
Using Machine Learning Methods to Forecast Air Quality: A Case Study in Macao

 ,
, 
 , and
, and
Abstract
:1. Introduction
2. Previous and Related Works
3. Materials and Methods
3.1. Air Quality Dataset of Macao
3.2. Learning Algorithms
3.2.1. Multiple Linear Regression (MLR)
3.2.2. Random Forest (RF)
3.2.3. Gradient Boosting (GB)
3.2.4. Support Vector Regression (SVR)
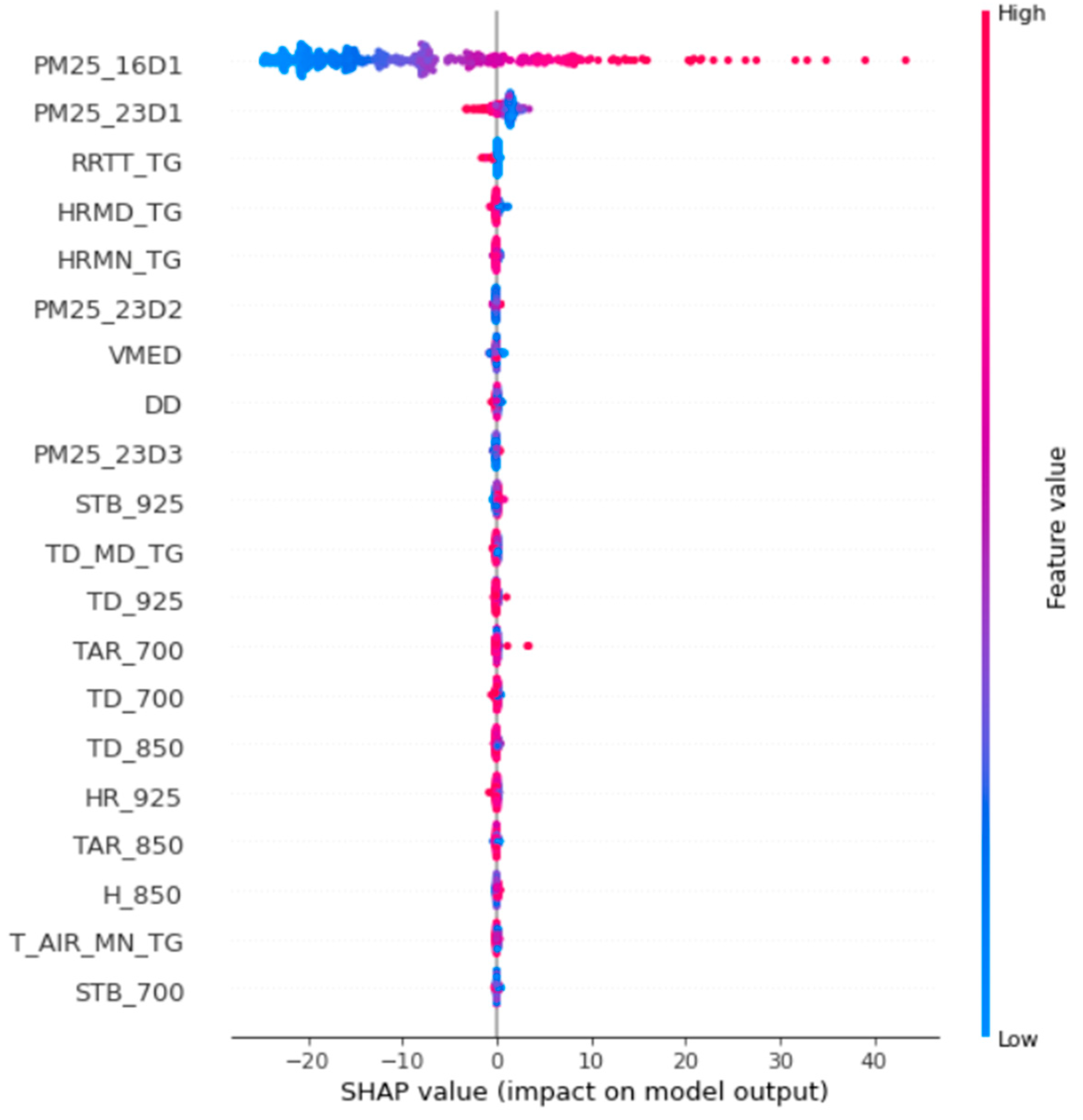
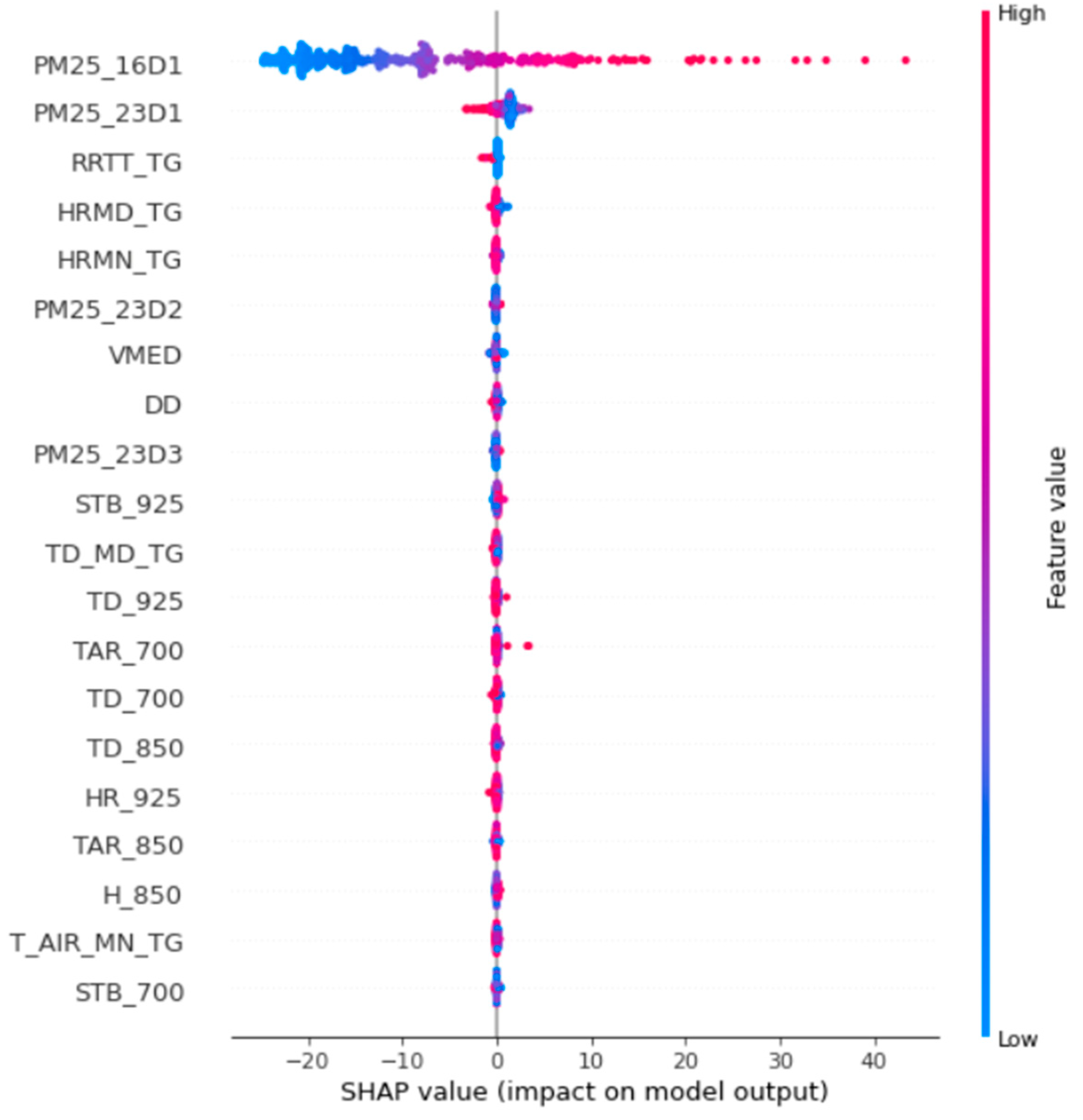
3.3. Feature Selection
3.4. Performance Measures
4. Results and Discussion
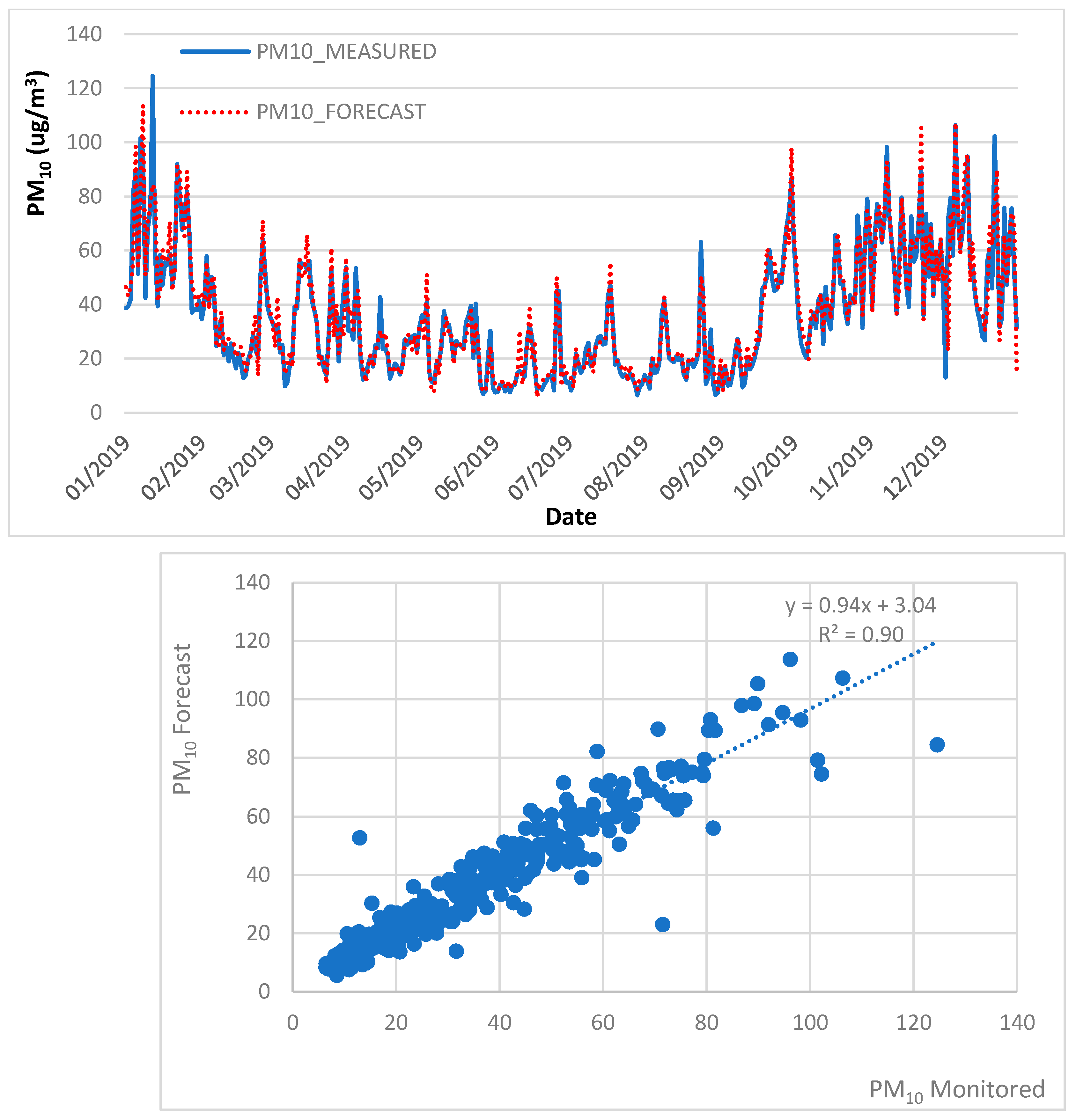
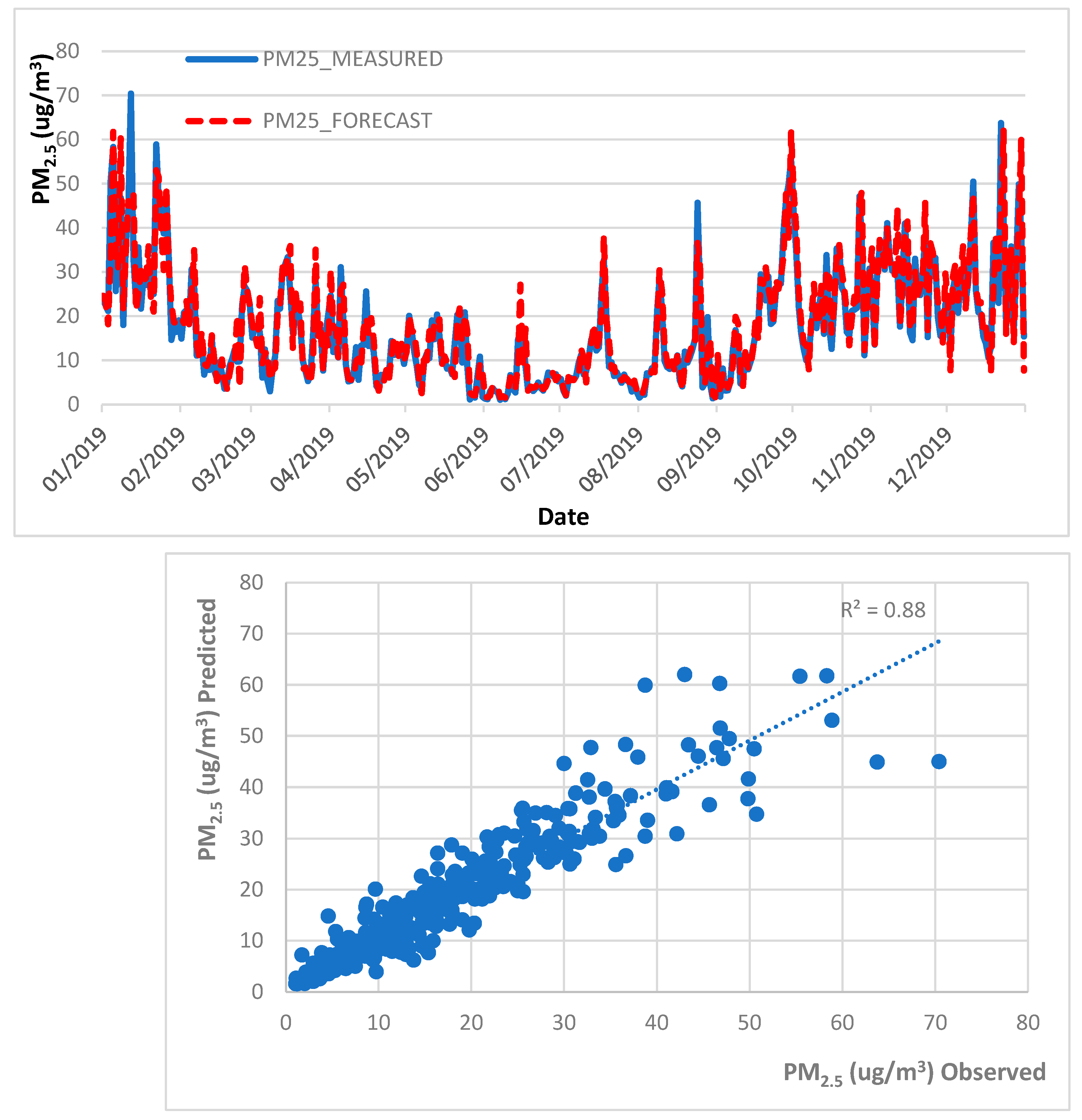
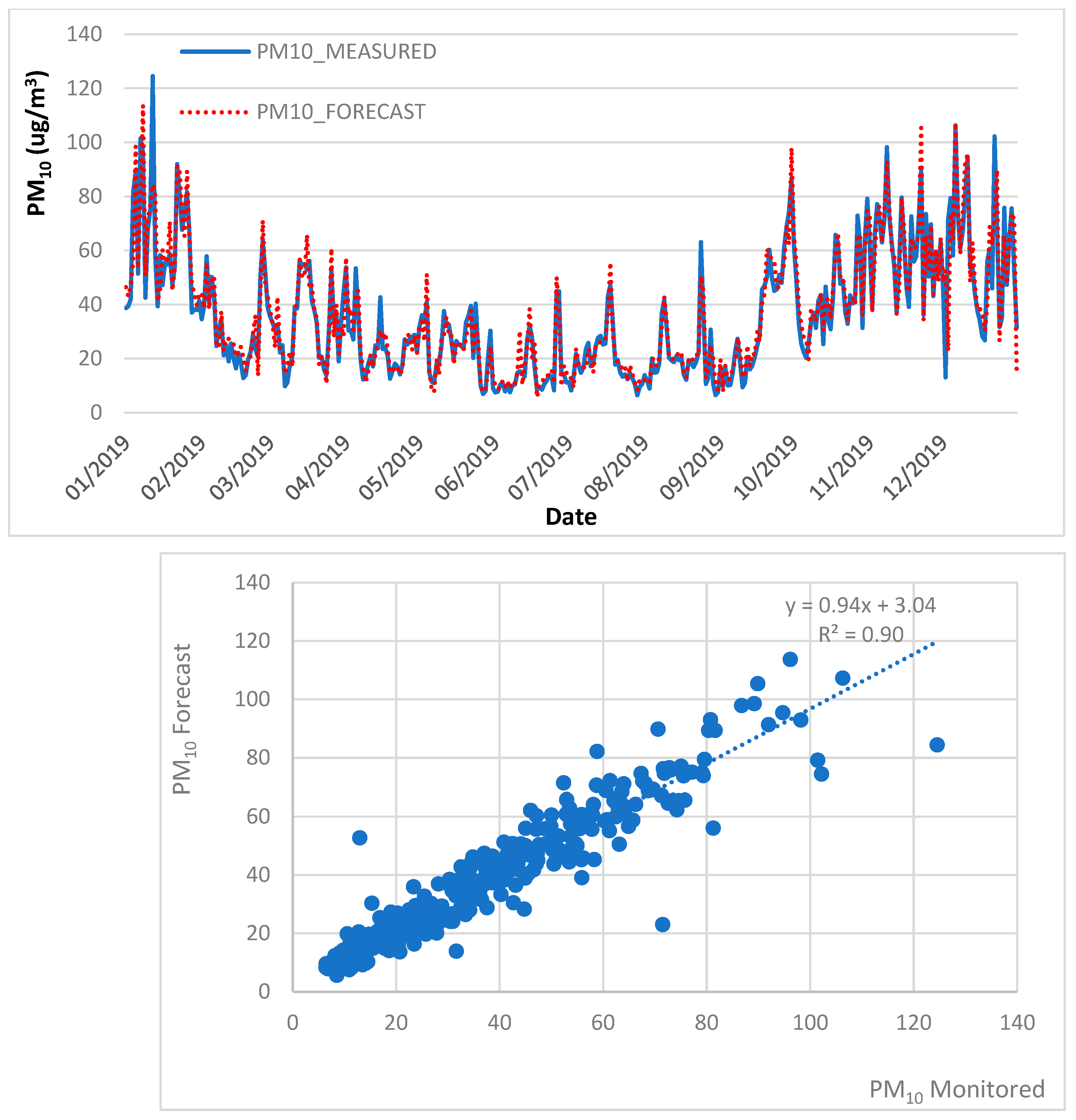
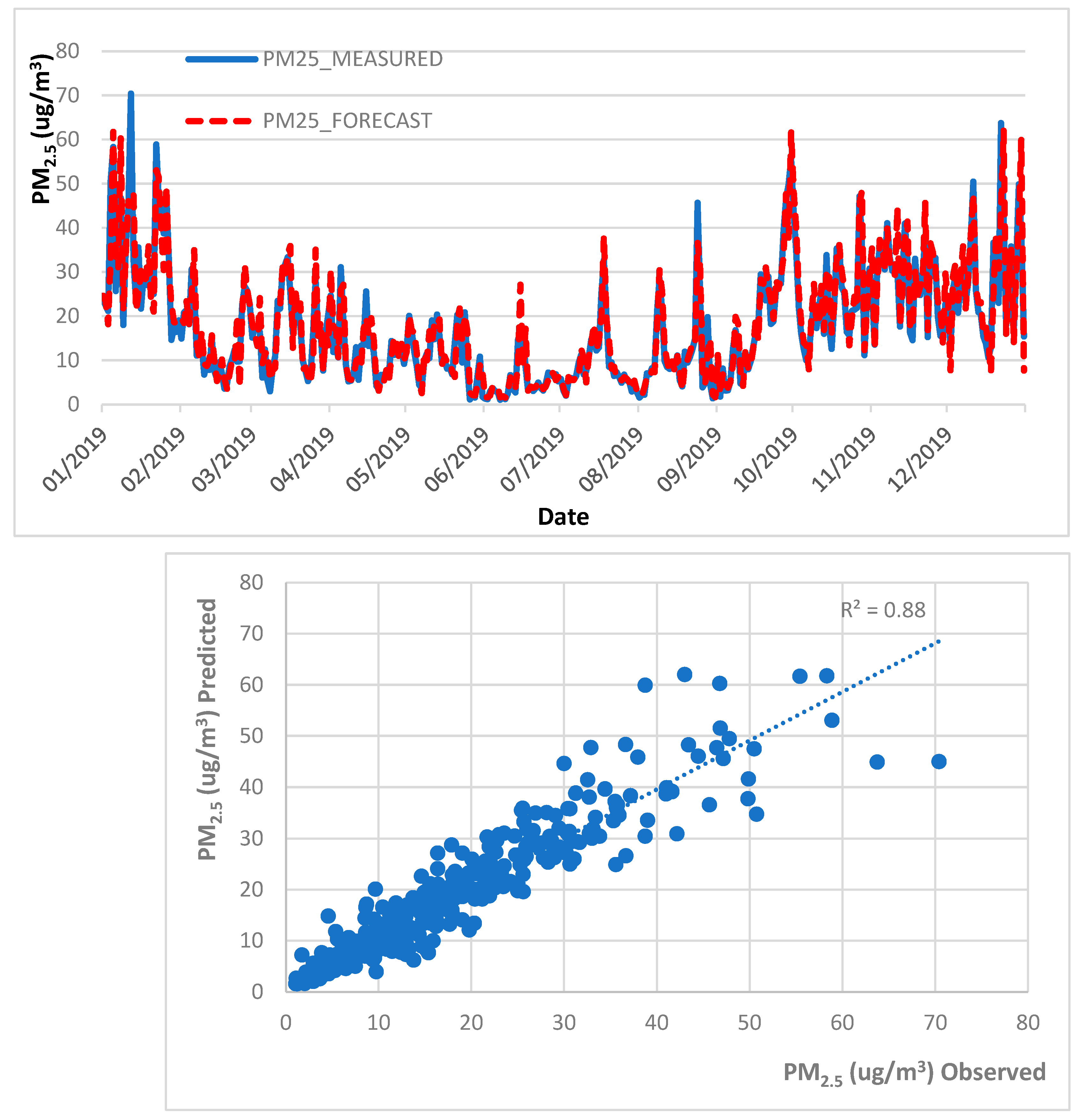
4.1. Air Quality Forecast, 2013–2018 Trained Data, 2019 Test Data
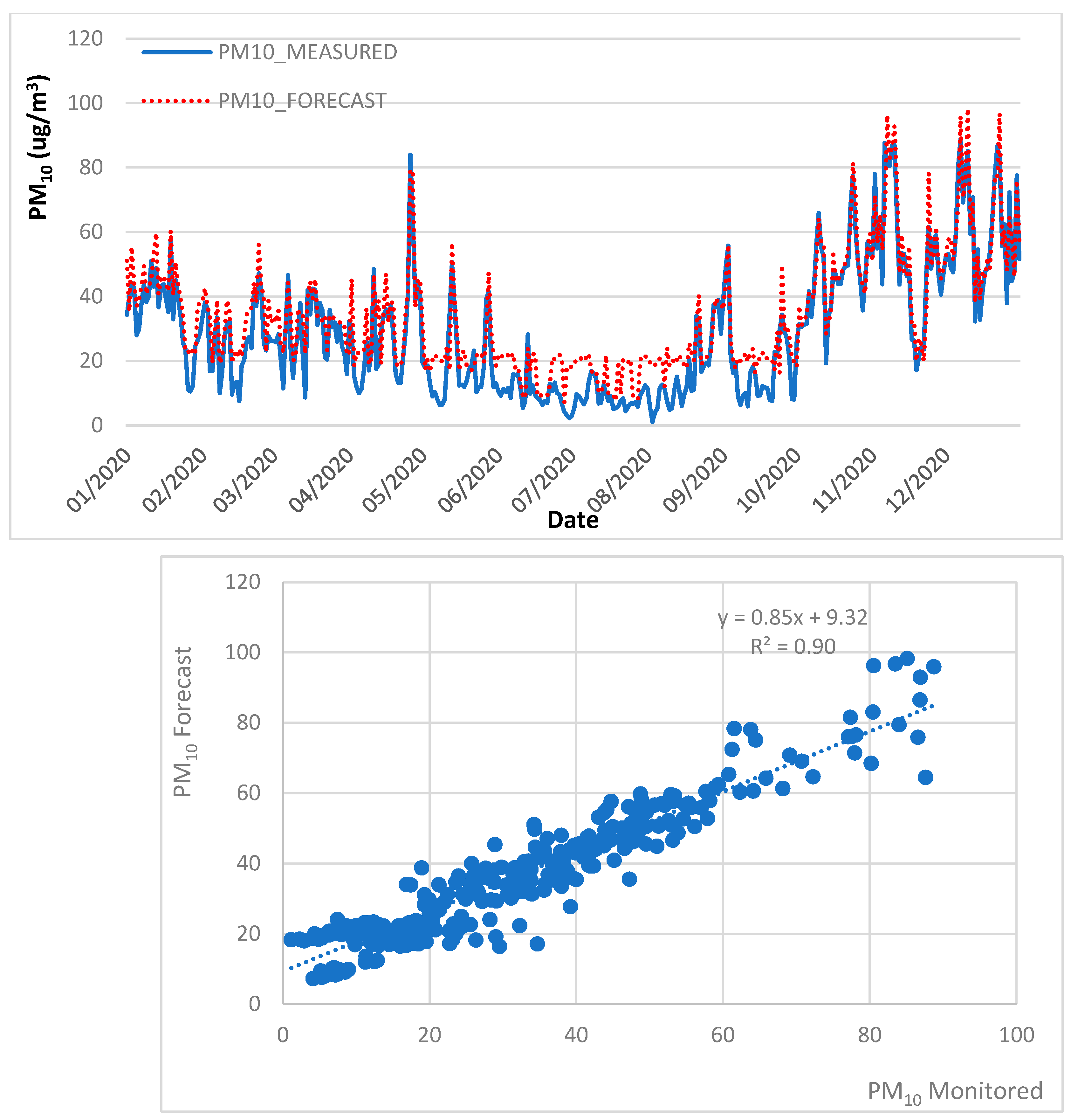
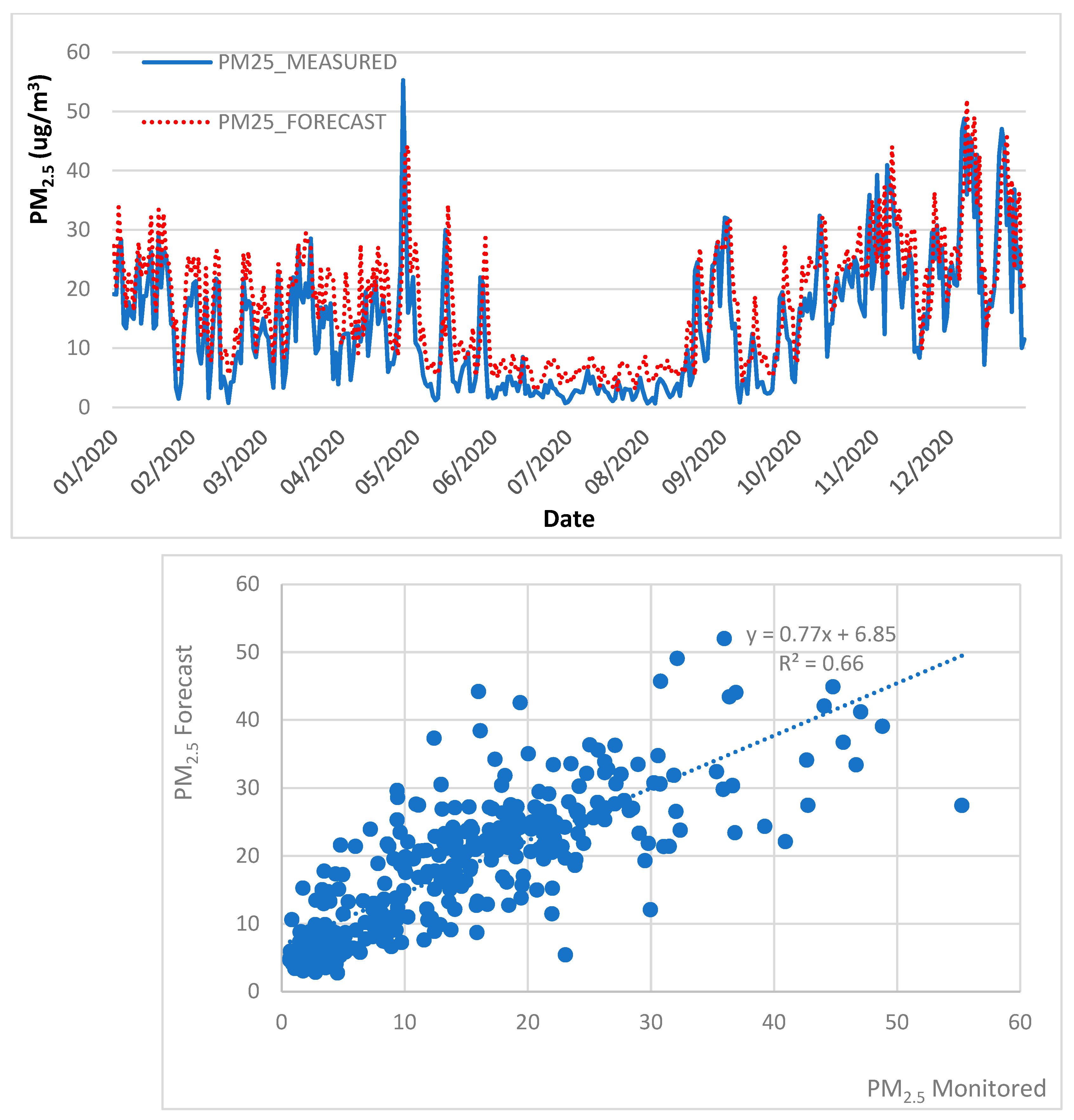
4.2. Air Quality Forecast, 2013 to 2018 Trained Data, 2020 Test Data
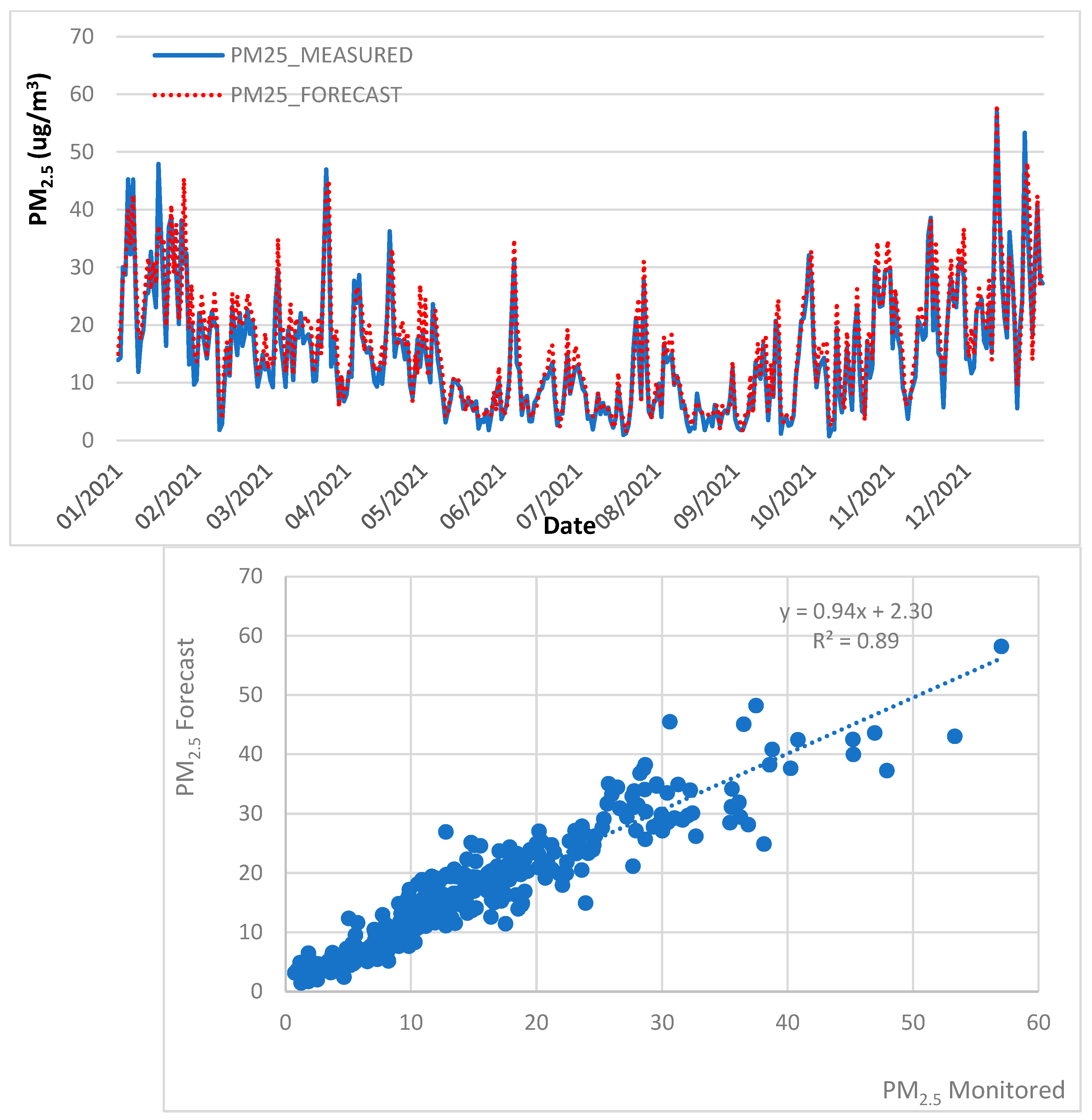
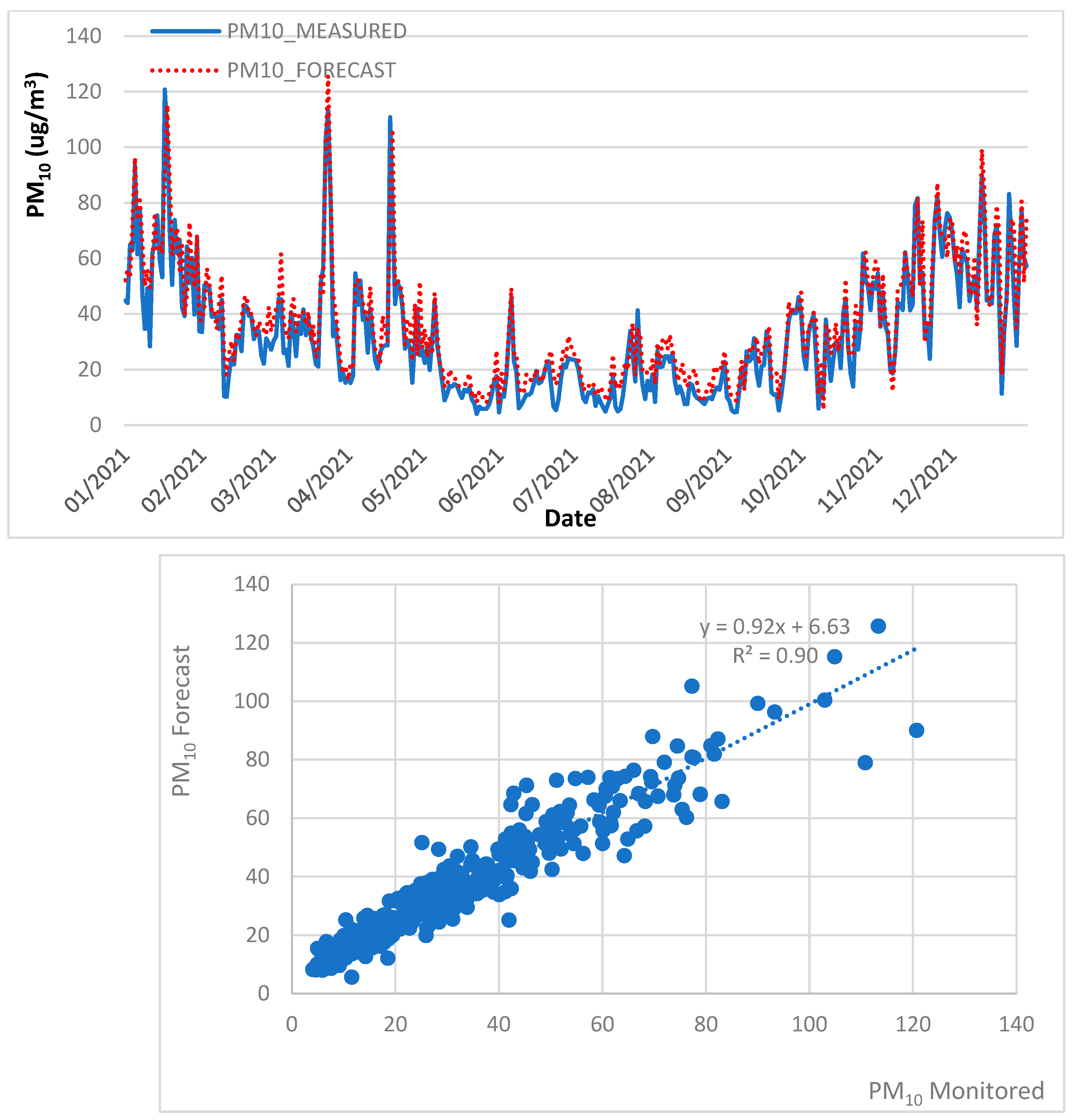
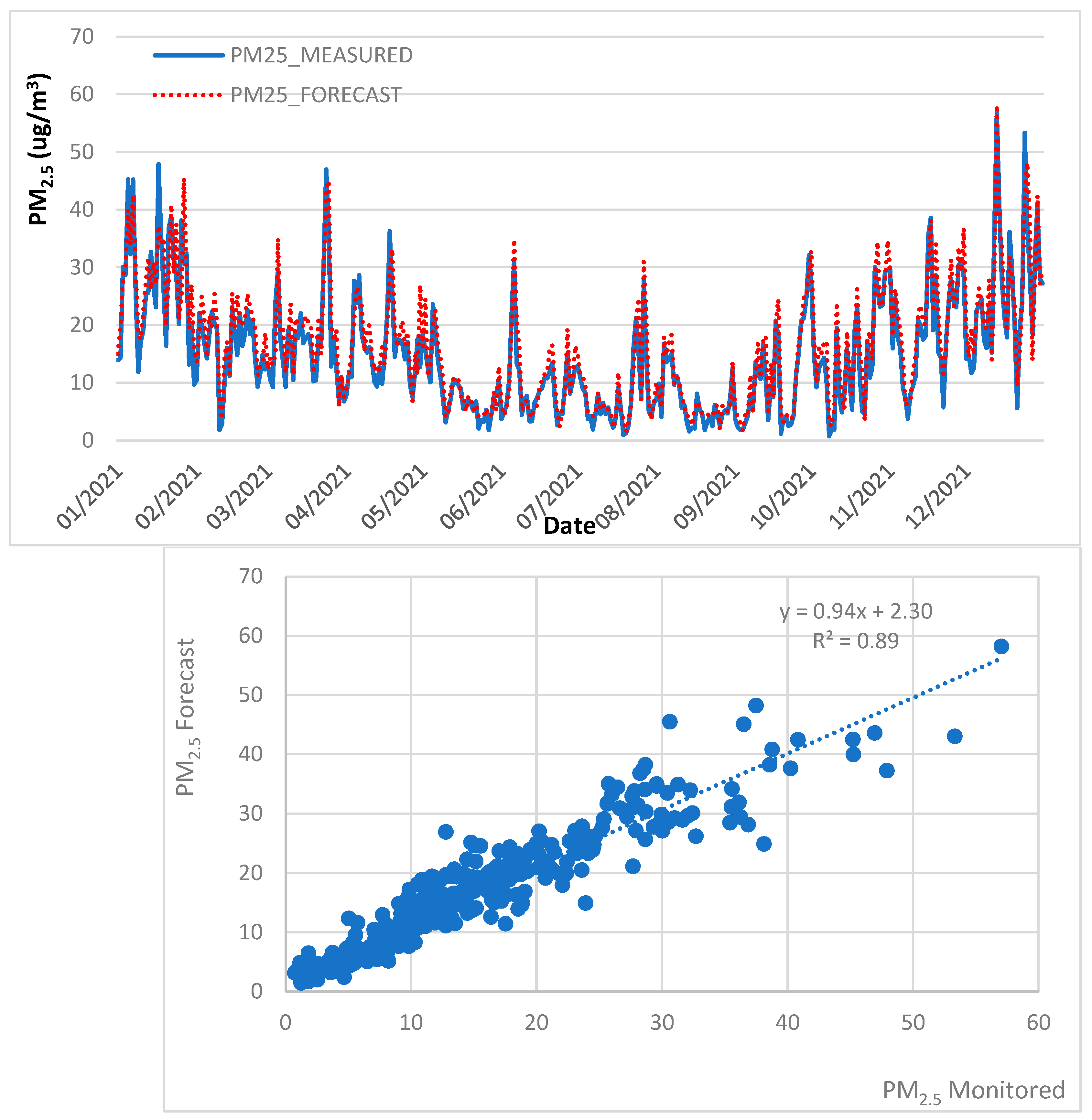
4.3. Air Quality Forecast, 2013 to 2018 Trained data, 2021 Test Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. World Health Statistics 2021: Monitoring Health for the SDGs, Sustainable Development Goals; WHO: Geneva, Switzerland, 2021. [Google Scholar]
- Zaheer, J.; Jeon, J.; Lee, S.-B.; Kim, J.S. Effect of Particulate Matter on Human Health, Prevention, and Imaging Using PET or SPECT. Prog. Med. Phys. 2018, 29, 81. [Google Scholar] [CrossRef]
