The process flow in the cement production, brick and tile production, coking industry, and ceramic products manufacturing industries is relatively short compared to that of the iron and steel industry, and the whole enterprise can be considered as a whole for this study in the process of constructing the model. It should be noted that the total power consumption in the production process of an enterprise, in addition to coming from purchased electricity, may also come from facilities such as the enterprise’s own power plant or waste heat power generation. As the electricity data used for modelling is purchased electricity data from the Electricity Big Data Centre, it does not include enterprise self-generation or waste heat generation. Enterprises that have confirmed the use of self-generated electricity or waste heat power generation through research are required to introduce an overall conversion factor based on the ratio of the total enterprise electricity consumption to the purchased electricity. In terms of model architecture, it mainly includes data collection and processing, feature extraction, and model prediction modules.
3.1. Data Acquisition and Processing
This study incorporates 2019 daily-scale electricity consumption data for each industry selected from the pilot city enterprise electricity data set, with enterprise Continuous Emission Monitoring System (CEMS) data obtained from the provincial ecological environment departments, as well as data from the pilot city air pollutant emission inventory and emergency emission reduction inventory. It also includes information on gross industrial output value, enterprise production capacity, enterprise energy consumption data, holidays, and data on the implementation of control measures. Because there are different types of data and different standards, the data need to be pre-processed.
Table 1 is the list of the variables used and their statistical information. The fields of external data and internal data are unified according to the electric power basic code standard to avoid different coding forms for the same fields. The data types represented by data fields are maintained so that the fields correspond to the correct data types and avoid the phenomenon of storing numbers and times as strings. This is because there are differences in how different data types are called; secondly, it can improve the efficiency of data conversion when performing operations such as the aggregation of data; and thirdly, it is conducive to the screening of abnormal data and the discovery of abnormal data in advance. Null checking and format checking are performed on the data to form a standardized data format specification.
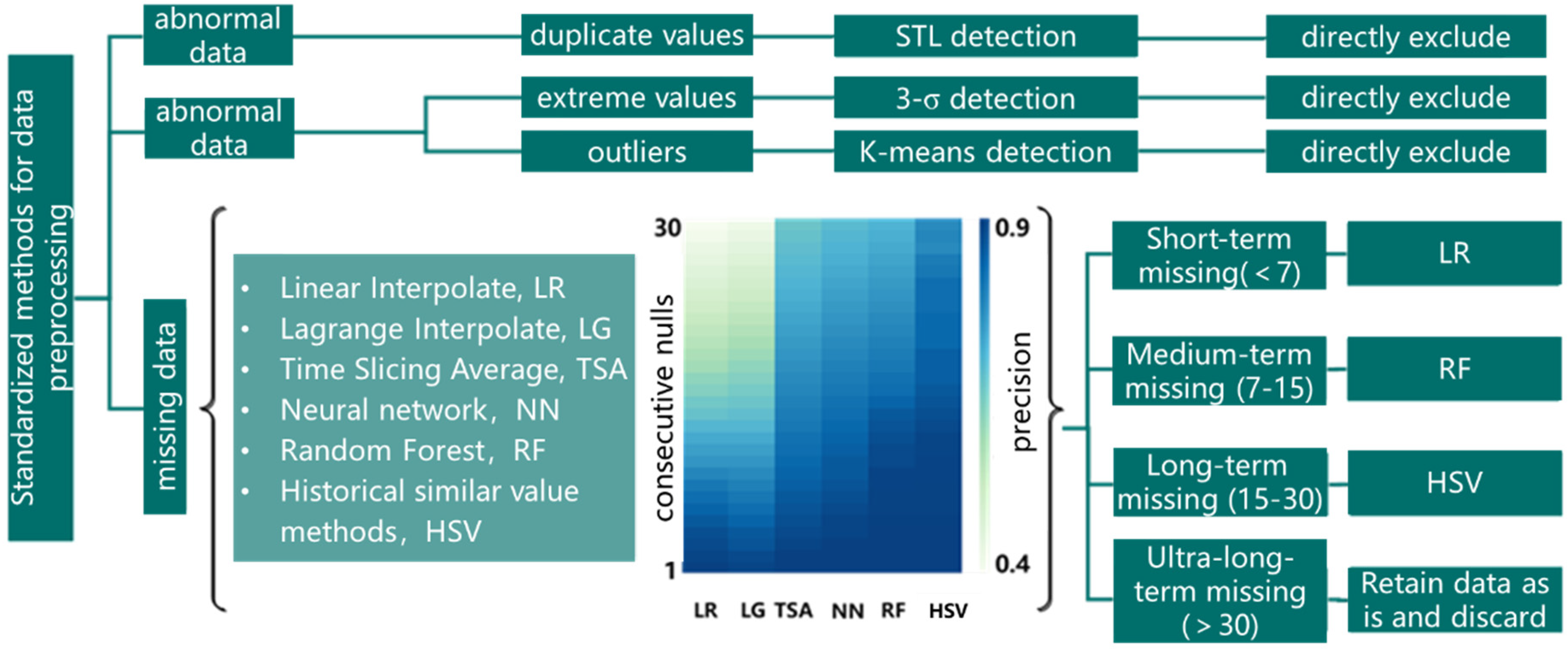
Through the application of statistical analysis, machine learning, and data mining methods, we explore the patterns, trends, and anomalies of data such as government public data, enterprise pollutant monitoring data, etc., study the governance algorithms of various types of data, realize the de-weighting, gap filling, and outlier processing of data, and standardize the data anomalies from the perspectives of qualitative and quantitative data. The method is shown in
Figure 1. The 3-σ method, box-and-line diagram method, and K-means method, combined with the moving window method, are used to identify data outliers. The magnitude of data jumps is identified by moving the window, and if the magnitude of data jumps does not conform to the normal distribution, it represents an anomaly in the original data. The outliers can be effectively culled or corrected by empirical judgment. Duplicate tables in the dataset or duplicate data in the table are identified and eliminated by the STL tool. For missing values, it is necessary to categorize them based on the method of statistical analysis, use the combination strategy of multiple filling methods, and select the most suitable filling method according to the continuous length and characteristics of the missing data.
