
Integration of Deep Learning Neural Networks and Feature-Extracted Approach for Estimating Future Regional Precipitation


Abstract
1. Introduction
2. Materials and Methods
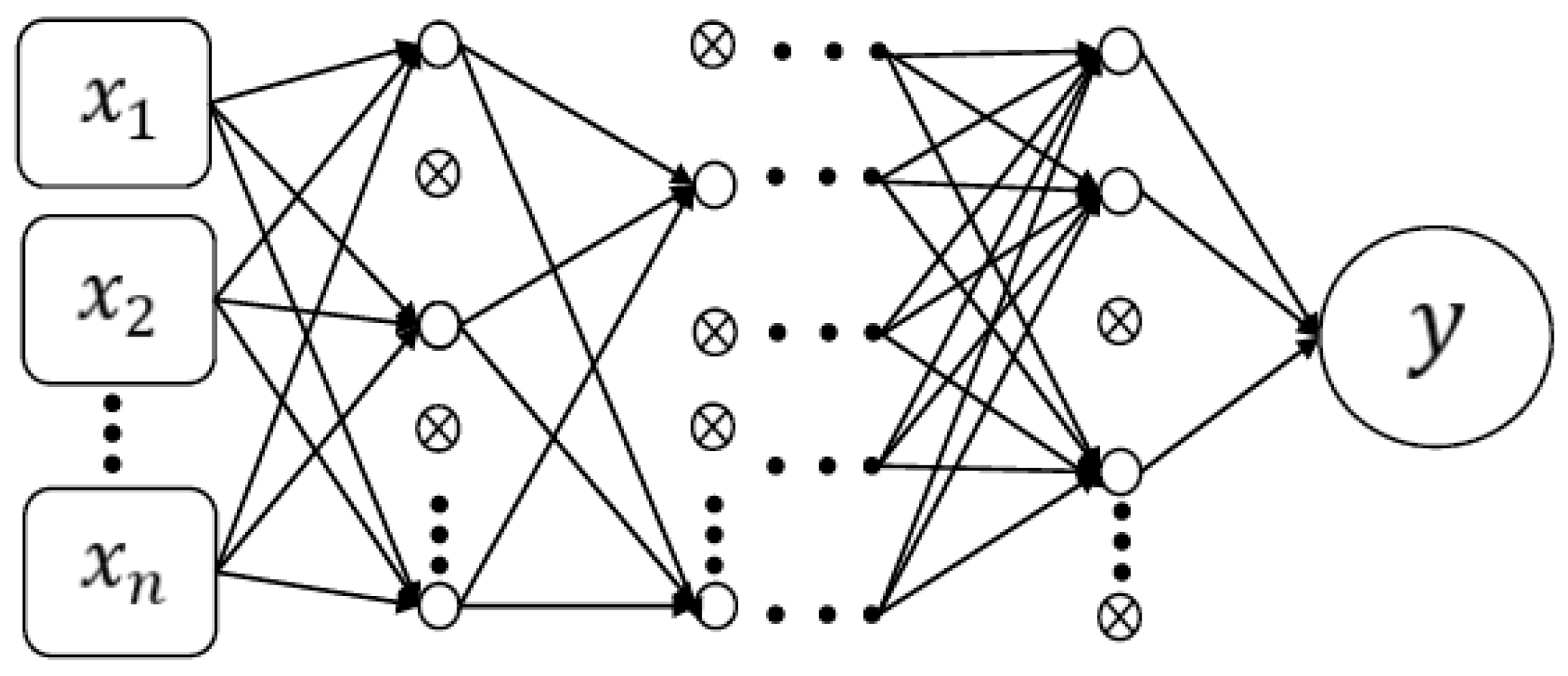
2.1. Deep Neural Network
2.2. Kernel Principal Component Analysis
3. Data
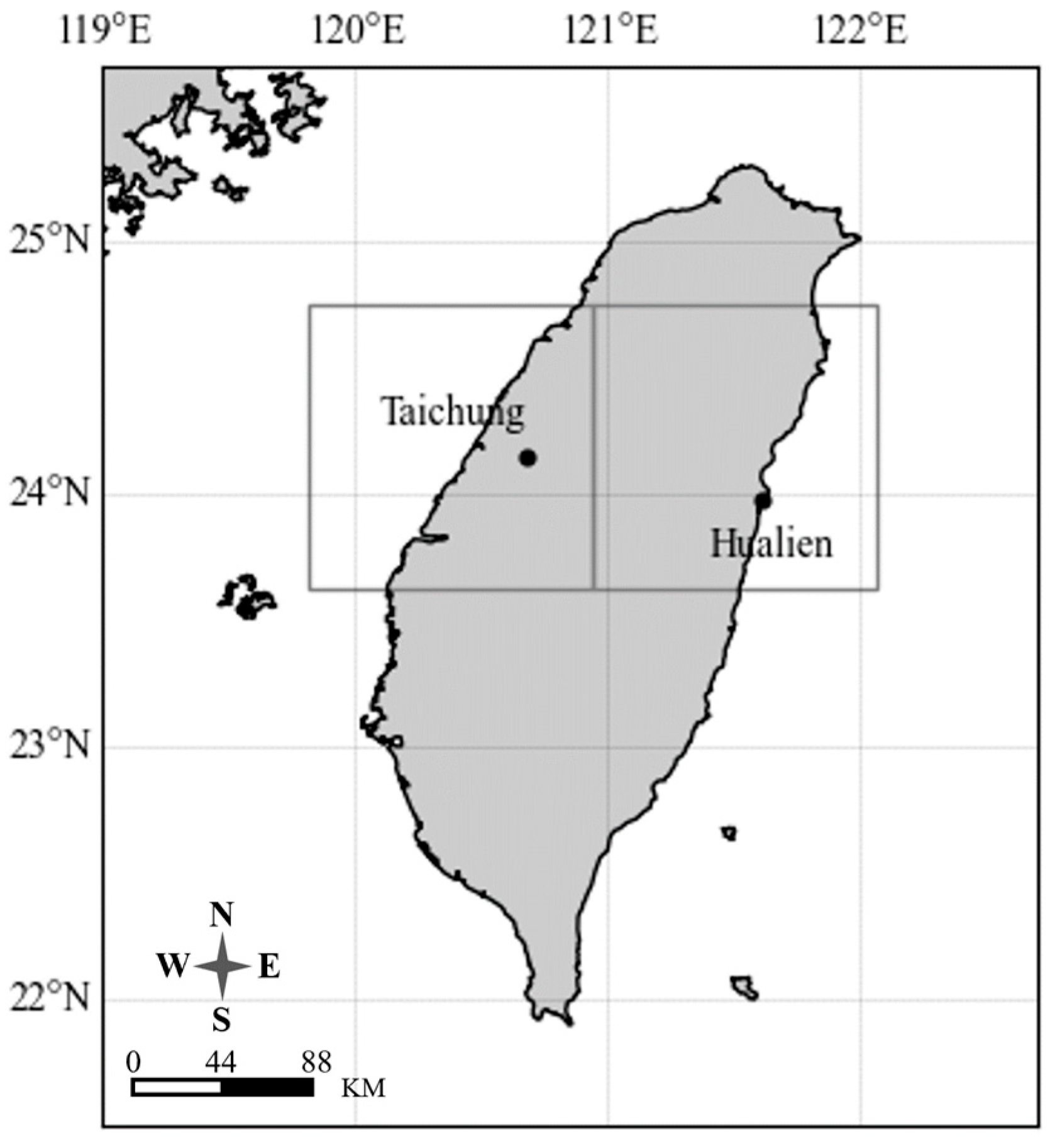
3.1. Case Area and Historical Rainfall
3.2. GCM Data
