Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs


Abstract
:1. Introduction
- (1)
- We propose a CNN-based approach that uses a dilated CNN to eliminate the time-consuming efforts dedicated to introducing handcrafted features because our method automatically extracts a group of practical features to train it. Asit is essential to use a sufficient amount of data for the training process, we assembled a large collection of images of different scenes depicting fire and smoke obtained from many sources. Images were selected from a well-known dataset [9]. Our dataset is also available for further research.
- (2)
- We used dilated convolutional layers to build our network architecture and briefly explain the principles thereof. Dilated convolution makes it possible to avoid learning much deeper, because it helps to learn larger features by ignoring smaller features.
- (3)
- Small window sizes are used to aggregate valuable values from fire and smoke scenes. The use of smaller window sizes in deep learning is known to enable smaller but complex features in an image to be captured, and it offers improved weight sharing. Therefore, we decided to use a smaller kernel size for the training process.
- (4)
- We determined the number of layers that are well suited to solve this task. Four convolutional layers were employed because an excessive number of layers allow the model to learn much deeper. This approach considers that, rather than having to classify a very large number of classes, the task is a simple binary classification. Therefore, employing many layers will exacerbate the overfitting problem. In Section 5, overfitting is demonstrated to occur. However, the latter studies used a larger number of layers, mostly six layers [6].
2. Related Work
2.1. Computer Vision Approaches for Fire and Smoke Detection
2.2. Deep Learning Approaches for Fire and Smoke Detection
3. Dataset
4. Proposed Architecture
4.1. Brief Summary of Well-Known Network Architectures
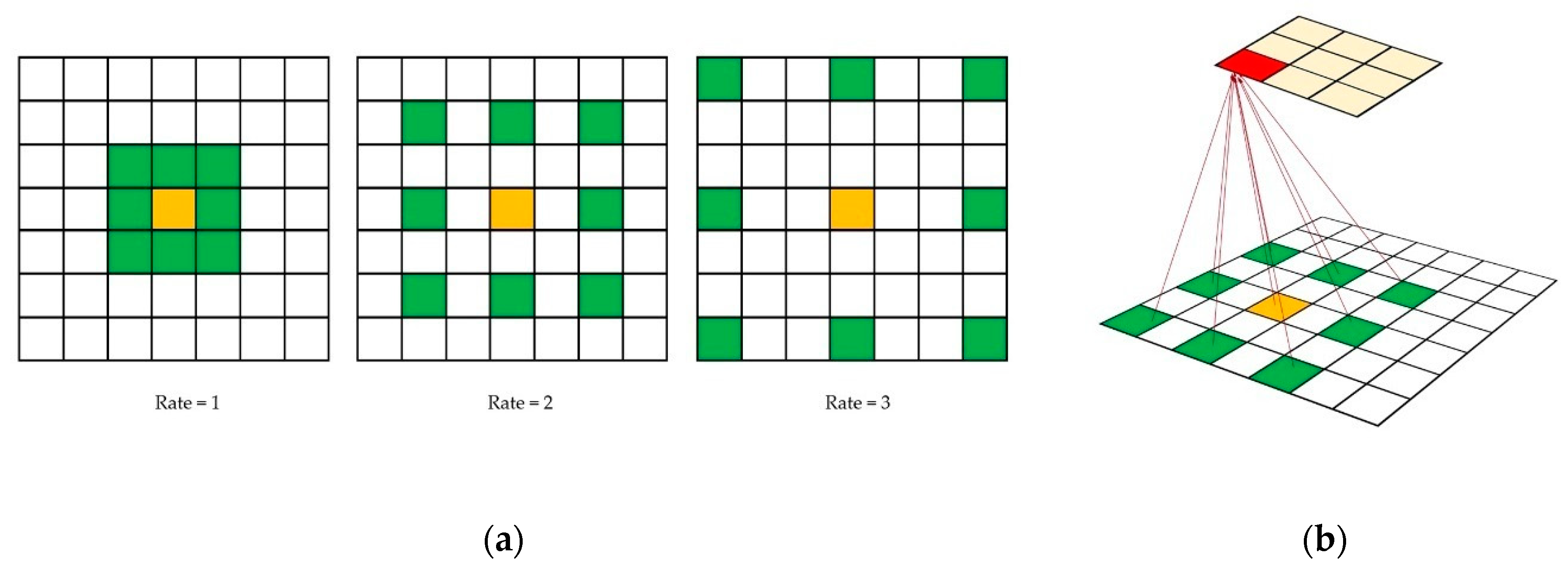
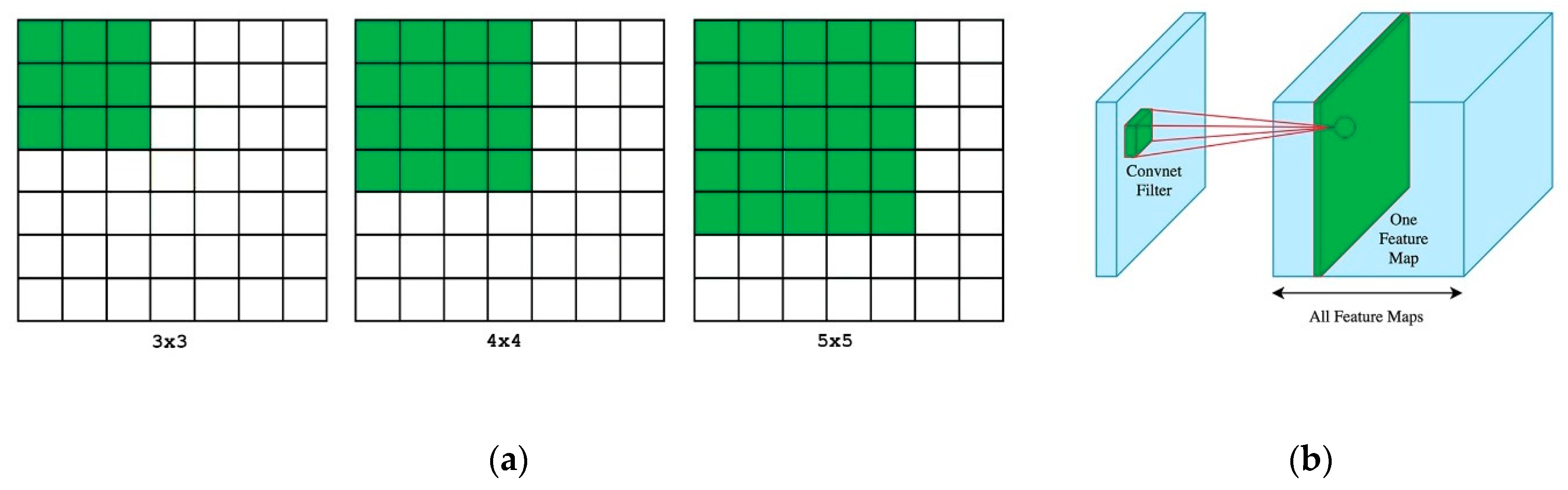
4.2. Dilated Convolution
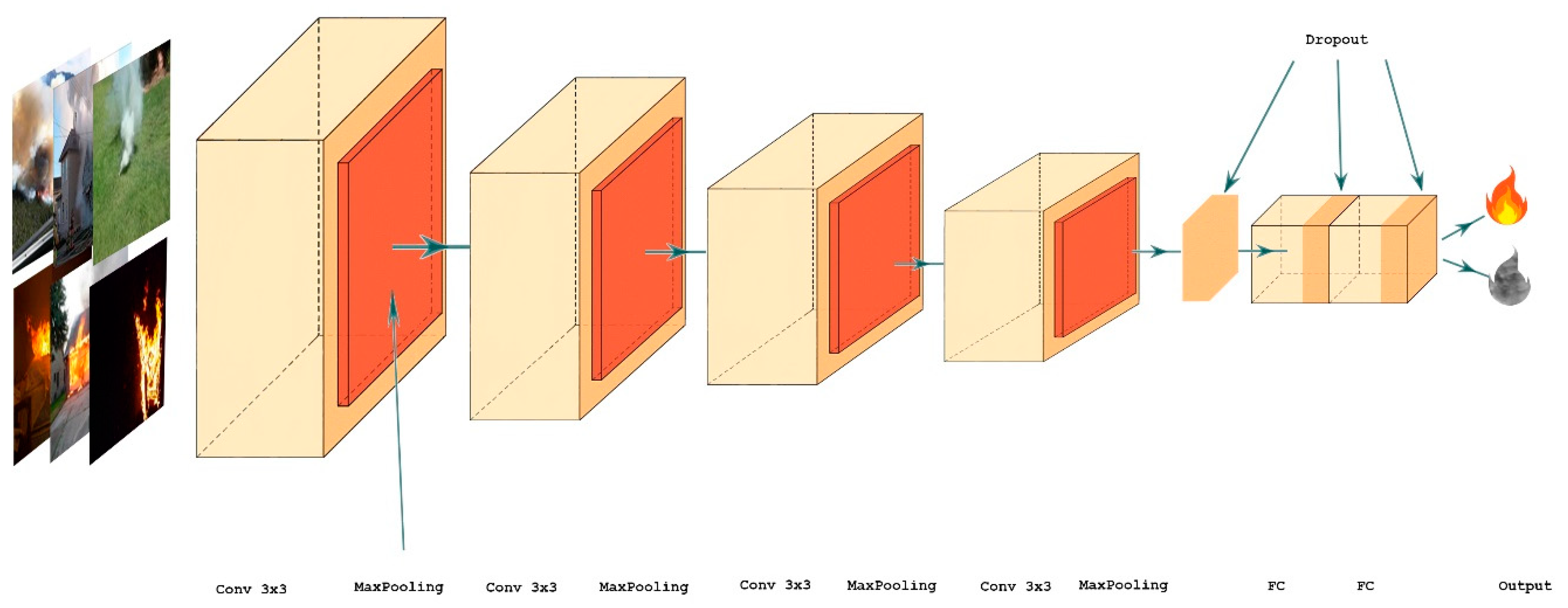
4.3. Proposed Network Architecture
5. Experiments and Discussion
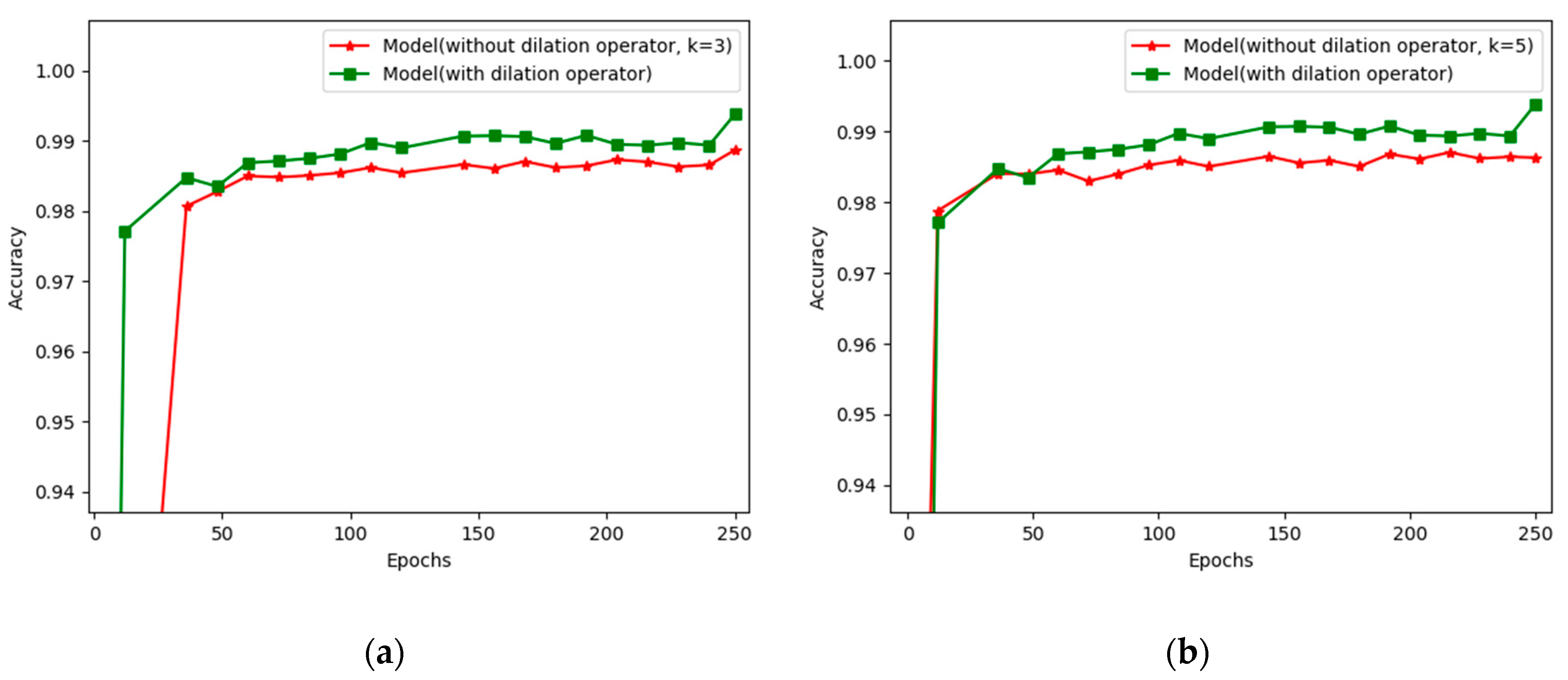
5.1. Investigating the Optimum Method for Fire and Smoke Detection
5.2. Comparison of Our Network Model with Well-Known Architectures by Conducting Experiments on Our Dataset
6. Limitations
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lim, J.S.; Lim, S.W.; Ahn, J.H.; Song, B.S.; Shim, K.S.; Hwang, I.T. New Korean reference for birth weight by gestational age and sex: Data from the Korean Statistical Information Service (2008–2012). Ann. Pediatr. Endocrinol. Metab. 2014, 19, 146–153. [Google Scholar] [CrossRef]
- Qiu, T.; Yan, Y.; Lu, G. An Autoadaptive Edge-Detection Algorithm for Flame and Fire Image Processing. IEEE Trans. Instrum. Meas. 2012, 61, 1486–1493. [Google Scholar] [CrossRef]
