1. Introduction
Polar mesoscale cyclones (MCs) are high-latitude marine atmospheric vortices. Their sizes range from 200 to 1000 km with lifetimes typically spanning from 6 to 36 h [
1]. A specific intense type of mesocyclones, the so-called polar lows (PLs), is characterized by surface winds of more than 15 m/s and strong surface fluxes. These PLs have a significant impact on local weather conditions causing rough seas. Being relatively small in size (compared to the extratropical cyclones), PLs contribute significantly to the generation of extreme air-sea fluxes and initialize intense surface transformation of water masses resulting in the formation of ocean deep water [
2,
3,
4]. These processes are most intense in the Weddel and Bellingshausen Seas in the Southern Hemisphere (SH) and in the Labrador, Greenland, and Irminger Seas in the Northern Hemisphere (NH).
One potential source of data is reanalyses. However, MCs, being critically important for many oceanographic and meteorological applications, are only partially detectable in different reanalysis datasets, primarily due to the inadequate resolution. Studies [
3,
5,
6,
7,
8] have demonstrated the significant underestimation of both number of mesocyclones and wind speeds by modern reanalyses in contrast with satellite observations of MCs cloud signatures and wind speeds. This hints that the spatial resolution of modern reanalyses is still not good enough for reliable and accurate detection of MCs. Press et al. argued for at least 10 × 10 grid points is necessary for effective capturing the MC [
9]. This implies a 30 km spatial resolution in the model or reanalysis is needed for detecting MC with the diameter of 300 km. Some studies [
5,
10] have demonstrated that 80% (64%) of MCs (PLs) in the SH (NH) are characterized by the diameters ranging from 200 to 500 km (250 to 450 km for NH in [
10]). The most recent study of Smirnova and Golubkin [
11] revealed that only 70% of those could be sustainably represented, even in the very high-resolution Arctic System Reanalysis (ASR) [
12]. At the same time only 53% of the observed MCs characterized by diameters less than 200 km [
5] are sustainably represented in ASR [
11]. It was also shown [
3,
5,
6] that both number of MCs and associated winds in modern reanalyses are significantly underestimated when compared to satellite observations of cloud signatures of MCs and satellite scatterometer observations of MC winds.
One might argue for the use of operational analyses for detecting MCs. However, these products are influenced by the changes in the numerics of a model and physics parameterization schemes with newly developed ones, and by the changes of the performance of data assimilation system and the amount of assimilated data. This leads to artificial trends at climatological timescales. In several studies, automated cyclone tracking algorithms that were originally developed for mid-latitude cyclones were adapted for MCs identification and tracking [
13,
14,
15]. These algorithms were applied to the preprocessed (spatially filtered) reanalysis data and delivered climatological assessments of MCs activity in reanalyses or revealed the direction for their improvement. However, reported estimates of MCs numbers, sizes, and lifecycle characteristics vary significantly in these studies.
Zappa et al. [
13] shows that ECMWF operational analysis makes it possible to detect up to 70% of the observed PLs, which is higher than ERA40 and ERA-Interim reanalyses (24%, 45%, or 55% depending on the procedure of tracking and the choice of reanalysis [
6,
13]). One bandpass filter in conjunction with different combinations of criteria used for the post-processing of the MC tracking results may result in a 30% spread in the number of PLs [
13]. Observational satellite-based climatologies of MCs and PLs [
5,
10,
16,
17,
18,
19] consistently reveal a mean vortex diameter of 300–350 km. In a number of reanalysis-based automated studies [
14,
20], the upper limit of MC and PL diameters was set to 1000 km, resulting in the mean values between 500 and 800 km. Thus, the estimates of MC sizes are still inconsistently derived with automated tracking algorithms. This inconsistency contrasts with the estimates for midlatitude cyclones’ characteristics derived with the ensemble of tracking schemes [
21] applied to a single dataset.
Satellite imagery of cloudiness is another data source for identification and tracking of MCs. These data allow for visual identification of cloud signatures that are associated with MCs. However, the manual procedure re Carleton quires enormous effort to build a long enough dataset. Pioneering work of Wilhelmsen [
22] used ten years of consecutive synoptic weather maps, coastal observational stations, and several satellite images over the Norwegian and Barents Seas to describe local PLs activity. Later, in the 1990s, the number of instruments and satellite crossovers increased. It provoked many studies [
16,
23,
24,
25,
26,
27,
28] evaluating the characteristics of MCs occurrence and lifecycle in different regions of both NH and SH. These studies identified major MCs generation regions, their dominant migration directions, and cloudiness signature types that are associated with MCs. Increases in the amount of satellite observations allowed for the development of robust regional climatologies of MCs occurrence and characteristics. For the SH, Carleton [
27] used twice daily cloudiness imagery of West Antarctica and classified for the first time four types of cloud signatures associated with PLs (comma, spiral, transitional type, and merry-go-round). This classification has been confirmed later in many works and it is widely used now. Harold et al. [
16,
26] used daily satellite imagery for building one of the most detailed datasets of MC characteristics for the Nordic Seas (Greenland, Norwegian, Iceland, and Northern Seas). Also, Harold et al. [
16,
26] developed a detailed description of the conventional methodology for the identification and tracking of MCs using satellite IR imageries.
There are also several studies regarding polar MCs and PLs activity in the Sea of Japan. Gang et al. [
29] conducted the first long-term (three winter months) research of PLs in the Sea of Japan based on visible and IR imagery from the geostationary satellite with hourly resolution. In the era of multi-sensor satellite observations, Gurvich and Pichugin [
30] developed the nine-year climatology of polar MCs based on water vapor, cloud water content and surface wind satellite data over the Western Pacific. This study reveals a mean MCs diameter of 200–400 km as well.
As these examples illustrate, most studies of MCs activity are regional [
10,
17,
18,
31,
32] and they cover relatively short time periods [
5] due to the very costly and time-consuming procedure of visual identification and tracking of MCs. Thus, development of the reliable long-term (multiyear) dataset covering the whole circumpolar Arctic or Antarctic remains a challenge.
