
A Neural-Network Based MPAS—Shallow Water Model and Its 4D-Var Data Assimilation System


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Methodology
2.1. MPAS-SW Dynamics
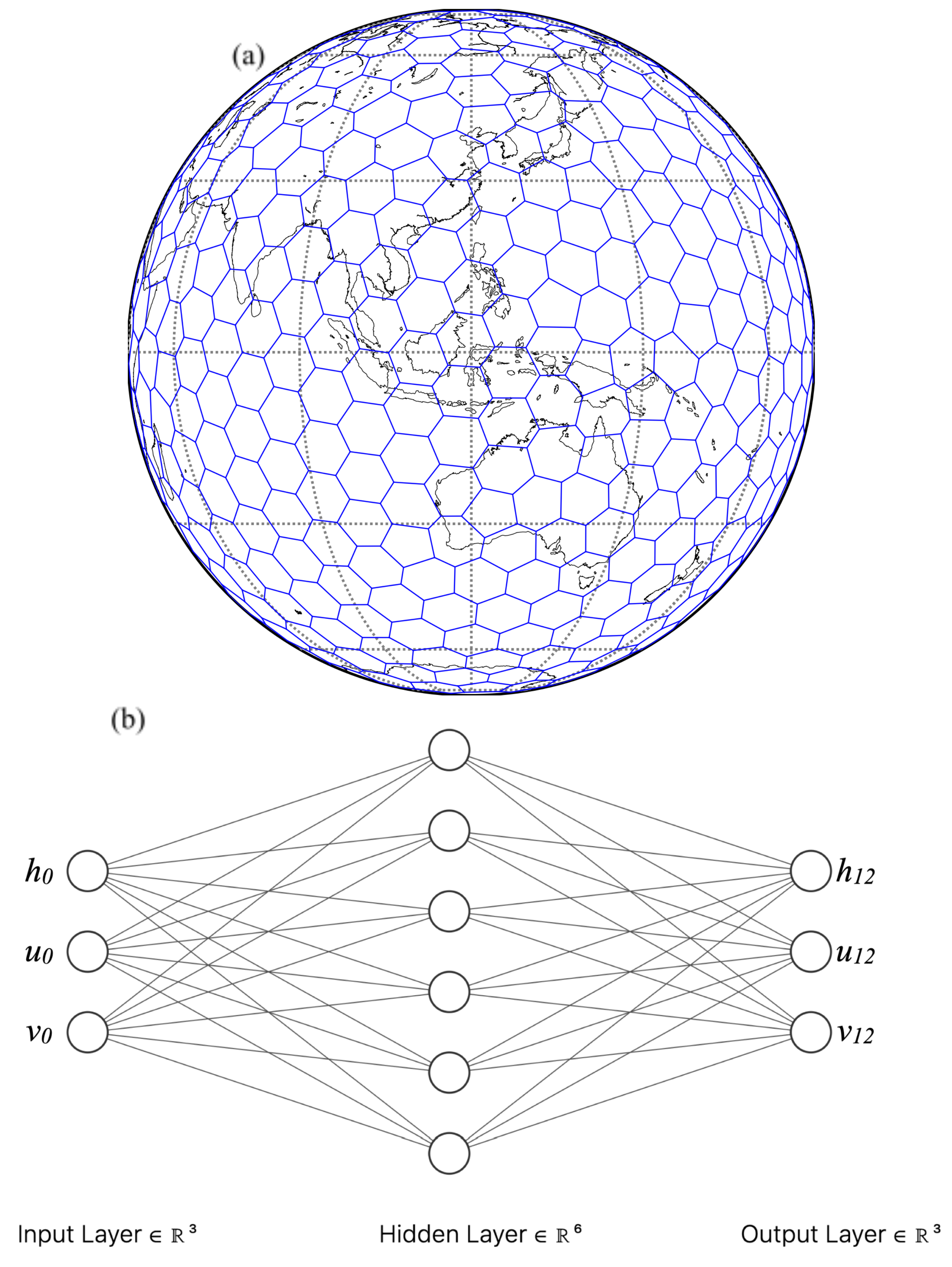
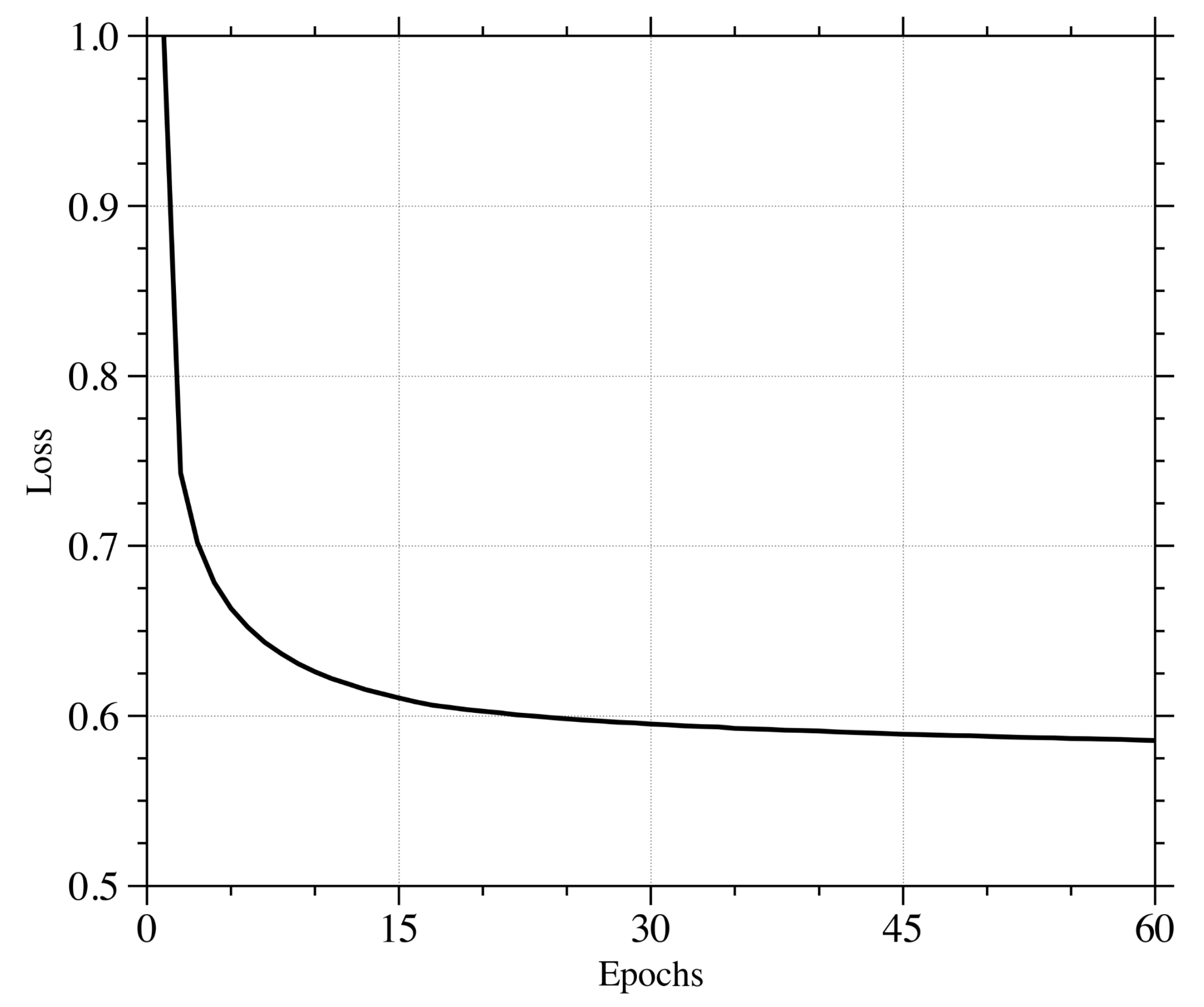
2.2. NN Emulator of MPAS-SW
2.3. The Tangent Linear and Adjoint Models
2.4. A Continuous 4D-Var DA System
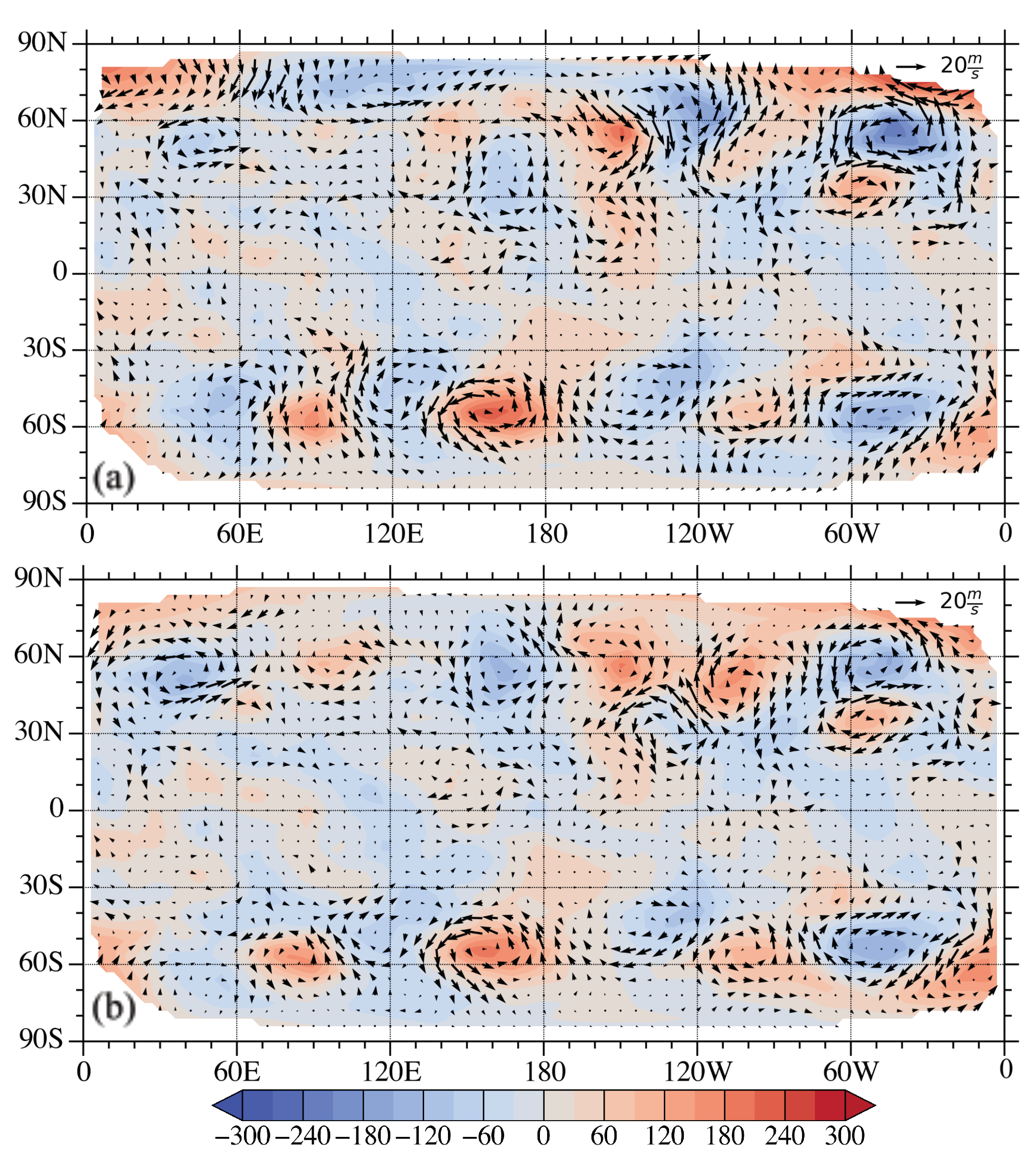
3. Experiment Design
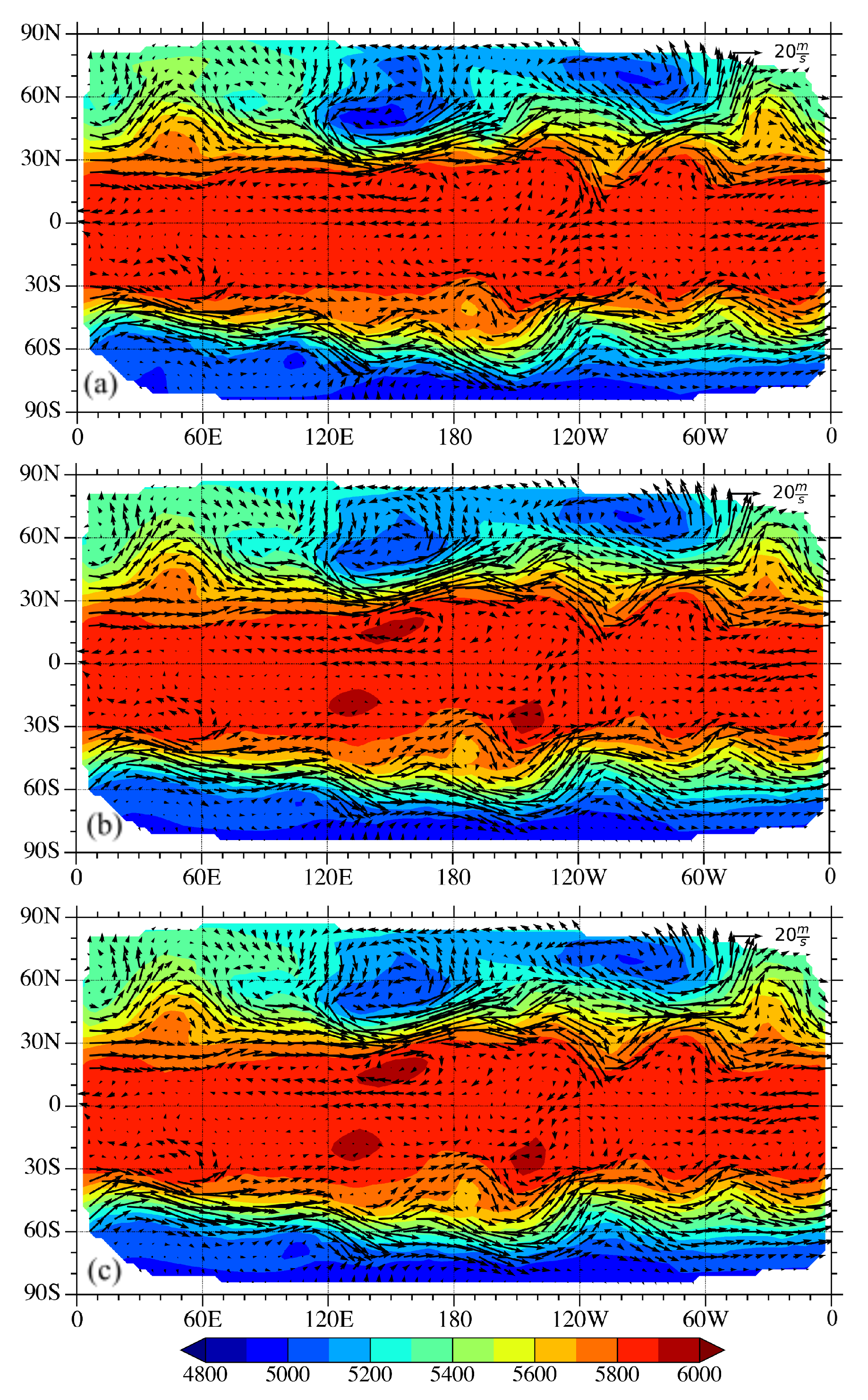
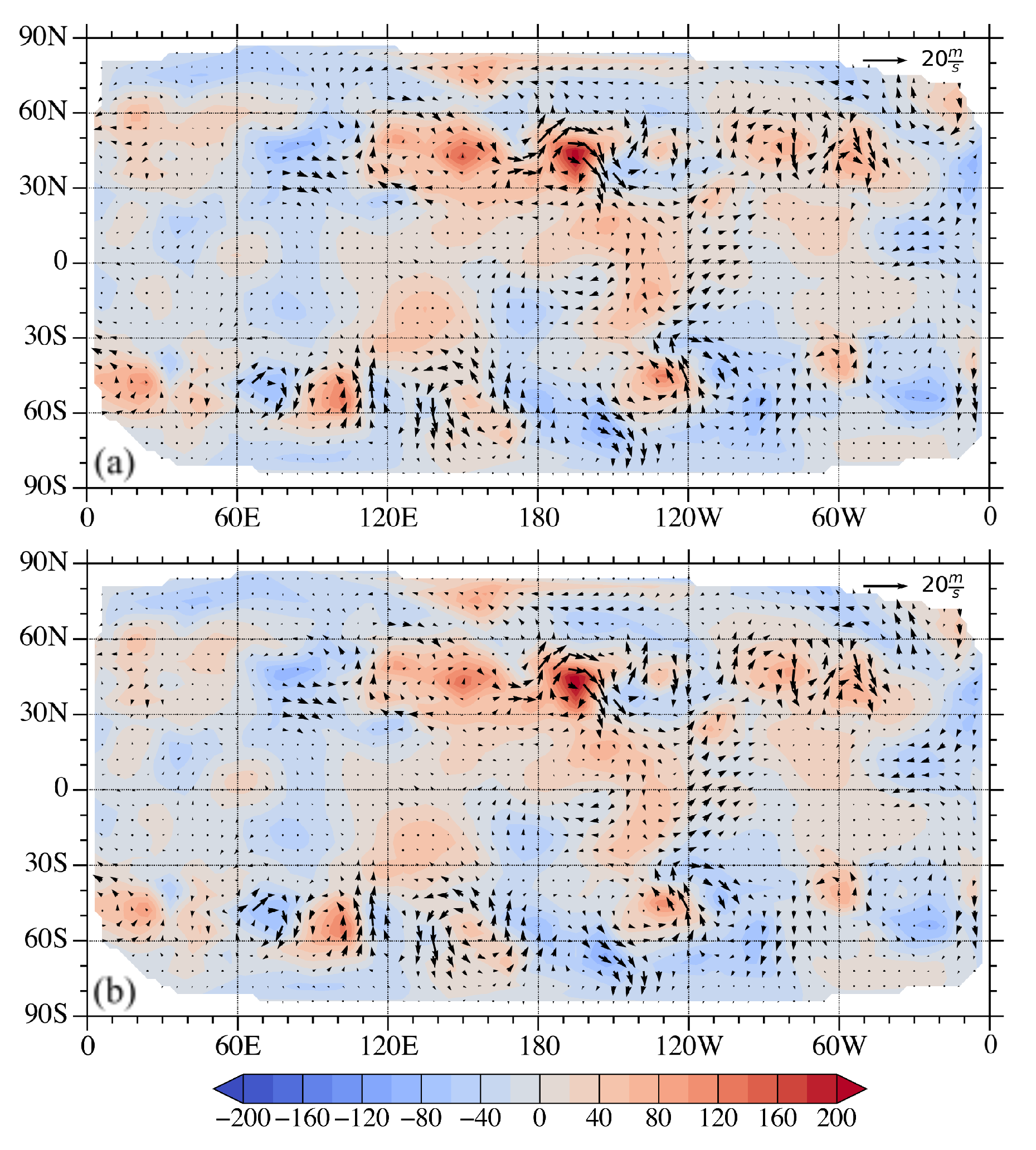
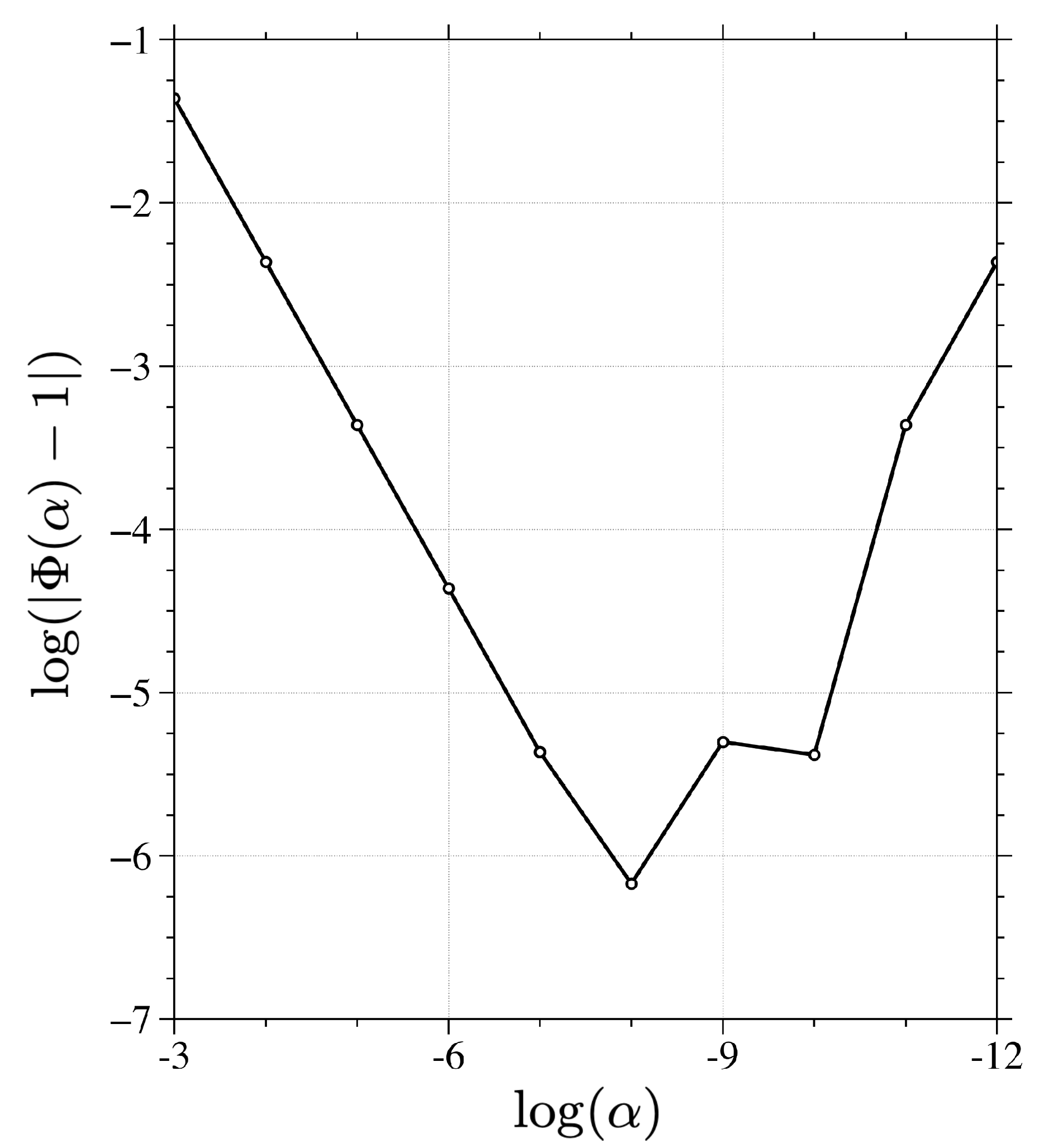
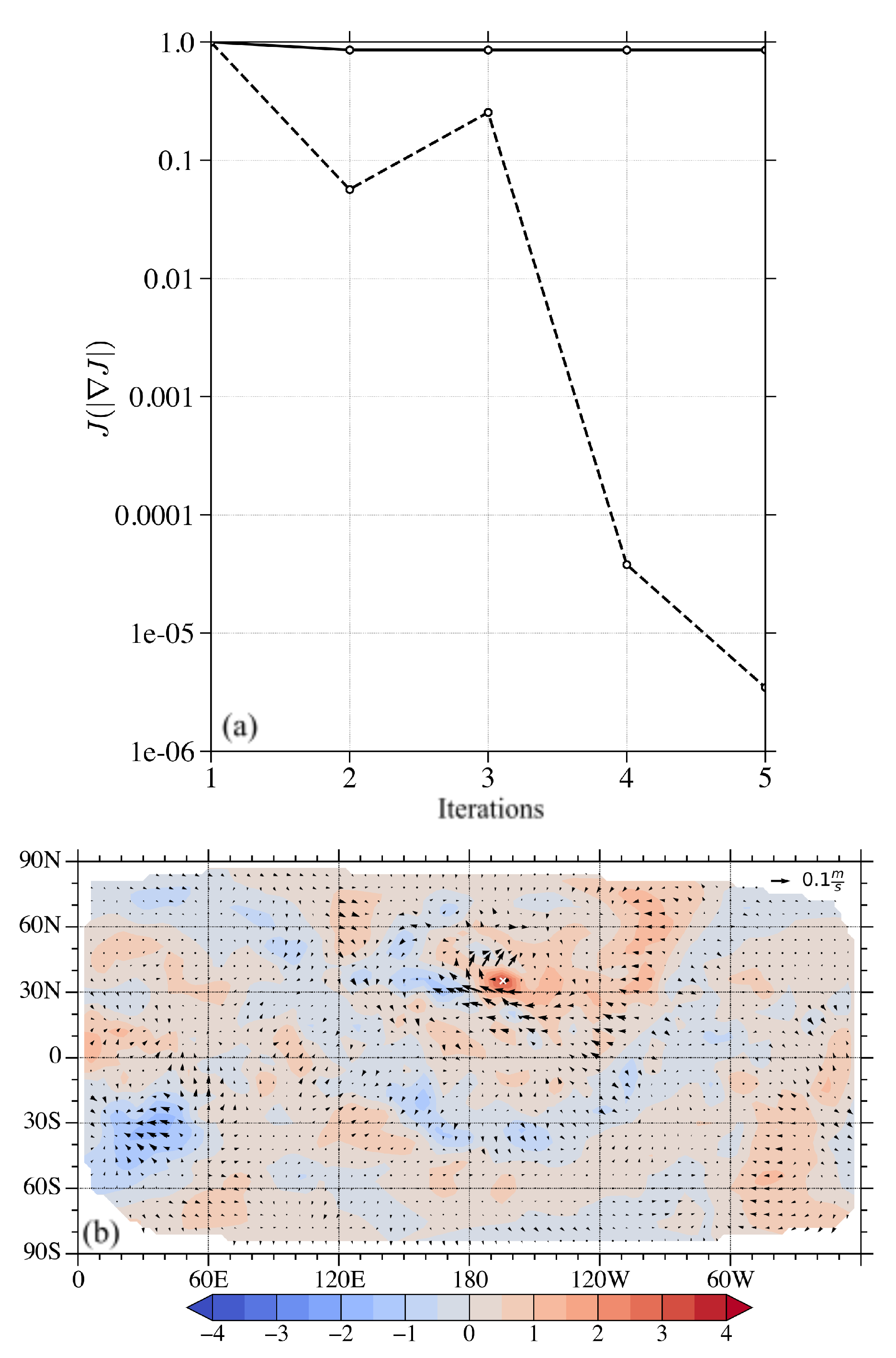
3.1. A Single Observation Experiment
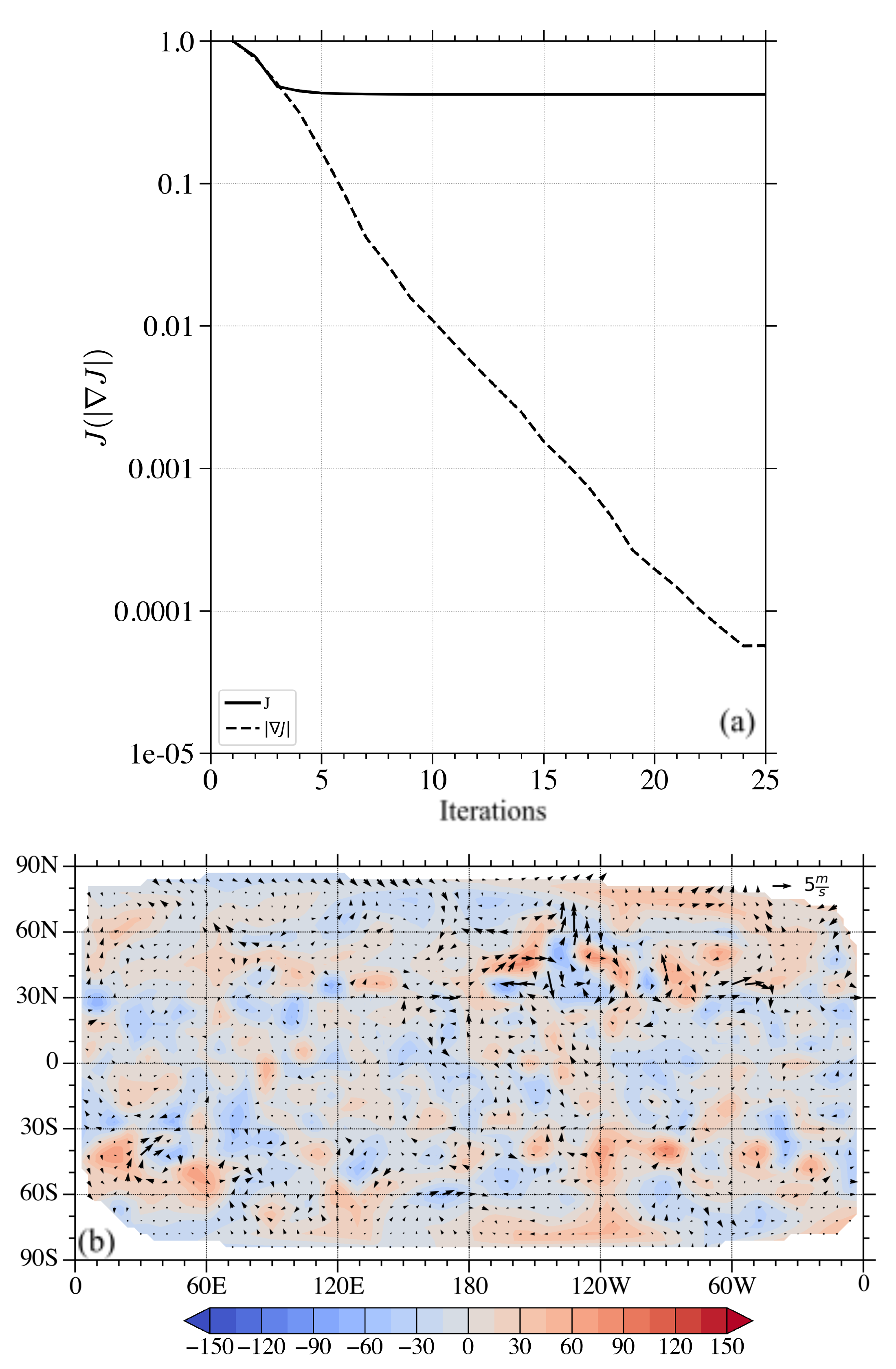
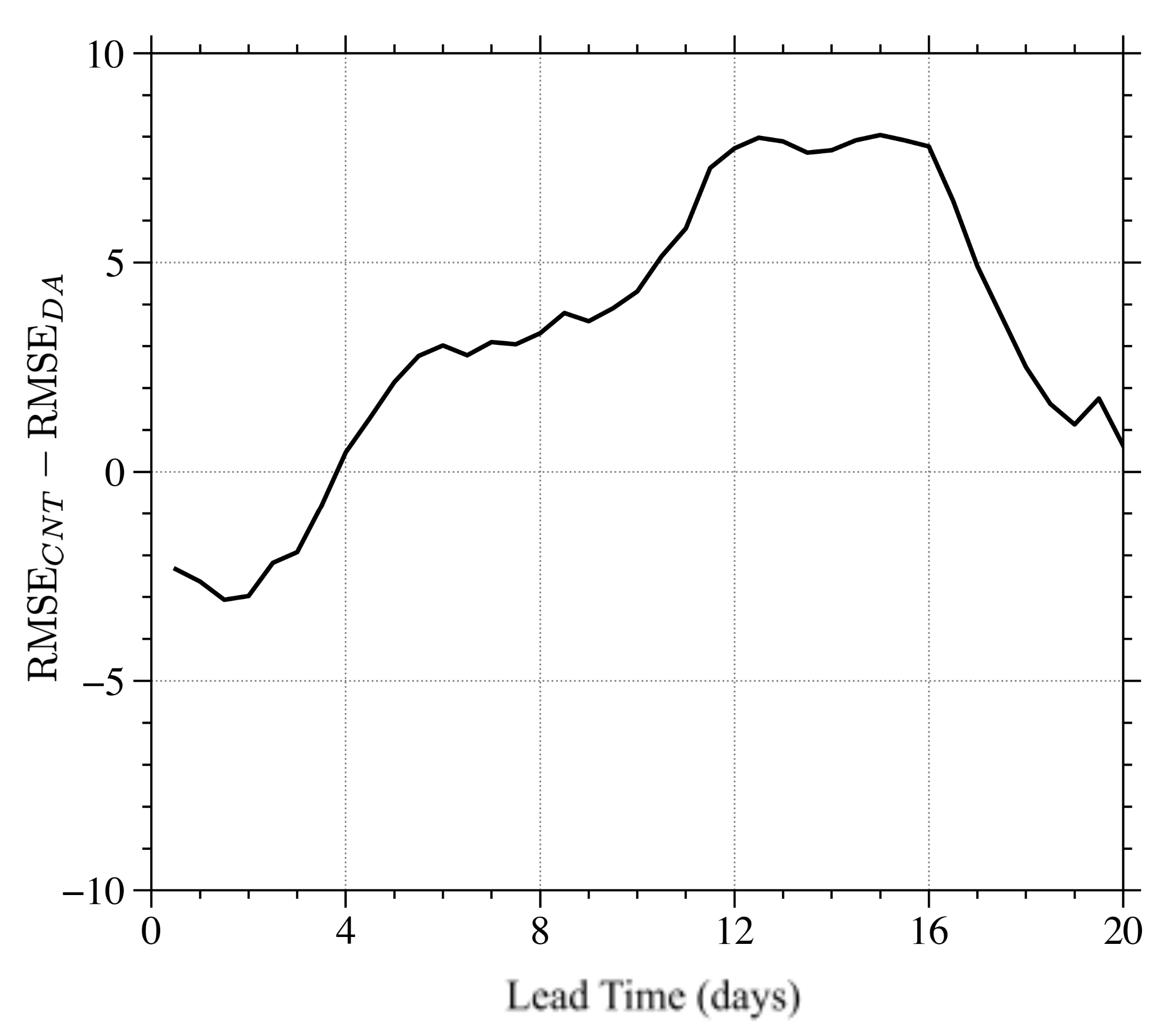
3.2. Full Vector Observation Experiment
3.3. Discussion
4. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Bauer, P.; Thorpe, A.; Brunet, G. The quiet revolution of numerical weather prediction. Nature 2015, 525, 47–55. