

Atmospheric Modeling for Wildfire Prediction


Abstract
1. Introduction
- A comparative evaluation of one-class classification algorithms and two-class models is conducted to determine their suitability for predicting wildfire risk using two fire incidence datasets.
- Shapley values [8] are used to interpret feature importance within one-class ML models, providing explainability and insights into the factors influencing wildfire predictions.
- A novel architecture for a web-based wildfire prediction tool is proposed, operationalizing the best-performing one-class ML model via a REST API.
2. Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| One-Class Model Type | Description | Key Strengths | Limitations | Citations | Performance |
|---|---|---|---|---|---|
| Density based | Uses data density estimation with thresholds to distinguish data. Works well with large datasets. Common algorithms: Gaussian and Parzen models. | Effective with large datasets | Requires a large number of training samples | [25] | Effective for large datasets; accuracy depends on density estimation quality. |
| Boundary based | Defines a boundary using inliers; outliers fall outside the boundary. Works well with smaller datasets. Common algorithms: one-class SVM, Support Vector Data Description. | Works well with smaller datasets | Difficult to optimize boundaries | [26] | Performs well on smaller datasets; sensitive to boundary optimization. |
| Reconstruction based | Uses historical data to categorize outliers based on reconstruction error. Common algorithms: k-means, PCA, Autoencoder, Multi-layer Perceptron. | Utilizes historical data for anomaly detection | High training time for neural network-based approaches | [27,28,29,30] | High performance in learning training data; long training time. |
| Ensemble based | Uses ensemble learning techniques to improve classification performance. Common algorithms: one-class Random Forest, Isolation Forest. | Enhances classification performance with artificial outlier generation | Complex model structure | [16,25,31] | Improves classification accuracy; suitable for artificial outlier detection. |
| Clustering based | Reduces processing time by clustering feature space. Not tested due to limited data events. | Reduces processing time | Limited applicability with small datasets | [32] | Fast processing; performance depends on clustering quality and dataset size. |
3. Methodology
4. Case Studies
5. Results
5.1. One-Class Machine Learning Model Results
5.2. Two-Class Machine Learning Model Results
5.3. Feature Importance Derived Using Shapley Values
6. Deployment of Machine Learning Models
- The Open Topo Data API, a freely accessible service providing elevation data for any given latitude and longitude.
- The OpenWeather API, which offers past, present, and forecasted weather conditions globally through REST API calls.
- The USGS Earth Explorer platform, which supplies LFMC data through vegetation indices formatted for all Californian locations based on a MODIS grid.
- The selection of historical wildfire events for model training and validate outputs. Users can also modify input parameters and analyze key contributing factors to wildfire risk as identified by the ML models.
- The ability to choose any location in California or Western Australia via an interactive map, manually input feature values, and generate wildfire risk probabilities.
- The retrieval of all predictive feature values for a seven-day period.
- The visualization of historical wildfire heatmaps based on training and testing datasets used in the ML model.
7. Web-Based Prototype Evaluation
8. Threats to Validity and Limitations
9. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine Learning; |
| API | Application Programming Interface; |
| AI | Artificial Intelligence; |
| SVM | Support Vector Machine; |
| IF | Isolation Forest; |
| AE | AutoEncoder; |
| VAE | Variational AutoEncoder; |
| DeepSVD | Deep Support Vector Data Description; |
| ALAD | Adversarially Learned Anomaly Detection; |
| CV | Cross-Validation; |
| OCSVM | One Class Support Vector Machine; |
| ANN | Artificial Neural Networks; |
| NOAA | National Oceanic and Atmospheric Administration; |
| MODIS | Moderate Resolution Imaging Spectroradiometer; |
| LFMC | Live Fuel Moisture Content; |
| GCP | Google Cloud Platform; |
| NZD | New Zealand Dollars; |
| LLM | Large Language Model. |
References
- Jain, P.; Coogan, S.C.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. Environ. Rev. 2020, 28, 478–505. [Google Scholar] [CrossRef]
- European Centre for Medium-Range Weather Forecasts. 2024 Was the Warmest Year on Record, Copernicus Data Show. Available online: https://www.ecmwf.int/en/about/media-centre/news/2025/2024-was-warmest-year-record-copernicus-data-show (accessed on 20 January 2025).
