
Simulation of the Spatiotemporal Distribution of PM2.5 Concentration Based on GTWR-XGBoost Two-Stage Model: A Case Study of Chengdu Chongqing Economic Circle

Abstract
:1. Introduction
2. Research Methods and Data Sources
2.1. Research Area
2.2. Data and Processing
2.3. Research Methods
2.3.1. Model Principles
2.3.2. Variable Screening
2.3.3. Two-Stage Model Construction and Experimental Scheme Design

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Cross-Validation | Forecast Validation | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE/ug·m−3 | MAE/ug·m−3 | R2 | RMSE/ug·m−3 | MAE/ug·m−3 | |
| LUR | 0.68 | 10.72 | 8.06 | 0.63 | 11.16 | 8.55 |
| GTWR | 0.82 | 7.65 | 5.42 | 0.78 | 8.64 | 5.82 |
| RF | 0.80 | 8.49 | 6.33 | 0.75 | 9.28 | 6.74 |
| XGBoost | 0.87 | 6.73 | 4.97 | 0.87 | 6.56 | 4.75 |
| Model | Cross-Validation | Forecast Validation | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE/ug·m−3 | MAE/u ug·m−3 | R2 | RMSE·ug/m−3 | MAE/ug·m−3 | |
| LUR | 0.71 | 10.24 | 7.60 | 0.69 | 10.29 | 7.80 |
| RF | 0.84 | 8.23 | 6.11 | 0.80 | 8.24 | 6.11 |
| GTWR | 0.78 | 7.86 | 7.22 | 0.76 | 8.86 | 6.68 |
| XGBoost | 0.91 | 5.60 | 4.23 | 0.90 | 5.59 | 3.99 |
| Model | Cross-Validation | Forecast Validation | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE/ug·m−3 | MAE/ug·m−3 | R2 | RMSE/ug·m−3 | MAE/ug·m−3 | |
| STXGBoost [31] | 0.90 | 5.86 | 4.39 | 0.88 | 6.32 | 4.33 |
| STRF [20] | 0.81 | 8.12 | 6.08 | 0.78 | 8.77 | 6.42 |
| LUR-RF [21] | 0.82 | 7.85 | 5.92 | 0.78 | 8.76 | 6.52 |
