
Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection


Abstract
:1. Introduction
- (1)
- In the process of VOCs prediction, due to practical conditions, data is mainly obtained through specific monitoring stations and by reference to pollutant emission inventories, and the study area is rarely divided into grids for fine-grained studies.
- (2)
- Most of the joint prevention and control of VOCs pollution is through the method of numerical simulation, which requires the collection of topographical and geographical data information that is difficult to obtain, and the simulation of the dispersion process is complicated. At the same time, the existing VOCs prediction is mainly reflected in small-scale studies, which fail to predict VOCs from the perspective of regional correlation considerations.
- (3)
- VOCs prediction mainly focuses on quantity prediction, and the prediction process takes less account of the influence of factors such as meteorological indicators on the accuracy of prediction results. Existing studies have not screened for relevant characteristics. Existing studies of air pollutants have failed to provide aggregated sensing of air pollutants in associated areas.
- (4)
- When there are many influencing factors, the model construction efficiency and prediction performance will be reduced. The existing VOCs prediction model lacks consideration of complex influencing factors, and the focus is mostly on model optimisation and accuracy.
- (1)
- In terms of the research object, the five cities of Xi’an, Baoji, Tongchuan, Weinan and Xianyang have poorer haze and air quality problems compared to other regions in China, so it is representative to perceive and predict VOCs concentrations in the cities where the region is located. In order to visualise the regional VOC pollution situation, regional gridding and modelling of the aggregation pattern, which enables the perception of the VOCs aggregation phenomenon in the associated areas, is of great importance for the environmental management of the atmosphere.
- (2)
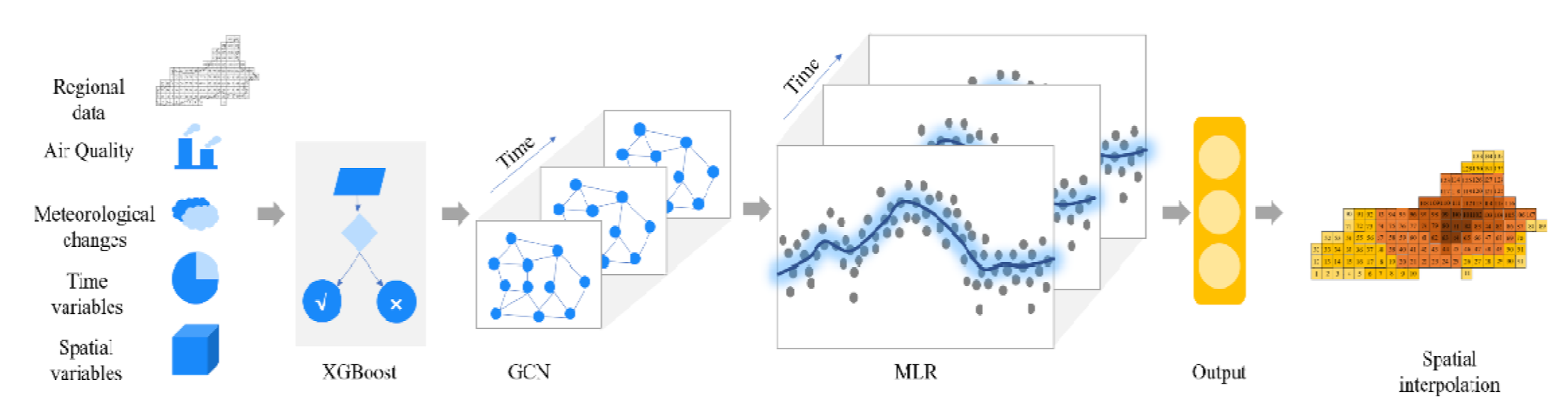
- In terms of the prediction model, the aim of this paper is to develop a concentration-based prediction method for sensing the aggregation of VOCs from a correlation area perspective and taking into account spatial and temporal characteristics. Combining the advantages of the three algorithms XGBoost, GCN and MLR, XGBoost can solve the traditional feature redundancy problem by eliminating redundant features according to their importance. The GCN extracts multi-scale spatial information from the associated regions and fuses it to construct feature representations. The MLR model handles complex samples with high-dimensional features well and can be targeted for migration and application in different scenarios. The features of VOCs are selected by applying XGBoost to the features, then the GCN is used for spatial feature extraction, and finally the extracted features are fed into the MLR model for prediction. The method considers the excellent characteristics of GCN-MLR in the temporal prediction of VOCs concentrations, while the XGBoost model can fully play an important role in the selection of VOCs related features. The XGBoost model and GCN-MLR model were combined to construct a VOCs concentration prediction model and VOCs aggregation potential values were obtained for VOCs aggregation perception analysis. Intelligent sensing of VOCs aggregation can visualise the development trend and status of regional VOCs aggregation, conveying more information and having some practical value. The aggregation sensing method can therefore provide decision support for regional VOCs pollution prevention and early warning.