- Miller, C.; Hilton, J.; Sullivan, A.; Prakash, M. SPARK—A Bushfire Spread Prediction Tool. In Environmental Software Systems. Infrastructures, Services and Applications; Denzer, R., Argent, R.M., Schimak, G., Hřebíček, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 262–271. [Google Scholar] [CrossRef]
- Bowman, D.M.J.S.; Williamson, G.J.; Price, O.F.; Ndalila, M.N.; Bradstock, R.A. Australian forests, megafires and the risk of dwindling carbon stocks. Plant Cell Environ. 2021, 44, 347–355. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Khan, S.S.; Madden, M.G. One-Class Classification: Taxonomy of Study and Review of Techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef]
- Nguyen, P.T.; Nguyen, T.T.; Nguyen, N.C.; Le, T.T. Multiclass breast cancer classification using convolutional neural network. In Proceedings of the 2019 International Symposium on Electrical and Electronics Engineering (ISEE), Ho Chi Minh City, Vietnam, 10–12 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 130–134. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Tyukavina, A.; Potapov, P.; Hansen, M.C.; Pickens, A.H.; Stehman, S.V.; Turubanova, S.; Parker, D.; Zalles, V.; Lima, A.; Kommareddy, I.; et al. Global Trends of Forest Loss Due to Fire from 2001 to 2019. Front. Remote Sens. 2022, 3, 825190. [Google Scholar] [CrossRef]
- Ismail, F.N. Novel Machine Learning Approaches for Wildfire Prediction to Overcome the Drawbacks of Equation-Based Forecasting. Ph.D. Thesis, University of Otago, Dunedin, New Zealand, 2022. [Google Scholar]
- Ismail, F.N.; Sengupta, A.; Woodford, B.J.; Licorish, S.A. A Comparison of One-Class Versus Two-Class Machine Learning Models for Wildfire Prediction in California. In Proceedings of the Australasian Conference on Data Science and Machine Learning—AusDM 2023, Auckland, New Zealand, 11–13 December 2023; pp. 239–253. [Google Scholar]
- Ismail, F.N.; Woodford, B.J.; Licorish, S.A.; Miller, A.D. An assessment of existing wildfire danger indices in comparison to one-class machine learning models. Nat. Hazards 2024, 120, 14837–14868. [Google Scholar] [CrossRef]
- Ismail, F.N.; Amarasoma, S. One-class Classification-Based Machine Learning Model for Estimating the Probability of Wildfire Risk. Procedia Comput. Sci. 2023, 222, 341–352. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support vector domain description. Pattern Recognit. Lett. 1999, 20, 1191–1199. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Piscataway, NJ, USA, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Alkhatib, R.; Sahwan, W.; Alkhatieb, A.; Schütt, B. A Brief Review of Machine Learning Algorithms in Forest Fires Science. Appl. Sci. 2023, 13, 8275. [Google Scholar] [CrossRef]
- Ntinopoulos, N.; Sakellariou, S.; Christopoulou, O.; Sfougaris, A. Fusion of Remotely-Sensed Fire-Related Indices for Wildfire Prediction through the Contribution of Artificial Intelligence. Sustainability 2023, 15, 11527. [Google Scholar] [CrossRef]
- Patterson, J.; Gibson, A. Deep Learning: A Practitioner’s Approach; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4393–4402. [Google Scholar]
- Kim, S.; Choi, Y.; Lee, M. Deep learning with support vector data description. Neurocomputing 2015, 165, 111–117. [Google Scholar] [CrossRef]
- Zenati, H.; Romain, M.; Foo, C.S.; Lecouat, B.; Chandrasekhar, V. Adversarially learned anomaly detection. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; IEEE Press: Piscataway, NJ, USA, 2018; pp. 727–736. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Seliya, N.; Zadeh, A.A.; Khoshgoftaar, T.M. A literature review on one-class classification and its potential applications in big data. J. Big Data 2021, 8, 1–31. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Cary, NC, USA, 1995. [Google Scholar]
- Jiang, M.F.; Tseng, S.; Su, C. Two-phase clustering process for outliers detection. Pattern Recognit. Lett. 2001, 22, 691–700. [Google Scholar] [CrossRef]
- Salekshahrezaee, Z.; Leevy, J.L.; Khoshgoftaar, T.M. A reconstruction error-based framework for label noise detection. J. Big Data 2021, 8, 1–16. [Google Scholar] [CrossRef]
- Japkowicz, N.; Myers, C.; Gluck, M. A novelty detection approach to classification. In IJCAI; Citeseer: Princeton, NJ, USA, 1995; Volume 1, pp. 518–523. [Google Scholar]
- Désir, C.; Bernard, S.; Petitjean, C.; Heutte, L. One class random forests. Pattern Recognit. 2013, 46, 3490–3506. [Google Scholar] [CrossRef]
- Krawczyk, B.; Wozniak, M.; Cyganek, B. Clustering-based ensembles for one-class classification. Inf. Sci. 2013, 264, 182–195. [Google Scholar] [CrossRef]