4. Downscaling Model Construction
- (1)
- Select input variables.
- (2)
- Determine DNN architecture, such as optimizers, activation functions, number of layers (NL), number of nodes per layer (NNPL).
- (3)
- DNN hyper-parameter optimization.
4.1. Predictive Variable Selection
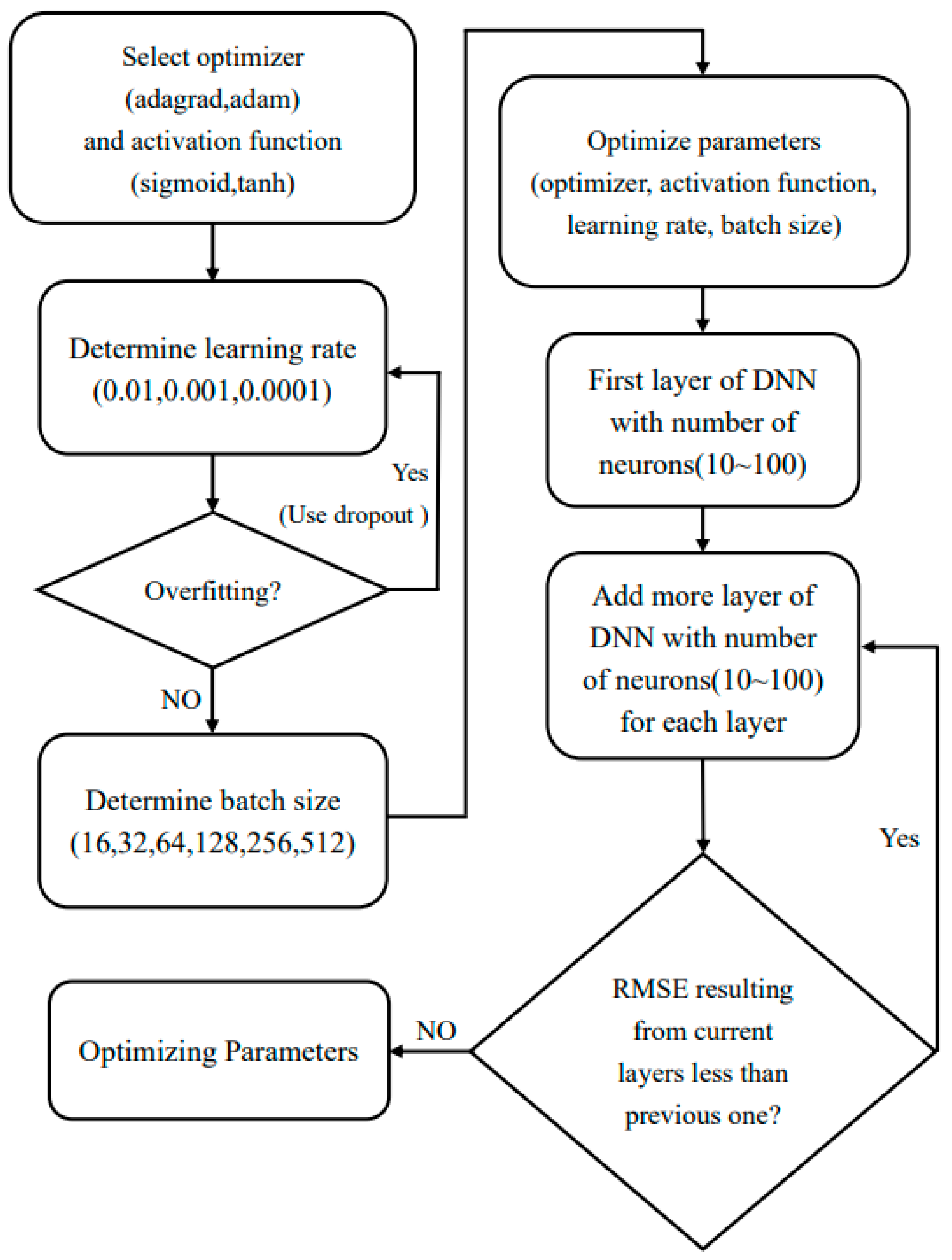
4.2. Model Parameter Optimization
- (1)
- Determine the hidden layers.
