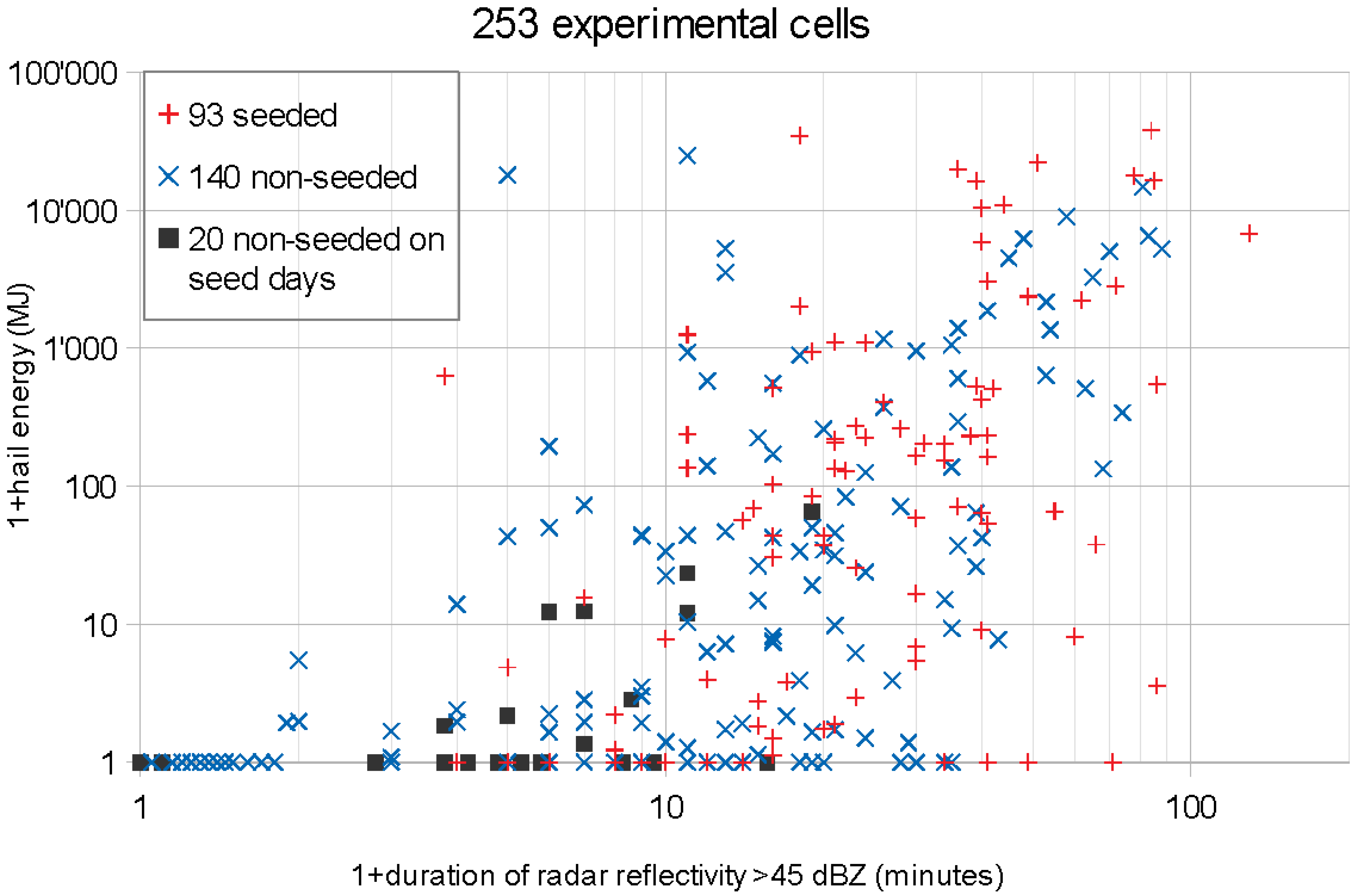
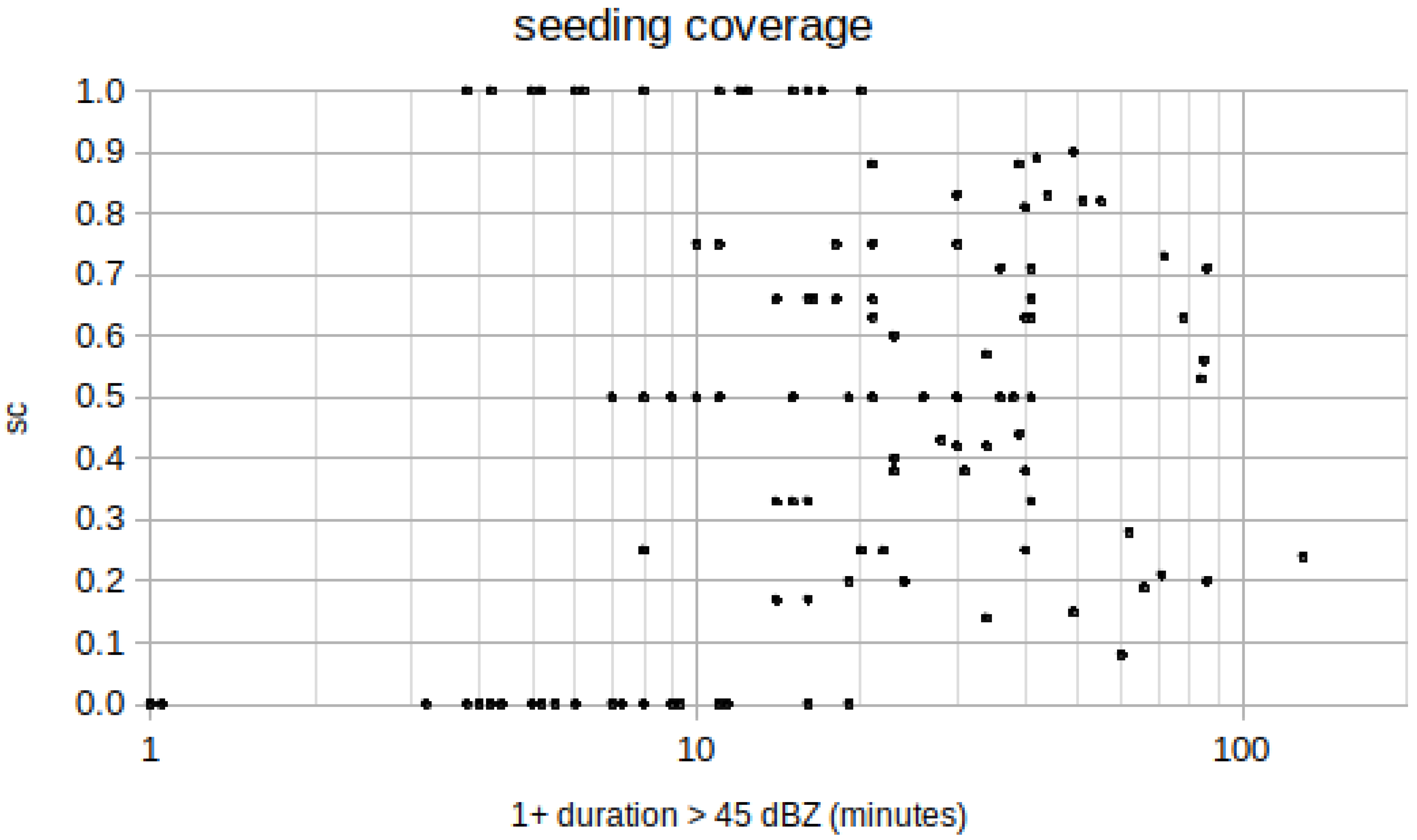
3.1. The Variables and Parameters
The present study is based on data found in the appendix of [
7]: the hail energy on the ground
, reconverted to
, the seeding coverage
, the beginning
and the end
of the seeding criterion met within the experimental area. The lifetime of a cell
serves to stratify the data for figures or to convert
from cells to days. As randomization was done for days, the data given for cells had to be converted to the values relevant for the 83 experimental days. For the hail energy it is the sum of
for each day. For
the daily average is needed:
. This is the really seeded fraction of the lifetime of all cells of a day.
We set the response variable
and the treatment variable
. The sample size
n is 253 cells or 83 days, whereas
is the number of seeded cells (93) or the number of days with at least one seeded cell (34). Our interest is in a couple of parameters which characterize the difference
or the ratio
of
y between seeded and non-seeded cells or days. There is a direct access from the variables
y and
x to the parameters
and
by the average of the non-seeded cells or days
and the weighted average of the seeded
. Obviously the relation to the parameters is
and
. The weighted seeded average
is calculated in this way:
A practical, more or less self explaining code for such expressions is used in the free software “Octave”, compatible with Matlab: , where .* indicates a term by term multiplication, and .
When later permutations are applied on x to calculate probabilities, a problem could arise for the parameter if . This could happen for certain permutations when there are less non-seeded cases than cases with no hail. However, this is not true for the hail data. Some hail is found within the non-seeded group for all permutations.
There is an elegant alternative to
and
: correlation and regression. A classical measure of association between
and
is the Pearson correlation coefficient
R, a versatile parameter. Two means as well as 2 × 2 contingency tables can be interpreted as a special case of correlation.
R is standardized as a product of two “studentized” variables resulting in
.
