
Statistical Approaches for Forecasting Primary Air Pollutants: A Review

 and
and
Abstract
1. Introduction
2. Data and Methods
2.1. Data Sources and Preprocessing
2.2. Bibliometric Analysis
2.3. Evolutionary Tree Analysis
3. Results
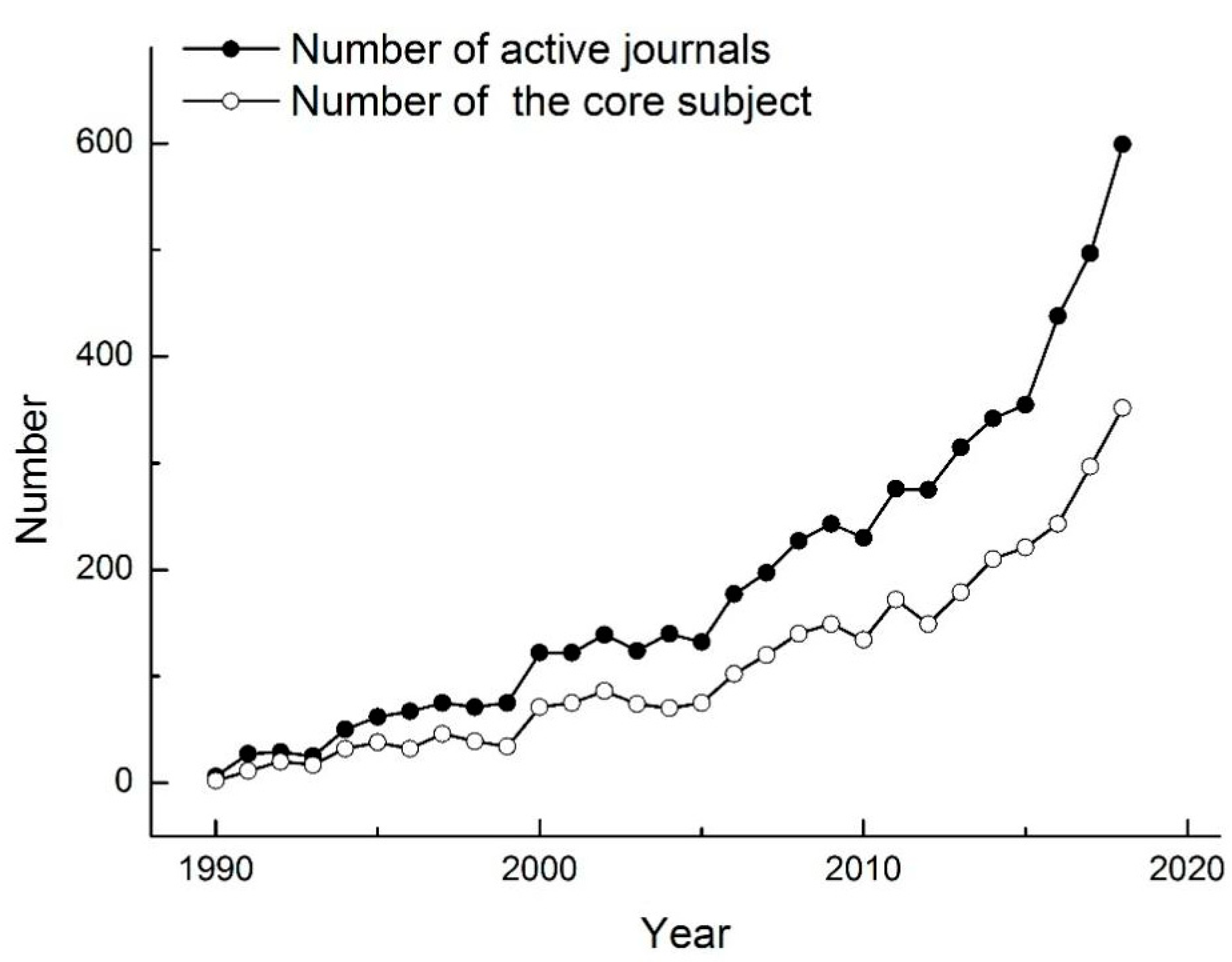
3.1. Basic Information
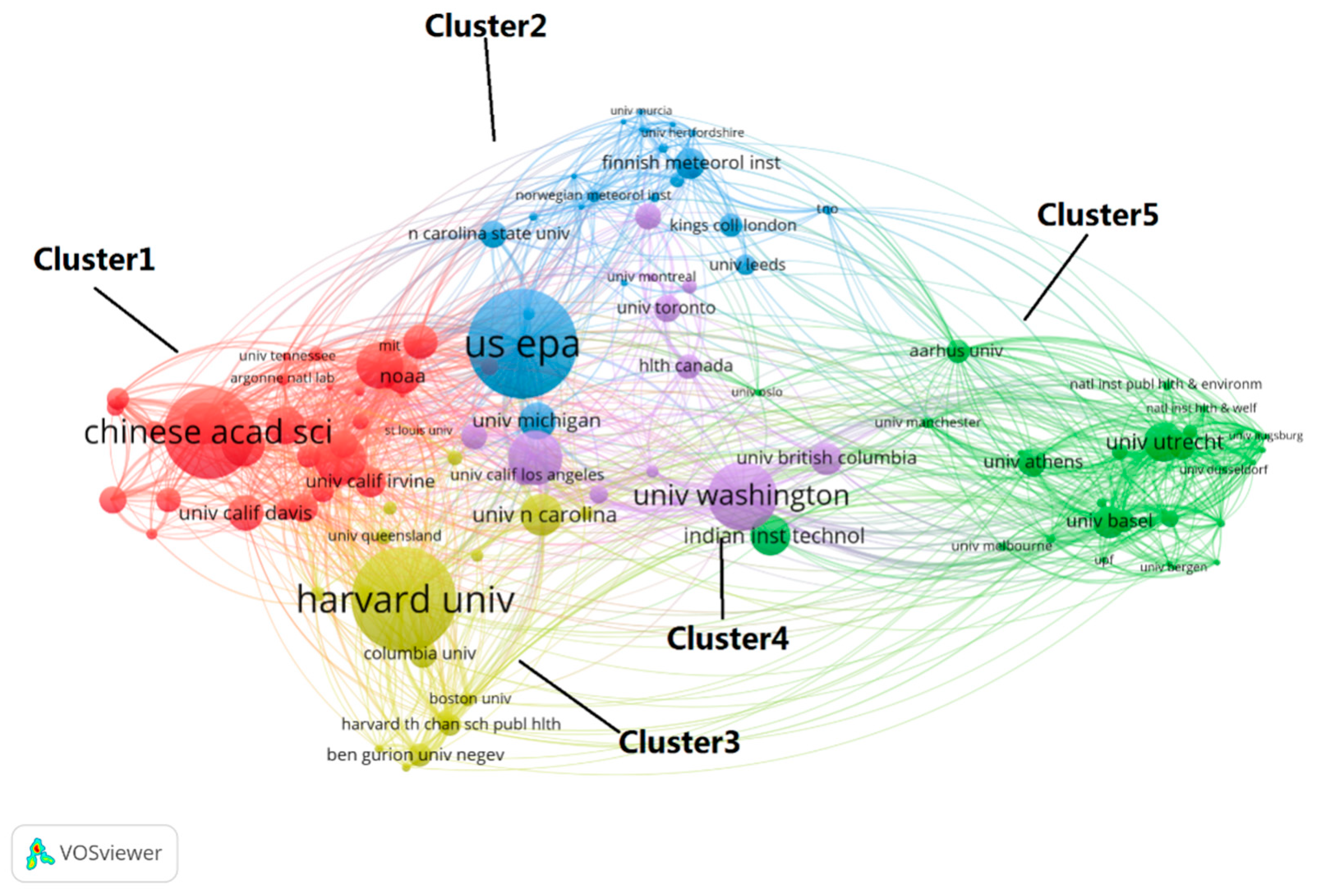
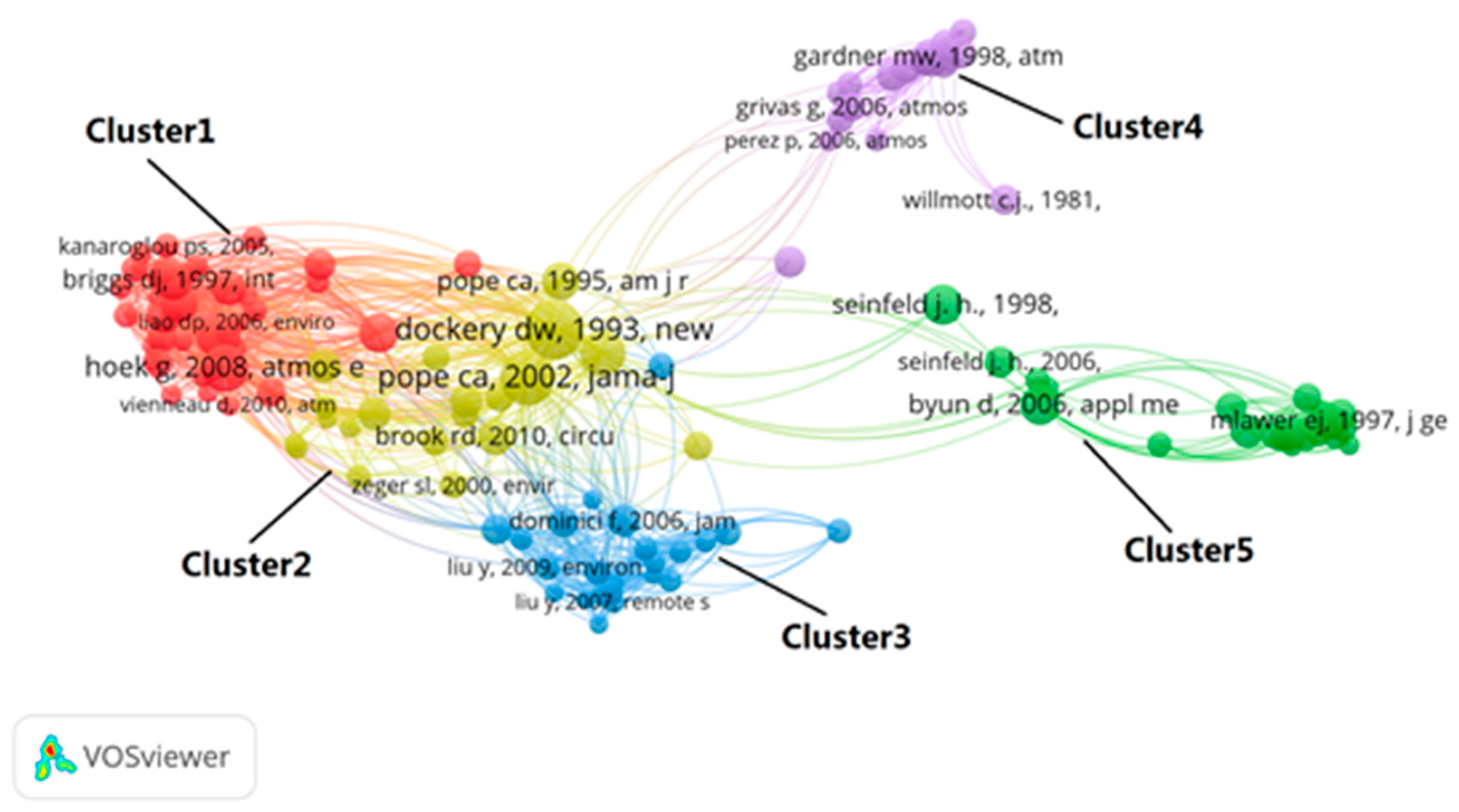
3.2. Analysis of Research Institutions and Co-Citation
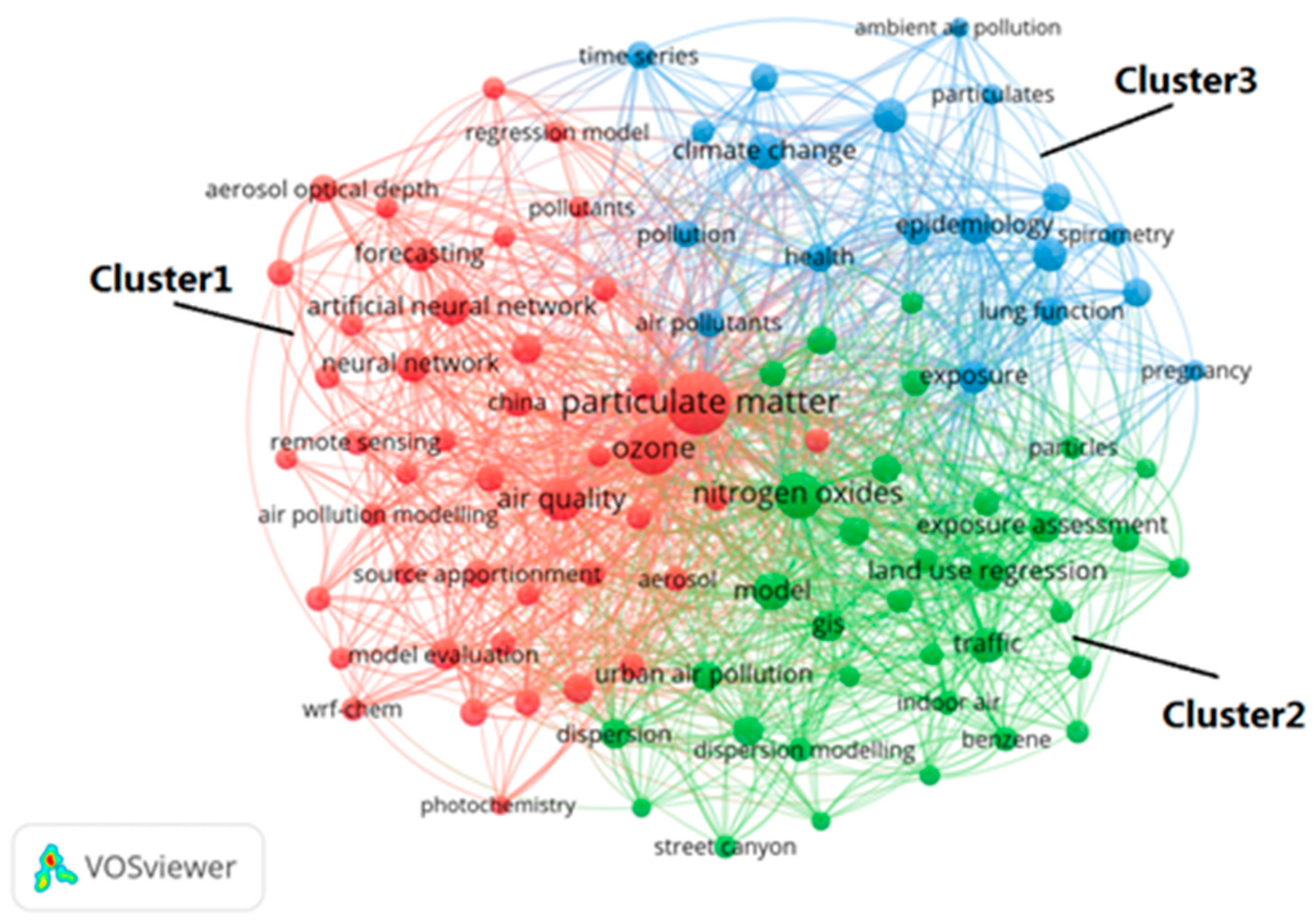
3.3. Keyword Analysis
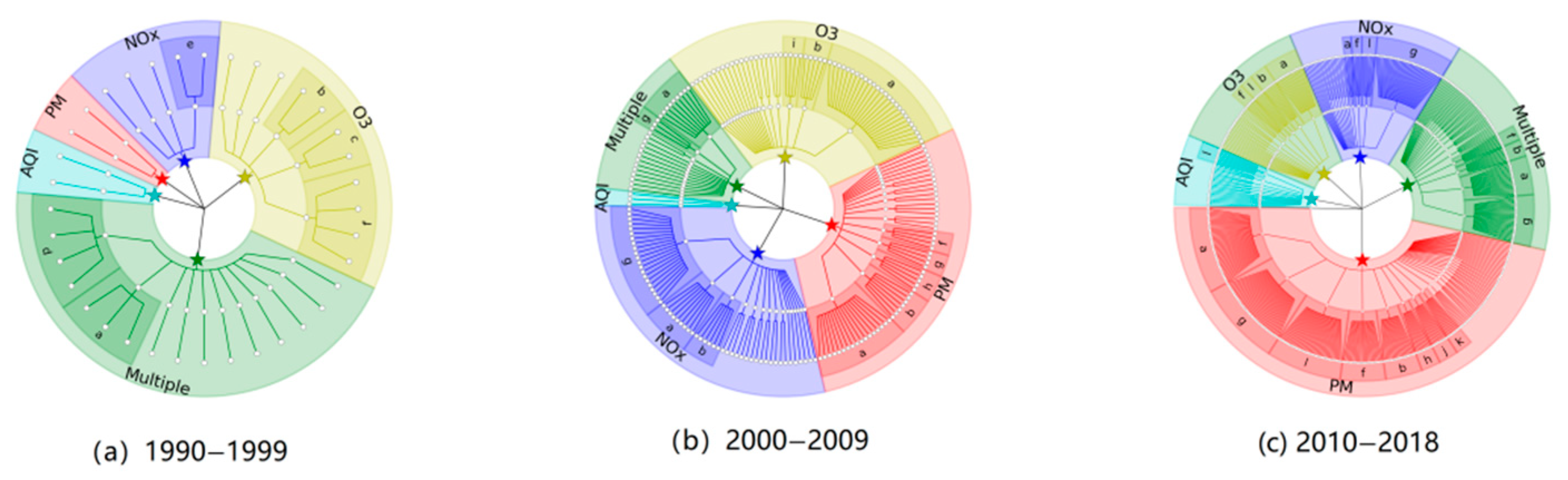
3.4. Evolutionary Tree Analysis
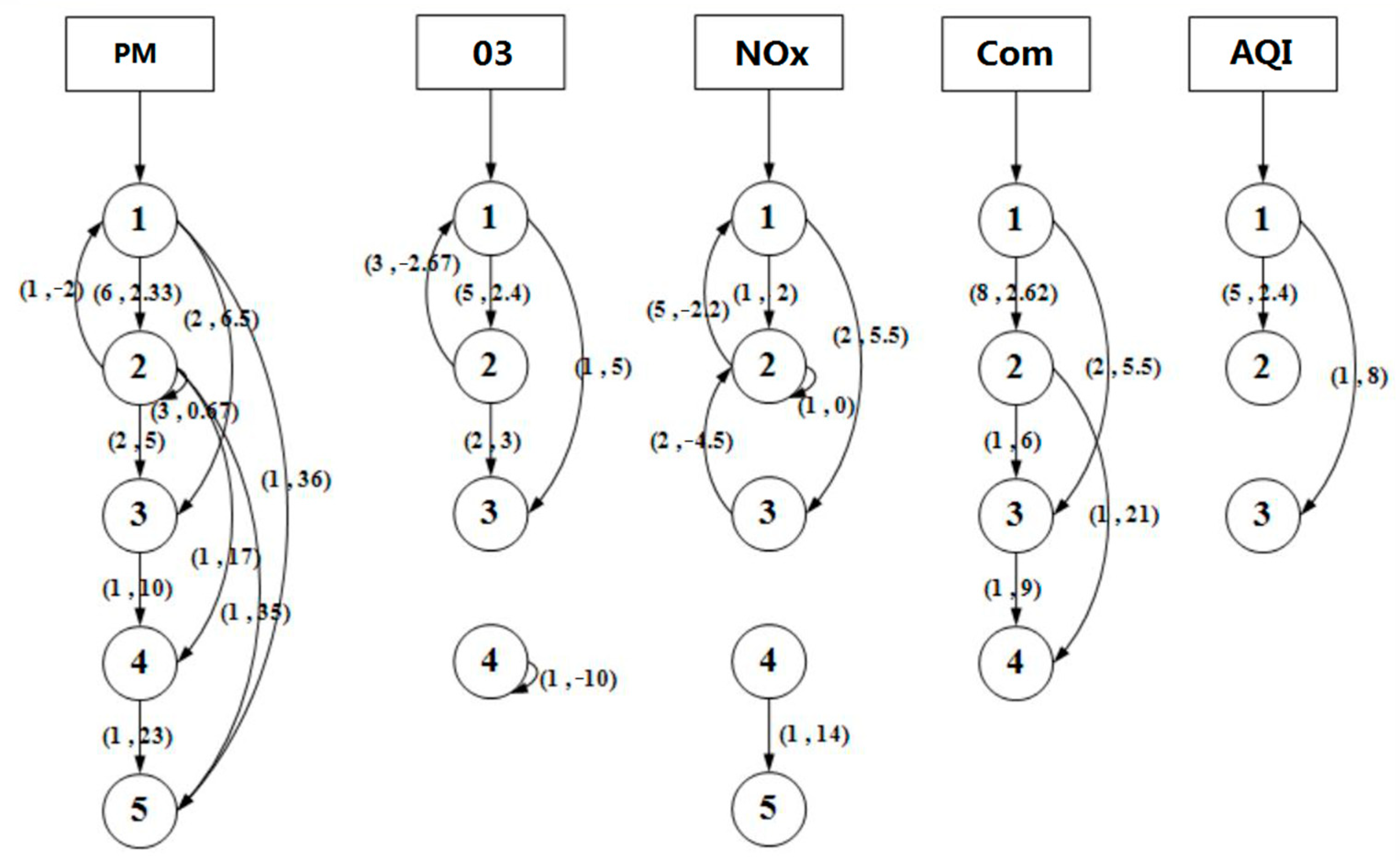
3.5. Markov Chain Analysis
4. Discussion
4.1. Particulate Matter (PM)
4.2. Ozone (O3)
4.3. Nitrogen Oxides (NOx)
4.4. Multiple Pollutants and AQI
4.5. Air Pollutants and Their Health Impacts
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1990–1999 | 2000–2009 | 2010–2018 | |||
|---|---|---|---|---|---|
| Subject Category | Number of Publications | Subject Category | Number of Publications | Subject Category | Number of Publications |
| Environmental Sciences & Ecology | 271 | Environmental Sciences & Ecology | 962 | Environmental Sciences & Ecology | 1957 |
| Meteorology & Atmospheric Sciences | 165 | Meteorology & Atmospheric Sciences | 527 | Meteorology & Atmospheric Sciences | 891 |
| Engineering | 93 | Engineering | 302 | Engineering | 507 |
| Public, Environmental, & Occupational Health | 55 | Public, Environmental, & Occupational Health | 175 | Public, Environmental, & Occupational Health | 408 |
| Toxicology | 31 | Toxicology | 128 | Science & Technology—Other Topics | 181 |