- Dantas, G.; Siciliano, B.; França, B.B.; da Silva, C.M.; Arbilla, G. The impact of COVID-19 partial lockdown on the air quality of the city of Rio de Janeiro, Brazil. Sci. Total Environ. 2020, 729, 139085. [Google Scholar] [CrossRef] [PubMed]
- Zambrano-Monserrate, M.A.; Ruano, M.A.; Sanchez-Alcalde, L. Indirect effects of COVID-19 on the environment. Sci. Total Environ. 2020, 728, 138813. [Google Scholar] [CrossRef] [PubMed]
- Fan, K.; Dhammapala, R.; Harrington, K.; Lamastro, R.; Lamb, B.; Lee, Y. Development of a Machine Learning Approach for Local-Scale Ozone Forecasting: Application to Kennewick, WA. Front. Big Data 2022, 5, 781309. [Google Scholar] [CrossRef]
- Saheer, L.B.; Bhasy, A.; Maktabdar, M.; Zarrin, J. Data-Driven Framework for Understanding and Predicting Air Quality in Urban Areas. Front. Big Data 2022, 5, 822573. [Google Scholar] [CrossRef] [PubMed]
- Chau, P.N.; Zalakeviciute, R.; Thomas, I.; Rybarczyk, Y. Deep Learning Approach for Assessing Air Quality During COVID-19 Lockdown in Quito. Front. Big Data 2022, 5, 842455. [Google Scholar] [CrossRef]
- Leong, W.C.; Kelani, R.O.; Ahmad, Z. Prediction of air pollution index (API) using support vector machine (SVM). J. Environ. Chem. Eng. 2020, 8, 103208. [Google Scholar] [CrossRef]
- Doreswamy; Harishkumar, K.S.; Km, Y.; Gad, I. Forecasting Air Pollution Particulate Matter (PM2.5) Using Machine Learning Regression Models. Procedia Comput. Sci. 2020, 171, 2057–2066. [Google Scholar] [CrossRef]