- (2)
- Determine the number of nodes in the hidden layer.
- i.
- Optimizers and activation functions.
- The initial batch size is 16, the NL is 1, and the number of nodes is 10 and 50 to determine its convergence trend. Its learning rate is adjusted to converge. Optimizers and activation functions are selected to achieve convergence. After selecting optimizers and activation functions, learning rates are adjusted to determine overfitting. If there is overfitting, dropout will be performed on the DNN architecture. Finally, according to RMSE, AdaGrad is selected as the optimizer, and sigmoid is selected as the activation function. The learning rate is and the batch size is optimized.
- ii.
- Batch size.
- The batch size is tested based on the selected optimizer, activation function, learning rate, and the setting of 1 DNN layer and 10 nodes. The batch size is changed from 16 to 512. After comparing RMSE, 64 is selected as the optimal batch size to optimize the number of node layers. First, it is assumed that DNN has 10 nodes per layer, with the number of nodes gradually increasing in units of 5 (10, 15, 20…, and 100). For in-order training, the number of nodes in the first layer is 85, which is the number of nodes at the minimum RMSE. After determining the number of nodes in the first layer, a second layer is added to the DNN architecture. The number of nodes in the second layer starts from 10 and gradually increases in units of 5. The number of nodes (35) at the minimum RMSE is taken as the number of nodes in the second layer. If the RMSE of the optimal number of nodes in the second layer is smaller than that of the optimal number of nodes in the first layer, a third layer will be added to DNN based on the above method. Otherwise, the DNN architecture is determined, and parameters are optimized.
- iii.
- NL and NNPL.
- The NL and NNPL are finally optimized to obtain optimal parameters. AdaGrad is selected as the optimizer, and sigmoid is selected as the activation function. The learning rate is and the batch size is 64. The first layer has 100 nodes, and the second layer has 35 nodes. The final optimized parameters of GCM at all stations are shown in Table 4. Y and X in Equation (5) are standardized before calculation, and KPCA is noticeably larger in dimensionless RMSE (DR) of the ACCESS and CSMK3 models. Most optimizers are AdaGrad, and most activation functions are sigmoid. Learning rates mostly fall in between and , and the batch sizes are 16, 32, or 64, usually with 1 layer.