- Liu, C.B.; Ahuja, N. Vision Based Fire Detection. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; pp. 134–137. [Google Scholar]
- Govil, K.; Welch, M.L.; Ball, J.T.; Pennypacker, C.R. Preliminary Results from a Wildfire Detection System Using Deep Learning on Remote Camera Images. Remote. Sens. 2020, 12, 166. [Google Scholar] [CrossRef]
- Pan, H.; Badawi, D.; Cetin, A.E. Computationally Efficient Wildfire Detection Method Using a Deep Convolutional Network Pruned via Fourier Analysis. Sensors 2020, 20, 2891. [Google Scholar] [CrossRef]
- Namozov, A.; Cho, Y.I. An Efficient Deep Learning Algorithm for Fire and Smoke Detection with Limited Data. Adv. Electr. Comput. Eng. 2018, 18, 121–128. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Foggia, P.; Saggese, A.; Vento, M. Real-Time Fire Detection for Video-Surveillance Applications Using a Combination of Experts Based on Color, Shape, and Motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Lu, G.; Gilabert, G.; Yan, Y. Vision based monitoring and characterization of combustion flames. J. Phys. Conf. Ser. 2005, 15, 194–200. [Google Scholar] [CrossRef]
- Bheemul, H.C.; Lu, G.; Yan, Y. Three-dimensional visualization and quantitative characterization of gaseous flames. Meas. Sci. Technol. 2002, 13, 1643–1650. [Google Scholar] [CrossRef]
- Ko, B.C.; Cheong, K.-H.; Nam, J.-Y. Fire detection based on vision sensor and support vector machines. Fire Saf. J. 2009, 44, 322–329. [Google Scholar] [CrossRef]