Recently, machine learning methods have been found to be quite effective for the classification of different cloud characteristics such as solar disk state and cloud types. There are studies in which different machine learning techniques are used for recognizing cloud types [
33,
34,
35]. Methodologies employed include deep convolutional neural networks (DCNNs [
36,
37]), k-nearest-neighbor classifier (KNN), and Support Vector Machine (SVM) and fully-connected neural networks (FCNNs). Krinitskiy [
38] used FCNNs for the detection of solar disk state and reported very high accuracy (96.4%) of the proposed method. Liu et al. [
39] applied DCNNs to the fixed-size multichannel images to detect extreme weather events and reported the success score of the detection of 89 to 99%. Huang et al. [
40] applied the neural network “DeepEddy” to the synthetic aperture radar images for detection of ocean meso- and submesoscale eddies. Their results are also characterized by high accuracy exceeding 96% success rate. However, Deep Learning (DL) methods have never been applied for detecting MCs.
DCNNs are known to demonstrate high skills in classification, pattern recognition, and semantic segmentation, when applied to two-dimensional (2D) fields, such as images. The major advantage of DCNNs is the depth of processing of the input 2D field. Similarly to the processing levels of satellite data (L0, L1, L2, L3, etc.), which allow retrieving, e.g., wind speed (L2 processing) from the raw remote measurements (L0), DCNNs are dealing with multiple levels of subsequent non-linear processing of an input image. In contrast to the expert-designed algorithms, the neural network levels of processing (so-called layers) are built in a manner that is common within each specific layer type (convolutional, fully-connected, subsampling, etc.). During the network training process, these layers of a DCNN acquire the ability to extract a broad set of patterns of different scales from the initial data [
41,
42,
43,
44]. In this sense, a trained DCNN closely simulates the visual pattern recognition process naturally used by a human operator. There exist several state-of-the-art network architectures, such as “AlexNet” [
35], “VGG16” and “VGG19” [
45], “Inception” of several subversions [
46], “Xception” [
47], and residual networks [
48]. Each of these networks has been trained and tested using a range of datasets, including the one that is considered as a “reference” for the further image processing, the so-called ImageNet [
49]. Continuous development of all DCNNs aims to improve the accuracy of the ImageNet classification. Today, the existing architectures demonstrate high accuracy with the error rate from 2% to 16% [
50].
A DCNN by design closely simulates the visual recognition process. IR and WV satellite mosaics can be interpreted as images. Thus, assuming that a human expert detects MCs on these mosaics on the basis of his visual perception, application of DCNN appears to be a promising approach to this problem. Liu et al. [
39] described a DCNN applied to the detection of tropical cyclones and atmospheric rivers in the 2D fields of surface pressure, temperature and precipitation stacked together into “image patches”. However, the proposed approach cannot be directly applied to the MC detection. This method is skillful for the detection of large-scale weather extremes that are discernible in reanalysis products. However, as noted above, MCs have a poorly observable footprint in geophysical variables of reanalyses.
In this study, we apply the DL technique [
51,
52,
53] to the satellite IR and WV mosaics distributed by Antarctic Meteorological Research Center [
54,
55]. This allows for the automated recognition of MCs cloud signatures. Our focus here is exclusively on the capability of DCNNs to perform a binary classification task regarding MCs patterns presence in patches of satellite imagery of cloudiness and/or water vapor, rather than on the DCNN-based MC tracking. This will indicate that a DCNN is capable of learning the hidden representation that is in accordance with the data and the MCs detection problem.
The paper is organized as follows.
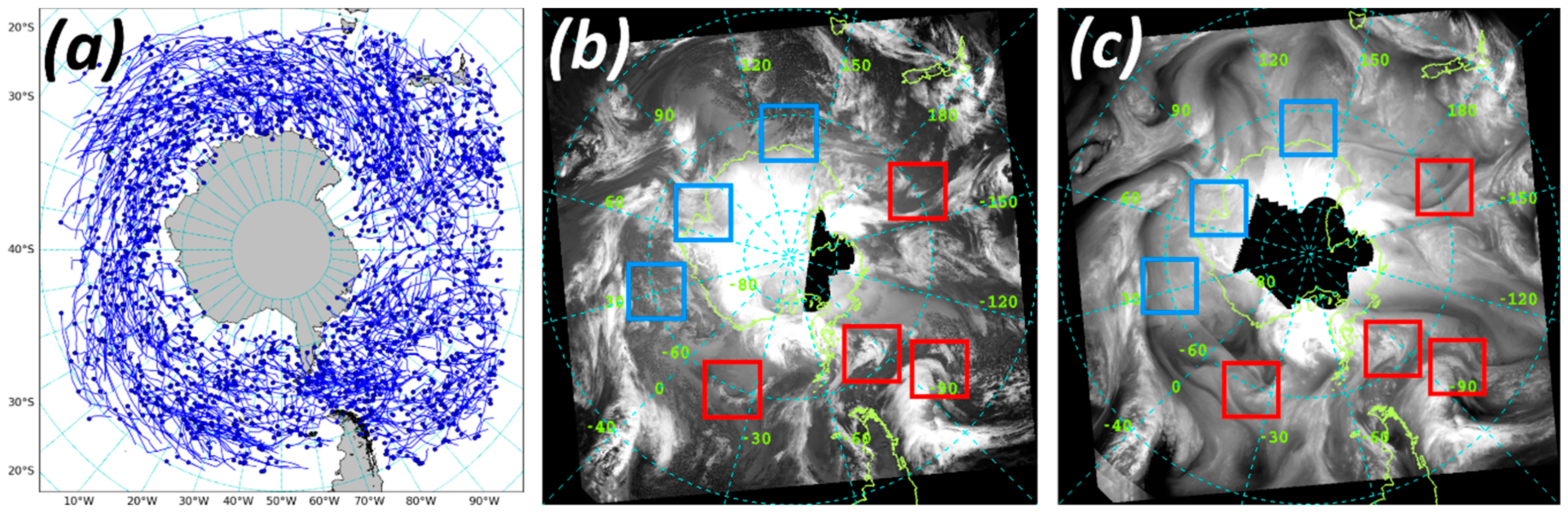
Section 2 describes the source data based on MC trajectories database [
5].