4.3. Assessment of the Effectiveness of Historical Scenarios
5. Result and Discussion
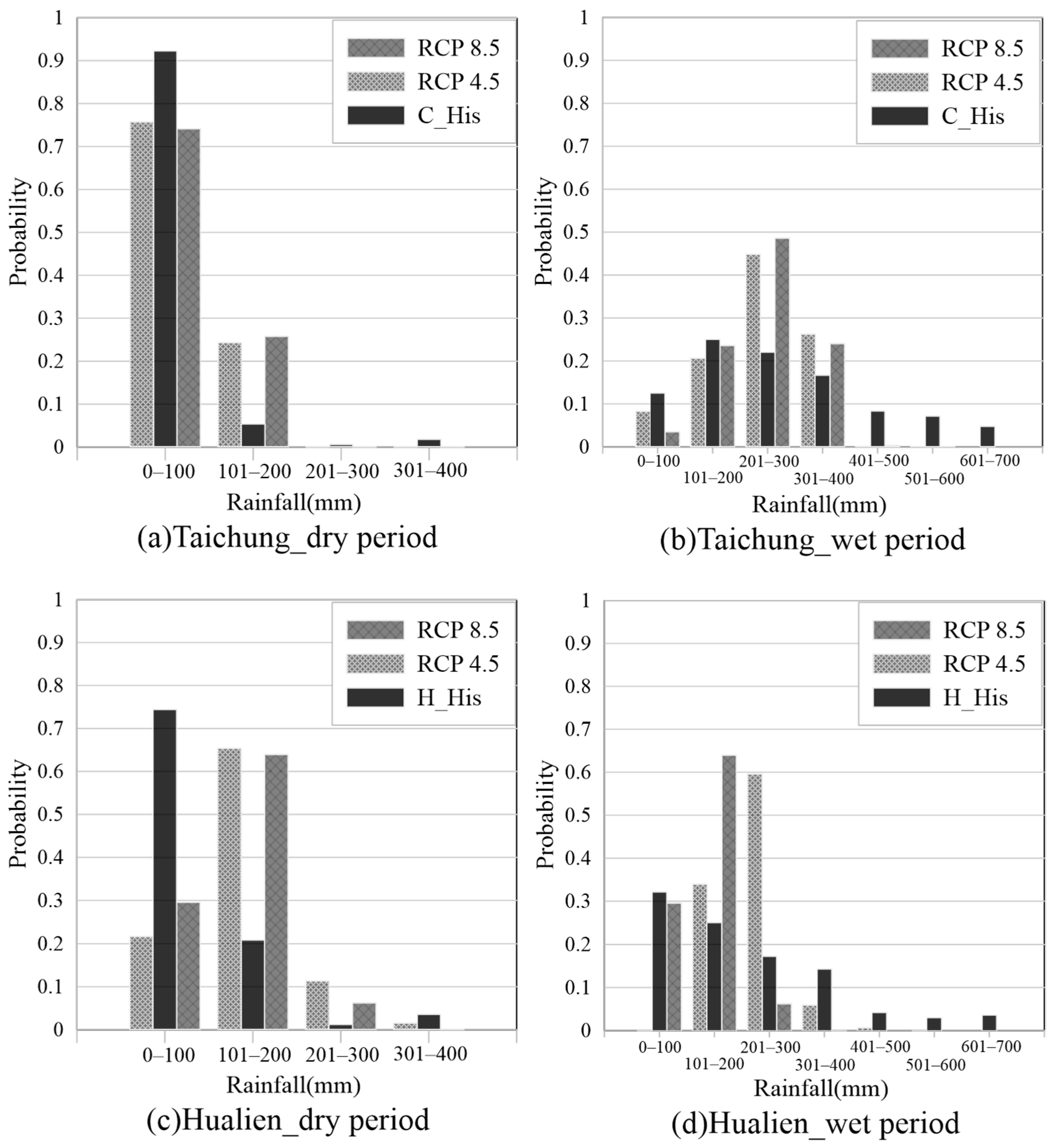
5.1. Statistical Probability Analysis of Rainfall in Future Scenarios
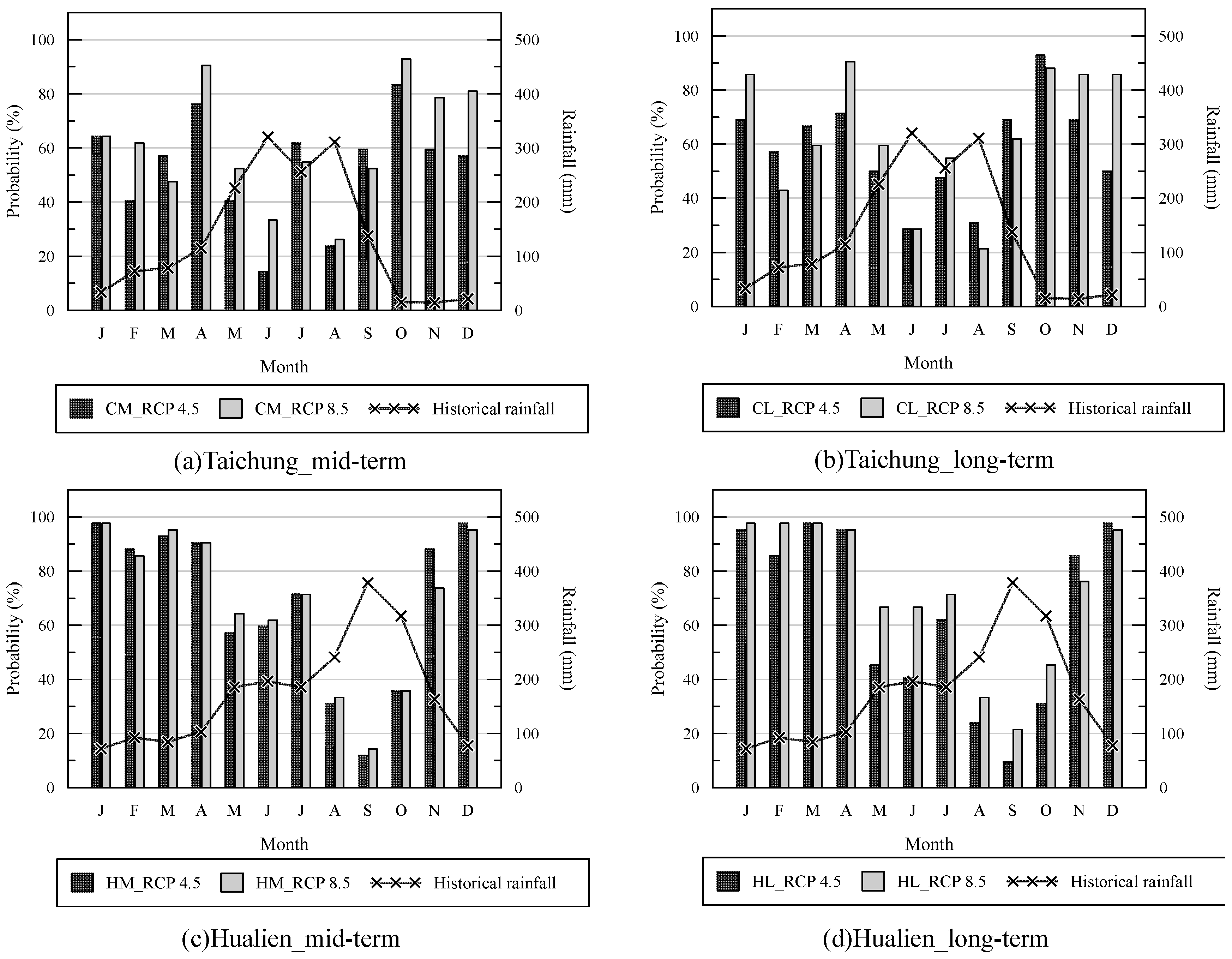
5.2. Mid-Term and Long-Term Rainfall Assessment in Future Scenarios
6. Conclusions
- 1.