- Liang, Y.C.; Maimury, Y.; Chen, A.H.L.; Juarez, J.R.C. Machine learning-based prediction of air quality. Appl. Sci. 2020, 10, 9151. [Google Scholar] [CrossRef]
- Martínez, N.M.; Montes, L.M.; Mura, I.; Franco, J.F. Machine Learning Techniques for PM 10 Levels Forecast in Bogotá. In Proceedings of the 2018 ICAI Workshops (ICAIW), Bogota, Colombia, 1–3 November 2018. [Google Scholar] [CrossRef]
- Juarez, E.K.; Petersen, M.R. A Comparison of Machine Learning Methods to Forecast Tropospheric Ozone Levels in Delhi. Atmosphere 2022, 13, 46. [Google Scholar] [CrossRef]
- Su, Y. Prediction of air quality based on Gradient Boosting Machine Method. In Proceedings of the 2020 International Conference on Big Data and Informatization Education (ICBDIE), Zhangjiajie, China, 23–25 April 2020; pp. 395–397. [Google Scholar] [CrossRef]
- De Oliveira, R.C.G.; Cunha, C.L.; Tôrres, A.R.; Corrêa, S.M. Forecasts of tropospheric ozone in the Metropolitan Area of Rio de Janeiro based on missing data imputation and multivariate calibration techniques. Environ. Monit. Assess. 2021, 193, 531. [Google Scholar] [CrossRef] [PubMed]
- Suárez Sánchez, A.; García Nieto, P.J.; Riesgo Fernández, P.; del Coz Díaz, J.J.; Iglesias-Rodríguez, F.J. Application of an SVM-based regression model to the air quality study at local scale in the Avilés urban area (Spain). Math. Comput. Model. 2011, 54, 1453–1466. [Google Scholar] [CrossRef]
