
Novel Integrated and Optimal Control of Indoor Environmental Devices for Thermal Comfort Using Double Deep Q-Network

Abstract
1. Introduction
2. Integrated Comfort Control Algorithm
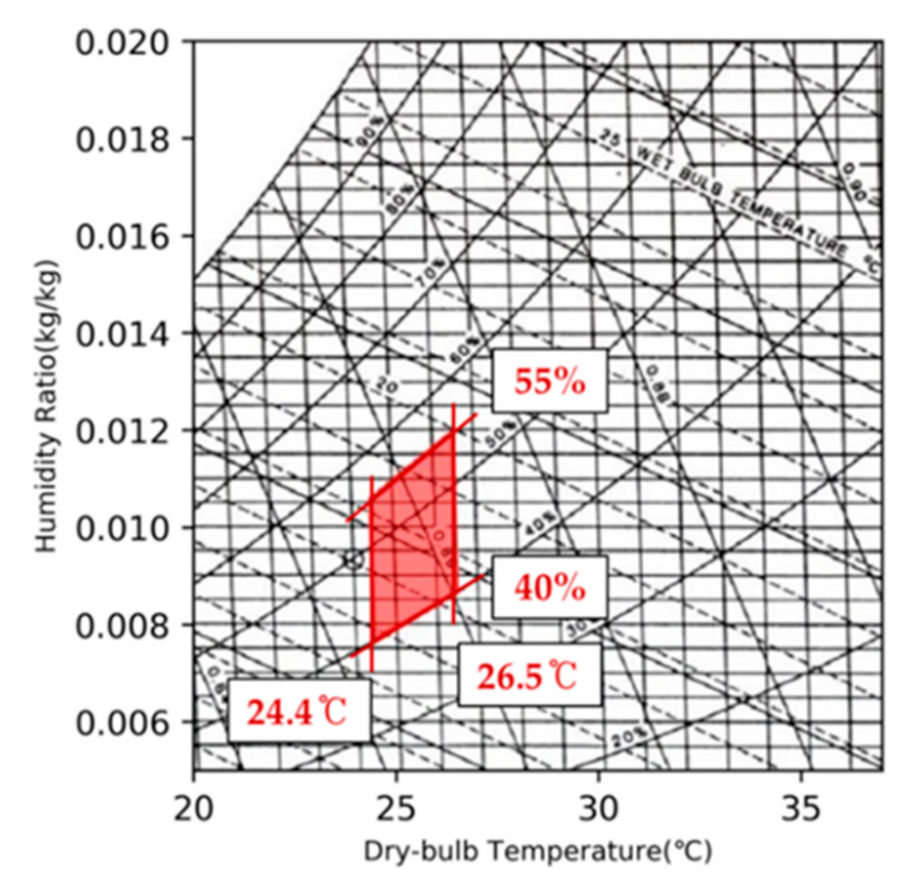
2.1. Thermal Comfort Range
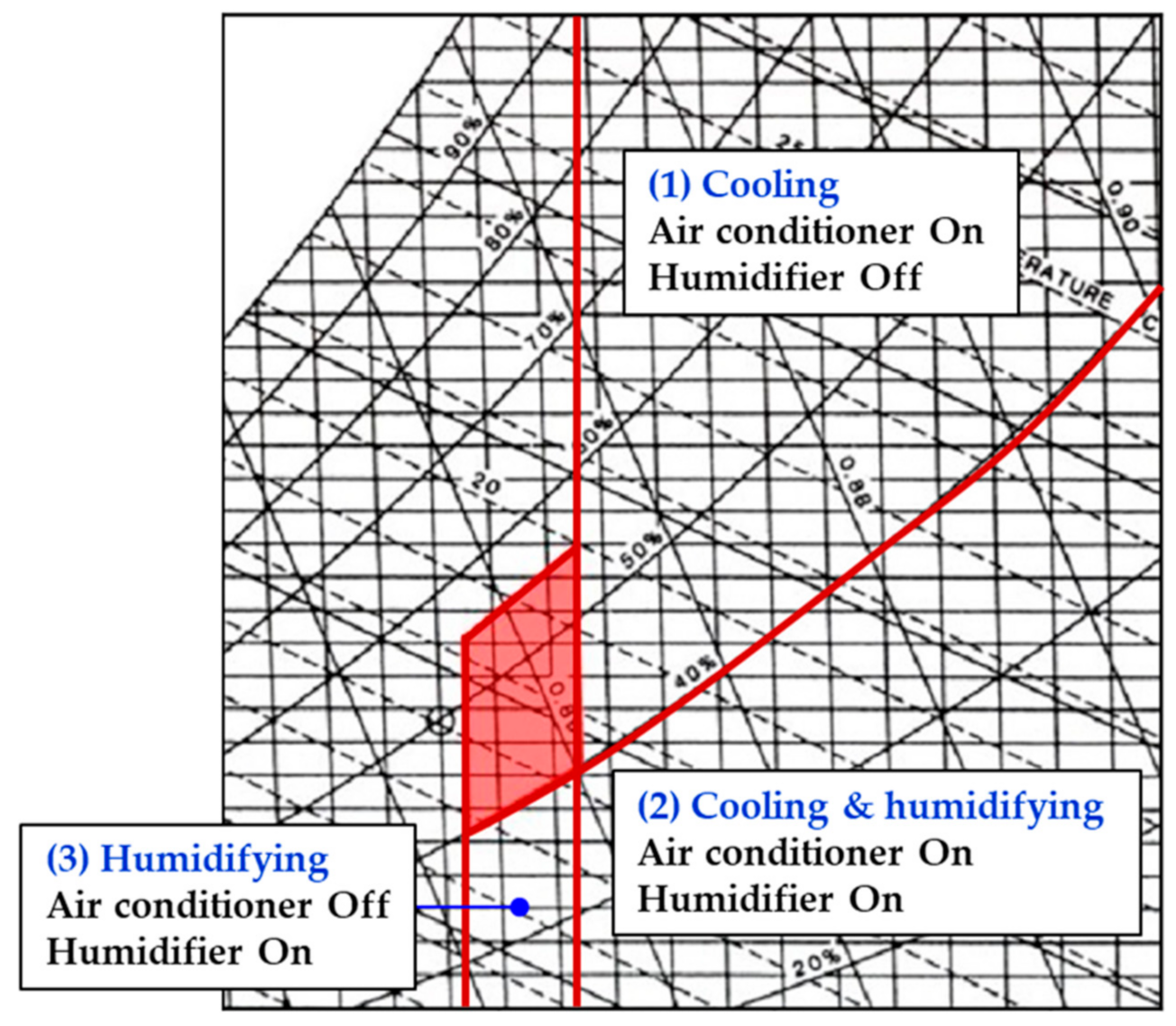
2.2. Concept of Integrated Comfort Control
- (1)
- The cooling zone is where the indoor air temperature is higher than 26.5 °C, and relative humidity is higher than 40%. In this zone, only the air conditioner operates without the humidifier because the state of the indoor air is hot and mild;
- (2)
- The cooling and humidifying zone is where the indoor air temperature is higher than 26.5 °C, and relative humidity is lower than 40%. In this zone, indoor air is hot and dry; hence, both the air conditioner and humidifier can be operated to reach the comfort zone;
- (3)
- The humidifying zone is where the indoor air temperature is between 24 and 26.5 °C, and relative humidity is lower than 40%. Only the humidifier is operated to reach the comfort zone because the indoor air is neutral and dry.