| Respiratory System | 19 | Computer Science | 81 | Toxicology | 143 |
| Mathematics | 19 | Mathematics | 66 | Mathematics | 123 |
| General & Internal Medicine | 18 | Water Resources | 49 | Chemistry | 100 |
| Computer Science | 17 | Chemistry | 38 | Computer Science | 99 |
| Energy & Fuels | 14 | Energy & Fuels | 37 | Geology | 91 |
| 1990–1999 | 2000–2009 | 2010–2018 | |||
|---|---|---|---|---|---|
| Journal | Number of Publications | Journal | Number of Publications | Journal | Number of Publications |
| Atmospheric Environment | 71 | Atmospheric Environment | 237 | Atmospheric Environment | 329 |
| Journal of the Air & Waste Management Association | 18 | Journal of Geophysical Research—Atmospheres | 70 | Atmospheric Chemistry and Physics | 179 |
| Journal of Geophysical Research—Atmospheres | 15 | Science of the Total Environment | 50 | Science of the Total Environment | 135 |
| Science of the Total Environment | 13 | Environmental Science & Technology | 47 | Environmental Science & Technology | 100 |
| Atmospheric Environment Part A—General Topics | 12 | Atmospheric Chemistry and Physics | 43 | Atmospheric Pollution Research | 73 |
| Environmental Science & Technology | 11 | International Journal of Environment and Pollution | 42 | Environmental Research | 70 |
| Environmental Pollution | 11 | Environmental Health Perspectives | 40 | Environmental Pollution | 69 |
| Water Air and Soil Pollution | 10 | Environmental Modelling & Software | 38 | Aerosol and Air Quality Research | 58 |
