


Max Fast Fourier Transform (maxFFT) Clustering Approach for Classifying Indoor Air Quality



Abstract
:1. Introduction
1.1. Background
1.2. Literature Review
1.3. Motivation
1.4. Contributions of the Research
2. Materials and Methods
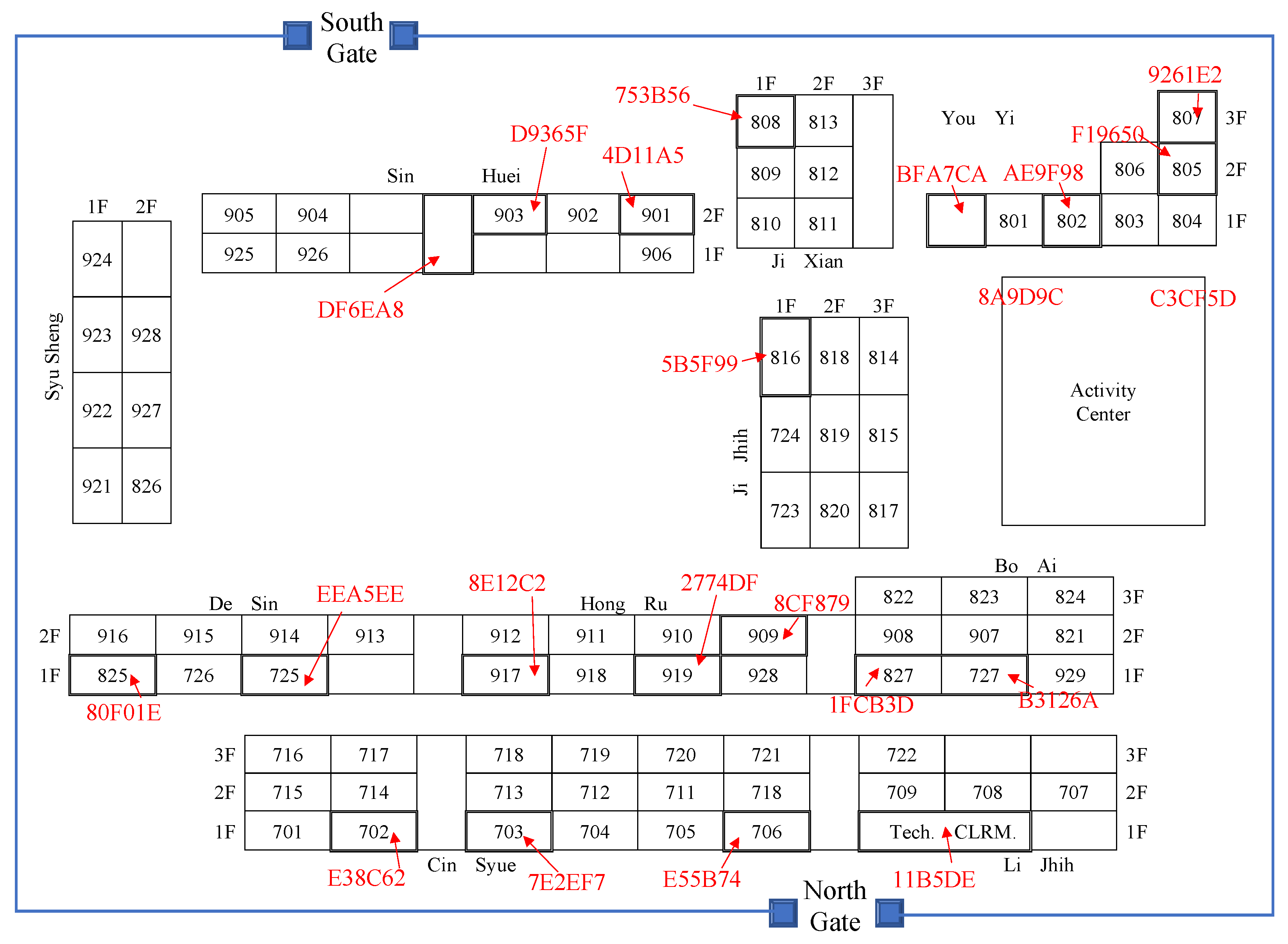
2.1. Study Area
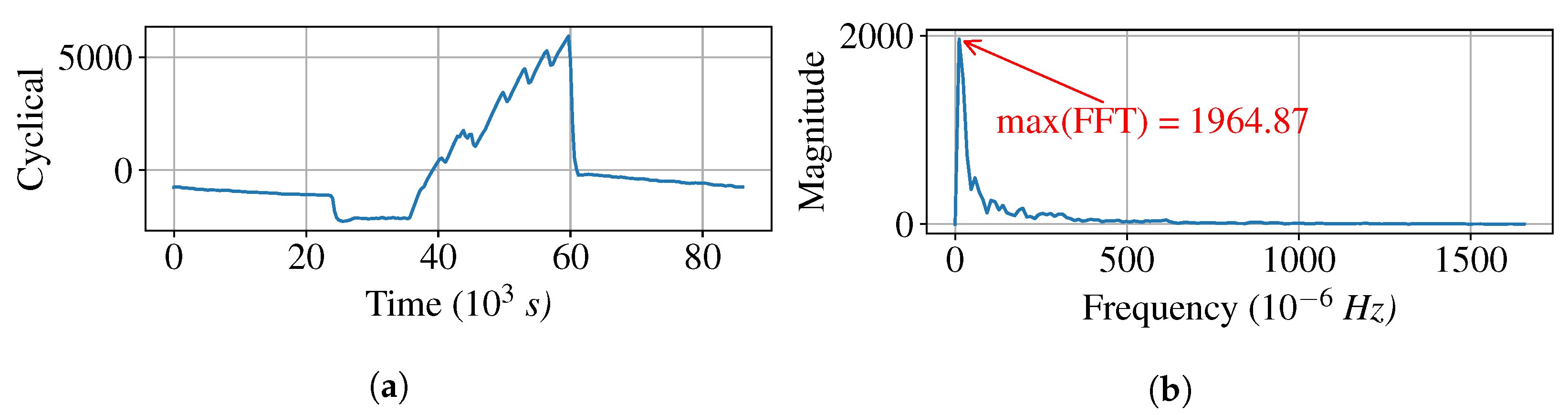
2.2. Overview of Maxfft
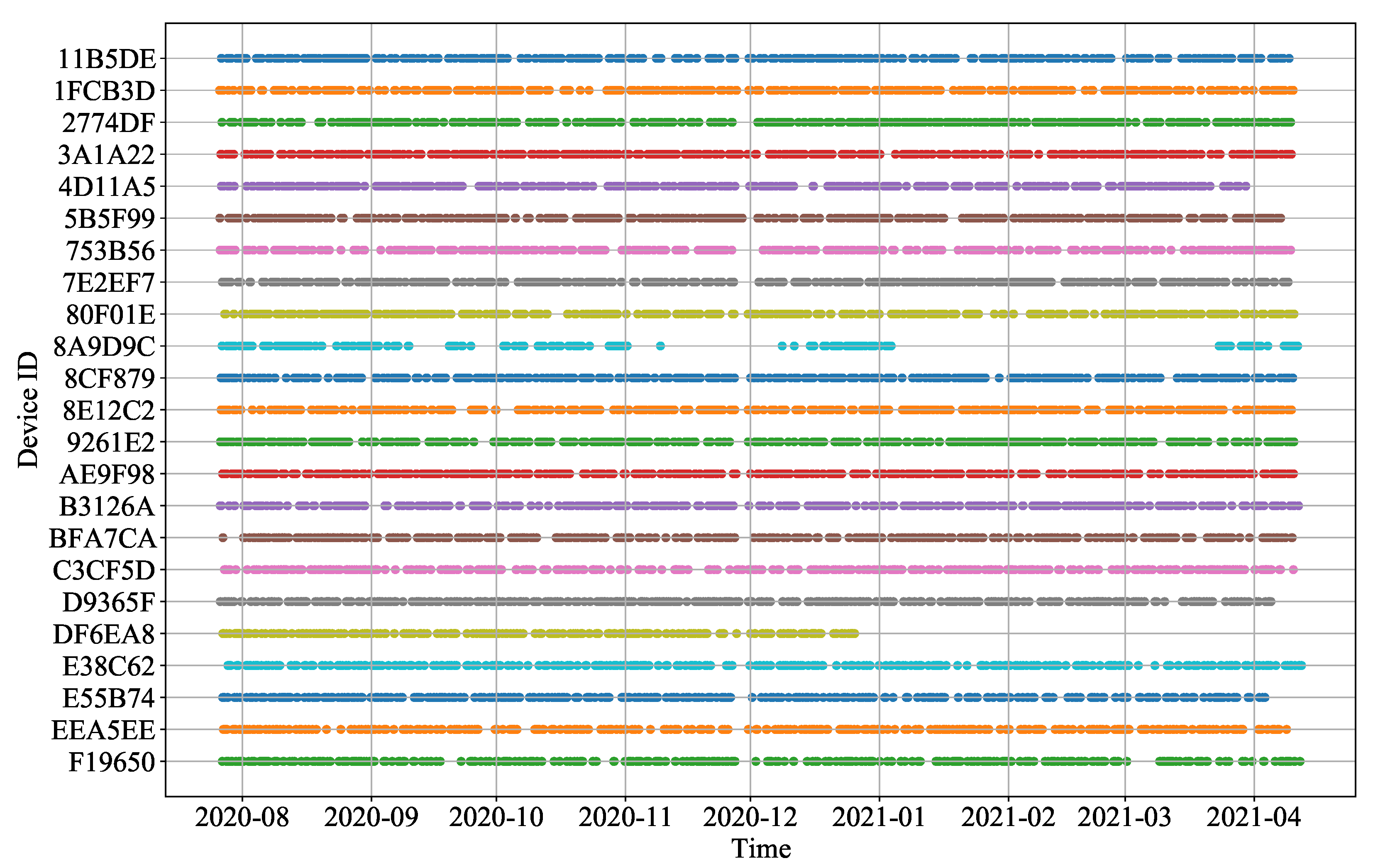
