
Dugs-UNet: A Novel Deep Semantic Segmentation Approach to Convection Detection Based on FY-4A Geostationary Meteorological Satellite

 ,
,  ,
,
Abstract
1. Introduction
2. Methodology
2.1. Convection Labeling
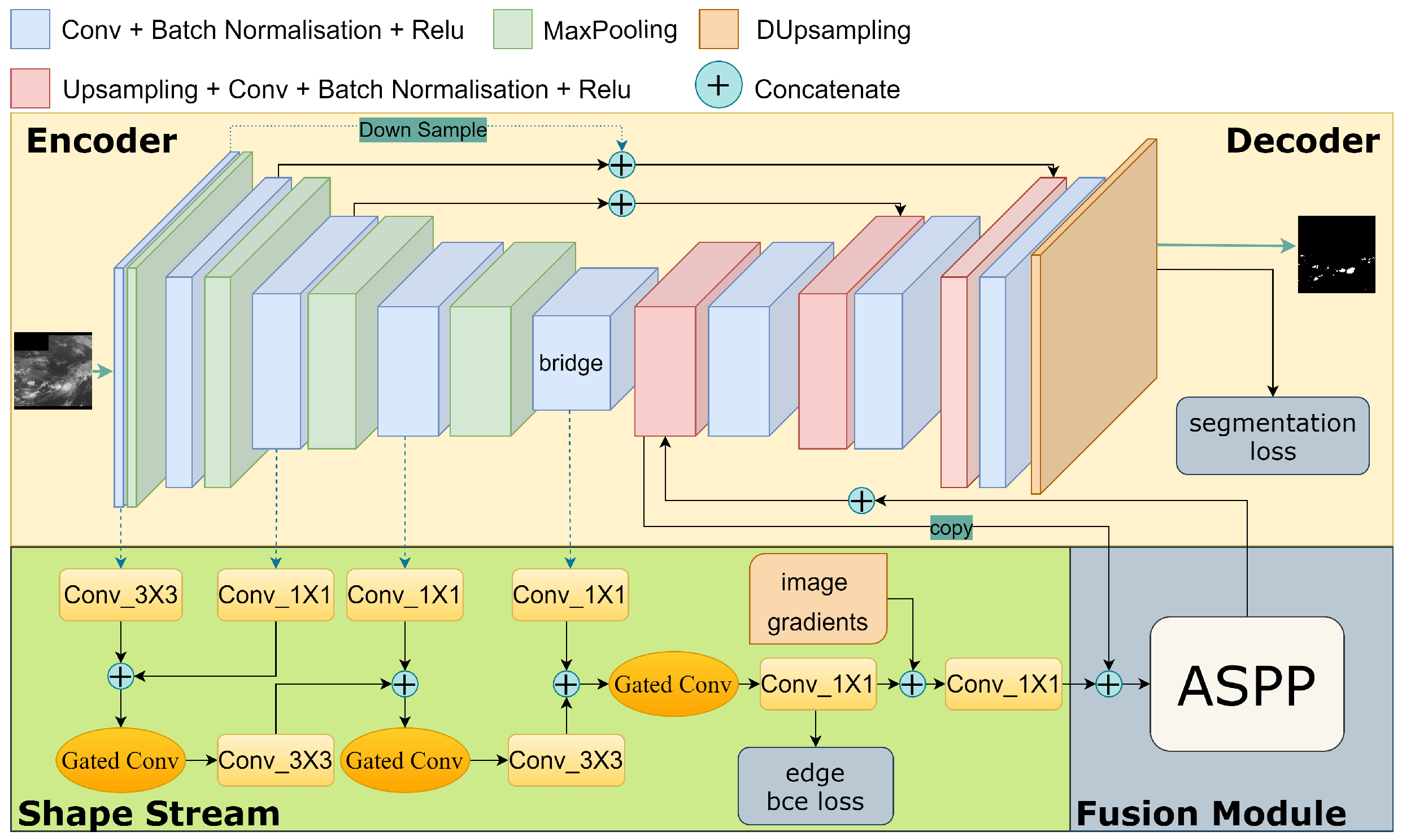
2.2. The Proposed Dugs-UNet
2.2.1. Overview
2.2.2. U-Net Backbone
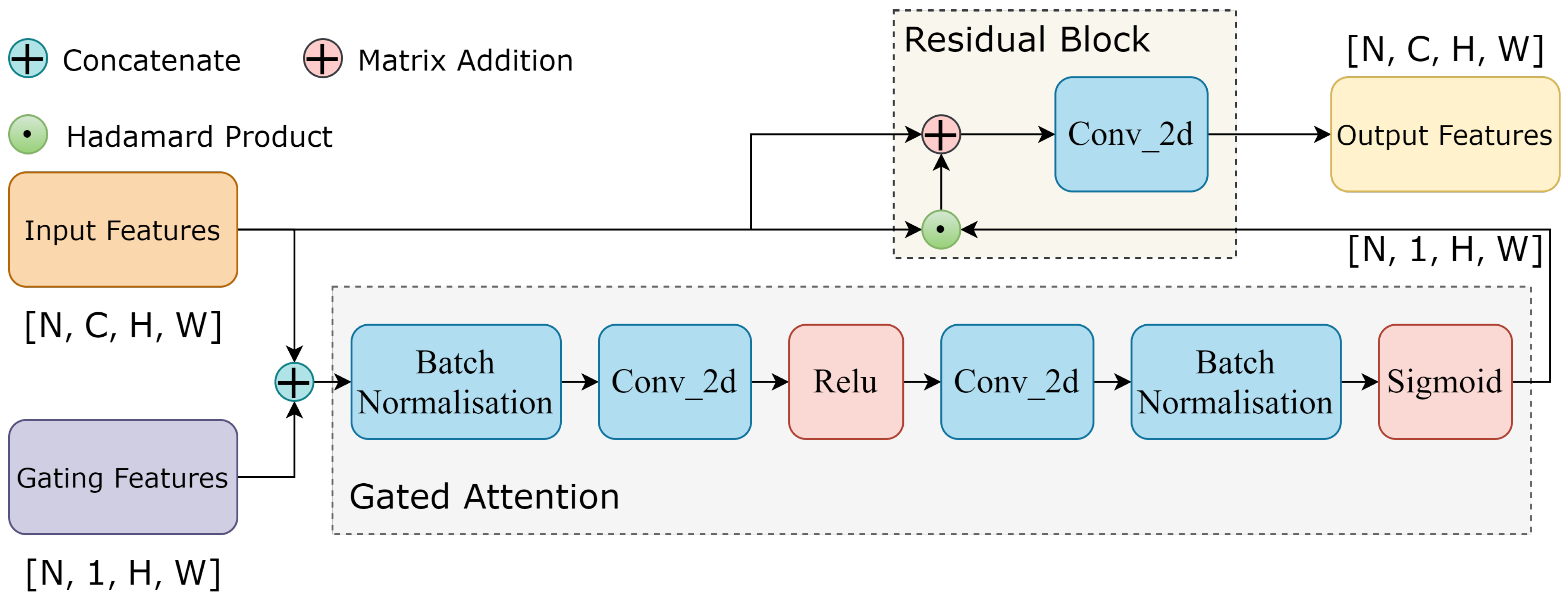
2.2.3. Shape Stream Module
2.2.4. Fusion Module
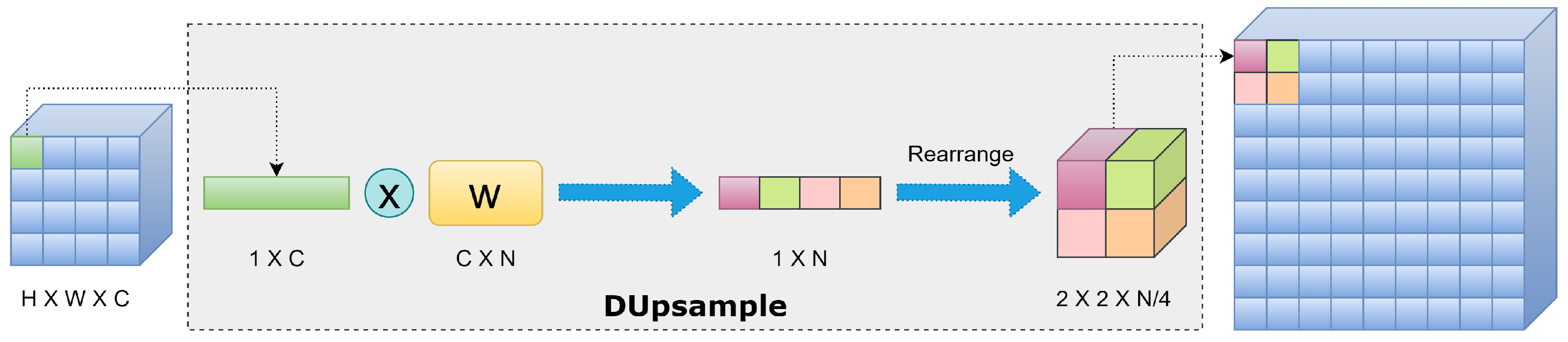
2.2.5. DUpsample Operation
2.2.6. Loss Function
3. Experiments
3.1. Experimental Setup
3.1.1. Data Sets
3.1.2. Evaluation Metrics
3.2. Baselines and Parameter Setting
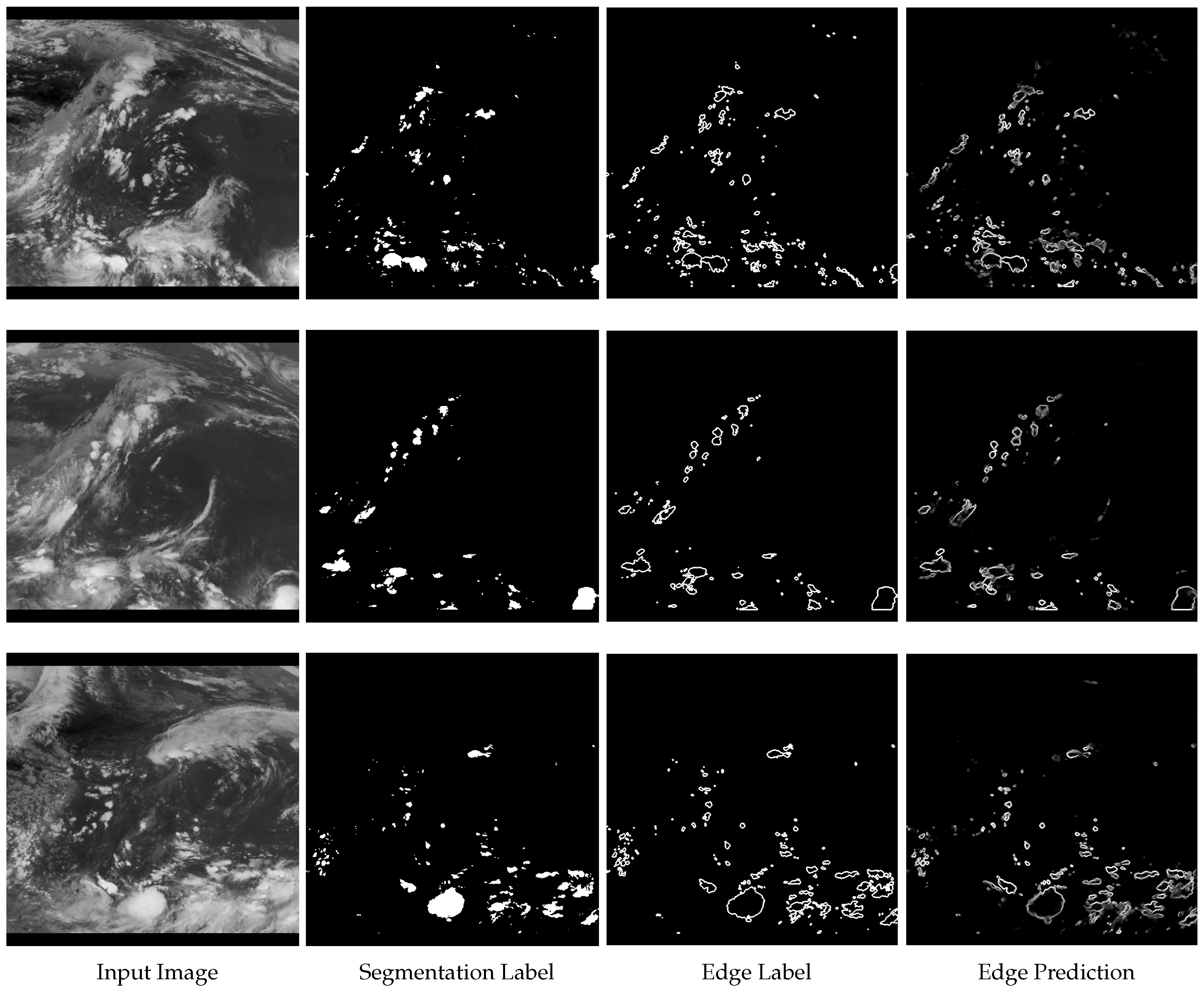
3.3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FY-4A | Fengyun 4A |
| AGRI | Advanced Geosynchronous Radiation Imager |
References
- Readhead, A.C.S. Equipartition brightness temperature and the inverse Compton catastrophe. Astrophys. J. 1994, 426, 51–59. [Google Scholar] [CrossRef]
- Adler, B.; Kalthoff, N.; Gantner, L. Initiation of deep convection caused by land-surface inhomogeneities in West Africa: A modelled case study. Meteorol. Atmos. Phys. 2011, 112, 15–27. [Google Scholar] [CrossRef]