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Moore, J.C. Mathematical and Physical Fundamentals of Climate Change; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Pathak, J.; Subramanian, S.; Harrington, P.; Raja, S.; Chattopadhyay, A.; Mardani, M.; Kurth, T.; Hall, D.; Li, Z.; Azizzadenesheli, K. Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators. arXiv 2022, arXiv:2202.11214. [Google Scholar]
- Schultz, M.G.; Betancourt, C.; Gong, B.; Kleinert, F.; Langguth, M.; Leufen, L.H.; Mozaffari, A.; Stadtler, S. Can deep learning beat numerical weather prediction? Philos. Trans. R. Soc. A 2021, 379, 20200097. [Google Scholar] [CrossRef] [PubMed]
- Irrgang, C.; Boers, N.; Sonnewald, M.; Barnes, E.A.; Kadow, C.; Staneva, J.; Saynisch-Wagner, J. Towards neural Earth system modelling by integrating artificial intelligence in Earth system science. Nat. Mach. Intell. 2021, 3, 667–674. [Google Scholar] [CrossRef]
- Scher, S.; Messori, G. Predicting weather forecast uncertainty with machine learning. Q. J. R. Meteorol. Soc. 2018, 144, 2830–2841. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, O.O. Improving forecasts of GARCH family models with the artificial neural networks: An application to the daily returns in Istanbul Stock Exchange. Expert Syst. Appl. 2009, 36, 7355–7362. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, O. Modeling Markov switching ARMA-GARCH neural networks models and an application to forecasting stock returns. Sci. World J. 2014, 2014, 497941. [Google Scholar] [CrossRef]
- Gagne, D.J.; McGovern, A.; Xue, M. Machine learning enhancement of storm-scale ensemble probabilistic quantitative precipitation forecasts. Weather Forecast. 2014, 29, 1024–1043. [Google Scholar] [CrossRef]
- McGovern, A.; Elmore, K.L.; Gagne, D.J.; Haupt, S.E.; Karstens, C.D.; Lagerquist, R.; Smith, T.; Williams, J.K. Using artificial intelligence to improve real-time decision-making for high-impact weather. Bull. Amer. Meteor. Soc. 2017, 98, 2073–2090. [Google Scholar] [CrossRef]