Section 3 describes the development of the MC detection method that is based on deep convolutional neural networks and necessary data preprocessing. In
Section 4, we present the results of the application of the developed methodology.
Section 5 summarizes the paper with the conclusions and provides an outlook.
4. Results
The designed DCNNs were applied to detect of Antarctic MCs for the period from June to September 2004. Summary of the results of the application of six models is presented in
Table 2. As we noted above, each model is characterized by the utilized data source (IR alone or IR + WV, columns “IR” and “WV” in
Table 2). These DCNNs are further categorized according to a chosen set of applied techniques in addition to the basic approach (see
Table 2 legend).
Table 2 also provides accuracy scores and probability thresholds estimated, as described in
Section 3.5, for the individual, second-, and third-order models of each architecture.
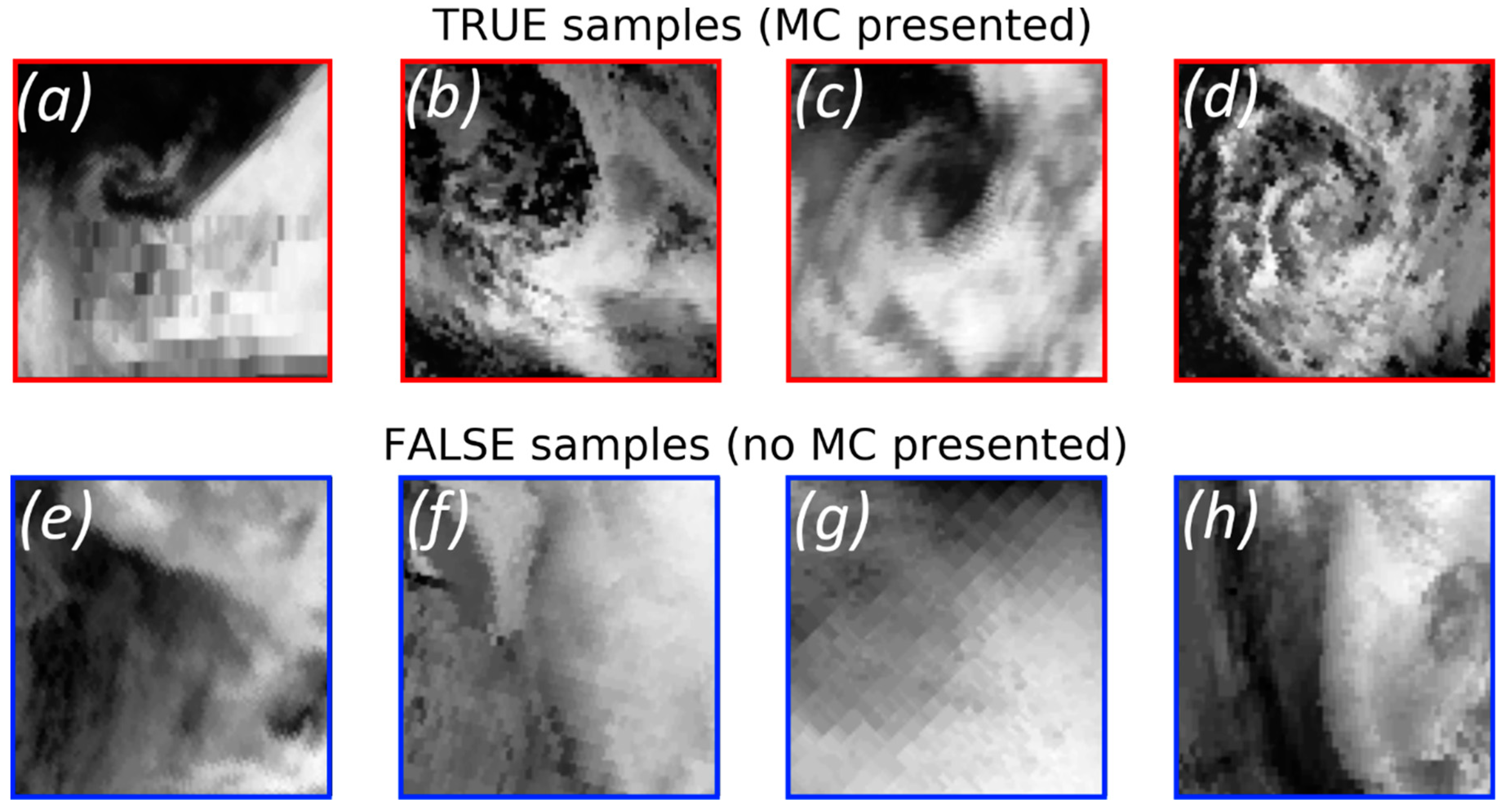
Figure 5 demonstrates four main types of false classified objects. The first and the second types are the ones for which IR data are missing completely or partially. The third type is the one for which the source satellite data were suspected to be corrupted. These three types of classifier errors originating from the lack of source data or the corruption of source data. For the fourth type, the source satellite data were realistic but the classifier has made a mistake. Thus, some of false classifications are model mistakes, and some are associated with the labeling issue where human expert could guess on the MC propagation over the area with missing or corrupted satellite data.
