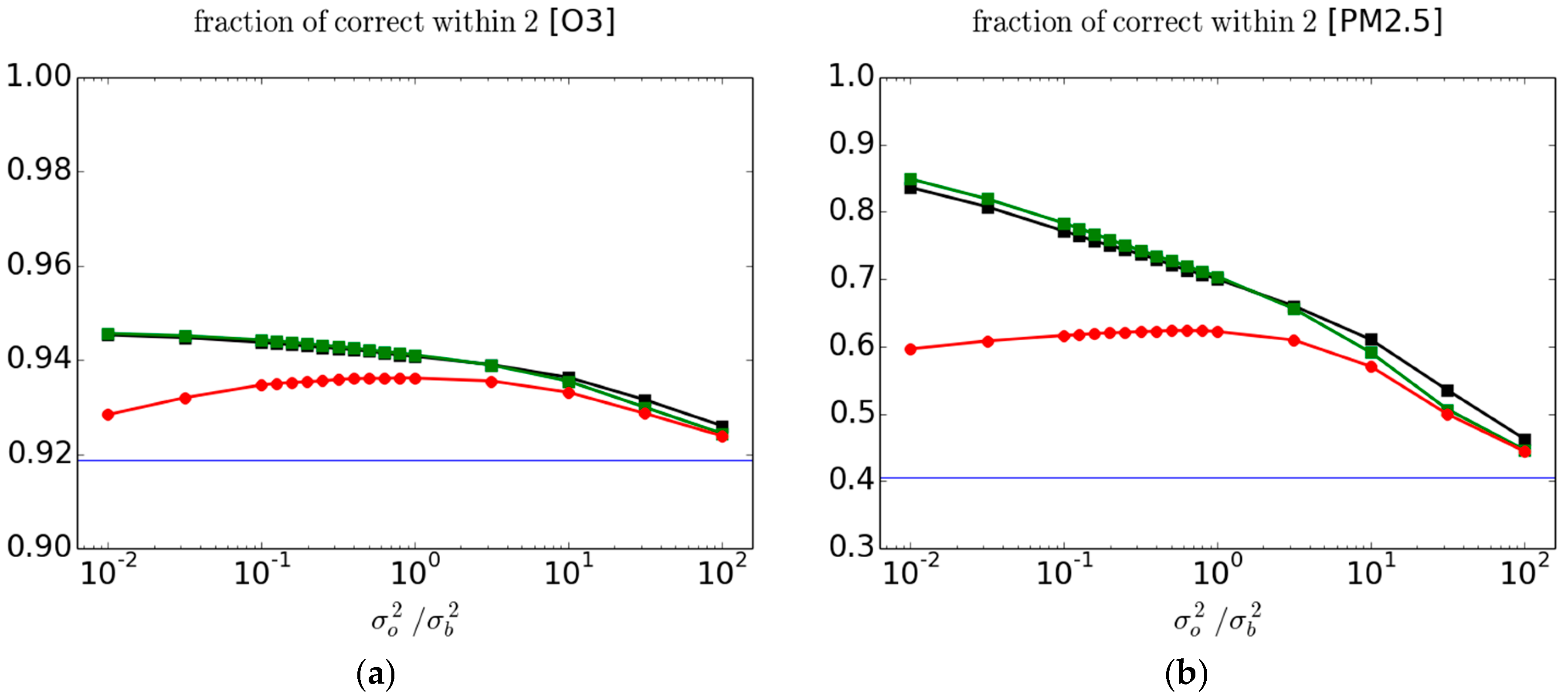
Another metric that we have considered is the FC2, Equation (5) [
3]. The evaluation of this metric against passive and active observations is presented in
Figure 4 for O
3 (left panel) and PM
2.5 (right panel). Note that the scale in the ordinate is quite different between the left and right panels. Although the results bear similarity with the correlation between
O and
A presented in
Figure 3, the maximum with passive observations is reached at larger
values than those obtained for
or
, which are identical. Individual fold results are presented in the
supplementary materials Figure S3.
