
A Branched Convolutional Neural Network for Forecasting the Occurrence of Hazes in Paris Using Meteorological Maps with Different Characteristic Spatial Scales


Abstract
1. Introduction
2. Data and Methodology
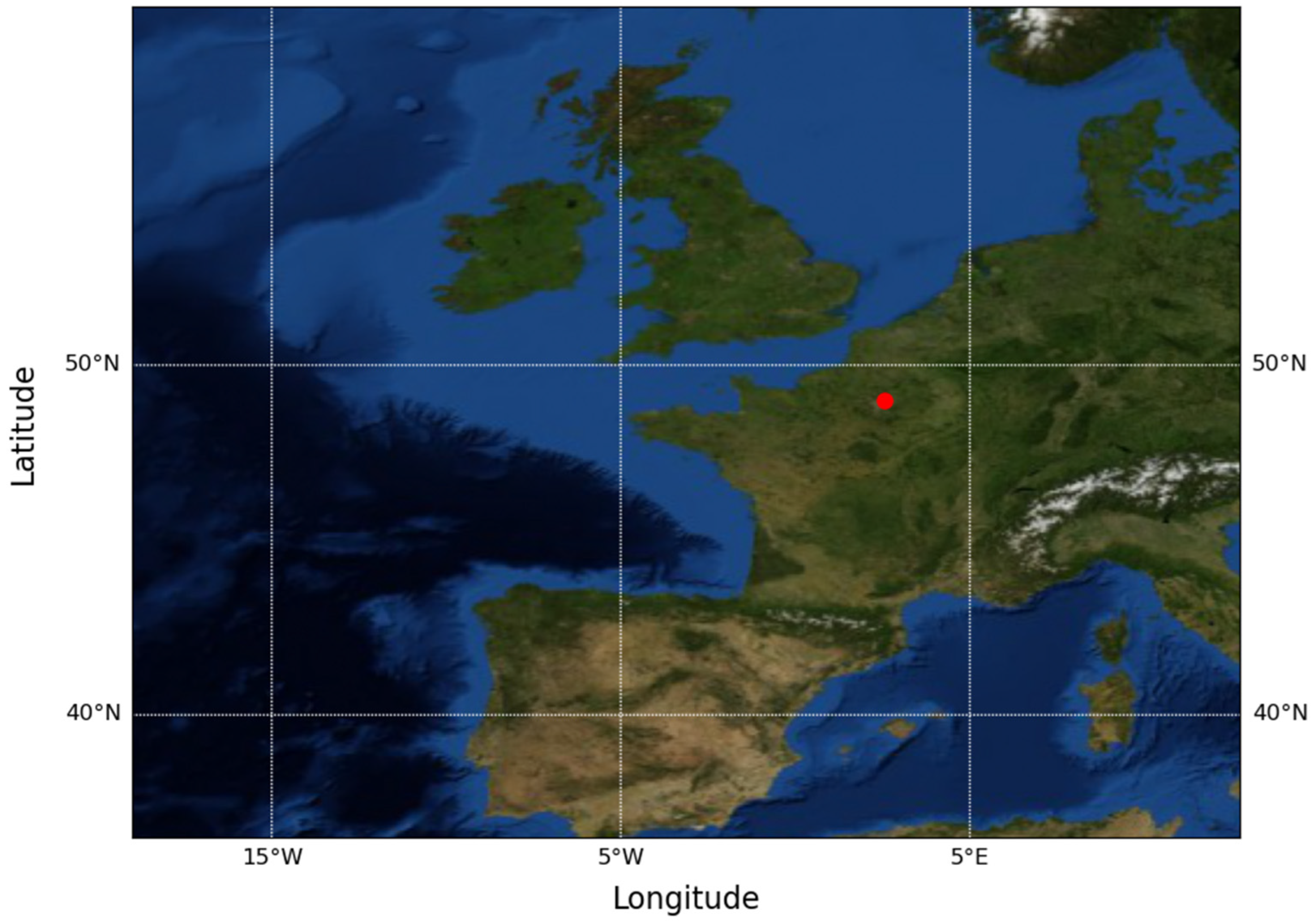
2.1. Data
2.2. Training–Validation–Evaluation Strategy
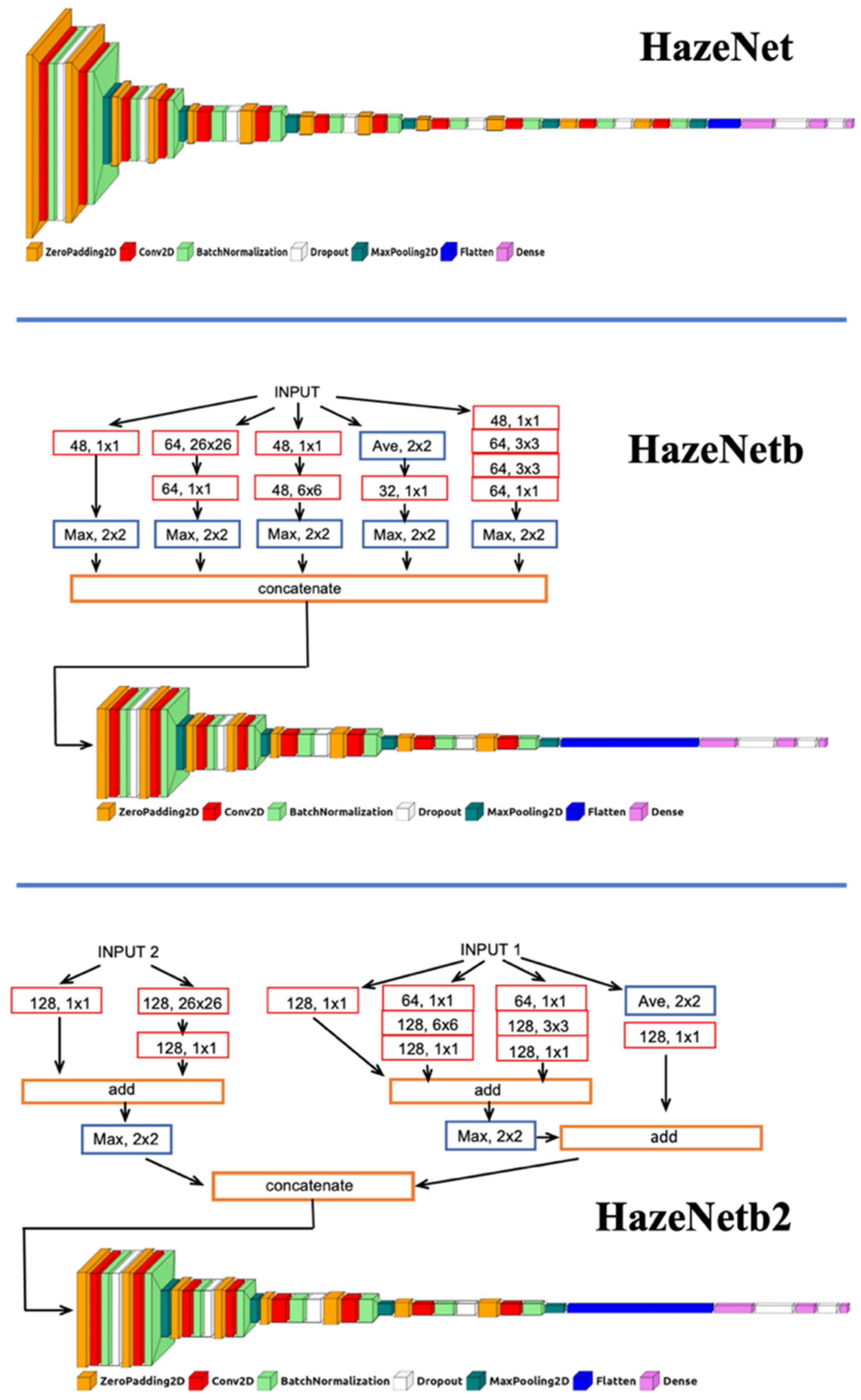
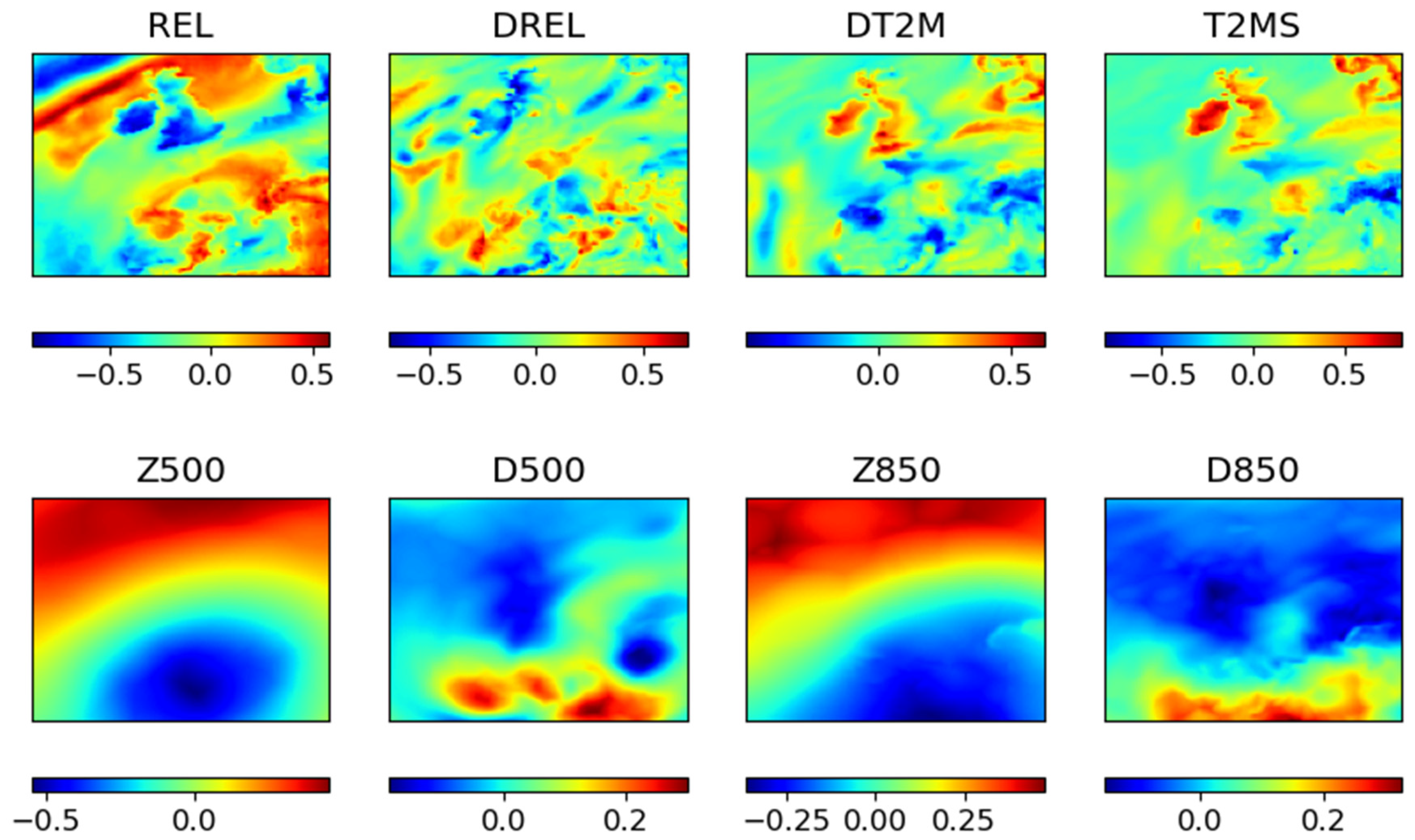
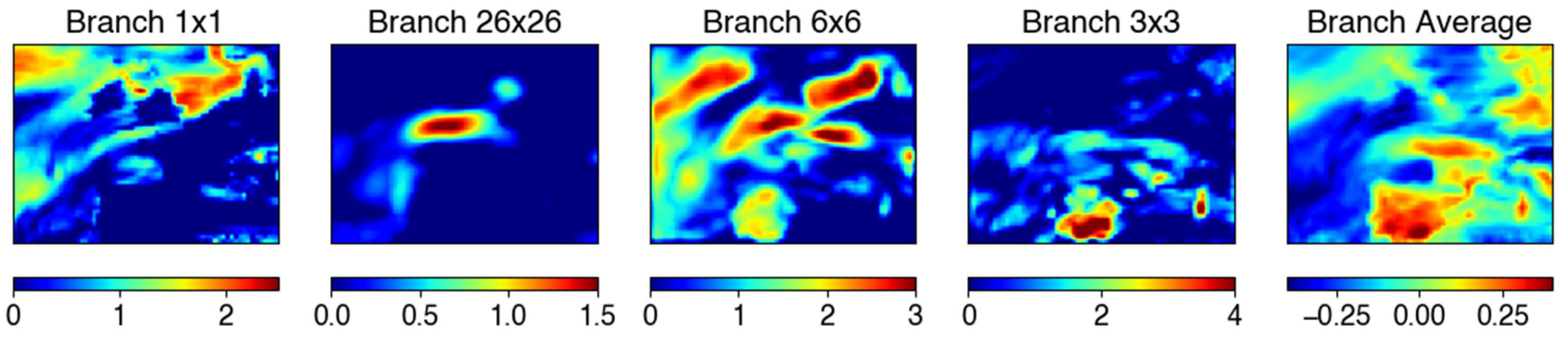
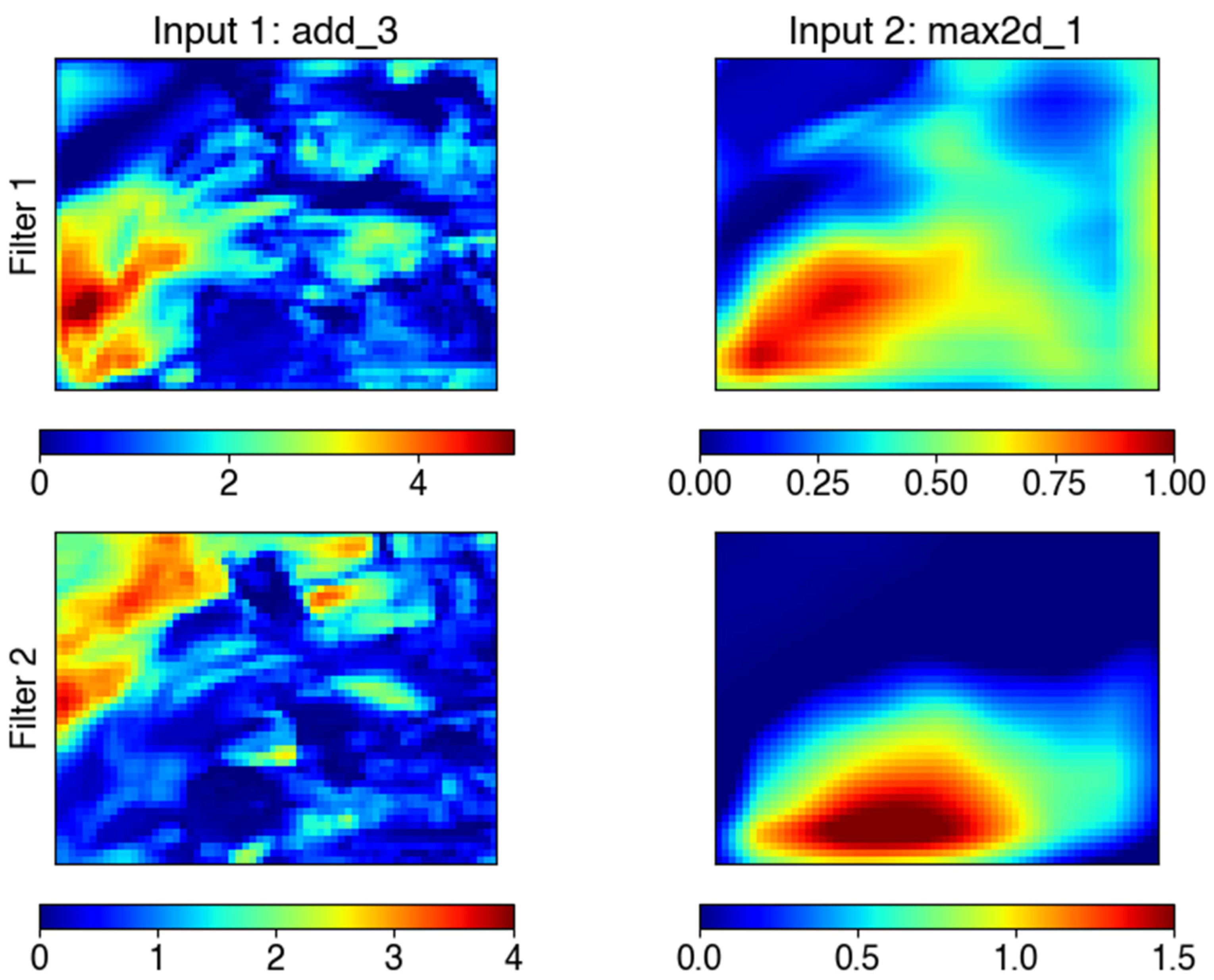
2.3. Architecture Improvement
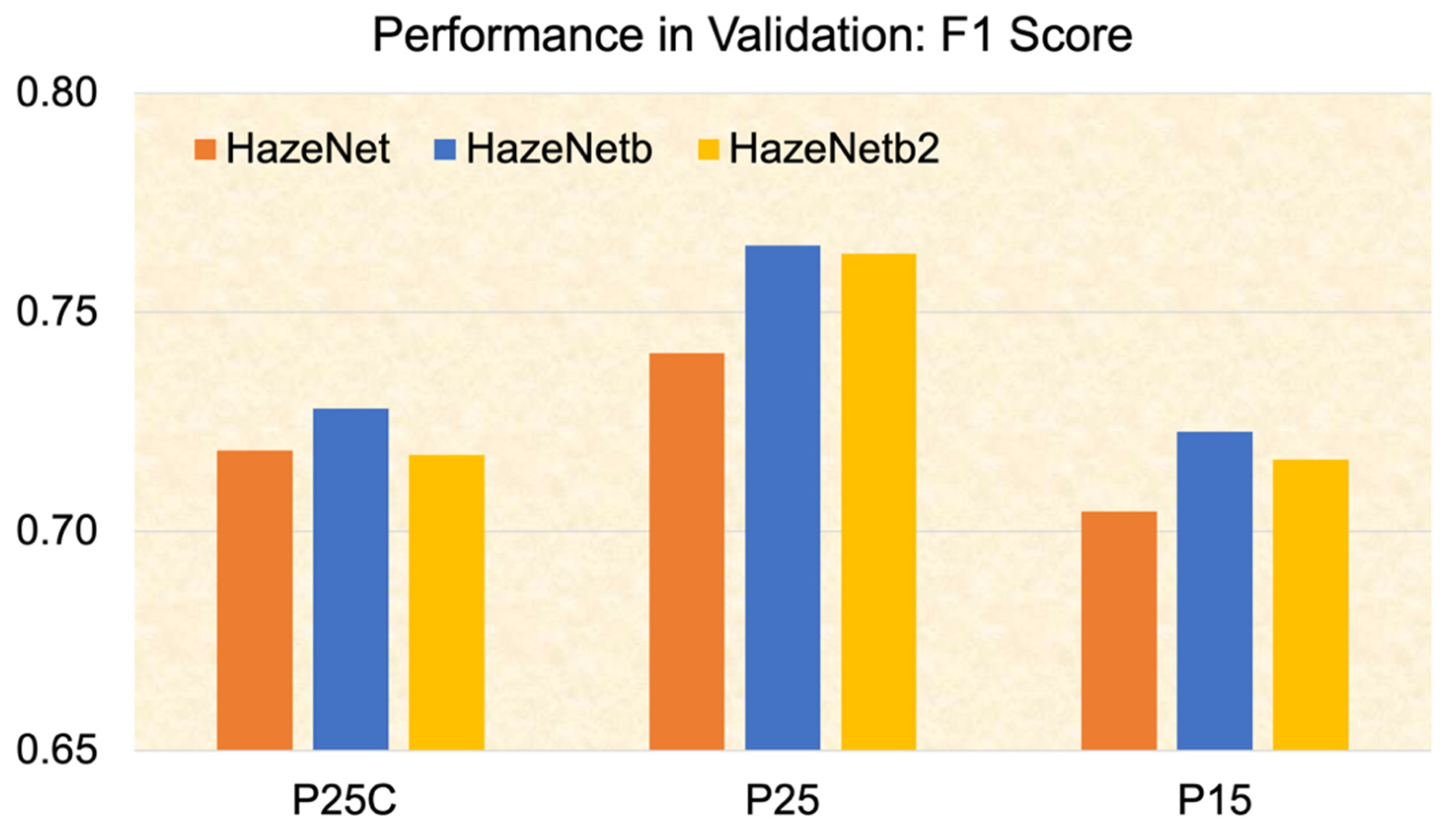
3. Performance in Validation of Trained Machines
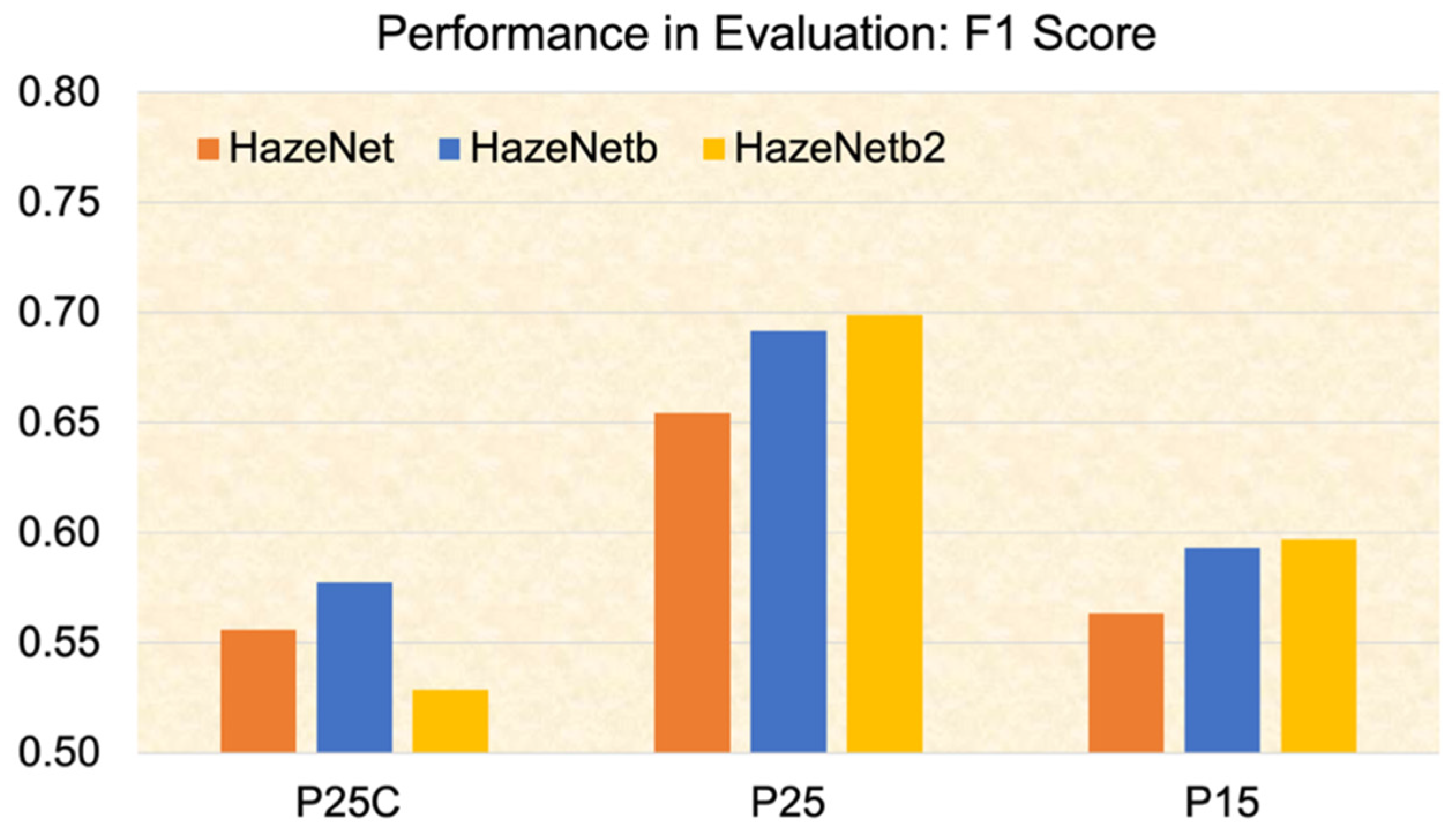
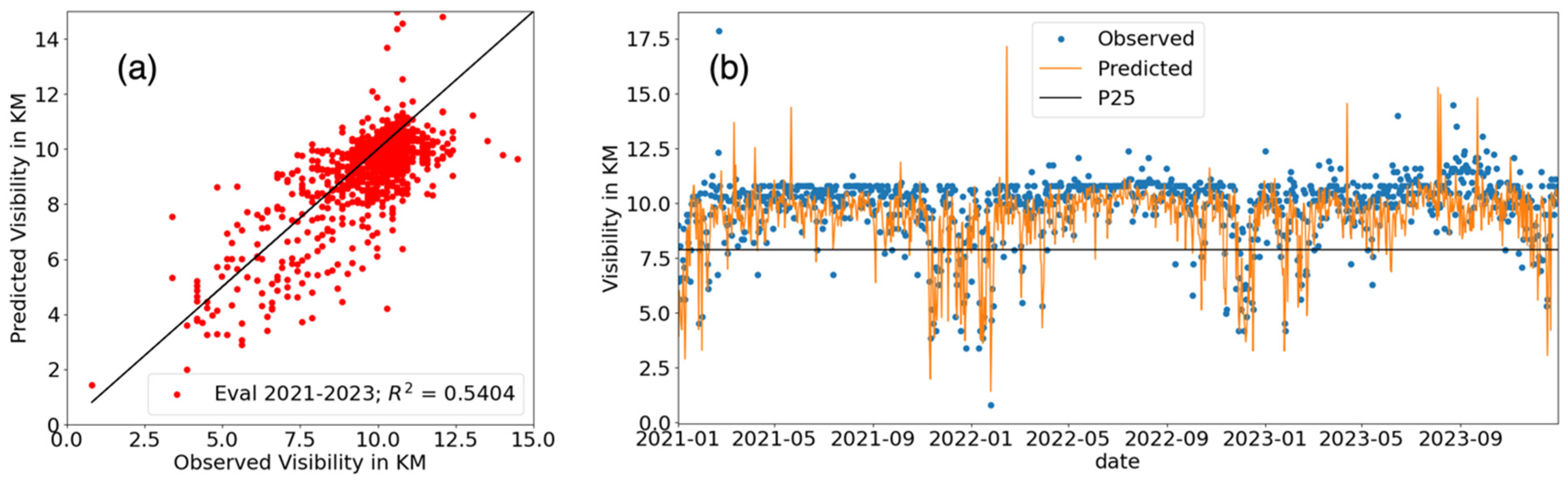
4. Evaluation of the Trained Machines Using 2021 and 2023 Data
5. Summary and Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Willet, H.C. Fog and haze, their causes, distribution, and forecasting. Mon. Weather Rev. 1928, 56, 435–468. [Google Scholar] [CrossRef]
- Lee, H.-H.; Bar-Or, R.; Wang, C. Biomass burning aerosols and the low visibility events in Southeast Asia. Atmos. Chem. Phys. 2017, 17, 965–980. [Google Scholar] [CrossRef]