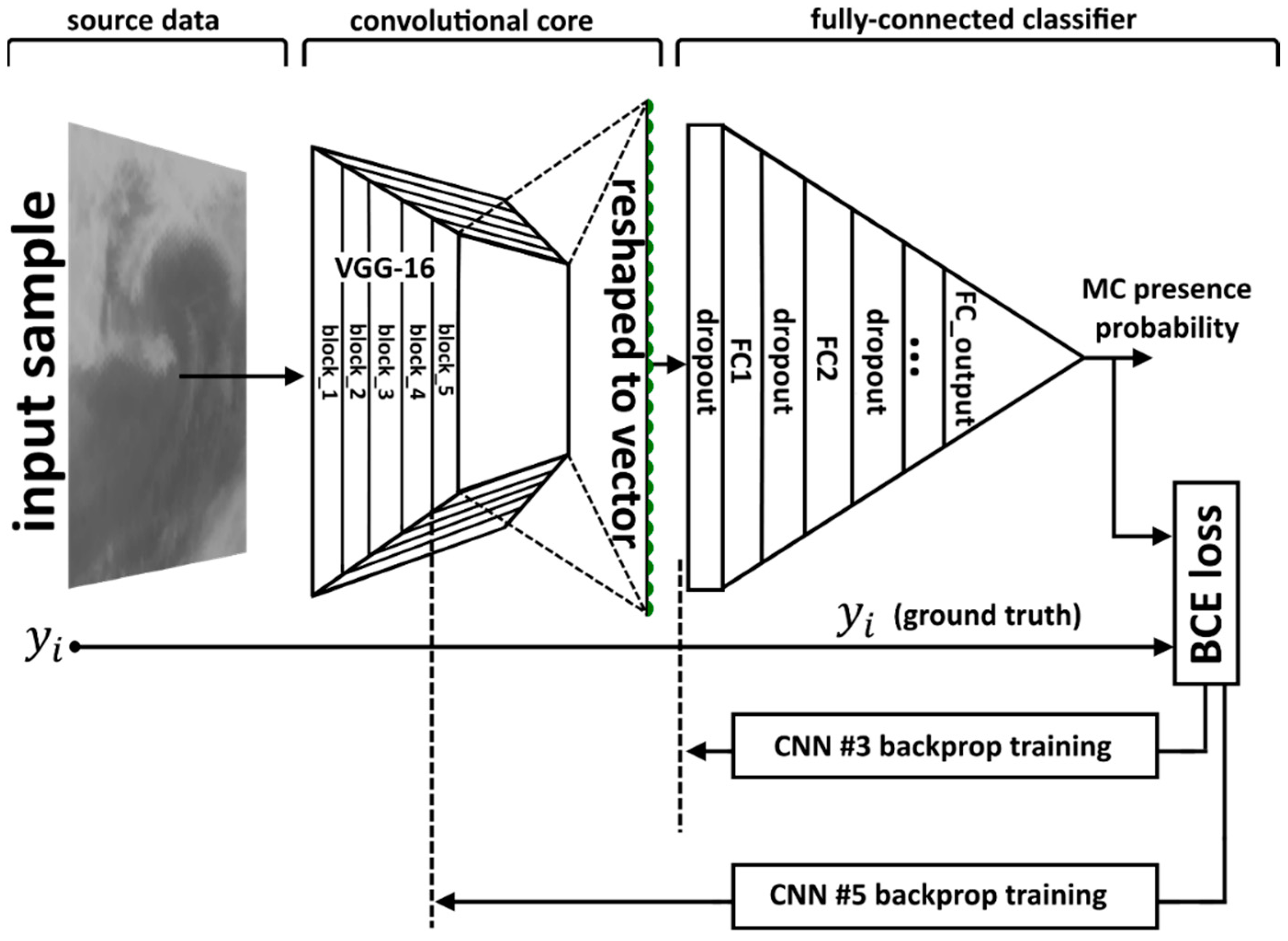
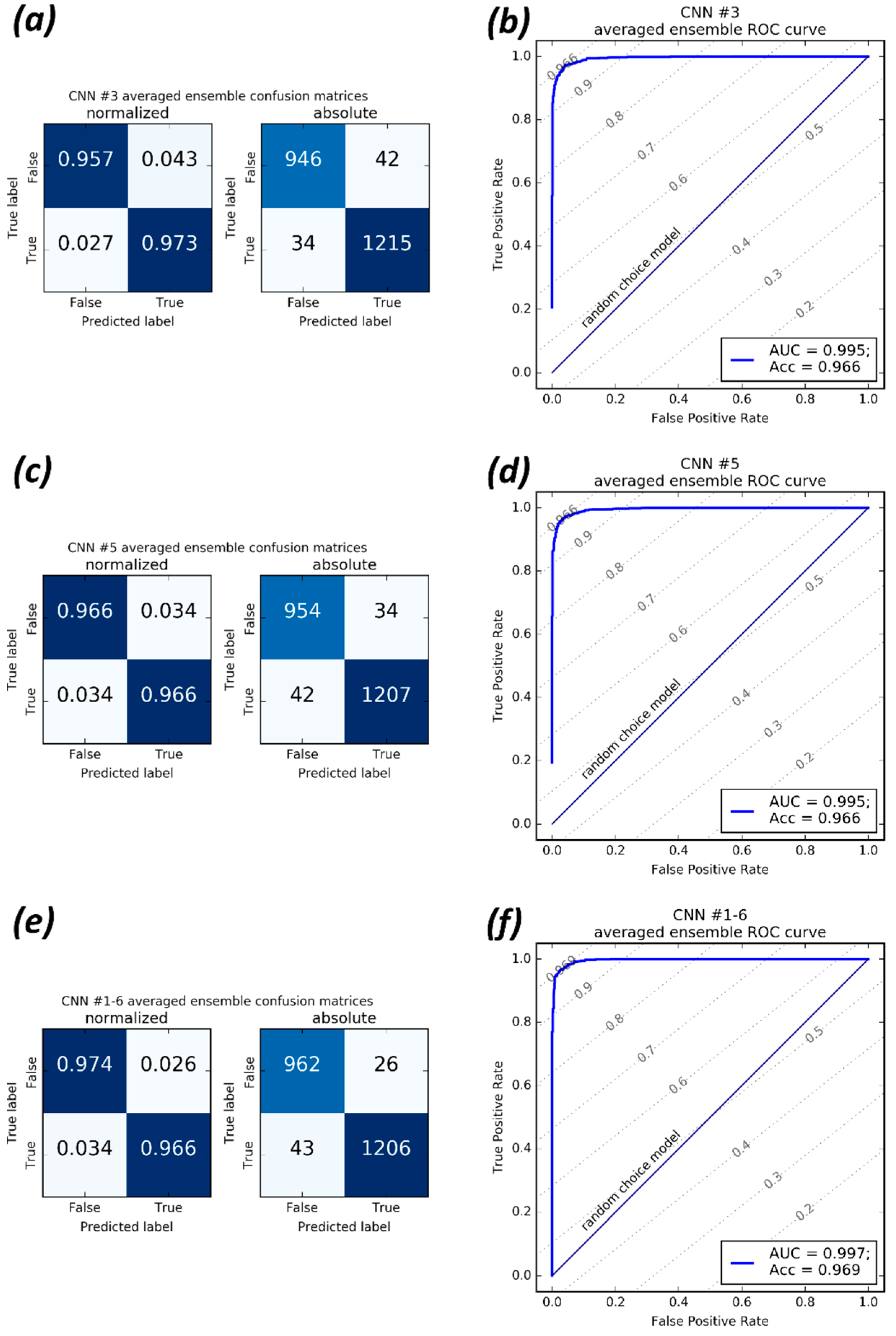
As shown in
Table 2, CNN #3 and CNN #5 demonstrated the best accuracy among the second-order models on a never-seen subset of objects. The best combination of hyper-parameters for these networks is presented in
Appendix B. Confusion matrices and receiver operating characteristic (ROC) curves for these models are shown in
