1. Introduction
Locating emission sources of an ambient pollution episode is a critical step for air pollution control. Back-calculation of source parameters based on ambient concentration monitoring is one of the popular methods for locating emission sources, and has attracted increasing attention from researchers and environmental protection authorities [
1,
2,
3,
4].
Measurements from a monitoring network with a proper scale are fundamental for precise back-calculation of source parameters. The required scale for a monitoring network depends on the number of unknown parameters. Increased monitoring sites might improve the obtained result. Penenko V et al. addressed the data from 10 monitors to obtain the probability distribution density function of radionuclide emission sources [
5]; Rude et al. indicated that at least 4 monitors on the ground were necessary to evaluate source location and source strength of a constant ground source by means of the inverse framework method [
6]; Cantelli et al. applied 25 monitors to retrieve 3 different pollution sources using the genetic algorithm inverse model (GAIM) successfully [
1].
This article presents a case study on the backtracking of organic ambient pollution sources in a chemical industrial park. Concentration measurements were provided by the ambient air quality monitoring network. There were five monitoring stations inside, however, only 1–2 of them could observe abnormal measurements in an air pollution episode in general. Obviously, the scale of this monitoring network was insufficient for the precise backtracking of pollution sources like those in the literature. Taking the positioning of emission sources as an example, the obtained solution domain was infinite if no prior information was available, or only measurements from 1–2 stations were given. The results obtained from source area analysis method shows that a fan-shaped source area in the upper wind of the monitors could be determined based on measurements from one monitor [
7], and the source area became narrower when measurements from two monitors were given. Significantly, source areas in the latter case were still not small enough to precisely detect the real source. Consequently, the backtracking of an ambient pollution incident was only able to determine the distribution of source location, rather than the precise source location in our study. We found that source areas from different pollution incidents in numerous cases might overlap under certain weather conditions. Such overlaps indicated that excessive emissions from a source might lead to concentration exceedances at different monitoring stations and different time. Therefore, we decided to examine source area characteristics for a series of pollution incidents during a long period and aimed to backtrack the potential emission source areas from violation records in a year.
Back-calculation methods in the literature were investigated to find a proper method for our case study. Many inverse methods have been reported in the literature for the determination of pollution source parameters, such as genetic algorithms [
1,
8,
9], simulated annealing algorithms [
2,
10], pattern search method [
11], least square method [
4,
12], and probability modeling methods, including Markov chain Monte Carlo [
3,
7], and Sequential Monte Carlo [
13]. These algorithms were used to find an optimal result of unknown parameters by looping over their solution domain, although they were with heavy computational loads. Finally, the method for source area analysis proposed by Huang et al. was adopted in this study, due to the relatively higher computational efficiency compared with other methods [
7]. In this method, solution domain for source location was gridded where the center of each grid was regarded as a hypothetical source position. After that, an inverse method was applied to the optimization of other source parameters.
The dispersion of pollutants played an important role in source area analysis. A dispersion model was needed to simulate concentration distributions of pollutants. There were many candidate models, such as the Gaussian dispersion model, Lagrangian stochastic model, and computational fluid dynamics (CFD) model. Gaussian dispersion models, especially Gaussian plume model [
13,
14,
15] and Gaussian puff model [
7,
16] were widely used as the forward dispersion simulation of air pollutants. Najafi and Gilbert and Annunzio et al. employed the Lagrangian puff models as the forward models [
17,
18]. A CFD model was used by Chow et al. in [
19] and Kovalets IV et al. in [
20]. Each model has its applicable conditions. In this study, Gaussian puff model was adopted. In theory, the Gaussian puff model is not the most suitable model for simulating the dispersion of organic air pollutants, like methyl mercaptan, which is the subject of this study. Precise dispersion models, like CFD, are preferable for exquisite simulation of the airflow and pollutant dispersion under complex terrain or surface, which is universal in industrial parks [
21]. Gaussian puff model was finally used as a forward model in this study for the following considerations. On one hand, Gaussian puff model is a simple diffusion model with more mature applications and more available input parameters. A host of detailed parameters and accurate modeling about underlying surface are required in high-resolution simulation. On the other hand, the use of precise models can also cause errors and it is uncertain whether high-resolution models are more accurate than Gaussian puff model in the absence of accurate information on prior information of source emission parameters and environmental conditions [
22]. To sum up, the inversion method combining Gaussian puff model with source area analysis was selected in this study.