- (3)
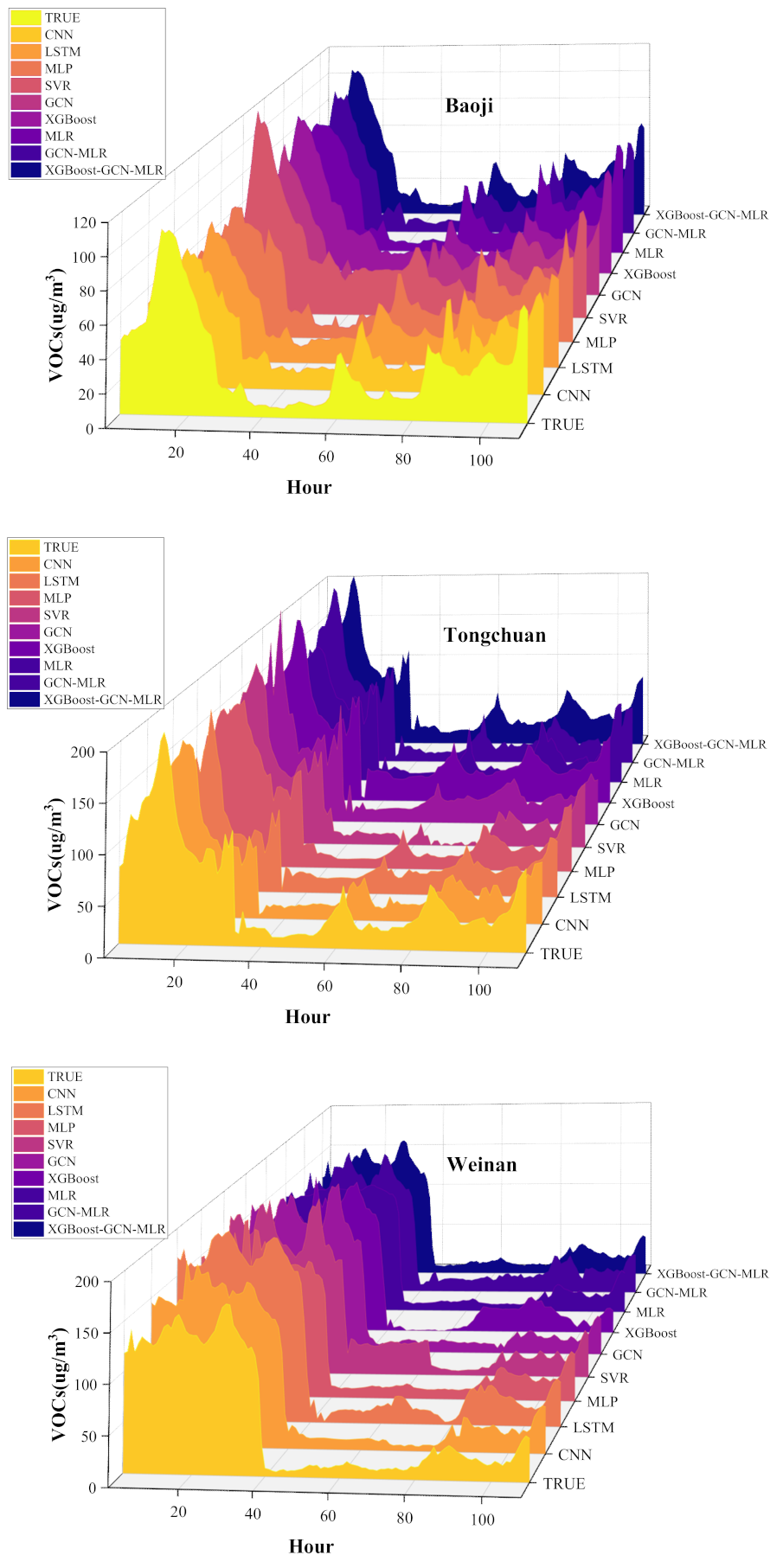
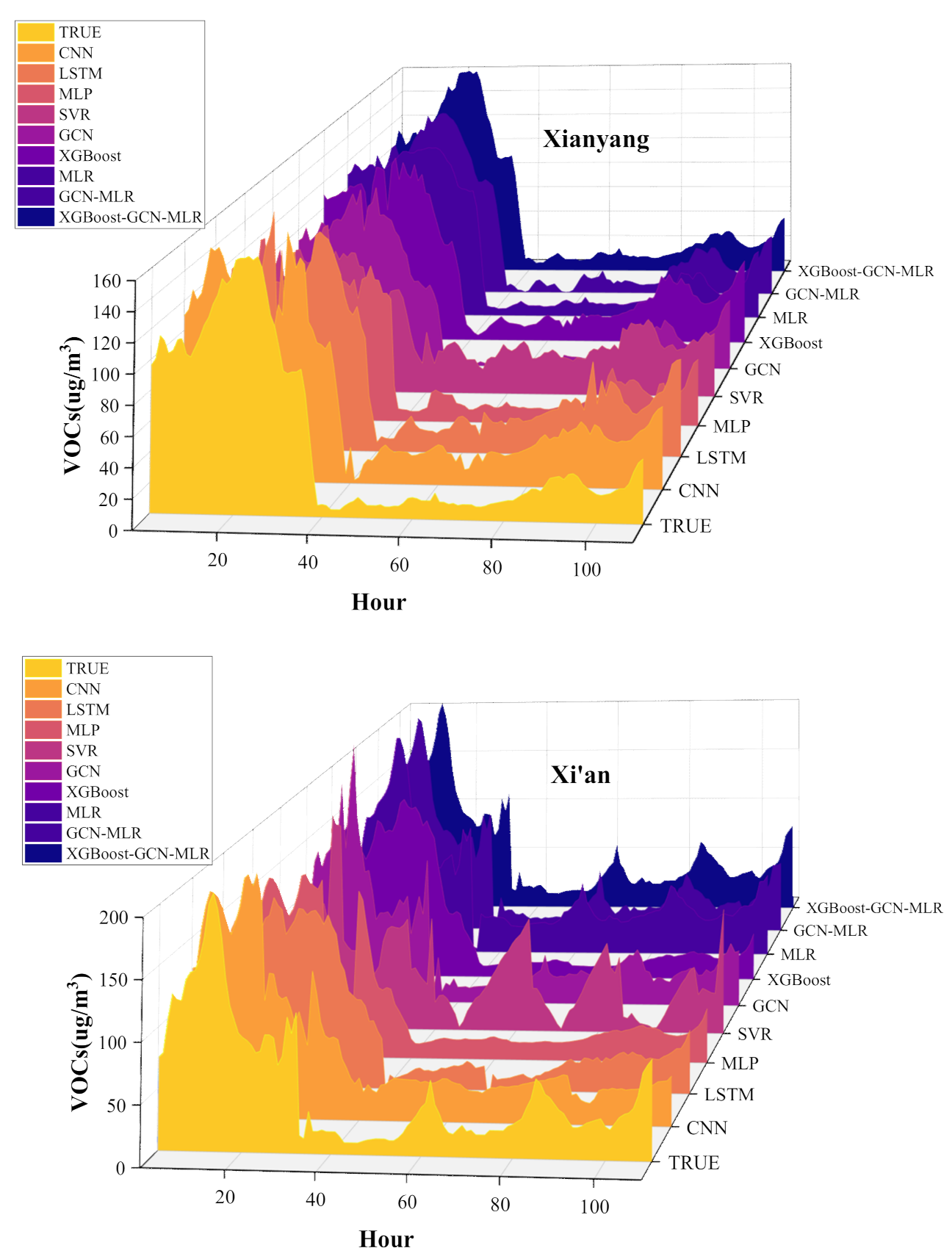
- In terms of prediction results, this paper takes the VOCs concentration of the regional grid as the entry point and proposes a concentration prediction-based VOCs aggregation sensing method. It was demonstrated that the combined prediction model proposed in this paper has higher prediction accuracy compared to other deep learning models. In this paper, the prediction results of XGBoost-GCN-MLR are generally better than those of CNN, LSTM, MLP, SVR, GCN, XGBoost, MLR and GCN-MLR, and the results of several experiments show that the proposed model has good robustness.
