
Enhancing the Encoding-Forecasting Model for Precipitation Nowcasting by Putting High Emphasis on the Latest Data of the Time Step



Abstract
1. Introduction
2. Data and Methods
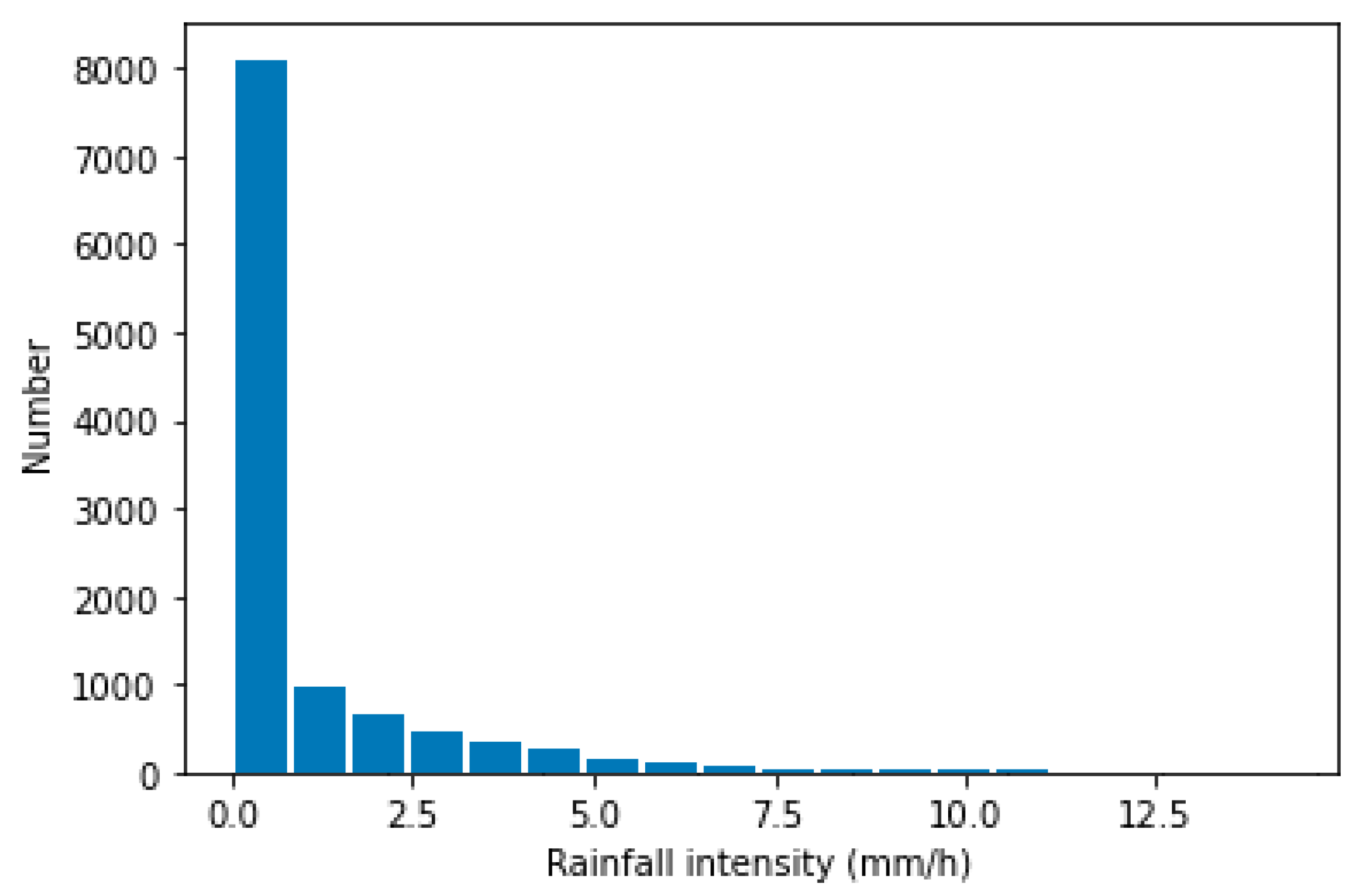
2.1. Dataset
2.2. Proposed Model
2.2.1. Preliminaries
- ConvLSTM Cell
- Encoding-forecasting model
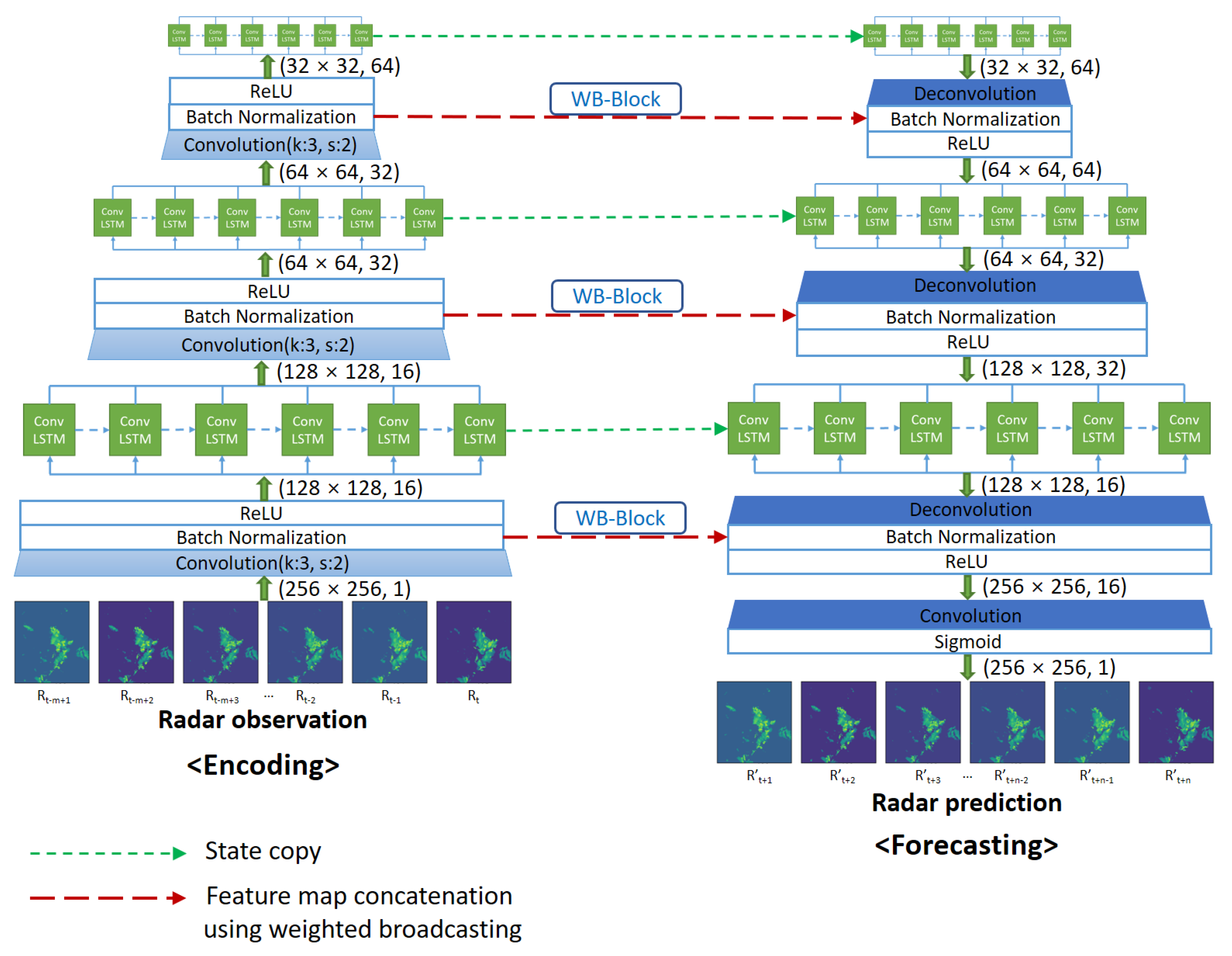
2.2.2. Model Description
2.3. Experimental Setup and Evaluation Metrics
2.3.1. Experimental Setup
2.3.2. Evaluation Metrics
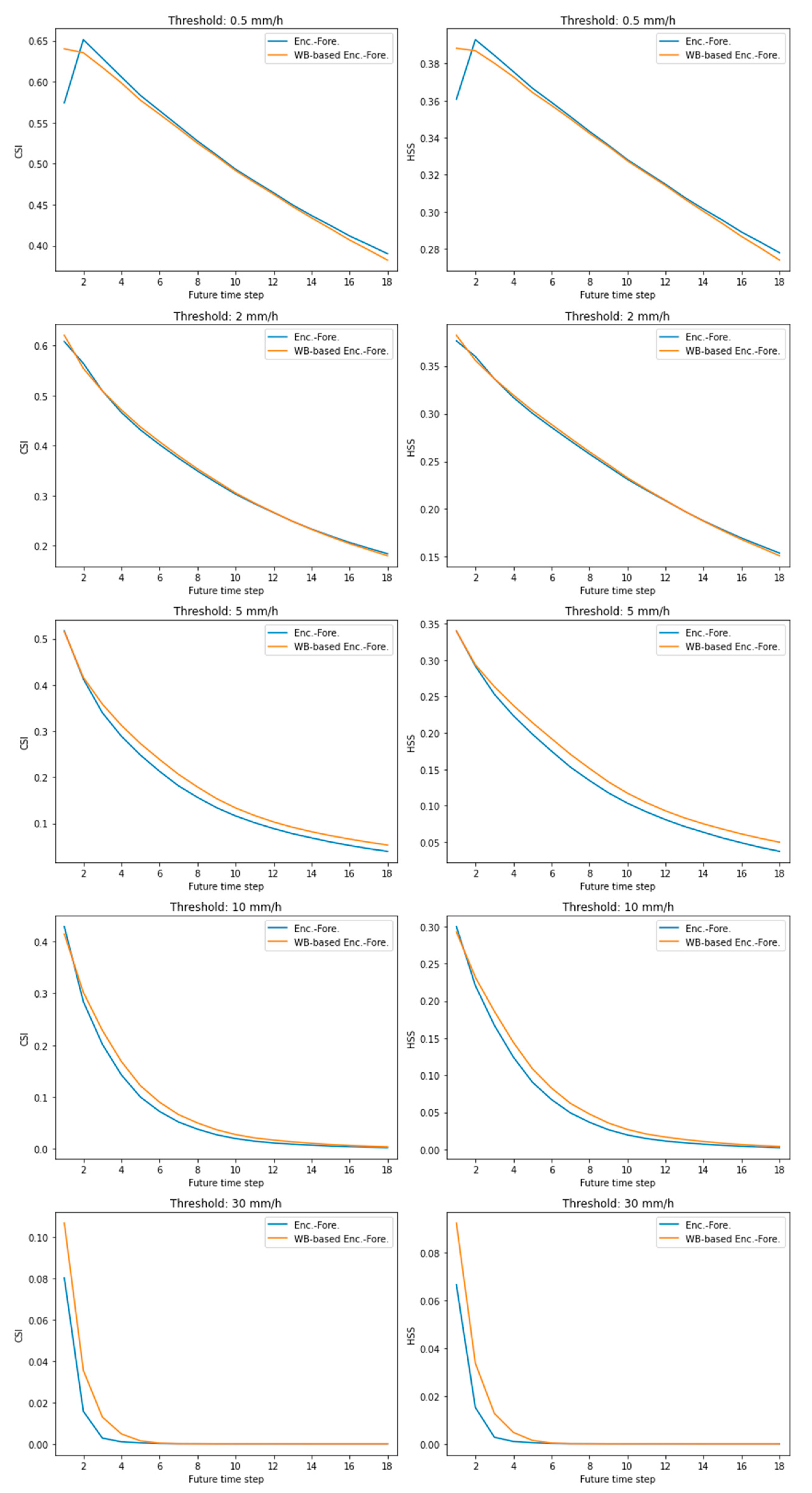
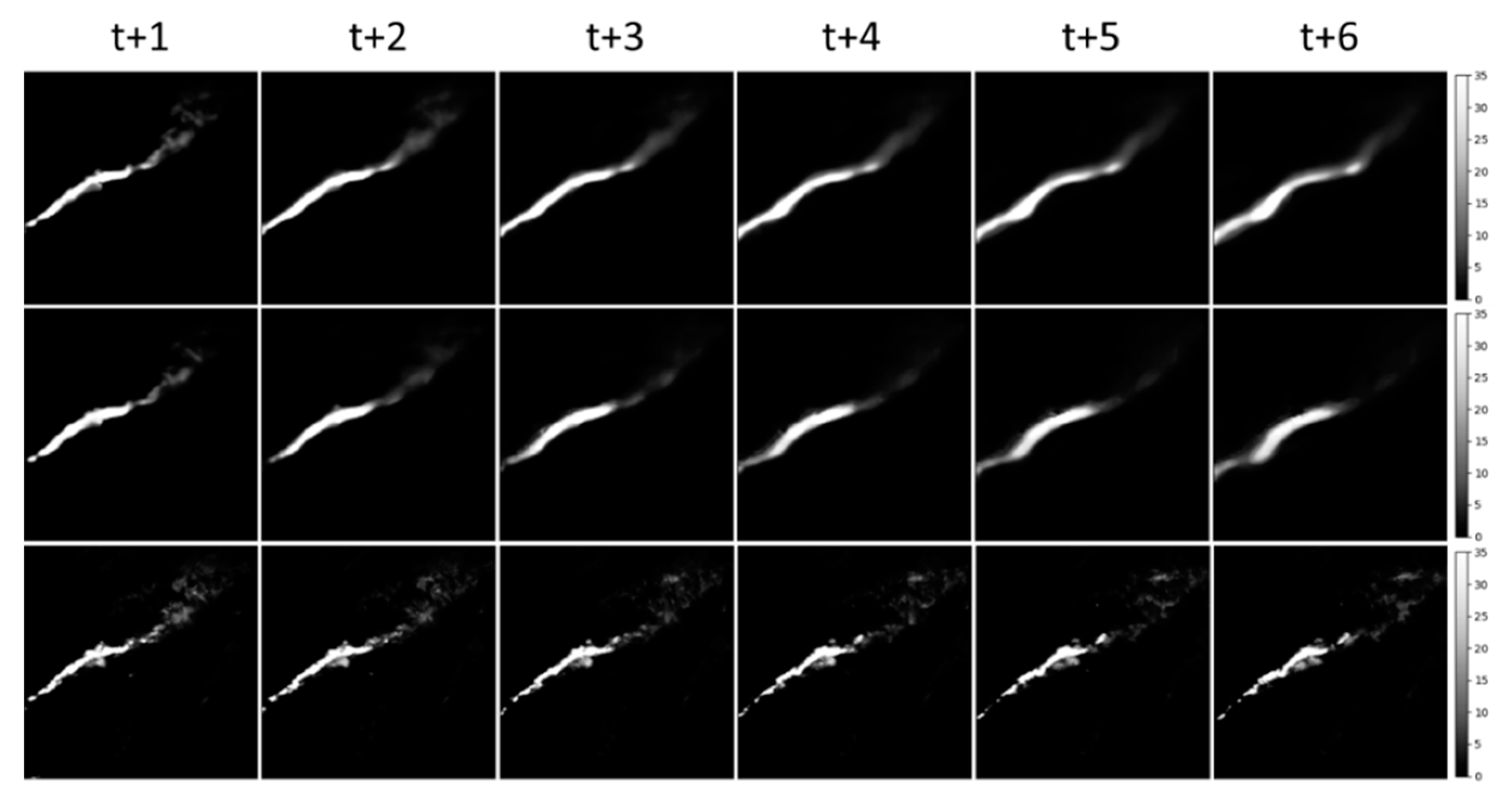
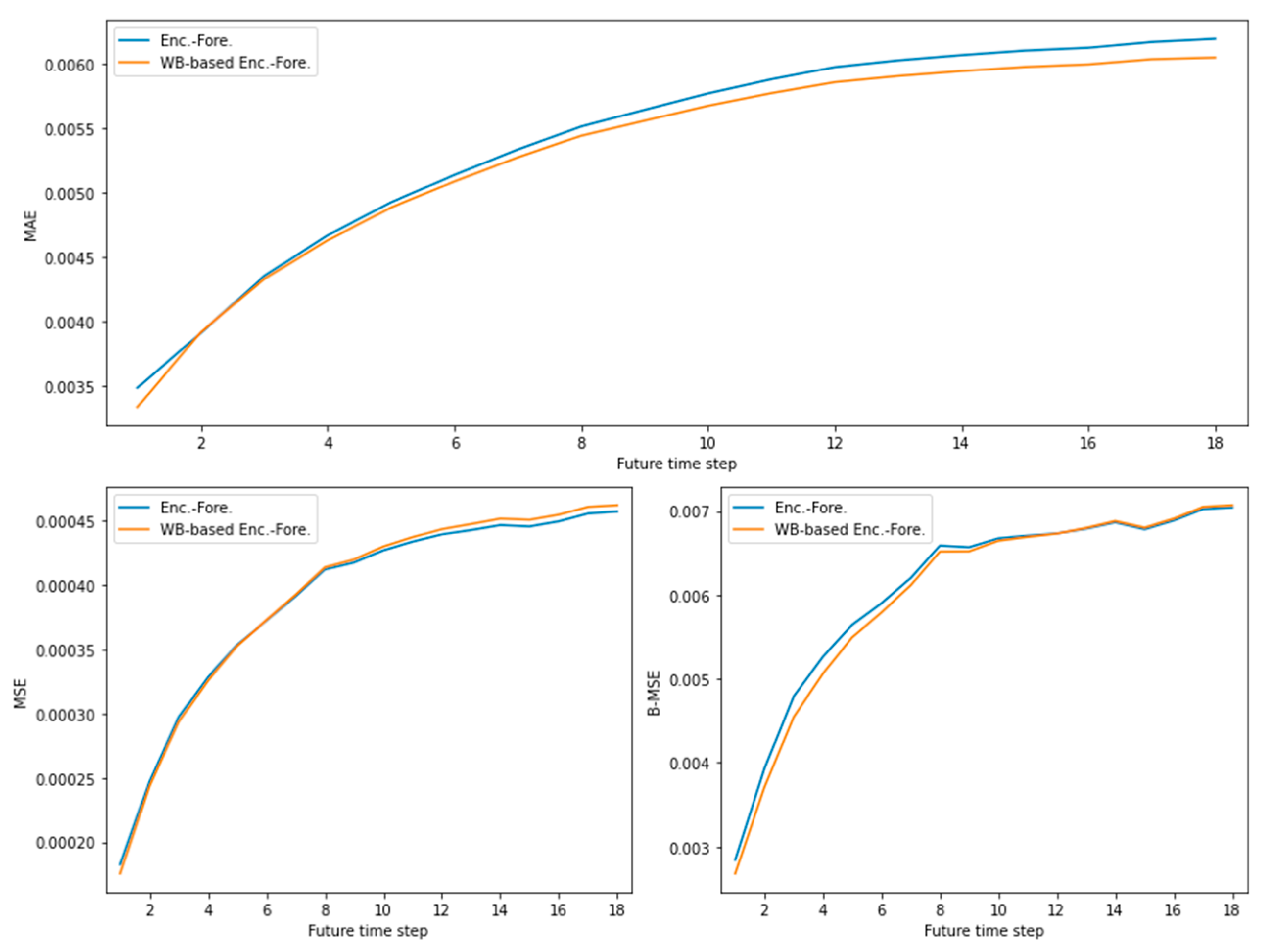
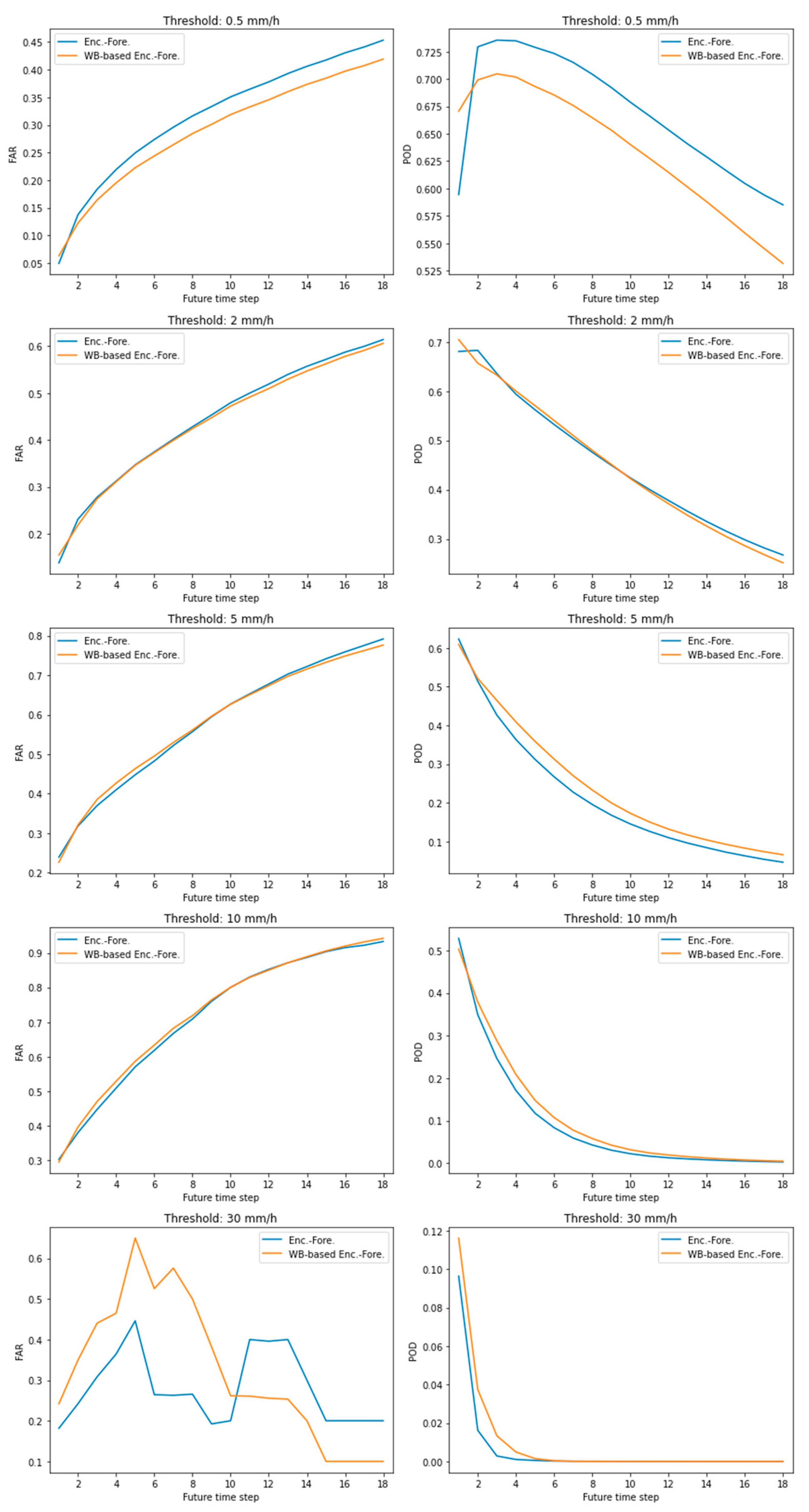