| Journal of Applied Meteorology | 9 | Journal of the Air & Waste Management Association | 34 | Environmental Health Perspectives | 55 |
| Environmental Health Perspectives | 9 | Environmental Monitoring and Assessment | 33 | Journal of Geophysical Research—Atmospheres | 55 |


| Symbol | Full Name | Explanation |
|---|---|---|
| PM | Particulate matter | Includes PM2.5 and PM10 |
| NOx | Nitrogen oxides | Includes NO2 and NO |
| O3 | Ozone | - |
| AQI | Air quality index | The names are all air quality indexes but the indexes defined in different articles may be different. |
| Multiple | Multiple pollutants | Multiple pollutants episodes, including at least one of PM, NOx, or O3. These three kinds of simultaneous multiple air pollutant forecasting cases are not included in this study. |
| ANN | Artificial neural network | Artificial neural network |
| ANFIS | Adaptive neuro-fuzzy inference system | Adaptive neuro-fuzzy inference system |
| SVM | Support vector machine | Includes support vector machine and support vector regression |
| RF | Random forest | Random forest |
| DL | Deep learn | Deep learning |
| PCA | Principal Component Analysis | Principal component analysis |
| LUR | Land use regression | Land use return |
| Kriging | Kriging interpolation method | Kriging spatial interpolation method |
| GP | Genetic programming | Genetic programming |
| PF | Probabilistic Forecasting | Probability prediction |
| ESM | Exponential Smoothing Method | Exponential smoothing method |
| ARIMA | Autoregressive integrated moving average model | Autoregressive comprehensive moving average model |