- Bergstra, J.; Yamins, D.; Cox, D.D. Making a Science of Model Search: Hyperparameter Optimization in Hundreds of Dimensions for Vision Architectures. In Proceedings of the 30th International Conference on International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 28, pp. I-115–I-123. [Google Scholar]
- Abdollahi, A.; Pradhan, B. Explainable artificial intelligence (XAI) for interpreting the contributing factors feed into the wildfire susceptibility prediction model. Sci. Total Environ. 2023, 879, 163004. [Google Scholar] [CrossRef]
- Tonini, M.; D’Andrea, M.; Biondi, G.; Degli Esposti, S.; Trucchia, A.; Fiorucci, P. A Machine Learning-Based Approach for Wildfire Susceptibility Mapping. The Case Study of the Liguria Region in Italy. Geosciences 2020, 10, 105. [Google Scholar] [CrossRef]
- Jaafari, A.; Pourghasemi, H.R. 28—Factors Influencing Regional-Scale Wildfire Probability in Iran: An Application of Random Forest and Support Vector Machine. In Spatial Modeling in GIS and R for Earth and Environmental Sciences; Pourghasemi, H.R., Gokceoglu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; pp. 607–619. [Google Scholar] [CrossRef]
- Donovan, G.H.; Prestemon, J.P.; Gebert, K. The Effect of Newspaper Coverage and Political Pressure on Wildfire Suppression Costs. Soc. Nat. Resour. 2011, 24, 785–798. [Google Scholar] [CrossRef]
- Jiménez-Ruano, A.; Mimbrero, M.R.; de la Riva Fernández, J. Understanding wildfires in mainland Spain. A comprehensive analysis of fire regime features in a climate-human context. Appl. Geogr. 2017, 89, 100–111. [Google Scholar] [CrossRef]
- Papadopoulos, A.; Paschalidou, A.; Kassomenos, P.; McGregor, G. On the association between synoptic circulation and wildfires in the Eastern Mediterranean. Theor. Appl. Climatol. 2014, 115, 483–501. [Google Scholar] [CrossRef]
- Nunes, A.; Lourenço, L.; Meira Castro, A.C. Exploring spatial patterns and drivers of forest fires in Portugal (1980–2014). Sci. Total Environ. 2016, 573, 1190–1202. [Google Scholar] [CrossRef]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer Series in Statistics; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- Tadić, J.M.; Ilić, V.; Biraud, S. Examination of geostatistical and machine-learning techniques as interpolators in anisotropic atmospheric environments. Atmos. Environ. 2015, 111, 28–38. [Google Scholar] [CrossRef]
- Tien Bui, D.; Bui, Q.T.; Nguyen, Q.P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Nhu, V.H.; Shirzadi, A.; Shahabi, H.; Singh, S.K.; Al-Ansari, N.; Clague, J.J.; Jaafari, A.; Chen, W.; Miraki, S.; Dou, J.; et al. Shallow Landslide Susceptibility Mapping: A Comparison between Logistic Model Tree, Logistic Regression, Naïve Bayes Tree, Artificial Neural Network, and Support Vector Machine Algorithms. Int. J. Environ. Res. Public Health 2020, 17, 2749. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Valizadeh Kamran, K.; Blaschke, T.; Aryal, J.; Naboureh, A.; Einali, J.; Bian, J. Spatial Prediction of Wildfire Susceptibility Using Field Survey GPS Data and Machine Learning Approaches. Fire 2019, 2, 43. [Google Scholar] [CrossRef]
- Michael, Y.; Helman, D.; Glickman, O.; Gabay, D.; Brenner, S.; Lensky, I.M. Forecasting fire risk with machine learning and dynamic information derived from satellite vegetation index time-series. Sci. Total Environ. 2021, 764, 142844. [Google Scholar] [CrossRef] [PubMed]
- Goldarag, Y.; Mohammadzadeh, A.; Ardakani, A. Fire Risk Assessment Using Neural Network and Logistic Regression. J. Indian Soc. Remote Sens. 2016, 44, 1–10. [Google Scholar] [CrossRef]
- de Bem, P.; de Carvalho Júnior, O.; Matricardi, E.; Guimarães, R.; Gomes, R. Predicting wildfire vulnerability using logistic regression and artificial neural networks: A case study in Brazil. Int. J. Wildland Fire 2018, 28, 35–45. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.; Jiang, F.; Gan, V.; Wang, M.; Zhai, C. Real-time detection of wildfire risk caused by powerline vegetation faults using advanced machine learning techniques. Adv. Eng. Inform. 2020, 44, 101070. [Google Scholar] [CrossRef]
- Jolly, W.M.; Freeborn, P.H.; Page, W.G.; Butler, B.W. Severe Fire Danger Index: A Forecastable Metric to Inform Firefighter and Community Wildfire Risk Management. Fire 2019, 2, 47. [Google Scholar] [CrossRef]
- National Interagency Fire Center; National Wildfire Coordinating Group (NWCG). Interagency Standards for Fire and Fire Aviation Operations; Createspace Independent Publishing Platform, Great Basin Cache Supply Office: Boise, ID, USA, 2019.