- Ceccarelli, S.; Guimares, E.P.; Weltzien, E. Selection methods Part 1: Organizational aspects of a plant breeding programme. In Plant Breeding and Farmer Participation; Publishing House: Rome, Italy, 2009; pp. 195–222. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015—18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the Computer Vision—ECCV 2018—15th European Conference, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5228–5237. [Google Scholar]
- Tian, Z.; He, T.; Shen, C.; Yan, Y. Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3126–3135. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision(ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Encoder | Layer | Filter | Stride | Output Size | Decoder | Layer | Filter | Stride | Output Size |
|---|---|---|---|---|---|---|---|---|---|---|
| One | Input_1 | 800 × 800 × 1 | Input_10 | 800 × 800 × 2 | ||||||
| Output_1 | Conv1 | 3 × 3/16 | 1 | 800 × 800 × 16 | ||||||
| Output_2 | Conv2 | 3 × 3/16 | 1 | 800 × 800 × 16 | Output_28 | Temperature | 800 × 800 × 2 | |||
| Output_3 | MaxPool | 2 × 2 | 2 | 400 × 400 × 16 | ||||||
| Two | Input_2 | 400 × 400 × 16 | Input_9 | 400 × 400 × 80 | ||||||
| Output_4 | Conv3 | 3 × 3/32 | 1 | 400 × 400 × 32 | Output_25 | Conv18 | 3 × 3/32 | 1 | 400 × 400 × 32 | |
| Output_5 | Conv4 | 3 × 3/32 | 1 | 400 × 400 × 32 | Output_26 | Conv19 | 3 × 3/32 | 1 | 400 × 400 × 32 | |
| Output_6 | MaxPool | 2 × 2 | 2 | 200 × 200 × 32 | Output_27 | DUpsample | 2 × 2/2 | 800 × 800 × 2 | ||
| Three | Input_3 | 200 × 200 × 32 | Input_8 | 200 × 200 × 128 | ||||||