The interpretation of this metric is, however, not clear. Although the ratio is a dimensionless quantity the spread of is generally not independent of the variance of A or O and there are cases where it is. So to count the number of occurrence of between the dimensionless values 0.5 and 2 is confusing. As a simplified illustration, suppose that A is normally distributed as and similarly with . The ratio of these two random variables is then a Cauchy distribution whose probability density function (pdf) is . The mean, variance and higher moments of Cauchy probability distributions are not defined since the integral of the pdf is not bounded; only the mode is defined. Cauchy distributions also have a spread parameter, which in this case is equal to . If the variance of A and O are equal, then the number count between the dimensionless bounds 0.5 and 2 depends only on the shape of the probability distribution function, not on the variance. If the variance of A and O are different, then it also depends on the ratio of variances. Furthermore, in principle this metric also depends on the bias (which is not the case here for these analyses). It may be a difficult metric to interpret but if used as a quality control, the FC2 have the unique ability of rejecting too low as well as too high values of .
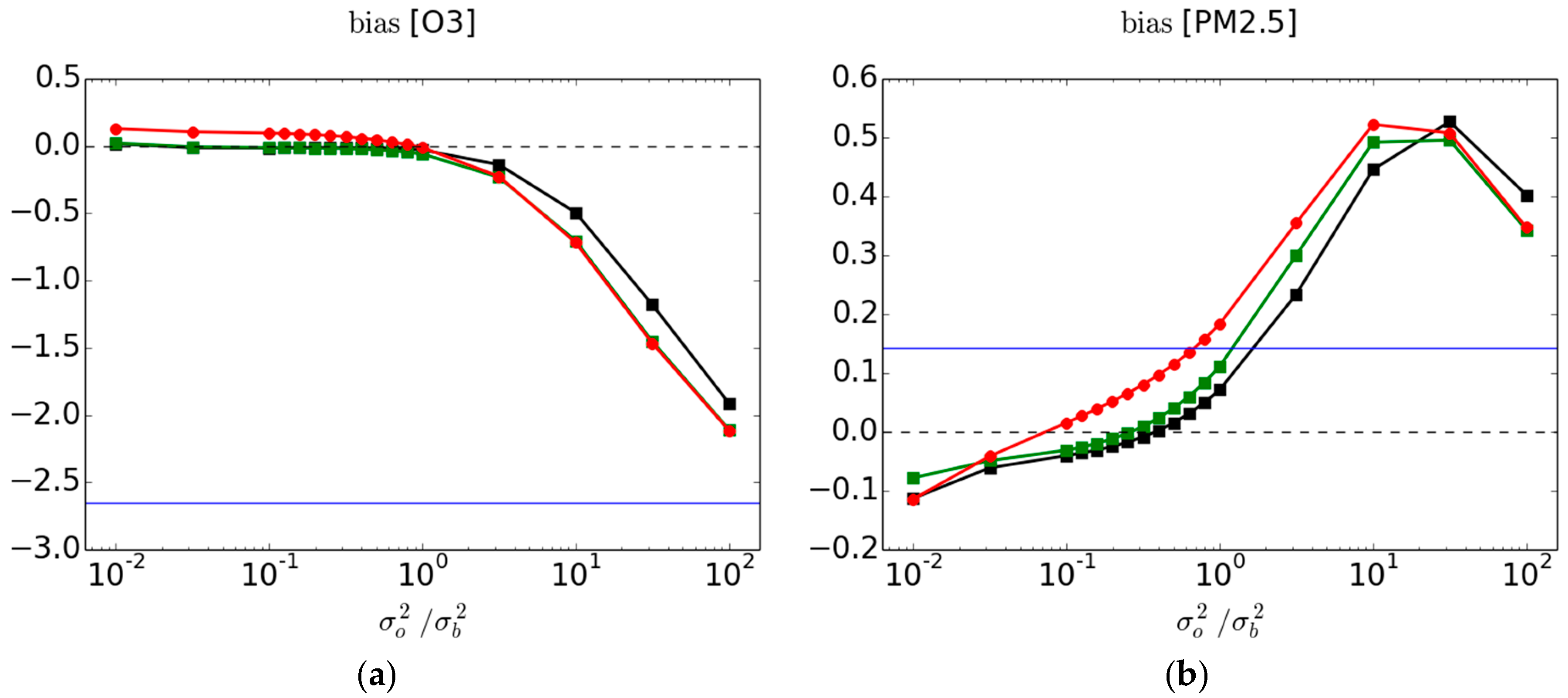
In
Figure 5 we present the bias between observations and analyses, and where the verification is made against passive and active observations as done with the other metrics. Bias is not a dimensionless quantity; note that the range and scale presented for O
3 and PM
2.5 in
Figure 5 are different. The blue curve is the mean
and thus indicates that for O
3 in average over all observation stations (for the time and dates considered) the model overpredicts, and that for PM
2.5 the model underpredicts.