| LUR-XGBoost [29] | 0.90 | 5.99 | 4.63 | 0.87 | 6.60 | 4.81 |
| GTWR-LUR | 0.85 | 7.24 | 5.50 | 0.82 | 7.81 | 5.72 |
| GTWR-RF | 0.86 | 7.15 | 5.30 | 0.84 | 7.31 | 5.57 |
| GTWR-XGBoost | 0.92 | 5.44 | 4.12 | 0.93 | 4.75 | 3.42 |
2.3.4. Accuracy Verification
3. Results and Analysis
3.1. Statistical Results
3.2. Model Comparison and Analysis
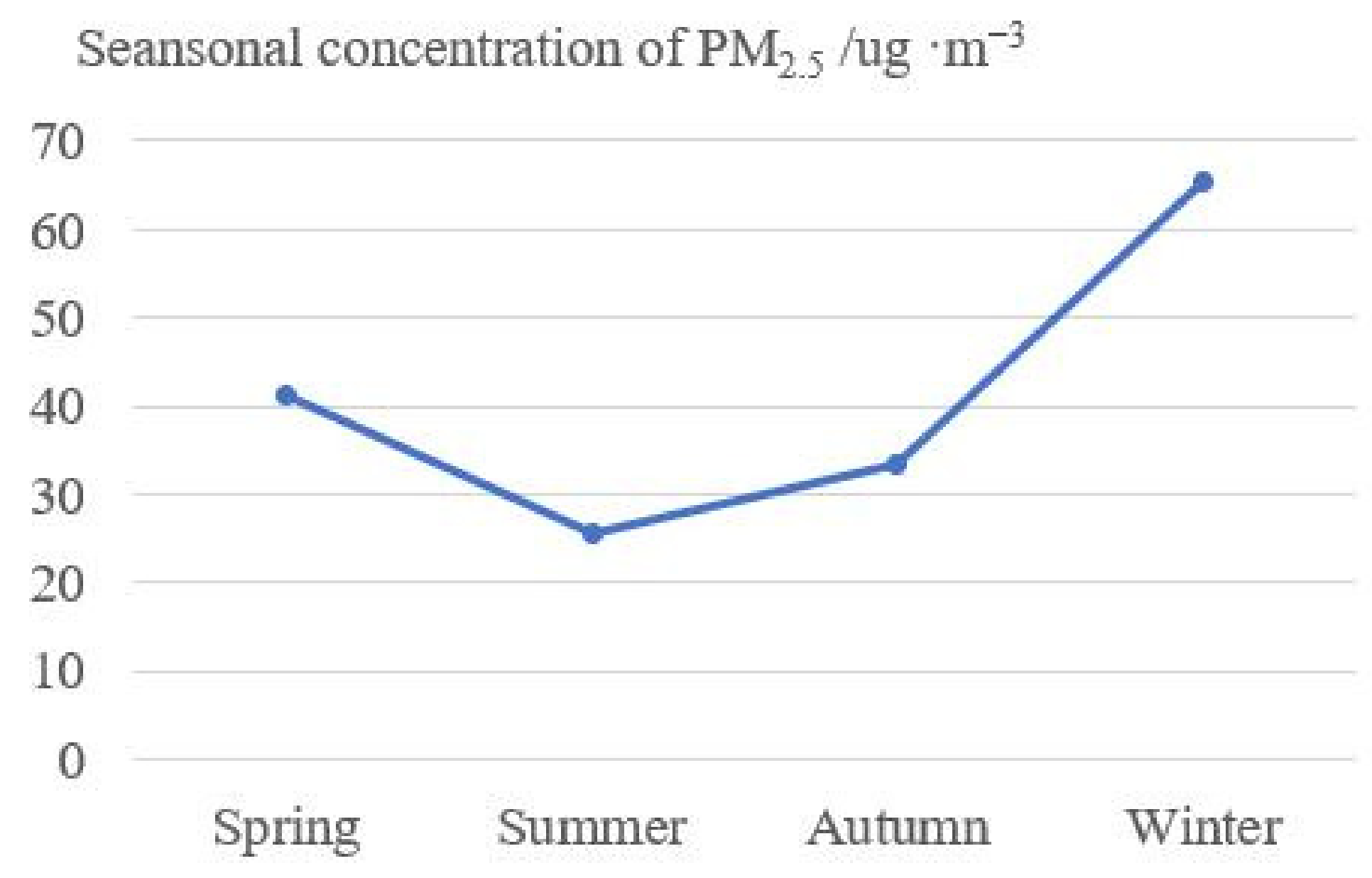
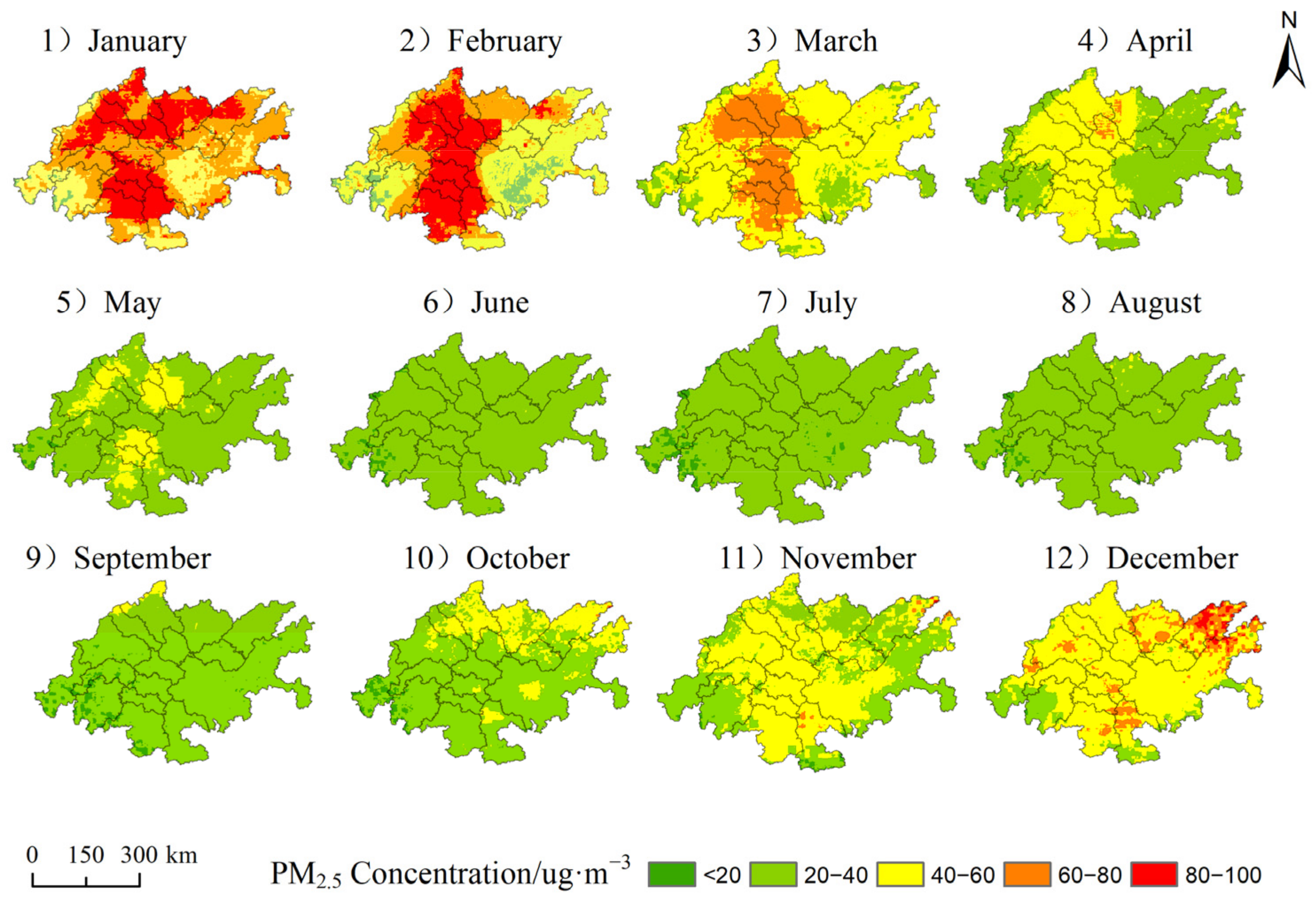
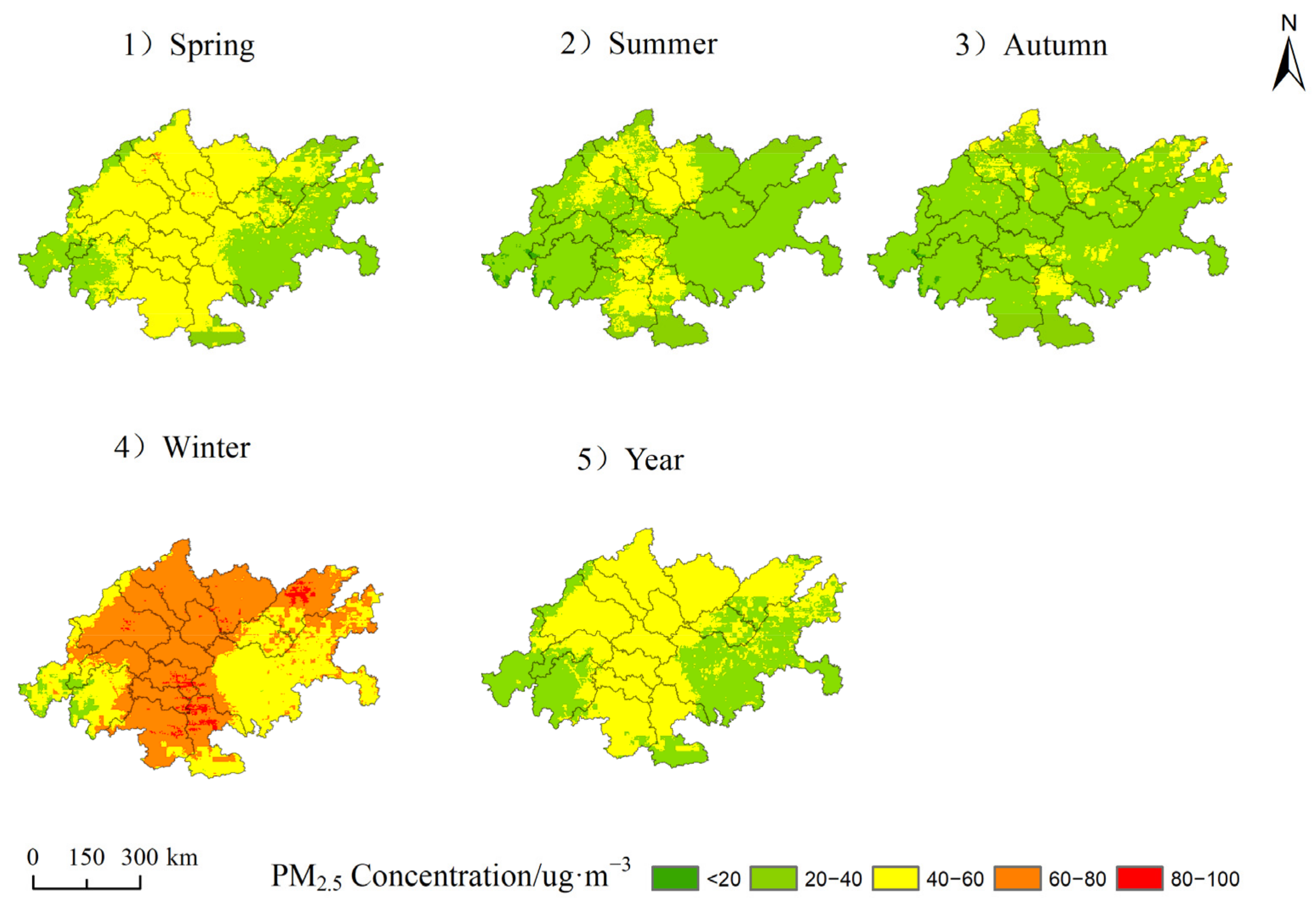
3.3. Spatiotemporal Distribution of PM2.5 Concentration in the Region
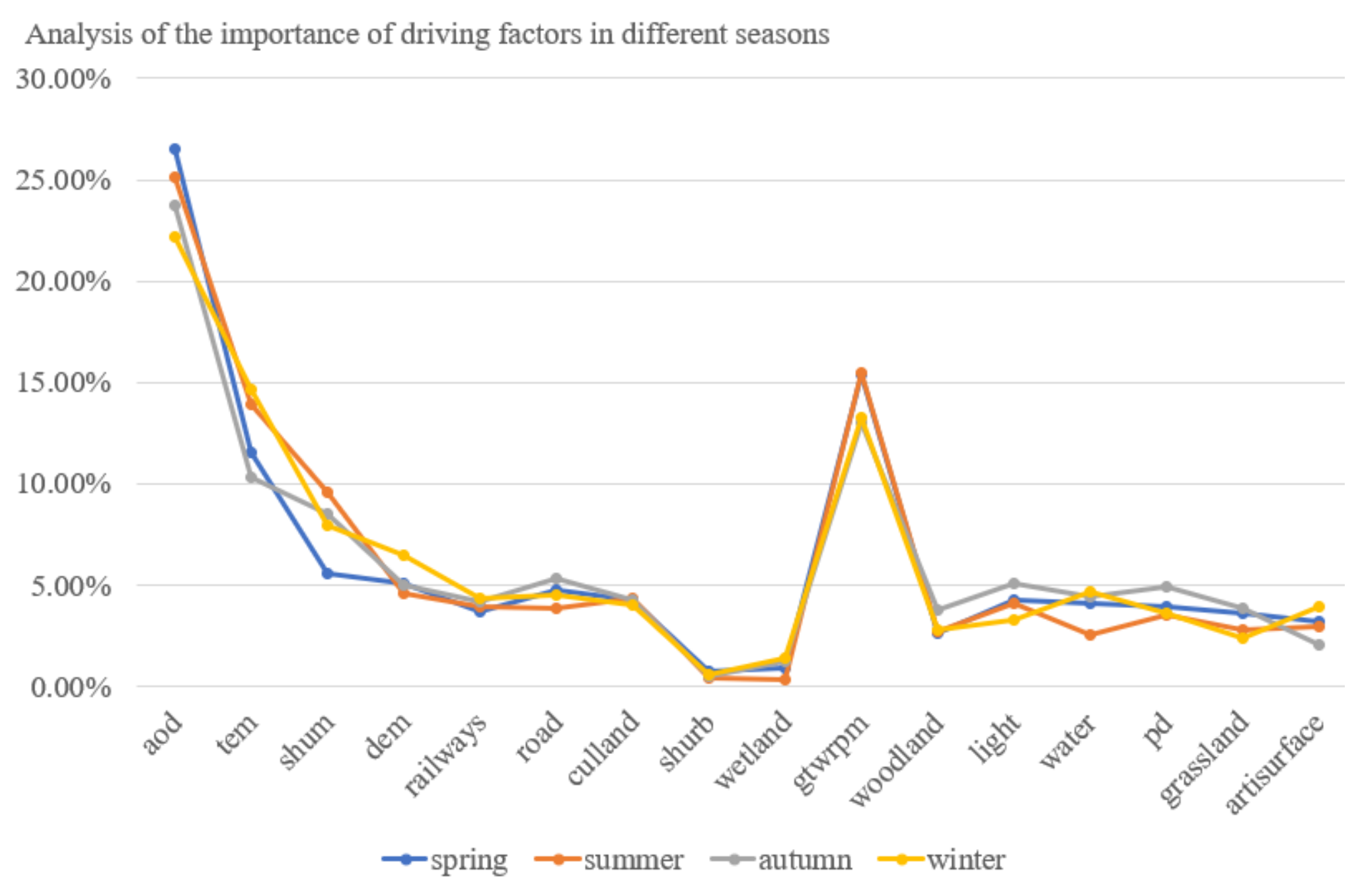
3.4. Analysis of Influencing Factors
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Sundar, C.; Pawan, G. Global Distribution of Column Satellite Aerosol Optical Depth to Surface PM2.5 Relationships. Remote Sens. 2020, 12, 1985. [Google Scholar]
- Cui, X. Prediction Model and Spatiotemporal Analysis of PM2.5 Concentration in Beijing-Tianjin-Hebei Region; Shandong University of Science and Technology: Qingdao, China, 2018. [Google Scholar]
- Jing, Y.; Sun, Y.; Xu, H. Estimation of daily PM2.5 concentration in the Beijing-Tianjin-Hebei Region based on the mixed-effect model. China Environ. Sci. 2018, 38, 2890–2897. [Google Scholar]
- Lee, H.J. Benefits of high-resolution PM2.5 prediction using satellite MAIAC AOD and land use regression for exposure assessment: California Examples. Environ. Sci. Technol. 2019, 53, 12774–12783. [Google Scholar] [CrossRef] [PubMed]
- Liang, F.C.; Xiao, Q.Y.; Wang, Y.J. MAIAC-based long-term spatiotemporal trends of PM2.5 in Beijing, China. Sci. Total Environ. 2018, 616–617, 1589–1598. [Google Scholar] [CrossRef]