| Output_7 | Conv5 | 3 × 3/64 | 1 | 200 × 200 × 64 | Output_21 | Conv15 | 3 × 3/64 | 1 | 200 × 200 × 64 | |
| Output_8 | Conv6 | 3 × 3/64 | 1 | 200 × 200 × 64 | Output_22 | Conv16 | 3 × 3/64 | 1 | 200 × 200 × 64 | |
| Output_9 | MaxPool | 2 × 2 | 2 | 100 × 100 × 64 | Output_23 | Upsample | 2 × 2 | 400 × 400 × 64 | ||
| Output_24 | Conv17 | 3 × 3/32 | 1 | 400 × 400 × 32 | ||||||
| Four | Input_4 | 100 × 100 × 64 | Input_7 | 100 × 100 × 512 | ||||||
| Output_10 | Conv7 | 3 × 3/128 | 1 | 100 × 100 × 128 | Output_17 | Conv12 | 3 × 3/128 | 1 | 100 × 100 × 128 | |
| Output_11 | Conv8 | 3 × 3/128 | 1 | 100 × 100 × 128 | Output_18 | Conv13 | 3 × 3/128 | 1 | 100 × 100 × 128 | |
| Output_12 | MaxPool | 2 × 2 | 2 | 50 × 50 × 128 | Output_19 | Upsample | 2 × 2 | 200 × 200 × 128 | ||
| Output_20 | Conv14 | 3 × 3/64 | 1 | 200 × 200 × 64 | ||||||
| Five | Input_5 | 50 × 50 × 128 | Input_6 | 50 × 50 × 256 | ||||||
| Output_13 | Conv9 | 3 × 3/256 | 1 | 50 × 50 × 256 | Output_15 | Upsample | 2 × 2 | 100 × 100 × 256 | ||
| Output_14 | Conv10 | 3 × 3/256 | 1 | 50 × 50 × 256 | Output_16 | Conv11 | 3 × 3/128 | 1 | 100 × 100 × 128 |
| Region | Model | POD | FAR | CSI | Model | Precision | Recall | F1 |
|---|---|---|---|---|---|---|---|---|
| All | threshold = 210 K | 0.6022 | 0.0339 | 0.5897 | threshold = 210 K | 0.9661 | 0.6022 | 0.7419 |