The number of consecutive nulls in the existing dataset ranges from 1 to 130. For short-term consecutive nulls (≤7 days), simple and efficient interpolation methods such as linear interpolation can be tried; for medium-term consecutive nulls (7 days < consecutive missing days ≤ 15 days), models such as limit gradient boosting algorithms are needed to achieve the filling; and for long-term nulls (15 days < consecutive missing days ≤ 30 days), the method of constructing the historical similarity values to fill them is tried. For consecutive missing days of more than 30 days, the original appearance is retained.
The historical similar value filling method constructed in this study is to use the data from similar days to supplement the missing data after extracting the recent one-year historical data. The steps are as follows. Construct the data set S′ = {A,B,C,D,E}, T = {T1,T2,T3,…,Tn}, T ∈ A,B,C,D,E. Column A in the data set represents the original data, and column B is derived according to whether the data are missing, and column B is the missing label (0 means missing and 1 means is missing). It is assumed that there is a more similar periodicity of data fluctuations in the time period corresponding to consecutive missing data. The day labels are then calibrated based on the holiday, date, and weekday attributes. Column C contains the holiday labels (0 for holidays and 1 for being a weekday). Column D contains the date labels (1:31), and column E contains the weekday data (0:6). The values in column B are used to divide the S’ set of missing data and the S″ set of complete data. The single missing data f = {am, bm, cm, dm, em} in S′ will be calculated separately from the complete data set S″ for similar days . Arrange the di from largest to smallest to obtain dj′. The selection of the number of similarity days has a more important impact on data completion; a single similarity day involves uncertainty, and too many similarity days will increase data uncertainty. Based on the 95% confidence interval test, this method sets the number of non-similar days to be 95% of the overall number of days. The similar day distance threshold dlimit = dm′, where m is j × 95% rounded to the nearest whole number, dynamically selects N similar days with di < dlimit. At this time, to fill , aj is the day data corresponding to dj. Repeat, moving data f to S″ until S′ is empty, completing the data fill as needed with the complete data set S″.
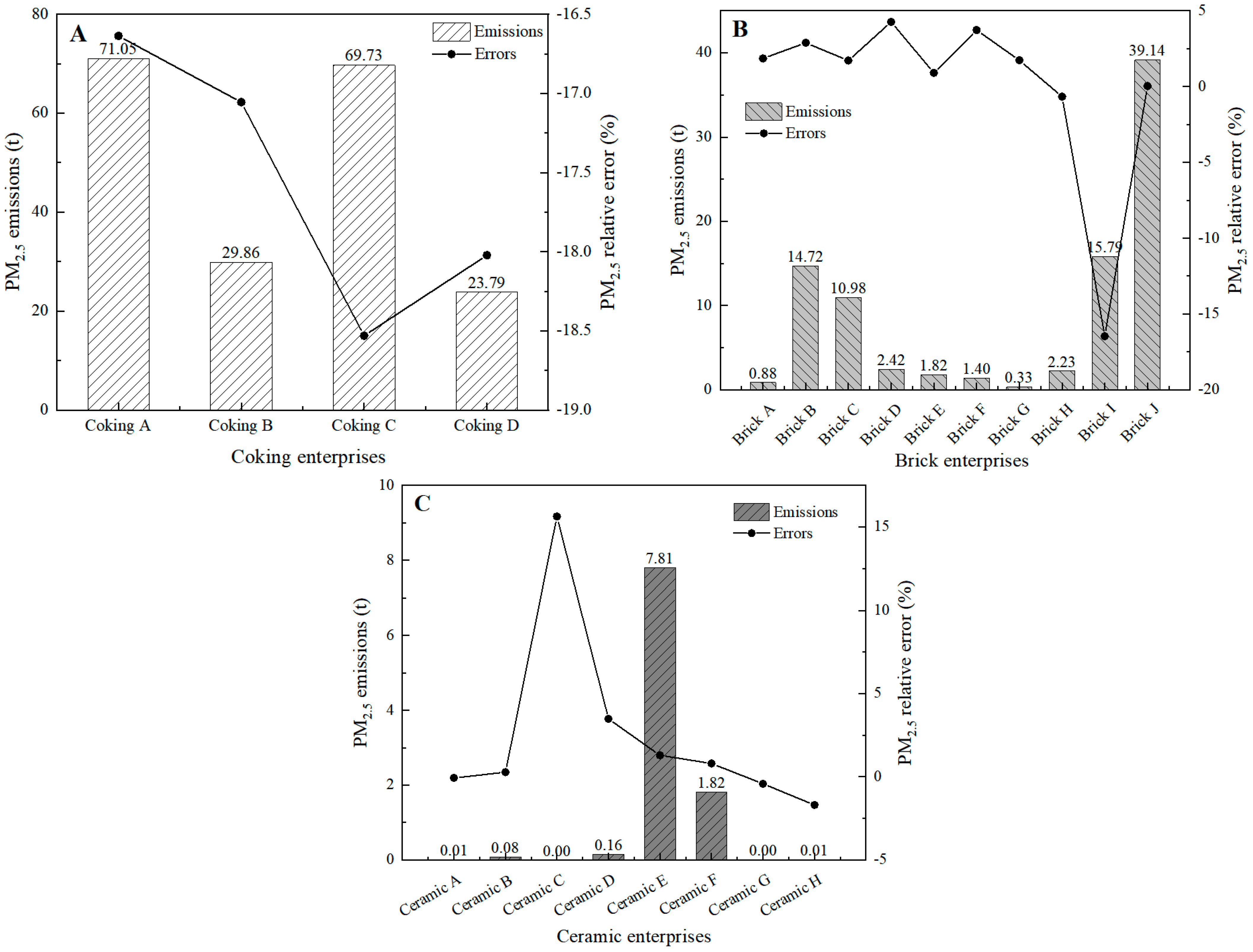