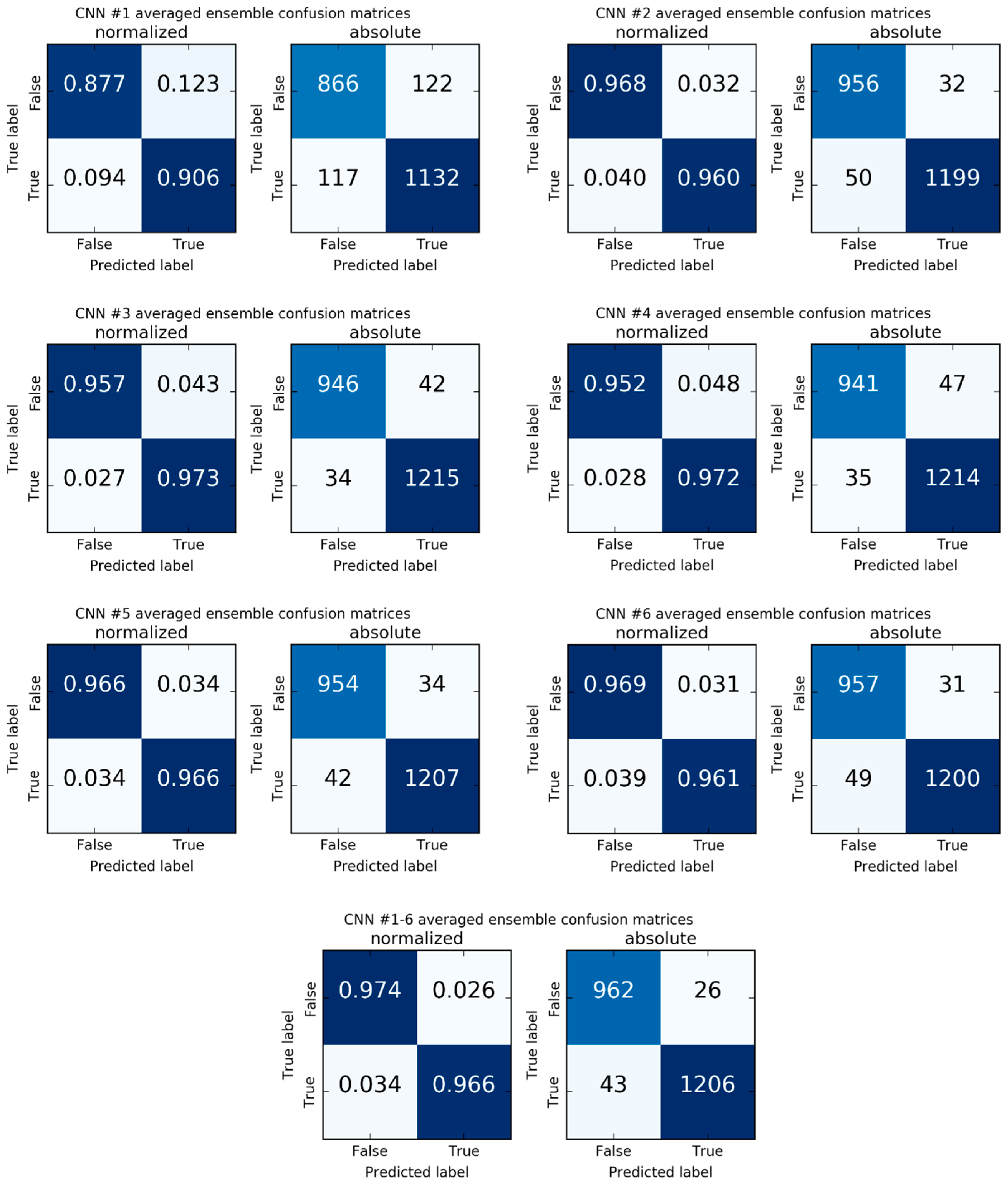
Figure 6a–d. Confusion matrices and ROC curves for all evaluated models are presented in
Appendix C.
Figure 6 clearly confirms that these two models perform almost equally for the true and the false samples. According to
Table 2, the best accuracy score is reached using different probability thresholds for each second- or third-order model.