- In DNN models, AdaGrad is a better optimizer, sigmoid is a better activation function, and one hidden layer is more appropriate.
- 2.
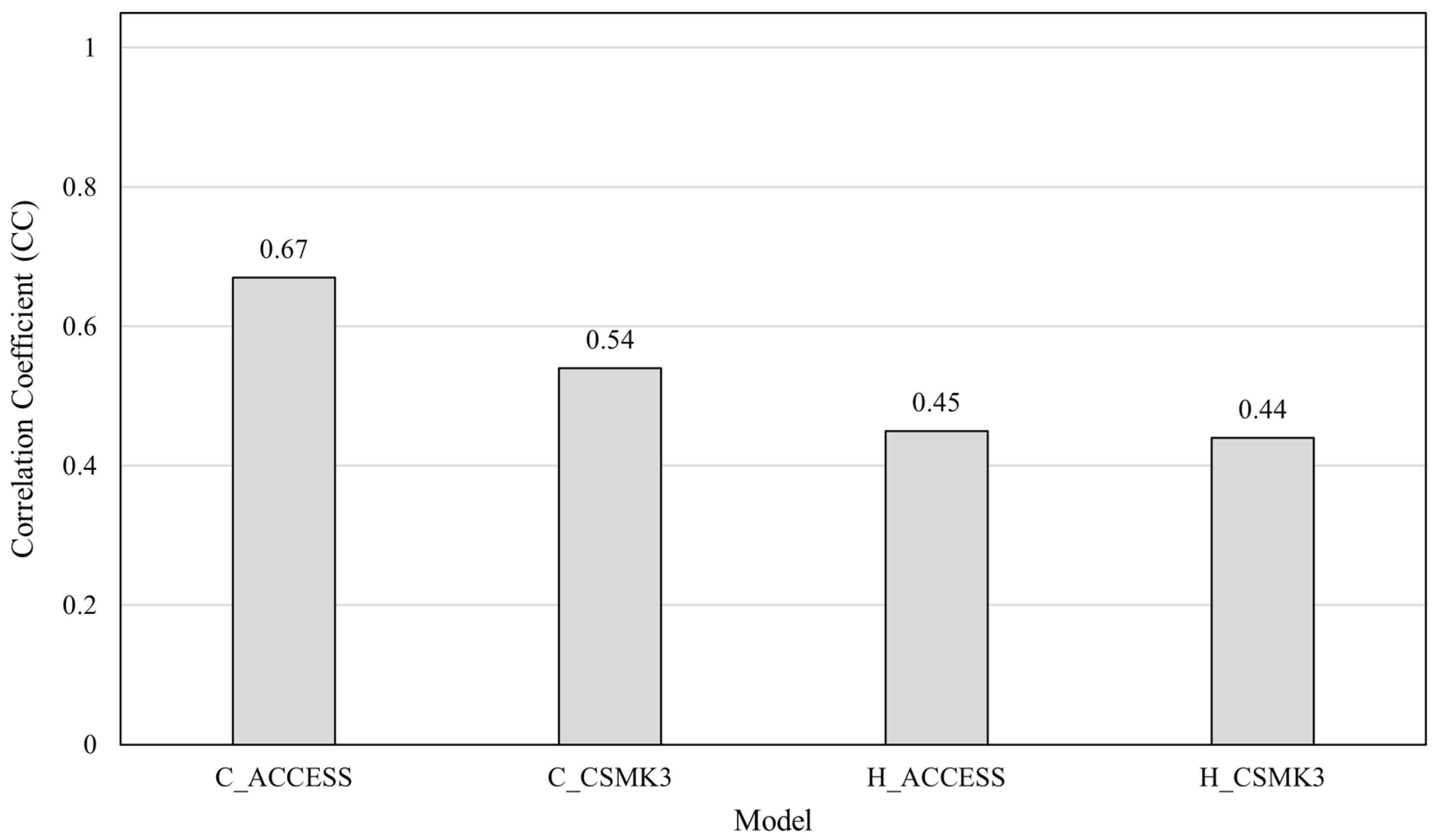
- The ACCESS GCM model considering both atmospheric and oceanic factors performs better for Taiwan.