| threshold = 215 K | 0.8292 | 0.1847 | 0.6981 | threshold = 215 K | 0.8153 | 0.8292 | 0.8222 | |
| threshold = 220 K | 0.9506 | 0.4014 | 0.5806 | threshold = 220 K | 0.5986 | 0.9506 | 0.7347 | |
| SegNet | 0.8780 | 0.0870 | 0.8103 | SegNet | 0.9130 | 0.8780 | 0.8952 | |
| PSPNet | 0.8340 | 0.1172 | 0.7509 | PSPNet | 0.8828 | 0.8340 | 0.8577 | |
| DeepLab-v3+ | 0.8602 | 0.1090 | 0.7784 | DeepLab-v3+ | 0.8910 | 0.8602 | 0.8754 | |
| U-Net | 0.8731 | 0.0623 | 0.8252 | U-Net | 0.9377 | 0.8731 | 0.9042 | |
| Dugs-UNet w.o. S | 0.8755 | 0.0611 | 0.8283 | Dugs-UNet w.o. S | 0.9389 | 0.8755 | 0.9061 | |
| Dugs-UNet w.o. D | 0.8854 | 0.0657 | 0.8336 | Dugs-UNet w.o. D | 0.9343 | 0.8854 | 0.9092 | |
| Dugs-UNet | 0.9002 | 0.0786 | 0.8360 | Dugs-UNet | 0.9214 | 0.9002 | 0.9107 | |
| North | threshold = 210 K | 0.0874 | 0.0182 | 0.0873 | threshold = 210 K | 0.9818 | 0.0874 | 0.1605 |
| threshold = 215 K | 0.3766 | 0.5974 | 0.2416 | threshold = 215 K | 0.4026 | 0.3766 | 0.3892 | |
| threshold = 220 K | 0.7788 | 0.7198 | 0.2596 | threshold = 220 K | 0.2802 | 0.7788 | 0.4121 | |
| SegNet | 0.6869 | 0.2545 | 0.5582 | SegNet | 0.7455 | 0.6896 | 0.7165 | |
| PSPNet | 0.8209 | 0.3787 | 0.5472 | PSPNet | 0.6213 | 0.8209 | 0.7073 | |
| DeepLab-v3+ | 0.7289 | 0.2525 | 0.5849 | DeepLab-v3+ | 0.7475 | 0.7289 | 0.7381 | |