In fact, there are very few cases like the ones in this article in practice. Studies about local pollution source identification in industrial parks are not enough to build a mature method system, and more studies are still in process. However, this article presented the research process and results from real cases. A statistical source identification method was developed successfully based on long-term monitoring data and plenty of violation records, in an industrial park with a huge number and widespread distribution of potential sources and insufficient source information. Under such situations, the statistical source area analysis method provides a guide to more direct information for daily emission source control, and can be used as a preliminary screening approach for pollution sources in an industrial park. Source location analysis of methylene mercaptan pollution episodes in a chemical industrial park in 2014 were addressed. Concentrations and meteorological measurements were analyzed, first, to develop a procedure for identifying independent pollution episodes and calculation scenarios. Then, the method to back-calculate source location distribution, as mentioned above, was applied repeatedly to find the potential source area for each independent episode. Finally, source area frequencies were summarized for all independent episodes to see whether there is some key suspected source area with high frequencies. The current work is organized as follows. The background of this study was described in
Section 2, including the characteristics of the long-term meteorological data and concentration observations. The specific procedure taken in this case study on the industrial source backtracking, as well as the method of source area analysis, were presented in
Section 3. Results were displayed in three parts in
Section 4. Firstly, the output of independent pollution episodes was summarized. Subsequently, the characteristics of the obtained source areas from typical independent pollution episodes were introduced. The comprehensive statistical results of the source area frequencies, along with some investigations, were analyzed on the third part. Finally, conclusions and discussions were given in
Section 5.
2. Case Description
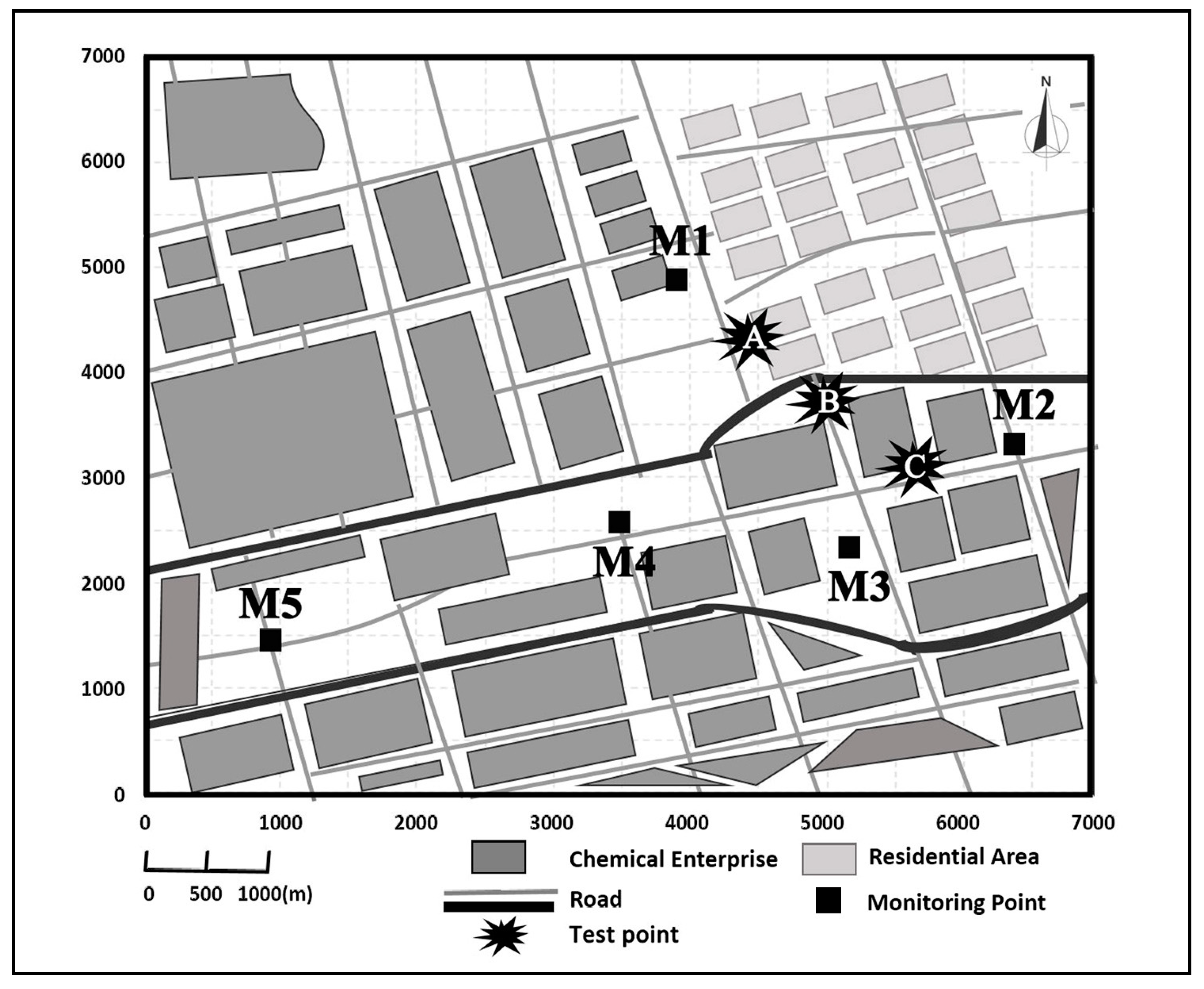
The studied case is a chemical industrial park about 22.5 km
2 (
Figure 1), in which there are lots of chemical industries specialized in petrochemicals, paints, inks, pigments, synthetic materials, medicines, pesticides, and several sewage treatments, etc. There are over 70 odor sources in this study region and there are few sources out of the study region. The source density in the northern part of this park was about 2–6 companies per square kilometer, while its southern counterpart was about 0.5–1.5 companies per square kilometer. Source heights range from 15 to 85 m. There are five fixed ambient air quality monitoring stations (M1–M5) and their surrounding conditions were described in
Table 1. Hourly measurements of wind and methyl mercaptan concentration, as well as SO
2 concentration observations, in 2014, were collected in this study.
