1. Introduction
Near-surface ozone has become one of the primary atmospheric pollutants. High ozone concentrations can be harmful to human beings and the environment, potentially causing respiratory issues and damaging plant growth [
1,
2]. Fluctuations in O
3 concentrations are primarily associated with temperature, relative humidity, wind speed, and wind direction. Different meteorological conditions have varying impacts on O
3 concentrations. In general, higher surface temperatures, lower relative humidity, and stronger solar radiation favor the photochemical reactions of O
3, leading to an increase in O
3 concentrations [
3,
4,
5]. Since the issuance of the “Action Plan for Air Pollution Prevention and Control” in 2013, China has achieved significant success in controlling PM
2.5 pollution. However, with the adjustment of industrial structure and changes in meteorological conditions, the issue of O
3 pollution has become increasingly prominent [
6,
7,
8,
9,
10], particularly in Beijing–Tianjin–Hebei and surrounding regions [
11]. Urban air quality forecast provides crucial information and acts as a basis for decision making, allowing local governments to initiate emergency responses to heavy polluted days, formulate pollution control measures, and identify technical means for air pollution control and precise regulation [
12]. Thus, in the face of a complex pollution situation, the accurate forecast of O
3 is the key for precise control decision making.
Currently, models used for O
3 forecasts mainly include numerical models, statistical models, and ensemble models. O
3 numerical models [
13], based on atmospheric dynamics and physical–chemical processes, predict future O
3 concentrations by simulating O
3 production and consumption processes in the real atmosphere. Their advantage lies in providing a physical interpretation of the simulation process, aiding in understanding the fundamental mechanisms of the atmospheric system. However, they require significant computational resources and detailed input data, including meteorological fields, topographic conditions, and emission inventories. O
3 statistical models [
14] employ traditional statistical methods (like regression analysis and time series analysis) or machine learning algorithms (such as non-linear or deep learning), which have been widely used in energy and medicine fields [
15,
16,
17]. They are used to analyze historical O
3 monitoring data and meteorological conditions, as well as to establish mathematical relationships for predicting future O
3 concentrations, since meteorological factors such as temperature, relative humidity, and solar radiation exhibit a strong correlation with O
3 concentration [
18]. The advantage of statistical models is the fast execution speed, but they lack detailed a physical–chemical interpretation of results and are considered black box models [
19,
20]. O
3 ensemble models [
21] utilize statistical methods to analyze and compute results based on numerical model forecasts combined with observed data, ultimately providing adjusted O
3 forecast results. The ensemble models can enhance the system’s resilience to noise and outliers, improving the overall model robustness [
22,
23]. However, the ensemble models depend on the outputs of individual sub-models. This may lead to difficulties in providing a clear model interpretation, which is a similar shortcoming for statistical models.
Yang et al. [
24], in a review of over 200 O
3 numerical model applications in China since 2010, found that O
3 numerical models are more widely adopted and perform well in the Yangtze River Delta and Pearl River Delta regions, but their applications are relatively limited in Beijing–Tianjin–Hebei and surrounding areas. In recent years, numerous researchers have conducted extensive research on the establishment and performance evaluation of O
3 statistical models [
25,
26,
27] in Beijing–Tianjin–Hebei and surrounding regions. However, the forecast lead time generally does not exceed 3 days, and the evaluation indicators used vary from model to model. The applications of O
3 ensemble models in China are relatively scarce. There is limited research on the evaluation of O
3 forecast model performance in the current operational processes in China, and the referential quality of various O
3 models in operational processes has not been investigated. This study conducted a comprehensive evaluation of O
3 forecast results in Beijing–Tianjin–Hebei and surrounding regions for June and July 2023 based on 30 models of numerical, statistical, and ensemble types. Multiple evaluation metrics were employed to provide a comprehensive assessment of their forecast performance, aiming to enhance the supportive role of model forecast in environmental management.