The sign of
R is important. A negative sign points towards hail suppression and a positive sign towards increased hail energy when seeding. Correlation is the key to regression with a slope
and an intercept
, allowing to calculate alternative estimates of
and
. The difference
is given in MJ per cell or per day, the ratio
is dimensionless (in 2 × 2 tables known as risk ratio). The difference
is just
R multiplied by a constant:
The sample size n, the number of seeded cases , the averages and as well as the std and do not change when x is permuted. Only the term is affected by permutation.
More delicate is the formula for
, because the intercept could become zero. This is explicitly shown in the following formula for
:
The critical constant
is
of the hail data is 0.44 and 0.66 for cells and days, respectively. These values are not changed by permutations. A second critical point
may be found at
, corresponding to
. When calculating probabilities for
by permutations or bootstrap,
of every permutation
i must be kept within these limits
and
. This does not change the medians of
R and
in the vicinity of
or
. Means, however, would be corrupted.
Table 1 shows the agreement and differences when calculating
and
by regression or by weighted averages. Both take unsatisfactory seeding into account, but in a different manner. The weighted average
neglects practically all of
y when the corresponding
x is close to zero. Regression is not affected by this kind of discontinuity. Therefore differences between the models must be expected. Ideally,
should be equal for the 83 days and 253 cells, whereas
is made to become comparable by converting
per day to