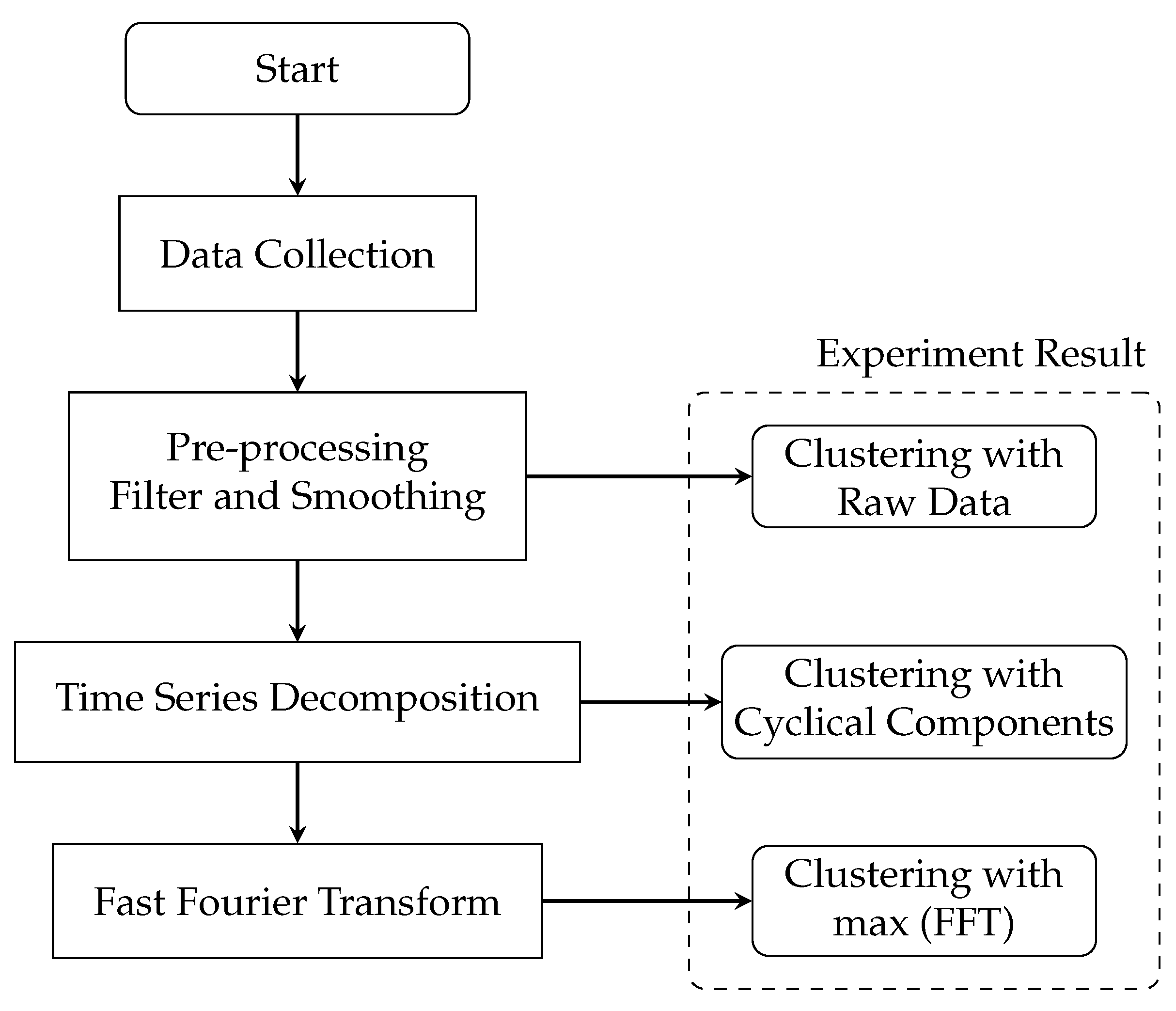
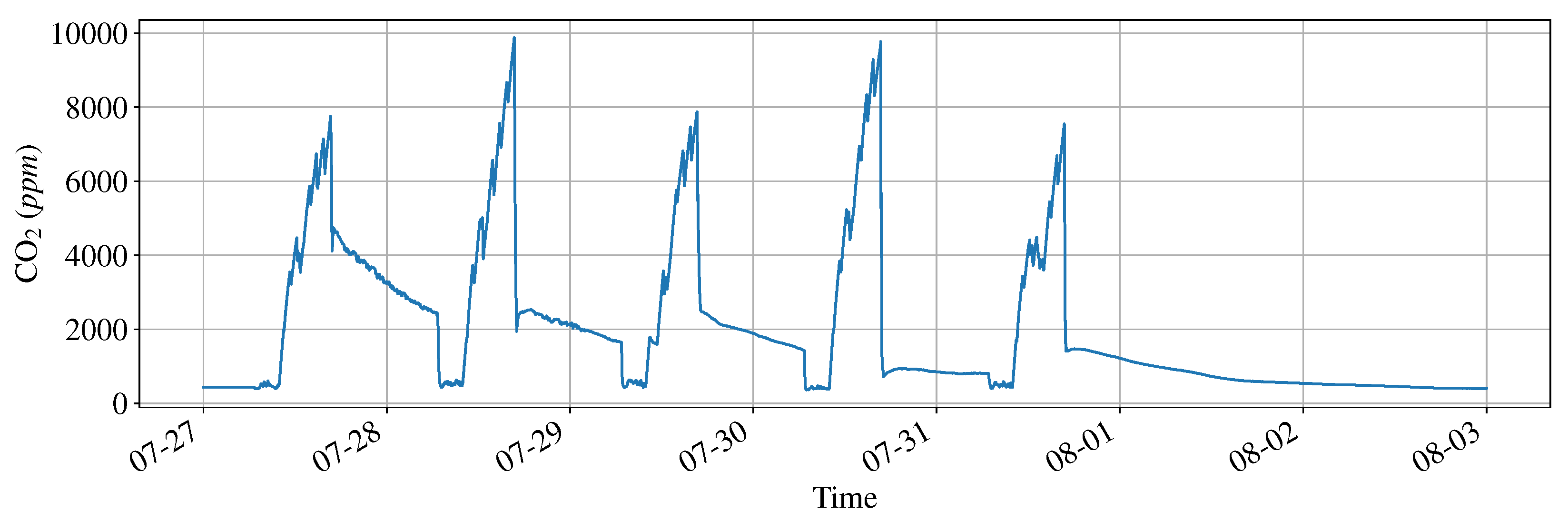
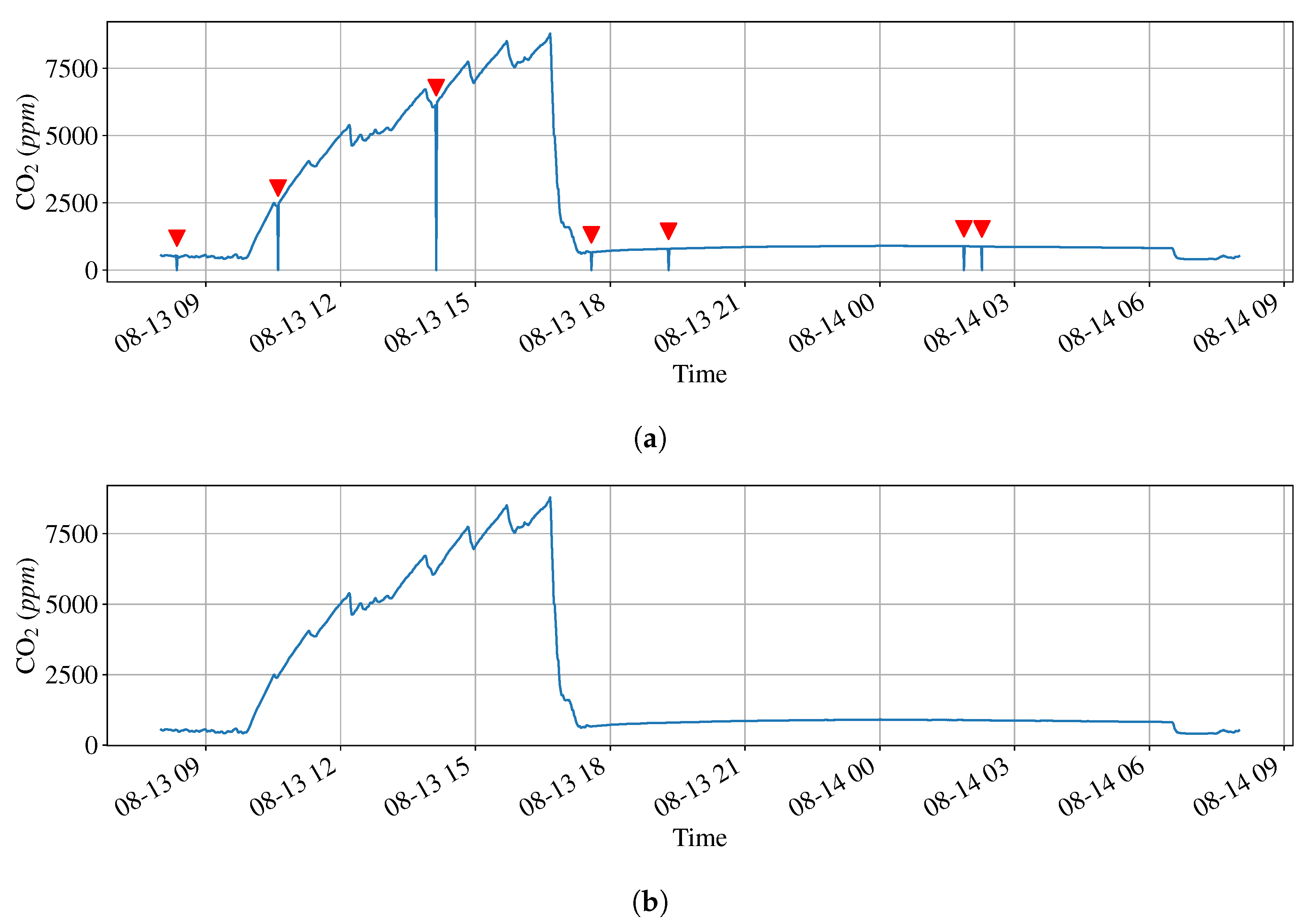
2.3. Data and Preprocessing
2.4. Methods
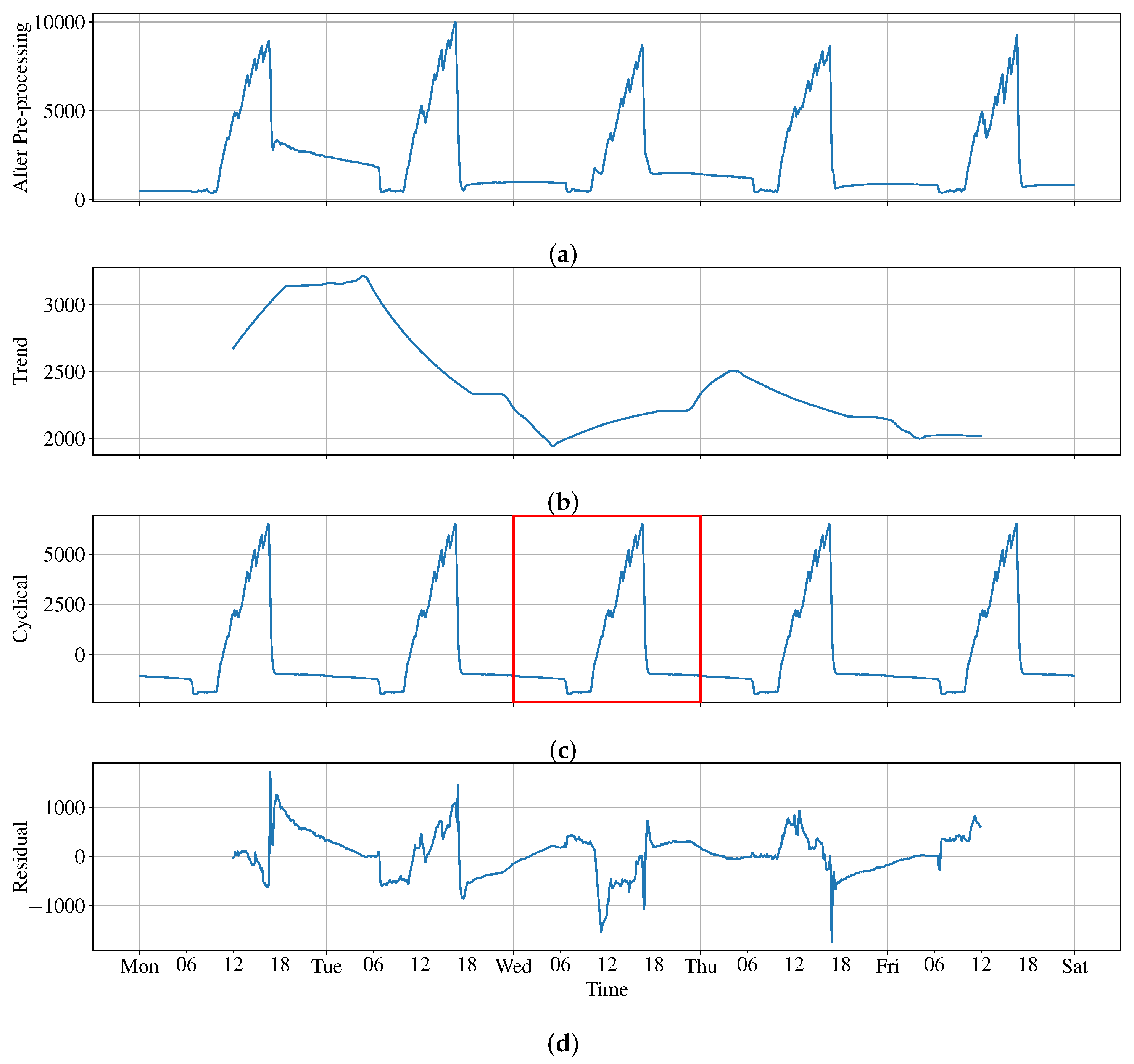
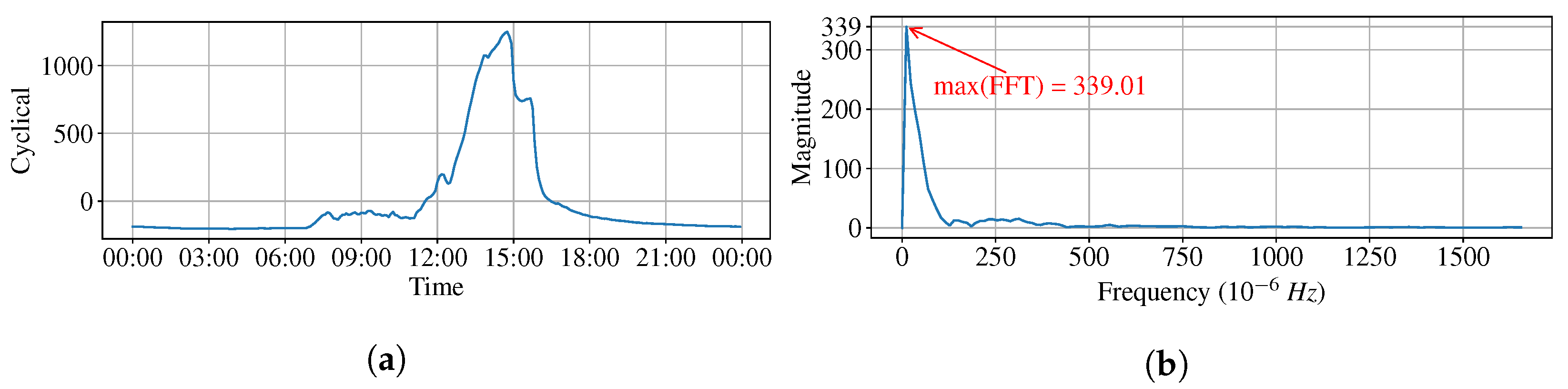
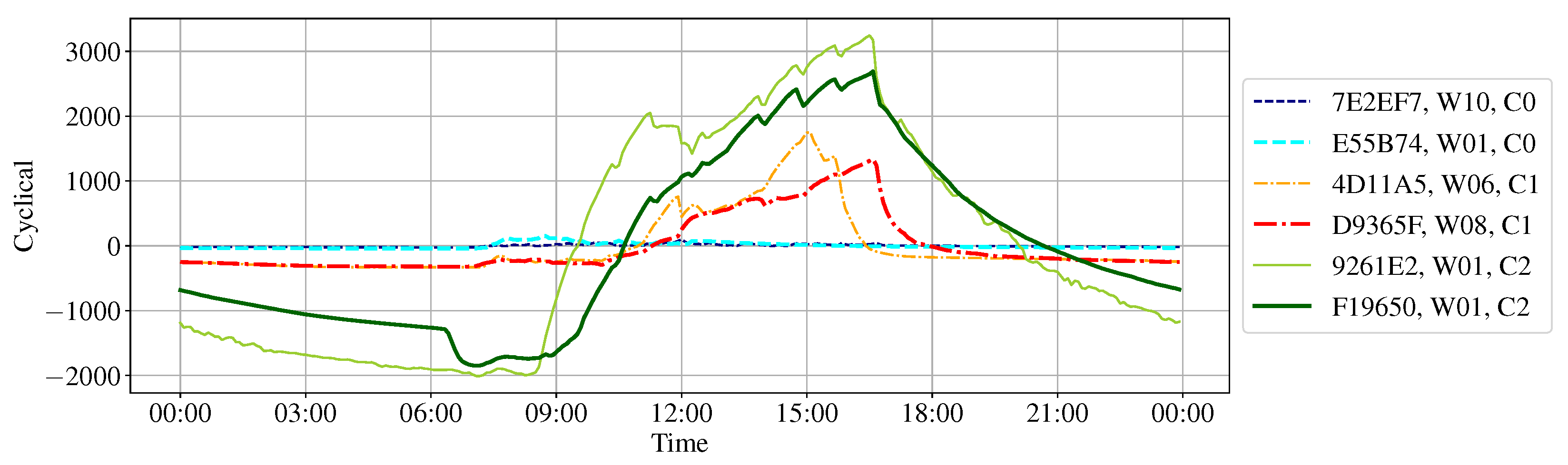
2.4.1. Time Series Decomposition