Contrary to all metric results seen so far, the 3-fold variability of the bias is substantial: it is of the order of
ppbv (in average) for O
3 at passive sites and of the order of
(in average) for the PM
2.5 at passive sites (results shown in the
supplementary material Figure S4). The distinction between the red, black and green curves may not be statistically significant for both O
3 and PM
2.5. However, the difference between the analysis bias and model bias is large and statistically significant (see
supplementary material). For O
3, the model bias is eliminated at the passive observation sites (red curve) as long as the observation weight
. The situation is not so clear for PM
2.5. In fact, when the observation weight is small, we get the intruiging result that the bias of the analysis is larger bias than the model. How can that be when the observation weight is small (i.e.,
); should the analysis not be close to the model values? This apparent contradiction reveals a more complex issue underlying the bias metric.
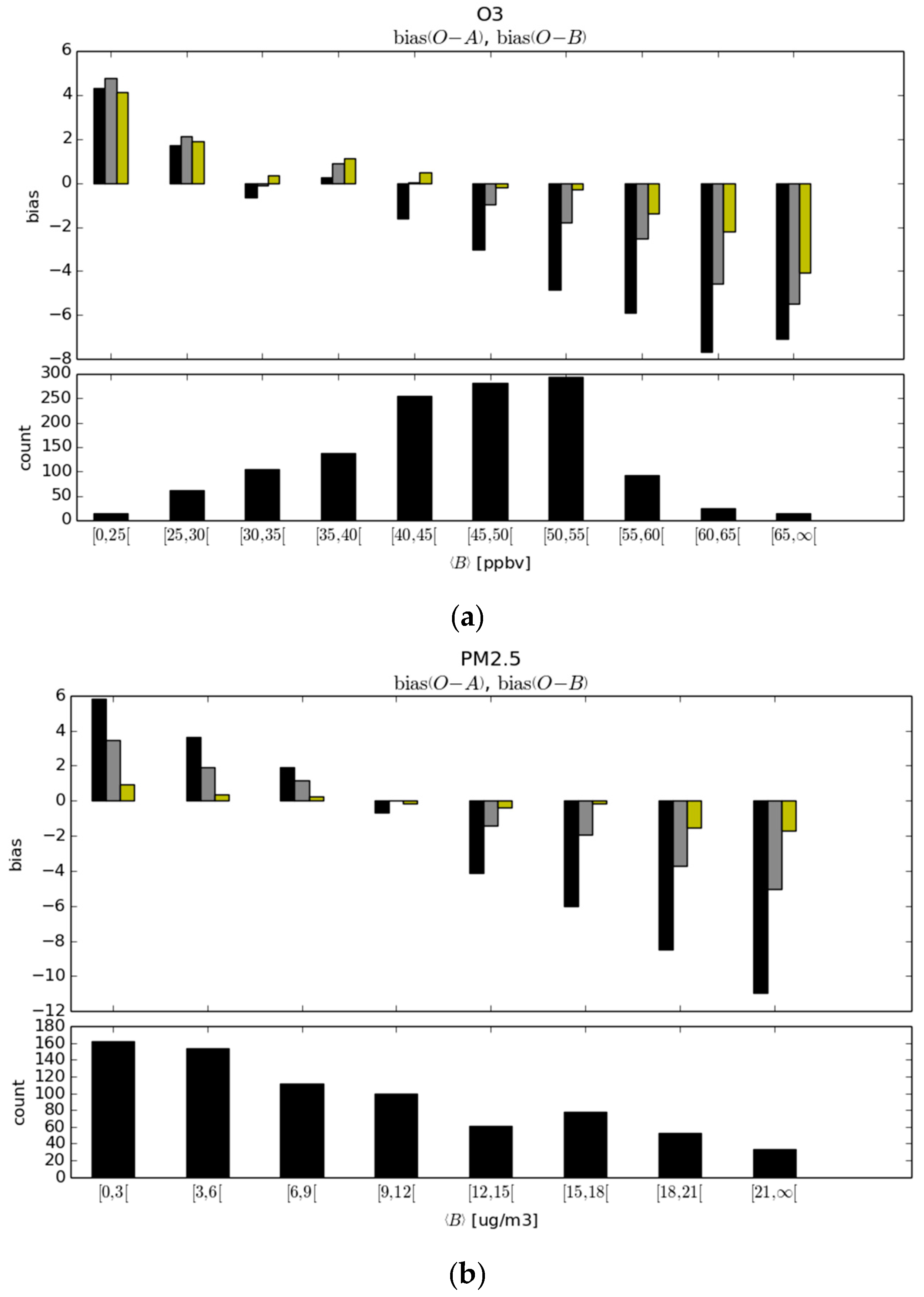
To explore the possible causes, we have calculated the bias per bin of model values, displayed in
Figure 6. In order to have a decent sample size per bin, we collect all the
and
over time and observation sites, create bins of model values and calculate the statistic per bin (and not per station as before). The result shows that the model bias is nearly linearly dependent on the model values (black boxes in the bias panel). Both O
3 and PM
2.5 show an underprediction for low model values and an overprediction for large model values. The origin of this bias is not known but one would argue that it is not directly related to chemistry as such since both constituents, O
3 and PM
2.5, present the same feature. Possible explanations could be related to the model boundary layer, the emissions being too low for low polluted areas and too large for polluted areas, insufficient transport away from polluted areas to unpolluted areas, species destruction/scavenging could be too low in low polluted areas and too high in polluted areas. The lower panels of
Figure 6a,b show the count of stations per model bin size. We observe that the majority of stations have O