| FTS | Fuzzy time series | Fuzzy time series |
| MLR | Multi-linear regression | Multiple linear regression |
| GAM | Generalized additive model | Generalized additive model |
| GLM | Generalized linear models | Generalized linear models |
| Bayesian | Bayesian model | Bayesian models and other Bayesian-related models |
| Markov | Markov model | Markov models and Markov-related models |
| Gaussian | Gaussian process model | Gaussian process models and Gaussian-related models |
| Multiple | The abovementioned methods are used simultaneously, each method is used (not mixed), and the discussion is not biased to a particular method. | |
| Hybrid | Mixtures of the above methods |
References
- Goldberg, M.S.; Burnett, R.T.; Bailar, J.C., 3rd; Brook, J.; Bonvalot, Y.; Tamblyn, R.; Singh, R.; Valois, M.F. The association between daily mortality and ambient air particle pollution in Montreal, Quebec. 1. Nonaccidental mortality. Environ. Res. 2001, 86, 12–25. [Google Scholar] [CrossRef]
- Gan, W.Q.; Davies, H.W.; Koehoorn, M.; Brauer, M. Association of long-term exposure to community noise and traffic-related air pollution with coronary heart disease mortality. Am. J. Epidemiol. 2012, 175, 898–906. [Google Scholar] [CrossRef] [PubMed]
- Andersen, T.K.; Radcliffe, D.E.; Shepherd, J.M. Quantifying Surface Energy Fluxes in the Vicinity of Inland-Tracking Tropical Cyclones. J. Appl. Meteorol. Climatol. 2013, 52, 2797–2808. [Google Scholar] [CrossRef]