2. Materials and Methods
2.1. Models and Setting
The forecast results evaluated in this study consisted of a total of 30 model sets, including numerical, statistical, and ensemble models. The forecast period for each set spanned from 1 June to 31 July 2023, covering 57 cities at the prefecture level and above in six provinces (or municipalities), namely Beijing, Tianjin, Hebei, Shanxi, Shandong, and Henan. The forecast content included hourly time series of O3 concentrations for the next 7 days in each city.
Numerical Models: The numerical model forecast results evaluated in this study consisted of a total of 20 sets. Among them, six sets utilized the Nested Air Quality Prediction Modeling System (NAQPMS) developed by the Institute of Atmospheric Physics, the Chinese Academy of Sciences. Another six sets used the Community Multiscale Air Quality (CMAQ) Model developed by the United States Environmental Protection Agency. Additionally, six sets employed the Comprehensive Air Quality Model with Extension (CAMx). One set was based on the Weather Research and Forecast—Chemistry (WRF-chem) Model developed by the National Oceanic and Atmospheric Administration (NOAA), and the last one set utilized the RuiTu Map (RMAPS)—Chemistry subsystem developed by the Beijing Urban Meteorological Research Institute based on WRF-chem. Meteorological driving data were sourced from National Centers for Environmental Prediction—Global Forecast System (NCEP-GFS) or China Meteorological Administration—Global Assimilation Forecast System (CMA-GFS).
Statistical Models: The statistical model forecast results evaluated in this study consisted of a total of 6 sets, all constructed using machine learning methods based on historical O3 concentrations and meteorological conditions over a period of time. The nonlinear machine learning methods employed included support vector regression (SVR), random forest regression (RFR), and other algorithms. Additionally, deep learning methods, such as long short-term memory (LSTM), recurrent neural networks (RNNs), and deep neural networks (DNNs) were utilized. One of the models considered the effects of pollutant emissions, and two models considered the spatial transport of pollutants. Multiple models incorporated advanced algorithms, such as extreme gradient boosting, time series analysis, and attention mechanisms, to enhance the predictive performance based on machine learning. The statistical models used in this study were not categorized by the applied machine learning methods because several different machine learning methods were applied to one single statistical model.
Ensemble Models: The ensemble model forecast results evaluated in this study consisted of a total of 4 sets. Two sets were constructed by merging multiple-source observation data based on the forecast results from the Community Multiscale Air Quality (CMAQ) Model. The remaining two sets were constructed by merging observation data based on forecast results from multiple numerical models, including NAQPMS, CMAQ, CAMx, and WRF-chem. The ensemble models used in this study were based on numerical forecast and observed data and generated new forecast results by establishing the relationship between them with machine learning methods.
2.2. Evaluation Methods
This study employed three categories of forecast performance evaluation indicators, including general statistical metrics, evaluation metrics for pollution events, and comprehensive assessment metrics based on the Individual Air Quality Index (IAQI) [
28] for O
3. The observation data sourced from the China National Environmental Monitoring Center, specifically data from 287 national-level ground monitoring stations in Beijing–Tianjin–Hebei and surrounding regions, were used for verification purposes. The O
3 concentration monitoring data had a temporal resolution of 1 h. Considering the timeliness of operational forecasting, only the forecast results generated before 8:00 AM (local time) each day were considered valid.
General Statistical Metrics: This category includes four common statistical indicators, namely the correlation coefficient (R), the root mean square error (RMSE), normalized mean bias (NMB), and mean bias (MB). These indicators are used to assess the forecast performance of O3 numerical models.
Pollution Event Evaluation Metrics: The O
3 daily assessment indicator is the 8 h sliding average maximum value (denoted as O
3–8h max). The limit value for O
3–8h max in cities was set at 160 μg/m
3, and exceeding this limit indicated the occurrence of a pollution event. The distribution of observed and model-predicted values was classified into four scenarios, where cities were designated as follows: “
a” for days when both observed and predicted values were below the limit; “
b” for days when observed values were below the limit but predicted values exceeded it; “
c” for days when observed values exceeded the limit but predicted values were below it; and “
d” for days when both observed and predicted values exceeded the limit. The threshold forecast accuracy (FC) is used to assess the overall performance of the model’s ability to predict the occurrence of O
3 pollution events and is calculated using Formula (1).