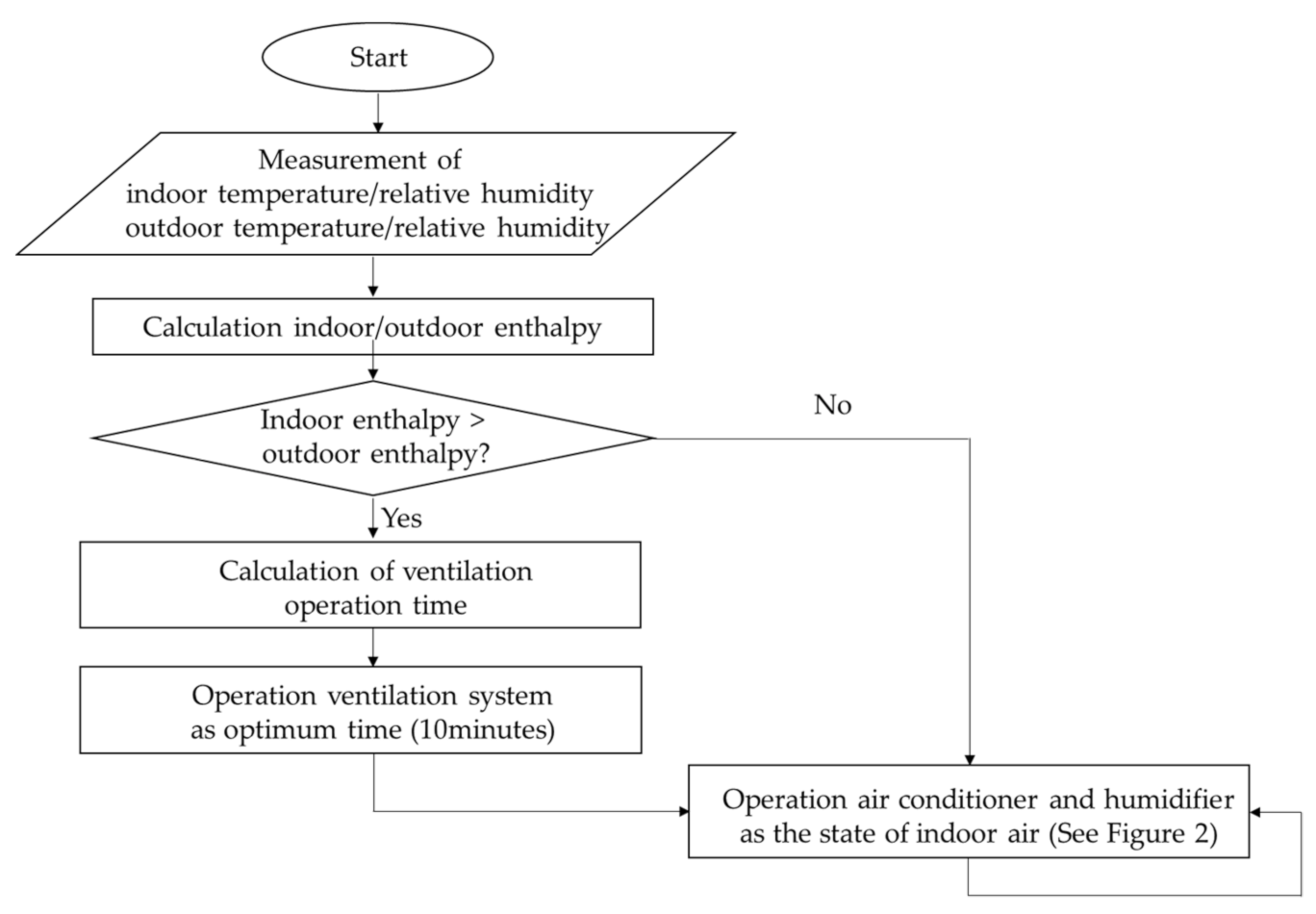
2.3. Limitation of Integrated Comfort Control
3. Artificial Intelligence Integrated Comfort Control (AI2CC) Using DDQN
3.1. Double Deep Q-Network (DDQN)
- Target Q-network
- Experience memory
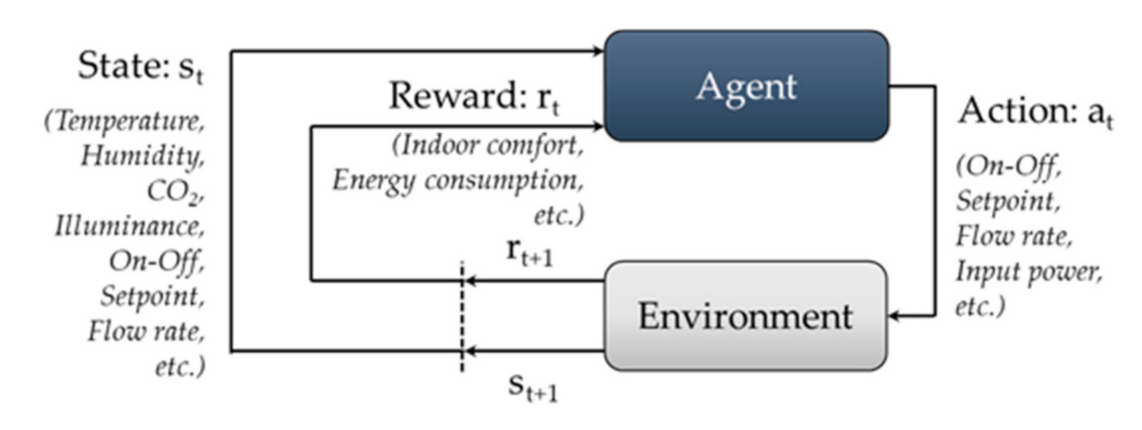
3.2. Double Deep Q-Network Training for AI2CC