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Model Comparison According to the Future Time Step


Appendix B. Monte Carlo Permutation Test

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | p-Value (Lower B ound) | p-Value (Upper Bound) | Significance |
|---|---|---|---|
| MAE | 0.0127048865051027 | 0.0174676687141277 | O |
| MSE | 0.3887458537481437 | 0.4079322515204518 | X |
| B-MSE | 0.3696391168057983 | 0.3886537340002310 | X |
| FAR-0.5 | 0.0 | 0.0006630497334598 | O |
| FAR-2.0 | 0.0 | 0.0006630497334598 | O |
| FAR-5.0 | 0.0 | 0.0006630497334598 | O |
| FAR-10.0 | 0.0 | 0.0006630497334598 | O |
| FAR-30.0 | 0.0 | 0.0006630497334598 | O |
| POD-0.5 | 0.0 | 0.0006630497334598 | O |
| POD-2.0 | 0.0 | 0.0006630497334598 | O |
| POD-5.0 | 0.0 | 0.0006630497334598 | O |
| POD-10.0 | 0.0 | 0.0006630497334598 | O |
| POD-30.0 | 0.0 | 0.0006630497334598 | O |
| CSI-0.5 | 0.0 | 0.0006630497334598 | O |
| CSI-2.0 | 0.0 | 0.0006630497334598 | O |
| CSI-5.0 | 0.0 | 0.0006630497334598 | O |
| CSI-10.0 | 0.0037298195795461 | 0.0075262018267390 | O |
| CSI-30.0 | 0.0207299852910959 | 0.0287007076153710 | O |
| HSS-0.5 | 0.0 | 0.0006630497334598 | O |
| HSS-2.0 | 0.0 | 0.0006630497334598 | O |
| HSS-5.0 | 0.0 | 0.0006630497334598 | O |
| HSS-10.0 | 0.0 | 0.0006630497334598 | O |