per cell by the factor 83/253. Hail cells are more interesting than days because the hail energy of cells can be compared to cells elsewhere, whereas for days such a comparison makes less sense.
Table 1 reveals quite a difference between the models and an appreciably better agreement between days and cells for regression. Therefore the model regression is preferable.
It is important to note that the direct way by and is identical to regression when is simplified to a binary seeded, non-seeded. This advantage does not outweigh the loss of accuracy when discarding the detailed information contained in .
3.2. The Calculation of Probabilities
The crucial question concerns the probability
. Could it be that the observed
R,
or
would be due to chance? If this chance is below the classical 2.5% in one of the two tails, the null hypothesis
is judged improbable. The task is to calculate the probability for the observed results assuming that
is true. Different methods will be compared with respect to the parameter
R. One of the oldest is based on student’s
t or Fisher’s
z. The latter is simpler and a close approximation to the probabilities obtained by
t.
It should be noted that the original data
are not transformed, only
R as part of the calculation of probability. If
x and
y are samples from normal distributions,
z is a standard normal distribution. In this case
as well as
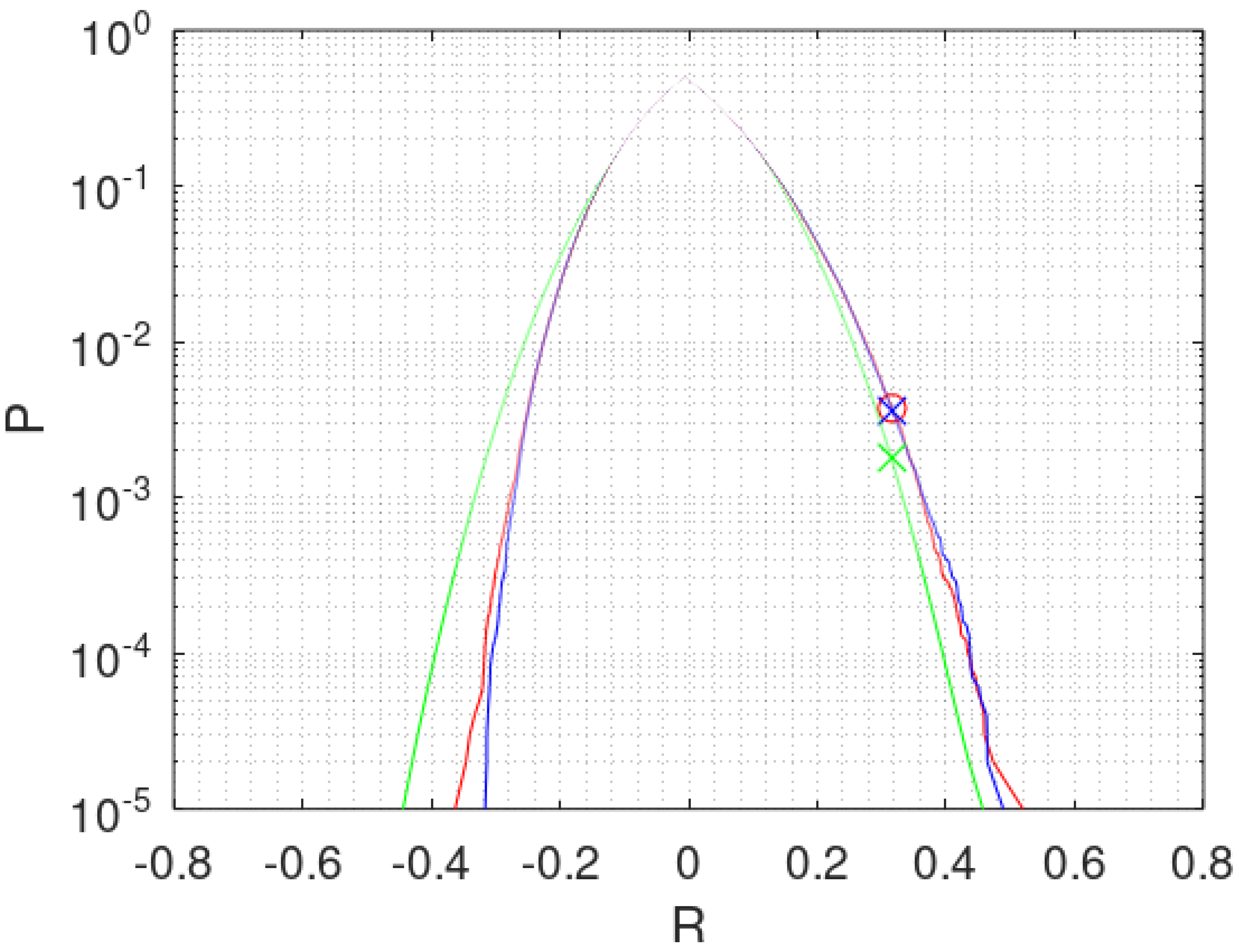
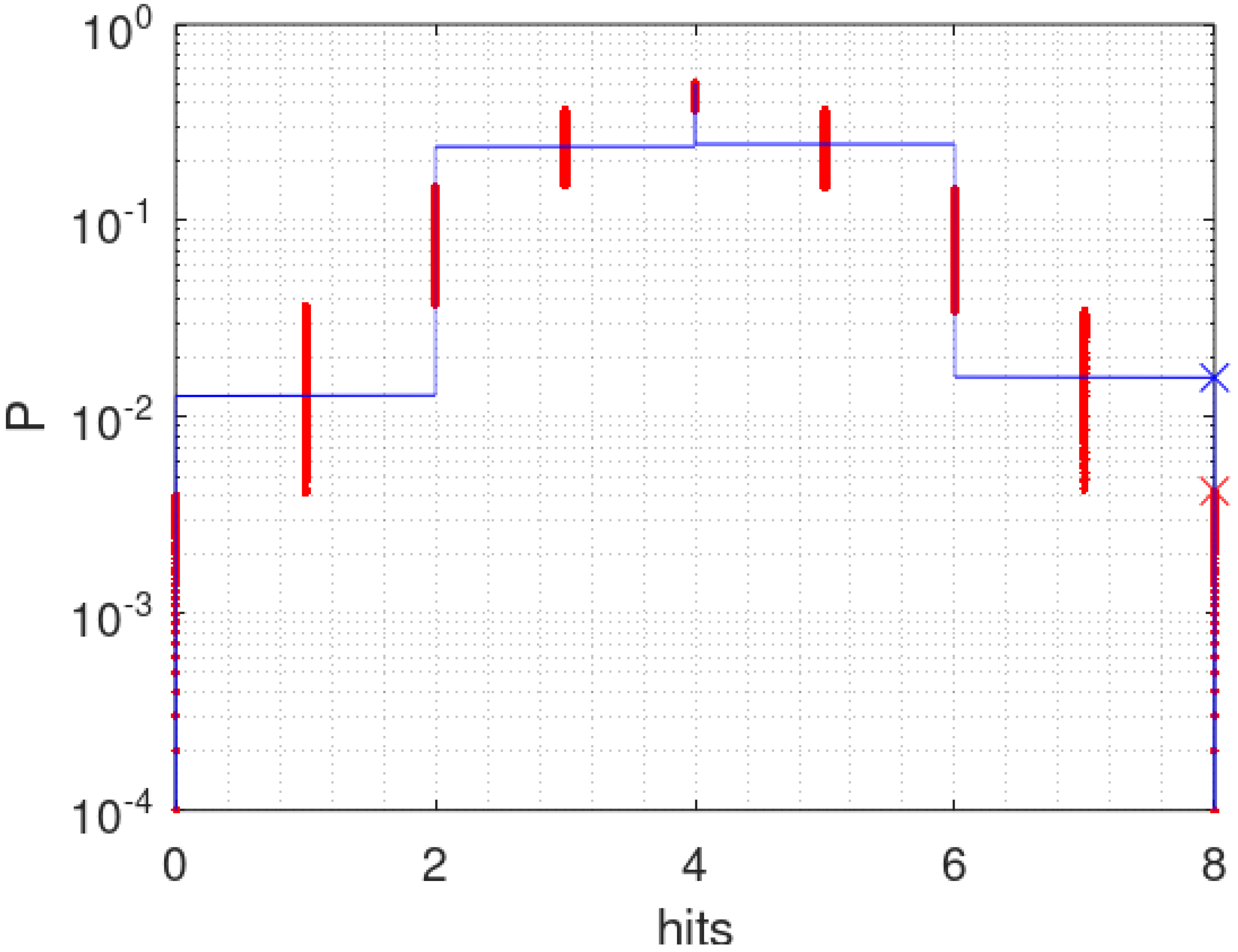
are known. The green line in
Figure 3 shows the accumulated probabilities min
for the 83 hail days starting from both extremes of
R. This way of plotting a cumulated distribution function (cdf) allows to use a logarithmic scale with adequate resolution and showing both tails, peaking at the median of
R.