- Lei, M.T.; Monjardino, J.; Mendes, L.; Gonçalves, D.; Ferreira, F. Macao air quality forecast using statistical methods. Air Qual. Atmos. Health 2019, 12, 1049–1057. [Google Scholar] [CrossRef]
- Lei, M.T.; Monjardino, J.; Mendes, L.; Gonçalves, D.; Ferreira, F. Statistical Forecast of Pollution Episodes in Macao during National Holiday and COVID-19. Int. J. Environ. Res. Public Health 2020, 17, 5124. [Google Scholar] [CrossRef]
- Mendes, L.; Monjardino, J.; Ferreira, F. Air Quality Forecast by Statistical Methods: Application to Portugal and Macao. Front. Big Data 2022, 5, 826517. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Machine learning approaches for outdoor air quality modelling: A systematic review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef]
- Liu, H.; Li, Q.; Yu, D.; Gu, Y. Air quality index and air pollutant concentration prediction based on machine learning algorithms. Appl. Sci. 2019, 9, 4069. [Google Scholar] [CrossRef]
- Ivanov, A.; Voynikova, D.; Stoimenova, M.; Gocheva-Ilieva, S.; Iliev, I. Random forests models of particulate matter PM10: A case study. AIP Conf. Proc. 2018, 2025, 030001. [Google Scholar] [CrossRef]
- Rybarczyk, Y.; Zalakeviciute, R. Assessing the COVID-19 Impact on Air Quality: A Machine Learning Approach. Geophys. Res. Lett. 2021, 48, e2020GL091202. [Google Scholar] [CrossRef]