- Zhao, B.; Liu, B. Estimation of ground PM2.5 concentration based on Stacking. Environ. Eng. 2020, 38, 153–159. [Google Scholar]
- Wang, J.; Christopher, S.A. Intercomparison between satellite-derived aerosol optical thickness and PM2.5 mass: Implications for air quality studies. Geophys. Res. Lett. 2003, 30, 2095. [Google Scholar] [CrossRef]
- Li, X.; Wu, S.; Xu, Y. Simulation of spatial-temporal variation pattern of PM2.5 mass concentration in Jiangsu province. Environ. Monitor. Manag. Technol. 2017, 29, 16–20. [Google Scholar]
- Xu, G.; Jiao, L.; Xiao, F. Land use a regression model to simulate the spatial distribution of PM2.5 concentration in Beijing-Tianjin-Hebei. J. Arid Land Resour. Environ. 2016, 30, 116–120. [Google Scholar]
- Yang, X.; Song, C.; Fan, L. Simulation and analysis of spatiotemporal variations of PM2.5 concentration in the Beijing-Tianjin-Hebei region. Environ. Sci. 2021, 42, 4083–4094. [Google Scholar]
- Sun, C.; Wang, W.; Liu, F.T. Spatiotemporal variation of PM2.5 concentration in Hebei province based on linear mixed effects model. Environ. Sci. Res. 2019, 32, 1500–1509. [Google Scholar]
- Fu, H.; Sun, Y.; Wang, B. Estimation of PM2.5 concentration in Beijing-Tianjin-Hebei Region based on AOD data and GWR model. China Environ. Sci. 2019, 39, 4530–4537. [Google Scholar]
- Jia, H.; Luo, J.; Xiao, D. Spatiotemporal characteristics of PM2.5 concentration in Chengdu based on remote sensing data and GWR model. Chin. J. Atmos. Environ. Opt. 2021, 16, 529–540. [Google Scholar]
