1. Introduction
Over the past few years, significant social concern has been generated by the increasingly serious issue of air pollution. [
1]. Prediction of pollutant concentrations in the air plays an essential role in environmental management and air pollution prevention [
2]. PM
2.5 (particulate matter less than
in diameter) is an important component of air pollutants [
3]. Therefore, the prediction of PM
2.5 concentration trends is considered a critical issue in the prediction of air pollutant concentrations.
Deterministic and statistical approaches can be used to forecast PM
2.5 concentrations based on the features of the study methods. [
4]. Deterministic methods simulate the emission, dispersion, transformation, and removal of PM
2.5 through meteorological principles and statistical methods [
5], thus enabling the prediction of PM
2.5 concentrations. There are several representative models for pollutant concentration prediction based on deterministic methods. There are a few representative models for forecasting PM
2.5 concentrations based on deterministic methods: a Community Multiscale Air Quality Modeling System (CMAQ) [
6], a nested air quality prediction modeling system (NAQPMS) [
7], and a Weather Research and Forecasting Model with Chemistry (WRF-Chem) [
8].
Different from the deterministic methods, the statistical methods do not have complex theoretical models, and they give better predictions through the learning and analysis of historical data on pollutants. Statistical methods are mainly classified into two approaches: machine learning approaches and deep learning approaches [
9]. The classical machine learning models used for the prediction of PM
2.5 concentrations include Random Forest (RF) [
10] models, Autoregressive Sliding Average (ARMA) Models [
11], Autoregressive Integrated Moving Average (ARIMA) Models [
12], Support Vector Regression (SVR) [
13], and Linear Regression (LR) models [
14].
Compared with machine learning methods, which suffer from slow convergence and inadequate generalization [
5], deep learning is widely used in PM
2.5 concentration prediction due to its ability to fit data more robustly and non-linearly [
15]. The following deep learning models have been used to forecast pollution concentrations: Convolutional neural networks (CNN) [
16], Back Propagation Neural Networks (BPNN) [
17], Recurrent Neural Networks (RNN) [
18], Gate Recurrent Units (GRU) [
19], Long Short-Term Memory networks (LSTM) [
20], and Bi-directional Long Short-Term Memory Neural Networks (Bi LSTM) [
21], attention-based ConvLSTM (Att-ConvLSTM) [
22], etc. Although the above models are widely used in PM
