
Methods for Urban Air Pollution Measurement and Forecasting: Challenges, Opportunities, and Solutions


 ,
,  ,
, 
Abstract
:1. Introduction
2. Related Work
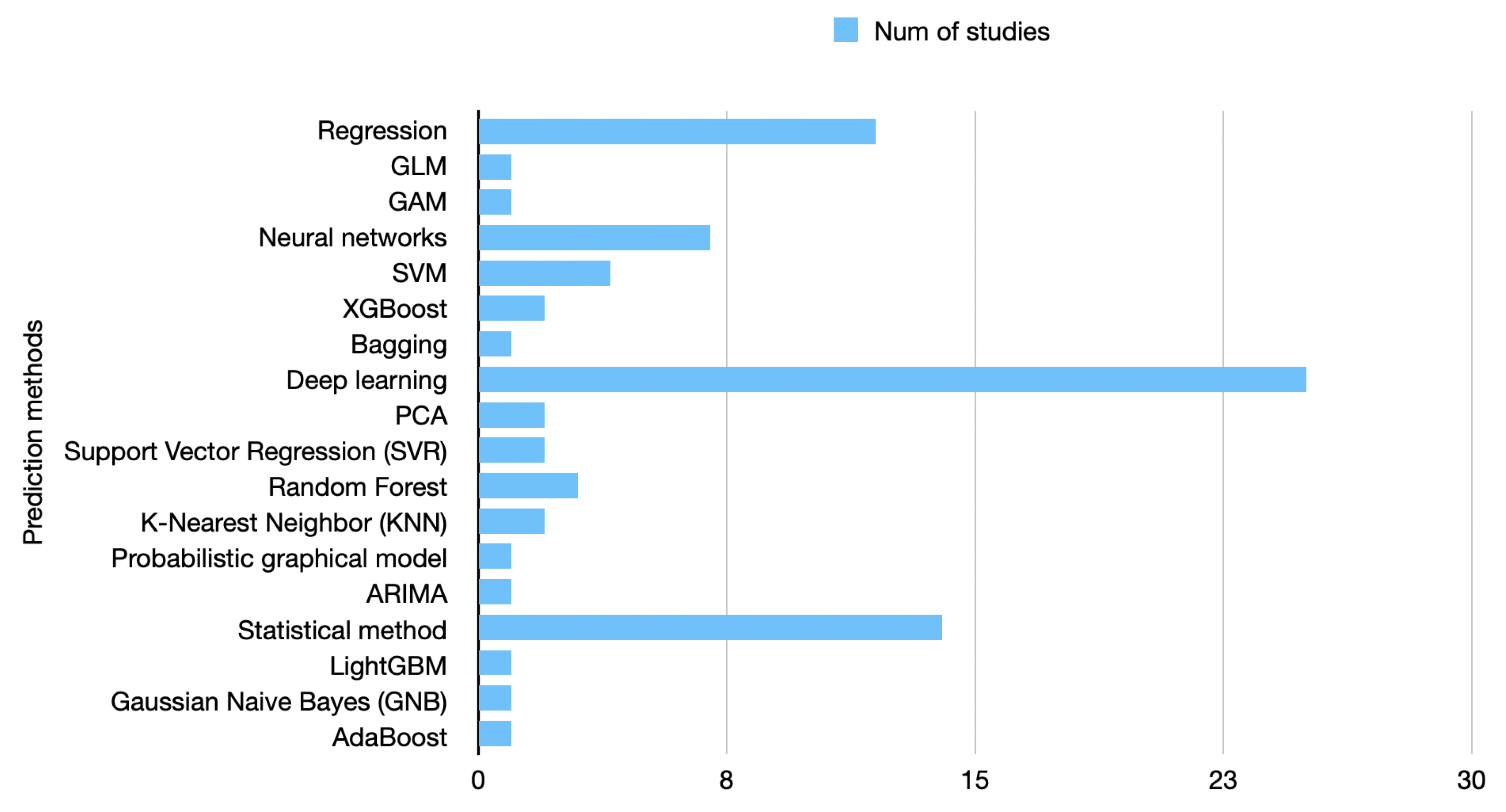
- What are the most prevalent methods for air pollution forecasting (i.e., prediction) published in the last eight years?
- What are the strengths and limitations of the ML approaches for air pollution forecasting?
- What are the most prevalent input data modalities for air pollution forecasting?
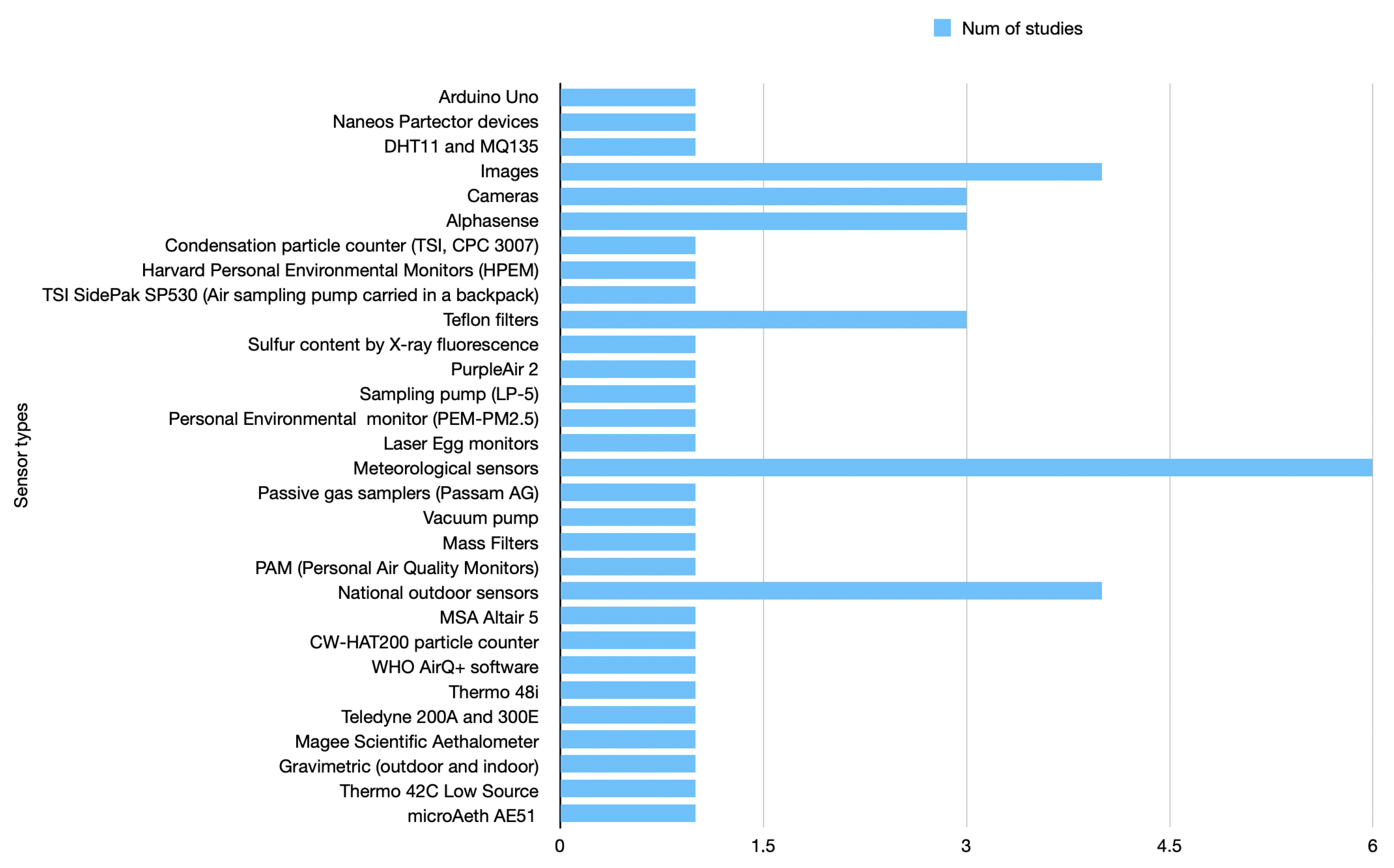
- What are the most dominant sensor types for urban air pollution forecasting?
- What are the current research and technological gaps in air pollution research related to the city of Skopje, North Macedonia?