- He, Q.; Huang, B. Satellite-based high-resolution PM2.5 estimation over the Beijing-Tianjin-Hebei region of China using an improved geographically and temporally weighted regression model. Environ. Pollut. 2018, 236, 1027–1037. [Google Scholar] [CrossRef]
- Du, Z.; Wu, S.; Wang, Z. Estimation of spatial distribution of PM2.5 concentration in China based on weighted regression of geographical neural network. J. Geo-Inform. Sci. 2020, 22, 122–135. [Google Scholar]
- Chen, B.; You, S.; Ye, Y. An interpretable self-adaptive deep neural network for estimating daily spatially-continuous PM2.5 concentrations across China. Sci. Total Environ. 2021, 768, 144724. [Google Scholar] [CrossRef]
- Xia, X.; Chen, J.; Wang, J. Analysis of influencing factors of PM2.5 concentration in China based on random forest model. Environ. Sci. 2020, 41, 2057–2065. [Google Scholar]
- Liu, L.; Zhang, Y.; Li, Y. Remote sensing retrieval of PM2.5 concentration in east China based on deep learning. Environ. Sci. 2020, 41, 1513–1519. [Google Scholar]
- Kang, J.F.; Huang, L.X.; Zhang, C.Y. Prediction and Comparative Analysis of Hourly PM2.5 in Multi-Machine Learning Model. China Environ. Sci. 2020, 40, 1895–1905. [Google Scholar]
- Wei, J.; Huang, W.; Li, Z. Estimating 1 km resolution PM2.5 concentrations across China using the space-time random forest approach. Remote Sens. Environ. 2019, 231, 111221. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, J.; Lu, D. Simulation of PM2.5 spatial distribution based on RF-LUR model: A case study of the Yangtze River Delta. Geogr. Geo-Inform. Sci. 2018, 34, 18–23. [Google Scholar]