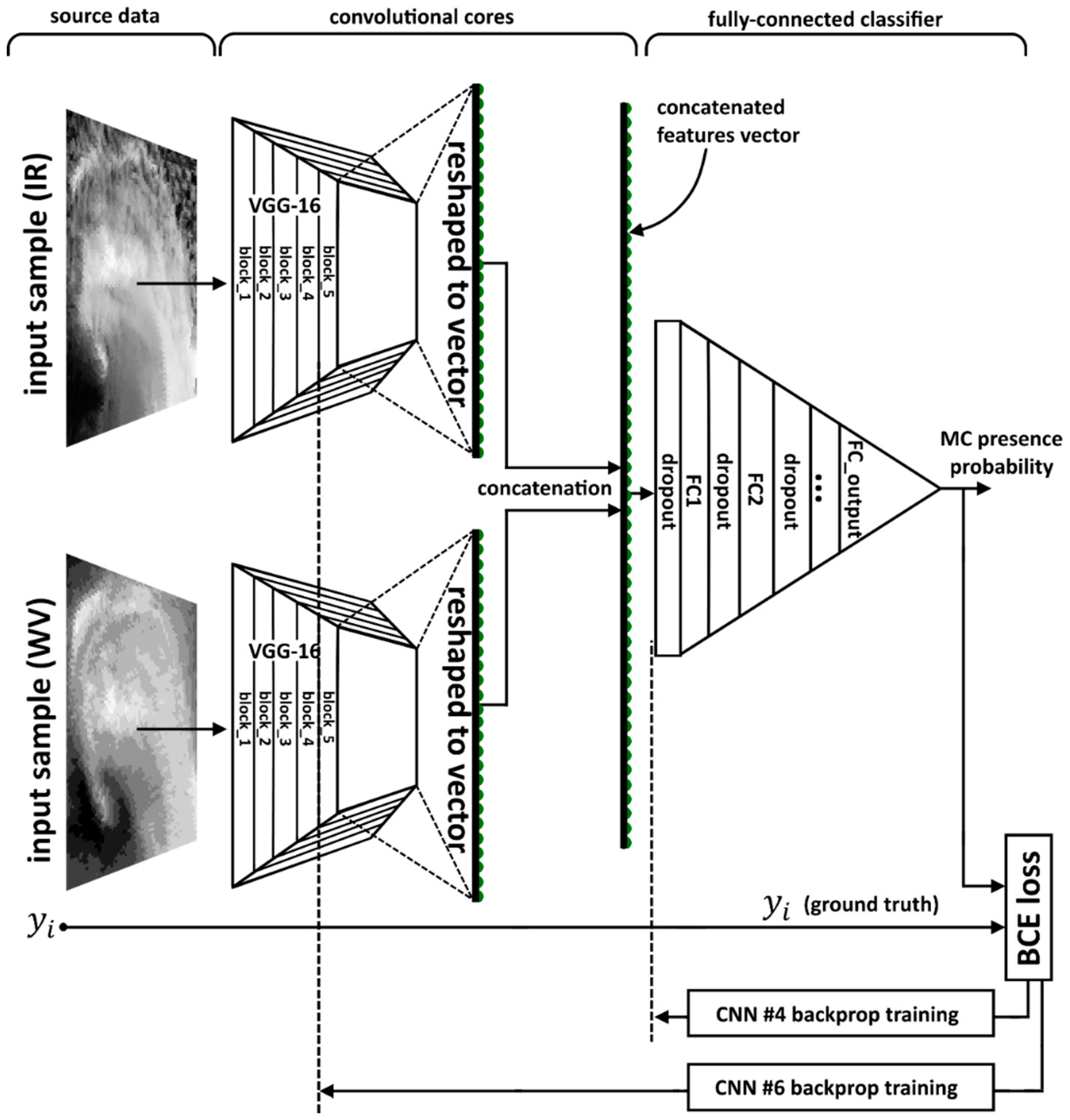
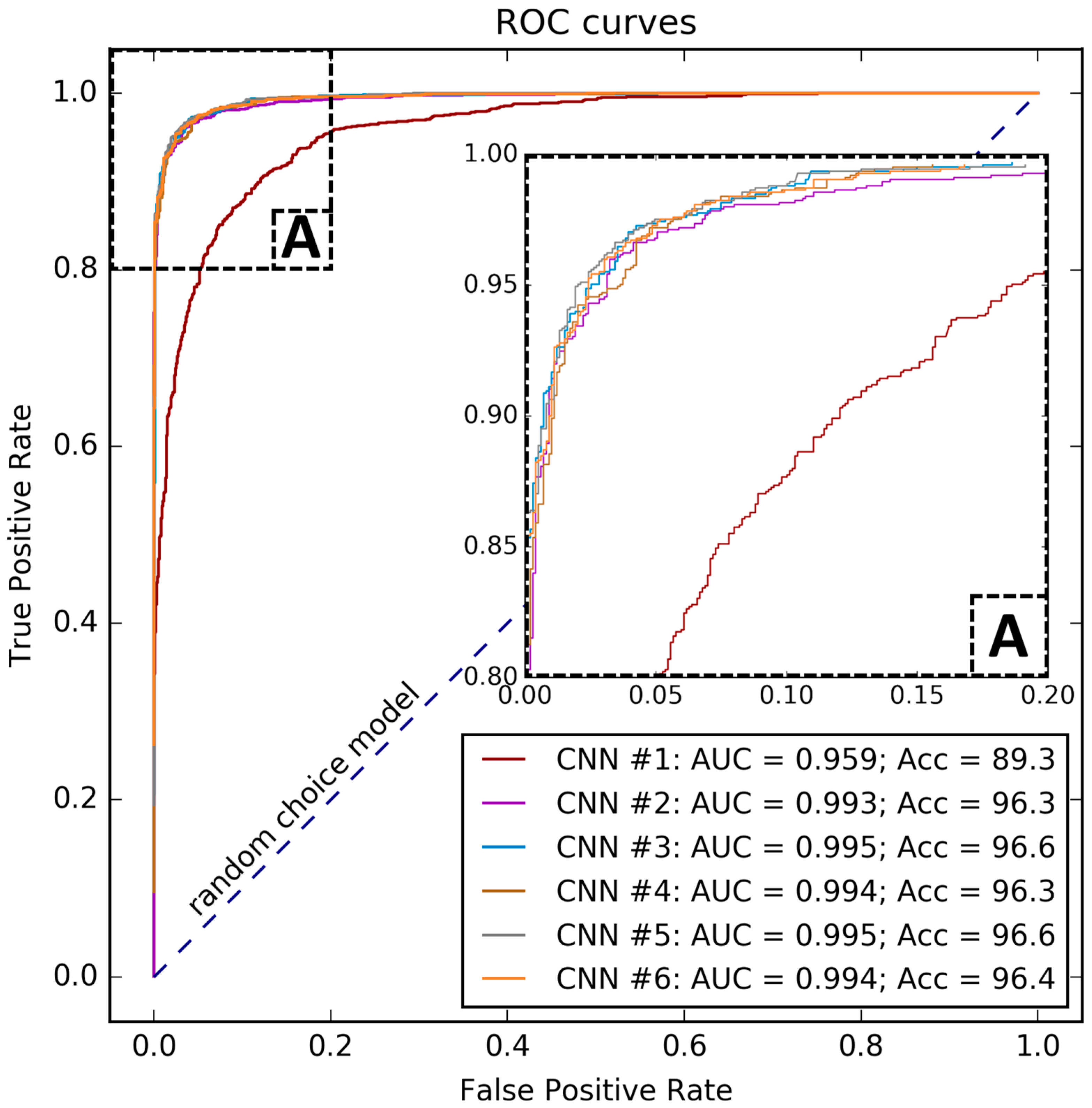
Comparison of CNN #1, CNN #2, on the one hand, and the remaining models, on the other hand, shows that DCNNs built with the use of TL technique demonstrate better performance when compared to the models built “from scratch”. Moreover, the accuracy score variances of CNN #1 and CNN #2 are higher than for the other architectures. Thus, models built with TL approach seem to be more stable, and their generalization ability is better, as compared to models built “from scratch”.
Comparing CNN #1 and CNN #2 qualities, we may conclude that the use of an additional data source (WV) results in the significant increase of the model accuracy score. Comparison of models within each pair of the network configurations (CNN #3 vs. CNN #5; CNN #4 vs. CNN #6) demonstrates that the FT approach does not provide significant improvement of the accuracy score in case of such a small size of the dataset. It is also obvious that the averaging over the ensemble members does increase the accuracy score from 0.6% for CNN #5 to 2.41% for CNN #1. However, in some cases, these score increases are comparable to the corresponding accuracy standard deviations.