3. Methods
3.1. Air Pollution Monitoring and Prediction
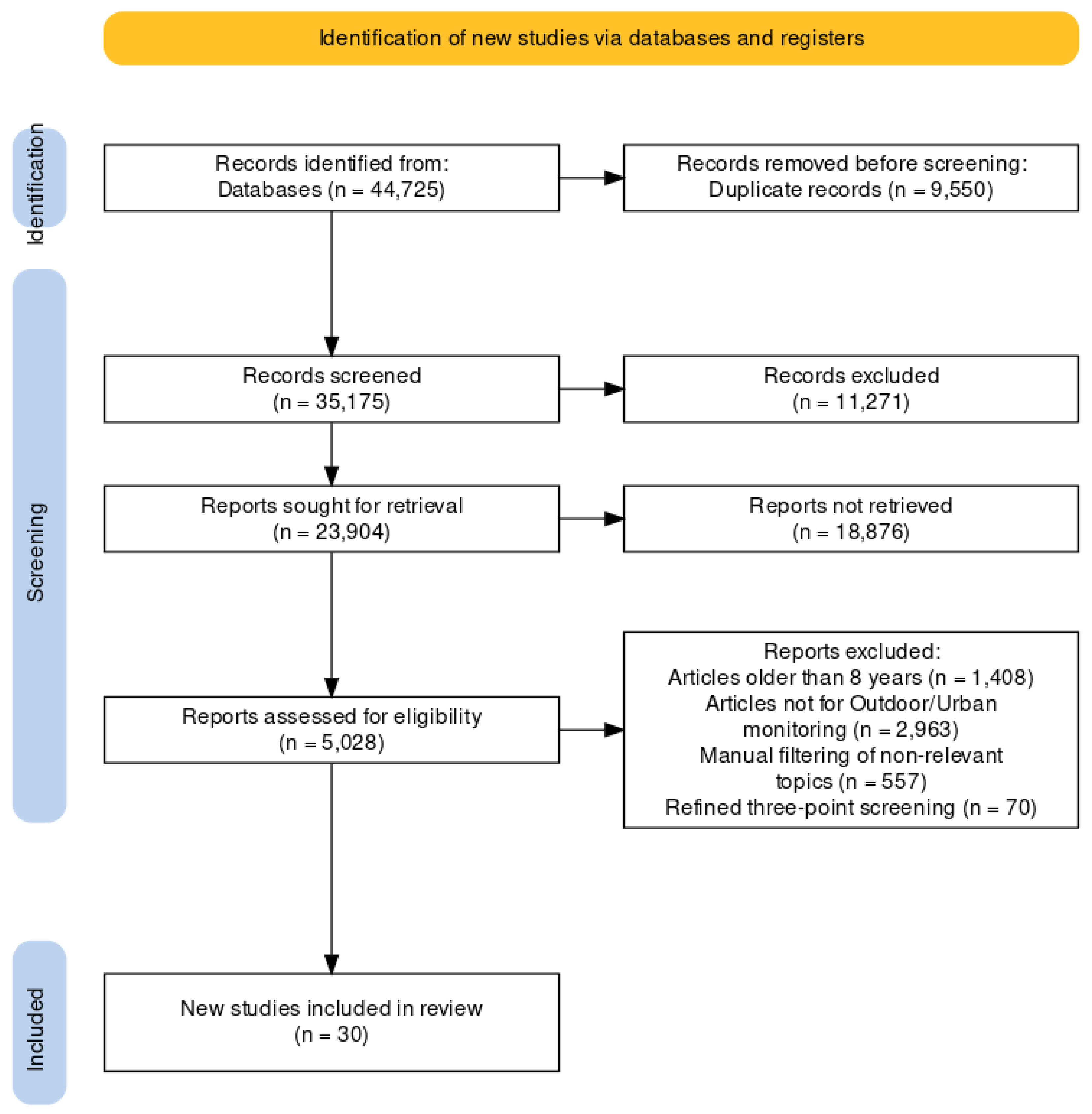
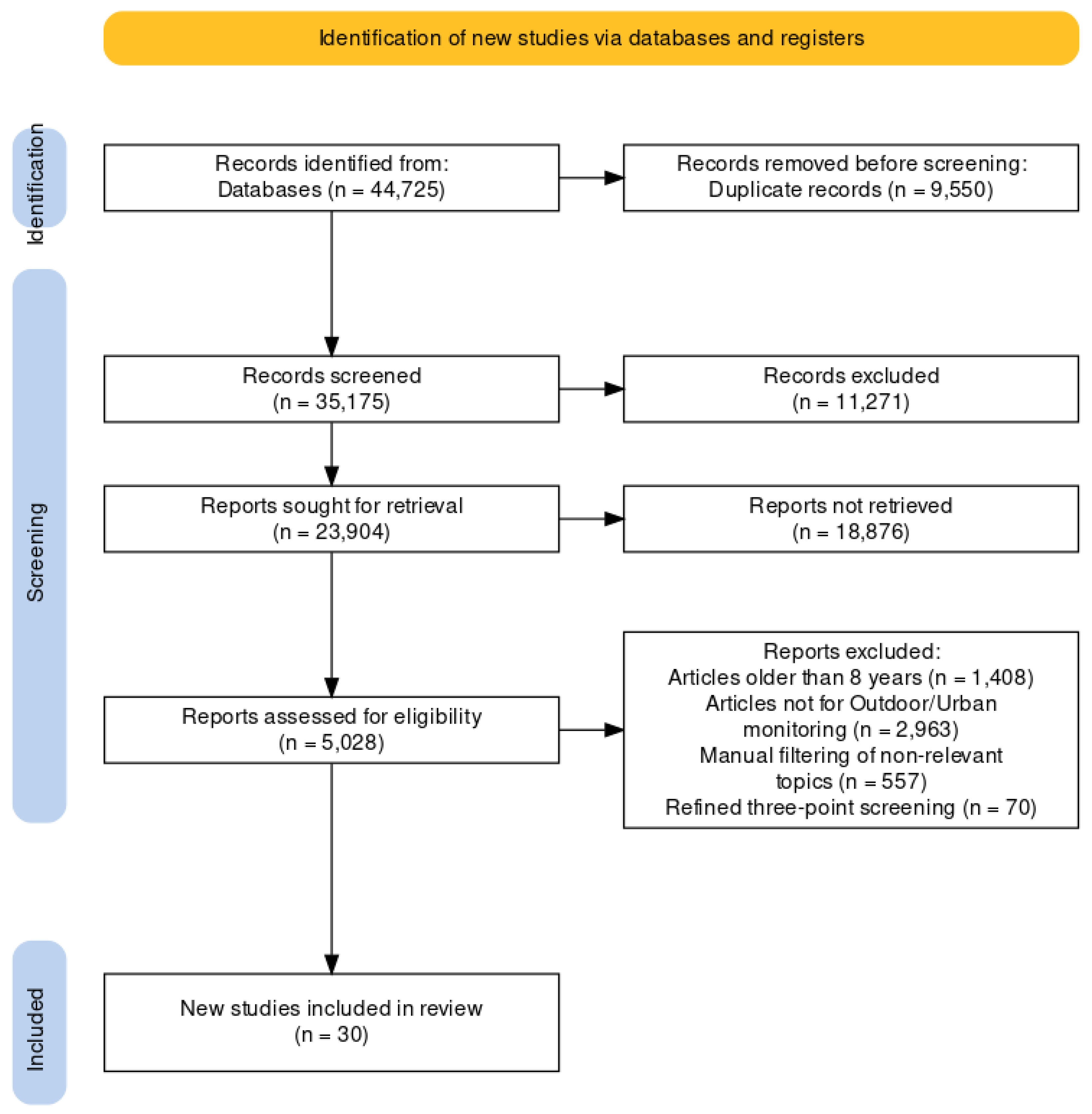
3.2. Search and Selection Strategy
4. Results
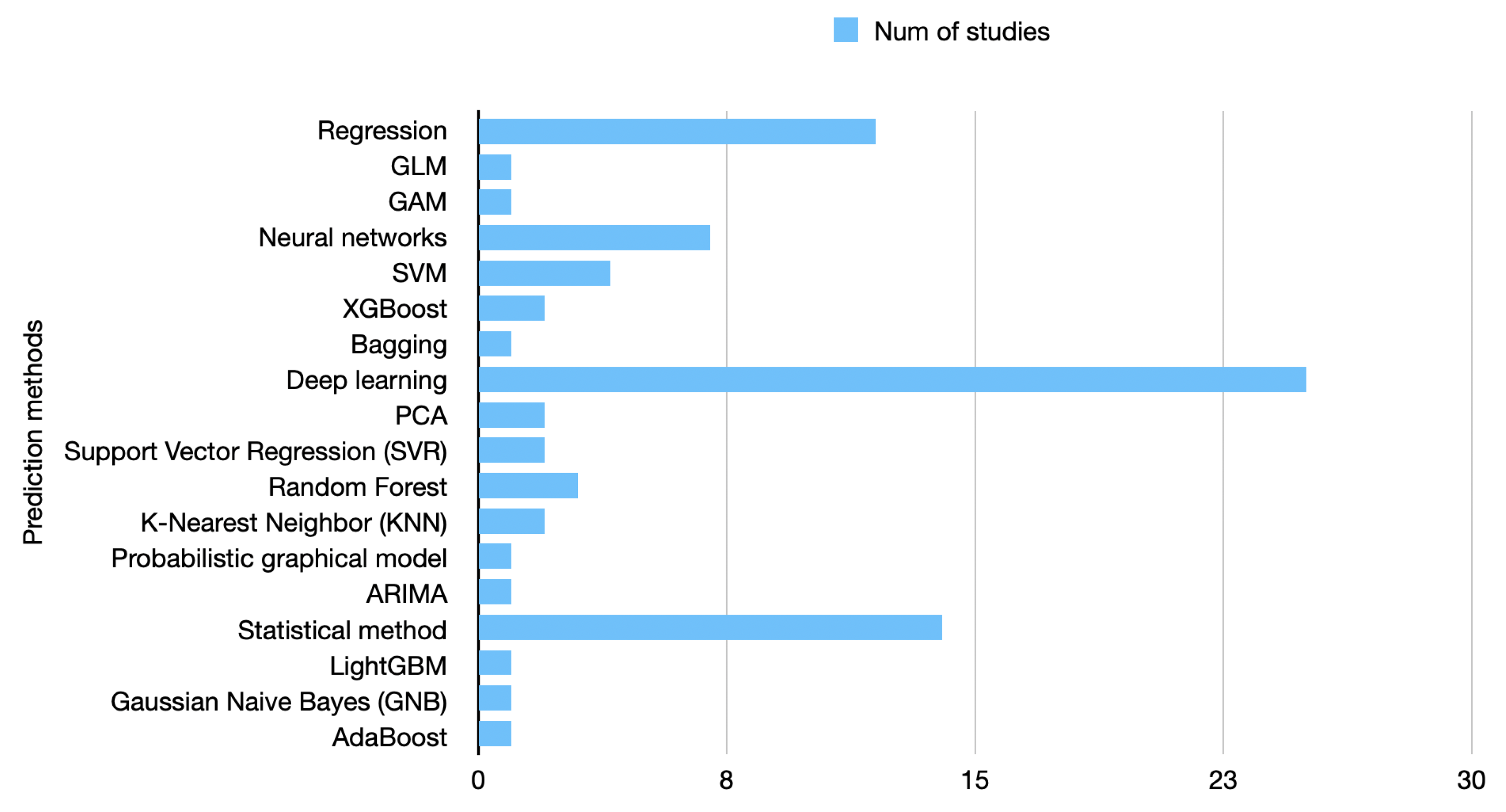
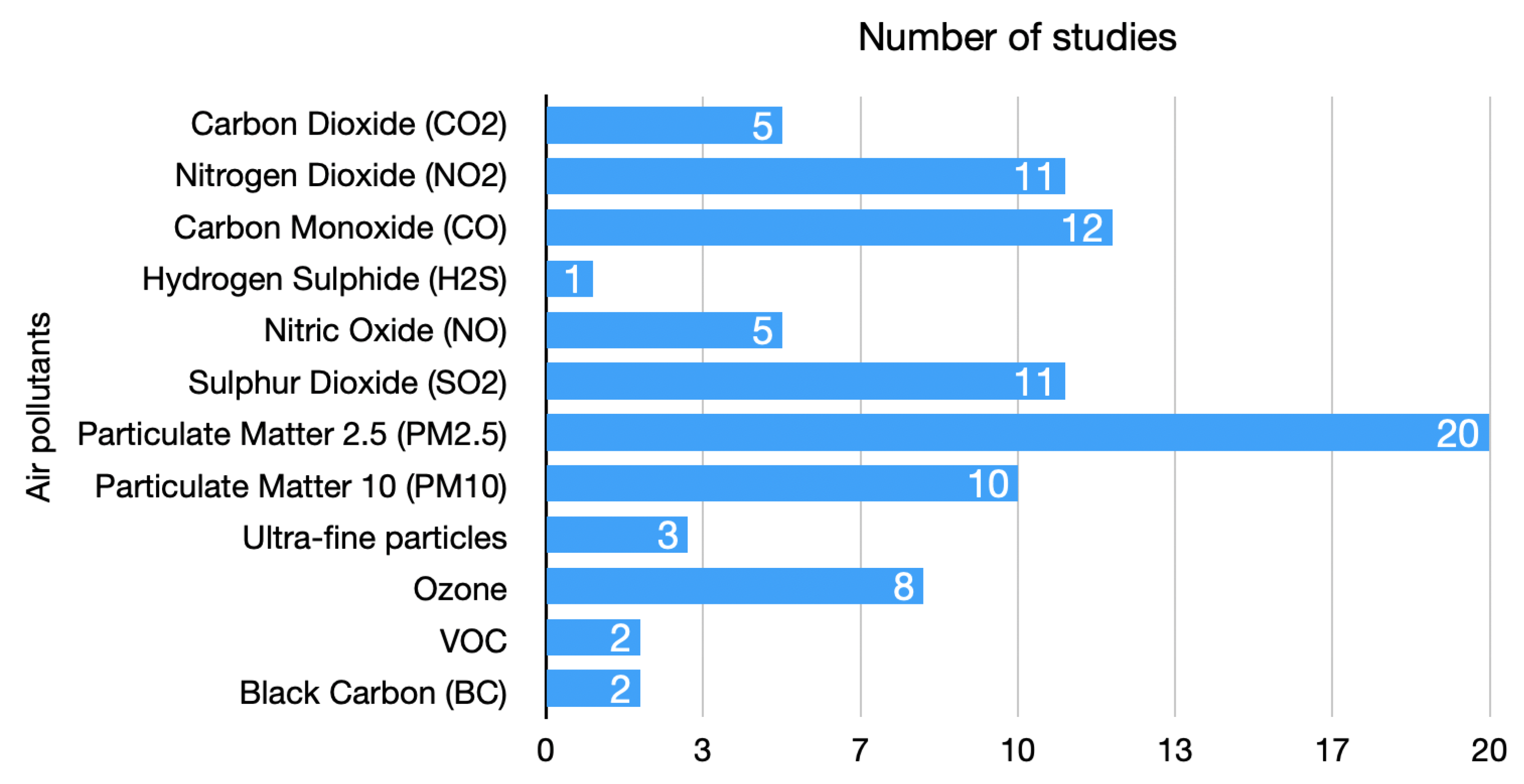
4.1. Data Extraction from Selected Papers
4.2. In-Depth Analysis of the Selected Papers
4.3. Interpretation of the Results
5. Discussion
- Long short-term memory (LSTM) networks: LSTM networks are a type of recurrent neural network (RNN) that are well-suited for time series forecasting tasks. LSTM models have been successfully applied to predict air pollutant concentrations by capturing long-term dependencies and patterns in temporal data.
- Convolutional neural networks (CNNs): Commonly used for image analysis, they have also shown promising results in air pollution prediction, particularly in spatial forecasting tasks. By treating air pollution data as spatio-temporal images, CNNs can capture spatial correlations and learn spatial features to make accurate predictions.
- Random forests: Random forests are an ensemble learning method that combines multiple decision trees to make predictions. Random forest models have been utilized for air pollution prediction, leveraging their ability to handle complex interactions between variables and capture nonlinear relationships.
- Gradient boosting machines (GBMs): GBMs are another ensemble learning method that sequentially trains weak learners to improve prediction accuracy. Models like XGBoost and LightGBM, which are variants of GBM, have been employed for air pollution prediction tasks, showing excellent performance in terms of accuracy and interpretability.
- Gaussian process regression (GPR): GPR is a probabilistic model that can capture uncertainty in predictions. It has been used in air pollution prediction to estimate pollutant concentrations and provide probabilistic forecasts, which are valuable for decision-making and risk assessment.