The probability of detection (POD) is defined as the proportion of forecasted exceedance days among all observed O
3 exceedance days. It examines how well the model predicts O
3 pollution events, with a higher POD indicating better performance. The POD is calculated using Formula (2):
The false alarm rate (FAR) is defined as the proportion of forecasted exceedance days among all days where observed values do not exceed the limit. It assesses the model’s tendency to issue false alarms for O
3 pollution events, with a lower FAR indicating better performance. The FAR is calculated using Formula (3):
IAQI Comprehensive Evaluation: The model-predicted O
3–8h max values for each city were converted into corresponding IAQI values. The IAQI forecast range was obtained by allowing a 25% fluctuation above and below the model-predicted IAQI values. If the observed IAQI value for the O
3–8h max value in a city fell within this forecast range, it was considered accurate; otherwise, it was determined as a high or low IAQI forecast. Based on the daily IAQI forecast range, corresponding IAQI forecast level ranges were determined. If the observed IAQI level for the daily O
3–8h max concentration fell within this forecast level range, it was considered an accurate forecast; otherwise, it was categorized as a high or low forecast. The IAQI comprehensive accuracy rate (S) is calculated using Formula (4):
n represents the number of days with an accurate IAQI comprehensive forecast and N represents the total number of valid days during the evaluation period.
3. Results and Discussion
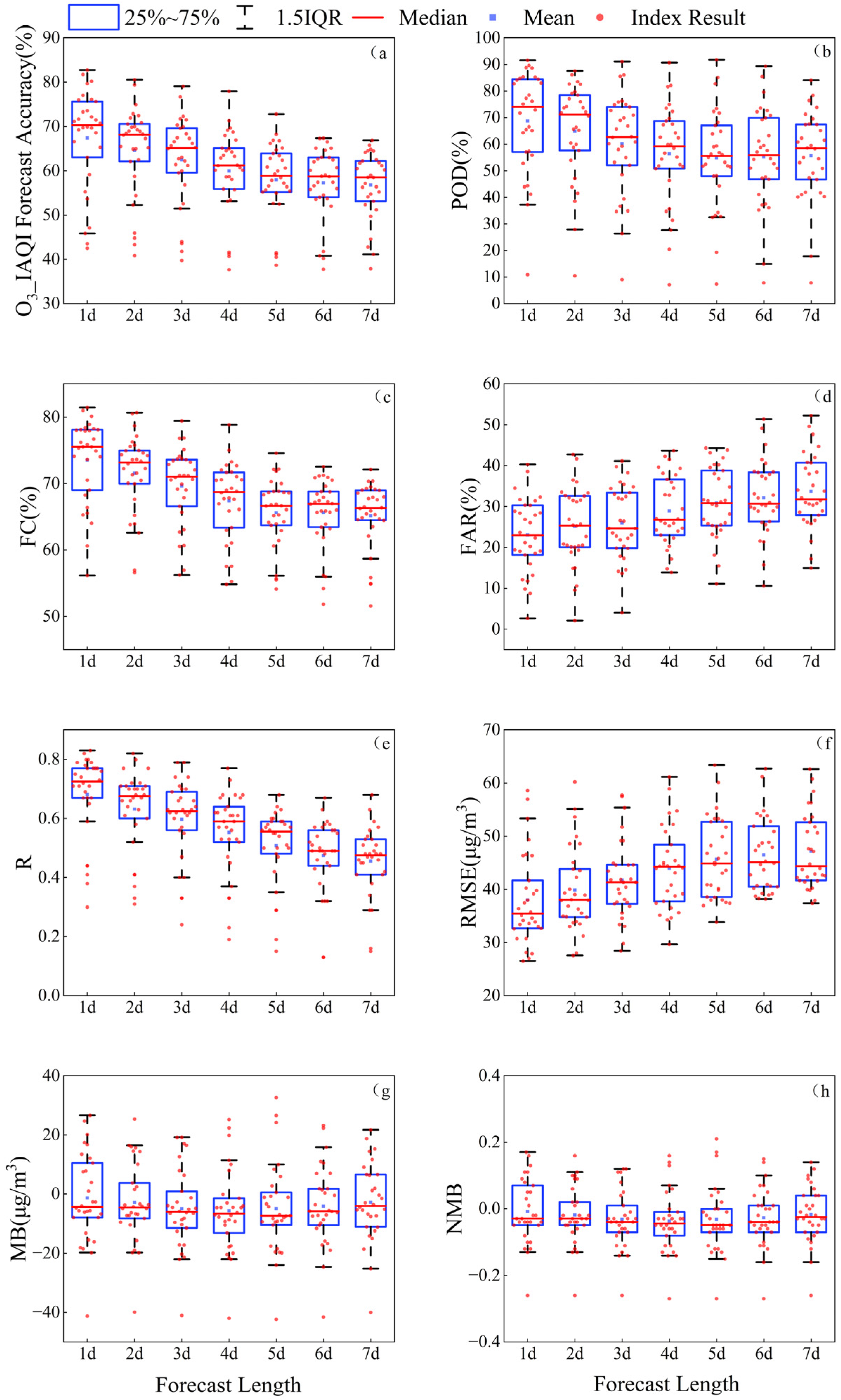
For the 30 sets of forecast results from cities in Beijing–Tianjin–Hebei and surrounding regions, evaluation metrics for different forecast lead times were calculated based on each city. The regional assessment results were represented by the average values of these metrics across all cities. In
Figure 1a, the distribution of regional O
3 IAQI comprehensive accuracy levels for different forecast lead times is presented (where the