- State variables
- Control actions
- Reward function
4. Implementation of AI2CC
4.1. Simulation Model
4.2. Co-Simulation Platform for AI2CC
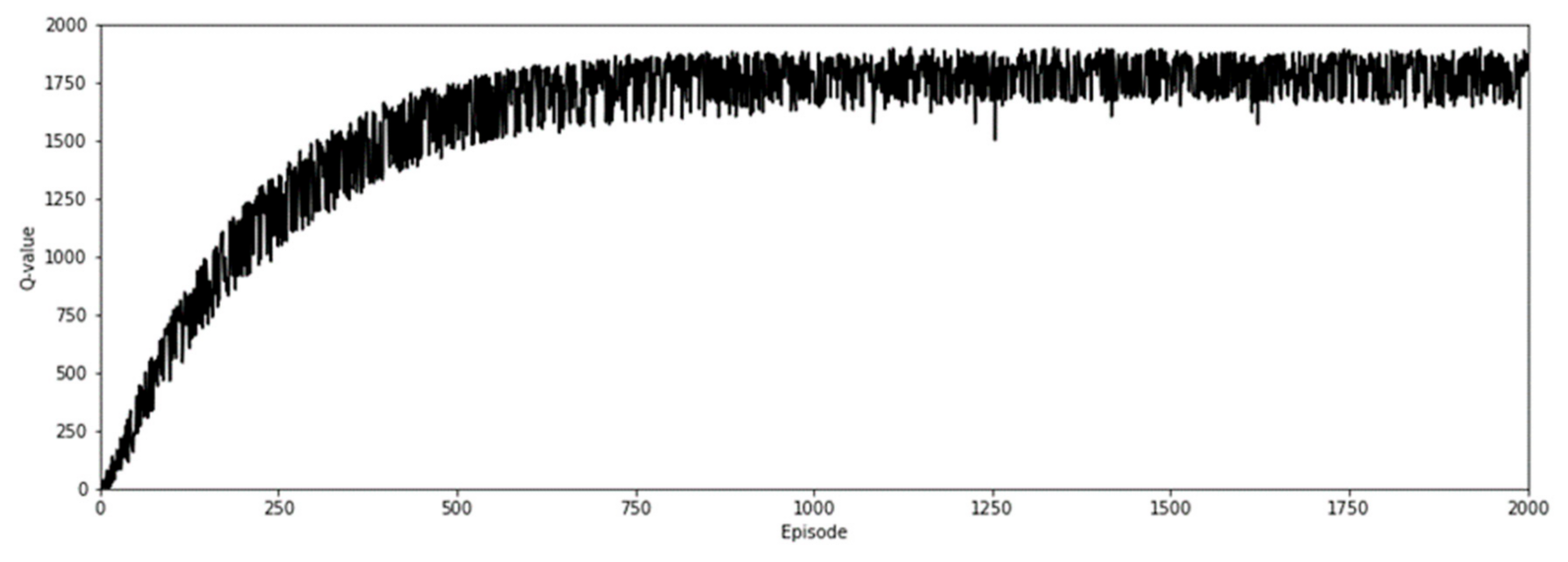
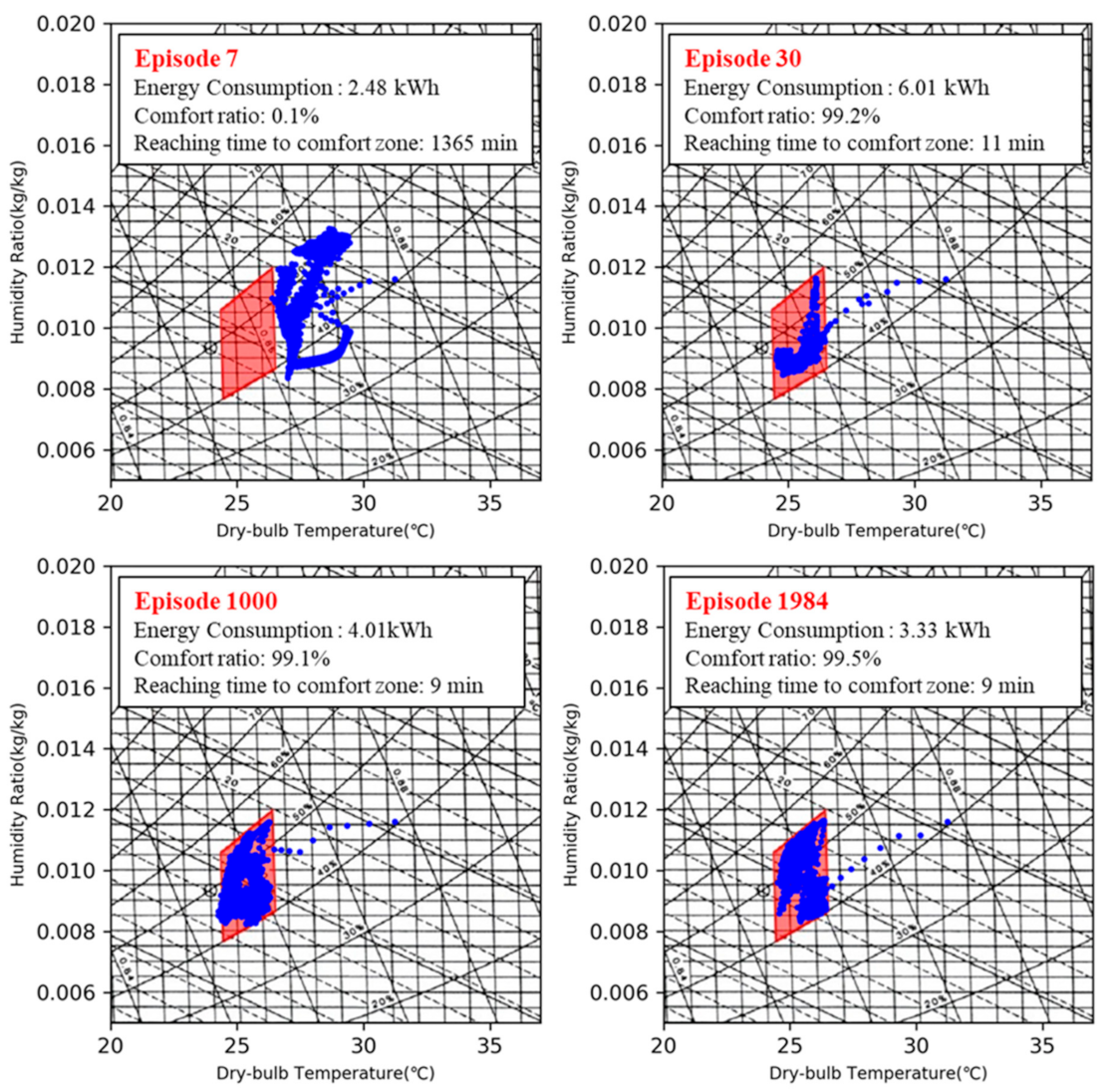
4.3. Training of the AI2CC
5. Evaluation of AI2CC
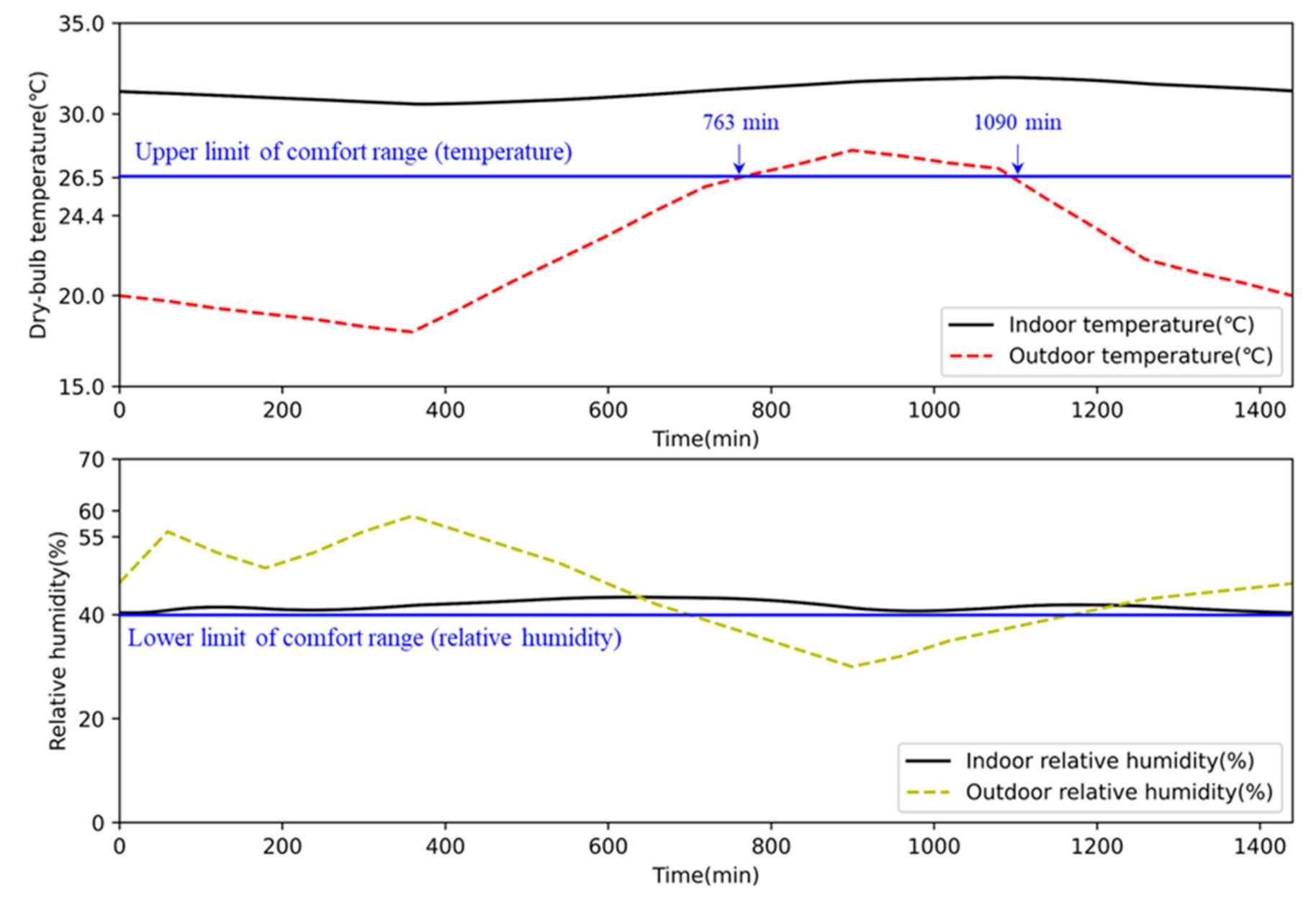