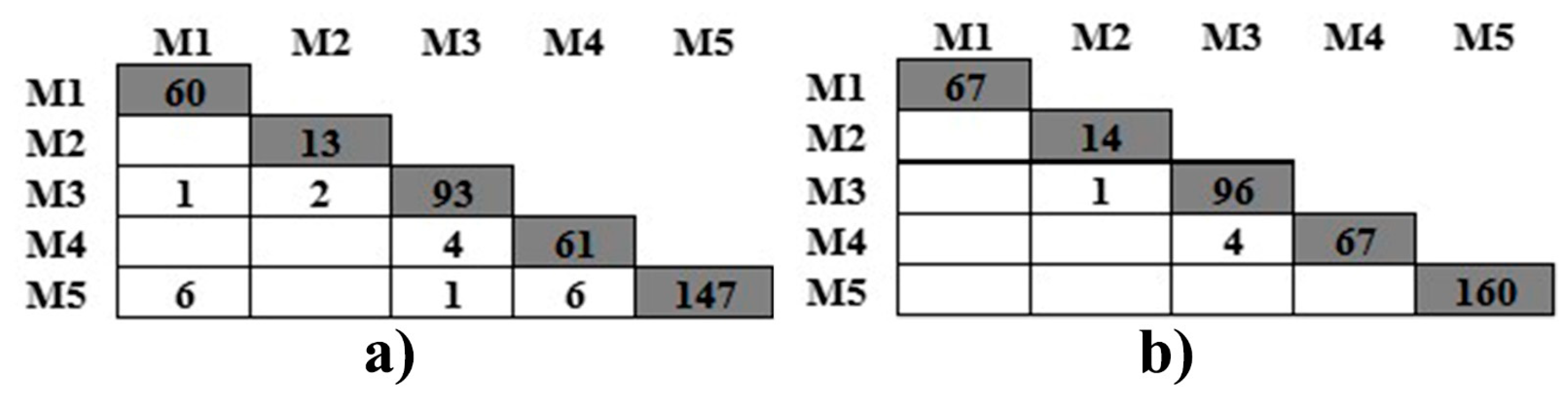
The number of effective records about methyl mercaptan concentrations at M1–M5 was 8130, 8324, 887, 8617, and 8478, respectively. A lack of data was due to instrument failures. The threshold for methyl mercaptan concentration, set in the alarm system, was 0.007 mg/m
3 according to MEEPRC (1993) [
23]. There were 67, 15, 101, 71, and 160 violation records at M1–M5, respectively. The highest concentration of methyl mercaptan was 0.618 mg/m
3, which was observed at M5. It could be presumed that the industrial park was the main pollution source area from the wind direction statistical results of pollution events, and a few pollution incidents might be from out of the study region, as shown in
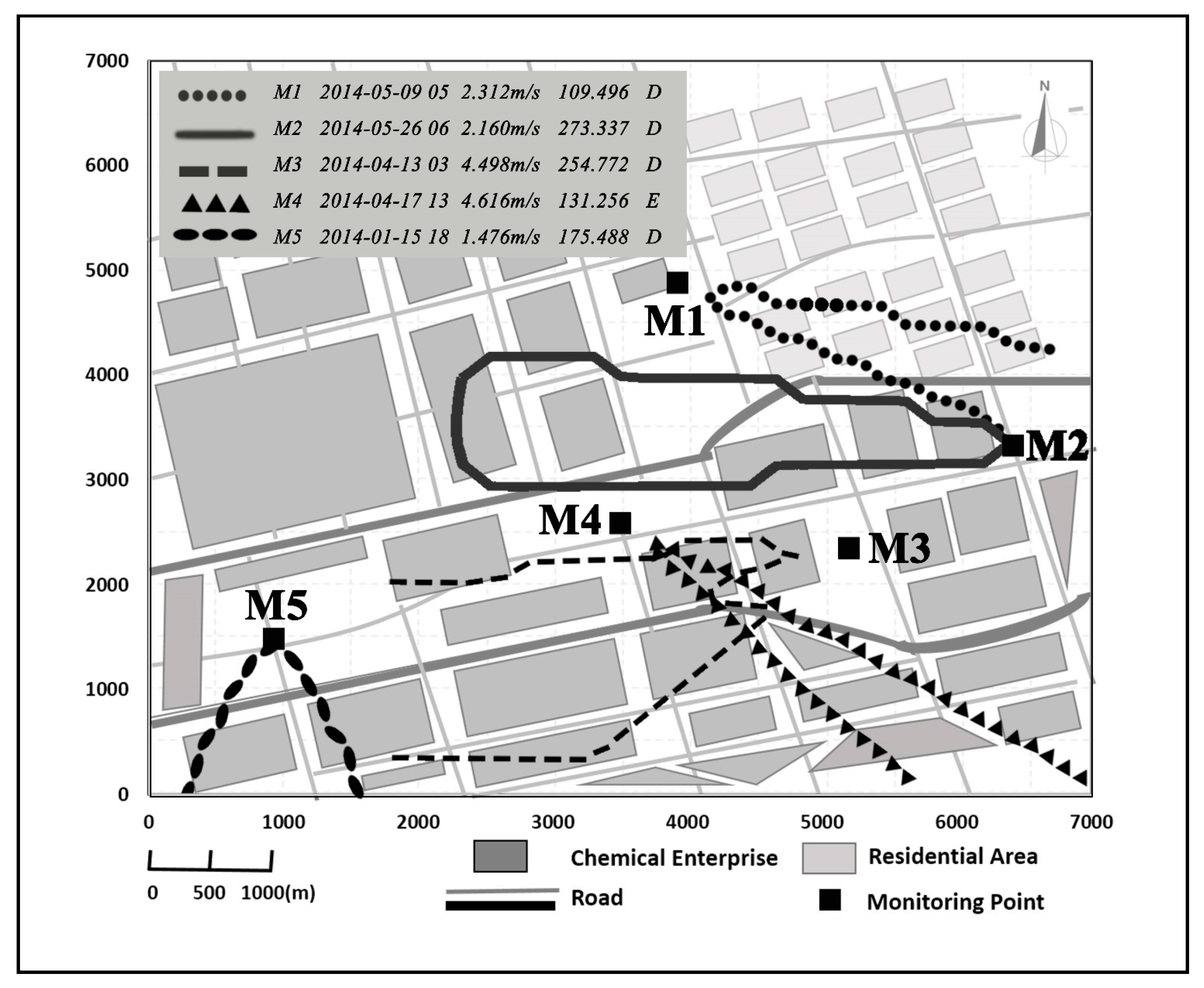
Figure 2, which meant sources in residential areas outside the industrial park had few contributions to methyl mercaptan pollution. Most pollution episodes at M1 occurred under wind from east-southeast (ESE), south-southwest (SSW), and west-southwest (WSW) directions. As can be seen from
Figure 2, the exceedances at M2 were mainly related to the westward wind. The main wind directions were WSW, east (E), ESE, and west-northwest (WNW) for exceedances at M3; northwest (NW), ESE, and southeast (SE) for exceedances at M4; and south-southeast (SSE) and south (S) for exceedances at M5. It seems that the main sources for pollution episodes at M5 are independent of the episodes at other sites. Similarly, the sources with wind direction of WSW at M1, and with wind direction of E at M3, are also independent of the sources at other sites. However, there might be some links among some pollution episodes. For example, a certain consistency might be discovered between the sources responsible for the episodes at M3 with wind direction of WNW, and the sources related to the episodes at M4 with wind direction of ESE due to their relative positions. These are preliminary diagnoses only, based on the relationships between site distributions and wind directions. Further evaluation on the possibility of those pollution episodes from the same sources would be carried out via source area analysis, which addresses the impacts of wind speed and atmospheric stability in addition to that of wind direction.
Besides, the differences in wind speed and other wind direction characteristics could not be ignored. More than 80% of meteorological conditions were with wind speed of 1–4 m/s and with the atmospheric stability of D–F in this study, as shown in
Figure 3. The real-time wind speed difference between the contaminated station and other stations was between 0.001 m/s and 6.414 m/s, and the real-time wind direction difference was in the range of 0°–178.457° at the same time. As can be seen in
Table 2, the highest wind speed difference appeared between M1 and M4, with a maximum of 2.421 m/s. The wind speed values at M1 were generally lower than values at other stations. By contrast, the wind speed values at M4 were higher than those at other stations. The largest wind direction difference occurred in M3 and M5, with a maximum of 40.364°.