- Jiang, Q.; Wang, Q. Large space fire image processing of improving canny edge detector based on adaptive smoothing. Proc. Int. CICC-ITOE 2010, 1, 264–267. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, J.; Zhang, D.; Qu, C.; Ke, Y.; Cai, B. Contour Based Forest Fire Detection Using FFT and Wavelet. In Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Hubei, China, 12–14 December 2008; Volume 1, pp. 760–763. [Google Scholar]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the International Conference on Image Processing (ICIP), Singapore, 24–27 October 2004; pp. 1707–1710. [Google Scholar]
- Celik, T.; Demirel, H.; Ozkaramanli, H.; Uyguroglu, M. Fire detection using statistical color model in video sequences. J. Vis. Commun. Image Represent. 2007, 18, 176–185. [Google Scholar] [CrossRef]
- Chun-yu, Y.; Fang, J.; Jin-jun, W.; Zhang, Y. Video Fire Smoke Detection Using Motion and Color Features. Fire Technol. 2009, 46, 651–663. [Google Scholar] [CrossRef]
- Zaidi, N.; Lokman, N.; Daud, M.; Chia, K. Fire recognition using RGB and YCbCr color space. ARPN J. Eng. Appl. Sci. 2015, 10, 9786–9790. [Google Scholar]
- Google’s AlphaGo AI wins three-match series against the world’s best Go player. TechCrunch. Available online: https://techcrunch.com/2017/05/23/googles-alphago-ai-beats-the-worlds-best-human-go-player/ (accessed on 25 May 2017).