| HSS-30.0 | 0.1706105467606014 | 0.1904134072389727 | X |
References
- Munoz-Organero, M.; Ruiz-Blaquez, R.; Sánchez-Fernández, L. Automatic detection of traffic lights, street crossings and urban roundabouts combining outlier detection and deep learning classification techniques based on GPS traces while driving. Comput. Environ. Urban Syst. 2018, 68, 1–8. [Google Scholar] [CrossRef]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An Empirical Evaluation of Deep Learning on Highway Driving. arXiv 2015, arXiv:1504.01716. [Google Scholar]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; Depristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Faust, O.; Hagiwara, Y.; Hong, T.J.; Lih, O.S.; Acharya, U.R. Deep learning for healthcare applications based on physiological signals: A review. Comput. Methods Programs Biomed. 2018, 161, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Purushotham, S.; Meng, C.; Che, Z.; Liu, Y. Benchmarking deep learning models on large healthcare datasets. J. Biomed. Informatics 2018, 83, 112–134. [Google Scholar] [CrossRef]
- Chen, Q.; Wang, W.; Wu, F.; De, S.; Wang, R.; Zhang, B.; Huang, X. A Survey on an Emerging Area: Deep Learning for Smart City Data. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 392–410. [Google Scholar] [CrossRef]
- Wang, L.; Sng, D. Deep Learning Algorithms with Applications to Video Analytics for A Smart City: A Survey. arXiv 2015, arXiv:1512.03131. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Guizani, M.; Oh, J.-S. Semisupervised Deep Reinforcement Learning in Support of IoT and Smart City Services. IEEE Internet Things J. 2017, 5, 624–635. [Google Scholar] [CrossRef]
- Skamarock, W.C.; Klemp, J.B.; Dudhia, J.; Gill, D.O.; Barker, D.M.; Duda, M.G.; Huang, X.-Y.; Wang, W.; Powers, J.G. A Description of the Advanced Research WRF Version 3. Available online: https://opensky.ucar.edu/islandora/object/technotes:500 (accessed on 15 February 2021).