It can be seen that the local wind flow in this region is very complicated. As demonstrated in the literature, the complexity of wind field in industrial parks results from the complex underlying surface factors, such as terrain, plant canopy, various buildings, and equipment [
21,
24,
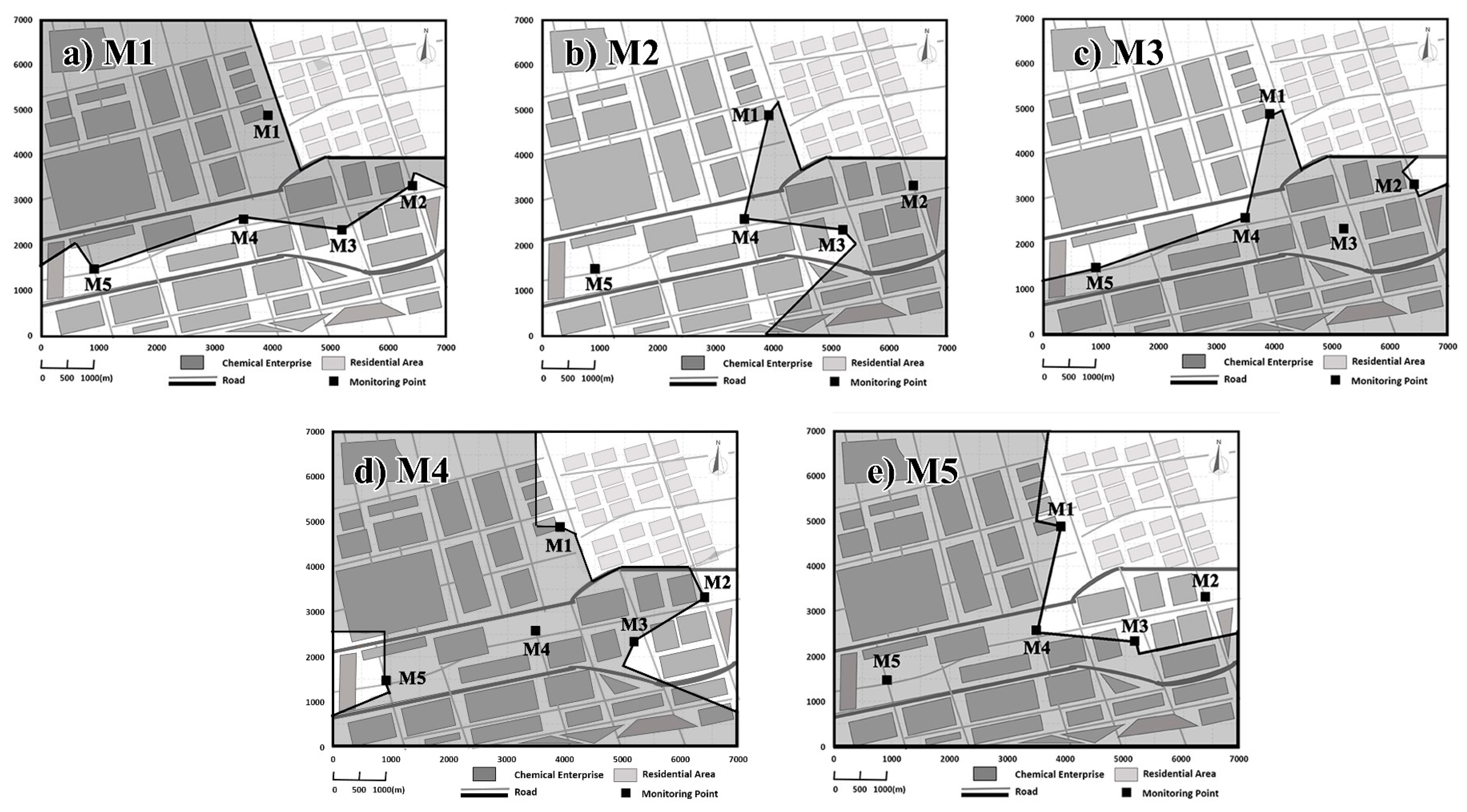
25]. With complex processes at microscales and limited information, the high-precision models, like CFD, are inapplicable. In this study, actual meteorological data were directly used in the calculation for source identification. Although they were probably not the true wind value in local environment, they were more suitable to describe the characteristics of the regional flows than the observations from the meteorological station which is located several kilometers to the east of M2. Representative regions were defined for each site to avoid misjudgment of the remote-distant pollution sources considering the strong wind differences.
5. Conclusions and Discussion
This work presents source identification cases based on long-term abnormal concentration measurements of methyl mercaptan in an industrial park with five fixed monitoring sites. There is a little possibility that an excessive emission caused the abnormal concentration changes of multiple sites at the same time or over several hours, due to the large area of the park and the sparse distribution of monitoring sites. In the case of all violation records, most are pollution episodes where abnormal concentrations were only observed at a single site. A few were episodes where two sites had simultaneous violations, and there were no episodes where three sites reached the alarm limit simultaneously. Source identification process mainly relies on ambient observations, including meteorological and concentration data. The huge number of long-term observations in 2014 were addressed for source identification analysis in the current study. Fortunately, they inspired us to develop a statistical method for source identification.