- Ciresan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. 2012 IEEE Conference on Computer Vision and Pattern Recognition. arXiv 2012, arXiv:1202.02745, 3642–3649. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks (PDF). In Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014), Montréal, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; IEEE: Piscataway, NJ, USA; pp. 877–882. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference onComputer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ba, R.; Chen, C.; Yuan, J.; Song, W.; Lo, S. SmokeNet: Satellite Smoke Scene Detection Using Convolutional Neural Network with Spatial and Channel-Wise Attention. Remote. Sens. 2019, 11, 1702. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Olga, R.; Jia, D.; Hao, S.; Jonathan, K.; Sanjeev, S.; Sean, M.; Zhiheng, H.; Andrej, K.; Aditya, K.; Michael, B.; et al. ImageNet Large Scale Visual Recognition Challenge. IJCV 2015, 115, 211–252. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); DCFS: Tallahassee, FL, USA, 2014; pp. 740–755. [Google Scholar]
- René, C.L.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 156–165. [Google Scholar]
- Van Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A Generative Model for Raw Audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; p. 125. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; Oord, A.V.D.; Graves, A.; Kavukcuoglu, K. Neural Machine Translation in Linear Time. arXiv 2017, arXiv:1511.07122v3. [Google Scholar]
- CS231n. Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/#overview (accessed on 26 May 2020).
- Nair, V.; Hinton, G.E. Rectified linear units improve Restricted Boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014, 15, 1929–1958. [Google Scholar]
- Kiefer, J.; Wolfowitz, J. Wolfowitz Stochastic Estimation of the Maximum of a Regression Function. Ann. Math. Statist. 1952, 23, 462–466. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Fire Images | Smoke Images | Total |
|---|---|---|---|
| Our dataset | 8430 | 8430 | 16,860 |
| Layer Type | Filters | Feature Map | Kernel Size | Stride |
|---|---|---|---|---|
| Input layer | 100 100 3 | |||
| 1st convolutional layer | 128 | 96 96 128 | 3 3 3 | 1 1 |
| Max-pooling layer | - | 32 32 128 | 2 2 | 3 3 |
| 2nd convolutional layer | 256 | 32 32 256 | 3 3 3 | 1 1 |
| Max-pooling layer | - | 16 16 256 | 2 2 | - |
| 3nd convolutional layer | 512 | 16 16 512 | 3 3 3 | 1 1 |
| Max-pooling layer | - | 8 8 512 | 2 2 | - |
| 4th convolutional layer | 512 | 8 8 512 | 3 3 3 | 1 1 |