2. Intelligent Sensing Model of VOCs Gathering Concentrations
2.1. Study Area
2.2. Modelling of VOCs Aggregation in Associated Areas
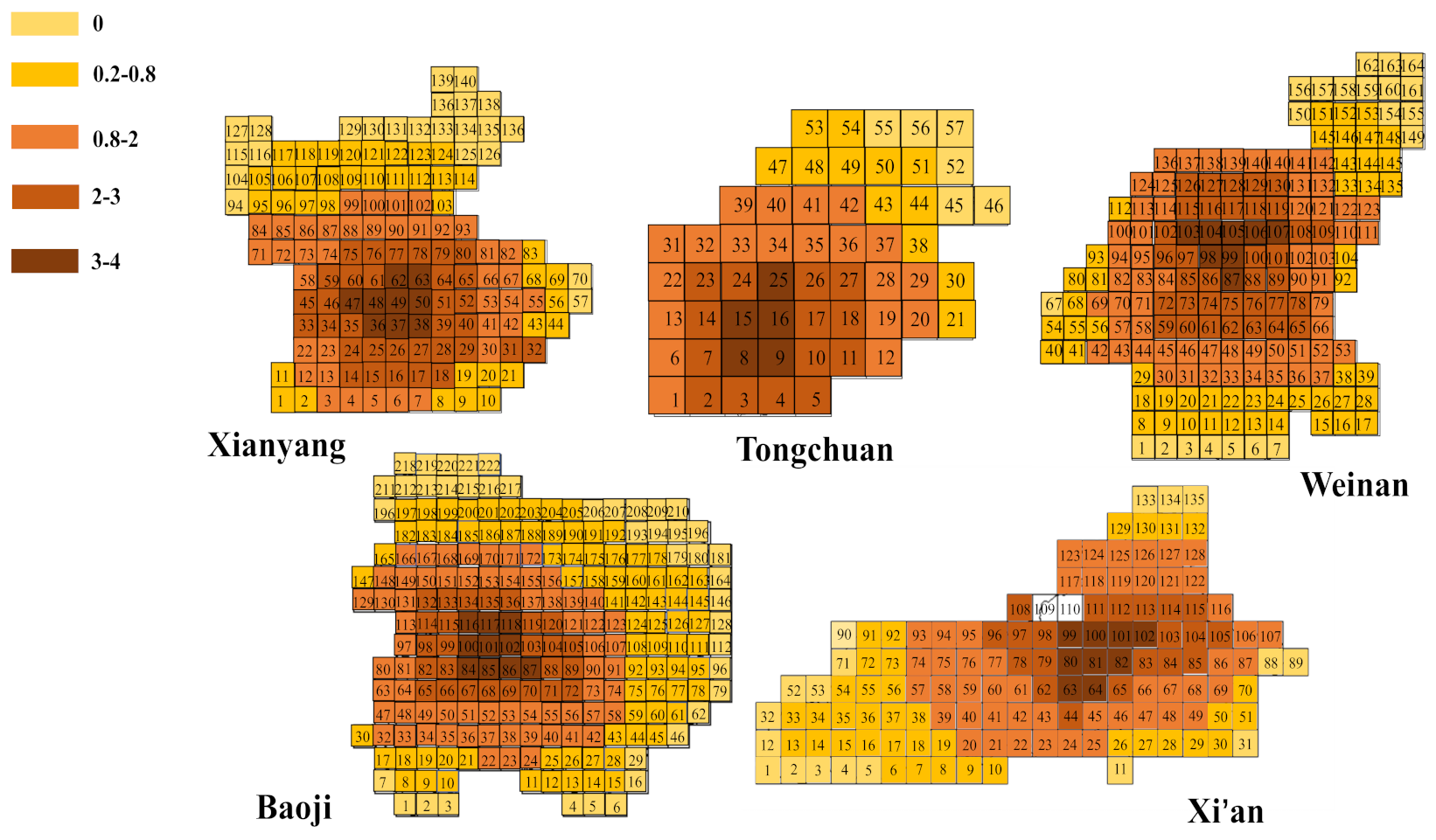
2.2.1. Regional Gridding
2.2.2. VOCs Aggregation Sensing Model Construction
2.3. Perceived Extent of VOCs Aggregation
2.4. Data Collection and Pre-Processing
2.4.1. Introduction to the Data
2.4.2. Data Collection
2.4.3. VOCs Data Characteristics
3. Methods
3.1. Graph Convolutional Neural Network (GCN)
3.2. Multiple Linear Regression
3.3. XGBoost Algorithm
3.4. Intelligent Sensing Model for VOCs Aggregation
3.5. Evaluation Indicators
4. Results
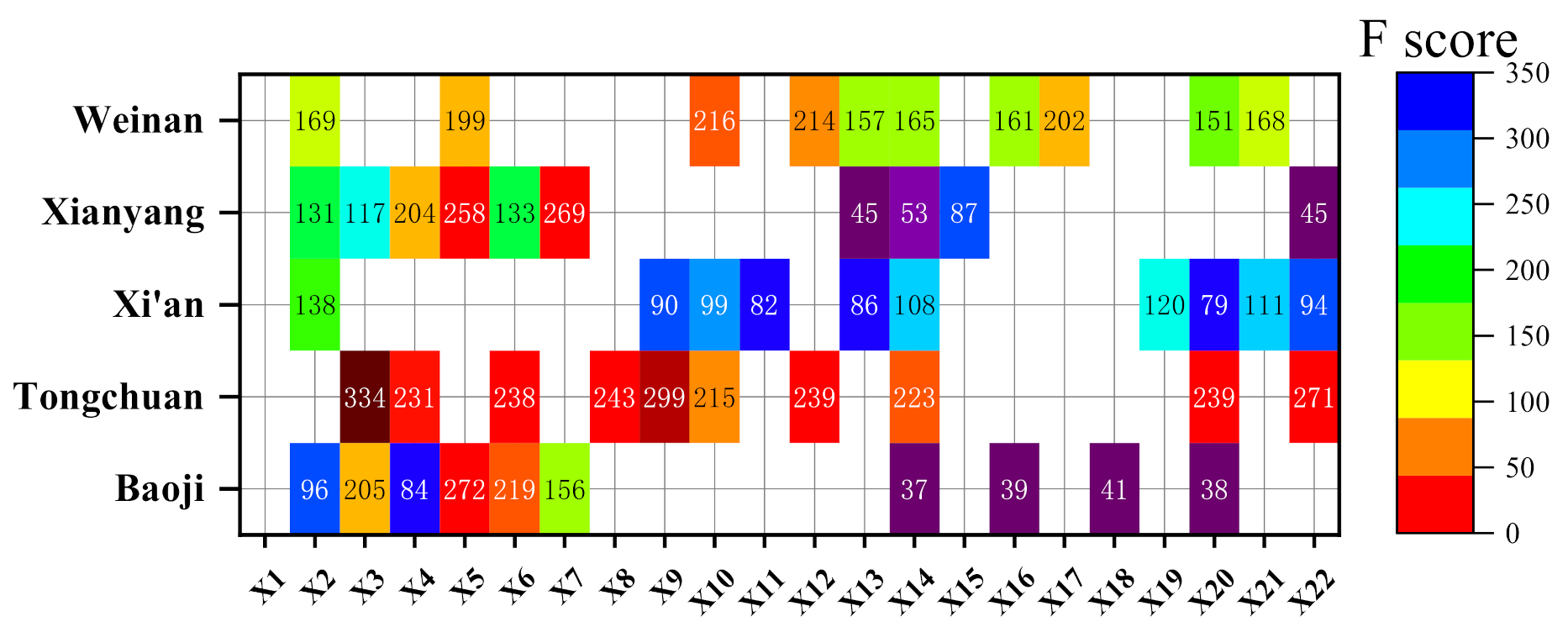
4.1. Feature Selection
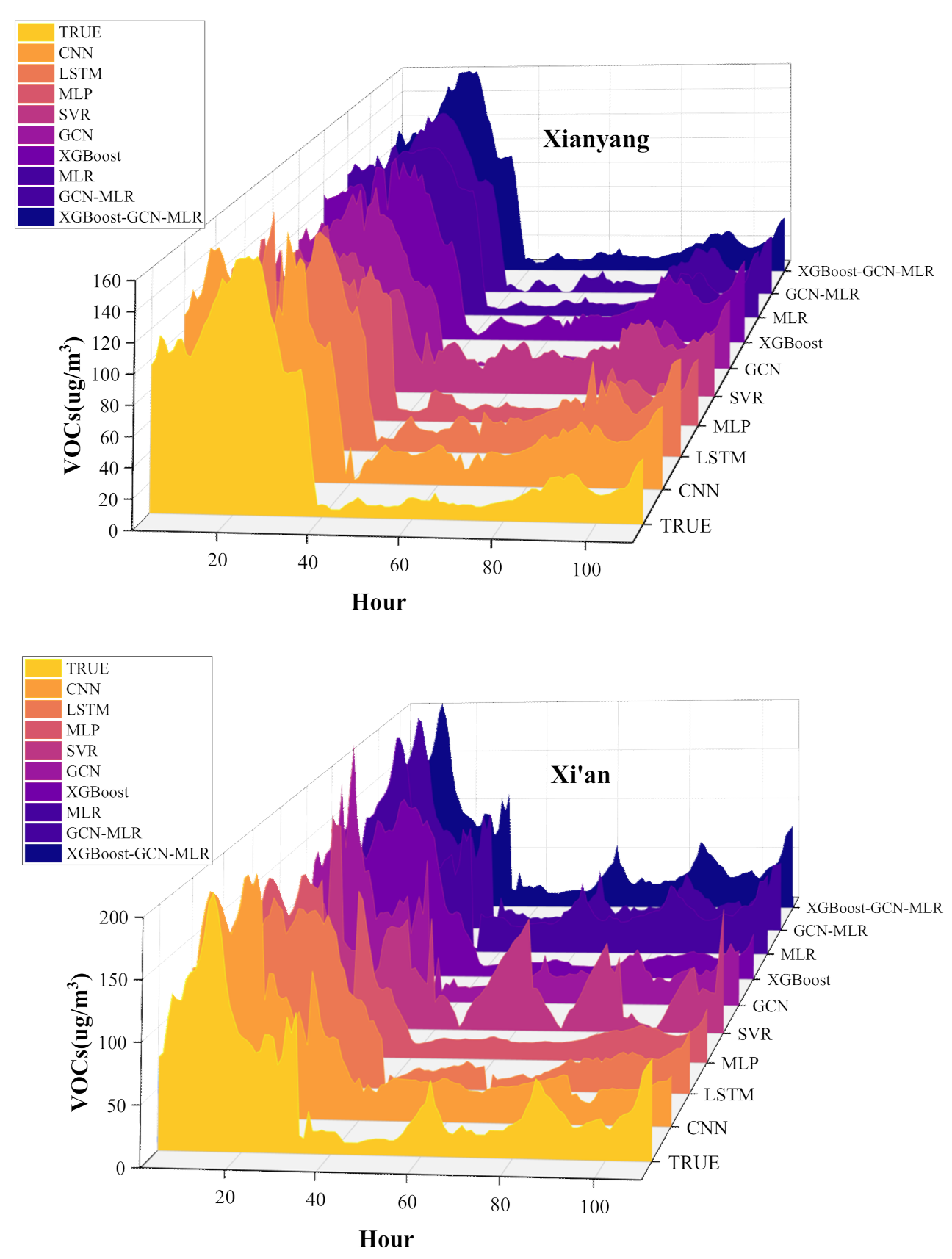
4.2. VOCs Concentration Prediction Based on XGBoost-GCN-MLR Model
4.3. DM Test
4.4. Robustness Test
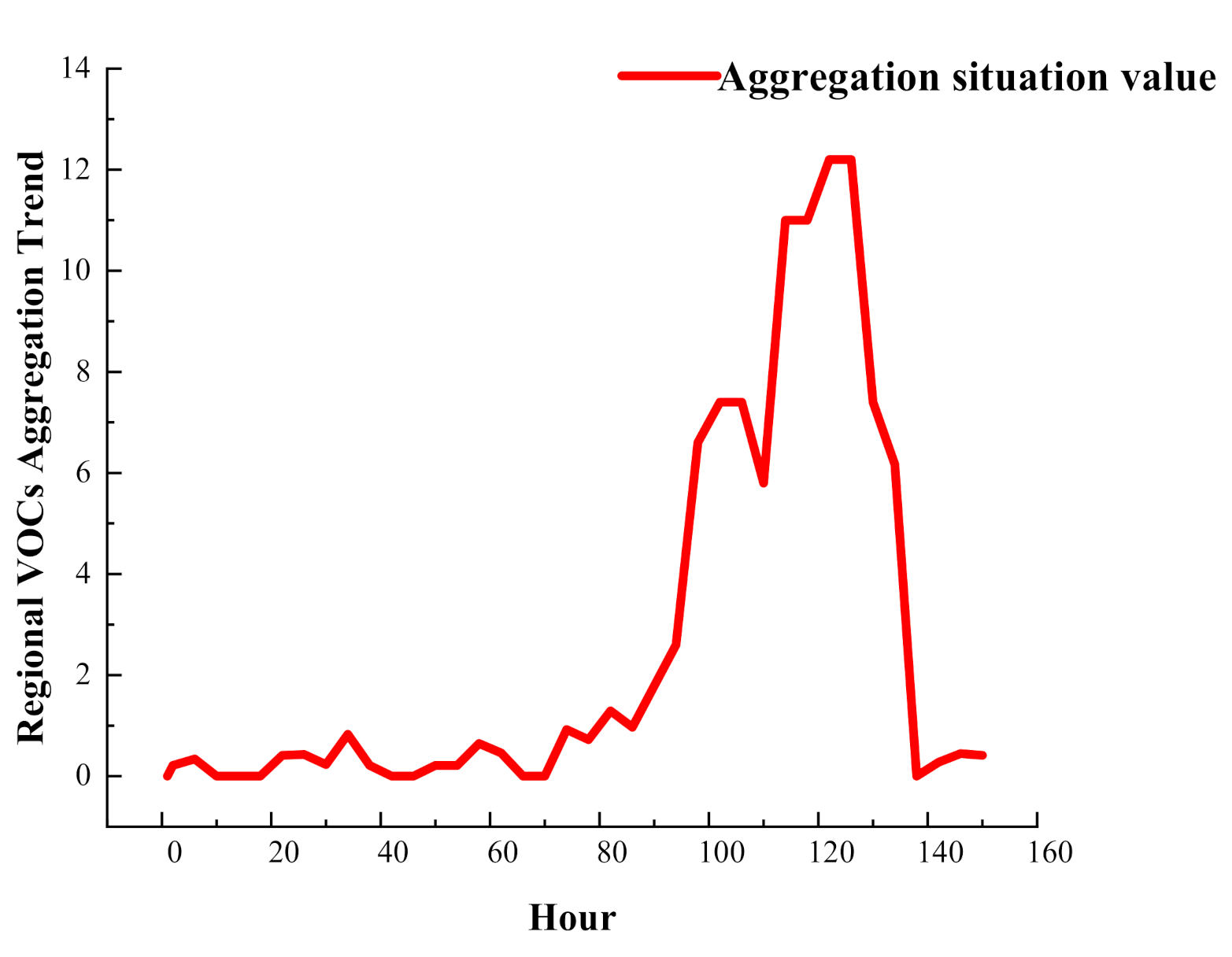
4.5. VOCs Aggregation Perception Analysis
5. Conclusions
- (1)
- Grid-based management of associated regions for joint prevention and control. Grid management is a key step in the refinement of regional management and the basis for pollution prevention and control. Information from different grids can be shared, and pollution from each grid can be monitored and summarised in real time.
- (2)
- Use the degree of influence of VOCs pollution between associated areas to apply preventive and control measures to the relevant areas. Monitor the pollution concentration in each sub-regional grid and propose relevant guidelines to reduce pollution and harm to the environment according to local conditions. VOCs emissions from different grid areas will be aggregated, with key monitoring of heavily polluted areas and timely release of grid and source information for heavily polluted areas. VOCs are also controlled at the source, regulated in the process and treated at the end of the process.
- (3)
- Prediction and early warning of VOCs pollution. The sources of VOCs pollution are identified through immediate prediction and early warning to further strengthen the management of pollution control. At the same time, the functions and tasks of each organisation’s personnel are assigned according to the degree of VOCs aggregation in the grid, and the relevant personnel are involved in timely follow-up and feedback.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Jiang, Q.; Wang, Z.; Fu, P.; Li, J.; Yang, T.; Yin, Y. Investigation of the sources and evolution processes of severe haze pollution in Beijing in January 2013. J. Geophys. Res.-Atmos. 2014, 119, 4380–4398. [Google Scholar] [CrossRef]
- Jiang, Z.; Grosselin, B.; Daële, V.; Mellouki, A.; Mu, Y. Seasonal and diurnal variations of BTEX compounds in the semi-urban environment of Orleans, France. Sci. Total Environ. 2017, 574, 1659–1664. [Google Scholar] [CrossRef] [PubMed]
- Delfino, R.J. Epidemiologic evidence for asthma and exposure to air toxics: Linkages between occupational, indoor, and community air pollution research. Environ. Health Perspect. 2002, 110, 573–589. [Google Scholar] [CrossRef] [PubMed]