x-axis represents 1d, 2d …7d, corresponding to forecasts for the next 1–7 days). The IAQI comprehensive accuracy could reach up to 83%, 81%, 79%, and 78% for lead times of 1–4 days, respectively, with average accuracy levels not falling below 60%. For lead times of 1–3 days, most models achieved accuracy levels above 65%.
Figure 1b–d present statistical results for pollution event assessment indicators. For lead times of 1–6 days, the POD of the top-performing forecast models could reach around 90%, with most models above 70% for lead times of 1–2 days. For lead times of 1–3 days, the FC could exceed 80%, with average values surpassing 70%, and the FAR for a lead time of 3 days could be as low as 4%, with most models having a FAR below 26%.
Figure 1e–h provide regional average statistical results for general statistical indicators. The correlation of O
3 forecasts significantly decreased with increasing lead times. For lead times of 1–4 days, the models with the highest correlation coefficients could reach 0.83, 0.82, 0.79, and 0.77, respectively, while for lead times of 5–7 days, the highest correlation coefficients were in the range of 0.67–0.68. For lead times of 1–3 days, most models had correlation coefficients exceeding 0.60. Smaller RMSE values indicated better forecasting performance. For lead times of 1–4 days, the models with the smallest RMSE were 27, 28, 28, and 30 μg/m
3, respectively, while most models did not exceed 40 μg/m
3. The MB and NMB were similar indicators, and when they approached 0, better model performance was achieved. Positive values indicated overestimation, while negative values indicated underestimation. The majority of models in the statistical period showed O
3 forecast results leaning toward underestimation. In summary, the comprehensive statistical results of all evaluation metrics for the 30 sets of O
3 forecasts in Beijing–Tianjin–Hebei and surrounding regions indicated a general deterioration trend with an increasing lead time. The results for forecasts within the next 1–3 day range showed significant reference significance.