- Sullivan, A.L. Physical Modelling of Wildland Fires. In Encyclopedia of Wildfires and Wildland-Urban Interface (WUI) Fires; Springer International Publishing: Cham, Switzerlands, 2019; pp. 1–8. ISBN 978-3-319-51727-8. [Google Scholar] [CrossRef]
- Taylor, S.W.; Woolford, D.G.; Dean, C.B.; Martell, D.L. Wildfire Prediction to Inform Fire Management: Statistical Science Challenges. Stat. Sci. 2013, 28, 586–615. [Google Scholar] [CrossRef]
- Watanabe, S.; Bansal, A.; Hutter, F. PED-ANOVA: Efficiently Quantifying Hyperparameter Importance in Arbitrary Subspaces. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, Macao, China, 19–25 August 2023; pp. 4389–4396. [Google Scholar] [CrossRef]

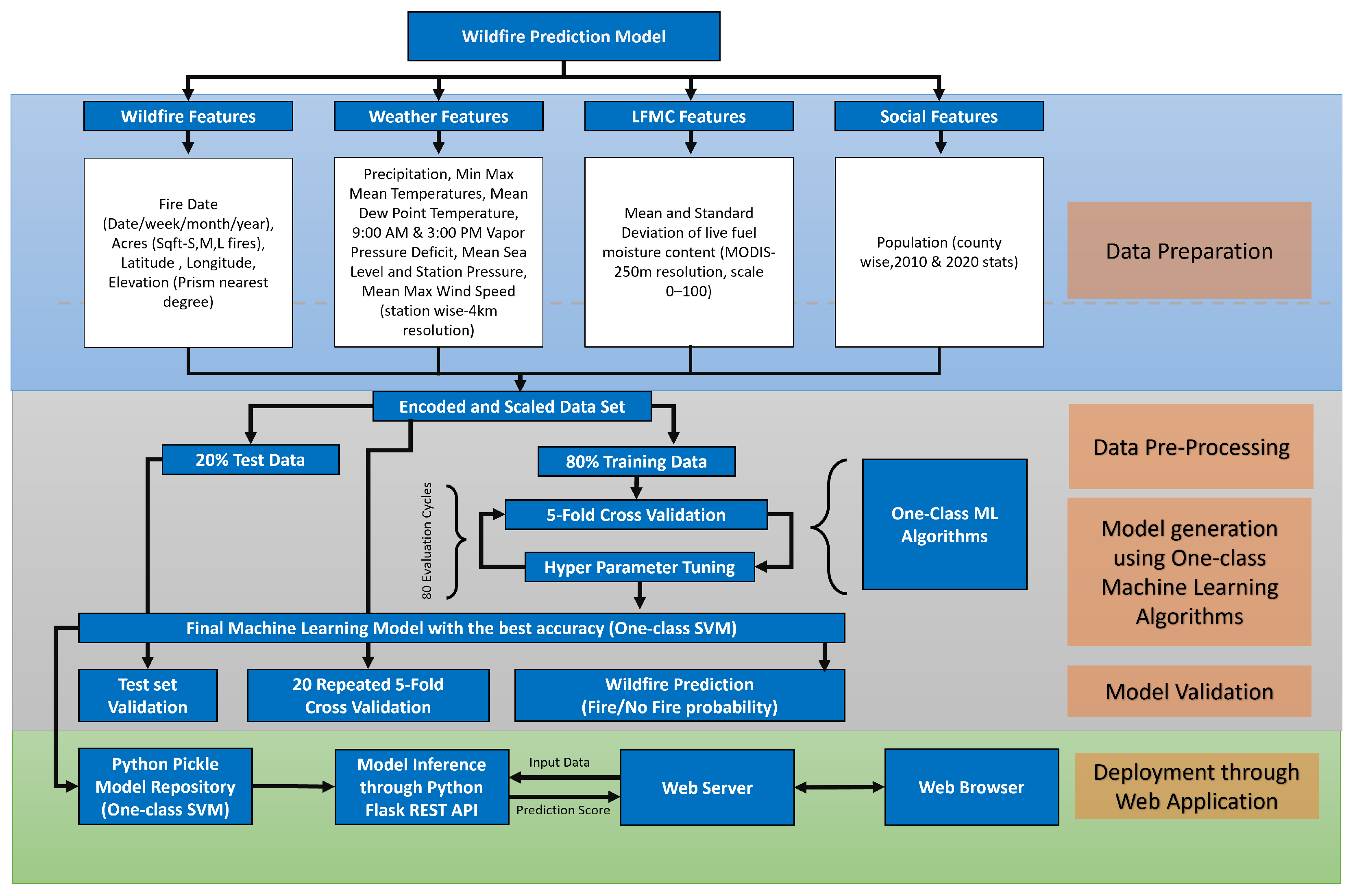
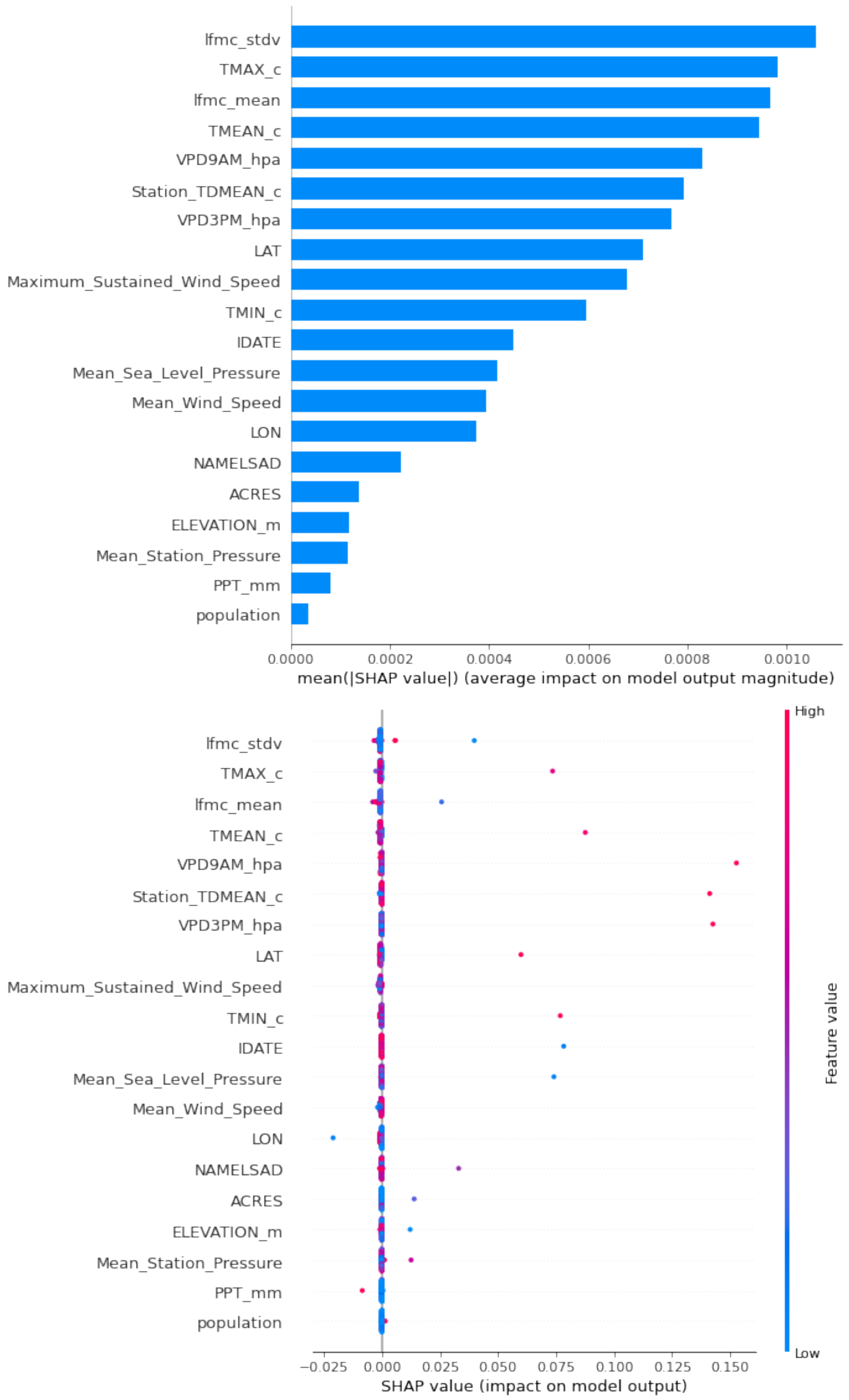
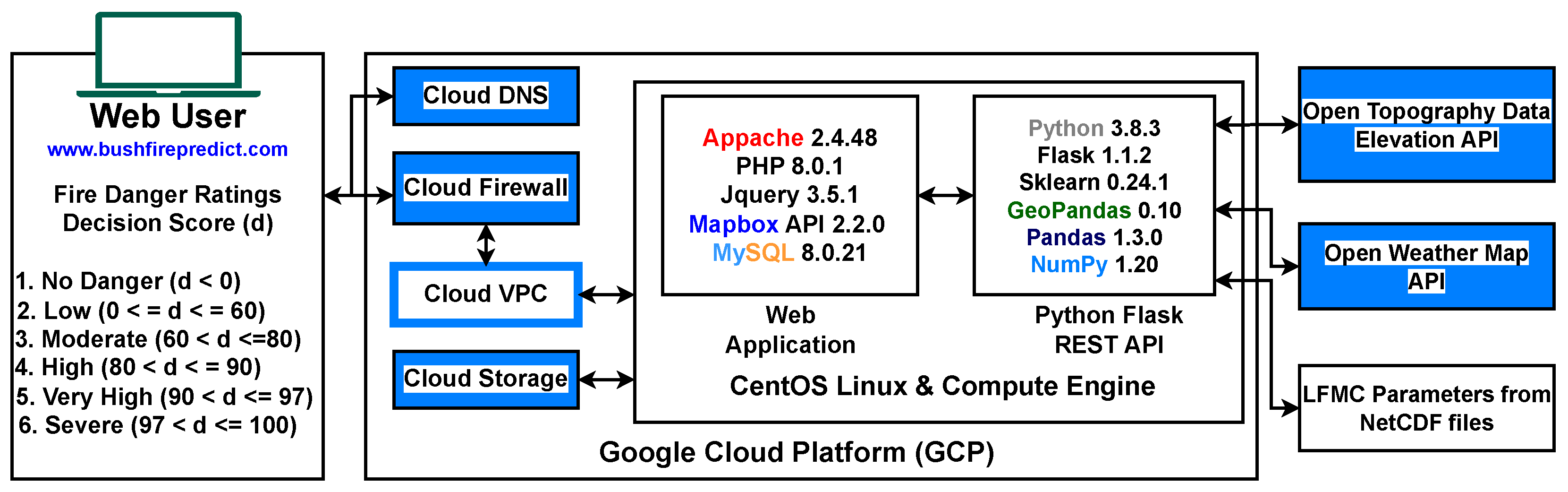

| No. | Feature | Description | Prior Research |
|---|---|---|---|
| 1 | IDATE | Fire occurrence date (month and date as an integer) | [34] |
| 2 | LAT | Fire location latitude (degrees) | [34,35,36] |
| 3 | LON | Fire location longitude (degrees) | [34,35,36] |
| 4 | ELEVATION_m | Fire location elevation (in meters) | [34,36,37] |
| 5 | ACRES | Acres burnt (in acres) | |
| 6 | PPT_mm | Precipitation (in mm for the fire incident date) | [34,36,38] |
| 7 | TMIN_c | Minimum temperature (in Celsius for the fire incident date) | [36,38] |
| 8 | TMEAN_c | Mean temperature (in Celsius for the fire incident date) | [36,38] |
| 9 | TMAX_c | Maximum temperature (in Celsius for the fire incident date) | [34,36,38] |
| 10 | TDMEAN_c | Mean dew point temperature (in Celsius for the fire incident date) | [36,38] |
| 11 | VPDMIN_hpa | Minimum vapor pressure (in hectopascals) | [37] |
| 12 | VPDMAX_hpa | Maximum vapor pressure (in hectopascals) | [37] |
| 13 | lfmc_mean | Mean fuel moisture for a particular day (numeric) | [36] |
| 14 | lfmc_stdv | Standard deviation of fuel moisture for a particular day (numeric) | [36] |
| 15 | Mean_Sea_Level _Pressure | Mean sea level pressure of the nearest weather station to the wildfire event (in hectopascals)—(Universal Kriging) | [39] |