Research Questions
- What are prevalent methods for air pollution forecasting (i.e., prediction) published in the last eight years? The field of air pollution forecasting continues to evolve, and researchers are exploring new techniques and approaches to improve air pollution predictions’ accuracy, reliability, and usability. Some prevalent air pollution forecasting methods published in the last eight years are machine learning (ML) approaches, since they have gained significant attention for air pollution forecasting. These include models such as random forests, support vector machines (SVM), artificial neural networks (ANNs), and gradient boosting machines (GBM). Next are the deep learning models, especially convolutional neural networks (CNNs) and recurrent neural networks (RNNs). CNN models have been used to analyze satellite imagery and spatial data for estimating pollutant levels. In contrast, RNN models, including long short-term memory (LSTM), have been employed for time series forecasting of pollutant concentrations. The third category would be hybrid models, where researchers combine multiple modeling techniques to leverage their respective strengths. Hybrid models often combine the advantages of both physics-based understanding and data-driven learning. Ensemble models integrate predictions from multiple individual models to generate a final forecast. Spatio-temporal models aim to capture air pollution dynamics over space and time. They often incorporate spatial interpolation techniques, spatial regression models, or spatio-temporal machine learning approaches to capture pollutants’ spatial variations and temporal patterns. Data assimilation methods combine observations from monitoring stations, satellite data, and numerical models to optimize predictions. Hybrid data fusion techniques integrate multiple data sources, such as ground-based measurements, satellite data, and numerical model outputs, to generate comprehensive air pollution forecasts. Probabilistic forecasting methods estimate the uncertainty associated with air pollution predictions, providing probabilistic distributions instead of point estimates. These methods employ techniques such as Bayesian modeling, Gaussian processes (GP), or ensemble modeling to quantify the uncertainty in the predictions.
- What are the strengths and limitations of the ML approaches for air pollution forecasting? Machine learning (ML) approaches have shown promise in air pollution forecasting, but they also have their strengths and limitations. Their strengths would be that they are data-driven, flexible, scalable, have real-time updates, and are easily adaptable. However, they also face some limitations, such as whether the data are available and of good quality and whether the technique is understandable or very complex and hard to grasp. It is essential that the models can draw generalizations well enough to quantify uncertain situations because, in air pollution forecasting, uncertainty estimation is crucial for decision-making. Last but not least, they are limited in their ability to capture complex relationships as well as unexpected events.
- What are the most prevalent input data modalities for air pollution forecasting? The choice of input data depends on the specific modeling approach and available data sources, so the most prevalent input data modalities used in air pollution forecasting would be meteorological data, emission data, air quality monitoring data, satellite imagery, geographic information system (GIS) data, historical air pollution data, socioeconomic data, and output data from different models. It is important to note that data availability and quality can vary across locations, and different modeling approaches may require different input datasets.
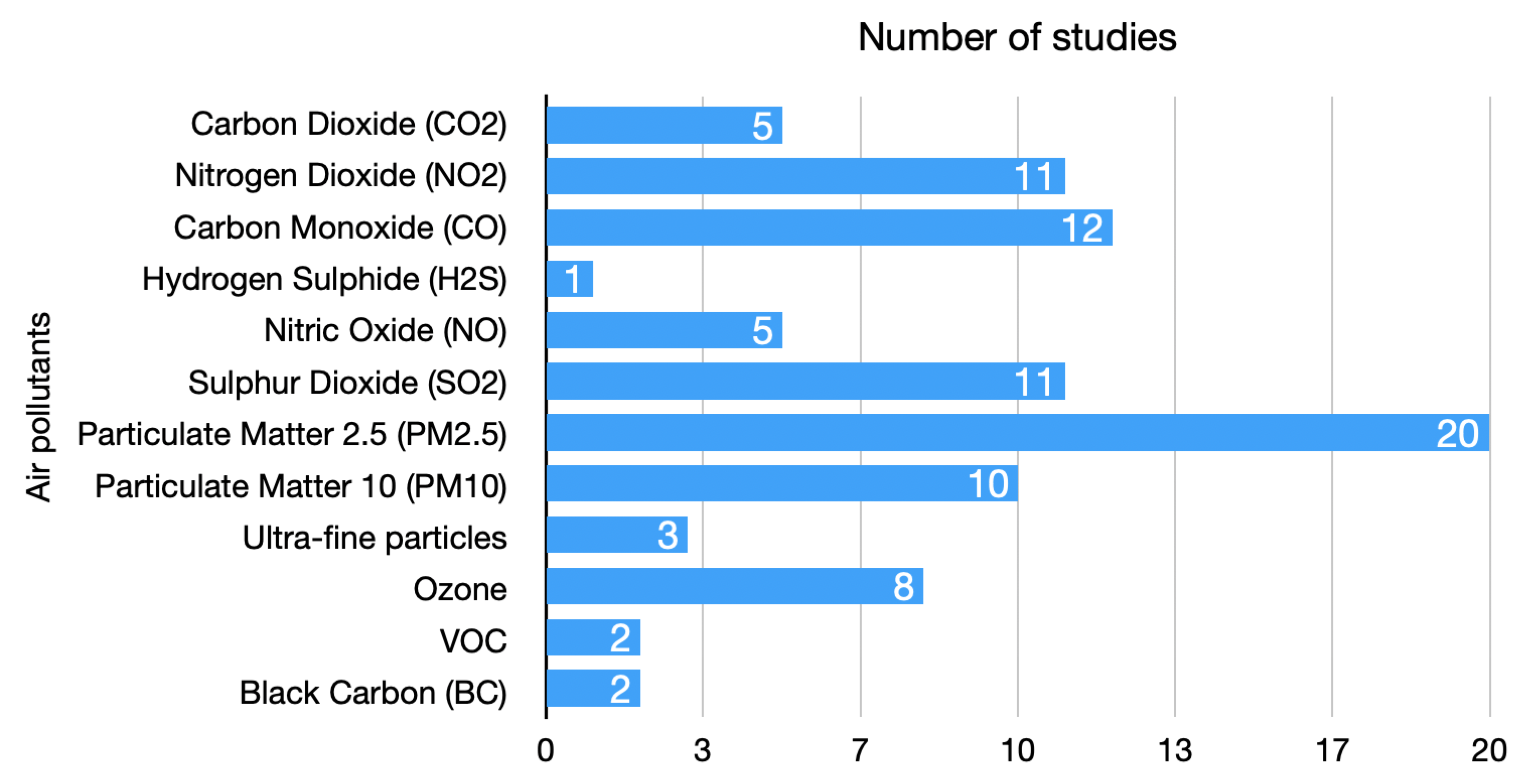
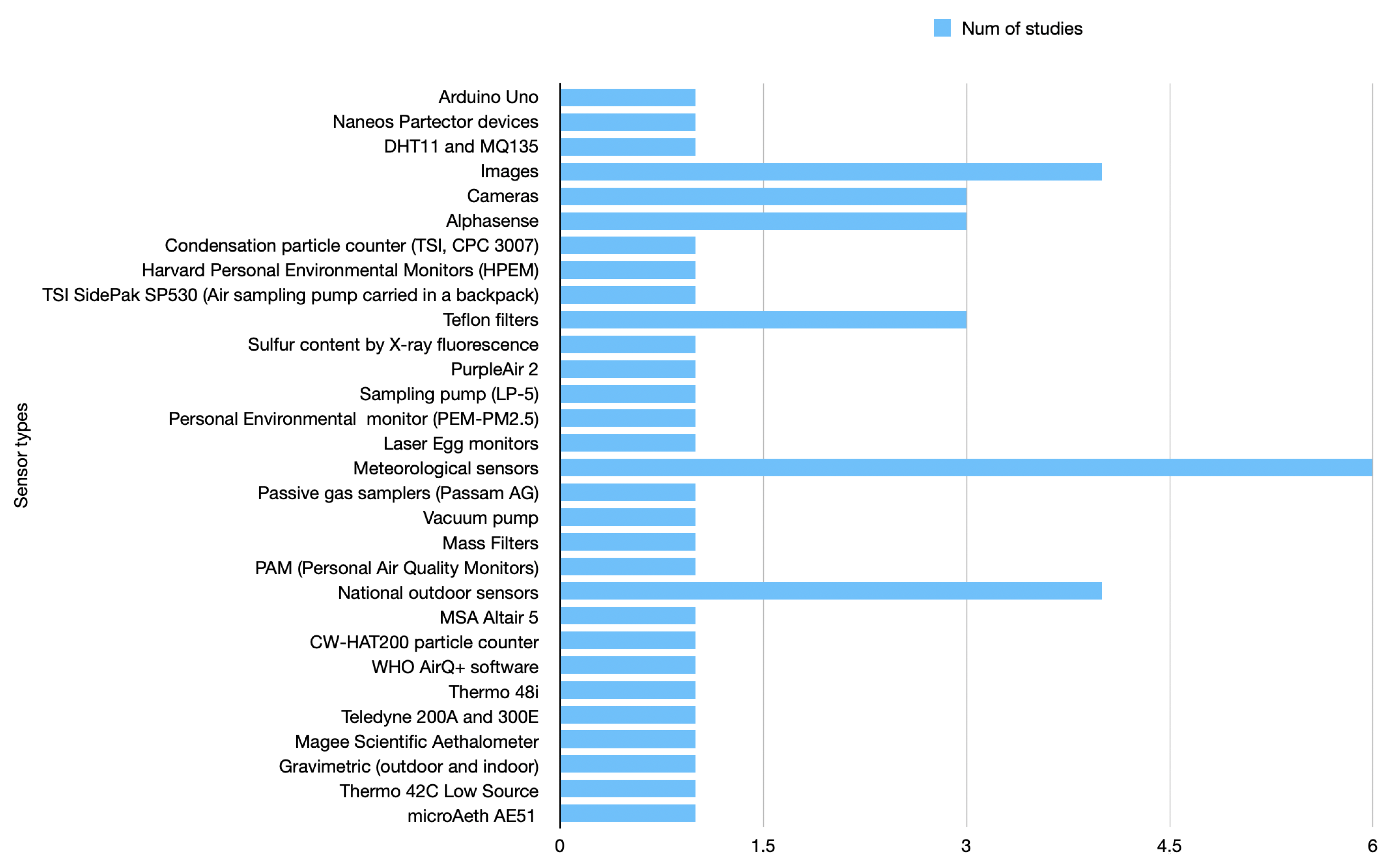
- Which are the most dominant sensor types for urban air pollution forecasting? Urban air pollution forecasting relies on various sensor types to monitor and measure pollutant concentrations in real time. The choice of sensors depends on more factors, such as the pollutant of interest, accuracy requirements, cost considerations, and the specific objectives of the forecasting system. Many studies are moving towards combining various inputs to achieve better results, especially in PM forecasting models. However, the most frequently used sensor types would still be particulate matter (PM) sensors, then gas sensors, weather stations, multi-gas monitors (for measuring multiple pollutants simultaneously), LiDAR (light detection and ranging), remote sensing instruments, and low-cost sensors, which in recent years have gained popularity for urban air pollution monitoring. Low-cost sensors are affordable and portable, allowing for dense monitoring networks in urban areas. While they may have lower accuracy compared to reference-grade instruments, their widespread deployment can provide valuable spatial coverage and enable localized air pollution measurements.