- For trend (T), the trend component at the time i represents the general direction of change with the original data.
- For cyclical (C), the cyclical component at the time i indicates the repeated but nonperiodic fluctuations.
- For seasonal (S), the seasonal component at the time i denotes the repeating ups and downs of the seasons.
- For random (R), the random component at the time i is also known as residual or noise, and represents data that do not belong to previous components.
2.4.2. Fast Fourier Transform
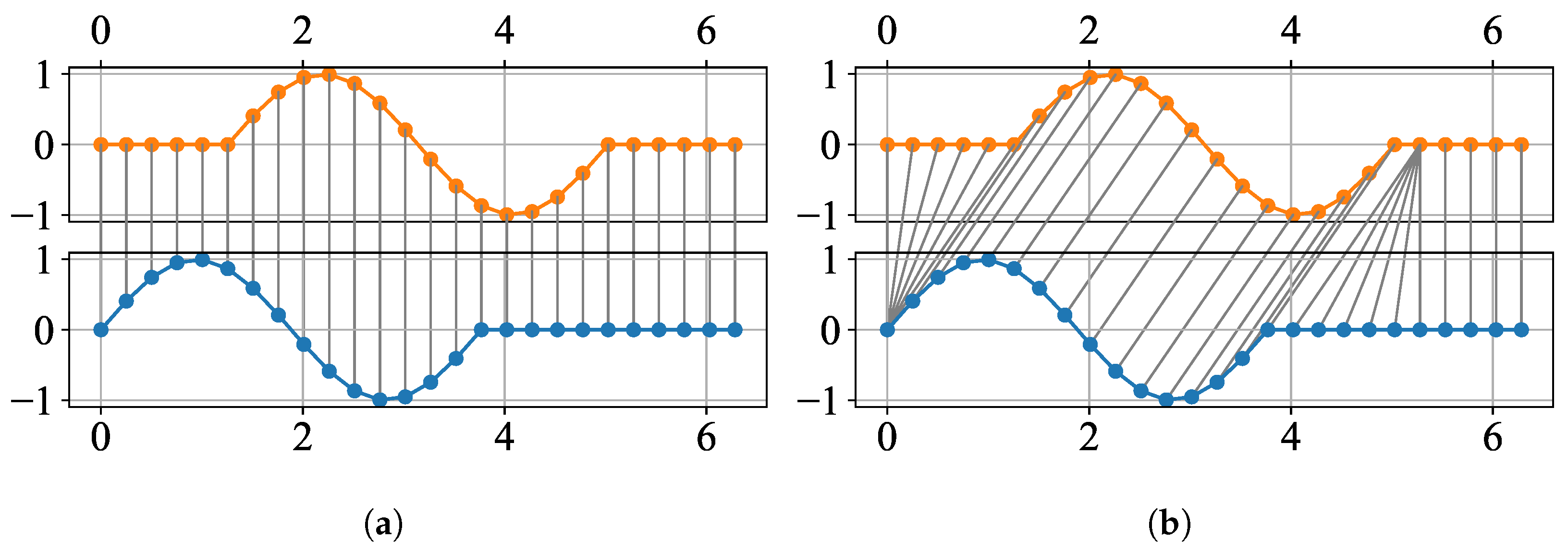
2.4.3. Dynamic Time Warping
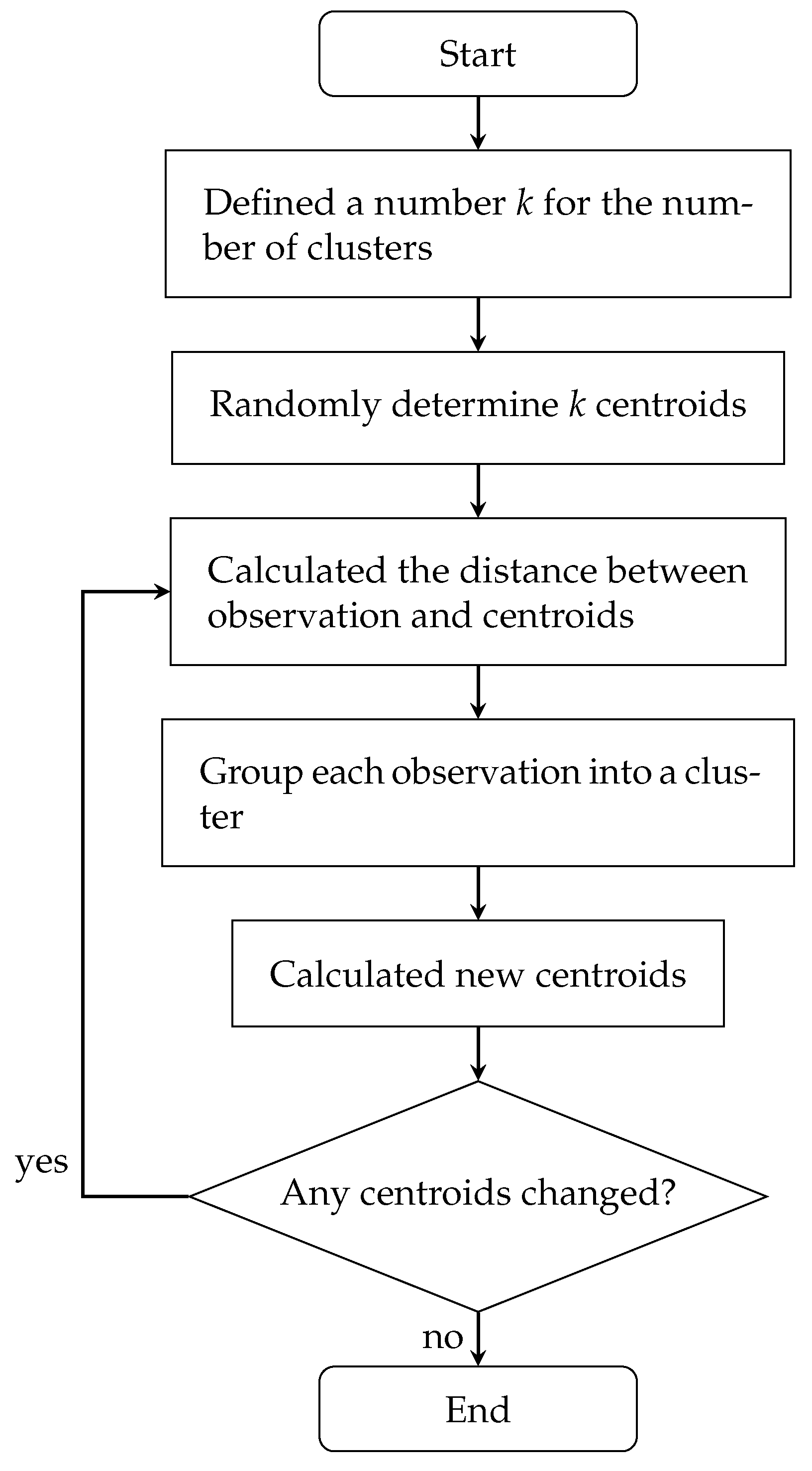
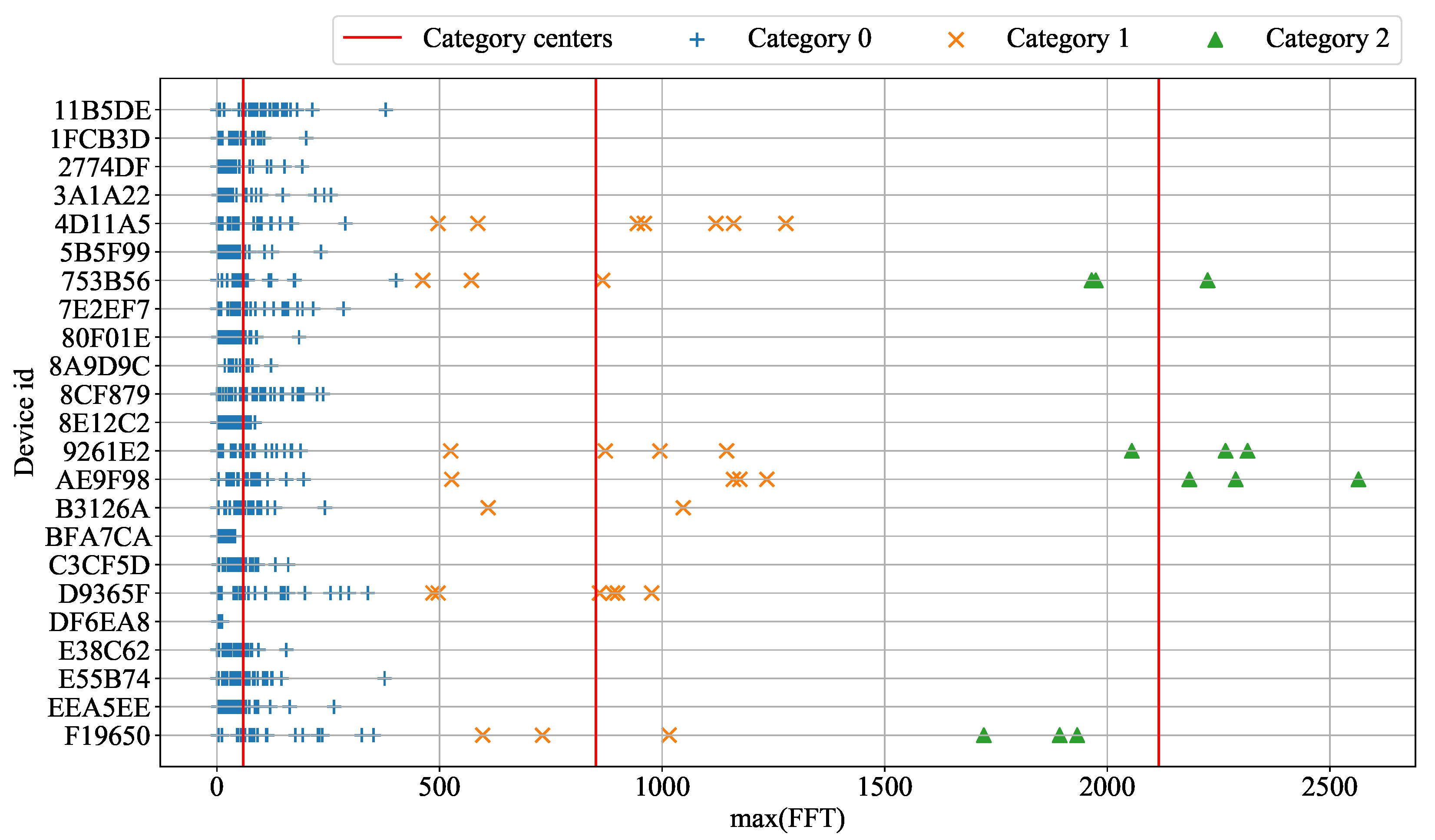
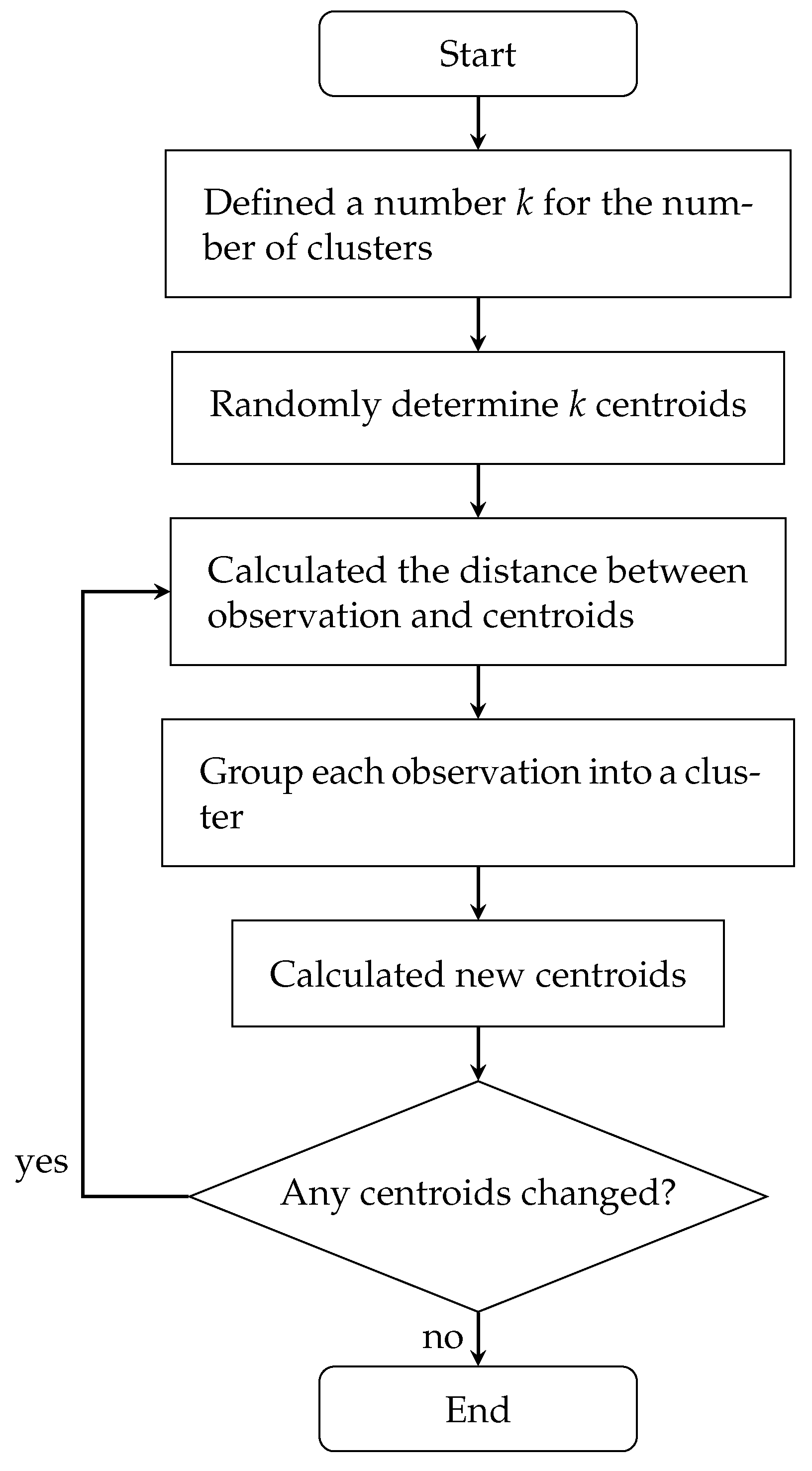
2.4.4. K-Means Clustering
- Define a number k for the number of clusters.
- Randomly determine k centroids.