2.5 concentration prediction due to their superiority in handling time series data, the current pollutant concentration prediction models described above have the following problem: owing to the single network model, it is limited by the feature dimension of the input data, in other words, the dimension of the hidden state is influenced by the dimension of the input data.
In order to solve the problem that the predictive power of a single deep learning network is limited, in recent years, hybrid deep learning models have been widely used in the research of pollutant concentration prediction. Hybrid deep learning models have several different network structures that allow better quantification of complex data [
23], which have been used for pollutant concentration prediction, including: LSTM-FC [
24], AC-LSTM [
25], EEMD-GRNN [
26], etc. Meanwhile, air pollution is a problem of regional dispersion with spatial dimensions [
27], and there is a spatial interrelationship of air pollution between adjacent sites. However, all of the above hybrid deep learning models have focused on the prediction of pollutant concentrations at individual stations and have not considered the spatial correlation of adjacent observation sites. CNN-LSTM [
15] is a recently proposed hybrid deep learning model, which can handle time series problems and has successfully interpreted the spatial distribution characteristics of air pollutant concentrations through the image analysis capability of CNN [
15]. However, there are also three crucial problems with CNN-LSTM [
28]. Firstly, the simple structure of CNN leads to the loss of feature information and the inability to extract deep spatial features of contaminant data [
29]. Secondly, CNN-LSTM has difficulty capturing the long time-series variation between pollutant concentrations. Finally, much of the work at the present stage confirms the complex interactions between pollutant data and meteorological data [
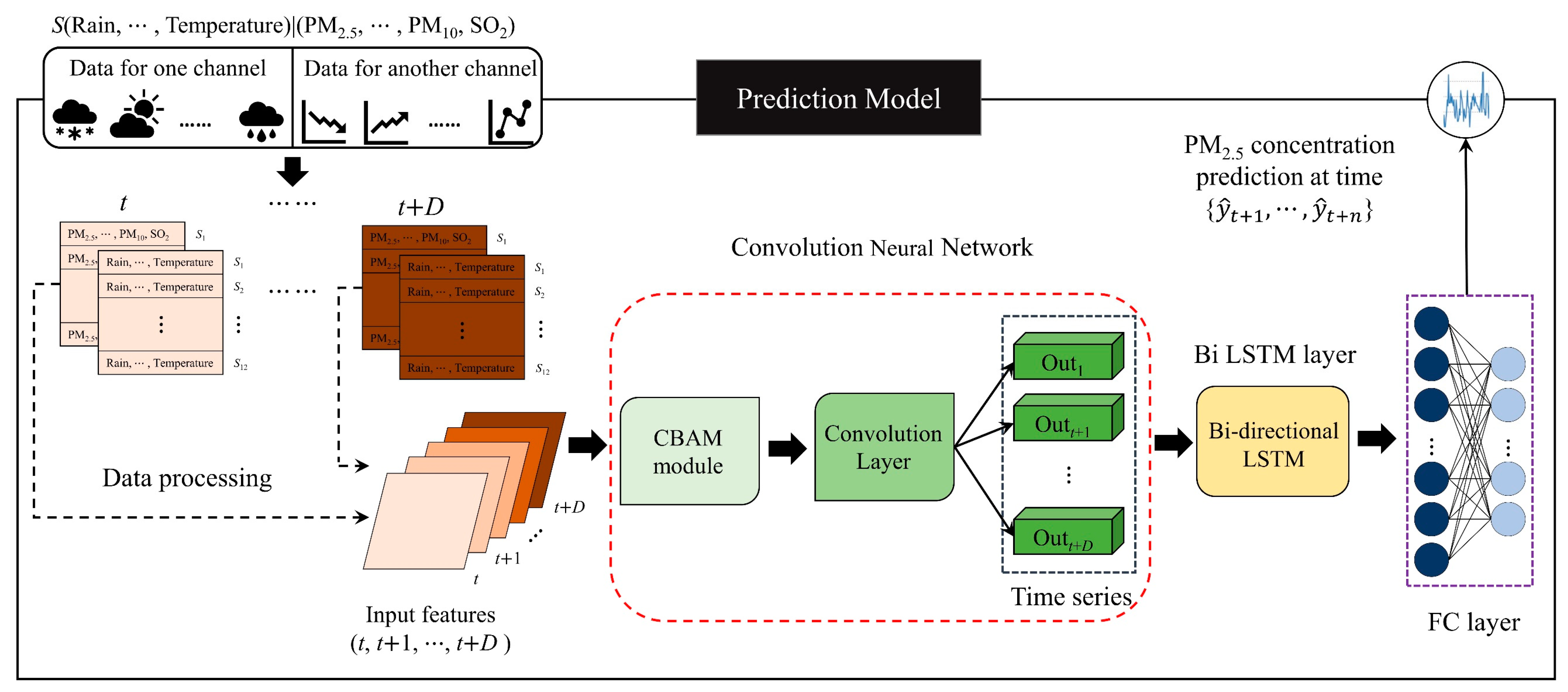
5]. CNN-LSTM has trouble obtaining complicated correlation characteristics between meteorological input and air pollution input. In view of the above, we introduced the convolutional block attention module (CBAM) to build a CNN-based prediction model: the CBAM-CNN-Bi LSTM model. The reasons are as follows.
- (1)
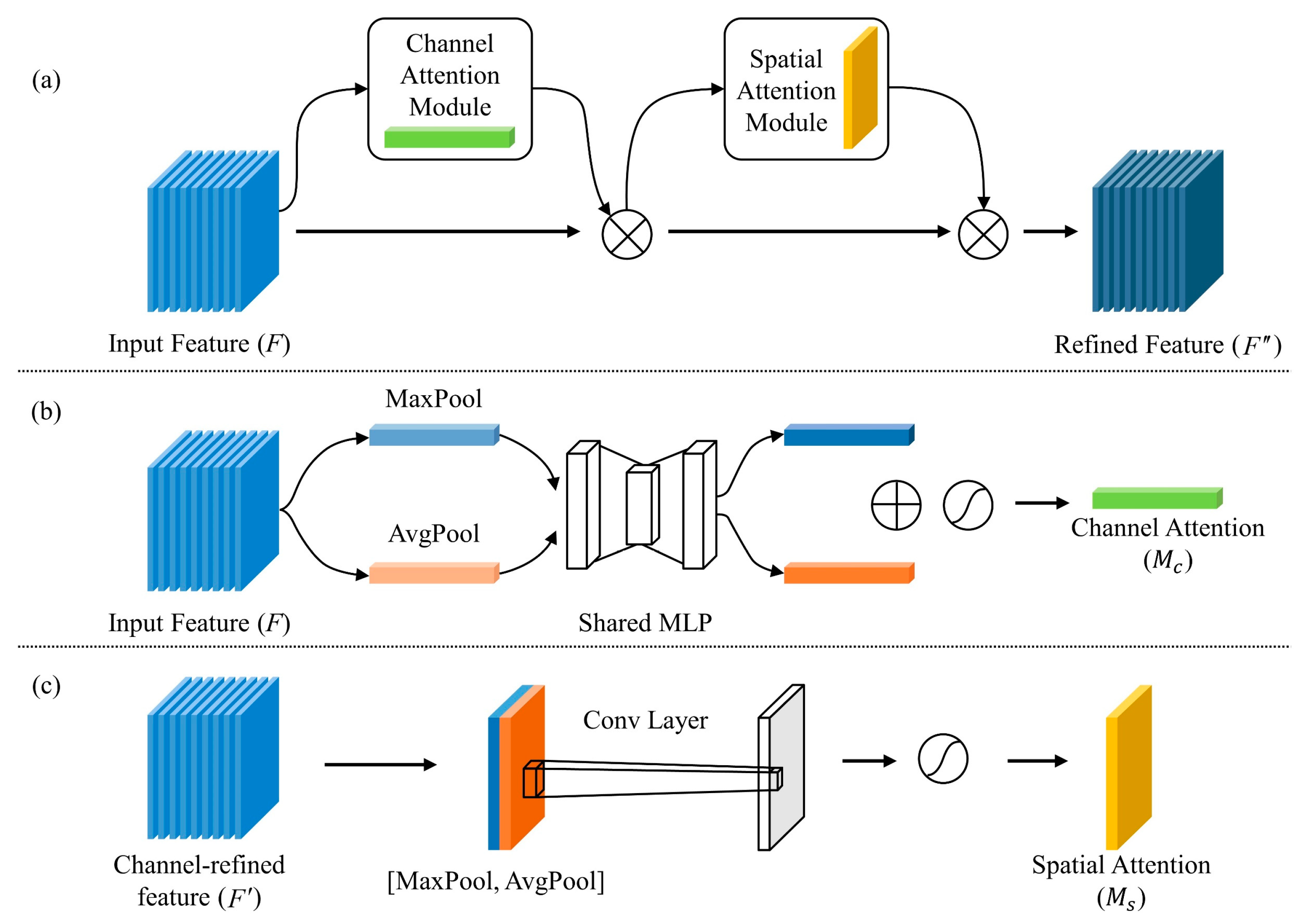
The convolutional block attention module includes the channel attention module (CAM) and the spatial attention module (SAM) [
30]. It is a simple and effective attention module that can be arbitrarily embedded into any 2D CNN model and does not consume too much of the computer’s running memory.