| 16 | Mean_Station _Pressure | Nearest mean weather station pressure to the wildfire event (in hectopascasl)—(Universal Kriging) | [39] |
| 17 | Mean_Wind_Speed | Mean wind speed for a given location (numeric mph)—(Universal Kriging) | [34,36,37] |
| 18 | Maximum_Sustained _Wind_Speed | Maximum sustained wind speed for a given location (numeric MPH)—(Universal Kriging) | [36,37] |
| 19 | NAMELSAD | County name (string) | [38] |
| 20 | Population | Number of residents living in the respective county (numeric) | [38,40] |
| No. | Feature | Description | Prior Research |
|---|---|---|---|
| 1 | IDATE | Fire occurrence date (month and date as an integer) | [34] |
| 2 | LAT | Fire location latitude (degrees) | [34,35,36] |
| 3 | LON | Fire location longitude (degrees) | [34,35,36] |
| 4 | ELEVATION_m | Fire location elevation (in meters) | [34,36,37] |
| 5 | ACRES | Acres burnt (in acres) | |
| 6 | PPT_mm | Precipitation (in mm for the fire incident date) | [34,36,38] |
| 7 | TMIN_c | Minimum temperature (in Celsius for the fire incident date) | [36,38] |
| 8 | TMEAN_c | Mean temperature (in Celsius for the fire incident date) | [36,38] |
| 9 | TMAX_c | Maximum temperature (in Celsius for the fire incident date) | [34,36,38] |
| 10 | TDMEAN_c | Mean dew point temperature (in Celsius for the fire incident date) | [36,38] |
| 11 | VPD9AM_hpa | Vapor pressure at 9AM (in hectopascals) | [37] |
| 12 | VPD3PM_hpa | Vapor pressure at 3PM (in hectopascals) | [37] |
| 13 | lfmc_mean | Mean fuel moisture for a particular day (numeric) | [36] |
| 14 | lfmc_stdv | Standard deviation of fuel moisture for a particular day (numeric) | [36] |
| 15 | Mean_Sea_Level _Pressure | Mean sea level pressure of the nearest weather station to the wildfire event (in hectopascals)—(Universal Kriging) | [39] |
| 16 | Mean_Station _Pressure | Nearest mean weather station pressure to the wildfire event (in hectopascasl)—(Universal Kriging) | [39] |