5.1. Case Studies
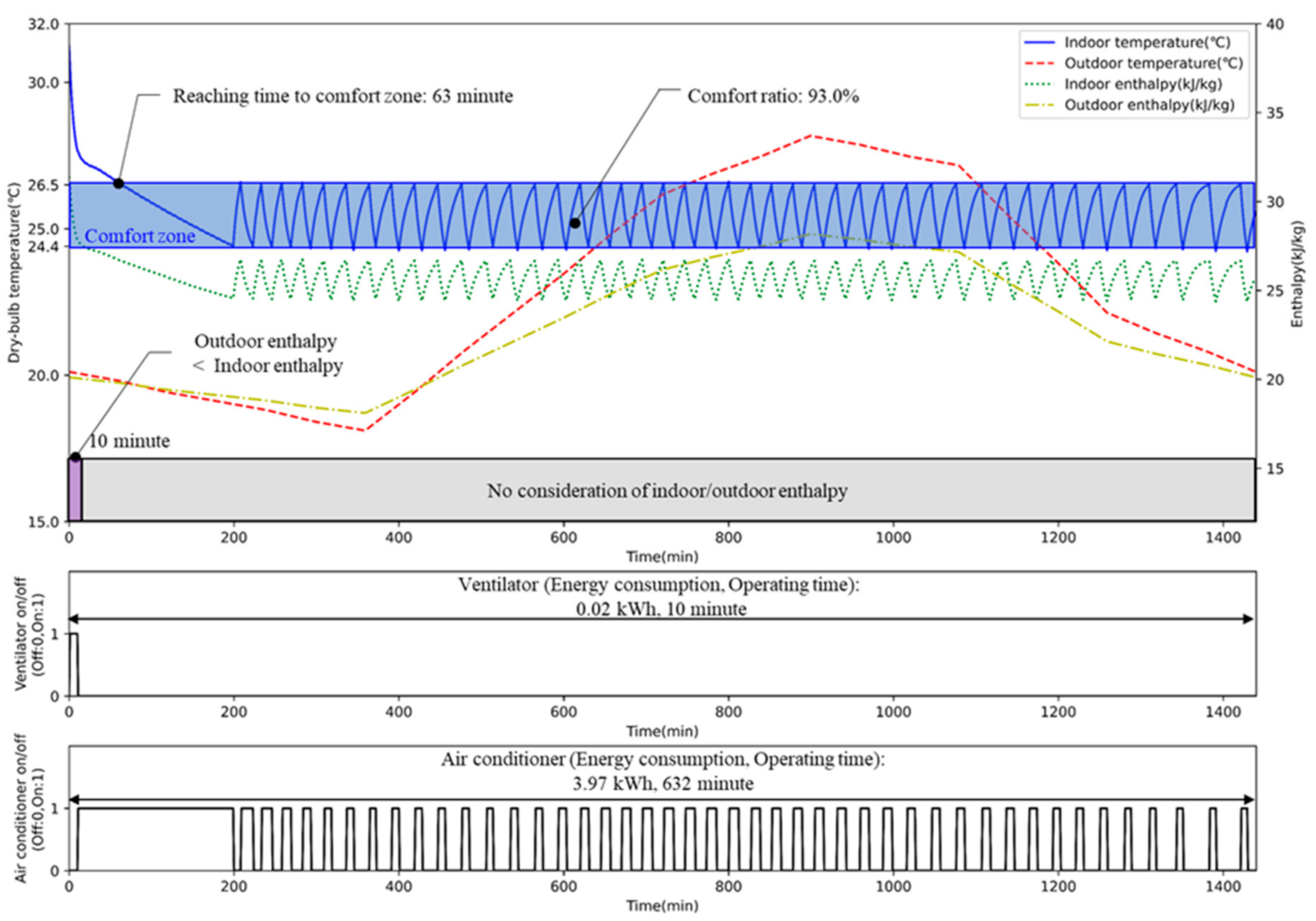
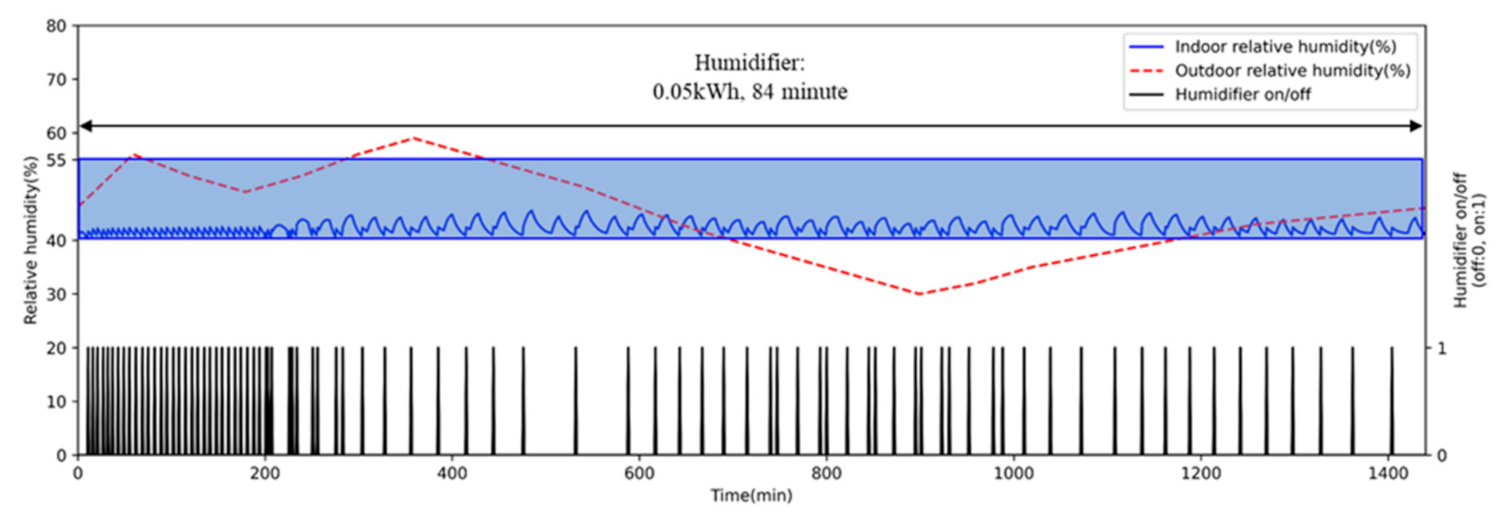
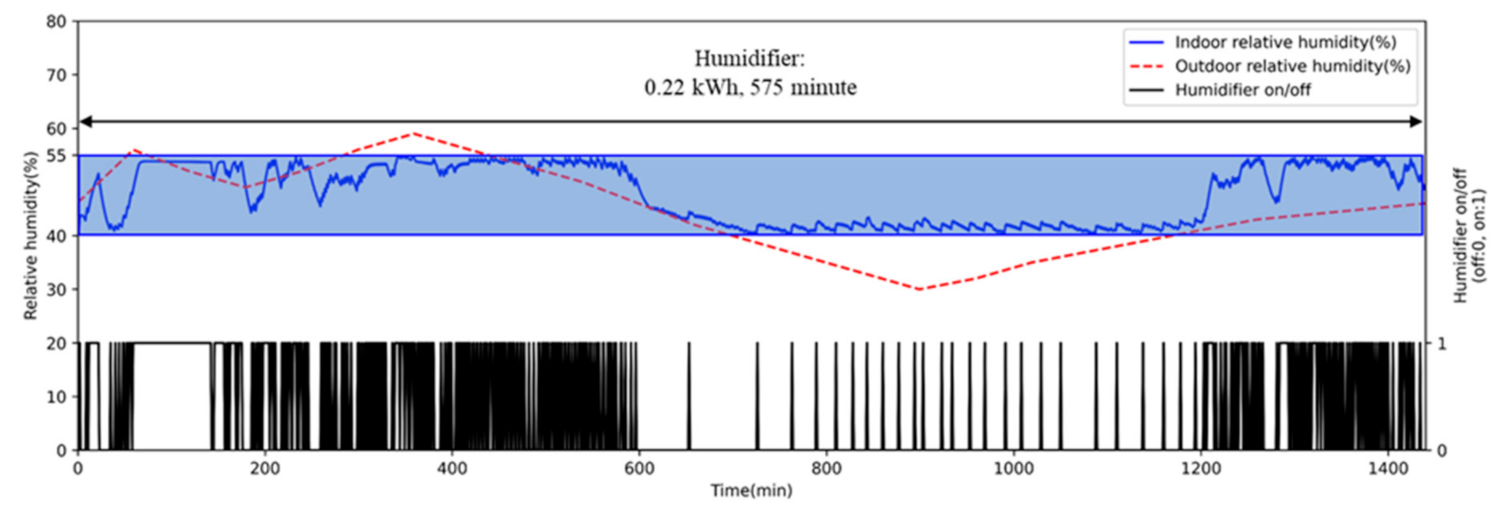
5.2. Performance of AI2CC
- Energy Consumption
- Thermal comfort
6. Discussion
- Our previous study proposed AICC algorithm, which combines ICC with an occupancy detection model to change the thermal comfort range according to occupancy status [8]. However, in this paper, for AI2CC, the occupancy activity was fixed as light work at a desk. Thus, we could not reflect the dynamic thermal comfort range, which changes continuously according to occupancy status.