- (2)
As the network depth is increased, convolutional neural networks degrade and lose feature information. Therefore, we introduce a spatial attention module to efficiently extract spatially relevant features of contaminant data between multiple stations [
29].
- (3)
The correlation characteristics between pollution data and meteorological data are not taken into account by the aforementioned prediction models. In order to optimize the prediction outcomes based on the intricate correlation characteristics of the model input data, we thoroughly analyze the prediction problems of pollution data and meteorological data at each station and present the channel attention module.
In this study, our proposed prediction model is fully taken into account to produce more accurate predictions of PM2.5 concentrations in the target city in the future, which should achieve the following goals: (1) efficiently utilizing historical pollutant concentration and meteorological big data from multiple stations; (2) accurately achieving long-term predictions of pollutant concentrations in the target city; and (3) in-depth exploration of the spatial and temporal correlation characteristics from multiple stations.
The remainder of the essay is structured as follows. The study area, the experimental data and the procedures for processing the experimental data, as well as the overall framework of the pollutant concentration prediction model, and a detailed explanation of each model component are described in
Section 2. The key findings and expectations are covered in
Section 3. The work is concluded in
Section 4, which also suggests areas for future investigation.
3. Results and Discussion
3.1. Performance Evaluation Indices
This paper uses RMSE, MAE, R
2, and IA to analyze how well the prediction models performed. The RMSE reflects the sensitivity of the model to error, and the MAE reflects the stability of the model; the closer the value of both to 0, the better the prediction result. R
2 represents the ability to forecast the actual data, and IA represents the similarity of the distribution between actual and predicted values, both variables’ values span from [0, 1], the closer to 1, the more consistent the predicted results are with the distribution of the true data. The calculation formula is shown as shown.
where
denotes the sample size in the dataset,
denotes predicted value corresponding to it,
denotes actual concentration of PM
2.5, and
represents the mean of all measurements of PM
2.5 concentrations.
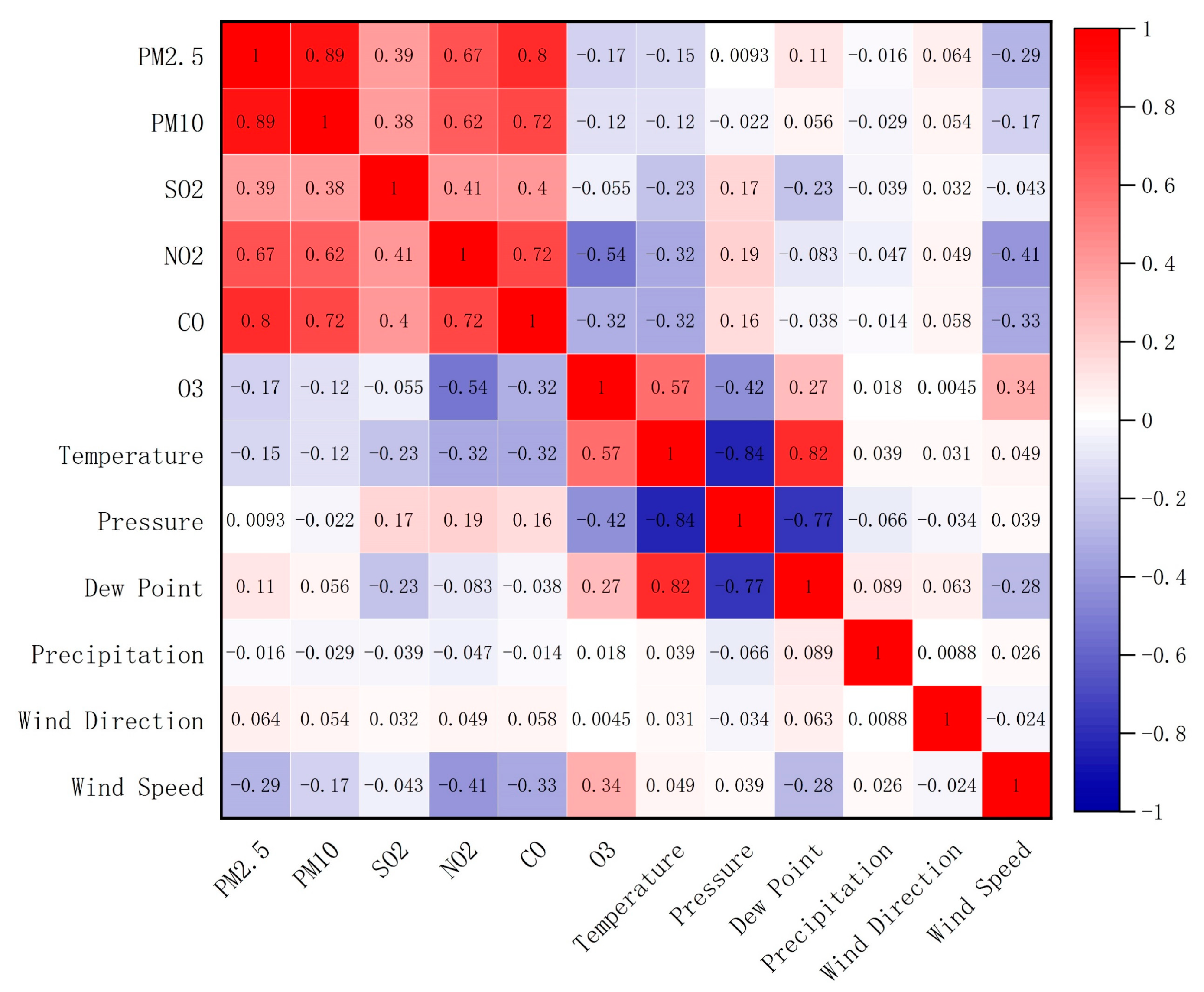
3.2. Correlation Analysis of Variables
In this subsection, we correlated PM
2.5 concentrations to achieve two objectives. First, we investigate the relationships between PM
2.5 concentrations, pollutant concentrations, and meteorological data. Furthermore, to ensure the convergence of the model, we placed the highly correlated factors of influence in the same channel. The correlations between the 12 variables in all sites are shown in
Figure 6. For absolute values of correlation, among the pollutants, the highest correlation between PM
2.5 and itself was found, with PM
10 (0.89), CO (0.80), NO
2 (0.67), SO
2 (0.39), and O
3 following (−0.17). Among the meteorological factors, wind speed (−0.29) had the strongest association with PM
2.5, followed by temperature (−0.15) and dew point (0.11). The absolute values of the correlation coefficients for all other influences were below 0.1. In this paper, the six influential factors with the highest absolute values of correlation coefficients with PM
2.5 are put into the same channel; they are PM
2.5, PM
10, CO, NO
2, SO
2, and wind speed. We put O
3 (−0.17), temperature, pressure, dew point, precipitation, and wind direction into another channel of the model input, forming a 12*6*2 “image”.