| 17 | Mean_Wind_Speed | Mean wind speed for a given location (numeric mph)—(Universal Kriging) | [34,36,37] |
| 18 | Maximum_Sustained _Wind_Speed | Maximum sustained wind speed for a given location (numeric MPH)—(Universal Kriging) | [36,37] |
| 19 | NAMELSAD | County name (string) | [38] |
| 20 | Population | Number of residents living in the respective county (numeric) | [38,40] |
| ML Technique | Dataset Type | Dataset Count | Inliers | Outliers | Mean Accuracy | Mean Precision | Mean Recall | Mean F1-Score | 20 × Five-Fold CV |
|---|---|---|---|---|---|---|---|---|---|
| OCSVM (sklearn) | Train (80%) | 5868 | 5806 | 62 | 0.989 | 1.000 | 0.989 | 0.994 | 0.990 ± 0.0030 |
| Test (20%) | 1467 | 1443 | 24 | 0.983 | 1.000 | 0.983 | 0.991 | ||
| OCSVM (PyOD) | Train (80%) | 5868 | 5809 | 59 | 0.989 | 1.000 | 0.990 | 0.990 | 0.990 ± 0.0028 |
| Test (20%) | 1467 | 1458 | 9 | 0.993 | 1.000 | 0.990 | 1.000 | ||
| AE (PyOD) | Train (80%) | 5868 | 5809 | 59 | 0.989 | 1.000 | 0.990 | 0.990 | 0.989 ± 0.0030 |
| Test (20%) | 1467 | 1454 | 13 | 0.991 | 1.000 | 0.990 | 1.000 | ||
| VAE (PyOD) | Train (80%) | 5868 | 5809 | 59 | 0.989 | 1.000 | 0.990 | 0.990 | 0.989 ± 0.0028 |
| Test (20%) | 1467 | 1454 | 13 | 0.991 | 1.000 | 0.990 | 1.000 | ||
| IF (PyOD) | Train (80%) | 5868 | 5809 | 59 | 0.989 | 1.000 | 0.990 | 0.990 | 0.989 ± 0.0028 |
| Test (20%) | 1467 | 1458 | 9 | 0.993 | 1.000 | 0.990 | 1.000 | ||
| DeepSVDD (PyOD) | Train (80%) | 5868 | 5281 | 587 | 0.899 | 1.000 | 0.900 | 0.950 | 0.897 ± 0.0101 |
| Test (20%) | 1467 | 1316 | 151 | 0.897 | 1.000 | 0.900 | 0.950 | ||
| ALAD (PyOD) | Train (80%) | 5868 | 5281 | 587 | 0.899 | 1.000 | 0.900 | 0.950 | 0.900 ± 0.0081 |
| Test (20%) | 1467 | 1272 | 195 | 0.867 | 1.000 | 0.870 | 0.930 |
| ML Technique | Dataset Type | Dataset Count | Inliers | Outliers | Mean Accuracy | Mean Precision | Mean Recall | Mean F1-Score | 20 × Five-Fold CV |
|---|---|---|---|---|---|---|---|---|---|
| OCSVM (sklearn) | Train (80%) | 26,640 | 26,336 | 304 | 0.988 | 1.000 | 0.988 | 0.994 | 0.998 ± 0.0015 |
| Test (20%) | 6660 | 6580 | 80 | 0.987 | 1.000 | 0.987 | 0.993 | ||