- Chen, C.C.; Wang, Y.R.; Ye, H.Y. Estimating monthly PM2.5 concentrations from satellite remote sensing data, meteorological variables, and land use data using ensemble statistical modeling and a random forest approach. Environ. Pollut. 2021, 291, 118159. [Google Scholar] [CrossRef] [PubMed]
- Dai, H.; Huang, G.; Zeng, H.; Zhou, F. PM2.5 volatility prediction by XGBoost-MLP based on GARCH models. J. Clean. Prod. 2022, 356, 131898. [Google Scholar] [CrossRef]
- Zhou, J.; Luo, Y.-F.; Lei, Y.-J.; Li, W.-J.; Feng, Y. Multi-scale Convolutional Neural Network Air Quality Prediction Model Based on Spatio-Temporal Optimization. Comput. Sci. 2020, 47, 535–540. [Google Scholar]
- Liu, Y.; Wang, P.; Li, Y.; Wen, L.; Deng, X. Air quality prediction models based on meteorological factors and real-time data of industrial waste gas. Sci. Rep. 2022, 12, 9253. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Xiao, D.; Wang, W. Estimation of near-surface PM2.5 concentration based on remote sensing data. Res. Environ. Sci. 2022, 35, 40–50. [Google Scholar]
- Zeng, D.; Chen, C. Spatiotemporal distribution of PM2.5 and its influencing factors in urban agglomeration. Res. Environ. Sci. 2019, 32, 1834–1843. [Google Scholar]
- He, Q.; Huang, B. Satellite-Based Mapping of Daily High-Resolution Ground PM2.5 in China Via Space-Time Regression Modeling. Remote Sens. Environ. 2018, 206, 72–83. [Google Scholar] [CrossRef]