Through data optimization and cleaning, the daily scale EPP data of 27 cement enterprises, 4 coking enterprises, 10 brick enterprises, and 8 ceramics enterprises in the pilot city were obtained. Among the 27 cement enterprises, there are 23 grinding stations, accounting for 85% of the total number of cement enterprises. The 4 coking enterprises are all independent coking companies using mechanized coke ovens and ancillary equipment for coking. The brick and tile industry has various types of furnaces and due to different statistical caliber, the capacity unit is different, divided into 10,000 t/year, 10,000 pieces/year, and 10,000 m2/year. Ceramic industry product categories are different, and capacity units are also divided into 10,000 t/year and 10,000 pieces/year.
3.2. Model Building
The use of fossil energy affects, to a certain extent, the linear relationship between electricity consumption—production load—pollution emission. In order to further investigate the feasibility of the EPA model, it is necessary to first examine the correlation between industry emissions and electricity consumption. To facilitate the comparison between different industries, it is necessary to consider the consistency of data sources and the characteristics of industry emissions. In grinding station companies, SO
2, NO
x, CO, VOCs, and NH
3 emissions are rare, and there is a significant difference, so this study selected PM
2.5 and PM
10 as representative pollutants, and fitted the annual scale electricity consumption data to the particulate (PM
2.5 and PM
10) emission data in the 2019 pilot city emergency emission reduction inventory, followed by Pearson correlation analysis (see Equation (1)).
where
and
are the sample means of variables
X and
Y, respectively.
The correlations between particulate matter emission and electricity consumption in the cement industry, coking industry, brick industry, and ceramic industry are calculated as 0.72, 0.97, 0.65, and 0.63, respectively. The correlation criteria are shown in
Table 2, which shows that the electricity consumption and pollutant emissions for four typical polluting industries in the pilot city are strongly correlated, strongly correlated, correlated, and correlated. Therefore, it is feasible to use electricity consumption data to construct the pollutant emission model.
The sample size for correlation analysis is increased, and Pearson correlation analysis is performed between the daily scale electricity consumption data of enterprises in typical polluting industries in the pilot city and the daily scale emission data calculated based on CEMS, to investigate the feasibility of constructing the EPA model based on the EPBD and CEMS data. The results are shown in
Table 3, with a weak correlation pattern. Further correlation analysis of the activity level (product output) data from the monthly statistical reports of enterprises in typical polluting industries with the monthly scale electricity consumption data, shows a correlation between the two, and it is significantly stronger than the correlation between electricity consumption and CEMS (
Table 3).