- 3.
- According to the analysis of the three-class rainfall classification in future scenarios, Taichung and Hualien have a high probability of future dry season rainfall exceeding the upper limit of historical normal. There is a high probability that future wet season rainfall will fall in the normal range of historical rainfall.
- 4.
- The dry season rainfall in Taichung and Hualien shows an increasing trend, but with higher variability and uncertainty. The wet season rainfall decreases significantly, but with lower variability, indicating that the uncertainty in the decreasing trend is smaller.
- 5.
- The probability of future dry season rainfall exceeding historical averages in Taichung and Hualien is greater than 60%, indicating a higher likelihood of increased rainfall. The probability of future wet season rainfall exceeding historical averages in Taichung and Hualien is lower than 50%, indicating a greater likelihood of reduced rainfall.
- 6.
- Under the RCP 8.5 scenario, the impacts on rainfall increase in the dry season and rainfall decrease in the wet season are more pronounced compared to RCP 4.5. This suggests that climate change has a greater impact on the spatio-temporal distribution of rainfall, and early adaptation strategies should be implemented.
7. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kitoh, A.; Endo, H.; Krishna Kumar, K.; Cavalcanti, I.F.; Goswami, P.; Zhou, T. Monsoons in a Changing World: A Regional Perspective in a Global Context. J. Geophys. Res. Atmos. 2013, 118, 3053–3065. [Google Scholar] [CrossRef]
- Manor, A.; Berkovic, S. Bayesian Inference Aided Analog Downscaling for Near-Surface Winds in Complex Terrain. Atmos. Res. 2015, 164, 27–36. [Google Scholar] [CrossRef]
- Salvi, K.; Ghosh, S. High-Resolution Multisite Daily Rainfall Projections in India with Statistical Downscaling for Climate Change Impacts Assessment. J. Geophys. Res. Atmos. 2013, 118, 3557–3578. [Google Scholar] [CrossRef]
- Al-Mukhtar, M.; Qasim, M. Future Predictions of Precipitation and Temperature in Iraq Using the Statistical Downscaling Model. Arab. J. Geosci. 2019, 12, 25. [Google Scholar] [CrossRef]
- Baghanam, A.H.; Eslahi, M.; Sheikhbabaei, A.; Seifi, A.J. Assessing the Impact of Climate Change over the Northwest of Iran: An Overview of Statistical Downscaling Methods. Theor. Appl. Climatol. 2020, 141, 1135–1150. [Google Scholar] [CrossRef]
- Xu, Z.; Han, Y.; Yang, Z. Dynamical Downscaling of Regional Climate: A Review of Methods and Limitations. Sci. China Earth Sci. 2019, 62, 365–375. [Google Scholar] [CrossRef]
- Zhang, H.; Singh, V.P.; Wang, B.; Yu, Y. CEREF: A Hybrid Data-Driven Model for Forecasting Annual Streamflow from a Socio-Hydrological System. J. Hydrol. 2016, 540, 246–256. [Google Scholar] [CrossRef]
- Kundu, S.; Khare, D.; Mondal, A. Future Changes in Rainfall, Temperature, and Reference Evapotranspiration in Central India by Least Square Support Vector Machine. Geosci. Front. 2017, 8, 583–596. [Google Scholar] [CrossRef]
- Li, C.Y.; Lin, S.S.; Chuang, C.M.; Hu, Y.L. Assessing Future Rainfall Uncertainties of Climate Change in Taiwan with a Bootstrapped Neural Network-Based Downscaling Model. Water Environ. J. 2020, 34, 77–92. [Google Scholar] [CrossRef]
- Sulaiman, N.A.; Shaharudin, S.M.; Zainuddin, N.H.; Najib, S.A. Improving Support Vector Machine Rainfall Classification Accuracy Based on Kernel Parameters Optimization for Statistical Downscaling Approach. Int. J. 2020, 9, 652–657. [Google Scholar] [CrossRef]
- Vidyarthi, V.K.; Jain, A. Advanced Rule-Based System for Rainfall Occurrence Forecasting by Integrating Machine Learning Techniques. J. Water Resour. Plan. Manage. 2023, 149, 04022072. [Google Scholar] [CrossRef]
- Dalto, M.; Matuško, J.; Vašak, M. Deep Learning Neural Networks for Ultra-Short-Term Wind Forecasting. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 1657–1663. [Google Scholar] [CrossRef]
- Wang, Y.; Basu, S. Using an artificial neural network approach to estimate surface-layer optical turbulence at Mauna Loa, Hawaii. Opt. Lett. 2016, 41, 2334–2337. [Google Scholar] [CrossRef] [PubMed]