The green curve for
is symmetrical, which is not realistic for the hail data. As the sample
is far from a normal distribution, combinative tests should be applied. The randomization test is such a test, characterized by the permutation of one variable. It was introduced by R. A. Fisher in 1924 according to [
17] (p. 3). The confirmatory test of Grossversuch IV was a complicated version of the randomization test and regression in two dimensions [
7]. It showed increased hail or whatever the logarithm meant, but did not reach statistical significance for several reasons already mentioned.
If
is true, the relation between
x and
y is random and can be replaced by other random allocations of
to
. This is systematically done by permutation of the scores in the samples
x or
y. Permutation changes only the covariance, the last expression in Equation (
3), all other terms are preserved. This condition is called “fixed marginals” for binary samples expressed in a 2 × 2 table.
There are n! equally probable possibilities to rearrange the products . If all permuted are sorted and plotted from both ends of smallest to larger and largest to smaller, a cdf of min is obtained. The endpoints of the cdf are the extreme correlations for both x and y sorted. The correlation between ascending x versus descending y gives the most negative or smallest . Ties in x or y lead to repetitions of the same and the probability increases in steps of . We checked numerically that the complete permutation of small binomial samples arrives at probabilities which are to Fisher’s exact solution for 2 × 2 tables.
In practice data of size
cannot be handled and the resolution
1/
n! is not needed. Therefore the permutation distribution is approximated by
N random samples. This is called resampling, rerandomization or Monte Carlo method. Such a plot starts and ends at
. The blue curve in
Figure 3 shows the approximation by
N = 100’000 points. Each permutation is represented by a point
. The points are sorted and connected to a line zigzagging from 0.001% to 0.002%, 0.003% and so forth. From 0.1% onward the curve becomes stable as may be seen.
The precision in terms of the std of
P is given by
This is also found in [
18] (p. 97). The resampling is done with replacement. The consequences of replacement are negligible in the context of permutations. It just means that the complete permutation distribution is never met exactly, even when
N is equal or larger than
, but the error is known.
Another combinative method to calculate probabilities is bootstrapping, mostly used for confidence intervals [
11]. The bootstrap creates new samples by selecting
n times from
y, from
x or from both, with replacement. In this way an association between
y and
x is also broken. Bootstrapping without replacement is like permuting. Bootstrapping with replacement creates new samples with different mean and std. We bootstrap
y, the most critical distribution. The red curve in
Figure 3 shows the result for applying bootstrap to
of the 83 hail days 100,000 times. The coincidence of the red curve with the blue curve from permutation is most remarkable. The probabilities
are 0.38% for both. Doing the same for the 253 cells shows also good coincidence (0.38% for permutation and 0.34% for bootstrap). The difference between permutation and bootstrap in
Figure 3 is negligible. In certain conditions the differences could be considerable as explained in the
Appendix A. However, in the case of the hail data, distributions and correlations are not sensitive to the model of calculation applied. Otherwise detailed knowledge of the experimental circumstances may have been necessary to chose the adequate model, if possible.
Calculations based on
R and regression have a great advantage insofar as permutations form
,
and
in the same succession, leading to identical probabilities
,
and
. This is not the case for the seemingly simpler model using averages
and
instead of
R and regression.
Table 1 shows the differences.
From this point in the analysis the regression model is pursued. The other data in
Table 1 are less compact, but all in a range of probabilities far below 2.5%. This is good evidence for a statistically significant correlation between
and
in the sense that the hail energy is increased when seeding.
3.3. Confidence Intervals and Standard Error
The next question is about the accuracy of
R and the derived
and
. Confidence intervals (
) are the means to treat these issues. Resampled distributions with
are needed assuming the alternative hypothesis
that
R found in the experiment is true and should correspond to the median of the resampled
. An old solution for normally distributed
y and
x is again Fisher’s
z for
.