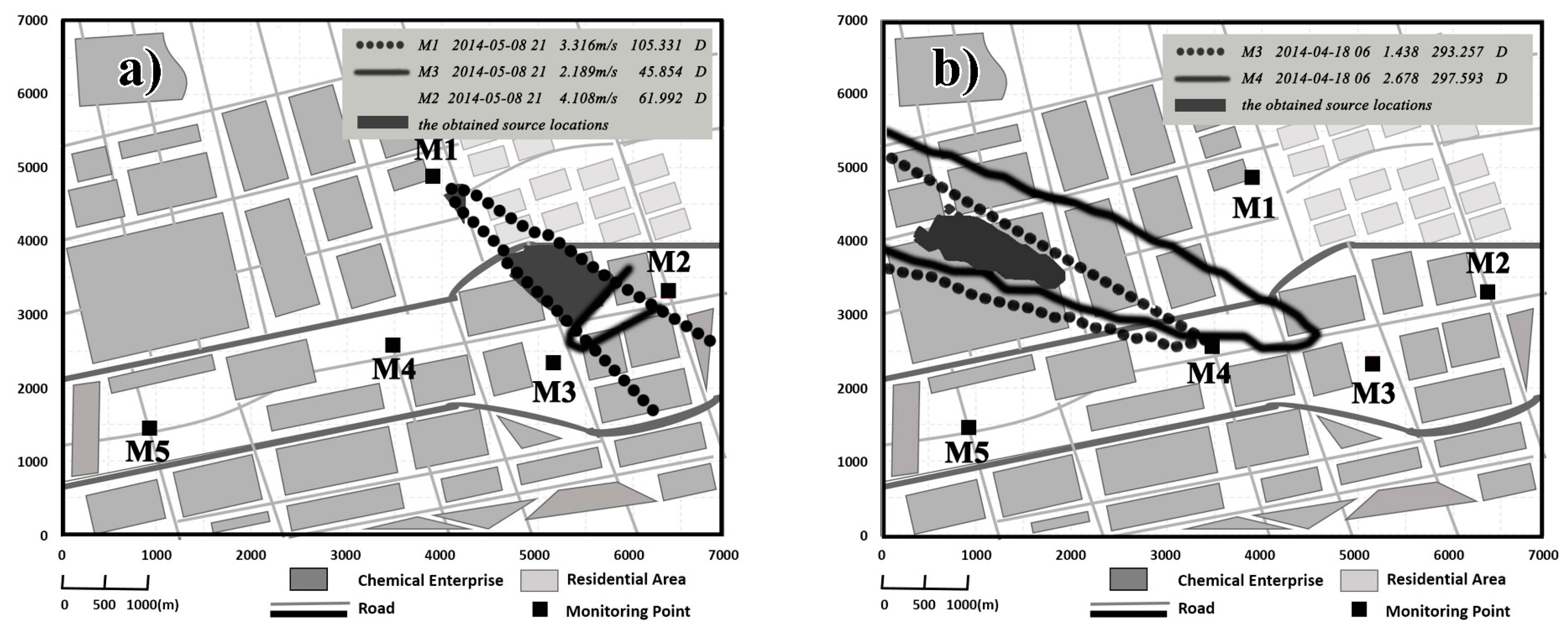
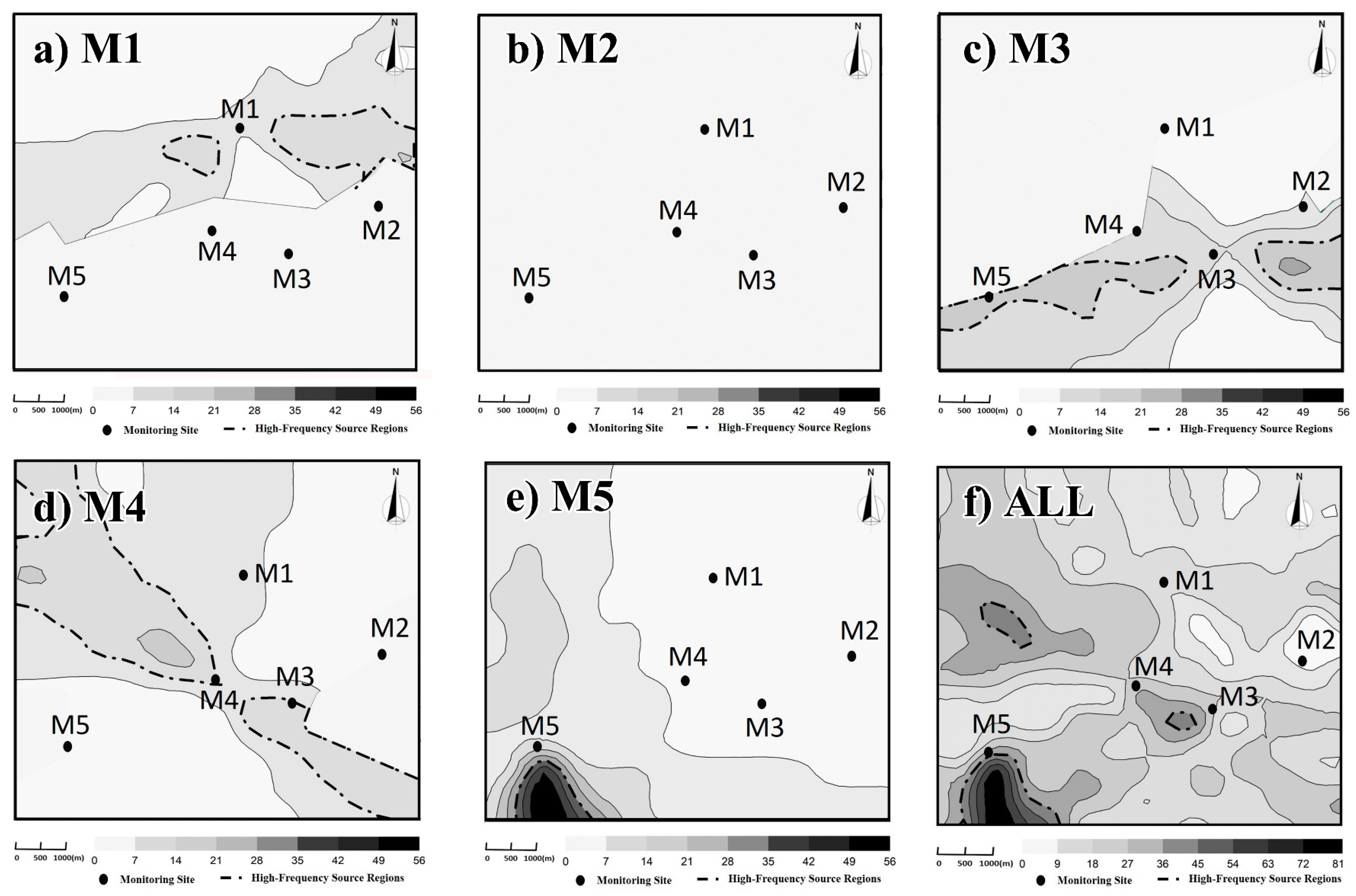
A statistical approach for source identification by means of long-term monitoring data is provided, including the selection of representative regions, the determination of independent pollution episodes and calculation scenarios, the back-calculation of the source area, and the statistical analysis of the obtained results. In the end, the spatial frequency distributions of the key suspected source locations are obtained. From the perspective of the high-frequency source regions, there is little possibility that pollutant emissions located in these regions can bring about multiple sites’ concentration changes simultaneously. This is consistent with the characteristics of a monitoring network for pollution events which are reflected by the observation data of each pollution incident. Under such a monitoring network, the source area obtained by one running calculation of a single site did not have a strong guide. By contrast, the spatial-temporal frequency statistical overlay analysis of the obtained source locations provides more direct information for pollution control.
A prerequisite for getting more accurate source information through spatial-temporal overlay analysis is, possibly, that potential common source areas are discovered from independent episodes at different monitors and different times. If some sources release pollutant regularly, pollution incidents at different sites and times will point at the actual emission sources. High-frequency source areas, in this paper, mainly appeared in two situations. Most of them appeared in the regions with a high-frequency wind direction of pollution incidents at every single site. If the high-frequency wind directions of pollution incidents at a certain site are adjacent, just like the ones of M5, its contribution to the high-frequency source region is more obvious after the overlay. In another situation, the high-frequency source area appeared due to the overlays of potential source areas from pollution incidents of multiple sites. As per the sparse monitoring network, few suspected cases appeared where a source emission caused the increased concentrations of multiples sites. In this study, the overlapping source area from M3 and M4, as well as the overlapping source area from M3, M1, and M5, belongs to this kind of situation. Emissions from the regions might lead to the concentration increase of one or several sites, at different times and under different conditions.
Admittedly, the uncertainties in source area results mainly come from the limited basic information of the studied case. There are many uncertainties in this methodology, due to limited monitoring site information. Also, absent prior information on the source adds difficulties to accurate source identification. Source area analysis method is expected to be a good approach to find meaning from limited information and uncertain factors. The uncertainties of source parameters had been considered partially, and all feasible solutions are obtained through the optimal solution for the uncertain source parameters (described at length in
Section 3.2.1).