- Lee, M.; Lin, L.; Chen, C.Y.; Tsao, Y.; Yao, T.H.; Fei, M.H.; Fang, S.H. Forecasting Air Quality in Taiwan by Using Machine Learning. Sci. Rep. 2020, 10, 145–154. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.C.; Binaykia, A.; Chang, P.C.; Tiwari, M.K.; Tsao, C.C. Urban air quality forecasting based on multidimensional collaborative Support Vector Regression (SVR): A case study of Beijing-Tianjin-Shijiazhuang. PLoS ONE 2017, 12, e0179763. [Google Scholar] [CrossRef]
- Arampongsanuwat, S.; Meesad, P. Prediction of PM 10 using Support Vector Regression. Int. Conf. Inf. Electron. Eng. 2011, 6, 120–124. [Google Scholar]
- Castelli, M.; Clemente, F.M.; Popovič, A.; Silva, S.; Vanneschi, L. A Machine Learning Approach to Predict Air Quality in California. Complexity 2020, 2020, 8049504. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Miao, J.; Niu, L. A Survey on Feature Selection. Procedia Comput. Sci. 2016, 91, 919–926. [Google Scholar] [CrossRef]
- Futagami, K.; Fukazawa, Y.; Kapoor, N.; Kito, T. Pairwise acquisition prediction with SHAP value interpretation. J. Financ. Data Sci. 2021, 7, 22–44. [Google Scholar] [CrossRef]
- Gramegna, A.; Giudici, P. SHAP and LIME: An Evaluation of Discriminative Power in Credit Risk. Front. Artif. Intell. 2021, 4, 752558. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Variable Name | Variable Description (Units)/Observations | |
|---|---|---|---|