- Windham, G.C.; Zhang, L.; Gunier, R.; Croen, L.A.; Grether, J.K. Autism spectrum disorders in relation to distribution of hazardous air pollutants in the San Francisco Bay area. Environ. Health Perspect. 2006, 114, 1438–1444. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; You, Y.; Bai, Z.; Hu, Y.; Zhang, J.; Zhang, N. Health risk assessment of personal inhalation exposure to volatile organic compounds in Tianjin, China. Sci. Total Environ. 2011, 409, 452–459. [Google Scholar] [CrossRef]
- Tagiyeva, N.; Sheikh, A. Domestic exposure to volatile organic compounds in relation to asthma and allergy in children and adults. Expert Rev. Clin. Immunol. 2014, 10, 1611–1639. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, S.; Li, Z.; Zhu, J.; Bi, Y.; Bai, Y.; Wang, H. Maternal benzene exposure during pregnancy and risk of childhood acute lymphoblastic leukemia: A meta-analysis of epidemiologic studies. PLoS ONE 2014, 9, e110466. [Google Scholar] [CrossRef]
- Huang, R.J.; Zhang, Y.; Bozzetti, C.; Ho, K.F.; Cao, J.J.; Han, Y.; Prévôt, A.S. High secondary aerosol contribution to particulate pollution during haze events in China. Nature 2014, 514, 218–222. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Tang, Z.; Chen, J. Migration Model of VOCs in Composite Package Materials. China Print. Packag. Study 2012, 4, 62–66. [Google Scholar]
- Zhang, W.; Tan, L.; Wang, Z.; Zhu, W.; Lu, Y.; Li, L. Assessment on VOCs in atmospheric air and their influence to health at Shapingba district of Chongqing city. China Meas. Test 2017, 43, 43–48. [Google Scholar]
- Zeng, J.; Han, G.; Wu, Q.; Tang, Y. Effects of agricultural alkaline substances on reducing the rainwater acidification: Insight from chemical compositions and calcium isotopes in a karst forests area. Agric. Ecosyst. Environ. 2020, 290, 106782. [Google Scholar] [CrossRef]
- Zeng, J.; Yue, F.; Li, S.-L.; Wang, Z.; Wu, Q.; Qin, C.; Yan, Z. Determining rainwater chemistry to reveal alkaline rain trend in Southwest China: Evidence from a frequent-rainy karst area with extensive agricultural production. Environ. Pollut. 2020, 266, 115166. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, H.; Tan, Y.; Zhang, M.; Zhang, X.; Wang, K.; Xiong, J. Using a machine learning approach to predict the emission characteristics of VOCs from furniture. Build. Environ. 2021, 196, 107786. [Google Scholar] [CrossRef]
- Nkeshita, F.C.; Adekunle, A.A.; Abegunrin, A. Prediction of Indoor Total Volatile Organic Compound in a University Hostel Using a Neural Network Model. NIJOTECH 2021, 40, 186–190. [Google Scholar] [CrossRef]
- Zhang, Q. Concentration Inversion of Multi-Component Volatile Organic Compounds Based on Deep Neural Network; Xi’an Institute of Optics & Precision Mechanics, Chinese Academy of Sciences: Xi’an, China, 2019. [Google Scholar]
- Ren, W.; Niu, Y. Application of GA-BP in VOCs Prediction Model in Chemical Industrial Parks. Comput. Appl. Softw. 2018, 35, 274–277. [Google Scholar]
- Zhao, L. Studies on Respone Interference of VOCs Gas Mixture and Recognition with Neural Network. Master’s Thesis, Dalian University of Technology, Dalian, China, 2017. [Google Scholar]
- Chen, Z. Research on VOCs Mixed Gas Detection Based on BP Neural Network. Master’s Thesis, Ningbo University, Ningbo, China, 2017. [Google Scholar]