- Wang, C. Forecasting and identifying the meteorological and hydrological conditions favoring the occurrence of severe hazes in Beijing and Shanghai using deep learning. Atmos. Chem. Phys. 2021, 21, 13149–13166. [Google Scholar] [CrossRef]
- Day, D.E.; Malm, W.C. Aerosol light scattering measurements as a function of relative humidity: A comparison between measurements made at three different sites. Atmos. Environ. 2001, 35, 5169–5176. [Google Scholar] [CrossRef]
- Hyslop, N.P. Impaired visibility: The air pollution people see. Atmos. Environ. 2009, 43, 182–195. [Google Scholar] [CrossRef]
- Bergot, T.; Terradella, E.; Cuxart, J.; Mira, A.; Liechti, O.; Mueller, M.; Nielsen, N.W. Intercomparison of single column numerical models for the prediction of radiation fog. J. Appl. Meteorol. Clim. 2007, 46, 504–521. [Google Scholar] [CrossRef]
- Marzban, C.; Leyton, S.; Colman, B. Ceiling and visibility forecast via neural networks. Weather Forecast. 2007, 22, 466–479. [Google Scholar] [CrossRef]
- Dutta, D.; Chaudhuri, S. Nowcasting visibility during wintertime fog over the airport of a metropolis of India: Decision tree algorithm and artificial neural network approach. Nat. Hazards 2016, 75, 1349–1368. [Google Scholar] [CrossRef]