In terms of pollutants, PM2.5 concentrations have a highly substantial association with PM10, CO, NO2, and SO2, and a bad relationship with O3 concentrations. This is due to the fact that PM2.5, PM10, CO, NO2, and SO2 are mostly derived from human activities such as coal combustion, vehicle exhausts, and industrial manufacturing. In addition, emissions of PM10, CO, NO2, and SO2 contribute to a certain extent to the increase in PM2.5 concentrations. Unlike other pollutants, O3 comes mainly from nature. As light and temperature increase, the concentration of O3 increases. Due to the high concentration of O3, there is a chance that some photochemical reactions will consume some PM2.5 and lower its concentration.
Compared to pollutants, meteorological factors have a relatively small but integral impact on PM2.5 concentrations. The relationship between wind speed and PM2.5 concentrations is negative. High wind speeds are conducive to PM2.5 dispersion and therefore have a substantial impact on the concentration of PM2.5. The increase in temperature causes instability in the atmosphere, which has a positive effect on the dispersion of PM2.5. The dew point, a measure of air humidity, is positively correlated with PM2.5 concentrations. An environment with high air humidity contributes to the formation of fine particulate matter, making PM2.5 less likely to disperse. Wind direction, barometric pressure, and rainfall are all weakly correlated with PM2.5 and their changes have little effect on PM2.5 concentrations.
3.3. Short-Term Prediction
Pollutant prediction models can be divided into short-term prediction models and long-term prediction models [
37]. Short-term prediction focuses on the accuracy of the forecast and ensures the safety of human activities in the short term by keeping the forecast time within 12 h [
38]. We will compare and analyze the short-term prediction performance of each model for pollutant concentrations in this section.
3.3.1. Effect of Convolution Kernel Size on Experimental Results
The convolutional kernel is a key part of the convolutional neural network model, which directly affects how well the features are extracted and how quickly the network converges. The size of the convolution kernel should be appropriate to the size of the input “image”. If the convolution kernel is too large, the local features cannot be extracted effectively; if the convolution kernel is too small, the overall features cannot be extracted successfully. Therefore, a convolution kernel of the right size should be selected to fit the input “image”. As the size of the input “image” of the CBAM-CNN-Bi LSTM model is 12*6*2, we set the convolution kernel to 2*2, 3*3, 4*4, 5*5 to forecast the PM2.5 concentrations in the next 6 h.
Table 3 gives the average of the performance evaluation indicators of the CBAM-CNN-Bi LSTM for PM
2.5 concentration prediction for the next 6 h at different convolutional kernel sizes. As shown in
Table 3, the test errors of the models do not differ significantly when the size of the convolution kernel varies. However, when the convolutional kernel size was 3*3, RMSE and MAE reached a minimum value of 29.65 and 18.58, and R
2 and IA reached a maximum value of 0.8192 and 96.01%.
This demonstrates that the highest prediction performance for our proposed model occurs when the convolution kernel is 3*3. When the convolution kernel is smaller than 3*3, the model has an underfitting problem for the overall spatial features of PM2.5 concentrations; when the size of the kernel is larger than 3*3, our model cannot effectively extract the local spatial features of PM2.5 concentrations. When the convolution kernel is 3*3, the model is capable of extracting both global and local spatial information related to PM2.5 concentrations. In the following experiments, the convolution kernel size is set to 3*3.