- Banadkooki, F.B.; Ehteram, M.; Ahmed, A.N.; Fai, C.M.; Afan, H.A.; Ridwam, W.M.; Sefelnasr, A.; El-Shafie, A. Precipitation Forecasting Using Multilayer Neural Network and Support Vector Machine Optimization Based on Flow Regime Algorithm Taking into Account Uncertainties of Soft Computing Models. Sustainability 2019, 11, 6681. [Google Scholar] [CrossRef]
- Nourani, V.; Uzelaltinbulat, S.; Sadikoglu, F.; Behfar, N. Artificial intelligence based ensemble modeling for multi-station prediction of precipitation. Atmosphere 2019, 10, 80. [Google Scholar] [CrossRef]
- Anh, D.T.; Dang, T.D.; Van, S.P. Improved Rainfall Prediction Using Combined Pre-Processing Methods and Feed-Forward Neural Networks. J. Multidiscip. Res. 2019, 2, 65–83. [Google Scholar]
- Benevides, P.; Catalao, J.; Nico, G. Neural Network Approach to Forecast Hourly Intense Rainfall Using GNSS Precipitable Water Vapor and Meteorological Sensors. Remote Sens. 2019, 11, 966. [Google Scholar] [CrossRef]
- Poornima, S.; Pushpalatha, M. Prediction of Rainfall Using Intensified LSTM Based Recurrent Neural Network with Weighted Linear Units. Atmosphere 2019, 10, 668. [Google Scholar] [CrossRef]
- Tran, Q.-K.; Song, S.-K. Multi-ChannelWeather Radar Echo Extrapolation with Convolutional Recurrent Neural Networks. Remote Sens. 2019, 11, 2303. [Google Scholar] [CrossRef]
- Wehbe, Y.; Temimi, M.; Adler, R.F. Enhancing Precipitation Estimates Through the Fusion of Weather Radar, Satellite Retrievals, and Surface Parameters. Remote Sens. 2020, 12, 1342. [Google Scholar] [CrossRef]
- Tran, Q.-K.; Song, S.-K. Computer Vision in Precipitation Nowcasting: Applying Image Quality Assessment Metrics for Training Deep Neural Networks. Atmosphere 2019, 10, 244. [Google Scholar] [CrossRef]
- Agrawal, S.; Barrington, L.; Bromberg, C.; Burge, J.; Gazen, C.; Hickey, J. Machine Learning for Precipitation Nowcasting from Radar Images. arXiv 2019, arXiv:1912.12132. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 802–810. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Deep Learning for Precipitation Nowcasting: A Benchmark and A New Model. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5617–5627. [Google Scholar]
- Ayzel, G.; Scheffer, T.; Heistermann, M. RainNet v1.0: A convolutional neural network for radar-based precipitation nowcasting. Geosci. Model Dev. 2020, 13, 2631–2644. [Google Scholar] [CrossRef]
- Lebedev, V.; Ivashkin, V.; Rudenko, I.; Ganshin, A.; Molchanov, A.; Ovcharenko, S.; Grokhovetskiy, R.; Bushmarinov, I.; Solomentsev, D. Precipitation Nowcasting with Satellite Imagery. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2680–2688. [Google Scholar]
- Ayzel, G.; Heistermann, M.; Sorokin, A.; Nikitin, O.; Lukyanova, O. All convolutional neural networks for radar-based precipitation nowcasting. Procedia Comput. Sci. 2019, 150, 186–192. [Google Scholar] [CrossRef]
- Kumar, A.; Islam, T.; Sekimoto, Y.; Mattmann, C.; Wilson, B. Convcast: An embedded convolutional LSTM based architecture for precipitation nowcasting using satellite data. PLoS ONE 2020, 15, e0230114. [Google Scholar] [CrossRef] [PubMed]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving deeper into convolutional networks for learning video representations. arXiv 2016, arXiv:1511.06432. [Google Scholar]
- Franch, G.; Nerini, D.; Pendesini, M.; Coviello, L.; Jurman, G.; Furlanello, C. Precipitation Nowcasting with Orographic Enhanced Stacked Generalization: Improving Deep Learning Predictions on Extreme Events. Atmosphere 2020, 11, 267. [Google Scholar] [CrossRef]