The reason should be that the pollutant emissions of enterprises not only include the organized CEMS emissions, but also include the unorganized emissions and the organized emissions without CEMS installation. Constructing a relationship between electricity consumption data and CEMS data directly will leave out a portion of enterprise emissions and fail to characterize the true level of enterprise emissions. According to the previous analysis, it is clear that the pollutant emissions of the industry are strongly correlated with the electricity consumption data, so the electricity consumption–CEMS correlation analysis will show a weak correlation result.
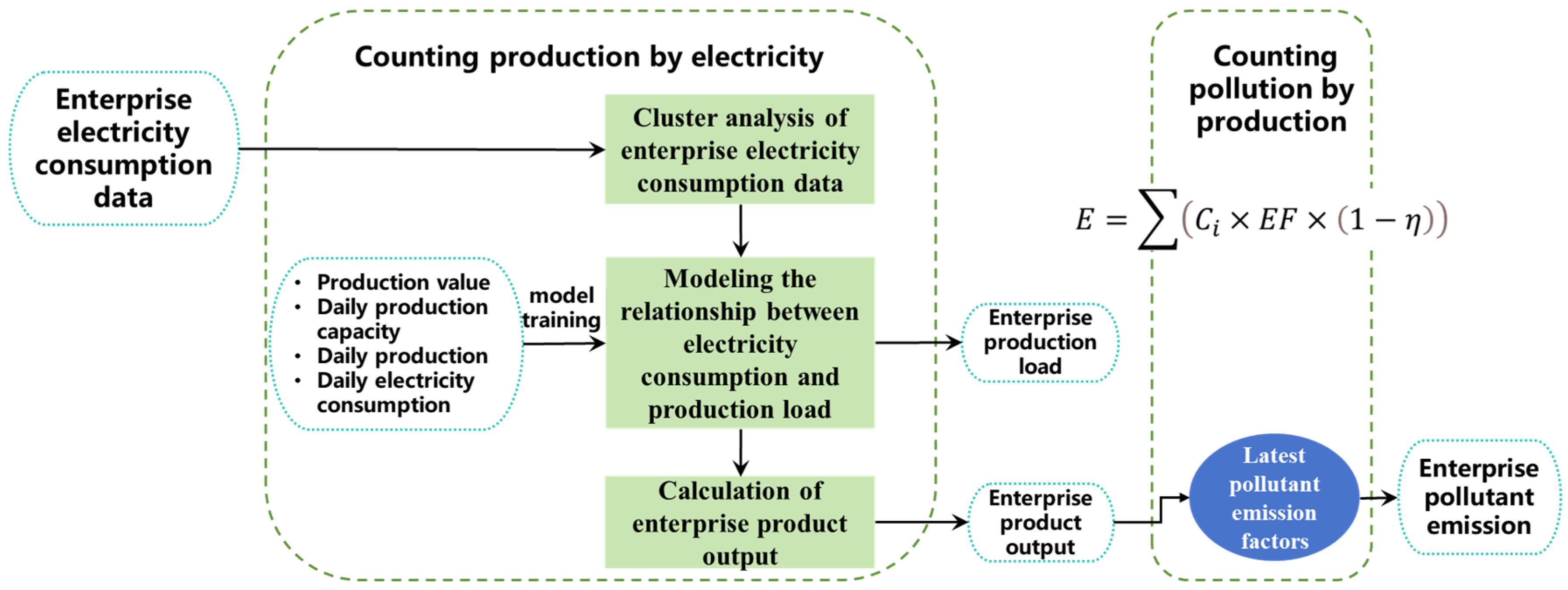
Therefore, in order to ensure the accuracy of data transmission and the comprehensiveness of the accounting link, the model first constructs the electricity–production (EP) relationship model based on the enterprise’s electricity consumption data and product output data, and then introduces the emission factor to accurately connect the production–pollution (PP) relationship. The EPP model of the enterprise is constructed according to the idea of “counting production by electricity and counting pollution by production”. The model architecture is shown in
Figure 2. In the part of counting production by electricity, the production load of enterprises is more stable in different power zones. Based on clustering analysis, the electricity consumption data of different enterprises are graded to obtain the range of each electricity consumption zone. Subsequently, the production load analysis model is obtained by training the model with the eigenvalues of graded electricity consumption, industrial output value, enterprise production capacity, and daily scale production. Finally, the output is calculated based on the production load. In the part of calculating pollution by production, the daily scale air pollutant emissions of the enterprise are calculated based on the product output data and the latest pollutant emission factors.