In addition to above factors, the representative error of meteorological data also has a significant impact on the obtained source area results. Further study will be intended to develop the simulation technologies for the local subgrid complex flow field, due to large spatial uniformity and complexities of the meteorological flow in this study area. The simulation technique, in this paper, takes meteorological data of every single site for calculation, rather than using the refined technique for complex flow field. The representative region of each site is determined according to real-time meteorological conditions, to avoid the misjudgment of feasible solutions caused by the uncertainties of the remote flow field. Such simplification might inevitably result in a lower statistical frequency of source locations in the far regions in some cases. There is still a certain error within the representative regions. The meteorological observation analysis in
Table 2 indicates that the real-time wind direction difference among five stations might be between 0°–178.457°, and the real-time wind speed difference might be between 0.001–6.414 m/s. It is very difficult to estimate the representation errors accurately, due to the unavailable real wind values. Thus inverse distance weighted (IDW , power = 2, [
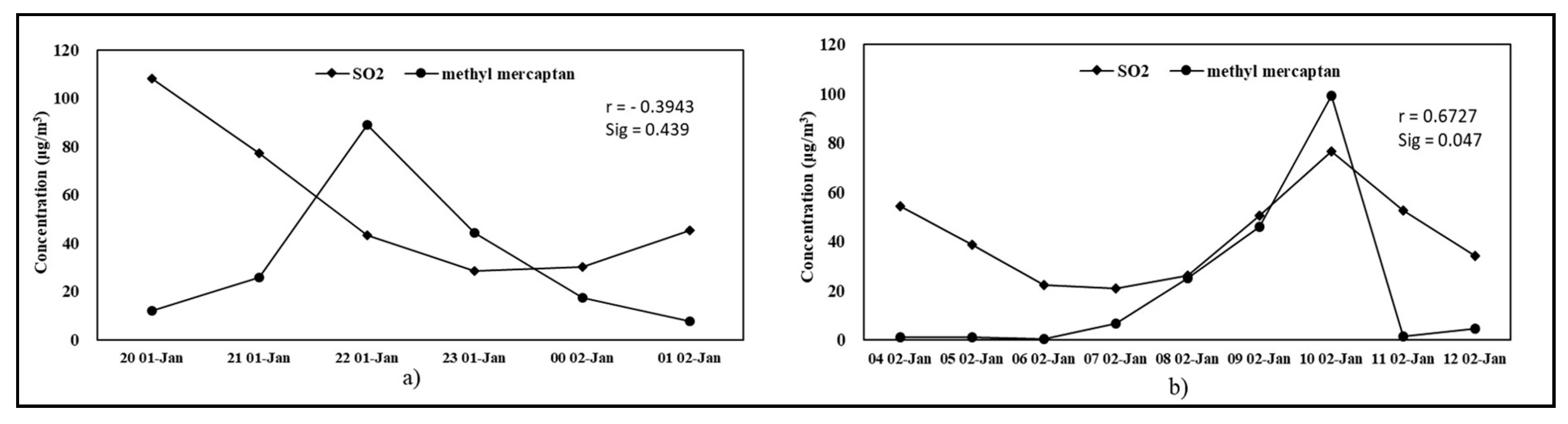
25]) is selected to calculate the real wind reference value, then compared with the uniform meteorological measurements within the representative regions, to assess the spatial nonuniformity level. A, B, and C, surrounded by M1–M3, are defined as test points for analysis, as plotted in
Figure 1. The distances to M1 from A, B, and C are 800, 1600, 2400 m, respectively. This region is the most appropriate area for interpolation analysis throughout the total computational domain because there are three monitoring stations surrounded. There are twelve pollution incidents with wind direction of ESE where three test points are located in its upwind direction of M1. In these records, the average pollution wind speed of M1 is 2.098 m/s, and the average pollution wind direction is 108°. The interpolated average wind speeds of A, B, and C are 2.154, 2.360, and 2.595 m/s, respectively, and the interpolated average wind directions are 106°, 101°, and 100°, respectively. It could be concluded that the closer it is to M1, the slighter the error in wind speed is. This also applies to wind direction. From the view of wind direction, a certain deviation existed between the interpolated wind directions of A, B, C, and the observed wind direction of M1. However, the error level is acceptable because the interpolated wind directions are near ESE. In general, the representative error of meteorological data is still a problem worth further research. Besides, the influence of buildings and other obstacles in canopy layer on vertical wind shear, wind measurements, and atmospheric turbulence also deserve more exploration. Refined simulation techniques are required to be developed for such local complex regions in future research, especially in industrial parks with plenty of production equipment and dense underlying surface, which are also the technical basis for the refined source identification results. Attempts to couple the urban canopy model in the weather research and forecasting model (WRF) with CFD, and the explicit explorations of atmospheric stability levels, might be considered for further study in meteorological perspectives.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}