- Yang, M.; Fan, H.; Zhao, K. PM2.5 prediction with a novel multi-step-ahead forecasting model based on dynamic wind field distance. Int. J. Environ. Res. Public Health 2019, 16, 4482. [Google Scholar] [CrossRef] [Green Version]
- Ghahremanloo, M.; Choi, Y.; Sayeed, A.; Salman, A.K.; Pan, S.; Amani, M. Estimating daily high-resolution PM2. 5 concentrations over Texas: Machine Learning approach. Atmos. Environ. 2021, 247, 118209. [Google Scholar] [CrossRef]
- Feng, R.; Gao, H.; Luo, K.; Fan, J.R. Analysis and accurate prediction of ambient PM2. 5 in China using Multi-layer Perceptron. Atmos. Environ. 2020, 232, 117534. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Prediction of Air Pollutant Concentration Based on One-Dimensional Multi-Scale CNN-LSTM Considering Spatial-Temporal Characteristics: A Case Study of Xi’an, China. Atmosphere 2021, 12, 1626. [Google Scholar] [CrossRef]
- Dhakal, S.; Gautam, Y.; Bhattarai, A. Exploring a deep LSTM neural network to forecast daily PM2.5 concentration using meteorological parameters in Kathmandu Valley, Nepal. Air Qual. Atmos. Health 2021, 14, 83–96. [Google Scholar] [CrossRef]
- Park, Y.; Kwon, B.; Heo, J.; Hu, X.; Liu, Y.; Moon, T. Estimating PM2.5 concentration of the conterminous United States via interpretable convolutional neural networks. Environ. Pollut. 2020, 256, 113395. [Google Scholar] [CrossRef]
- Lv, B.; Cobourn, W.G.; Bai, Y. Development of nonlinear empirical models to forecast daily PM2.5 and ozone levels in three large Chinese cities. Atmos. Environ. 2016, 147, 209–223. [Google Scholar] [CrossRef]
- Al-Qaness, M.A.; Fan, H.; Ewees, A.A.; Yousri, D.; Elaziz, M.A. Improved ANFIS model for forecasting Wuhan City air quality and analysis COVID-19 lockdown impacts on air quality. Environ. Res. 2021, 194, 110607. [Google Scholar] [CrossRef]
- Prihatno, A.T.; Nurcahyanto, H.; Ahmed, M.; Rahman, M.; Alam, M.; Jang, Y.M. Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method. Electronics 2021, 10, 1808. [Google Scholar] [CrossRef]
- Guo, H.; Guo, Y.; Zhang, W.; He, X.; Qu, Z. Research on a Novel Hybrid Decomposition–Ensemble Learning Paradigm Based on VMD and IWOA for PM2.5 Forecasting. Int. J. Environ. Res. Public Health 2021, 18, 1024. [Google Scholar] [CrossRef]
- Huang, G.; Li, X.; Zhang, B.; Ren, J. PM2.5 concentration forecasting at surface monitoring sites using GRU neural network based on empirical mode decomposition. Sci. Total Environ. 2021, 768, 144516. [Google Scholar] [CrossRef]
- Photphanloet, C.; Lipikorn, R. PM10 concentration forecast using modified depth-first search and supervised learning neural network. Sci. Total Environ. 2020, 727, 138507. [Google Scholar] [CrossRef]
- Durao, R.M.; Mendes, M.T.; Pereira, M.J. Forecasting O3 levels in industrial area surroundings up to 24 h in advance, combining classification trees and MLP models. Atmos. Pollut. Res. 2016, 7, 961–970. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Lau, A.K.; Sandbrink, K.; Fung, J.C. Time series forecasting of air quality based on regional numerical modeling in Hong Kong. J. Geophys. Res.-Atmos. 2018, 123, 4175–4196. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Qiu, X.; Yin, Y.; Fang, M.; Liu, X.; Zhao, X.; Shi, Y. Two-step-hybrid model based on data preprocessing and intelligent optimization algorithms (CS and GWO) for NO2 and SO2 forecasting. Atmos. Pollut. Res. 2019, 10, 1326–1335. [Google Scholar] [CrossRef]