It is also clear from the last row of
Table 2, that the third-order model, which averages probabilities that are estimated by all trained models CNN #1–6, produces the accuracy of
which outperforms all scores of individual models and second-order ensemble models. ROC curve and confusion matrices for this model are presented in
Figure 6e,f.
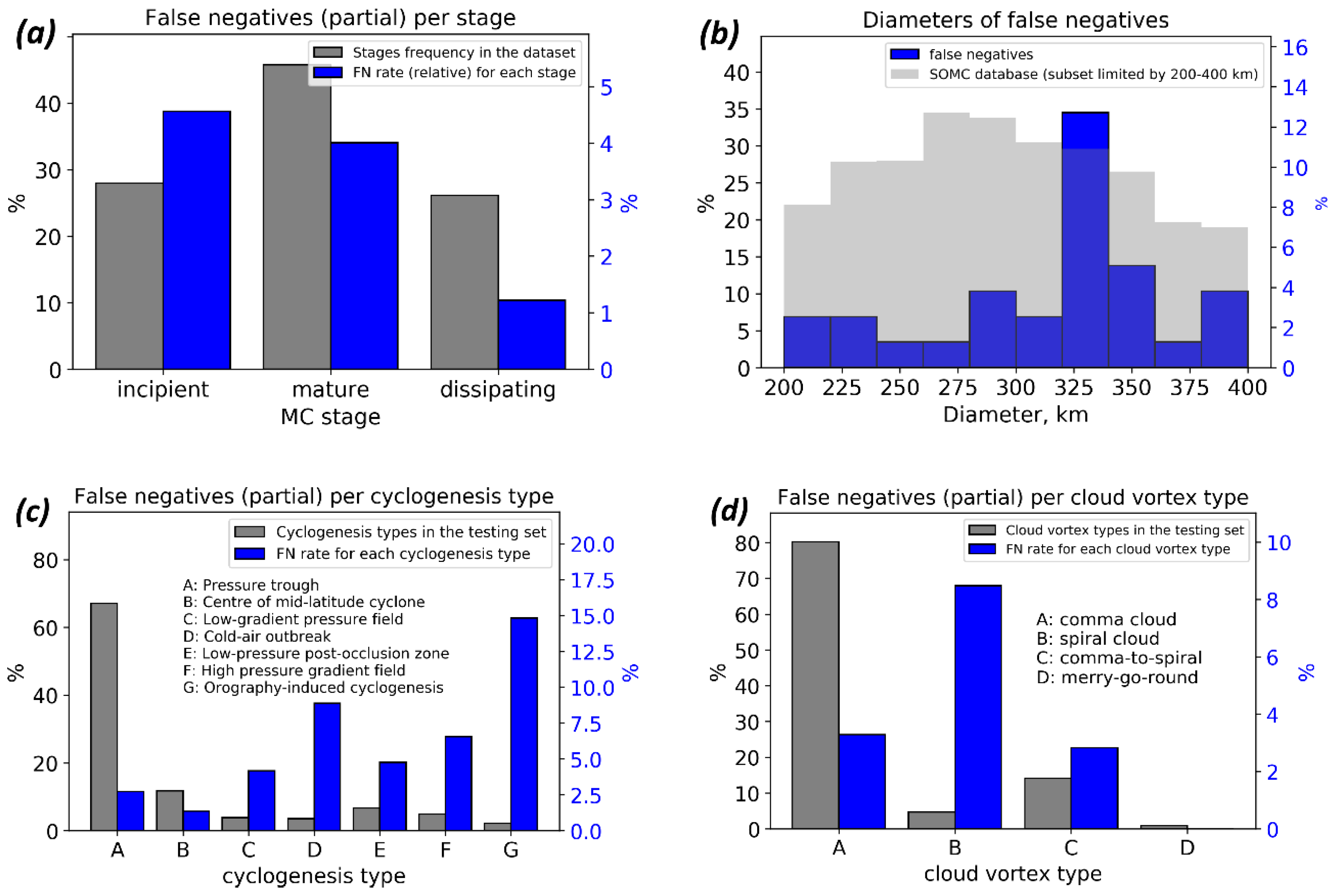
Figure 7 demonstrates the characteristics of the best model (third-order ensemble-averaging model) regarding false negatives (FN). Since the testing set is unbalanced with respect to stages, types of cyclogenesis and cloud vortex types, which we present in
Figure 7a,c,d relative FN rates for each separate class in each taxonomy. We present the testing set distribution of classes for these taxonomies as well. Note that scales are different for reference distributions of classes of the testing set and the distributions of missed MCs. Detailed false negatives characteristics may be found in
Appendix D.