| Air quality variables | NO2, PM10, PM2.5 | Average hourly concentration values (µg/m3) | |
| O3 MAX | Maximum hourly concentration values (µg/m3) | ||
| 16D#, 23D# | 23D#: 24 h concentration averaging period between 00 h and 23 h 16D#: 24 h concentration averaging period between 16 h of D1 and 15 h of D0 e.g.: PM10_16D1, O3_MAX_23D1. | ||
| D0, D1, D2, D3 | D0: Forecast Day; D1: Previous Day (Forecast Day-1); D2: Forecast Day-2; and D3: Forecast Day-3. | ||
| Meteorological variables | Upper-air obs. * | H1000, H850, H700, H500 | Geopotential height of 1000 hPa, 850 hPa, 700 hPa, and 500 hPa (m)/indicator of synoptic-scale weather pattern. |
| TAR925, TAR850, TAR700 | Air temperature of 925 hPa, 850 hPa, and 700 hPa (°C)/measure of strength and height of the subsidence inversion. | ||
| HR925, HR850, HR700 | Relative humidity of 925 hPa, 850 hPa, and 700 hPa (%). | ||
| TD925, TD850, TD700 | Dew point temperature of 925 hPa, 850 hPa, and 700 hPa (°C). | ||
| THI850, THI700, THI500 | Thickness of 850 hPa, 700 hPa, and 500 hPa (m)/related to the mean temperature in the layer. | ||
| STB925, STB850, STB700 | Stability of 925 hPa, 850 hPa, and 700 hPa (°C)/indicator of atmospheric stability. | ||
| Surface observations | T_AIR_MX, T_AIR_MD, T_AIR_MN | Maximum, average, and minimum air temperature (°C) | |
| HRMX, HRMD, HRMN | Maximum, average, and minimum relative humidity (%) | ||
| TD_MD | Average dew point temperature (ground level) (°C) | ||