3.3.2. Effect of Different Models on Experimental Results
The quantitative results for single-step PM
2.5 concentrations prediction are given in
Table 4, which gives a comparison of the RMSE, MAE, R
2 and IA for CNN, LSTM, Bi LSTM, CNN-LSTM and CBAM-CNN-Bi LSTM. As shown in
Table 4, our proposed model performed better than other deep learning models in single-step PM
2.5 concentration prediction. In contrast to other models, our proposed model has the minimum prediction error and the greatest prediction accuracy and reduces RMSE to 18.90, MAE to 11.20, improves R
2 to 0.9397, and IA to 98.54%. However, the prediction results of our proposed model are not much ahead of Bi LSTM because the single-step prediction is relatively simple and does not reflect the advantages of our designed architecture. In addition, CNN has the worst prediction performance, and LSTM and Bi LSTM perform predictions more accurately than CNN-LSTM. This means that the LSTM and Bi LSTM, with their excellent time series data processing capability, are more suitable than CNN-LSTM for the PM
2.5 concentration single-step prediction task.
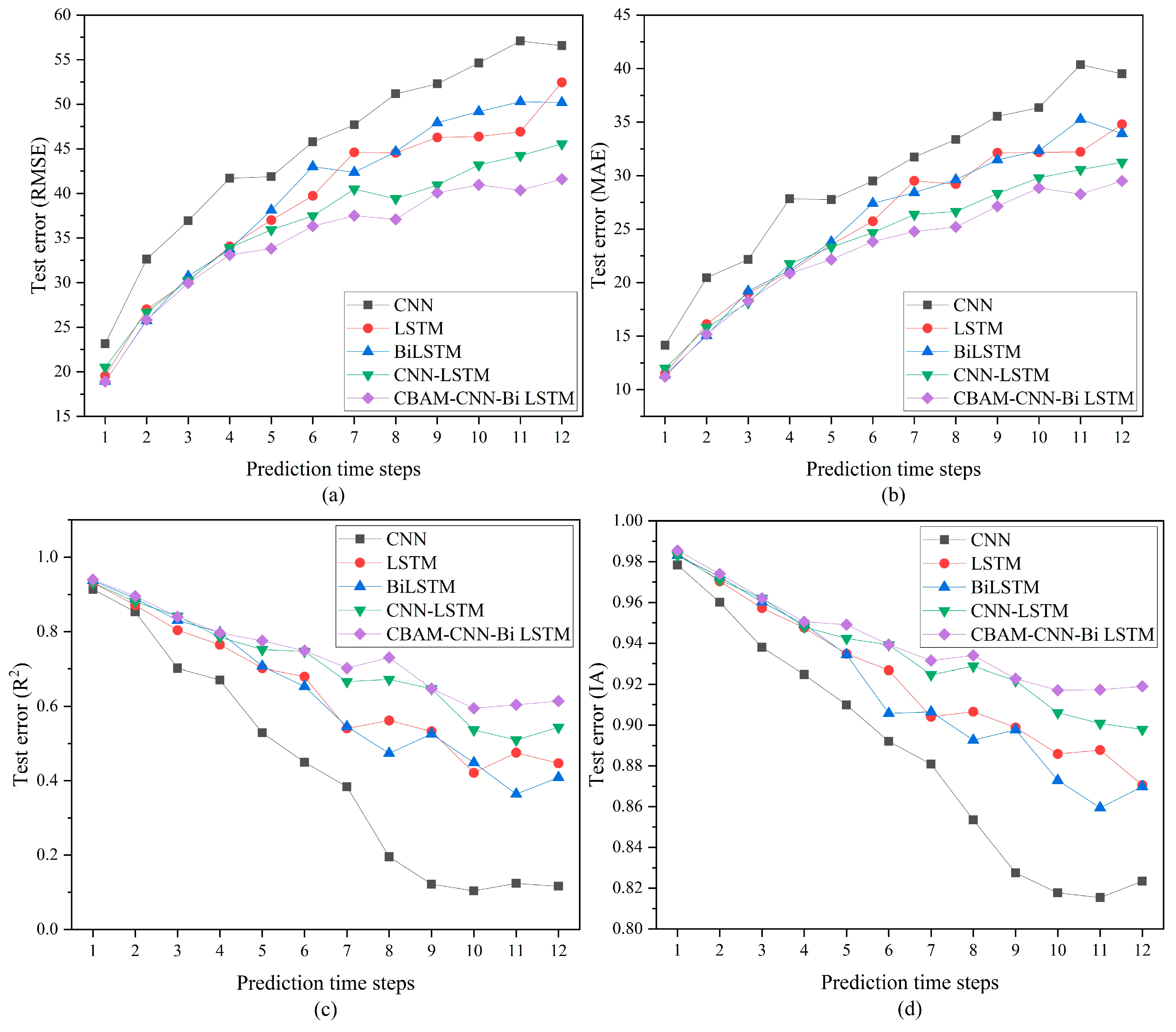
It is well known that with the increase in forecast time steps, forecasting becomes more difficult. To further evaluate the PM
2.5 concentrations short-term prediction capability of CBAM-CNN-Bi LSTM and other deep learning models, we predicted PM
2.5 concentrations for the next 2–12 h and presented the predicted quantitative results through the change curves of RMSE, MAE, R
2 and IA in
Figure 7. As shown in
Figure 7, the predictive ability of all prediction models declines as the prediction time step rises. We observed that four performance evaluation indicators of CNN were always worse than other deep learning models, and the LSTM and Bi LSTM prediction performance was generally consistent. Interestingly, as shown in
Figure 7a,b, in cases where the predicted time step is under five, compared to the LSTM and Bi LSTM, the CNN-LSTM has a greater prediction error. Does this mean that CNN-LSTM has poorer short-term prediction performance than LSTM and Bi LSTM? In fact, we will find that four metrics for evaluating the performance of the CNN-LSTM start to outperform the LSTM and Bi LSTM when the prediction step size is greater than five. This suggests that CNN-LSTM, with its hybrid model structure, can better quantify complex data when prediction problems become difficult. It is worth noting that when prediction time steps are greater than 4, our proposed model consistently maintains optimal prediction performance with the lowest RMSE and MAE, and the highest R
2 and IA.