| OCSVM (PyOD) | Train (80%) | 26,640 | 26,373 | 267 | 0.989 | 1.000 | 0.989 | 0.994 | 0.989 ± 0.0012 |
| Test (20%) | 6660 | 6652 | 8 | 0.998 | 1.000 | 0.998 | 0.999 | ||
| AE (PyOD) | Train (80%) | 26,640 | 26,373 | 267 | 0.989 | 1.000 | 0.989 | 0.994 | 0.989 ± 0.0012 |
| Test (20%) | 6660 | 6,611 | 49 | 0.992 | 1.000 | 0.992 | 0.996 | ||
| VAE (PyOD) | Train (80%) | 26,640 | 26,373 | 267 | 0.989 | 1.000 | 0.989 | 0.994 | 0.989 ± 0.0012 |
| Test (20%) | 6660 | 6611 | 49 | 0.992 | 1.000 | 0.992 | 0.996 | ||
| IF (PyOD) | Train (80%) | 26,640 | 26,378 | 262 | 0.990 | 1.000 | 0.990 | 0.995 | 0.989 ± 0.0015 |
| Test (20%) | 6660 | 6620 | 40 | 0.993 | 1.000 | 0.993 | 0.996 | ||
| DeepSVDD (PyOD) | Train (80%) | 26,640 | 23,976 | 2664 | 0.900 | 1.000 | 0.900 | 0.950 | 0.899 ± 0.0047 |
| Test (20%) | 6660 | 5865 | 795 | 0.880 | 1.000 | 0.880 | 0.940 | ||
| ALAD (PyOD) | Train (80%) | 26,640 | 23,976 | 2664 | 0.900 | 1.000 | 0.900 | 0.950 | 0.900 ± 0.0039 |
| Test (20%) | 6660 | 6379 | 281 | 0.957 | 1.000 | 0.960 | 0.980 |
| ML Technique | Dataset Type | Dataset Count | Mean Accuracy | Mean Precision | Mean Recall | Mean F1-Score | 20 × Five-Fold CV |
|---|---|---|---|---|---|---|---|
| SVM [36,45,46] | Train (80%) | 11,756 | 0.628 | 0.657 | 0.763 | 0.706 | 0.670 ± 0.0648 |
| Test (20%) | 2939 | 0.674 | 0.645 | 0.773 | 0.703 | ||
| RF [36,46,47] | Train (80%) | 11,756 | 0.679 | 0.664 | 0.724 | 0.693 | 0.677 ± 0.0713 |
| Test (20%) | 2939 | 0.670 | 0.639 | 0.779 | 0.703 | ||
| Logistic Regression [45,48,49] | Train (80%) | 11,756 | 0.676 | 0.651 | 0.756 | 0.697 | 0.676 ± 0.0743 |
| Test (20%) | 2939 | 0.676 | 0.651 | 0.756 | 0.699 | ||
| XGBoost Regression [47,50] | Train (80%) | 11,756 | 0.675 | 0.660 | 0.717 | 0.688 | 0.675 ± 0.0665 |
| Test (20%) | 2939 | 0.674 | 0.660 | 0.717 | 0.687 | ||
| ANN [45,46,48] | Train (80%) | 11,756 | 0.682 | 0.665 | 0.732 | 0.697 | 0.677 ± 0.0742 |
| Test (20%) | 2939 | 0.674 | 0.650 | 0.751 | 0.694 |