- Makkonen, M.; Berg, M.P.; Handa, I.T.; Hattenschwiler, S.; van Ruijven, J.; van Bodegom, P.M.; Aerts, R. Highly consistent effects of plant litter identity and functional traits on decomposition across a latitudinal gradient. Ecol. Lett. 2012, 15, 1033–1041. [Google Scholar] [CrossRef] [PubMed]
- Garaga, R.; Sahu, S.K.; Kota, S.H. A Review of Air Quality Modeling Studies in India: Local and Regional Scale. Curr. Pollut. Rep. 2018, 4, 59–73. [Google Scholar] [CrossRef]
- Hu, J.L.; Chen, J.J.; Ying, Q.; Zhang, H.L. One-year simulation of ozone and particulate matter in China using WRF/CMAQ modeling system. Atmos. Chem. Phys. 2016, 16, 10333–10350. [Google Scholar] [CrossRef]
- Mathur, R.; Xing, J.; Gilliam, R.; Sarwar, G.; Hogrefe, C.; Pleim, J.; Pouliot, G.; Roselle, S.; Spero, T.L.; Wong, D.C. Extending the Community Multiscale Air Quality (CMAQ) modeling system to hemispheric scales: Overview of process considerations and initial applications. Atmos. Chem. Phys. 2017, 17, 12449–12474. [Google Scholar] [CrossRef]
- Rafee, S.A.; Martins, L.D.; Kawashima, A.B.; Almeida, D.S.; Morais, M.; Souza, R.; Oliveira, M.B.L.; Souza, R.A.F.; Medeiros, A.S.S.; Urbina, V. Contributions of mobile, stationary and biogenic sources to air pollution in the Amazon rainforest: A numerical study with the WRF-Chem model. Atmos. Chem. Phys. 2017, 17, 7977–7995. [Google Scholar] [CrossRef]
- Zhang, Y.; Baklanov, A. Training Materials and Best Practices for Chemical Weather/Air Quality Forecasting; Report ETR-26; World Meteorological Organization: Geneva, Switzerland, 2020; Available online: https://library.wmo.int/index.php?lvl=notice_display&id=21801 (accessed on 18 May 2021).