In summary, for PM2.5 concentrations short-term prediction, when the convolution kernel is 3*3, CBAM-CNN-Bi LSTM obtains the best prediction performance and maintains the best results among all deep learning models. This means that CBAM plays a key role in the prediction of deep learning models. CBAM obtains the feature relationship between pollutant data and meteorological data, optimizes the CNN spatial feature extraction, and improves the model prediction accuracy.
3.4. Long-Term Prediction
The research on pollutant concentration prediction has mainly focused on pollutant concentration short-term prediction, but this is not sufficient to meet the actual demand. The purpose of long-term forecasting is to forecast pollutant concentrations for a longer period of time in the future, and its predictions can serve as a useful reference for managers. It can be seen that long-term predictions of pollutant concentrations are very meaningful. We will analyze the pollutant concentration long-term prediction performance of each model in this section.
3.4.1. PM2.5 Concentration Prediction
The quantitative results of the long-term PM
2.5 concentration prediction (h13~h18) are given in
Table 5, which gives the comparison of RMSE, MAE, R
2, and IA for CNN, LSTM, Bi LSTM, CNN-LSTM, and our proposed model. As shown in
Table 5, our proposed model outperforms other deep learning models in PM
2.5 concentration prediction (h13~h18). In comparison to alternative models, CBAM-CNN-Bi LSTM has the lowest prediction error and the highest prediction accuracy and reduces RMSE to 37.33, MAE to 26.54, R
2 to 0.6981, and IA to 93.50%. As shown in
Table 5, the R
2 of CNN has decreased to −0.2546, which indicates that CNN is inappropriate for long-term PM
2.5 concentration prediction. It is worth noting that the prediction performance of CNN-LSTM is superior to Bi LSTM and LSTM, this shows that the hybrid model of CNN-LSTM is more suitable for long-term PM
2.5 concentration prediction.
Next, we analyze the effect of the size of the prediction time steps on CNN, LSTM, Bi LSTM, CNN-LSTM, and our proposed model. As shown in
Table 6,
Table 7 and
Table 8, when the prediction time steps are the same as h13~h18, the larger the window size, the more accurate the model’s prediction performance. This means that deep learning models can optimize the prediction results by learning more historical data.
Table 5 shows that the prediction performance of all deep learning methods steadily declines as prediction step size increases. It is evident that, in contrast to other deep learning methods, our proposed model has the minimum prediction error (RMSE and MAE) and the highest prediction accuracy (R
2 and IA) for different prediction time steps.
To verify the effectiveness of our proposed model, we analyzed the variations of RMSE, MAE, R
2, and IA for each model within the prediction step of 48 h. As shown in
Table 7 and
Table 8, the four performance evaluation indicator metrics of CNN, Bi LSTM, LSTM, and CNN-LSTM fluctuated widely in the long-term prediction. Furthermore, what is interesting about the data in
Table 7 and
Table 8 is that our proposed model can continue to outperform the CNN-LSTM significantly as the prediction time step grows. In addition, the four evaluation indicators of our proposed model fluctuated less (with little change in values) as the prediction time steps increased, which shows that CBAM-CNN-Bi LSTM is most suitable for long-term PM
2.5 concentration prediction. In conclusion, our proposed model can be used to maintain the best and most stable prediction performance in long-term PM
2.5 concentration prediction.