- Bi, C.; Qing, C.; Wu, P.; Jin, X.; Liu, Q.; Qian, X.; Zhu, W.; Weng, N. Optical turbulence profile in marine environment with artificial neural network model. Remote Sens. 2022, 14, 2267. [Google Scholar] [CrossRef]
- Frame, J.M.; Kratzert, F.; Klotz, D.; Gauch, M.; Shalev, G.; Gilon, O.; Qualls, L.M.; Gupta, H.V.; Nearing, G.S. Deep Learning Rainfall–Runoff Predictions of Extreme Events. Hydrol. Earth Syst. Sci. 2022, 26, 3377–3392. [Google Scholar] [CrossRef]
- Shikhovtsev, A.Y.; Kovadlo, P.G.; Kiselev, A.V.; Eselevich, M.V.; Lukin, V.P. Application of Neural Networks to Estimation and Prediction of Seeing at the Large Solar Telescope Site. Publ. Astron. Soc. Pac. 2023, 135, 014503. [Google Scholar] [CrossRef]
- Aswin, S.; Geetha, P.; Vinayakumar, R. Deep Learning Models for the Prediction of Rainfall. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 657–661. [Google Scholar] [CrossRef]
- Yen, M.H.; Liu, D.W.; Hsin, Y.C.; Lin, C.E.; Chen, C.C. Application of the Deep Learning for the Prediction of Rainfall in Southern Taiwan. Sci. Rep. 2019, 9, 12774. [Google Scholar] [CrossRef] [PubMed]
- Basha, C.Z.; Bhavana, N.; Bhavya, P.; Sowmya, V. Rainfall Prediction Using Machine Learning & Deep Learning Techniques. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 92–97. [Google Scholar] [CrossRef]
- Liu, F.; Xu, F.; Yang, S. A Flood Forecasting Model Based on Deep Learning Algorithm via Integrating Stacked Autoencoders with BP Neural Network. In Proceedings of the 2017 IEEE Third International Conference on Multimedia Big Data (BigMM), Laguna Hills, CA, USA, 19–21 April 2017; pp. 58–61. [Google Scholar] [CrossRef]
- Xiang, Y.; Gou, L.; He, L.; Xia, S.; Wang, W. A SVR–ANN Combined Model Based on Ensemble EMD for Rainfall Prediction. Appl. Soft Comput. 2018, 73, 874–883. [Google Scholar] [CrossRef]
- Lin, S.S.; Hu, Y.L.; Zhu, K.Y. Downscaling Model for Rainfall Based on the Influence of Typhoon under Climate Change. J. Water Clim. Change. 2022, 13, 2443–2458. [Google Scholar] [CrossRef]
- Pulkkinen, S. Nonlinear Kernel Density Principal Component Analysis with Application to Climate Data. Stat. Comput. 2016, 26, 471–492. [Google Scholar] [CrossRef]
- Hu, J.N.; Lin, S.S.; Zhu, K.Y. Integrating Nonlinear Principal Component Analysis and Neural Networks to Develop a Downscaling Model Evaluating Future Rainfall of Taichung and Hualien. J. Taiwan Agric. Eng. 2020, 67, 78–90. [Google Scholar] [CrossRef]
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef]
- Fischer, A.; Bunke, H. Kernel PCA for HMM-Based Cursive Handwriting Recognition. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Münster, Germany, 2–4 September 2009; Springer: Berlin, Heidelberg, 2009; pp. 181–188. [Google Scholar] [CrossRef]
- Debruyne, M. Detecting Influential Observations in Kernel PCA. Comput. Stat. Data Anal. 2010, 54, 3007–3019. [Google Scholar] [CrossRef]
- Jiang, M.; Zhu, L.; Wang, Y.; Xia, L.; Shou, G.; Liu, F.; Crozier, S. Application of Kernel Principal Component Analysis and Support Vector Regression for Reconstruction of Cardiac Transmembrane Potentials. Phys. Med. Biol. 2011, 56, 1727. [Google Scholar] [CrossRef] [PubMed]
- Alam, M.A.; Fukumizu, K. Hyperparameter selection in kernel principal component analysis. J. Comput. Sci. 2014, 10, 1139. [Google Scholar] [CrossRef]
- Kaneko, H. k-Nearest Neighbor Normalized Error for Visualization and Reconstruction—A New Measure for Data Visualization Performance. Chemom. Intell. Lab. Syst. 2018, 176, 22–33. [Google Scholar] [CrossRef]
- Ezukwoke, K.; Zareian, S.J. Kernel Methods for Principal Component Analysis (PCA): A Comparative Study of Classical and Kernel PCA. A Prepr. 2019. [Google Scholar] [CrossRef]
- Li, C.H.; Lin, C.T.; Kuo, B.C.; Ho, H.H. An Automatic Method for Selecting the Parameter of the Normalized Kernel Function to Support Vector Machines. In Proceedings of the 2010 International Conference on Technologies and Applications of Artificial Intelligence, Hsinchu, Taiwan, 18–20 November 2010; pp. 226–232. [Google Scholar] [CrossRef]
- Li, C.H.; Hsien, P.J.; Lin, L.H. A Fast and Automatic Kernel-Based Classification Scheme: GDA+SVM or KNWFE+SVM. J. Inf. Sci. Eng. 2018, 34, 1–12. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Majhi, S.; Pattnayak, K.C.; Pattnayak, R. Projections of Rainfall and Surface Temperature over Nabarangpur District Using Multiple CMIP5 Models in RCP 4.5 and 8.5 Scenarios. Int. J. Appl. Res. 2016, 2, 399–405. [Google Scholar]