As above, a standard normal distribution with
is expected when
y and
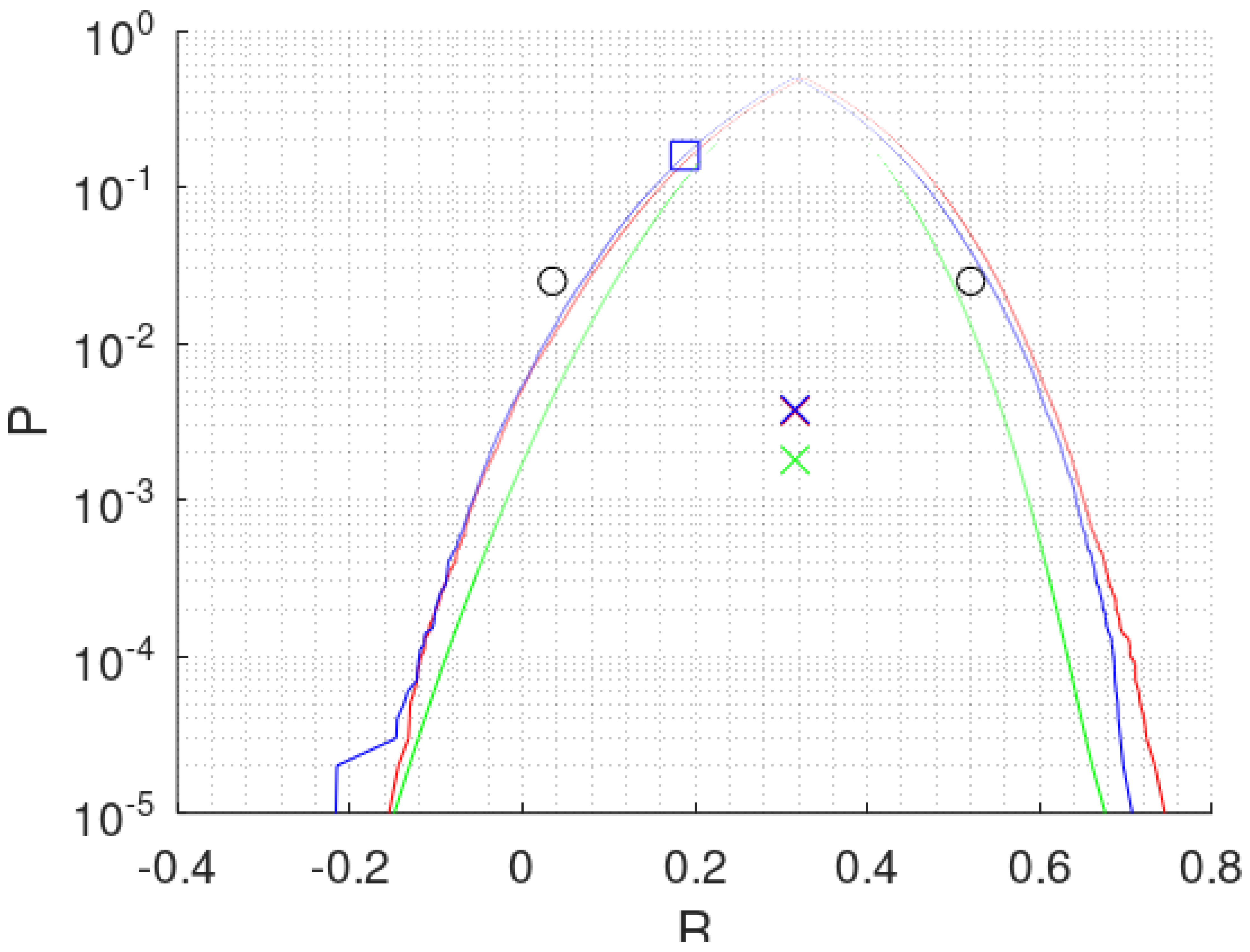
x are Gaussian. The green curve in
Figure 4 is again shown for comparison with the solutions by combinative methods.
One such method is "bivariate" bootstrapping to calculate
by resampling the originally associated
and
pairwise with replacement. In this way the correlation of the sample is preserved in the average of all bootstraps producing
, although median
is not guaranteed. Performing this bootstrap leads to the red curve in
Figure 4.
Instead, permutation keeps all terms of
y and
x but varies the associations between, which destroys any correlation. In the course of this work, a simple and transparent way was found to impose the observed (or any other possible)
R as the median of all permutations. After permutation, a random sequence of length
is sorted to produce the maximum positive or, when
R is negative, the maximum negative correlation. This
is used to compensate, by construction, for the loss of correlation in the randomly permuted terms. The task is to find the correct
which guarantees median
(see
Figure 4). An adequate
to start with is:
The term
is an optional number of randomly selected pairs keeping their original association (as with bivariate bootstrapping). The portion of the sample subjected to permutation is
. This procedure to resample
by permuting and maximising the association of
random terms may be named “correlation imposed permutation” (CIP). CIP keeps all terms of
y and
x and plays with the associations between
y and
x to form a permutation distribution for
. There are
permutations, approximated by
N scores
as explained in
Section 3.2.