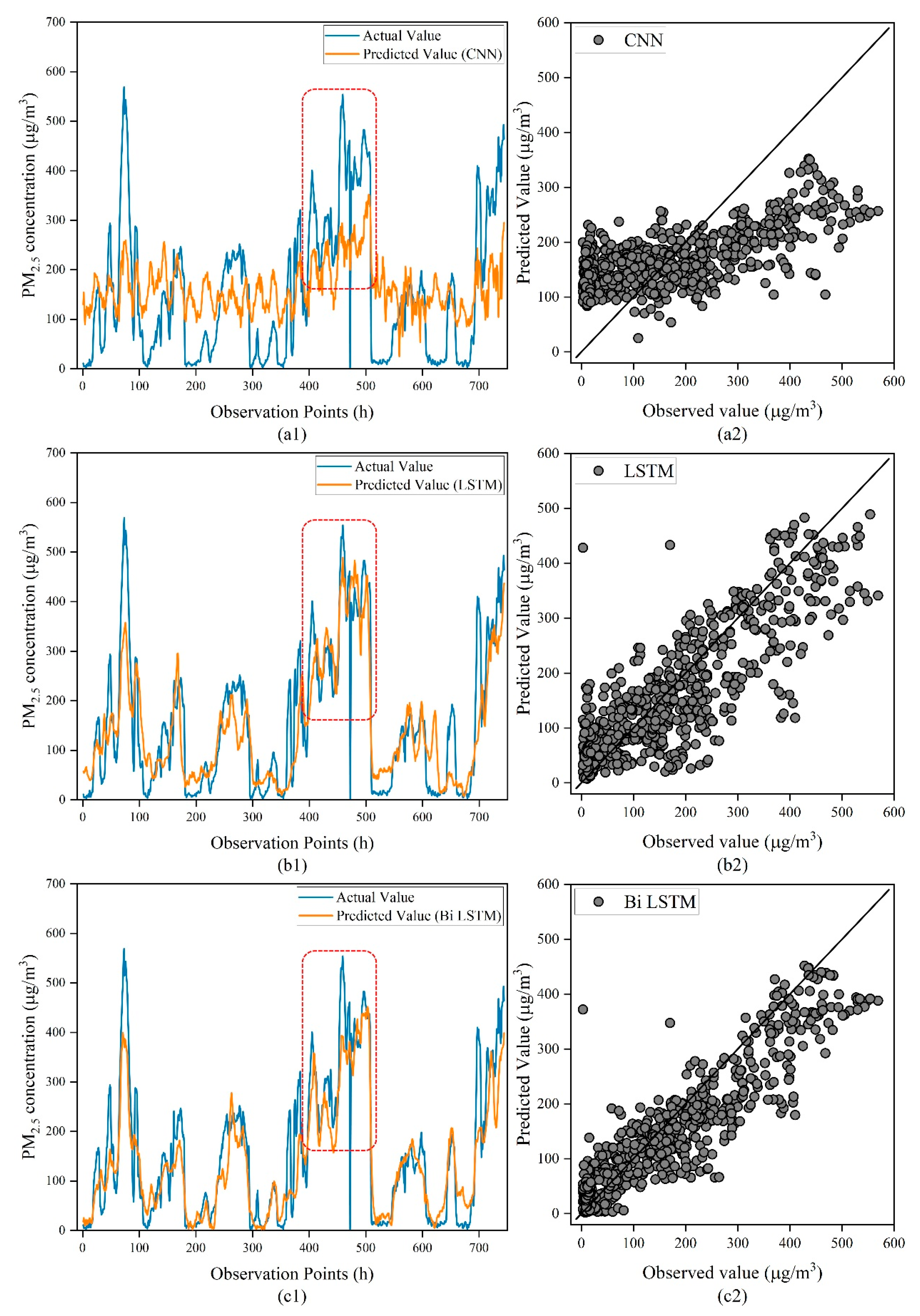
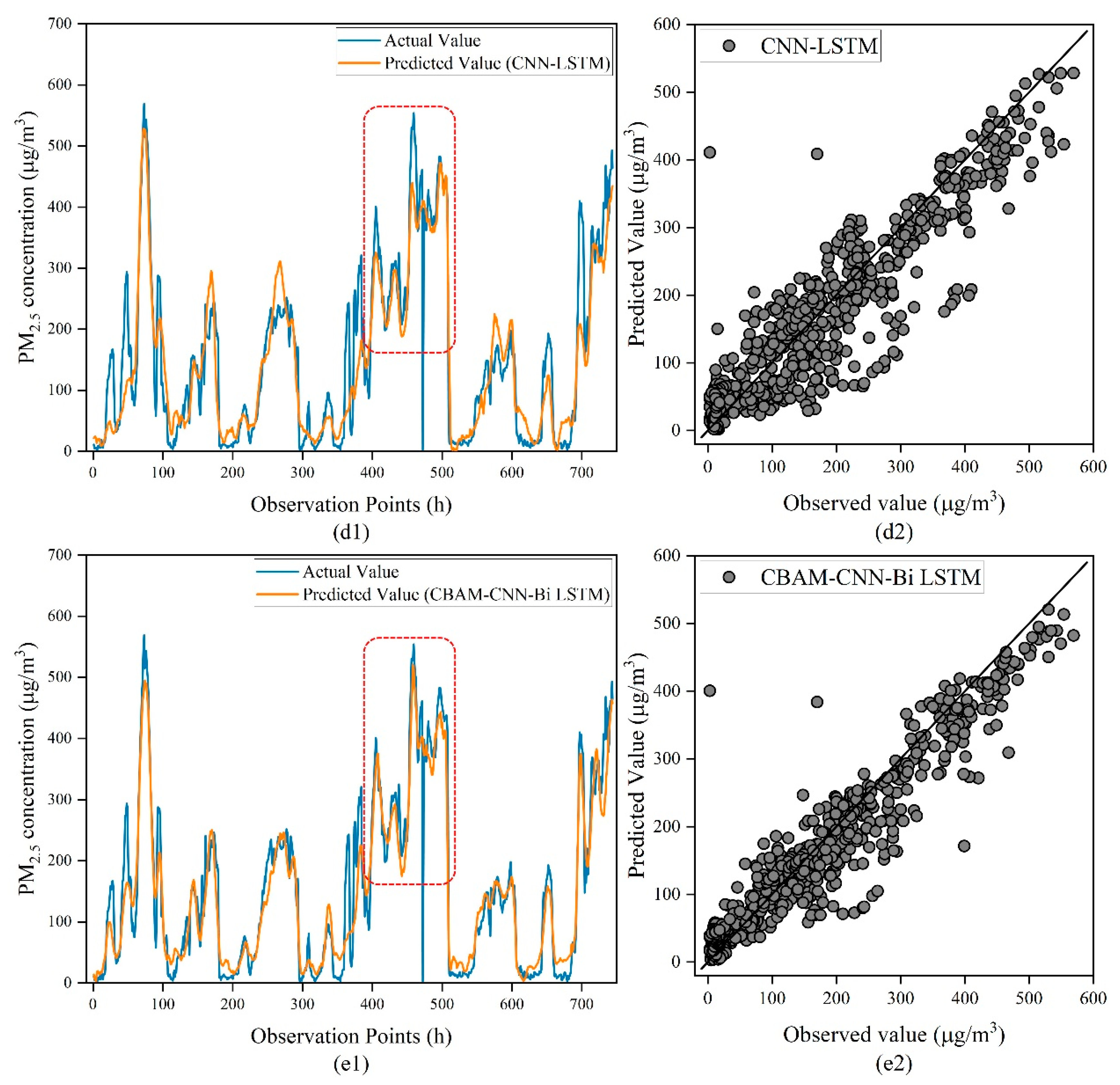
To further validate the prediction performance of our proposed model, we analyzed the fitting ability of our proposed model and four other deep learning models for PM
2.5 concentrations at a prediction time step of 48 h. As shown in
Figure 8a1–e1, we found that the CNN has the worst prediction performance and cannot describe the trend of PM
2.5 concentrations. Compared to LSTM and Bi LSTM, CNN-LSTM has a higher long-term prediction ability for PM
2.5 concentrations, but the accuracy of the prediction of sudden change points of PM
2.5 concentrations is not enough. Our proposed model shown in
Figure 8 outperforms other comparative models in the prediction of sudden change points in PM
2.5 concentrations. We observed that when the PM
2.5 concentrations were larger than 200 μg/m
3, the comparison model’s predicted outcomes were unable to capture the true trend. This also reflects that when the PM
2.5 concentrations are too high, it makes precise prediction using the model challenging. Moreover, the predictions of our proposed model and the observed outcomes are virtually identical (as shown in the red wireframe part in
Figure 8). This means that our proposed model has a good fit for the prediction of high PM
2.5 concentration values.
Combined with the capability of fitting the model in
Figure 8, we can draw the following conclusions: (1) CBAM-CNN-Bi LSTM has better prediction performance in all time periods and can effectively forecast PM
2.5 concentrations in different environments; (2) in the case of high PM
2.5 concentration values, the CBAM-CNN-Bi LSTM has a good fitting effect, making the predicted and observed values basically consistent; (3) we can see that the number of sudden change point samples is relatively small. This phenomenon causes the deep learning model to insufficiently learn the change pattern of PM
2.5 concentrations in the case of sudden changes. This is the reason why the deep learning model is difficult to fit to the sudden change points.
3.4.2. Other Pollutant Concentration Prediction
To confirm the applicability of our suggested model. In this section, PM
10 and SO
2 are used as examples, and
Table 9 and
Table 10 display the evaluation indices of model prediction performance. As shown in
Table 9, our proposed model still has the best prediction ability. The prediction performance of our proposed model is significantly better than that of the single framework model. Compared with the CNN-LSTM model, our proposed model reduces RMSE by 3.57, MAE by 2.65, R
2 by 0.0115, and IA by 0.59%. This indicates that the convolutional block attention module optimizes the model and improves the prediction accuracy. The predicted results for SO