| No. | Feature | One-Class SVM (scikit-learn) | One-Class SVM (PyOD) | AutoEncoder (PyOD) | Variational AutoEncoder (PyOD) | Isolation Forest (PyOD) |
|---|---|---|---|---|---|---|
| 1 | IDATE | 6.36% | 9.85% | 1.84% | 1.84% | 10.26% |
| 2 | LAT | 6.37% | 5.90% | 0.64% | 0.51% | 2.17% |
| 3 | LON | 7.42% | 3.74% | 0.5% | 0.59% | 2.10% |
| 4 | ELEVATION_m | 12.39% | 0.28% | 0.57% | 0.41% | 3.23% |
| 5 | ACRES | 0.88% | 4.70% | 15.93% | 15.94% | 14.97% |
| 6 | PPT_mm | 5.47% | 7.13% | 45.24% | 45.40% | 3.28% |
| 7 | TMIN_c | 3.45% | 7.55% | 2.91% | 2.99% | 4.23% |
| 8 | TMEAN_c | 4.45% | 9.59% | 4.01% | 4.23% | 3.21% |
| 9 | TMAX_c | 6.32% | 11.30% | 3.64% | 3.86% | 10.13% |
| 10 | TDMEAN_c | 5.34% | 7.89% | 0.84% | 1.23% | 2.61% |
| 11 | VPDMIN_hpa | 6.77% | 0.81% | 2.12% | 2.10% | 3.86% |
| 12 | VPDMAX_hpa | 6.58% | 5.66% | 2.94% | 2.87% | 7.31% |
| 13 | lfmc_mean | 6.11% | 6.67% | 4.10% | 4.05% | 2.89% |
| 14 | lfmc_stdv | 6.44% | 4.70% | 3.20% | 2.69% | 1.69% |
| 15 | Mean_Sea_Level_Pressure | 3.62% | 7.86% | 1.02% | 0.81% | 4.91% |
| 16 | Mean_Station_Pressure | 4.27% | 3.32% | 0.27% | 0.28% | 2.80% |
| 17 | Mean_Wind_Speed | 2.33% | 1.56% | 3.00% | 2.80% | 3.07% |
| 18 | Maximum_Sustained_Wind_Speed | 2.15% | 0.91% | 3.16% | 3.44% | 4.07% |
| 19 | NAMELSAD | 1.45% | 0.05% | 0.29% | 0.14% | 1.96% |
| 20 | Population | 1.86% | 0.52% | 3.77% | 3.81% | 11.26% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ismail, F.N.; Woodford, B.J.; Licorish, S.A. Atmospheric Modeling for Wildfire Prediction. Atmosphere 2025, 16, 441. https://doi.org/10.3390/atmos16040441
Ismail FN, Woodford BJ, Licorish SA. Atmospheric Modeling for Wildfire Prediction. Atmosphere. 2025; 16(4):441. https://doi.org/10.3390/atmos16040441
Chicago/Turabian StyleIsmail, Fathima Nuzla, Brendon J. Woodford, and Sherlock A. Licorish. 2025. "Atmospheric Modeling for Wildfire Prediction" Atmosphere 16, no. 4: 441. https://doi.org/10.3390/atmos16040441
APA StyleIsmail, F. N., Woodford, B. J., & Licorish, S. A. (2025). Atmospheric Modeling for Wildfire Prediction. Atmosphere, 16(4), 441. https://doi.org/10.3390/atmos16040441