| Max-pooling | - | 4 4 512 | 2 2 | - |
| Dropout | - | |||
| 1st fc layer | 2048 | |||
| Dropout | - | |||
| 2nd fc layer | 2048 | |||
| Dropout | - | |||
| Classification(output)layer | 2 | |||
| Method | Training Scores | Testing Scores |
|---|---|---|
| Model (without dilation operator, k = 3) | 98.86% | 97.53% |
| Model (without dilation operator, k = 5) | 98.63% | 95.81% |
| Model (with dilation operator) | 99.3% | 99.06% |
| Method | Training Scores | Testing Scores |
|---|---|---|
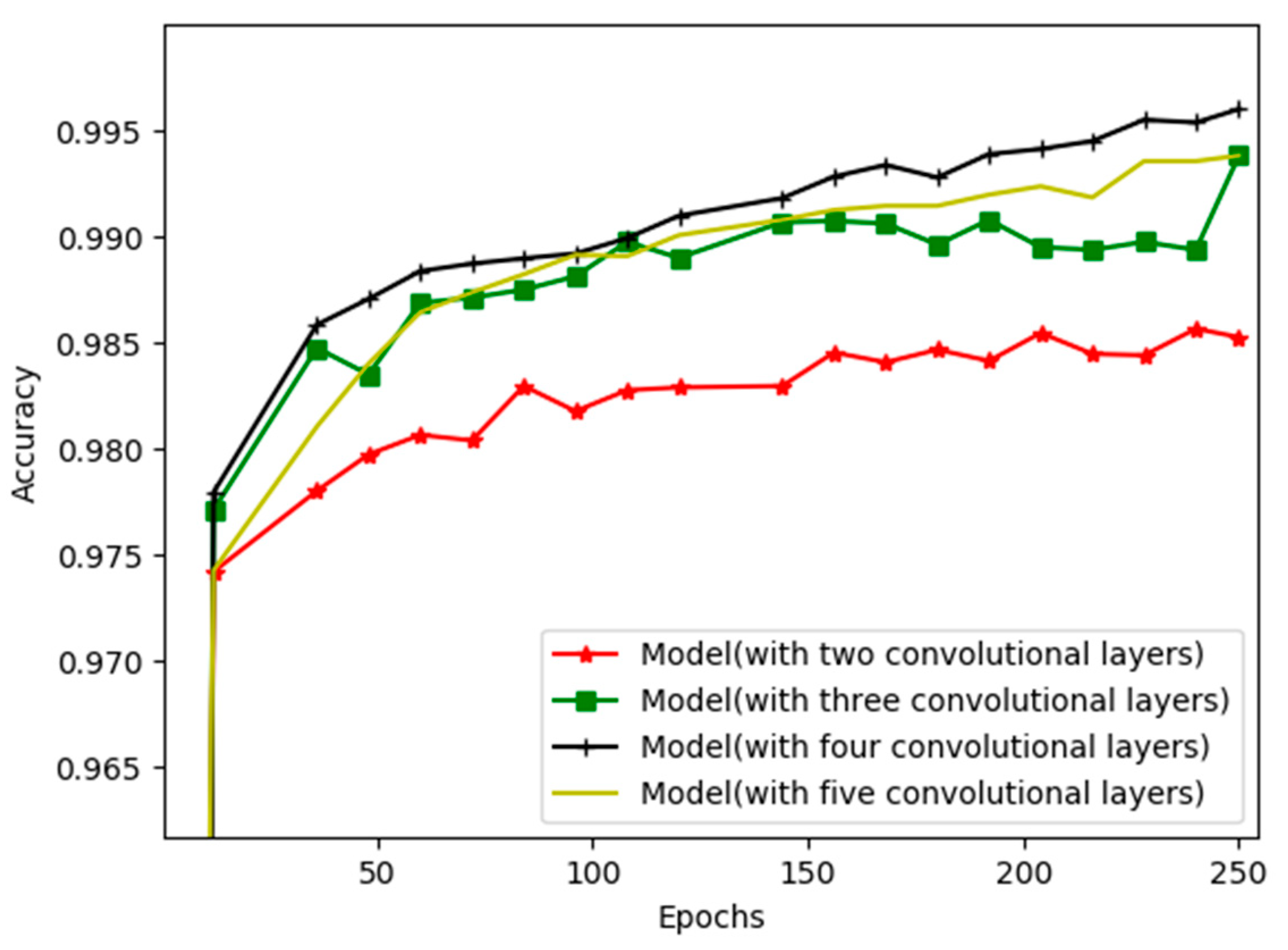
| Model (with two convolutional layers) | 98.52% | 98.03% |
| Model (with three convolutional layers) | 99.38% | 99.06% |
| Model (with four convolutional layers) | 99.60% | 99.53% |
| Model (with five convolutional layers) | 99.36% | 98.07% |
| Method | Training Scores | Testing Scores |
|---|---|---|
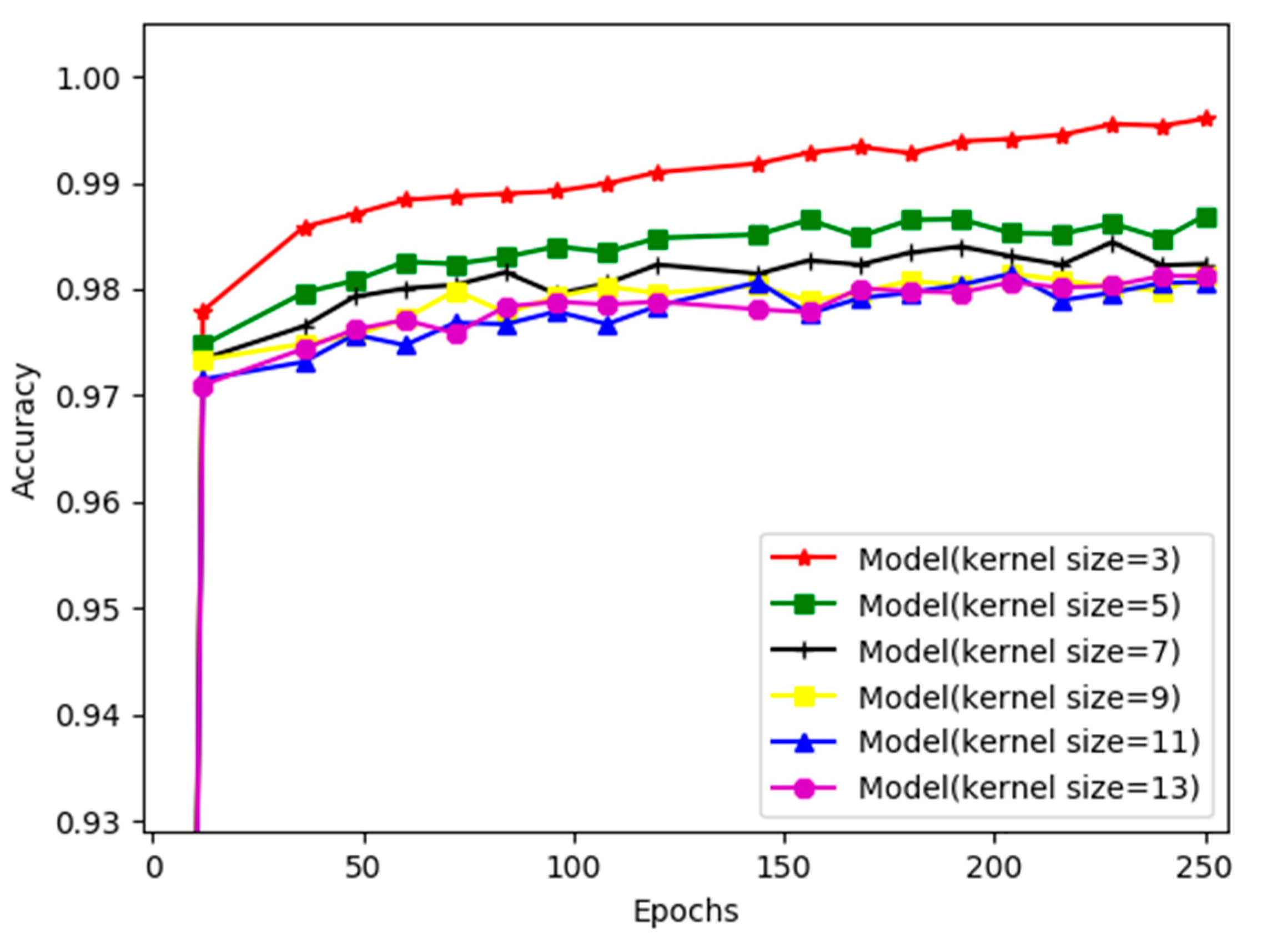
| Model (kernel size = 3) | 99.60% | 99.53% |
| Model (kernel size = 5) | 98.69% | 98.07% |
| Model (kernel size = 7) | 98.23% | 98.83% |
| Model (kernel size = 9) | 98.13% | 98.31% |
| Model (kernel size = 11) | 98.06% | 98.19% |
| Model (kernel size = 13) | 98.12% | 97.95% |
| Method | Training Scores | Testing Scores | F1-Score | Recall | Precision |
|---|---|---|---|---|---|
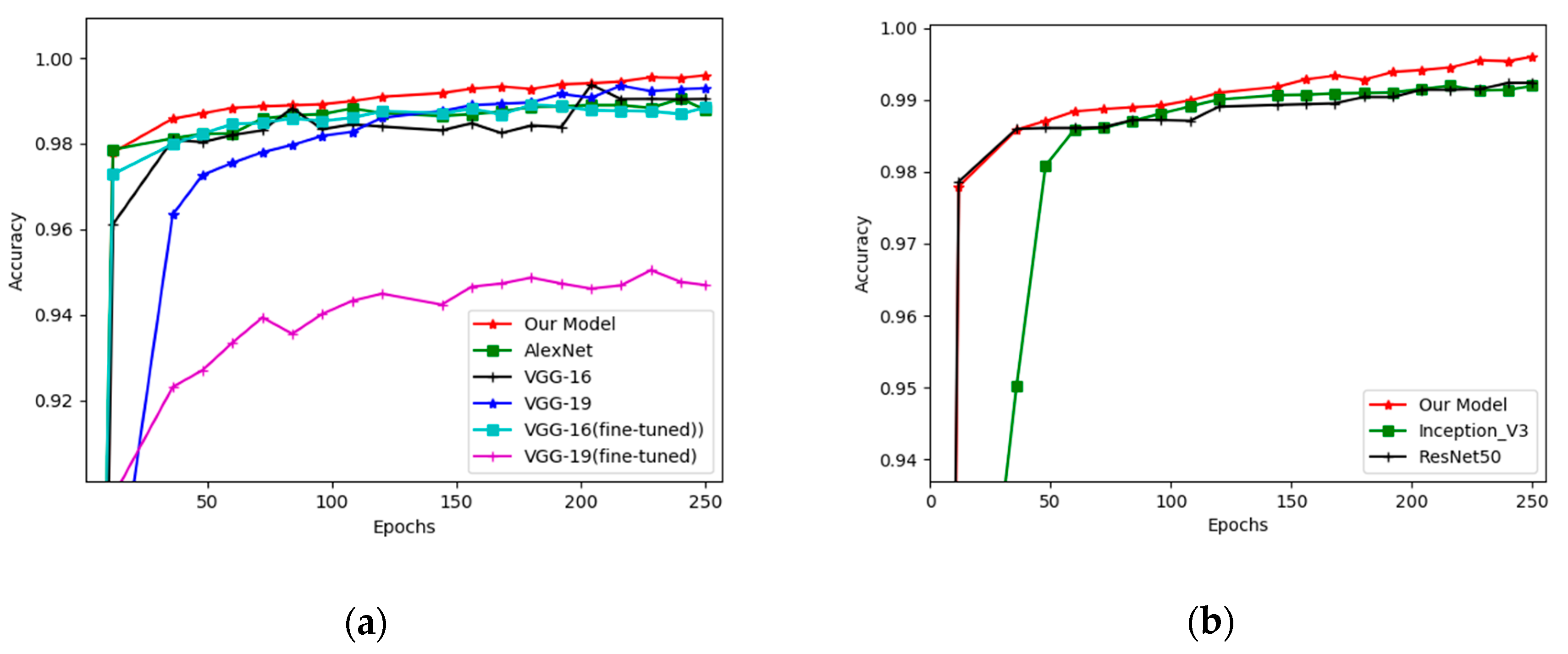