- Castillo-Botón, C.; Casillas-Pérez, D.; Casanova-Mateo, C.; Ghimire, S.; Cerro-Prada, E.; Gutierrez, P.A.; Deo, R.C.; Salcedo-Sanz, S. Machine learning regression and classification methods for fog events prediction. Atmos. Res. 2022, 272, 106157. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Y.; Zhu, Y.; Yang, L.; Ge, L.; Luo, C. Visibility prediction based on machine learning algorithms. Atmosphere 2022, 13, 1125. [Google Scholar] [CrossRef]
- Gagne, D.J., III; Haupt, S.E.; Nychka, D.W.; Thompson, G. Interpretable deep learning for spatial analysis of severe hailstorms. Mon. Weather Rev. 2019, 137, 2827–2856. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Nabizadeh, E.; Hassanzadeh, P. Analog forecasting of extreme-causing weather patterns using deep learning. J. Adv. Model. Earth Syst. 2020, 12, e2019MS001958. [Google Scholar] [CrossRef]
- Chen, K.; Zhou, Y.; Ren, T.; Li, X. Short-term sea fog area forecast: A new data set and deep learning approach. J. Geophys. Res. Mach. Learn. Comput. 2024, 1, e2024JH000230. [Google Scholar] [CrossRef]
- Yang, N.; Wang, C.; Li, X. Improving tropical cyclone precipitation forecasting with deep learning and satellite image sequencing. J. Geophys. Res. Mach. Learn. Comput. 2024, 1, e2024JH000175. [Google Scholar] [CrossRef]
- Wang, C. Exploiting deep learning in forecasting the occurrence of severe haze in Southeast Asia. arXiv 2020. [Google Scholar] [CrossRef]
- Smith, A.; Lott, N.; Vose, R. The integrated surface database: Recent developments and partnerships. Bull. Am. Meteorol. Soc. 2011, 92, 704–708. [Google Scholar] [CrossRef]
- Wang, C. A modeling study on the climate impacts of black carbon aerosols. J. Geophys. Res. 2004, 109, D03106. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Han, J.; Morag, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In From Natural to Artificial Neural Computation; Lecture Notes in Computer Science; Mira, J., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; Volume 930, pp. 195–201. [Google Scholar] [CrossRef]
- Bridle, J.S. Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition. In Neurocomputing: Algorithms, Architectures and Applications; NATO ASI Series (Series F: Computer and Systems Sciences); Soulié, F.F., Hérault, J., Eds.; Springer: Berlin/Heidelberg, Germany, 1990; Volume 68, pp. 227–236. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Holton, J.R. An Introduction to Dynamic Meteorology, 4th ed.; Elsevier Academic Press: Boston, MA, USA, 2004; 535p. [Google Scholar]
- Markowski, P.; Richardson, Y. Mesoscale Meteorology in Midlatitudes; Willey-Blackwell: West Sussex, UK, 2010; 430p. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. arXiv 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2014. [Google Scholar] [CrossRef]
- Wang, H.; Wang, S.; Qin, Z.; Zhang, Y.; Li, R.; Xia, Y. Triple attention learning for classification of 14 thoracic diseases using chest radiography. Med. Image Anal. 2021, 67, 101846. [Google Scholar] [CrossRef]
- Wang, C. A branched deep convolutional neural network for forecasting the occurrence of hazes in Paris using meteorological maps with different characteristic spatial scales. arXiv 2023. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P5 | P10 | P15 | P20 | P25 | |
|---|---|---|---|---|---|
| vis. (KM) | 3.70 | 5.15 | 6.44 | 7.24 | 7.89 |
| Events without fog label | 251 | 665 | 1241 | 1788 | 2374 |
| All events | 878 | 1670 | 2579 | 3359 | 4110 |
| Short Name | Long Name | Branch in HazeNetb2 |
|---|---|---|
| REL | Surface relative humidity | 1 |
| DREL | Diurnal change in REL, [14:19]mean–[6:12]mean | 1 |
| DT2M | Diurnal change of 2 m in temperature | 1 |
| T2MS | Daily standard deviation of 2 m in temperature | 1 |
| U10 | 10 m wind, zonal component | 1 |
| V10 | 10 m wind, meridional component | 1 |
| TCW | Total column water | 1 |
| TCV | Total column water vapor | 1 |
| DTCV | Diurnal change in TCV | 1 |
| BLH | Height of planetary boundary layer | 1 |
| DBLH | Diurnal change in BLH | 1 |
| SW1 | Volumetric soli water, layer 1 | 1 |
| SW2 | Volumetric soil water, layer 2 | 1 |
| LCC | Low cloud cover | 1 |
| Z500 | Geopotential at 500 hPa level | 2 |
| D500 | Diurnal change in Z500 | 2 |
| Z850 | Geopotential at 850 hPa level | 2 |
| D850 | Diurnal change in Z850 | 2 |
| Accuracy | Precision | Recall | F1-Score | |
|---|---|---|---|---|
| Classification (P25C) | ||||
| HazeNet | 0.851 | 0.717 | 0.721 | 0.719 |
| HazeNetb | 0.858 | 0.732 | 0.724 | 0.728 |