- Rasp, S.; Lerch, S. Neural networks for postprocessing ensemble weather forecasts. Mon. Weather Rev. 2018, 146, 3885–3900. [Google Scholar] [CrossRef]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine learning for precipitation nowcasting from radar images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Grönquist, P.; Yao, C.; Ben-Nun, T.; Dryden, N.; Dueben, P.; Li, S.; Hoefler, T. Deep learning for post-processing ensemble weather forecasts. Philos. Trans. R. Soc. A 2021, 379, 20200092. [Google Scholar] [CrossRef] [PubMed]
- Lam, R.; Sanchez-Gonzalez, A.; Willson, M.; Wirnsberger, P.; Fortunato, M.; Pritzel, A.; Ravuri, S.; Ewalds, T.; Alet, F.; Eaton-Rosen, Z. GraphCast: Learning skillful medium-range global weather forecasting. arXiv 2022, arXiv:2212.12794. [Google Scholar]
- Keisler, R. GraphCast: Forecasting Global Weather with Graph Neural Networks. arXiv 2022, arXiv:2202.07575. [Google Scholar]
- Chevallier, F.; Chéruy, F.; Scott, N.A.; Chédin, A. A neural network approach for a fast and accurate computation of a longwave radiative budget. J. Appl. Meteor. Climatol. 1998, 37, 1385–1397. [Google Scholar] [CrossRef]