3 model values in the range of 40 to 55 ppbv, where the bias is negative. Over all the stations, this gives rise to a negative mean
, and this is how we make the claim that the model overpredicts. However, for PM
2.5 the situation is different: the majority of stations lie in the low model value range, and there are gradually less stations for increasingly larger model values. Although the
have large negative values in the high model value bin while small model value bins have positives
’s, the effect over all stations is to yield a modestly positive mean
and thus the model underestimates the PM
2.5. The results of the analysis evaluated at the passive observation sites are presented with the yellow and grey histogram boxes. In yellow, near optimal analyses with optimal observation weight, as determined by the minimum of
are used, and in grey non-optimal analyses with
.
We observe that the effect of the optimal analysis is nearly insentive to model bin values, where near zero biases are obtained in most of the range except for very small and very large model values. The fact that we are not able to capture the full benefit of analysis on all model values may be an artefact of the assumption that we are using uniform observation and background error variances whereas the model values varies considerably. In grey, we used the non-optimal analyses with a small observation weight were we set
. In the non-optimal case, the state-dependent bias is still present but appears to be nearly perfectly anti-symmetric, positive in the low model value bins and nearly the exact opposite in high model value bins. Since for O
3 the majority of observations lie in the range 40 to 55 ppbv,
for the optimal analyses at passive observation sites is nearly zero. However, for the non-optimal analysis with
, the
at passive sites is negative, i.e., the analysis is overpredicting, as shown in
Figure 5.
For PM
2.5, the weighted sum of the
bins is such that over all stations the bias for an optimal analysis is nearly zero. In the case of the non-optimal analysis with
, the weighted sum of the nearly anti-symmetric
bias per bin gives more weight to the positive bias at smaller model values, so that overall there is a positive
, as in
Figure 5.