- In this study, we adopted thermal comfort to evaluate indoor comfort conditions. However, comfort conditions are affected by thermal comfort and indoor air quality and visual comfort [56]. A more sophisticated and integrated indoor comfort index could be studied and machine learning techniques in built environments.
- Vary the thermal comfort range according to occupancy status [39]. To satisfy the thermal comfort needs for various activities, we will combine the occupancy status detection algorithm with the AI2CC to apply an appropriate comfort range based on occupancy status (e.g., working, sleeping, resting, or exercising).
- In a building, reinforcement learning could improve indoor comfort, such as thermal comfort, air quality, light requirement, and noise [57]. In addition to thermal comfort, IAQ (e.g., CO2 and particulate matter) and visual comfort (e.g., illuminance and glare) will be added to the evaluation factors of indoor comfort conditions. Other devices may be included in the control to satisfy these factors, such as air purifiers, kitchen hood, and blinds.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pérez-Lombard, L.; Ortiz, J.; Pout, C. A review on buildings energy consumption information. Energy Build. 2008. [Google Scholar] [CrossRef]
- Shaikh, P.H.; Nor, N.B.M.; Nallagownden, P.; Elamvazuthi, I. Building energy management through a distributed fuzzy inference system. Int. J. Eng. Technol. 2013, 5, 3236–3242. [Google Scholar]
- ASHRAE. Thermal Environmental Conditions for Human Occupancy; ANSI/ASHRAE Standard 55-2004; American Society of Heating, Refrigerating and Air Conditioning Engineers, Inc.: Atlanta, GA, USA, 2004. [Google Scholar]
- Moon, H.J.; Yang, S.H. Evaluation of the energy performance and thermal comfort of an air conditioner with temperature and humidity controls in a cooling season. HVAC R Res. 2014. [Google Scholar] [CrossRef]
- Yang, W.; Elankumaran, S.; Marr, L.C. Relationship between Humidity and Influenza A Viability in Droplets and Implications for Influenza’s Seasonality. PLoS ONE 2012, 7, e46789. [Google Scholar] [CrossRef]
- Yoshikuni, K.; Tagami, H.; Inoue, K.; Yamada, M. Evaluation of the influence of ambient temperature and humidity on the hydration level of the stratum corneum. Nippon Hifuka Gakkai Zasshi. Jpn. J. Dermatol. 1985. [Google Scholar] [CrossRef]
- Kim, J.W.; Yang, W.; Moon, H.J. An integrated comfort control with cooling, ventilation, and humidification systems for thermal comfort and low energy consumption. Sci. Technol. Built Environ. 2017, 23, 264–276. [Google Scholar] [CrossRef]
- Kim, S.H.; Moon, H.J. Case study of an advanced integrated comfort control algorithm with cooling, ventilation, and humidification systems based on occupancy status. Build. Environ. 2018, 133, 246–264. [Google Scholar] [CrossRef]
- Shaikh, P.H.; Nor, N.B.M.; Nallagownden, P.; Elamvazuthi, I.; Ibrahim, T. A review on optimized control systems for building energy and comfort management of smart sustainable buildings. Renew. Sustain. Energy Rev. 2014, 34, 409–429. [Google Scholar] [CrossRef]
- Serale, G.; Fiorentini, M.; Capozzoli, A.; Bernardini, D.; Bemporad, A. Model Predictive Control (MPC) for enhancing building and HVAC system energy efficiency: Problem formulation, applications and opportunities. Energies 2018, 11, 631. [Google Scholar] [CrossRef]
- Aftab, M.; Chen, C.; Chau, C.K.; Rahwan, T. Automatic HVAC control with real-time occupancy recognition and simulation-guided model predictive control in low-cost embedded system. Energy Build. 2017, 154, 141–156. [Google Scholar] [CrossRef]
- Hu, M.; Xiao, F.; Jørgensen, J.B.; Li, R. Price-responsive model predictive control of floor heating systems for demand response using building thermal mass. Appl. Therm. Eng. 2019, 153, 316–329. [Google Scholar] [CrossRef]
- Berouinev, A.; Ouladsine, R.; Bakhouya, M.; Lachhab, F.; Essaaidi, M. A Model Predictive Approach for Ventilation System Control in Energy Efficient Buildings. In Proceedings of the 2019 4th World Conference on Complex Systems (WCCS), Ouarzazate, Morocco, 22–25 April 2019; pp. 9–14. [Google Scholar] [CrossRef]
- Wei, T.; Wang, Y.; Zhu, Q. Deep Reinforcement Learning for Building HVAC Control. Proc. Des. Autom. Conf. 2017, 2017. [Google Scholar] [CrossRef]
- Li, B.; Xia, L. A multi-grid reinforcement learning method for energy conservation and comfort of HVAC in buildings. IEEE Int. Conf. Autom. Sci. Eng. 2015, 2015, 444–449. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H. Learning from Delayed Rewards; University of Cambridge: Cambridge, UK, 1989. [Google Scholar]
- Chen, Y.; Norford, L.K.; Samuelson, H.W.; Malkawi, A. Optimal control of HVAC and window systems for natural ventilation through reinforcement learning. Energy Build. 2018, 169, 195–205. [Google Scholar] [CrossRef]
- Baghaee, S.; Ulusoy, I. User comfort and energy efficiency in HVAC systems by Q-learning. In Proceedings of the 26th IEEE Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Fazenda, P.; Veeramachaneni, K.; Lima, P.; O’Reilly, U.M. Using reinforcement learning to optimize occupant comfort and energy usage in HVAC systems. J. Ambient Intell. Smart Environ. 2014, 6, 675–690. [Google Scholar] [CrossRef]
- Yang, L.; Nagy, Z.; Goffin, P.; Schlueter, A. Reinforcement learning for optimal control of low exergy buildings. Appl. Energy 2015. [Google Scholar] [CrossRef]
- Yoon, Y.R.; Moon, H.J. Performance based thermal comfort control (PTCC) using deep reinforcement learning for space cooling. Energy Build. 2019, 203. [Google Scholar] [CrossRef]