- Rybarczyk, Y.; Zalakeviciute, R. Machine Learning Approaches for Outdoor Air Quality Modelling: A Systematic Review. Appl. Sci. 2018, 8, 2570. [Google Scholar] [CrossRef]
- Taheri Shahraiyni, H.; Sodoudi, S. Statistical Modeling Approaches for PM10 Prediction in Urban Areas; A Review of 21st-Century Studies. Atmosphere 2016, 7, 15. [Google Scholar] [CrossRef]
- Bai, L.; Wang, J.; Ma, X.; Lu, H. Air Pollution Forecasts: An Overview. Int. J. Environ. Res. Public Health 2018, 15, 780. [Google Scholar] [CrossRef]
- Wu, Z.F.; Ren, Y. A bibliometric review of past trends and future prospects in urban heat island research from 1990 to 2017. Environ. Rev. 2019, 27, 241–251. [Google Scholar] [CrossRef]
- Zuo, S.D.; Dou, P.F.; Ren, Y. Mapping sources of atmospheric pollution: Integrating spatial and cluster bibliometrics. Environ. Rev. 2020, 28, 1–11. [Google Scholar] [CrossRef]
- Franceschi, F.; Cobo, M.; Figueredo, M. Discovering relationships and forecasting PM10 and PM2.5 concentrations in Bogotá, Colombia, using Artificial Neural Networks, Principal Component Analysis, and k-means clustering. Atmos. Pollut. Res. 2018, 9, 912–922. [Google Scholar] [CrossRef]
- Weber, R.J.; Guo, H.; Russell, A.G.; Nenes, A. High aerosol acidity despite declining atmospheric sulfate concentrations over the past 15 years. Nat. Geosci. 2016, 9, 282–285. [Google Scholar] [CrossRef]
- Duan, C.; Zuo, S.; Wu, Z.; Qiu, Y.; Wang, J.; Lei, Y.; Liao, H.; Ren, Y. A review of research hotspots and trends in biogenic volatile organic compounds (BVOCs) emissions combining bibliometrics with evolution tree methods. Environ. Res. Lett. 2020, 16, 013003. [Google Scholar] [CrossRef]
- Hoek, G.; Kos, G.; Harrison, R.M.; de Hartog, J.; Meliefste, K.; ten Brink, H.; Katsouyanni, K.; Karakatsani, A.; Lianou, M.; Kotronarou, A.; et al. Indoor-outdoor relationships of particle number and mass in four European cities. Atmos. Environ. 2008, 42, 156–169. [Google Scholar] [CrossRef]
- Vienneau, D.; de Hoogh, K.; Beelen, R.; Fischer, P.; Hoek, G.; Briggs, D. Comparison of land-use regression models between Great Britain and the Netherlands. Atmos. Environ. 2010, 44, 688–696. [Google Scholar] [CrossRef]
- Briggs, D.J.; Collins, S.; Elliott, P.; Fischer, P.; Kingham, S.; Lebret, E.; Pryl, K.; VanReeuwijk, H.; Smallbone, K.; VanderVeen, A. Mapping urban air pollution using GIS: A regression-based approach. Int. J. Geogr. Inf. Sci. 1997, 11, 699–718. [Google Scholar] [CrossRef]
- Liao, D.P.; Peuquet, D.J.; Duan, Y.K.; Whitsel, E.A.; Dou, J.W.; Smith, R.L.; Lin, H.M.; Chen, J.C.; Heiss, G. GIS approaches for the estimation of residential-level ambient PM concentrations. Environ. Health Perspect. 2006, 114, 1374–1380. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A.; Thun, M.J.; Namboodiri, M.M.; Dockery, D.W.; Evans, J.S.; Speizer, F.E.; Heath, C.W. Particulate air-pollution as a predictor of mortality in a prospective-study of us adults. Am. J. Respir. Crit. Care Med. 1995, 151, 669–674. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A.; Burnett, R.T.; Thun, M.J.; Calle, E.E.; Krewski, D.; Ito, K.; Thurston, G.D. Lung cancer, cardiopulmonary mortality, and long-term exposure to fine particulate air pollution. J. Am. Med. Assoc. 2002, 287, 1132–1141. [Google Scholar] [CrossRef] [PubMed]
- Dockery, D.W.; Pope, C.A.; Xu, X.P.; Spengler, J.D.; Ware, J.H.; Fay, M.E.; Ferris, B.G.; Speizer, F.E. An association between air-pollution and mortality in 6 united-states cities. N. Engl. J. Med. 1993, 329, 1753–1759. [Google Scholar] [CrossRef] [PubMed]
- Dominici, F.; Peng, R.D.; Bell, M.L.; Pham, L.; McDermott, A.; Zeger, S.L.; Samet, J.M. Fine particulate air pollution and hospital admission for cardiovascular and respiratory diseases. J. Am. Med. Assoc. 2006, 295, 1127–1134. [Google Scholar] [CrossRef]
- Gardner, M.W.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Byun, D.; Schere, K.L. Review of the governing equations, computational algorithms, and other components of the models-3 Community Multiscale Air Quality (CMAQ) modeling system. Appl. Mech. Rev. 2006, 59, 51–77. [Google Scholar] [CrossRef]
- Hu, J.; Jathar, S.; Zhang, H.; Ying, Q.; Chen, S.-H.; Cappa, C.D.; Kleeman, M.J. Long-term particulate matter modeling for health effect studies in California–Part 2: Concentrations and sources of ultrafine organic aerosols. Atmos. Chem. Phys. 2017, 17, 5379–5391. [Google Scholar] [CrossRef]
- Wang, Y.Y.; Li, Q.; Guo, Y.; Zhou, H.; Wang, X.; Wang, Q.; Shen, H.; Zhang, Y.; Yan, D.; Zhang, Y.; et al. Association of Long-term Exposure to Airborne Particulate Matter of 1 mum or Less With Preterm Birth in China. JAMA Pediatr. 2018, 172, e174872. [Google Scholar] [CrossRef] [PubMed]
- Alimissis, A.; Philippopoulos, K.; Tzanis, C.G.; Deligiorgi, D. Spatial estimation of urban air pollution with the use of artificial neural network models. Atmos. Environ. 2018, 191, 205–213. [Google Scholar] [CrossRef]
- Song, X.H.; Hopke, P.K. Analysis of source contributions to the ambient aerosol sample by simulated annealing. Chemom. Intell. Lab. Syst. 1996, 34, 275–281. [Google Scholar] [CrossRef]
- Perez, P.; Trier, A.; Reyes, J. Prediction of PM2.5 concentrations several hours in advance using neural networks in Santiago, Chile. Atmos. Environ. 2000, 34, 1189–1196. [Google Scholar] [CrossRef]
- Ceylan, Z.; Bulkan, S. Forecasting PM10 levels using ANN and MLR: A case study for Sakarya City. Global Nest J. 2018, 20, 281–290. [Google Scholar]
- Qiao, J.; Wang, G.; Li, X.; Li, W. A self-organizing deep belief network for nonlinear system modeling. Appl. Soft Comput. 2018, 65, 170–183. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Ross, Z.; Jerrett, M.; Ito, K.; Tempalski, B.; Thurston, G. A land use regression for predicting fine particulate matter concentrations in the New York City region. Atmos. Environ. 2007, 41, 2255–2269. [Google Scholar] [CrossRef]