| U-Net | 0.7500 | 0.2191 | 0.6196 | U-Net | 0.7809 | 0.7500 | 0.7651 | |
| Dugs-UNet w.o. S | 0.8123 | 0.2551 | 0.6355 | Dugs-UNet w.o. S | 0.7449 | 0.8123 | 0.7772 | |
| Dugs-UNet w.o. D | 0.7931 | 0.2076 | 0.6567 | Dugs-UNet w.o. D | 0.7924 | 0.7931 | 0.7928 | |
| Dugs-UNet | 0.8240 | 0.2165 | 0.6711 | Dugs-UNet | 0.7835 | 0.8240 | 0.8032 | |
| South | threshold = 210 K | 0.6579 | 0.0341 | 0.6430 | threshold = 210 K | 0.9659 | 0.6579 | 0.7827 |
| threshold = 215 K | 0.8782 | 0.1440 | 0.7652 | threshold = 215 K | 0.8560 | 0.8782 | 0.8670 | |
| threshold = 220 K | 0.9692 | 0.3357 | 0.6506 | threshold = 220 K | 0.6643 | 0.9692 | 0.7883 | |
| SegNet | 0.8547 | 0.0684 | 0.8042 | SegNet | 0.9316 | 0.8547 | 0.8915 | |
| PSPNet | 0.8320 | 0.1017 | 0.7604 | PSPNet | 0.8983 | 0.8320 | 0.8639 | |
| DeepLab-v3+ | 0.8665 | 0.0800 | 0.8058 | DeepLab-v3+ | 0.9200 | 0.8665 | 0.8925 | |
| U-Net | 0.8922 | 0.0551 | 0.8481 | U-Net | 0.9449 | 0.8922 | 0.9178 | |
| Dugs-UNet w.o. S | 0.8918 | 0.0498 | 0.8520 | Dugs-UNet w.o. S | 0.9502 | 0.8918 | 0.9201 | |
| Dugs-UNet w.o. D | 0.9019 | 0.0615 | 0.8516 | Dugs-UNet w.o. D | 0.9385 | 0.9019 | 0.9198 | |
| Dugs-UNet | 0.9219 | 0.0727 | 0.8598 | Dugs-UNet | 0.9273 | 0.9219 | 0.9246 |
| Number of Parameters | Number of Floating Operations (FLOPs) | Inference Time for a Satellite Image | |
|---|---|---|---|