The comprehensive analysis of the forecast results for three types of models (numerical, statistical, and ensemble) for a lead time of 3 days is presented in
Figure 2. The figure provides a synthesis of the regional average RMSE, NMB, and R values for each set of forecasts. In the plot, each circle represents a set of forecast results, with the
y-axis corresponding to the RMSE, the
x-axis corresponding to the NMB, and the size of the circle indicating the magnitude of R. The figure shows that the statistical models exhibited better overall performance in terms of RMSE and R values compared to the numerical and ensemble models. The majority of numerical and ensemble models showed small biases, while the statistical models demonstrated good consistency in all three evaluation metrics. The statistical models with the smallest RMSE also exhibited good NMB and correlation coefficients. For the four ensemble forecasts, R values were very close, ranging from 0.6 to 0.7, with RMSE differences not exceeding 8 μg/m
3. However, there was a notable disparity in the distribution of NMB, ranging from −0.26 to 0.12. The results from the twenty numerical models showed significant variability, but the best-performing numerical model was comparable to the statistical models and the best ensemble model. Overall, the statistical models demonstrated a closer resemblance to the observed O
3–8h max concentrations, and the best-performing numerical and ensemble models achieved a similar forecasting level.
In terms of IAQI comprehensive accuracy with a lead time of 3 days, the optimal model forecast results were selected as the top model. The models with the best IAQI comprehensive accuracy in numerical, statistical, and ensemble categories were denoted as top numerical, top statistical, and top ensemble, respectively.