- Calculate the distance between observation data point and centroids.
- Group each observation into a cluster.
- Calculate new centroids.
- Go to the next step if all centroids are unchanged; otherwise, go to step 3
- End of clustering.
3. Results and Discussion
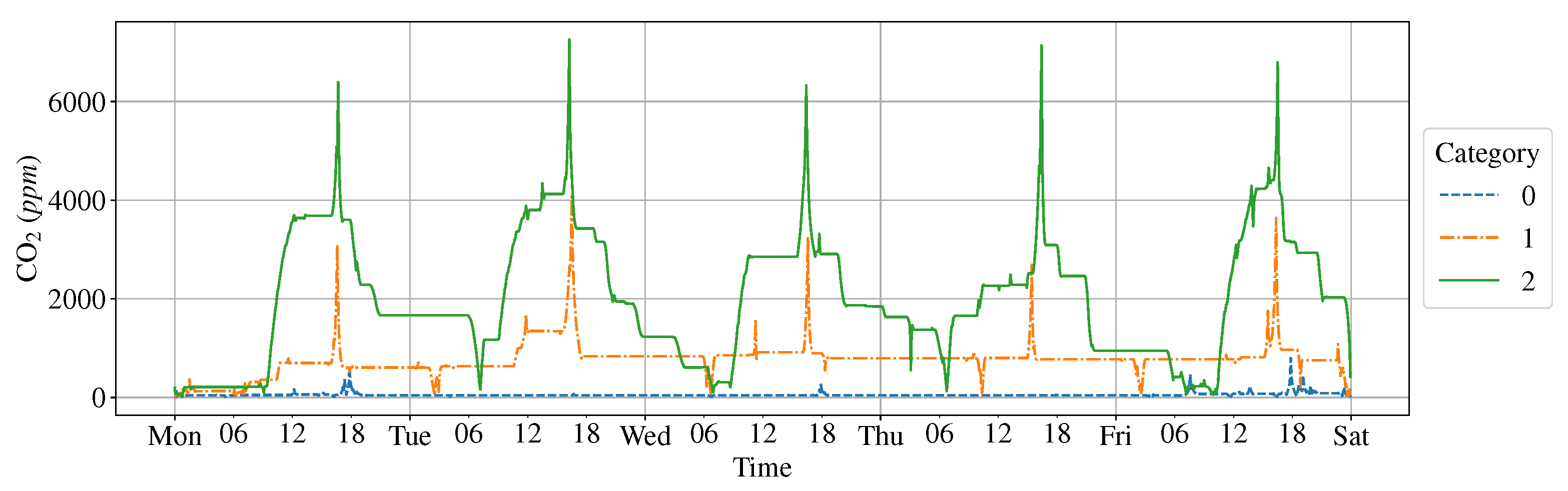
3.1. Cluster Result with Raw Data
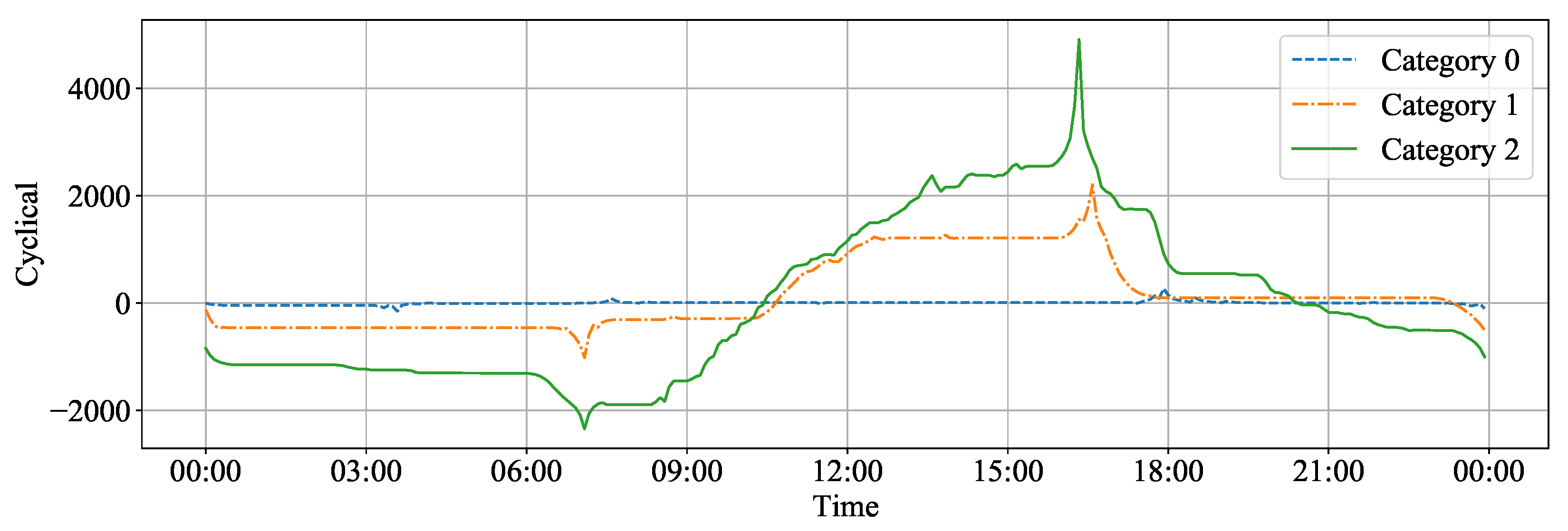