- What are the current research and technological gaps in air pollution research related to the city of Skopje, North Macedonia? The research and development landscape is similar to the other countries around the world with similar air pollution rates. Because it is ranked as one of the most polluted cities in the world, citizens are very interested in measuring, predicting, and preventing air pollution. After examining the available publications, we concluded that there is ongoing development in both research and application tackling air pollution monitoring and prediction. Several completed studies and projects have been improved to increase awareness and measure pollution more precisely. The air pollution measurement and prediction methods are similar to the state-of-art methods. Further examination is needed to analyze the potential usage of low-cost sensors for pollution forecasting. An ongoing project, CleanBREATHE (http://www.cleanbreathe.eu, accessed on 1 August 2023), aims to increase awareness regarding air pollution and improve pollution measurement and prediction capabilities by researching and developing new algorithms and proposing an adequate, sustainable business model for air pollution-related applications.
6. Case Study: Insights from Air Pollution Research in the City of Skopje
Future Research
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- WHO. New WHO Global Air Quality Guidelines Aim to Save Millions of Lives from Air Pollution. 2022. Available online: https://www.who.int/news/item/22-09-2021-new-who-global-air-quality-guidelines-aim-to-save-millions-of-lives-from-air-pollution (accessed on 30 September 2022).
- WHO. Health Consequences of Air Pollution on Populations. 2019. Available online: https://www.who.int/news/item/15-11-2019-what-are-health-consequences-of-air-pollution-on-populations (accessed on 30 September 2022).
- The Murky Issue of Air Pollution in North Macedonia. Available online: https://www.euronews.com/2021/06/01/the-murky-issue-of-air-pollution-in-north-macedonia (accessed on 30 September 2022).
- Arsov, M.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Koteli, N.; Gramatikov, S.; Mitreski, K.; Trajkovik, V. Multi-Horizon Air Pollution Forecasting with Deep Neural Networks. Sensors 2021, 21, 1235. [Google Scholar] [CrossRef]
- Liu, W.; Xu, Z.; Yang, T. Health effects of air pollution in China. Int. J. Environ. Res. Public Health 2018, 15, 1471. [Google Scholar] [CrossRef]
- Zaini, N.; Ean, L.W.; Ahmed, A.N.; Malek, M.A. A systematic literature review of deep learning neural network for time series air quality forecasting. Environ. Sci. Pollut. Res. 2022, 29, 4958–4990. [Google Scholar] [CrossRef]
- ABCnews. North Macedonia Takes Emergency Anti-Pollution Steps. 2022. Available online: https://abcnews.go.com/International/wireStory/north-macedonia-takes-emergency-anti-pollution-steps-95809578 (accessed on 10 January 2022).
- IQAir. Air Quality Analysis and Statistics for Skopje. 2023. Available online: https://www.iqair.com/north-macedonia/skopje (accessed on 10 January 2022).
- Carballo, I.H.; Bakola, M.; Stuckler, D. The impact of air pollution on COVID-19 incidence, severity, and mortality: A systematic review of studies in Europe and North America. Environ. Res. 2022, 215, 114155. [Google Scholar] [CrossRef]
- Wong, Y.J.; Yeganeh, A.; Chia, M.Y.; Shiu, H.Y.; Ooi, M.C.G.; Chang, J.H.W.; Shimizu, Y.; Ryosuke, H.; Try, S.; Elbeltagi, A. Quantification of COVID-19 impacts on NO2 and O3: Systematic model selection and hyperparameter optimization on AI-based meteorological-normalization methods. Atmos. Environ. 2023, 301, 119677. [Google Scholar] [CrossRef]
- Kang, G.K.; Gao, J.Z.; Chiao, S.; Lu, S.; Xie, G. Air quality prediction: Big data and machine learning approaches. Int. J. Environ. Sci. Dev. 2018, 9, 8–16. [Google Scholar] [CrossRef]
- Méndez, M.; Merayo, M.; Núñez, M. Machine learning algorithms to forecast air quality: A survey. Artif. Intell. Rev. 2023, 56, 10031–10066. [Google Scholar] [CrossRef]
- Airpointer®. Available online: https://ambilabs.com/instruments/airpointer/ (accessed on 10 December 2022).