| HazeNetb2 | 0.854 | 0.726 | 0.718 | 0.722 |
| Regression–Classification (P25) | ||||
| HazeNet | 0.875 | 0.815 | 0.680 | 0.741 |
| HazeNetb | 0.885 | 0.826 | 0.713 | 0.765 |
| HazeNetb2 | 0.882 | 0.806 | 0.725 | 0.763 |
| Regression–Classification (P20) | ||||
| HazeNet | 0.892 | 0.800 | 0.679 | 0.734 |
| HazeNetb | 0.896 | 0.811 | 0.683 | 0.742 |
| HazeNetb2 | 0.894 | 0.796 | 0.694 | 0.742 |
| Regression–Classification (P15) | ||||
| HazeNet | 0.905 | 0.750 | 0.665 | 0.705 |
| HazeNetb | 0.913 | 0.784 | 0.670 | 0.723 |
| HazeNetb2 | 0.909 | 0.756 | 0.681 | 0.716 |
| Regression–Classification (P10) | ||||
| HazeNet | 0.928 | 0.722 | 0.586 | 0.647 |
| HazeNetb | 0.925 | 0.735 | 0.530 | 0.616 |
| HazeNetb2 | 0.926 | 0.733 | 0.547 | 0.627 |
| Regression–Classification (P5) | ||||
| HazeNet | 0.952 | 0.698 | 0.342 | 0.459 |
| HazeNetb | 0.950 | 0.721 | 0.255 | 0.377 |
| HazeNetb2 | 0.952 | 0.759 | 0.272 | 0.400 |
| HazeNet | HazeNetb | HazeNetb2 | |
|---|---|---|---|
| Mean absolute percentage error (%) | 10.02 | 9.82 | 9.92 |
| R2 | 0.53 | 0.58 | 0.54 |
| F1 score of P25C | 0.56 | 0.58 | 0.53 |
| F1 score of P25 | 0.65 | 0.69 | 0.70 |