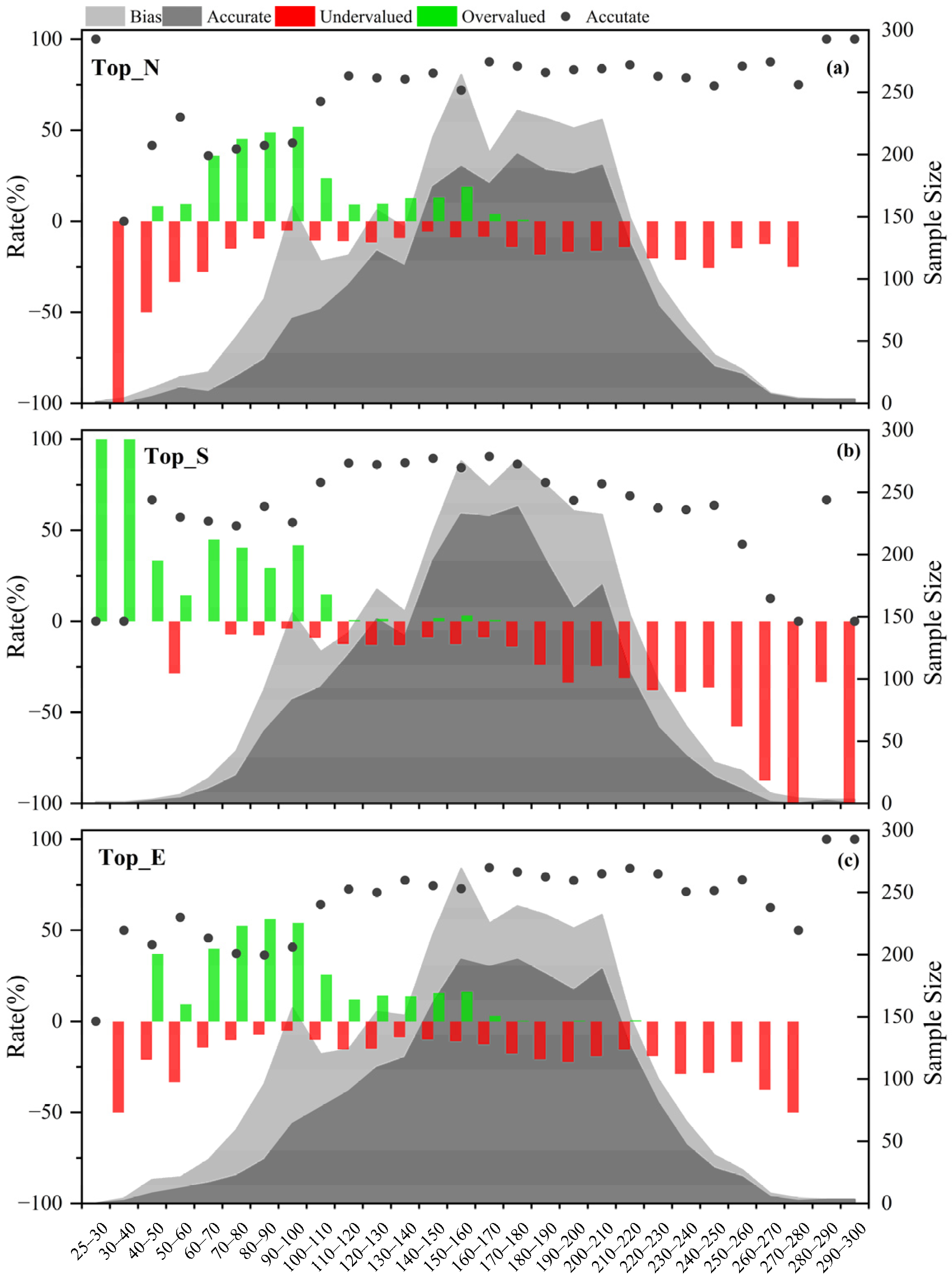
Figure 3a displays the regional average forecast performance for the top numerical, top statistical, and top ensemble models, which are abbreviated in the figure as Top_n, Top_s, and Top_e, respectively. The average IAQI comprehensive accuracy is ranked as follows: top statistical (65%) > top numerical (59%) > top ensemble (58%). Both numerical and ensemble models tended to overestimate, while statistical models tended to underestimate the O
3 concentration observation value. When a day had a O
3–8h max concentration over 160 μg/m
3, this day was defined as a polluted day.
Figure 3b focuses on evaluating the model’s forecast performance on polluted days during the evaluation period. The average IAQI comprehensive accuracy was ranked as follows: top ensemble (65%) > top numerical (64%) > top statistical (62%). The forecast accuracy of numerical and ensemble models improved on polluted days and surpassed that of statistical models. Additionally, it was observed that the top statistical bias rate is significantly higher than that of top numerical and top ensemble. This may be attributed to the limited predictive ability of statistical models concerning atypical events due to the quality and quantity of historical data [
29,
30]. Moreover, the lack of a description of long-distance transport and terrain for O
3 and its precursors can lead to significant deviations in pollution forecasting from complex environments [
31,
32]. Considering the varying performance of each model in different cities,
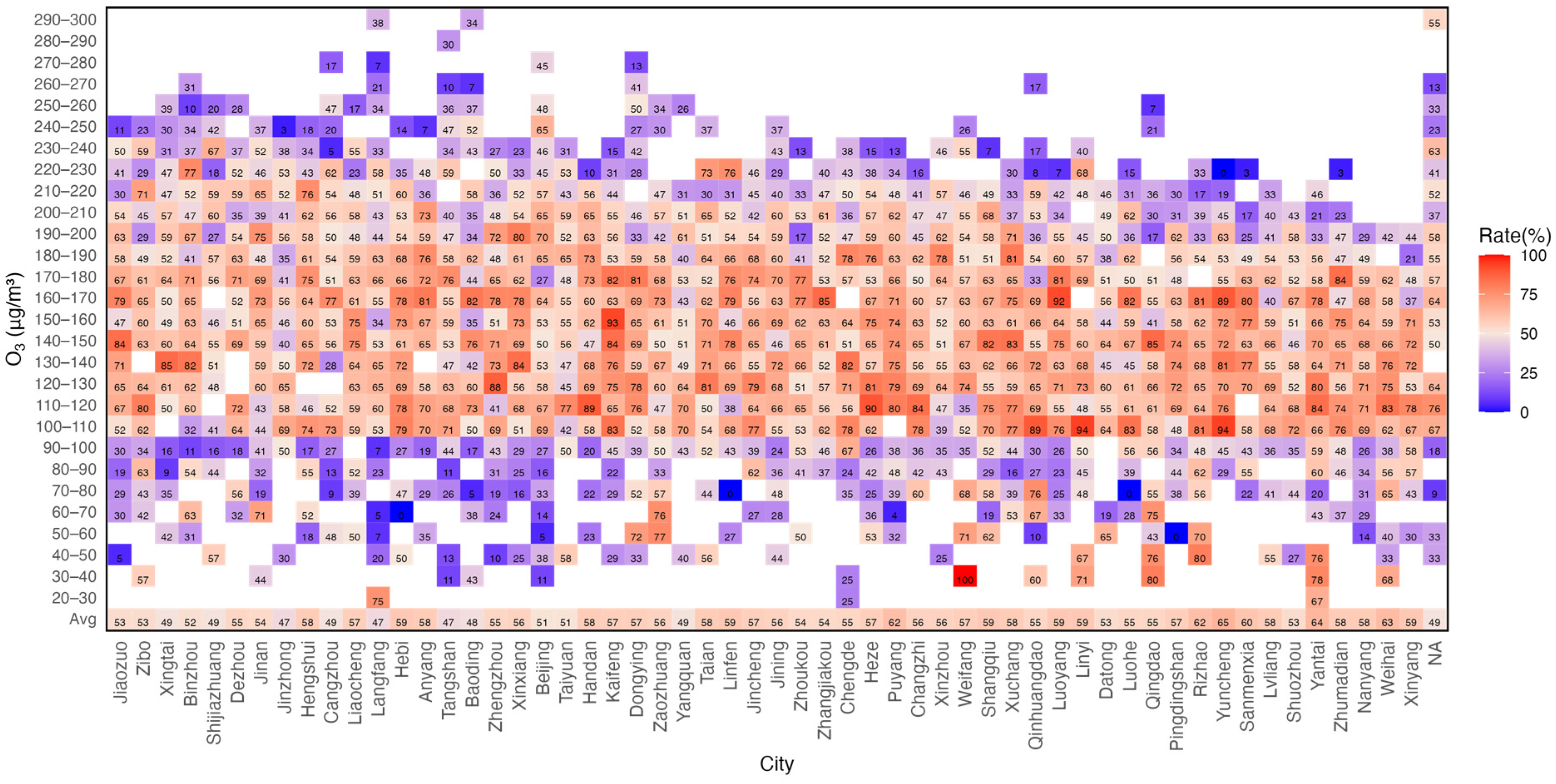
Figure 3c provides a breakdown of the forecast results for top models in each city. For all days in June and 25 July 2023, out of 57 cities, the top model had an accuracy exceeding 80%, with three cities reaching 90%. Additionally, 30 cities had top model accuracy ranging between 70% and 80%.