| RRTT | Precipitation (mm)/associated with atmospheric washout | ||
| VMED | Average wind speed (m/s)/related to dispersion | ||
| Other variables | DD | Duration of the day: number of hours of sun per day (h) | |
| FF | Weekday indicator (flag): weekday = 0, weekend = 1 | ||
| Method | Pollutant | Model Performance Indicator | Model Built Using SHAP/Feature Selection | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | BIAS | Yes | No | ||
| MLR | PM10 | 0.90 | 7.14 | 4.60 | 0.81 | ✓ | |
| PM2.5 | 0.89 | 4.26 | 2.84 | 0.57 | ✓ | ||
| RF | PM10 | 0.89 | 7.49 | 4.73 | 1.01 | ✓ | |
| PM2.5 | 0.88 | 4.56 | 3.00 | 0.67 | ✓ | ||
| GB | PM10 | 0.89 | 7.47 | 4.73 | 0.80 | ✓ | |
| PM2.5 | 0.88 | 4.47 | 2.95 | 0.77 | ✓ | ||
| SVR | PM10 | 0.89 | 7.65 | 4.70 | 0.16 | ✓ | |
| PM2.5 | 0.88 | 4.57 | 2.92 | 0.04 | ✓ | ||
| Method | Pollutant | Model Performance Indicator | Model Built Using SHAP/Feature Selection | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | BIAS | Yes | No | ||
| MLR | PM10 | 0.81 | 10.74 | 7.83 | 6.12 | ✓ | |
| PM2.5 | 0.61 | 7.67 | 5.52 | 2.91 | ✓ | ||
| RF | PM10 | 0.90 | 8.15 | 6.64 | 5.02 | ✓ | |
| PM2.5 | 0.65 | 6.89 | 4.78 | 1.59 | ✓ | ||
| GB | PM10 | 0.85 | 10.59 | 8.54 | 7.11 | ✓ | |
| PM2.5 | 0.66 | 7.43 | 5.71 | 3.72 | ✓ | ||
| SVR | PM10 | 0.68 | 16.13 | 13.01 | 11.18 | ✓ | |
| PM2.5 | 0.57 | 11.11 | 9.24 | 8.06 | ✓ | ||
| Method | Pollutant | Model Performance Indicator | Model Built Using SHAP/Feature Selection | ||||