- Li, P.W.; Wong, W.K.; Chan, K.Y.; Lai, E.S.T. SWIRLS—An Evolving Nowcasting System. Available online: http://www.hko.gov.hk/publica/tn/tn100.pdf (accessed on 15 February 2021).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 4, 3104–3112. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Hogan, R.J.; Ferro, C.A.T.; Jolliffe, I.T.; Stephenson, D.B. Equitability revisited: Why the ‘equitable threat score’ is not equitable. Weather Forecast. 2010, 25, 710–726. [Google Scholar] [CrossRef]
- Gude, V.; Corns, S.; Long, S. Flood Prediction and Uncertainty Estimation Using Deep Learning. Water 2020, 12, 884. [Google Scholar] [CrossRef]
- Kim, H.I.; Han, K.Y. Urban flood prediction using deep neural network with data augmentation. Water 2020, 12, 899. [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef]
- mcpt: Monte Carlo Permutation Tests for Python, Version 0; Available online: https://pypi.org/project/mcpt/ (accessed on 15 February 2021).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]








| Category | Period | No of Instances | Spatial Resolution (Grid Number) | Temporal Resolution | ||
|---|---|---|---|---|---|---|
| Year | Month | Day | ||||
| Training | 2012–2017 | 6–9 | Odd-numbered days | 3335 | 2 km (256 × 256) | 10 min |
| Validation | 2012, 2014, 2016 | 6, 8 | Even-numbered days | 2321 | ||
| 2013, 2015, 2017 | 7, 9 | |||||
| Test | 2012, 2014, 2016 | 7, 9 | Even-numbered days | 1894 | ||
| 2013, 2015, 2017 | 6, 8 | |||||
| Rainfall Rate (mm/h) | Rainfall Level | Weight of The Loss Penalty |
|---|---|---|
| None/hardly noticeable | 1.0 | |
| Light | 1.0 | |
| Light to moderate | 2.0 | |
| Moderate | 5.0 | |
| Moderate to heavy | 10.0 | |
| Rainstorm warning | 30.0 |
| Event Forecast | Event Observed | |
|---|---|---|
| Yes | No | |
| Yes | TP (Hit) | FP (False alarm) |
| No | FN (Miss) | TN (Correct rejection) |
| Model | MAE | MSE | B-MSE |
|---|---|---|---|
| Enc.-Fore. | 0.5407 × 10−2 | 0.3886 × 10−3 | 0.6068 × 10−2 |
| WB-based Enc.-Fore. | 0.5313 × 10−2 | 0.3896 × 10−3 | 0.6002 × 10−2 |
| Rainfall Rate (mm/h) | FAR | POD | ||
|---|---|---|---|---|
| Enc.-Fore. | WB-Based Enc.-Fore. | Enc.-Fore. | WB-Based Enc.-Fore. | |
| 0.5 | 0.3258 | 0.2960 | 0.6690 | 0.6403 |
| 2.0 | 0.4302 | 0.4199 | 0.4578 | 0.4513 |
| 5.0 | 0.5076 | 0.5141 | 0.2225 | 0.2409 |
| 10.0 | 0.5297 | 0.5653 | 0.1010 | 0.1126 |
| 30.0 | 0.3066 | 0.3072 | 0.0071 | 0.0110 |
| Rainfall Rate (mm/h) | CSI | HSS | ||
|---|---|---|---|---|
| Enc.-Fore. | WB-Based Enc.-Fore. | Enc.-Fore. | WB-Based Enc.-Fore. | |
| 0.5 | 0.5025 | 0.5031 | 0.2881 | 0.2909 |
| 2.0 | 0.3383 | 0.3393 | 0.2307 | 0.2318 |
| 5.0 | 0.1804 | 0.1912 | 0.1455 | 0.1529 |
| 10.0 | 0.0897 | 0.0980 | 0.0806 | 0.0874 |
| 30.0 | 0.0070 | 0.0108 | 0.0068 | 0.0106 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, C.H.; Kim, W.; Joo, W.; Jang, D.; Yi, M.Y. Enhancing the Encoding-Forecasting Model for Precipitation Nowcasting by Putting High Emphasis on the Latest Data of the Time Step. Atmosphere 2021, 12, 261. https://doi.org/10.3390/atmos12020261
Jeong CH, Kim W, Joo W, Jang D, Yi MY. Enhancing the Encoding-Forecasting Model for Precipitation Nowcasting by Putting High Emphasis on the Latest Data of the Time Step. Atmosphere. 2021; 12(2):261. https://doi.org/10.3390/atmos12020261
Chicago/Turabian StyleJeong, Chang Hoo, Wonsu Kim, Wonkyun Joo, Dongmin Jang, and Mun Yong Yi. 2021. "Enhancing the Encoding-Forecasting Model for Precipitation Nowcasting by Putting High Emphasis on the Latest Data of the Time Step" Atmosphere 12, no. 2: 261. https://doi.org/10.3390/atmos12020261
APA StyleJeong, C. H., Kim, W., Joo, W., Jang, D., & Yi, M. Y. (2021). Enhancing the Encoding-Forecasting Model for Precipitation Nowcasting by Putting High Emphasis on the Latest Data of the Time Step. Atmosphere, 12(2), 261. https://doi.org/10.3390/atmos12020261