Figure 3d evaluates the forecast performance on polluted days, where black dots represent polluted days (i.e., the sample size for IAQI forecast performance assessment). It was observed that three cities had a top model accuracy rate of 100%, indicating accurate forecasts for all polluted days. Furthermore, 34 cities achieved accuracy rates exceeding 90%, with only three cities having accuracy rates below 80%. The forecast bias in all cities was mainly characterized by underestimation, demonstrating that the models tended to underestimate pollution events.
Figure 4 illustrates the relationship between O
3 concentration and the accuracy of model forecasts. The shaded areas represent the percentage of models with accurate IAQI comprehensive forecasts within the corresponding O
3 concentration range for each city. The
x-axis arranges cities in descending order based on the number of polluted days with daily mean O
3–8h max concentration above 200 μg/m
3, which is used to represent the pollution level. As the pollution level in cities decreased, there was an overall upward trend in the percentage of accurate models. When O
3–8h max concentrations ranged from 100 to 200 μg/m
3, over 60% of models could make accurate forecasts. Specifically, in the concentration range [100, 160), corresponding to the “Good” IAQI level, 63% of models provided accurate forecasts. In the concentration range of “Light Pollution” [160, 215), an average of 57% of models could accurately predict O
3 levels. However, when O
3–8h max was less than 100 μg/m
3 or greater than 215 μg/m
3, the percentage of models with accurate forecasts significantly dropped below 40%, especially when O
3–8h max reached the “Heavy Pollution” level, with the accuracy rate dropping to 28%.