2 are similar to those for PM
10. As shown in
Table 10, our model reduced the RMSE to 9.87, MAE to 6.14, R
2 to 0.7175, and IA to 93.76%. In the prediction of SO
2 and PM
10, our model also maintains the optimal prediction results. This indicates that our proposed prediction approach is applicable to the prediction of other pollutants and is as successful.
4. Conclusions and Future
In my research, a unique PM2.5 concentration prediction model (CBAM-CNN-Bi LSTM) is proposed, which gives a reasonable prediction by learning from a large amount of pollutant data and meteorological data. CBAM-CNN-Bi LSTM is a hybrid deep learning model which consists of CBAM, CNN, and Bi LSTM. The advantages of CBAM-CNN-Bi LSTM are concluded as below:
- (1)
By utilizing the convolutional block attention module, the CNN network degradation issue may be solved. The spatial attention module assists CNN in efficiently acquiring spatial correlation features between multiple sites to extract pollutants and meteorological data. The channel attention module is used to capture the complex relationship features between the influencing factors of model inputs. Convolutional block attention modules optimize convolutional neural networks to provide more reliable data for more precise result prediction;
- (2)
By using Bi LSTM as the output prediction layer, the model not only obtains the performance advantage of long-time series prediction through Bi LSTM, avoiding the problem of underutilization of contextual information, but also extracts the effective association features of the output of the convolutional neural network layer to achieve the goal of mining data spatiotemporal association;
- (3)
Our proposed model can be simultaneously applied to meteorological and pollution data from multiple stations for environmental monitoring of big data while considering the changes in the spatial and temporal distribution of the data to achieve the prediction of air pollutant concentrations in the target city. Experiments conducted on the dataset show that our framework obtains better results than other methods.
Based on the aforementioned experimental findings, the effectiveness of our proposed model is demonstrated. In comparison to other models, our proposed model gives accurate PM2.5 concentration predictions by fully extracting the temporal and spatial characteristics of PM2.5 and the correlation between pollutant data and meteorological data and overcoming the problem of long-time dependence of PM2.5 concentrations. Therefore, our proposed model overcomes the weaknesses of CNN-LSTM and has more practical value. However, traffic, vegetation cover, and pedestrian flow are not considered in this paper, which will be addressed in future studies.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}