| F1 score of P20 | 0.67 | 0.65 | 0.66 |
| F1 score of P15 | 0.56 | 0.59 | 0.60 |
| F1 score of P10 | 0.54 | 0.47 | 0.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C. A Branched Convolutional Neural Network for Forecasting the Occurrence of Hazes in Paris Using Meteorological Maps with Different Characteristic Spatial Scales. Atmosphere 2024, 15, 1239. https://doi.org/10.3390/atmos15101239
Wang C. A Branched Convolutional Neural Network for Forecasting the Occurrence of Hazes in Paris Using Meteorological Maps with Different Characteristic Spatial Scales. Atmosphere. 2024; 15(10):1239. https://doi.org/10.3390/atmos15101239
Chicago/Turabian StyleWang, Chien. 2024. "A Branched Convolutional Neural Network for Forecasting the Occurrence of Hazes in Paris Using Meteorological Maps with Different Characteristic Spatial Scales" Atmosphere 15, no. 10: 1239. https://doi.org/10.3390/atmos15101239
APA StyleWang, C. (2024). A Branched Convolutional Neural Network for Forecasting the Occurrence of Hazes in Paris Using Meteorological Maps with Different Characteristic Spatial Scales. Atmosphere, 15(10), 1239. https://doi.org/10.3390/atmos15101239