- Li, R.; Ma, T.; Xu, Q.; Song, X. Using MAIAC AOD to verify the PM2.5 spatial patterns of a land use regression model. Environ. Pollut. 2018, 243, 501–509. [Google Scholar] [CrossRef]
- Liu, W.; Li, X.; Chen, Z.; Zeng, G.; León, T.; Liang, J.; Huang, G.; Gao, Z.; Jiao, S.; He, X.; et al. Land use regression models coupled with meteorology to model spatial and temporal variability of NO2 and PM10 in Changsha, China. Atmos. Environ. 2015, 116, 272–280. [Google Scholar] [CrossRef]
- Ng, K.Y.; Awang, N. Multiple linear regression and regression with time series error models in forecasting PM10 concentrations in Peninsular Malaysia. Environ. Monit. Assess. 2018, 190, 63. [Google Scholar] [CrossRef]
- Dimitriou, K.; Kassomenos, P. A study on the reconstitution of daily PM10 and PM2.5 levels in Paris with a multivariate linear regression model. Atmos. Environ. 2014, 98, 648–654. [Google Scholar] [CrossRef]
- Dimitriou, K. Upgrading the Estimation of Daily PM10 Concentrations Utilizing Prediction Variables Reflecting Atmospheric Processes. Aerosol Air Qual. Res. 2016, 16, 2245–2254. [Google Scholar] [CrossRef]
- Hou, X.; Fei, D.; Kang, H.; Zhang, Y.; Gao, J. Seasonal statistical analysis of the impact of meteorological factors on fine particle pollution in China in 2013–2017. Nat. Hazards 2018, 93, 677–698. [Google Scholar] [CrossRef]
- Garcia Nieto, P.J.; Sanchez Lasheras, F.; Garcia-Gonzalo, E.; de Cos Juez, F.J. PM10 concentration forecasting in the metropolitan area of Oviedo (Northern Spain) using models based on SVM, MLP, VARMA and ARIMA: A case study. Sci. Total Environ. 2018, 621, 753–761. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Christakos, G. Uncertainty assessment of heavy metal soil contamination mapping using spatiotemporal sequential indicator simulation with multi-temporal sampling points. Environ. Monit. Assess. 2015, 187, 187. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Jiang, H.; Wang, J.; Zhou, J. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.Z.; Wang, W.J.; Wang, X.K.; Yan, S.H.; Lam, J.C. Potential assessment of a neural network model with PCA/RBF approach for forecasting pollutant trends in Mong Kok urban air, Hong Kong. Environ. Res 2004, 96, 79–87. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Rasanen, T.; Karppinen, A.; Kolehmainen, M. Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Chen, D.; Xu, T.; Li, Y.; Zhou, Y.; Lang, J.; Liu, X.; Shi, H. A Hybrid Approach to Forecast Air Quality during High-PM Concentration Pollution Period. Aerosol Air Qual. Res. 2015, 15, 1325–1337. [Google Scholar] [CrossRef]
- Wu, C.D.; Zeng, Y.T.; Lung, S.C. A hybrid kriging/land-use regression model to assess PM2.5 spatial-temporal variability. Sci. Total Environ. 2018, 645, 1456–1464. [Google Scholar] [CrossRef]
- Xu, S.; Zou, B.; Shafi, S.; Sternberg, T. A hybrid Grey-Markov/ LUR model for PM10 concentration prediction under future urban scenarios. Atmos. Environ. 2018, 187, 401–409. [Google Scholar] [CrossRef]
- Fast, J.D.; Zhong, S. Meteorological factors associated with inhomogeneous ozone concentrations within the Mexico City basin. J. Geophys. Res. Atmos. 1998, 103, 18927–18946. [Google Scholar] [CrossRef]
- Wotawa, G.; Stohl, A.; Neininger, B. The urban plume of Vienna: Comparisons between aircraft measurements and photochemical model results. Atmos. Environ. 1998, 32, 2479–2489. [Google Scholar] [CrossRef]
- Abdul-Wahab, S.; Bouhamra, W.; Ettouney, H.; Sowerby, B.; Crittenden, B.D. Predicting ozone levels—A statistical model for predicting ozone levels in the Shuaiba Industrial Area, Kuwait. Environ. Sci. Pollut. Res. 1996, 3, 195–204. [Google Scholar] [CrossRef]
- Nghiem-Buffet, S.; Cohen, S.Y. Retinal vein occlusion: Anti-VEGF treatments. J. Fr. D’ophtalmologie 2009, 32, 679–686. [Google Scholar] [CrossRef]
- Gao, M.; Yin, L.; Ning, J. Artificial neural network model for ozone concentration estimation and Monte Carlo analysis. Atmos. Environ. 2018, 184, 129–139. [Google Scholar] [CrossRef]
- Wang, W.; Lu, W.; Wang, X.; Leung, A.Y.T. Prediction of maximum daily ozone level using combined neural network and statistical characteristics. Environ. Int. 2003, 29, 555–562. [Google Scholar] [CrossRef]
- Ortiz-García, E.G.; Salcedo-Sanz, S.; Pérez-Bellido, Á.M.; Portilla-Figueras, J.A.; Prieto, L. Prediction of hourly O3 concentrations using support vector regression algorithms. Atmos. Environ. 2010, 44, 4481–4488. [Google Scholar] [CrossRef]
- Zhan, Y.; Luo, Y.; Deng, X.; Grieneisen, M.L.; Zhang, M.; Di, B. Spatiotemporal prediction of daily ambient ozone levels across China using random forest for human exposure assessment. Environ. Pollut. 2018, 233, 464–473. [Google Scholar] [CrossRef]
- Di, Q.; Rowland, S.; Koutrakis, P.; Schwartz, J. A hybrid model for spatially and temporally resolved ozone exposures in the continental United States. J. Air Waste Manag. Assoc. 2017, 67, 39–52. [Google Scholar] [CrossRef]
- Durão, R.M.; Mendes, M.T.; João Pereira, M. Forecasting O3 levels in industrial area surroundings up to 24 h in advance, combining classification trees and MLP models. Atmos. Pollut. Res. 2016, 7, 961–970. [Google Scholar] [CrossRef]
- Tan, K.C.; Lim, H.S.; Mat Jafri, M.Z. Multiple regression analysis in modeling of columnar ozone in Peninsular Malaysia. Environ. Sci. Pollut. Res. Int. 2014, 21, 7567–7577. [Google Scholar] [CrossRef]
- Novotny, E.V.; Bechle, M.J.; Millet, D.B.; Marshall, J.D. National satellite-based land-use regression: NO2 in the United States. Environ. Sci. Technol. 2011, 45, 4407–4414. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Zhang, C.; Bi, J. Development of land use regression models for PM2.5, SO2, NO2 and O3 in Nanjing, China. Environ. Res. 2017, 158, 542–552. [Google Scholar]