- Nourani, V.; Karimzadeh, H.; Baghanam, A.H. Forecasting CO pollutant concentration of Tabriz city air using artificial neural network and adaptive neuro-fuzzy inference system and its impact on sustainable development of urban. Environ. Earth Sci. 2021, 80, 136. [Google Scholar] [CrossRef]
- Wong, P.Y.; Lee, H.Y.; Chen, Y.C.; Zeng, Y.T.; Chern, Y.R.; Chen, N.T.; Wu, C.D. Using a land use regression model with machine learning to estimate ground level PM2.5. Environ. Pollut. 2021, 277, 116846. [Google Scholar] [CrossRef] [PubMed]
- Just, A.C.; Arfer, K.B.; Rush, J.; Dorman, M.; Shtein, A.; Lyapustin, A.; Kloog, I. Advancing methodologies for applying machine learning and evaluating spatiotemporal models of fine particulate matter (PM2.5) using satellite data over large regions. Atmos. Environ. 2020, 239, 117649. [Google Scholar] [CrossRef] [PubMed]
- Muthukumar, P.; Cocom, E.; Nagrecha, K.; Comer, D.; Burga, I.; Taub, J.; Pourhomayoun, M. Predicting PM2.5 atmospheric air pollution using deep learning with meteorological data and ground-based observations and remote-sensing satellite big data. Air Qual. Atmos. Health 2021, 11, 1–14. [Google Scholar] [CrossRef]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef]
- Ren, M.; Sun, W.; Chen, S. Combining machine learning models through multiple data division methods for PM2.5 forecasting in Northern Xinjiang, China. Environ. Monit. Assess. 2021, 193, 476. [Google Scholar] [CrossRef]
- Kim, S.M.; Koo, J.H.; Lee, H.; Mok, J.; Choi, M.; Go, S.; Kim, J. Comparison of PM2.5 in Seoul, Korea Estimated from the Various Ground-Based and Satellite AOD. Appl. Sci. 2021, 11, 10755. [Google Scholar] [CrossRef]
- Chen, C.C.; Wang, Y.R.; Yeh, H.Y.; Lin, T.H.; Huang, C.S.; Wu, C.F. Estimating monthly PM2.5 concentrations from satellite remote sensing data, meteorological variables, and land use data using ensemble statistical modeling and a random forest approach. Environ. Pollut. 2021, 291, 118159. [Google Scholar] [CrossRef]
- Lu, X. Characteristics of O3 and PM2.5 Complex Pollution and the VOCs Contributions in Handan. Master’s Thesis, Hebei University of Engineering, Handan, China, 2020. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification withgraph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- You, S.; Yan, Y. Stepwise Regression Analysis and Its Application. Stat. Decis. 2017, 14, 31–35. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining-KDD’16; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar]
- Kim, T.Y.; Cho, S.B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Lu, H.; Azimi, M.; Iseley, T. Short-term load forecasting of urban gas using a hybrid model based on improved fruit fly optimization algorithm and support vector machine. Energy Rep. 2019, 5, 666–677. [Google Scholar] [CrossRef]
- Dai, H.; Huang, G.; Zeng, H.; Yang, F. PM2.5 Concentration Prediction Based on Spatiotemporal Feature Selection Using XGBoost-MSCNN-GA-LSTM. Sustainability 2021, 13, 12071. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Concentration | Aggregation | Weights |