Equation (
10) situates the median of the permutations already in the vicinity of
R. The correction to establish a better
for the next approximation is (
R-median
. By two or three further runs median
is reached with adequate precision.
Figure 4 shows the blue curve for CIP,
n = 83 days,
,
. A non integer
is needed for the accuracy of the condition median
. It is realized by alternating in the present case between 7 times
and 3 times
. The blue curve in
Figure 4 is close to the red curve as already found in
Figure 3. Again, the hail data are indifferent with respect to the two models applied for calculation.
Concerning
there is an interesting suggestion based on Equation (
9): when using
z,
, indicated by a green cross in the middle of
Figure 4, is identical to
. As an option, this condition could be applied to determine
in CIP. Increasing
decreases slightly
. Introducing
for the 83 hail days or
for the 253 hail cells complies with this option.
In
Figure 4 the confidence interval
is the distance between the two tails of a curve at e.g.,
. At this level the
is about four std (3.9 for normal distributions) and comprises 95% of all randomly resampled cases. Two black circles are noted outside the curves. They were calculated by the “bias corrected and accelerated” (BCa) bootstrap method going also back to Efron [
19]. BCa is complicated and seems to us less convincing than the simple bootstrap or CIP. It was checked that CIP fits best Fisher’s
z when the samples
y and
x are representative for normal distributions. A survey on bootstrapping dealing also with shortcomings is found in [
10]. A further critical point mentioned by Cox [
20] are samples that are too small to be representative for a parent distribution. The
Appendix A deals with this problem.
Instead of reading the curves for
at 2.5% we prefer the blue square at a probability of 15.9% in
Figure 4. The value of 15.9% corresponds to
in normal distributions. The standard error (
) is an adequate measure of error. The interesting side is towards zero effect, therefore the parameters
and
will be shown in
Table 2. The other side of the 15.9% probability is asymmetric and vulnerable with respect to the parameter
. The influence of a nearby singularity at
may distort the cdf (see Equation (
6)).
3.4. Re-Evaluated Results of Grossversuch IV
The most important results of the statistical evaluations are found in
Table 1 and in
Figure 3 and
Figure 4. The following
Table 2 provides some further insight. It starts with the results of the regression model in rows 1 and 2, continuing with a binary
x reducing
to 0 or 1 in order to compare the present evaluations with results presented in 1986 [
7].
Statistical significance is best in rows 1 and 2 because the information contained in
is used. The bold scores show the most reliable results. Looking at cells is closer to the question asked, but the randomization was done for days. Therefore
earns more credit when calculated for days. The difference between the evaluation of
in row 1 and 2 of
Table 2 is astonishingly small in view of the big difference of
n. The aggregation of data from cells to days reduces stochastic variations as well as skewness and kurtosis.
In rows 3 and 4 of
Table 2 most information with respect to unsatisfactory seeding is lost. A big misinterpretation happens for row 3 because 17 non-seeded cells are taken into account as seeded in the seeded days. Only 3 cells occurring alone on 3 seeded days shift to non-seeded. Correspondingly
jumps to 2.0%. The loss in row 4 is less severe because 20 cases of planned but not performed seeding are transferred to non-seeded. Therefore the influence on
is not dramatic.
To allow a comparison with the results of Table 21 (last row) in [
7], all 20 non-seeded cells on planned seed days were taken as perfectly seeded in rows 5 and 6. This merging of data causes a distortion that leads to the loss of statistical significance in our evaluation. By the way, the
-test used in [
7] (p. 945) is not adequate. It can reveal a constant multiplicative seeding effect, but this implies that the distributions of the seeded and non-seeded
may differ by scale but not by shape. The skewness and kurtosis are kinds of shape parameters. For the seeded and non-seeded (in parentheses) cells, 3.6 (5.8) is found for the skewness, 16.3 (40) for the kurtosis. This does not look good enough for a
-test, the randomization test must be preferred.
Row 7 shows that the probability for a cell to produce hail is significantly increased by some 20% when seeding. The data from hailpads (row 8) confirm this finding, but the significance becomes marginal because of reasons discussed later. For rows 7 and 8 the results of bootstrapping were chosen because the fixed marginals anticipated by permutation are not adequate here and the differences in 2 × 2 tables notable:
= 0.7% and 2.8% would be obtained. A more impressive example is discussed in the
Appendix A.
To sum up
Table 2: Seeding increased the hail energy by a factor of 3, the difference with respect to non-seeded was about 1600 MJ per cell and the chance to obtain this result accidentally was 0.4%, therefore statistically significant. The results hold for an average seeding of
. An extrapolation to perfect seeding is not recommended.