3.3. Counting Production by Electricity
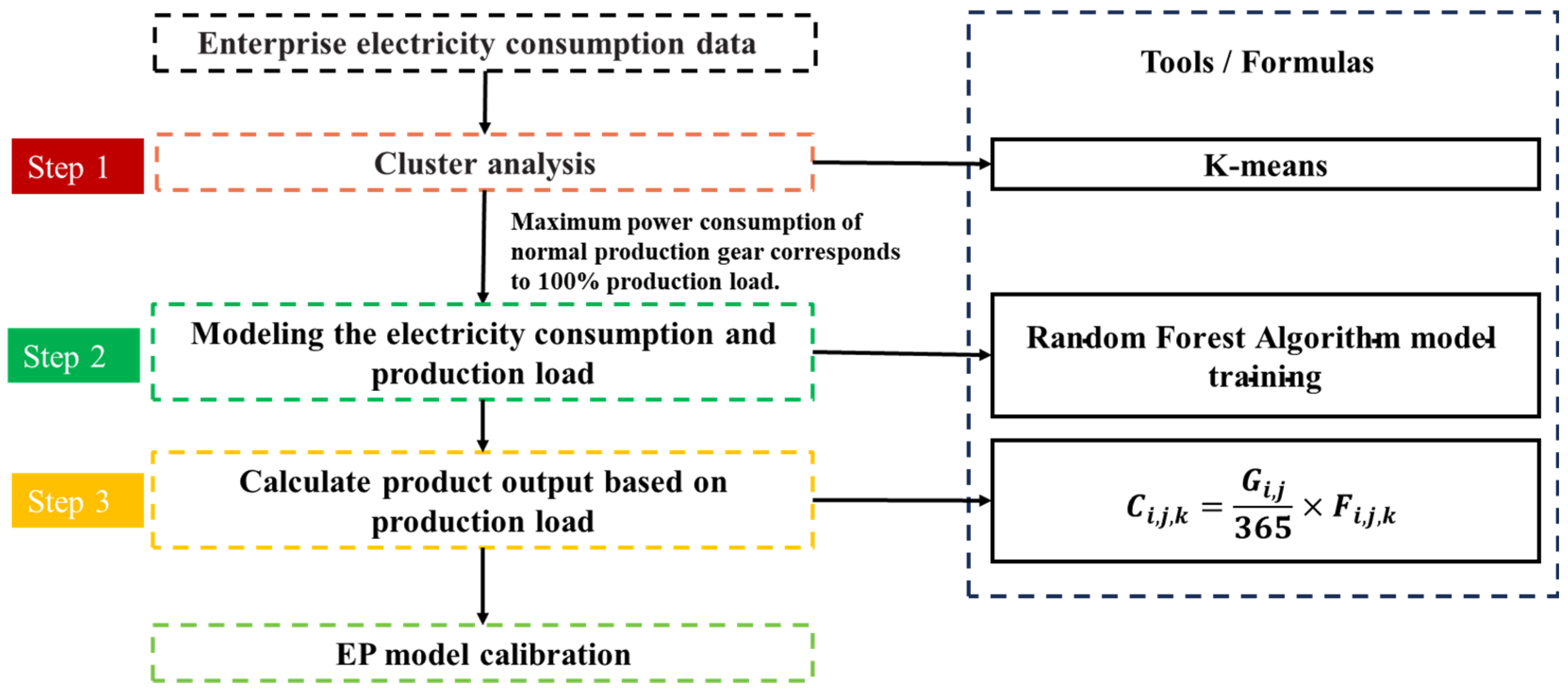
Counting production by electricity is the most important part of the enterprise EPP model, as shown in
Figure 3, including three steps. Step 1 is the cluster analysis of enterprise electricity consumption data, using the Python 3.8.10 cluster analysis program to classify the day-by-day electricity consumption data of each enterprise. Step 2 constructs the relationship model between electricity consumption and production load. Step 3 calculates the enterprise product output, multiplying the process capacity and daily production load to derive the enterprise daily scale sub-process product output data.
The main purpose of constructing the relational model in Step 2 is to build a complex mathematical correspondence between the enterprise electricity consumption data and the production load data through machine learning algorithms. The random forest (RF) model captures complex nonlinear relationships in the data and is suitable for problems that are difficult to model with a linear model; it can effectively deal with large and high-dimensional data with high computational efficiency; it is robust to noisy data and outliers, and has high computational stability; it integrates multiple decision trees, which usually have higher prediction accuracy than a single decision tree; it is validated by out-of-bag (OOB) data, which reduces the risk of overfitting and improves the generalization ability of the model; and it provides feature importance indicators to help identify key features and facilitate feature selection and model interpretation. In view of these multiple advantages, this study utilizes the RF algorithm to train a production load forecasting model based on EPBD.
Step 1: Cluster analysis of enterprise electricity consumption data.