- Krasnopolsky, V.M.; Fox-Rabinovitz, M.S.; Chalikov, D.V. New approach to calculation of atmospheric model physics: Accurate and fast neural network emulation of longwave radiation in a climate model. Mon. Weather Rev. 2005, 133, 1370–1383. [Google Scholar] [CrossRef]
- Rasp, S.; Pritchard, M.S.; Gentine, P. Deep learning to represent subgrid processes in climate models. Proc. Natl. Acad. Sci. USA 2018, 115, 9684–9689. [Google Scholar] [CrossRef]
- Brenowitz, N.D.; Bretherton, C.S. Spatially extended tests of a neural network parametrization trained by coarse-graining. J. Adv. Model. Earth Syst. 2019, 11, 2728–2744. [Google Scholar] [CrossRef]
- Hatfield, S.; Chantry, M.; Dueben, P.; Lopez, P.; Geer, A.; Palmer, T. Building Tangent-Linear and Adjoint Models for Data Assimilation With Neural Networks. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002521. [Google Scholar] [CrossRef]
- Nonnenmacher, M.; Greenberg, D.S. Deep emulators for differentiation, forecasting, and parametrization in Earth science simulators. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002554. [Google Scholar] [CrossRef]
- Scher, S.; Messori, G. Generalization properties of feed-forward neural networks trained on Lorenz systems. Nonlinear Process. Geophys. 2019, 26, 381–399. [Google Scholar] [CrossRef]
- Ringler, T.; Ju, L.; Gunzburger, M. A multiresolution method for climate system modeling: Application of spherical centroidal Voronoi tessellations. Ocean Dyn. 2008, 58, 475–498. [Google Scholar] [CrossRef]
- Ringler, T.D.; Thuburn, J.; Klemp, J.B.; Skamarock, W.C. A unified approach to energy conservation and potential vorticity dynamics for arbitrarily-structured C-grids. J. Comput. Phys. 2010, 229, 3065–3090. [Google Scholar] [CrossRef]
- Hoffmann, L.; Günther, G.; Li, D.; Stein, O.; Wu, X.; Griessbach, S.; Heng, Y.; Konopka, P.; Müller, R.; Vogel, B. From ERA-Interim to ERA5: The considerable