- Ren, Y.; Yao, X.; Liu, Y.; Liu, S.; Li, X.; Huang, Q.; Liu, F.; Li, N.; Lu, Y.; Yuan, Z.; et al. Outdoor air pollution pregnancy exposures are associated with behavioral problems in China’s preschoolers. Environ. Sci. Pollut. Res. 2019, 26, 2397–2408. [Google Scholar] [CrossRef]
- Deng, Q.; Lu, C.; Yu, Y.; Li, Y.; Sundell, J.; Norbäck, D. Early life exposure to traffic-related air pollution and allergic rhinitis in preschool children. Respir. Med. 2016, 121, 67–73. [Google Scholar] [CrossRef]
- Zdravevski, E.; Lameski, P.; Trajkovik, V.; Chorbev, I.; Goleva, R.; Pombo, N.; Garcia, N.M. Automation in Systematic, Scoping and Rapid Reviews by an NLP Toolkit: A Case Study in Enhanced Living Environments. In Enhanced Living Environments: Algorithms, Architectures, Platforms, and Systems; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–18. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. Int. J. Surg. 2021, 88, 105906. [Google Scholar] [CrossRef]
- Marjovi, A.; Arfire, A.; Martinoli, A. High Resolution Air Pollution Maps in Urban Environments Using Mobile Sensor Networks. In Proceedings of the 2015 International Conference on Distributed Computing in Sensor Systems, Fortaleza, Brazil, 10–12 June 2015; pp. 11–20. [Google Scholar] [CrossRef]
- Ayele, T.W.; Mehta, R. Air pollution monitoring and prediction using IoT. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 1741–1745. [Google Scholar] [CrossRef]
- Sardar Maran, P.; Reddy, B.S.; Saiharshavardhan, C. Air Quality Prediction (IoT) Using Machine Learning. In Advances in Electronics, Communication and Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 583–591. [Google Scholar]
- Dua, R.D.; Madaan, D.M.; Mukherjee, P.M.; Lall, B.L. Real Time Attention Based Bidirectional Long Short-Term Memory Networks for Air Pollution Forecasting. In Proceedings of the 2019 IEEE Fifth International Conference on Big Data Computing Service and Applications (BigDataService), Newark, CA, USA, 4–9 April 2019; pp. 151–158. [Google Scholar] [CrossRef]
- Pasupuleti, V.R.; Uhasri; Kalyan, P.; Srikanth; Reddy, H.K. Air Quality Prediction of Data Log by Machine Learning. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 1395–1399. [Google Scholar] [CrossRef]
- Luna, A.; Talavera, A.; Navarro, H.; Cano, L. Monitoring of Air Quality with Low-Cost Electrochemical Sensors and the Use of Artificial Neural Networks for the Atmospheric Pollutants Concentration Levels Prediction. In Proceedings of the 5th International Conference, Information Management and Big Data, Lima, Peru, 3–5 September 2018; Lossio-Ventura, J.A., Muñante, D., Alatrista-Salas, H., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 137–150. [Google Scholar]
- Rijal, N.; Gutta, R.T.; Cao, T.; Lin, J.; Bo, Q.; Zhang, J. Ensemble of deep neural networks for estimating particulate matter from images. In Proceedings of the 2018 IEEE 3rd international conference on image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 733–738. [Google Scholar]
- Bo, Q.; Yang, W.; Rijal, N.; Xie, Y.; Feng, J.; Zhang, J. Particle pollution estimation from images using convolutional neural network and weather features. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3433–3437. [Google Scholar]
- Song, S.; Lam, J.C.; Han, Y.; Li, V.O. ResNet-LSTM for Real-Time PM 2.5 and PM10 Estimation Using Sequential Smartphone Images. IEEE Access 2020, 8, 220069–220082. [Google Scholar] [CrossRef]
- Kerckhoffs, J.; Hoek, G.; Portengen, L.; Brunekreef, B.; Vermeulen, R.C. Performance of prediction algorithms for modeling outdoor air pollution spatial surfaces. Environ. Sci. Technol. 2019, 53, 1413–1421. [Google Scholar] [CrossRef] [PubMed]
- Butland, B.K.; Samoli, E.; Atkinson, R.W.; Barratt, B.; Katsouyanni, K. Measurement error in a multi-level analysis of air pollution and health: A simulation study. Environ. Health 2019, 18, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Kumar, K.; Pande, B.P. Air pollution prediction with machine learning: A case study of Indian cities. Int. J. Environ. Sci. Technol. 2023, 20, 5333–5348. [Google Scholar] [CrossRef] [PubMed]
- Miller, K.A.; Spalt, E.W.; Gassett, A.J.; Curl, C.L.; Larson, T.V.; Avol, E.; Allen, R.W.; Vedal, S.; Szpiro, A.A.; Kaufman, J.D. Estimating ambient-origin PM2. 5 exposure for epidemiology: Observations, prediction, and validation using personal sampling in the Multi-Ethnic Study of Atherosclerosis. J. Expo. Sci. Environ. Epidemiol. 2019, 29, 227–237. [Google Scholar] [CrossRef] [PubMed]
- Abirami, S.; Chitra, P.; Madhumitha, R.; Kesavan, S.R. Hybrid spatio-temporal deep learning framework for particulate matter (pm 2.5) concentration forecasting. In Proceedings of the 2020 International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 13–14 February 2020; pp. 1–6. [Google Scholar]
- Connolly, R.E.; Yu, Q.; Wang, Z.; Chen, Y.H.; Liu, J.Z.; Collier-Oxandale, A.; Papapostolou, V.; Polidori, A.; Zhu, Y. Long-term evaluation of a low-cost air sensor network for monitoring indoor and outdoor air quality at the community scale. Sci. Total Environ. 2022, 807, 150797. [Google Scholar] [CrossRef]
- Gao, S.; Zhao, H.; Bai, Z.; Han, B.; Xu, J.; Zhao, R.; Zhang, N.; Chen, L.; Lei, X.; Shi, W.; et al. Combined use of principal component analysis and artificial neural network approach to improve estimates of PM2. 5 personal exposure: A case study on older adults. Sci. Total Environ. 2020, 726, 138533. [Google Scholar] [CrossRef]
- Zhang, Q.; Fu, F.; Tian, R. A deep learning and image-based model for air quality estimation. Sci. Total Environ. 2020, 724, 138178. [Google Scholar] [CrossRef]
- Liang, Y.C.; Maimury, Y.; Chen, A.H.L.; Juarez, J.R.C. Machine Learning-Based Prediction of Air Quality. Appl. Sci. 2020, 10, 9151. [Google Scholar] [CrossRef]
- Ben, Y.; Ma, F.; Wang, H.; Hassan, M.A.; Yevheniia, R.; Fan, W.; Li, Y.; Dong, Z. A spatio-temporally weighted hybrid model to improve estimates of personal PM2. 5 exposure: Incorporating big data from multiple data sources. Environ. Pollut. 2019, 253, 403–411. [Google Scholar] [CrossRef]
- Rivera-González, L.O.; Zhang, Z.; Sánchez, B.N.; Zhang, K.; Brown, D.G.; Rojas-Bracho, L.; Osornio-Vargas, A.; Vadillo-Ortega, F.; O’Neill, M.S. An assessment of air pollutant exposure methods in Mexico City, Mexico. J. Air Waste Manag. Assoc. 2015, 65, 581–591. [Google Scholar] [CrossRef] [PubMed]
- Saucy, A.; Röösli, M.; Künzli, N.; Tsai, M.Y.; Sieber, C.; Olaniyan, T.; Baatjies, R.; Jeebhay, M.; Davey, M.; Flückiger, B.; et al. Land use regression modelling of outdoor NO2 and PM2.5 concentrations in three low income areas in the western cape province, South Africa. Int. J. Environ. Res. Public Health 2018, 15, 1452. [Google Scholar] [CrossRef] [PubMed]
- Chatzidiakou, L.; Krause, A.; Han, Y.; Chen, W.; Yan, L.; Popoola, O.A.; Kellaway, M.; Wu, Y.; Liu, J.; Hu, M.; et al. Using low-cost sensor technologies and advanced computational methods to improve dose estimations in health panel studies: Results of the AIRLESS project. J. Expo. Sci. Environ. Epidemiol. 2020, 30, 981–989. [Google Scholar] [CrossRef] [PubMed]
- Aliyu, Y.A.; Botai, J.O. An exposure appraisal of outdoor air pollution on the respiratory well-being of a developing city population. J. Epidemiol. Glob. Health 2018, 8, 91. [Google Scholar] [CrossRef] [PubMed]
- Delavar, M.R.; Gholami, A.; Shiran, G.R.; Rashidi, Y.; Nakhaeizadeh, G.R.; Fedra, K.; Hatefi Afshar, S. A Novel Method for Improving Air Pollution Prediction Based on Machine Learning Approaches: A Case Study Applied to the Capital City of Tehran. ISPRS Int. J. Geo-Inf. 2019, 8, 99. [Google Scholar] [CrossRef]
- Liang, D.; Golan, R.; Moutinho, J.L.; Chang, H.H.; Greenwald, R.; Sarnat, S.E.; Russell, A.G.; Sarnat, J.A. Errors associated with the use of roadside monitoring in the estimation of acute traffic pollutant-related health effects. Environ. Res. 2018, 165, 210–219. [Google Scholar] [CrossRef] [PubMed]
- Sabath, M.B.; Di, Q.; Braun, D.; Schwartz, J.; Dominici, F.; Choirat, C. Airpred: A Flexible R Package Implementing Methods for Predicting Air Pollution. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 577–583. [Google Scholar]
- Dai, H.; Huang, G.; Zeng, H.; Zhou, F. PM2.5 volatility prediction by XGBoost-MLP based on GARCH models. J. Clean. Prod. 2022, 356, 131898. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Zeng, H.; Yu, R. Haze Risk Assessment Based on Improved PCA-MEE and ISPO-LightGBM Model. Systems 2022, 10, 263. [Google Scholar] [CrossRef]
- Goswami, P.; Prakash, M.; Rajan, R.; Prakash, A. A Hybrid Deep Learning Model for Multi-step Ahead Prediction of PM2.5 Concentration Across India. Environ. Model. Assess. 2023, 1–14. [Google Scholar] [CrossRef]
- Thu, M.Y.; Htun, W.; Aung, Y.L.; Shwe, P.E.E.; Tun, N.M. Smart Air Quality Monitoring System with LoRaWAN. In Proceedings of the 2018 IEEE International Conference on Internet of Things and Intelligence System (IOTAIS), Bali, Indonesia, 1–3 November 2018; pp. 10–15. [Google Scholar] [CrossRef]
- Avis, R. Causes and consequences of air pollution in North Macedonia. Environ. Sci. Pollut. Res. 2022. Available online: https://opendocs.ids.ac.uk/opendocs/handle/20.500.12413/17672 (accessed on 1 August 2023).