- Wong, P.-Y.; Lee, H.-Y.; Chen, Y.; Zeng, Y.; Chern, Y.; Chen, N.; Candice Lung, S.-C.; Su, H.; Wu, C. Using a land use regression model with machine learning to estimate ground-level PM2.5. Environ. Pollut. 2021, 277, 116846. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, W.; Pan, M. Spatial interpolation method of PM2.5 concentration based on GTWRK. Radio Eng. 2022, 52, 1018–1024. [Google Scholar]
- Hu, Z.; Chen, C.H. Health care, Remote sensing Inversion of PM2.5 concentration in China based on spatiotemporal XGBoost. Chin. J. Environ. Sci. 2021, 41, 4228–4237. [Google Scholar]
- Guo, X. Observation and Simulation of Air Quality Climate Characteristics and Its EFFECT on Large Terrain in Sichuan Basin; Nanjing University of Information Science and Technology: Nanjing, China, 2016. [Google Scholar]
- Deng, D.; Lu, P.; Duan, L. Spatiotemporal distribution of PM2.5 and its influencing factors in region. Environ. Impact Assess. 2021, 43, 84–90. [Google Scholar]
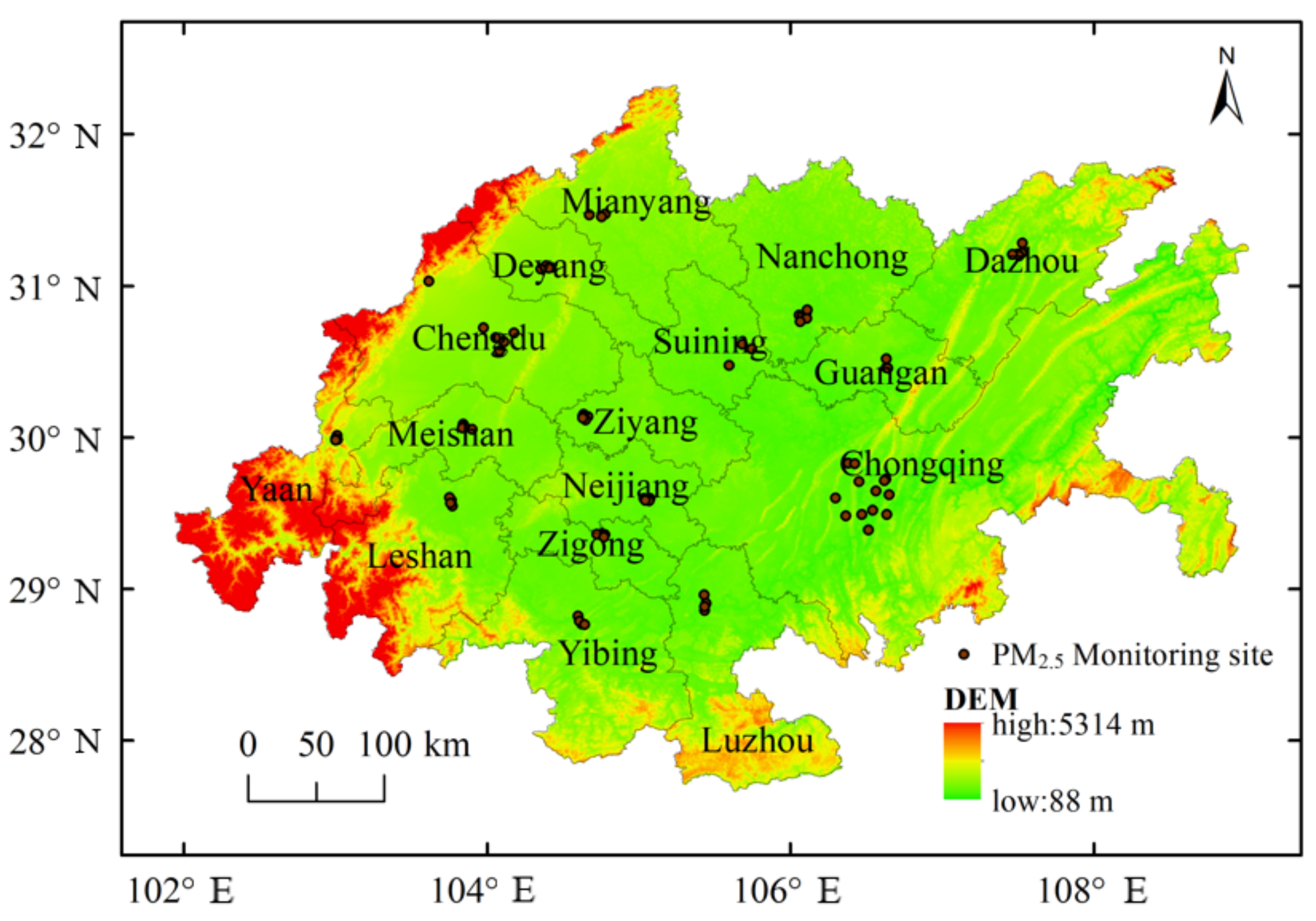
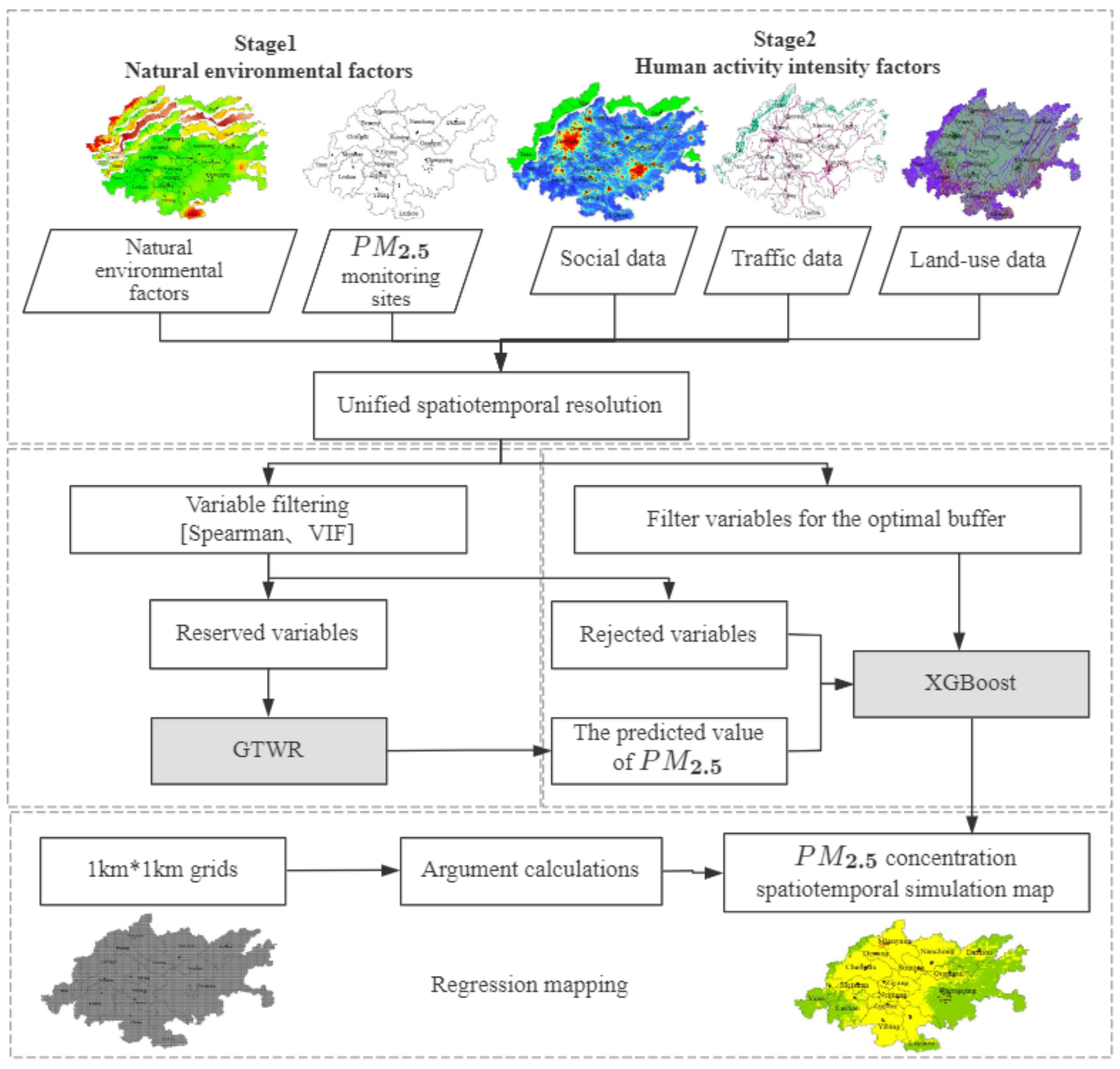

| Type | Name | English Abbreviations | Unit | Year | Spatial Resolution | Source |
|---|---|---|---|---|---|---|
| PM2.5 Monitoring data | Environmental monitoring station data | PM2.5 | ug·m−3 | 2018 | - | http://www.cnemc.cn/ (accessed on 10 December 2021) |
| Natural environmental factors | Aerosol Optical Depth | AOD | - | 2018 | 1 km | https://ladsweb.modaps.eosdis.nasa.gov/ (accessed on 20 December 2021) |
| Wind speed | WIN | m·s−1 | 2018 | 0.1° × 0.1° | http://data.tpdc.ac.cn/zh-hans/data/ (accessed on 20 December 2021) | |