- Mocanu, E.; Nguyen, P.H.; Kling, W.L.; Gibescu, M. Unsupervised energy prediction in a Smart Grid context using reinforcement cross-building transfer learning. Energy Build. 2016, 116, 646–655. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Yu, L.; Sun, Y.; Xu, Z.; Shen, C.; Yue, D.; Jiang, T.; Guan, X. Multi-Agent Deep Reinforcement Learning for HVAC Control in Commercial Buildings. IEEE Trans. Smart Grid 2021, 12, 407–419. [Google Scholar] [CrossRef]
- Nagy, A.; Kazmi, H.; Cheaib, F.; Driesen, J. Deep reinforcement learning for optimal control of space heating. arXiv 2018, arXiv:1805.03777. [Google Scholar]
- Thrun, S.; Schwartz, A. Issues in Using Function Approximation for Reinforcement Learning. In Proceedings of the Connectionist Models Summer School, Hillsdale, NJ, USA, 21 June–3 July 1993; pp. 1–9. [Google Scholar]
- van Hasselt, H. Insights in Reinforcement Learning: Formal Analysis and Empirical Evaluation of Temporal-Difference Learning Algorithms. Ph.D. Thesis, Utrecht University, Utrecht, The Netherlands, 2011. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double Q-Learning. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI-16), Phoenix, AZ, USA, 12–17 February 2016; pp. 2094–2100. [Google Scholar]
- Valladares, W.; Galindo, M.; Gutiérrez, J.; Wu, W.C.; Liao, K.K.; Liao, J.C.; Lu, K.C.; Wang, C.C. Energy optimization associated with thermal comfort and indoor air control via a deep reinforcement learning algorithm. Build. Environ. 2019, 155, 105–117. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Z.; Loftness, V. Bio-sensing and reinforcement learning approaches for occupant-centric control. ASHRAE Trans. 2019, 125, 364–371. [Google Scholar]
- Liu, Y.; Zhang, D.; Gooi, H.B. Optimization strategy based on deep reinforcement learning for home energy management. CSEE J. Power Energy Syst. 2020, 6, 572–582. [Google Scholar] [CrossRef]
- Nagarathinam, S.; Menon, V.; Vasan, A.; Sivasubramaniam, A. MARCO—Multi-Agent Reinforcement learning based COntrol of building HVAC systems. In Proceedings of the Eleventh ACM International Conference on Future Energy Systems, Melbourne, Australia, 22–26 June 2020; ACM: New York, NY, USA, 2020; pp. 57–67. [Google Scholar]
- Chegari, B.; Tabaa, M.; Simeu, E.; Moutaouakkil, F.; Medromi, H. Multi-objective optimization of building energy performance and indoor thermal comfort by combining artificial neural networks and metaheuristic algorithms. Energy Build. 2021, 239. [Google Scholar] [CrossRef]
- Zhao, J.; Du, Y. Multi-objective optimization design for windows and shading configuration considering energy consumption and thermal comfort: A case study for office building in different climatic regions of China. Sol. Energy 2020, 206, 997–1017. [Google Scholar] [CrossRef]
- Yang, Z.; Becerik-Gerber, B. How does building occupancy influence energy efficiency of HVAC systems? Energy Procedia 2016, 88, 775–780. [Google Scholar] [CrossRef]
- Anand, P.; Sekhar, C.; Cheong, D.; Santamouris, M.; Kondepudi, S. Occupancy-based zone-level VAV system control implications on thermal comfort, ventilation, indoor air quality and building energy efficiency. Energy Build. 2019, 204. [Google Scholar] [CrossRef]
- Anand, P.; Cheong, D.; Sekhar, C. Computation of zone-level ventilation requirement based on actual occupancy, plug and lighting load information. Indoor Built Environ. 2020, 29, 558–574. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; de Dear, R.; Luo, M.; Lin, B.; He, Y.; Ghahramani, A. Individual difference in thermal comfort: A literature review Individual di ff erence in thermal comfort : A literature review. Build. Environ. 2018, 138, 181–193. [Google Scholar] [CrossRef]
- Luo, M.; Wang, Z.; Ke, K.; Cao, B.; Zhai, Y.; Zhou, X. Human metabolic rate and thermal comfort in buildings: The problem and challenge. Build. Environ. 2018, 131, 44–52. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, Z. Standard effective temperature based adaptive-rational thermal comfort model. Appl. Energy 2020, 264, 114723. [Google Scholar] [CrossRef]
- Kum, J.S.; Kim, D.K.; Choi, K.H.; Kim, J.R.; Lee, K.H.; Choi, H.S. Experimental study on thermal comfort sensation of Korean (Part II: Analysis of subjective judgement in summer experiment). Korean J. Sci. Emot. Sensib. 1998, 1, 65–73. [Google Scholar]
- Bae, G.N.; Lee, C. Evaluation of Korean Thermal Sensation in Office Buildings During the Summer Season. Korean J. Air Cond. Refrig. Eng. 1995, 7, 341–352. [Google Scholar]
- Wang, Z.; Hong, T. Reinforcement learning for building controls: The opportunities and challenges. Appl. Energy 2020, 269. [Google Scholar] [CrossRef]
- Watkins, C.J.C.H.P. Dayan Q-Learning. Mach. Learn. 1992, 292, 279–292. [Google Scholar] [CrossRef]
- Givan, B.; Parr, R. An Introduction to Markov Decision Processes. Available online: http://faculty.kfupm.edu.sa/coe/ashraf/RichFilesTeaching/COE101_540/Projects/givan1.pdf (accessed on 9 April 2021).
- Claessens, B.J.; Vanhoudt, D.; Desmedt, J.; Ruelens, F. Model-free control of thermostatically controlled loads connected to a district heating network. Energy Build. 2017, 159, 1–10. [Google Scholar] [CrossRef]
- Frontczak, M.; Wargocki, P. Literature survey on how different factors influence human comfort in indoor environments. Build. Environ. 2011, 46, 922–937. [Google Scholar] [CrossRef]
- Philip, S. Eppy Documentation; Github Repository. 2019. Available online: https://pypi.org/project/eppy/ (accessed on 9 April 2021).