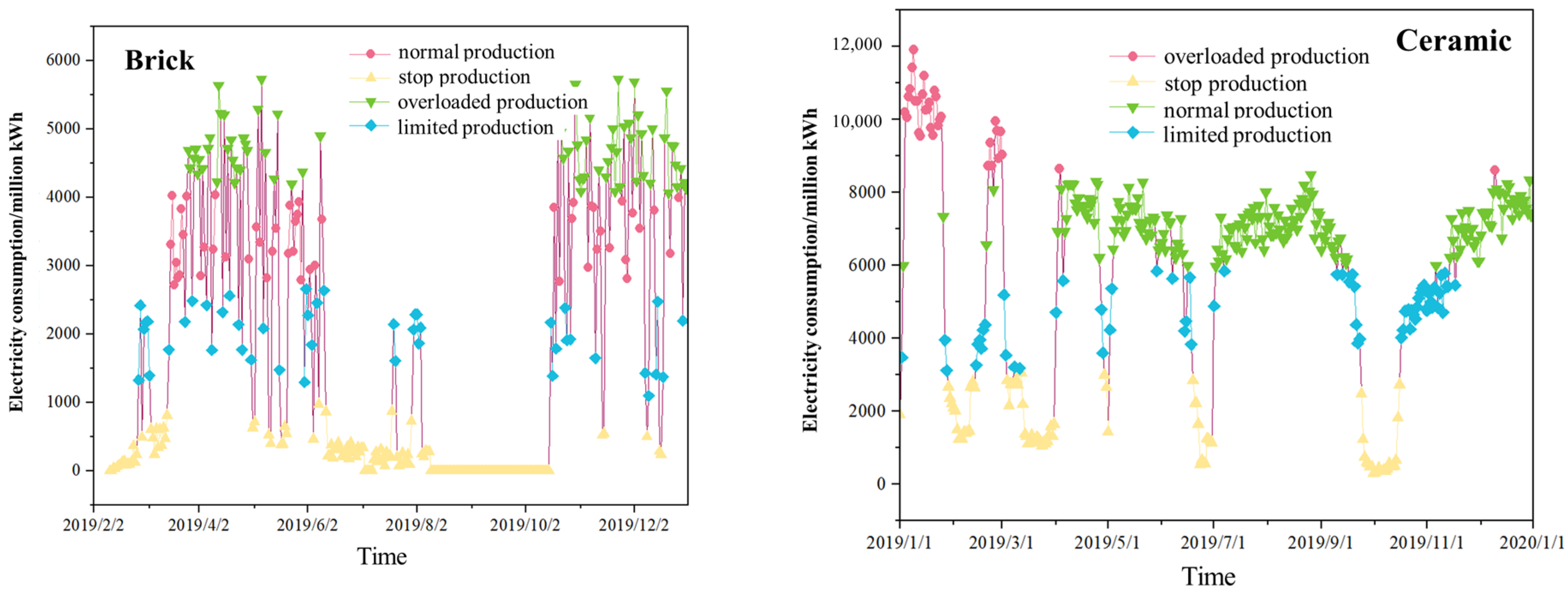
By mining the electricity consumption information of typical enterprises in different industries, this study finds that the electricity consumption of enterprises has obvious step-like characteristics. The actual production status of each enterprise can be roughly categorized into several kinds: in the stable production period, the production load is high, the power consumption is high, and the volatility of load and power is not large; in the control production period, the load level decreases, and the theoretical volatility of load and power is large, especially in some industries that contain processes that can be started and stopped at any time; and in the shutdown stage, the production load is low and the power consumption is low, and the load and power curves during the shutdown period show a smooth nature. There are also some special states, such as the cement industry, where there is an overloaded production state.
Due to the differences in the process and control measures of enterprises in various industries, it is not only a large amount of work but also a poor theoretical basis for the division of the state if the production state is divided for each enterprise individually. Therefore, according to the characteristics of each enterprise’s electricity consumption, the cluster analysis method is used to classify the electricity consumption, so as to characterize the different production states of enterprises every day.
Specifically, the K-means algorithm, a python cluster analysis program in machine learning, is used to adaptively determine the number of power consumption clusters for each enterprise to differentiate between the different power consumption states of the enterprises. Based on the classification results, the electricity consumption of each industry can be categorized into four classes (
Figure 4), i.e., normal production, production restriction, production stoppage, and overloaded production.
Step 2: Modeling the relationship between electricity consumption and production load.
Based on the capacity, production, and total industrial output values of different enterprises in the emergency emission reduction inventory, machine learning algorithms are used to clarify the specific functional relationship between electricity consumption and production load and to capture the nonlinear relationship and complex interaction effects among the data. A model is constructed of the relationship between electricity consumption and production load.
Due to statistical caliber and other reasons, there are differences in the capacity units based on the emergency emission reduction inventory. Therefore, this study establishes the load relationship model for different product units in typical industries separately. In the cement industry, the main pollutants come from clinker and powder mill, so the RF model of the cement industry only considers the clinker and powder mill enterprises in it, and the production capacity unit is 10,000 t/year. The brick and tile industries are classified into four levels according to the furnace type, and the production capacity units of different furnace types are different, so they are divided into 10,000 t/year, 10,000 pieces/year, and 10,000 m2/year for the establishment of the RF model, respectively.