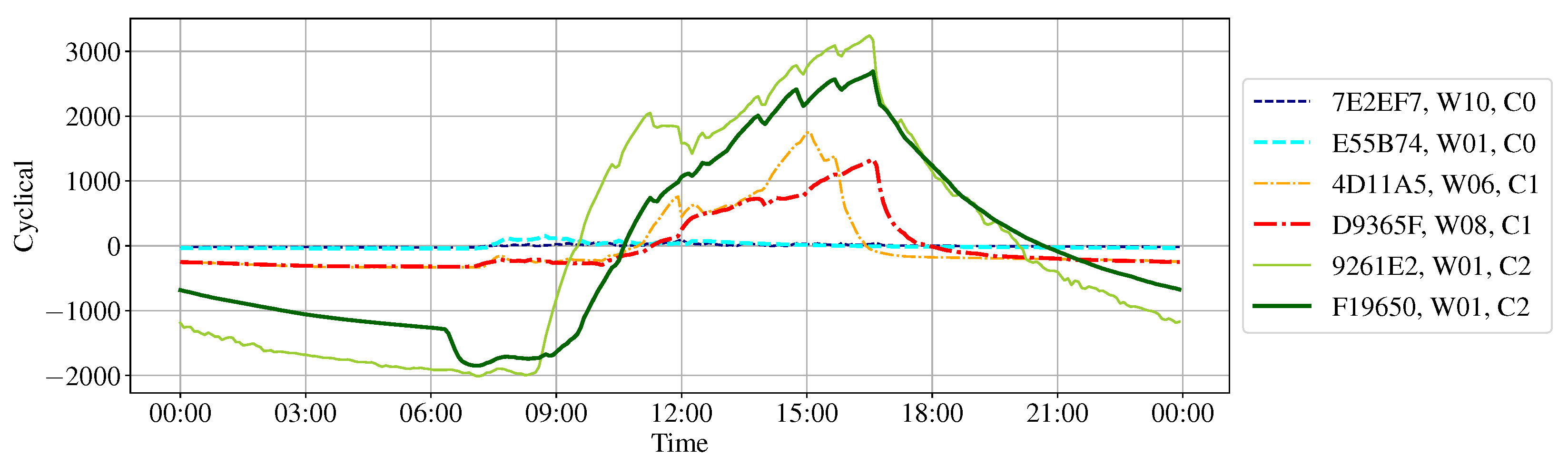
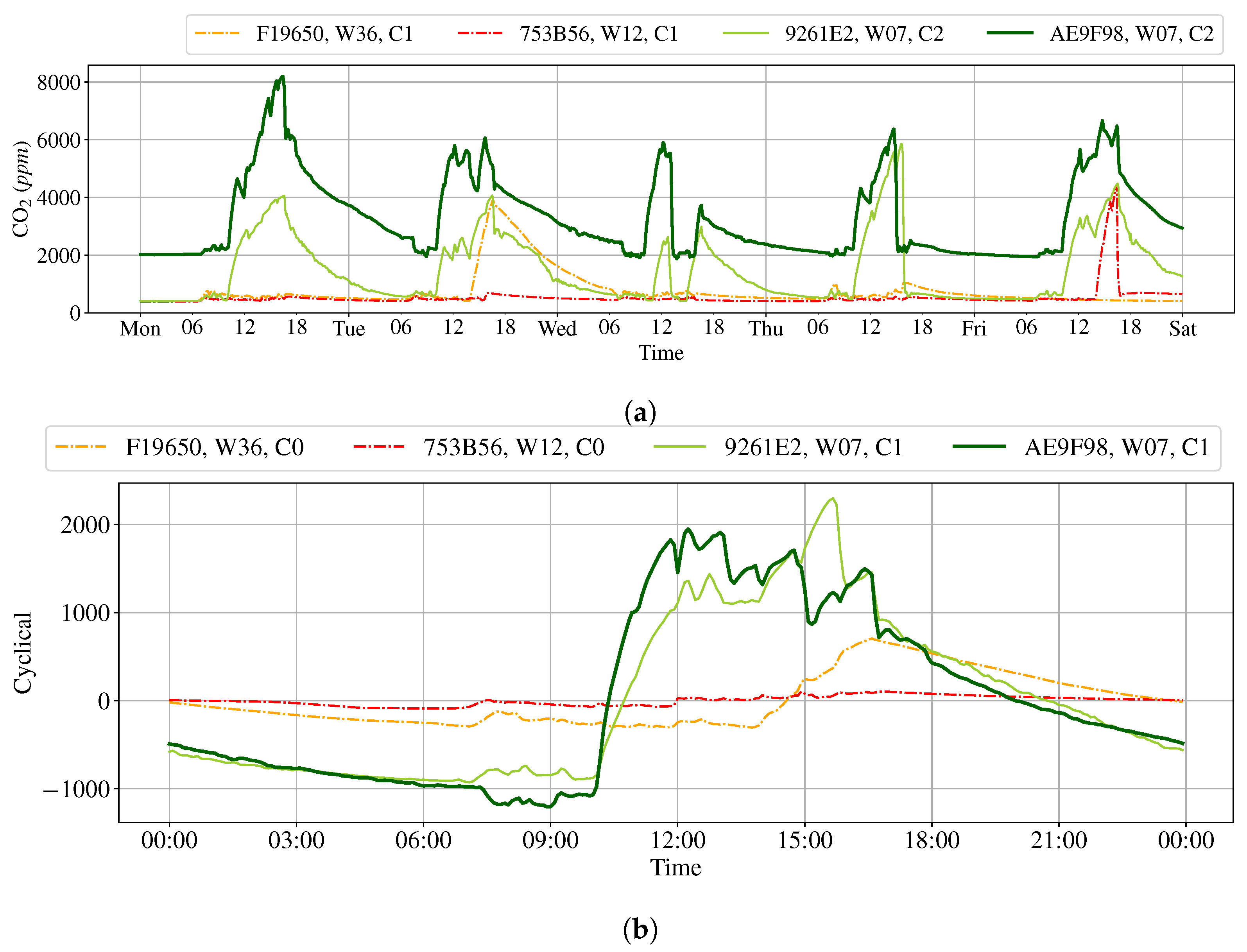
3.2. Cluster Result with Cyclical Components
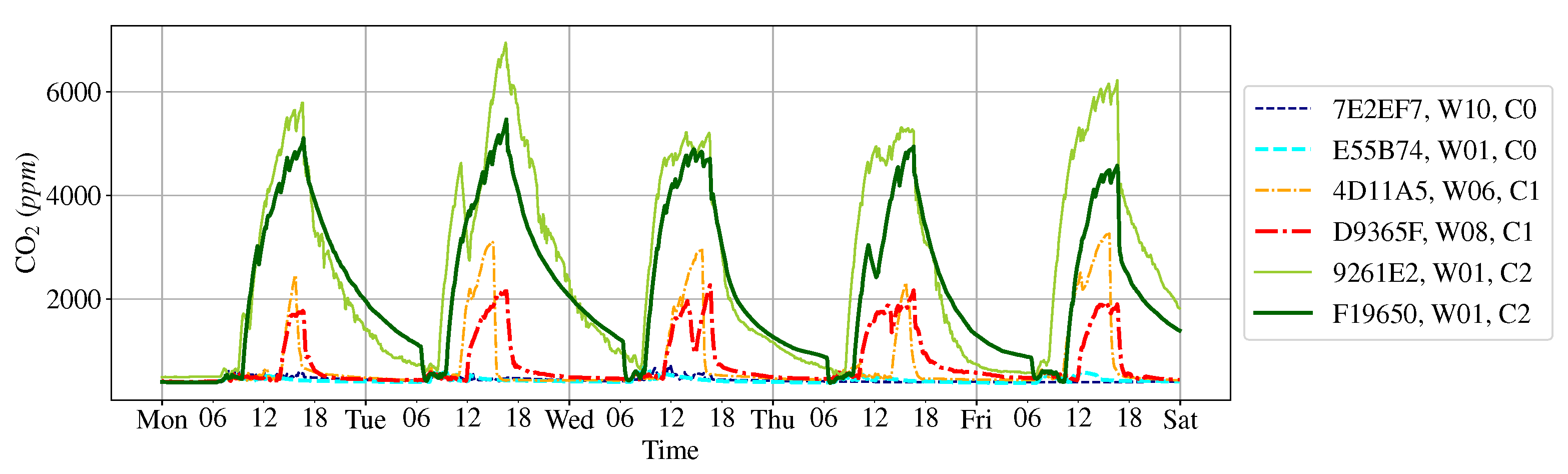
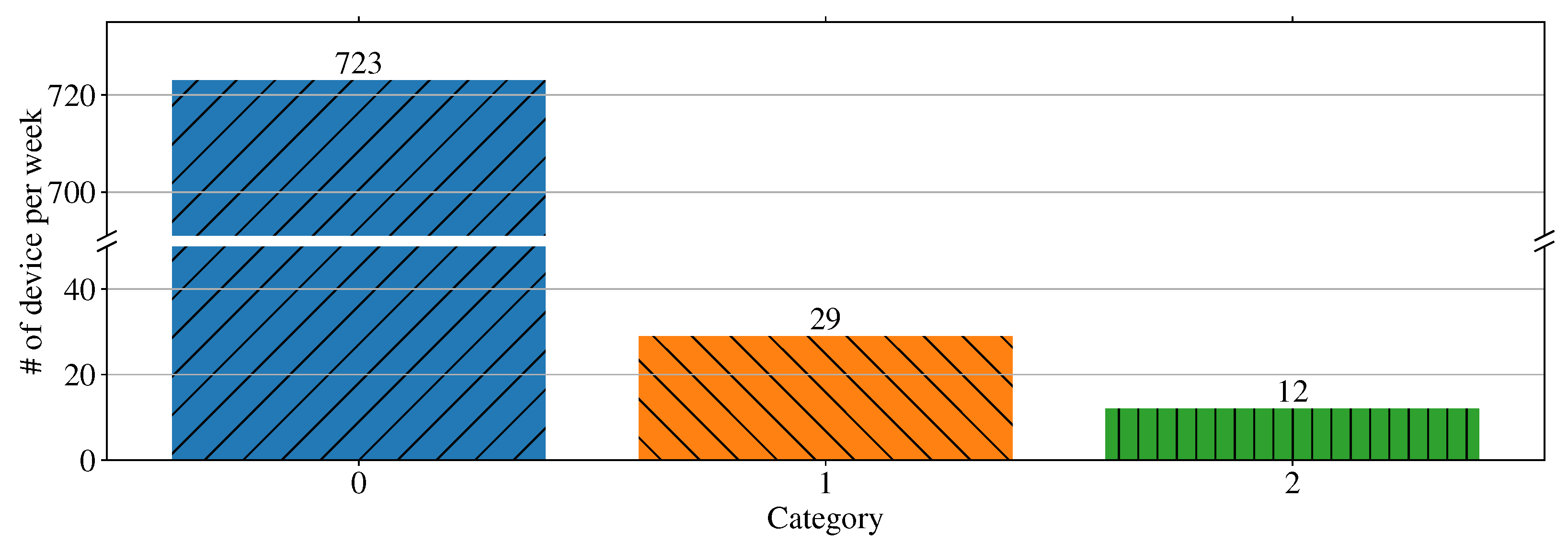
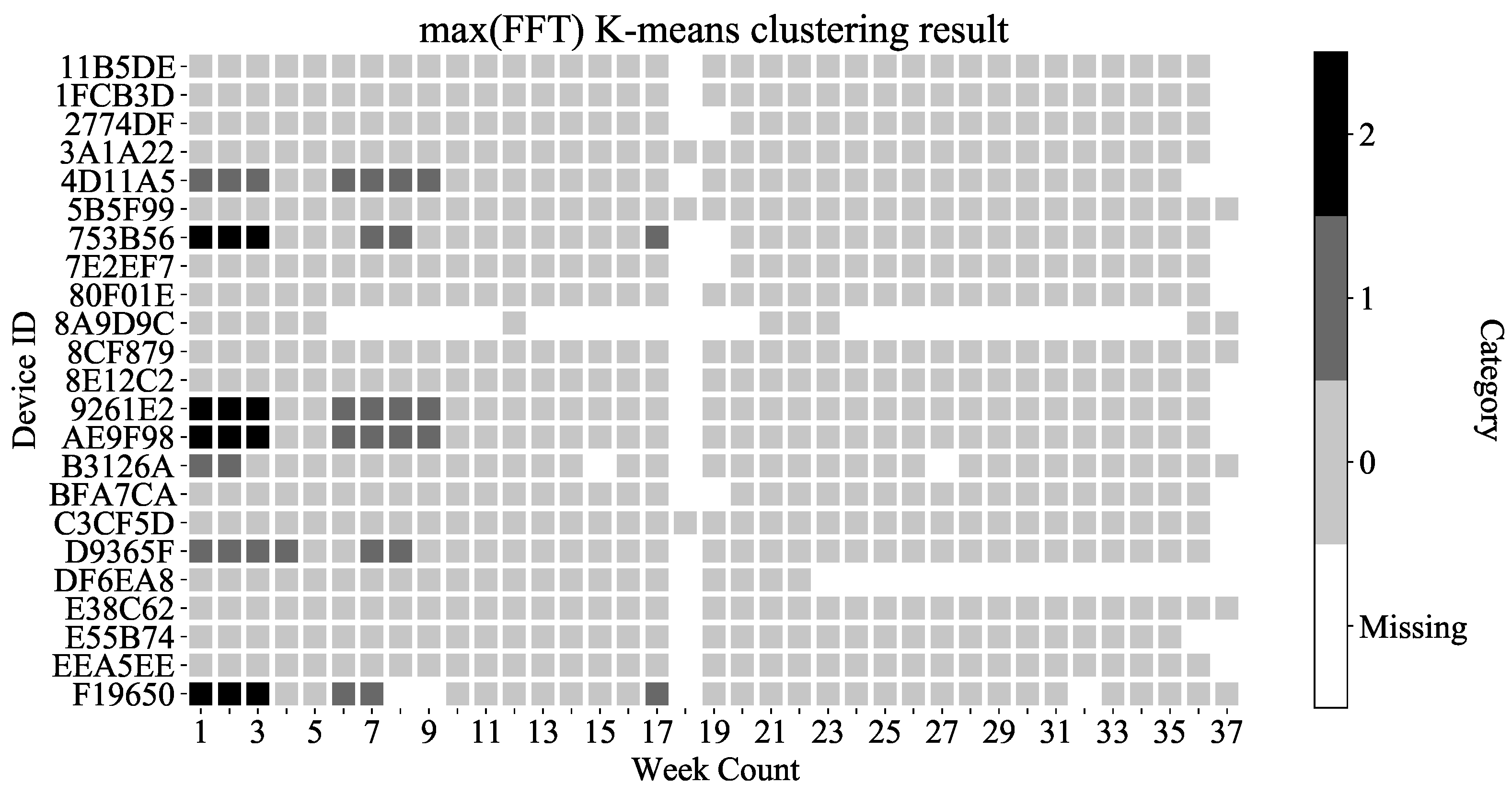
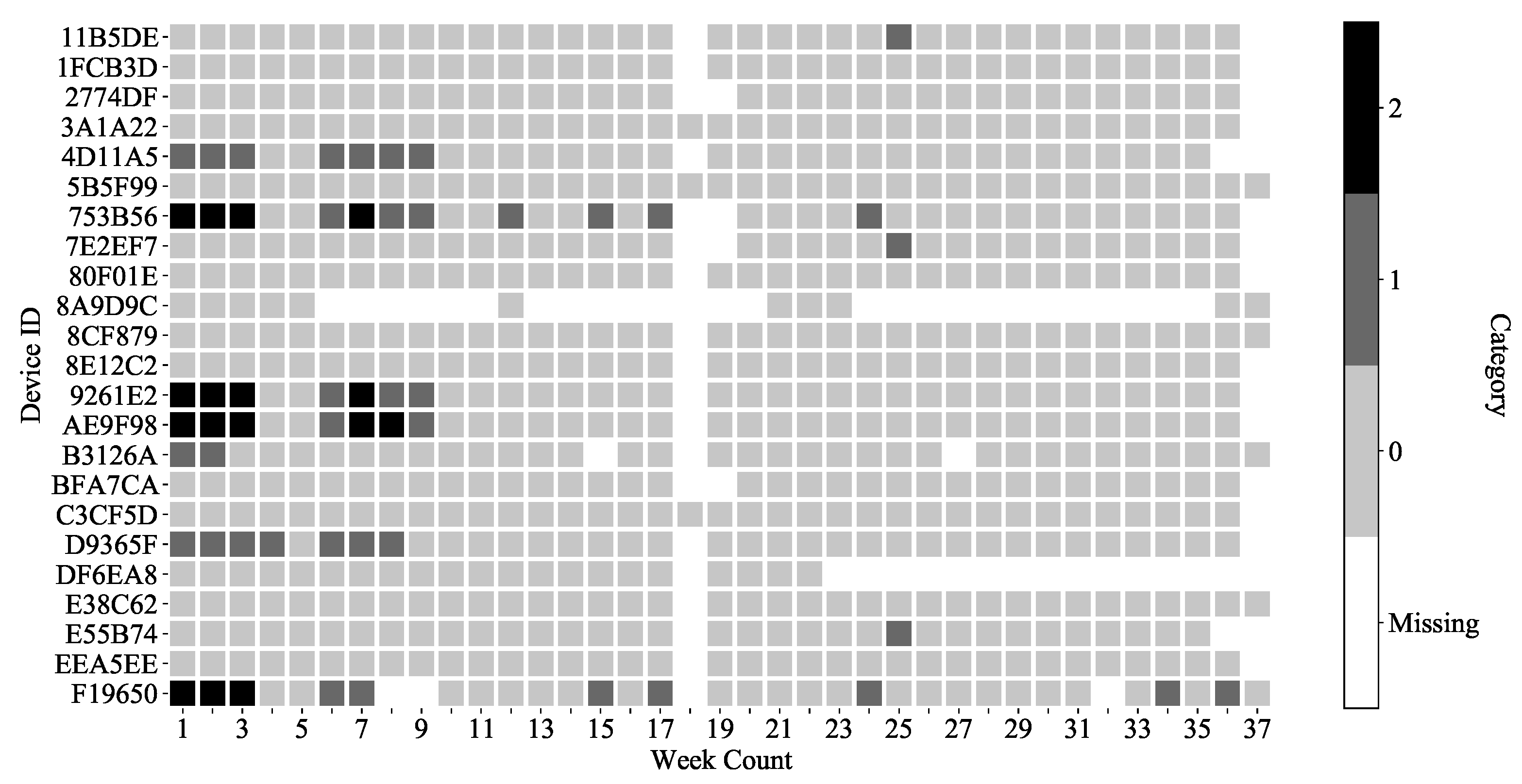
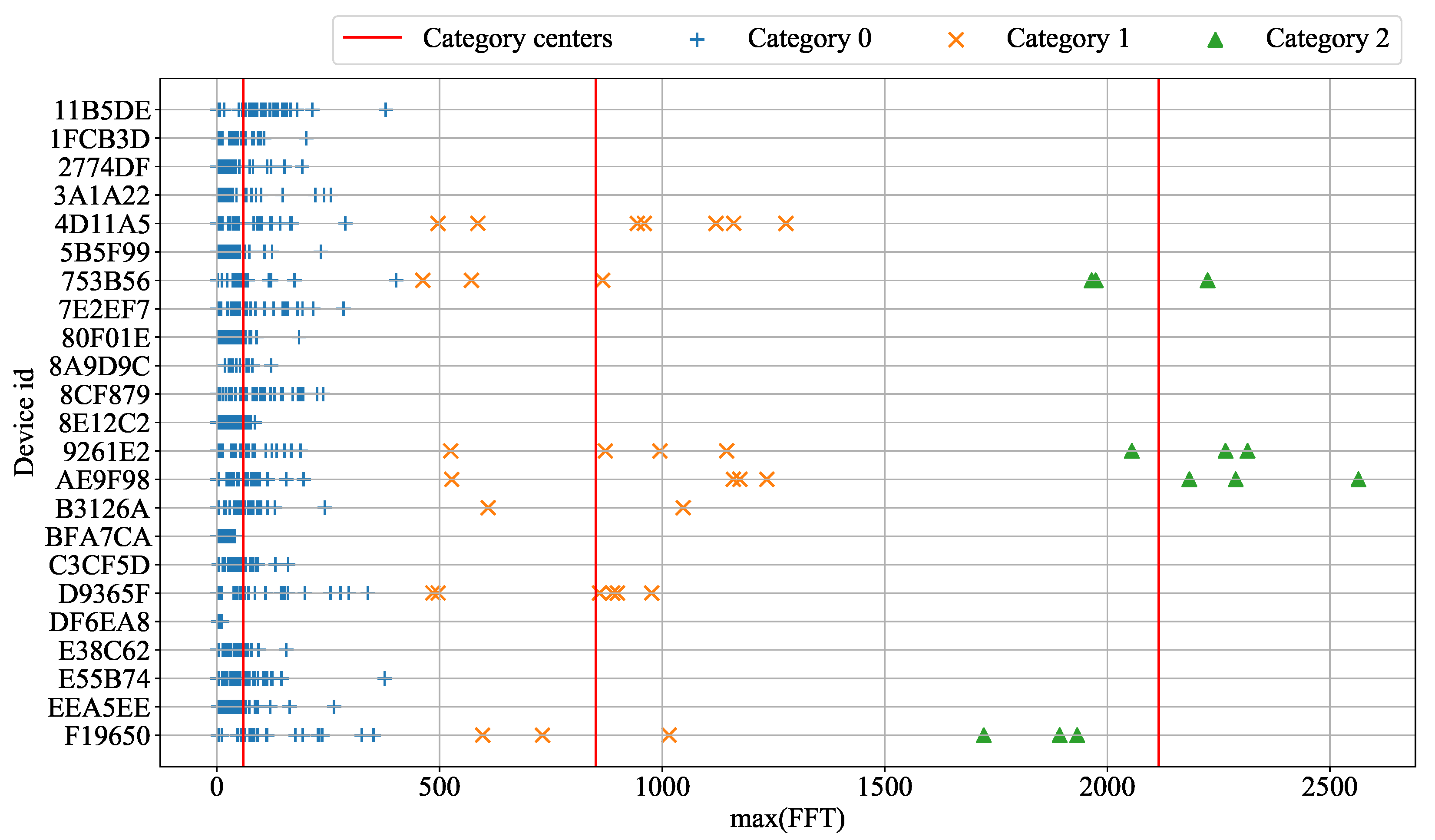
3.3. Cluster Result with Max (FFT)