- Korea Metorrological Administration. Korea Cimate Change Report; Korea Metorrological Administration: Seoul, Korea, 2013.
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Paola, J. Neural Network Classification of Multispectral Imagery. Master’s Thesis, The University of Arizona, Tucson, AZ, USA, 1994. [Google Scholar]
- May, R. The Reinforcement Learning Method: A Feasible and Sustainable Control Strategy for Efficient Occupant-Centred Building Operation in Smart Cities. Ph.D. Thesis, Dalarna University, Falun, Sweden, 2019. [Google Scholar]
- Ruelens, F.; Claessens, B.J.; Quaiyum, S.; De Schutter, B.; Babuška, R.; Belmans, R. Reinforcement Learning Applied to an Electric Water Heater: From Theory to Practice. IEEE Trans. Smart Grid 2018, 9, 3792–3800. [Google Scholar] [CrossRef]
- Cheng, Z.; Zhao, Q.; Wang, F.; Jiang, Y.; Xia, L.; Ding, J. Satisfaction based Q-learning for integrated lighting and blind control. Energy Build. 2016, 127, 43–55. [Google Scholar] [CrossRef]
- Pargfrieder, J.; Jörgl, H.P. An integrated control system for optimizing the energy consumption and user comfort in buildings. In Proceedings of the 2002 IEEE Symposium on Computer-Aided Control System Design, Glasgow, UK, 20–20 September 2002; pp. 127–132. [Google Scholar] [CrossRef]
- Profile, S.E.E. Thermal comfort and indoor air quality. Green Energy Technol. 2012, 84, 1–13. [Google Scholar] [CrossRef]
- Dalamagkidis, K.; Kolokots, D. Reinforcement Learning for Building Environmental Control. Reinf. Learn. 2008. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | Unit | |
|---|---|---|
| Environmental state | Outdoor dry-bulb temperature | °C |
| Outdoor relative humidity | % | |
| Outdoor enthalpy | kg/kg′ | |
| Indoor dry-bulb temperature | °C | |
| Indoor relative humidity | % | |
| Indoor enthalpy | kg/kg′ | |
| State of indoor environmental devices | On/off of the air conditioner | - |
| Cooling setpoint of the air conditioner | °C | |
| Airflow rate of the air conditioner | m3/s | |
| On/off of the ventilation system | - | |
| On/off of the humidifier | - | |
| Action | Unit | Value | |
|---|---|---|---|
| Air-conditioner | On/off | - | 1/0 |
| Cooling setpoint | °C | 24, 25, 26 | |
| Air flow rate | m3/s | 0.11, 0.13, 0.15 | |
| Ventilation system | On/off | - | 1/0 |
| Humidifier | On/off | - | 1/0 |
| BICT | Size | 4.0 m × 5.0 m × 2.4 m | |
| Materials | Laminate floor on concrete and urethane layers | ||
| Urethane panel with gypsum lapping | |||
| Double-glazed window with 5 mm glass panes and 5 mm air cavity | |||
| Environmental Control Systems | Ventilation system | Supply airflow rate | 0.03 m3/s |
| Exhaust airflow rate | 0.03 m3/s | ||
| Rated power | 400 W | ||
| Air-conditioner | Rated total cooling capacity | 2.3 kW | |
| Rate cooling COP | 2.7 | ||
| Min outdoor T in cooling mode | −5 °C | ||
| Max outdoor T in cooling mode | 48 °C | ||
| Humidifier | Rated capacity | 5.11 × 10−7 m3/s | |
| Rated power | 35 W | ||
| Mean Temperature (°C) | Daily Maximum Temperature (°C) | Daily Minimum Temperature (°C) | Precipitation (mm) | Wind Speed (m/s) | Relative Humidity (%) | Cloud Coverage (%) |
|---|---|---|---|---|---|---|
| 23.6 | 28.4 | 19.7 | 723.2 | 1.8 | 70.0 | 65 |
| State (st) | Action (at) | Reward (rt) | Next State (st+1) |
|---|---|---|---|
| Environmental state at t State of indoor environmental devices at t (see Table 1) | Action combination of air conditioner, ventilation system, and humidifier (see Table 2) | Reward for thermal comfort + Reward for energy consumption | Environmental state at t+1 State of indoor environmental devices at t+1 (see Table 1) |
| Weather File | Seoul, Korea (epw) | ||
| Period | 8 June (hot and dry) | ||
| Internal Heat Gain | People | Light work | Equipment |
| 117 W/person | 8.6 W/m2 | 65 W | |
| Schedule | 00:00–24:00: 100% | ||
| Number of Occupants | One person | ||
| Evaluation Factor | ICC | AI2CC 1 | |
|---|---|---|---|
| Energy consumption (kWh) | Ventilation system | 0.02 | 1.15 (±0.06) |
| Air-conditioner | 3.97 | 2.08 (±0.13) | |
| Humidifier | 0.05 | 0.21 (±0.01) | |
| Total | 4.04 | 3.44 (±0.11) | |
| Comfort ratio (%) | 93.0 | 99.4 (±0.10) | |
| Time to reach comfort zone (minutes) | 63 | 8.9 (±0.3) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-H.; Yoon, Y.-R.; Kim, J.-W.; Moon, H.-J. Novel Integrated and Optimal Control of Indoor Environmental Devices for Thermal Comfort Using Double Deep Q-Network. Atmosphere 2021, 12, 629. https://doi.org/10.3390/atmos12050629
Kim S-H, Yoon Y-R, Kim J-W, Moon H-J. Novel Integrated and Optimal Control of Indoor Environmental Devices for Thermal Comfort Using Double Deep Q-Network. Atmosphere. 2021; 12(5):629. https://doi.org/10.3390/atmos12050629
Chicago/Turabian StyleKim, Sun-Ho, Young-Ran Yoon, Jeong-Won Kim, and Hyeun-Jun Moon. 2021. "Novel Integrated and Optimal Control of Indoor Environmental Devices for Thermal Comfort Using Double Deep Q-Network" Atmosphere 12, no. 5: 629. https://doi.org/10.3390/atmos12050629
APA StyleKim, S.-H., Yoon, Y.-R., Kim, J.-W., & Moon, H.-J. (2021). Novel Integrated and Optimal Control of Indoor Environmental Devices for Thermal Comfort Using Double Deep Q-Network. Atmosphere, 12(5), 629. https://doi.org/10.3390/atmos12050629