The specific process of model construction is as follows. Obtain the day-by-day product output data of enterprises. When it is difficult to obtain day-scale data, the Litterman method from the field of econometric analysis can be considered [
22]. High-frequency indicator information such as weekly data, holiday information, and information on the implementation of control measures are introduced as explanatory variables, and the low-frequency monthly-scale product output data are converted into high-frequency daily-scale data by estimating high-frequency interpolated series data. The daily production capacity of enterprises is taken as the daily average of annual or monthly production capacity. The ratio of daily production and daily capacity is then calculated to obtain the daily-scale production load data of the enterprise. The daily scale production load data and the clustered and graded daily electricity consumption data (with the graded logo) are taken as the main features, and the industrial output value, enterprise production capacity, enterprise energy consumption data, holiday information, and information on the implementation of control measures are taken as the other input features, which are inputted into the RF algorithm, to train the “Electricity Consumption—Production Load” model, namely EP model.
In this algorithm, 70% of the data is randomly used as the training set and 30% as the validation set. The RF algorithm in this study is based on the sklearn data package in scikit-learn (version 1.0. 1) and scipy (version 1.8.1). Due to the version issue, the output results need to be parameter corrected. The training set data is input into the above RF for continuous training. Each parameter is adjusted so that the forecasts calculated using the staggered power data of the validation set are constantly close to the true value of production loads.
The introduction of multiple other features and the high-frequency transformation of product yield data increases the uncertainty of the model’s prediction results while correcting the model accuracy and refining the time scale. Thus, the stability of the model was assessed by global sensitivity analysis, and the Sobol index method was used to quantify the contribution of each feature and its interaction to the model output.
Suppose the computational model is
Y =
f(
X), where
X = (
X1,
X2,
…,
Xn) is the input feature,
Y is the output variable, and
f is the model function. Each input feature
Xi independently obeys its probability distribution
P(
Xi). Sample points are generated using random sampling or low-discrepancy sequences (e.g., Sobol sequences). Assume that N samples are generated, each containing n input features. For each sample point
X(j) = (
X1(j),
X2(j),
…,
Xn(j)), calculate the output
Y(j) =
f(
X(j)). The expected value
E[
Y] and variance
D[
Y] of the output variable
Y are as follows:
The first order Sobol index
measures the separate contribution of the input features
to the output
Y. The calculation starts by generating
N auxiliary samples for each feature variable
, where
varies independently from the other feature variables. The conditional expectation of
Y at fixed
is
:
The variance of conditional expectation
is as follows:
Then the index
is as follows:
The second-order Sobol index
measures the contribution of the interaction between the input variables
and
to the output
Y. The calculation generates
N auxiliary samples for each variable pair
, where
and
vary independently from the other variables. Calculate the conditional expectation
for
Y when fixing
and
:
Calculate the variance of the conditional expectation
:
Then the second-order Sobol index
is as follows:
The first-order Sobol index
denotes the individual contribution of the variable
. The second-order Sobol index
denotes the interaction contribution of the variables
and
. The sum of all Sobol indices should satisfy Equation (10) to verify the correctness of the calculation.
Through the above steps, the contribution of each input variable and its interaction to the output is quantified, thus a global sensitivity analysis is performed.
Step 3: Calculation of enterprise product output.
Different enterprises in the cement industry contain different processes (single process for grinding or clinker only, or double process for both), and the different processes of an enterprise must be measured separately. The annual production capacity of the enterprise is evenly distributed to 365 days to obtain the theoretical value of daily production capacity; by multiplying the daily production capacity of each process with the corresponding date and the production load of the corresponding process, the measured value of its daily output can be obtained.
The product output for each process of an enterprise can be calculated by the following formula:
Style:
i, j, k represent firm, process, and date, respectively;
C represents real-time production accounting results (t);
G represents the annual capacity data of different processes of the enterprise (t);
F represents the production load (%).
3.4. Counting Pollution by Production
The correlation between the production load and electricity consumption of polluting enterprises is obvious, and real-time output can be obtained based on the calculation of production load, so this study uses the emission factor method to construct the pollutant emission accounting model of typical polluting industries. The production load data used in the accounting model come from the output of the relationship model between electricity consumption and production load of enterprises in various industries.