- Beecham, S.; Rashid, M.; Chowdhury, R.K. Statistical Downscaling of Multi-Site Daily Rainfall in a South Australian Catchment Using a Generalized Linear Model. Int. J. Climatol. 2014, 34, 3654–3670. [Google Scholar] [CrossRef]
- Bai, Y.; Chen, Z.; Xie, J.; Li, C. Daily Reservoir Inflow Forecasting Using Multiscale Deep Feature Learning with Hybrid Models. J. Hydrol. 2016, 532, 193–206. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, Z.; Zeng, B.; Deng, J.; Li, C. A Multi-Pattern Deep Fusion Model for Short-Term Bus Passenger Flow Forecasting. Appl. Soft Comput. 2017, 58, 669–680. [Google Scholar] [CrossRef]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 437–478. [Google Scholar]
- Busseti, E. Deep Learning for Time Series Modeling. In Technical Report; Stanford University: Stanford, CA, USA, 2012; pp. 1–5. [Google Scholar]
- Coppola, E.A., Jr.; Rana, A.J.; Poulton, M.M.; Szidarovszky, F.; Uhl, V.W. A Neural Network Model for Predicting Aquifer Water Level Elevations. Groundwater 2005, 43, 231–241. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Station Code | Longitude | Latitude | Altitude (m) | Date |
|---|---|---|---|---|---|
| Taichung | 467490 | 120°40′33.31″ E | 24°08′50.98″ N | 16 | January 1950–December 2000 |
| Hualien | 466990 | 121°36′17.98″ E | 23°58′37.10″ N | 34 | January 1950–December 2000 |
| Model | Factors | Factor Full Name |
|---|---|---|
| ACCESS and CSMK3 | Atmosphere | Total Cloud Fraction |
| Evaporation | ||
| Specific Humidity | ||
| Near-Surface Specific Humidity | ||
| Precipitation | ||
| Surface Air Pressure | ||
| Sea Level Pressure | ||
| Surface Net Downward Longwave Radiation | ||
| Near-Surface Air Temperature | ||
| Eastward Near-Surface Wind | ||
| Northward Near-Surface Wind | ||
| Aerosol Glue | Total Emission Rate of SO2 | |
| ACCESS | Ocean | Water Evaporation Flux Where Ice Free Ocean over Sea |
| Northward Ocean Heat Transport | ||
| Ocean Heat X Transport | ||
| Ocean Heat Y Transport | ||
| Rainfall Flux Where Ice Free Ocean over Sea | ||
| Net Downward Shortwave Radiation at Sea Water Surface |
| Station | GCM Model | Accuracy (%) | KPC |
|---|---|---|---|
| Taichung | Access | 82.4 | 4 |
| CSMK3 | 78.6 | 5 | |
| Hualien | Access | 81.3 | 13 |
| CSMK3 | 79.2 | 3 |
| GCM | Station | Type | Quantity | Gamma | Optimizer | Activation Function | Learning Rate | Batch Size | Layer 1 | Layer 2 | Dimensionless RMSE |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ACCESS | Taichung | original | 19 | 0.099 | adagrad | sigmoid | 0.0001 | 16 | 80 | 0.803 | |
| KPCA | 4 | adagrad | sigmoid | 0.0041 | 64 | 100 | 35 | 0.835 | |||
| Hualien | original | 19 | 0.427 | adagrad | sigmoid | 0.001 | 64 | 55 | 1.007 | ||
| KPCA | 13 | adagrad | sigmoid | 0.0001 | 16 | 70 | 1.105 | ||||
| CSMK3 | Taichung | original | 12 | 0.082 | adagrad | sigmoid | 0.001 | 64 | 40 | 0.845 | |
| KPCA | 5 | adagrad | sigmoid | 0.001 | 32 | 10 | 1.593 | ||||
| Hualien | original | 12 | 0.667 | adagrad | tanh | 0.01 | 16 | 90 | 1.038 | ||
| KPCA | 12 | adam | tanh | 0.001 | 16 | 10 | 1.191 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.-S.; Zhu, K.-Y.; Huang, H.-Y. Integration of Deep Learning Neural Networks and Feature-Extracted Approach for Estimating Future Regional Precipitation. Atmosphere 2025, 16, 165. https://doi.org/10.3390/atmos16020165
Lin S-S, Zhu K-Y, Huang H-Y. Integration of Deep Learning Neural Networks and Feature-Extracted Approach for Estimating Future Regional Precipitation. Atmosphere. 2025; 16(2):165. https://doi.org/10.3390/atmos16020165
Chicago/Turabian StyleLin, Shiu-Shin, Kai-Yang Zhu, and He-Yang Huang. 2025. "Integration of Deep Learning Neural Networks and Feature-Extracted Approach for Estimating Future Regional Precipitation" Atmosphere 16, no. 2: 165. https://doi.org/10.3390/atmos16020165
APA StyleLin, S.-S., Zhu, K.-Y., & Huang, H.-Y. (2025). Integration of Deep Learning Neural Networks and Feature-Extracted Approach for Estimating Future Regional Precipitation. Atmosphere, 16(2), 165. https://doi.org/10.3390/atmos16020165