| SegNet | 29.4 M | 1374.0G | 99.04 ms |
| PSPNet | 46.7 M | 232.0G | 47.93 ms |
| DeepLab-v3+ | 59.2 M | 215.2G | 65.72 ms |
| U-Net | 13.4 M | 289.9G | 64.82 ms |
| Dugs-UNet | 2.7 M | 43.1G | 34.44 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Shi, X.; Deng, G.; Li, X.; Sun, F.; Zhang, Y.; Qin, D. Dugs-UNet: A Novel Deep Semantic Segmentation Approach to Convection Detection Based on FY-4A Geostationary Meteorological Satellite. Atmosphere 2024, 15, 243. https://doi.org/10.3390/atmos15030243
Li Y, Shi X, Deng G, Li X, Sun F, Zhang Y, Qin D. Dugs-UNet: A Novel Deep Semantic Segmentation Approach to Convection Detection Based on FY-4A Geostationary Meteorological Satellite. Atmosphere. 2024; 15(3):243. https://doi.org/10.3390/atmos15030243
Chicago/Turabian StyleLi, Yan, Xiaochang Shi, Guangbo Deng, Xutao Li, Fenglin Sun, Yanfeng Zhang, and Danyu Qin. 2024. "Dugs-UNet: A Novel Deep Semantic Segmentation Approach to Convection Detection Based on FY-4A Geostationary Meteorological Satellite" Atmosphere 15, no. 3: 243. https://doi.org/10.3390/atmos15030243
APA StyleLi, Y., Shi, X., Deng, G., Li, X., Sun, F., Zhang, Y., & Qin, D. (2024). Dugs-UNet: A Novel Deep Semantic Segmentation Approach to Convection Detection Based on FY-4A Geostationary Meteorological Satellite. Atmosphere, 15(3), 243. https://doi.org/10.3390/atmos15030243