|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | BIAS | Yes | No | ||
| MLR | PM10 | 0.90 | 7.90 | 6.08 | 4.16 | ✓ | |
| PM2.5 | 0.88 | 3.92 | 2.97 | 1.65 | ✓ | ||
| RF | PM10 | 0.89 | 8.05 | 6.14 | 3.84 | ✓ | |
| PM2.5 | 0.89 | 3.72 | 2.74 | 1.47 | ✓ | ||
| GB | PM10 | 0.89 | 8.98 | 7.32 | 5.30 | ✓ | |
| PM2.5 | 0.88 | 4.60 | 3.85 | 2.96 | ✓ | ||
| SVR | PM10 | 0.86 | 13.96 | 11.92 | 11.30 | ✓ | |
| PM2.5 | 0.79 | 8.87 | 7.58 | 7.40 | ✓ | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, T.M.T.; Siu, S.W.I.; Monjardino, J.; Mendes, L.; Ferreira, F. Using Machine Learning Methods to Forecast Air Quality: A Case Study in Macao. Atmosphere 2022, 13, 1412. https://doi.org/10.3390/atmos13091412
Lei TMT, Siu SWI, Monjardino J, Mendes L, Ferreira F. Using Machine Learning Methods to Forecast Air Quality: A Case Study in Macao. Atmosphere. 2022; 13(9):1412. https://doi.org/10.3390/atmos13091412
Chicago/Turabian StyleLei, Thomas M. T., Shirley W. I. Siu, Joana Monjardino, Luisa Mendes, and Francisco Ferreira. 2022. "Using Machine Learning Methods to Forecast Air Quality: A Case Study in Macao" Atmosphere 13, no. 9: 1412. https://doi.org/10.3390/atmos13091412
APA StyleLei, T. M. T., Siu, S. W. I., Monjardino, J., Mendes, L., & Ferreira, F. (2022). Using Machine Learning Methods to Forecast Air Quality: A Case Study in Macao. Atmosphere, 13(9), 1412. https://doi.org/10.3390/atmos13091412