- AirCare. Available online: https://getaircare.com (accessed on 10 December 2022).
- Pulse.eco. Available online: https://pulse.eco (accessed on 10 December 2022).
- PM Alarm. Available online: https://aqf.finki.ukim.mk (accessed on 10 December 2022).
- Spiridonov, V.; Jakimovski, B.; Spiridonova, I.; Pereira, G. Development of air quality forecasting system in Macedonia, based on WRF-Chem model. Air Qual. Atmos. Health 2019, 12, 825–836. [Google Scholar] [CrossRef]
- Anchev, N.; Jakimovski, B.; Spiridonov, V.; Velinov, G. Temperature Dependent Initial Chemical Conditions for WRF-Chem Air Pollution Simulation Model. In Proceedings of the International Conference on ICT Innovations, Skopje, North Macedonia, 24–26 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–14. [Google Scholar]
- Arsov, M.; Zdravevski, E.; Lameski, P.; Corizzo, R.; Koteli, N.; Mitreski, K.; Trajkovik, V. Short-term air pollution forecasting based on environmental factors and deep learning models. In Proceedings of the 2020 15th Conference on Computer Science and Information Systems (FedCSIS), Sofia, Bulgaria, 6–9 September 2020; pp. 15–22. [Google Scholar]
- Kalajdjieski, J.; Zdravevski, E.; Corizzo, R.; Lameski, P.; Kalajdziski, S.; Pires, I.M.; Garcia, N.M.; Trajkovik, V. Air Pollution Prediction with Multi-Modal Data and Deep Neural Networks. Remote Sens. 2020, 12, 4142. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Mirceva, G.; Kalajdziski, S. Attention Models for PM2.5 Prediction. In Proceedings of the 2020 IEEE/ACM International Conference on Big Data Computing, Applications and Technologies (BDCAT), Leicester, UK, 7–10 December 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Kalajdjieski, J.; Trivodaliev, K.; Mirceva, G.; Kalajdziski, S.; Gievska, S. A complete air pollution monitoring and prediction framework. IEEE Access 2023, 11, 88730–88744. [Google Scholar] [CrossRef]
- Stojov, V.; Koteli, N.; Lameski, P.; Zdravevski, E. Application of machine learning and time-series analysis for air pollution prediction. In Proceedings of the Conference on Computational Intelligence and Information Technology, Cochin, India, 13–14 July 2018. [Google Scholar]
- Kalajdjieski, J.; Korunoski, M.; Stojkoska, B.R.; Trivodaliev, K. Smart City Air Pollution Monitoring and Prediction: A Case Study of Skopje. In Proceedings of the International Conference on ICT Innovations, Skopje, North Macedonia, 24–26 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 15–27. [Google Scholar]
- Korunoski, M.; Stojkoska, B.R.; Trivodaliev, K. Internet of things solution for intelligent air pollution prediction and visualization. In Proceedings of the IEEE EUROCON 2019—18th International Conference on Smart Technologies, Novi Sad, Serbia, 1–4 July 2019; pp. 1–6. [Google Scholar]
- Ministry for Environment and Physical Planning: Cheap Sensors for Air pollution are Not Reliable Nor Valid. Available online: https://a1on.mk/macedonia/ministerstvo-za-zhivotna-sredina-evtinite-senzori-za-aerozagaduvanjeto-ne-se-sigurni-nitu-se-validni/ (accessed on 10 December 2022).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Year of Publication | Dataset | Sensors | ML Approach or Statistical Method |
|---|---|---|---|---|
| [18] | 2015 | 14 months, 44.5 million geo- and time-stamped real lung deposited surface area (LDSA) measurements, local sampling node, GPRS, database server | Static sensors on buses, LDSA estimation sensors, which are Naneos Partector devices | Log-linear regression model, KNN model, network-based log linear regression model, and probabilistic graphical model |
| [19] | 2018 | Parameters remotely observed using IoT, information stored on cloud, expand the assessed drift on the browser | DHT11 and MQ135 sensors | LSTM (long short-term memory network) and RNNs (recurrent neural networks) |
| [20] | 2021 | NO2 and SO2 time series data, IoT infrastructure | Sensors for NO2 and SO2 | Recurrent neural networks (RNNs) |
| [21] | 2019 | Real-time air quality monitoring dataset, Central Pollution Control Board database (703 operating stations) in India, 78 stations in Delhi. Collected data stored on Google Cloud storage | SO2, NO2, PM2.5, PM10, CO, and O3 (on an hourly basis), meteorological data and a date/time stamp | LSTM (long short-term memory network), LSTM-A (attention-based long short-term memory network), BiLSTM (bidirectional long short-term memory network), BiLSTM-A (attention-based bidirectional LSTM network) |
| [22] | 2020 | Combination of pollution data and meteorological data from data logs collected using Arduino Uno platform | CO, SO2, O3 sensors | Linear regression (LR), random forest regression, decision tree |
| [23] | 2019 | Data from Alphasense outdoor sensors | Electrochemical sensors measuring: CO2, VOC (alcohols, aldehydes, aliphatic hydrocarbons, amines, aromatic hydrocarbons, CH4, LP G, ketones, and organic acids) CO, SO2, O3, and NO2 | Artificial neural network (ANN), 3 hidden layers |
| [24] | 2018 | Public PM2.5 image dataset | Images, cameras | Deep learning, CNN architectures, VGG-16, Inception-V3, ResNet50, 5-layer feed-forward network |
| [25] | 2018 | Shangai image dataset, Beijing image dataset, combined with PM2.5 indices | Cameras, images | Comparing PCA, sequential backward feature selection (SBFS), support vector regression (SVR), ResNet-based CNN model classifier (with weather features) |
| [26] | 2020 | Images (from a single object taken from various distances), combined with Alphasense sensor data | Alphasense OPC-N2 sensor, images (focusing on one single building) | ResNet18, LSTM, deep learning architecture |
| [27] | 2019 | Short-term stationary ultrafine particles (UFP) data, mobile UFP data | Condensation particle counter (TSI, CPC 3007) | Linear regression, LASSO, elastic net, ridge, GLM, Mars, GAM, KRLS, neural networks, SVM, extreme boosting, bagging |
| [28] | 2019 | 63,865 daily mean NO2 measurements, 48,151 daily mean PM10 measurements from 47 (1 suburban and 46 urban) and 37 (2 suburban and 35 urban) background monitoring sites, respectively, for the period 2009–2013 | Public sensors, no details | Statistical simulation |
| [29] | 2022 | Air pollution data from 23 Indian cities over a 6-year period | Analyzes 12 air pollutants and AQI | 5 mL models: KNN, Gaussian naive Bayes (GNB), SVM, RF, and XGBoost employed with and without SMOTE resampling technique |
| [30] | 2018 | 14-day time-scale data, exposure metrics using environmental monitors | MESA Air (PM), Harvard Personal Environmental Monitors (HPEM, Cambridge, MA, USA), TSI SidePak SP530, Shoreview, MN (air sampling pump carried in a backpack), PM2.5 mass concentrations from Teflon filters, sulfur content by X-ray fluorescence | Pearson correlation coefficient (R), mean relative percent difference (RPD), and root mean square error (RMSE) |
| [31] | 2020 | 9 measurement stations, 1 h recording intervals from August 2014 to October 2014; the data are part of the CityPulse Pollution Dataset collection | Air pollutant sensors: ozone, PM2.5, SO2, CO, NO2; no details about the sensors given | Comparison of convLSTM with a proposed CNN–LSTM architecture |