| Pressure | PRES | hPa | 2018 | |||
| Temperature | TEM | K | 2018 | |||
| air humidity ratio | SHUM | - | 2018 | |||
| Precipitation | PREC | mm | 2018 | |||
| Planetary Boundary Layer Height | PBLH | m | 2018 | 0.25° × 0.3° | ftp://rain.ucis.dal.ca/ctm/ (accessed on 20 December 2021) | |
| Digital Elevation Model | DEM | m | 2018 | 90 m | http://www.gscloud.cn/search (accessed on 20 December 2021) | |
| Normalized Difference Vegetation Index | NDVI | % | 2018 | 1 km | Data Center for Resources and Environmental Sciences, Chinese Academy of Sciences (https://www.resdc.cn) (accessed on 20 December 2021) | |
| Human activity intensity factor | population density | POP | - | 2018 | 100 m | World pop https://www.worldpop.org (accessed on 28 December 2021) |
| Night light | NL | - | 2018 | 1.5 km | http://satsee.radi.ac.cn/cfimage/nightlight (accessed on 28 December 2021) | |
| Road way | WAY | - | 2018 | - | http://www.openstreetmap.org (accessed on 28 December 2021) | |
| Land use | LU | - | 2010 | 30 m | http://www.globallandcover.com (accessed on 28 December 2021) |
| Variable | Correlation Coefficient | VIF Value |
|---|---|---|
| AOD | 0.32 | 1.17 |
| WIN | −0.06 | 2.36 |
| PRES | 0.20 | 3.12 |
| TEM | −0.77 | 14.74 |
| SHUM | −0.77 | 18.09 |
| PREC | −0.65 | 2.68 |
| PBLH | −0.70 | 2.11 |
| DEM | −0.04 | 6.46 |
| NDVI | −0.50 | 2.96 |
| Variable | Average | Minimum | Maximum | Standard Deviation |
|---|---|---|---|---|
| PM2.5/ug m−3 | 41.38 | 4.99 | 112.43 | 18.95 |