impact of ECMWF’s next-generation reanalysis on Lagrangian transport simulations. Atmos. Chem. Phys. 2019, 19, 3097–3124. [Google Scholar] [CrossRef]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Tian, X. Evolutions of Errors in the Global Multiresolution Model for Prediction Across Scales - Shallow Water (MPAS-SW). Q. J. Royal Meteorol. Soc. 2020, 734, 382–391. [Google Scholar] [CrossRef]
- Tian, X.; Ide, K. Hurricane Predictability Analysis with Singular Vectors in the Multiresolution Global Shallow Water Model. J. Atmos. Sci. 2021, 78, 1259–1273. [Google Scholar] [CrossRef]
- Zou, X.; Kuo, Y.H.; Guo, Y.R. Assimilation of atmospheric radio refractivity using a nonhydrostatic adjoint model. Mon. Weather Rev. 1995, 123, 2229–2250. [Google Scholar] [CrossRef]
- Zou, X.; Vandenberghe, F.; Pondeca, M.; Kuo, Y.H. Introduction to Adjoint Techniques and the MM5 Adjoint Modeling System; NCAR Technical Note; NCAR: Boulder, CO, USA, 1997. [Google Scholar]
- Tian, X.; Zou, X. Validation of a Prototype Global 4D-Var Data Assimilation System for the MPAS-Atmosphere Model. Mon. Weather Rev. 2021, 149, 2803–2817. [Google Scholar] [CrossRef]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, X.; Conibear, L.; Steward, J. A Neural-Network Based MPAS—Shallow Water Model and Its 4D-Var Data Assimilation System. Atmosphere 2023, 14, 157. https://doi.org/10.3390/atmos14010157
Tian X, Conibear L, Steward J. A Neural-Network Based MPAS—Shallow Water Model and Its 4D-Var Data Assimilation System. Atmosphere. 2023; 14(1):157. https://doi.org/10.3390/atmos14010157
Chicago/Turabian StyleTian, Xiaoxu, Luke Conibear, and Jeffrey Steward. 2023. "A Neural-Network Based MPAS—Shallow Water Model and Its 4D-Var Data Assimilation System" Atmosphere 14, no. 1: 157. https://doi.org/10.3390/atmos14010157
APA StyleTian, X., Conibear, L., & Steward, J. (2023). A Neural-Network Based MPAS—Shallow Water Model and Its 4D-Var Data Assimilation System. Atmosphere, 14(1), 157. https://doi.org/10.3390/atmos14010157