Tracking procedure requires the sustainable ability of the MCs detection scheme to recognize mesocyclone cloud shape imprints during the whole MC life cycle.
Figure 7a demonstrates that the best model classifies mesocyclone imprints almost equally for incipient (~4.6% incipient missed) and mature (~4% mature missed) stages. The fraction of missed MCs in its dissipating stage is lower (~4% missed among MCs in dissipating stage). As for distribution of missed MCs with respect to their diameters (see
Figure 7b), the histogram demonstrates fractions of FN objects relative to the whole FN number. The distribution of MC diameters in the testing set in
Figure 7b is shown as a reference. There is a peak around the diameter value of 325 km, which does not coincide with any issues of distributions of MC diameters when the testing set is subset by any particular class of any taxonomy. However, since the total number of missed MCs is too small, there is no obvious reason to make assumptions on the origin of this issue. The FN rates per cyclogenesis types (
Figure 7c) demonstrate the only issue for the orography-induced MCs. This issue is caused by the total number of that cyclogenesis type, which is small (only 27 MCs in the testing set and only 134 in the training set), so the four that were missed is a substantial fraction of it. The same issue is demonstrated for the FN rates per cloud vortex types. Since the total number of “spiral cloud” type in the testing set is relatively small (59 of 1253), the five missed are a substantial fraction of it, as compared to 33 missed of 1006 for “comma cloud” type.
5. Conclusions and Outlook
In this study, we present an adaptation of a DCNN method resulting in an algorithm that recognizes MCs signatures in preselected patches of satellite imagery of cloudiness and spatially collocated WV imagery. The DCNN technique shows very high accuracy in this problem. The best accuracy score of 97% is reached using the third-order ensemble-averaging model (six models ensemble) and the combination of both IR and WV images as input. We assess the accuracy of MCs recognition by comparison of identified MCs (true/false—image contain MC/no MC on the image parameter) with a reference dataset [
5]. We demonstrate that deep convolutional networks are capable of effectively detecting the presence of polar mesocyclone signatures in satellite imagery patches of size 500 × 500 km. We also conclude that the quality of the satellite mosaics is sufficient enough for performing the task of binary classification regarding the MCs presence in 500 × 500 km patches, and for performing other similar tasks of pattern recognition type, e.g., semantic segmentation of MCs.
Since the satellite-based studies of polar mesocyclone activity conducted in the SH (and in NH as well) have never reported season-dependent variations of IR imprint of cloud shapes of MCs [
23,
27,
68,
69], we assume the proposed methodology to be applicable to satellite imageries of polar MCs that are available for the whole satellite observation era in SH. In the NH, the direct application of the models that were trained on SH dataset is restricted due to the opposite sign of relative vorticity, and thus, different cloud shape orientation. However the proposed approach is still applicable, and the only need is a dataset of tracks of MCs from the NH.
It was also shown that the accuracy of MCs detection by DCNNs is sensitive to the single (IR only) or double (IR + WV) input data usage. IR+WV combination provides significant improvement of the detection of MCs and allows a weak DCNN (CNN #2) to detect MCs with higher accuracy compared to the weak CNN #1 (89.3% and 96.3% correspondingly). The computational cost of DCNN training and hyper-parameters optimization for deep neural networks are time- and computational-consuming. However, once trained, the computational cost of the DCNN inference is low. Furthermore, the trained DCNN performs much faster when compared to a human expert. Another advantage of the proposed method is the low computational cost of data preprocessing that allows the processing of satellite imagery in real time or the processing of large amounts of collected satellite data.
We plan to extend the usage of this set of DCNNs (
Table 2) for the development of an MCs tracking method based on machine learning and using satellite IR and WV mosaics. These efforts would be mainly focused on the development of the optimal choice of the “cut-off” window that has to be applied to the satellite mosaic. In the case of a sliding-window approach (e.g., running the 500 × 500 km sliding window through the mosaics), the virtual testing dataset of the whole mosaic is highly unbalanced, so a model with non-zero FPR evaluated on balanced dataset would produce much higher FPR. Thus, we expect the sliding-window approach not to be accurate enough in the problem of MC detection. In the future, instead of the sliding-window, the Unet-like [
70,
71] architecture should be considered with the binary semantic segmentation problem formulation. Since the models that have been applied in this study (specifically their convolutional cores) are capable of extracting the hidden representation that is relevant to MCs signatures, they may be used as the encoder part of the Unet-like encoder-decoder neural network for MCs identification and tracking. Considering MC tracking development, an approach proposed in a number of face recognition studies should be reassuring [
72,
73]. This approach can be applied in a manner of triple-based training of the DCNN to estimate a measure of similarity between one particular MC signatures in consecutive satellite mosaics.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