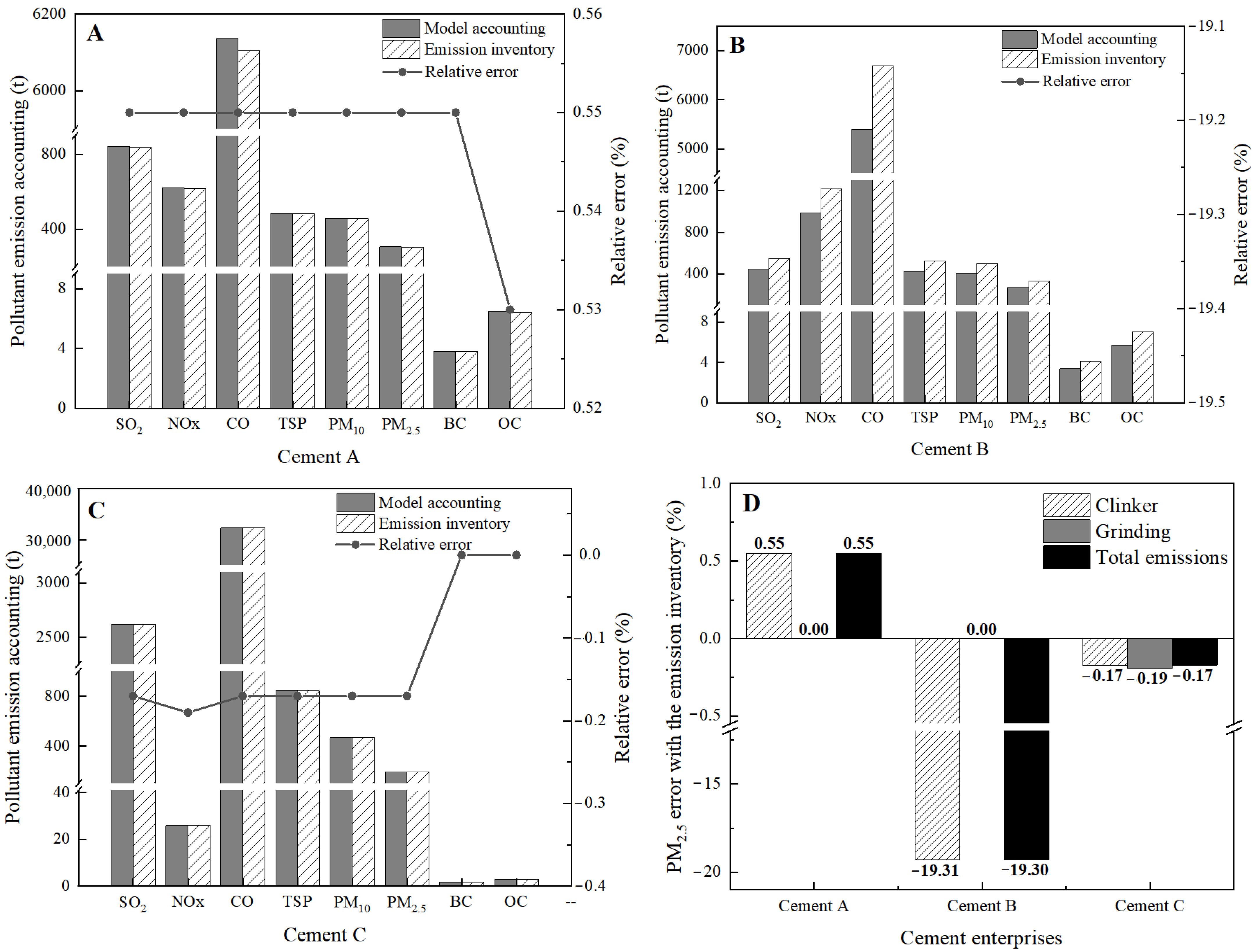
In addition, it should be noted that cement enterprises can be divided into grinding, clinker and dual-process categories according to the process, which need to be combined with the proportion of different processes for model construction. Dual-process enterprises are analyzed based on the literature [
23,
24] by folding the electricity consumption by clinker electricity consumption: grinding electricity consumption = 0.684211; other industries are considered by a single production line.
The formula for counting pollution by production is as follows:
E is the air pollutant emissions from the process of a company in a typical industry of air pollution, EF is the emission factor, C is the real-time production, η is the pollutant control and emission reduction efficiency, and i, j, and k represent the company, process, and date, respectively.
In particular, the installation of pollutant control measures in each enterprise was obtained from enterprise surveys and other environmental public reports. Pollution control efficiency
η for each industry comes from the Manual for Preparation of Urban Air Pollutant Emission Inventory (
Table 4). The emission factor EF is the latest industry emission factor obtained by cumulative updating and expansion based on the nine technical guidelines for the compilation of pollution source inventories issued by the Ministry of Ecology and Environment, based on the results of the National Atmospheric Special Project and other research projects, and combined with the current production and pollution control processes, and the emission factors of key industries such as cement, coking, and iron and steel can be refined by the process. It is more comprehensive and detailed than the emission factors announced by the state, and is led by Tsinghua University and jointly researched by 7 universities and scientific research institutions, and released in the form of a group standard [
25].








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}