Not included in
Table 2 are some further evaluations performed with cleaned up sets of data: either 118 cells of lifetimes less than 15 min for the 45 dBZ contour, or 39 cells with unsatisfactory seeding (
) could be excluded. The latter was planned in the original design of Grossversuch IV (see [
7] (p. 925)). The first 4 rows of
Table 2 were combined with one or both of these exclusions yielding 12 further evaluations. There is always an increase for seeding, all at a significance level below or close to 2.5%. A trend to still lower
than in
Table 2 was observed when excluding cells of short duration. All these different evaluations and models form a homogeneous picture. Even the linear regression associated with
may be changed to a power
p within
. The homogeneous picture does not change. Powers
p much larger than 1 do not make sense. A power very close to zero leads to the binary simplification seeded or non-seeded.
The preparation of the data and the evaluations are easily performed using the spreadsheet “DataHail-FMA” available in the
Supplementary Materials. The evaluation of
in the spreadsheet is based on the first four moments of the permutation distribution, a method proposed by Pitman [
21]. This procedure is less robust than permutations or bootstrapping but quick and precise for the hail data. The spreadsheet contains also the calculations concerning autocorrelation, which is the next issue.
Federer [
7] (p. 929) observed a weak intra-day correlation, amounting to 0.33 for
. For non-transformed
and non-seeded cells we found a lag-1 intra-day autocorrelation of
R = 0.47 at
= 1.0%. For cells on seeded days the autocorrelation disappears:
at
= 44%. As
changes under the influence of a varying
, the autocorrelation is destroyed.
R,
or
are not affected by the autocorrelation, only the calculation of
may be too optimistic when the independence of the units is not perfect. The following experiment localizes the effect of autocorrelation on
.
The distribution of with cells is varied in the set of non-seeded data, while the daily total of remains unchanged. The two most extreme cases are:
Each cell contributes the same amount to the daily of non-seeded cells, corresponding to total intraday autocorrelation. The result of the permutation test for the 253 cells is = 3.0, = 0.27%.
The daily total comes from only one cell, the other cells of the same day are without hail. In this case = 3.0, = 0.74% is obtained.
In this bandwidth from 0.27% to 0.74% the observed result is found:
= 3.0,
= 0.38%, equal to the result for days (
= 3.3,
= 0.38%). It seems that the intraday autocorrelation of non-seeded cells is not really disturbing. Also Federer Table 22 [
7] based 16 of their 21 tests on cells. Autocorrelation could have been a real problem if the several severe hailstorms would have been aggregated on a few days. However, there is only one day, 18 July 1978, non-seeded, with two very large cells, causing the daily maximum of
MJ. A plausible explanation of the autocorrelation is the aggregation of cases with zero or little hail on days with meteorological conditions not suitable to produce severe storms.
Autocorrelation is not observed in the data from hailpads. This has to do with an interesting question: how do stochastic uncertainties in the measurements influence the results? From [
13,
14] we estimate the uncertainty of the radar based
within 25%. In case of a systematic multiplicative error in the radar calibration and thus in
, the significance level
remains unchanged. The reason is that linear transformations do not change
R. If the error in
is stochastic, it has an impact on
, as a simple numerical test can show. We added a random error of 20% to
of unit days, first row in
Table 2, repeating the experiment 100 times. The significance level diminishes as
increases from 0.33% to an average of 0.55%. When increasing the error to 40%, there is a further impairment of
to 1.1%. In both cases
remains practically unchanged and
remains below 2.5%.
We learn from this that data suffering from too much inaccuracy lose power. Unfortunately, this seems to be the case for the data obtained from hailpads. Also the hailpad data show an increase of hail energy for seeded data, but statistical significance is not reached, e. g. for cells
= 1.58,
= 16%. Federer’s Table 21 [
7] reports
= 1.58,
= 24% for the
test. The data from hailpads lack 40 cells mainly from the year 1982. However, this can not be the decisive point, as the radar data reach for the same 213 cells still
= 2.79,
= 0.7%. We suspect that the sampling by hailpads introduces intolerable stochastic variations. This hypothesis was tested by looking at the intraday autocorrelation of the hail energies from hailpads for unseeded days. Comparing the radar data for the same 79 cells to the hailpad data reveals
R = 0.47,
= 1.2% for the radar, degrading to
R = 0.09,
= 16% for the hailpads. This is a strong hint that the accuracy of the hailpad measurements is not adequate to show the intraday autocorrelation. Furthermore, the total hail energy is 0.41 times that of the corresponding
. The conjecture is that the hailpad network not only introduces large stochastic errors but causes a loss of information which is important for the evaluation of hail energies. Less demanding is the question whether at least one hailpad was hit, indicating hail or no hail. Again, the hailpads identified less hail (51%) than the radar (75%) for both seeded and non-seeded experimental cells.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}