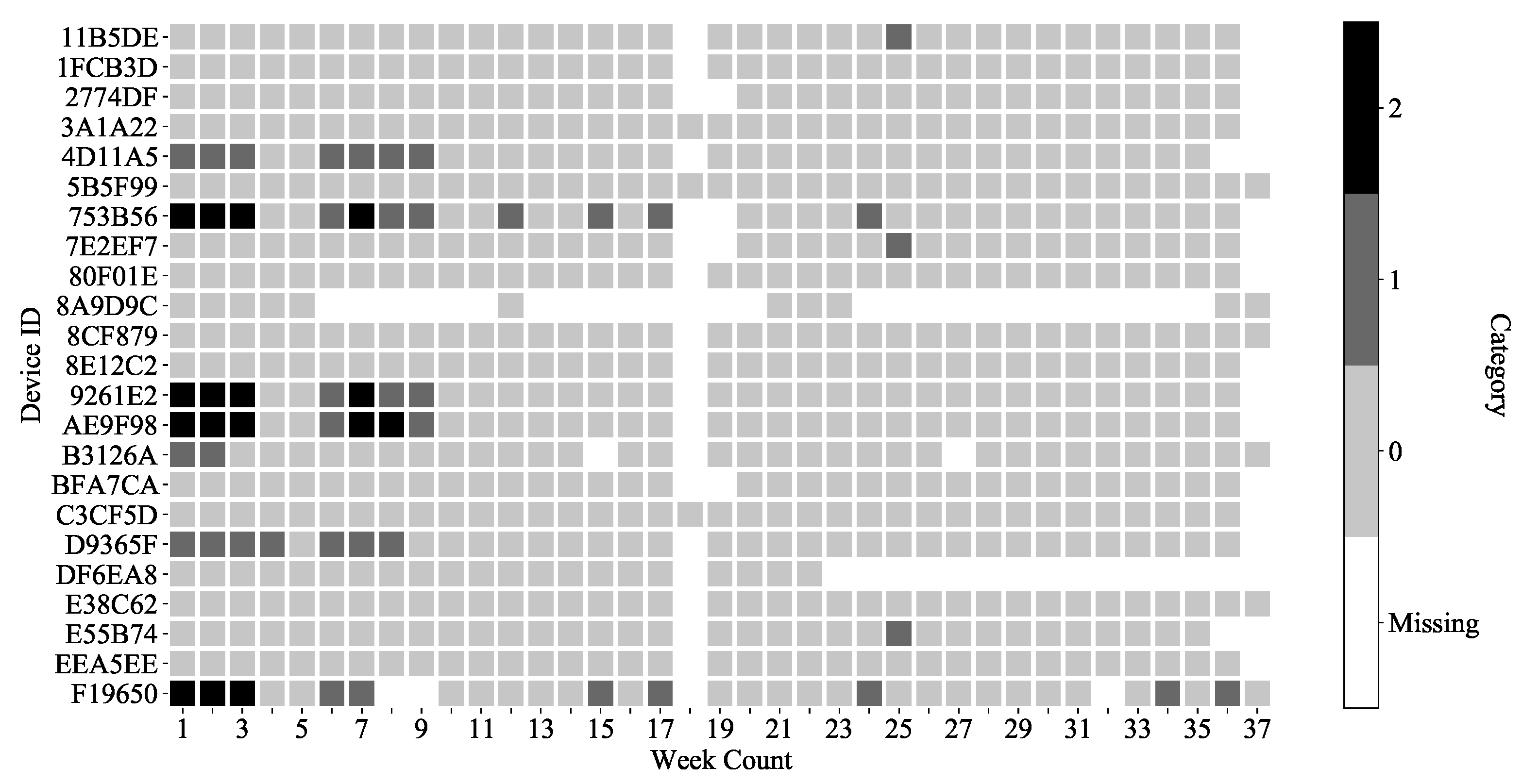
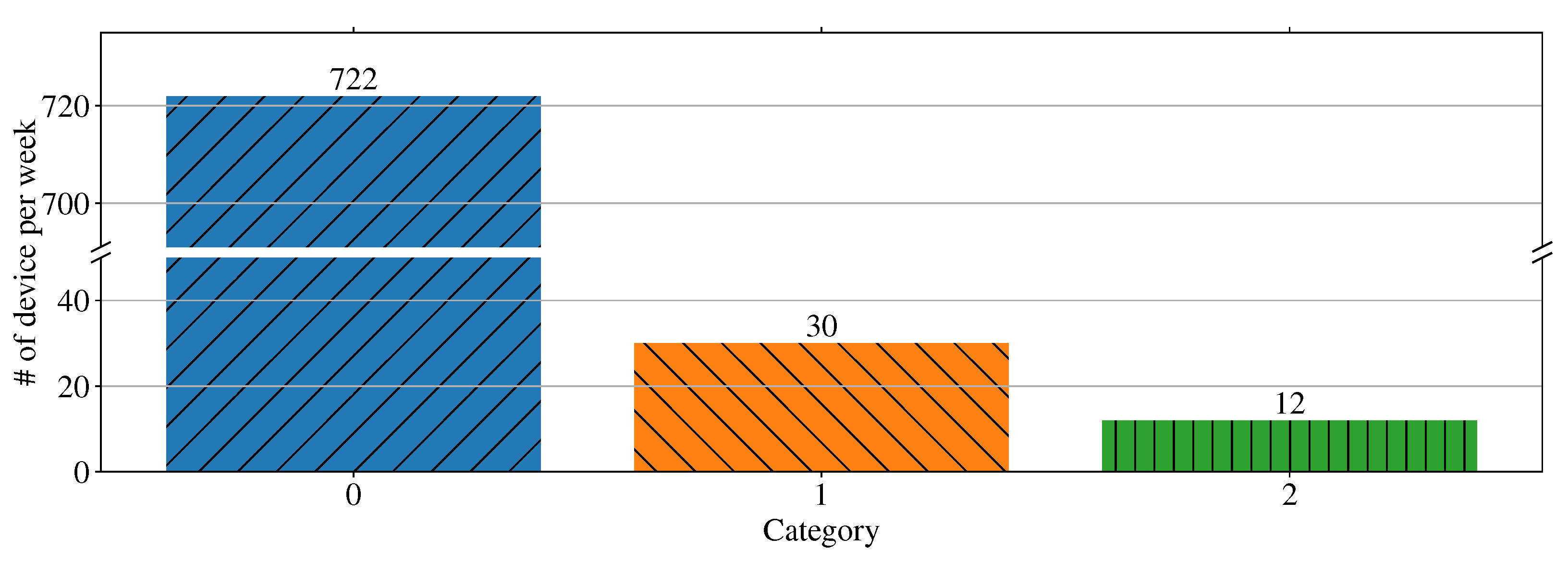
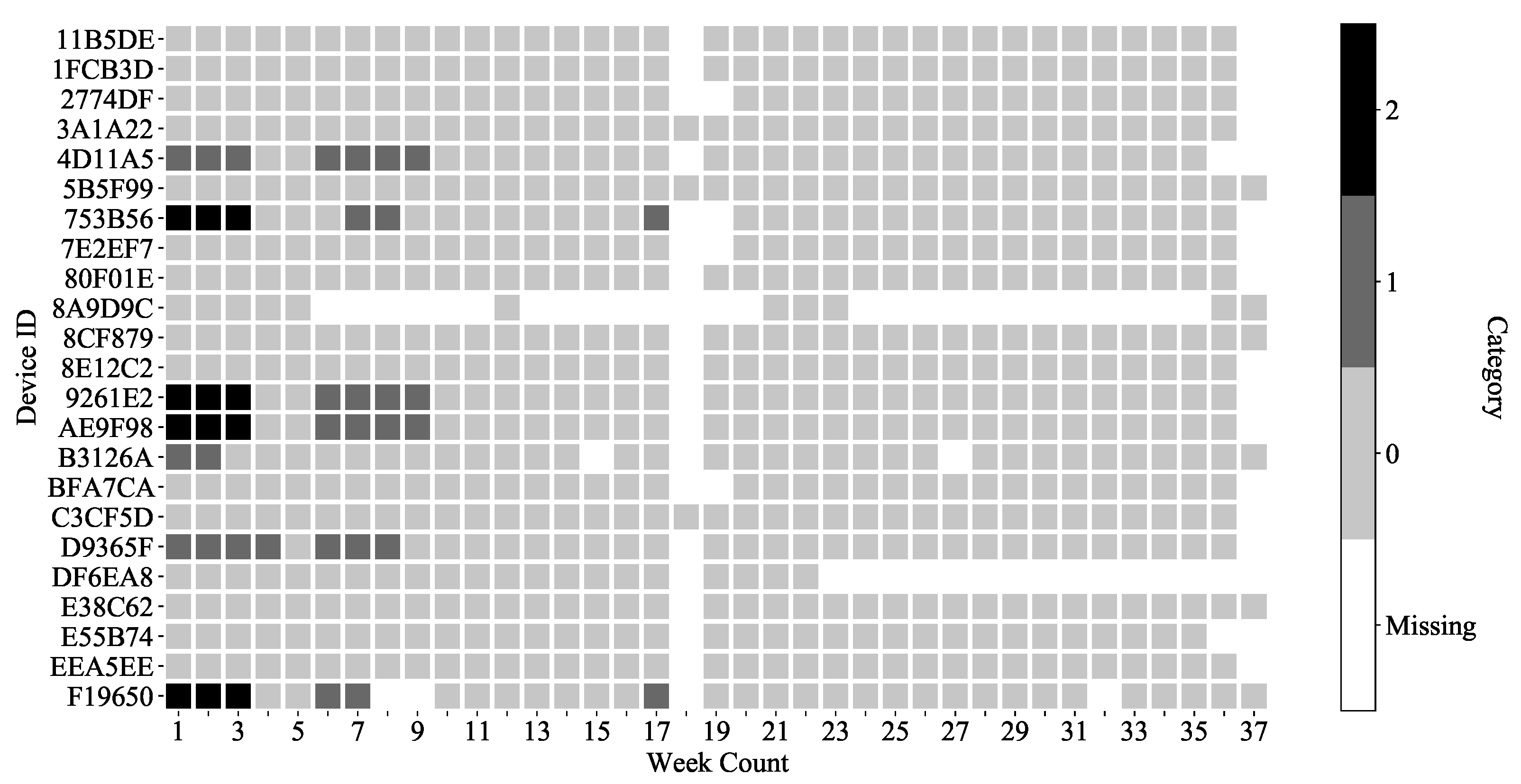
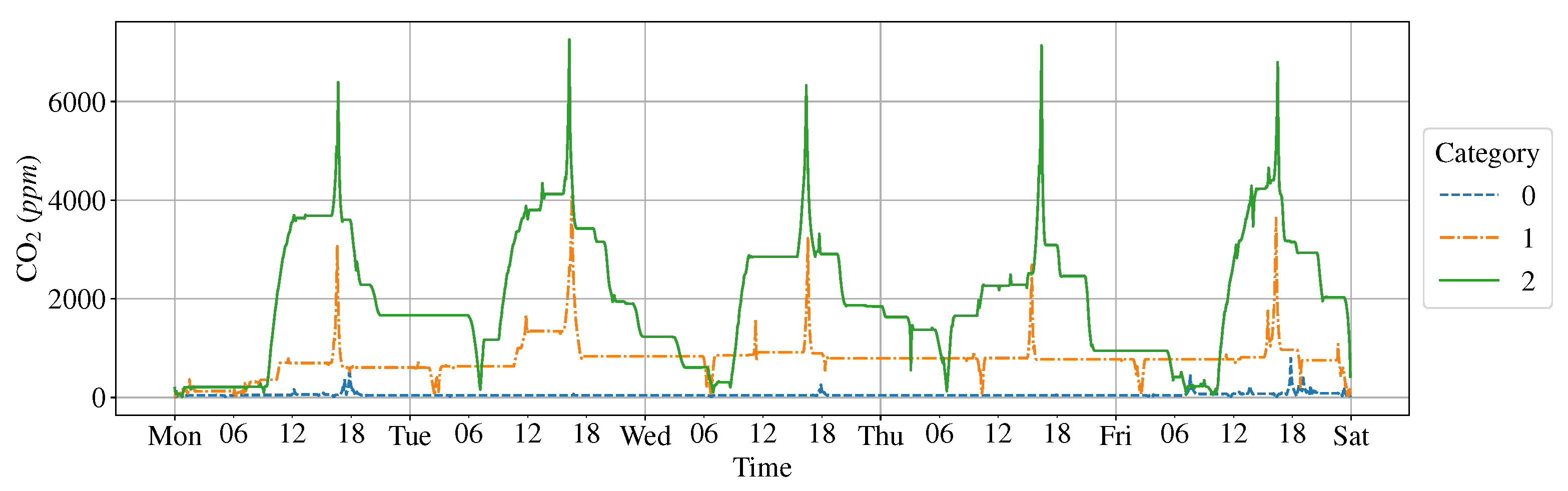
3.4. Type Definition on K-Means Clustering Result
- Type 2 is devices with any weekly data classified as Category 2.
- Type 1 is devices with any weekly data classified as Category 1.
- Type 0 is the remaining devices.