To analyze the forecast performance of different models across different O
3 concentration ranges, the IAQI comprehensive accuracy of the next 3-day was used as the indicator to pick the top numerical, statistical, and ensemble models for each city. The forecast performance for all cities against the variations in the observed O
3 was then analyzed in
Figure 5. When O
3–8h max was in the concentration range of [110, 190), the accuracy of all three models was relatively high, i.e., around 80%. When the O
3–8h max value was low, both overestimation and underestimation could be observed in the numerical and ensemble models, while the statistical models tended to overestimate only. When the O
3–8h max value was high, the forecast bias for all three types of models was mainly underestimation. The numerical models had significantly more accuracy than the statistical models and slightly more accuracy than the ensemble models. The statistical models showed a significantly higher underestimation rate than the numerical and ensemble models, indicating that the statistical models have higher possibilities in failing to report high-concentration O
3 pollution events.
4. Conclusions
This study conducted O3 forecast experiments for all cities in Beijing–Tianjin–Hebei and surrounding regions, generating 30 sets of data from different numerical, statistical, and ensemble forecasting models. A comprehensive evaluation of 30 sets of forecasts results was explored and the conclusions are listed below:
When the lead time increases, the declining trend in O3 concentration forecast performance becomes more evident. The forecasts for lead times of 1–3 days had higher reference significance, while the forecasts for 5–7 days had larger errors. At a lead time of 3 days, most models achieved an IAQI forecast accuracy rate exceeding 65%, with the highest reaching 79%. For most models, the POD values surpassed 65%, with the highest being 90%. The lowest FAR did not exceed 4% and most models had a FAR below 26%. However, at a lead time of 5–7 days, forecast performance significantly declined, with an average IAQI forecast accuracy rate below 60%, POD averaging around 60%, a FAR over at least 10%, an average RMSE exceeding 40 μg/m3, and an average R dropping below 0.6.
An evaluation of different models across cities with varying pollution levels revealed that when O3–8h max is in the concentration range of (100, 200), over 60% of models can accurately predict it. However, beyond this concentration range, the proportion of models with accurate predictions significantly dropped to less than 40%. Overall, as the pollution level in cities increased, the proportion of models with accurate predictions showed a decreasing trend, indicating that there are still considerable shortcomings in the ability of various O3 models that can be used to accurately predict polluted days. Future efforts should focus on optimizing models to enhance the forecasting capability of O3 pollution processes.
From the perspective of statistical metrics, such as RMSE, NMB, and R, statistical models outperform numerical models and ensemble models in general. Numerical models exhibited significant performance variations, with only the best-performing numerical and ensemble models being comparable to statistical models, suggesting that well-designed numerical models have the potential to achieve high forecast accuracy. The continuous optimization of numerical models has significant importance. In terms of IAQI forecast-related metrics, statistical models exhibited significantly higher rates of underestimation compared to numerical and ensemble models. For the forecast of polluted days, numerical models and ensemble models could achieve accuracy rates of 65% and 64%, respectively, surpassing statistical models at 62%. The underestimation rate of numerical models was 25%, lower than that of other models. As underestimation may lead to missed opportunities for implementing control measures in advance, the results from best-performing numerical and ensemble forecasts provide more meaningful insight into pollution process. The best-performing numerical model showed significantly better forecasting performance in the high O3 concentration range compared to the best-performing statistical model, and slightly outperformed the best-performing ensemble model. In general, the overall forecast performance of numerical models was less accurate than that of statistical models, but the statistical model was less effective in predicting the O3 pollution process.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}