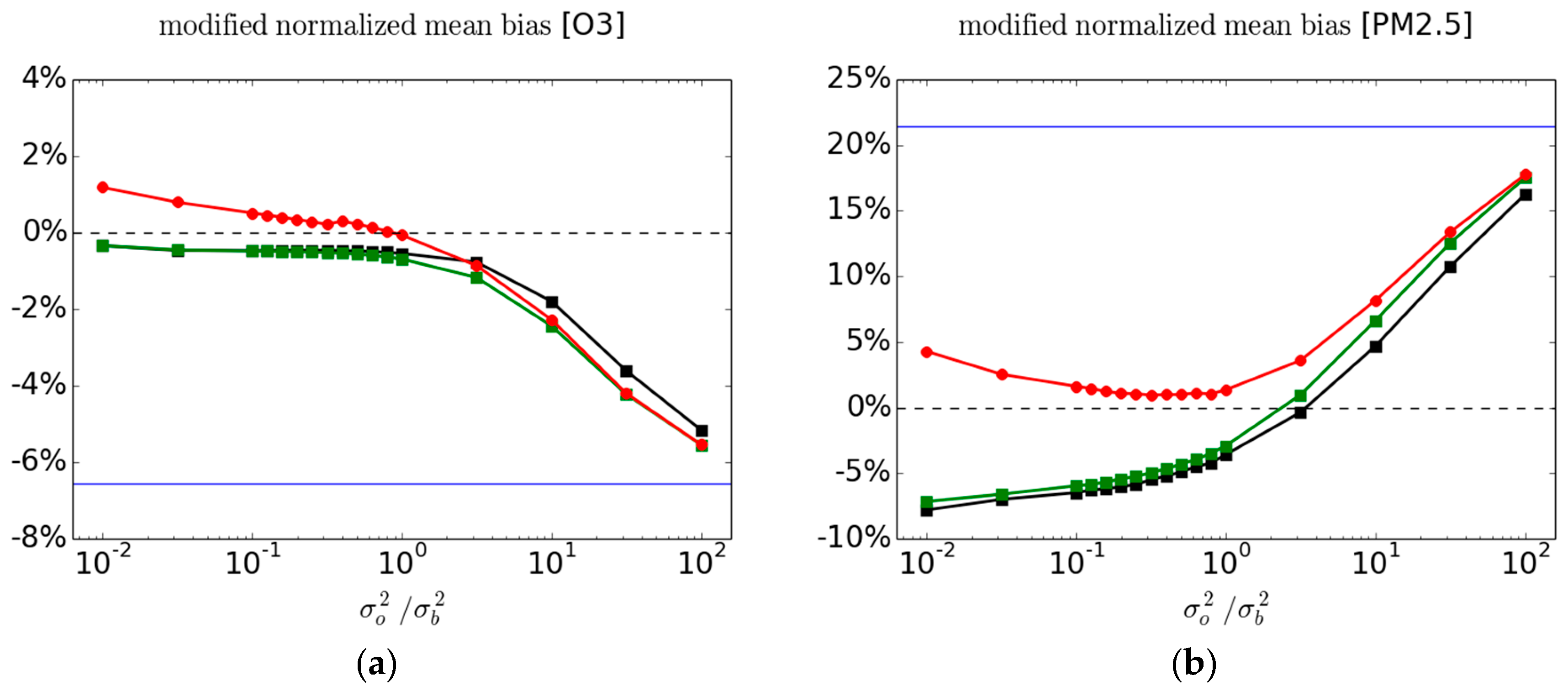
To circumvent the state-dependency of the
biases it is useful to consider instead a fractional bias metric, such as the modified normalized mean bias, MNMB Equation (4). The MNMB metric is a dimensionless measure and as defined with a factor of 2, Equation (4), represents a % error. The MNMB metric is a relative measure with respect to the mean observed-analysis value and is thus less sensitive to spatially varying distribution of the concentrations, revealing instead the intrinsic difference between the fields. The MNMB for O
3 and PM
2.5 for passive and active observations are displayed in
Figure 7 using the same color as in
Figure 2. We note immediately that the MNMB analysis bias does not exceed the MNMB model bias as we observed for the bias metric of PM
2.5 (
Figure 5 right panel). The MNMB bias also varies smoothly as a function of
(at variance with the bias metric for PM
2.5—
Figure 5).
Furthermore, examining the 3-fold variability of the cross-validation analysis MNMB at the passive sites and the variability of the MNMB at the active sites (see
Figure S5 in supplementary materials), we infer that for PM
2.5, where we can actually deduce that the difference between the cross-validation and the validation against active observations is statistically significant when
. There is also another important point to make; although analyses are designed to reduce the error variance, it so happens that for a near optimal analysis the fractional bias MNMB is very small, around 1% for O