| Our Model | 99.60% | 99.53% | 0.9892 | 0.9746 | 0.9827 |
| Inception V3 [29] | 99.19% | 98.31% | 0.9744 | 0.9980 | 0.9532 |
| AlexNet [7] | 98.78% | 86.74% | 0.7513 | 0.6131 | 0.7332 |
| ResNet [28] | 99.23% | 98.79% | 0.9425 | 0.9364 | 0.9486 |
| VGG16 [8] | 99.04% | 98.67% | 0.9278 | 0.8799 | 0.875 |
| VGG19 [8] | 99.29% | 98.37% | 0.9206 | 0.8566 | 0.9949 |
| VGG16 (fine-tuned) | 98.85% | 98.76% | 0.8754 | 0.8215 | 0.9368 |
| VGG19 (fine-tuned) | 94.6% | 94.88% | 0.8548 | 0.887 | 0.8248 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valikhujaev, Y.; Abdusalomov, A.; Cho, Y.I. Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere 2020, 11, 1241. https://doi.org/10.3390/atmos11111241
Valikhujaev Y, Abdusalomov A, Cho YI. Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere. 2020; 11(11):1241. https://doi.org/10.3390/atmos11111241
Chicago/Turabian StyleValikhujaev, Yakhyokhuja, Akmalbek Abdusalomov, and Young Im Cho. 2020. "Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs" Atmosphere 11, no. 11: 1241. https://doi.org/10.3390/atmos11111241
APA StyleValikhujaev, Y., Abdusalomov, A., & Cho, Y. I. (2020). Automatic Fire and Smoke Detection Method for Surveillance Systems Based on Dilated CNNs. Atmosphere, 11(11), 1241. https://doi.org/10.3390/atmos11111241