|---|---|---|---|
| 1 | (0, 75) | Good | 0 |
| 2 | (75, 125) | Mild | 0.2 |
| 3 | (125, 160) | Moderate | 0.4 |
| 4 | (160, 190) | Heavy | 0.6 |
| 5 | (190, 260) | Severe | 0.8 |
| 6 | (260, 500) | Extreme | 1 |
| Pollutants | Grid | |||
|---|---|---|---|---|
| Grid 1 | Grid 2 | … | Grid n | |
| Benzene | V1(1) | V2(1) | … | Vn(1) |
| Methylbenzene | V1(2) | V2(2) | … | Vn(2) |
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ |
| Styrene | V1(12) | V2(12) | … | Vn(12) |
| Category | Factors | Representation | Unit |
|---|---|---|---|
| Atmospheric pollutant factors | VOCs | X1 | μg/m3 |
| PM2.5 | X2 | μg/m3 | |
| PM10 | X3 | μg/m3 | |
| SO2 | X4 | μg/m3 | |
| NO2 | X5 | μg/m3 | |
| O3 | X6 | μg/m3 | |
| CO | X7 | μg/m3 | |
| Meteorological factors | Daily average surface temperature | X8 | 0.1 ℃ |
| Daily maximum surface temperature | X9 | 0.1 ℃ | |
| Daily minimum surface temperature | X10 | 0.1 ℃ | |
| Average wind speed | X11 | km/h | |
| Maximum wind speed | X12 | km/h | |
| Daily maximum wind speed wind direction | X13 | - | |
| Extreme wind speed | X14 | km/h | |
| Average temperature | X15 | 0.1 ℃ | |
| Highest temperature | X16 | 0.1 ℃ | |
| Lowest temperature | X17 | 0.1 ℃ | |
| Hours of sunshine | X18 | 0.1 h | |
| Average humidity | X19 | 1% | |
| Lowest humidity | X20 | 1% | |
| Average air pressure | X21 | 0.1 hpa | |
| Lowest air pressure | X22 | 0.1 hpa |
| City | Evaluation Index | CNN | LSTM | MLP | SVR | GCN | XGBoost | MLR | GCN-MLR | XGBoost- GCN-MLR |
|---|---|---|---|---|---|---|---|---|---|---|
| Baoji | RMSE | 8.7331 | 8.9924 | 8.8620 | 13.0087 | 8.377 | 5.252 | 5.9861 | 4.4833 | 3.2436 |
| MAE | 6.2389 | 6.4813 | 6.0716 | 10.3413 | 6.0049 | 4.2827 | 3.9951 | 3.4183 | 2.9516 | |
| MAPE | 0.2610 | 0.3291 | 0.2122 | 0.8211 | 0.2201 | 0.2932 | 0.1025 | 0.1364 | 0.0685 | |
| R2 | 0.7943 | 0.7879 | 0.7912 | 0.7655 | 0.8028 | 0.8618 | 0.8503 | 0.8721 | 0.8979 | |
| Tongchuan | RMSE | 17.0812 | 11.7999 | 12.0799 | 13.0087 | 11.6993 | 10.0232 | 9.7749 | 6.5573 | 5.4892 |
| MAE | 11.2308 | 9.6179 | 9.1894 | 10.3413 | 8.4598 | 8.8154 | 6.2045 | 4.6676 | 4.1168 | |
| MAPE | 0.2100 | 0.2209 | 0.2013 | 0.8211 | 0.204 | 0.4016 | 0.1555 | 0.1305 | 0.1019 | |
| R2 | 0.7719 | 0.8389 | 0.8359 | 0.7955 | 0.8399 | 0.8559 | 0.858 | 0.8811 | 0.8947 | |
| Weinan | RMSE | 12.7652 | 22.3230 | 12.2303 | 17.8997 | 10.2787 | 12.2824 | 7.0161 | 6.3676 | 5.2561 |
| MAE | 8.4136 | 16.1408 | 7.8273 | 13.3125 | 6.7729 | 10.1576 | 5.9529 | 4.3599 | 3.9111 | |
| MAPE | 0.2811 | 0.3963 | 0.1810 | 0.7880 | 0.1789 | 0.4881 | 0.3732 | 0.1276 | 0.1192 | |
| R2 | 0.8520 | 0.7532 | 0.8559 | 0.8056 | 0.8689 | 0.8556 | 0.8855 | 0.8881 | 0.8985 | |
| Xi’an | RMSE | 26.8876 | 23.4873 | 23.9599 | 33.0032 | 11.6993 | 10.1385 | 10.0232 | 6.5573 | 3.4892 |
| MAE | 19.6508 | 17.7037 | 17.9471 | 26.3624 | 8.4598 | 8.2763 | 8.8154 | 4.6676 | 3.1168 | |
| MAPE | 0.4780 | 0.4046 | 0.5651 | 0.7818 | 0.2040 | 0.1688 | 0.4016 | 0.1019 | 0.1305 | |
| R2 | 0.6825 | 0.7577 | 0.7479 | 0.5217 | 0.8399 | 0.8511 | 0.8559 | 0.8811 | 0.8947 | |