3 and about 1–2% for PM
2.5. We argue that it results from an optimal use of observations.
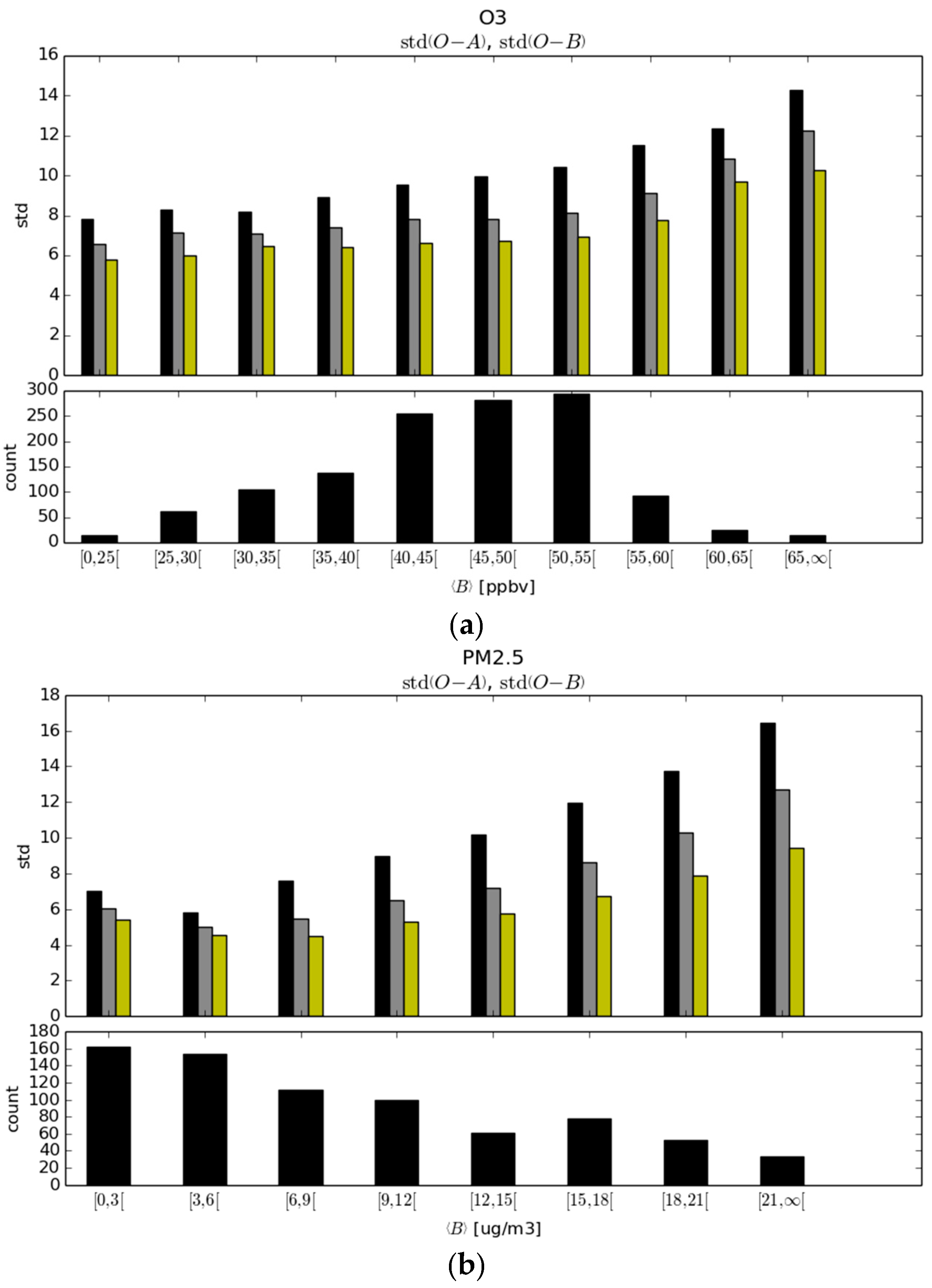
There is also some information to gain from the variance of observed-minus-analysis per bin size, as illustrated in
Figure 8, using the same color histograms as in
Figure 6. We note that for O
3, the model error variance against observations increases gradually with larger model values. However, the fraction of analysis variance vs. model variance is roughly uniform across all bins. This can be explained by the fact that the observation and background error variances are uniform, and thus the reduction of variance across all bins is uniform as well. However, the situation is different for PM
2.5. We note a relatively poor performance of the model at low model values, with standard deviation of 7 μg/m
3. For slightly larger model values (3–6 μg/m
3), the error variance is smaller to 5.5 μg/m
3 and then increases almost linearly with model values. The fraction of analysis variance vs. model variance decreases steadily with larger model values. These results thus indicate that the assumption that observation and background error variances are uniform and independent of the model value may have to be revisited.