- Michanowicz, D.R.; Shmool, J.L.C.; Tunno, B.J.; Tripathy, S.; Gillooly, S.; Kinnee, E.; Clougherty, J.E. A hybrid land use regression/AERMOD model for predicting intra-urban variation in PM2.5. Atmos. Environ. 2016, 131, 307–315. [Google Scholar] [CrossRef]
- Mavko, M.E.; Tang, B.; George, L.A. A sub-neighborhood scale land use regression model for predicting NO2. Sci. Total Environ. 2008, 398, 68–75. [Google Scholar] [CrossRef] [PubMed]
- Arain, M.A.; Blair, R.; Finkelstein, N.; Brook, J.R.; Sahsuvaroglu, T.; Beckerman, B.; Zhang, L.; Jerrett, M. The use of wind fields in a land use regression model to predict air pollution concentrations for health exposure studies. Atmos. Environ. 2007, 41, 3453–3464. [Google Scholar] [CrossRef]
- Li, X.; Liu, W.; Chen, Z.; Zeng, G.; Hu, C.; León, T.; Liang, J.; Huang, G.; Gao, Z.; Li, Z.; et al. The application of semicircular-buffer-based land use regression models incorporating wind direction in predicting quarterly NO2 and PM10 concentrations. Atmos. Environ. 2015, 103, 18–24. [Google Scholar] [CrossRef]
- Weissert, L.F.; Salmond, J.A.; Miskell, G.; Alavi-Shoshtari, M.; Williams, D.E. Development of a microscale land use regression model for predicting NO2 concentrations at a heavy trafficked suburban area in Auckland, NZ. Sci. Total Environ. 2018, 619–620, 112–119. [Google Scholar] [CrossRef]
- Young, M.T.; Bechle, M.J.; Sampson, P.D.; Szpiro, A.A.; Marshall, J.D.; Sheppard, L.; Kaufman, J.D. Satellite-Based NO2 and Model Validation in a National Prediction Model Based on Universal Kriging and Land-Use Regression. Environ. Sci. Technol. 2016, 50, 3686–3694. [Google Scholar] [CrossRef] [PubMed]
- Araki, S.; Shima, M.; Yamamoto, K. Spatiotemporal land use random forest model for estimating metropolitan NO2 exposure in Japan. Sci. Total Environ. 2018, 634, 1269–1277. [Google Scholar] [CrossRef]
- Wu, L.; Li, N.; Yang, Y. Prediction of air quality indicators for the Beijing-Tianjin-Hebei region. J. Clean. Prod. 2018, 196, 682–687. [Google Scholar] [CrossRef]
- Gupta, S.; Pebesma, E.; Degbelo, A.; Costa, A. Optimising Citizen-Driven Air Quality Monitoring Networks for Cities. ISPRS Int. J. Geo-Inf. 2018, 7, 468. [Google Scholar] [CrossRef]
- Tong, C.H.M.; Yim, S.H.L.; Rothenberg, D.; Wang, C.; Lin, C.-Y.; Chen, Y.D.; Lau, N.C. Assessing the impacts of seasonal and vertical atmospheric conditions on air quality over the Pearl River Delta region. Atmos. Environ. 2018, 180, 69–78. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J. A new air quality monitoring and early warning system: Air quality assessment and air pollutant concentration prediction. Environ. Res 2017, 158, 105–117. [Google Scholar] [CrossRef] [PubMed]
- Benmerad, M.; Slama, R.; Botturi, K.; Claustre, J.; Roux, A.; Sage, E.; Reynaud-Gaubert, M.; Gomez, C.; Kessler, R.; Brugiere, O.; et al. Chronic effects of air pollution on lung function after lung transplantation in the Systems prediction of Chronic Lung Allograft Dysfunction (SysCLAD) study. Eur. Respir. J. 2017, 49, 1600206. [Google Scholar] [CrossRef] [PubMed]
- Warren, J.L.; Stingone, J.A.; Herring, A.H.; Luben, T.J.; Fuentes, M.; Aylsworth, A.S.; Langlois, P.H.; Botto, L.D.; Correa, A.; Olshan, A.F.; et al. Bayesian multinomial probit modeling of daily windows of susceptibility for maternal PM2.5 exposure and congenital heart defects. Stat. Med. 2016, 35, 2786–2801. [Google Scholar] [CrossRef]
- Harris, M.H.; Gold, D.R.; Rifas-Shiman, S.L.; Melly, S.J.; Zanobetti, A.; Coull, B.A.; Schwartz, J.D.; Gryparis, A.; Kloog, I.; Koutrakis, P.; et al. Prenatal and childhood traffic-related air pollution exposure and childhood executive function and behavior. Neurotoxicol. Teratol. 2016, 57, 60–70. [Google Scholar] [CrossRef]
- Tiwari, A.; Singh, S.; Nagar, R. Feasibility assessment for partial replacement of fine aggregate to attain cleaner production perspective in concrete: A review. J. Clean. Prod. 2016, 135, 490–507. [Google Scholar] [CrossRef]
- Jiang, K.; Liao, Q.M.; Xiong, Y. A novel white blood cell segmentation scheme based on feature space clustering. Soft Comput. 2006, 10, 12–19. [Google Scholar] [CrossRef]
- Leng, X.; Qian, X.; Yang, M.; Wang, C.; Li, H.; Wang, J. Leaf magnetic properties as a method for predicting heavy metal concentrations in PM2.5 using support vector machine: A case study in Nanjing, China. Environ. Pollut. 2018, 242, 922–930. [Google Scholar] [CrossRef]




| Database | Web of Science Core Collection |
|---|---|
| Retrieval method | TS = ((“air pollutants” OR “air pollution” OR “atmospheric pollutants” OR “atmospheric pollutant”) AND (Predict OR Prediction OR Forecast OR Forecasts)) |
| Timespan | 1990–2018 |
| Document type | Articles and reviews |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, K.; Huang, X.; Dang, H.; Ren, Y.; Zuo, S.; Duan, C. Statistical Approaches for Forecasting Primary Air Pollutants: A Review. Atmosphere 2021, 12, 686. https://doi.org/10.3390/atmos12060686
Liao K, Huang X, Dang H, Ren Y, Zuo S, Duan C. Statistical Approaches for Forecasting Primary Air Pollutants: A Review. Atmosphere. 2021; 12(6):686. https://doi.org/10.3390/atmos12060686
Chicago/Turabian StyleLiao, Kuo, Xiaohui Huang, Haofei Dang, Yin Ren, Shudi Zuo, and Chensong Duan. 2021. "Statistical Approaches for Forecasting Primary Air Pollutants: A Review" Atmosphere 12, no. 6: 686. https://doi.org/10.3390/atmos12060686
APA StyleLiao, K., Huang, X., Dang, H., Ren, Y., Zuo, S., & Duan, C. (2021). Statistical Approaches for Forecasting Primary Air Pollutants: A Review. Atmosphere, 12(6), 686. https://doi.org/10.3390/atmos12060686