| Xianyang | RMSE | 21.997 | 20.085 | 22.9112 | 29.9232 | 19.6825 | 15.6156 | 10.7567 | 9.0542 | 6.6113 |
| MAE | 16.301 | 15.617 | 12.2295 | 23.971 | 12.476 | 11.974 | 5.6525 | 5.8845 | 4.3458 | |
| MAPE | 0.6324 | 0.6369 | 0.2118 | 1.0896 | 0.348 | 0.4199 | 0.0897 | 0.1984 | 0.063 | |
| R2 | 0.7311 | 0.7592 | 0.8168 | 0.6875 | 0.8648 | 0.8149 | 0.8596 | 0.8714 | 0.8991 |
| Compared Algorithm | DM | P(DM) |
|---|---|---|
| CNN | −7.3356 | 1.6635 × 10−6 |
| LSTM | −8.4718 | 2.4563 × 10−5 |
| MLP | −7.3629 | 2.1878 × 10−5 |
| SVR | −7.5231 | 3.7718 × 10−4 |
| GCN | −6.6567 | 5.3325 × 10−4 |
| XGBoost | −6.6209 | 2.354 × 10−4 |
| MLR | −3.7377 | 3.265 × 10−4 |
| GCN-MLR | −3.6826 | 2.5689 × 10−3 |
| Data | Error Values/(ug/m3) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| CNN | LSTM | MLP | SVR | GCN | XGBoost | MLR | GCN- MLR | XGBoost- GCN-MLR | |
| Normal | 19.6508 | 17.7037 | 17.9471 | 26.3624 | 8.4598 | 8.2763 | 8.8154 | 4.6676 | 3.1168 |
| 5%Noise | 22.5002 (+14.5%) | 20.4832 (+15.7%) | 20.5674 (+14.6%) | 30.0795 (+14.1%) | 9.6188 (+13.7%) | 9.3274 (+12.7%) | 9.8115 (+11.3%) | 5.0550 (+8.3%) | 3.2321 (+3.7%) |
| 10%Noise | 28.3727 (+26.1%) | 25.6654 (+25.3%) | 25.6270 (+24.6%) | 37.0579 (+23.2%) | 11.5618 (+20.2%) | 11.3421 (+21.6%) | 11.6561 (+18.8%) | 5.9093 (+16.9%) | 3.5036 (+8.4%) |
| t | Weight | T | At | t | Weight | T | At | t | Weight | T | At |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 50 | 0.2 | 1 | 0.21532 | 102 | 0.4 | 18 | 7.4 |
| 2 | 0.2 | 1 | 0.21532 | 54 | 0.2 | 1 | 0.21532 | 106 | 0.4 | 18 | 7.4 |
| 6 | 0.2 | 1 | 0.34132 | 58 | 0.2 | 3 | 0.64596 | 110 | 0.4 | 14 | 5.8 |
| 10 | 0 | 0 | 0 | 62 | 0.2 | 2 | 0.46128 | 114 | 0.6 | 18 | 11 |
| 14 | 0 | 0 | 0 | 66 | 0 | 0 | 0 | 118 | 0.6 | 18 | 11 |
| 18 | 0 | 0 | 0 | 70 | 0 | 0 | 0 | 122 | 0.6 | 20 | 12.2 |
| 22 | 0.2 | 2 | 0.41532 | 74 | 0.2 | 4 | 0.92256 | 126 | 0.6 | 20 | 12.2 |
| 26 | 0.2 | 2 | 0.43064 | 78 | 0.2 | 3 | 0.72256 | 130 | 0.4 | 18 | 7.4 |
| 30 | 0.2 | 1 | 0.23064 | 82 | 0.2 | 6 | 1.29192 | 134 | 0.4 | 15 | 6.1686 |
| 34 | 0.2 | 4 | 0.83064 | 86 | 0.2 | 4 | 0.96852 | 138 | 0 | 0 | 0 |
| 38 | 0.2 | 1 | 0.21532 | 90 | 0.2 | 8 | 1.78382 | 142 | 1 | 1 | 0.2766 |
| 42 | 0 | 0 | 0 | 94 | 0.2 | 12 | 2.6 | 146 | 1 | 2 | 0.44596 |
| 46 | 0 | 0 | 0 | 98 | 0.4 | 16 | 6.6 | 150 | 1 | 2 | 0.41532 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, H.; Huang, G.; Wang, J.; Zeng, H.; Zhou, F. Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection. Atmosphere 2022, 13, 483. https://doi.org/10.3390/atmos13030483
Dai H, Huang G, Wang J, Zeng H, Zhou F. Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection. Atmosphere. 2022; 13(3):483. https://doi.org/10.3390/atmos13030483
Chicago/Turabian StyleDai, Hongbin, Guangqiu Huang, Jingjing Wang, Huibin Zeng, and Fangyu Zhou. 2022. "Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection" Atmosphere 13, no. 3: 483. https://doi.org/10.3390/atmos13030483
APA StyleDai, H., Huang, G., Wang, J., Zeng, H., & Zhou, F. (2022). Regional VOCs Gathering Situation Intelligent Sensing Method Based on Spatial-Temporal Feature Selection. Atmosphere, 13(3), 483. https://doi.org/10.3390/atmos13030483