| [32] | 2022 | Data collected from December 2017 to June 2019, particle sensor | PurpleAir 2 sensors, low-cost sensors for particle counting | Correlation coefficient, coefficients of divergence to compare sensor performance |
| [33] | 2020 | 13 June to 2 July 2011 and 30 November to 12 December 2011 data for personal exposure to PM2.5 particles | Sampling pump (LP-5, BUCK, FL, USA), exposure monitor (PEM-PM2.5, BGI, MA, USA) with Teflon filter (R2PJ037, PALL, NY, USA) | PCA, ANN compared with ANN only for personal exposure to PM2.5 prediction |
| [34] | 2020 | NWNU-AQI image dataset | AQI levels from nearest base stations, a camera, the micro stations (1 km radius), GPS, camera used for images | SVM compared with deep learning architectures based on VGG, ResNet, newly proposed architecture AQC-Net |
| [35] | 2020 | 11-year dataset collected by Taiwan’s Environmental Protection Administration (EPA) | Measured O3, SO2 , PM10, and PM2.5, CO, CO2, NO2 | Adaptive boosting (AdaBoost), artificial neural network (ANN), random forest, stacking ensemble, and support vector machine (SVM) for AQI index prediction |
| [36] | 2019 | Data from outdoor, indoor, and in-vehicle measurements (subway, bus, and private cars) | No details for available PM2.5 sensors; indoor sensors are commercial Laser Egg monitors | Spatio-temporally weighted PM2.5 exposure model |
| [37] | 2015 | 2008 hourly data points from Mexico City’s monitoring network | Public sensors for PM10, PM2.5, O3, CO, NO2, and SO2; no details | Citywide averaging (CWA), nearest monitor (NM), inverse distance weighting (IDW), ordinary Kriging (OK), and variogram modeling to estimate point exposure; statistics calculated for each exposure method |
| [38] | 2018 | November 2015 to March 2016 (warm season), June to September 2016 (cold season), weekly measurements | NO2 measured with passive gas samplers (Passam AG, Switzerland), integrated PM2.5 mass filters, Teflon filter connected to a vacuum pump (PM2.5) | Land use regression (LUR) models to estimate distribution of NO2 and PM2.5 pollution |
| [39] | 2020 | Personal air quality Monitor (PAM), one week, each season, with outdoor pollution measurements, time resolution of 1 min | CO, NO2, O3, NO, and PM2.5 measurement with both PAM and outdoor sensors | Correlation between pollutants and measurements of PAM and outdoor sensors; proposed time-activity model for estimation of exposure |
| [40] | 2018 | Portable pollutant monitor data combined with respiratory health records, WHO AirQ+ software, American Thoracic Society (ATS) questionnaire data | MSA Altair 5 for CO and SO2, CW-HAT200 particulate counter for PM2.5 and PM10 | Various statistical methods for pollution distribution and influence of pollution on reported symptoms |
| [41] | 2019 | Meteorological data, PM10 and PM2.5 pollutants measured from AQCC from 2006 to 2016, using 24 stations in Tehran | Public AQCC and meteorological organization | SVR, GWR, ANN, and NARX with external input |
| [42] | 2018 | Roadside, indoor pollution data | Measuring CO, NO, NO2, PM2.5, BC, and PM2.5 mass (Thermo 48i, Teledyne 200A, Magee Scientific Aethalometer and Gravimetric), outdoor location, Teledyne 300E, Thermo 42C Low Source, microAeth AE51, and Gravimetric outdoor and indoors | Correlation between pollutant concentrations and spatio-temporal regression models |
| [43] | 2018 | Various datasets | Not available | Part of H2O (big data R AI cloud platform) |
| [44] | 2022 | Measuring PM2.5, PM10, NO2, SO2, O3, CO on an hourly basis, 26 weather parameters, as well as human-caused factors from 2016 to 2020 in 10 cities in Shaanxi Province, China | China Environmental Protection Agency (EPA) open air quality observation data from ground monitoring stations | A hybrid model for determining PM2.5 concentrations and volatility, XGBoost (extreme gradient boosting), four GARCH (generalized auto-regressive conditional heteroskedasticity) models, and MLP (multi-layer perceptrons) |
| [45] | 2022 | Yearly average concentrations of PM10, PM2.5, SO2 , VOCs, and NO2 ; some data were taken from the Shaanxi and Henan Provincial Statistical Yearbook from 2016 to 2021 for haze hazard forecasting | National Urban Air Quality Real-Time Release Platform data source | PCA (principal component analysis)–MEE (matter element extension)–ISPO (improving particle swarm optimization)–LightGBM (light gradient boosting machine) air quality forecasting model |
| [46] | 2023 | 26 Indian cities, data taken from the Central Pollution Control Board (CPCB), data from 1 January 2015 to 31 May 2020 | Prediction of PM2.5 | Hybrid deep learning model using encoder–decoder, LSTM, bidirectional LSTM, convolutional LSTM, 3D convolution neural network, PM2.5, multistep ahead prediction, SNR |
| [47] | 2018 | A dataset containing temperature, humidity, dust, and CO2 collected as mean, each day, from 1 June 2018 to 22 July 2018 | No details about sensors given | Auto-regressive integrated moving average (ARIMA) |
| Reference | Supervised Learning | Unsupervised Learning | Deep Learning | Optimization & Heuristic | Other |
|---|---|---|---|---|---|
| [18] | ✕ | ||||
| [19] | ✕ | ✕ | |||
| [20] | ✕ | ✕ | |||
| [21] | ✕ | ✕ | |||
| [22] | ✕ | ||||
| [23] | ✕ | ✕ | |||
| [24] | ✕ | ✕ | |||
| [25] | ✕ | ✕ | ✕ | ✕ | |
| [26] | ✕ | ✕ | |||
| [27] | ✕ | ✕ | ✕ | ||
| [28] | ✕ | ||||
| [29] | ✕ | ||||
| [30] | ✕ | ||||
| [31] | ✕ | ✕ | |||
| [32] | ✕ | ||||
| [33] | ✕ | ✕ | |||
| [34] | ✕ | ✕ | |||
| [35] | ✕ | ✕ | |||
| [36] | ✕ | ||||
| [37] | ✕ | ✕ | |||
| [38] | ✕ | ||||
| [39] | ✕ | ||||
| [40] | ✕ | ||||
| [41] | ✕ | ✕ | |||
| [42] | ✕ | ✕ | |||
| [43] | ✕ | ||||
| [44] | ✕ | ✕ | |||
| [45] | ✕ | ✕ | ✕ | ||
| [46] | ✕ | ✕ | |||
| [47] | ✕ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitreska Jovanovska, E.; Batz, V.; Lameski, P.; Zdravevski, E.; Herzog, M.A.; Trajkovik, V. Methods for Urban Air Pollution Measurement and Forecasting: Challenges, Opportunities, and Solutions. Atmosphere 2023, 14, 1441. https://doi.org/10.3390/atmos14091441
Mitreska Jovanovska E, Batz V, Lameski P, Zdravevski E, Herzog MA, Trajkovik V. Methods for Urban Air Pollution Measurement and Forecasting: Challenges, Opportunities, and Solutions. Atmosphere. 2023; 14(9):1441. https://doi.org/10.3390/atmos14091441
Chicago/Turabian StyleMitreska Jovanovska, Elena, Victoria Batz, Petre Lameski, Eftim Zdravevski, Michael A. Herzog, and Vladimir Trajkovik. 2023. "Methods for Urban Air Pollution Measurement and Forecasting: Challenges, Opportunities, and Solutions" Atmosphere 14, no. 9: 1441. https://doi.org/10.3390/atmos14091441
APA StyleMitreska Jovanovska, E., Batz, V., Lameski, P., Zdravevski, E., Herzog, M. A., & Trajkovik, V. (2023). Methods for Urban Air Pollution Measurement and Forecasting: Challenges, Opportunities, and Solutions. Atmosphere, 14(9), 1441. https://doi.org/10.3390/atmos14091441