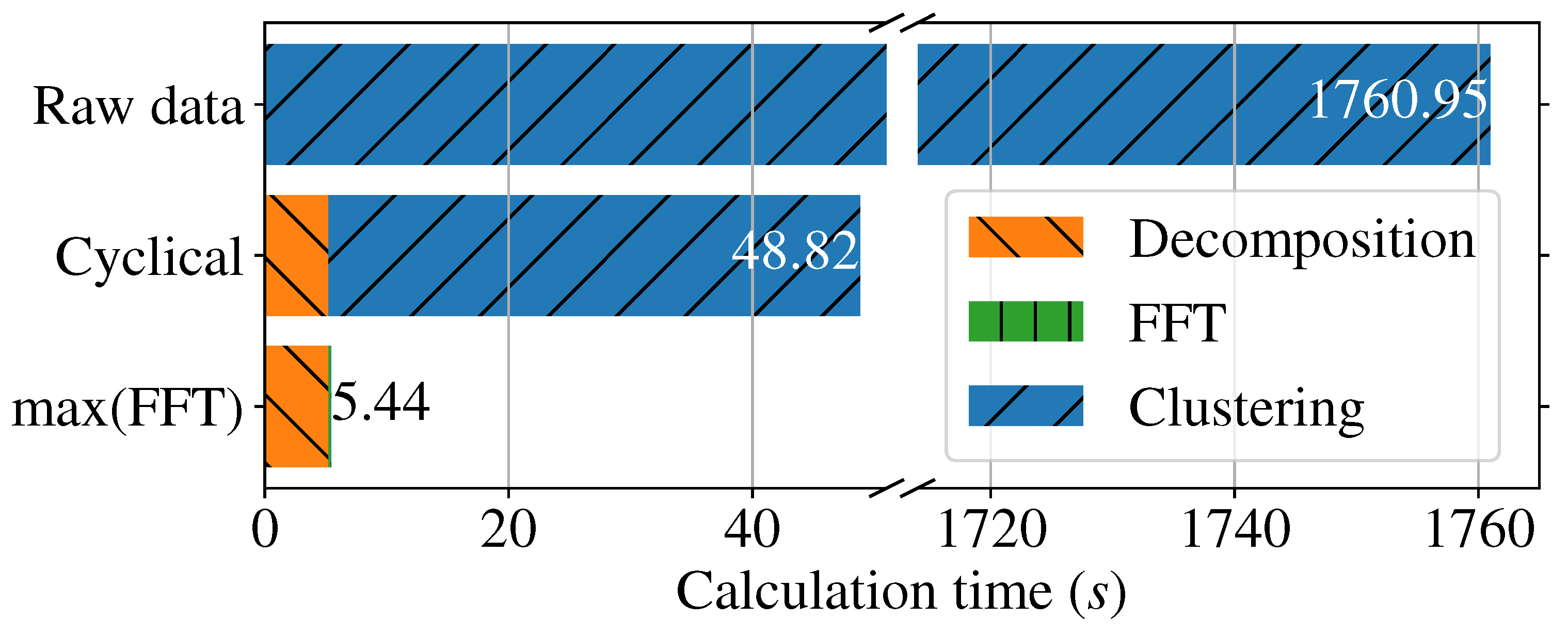
3.5. Calculation Time
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. Air Pollution. 2016. Available online: https://www.who.int/health-topics/air-pollution (accessed on 20 July 2022).
- Mahyuddin, N.; Awbi, H. A Review of CO2 Measurement Procedures in Ventilation Research. Int. J. Vent. 2012, 10, 353–370. [Google Scholar] [CrossRef]
- U.S. EPA. Indoor Air Quality (IAQ). Available online: https://www.epa.gov/indoor-air-quality-iaq (accessed on 20 July 2022).
- Jones, A. Indoor air quality and health. Atmos. Environ. 1999, 33, 4535–4564. [Google Scholar] [CrossRef]
- Bramer, M. Clustering; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Danielsson, P.E. Euclidean distance mapping. Comput. Graph. Image Process. 1980, 14, 227–248. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Chakraborty, A.; Faujdar, N.; Punhani, A.; Saraswat, S. Comparative Study of K-Means Clustering Using Iris Data Set for Various Distances. In Proceedings of the 2020 10th International Conference on Cloud Computing, Data Science Engineering (Confluence), Noida, India, 29–31 January 2020; pp. 332–335. [Google Scholar] [CrossRef]
- Caron, A.; Redon, N.; Coddeville, P.; Hanoune, B. Identification of indoor air quality events using a K-means clustering analysis of gas sensors data. Sens. Actuators B Chem. 2019, 297, 126709. [Google Scholar] [CrossRef]
- Sunori, S.K.; Negi, P.B.; Maurya, S.; Juneja, P.; Rana, A. K-Means Clustering of Ambient Air Quality Data of Uttarakhand, India during Lockdown Period of COVID-19 Pandemic. In Proceedings of the 2021 6th International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 20–22 January 2021; pp. 1254–1259. [Google Scholar]
- Chen, Y.; Wang, L.; Li, F.; Du, B.; Choo, K.K.R.; Hassan, H.; Qin, W. Air quality data clustering using EPLS method. Inf. Fusion 2017, 36, 225–232. [Google Scholar] [CrossRef]
- Zhu, C.; Li, N. Study on grey clustering model of indoor air quality indicators. Procedia Eng. 2017, 205, 2815–2822. [Google Scholar] [CrossRef]
- Delgado, A.; Montellanos, P.; Llave, J. Air quality level assessment in Lima city using the grey clustering method. In Proceedings of the 2018 IEEE International Conference on Automation/XXIII Congress of the Chilean Association of Automatic Control (ICA-ACCA), Concepcion, Chile, 17–19 October 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Chang, J.H.; Tseng, C.Y.; Chiang, H.H.; Hwang, R.H. Analysis of Influential Factors in Secondary PM2.5 by K-Medoids and Correlation Coefficient. In Proceedings of the 2017 IEEE 7th International Symposium on Cloud and Service Computing (SC2), Kanazawa, Japan, 22–25 November 2017; pp. 177–182. [Google Scholar]
- Aghabozorgi, S.; Seyed Shirkhorshidi, A.; Ying Wah, T. time series clustering—A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Dincer, N.G.; Akkuş, Ö. A new fuzzy time series model based on robust clustering for forecasting of air pollution. Ecol. Inform. 2018, 43, 157–164. [Google Scholar] [CrossRef]
- Alahamade, W.; Lake, I.; Reeves, C.E.; De La Iglesia, B. A multi-variate time series clustering approach based on intermediate fusion: A case study in air pollution data imputation. Neurocomputing 2021, 490, 229–245. [Google Scholar] [CrossRef]
- Li, J.; Izakian, H.; Pedrycz, W.; Jamal, I. Clustering-based anomaly detection in multivariate time series data. Appl. Soft Comput. 2021, 100, 106919. [Google Scholar] [CrossRef]
- Samet, J.M.; Marbury, M.C.; Spengler, J.D. Health Effects and Sources of Indoor Air Pollution. Part I. Am. Rev. Respir. Dis. 1987, 136, 1486–1508. [Google Scholar] [CrossRef] [PubMed]
- Abdullahi, K.L.; Delgado-Saborit, J.M.; Harrison, R.M. Emissions and indoor concentrations of particulate matter and its specific chemical components from cooking: A review. Atmos. Environ. 2013, 71, 260–294. [Google Scholar] [CrossRef]
- Samet, J.M. Radon and Lung Cancer. JNCI J. Natl. Cancer Inst. 1989, 81, 745–758. [Google Scholar] [CrossRef]
- Turanjanin, V.; Vučićević, B.; Jovanović, M.; Mirkov, N.; Lazović, I. Indoor CO2 measurements in Serbian schools and ventilation rate calculation. Energy 2014, 77, 290–296. [Google Scholar] [CrossRef]
- Scheff, P.A.; Paulius, V.K.; Huang, S.W.; Conroy, L.M. Indoor Air Quality in a Middle School, Part I: Use of CO2 as a Tracer for Effective Ventilation. Appl. Occup. Environ. Hyg. 2000, 15, 824–834. [Google Scholar] [CrossRef]
- Satish, U.; Mendell, M.J.; Shekhar, K.; Hotchi, T.; Sullivan, D.; Streufert, S.; Fisk, W.J. Is CO2 an Indoor Pollutant? Direct Effects of Low-to-Moderate CO2 Concentrations on Human Decision-Making Performance. Environ. Health Perspect. 2012, 120, 1671–1677. [Google Scholar] [CrossRef]
- Azuma, K.; Kagi, N.; Yanagi, U.; Osawa, H. Effects of low-level inhalation exposure to carbon dioxide in indoor environments: A short review on human health and psychomotor performance. Environ. Int. 2018, 121, 51–56. [Google Scholar] [CrossRef]
- Oneṭ, A.; Ilieș, D.C.; Ilieṣ, A.; Herman, G.V.; Burtă, L.; Marcu, F.; Buhaṣ, R.; Caciora, T.; Baias, Ṣ.; Oneṭ, C.; et al. Indoor air quality assessment and its perception. Case study–historic wooden church, Romania. Rom. Biotechnol. Lett. 2020, 25, 1547–1553. [Google Scholar] [CrossRef]
- Ilieș, D.C.; Hodor, N.; Indrie, L.; Dejeu, P.; Ilieș, A.; Albu, A.; Caciora, T.; Ilieș, M.; Barbu-Tudoran, L.; Grama, V. Investigations of the Surface of Heritage Objects and Green Bioremediation: Case Study of Artefacts from Maramureş, Romania. Appl. Sci. 2021, 11, 6643. [Google Scholar] [CrossRef]
- Chen, L.J.; Ho, Y.H.; Lee, H.C.; Wu, H.C.; Liu, H.M.; Hsieh, H.H.; Huang, Y.T.; Lung, S.C.C. An Open Framework for Participatory PM2.5 Monitoring in Smart Cities. IEEE Access 2017, 5, 14441–14454. [Google Scholar] [CrossRef]
- Ho, Y.H.; Li, P.E.; Chen, L.J.; Liu, Y.L. Indoor Air Quality Monitoring System for Proactive Control of Respiratory Infectious Diseases: Poster Abstract. In Proceedings of the 18th Conference on Embedded Networked Sensor Systems, Virtual, 16–19 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 693–694. [Google Scholar] [CrossRef]
- Upton, E.; Halfacree, G. Raspberry Pi User Guide; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- WEST, M. Time series decomposition. Biometrika 1997, 84, 489–494. [Google Scholar] [CrossRef]
- Heideman, M.T.; Johnson, D.H.; Burrus, C.S. Gauss and the history of the fast Fourier transform. Arch. Hist. Exact Sci. 1985, 34, 265–277. [Google Scholar] [CrossRef]
- Winograd, S. On computing the discrete Fourier transform. Math. Comput. 1978, 32, 175–199. [Google Scholar] [CrossRef]
- Dynamic Time Warping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germany, 2007; pp. 69–84. [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar]
- Location Aware Sensor System, LASS. 2016. Available online: https://lass-net.org/ (accessed on 20 July 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensing | Brand | Model | Units |
|---|---|---|---|
| Temperature (Temp) | Sensirion | STH31 | °C |
| Relative humidity (RH) | Sensirion | STH31 | %RH |
| Carbon dioxide (CO2) | SenseAir | S8 | ppm |
| Volatile organic compounds (VOCs) | SenseAir | SGP30 | ppb |
| Particulate matter (PM) | Plantower | PMS3003 | μg/m3 |
| Luminosity | Sunrom | TCS34725 | Lux |
| Calculation Time (in s) | Decomposition | FFT | Clustering | Total |
|---|---|---|---|---|
| Raw | N/A | N/A | 1760.95 | 1760.95 |
| Cyclical | 5.221 | N/A | 43.596 | 48.817 |
| max(FFT) | 5.221 | 0.194 | 0.025 | 5.444 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, K.-U.; Ho, Y.-H. Max Fast Fourier Transform (maxFFT) Clustering Approach for Classifying Indoor Air Quality. Atmosphere 2022, 13, 1375. https://doi.org/10.3390/atmos13091375
Chu K-U, Ho Y-H. Max Fast Fourier Transform (maxFFT) Clustering Approach for Classifying Indoor Air Quality. Atmosphere. 2022; 13(9):1375. https://doi.org/10.3390/atmos13091375
Chicago/Turabian StyleChu, Ka-Ui, and Yao-Hua Ho. 2022. "Max Fast Fourier Transform (maxFFT) Clustering Approach for Classifying Indoor Air Quality" Atmosphere 13, no. 9: 1375. https://doi.org/10.3390/atmos13091375
APA StyleChu, K.-U., & Ho, Y.-H. (2022). Max Fast Fourier Transform (maxFFT) Clustering Approach for Classifying Indoor Air Quality. Atmosphere, 13(9), 1375. https://doi.org/10.3390/atmos13091375