| WIN/m s−1 | 1.89 | 1.06 | 3.49 | 0.46 |
| TEM/K | 290.99 | 274.54 | 305.23 | 7.5 |
| SHUM | 0.018 | 0 | 0.03 | 0 |
| PRES/hPa | 96,337.89 | 85,962 | 99,940 | 2333.02 |
| PREC/mm | 0.18 | 0 | 0.79 | 0.12 |
| AOD | 618.88 | 0 | 1798.25 | 433.43 |
| PBLH/m | 674.61 | 296.48 | 892.52 | 168.89 |
| NDVI | 0.38 | 0.018 | 0.888 | 0.17 |
| dem/m | 390.33 | 199 | 1346 | 147.16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Luo, X.; Qi, L.; Liao, X.; Chen, C. Simulation of the Spatiotemporal Distribution of PM2.5 Concentration Based on GTWR-XGBoost Two-Stage Model: A Case Study of Chengdu Chongqing Economic Circle. Atmosphere 2023, 14, 115. https://doi.org/10.3390/atmos14010115
Liu M, Luo X, Qi L, Liao X, Chen C. Simulation of the Spatiotemporal Distribution of PM2.5 Concentration Based on GTWR-XGBoost Two-Stage Model: A Case Study of Chengdu Chongqing Economic Circle. Atmosphere. 2023; 14(1):115. https://doi.org/10.3390/atmos14010115
Chicago/Turabian StyleLiu, Minghao, Xiaolin Luo, Liai Qi, Xiangli Liao, and Chun Chen. 2023. "Simulation of the Spatiotemporal Distribution of PM2.5 Concentration Based on GTWR-XGBoost Two-Stage Model: A Case Study of Chengdu Chongqing Economic Circle" Atmosphere 14, no. 1: 115. https://doi.org/10.3390/atmos14010115
APA StyleLiu, M., Luo, X., Qi, L., Liao, X., & Chen, C. (2023). Simulation of the Spatiotemporal Distribution of PM2.5 Concentration Based on GTWR-XGBoost Two-Stage Model: A Case Study of Chengdu Chongqing Economic Circle. Atmosphere, 14(1), 115. https://doi.org/10.3390/atmos14010115