4. Conclusions
We have developed an approach by which analyses can be evaluated and optimized without using a model forecast but rather by partitioning the original observation data set into a training set, to create the analysis, and an independent (or passive) set, used to evaluate the analysis. This kind of evaluation by partitioning is called cross-validation.
The need for such a technique came about from our desire to evaluate our operational surface air quality analyses that are created off-line with no assimilation cycling. Evaluating a surface air quality analysis based on its chemical forecast does in fact require additional information or assumptions, such as vertical correlation, aerosol speciation and bin distribution (while surface measurement is primarily about mass) or unobserved chemical variables correlations, and so on. So that the quality of the chemical forecast is not solely dependent on the quality of the analysis and, if there are compensating errors, can actually be a misleading assessment of the quality of the analysis.
We have applied this cross-validation procedure to the operational analyses of surface O3 and PM2.5 over North America for a period of 60 days and present an evaluation using different metrics; bias, modified normalized mean bias, variance of observation-minus-analysis residuals, correlation between observation and analysis, and fraction of correction within a factor of 2.
Our results show that, in terms of variance and correlation, the verification of analyses against active observations always yield an overestimation of the accuracy of the analysis. This overestimation also increases as the observation weight increases. On the other hand for biases, the distinction between the verification against active observations and passive observations is unclear and drowned in the sample variability. However, using a fractional bias metric, in particular the MNMB, shows that the verification against passive observations can be close to one percent for an optimal analysis while the verification against active observations is much larger.
Results also show the importance of having an optimal analysis for verification. The variance of the analysis with respect to independent observations is minimum and the correlation between the analysis and independent observations is maximum for an optimal analysis. By being a compromise between an overfit to the active observations (which produce noisy analysis field) and an underfit, the optimal analysis offers the best use of observations throughout. At optimality, the analysis fractional bias (MNMB) at the passive observation sites has only one or two percent error whereas the fractional bias of the model is 6.5% for O3 and 21% for PM2.5. The correlation between the analysis and independent observations is also significantly improved with an optimal analysis: the correlation between the model and independent observations is 0.55 for O3 and increases to 0.74 with the analysis, while for PM2.5 the correlation between the model and independent observations is only 0.3 (which is basically no skill) but rises to 0.54 for the analysis.
We also argue that the fraction of correct within a factor of 2, is a metric whose interpretation is unclear as it mixes information about bias, variance and probability distribution in a non-uniform way and does not seem to add anything new to other metrics. The bias is also very sensitive to sample variability and can lead to wrong conclusions. For example, we have seen that the mean analysis bias can be larger than the mean model bias, whether verifying against active or passive observations. However, since an analysis is always closer to the truth than its prior (i.e., the model), it results in an apparent contradiction. This implies that the bias metric cannot be used to faithfully compare model states accurately. Such wrongful conclusions do not arise, however, with the MNMB. We thus recommend avoiding using bias as a measure of truthfulness, and use instead a fractional bias measure such as the MNMB.
We also found that errors in the GEM-MACH model grow almost linearly with the model value. This is particularly evident for the bias where the model underestimates at small model values and overestimates at large model values. Furthermore, this occurs in equal ways for O3 and PM2.5, thus indicating that the source of this bias is not related to chemistry. The fact that, over the entire domain, the model overestimates O3, and underestimates PM2.5 is simply a result of the concentrations. We have not conducted a systematic study of model error for other times of the day and other periods of the year, but it would be very interesting to look at this, to see whether or not changes of biases are due primarily to changes in the distribution of values rather than a fundamental change in the bias per model value bin.
Finally, we have also examined the variance against independent observations per model value bin, and concluded that the error variance is not quite uniform with model values but increases slowly with model values for O3 and in a more pronounced way for PM2.5.
In part two, we will focus on the estimation of the analysis error variance and develop a mathematical formalism that permits the comparison of different diagnostics of variance under different assumptions, optimizes the analysis parameters and gains confidence on the estimate of analysis error as we obtain coherent estimated values across different diagnostics.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







